Embed Size (px)
Citation preview

On The Analysis Of Hardware Event
Monitors Accuracy In MPSoCs For Real-time
Computing Systems
Author:
Javier Enrique Barrera Herrera
Supervisor:
Hamid Tabani Barcelona Supercomputing Center
Co-supervisor:
Francisco J. Cazorla Barcelona Supercomputing Center
Tutor:
Leonidas Kosmidis Department of Computer Architecture
Universitat Politecnica de Catalunya
Barcelona Supercomputing Center
High Performance Computing
Master in Innovation and Research in Informatics
Facultat d’Informatica de Barcelona
Universitat Politecnica de Catalunya
Computer Architecture - Operating Systems Departament
Barcelona Supercomputing Center
June 23, 2020

Acknowledgements
In the first place, I would like to thank my advisors, Hamid, Fran and Leonidas for their guidance
and mentoring through the development of this Thesis.
I also want to thank the rest of the people of the CAOS group at BSC who have always offered
help when needed.
Moreover, I would like to acknowledge the BSC institution for financially support my Master studies,
and also to the following institutions that have partially supported this work: the Spanish Ministry
of Economy and Competitiveness (MINECO) under grant TIN2015-65316-P, the UP2DATE Eu-
ropean Union’s Horizon 2020 (H2020) research and innovation programme under grant agreement
No 871465, the SuPerCom European Research Council (ERC) project under the European Union’s
Horizon 2020 research and innovation programme (grant agreement No. 772773), and the HiPEAC
Network of Excellence.
Last but not least, I would like to thank my family for their unconditional support in my life and
studies.

Abstract
The number of mechanical subsystems enhanced or completely replaced by electrical/electronic
components is on the rise in critical real-time embedded systems (CRTES) like those in cars,
planes, trains, and satellites. In this line, software is increasingly used to control (safety-related)
critical aspects of CRTES. More complex software requires unprecedented computing performance
requirements, that can only be achieved by deploying aggressive processor designs, multiprocessor
system on chips (SoCs or MPSoCs). The other side of the coin is that MPSoCs make software
timing analysis – a mandatory pre-requisite for CRTES – more complex.
Performance Monitoring Units (PMUs) are at the heart of most advanced software timing analysis
techniques to control and bound the impact of contention in Commercial Off-The-Shelf (COTS)
System-on-Chips (SoCs) with shared resources (e.g., GPUs and multicore CPUs). However, PMUs
are designed with an assurance level below the role they assume in software timing analysis.
In this Thesis, we aim at taking an initial step toward reconciling PMU verification with its key
role for timing analysis. In particular, this Thesis covers the analysis of the correctness of hardware
event monitor (HEM) in embedded processors for CRTES domains. This Thesis illustrates that
some event monitors do not behave as expected in their specification, which can in turn invalidate
the software timing analysis process performed building on those HEMs. For three real processors
used in different CRTES domains, we report discrepancies on the values obtained from the PMU’s
HEMs and the number of events expected based on HEM description in the processor’s official
documentation. Discrepancies, which may be either due to actual errors or inaccurate specifications,
make PMU readings unreliable. This is particularly problematic in consideration of the critical role
played by event monitors for timing analysis in domains such as automotive and avionics.
This Thesis proposes a systematic procedure for event monitor validation. We apply this proce-
dure to validate event monitors in the NVIDIA AGX Xavier, NVIDIA TX2, and the Xilinx Zynq
UltraScale+ MPSoC. We show that while some event monitors count as expected, this is not the
case for others whose discrepancies with expected values we analyze.

GlossaryTerm Definition
HEM Hardware Event Monitor
SoC System on Chip
MPSoC MultiProcessor System on Chip
WCET Worst-Case Execution Time
RTES Real-Time Embedded Systems
CRTES Critical Real-Time Embedded Systems
ISO-26262 Safety standard for CRTES in the automotive domain
DO-178C Safety standard for CRTES in the avionics domain
CAST-32A Certification Guidance for the use of multicores in the avionics domain
EN 50128 Safety standard for CRTES in the railway domain
ASIL Automation Safety Integrity Level, a risk classification scheme
V&V Validation and Verification process
GPU Graphics Processing Unit
COTS Commercial Off-The-Shelf
PMU Performance Monitoring Unit
SDTA Static Deterministic Timing Analysis
MBDTA Measurement-Based Deterministic Timing Analysis
HDTA Hybrid Deterministic Timing Analysis
SPTA Static Probabilistic Timing Analysis
MBPTA Measurement-Based Probabilistic Timing Analysis
HYPTA Hybrid Probabilistic Timing Analysis
PMC Performance Monitoring Counter
CPU Central Processing Unit
pWCET probabilistic Worst-Case Execution Time
ILP Integer Linear Programming
EMVP Event Monitor Validation Process
PUD Platform Usage Domain
rbe representative benchmark
ISA Instruction Set Architecture
OEM Original Equipment Manufacturer
CUDA Compute Unified Device Architecture
SASS GPU Assembly Code for NVIDIA GPUs

Contents
1 Introduction 5
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2 Background and Related Work 11
2.1 Timing Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.1 SDTA: Static Deterministic Timing Analysis . . . . . . . . . . . . . . . . . . 11
2.1.2 MBDTA: Measurement-Based Deterministic Timing Analysis . . . . . . . . . 12
2.1.3 HDTA: Hybrid Deterministic Timing Analysis . . . . . . . . . . . . . . . . . 12
2.1.4 SPTA: Static Probabilistic Timing Analysis . . . . . . . . . . . . . . . . . . . 13
2.1.5 MBPTA: Measurement-Based Probabilistic Timing Analysis . . . . . . . . . 13
2.1.6 HYPTA: Hybrid Probabilistic Timing Analysis . . . . . . . . . . . . . . . . . 14
2.2 Using PMCs in the Timing Analysis Process . . . . . . . . . . . . . . . . . . . . . . 14
3 Event Monitor Validation Process 17
3.1 Event Monitor Validation Process (EMVP) . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Systematic and Automated Validation . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Automation Opportunities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1

Contents
4 Assessment of EMVP on the NVIDIA Jetson AGX Xavier 22
4.1 Experiment and representative benchmark design . . . . . . . . . . . . . . . . . . . . 23
4.2 First Validation Step . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.3 Second Validation Step . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4 Third Validation Step . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.5 Assessment on Complex Code . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5 Assessment of EMVP on the NVIDIA Jetson TX2 32
5.1 Experiment and representative benchmark design . . . . . . . . . . . . . . . . . . . . 33
5.2 First Validation Step . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6 Assessment of EMVP on the Xilinx Zynq Ultrascale+ 37
6.1 Experiment and representative benchmark design . . . . . . . . . . . . . . . . . . . . 37
6.2 Assessment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
7 Conclusions and Future Work 42
7.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
7.2 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2

List of Figures
2.1 Example of pWCET curve [44] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.1 EMVP Diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.1 CUDA/SASS code of matrix copy benchmark for AGX Xavier. . . . . . . . . . . . . 24
4.2 SASS code of the combined example. . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 MISC inst. counted and expected (example in Fig. 4.2). . . . . . . . . . . . . . . . . . 27
4.4 SASS code of two examples with NOP instructions. . . . . . . . . . . . . . . . . . . . 29
4.5 SASS code for the vector addition in Global Mem. . . . . . . . . . . . . . . . . . . . 30
5.1 CUDA/SASS code of matrix copy benchmark at TX2. . . . . . . . . . . . . . . . . . 36
6.1 Diagram of the Cortex-A53 CPU cluster [1] . . . . . . . . . . . . . . . . . . . . . . . 38
6.2 C/ARM Assembly code of matrix copy in the Zynq. . . . . . . . . . . . . . . . . . . 39
3

List of Tables
2.1 Taxonomy of WCET techniques. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.1 Instruction types used in this analysis for the NVIDIA Jetson AGX Xavier GPU. . . 23
4.2 Measured/Expected values for matrix copy benchmark for Nvidia Jetson AGX Xavier 25
4.3 Instruction types in Figure 4.2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4 Event counts for the vector addition benchmarks. . . . . . . . . . . . . . . . . . . . . 30
5.1 Instruction types used in this analysis for the NVIDIA Jetson TX2 GPU. . . . . . . 32
5.2 Measured/Expected values for matrix copy benchmark at Nvidia Jetson TX2 . . . . 33
5.3 Measured/Expected values for matrix copy benchmark at Nvidia Jetson TX2 after
applying PMC correction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.1 Instruction types used in the analysis for the Xilinx Ultrascale+ ARM Cortex-A53
CPUs [1]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
6.2 Measured/Expected values for matrix copy . . . . . . . . . . . . . . . . . . . . . . . 40
4

Chapter 1
Introduction
The Real-Time Embedded Systems (RTES) industry represents a key part of the global chip market
and some predictions point out that it will drive the global chip demand in the following years [39].
RTES comprise a wide range of commercial products: from low-cost commodity appliances such as
microwave ovens to expensive and critical systems like cars or planes.
In RTES, the timely execution of software is as important as its correctness. In particular, evidence
must be provided that the software finishes its processing before a given time bound which is
called deadline. Depending on its criticality real-time systems can be classified broadly into several
main categories:
• Hard real-time systems: these systems control critical operations, usually where a systematic
failure of the system can result in a catastrophic event, e.g. Anti-lock Braking System (ABS)
of a car or flight control system in planes. This can be caused by frequent deadline misses
which can have severe consequences. These systems are also known as Critical Real-Time
Embedded Systems (CRTES).
• Soft real-time systems: the system can afford missing several deadlines since it will not result
in a critical outcome. As an example, in a video decoding processor, if the processing of a
video frame does not meet the deadline, this likely will not be noticeable for the end user.
Even in an event of missing the deadline for several consecutive frames, although undesirable,
the system will experience deteriorated quality of service, but still the user will be able to
continue watching the movie.
• Firm real-time systems: the system can miss an occasional deadline and it will not cause a
critical outcome, but the results will be discarded since they are of no use after the deadline.
An example of this is Software-defined radio (SDR), where a missed deadline will result in
some part of the audio stream not being heard by the user.
5

Chapter 1. Introduction
CRTES comprise safety-critical systems whose failure could cause fatalities, injuries or severe dam-
ages to objects (including the system itself); and mission-critical systems whose failure may typically
cause economical losses such as, for instance, systems controlling measurement instruments in a
satellite. Even if those systems do not compromise the integrity of the satellite itself, they may
lead to a failure of accomplishing the mission, which ultimately is a severe consequence.
The expected correct behavior of CRTES is defined in generic [30] or domain safety standards such
as ISO-26262 [31] for road vehicles, DO-178C [58]CAST-32A [22] for airborne systems, and EN
50128 [14] for railway. Those standards described the required functional and timing verification to
provide evidence – qualitatively and quantitatively – the absence failure or the risk of failure can
be regarded as residual. In other words, the validation and verification (V&V) process provides
evidence that all relevant scenarios have been considered and safety measures have been put in
place to mitigate risks.
The certification processes are required in order to guarantee that a certain system or software is
safe to be used in the target domain. An example of certification standard in automotive electrical
and electronics is ISO-26262 [31] safety standard which defines the Automotive Safety Integrity
Level (ASIL) which is a risk classification scheme. This is an adaptation of the Safety Integrity
Level used in IEC 61508 [30] for the automotive industry. This classification helps defining the
safety requirements necessary to be in line with the ISO-26262 standard. The ASIL is established
by performing a risk analysis of a potential hazard by looking at the Severity, Exposure and
Controllability of the vehicle operating scenario. The safety goal for that hazard in turn carries
the ASIL requirements. There are four ASILs identified by the standard: ASIL A, ASIL B, ASIL
C, ASIL D. ASIL D dictates the highest integrity requirements on the product and ASIL A the
lowest.
Until recently, CRTES built upon relatively-simple software running on relatively low-performance
(and low-complexity) hardware. For instance, many avionics systems still today are built upon
single-core processors with an in-order execution pipeline and without cache memories or many
other advanced microarchitecture techniques. The advantage of those systems is that timing verifi-
cation is relatively simple since execution time variability is low and the system’s behavior is quite
predictable. However, the increasing automation of systems first, and the trend towards fully au-
tonomous systems later, pushes CRTES industry for adopting hardware platforms delivering much
higher performance to respond to the performance demands of complex functionalities. Multicore
and manycore processors are one such type of hardware platform. They consist of a number of cores
capable of executing software simultaneously, as well as an interconnection network to communicate
cores among them and with neighbor devices (e.g. main memory) [26,33,53,59,60].
6

