Embed Size (px)
Citation preview

1
Método de imputación de los valores no observados.
Una aplicación en el análisis de la importancia de las becas escolares
Mauro Mediavilla
Universitat de València & IEB & GIPE
Segunda versión: abril 2012
Abstract
La estimación de una base de datos con observaciones faltantes (missings values) genera un fenómeno de
attrition que puede cambiar el grado de significatividad de las variables, disminuir la robustez en
términos de eficiencia de los resultados obtenidos e incrementar la posibilidad de una mala especificación
del modelo final estimado. El objetivo del trabajo es comprobar la importancia de la imputación de las
observaciones faltantes mediante dos metodologías (la imputación a la media y la imputación múltiple)
como vías para obtener estimaciones más robustas. Para ello se realiza un análisis comparativo
empleando los resultados obtenidos en el análisis descriptivo y de regresión logística.
Los resultados muestran el incremento en la eficiencia de la estimación en el caso de las bases imputadas
entendida como una reducción del error estándar y una mejora en los indicadores de bondad del ajuste.
Por otra parte, los cambios en los signos y la significatividad de algunas variables observadas son un claro
ejemplo de las diferencias que se pueden llegar a producir como consecuencia de estimar con bases de
datos imputadas o no. Estos resultados pueden provocar la estimación de un modelo no correctamente
especificado. La principal conclusión que se deriva es que resulta recomendable imputar aquellas bases de
datos con observaciones faltantes y, dentro de las metodologías de imputación aquí presentadas, la
imputación múltiple da muestra de una mayor eficiencia. Asimismo, y sobre todo para bases no muy
amplias (menos de 1000 observaciones, por ejemplo), la imputación no sólo permite una mayor precisión
en los coeficientes sino que evita interpretaciones erróneas de los fenómenos económicos analizados fruto
de una base de datos, efectivamente estimada, que sólo parcialmente refleja a la población objetivo.
Palabras Clave: observaciones perdidas, imputación múltiple, eficiencia en la estimación.

2
1. Introducción
Habitualmente, la literatura empírica en el campo de la economía aplicada basa sus
estimaciones poblaciones que sólo contienen las observaciones con información válida para
todas las variables implicadas, eliminando toda aquella información considerada parcial. Como
consecuencia de esta pérdida de información se pueden originar dos problemas: una pérdida de
eficiencia y un incremento en la probabilidad de llegar a una mala especificación del modelo.
En el primer caso, se puede generar un incremento de la varianza y en los desvíos estándar,
además de aumentar la probabilidad de realizar estimaciones a partir de una muestra
escasamente representativa de la población analizada. En este sentido, si bien la potencial
disminución de las observaciones no tiene por qué ser un problema en si misma, la
representatividad se ve afecta cuando este fenómeno influye no aleatoriamente en las variables
con valores no observados. En el segundo caso, se considera que un modelo estimado con bases
de datos con problemas de información podría inducir al investigador a escoger una estructura
modelística que no responda a la realidad de la muestra incurriendo en dos posibles problemas:
omisión de variables relevantes (infraespecificación) y/o inclusión de variables irrelevantes
(sobreespecificación). Las consecuencias directas implican calcular estadísticos t y F
distorsionados (Maddala, 1996).
En un intento por mejorar las estimaciones realizadas, algunos autores han sugerido que
la manera más adecuada para disminuir estos potenciales problemas era substituyendo los
valores perdidos mediante algunas de las técnicas de imputación desarrolladas (Schafer, 1999;
Acock, 2005).
Con el objeto de comprobar las ventajas de la imputación, en el presente trabajo se
desarrollaran tres metodologías de imputación y su aplicabilidad según sea el patrón seguido por
las variables con valores perdidos. Asimismo, se plantea un caso práctico -relevancia de las
becas en el logro educativo de los individuos en el nivel secundario post-obligatorio en España-
que permite al lector observar las principales diferencias obtenidas a partir de una misma base
de datos original que se ve modificada según sea la opción de imputación escogida siguiendo la
idea planteada por Allison (Allison, 2000).
Los resultados obtenidos en el análisis descriptivo y en la regresión logística posterior
indican que, en relación con la no imputación, las metodologías de imputación de datos faltantes
mejoran la eficiencia en la estimación y obtienen una mayor bondad del ajuste. Resulta
trascendente, desde el punto de vista de la interpretación de los propios resultados, algunos
cambios de signo y de significatividad ocurridos. Los mismos implican que las metodologías de

3
imputación, y especialmente aquella que emplea la imputación múltiple, al trabajar con toda la
información disponible mejoran los resultados obtenidos y permiten al investigador obtener
resultados más robustos.
El trabajo se inicia con una breve revisión teórica de las diferentes metodologías de
imputación haciendo hincapié en la importancia de conocer el patrón por el cual se generan los
valores perdidos. En el capítulo 3, se introduce el caso práctico con el cual se comparan las tres
metodologías de imputación utilizadas. En el capítulo 4, se realiza la comparación de las
estimaciones resultantes y, en el capítulo final, se introducen las principales conclusiones.
2. Análisis de los datos perdidos
La presencia de información faltante es un problema constante con el que deben lidiar
los investigadores en las diferentes áreas de la economía aplicada. La misma se puede originarse
por un registro defectuoso de la información, por la falta de respuesta a las preguntas del
encuestador (sea la misma total o parcial) o, directamente, por la ausencia natural de la
información (Allison, 2001; Perez, 2004). Su tratamiento estadístico obliga a la selección de una
metodología de imputación que debe ser el resultado natural de un análisis previo sobre el
patrón por el cual se generan los valores perdidos.
2.1 Patrones de comportamiento de los valores perdidos
En primer lugar, se puede determinar que el patrón seguido por los valores perdidos es
totalmente aleatorio (MCAR, Missing Completely At Random) o establecer un supuesto no tan
restrictivo indicando que su generación ha sido de manera aleatoria (MAR, Missing At
Random). En este caso, los valores perdidos pueden ser determinados a partir de otras variables
observables siguiendo la siguiente forma funcional:
,,|Pr,,|Pr obsmissmiss XYYXYY ,
donde hace referencia a los parámetros desconocidos. Desafortunadamente, no existe un test
que categóricamente indique si el supuesto MAR se satisface, por lo que se deben optar por vías
indirectas de control como la prueba de las correlaciones dicotómicas, el test conjunto de
aleatoriedad de Little o el análisis de sensibilidad de la estabilidad de los resultados, inferidos a
partir de diferentes modelos de imputación (Perez, 2004; Carpenter, 2007). Por último, se puede

4
suponer que los valores perdidos fueron generados de manera no aleatoria (MNAR, Missings
Not At Random), por lo que seguirían un patrón sistémico específico (Rubin, 1976).
En el siguiente apartado se detallan las principales opciones de imputación existente en
la literatura y su aplicabilidad según el patrón que se suponga que siguen los valores perdidos.
2.2. Diferentes metodologías de imputación1
2.2.1 Imputación Listwise (eliminación)
En primer lugar, la eliminación directa es una técnica comúnmente empleada en el
análisis empírico, en la cual se elimina la fila donde existe un vacío de información. Con el
objeto de obtener una base completa sólo con valores originariamente válidos se provoca una
reducción de la base de datos inicial (Perez, 2004). En caso de suponer un patrón MCAR, la
eliminación directa de las observaciones generaría una muestra más pequeña pero aún
representativa, lo que permitiría una estimación no sesgada de los estimadores. Aún así, este
proceso conllevaría una pérdida de información y un incremento en los errores estándar. No
obstante, si la base de datos no sigue un patrón MCAR, tal eliminación introduce un sesgo a la
hora de la estimación de los parámetros, que afecta la eficiencia de la propia estimación y podría
inducir a una mala especificación del modelo utilizado (Howell, 2007).
2.2.2 Imputación determinística: imputación a la media
En segundo lugar, la imputación determinística se basa en la sustitución del dato
perdido por la media de las observaciones válidas. Si bien su aplicación es muy sencilla, tiene
como desventaja que modifica la distribución de la variable reduciendo artificialmente su
varianza, efecto que no debe sorprender dado que se incrementa artificialmente la muestra sin
agregar información (Howell, 2007). El fundamento teórico para su empleo está basado en el
hecho de que ambos parámetros serían un valor esperado en el caso de una observación
seleccionada al azar de una distribución normal. En el caso de valores perdidos con un patrón no
estrictamente al azar (MAR o MNAR), esta metodología genera valores que reflejan
escasamente los valores originales.
1 Otros métodos empleados para imputar valores perdidos y aquí no desarrollados son la imputación HotDecking propuesta por Todeschini (1990) que propone estimar los valores perdidos mediante una estimación basada en sus “k-vecinos” más próximos, la imputación pairwise deletion y la substitución vía regresión.

