Embed Size (px)
Citation preview

Utility-Based Partitioning :A Low-Overhead, High-Performance, Run-time Mechanism to Partition Shared Caches
Moinuddin K.Qureshi, Univ of Texas at Austin MICRO’2006
2007, 12, 05PAK, EUNJI

Outline
Introduction and Motivation Utility-Based Cache Partitioning Evaluation Scalable Partitioning Algorithm Related Work and Summary

Introduction
CMP and shared caches are common
Applications compete for the shared cache
Partitioning policies critical for high per-formance
Traditional policies: Equal (half-and-half) Performance isolation. No adaptation LRU Demand based. Demand ≠ benefit (e.g. streaming)

Background
Low Utility
High Utility
Saturating Utility
Utility Uab = Misses with a ways – Misses with b ways

Motivation
Improve performance by giving more cache to the application that benefits more from cache

Framework for UCP
Three components: Utility Monitors (UMON) per core Partitioning Algorithm (PA) Replacement support to enforce parti-
tions
I$
D$Core1
I$
D$Core2
SharedL2 cache
Main Memory
UMON1 UMON2PA

Utility Monitors (UMON)
For each core, simulate LRU policy using ATD Hit counters in ATD to count hits per recency
position LRU is a stack algorithm: hit counts utility
E.g. hits(2 ways) = H0+H1MTD
Set B
Set E
Set G
Set A
Set CSet D
Set F
Set H
ATD
Set B
Set E
Set G
Set A
Set CSet D
Set F
Set H
++++(MRU)H0 H1 H2…H15(LRU)

Dynamic Set Sampling (DSS) Extra tags incur hardware and power
overhead DSS reduces overhead [Qureshi,ISCA’06] 32 sets sufficient (analytical bounds) Storage < 2kB/UMON
MTD
ATD Set B
Set E
Set G
Set A
Set CSet D
Set F
Set H
++++(MRU)H0 H1 H2…H15(LRU)
Set B
Set E
Set G
Set A
Set CSet D
Set F
Set H
Set B
Set E
Set G
Set A
Set CSet D
Set F
Set H
Set BSet ESet G
UMON (DSS)

DSS Bounds with Analytical Model
Us = Sampled mean (Num ways allocated by DSS) Ug = Global mean (Num ways allocated by Global)
P = P(Us within 1 way of Ug)
By Cheb. inequality:P ≥ 1 – variance/n
n = number of sampled sets
In general, variance ≤ 3

Partitioning algorithm
Evaluate all possible partitions and select the best
With a ways to core1 and (16-a) ways to core2: Hitscore1 = (H0 + H1 + … + Ha-1) ---- from UMON1
Hitscore2 = (H0 + H1 + … + H16-a-1) ---- from UMON2
Select a that maximizes (Hitscore1 + Hitscore2)
Partitioning done once every 5 million cycles

Way Partitioning
Way partitioning support: [Suh+ HPCA’02, Iyer ICS’04] Each line has core-id bits On a miss, count ways_occupied in set by miss-
causing application
ways_occupied < ways_given
Yes No
Victim is the LRU line from other app
Victim is the LRU line from miss-caus-ing app

Evaluation Methodology
Configuration Two cores: 8-wide, 128-entry window Private L1s L2: Shared, unified, 1MB, 16-way LRU-based Memory: 400 cycles, 32 banks
Benchmarks Two-threaded workloads divided into 5 categories
Used 20 workloads (four from each type)
1.0 1.2 1.4 1.6 1.8 2.0
Weighted speedup for the baseline

Metrics
Weighted Speedup (default metric) perf = IPC1/SingleIPC1 + IPC2/SingleIPC2 correlates with reduction in execution time
Throughput perf = IPC1 + IPC2 can be unfair to low-IPC application
Hmean-fairness perf = hmean(IPC1/SingleIPC1, IPC2/SingleIPC2) balances fairness and performance