Chapter 1. Introduction
1.1 Motivation
Complex state-of-the-art microprocessors present performance-improving features that have been
traditionally used for the high-performance domain, however, they are being increasingly used in
processors in domains like automotive [13]. Those features include multicores, multi-level cache hi-
erarchies, complex on-chip networks and accelerators, among which GPUs have a dominant position
[5,40,62]. This transition from the usage of simple micro-controllers to complex microprocessors in
the CRTES is driven by the unprecedented performance requirements of complex critical software
in order to support advanced functionalities such as autonomous driving in automotive and more
autonomous missions in space [7, 67].
Timing Verification and Validation (V&V) provides evidence for the correct temporal schedulabil-
ity of the system. This builds on deriving tight and reliable Worst-Case Execution Time (WCET)
estimates (budgets) to software execution time. The quality of the WCET estimates often depends
on the engineer’s previous experience. For instance, common industrial practice for timing analysis
consists of running several tests measuring the highest execution or high watermark and adding
an experience-based safety margin to it to cover the impact on ‘unobserved’ effects [65]. How-
ever, multicore systems, although enabling higher performance, introduce timing variability due to
contention between the different cores when accessing shared resources. Therefore, timing is not
deterministic and time predictability is needed, however, COTS processors in critical domains have
limited hardware support for time predictability. This includes automotive processors and SoCs
such as the NVIDIA Drive SoCs (Parker [47] and Xavier [46] SoCs), RENESAS R-Car H3 [57],
QUALCOMM SnapDragon 820 [55], and Intel Go [29]. Similar concerns also arise on SoCs such as
the Xilinx Zynq UltraScale+, which is increasingly considered for avionics and railway applications
among others [69].
It has been shown to be insufficient to try to achieve full isolation by software, resorting, for
example, to page (memory) coloring techniques 1 since there is an existing interference at the
shared queues and buffers [63]. Software solutions for Quota Monitoring and Enforcement have
been proposed to handle contention in multicore generic processors with limited hardware support
for time predictability [18, 45, 54, 72]. Quota enforcement approaches build on limiting per task
(core) maximum shared resources utilization. The operating system monitors the task’s activities
via the hardware event monitors which are offered by processors’ PMUs and suspends or slows
down the task’s execution when their assigned budget is about to be exhausted.
Existing software approaches and solutions for quota event monitoring and enforcement, as well as
software debugging processes, build on the naive assumption that event monitors and their docu-
mentation are always correct. In fact, the trustworthiness of event monitors in COTS processors
1Coloring is a well-known technique to segregate accesses to the different blocks of memory-like resources [38],
like banks of the shared last-level on-chip cache, the banks and ranks in a DDR memory system [37, 52, 71], or even
combined cache-memory segregation [61].
7

Chapter 1. Introduction
has not been questioned yet in the real-time research community, despite their critical role as func-
tional and non-functional verification means. The validity of all quota-based software solutions
cannot be sustained without providing evidence of a correct functioning of the event monitors,
according to the specification available in the official documentation. The lack of such support-
ive evidence ultimately jeopardizes the timing arguments and potentially invalidates the evidence
gathered to successfully undergo the mandatory timing Verification and Validation (V&V) process,
in accordance with safety regulations.
While the PMUs in mainstream processors do offer a promising baseline for this low-level analysis,
the historical role and limited relevance PMUs have been given in mainstream systems – from where
PMU design in CRTES chips is inherited – is in strident contrast with the critical role they would
acquire for timing analysis. In fact, PMUs and Performance Monitoring Counters (PMCs 2) have
been traditionally intended to capture average behavior rather than the worst-case one and have
been used as cursory, low-level debugging support by the chip manufacturer (hence, with reduced
need for detailed documentation). Moreover, the fact that PMU and PMCs do not directly impact
the timing and functional behavior of applications running on top of the platform has a twofold
consequence:
1. PMU’s inclusion in the hardware design usually occurs in late design phases, with reduced
flexibility to incorporate new counters or to fix potential deviations
2. The PMU does not need to comply with high-integrity constraints and can be designed
according to low-integrity (e.g., ASIL-A) requirements.
This difference in integrity level exposes system designers to the evident paradox of using low
integrity, poorly-documented PMUs as the basis for timing analysis mechanisms that are expected
to guarantee that the system achieves enough freedom from interference for higher-integrity tasks
(e.g., ASIL-C/D). High-integrity (i.e. ASIL C/D), WCET-aware, well-documented PMUs will
become an instrumental tool to simplify and consolidate the arguments in support to timing V&V
in the presence of automotive multicore complex processors [42].
1.2 Contribution
In this Thesis, we take a step towards reconciling PMU verification, which is often disregarded,
with its critical role for timing analysis. Our contributions are as follows:
1. Analysis of Event Monitor Correctness. We perform an analysis for several event monitors
which are present i) in the GPU of the NVIDIA AGX Xavier and TX2 development boards,
2PMCs are the software visible and programmable registers to read HEMs. The latter store counts of events that
are made visible to the software via PMCs. For simplicity, we refer to both indistinctly.
8

Chapter 1. Introduction
and ii) in the CPU of the Xilinx UltraScale+ SoC, and we assess them against their techni-
cal specification provided by the manufacturer. Our goal is not to cover all event monitors
supported by those architectures, since they comprise several hundreds [32]. Our focus is,
instead, illustrating that some event monitors might not behave as one would expect, and, for
specific code snippets, we show that some discrepancies occur between observed event counts
and the expected values that a performance analyst would expect based on the event mon-
itors specification provided in the corresponding product manuals. Such evidence supports
our claim that OEMs/TIER/timing analysis companies cannot blindly trust event monitors
without a preliminary validation process.
2. Monitor Validation Process. We describe the steps to follow in a manual validation process
that helps in the validation of the event monitors of COTS SoCs. We also show a practical
application of this process to a small subset of monitors in i) the NVIDIA Jetson AGX
Xavier, ii) the TX2 and in iii) the Zynq UltraScale+ MPSoC. Those event monitors, for
which discrepancies are detected w.r.t. the expected values, are put under quarantine and
investigated. For some of them, and as a result of the application of the validation process,
we show that discrepancies can be explained, hence regaining trust on the correctness of the
hardware event monitor.
3. Assessment of an automatic validation process. We discuss the difficulties of developing a
systematic and automatic process for event monitor validation. In contrast with other verifi-
cation activities (e.g., unit testing), the PMU validation process cannot be easily automated
because event counters are extremely target-specific and their operation may differ depending
on the processor vendor and the specific hardware/software configuration. However, manual
procedures are frequent in verification and certification processes. This includes all safety-
related software in an automotive system that needs to undergo a manual inspection process
in order to be certified.
The contribution of this Thesis has been published in the following paper [8]:
• On the reliability of hardware event monitors in MPSoCs for critical domains
Barrera, J.; Kosmidis, L.; Tabani, H.; Mezzetti, E.; Abella, J.; Fernandez, M.; Bernat, G.;
Cazorla, F. J. . On the reliability of hardware event monitors in MPSoCs for critical domains.
A: ACM Symposium on Applied Computing. ”The 35th Annual ACM Symposium on Applied
Computing: Brno, Czech Republic, March 30-April 3, 2020”. New York: Association for
Computing Machinery (ACM), 2020, p. 580-589.
1.3 Thesis Organization
The rest of this Thesis is organized as follows:
9

Chapter 1. Introduction
• Chapter 2 provides the necessary information in order to understand the context of the field
as well as the purpose of this Thesis and its main related works.
• Chapter 3 presents a methodological approach to validate event monitors against their spec-
ification and discusses the difficulties of making this process fully automated.
• Chapter 4, Chapter 5, and Chapter 6 report on the application of the proposed validation
process to a selection of event monitors in the NVIDIA Jetson AGX Xavier, the NVIDIA
Jetson TX2, and the Xilinx Zynq Ultrascale+ respectively.
• Chapter 7 concludes the Thesis presenting the main take away messages.
10

Chapter 2
Background and Related Work
In this Chapter, we present a brief summary of timing analysis approaches for real-time systems,
as well as the role that performance counters play in the validity of these methods. Finally, we
present the most relevant works to ours.
2.1 Timing Analysis
In this Thesis, we focus on the timing verification of CRTES, which is equally important to its
functional verification. The purpose of timing verification is to ensure that the software complies
with its timing requirements, which are expressed in terms of tasks’ periods and deadlines. This
is achieved by performing a process known as timing analysis, which is used in order to compute
(or estimate) the Worst-Case Execution Time (WCET) of the task under analysis, which is the
maximum time a task can take under any circumstances. However, determining this time precisely
is very hard to achieve – if at all possible for large, complex programs – so frequently it is enough
to select an upper bound of this time, which is frequently used as WCET.
There are several methods in the literature which can be used for computing the WCET, which are
summarized in Table 2.1. It is worth to note that there is no perfect WCET computation technique,
since each one is based on a set of assumptions [4]. Whether these assumptions are satisfied has an
effect in the soundness and accuracy of each method. In the following sections we briefly examine
the characteristics of each one.
2.1.1 SDTA: Static Deterministic Timing Analysis
The SDTA techniques derive the WCET bounds for a given task without executing it in the target
platform, instead, it combines the results from two models, the abstract hardware model and
11

Chapter 2. Background and Related Work
Deterministic Probabilistic
Static SDTA SPTA
Measurement-based MBDTA MBPTA
Hybrid HYDTA HYPTA
Table 2.1: Taxonomy of WCET techniques.
the structural representation of the task under analysis. SDTA approaches consider all possible
inputs for a program and the search space is kept within a tractable dimension only by using
safe abstractions of the software and hardware. Despite the precision of STDA, the inputs and
assumptions in the analysis steps may result into inaccuracies if they are defective. Nevertheless,
STDA is an industrially-viable option for timing analysis if the hardware and software are simple
and well documented.
2.1.2 MBDTA: Measurement-Based Deterministic Timing Analysis
MBDTA derives the WCET estimates by collecting measurements from the execution on top of
the target platform. MBDTA trustworthiness is dependant on whether the target platform is the
same as the ones for deployment, if the input data include the scenario leading to the WCET and
finally, if the measurements are accurate and they are used for the WCET estimation. Since it is
unknown whether the input data includes the scenario leading to the WCET – an input known
as the Worst-Case Input, whose identification is an open problem and usually it depends on the
software developer’s knowledge of the software –, the gap between the highest observed execution
time (HOET) and the WCET is not known. Therefore, it is common to apply a certain engineering
factor to the HOET to estimate the WCET if the user has a non-negligible knowledge of both
hardware and software being analysed. For example, a common engineering margin used in the
avionics sector is 20%, for the particular software and hardware used in this sector [65].
2.1.3 HDTA: Hybrid Deterministic Timing Analysis
The HDTA approaches purpose is to bring the best from SDTA and MBDTA into a single technique,
increasing the confidence in the measurements with static information while keeping industrial
viability of the approach. The hybrid approaches achieve a better trustworthiness than MBDTA
as well as they help to aliviate the workload of the user when it comes to produce tests. Hybrid
analysis techniques use measurements to infer hardware properties required to build the static
model [45] which makes them susceptible to the accuracy of the performance counters used to
derive the model.
12

Chapter 2. Background and Related Work
Figure 2.1: Example of pWCET curve [44]
2.1.4 SPTA: Static Probabilistic Timing Analysis
As well as SDTA, SPTA is limited to simple processor models, but with the addition of limitations
on the associativity of caches. The applicability of SPTA to more realistic processor designs has
not been proven yet, which makes it a non-viable alternative for industrial use. Nevertheless, the
trustworthiness of SPTA suffers from the same challenges as SDTA techniques.
2.1.5 MBPTA: Measurement-Based Probabilistic Timing Analysis
In contrast with STA, the Measurement-Based Probabilistic Timing Analysis (MBPTA) techniques
execute the program in the real system or in a simulator, measuring the time it takes to execute.
After taking several execution times, an upper-bounded WCET is derived from the execution
time distribution and the proper probabilistic and statistical methods in order to ensure that the
estimation of the WCET is representative. MBPTA on top of MBPTA-friendly hardware keeps
the industrial viability of MBDTA while gaining a higher level of trustworthiness, as it has been
shown in several industrial case studies [25, 64, 65]. Moreover, the same effect can be achieved
in using software only techniques such as software randomization, in order to enable MBPTA on
conventional architectures [17,35,36,64].
The idea behind the probabilistic approach is to produce more than one WCET with an assigned
probability. This enables the system designer to choose a pessimism level with a function that
MBPTA approach collects the execution time and, by applying extreme value theory, can predict
how WCET will behave in extreme cases. With a high enough number of runs, it is possible to see
the curve that, given a probability, provides a WCET value as Figure 2.1 shows. The WCET takes
into acount the deterministic base time and the additional delay (worst-impact) due to contention
13

Chapter 2. Background and Related Work
that happens in the execution.
MBPTA is capable of deriving a tight and reliable WCET with less information than other timing
analysis techniques. In order to achieve this, some hardware components are randomized, since
true random behavior is independent and identically distributed.
2.1.6 HYPTA: Hybrid Probabilistic Timing Analysis
HYPTA is at an infant phase and thus, there is no viable alternative for industrial use. To the best
of our knowledge, PUB [34] and EPC [41, 74] are the main HYPTA techniques so far. Although
PUB increases the path coverage with respect to MBPTA, it relies on automatic code modifications.
Some work has been done in order to increase the path coverage of MBPTA by means of HYPTA
approaches without needing to modify the application under analysis [43]. However, how to link
these new methods to certification processes is still an issue to be tackled.
2.2 Using PMCs in the Timing Analysis Process
As the complexity of MPSoCs in CRTES continues to increase, we are witnessing an increasing
number of works that propose building on PMCs to get timing analysis. These works cover both
static and measurement-based timing analysis techniques.
The increase in complexity of multicore hardware and advanced software functionalities jeopar-
dizes the applicability and effectiveness of conventional timing analysis approaches [4, 56, 68]. It is
then becoming increasingly evident that novel forms of timing analysis are required that capture
the peculiarities of multicore execution [42]. Specific MPSoC execution aspects like utilization of
shared resources and contention delay are captured to meet emerging certification and qualification
requirements (e.g., interference channels characterization [22] and freedom from interference [31]).
Monitoring and profiling solutions are becoming fundamental aspects in the timing verification.
While several profiling and monitoring solutions exist, they have been designed and deployed for
software/hardware debugging and (average) performance optimization purposes, and are not par-
ticularly tailored to timing analysis. In the following, we cover some of the key trade-offs when
considering different tracing solutions, with particular focus on the specific end user requirements.
• Static timing analysis techniques are migrating towards hybrid approaches in which the mea-
surement of PMCs is used to validate the predictions made in metrics like execution time or
access counts [20,21].
• For measurement-based techniques, a full breath of approaches build on PMCs to derive
quotas to the maximum number of events of a given type tasks can generate [18,19,45,54,72].
14