5
Existen algunas variantes en su aplicación que intentan ajustar mejor los valores
imputados mediante esta técnica. En primer lugar, dividiendo la base de datos por secciones con
diferente media y a cada registro perdido imputándosele la media correspondiente. En segundo
lugar, creando una variable dummy por cada variable que contenga valores perdidos que
indiquen si la fila contiene alguna variable imputada. Las mismas se introducen en las
estimaciones posteriores y sus coeficientes estarían indicando la existencia de un efecto missing
en la estimación del parámetro de interés (Acock, 2005). Ambas opciones se pueden aplicar
simultáneamente. Asimismo, en caso de existir valores extremos en las variables a imputar se
deberían sustituir los valores ausentes por la mediana, estadístico más robusto para este caso en
particular2.
2.2.3 Imputación estocástica: imputación múltiple3
La técnica de imputación múltiple, si bien es conocida desde la década de 1970 (Rubin,
1976), su desarrollo y aplicación se ha ido extendiendo en los últimos años como consecuencia,
principalmente, de dos factores. En primer lugar, a causa de su introducción en los programas
econométricos que han permitido su generalización entre la comunidad académica (Little y
Rubin, 1987; Rubin, 1996; Van Buuren et al., 1999; Royston, 2004, 2005; Reiter y
Raghunathan, 2007). En segundo lugar, a partir de la publicación de diferentes estudios que han
demostrado las ventajas de la imputación múltiple frente a los procedimientos tradicionales de
tratamiento de los valores perdidos (Gómez y Palarea, 2003; Acock, 2005; Ambler y Omar,
2007).
Esta técnica, de característica estocástica, permite hacer un uso eficiente de los datos,
obtener estimadores no sesgados y reflejar la incertidumbre que la no-respuesta parcial
introduce en la estimación de los parámetros (Rubin, 1996). Su aplicación se basa en sustituir
los datos no observados por m>1 valores posibles simulados4. La aplicabilidad de este método
se ha visto potenciada con la incorporación, en su esquema general, de los métodos de Monte
Carlo basados en cadenas de Markov, conocidos como algoritmos MICE (Multiple imputation
by chained equations)5,6. Asimismo, a la imputación múltiple se la considera una metodología
2 Para una explicación de ésta y otras metodologías de imputación alternativas, véase Perez (2004; pp. 46-48). 3 Otra metodología de imputación aquí no desarrollada aplica el Expectation-Maximization algorithm (Schafer, 1997). 4 Para una explicación teórica detallada, véase Schafer (1999). 5 Otros métodos que han sido también empleados son el algoritmo EM (Expectation-Maximization); la aproximación de Monte Carlo Newton Raspón y Monte Carlo mediante una aproximación de máxima verosimilitud.

6
flexible que permite trabajar con datos multivariados y con distribuciones monótonas o
arbitrarias de los valores perdidos. Su aplicabilidad requiere que el patrón de distribución de los
valores perdidos sea aleatoria (MCAR o MAR).
El proceso de imputación múltiple consta de tres etapas. En la primera, cada valor
perdido se reemplaza por un conjunto de m>1 valores generados por simulación, con los que se
crean m matrices de datos completas. Para generar estos valores posibles se debe establecer un
método de estimación particular para cada variable a imputar a partir de sus características
propias. En la segunda etapa, el investigador debe aplicar a cada matriz simulada el análisis
deseado que se hubiese aplicado a la base original en caso de no haber contenido observaciones
perdidas. Por último, se combinan los resultados obtenidos en cada matriz para obtener una
estimación del parámetro estimado que, según Rubin (1987), se llevaría a cabo a partir del
cálculo de la media aritmética.
El número óptimo de bases de datos simuladas (m) depende del porcentaje de
información perdida. Si bien, hasta hace unos años se consideraba correcto el empleo de no más
de 10 bases imputadas para aproximar la incertidumbre asociada a la información no existente
(Schafer, 1999), la literatura actual considera óptimo realizar entre 3 y 20 imputaciones en caso
de tener una baja fracción de información perdida (un 20% como máximo de valores perdidos)
y hasta 50 imputaciones en caso de proporciones altas de datos no observados (Van Buuren et
al., 1999; Kenward y Carpenter, 2007). Por su parte, STATA recomienda realizar un mínimo de
20 imputaciones con el objetivo de reducir los posibles errores muestrales generados a partir de
las propias imputaciones (StataCorp, 2009).
Para su uso empírico, esta metodología ha sido trasladada a los diferentes paquetes
econométricos a partir de los trabajos de Van Buuren et al. (1999) y la implementación directa,
en el caso de STATA 10, a través del comando elaborado por Royston (Royston, 2004, 2005)
llamado ice, el cual permite realizar las estimaciones a partir de una distribución arbitraria de
los datos perdidos o mediante toda una familia de comandos mi que se incorporan a partir de la
versión 11. Asimismo, se han desarrollado otras aproximaciones en el caso del programa
SOLAS, SAS y S-Plus (Horton y Lipsitz, 2001).
6 En los últimos años se han desarrollado extensiones, como la imputación múltiple mediante árboles de clasificación (Bacallao y Bacallao, 2010).

7
3. Caso aplicado: evaluación de la relevancia de las becas en el logro educativo en
España
3.1 Base de datos empleada: Encuesta de Condiciones de Vida (ECV)
La Encuesta de Condiciones de Vida (en adelante, ECV7) es una base de datos novedosa
dirigida a hogares que viene a reemplazar el Panel de Hogares de la Unión Europea (PHOGUE),
realizado durante el periodo 1994-2001. El objetivo fundamental que se persigue con la ECV es
disponer de una fuente de referencia sobre estadísticas comparativas de la distribución de
ingresos y la exclusión social en el ámbito europeo. Aunque los datos se refieren tanto a la
dimensión transversal como a la longitudinal, se da prioridad a la producción de datos
transversales de alta calidad en lo que respecta a la puntualidad y a la comparabilidad.
La componente longitudinal permite seguir en el tiempo a las mismas personas, estudiar
los cambios que se producen en sus vidas cuando las condiciones y las políticas
socioeconómicas se modifican, y cómo reaccionan a estos cambios. Formalmente, la ECV
comienza en 2004 (si bien algunos países comenzaron más tarde y otros en 2003) y los ficheros
de microdatos (tanto transversales como longitudinales) se generan con una periodicidad anual.
A partir del año 2005 se van introduciendo módulos adicionales en la componente transversal
sobre diferentes temas de especial interés.
Especificidades técnicas
La población de referencia son los hogares y todas las personas mayores de 16 años que
se encuentren residiendo en un hogar dentro del territorio de los estados miembros en el
momento de realizarse la encuesta. Quedan excluidas las personas que viven en hogares
colectivos (residencias para la tercera edad, por ejemplo) o en algunos territorios que no son
incorporados por sus propios países en la base de datos (territorios franceses fuera de sus
fronteras europeas, por ejemplo). Los datos son recogidos por cada país mediante una
institución que, en España, es el Instituto Nacional de Estadística (INE). Estrictamente, la
población objeto de investigación (población objetivo) son las personas miembros de hogares
privados que residen en viviendas familiares principales. Aunque las personas de todas las
edades forman parte de la población objetivo no todas las personas son encuestadas
exhaustivamente, ya que sólo son seleccionables en este caso, los miembros del hogar con 16 o
más años el 31 de diciembre del año anterior a la fecha de la entrevista.
7 EU-SILC (European Union Statistics on Income and Living Conditions), en sus siglas en inglés.