Results for weighted speedup
UCP improves average weighted speedup by 11%

Results for throughput
UCP improves average throughput by 17%

Results for hmean-fair-ness
UCP improves average hmean-fairness by 11%
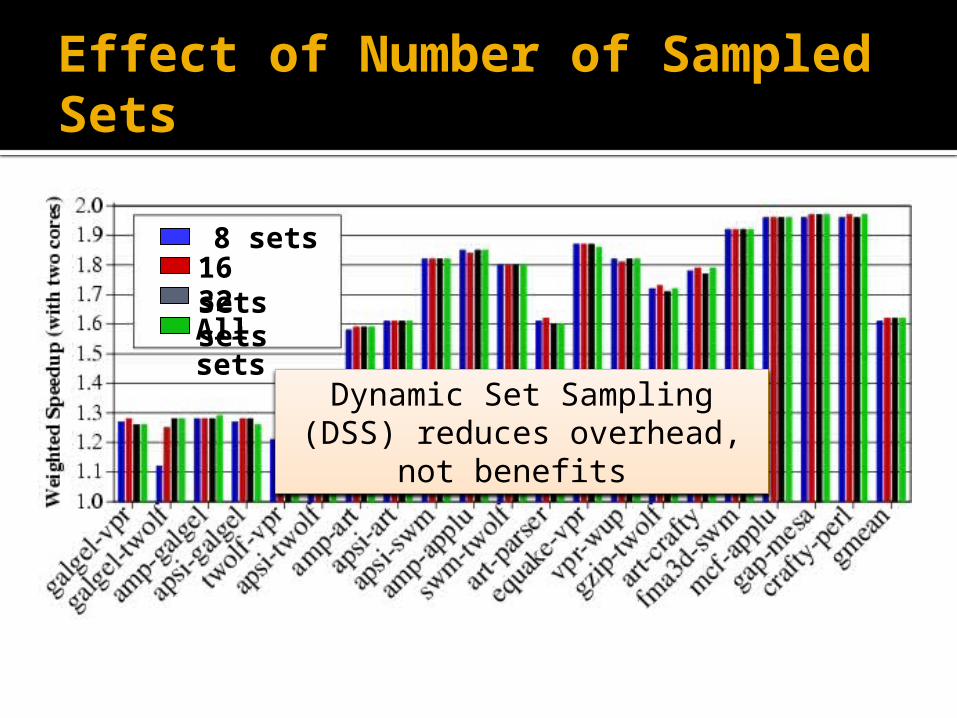
Effect of Number of Sampled Sets
Dynamic Set Sampling (DSS) reduces overhead, not bene-
fits
8 sets16 sets32 setsAll sets

Scalability issues
Time complexity of partitioning low for two cores(number of possible partitions ≈ number of ways)
Possible partitions increase exponentially with cores
For a 32-way cache, possible partitions: 4 cores 6545 8 cores 15.4 million
Problem NP hard need scalable partitioning al-gorithm

Greedy Algorithm [Stone+ ToC ’92]
GA allocates 1 block to the app that has the max utility for one block. Repeat till all blocks allocated
Optimal partitioning when utility curves are convex
Pathological behav-ior for non-convex curves

Problem with Greedy Algo-rithm
0
10
20
30
40
50
60
70
80
90
100
0 1 2 3 4 5 6 7 8
A
B
In each iteration, the utility for 1 block:
U(A) = 10 misses U(B) = 0 misses
Problem: GA considers benefit only from the imme-diate block. Hence it fails to exploit huge gains from ahead
Blocks assigned
Mis
ses
All blocks assigned to A, even if B has same miss reduc-tion with fewer blocks

Lookahead Algorithm
Marginal Utility (MU) = Utility per cache resource MUa
b = Uab/(b-a)
GA considers MU for 1 block. LA considers MU for all possible allocations
Select the app that has the max value for MU. Allocate it as many blocks required to get max MU
Repeat till all blocks assigned