Chapter 2. Background and Related Work
This includes cache access counts and misses.
In this line, we can find a handful of prior works that build on performance counters for software
timing estimation both for deterministic and probabilistic timing analysis methods. Paulisch et
al. [45] build on performance counter events to create an analysis and runtime monitoring solution
for limiting task contention in multicore CPU architectures. Diaz et al. [?] inflate multicore pWCET
estimations derived by MBPTA based on number of cache events obtained with performance coun-
ters, to account for cache contention. In [19] an ILP-based contention model is proposed for the
AURIX automotive microcontroller building on the performance counters available on that plat-
form. In addition, the authors identified limitations in the counting of events of interest using the
available performance counters. Authors in [23, 24] show the importance of documentation since
the lack of it leads to uncontrolled and unknown activities that jeopardizes the WCET estimations
for MBTA.
In [28], authors use performance counters in the CPU of multicore systems for WCET estimation
using measurement-based probabilistic timing analysis. Authors of [27] also used performance
counters for WCET estimation of CPU tasks on multicore systems proposing a method to select the
performance counter with highest contribution and a forecast model to predict execution time under
unseen configurations. Authors in [66, 73] study the variability caused due to non-deterministic
performance counter implementations in CPUs, without analyzing whether values are as expected,
which is instead the target of our work. Nevertheless, in these works, authors observe non-null but
relatively low variability across measurements.
Several works [6, 51] have focused on automotive platforms featuring GPUs such as NVIDIA’s
TX1 and TX2. Some of them have discovered undocumented features of those hardware platforms
like the scheduling policy [6] or exposed mismatches in the software documentation regarding
blocking or asynchronous behavior of CUDA API calls [70]. However, none of these works studies
event monitors, whose behavior and documentation mismatches we expose in this work. To our
knowledge, there is no other work in the real-time literature which considers GPU performance
counters.
In addition, [12, 51] present benchmarking and platform characterization studies of automotive
platforms. Regarding timing modeling of GPUs, in the literature we can find the seminal works [9–
11]. The first two papers build on a simulated GPU for WCET estimation, while our work uses a
real GPU for event monitor validation. On the other hand, [10] relies on end-to-end measurements
on a real-GPU platform for WCET estimation and timing analysis, not validation of performance
counters.
All these works build on the counters from the PMU, trusting that this unit is a reliable source of
information, but no work has performed an assessment on whether the PMU can be trusted as it is.
This lack of verification leaves open the possibility of errors, which can affect the trustworthiness
of the timing analysis.
15

Chapter 2. Background and Related Work
Conclusion. While PMUs may vary depending on the different architecture and family of proces-
sors and platforms, they generally offer the capability to track a large number of events, typically
in the extent of few hundreds or even thousands, related to multiple aspects of execution: from
cache-hierarchy statistics to accesses over the interconnects, as well as instruction counts for dif-
ferent instruction types. Instruction counts are fundamental to assess that the program has been
executed correctly. At type level, memory operations such as loads and stores are needed to derive
cache miss rates. Likewise, uncacheable loads and stores allow to assess the memory accesses of
the program.
The fine-grained information that can be obtained from hardware event monitors can be used
to improve the understanding of the timing behavior of an application [18, 19], to enforce usage
thresholds for shared components [45], and to define a more accurate timing model of contention-
prone hardware resources [19]. Ultimately, these aspects concur with the sought-after properties
of freedom from interference in ISO-26262 (and interference channels identification in CAST-32A)
to guarantee that timing faults cannot propagate across software elements with different criticality
levels. However, the following question arises: whether the information derived from event monitors
in PMUs can be trusted for supporting timing evidence for certification purposes [42].
The critical role of PMU information clashes with their intended purpose, as PMUs were originally
devised as means to support low-level performance tuning and to provide rough outlines about
the average behavior of the software running on top of it. In fact, PMUs have been traditionally
developed at the lowest-integrity levels (if any), under quite relaxed V&V criteria, and are, thus,
more error prone than components intended for higher integrity levels [42]. Moreover, PMUs are
generally accompanied with scarce and inaccurate documentation [50]. Therefore, PMU information
cannot be straightforwardly used as a cornerstone for the provision of solid certification arguments
on the timing behavior. Instead, PMU must undergo a rigorous validation process to guarantee
the information they provide can be trusted for timing V&V.
16

Chapter 3
Event Monitor Validation Process
In this Thesis we contend that it is required to use a methodological approach to validate event
monitors in order to use Performance Monitoring Counters (PMCs) with high confidence as part
of MPSoC timing verification [18, 45, 54, 72]. Defining a generic toolkit for validation is not usu-
ally practical due to the large number of available events with differences in terms of operation
and characteristics across processor vendors or even across models from the same vendor and they
depend on the hardware and system software configuration. Nevertheless, what can be done in-
stead, is defining a general methodological process that can be later fine-grained defined, based on
expertise knowledge, for a specific event monitor and platform configuration. We call this general
methodology Event Monitor Validation Process (EMVP).
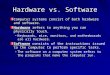
3.1 Event Monitor Validation Process (EMVP)
The validation of event monitors is a test driven process in which each monitor is exercised while
running specifically designed programs. The value counted by the monitor is compared with an
expected value, estimated based on the target platform hardware and software and the test program
to assess whether it can be deemed as a trusted monitor, i.e. the counted value and the expected
value match or present a gap within acceptable threshold, or not. The proposed EMVP comprises
several steps as seen at Figure 3.1. From the steps on the process, some of them require technical
knowledge in order to do an informed tailoring, hence, an expert analyst will perform some of the
activities.
Event Selection. Following the trend of processors in the high-performance domain, the number of
event monitors in the latest processors in domains such as automotive is in the order of hundreds.
As an example, the Xavier SoC offers 273 event monitors accessible from the profiler and the
debugger for its Pascal GPU. Hence, an exhaustive validation of all event monitors can be too
costly in general. Instead, the analyst can discard those event monitors that do no affect the
17

Chapter 3. Event Monitor Validation Process
Figure 3.1: EMVP Diagram
timing/safety argumentation based on requirements coming from the upper timing V&V, and
hence, do not require any validation. Also, in some architectures, the hardware allows multiple
configurations (a.k.a. platform usage domain or Critical Configuration Setting [22], which impact
the event monitors to validate. For instance, if a given resource is partitioned (segregated) it might
not be needed to track per-core/task access counts to it. Note that, strictly speaking, this step,
represented as 0 in Figure 3.1, is not part of the monitor validation process, which only focuses on
the validation of the events provided as input. We have added this preliminary step to the diagram
for completeness.
Experiment and representative benchmark (rbe) design. From the description of the events
in the processor manuals or programmers’ guidelines and the understanding of the processor ar-
chitecture, the analyst designs one or several baseline representative benchmarks or rbe 1 . The
rbe must have two key characteristics. First, the rbe needs to exercise the event monitor. Second,
the analyst can derive the expected value of the event monitor for that rbe, which means that the
rbe must be simple enough to allow the analyst to place enough confidence on the expected values.
For a certification argument, the completeness of the used rbe to exercise the event monitor under
validation must be justified.
Validation campaign. Empirical evidence is collected on the target. The rbe is executed in
controlled scenarios 2 configured by the analysis on the target platform to reduce as much as
18

Chapter 3. Event Monitor Validation Process
possible external sources of variability, e.g. operating system. In each run, the PMU is configured
to read the event monitor under validation.
Acceptance criteria. Next the analyst compares the expected results and those captured with
event monitors 3 . In case a discrepancy is detected, this can be due to either an imprecise technical
documentation of the event monitor in the users’ manual, or an actual misbehavior in the counter
logic. Either the case, the counter cannot be used as-is for timing V&V purposes and further
investigation is required to understand, and possibly resolve, the cause of the inconsistency. If no
discrepancy is detected in the tests carried out, the counter is deemed as trustable 4 based on the
tests performed.
Formulate hypotheses. For those counters whose measured values do not match expected ones,
the analyst formulates hypotheses 5 on the causes for the observed misbehaviour. This relates to
understand the experiment, the architecture and the expected results. For instance, by determining
the magnitude of the discrepancy and the expected values for other related events, the analyst can
formulate further hypotheses to be verified. The process continues, going back to step 1, in which
the same or new rbe are used to accept/reject the hypotheses. In case it is accepted, then the
discrepancy between the observed and the expected values is understood and can be corrected.
Instead, if it is rejected, time/effort allowing, new hypotheses are formulated and the whole process
starts over. If no further hypotheses can be formulated and/or tested, the event monitor is regarded
as untrusted 6 .
3.2 Systematic and Automated Validation
The apparently simple assessment process is inherently platform-specific and requires deep technical
knowledge on both the nominal behavior of the target hardware components and the manifold
platform and PMU configurations. Hardware and software development have benefited from some
form of automated functional verification based on relatively high-level models of both hardware
and software. However, no abstraction model is available for the verification of PMUs. PMUs touch
the lowest levels of hardware design and their black-box verification can only be performed building
on the understanding and expertise of a hardware expert. In particular, expertise is required in
order to select the subset of relevant event monitors to be empirically validated. Further it is not
possible to automatically generate the platform configuration and verification snippets necessary
to validate a given monitor because both vary across ISA, platforms, models, and versions.
Having an expert supervising a verification or certification process, however, is consolidated prac-
tice. Several aspects in testing are delegated to the expertise of testing engineers, especially for
the verification of system-wide properties. Several objectives in CAST-32A rely on the guidance
of an external assessment as, for example, the identification of interference channels, the verifica-
tion of inter-core data and control coupling, or the implementation (and coverage) of the safety
19

Chapter 3. Event Monitor Validation Process
net [22]. In some of these cases, there is not even a metric or criteria (such as MC/DC - Modified
Condition/Decision Coverage or branch for structural coverage) to determine when testing can be
deemed sufficient.
3.3 Automation Opportunities
Following the discussion in Section 3.2, a question that arises is whether some of the steps in the
proposed methodological approach can benefit from some form of automation.
Regarding step 1 , on experiment and rbe design, while specific procedures can be set, we are not
aware of any technology that from the technical reference manual of a processor and the event
monitor to validate, can systematically and automatically define a (set of) rbe(s) to validate it.
Instead, this task is to be done manually by a performance analyst, i.e. following predefined
procedures, as for design inspection and walkthrough in functional safety verification processes.
Once rbe(s) are defined, tool support can be used to derive the expected value for some of the
event monitors for that rbe. The analyst could also exploit a database of rbe(s) with precomputed
event monitor values, which can be obtained through state-of-the-art simulators or assembly-code
analyzers. This of course implies that the used tools shall be qualified to the appropriate criticality
level according to the applicable safety standards.
Step 2 is mostly procedural and can be in large part automated building on an automated test
framework.
In terms of acceptance criteria 3 , similarly to step 1 , there is no systematic approach to determine
which acceptance criterion is correct to apply on each case. In fact, such criterion is to be assessed
by the expert analyst and properly described and sustained in front of the certification authorities,
building upon repeatable protocols.
Likewise, in step 5 and once a deviation is detected in the event counter, we are not aware of any
solution to automatically formulate hypotheses to explain the observed behavior and design new
experiments (and likely a rbe) to assess them. Hence, it also requires human intervention.
3.4 Conclusion
While full automation is not possible, it is important to establish well-defined procedures that
allow performing the verification processes exhaustively and reviewing them easily and avoiding
ambiguities and misunderstandings. In the particular case of the reliability of event monitors, the
focus of this work, we propose a specific procedure that we apply in specific events and platform
examples. This procedure and its results, in the form of evidence verifying what each event monitor
counts in practice is the basis upon which OEMs/TIER/tool vendors can build timing analysis
20

Chapter 3. Event Monitor Validation Process
methods and tools for complex SoCs where timing guarantees build upon event quota budgeting,
monitoring, and enforcement [18,45,54,72].
In the following three chapters, we apply EMVP to some platforms from different vendors and
architectures. The assessments on the platforms will be performed as follows:
1. NVIDIA Jetson AGX Xavier: Assessment on its Nvidia Volta GPU
2. NVIDIA Jetson TX2: Assessment on Nvidia its Pascal GPU
3. Xilinx Zynq Ultrascale+: Assessment on its Cortex-A53 CPU
21

Chapter 4
Assessment of EMVP on the NVIDIA
Jetson AGX Xavier
We start assessing our validation approach on a selection of event monitors in the NVIDIA Jetson
AGX Xavier. In particular, we focus on type-based instruction counts, a basic information element
used for several aspects of timing analysis. This includes the following:
1. For quota monitoring, store counts is important when first level data caches are write-through
as each store causes a transfer to the inter-core shared interconnection or the next (second
level) shared cache level.
2. Instruction counts for uncacheable loads and stores determine how many times specific de-
vices, subject to contention, are used.
3. Instruction counts are also used for timing validation as they allow assessing whether programs
experience preemption by comparing instruction counts between runs on bare metal and on
top of the analysed RTOS.
Table 4.1 shows the instruction types used in this analysis for the NVIDIA Jetson AGX Xavier
GPU. The first column describes the particular event monitors to validate, while the second column
provides the description in the official GPU provider documentation. To obtain this information, we
used the NVPROF tool [48] from CUDA 10.0 version toolkit as follows: nvprof --query-events
--query-metrics. As it can be seen, each event monitor counts certain instruction types. The
particular operation codes under each instruction type are provided in a different document [2]. The
third column lists the subset of opcodes under each instruction type on which we focus (extending
this to other opcodes is an engineering work following the same EVMP approach). For instance,
inst integer captures the following opcodes: BMSK, BREV, FLO, IABS, IADD, IADD3, IADD32I, IDP,
IDP4A, IMAD, IMMA, IMNMX, IMUL, IMUL32I, ISCADD, ISCADD32I, ISETP, LEA, LOP, LOP3, LOP32I,
22