8
La base de datos proporciona de microdatos transversales y longitudinales con
información personalizada sobre ingresos, educación, salud, ocupación, entre otros, que permite
conocer las condiciones en que viven los encuestados y las posibles situaciones de pobreza y
exclusión social. En el caso de los ingresos, es de especial interés para este trabajo la
información relacionada con las transferencias dinerarias recibidas por el individuo en concepto
de becas y, en el caso de las variables educativas, aquellas que permiten seguir su evolución
dentro del sistema educativo.
Caso español
En el caso de España, la encuesta es de tipo “panel rotante”, es decir, al ser un panel se
investiga a las mismas unidades a lo largo de los años pero, a diferencia del PHOGUE en que
las unidades panel eran fijas a lo largo de los ocho años de duración del estudio, en la ECV las
unidades panel se encuestan durante cuatro años y luego son reemplazadas. La muestra se
compone de 4 submuestras panel, de forma que cada año una de ellas se sustituye por una nueva
submuestra. Para la selección de cada submuestra se sigue un diseño bietápico con
estratificación de las unidades de primera etapa. La primera etapa la forman las secciones
censales y la segunda etapa las viviendas familiares principales. Dentro de ellas no se realiza
submuestreo alguno, investigándose a todos los hogares que tienen su residencia habitual en las
mismas. La selección de la muestra se realiza a partir del Padrón Municipal de habitantes de
2003 (INE) y, por ejemplo, en la ECV 2007 la muestra transversal para España cuenta con
información de 12.329 hogares y 34.635 individuos.
3.2. Selección de la muestra
Para el análisis empírico se emplean los datos correspondientes a la Encuesta de
Condiciones de Vida (ECV)8, elaborada por EUROSTAT con datos longitudinales para el
período 2004-2006, publicada en 2009. Los datos disponibles hacen referencia a los países de la
Unión Europea y en el caso español, la muestra comprende 58.740 individuos. Para el estudio
de impacto de las becas y ayudas al estudio en el logro educativo de los estudiantes, la variable
dependiente hace referencia al nivel educativo que posee la persona a los 19 años (véase tabla
1).
8 Contrato n. EU-SILC/2006/19. En él se establece la obligación, en el momento de publicar los resultados, de comunicar lo siguiente: “EUROSTAT no es responsable de los resultados y las conclusiones, responsabilidad que corresponde al investigador”.
9
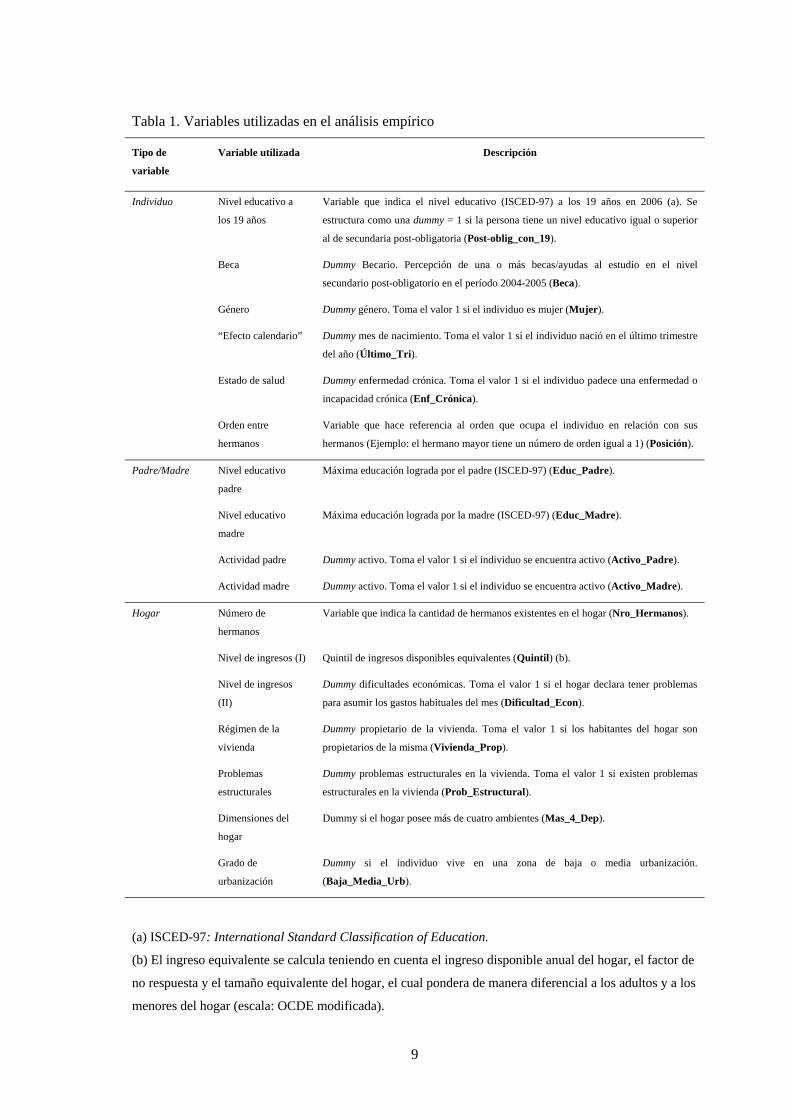
Tabla 1. Variables utilizadas en el análisis empírico
Tipo de
variable
Variable utilizada Descripción
Individuo Nivel educativo a
los 19 años
Variable que indica el nivel educativo (ISCED-97) a los 19 años en 2006 (a). Se
estructura como una dummy = 1 si la persona tiene un nivel educativo igual o superior
al de secundaria post-obligatoria (Post-oblig_con_19).
Beca Dummy Becario. Percepción de una o más becas/ayudas al estudio en el nivel
secundario post-obligatorio en el período 2004-2005 (Beca).
Género Dummy género. Toma el valor 1 si el individuo es mujer (Mujer).
“Efecto calendario” Dummy mes de nacimiento. Toma el valor 1 si el individuo nació en el último trimestre
del año (Último_Tri).
Estado de salud Dummy enfermedad crónica. Toma el valor 1 si el individuo padece una enfermedad o
incapacidad crónica (Enf_Crónica).
Orden entre
hermanos
Variable que hace referencia al orden que ocupa el individuo en relación con sus
hermanos (Ejemplo: el hermano mayor tiene un número de orden igual a 1) (Posición).
Padre/Madre Nivel educativo
padre
Máxima educación lograda por el padre (ISCED-97) (Educ_Padre).
Nivel educativo
madre
Máxima educación lograda por la madre (ISCED-97) (Educ_Madre).
Actividad padre Dummy activo. Toma el valor 1 si el individuo se encuentra activo (Activo_Padre).
Actividad madre Dummy activo. Toma el valor 1 si el individuo se encuentra activo (Activo_Madre).
Hogar Número de
hermanos
Variable que indica la cantidad de hermanos existentes en el hogar (Nro_Hermanos).
Nivel de ingresos (I) Quintil de ingresos disponibles equivalentes (Quintil) (b).
Nivel de ingresos
(II)
Dummy dificultades económicas. Toma el valor 1 si el hogar declara tener problemas
para asumir los gastos habituales del mes (Dificultad_Econ).
Régimen de la
vivienda
Dummy propietario de la vivienda. Toma el valor 1 si los habitantes del hogar son
propietarios de la misma (Vivienda_Prop).
Problemas
estructurales
Dummy problemas estructurales en la vivienda. Toma el valor 1 si existen problemas
estructurales en la vivienda (Prob_Estructural).
Dimensiones del
hogar
Dummy si el hogar posee más de cuatro ambientes (Mas_4_Dep).
Grado de
urbanización
Dummy si el individuo vive en una zona de baja o media urbanización.
(Baja_Media_Urb).
(a) ISCED-97: International Standard Classification of Education.
(b) El ingreso equivalente se calcula teniendo en cuenta el ingreso disponible anual del hogar, el factor de
no respuesta y el tamaño equivalente del hogar, el cual pondera de manera diferencial a los adultos y a los
menores del hogar (escala: OCDE modificada).

10
Si bien la edad teórica para finalizar el nivel secundario post-obligatorio son los 18
años, se ha optado por seleccionar un año más para evitar encontrar individuos con 18 años que
aún no tengan este nivel educativo alcanzado sólo porque la encuesta se ha realizado antes de
finalizar su curso lectivo. Como variables independientes se consideran diferentes variables
relacionadas con el individuo, sus progenitores, su hogar y el entorno que lo rodea.
A partir del total de observaciones válidas para la variable dependiente
(Post_Oblig_con_19), se genera una sub-base de datos con 783 observaciones de individuos de
19 años durante el período analizado que contiene valores perdidos para algunas de las variables
independientes, básicamente localizadas en aquellas que hacen referencia a los progenitores
(véase tabla 2), si bien en ningún caso superan el 20%.
3.3 Aplicación de la metodología de imputación
3.3.1. Análisis del patrón de comportamiento de los datos perdidos
Como paso previo al proceso de imputación, se debe comprobar la aleatoriedad (sea
parcial o total) de los valores ausentes. En este caso, los bajos niveles de significación obtenidos
en la prueba de las correlaciones dicotomizadas, donde las correlaciones indican el grado de
asociación entre los valores perdidos, permiten considerar que los valores perdidos se estarían
generando aleatoriamente9. Esta conclusión permite aplicar algunas de las metodologías de
imputación desarrolladas en la literatura empírica.
3.3.2. Metodologías tradicionales de imputación
En primer lugar, se emplean las dos metodologías tradicionalmente utilizadas por la
literatura empírica: la eliminación de todas las variables con observaciones faltantes (listwise) y
la imputación con el valor de la media aritmética.
3.3.3. Imputación Múltiple
En segundo lugar, se aplica la imputación múltiple para substituir los datos faltantes.
Siguiendo la literatura, se aplica una estimación múltiple a partir del algoritmo MICE,
sistematizado para el programa STATA mediante el comando ice. La imputación aquí aplicada
9 Previo al cálculo de los coeficientes de correlación se comprobó la ausencia de valores atípicos a partir de gráficos de caja. Todo este análisis previo se encuentra disponible para los lectores que así lo soliciten.
11
genera valores posibles a partir de una serie de modelos univariantes en los cuales una variable
única es imputada en base a un grupo de variables.
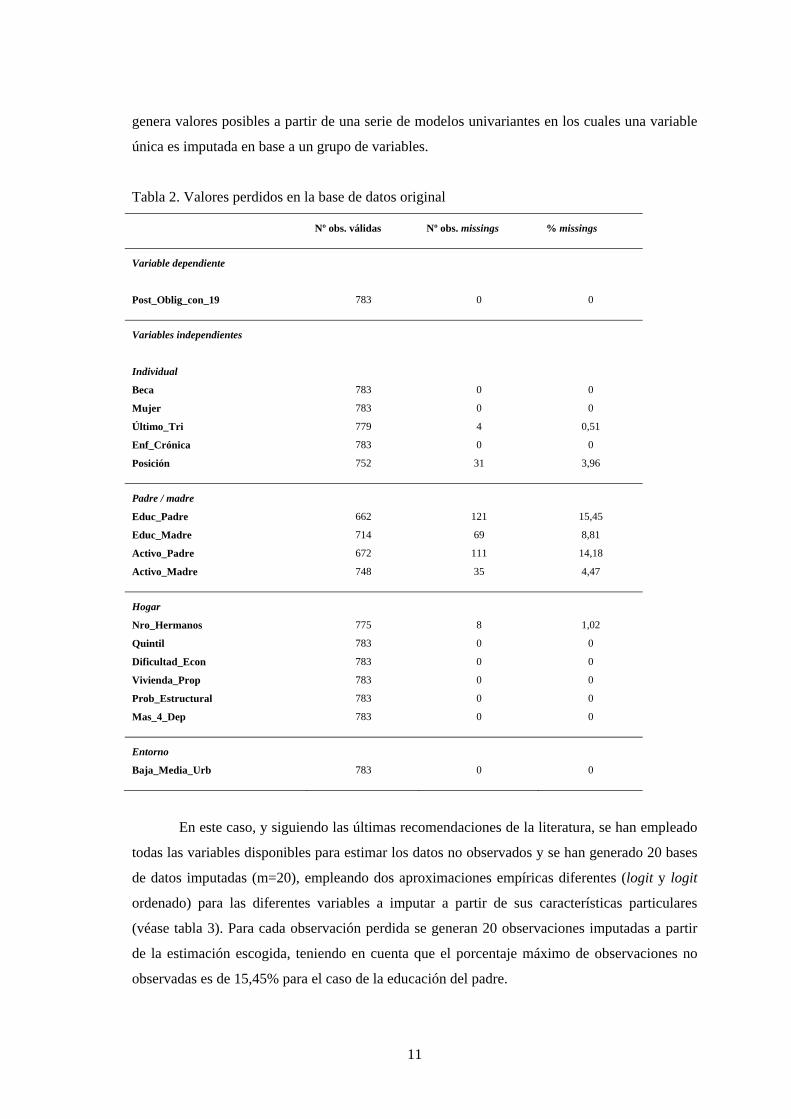
Tabla 2. Valores perdidos en la base de datos original
Nº obs. válidas Nº obs. missings % missings
Variable dependiente
Post_Oblig_con_19 783 0 0
Variables independientes
Individual
Beca 783 0 0
Mujer 783 0 0
Último_Tri 779 4 0,51
Enf_Crónica 783 0 0
Posición 752 31 3,96
Padre / madre
Educ_Padre 662 121 15,45
Educ_Madre 714 69 8,81
Activo_Padre 672 111 14,18
Activo_Madre 748 35 4,47
Hogar
Nro_Hermanos 775 8 1,02
Quintil 783 0 0
Dificultad_Econ 783 0 0
Vivienda_Prop 783 0 0
Prob_Estructural 783 0 0
Mas_4_Dep 783 0 0
Entorno
Baja_Media_Urb 783 0 0
En este caso, y siguiendo las últimas recomendaciones de la literatura, se han empleado
todas las variables disponibles para estimar los datos no observados y se han generado 20 bases
de datos imputadas (m=20), empleando dos aproximaciones empíricas diferentes (logit y logit
ordenado) para las diferentes variables a imputar a partir de sus características particulares
(véase tabla 3). Para cada observación perdida se generan 20 observaciones imputadas a partir
de la estimación escogida, teniendo en cuenta que el porcentaje máximo de observaciones no
observadas es de 15,45% para el caso de la educación del padre.