Lookahead Algorithm (ex-ample)
Time complexity ≈ ways2/2 (512 ops for 32-ways)
0
10
20
30
40
50
60
70
80
90
100
0 1 2 3 4 5 6 7 8
A
B
Iteration 1:MU(A) = 10/1 block MU(B) = 80/3 blocks
B gets 3 blocks
Result: A gets 5 blocks and B gets 3 blocks (Op-timal)
Next five iterations: MU(A) = 10/1 block MU(B) = 0A gets 1 block
Blocks assigned
Mis
ses
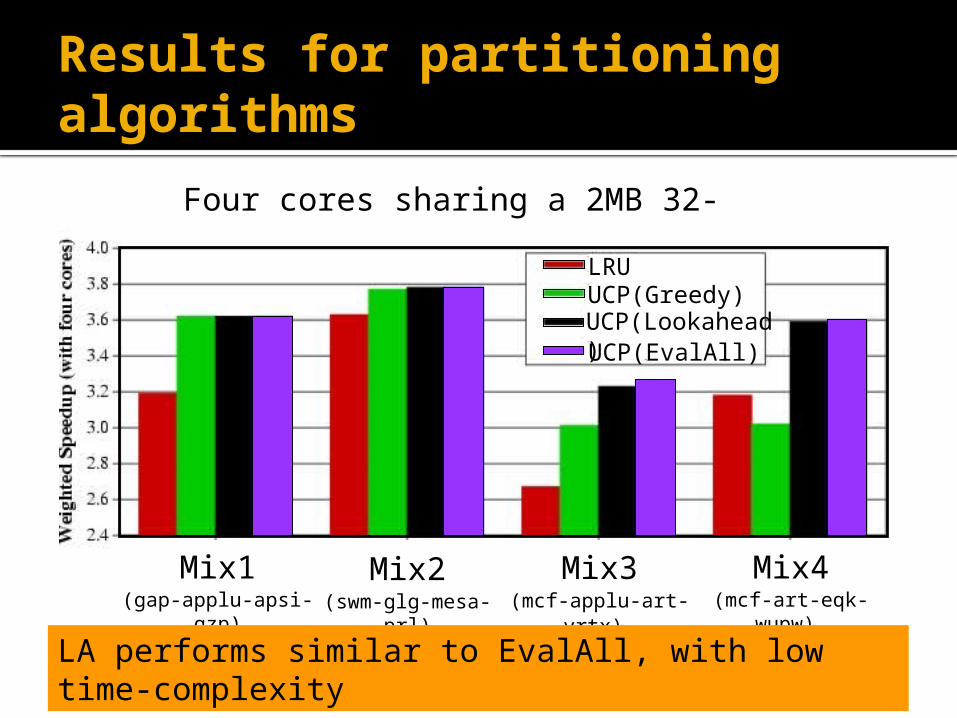
Results for partitioning al-gorithms
Four cores sharing a 2MB 32-way L2
Mix2(swm-glg-mesa-prl)
Mix3(mcf-applu-art-vrtx)
Mix4(mcf-art-eqk-wupw)
Mix1(gap-applu-apsi-
gzp)
LA performs similar to EvalAll, with low time-com-plexity
LRUUCP(Greedy)UCP(Lookahead)UCP(EvalAll)

Summary
CMP and shared caches are common
Partition shared caches based on utility, not demand
UMON estimates utility at runtime with low overhead
UCP improves performance: Weighted speedup by 11% Throughput by 17% Hmean-fairness by 11%
Lookahead algorithm is scalable to many cores shar-ing a highly associative cache














![Khwaja Gharib Nawaz Hudhrat Syed Moinuddin al-Chishti (Rehmatullahi Alehe) [Urdu]](https://img.dokumen.tips/doc/110x75/577cd13b1a28ab9e7893ee73/khwaja-gharib-nawaz-hudhrat-syed-moinuddin-al-chishti-rehmatullahi-alehe.jpg)