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
Table 4.1: Instruction types used in this analysis for the NVIDIA Jetson AGX Xavier GPU.
Event [2] Official Description [2] Opcodes
counted [2]
inst integer Number of integer instructions executed by non-
predicated threads
IMAD, IADD3, SHF,
LOP3, ISETP
inst fp 32 No. of single-precision fp instructions executed by non-
predicated threads (arithmetic, compare, etc.)
FSETP, FMUL,
FADD, FSEL
inst compute ld st Number of compute load/store instructions executed by
non-predicated threads
LDS, LDG, STS,
STG
inst control Number of control-flow instructions executed by non-
predicated threads (jump, branch, etc.)
BRA, EXIT
inst bit convert Number of bit-conversion instructions executed by non-
predicated threads
I2F
no event Instructions that move data across registers MOV, SHFL
inst misc Number of miscellaneous instructions executed by non-
predicated threads
NOP, S2R, BAR
not pred off thread inst exec Number of thread instructions executed that are not
predicated off
Total
POPC, SHF, SHL, SHR, VABSDIFF, VABSDIFF4. From those we focus on those boldfaced as they are
the only ones that appear in our tests. Interestingly, there is not event counter to track MOV and
SHFL instructions.
4.1 Experiment and representative benchmark design
We build on a matrix copy program on which we can derive the number of instructions expected of
each type. Figure 4.1 (top) shows the C code with CUDA calls of the program, and the correspond-
ing GPU assembly (SASS) code produced for this specific GPU, by using cuobjdump (bottom).
Instructions 1 and 2 in the SASS code comprise the kernel’s prologue, performing the kernel ini-
tialization. Instructions 3 to 6 load to registers the thread and block identifiers which are used in
the right hand side of the CUDA source code in lines 4 and 5. Instructions 7 to 9 in the SASS code
compute the thread access positions stored in the variables in the left hand side of source code lines
4 and 5. Instruction 10 calculates the index within the brackets of source code line 6. Instructions
11 and 13 calculate the memory address for arrays d x and d y respectively. Instruction 12 performs
the load access from d x while instruction 14 carries out the store access to d y. Finally, instruction
15 terminates the kernel.
As shown in the kernel invocation in line 23 of the source code, the kernel is launched with 1024x1024
threads. Each instruction is executed by all threads, which allows us to compute the number of
expected instructions for each type of instruction, in order to validate it with the measurements
of those instructions obtained with performance counters in the next step. Therefore, we expect
the SASS code on the right to be executed 1,048,576 times, thus leading to 16,777,216 (16 · 220)
23

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
1 #inc lude <s t d i o . h>
2
3 global void copy ( i n t N, f l o a t ∗d x , f l o a t ∗d y ) {4 i n t x = blockDim . x∗blockIdx . x + threadIdx . x ;
5 i n t y = blockDim . y∗blockIdx . y + threadIdx . y ;
6 d y [N∗y + x]=d x [N∗y + x ] ;
7 }8
9 i n t main ( void ) {10 i n t N = 1024 ;
11 f l o a t ∗x , ∗y , ∗d x , ∗d y ;
12 x = ( f l o a t ∗) mal loc (N∗N∗ s i z e o f ( f l o a t ) ) ;13 y = ( f l o a t ∗) mal loc (N∗N∗ s i z e o f ( f l o a t ) ) ;14 dim3 g r id (32 ,32) ;
15 dim3 block (N/32 ,N/32) ;
16 cudaMalloc(&d x , N∗N∗ s i z e o f ( f l o a t ) ) ;17 cudaMalloc(&d y , N∗N∗ s i z e o f ( f l o a t ) ) ;18 f o r ( i n t i =0; i<N∗N; i++){19 x [ i ]=42.0 f ;
20 }21 cudaMemcpy( d x , x ,N∗N∗ s i z e o f ( f l o a t ) , cudaMemcpyHostToDevice ) ;
22 copy<<<gr id , block>>>(N, d x , d y ) ;
23 cudaMemcpy(y , d y ,N∗N∗ s i z e o f ( f l o a t ) , cudaMemcpyDeviceToHost ) ;
24 cudaFree ( d x ) ;
25 cudaFree ( d y ) ;
26 f r e e ( x ) ;
27 f r e e ( y ) ;
28 }29
1 /∗0000∗/ MOV R1 , c [ 0 x0 ] [ 0 x28 ] ;
2 /∗0010∗/ @!PT SHFL. IDX PT, RZ, RZ, RZ, RZ;
3 /∗0020∗/ S2R R0 , SR CTAID .X;
4 /∗0030∗/ S2R R2 , SR TID .X;
5 /∗0040∗/ S2R R3 , SR CTAID .Y;
6 /∗0050∗/ S2R R4 , SR TID .Y;
7 /∗0060∗/ MOV R5 , 0x4 ;
8 /∗0070∗/ IMAD R0 , R0 , c [ 0 x0 ] [ 0 x0 ] , R2 ;
9 /∗0080∗/ IMAD R2 , R3 , c [ 0 x0 ] [ 0 x4 ] , R4 ;
10 /∗0090∗/ IMAD R0 , R2 , c [ 0 x0 ] [ 0 x160 ] , R0 ;
11 /∗00a0∗/ IMAD.WIDE R2 , R0 ,R5 , c [ 0 x0 ] [ 0 x168 ] ;
12 /∗00b0∗/ LDG.E.SYS R2 , [R2 ] ;
13 /∗00 c0 ∗/ IMAD.WIDE R4 , R0 ,R5 , c [ 0 x0 ] [ 0 x170 ] ;
14 /∗00d0∗/ STG.E.SYS [R4 ] , R2 ;
15 /∗00 e0 ∗/ EXIT ;
16 /∗00 f0 ∗/ BRA 0xf0 ;
17
Figure 4.1: CUDA/SASS code of matrix copy benchmark for AGX Xavier.
instructions. Those instructions are broken down into 3 ·220 data movement (MOV and SHFL), 4 ·220
miscellaneous (S2R), 5 · 220 integer (IMAD), 2 · 220 load/store (LDG and STG), and 1 · 220 control
flow (EXIT and BRA). Note that EXIT acts as a safeguard following the kernel termination.
24

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
Table 4.2: Measured/Expected values for matrix copy benchmark for Nvidia Jetson AGX Xavier
Event Expected Measured Discrepancy
(1) ‘DMOV’ 3,145,728 0 -3,145,728
(2) inst misc 4,194,304 6,291,456 2,097,152
(3) inst integer 5,242,880 5,242,880 0
(4) inst compute ld st 2,097,152 2,097,152 0
(5) inst control 2,097,152 1,048,576 -1,048,576
(6) Total 16,777,216 14,680,064 -2,097,152
4.2 First Validation Step
From the collected values we have detected several discrepancies in comparison to the expected
values, as shown in Table 4.2. For each instruction type we report the number of instructions
expected based on our analysis of the SASS code, those counted with the event monitors, and
the discrepancies. Note that we exclude those types for which we both expect and count zero
instructions. We extract the following conclusions:
(1) Data movement instructions, as expected, are not counted at all since there is no specific event
to count them.
(2) Surprisingly, the number of miscellaneous instructions measured is higher than that in the SASS
code. In particular, there are 4 S2R in the SASS code executed ≈ 1 million times each (1,048,576
threads), so we would expect ≈ 4 million MISC instructions counted. However, inst misc reports
≈ 6 million MISC instructions, as if there were 2 additional MISC instructions per thread in the
SASS code.
(3), (4) Integer and loads/stores are counted properly.
(5) The total number of instructions measured matches the addition of the individual types counted.
However, this number is different from the total number of expected instructions. Hence, we
need to further analyse the event counters inst misc, ‘DMOV’, and Total. On the contrary, for
inst integer, inst control and inst compute ld st, since the counts we observe for both ex-
periments in Figure 4.1 and Figure 4.2 – explained later – are precise, we consider them reliable.
First set of Hypotheses. From these results, we formulate the following hypotheses. The
inst misc monitor counts two instructions beyond those appearing in the SASS code and regarded
as MISC according to NVIDIA’s documentation [2]. We hypothesize that other instructions are
counted as MISC:
• Hypothesis 1a. Either those other instructions correspond to a different category, but are
counted as MISC.
• Hypothesis 1b. Or they are instructions not shown in the SASS code. After reviewing the
25

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
Pre-loop
loop
prolog
Loop body
Post loop
Figure 4.2: SASS code of the combined example.
semantics of the program in the SASS code, we verify that addresses are properly computed,
data read from the source matrix and written in the destination matrix. Thus, we cannot
attribute any specific operation to the potentially hidden instructions (e.g. they could be NOP
instructions).
26

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
Figure 4.3: MISC inst. counted and expected (example in Fig. 4.2).
4.3 Second Validation Step
In order to test the hypotheses above, we have performed a number of individual experiments. Each
of them aims at varying the instruction counts for the different instruction types whose counters
report discrepancies w.r.t. the expected values. By doing so and comparing the expected number
of instructions for those instruction types against actual event counts, we expect to discern which
of the formulated hypotheses is the right one in each case and, if all of them are rejected, obtain
additional information to raise new informed hypotheses. For the sake of simplicity, we have merged
all experiments into a single one. The combined experiment contains a loop within which we can
vary the number of iterations and hence, the number of executed instructions of each type. The
SASS code of this example is shown in Figure 4.2. Hexadecimal numbers on the left show the
instruction address. Arrows indicate the direction of the conditional branches, which in fact are
predicated unconditional branches. Predicates are shown as @!PT, @!P0 and @!P1. The program
starts by executing instructions 10h-30h. When the loop is executed at least once, BRA at 40h is
not taken and the rest of the execution continues until the BRA in 120h. That branch is taken
for each additional iteration, thus looping in instructions 90h-120h. Whenever it is not taken,
instructions from 130h until the end of the program are executed. Therefore, instructions 10h-40h
and 130h-1F0h are executed exactly once. Instructions 50h-80h are executed exactly once as long
as the loop iterates at least once. Instructions 90h-120h are executed as many times as the loop is
intended to execute. Note that, in theory, instructions 200h-270h should not be executed since the
EXIT instruction at address 1F0h should terminate the kernel execution. Why those instructions
are part of the SASS code is not documented by NVIDIA and, in any case, they should not have
any functional effect.
For runs with 0, 1, 2 and 10 iterations, Table 4.3 shows that inst control, inst compute ld st,
inst fp 32, inst integer, and inst bit convert event counters match exactly the number of
instructions executed. For instance, in the case of 1 loop iteration, where all instructions in the SASS
code are executed exactly once, one would expect 9 INT, 7 FP32, 3 LDST and 1 CONV instructions (see
Table 4.1) for each of the 1,024 threads, which matches exactly the corresponding event counters.
Also for inst control, when the number of iterations is 0, the BRA at 40h is taken, and then only
27

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
Table 4.3: Instruction types in Figure 4.2.
Event Exp. Meas. Exp. Meas. Exp. Meas.
0 iter 0 iter 1 iter 1 iter 10 iter 10 iter
‘DMOV’ 4,096 0 6,144 0 15,360 0
inst misc 9,216 5,120 9,216 7,168 9,216 16,384
inst integer 4,096 4,096 9,216 9,216 36,864 36,864
inst fp 32 3,072 3,072 7,168 7,168 34,816 34,816
inst compute ld st 3,072 3,072 3,072 3,072 3,072 3,072
inst control 3,072 2,048 2,048 1,024 11,264 10,240
inst bit convert 0 0 1,024 1,024 10,240 10,240
Total 26,624 17,408 37,888 28,672 120,832 111,616
the EXIT instruction at the end is executed (the BRA at 200h is never executed). When the number
of iterations is N , N > 0, then the BRA at 40h is not taken, the BRA at 120h is taken N − 1 times
and not-taken once, the EXIT and the BRA at the end are executed also once. Overall, we expect
N + 1 (BRA+EXIT) instructions.
Assessing hypotheses 1a and 1b. In order to determine the source of the unexpected MISC
instructions, we build upon the example in Figure 4.2. In particular, consider the case with 1
loop iteration for simplicity, so that all instructions are executed exactly once. The event counter
indicates that there are 7 MISC instructions per thread. In the SASS code, we can identify 2 S2R and
7 NOP instructions. Thus, differently to the previous example, where we were expecting more events
than the ones provided by the event monitor, this time the monitor is undercounting. In order to
have additional information, we also include the result of executing the loop 10 times, where we
still would expect 9 MISC instructions per thread, since S2R and NOP instructions are outside the
loop, but the MISC counter then counts 16 instructions. Thus, by having 9 additional iterations,
the counter increases by 9. This behaviour also holds for other numbers of loop iterations. We
conclude that:
(1) Exactly one instruction in the loop (90h-120h) is counted as MISC. If we discard all INT, FP32
and CONV instructions in the loop, which we regarded as precisely counted by their corresponding
event counters, we get only a MOV instruction. Thus, we consider that MOV instructions are counted
as MISC.
(2) We revisit the example of the matrix copy in Figure 4.1, where we have exactly 4 S2R and
2 MOV instructions per thread. If we analyse the MISC counter in that case, which overcounted 2
instructions per thread, we realize it is fully precise if we include MOV instructions. Therefore, we
conclude that both, S2R and MOV instructions are counted as MISC.
(3) We compare MISC measured against theoretical MISC (S2R+NOP), MISC and MOV (S2R+NOP+MOV),
and only S2R+MOV, see Figure 4.3.
Overall, we conclude that although MOV instructions are classified as data movement instructions
28