12
Tabla 3. Aproximaciones empíricas utilizadas para la imputación
Variable a imputar Característica Aproximación empírica
Último_Tri Dummy (0-1) Logit
Activo_Padre Dummy (0-1)
Activo_Madre Dummy (0-1)
Posición Discreta (1-3) Logit ordenado
Educ_Padre Discreta (1-5)
Educ_Madre Discreta (1-5)
Nro_Hermanos Discreta (0-3)
3.4. Base de datos obtenida mediante las diferentes metodologías de imputación
Para analizar descriptivamente las bases de datos obtenidas, se presentan los valores de
la media y la desviación estándar para todas las variables utilizadas. Asimismo, y en los casos
en que la variable posea valores no observados, se calculan los valores resultantes para las tres
metodologías utilizadas: la no imputación, la imputación con la media aritmética y la
imputación múltiple. En el caso de la no imputación, los valores surgen a partir de las
observaciones finalmente empleadas en la estimación (en este caso, 616 observaciones) y, en el
caso de la imputación múltiple, el valor publicado refleja el promedio de las 20 bases generadas.
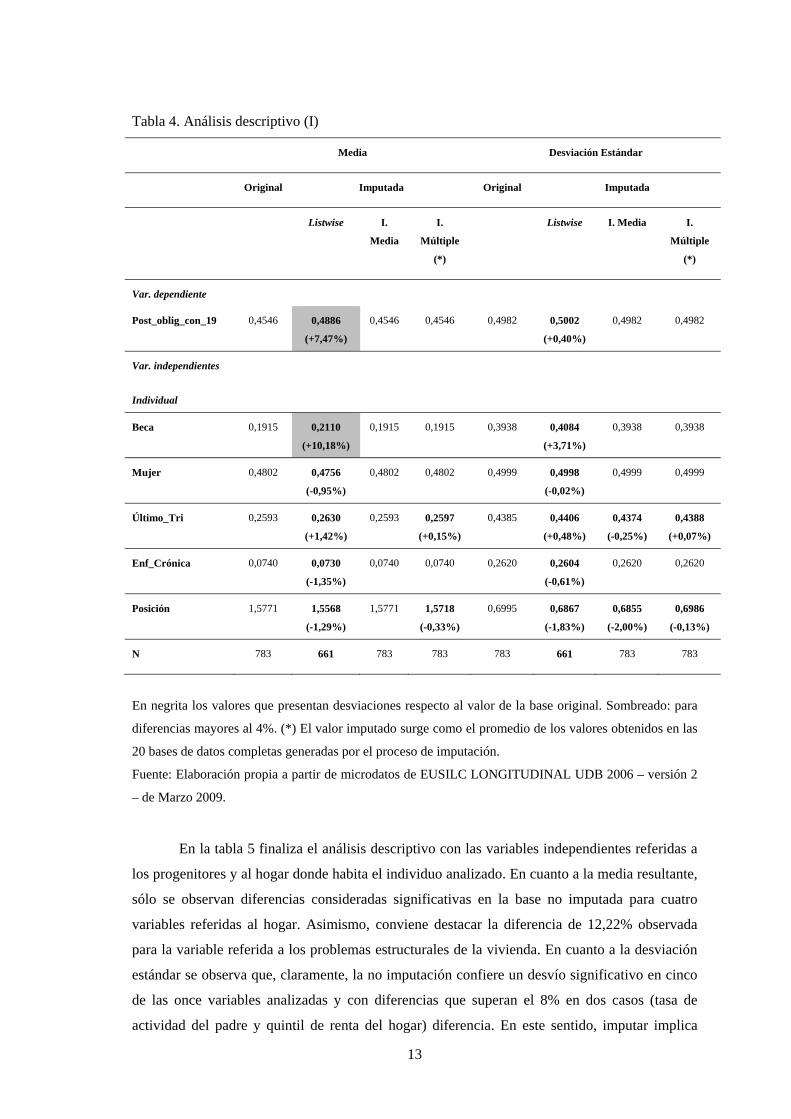
En la tabla 4 se observan los resultados para la variable dependiente y las variable
independientes referidas al ámbito del individuo. Teniendo en cuenta que se consideran
diferencias relevantes aquellas por encima del 4%, sólo en el caso de la no imputación existen
diferencias entre la base original y la finalmente utilizada para la estimación. Es el caso de la
variable dependiente con una diferencia que supera el 7% y la que indica si el individuo ha
recibido o no una beca, con una diferencia superior al 10%. Asimismo, en el caso de la no
imputación (listwise) se observa que el número de observaciones empleadas es de 661 con una
pérdida de 122 observaciones respecto a la base original que significan un 15,58% de la muestra
original. Finalmente, conviene recalcar que si bien la estimación múltiple se aplica en todas las
variables con valores no observados y, por tanto, hace variar el valor promedio y la desviación
estándar, en ningún caso se obtiene una diferencia significativa en relación a la muestra original.
13
Tabla 4. Análisis descriptivo (I)
Media Desviación Estándar
Original Imputada Original Imputada
Listwise
I.
Media
I.
Múltiple
(*)
Listwise I. Media I.
Múltiple
(*)
Var. dependiente
Post_oblig_con_19 0,4546 0,4886
(+7,47%)
0,4546 0,4546 0,4982 0,5002
(+0,40%)
0,4982 0,4982
Var. independientes
Individual
Beca 0,1915 0,2110
(+10,18%)
0,1915 0,1915 0,3938 0,4084
(+3,71%)
0,3938 0,3938
Mujer 0,4802 0,4756
(-0,95%)
0,4802 0,4802 0,4999 0,4998
(-0,02%)
0,4999 0,4999
Último_Tri 0,2593 0,2630
(+1,42%)
0,2593 0,2597
(+0,15%)
0,4385 0,4406
(+0,48%)
0,4374
(-0,25%)
0,4388
(+0,07%)
Enf_Crónica 0,0740 0,0730
(-1,35%)
0,0740 0,0740 0,2620 0,2604
(-0,61%)
0,2620 0,2620
Posición 1,5771 1,5568
(-1,29%)
1,5771 1,5718
(-0,33%)
0,6995 0,6867
(-1,83%)
0,6855
(-2,00%)
0,6986
(-0,13%)
N 783 661 783 783 783 661 783 783
En negrita los valores que presentan desviaciones respecto al valor de la base original. Sombreado: para
diferencias mayores al 4%. (*) El valor imputado surge como el promedio de los valores obtenidos en las
20 bases de datos completas generadas por el proceso de imputación.
Fuente: Elaboración propia a partir de microdatos de EUSILC LONGITUDINAL UDB 2006 – versión 2
– de Marzo 2009.
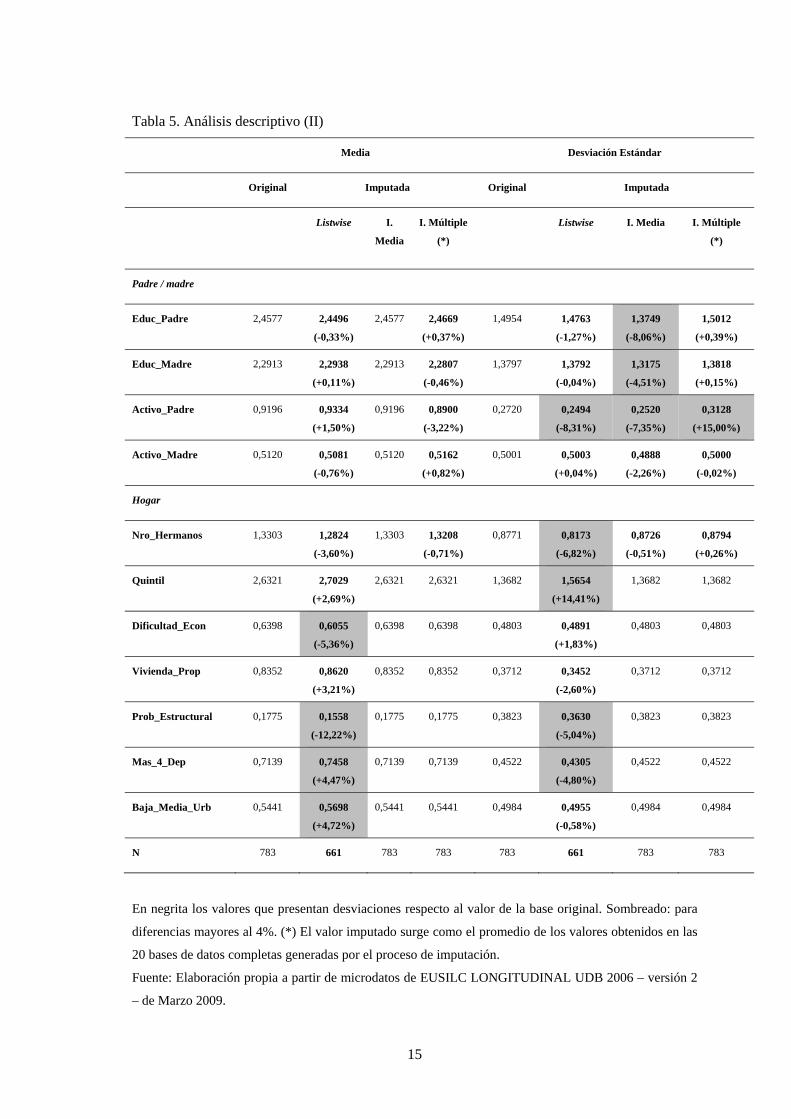
En la tabla 5 finaliza el análisis descriptivo con las variables independientes referidas a
los progenitores y al hogar donde habita el individuo analizado. En cuanto a la media resultante,
sólo se observan diferencias consideradas significativas en la base no imputada para cuatro
variables referidas al hogar. Asimismo, conviene destacar la diferencia de 12,22% observada
para la variable referida a los problemas estructurales de la vivienda. En cuanto a la desviación
estándar se observa que, claramente, la no imputación confiere un desvío significativo en cinco
de las once variables analizadas y con diferencias que superan el 8% en dos casos (tasa de
actividad del padre y quintil de renta del hogar) diferencia. En este sentido, imputar implica