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
1 /∗0000∗/ MOV R1 ,2 c [ 0 x0 ] [ 0 x28 ] ;3 /∗0010∗/ @!PT SHFL. IDX PT,4 RZ, RZ, RZ, RZ;5 /∗0020∗/ S2R R4 ,SR CTAID .X;6 /∗0030∗/ S2R R2 , SR TID .X;7 /∗0040∗/ MOV R5 , 0x4 ;8 /∗0050∗/ NOP;9 /∗0060∗/ IMAD R4 , R4 ,
10 c [ 0 x0 ] [ 0 x0 ] ,R2 ;11 /∗0070∗/ IMAD.WIDE R2 , R4 ,12 R5 , c [ 0 x0 ] [ 0 x168 ] ;13 /∗0080∗/ LDG.E.SYS R2 ,14 [R2 ] ;15 /∗0090∗/ IMAD.WIDE R4 , R4 ,16 R5 , c [ 0 x0 ] [ 0 x170 ] ;17 /∗00a0∗/ STG.E.SYS [R4 ] ,R2 ;18 /∗00b0∗/ EXIT ;19 /∗00 c0 ∗/ BRA 0xc0 ;20 /∗00d0∗/ NOP;21 /∗00 e0 ∗/ NOP;22 /∗00 f0 ∗/ NOP;
1 /∗0000∗/ MOV R1 ,2 c [ 0 x0 ] [ 0 x28 ] ;3 /∗0010∗/ @!PT SHFL. IDX PT,4 RZ, RZ, RZ,RZ;5 /∗0020∗/ S2R R4 ,SR CTAID .X;6 /∗0030∗/ S2R R2 , SR TID .X;7 /∗0040∗/ MOV R5 , 0x4 ;8 /∗0050∗/ NOP;9 /∗0060∗/ NOP;
10 /∗0070∗/ NOP;11 /∗0080∗/ IMAD R4 , R4 ,12 c [ 0 x0 ] [ 0 x0 ] ,R2 ;13 /∗0090∗/ IMAD.WIDE R2 , R4 ,14 R5 , c [ 0 x0 ] [ 0 x168 ] ;15 /∗00a0∗/ LDG.E.SYS R2 ,16 [R2 ] ;17 /∗00b0∗/ IMAD.WIDE R4 , R4 ,18 R5 , c [ 0 x0 ] [ 0 x170 ] ;19 /∗00 c0 ∗/ STG.E.SYS [R4 ] ,R2 ;20 /∗00d0∗/ EXIT ;21 /∗00 e0 ∗/ BRA 0xe0 ;22 /∗00 f0 ∗/ NOP;
Figure 4.4: SASS code of two examples with NOP instructions.
in [2], they are effectively counted as MISC instructions. Instead, NOP instructions, classified as MISC,
are not counted. However, all those NOP instructions are exactly after the last BRA instruction, thus
not executed in practice. Hence, it remains unknown whether MISC counts executed NOP instructions
or it never counts them.
Observation 1: inst misc counts S2R and MOV and it remains unknown whether it counts
executed NOP instructions.
Second set of Hypotheses. We formulate two hypotheses, as consequence of the investigation
of hypotheses 1a and 1b;
• Hypothesis 2a. MISC does not count NOPs, which matches the fact that, so far, those NOPs
found in the SASS code have not been counted in any experiment.
• Hypothesis 2b. MISC counts NOP instructions only if effectively executed, which would be in
line with NVIDIA documentation [2] for executed NOPs.
4.4 Third Validation Step
Assessing hypotheses 2a and 2b. To assess whether NOP instructions before the final BRA
are counted under inst misc, we have performed several experiments but, for the sake of space
limitations, we present the simplest ones solving the unknown. In particular, we manipulated the
source code of the example to enforce the use of NOP instructions, which do not have any functional
impact.
As shown in Figure 4.4, the SASS code of these programs includes NOP instructions before and after
the final BRA instruction. According to the observations before, MISC must be at least 4 per thread.
29

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
1 /∗0000∗/ MOV R1 , c [ 0 x0 ] [ 0 x28 ] ;2 /∗0010∗/ @!PT SHFL. IDX PT, RZ, RZ, RZ, RZ;3 /∗0020∗/ S2R R6 , SR CTAID .X;4 /∗0030∗/ S2R R0 , SR TID .X;5 /∗0040∗/ MOV R7 , 0x4 ;6 /∗0050∗/ IMAD R6 , R6 , c [ 0 x0 ] [ 0 x0 ] , R0 ;7 /∗0060∗/ IMAD.WIDE R2 ,R6 . reuse ,R7 . reuse , c [ 0 x0 ] [ 0 x168 ] ;8 /∗0070∗/ IMAD.WIDE R4 , R6 , R7 , c [ 0 x0 ] [ 0 x170 ] ;9 /∗0080∗/ LDG.E.SYS R2 , [R2 ] ;
10 /∗0090∗/ LDG.E.SYS R4 , [R4 ] ;11 /∗00a0∗/ IMAD.WIDE R6 , R6 , R7 , c [ 0 x0 ] [ 0 x178 ] ;12 /∗00b0∗/ FADD R0 , R2 , R4 ;13 /∗00 c0 ∗/ STG.E.SYS [R6 ] , R0 ;14 /∗00d0∗/ EXIT ;15 /∗00 e0 ∗/ BRA 0xe0 ;16 /∗00 f0 ∗/ NOP;
Figure 4.5: SASS code for the vector addition in Global Mem.
In particular, MISC must count the 2 S2R and the 2 MOV instructions, and exclude the NOP(s) after
the final BRA. If NOP instructions before the final BRA were not counted, we would obtain in both
cases that MISC is exactly 4. However, in the example in the left figure MISC is 5, whereas in the
right figure MISC is 7, thus including those 1 and 3 NOPs before the final BRA respectively.
Table 4.4: Event counts for the vector addition benchmarks.
Event Gmem Smem VSmem Smem Smem
0 sync 0 sync 1 sync 2 sync
inst misc 4,096 4,096 4,096 5,120 6,144
inst integer 4,096 5,120 5,120 5,120 5,120
inst fp 32 1,024 1,024 1,024 1,024 1,024
inst compute ld st 3,072 6,144 9,216 8,192 9,216
inst control 1,024 1,024 1,024 1,024 1,024
Total 13,312 17,408 20,480 20,480 22,528
Observation 2: inst misc also counts NOP instructions if executed (thus excluding those after
the final BRA).
4.5 Assessment on Complex Code
In order to further assess our findings, we have evaluated several benchmarks, as well as kernels
extracted from the Rodinia benchmark suite [15, 16], a widely used benchmark suite for GPUs.
In this Thesis, we report the results we obtained on benchmarks, which suffices for illustrative
purposes. In particular, we analyse a vector addition benchmark whose SASS code has no loops
and the only predicated instruction is a DMOV instruction (hence not counted). In Figure 4.5
we analyse the global memory (GMEM) incarnations of that same benchmark, the other variants
(shared memory (Smem) with variable synchronization (sync) points) are not listed due to space
constraints.
Event counts are shown in Table 4.4, with each benchmark executing 1,024 threads. Hence, in-
structions per thread can be matched by dividing by 1,024 the values in the table. For instance,
30

Chapter 4. Assessment of EMVP on the NVIDIA Jetson AGX Xavier
MISC instructions count 2 MOV and 2 S2R instructions in all cases, plus 1 and 2 BAR instructions in
the two last cases respectively.
In all experiments, the observations we made as part of the application our process hold, hence,
event monitor reads match in all cases the (new) expected values:
(i) inst misc includes MOV instructions as well as MISC instructions (excluding NOPs after the final
BRA);
(ii) inst integer, inst control, inst fp 32, inst bit convert, and inst compute ld st, count
their expected instruction types precisely;
(iii) And total instructions match the addition of the other counters.
Overall, the large set of tests conducted for the validation of the event monitors of the Xavier, the
most relevant subset of which is presented in this Thesis, reveals that a methodology like the one
we propose is a prerequisite for a reliable use of the even monitors of GPUs in the timing V&V
process.
31

Chapter 5
Assessment of EMVP on the NVIDIA
Jetson TX2
In order to verify that the validation process works for more than one GPU family, we have also
assessed the PMCs available at the NVIDIA Jetson TX2 Development Board, from the Nvidia
Pascal Family. As we did with the assessment on NVIDIA AGX Xavier, we use the instruction
count’s PMCs as the example PMC set.
Table 5.1: Instruction types used in this analysis for the NVIDIA Jetson TX2 GPU.
Event [2] Official Description [2] Opcodes
counted [2]
inst integer Number of integer instructions executed by non-
predicated threads
XMAD, IADD, SHL,
SHR
inst compute ld st Number of compute load/store instructions executed by
non-predicated threads
LDS, LDG, STS,
STG
inst control Number of control-flow instructions executed by non-
predicated threads (jump, branch, etc.)
BRA, EXIT
no event Instructions that move data across registers MOV
inst misc Number of miscellaneous instructions executed by non-
predicated threads
NOP, S2R, BAR
not pred off thread inst exec Number of thread instructions executed that are not
predicated off
Total
The first column in Table 5.1 describes the particular event monitors to validate, while the sec-
ond column provides the description in the official GPU provider documentation. To obtain this
information we used the NVPROF tool [49] from CUDA 9.2 version toolkit as follows: nvprof
--query-events --query-metrics. As it can be seen, each event monitor counts certain instruc-
tion types. The particular operation codes under each instruction type are provided in a different
document [2]. Column three lists the subset of opcodes under each instruction type on which
we focus (extending this to other opcodes is an engineering work following the same EVMP ap-
32

Chapter 5. Assessment of EMVP on the NVIDIA Jetson TX2
proach). For instance, inst integer captures the following opcodes: BFE, BFI, FLO, IADD, IADD3,
ICMP, IMAD, IMADSP, IMNMX, IMUL, ISCADD, ISET, ISETP, LEA, LOP, LOP3, POPC, SHF, SHL, SHR,
XMAD. From those we focus on those boldfaced as they are the only ones that appear in our tests.
Interestingly, there is not event counter to track MOV instructions.
5.1 Experiment and representative benchmark design
Since we are building the analysis of Nvidia Jetson TX2 based on the previous assessment with
Nvidi Jetson AGX Xavier, the experimental source code is the same, although, when compiled, the
SASS code generate differs due to the change of GPU generation (from Volta to Pascal) and CUDA
version used (from 10.0 to 9.2). The experiment case shown in this section, is the same matrix
copy benchmark shown in section 4.1. Figure 5.1 (top) shows the C code with CUDA calls of the
program, and the corresponding GPU assembly (SASS) code produced for this specific GPU, by
using cuobjdump (bottom).
Instruction 1 in the SASS code comprise the kernel’s prologue, performing the kernel initialization.
Instructions 2 to 5 load to registers the thread and block identifiers which are used in the right
hand side of the CUDA source code in lines 4 and 5. Instructions 6 to 11 in the SASS code
compute the thread access positions stored in the variables in the left hand side of source code
lines 4 and 5. Instructions 12 to 16 calculates the index within the brackets of source code line
6. Instruction couples [17,18] and [20,21] calculate the memory address for arrays d x and d y
respectively. Instruction 19 performs the load access from d x while instruction 22 carries out the
store access to d y. Finally, instruction 23 terminates the kernel.
As shown in the kernel invocation in line 22 of the source code, the kernel is launched with 1024x1024
threads. Each instruction is executed by all threads, which allows us to compute the number of
expected instructions for each type of instruction, in order to validate it with the measurements
of those instructions obtained with performance counters in the next step. Therefore, we expect
the SASS code on the right to be executed 1,048,576 times, thus leading to 25,165,824 (25 · 220)
instructions. Those instructions are broken down into 1 · 220 data movement (MOV), 4 · 220 miscella-
neous (S2R), 15 · 220 integer (XMAD, IADD, SHL, SHR), 2 · 220 load/store (LDG and STG), and 1 · 220
control flow (EXIT and BRA). Note that EXIT acts as a safeguard following the kernel termination.
Table 5.2: Measured/Expected values for matrix copy benchmark at Nvidia Jetson TX2
Event Expected Measured Discrepancy
(1) ‘DMOV’ 1,048,576 0 -1,048,576
(2) inst misc 4,194,304 5,242,880 1,048,576
(3) inst integer 15,728,640 15,728,640 0
(4) inst compute ld st 2,097,152 2,097,152 0
(5) inst control 2,097,152 1,048,576 -1,048,576
(6) Total 25,165,824 24,117,248 -1,048,576
33

Chapter 5. Assessment of EMVP on the NVIDIA Jetson TX2
5.2 First Validation Step
From the collected values we have detected several discrepancies in comparison to the expected
values, as shown in Table 5.2. For each instruction type we report the number of instructions
expected based on our analysis of the SASS code, those counted with the event monitors, and
the discrepancies. Note that we exclude those types for which we both expect and count zero
instructions. We extract the following conclusions:
(1) Data movement instructions, as expected, are not counted at all since there is no specific event
to count them.
(2) The number of miscellaneous instructions measured is higher than that in the SASS code. In
particular, there are 4 S2R in the SASS code executed ≈ 1 million times each (1,048,576 threads),
so we would expect ≈ 4 million MISC instructions counted. However, inst misc reports ≈ 5 million
MISC instructions, as if there were 1 additional MISC instructions per thread in the SASS code.
(3), (4) Integer and loads/stores are counted properly.
(5) The total number of instructions measured matches the addition of the individual types counted.
However, this number is different from the total number of expected instructions.
Hence, we need to further analyse the event counters inst misc, ‘DMOV’, and Total. On the
contrary, for inst integer, inst control and inst compute ld st, since the counts we observe
for experiment in Figure 5.1 – explained later – are precise, we consider them reliable.
Set of Hypotheses. From these results, we formulate the following hypotheses. The inst misc
monitor counts one instruction beyond those appearing in the SASS code and regarded as MISC
according to NVIDIA’s documentation [2]. We hypothesize that other instructions are counted as
MISC:
• Hypothesis 1a. Jetson TX2 behaviour for MISC counter is the same as in Jetson AGX Xavier,
and therefore, MOV instructions are being counted as MISC.
• Hypothesis 1b. The behaviour of Jetson TX2 MISC counter differs from the observation and
validation perform in Jetson AGX Xavier.
Table 5.3: Measured/Expected values for matrix copy benchmark at Nvidia Jetson TX2 after
applying PMC correction
Event Expected Measured Discrepancy
(1) ‘DMOV’ 0 0 0
(2) inst misc 5,242,880 5,242,880 0
(3) inst integer 15,728,640 15,728,640 0
(4) inst compute ld st 2,097,152 2,097,152 0
(5) inst control 1,048,576 1,048,576 0
(6) Total 24,117,248 24,117,248 0
34

Chapter 5. Assessment of EMVP on the NVIDIA Jetson TX2
Table 5.3 shows the expected, measured and discrepancy values after applying the corrections.
Since the number of MISC instructions matches, we regard that the MISC counter at Jetson TX2
behaves in the same way as Jetson AGX Xavier, assessing the hypothesis 1a. What this shows, is
that some problems on the PMCs w.r.t. their documentation is replicated across different GPU
generations and that the validation process can be applied to a different processor family with ease.
35

Chapter 5. Assessment of EMVP on the NVIDIA Jetson TX2
1 #inc lude <s t d i o . h>
2
3 global void copy ( i n t N, f l o a t ∗d x , f l o a t ∗d y ) {4 i n t x = blockDim . x∗blockIdx . x + threadIdx . x ;
5 i n t y = blockDim . y∗blockIdx . y + threadIdx . y ;
6 d y [N∗y + x]=d x [N∗y + x ] ;
7 }8
9 i n t main ( void ) {10 i n t N = 1024 ;
11 f l o a t ∗x , ∗y , ∗d x , ∗d y ;
12 x = ( f l o a t ∗) mal loc (N∗N∗ s i z e o f ( f l o a t ) ) ;13 y = ( f l o a t ∗) mal loc (N∗N∗ s i z e o f ( f l o a t ) ) ;14 dim3 g r id (32 ,32) ;
15 dim3 block (N/32 ,N/32) ;
16 cudaMalloc(&d x , N∗N∗ s i z e o f ( f l o a t ) ) ;17 cudaMalloc(&d y , N∗N∗ s i z e o f ( f l o a t ) ) ;18 f o r ( i n t i =0; i<N∗N; i++){19 x [ i ]=42.0 f ;
20 }21 cudaMemcpy( d x , x ,N∗N∗ s i z e o f ( f l o a t ) , cudaMemcpyHostToDevice ) ;
22 copy<<<gr id , block>>>(N, d x , d y ) ;
23 cudaMemcpy(y , d y ,N∗N∗ s i z e o f ( f l o a t ) , cudaMemcpyDeviceToHost ) ;
24 cudaFree ( d x ) ;
25 cudaFree ( d y ) ;
26 f r e e ( x ) ;
27 f r e e ( y ) ;
28 }29
1 /∗0008∗/ MOV R1 , c [ 0 x0 ] [ 0 x20 ] ;
2 /∗0010∗/ S2R R0 , SR CTAID .X;
3 /∗0018∗/ S2R R2 , SR TID .X;
4 /∗0028∗/ S2R R3 , SR CTAID .Y;
5 /∗0030∗/ S2R R4 , SR TID .Y;
6 /∗0038∗/ XMAD R2 , R0 . reuse , c [ 0 x0 ] [ 0 x8 ] , R2 ;
7 /∗0048∗/ XMAD.MRG R5 , R0 , c [ 0 x0 ] [ 0 x8 ] . H1 , RZ;
8 /∗0050∗/ XMAD R4 , R3 , c [ 0 x0 ] [ 0 xc ] , R4 ;
9 /∗0058∗/ XMAD.MRG R6 , R3 . reuse , c [ 0 x0 ] [ 0 xc ] . H1 , RZ;
10 /∗0068∗/ XMAD.PSL .CBCC R0 , R0 .H1 , R5 .H1 , R2 ;
11 /∗0070∗/ XMAD.PSL .CBCC R2 , R3 .H1 , R6 .H1 , R4 ;
12 /∗0078∗/ XMAD R0 , R2 . reuse , c [ 0 x0 ] [ 0 x140 ] , R0 ;
13 /∗0088∗/ XMAD.MRG R3 , R2 . reuse , c [ 0 x0 ] [ 0 x140 ] . H1 , RZ;
14 /∗0090∗/ XMAD.PSL .CBCC R2 , R2 .H1 , R3 .H1 , R0 ;
15 /∗0098∗/ SHL R4 , R2 . reuse , 0x2 ;
16 /∗00a8∗/ SHR R5 , R2 , 0x1e ;
17 /∗00b0∗/ IADD R2 .CC, R4 . reuse , c [ 0 x0 ] [ 0 x148 ] ;
18 /∗00b8∗/ IADD.X R3 , R5 , c [ 0 x0 ] [ 0 x14c ] ;
19 /∗00 c8 ∗/ LDG.E R2 , [R2 ] ;
20 /∗00d0∗/ IADD R4 .CC, R4 , c [ 0 x0 ] [ 0 x150 ] ;
21 /∗00d8∗/ IADD.X R5 , R5 , c [ 0 x0 ] [ 0 x154 ] ;
22 /∗00 e8 ∗/ STG.E[R4 ] , R2 ;
23 /∗00 f0 ∗/ EXIT ;
24 /∗00 f8 ∗/ BRA 0xf8 ;
25
Figure 5.1: CUDA/SASS code of matrix copy benchmark at TX2.
36

Chapter 6
Assessment of EMVP on the Xilinx
Zynq Ultrascale+
As a confirmation of the generality of our approach, we also applied our approach to another
architecture from a different vendor, the Xilinx Zynq UltraScale+, and in particular, to the CPUs
in the Application Processor Unit cluster (see Figure 6.1). The ARM Cortex-A53 CPUs [1] contains
more than 63 events from which we focus on a subset, selecting again the number of instructions
executed, as well as the number of memory related events. A notable difference between this
platform and the Xavier is the lack of event counters breaking down the arithmetic instruction
categories. Instead, there are only PMCs about memory operations, branches and total instructions.
On the other hand, more events are provided regarding the microarchitectural events taking place.
It is important to note that according to the ARM Cortex-A53 CPU technical reference manual [1]
and the ARMv8-A architecture reference manual [3], the event values are not expected to be
completely accurate, and that the microarchitectural implementation may introduce small absolute
variations in the actual number of the events reported due to pipeline effects. For this reason, we
perform our validation in rough numbers, reporting only big discrepancies whenever found.
6.1 Experiment and representative benchmark design
Table 6.1 lists the selected PMCs for validation. For the validation experiment, we use a bare-metal
configuration in order to guarantee no interference from the operating system, something that was
not possible in the Xavier, since the use of the GPU can only be supported by a driver within the
operating system. As rbe we selected the same application presented in the previous section and
used in the validation of the NVIDIA platform, matrix copy, which we compile with the ARM gcc
compiler. For the PMC readings we directly read their values from their memory mapped locations.
We disable the hardware prefetcher in to force a more predictable behaviour.
37

Chapter 6. Assessment of EMVP on the Xilinx Zynq Ultrascale+
Zynq UltraScale+ Device TRM 54UG1085 (v1.9) January 17, 2019 www.xilinx.com
Chapter 3: Application Processing Unit
When a Cortex-A53 MPCore processor is brought up in 32-bit mode using the APU_CONFIG0 [VINITHI] parameter register, its exception table cannot be relocated at run time. The V[13] bit of the system control register defines the base address of the exception vector.
See the Zynq UltraScale+ MPSoC Software Developer�s Guide (UG1137) [Ref 3] for more information.
Figure 3-2 shows a top-level functional diagram of the Cortex-A53 MPCore processor.
X-Ref Target - Figure 3-2
Figure 3-2: APU Block Diagram
Cortex-A53 Processor
APB Decoder APB ROM APB Multiplexer CTM
Governor
CTI Retention Control
Debug Over Power Down
Arch Timer
Clock and Reset
GIC CPU interface
Core 0 Governor
Core 0
FPU and NEON Extension
Crypto Extension
L1 ICache
L1 DCache
Debug and Trace
CTI Retention Control
Debug Over Power Down
Arch Timer
Clock and Reset
GIC CPU interface
Core 1 Governor
Core 1
FPU and NEON Extension
Crypto Extension
L1 ICache
L1 DCache
Debug and Trace
CTI Retention Control
Debug Over Power Down
Arch Timer
Clock and Reset
GIC CPU interface
Core 2 Governor
Core 2
FPU and NEON Extension
Crypto Extension
L1 ICache
L1 DCache
Debug and Trace
CTI Retention Control
Debug Over Power Down
Arch Timer
Clock and Reset
GIC CPU interface
Core 3 Governor
Core 3
FPU and NEON Extension
Crypto Extension
L1 ICache
L1 DCache
Debug and Trace
Level 2 Memory System
L2 Cache SCU ACE Master Bus Interface ACP Slave
X15287-092916
�������������
Figure 6.1: Diagram of the Cortex-A53 CPU cluster [1]
Table 6.1: Instruction types used in the analysis for the Xilinx Ultrascale+ ARM Cortex-A53
CPUs [1].
Event Official Description Instruction Types counted [3]
L1D CACHE REFILL Level 1 data cache refill Loads and stores missing L1
L1D CACHE Level 1 data cache access Loads and stores
LD RETIRED Instruction architecturally executed,
Condition code check pass, load
Loads
ST RETIRED Instruction architecturally executed,
Condition code check pass, store
Stores
INST RETIRED Instruction architecturally executed All instructions
MEM ACCESSES Data memory access Loads and stores
L2D CACHE Level 2 data cache access Loads, stores and instructions missing L1
caches
L2D CACHE REFILL Level 2 data cache refill Loads, stores and instructions missing L2
BUS ACCESS Bus access Bus acccesses from loads and stores missing
the last level cache
In Figure 6.2 we show the C code implementing the matrix copy benchmark, followed by its assembly
form. The memory instructions which are of our interest are shown in bold, and load operations
are shown in italics to ease load and store identification. In the assembly code we notice again
different code sections. The main loop of the benchmark is between the lines 4-24.
Load instructions in lines 5, 11, 16 and 21, and the store instruction in line 19 serve the purpose of
loading or updating the loop index, which is located in a fixed memory location so the instructions
will cause 5 cache hits (4 load hits, 1 store hit) per iteration.
The load instruction in line 9 loads the data from the source array (from[]), which may cause cache
38

Chapter 6. Assessment of EMVP on the Xilinx Zynq Ultrascale+
misses when crossing cache line boundaries, and the store instruction in line 14 stores the value
loaded from the source array into the destination array (to[]), which may also cause cache misses
when crossing cache line boundaries.
Lines 20-24 perform the out of boundaries check to determine if more iterations are needed or the
algorithm has ended. Knowing the number of total iterations and the assembly representation, we
are able to tightly estimate the number of expected instructions and events for each of the selected
PMCs.
1 #de f i n e SIZE 2∗1024∗1024/ s i z e o f ( i n t ) /∗512K∗/2 i n t from [ SIZE ] , to [ SIZE ] ;
3
4 f o r ( i n t i = 0 ; i < SIZE ; i++) {5 to [ i ] = from [ i ] ;
6 }7
1 /∗3358∗/ add x0 , x29 , #0x400 , l s l #12
2 /∗335 c∗/ str wzr , [ x0 ,#24]
3 /∗3360∗/ b 33a4 <main+0xd4>
4 /∗3364∗/ add x0 , x29 , #0x400 , l s l #12
5 /∗3368∗/ ldrsw x0 , [ x0 ,#24]
6 /∗336 c∗/ l s l x0 , x0 , #2
7 /∗3370∗/ add x1 , x29 , #0x200 , l s l #12
8 /∗3374∗/ add x1 , x1 , #0x18
9 /∗3378∗/ ldr w2 , [ x1 , x0 ]
10 /∗337 c∗/ add x0 , x29 , #0x400 , l s l #12
11 /∗3380∗/ ldrsw x0 , [ x0 ,#24]
12 /∗3384∗/ l s l x0 , x0 , #2
13 /∗3388∗/ add x1 , x29 , #0x18
14 /∗338 c∗/ str w2 , [ x1 , x0 ]
15 /∗3390∗/ add x0 , x29 , #0x400 , l s l #12
16 /∗3394∗/ ldr w0 , [ x0 ,#24]
17 /∗3398∗/ add w0 , w0 , #0x1
18 /∗339 c∗/ add x1 , x29 , #0x400 , l s l #12
19 /∗33a0∗/ str w0 , [ x1 ,#24]
20 /∗33a4∗/ add x0 , x29 , #0x400 , l s l #12
21 /∗33a8∗/ ldr w1 , [ x0 ,#24]
22 /∗33 ac ∗/ mov w0 , #0x 7 f f f f //#524287
23 /∗33b0∗/ cmp w1 , w0
24 /∗33b4∗/ b . l s 3364 <main+0x94>
25 /∗33b8∗/ adrp x0 , 1 e000 < ex idx end>
26 /∗33bc∗/ add x0 , x0 , #0x3c0
27 /∗33 c0 ∗/ ldr w2 , [ x0 ]
28 /∗33 c4 ∗/ adrp x0 , 14000 <z e r o e s .5791+0x1c0>
29 /∗33 c8 ∗/ add x0 , x0 , #0x450
30 /∗33 cc ∗/ ldr x0 , [ x0 ]
31 /∗33d0∗/ mov x1 , x0
32 /∗33d4∗/ mov w0 , w2
33
Figure 6.2: C/ARM Assembly code of matrix copy in the Zynq.
39