14
reducir las diferencias con respecto a la base original. Mientras la imputación con la media
aritmética genera diferencias superiores al 4% en tres variables, con la imputación múltiple sólo
se genera una diferencia destacada en una variable de entre todas las características tenidas en
cuenta.
Asimismo, cabe consignar que todos los valores obtenidos bajo la imputación a la
media generan desvíos con respecto al valor inicial siempre menores, con lo que implica una
variabilidad menor de la base imputada en relación a la original e, implícitamente, ésta restando
representatividad a la muestra final respecto de la original. Asimismo, se ha realizado el análisis
de correlación bivariada de Pearson para cada base evaluada observándose dos aspectos
relevantes a destacar. En primer lugar, que los signos y la intensidad de los coeficientes queda
reflejado en los coeficientes obtenidos en la regresiones que se presentan en el próximo
apartado y; por último, que en ningún caso se observan relaciones por encima de 0,60 y sólo tres
emparejamientos muestran valores por encima de 0,40 (para una revisión de la totalidad de los
coeficientes, véase anexo).
El análisis descriptivo de las diferentes bases de datos indica que, mientras la base no
imputada presenta los mayores problemas de representatividad en términos de diferencias
relevantes tanto en la media como en la desviación estándar y la base imputada a la media
mejora la aproximación pero reduce los niveles de variabilidad de las variables con valores no
observables, la imputación múltiple ofrece una alternativa que permite incorporar el máximo de
información sin perder representatividad de la base imputada respecto a la original y
manteniendo el grado de variabilidad de todas las variables involucradas en la estimación.
4. Comparación de las estimaciones obtenidas a partir de diferentes bases de datos:
imputadas y no imputadas
En este apartado se comparan los resultados obtenidos en una regresión logística
binomial aplicada a las tres bases de datos resultantes: la base no imputada, la base imputada
con la media aritmética y la base imputada mediante un proceso de imputación múltiple (véase
tabla 6). En este último caso se plantean tres resultados diferentes: el valor medio de los
resultados obtenidos en las 20 bases imputadas y los resultados generados por la base imputada
más y menos eficiente en términos de minimización del error estándar. El objetivo del ejercicio
es determinar la importancia de las becas en el logro educativo de los alumnos.
15
Tabla 5. Análisis descriptivo (II)
Media Desviación Estándar
Original Imputada Original Imputada
Listwise
I.
Media
I. Múltiple
(*)
Listwise I. Media I. Múltiple
(*)
Padre / madre
Educ_Padre 2,4577 2,4496
(-0,33%)
2,4577 2,4669
(+0,37%)
1,4954 1,4763
(-1,27%)
1,3749
(-8,06%)
1,5012
(+0,39%)
Educ_Madre 2,2913 2,2938
(+0,11%)
2,2913 2,2807
(-0,46%)
1,3797 1,3792
(-0,04%)
1,3175
(-4,51%)
1,3818
(+0,15%)
Activo_Padre 0,9196 0,9334
(+1,50%)
0,9196 0,8900
(-3,22%)
0,2720 0,2494
(-8,31%)
0,2520
(-7,35%)
0,3128
(+15,00%)
Activo_Madre 0,5120 0,5081
(-0,76%)
0,5120 0,5162
(+0,82%)
0,5001 0,5003
(+0,04%)
0,4888
(-2,26%)
0,5000
(-0,02%)
Hogar
Nro_Hermanos 1,3303 1,2824
(-3,60%)
1,3303 1,3208
(-0,71%)
0,8771 0,8173
(-6,82%)
0,8726
(-0,51%)
0,8794
(+0,26%)
Quintil 2,6321 2,7029
(+2,69%)
2,6321 2,6321 1,3682 1,5654
(+14,41%)
1,3682 1,3682
Dificultad_Econ 0,6398 0,6055
(-5,36%)
0,6398 0,6398 0,4803 0,4891
(+1,83%)
0,4803 0,4803
Vivienda_Prop 0,8352 0,8620
(+3,21%)
0,8352 0,8352 0,3712 0,3452
(-2,60%)
0,3712 0,3712
Prob_Estructural 0,1775 0,1558
(-12,22%)
0,1775 0,1775 0,3823 0,3630
(-5,04%)
0,3823 0,3823
Mas_4_Dep 0,7139 0,7458
(+4,47%)
0,7139 0,7139 0,4522 0,4305
(-4,80%)
0,4522 0,4522
Baja_Media_Urb 0,5441 0,5698
(+4,72%)
0,5441 0,5441 0,4984 0,4955
(-0,58%)
0,4984 0,4984
N 783 661 783 783 783 661 783 783
En negrita los valores que presentan desviaciones respecto al valor de la base original. Sombreado: para
diferencias mayores al 4%. (*) El valor imputado surge como el promedio de los valores obtenidos en las
20 bases de datos completas generadas por el proceso de imputación.
Fuente: Elaboración propia a partir de microdatos de EUSILC LONGITUDINAL UDB 2006 – versión 2
– de Marzo 2009.
16
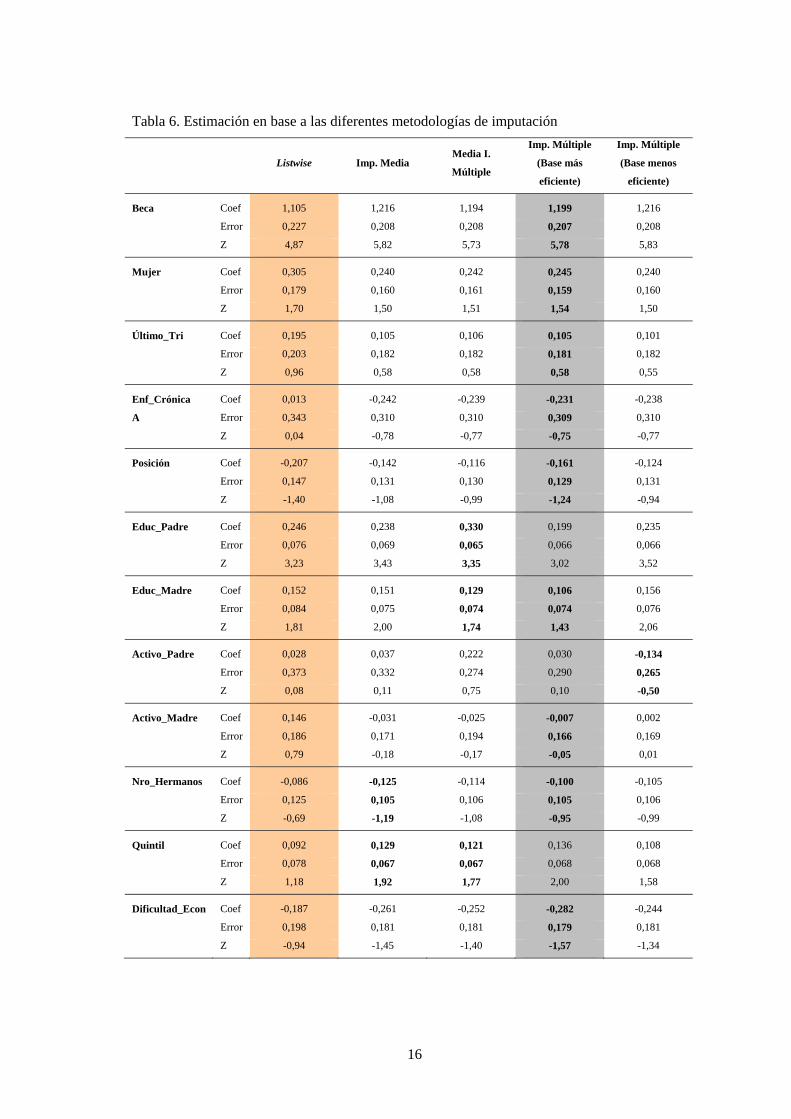
Tabla 6. Estimación en base a las diferentes metodologías de imputación
Listwise Imp. Media Media I.
Múltiple
Imp. Múltiple
(Base más
eficiente)
Imp. Múltiple
(Base menos
eficiente)
Beca Coef 1,105 1,216 1,194 1,199 1,216
Error 0,227 0,208 0,208 0,207 0,208
Z 4,87 5,82 5,73 5,78 5,83
Mujer Coef 0,305 0,240 0,242 0,245 0,240
Error 0,179 0,160 0,161 0,159 0,160
Z 1,70 1,50 1,51 1,54 1,50
Último_Tri Coef 0,195 0,105 0,106 0,105 0,101
Error 0,203 0,182 0,182 0,181 0,182
Z 0,96 0,58 0,58 0,58 0,55
Enf_Crónica Coef 0,013 -0,242 -0,239 -0,231 -0,238
A Error 0,343 0,310 0,310 0,309 0,310
Z 0,04 -0,78 -0,77 -0,75 -0,77
Posición Coef -0,207 -0,142 -0,116 -0,161 -0,124
Error 0,147 0,131 0,130 0,129 0,131
Z -1,40 -1,08 -0,99 -1,24 -0,94
Educ_Padre Coef 0,246 0,238 0,330 0,199 0,235
Error 0,076 0,069 0,065 0,066 0,066
Z 3,23 3,43 3,35 3,02 3,52
Educ_Madre Coef 0,152 0,151 0,129 0,106 0,156
Error 0,084 0,075 0,074 0,074 0,076
Z 1,81 2,00 1,74 1,43 2,06
Activo_Padre Coef 0,028 0,037 0,222 0,030 -0,134
Error 0,373 0,332 0,274 0,290 0,265
Z 0,08 0,11 0,75 0,10 -0,50
Activo_Madre Coef 0,146 -0,031 -0,025 -0,007 0,002
Error 0,186 0,171 0,194 0,166 0,169
Z 0,79 -0,18 -0,17 -0,05 0,01
Nro_Hermanos Coef -0,086 -0,125 -0,114 -0,100 -0,105
Error 0,125 0,105 0,106 0,105 0,106
Z -0,69 -1,19 -1,08 -0,95 -0,99
Quintil Coef 0,092 0,129 0,121 0,136 0,108
Error 0,078 0,067 0,067 0,068 0,068
Z 1,18 1,92 1,77 2,00 1,58
Dificultad_Econ Coef -0,187 -0,261 -0,252 -0,282 -0,244
Error 0,198 0,181 0,181 0,179 0,181
Z -0,94 -1,45 -1,40 -1,57 -1,34
17
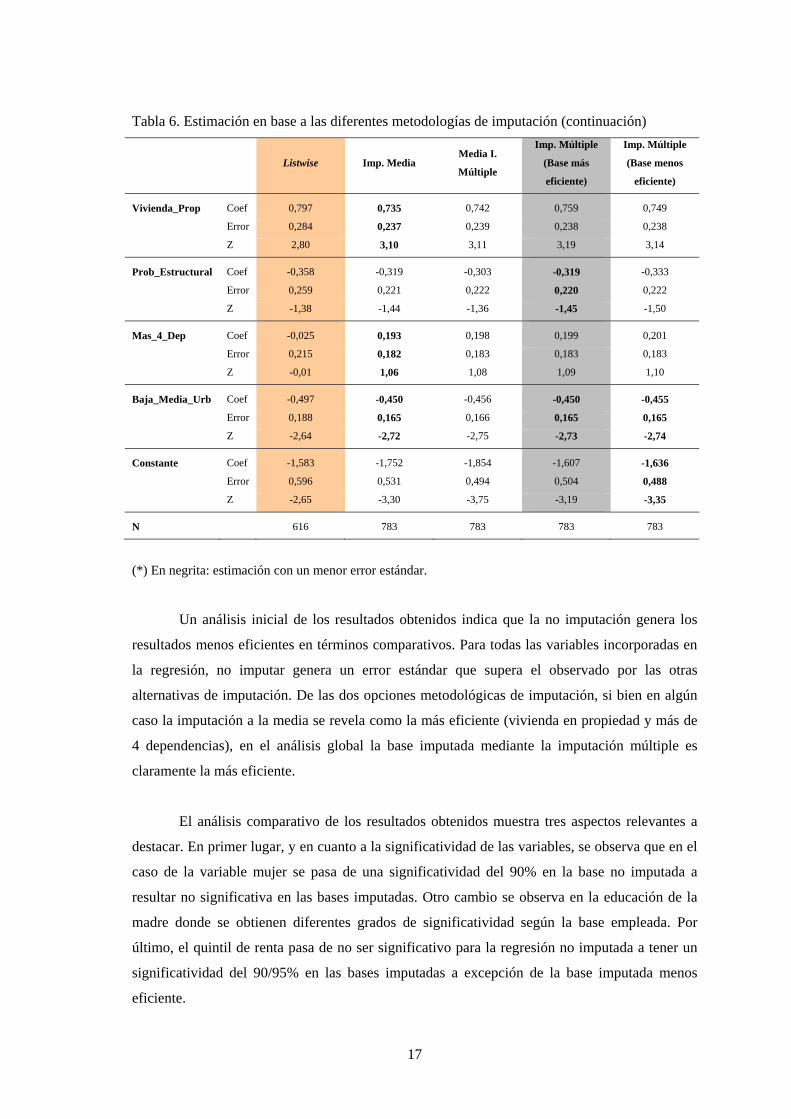
Tabla 6. Estimación en base a las diferentes metodologías de imputación (continuación)
Listwise Imp. Media Media I.
Múltiple
Imp. Múltiple
(Base más
eficiente)
Imp. Múltiple
(Base menos
eficiente)
Vivienda_Prop Coef 0,797 0,735 0,742 0,759 0,749
Error 0,284 0,237 0,239 0,238 0,238
Z 2,80 3,10 3,11 3,19 3,14
Prob_Estructural Coef -0,358 -0,319 -0,303 -0,319 -0,333
Error 0,259 0,221 0,222 0,220 0,222
Z -1,38 -1,44 -1,36 -1,45 -1,50
Mas_4_Dep Coef -0,025 0,193 0,198 0,199 0,201
Error 0,215 0,182 0,183 0,183 0,183
Z -0,01 1,06 1,08 1,09 1,10
Baja_Media_Urb Coef -0,497 -0,450 -0,456 -0,450 -0,455
Error 0,188 0,165 0,166 0,165 0,165
Z -2,64 -2,72 -2,75 -2,73 -2,74
Constante Coef -1,583 -1,752 -1,854 -1,607 -1,636
Error 0,596 0,531 0,494 0,504 0,488
Z -2,65 -3,30 -3,75 -3,19 -3,35
N 616 783 783 783 783
(*) En negrita: estimación con un menor error estándar.
Un análisis inicial de los resultados obtenidos indica que la no imputación genera los
resultados menos eficientes en términos comparativos. Para todas las variables incorporadas en
la regresión, no imputar genera un error estándar que supera el observado por las otras
alternativas de imputación. De las dos opciones metodológicas de imputación, si bien en algún
caso la imputación a la media se revela como la más eficiente (vivienda en propiedad y más de
4 dependencias), en el análisis global la base imputada mediante la imputación múltiple es
claramente la más eficiente.
El análisis comparativo de los resultados obtenidos muestra tres aspectos relevantes a
destacar. En primer lugar, y en cuanto a la significatividad de las variables, se observa que en el
caso de la variable mujer se pasa de una significatividad del 90% en la base no imputada a
resultar no significativa en las bases imputadas. Otro cambio se observa en la educación de la
madre donde se obtienen diferentes grados de significatividad según la base empleada. Por
último, el quintil de renta pasa de no ser significativo para la regresión no imputada a tener un
significatividad del 90/95% en las bases imputadas a excepción de la base imputada menos
eficiente.
18
En segundo lugar, el análisis se centra en los valores de los coeficientes donde se
detectan diferencias relevantes entre las distintas regresiones. En la gran mayoría de variables
los porcentajes de variación son elevados (cuya influencia es relevante dado que el investigador
puede sacar conclusiones de coeficientes relativamente sobre o subestimados) y en tres casos
(enfermedad crónica, activo madre y más de 4 dependencia) el coeficiente cambia de signo. Éste
último fenómeno es necesario destacar ya que en dos de los casos el cambio se alinea con un
resultado esperado en base a la teoría. Finalmente, en la variable clave para el ejercicio
propuesto (Beca) se observa que las bases de datos imputadas le asignan un impacto mayor en
cuanto a su efecto en el éxito escolar en el nivel secundario post-obligatorio en España.
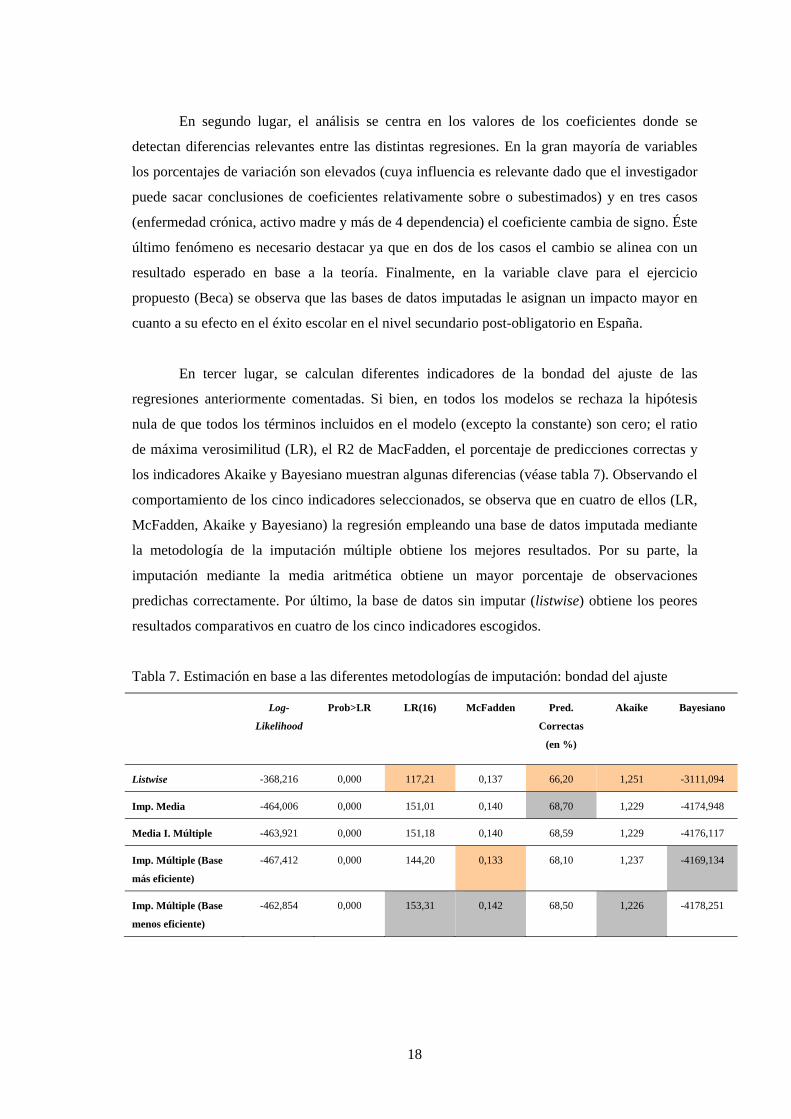
En tercer lugar, se calculan diferentes indicadores de la bondad del ajuste de las
regresiones anteriormente comentadas. Si bien, en todos los modelos se rechaza la hipótesis
nula de que todos los términos incluidos en el modelo (excepto la constante) son cero; el ratio
de máxima verosimilitud (LR), el R2 de MacFadden, el porcentaje de predicciones correctas y
los indicadores Akaike y Bayesiano muestran algunas diferencias (véase tabla 7). Observando el
comportamiento de los cinco indicadores seleccionados, se observa que en cuatro de ellos (LR,
McFadden, Akaike y Bayesiano) la regresión empleando una base de datos imputada mediante
la metodología de la imputación múltiple obtiene los mejores resultados. Por su parte, la
imputación mediante la media aritmética obtiene un mayor porcentaje de observaciones
predichas correctamente. Por último, la base de datos sin imputar (listwise) obtiene los peores
resultados comparativos en cuatro de los cinco indicadores escogidos.
Tabla 7. Estimación en base a las diferentes metodologías de imputación: bondad del ajuste
Log-
Likelihood
Prob>LR LR(16) McFadden Pred.
Correctas
(en %)
Akaike Bayesiano
Listwise -368,216 0,000 117,21 0,137 66,20 1,251 -3111,094
Imp. Media -464,006 0,000 151,01 0,140 68,70 1,229 -4174,948
Media I. Múltiple -463,921 0,000 151,18 0,140 68,59 1,229 -4176,117
Imp. Múltiple (Base
más eficiente)
-467,412 0,000 144,20 0,133 68,10 1,237 -4169,134
Imp. Múltiple (Base
menos eficiente)
-462,854 0,000 153,31 0,142 68,50 1,226 -4178,251