Chapter 6. Assessment of EMVP on the Xilinx Zynq Ultrascale+
Table 6.2: Measured/Expected values for matrix copy
Event Expected Measured Discrepancy
(A) L1D CACHE REFILL 64K 65566 0
(B) L1D CACHE 3.5M 3670319 0
(C) LD RETIRED 2.5M 2621612 0
(D) ST RETIRED 1M 1048626 0
(E) INST RETIRED 10.5M 11010313 0
(F) MEM ACCESSES 3.5M 3670057 0
(G) L2D CACHE 64K 130772 64K
(H) L2D CACHE REFILL 64K 65559 0
(I) BUS ACCESS 352K 360309 0
6.2 Assessment
Table 6.2 shows the obtained values from the PMCs, together with their expected values. As a
first validation step, we validate the accuracy of the instructions that we know. We perform 512K
iterations in which we access 5 loads and 2 store instructions. The number of load and stores are as
expected (rows C and D). Likewise the number of L1 cache accesses and total memory operations
match their expected value (rows B and F). The number of total instructions within the loop is 21,
resulting in a total of 10.5M instructions executed (row E).
The total memory footprint of the application is 4MB, as it copies a 2MB array into a new location.
Since no data is reused, every read and write accessing a new cache line of data and L2 caches is
expected to generate a cache miss, whereas the remaining accesses to those cache lines are expected
to hit due to spatial locality. Given that our application has a sequential access pattern, that the
cache line size is 64B in both the data and L2 caches, and that the data type used by the application
is 4B, we expect that both, source loads and destination store instructions produce 1 miss followed
by 15 hits for each cache line. Therefore, we expect 32K read misses and 32K write misses out of
a total of 512K accesses of each type, as a new line is accessed once every 16 memory accesses.
Note that only a load and a store instruction may miss the caches each iteration, as explained in
section 6.1. Note that the code is small enough to fit in the instruction cache after the first loop
iteration. Thus, instructions should cause few (below 10) L2 cache misses, so L2 misses roughly
correspond to data misses only. The measured misses in each cache are 64K as expected (rows A
and H).
The bus access counter (row I) counts the number of bus transactions issued, which are caused by
L2 load misses, L2 store misses, or L2 dirty evictions. A total of 32K load misses and 32K store
misses are expected, while only 24K dirty evictions are expected, as 512KB -a fourth- of the data
stored will still remain in the L2 when the execution finishes. The total amount of lines issued by
the L2 to the bus is 88K, however the bus width is 16B [1], so each line is split in 4 transactions,
causing a total of 352K bus accesses. As shown in row I, this counter is precise.
40

Chapter 6. Assessment of EMVP on the Xilinx Zynq Ultrascale+
Finally, L2 accesses (row G) should be either counting the 32K load misses and 32K store misses
(so 64K accesses), or include also the almost 32K dirty evictions (so 96K accesses). However, it
counts 128K accesses. According to the ARM Cortex-A53 CPU technical reference manual [1],
L1 load misses sent to L2 are served through a 16B bus, whereas write operations use a 32B bus.
We have leveraged this information to guess whether they influenced the number of L2 accesses
counted, but no reasonable combination led to 128K accesses. In fact, we have conducted additional
experiments (e.g. only read misses) and in all cases the number of L2 accesses has doubled the
number of L1 data cache misses. However, we could not formulate any reasonable hypothesis to
justify this behavior. In fact, our past work on ARM-based platforms already revealed mismatches
between event counters obtained and values expected [?].
Observation 3: In the absence of any evidence on the existence of additional L2 cache access
activity, we regard L2D CACHE as unreliable for timing validation purposes.
41

Chapter 7
Conclusions and Future Work
7.1 Conclusions
The increasing need for the adoption of high-performance hardware to execute performance-demanding
critical real-time software poses stringent V&V constraints on those systems. More complex and
sophisticated safety-related software is used in CRTES which can benefit the advanced SoCs. Con-
sequently, software timing analysis, as a mandatory requirement for CRTES, becomes much more
complex.
PMUs are key to efficiently enable monitoring task activities such as quota monitoring and software
debugging. However, existing solutions and software approaches rely on the assumption that event
monitors and their documentations are fully correct and can be trusted. Therefore, trustworthiness
of event monitors is a precondition for the reliability of the critical V&V processes built atop.
In this Thesis, first, we show that even some of the most basic event counters may fail to match
their specifications. This can result in misunderstanding or misinterpretation of the outcome of
event counters and, therefore, HEMs cannot be trusted airily.
Next, we propose a methodology to validate the event monitors via the analysis of GPUs for the
automotive domain (NVIDIA Xavier and TX2) and multicores for the railway and avionics domains
(Xilinx Zynq UltraScale+). Our methodology allows, in many cases, discern what they count,
which is the basis to build reliable processes for critical real-time systems atop. In particular, by
performing specific empirical tests, we are able to accept or reject plausible hypotheses and collect
evidence supporting our conclusions. We show how some instructions are misclassified, some others
are counted in non-obvious ways, and some events may fully mismatch expectations. However, once
this information is obtained and verified empirically, validated event counters in complex hardware
can be used for the V&V of critical real-time systems.
Lastly, we have discussed the automated validation and tooling support and the existing challenges
42

Chapter 7. Conclusions and Future Work
on the assessment process. We have seen that by defining representative benchmarks, tool support
can be used to derive the expected value for some of the event monitor values. We discussed that
while a full automation procedure is not feasible, establishing well-defined procedures to perform
the verification process exhaustively and providing an easy review process without ambiguity and
misunderstanding is very important.
7.2 Future work
This Thesis has only scratched the surface of the validation of performance counters, therefore it
can be extended in several ways. For example, as we discussed in Section 3.3, there are several
opportunities for automating Event Monitor Validation Process we introduced, in order to facilitate
the inevitable manual work required by the expert analyst who has to supervise the process. In
particular, some of the directions to follow in that aspect are to develop tools to derive the expected
value of event monitors for a given rbe or the creation of a database of rbe(s) with precomputed
values from previous analyses. An interesting extension is to work on tranferring this technology
to industry by qualifying the new tools which will be developed and commercialise it.
As another future work direction, the methodology of this Thesis can be replicated to extend the
verification of more performance counters than the ones that were already analysed in this work in
the three evaluated platforms. In addition, it will be interesting to apply our methodology to more
architectures which are considered in critical real-time systems. Some candidate platforms for such
future analysis are the T2080 from NXP, the hard real-time R5 cores found in Xilinx FPGA SoCs,
as well as other embedded GPUs such the GPU found in the Jetson Nano SoC from NVIDIA which
was introduced after the TX2 and the Xavier used in this work and the latest generation of ARM
GPUs which can be found in newly released products such as the Mali G72.
43

Bibliography
[1] ARM Cortex-A53 MPCore Processor, 2014.
[2] CUDA Binary Utilities, 2018.
[3] ARMv8 Reference Manual v8.5 EAC, 2019.
[4] Jaume Abella, Carles Hernandez, Eduardo Quinones, Francisco J Cazorla, Philippa Ryan
Conmy, Mikel Azkarate-Askasua, Jon Perez, Enrico Mezzetti, and Tullio Vardanega. Wcet
analysis methods: Pitfalls and challenges on their trustworthiness. In 10th IEEE International
Symposium on Industrial Embedded Systems (SIES), pages 1–10. IEEE, 2015.
[5] Sergi Alcaide, Leonidas Kosmidis, Hamid Tabani, Carles Hernandez, Jaume Abella, and Fran-
cisco J Cazorla. Safety-Related Challenges and Opportunities for GPUs in the Automotive
Domain. IEEE Micro, 38(6):46–55, 2018.
[6] Tanya Amert, Nathan Otterness, Ming Yang, James H Anderson, and F Donelson Smith. GPU
scheduling on the NVIDIA TX2: Hidden details revealed. In 2017 IEEE Real-Time Systems
Symposium (RTSS), pages 104–115. IEEE, 2017.
[7] ARM. ARM Expects Vehicle Compute Performance to Increase 100x in Next Decade, 2015.
https://www.arm.com/about/newsroom/arm-expects-vehicle-compute-performance-t
o-increase-100x-in-next-decade.php.
[8] Javier Barrera, Leonidas Kosmidis, Hamid Tabani, Enrico Mezzetti, Jaume Abella, Mikel
Fernandez, Guillem Bernat, and Francisco J Cazorla. On the reliability of hardware event
monitors in mpsocs for critical domains. In Proceedings of the 35th Annual ACM Symposium
on Applied Computing, pages 580–589, 2020.
[9] Kostiantyn Berezovskyi, Konstantinos Bletsas, and Bjorn Andersson. Makespan computa-
tion for GPU threads running on a single streaming multiprocessor. In 2012 24th Euromicro
Conference on Real-Time Systems, pages 277–286. IEEE, 2012.
[10] Kostiantyn Berezovskyi, Fabrice Guet, Luca Santinelli, Konstantinos Bletsas, and Eduardo
Tovar. Measurement-based probabilistic timing analysis for graphics processor units. In In-
ternational Conference on Architecture of Computing Systems, pages 223–236. Springer, 2016.
44

Bibliography
[11] Adam Betts and Alastair Donaldson. Estimating the WCET of GPU-accelerated applications
using hybrid analysis. In 2013 25th Euromicro Conference on Real-Time Systems, pages 193–
202. IEEE, 2013.
[12] Nicola Capodieci, Roberto Cavicchioli, Marko Bertogna, and Aingara Paramakuru. Deadline-
based scheduling for gpu with preemption support. In 2018 IEEE Real-Time Systems Sympo-
sium (RTSS), pages 119–130. IEEE, 2018.
[13] Francisco J Cazorla, Jaume Abella, Enrico Mezzetti, Carles Hernandez, Tullio Vardanega, and
Guillem Bernat. Reconciling time predictability and performance in future computing systems.
IEEE Design & Test, 35(2):48–56, 2018.
[14] CENELEC. EN50128 Railway Applications: Software for Railway Control and Protection,
2001.
[15] Shuai Che, Michael Boyer, Jiayuan Meng, David Tarjan, Jeremy W Sheaffer, Sang-Ha Lee,
and Kevin Skadron. Rodinia: A benchmark suite for heterogeneous computing. In 2009 IEEE
international symposium on workload characterization (IISWC), pages 44–54. Ieee, 2009.
[16] Shuai Che, Jeremy W Sheaffer, Michael Boyer, Lukasz G Szafaryn, Liang Wang, and Kevin
Skadron. A characterization of the rodinia benchmark suite with comparison to contemporary
cmp workloads. In IEEE International Symposium on Workload Characterization (IISWC’10),
pages 1–11. IEEE, 2010.
[17] Fabrice Cros, Leonidas Kosmidis, Franck Wartel, David Morales, Jaume Abella, Ian Broster,
and Francisco J Cazorla. Dynamic software randomisation: Lessons learnec from an aerospace
case study. In Design, Automation & Test in Europe Conference & Exhibition (DATE), 2017,
pages 103–108. IEEE, 2017.
[18] Dakshina Dasari, Bjorn Andersson, Vincent Nelis, Stefan M Petters, Arvind Easwaran, and
Jinkyu Lee. Response time analysis of COTS-based multicores considering the contention on
the shared memory bus. In 2011IEEE 10th International Conference on Trust, Security and
Privacy in Computing and Communications, pages 1068–1075. IEEE, 2011.
[19] Enrique Dıaz, Enrico Mezzetti, Leonidas Kosmidis, Jaume Abella, and Francisco J Cazorla.
Modelling multicore contention on the aurix tm tc27x. In Proceedings of the 55th Annual
Design Automation Conference, pages 1–6, 2018.
[20] Boris Dreyer, Christian Hochberger, Alexander Lange, Simon Wegener, and Alexander Weiss.
Continuous non-intrusive hybrid WCET estimation using waypoint graphs. In 16th Interna-
tional Workshop on Worst-Case Execution Time Analysis (WCET 2016). Schloss Dagstuhl-
Leibniz-Zentrum fuer Informatik, 2016.
[21] Boris Dreyer, Christian Hochberger, Simon Wegener, and Alexander Weiss. Precise continuous
non-intrusive measurement-based execution time estimation. In 15th International Workshop
45