19
5. Conclusiones
El presente trabajo se planteó el reto de comprobar las diferencias existentes entre la
simple no imputación de las observaciones con datos faltantes y las alternativas ofrecidas por la
literatura en términos de diferentes metodologías de imputación. Para ello se realizó un análisis
comparativo entre las distintas bases de datos generadas a partir de un análisis descriptivo, de
correlación y de regresión logística.
Los resultados obtenidos muestran que la imputación, por las dos vías exploradas,
incrementan la eficiencia de la estimación entendida como una reducción del error estándar y
una mejora en los indicadores de bondad del ajuste. Asimismo, los cambios en los signos y de
significatividad de algunas variables muestran las diferencias que se pueden llegar a producir a
causa de la pérdida de observaciones producida por la no imputación, en un claro efecto
atrittion.
La principal conclusión que se deriva es que resulta recomendable imputar aquellas
bases de datos con observaciones faltantes y, dentro de las metodologías de imputación aquí
presentadas, la imputación múltiple da muestra de una mayor eficiencia. Asimismo, y sobre
todo para bases de datos no muy amplias (menos de 1000 observaciones, por ejemplo), la
imputación no sólo permite una mayor precisión en los coeficientes sino que también una menor
probabilidad de realizar interpretaciones erróneas fruto de una base de datos efectivamente
estimada que no es representativa de la muestra original.
Bibliografía
Acock, Alan. 2005. "Working with Missing Values." Journal of Marriage and Family, 67, pp. 1012-28. Allison, Paul. 2000. "Multiple imputation for missing data: a cautionary tale." Sociological Methods & Research, 28:3, pp. 301-09. Allison, Paul. 2001. Missing values. Thousand Oaks, CA: Sage Publications. Ambler, Gareth y Rumana Omar. 2007. "A comparison of imputation techniques for handling missing predictor values in a risk model with a binary outcome." Statistical Methods in Medical Research, 16, pp. 227-98. Bacallao, Jorge y Jorge Bacallao. 2010. "Imputación Múltiple en Variables Categóricas usando Data Augmentation y Árboles de Clasificación." Revista Investigación Operacional, 31:2, pp. 133-39.