Bibliography
on Worst-Case Execution Time Analysis (WCET 2015). Schloss Dagstuhl-Leibniz-Zentrum
fuer Informatik, 2015.
[22] Federal Aviation Administration, Certification Authorities Software Team (CAST). CAST-
32A Multi-core Processors, 2016.
[23] Gabriel Fernandez, Francisco Cazorla, and Jaume Abella. Consumer Electronics Processors
for Critical Real-Time Systems: a (Failed) Practical Experience. 2018.
[24] Gabriel Fernandez, Francisco J Cazorla, Jaume Abella, and Sylvain Girbal. Assessing Time
Predictability Features of ARM Big. LITTLE Multicores. In 2018 30th International Sympo-
sium on Computer Architecture and High Performance Computing (SBAC-PAD), pages 258–
261. IEEE, 2018.
[25] Mikel Fernandez, David Morales, Leonidas Kosmidis, Alen Bardizbanyan, Ian Broster, Car-
les Hernandez, Eduardo Quinones, Jaume Abella, Francisco Cazorla, Paulo Machado, et al.
Probabilistic timing analysis on time-randomized platforms for the space domain. In Design,
Automation & Test in Europe Conference & Exhibition (DATE), 2017, pages 738–739. IEEE,
2017.
[26] Kees Goossens, Arnaldo Azevedo, Karthik Chandrasekar, Manil Dev Gomony, Sven Goossens,
Martijn Koedam, Yonghui Li, Davit Mirzoyan, Anca Molnos, Ashkan Beyranvand Nejad, et al.
Virtual execution platforms for mixed-time-criticality systems: the compsoc architecture and
design flow. ACM SIGBED Review, 10(3):23–34, 2013.
[27] David Griffin, Benjamin Lesage, Iain Bate, Frank Soboczenski, and Robert I Davis. Forecast-
based interference: Modelling multicore interference from observable factors. In Proceedings of
the 25th International Conference on Real-Time Networks and Systems, pages 198–207, 2017.
[28] Fabrice Guet, Luca Santinelli, and Jerome Morio. Probabilistic analysis of cache memories
and cache memories impacts on multi-core embedded systems. In 2016 11th IEEE Symposium
on Industrial Embedded Systems (SIES), pages 1–10. IEEE, 2016.
[29] Intel. Intel GO, 2017. https://www.nxp.com/docs/en/errata/IMX6SLLCE.pdf.
[30] International Electrotechnical Commission. International Electrotechnical Commission,
IEC61508. Functional safety of electrical/electronic/programmable eletronic safety-related sys-
tems, 2010.
[31] International Organization for Standardization. ISO/DIS 26262. Road Vehicles – Functional
Safety, 2009.
[32] Javier Jalle, Mikel Fernandez, Jaume Abella, Jan Andersson, Mathieu Patte, Luca Fossati,
Marco Zulianello, and Francisco J Cazorla. Contention-aware performance monitoring counter
support for real-time MPSoCs. In 2016 11th IEEE Symposium on Industrial Embedded Systems
(SIES), pages 1–10. IEEE, 2016.
46

Bibliography
[33] Hermann Kopetz and Gunther Bauer. The time-triggered architecture. Proceedings of the
IEEE, 91(1):112–126, 2003.
[34] Leonidas Kosmidis, Jaume Abella, Franck Wartel, Eduardo Quinones, Antoine Colin, and
Francisco J Cazorla. PUB: Path upper-bounding for measurement-based probabilistic timing
analysis. In 2014 26th Euromicro Conference on Real-Time Systems, pages 276–287. IEEE,
2014.
[35] Leonidas Kosmidis, Davide Compagnin, David Morales, Enrico Mezzetti, Eduardo Quinones,
Jaume Abella Ferrer, Tullio Vardanega, and Francisco Javier Cazorla Almeida. Measurement-
based timing analysis of the aurix caches. In 16th International Workshop on Worst-Case
Execution Time Analysis (WCET 2016), pages 9–1. Schloss Dagstuhl-Leibniz-Zentrum fur
Informatik, 2016.
[36] Leonidas Kosmidis, Cristian Maxim, Victor Jegu, Francis Vatrinet, and Francisco J Cazorla.
Industrial experiences with resource management under software randomization in ARINC653
avionics environments. In 2018 IEEE/ACM International Conference on Computer-Aided
Design (ICCAD), pages 1–7. IEEE, 2018.
[37] Lei Liu, Zehan Cui, Mingjie Xing, Yungang Bao, Mingyu Chen, and Chengyong Wu. A soft-
ware memory partition approach for eliminating bank-level interference in multicore systems.
In 2012 21st International Conference on Parallel Architectures and Compilation Techniques
(PACT), pages 367–375. IEEE, 2012.
[38] Renato Mancuso, Roman Dudko, Emiliano Betti, Marco Cesati, Marco Caccamo, and Rodolfo
Pellizzoni. Real-time cache management framework for multi-core architectures. In 2013 IEEE
19th Real-Time and Embedded Technology and Applications Symposium (RTAS), pages 45–54.
IEEE, 2013.
[39] MarketsandMarkets. Embedded System Market Worth 116.2 Billion Dollars by 2025 - Exclu-
sive Report by MarketsandMarkets, 2020. https://www.bloomberg.com/press-releases/2
020-03-17/embedded-system-market-worth-116-2-billion-by-2025-exclusive-repor
t-by-marketsandmarkets.
[40] Fabio Mazzocchetti, Pedro Benedicte, Hamid Tabani, Leonidas Kosmidis, Jaume Abella, and
Francisco J Cazorla. Performance analysis and optimization of automotive gpus. In 2019
31st International Symposium on Computer Architecture and High Performance Computing
(SBAC-PAD), pages 96–103. IEEE, 2019.
[41] Enrico Mezzetti, Jaume Abella, Carles Hernandez, and Francisco J Cazorla. Work-in-Progress
paper: An Analysis of the Impact of Dependencies on Probabilistic Timing Analysis and Task
Scheduling. In 2017 IEEE Real-Time Systems Symposium (RTSS), pages 357–359. IEEE, 2017.
47

Bibliography
[42] Enrico Mezzetti, Leonidas Kosmidis, Jaume Abella, and Francisco J Cazorla. High-integrity
performance monitoring units in automotive chips for reliable timing V&V. IEEE Micro,
38(1):56–65, 2018.
[43] Suzana Milutinovic, Jaume Abella, Enrico Mezzetti, and Francisco J Cazorla. Measurement-
based cache representativeness on multipath programs. In Proceedings of the 55th Annual
Design Automation Conference, pages 1–6, 2018.
[44] Suzana Milutinovic, Jaume Abella Ferrer, and Francisco Javier Cazorla Almeida. Validating
the Reliability of WCET Estimates with MBPTA. In Book of abstracts, pages 68–70. Barcelona
Supercomputing Center, 2015.
[45] Jan Nowotsch, Michael Paulitsch, Daniel Buhler, Henrik Theiling, Simon Wegener, and
Michael Schmidt. Multi-core interference-sensitive WCET analysis leveraging runtime resource
capacity enforcement. In 2014 26th Euromicro Conference on Real-Time Systems, pages 109–
118. IEEE, 2014.
[46] Nvidia. Nvidia Jetson AGX Xavier, 2017. https://www.nvidia.com/en-us/autonomous-ma
chines/embedded-systems/jetson-agx-xavier/.
[47] Nvidia. Nvidia Jetson TX2, 2017. https://www.nvidia.com/en-us/autonomous-machines
/embedded-systems/jetson-tx2/.
[48] NVIDIA. CUDA 10.0 toolkit documentation., 2018.
[49] NVIDIA. CUDA 9.2 toolkit documentation., 2018.
[50] NXP. Chip Errata for the i.MX 6SLL, 2017. https://www.nxp.com/docs/en/errata/IMX6S
LLCE.pdf.
[51] Nathan Otterness, Ming Yang, Sarah Rust, Eunbyung Park, James H Anderson, F Donelson
Smith, Alex Berg, and Shige Wang. An evaluation of the NVIDIA TX1 for supporting real-
time computer-vision workloads. In 2017 IEEE Real-Time and Embedded Technology and
Applications Symposium (RTAS), pages 353–364. IEEE, 2017.
[52] Xing Pan and Frank Mueller. Controller-aware memory coloring for multicore real-time sys-
tems. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, pages
584–592, 2018.
[53] Milos Panic, Eduardo Quinones, Pavel G Zavkov, Carles Hernandez, Jaume Abella, and Fran-
cisco J Cazorla. Parallel many-core avionics systems. In 2014 International Conference on
Embedded Software (EMSOFT), pages 1–10. IEEE, 2014.
[54] Rodolfo Pellizzoni, Andreas Schranzhofer, Jian-Jia Chen, Marco Caccamo, and Lothar Thiele.
Worst case delay analysis for memory interference in multicore systems. In 2010 Design,
48

Bibliography
Automation & Test in Europe Conference & Exhibition (DATE 2010), pages 741–746. IEEE,
2010.
[55] Qualcomm. Qualcomm Snapdragon 820, 2017. https://www.qualcomm.com/products/snap
dragon-820-mobile-platform.
[56] Jan Reineke. Challenges for Timing Analysis of Multi-Core Architectures. Workshop on
Foundational and Practical Aspects of Resource Analysis, 2017. Invited Talk.
[57] Renesas. Renesas R-Car H3, 2017. https://www.renesas.com/us/en/solutions/automoti
ve/soc/r-car-h3.html.
[58] RTCA and EUROCAE. DO-178C / ED-12C, Software Considerations in Airborne Systems
and Equipment Certification, 2011.
[59] Martin Schoeberl, Florian Brandner, Jens Sparsø, and Evangelia Kasapaki. A statically sched-
uled time-division-multiplexed network-on-chip for real-time systems. In 2012 IEEE/ACM
Sixth International Symposium on Networks-on-Chip, pages 152–160. IEEE, 2012.
[60] Jens Sparsø. Design of networks-on-chip for real-time multi-processor systems-on-chip. In 2012
12th International Conference on Application of Concurrency to System Design, pages 1–5.
IEEE, 2012.
[61] Noriaki Suzuki, Hyoseung Kim, Dionisio De Niz, Bjorn Andersson, Lutz Wrage, Mark Klein,
and Ragunathan Rajkumar. Coordinated bank and cache coloring for temporal protection of
memory accesses. In 2013 IEEE 16th International Conference on Computational Science and
Engineering, pages 685–692. IEEE, 2013.
[62] Hamid Tabani, Leonidas Kosmidis, Jaume Abella, Francisco J Cazorla, and Guillem Bernat.
Assessing the adherence of an industrial autonomous driving framework to iso 26262 software
guidelines. In 2019 56th ACM/IEEE Design Automation Conference (DAC), pages 1–6. IEEE,
2019.
[63] Prathap Kumar Valsan, Heechul Yun, and Farzad Farshchi. Taming non-blocking caches to
improve isolation in multicore real-time systems. In 2016 IEEE Real-Time and Embedded
Technology and Applications Symposium (RTAS), pages 1–12. IEEE, 2016.
[64] Franck Wartel, Leonidas Kosmidis, Adriana Gogonel, Andrea Baldovino, Zoe Stephenson,
Benoit Triquet, Eduardo Quinones, Code Lo, Enrico Mezzetta, Ian Broster, et al. Timing
analysis of an avionics case study on complex hardware/software platforms. In 2015 Design,
Automation & Test in Europe Conference & Exhibition (DATE), pages 397–402. IEEE, 2015.
[65] Franck Wartel, Leonidas Kosmidis, Code Lo, Benoit Triquet, Eduardo Quinones, Jaume
Abella, Adriana Gogonel, Andrea Baldovin, Enrico Mezzetti, Liliana Cucu, et al.
49

Bibliography
Measurement-based probabilistic timing analysis: Lessons from an integrated-modular avion-
ics case study. In 2013 8th IEEE International Symposium on Industrial Embedded Systems
(SIES), pages 241–248. IEEE, 2013.
[66] Vincent M Weaver, Dan Terpstra, and Shirley Moore. Non-determinism and overcount on
modern hardware performance counter implementations. In 2013 IEEE International Sym-
posium on Performance Analysis of Systems and Software (ISPASS), pages 215–224. IEEE,
2013.
[67] Adam West. NASA Study on Flight Software Complexity. Final Report. Technical report,
NASA, 2009.
[68] Reinhard Wilhelm and Jan Reineke. Embedded systems: Many cores—Many problems. In 7th
IEEE International Symposium on Industrial Embedded Systems (SIES’12), pages 176–180.
IEEE, 2012.
[69] Xilinx. Rockwell Collins Uses Zynq UltraScale+ RFSoC Devices in Revolutionizing How Arrays
are Produced and Fielded: Powered by Xilinx, 2019.
[70] Ming Yang, Nathan Otterness, Tanya Amert, Joshua Bakita, James H Anderson, and F Donel-
son Smith. Avoiding pitfalls when using nvidia gpus for real-time tasks in autonomous sys-
tems. In 30th Euromicro Conference on Real-Time Systems (ECRTS 2018). Schloss Dagstuhl-
Leibniz-Zentrum fuer Informatik, 2018.
[71] Heechul Yun, Renato Mancuso, Zheng-Pei Wu, and Rodolfo Pellizzoni. PALLOC: DRAM
bank-aware memory allocator for performance isolation on multicore platforms. In 2014 IEEE
19th Real-Time and Embedded Technology and Applications Symposium (RTAS), pages 155–
166. IEEE, 2014.
[72] Heechul Yun, Gang Yao, Rodolfo Pellizzoni, Marco Caccamo, and Lui Sha. Memguard: Mem-
ory bandwidth reservation system for efficient performance isolation in multi-core platforms. In
2013 IEEE 19th Real-Time and Embedded Technology and Applications Symposium (RTAS),
pages 55–64. IEEE, 2013.
[73] Dmitrijs Zaparanuks, Milan Jovic, and Matthias Hauswirth. Accuracy of performance counter
measurements. In 2009 IEEE International Symposium on Performance Analysis of Systems
and Software, pages 23–32. IEEE, 2009.
[74] Marco Ziccardi, Enrico Mezzetti, Tullio Vardanega, Jaume Abella, and Francisco Javier Ca-
zorla. Epc: extended path coverage for measurement-based probabilistic timing analysis. In
2015 IEEE Real-Time Systems Symposium, pages 338–349. IEEE, 2015.
50