20
Carpenter, James, Michael Kenward, e Ian White. 2007. "Sensitivity analysis after multiple imputation under missing at random: a weighting approach." Statistical Methods in Medical Research, 16, pp. 259-75. Gómez, Juan y Javier Palarea. 2003. "Inferencia basada en imputación múltiple en problemas con información incompleta." Comunicación presentada en la IX Conferencia Española de Biometría. Horton, Nocholas y Stuart Lipsitz. 2001. "Multiple Imputation in Practice: Comparison of Software Packages for Regression Models with Missings Variables." The American Statistician, 55:3, pp. 244-54. Howell, David. (2007). "The treatment of missing data”. En: W. Outhwaite y S. Turner (eds.), The SAGE Handbook of social science methodology (208-224). London: Sage Publications. Kenward, Michael y James Carpenter. 2007. "Multiple imputation: current perspectives." Statistical Methods in Medical Research, 16, pp. 199-218. Little, Roderick y Donald Rubin. 1987. Statistical Analysis with Missing Data. New York: John Wiley & Sons. Maddala, Gangadharrao. 1996. Introducción a la econometria. México: Prentice-Hall Hispanoamericana (2da edición). Perez, Cesar. 2004. Técnicas de análisis multivariante de datos: aplicaciones con SPSS. Madrid: Prentice Hall. Reiter, Jerome y Trivellore Raghunathan. 2007. "The Multiple Adaptations of Multiple Imputation." Journal of the American Statistical Association, 102:480, pp. 1462-71. Royston, Patrick. 2004. "Multiple imputation of missing values." The Stata Journal, 4:3, pp. 227-41. Royston, Patrick. 2005. "Multiple imputation of missings values: update." The Stata Journal, 5:2, pp. 1-14. Rubin, Donald. 1976. "Inference and missing data." Biometrika, 63:3, pp. 581-92. Rubin, Donald. 1987. Multiple imputation for nonresponse in Surveys. New York: Wiley. Rubin, Donald. 1996. "Multiple Imputation After 18+ Years." Journal of the American Statistical Association, 91:434, pp. 473-89. Schafer, Joseph. 1997. Analysis of incomplete multivariate data. London: Chapman & Hall. Schafer, Joseph. 1999. "Multiple imputation: a primer." Statistical Methods in Medical Research, 8, pp. 3-15. StataCorp. 2009. Stata: Release 11. Multiple Imputation. Texas: Stata Press. Todeschini, Roberto. 1990. "Weighted k-nearest neighbour method for the calculation of missing values." Chenometrics and Intelligent Laboratory Systems, 9, pp. 201-05. Van Buuren, Stef, Hendriek Boshuizen, y Dirk Knook. 1999. "Multiple imputation of missing blood pressure covariates in survival analysis." Statistics in Medicine, 18, pp. 681-94.

21
Anexo
Tabla de correlaciones según diferentes bases de datos
1. Base sin imputar (listwise)
2. Base imputada a la media
medio_bajo~b 0.1293 0.0613 1.0000mas_4_ambi~e -0.0361 1.0000problemas_~i 1.0000 proble~i mas_4_~e medio_~b
medio_bajo~b -0.1907 -0.0479 -0.0351 0.0556 -0.2325 0.1574 -0.0054mas_4_ambi~e 0.0969 0.0144 -0.0096 0.0816 0.0612 -0.1202 0.1550problemas_~i -0.1208 -0.0828 0.0199 0.0980 -0.0541 0.1179 -0.1006vivienda_p~p 0.0682 0.0631 -0.0265 -0.0633 0.1958 -0.1496 1.0000dif_final_~s -0.2593 -0.0290 -0.0832 0.1572 -0.3462 1.0000 quintil 0.3970 0.0135 0.1880 -0.1607 1.0000nro_herman~s -0.1877 -0.0033 -0.1726 1.0000activo_madre 0.2381 -0.0022 1.0000activo_padre 0.0569 1.0000 educ_madre 1.0000 educ_m~e ac~padre ac~madre nro_he~s quintil dif_fi~s vivien~p
medio_bajo~b -0.1608 0.1199 0.0069 -0.0619 -0.0081 0.0457 -0.1886mas_4_ambi~e 0.0437 0.0173 -0.0316 -0.0539 -0.0141 -0.0106 0.1123problemas_~i -0.1156 0.0191 0.0658 -0.0432 -0.0174 0.0884 -0.1249vivienda_p~p 0.1651 0.0454 -0.0054 0.0145 -0.0143 -0.0320 0.0901dif_final_~s -0.1413 0.1000 0.0770 0.0370 0.0607 0.0305 -0.2381 quintil 0.1986 -0.0973 -0.0285 0.0085 -0.0120 0.0588 0.3801nro_herman~s -0.1393 -0.0717 0.0208 0.0372 -0.0436 0.4117 -0.1364activo_madre 0.0848 -0.0084 -0.0057 -0.0540 0.0391 -0.1149 0.0886activo_padre 0.0526 0.0104 -0.0195 0.0560 -0.0252 -0.0776 0.1300 educ_madre 0.2558 -0.0410 -0.0380 0.0198 -0.0236 -0.1473 0.5811 educ_padre 0.2766 -0.0579 0.0005 -0.0046 -0.0306 -0.1030 1.0000posicion_bis -0.1306 -0.0950 0.0135 0.0204 0.0268 1.0000 enf_cronica 0.0001 0.0383 0.0199 -0.0402 1.0000 ultimo_tri 0.0357 -0.0288 0.0070 1.0000 mujer 0.0574 0.0571 1.0000 con_beca1 0.1709 1.0000post_obli~18 1.0000 post_~18 con_be~1 mujer ultimo~i enf_cr~a posici~s educ_p~e
medio_bajo~b 0.1233 0.0787 1.0000mas_4_ambi~e -0.0461 1.0000problemas_~i 1.0000 proble~i mas_4_~e medio_~b
medio_bajo~b -0.1751 -0.0198 -0.0679 0.0537 -0.1956 0.1358 0.0082mas_4_ambi~e 0.0996 0.0096 -0.0374 0.0627 0.0653 -0.1158 0.1455problemas_~i -0.1286 -0.0929 -0.0005 0.1165 -0.1072 0.1466 -0.1000vivienda_p~p 0.0591 0.0635 -0.0393 -0.0739 0.1852 -0.1754 1.0000dif_final_~s -0.2599 -0.0694 -0.0910 0.1876 -0.3652 1.0000 quintil 0.3848 0.0660 0.1830 -0.1801 1.0000nro_herman~a -0.1942 -0.0470 -0.1904 1.0000activo_mad~a 0.2451 0.0042 1.0000activo_pad~a 0.0570 1.0000educ_madre~a 1.0000 educ_m~a activo.. activo.. nro_he~a quintil dif_fi~s vivien~p
medio_bajo~b -0.1374 0.1068 0.0484 -0.0364 0.0044 0.0093 -0.1810mas_4_ambi~e 0.0899 0.0640 -0.0364 -0.0497 -0.0152 -0.0081 0.1090problemas_~i -0.1222 0.0116 0.0418 -0.0270 -0.0165 0.1072 -0.1266vivienda_p~p 0.1774 0.0762 -0.0279 0.0094 -0.0453 -0.0059 0.0885dif_final_~s -0.1752 0.0678 0.0768 0.0479 0.0700 0.0416 -0.2366 quintil 0.2156 -0.0660 -0.0443 -0.0114 -0.0202 0.0203 0.3489nro_herman~a -0.1498 -0.0839 0.0072 0.0312 -0.0512 0.4060 -0.1329activo_mad~a 0.0491 -0.0250 -0.0199 -0.0367 0.0634 -0.1259 0.0805activo_pad~a 0.0598 0.0238 -0.0131 0.0356 -0.0028 -0.0756 0.1323educ_madre~a 0.2435 -0.0206 -0.0261 0.0323 -0.0201 -0.1481 0.5234educ_padre~a 0.2616 -0.0562 -0.0254 -0.0158 -0.0425 -0.1020 1.0000posicion_b~a -0.1080 -0.0825 0.0223 0.0245 0.0018 1.0000 enf_cronica -0.0330 0.0358 0.0210 -0.0116 1.0000ultimo_tri~a 0.0173 -0.0141 0.0571 1.0000 mujer 0.0310 0.0453 1.0000 con_beca1 0.1942 1.0000post_obli~18 1.0000 post_~18 con_be~1 mujer ultimo~a enf_cr~a posici~a educ_p~a

22
3. Base imputada mediante la imputación múltiple
3.1. Modelo más eficiente
3.2. Modelo menos eficiente
medio_bajo~b 0.1233 0.0787 1.0000mas_4_ambi~e -0.0461 1.0000problemas_~i 1.0000 proble~i mas_4_~e medio_~b
medio_bajo~b -0.1777 -0.0299 -0.0676 0.0538 -0.1956 0.1358 0.0082mas_4_ambi~e 0.1121 0.0280 -0.0355 0.0733 0.0653 -0.1158 0.1455problemas_~i -0.1423 -0.1442 -0.0012 0.0968 -0.1072 0.1466 -0.1000vivienda_p~p 0.0719 0.0621 -0.0409 -0.0731 0.1852 -0.1754 1.0000dif_final_~s -0.2926 -0.1044 -0.1042 0.1859 -0.3652 1.0000 quintil 0.4178 0.0535 0.2083 -0.1761 1.0000nro_herman~s -0.1974 -0.0190 -0.2022 1.0000activo_madre 0.2644 0.0126 1.0000activo_padre 0.0762 1.0000 educ_madre 1.0000 educ_m~e ac~padre ac~madre nro_he~s quintil dif_fi~s vivien~p
medio_bajo~b -0.1374 0.1068 0.0484 -0.0319 0.0044 0.0130 -0.1791mas_4_ambi~e 0.0899 0.0640 -0.0364 -0.0511 -0.0152 -0.0022 0.0975problemas_~i -0.1222 0.0116 0.0418 -0.0308 -0.0165 0.0987 -0.1430vivienda_p~p 0.1774 0.0762 -0.0279 0.0113 -0.0453 0.0090 0.1023dif_final_~s -0.1752 0.0678 0.0768 0.0492 0.0700 0.0390 -0.2632 quintil 0.2156 -0.0660 -0.0443 -0.0114 -0.0202 0.0263 0.3938nro_herman~s -0.1434 -0.0779 0.0014 0.0329 -0.0477 0.4292 -0.1675activo_madre 0.0651 -0.0248 -0.0182 -0.0406 0.0517 -0.1336 0.1243activo_padre 0.0535 0.0379 -0.0343 0.0422 -0.0241 -0.0636 0.1738 educ_madre 0.2610 -0.0212 -0.0459 0.0265 -0.0288 -0.1423 0.5789 educ_padre 0.2817 -0.0360 -0.0217 -0.0078 -0.0384 -0.1099 1.0000posicion_bis -0.0995 -0.0732 0.0138 0.0310 -0.0052 1.0000 enf_cronica -0.0330 0.0358 0.0210 -0.0115 1.0000 ultimo_tri 0.0158 -0.0140 0.0555 1.0000 mujer 0.0310 0.0453 1.0000 con_beca1 0.1942 1.0000post_obli~18 1.0000 post_~18 con_be~1 mujer ultimo~i enf_cr~a posici~s educ_p~e
medio_bajo~b 0.1233 0.0787 1.0000mas_4_ambi~e -0.0461 1.0000problemas_~i 1.0000 proble~i mas_4_~e medio_~b
medio_bajo~b -0.1747 -0.0480 -0.0601 0.0538 -0.1956 0.1358 0.0082mas_4_ambi~e 0.1158 0.0166 -0.0396 0.0733 0.0653 -0.1158 0.1455problemas_~i -0.1372 -0.0977 0.0043 0.0968 -0.1072 0.1466 -0.1000vivienda_p~p 0.0402 0.0516 -0.0329 -0.0731 0.1852 -0.1754 1.0000dif_final_~s -0.2752 -0.0701 -0.0917 0.1859 -0.3652 1.0000 quintil 0.4113 0.0842 0.1885 -0.1761 1.0000nro_herman~s -0.2296 -0.0518 -0.1886 1.0000activo_madre 0.2483 0.0040 1.0000activo_padre 0.0734 1.0000 educ_madre 1.0000 educ_m~e ac~padre ac~madre nro_he~s quintil dif_fi~s vivien~p
medio_bajo~b -0.1374 0.1068 0.0484 -0.0350 0.0044 0.0063 -0.2095mas_4_ambi~e 0.0899 0.0640 -0.0364 -0.0556 -0.0152 0.0018 0.1184problemas_~i -0.1222 0.0116 0.0418 -0.0245 -0.0165 0.1067 -0.1530vivienda_p~p 0.1774 0.0762 -0.0279 0.0048 -0.0453 -0.0001 0.0885dif_final_~s -0.1752 0.0678 0.0768 0.0513 0.0700 0.0446 -0.2495 quintil 0.2156 -0.0660 -0.0443 -0.0148 -0.0202 0.0189 0.3819nro_herman~s -0.1434 -0.0779 0.0014 0.0384 -0.0477 0.4270 -0.1566activo_madre 0.0525 -0.0196 -0.0053 -0.0392 0.0705 -0.1264 0.0965activo_padre 0.0650 0.0181 -0.0259 0.0354 0.0044 -0.0974 0.1633 educ_madre 0.2325 -0.0144 -0.0453 0.0224 -0.0221 -0.1674 0.5821 educ_padre 0.2566 -0.0481 -0.0360 -0.0227 -0.0471 -0.1174 1.0000posicion_bis -0.1108 -0.0838 0.0124 0.0459 0.0052 1.0000 enf_cronica -0.0330 0.0358 0.0210 -0.0123 1.0000 ultimo_tri 0.0131 -0.0154 0.0585 1.0000 mujer 0.0310 0.0453 1.0000 con_beca1 0.1942 1.0000post_obli~18 1.0000 post_~18 con_be~1 mujer ultimo~i enf_cr~a posici~s educ_p~e





























