Embed Size (px)
Citation preview

Matrix Completion and Large-scale SVDComputations
Trevor HastieStanford Statistics
with Rahul Mazumder, Jason Lee, Reza Zadeh and Rob Tibshirani
Reykjavik, June 2015
Many thanks to Kourosh Modarresi for oranizing this session,and for his care in managing the arrangements.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 1/ 27

Matrix Completion and Large-scale SVDComputations
Trevor HastieStanford Statistics
with Rahul Mazumder, Jason Lee, Reza Zadeh and Rob Tibshirani
Reykjavik, June 2015
Many thanks to Kourosh Modarresi for oranizing this session,and for his care in managing the arrangements.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 1/ 27

Outline of Talk
I Convex matrix completion, collaborative filtering(Mazumder, Hastie, Tibshirani 2010 JMLR)
I Recent algorithmic advances and large-scale SVD(Hastie, Mazumder, Lee, Zadeh Arxiv Oct 2014, to appear JMLR)
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 2/ 27

The Netflix Prize
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 3/ 27

The Netflix Data Set
mov
ieI
mov
ieII
mov
ieII
I
mov
ieIV
· · ·User A 1 ? 5 4 · · ·User B ? 2 3 ? · · ·User C 4 1 2 ? · · ·User D ? 5 1 3 · · ·User E 1 2 ? ? · · ·...
......
......
. . .
I Training Data:480K users, 18K movies,100M ratingsratings 1-5(99 % ratings missing)
I Goal:$1M prize for 10 % reductionin RMSE over Cinematch
I BellKor’s Pragmatic Chaosdeclared winners on 9/21/2009
used ensemble of models, animportant ingredient beinglow-rank factorization
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 4/ 27

Matrix Completion/ Collaborative Filtering:Problem Definition
Use
rs
Movie Ratings
I Large matrices# rows | #columns ≈ 105, 106
I Very under-determined(often only 1− 2 % observed)
I Exploit matrix structure, row | columninteractions
I Task: “fill-in” missing entries
I Applications: recommender systems,image-processing, imputation of NAs forgenomic data, rank estimation for SVD.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 5/ 27

Model Assumption : Low Rank + Noise
I Under-determined – assumelow-rank
I Meaningful?
Interpretation – User & itemfactors induce collaboration
Empirical – Netflix successes
Theoretical – “Reconstruction”possible under low-rank ®ularity conditions
Srebro et al (2005); Candes and Recht(2008); Candes and Tao (2009); Keshavan et.al. (2009); Negahban and Wainwright (2012)
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 6/ 27

Optimization problem
Find Zn×m of (small) rank r such that training error is small.
minimizeZ
∑Observed(i ,j)
(Xij − Zij)2 subject to rank(Z ) = r
Impute missing Xij with Zij
True X Observed X Fitted Z Imputed X
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 7/ 27

Our Approach: Nuclear Norm Relaxation
I The rank(Z ) constraint makes the problem non-convex— combinatorially very hard (although good algorithms exist).
I ‖Z‖∗ =∑
j λj(Z ) — sum of singular values of Z — is convexin Z . Called the “nuclear norm” of Z .
I ‖Z‖∗ tightest convex relaxation of rank(Z )(Fazel, Boyd, 2002)
We solve instead
minimizeZ
∑Observed(i ,j)
(Xij − Zij)2 subject to ||Z ||∗ ≤ τ
which is convex in Z .
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 8/ 27

Our Approach: Nuclear Norm Relaxation
I The rank(Z ) constraint makes the problem non-convex— combinatorially very hard (although good algorithms exist).
I ‖Z‖∗ =∑
j λj(Z ) — sum of singular values of Z — is convexin Z . Called the “nuclear norm” of Z .
I ‖Z‖∗ tightest convex relaxation of rank(Z )(Fazel, Boyd, 2002)
We solve instead
minimizeZ
∑Observed(i ,j)
(Xij − Zij)2 subject to ||Z ||∗ ≤ τ
which is convex in Z .
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 8/ 27

Our Approach: Nuclear Norm Relaxation
I The rank(Z ) constraint makes the problem non-convex— combinatorially very hard (although good algorithms exist).
I ‖Z‖∗ =∑
j λj(Z ) — sum of singular values of Z — is convexin Z . Called the “nuclear norm” of Z .
I ‖Z‖∗ tightest convex relaxation of rank(Z )(Fazel, Boyd, 2002)
We solve instead
minimizeZ
∑Observed(i ,j)
(Xij − Zij)2 subject to ||Z ||∗ ≤ τ
which is convex in Z .
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 8/ 27

Our Approach: Nuclear Norm Relaxation
I The rank(Z ) constraint makes the problem non-convex— combinatorially very hard (although good algorithms exist).
I ‖Z‖∗ =∑
j λj(Z ) — sum of singular values of Z — is convexin Z . Called the “nuclear norm” of Z .
I ‖Z‖∗ tightest convex relaxation of rank(Z )(Fazel, Boyd, 2002)
We solve instead
minimizeZ
∑Observed(i ,j)
(Xij − Zij)2 subject to ||Z ||∗ ≤ τ
which is convex in Z .
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 8/ 27

Notation
Following Cai et al (2010) define PΩ(X )n×m: projection onto theobserved entries
PΩ(X )i ,j =
Xi ,j if (i , j) is observed0 if (i , j) is missing
Criterion rewritten as:∑Observed(i ,j)
(Xij − Zij)2 = ‖PΩ(X )− PΩ(Z )‖2
F
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 9/ 27

Soft SVD — Prox operator for Nuclear Norm
Let (fully observed) Xn×m have SVD
X = U · diag[σ1, . . . , σm] · V ′
Consider the convex optimization problem
minimizeZ
12‖X − Z‖2
F + λ‖Z‖∗
Solution is soft-thresholded SVD
Sλ(X ) := U · diag[(σ1 − λ)+, . . . , (σm − λ)+] · V ′
Like lasso for SVD: singular values are shrunk to zero, with manyset to zero. Smooth version of best-rank approximation.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 10/ 27

Convex Optimization Problem
Back to missing data problem, in Lagrange form:
minimizeZ
12‖PΩ(X )− PΩ(Z )‖2
F + λ‖Z‖∗
I This is a semi-definite program (SDP), convex in Z .
I Complexity of existing off-the-shelf solvers:
– interior-point methods: O(n4) . . .O(n6) . . .– (black box) first-order methods complexity: O(n3)
I We solve using an iterative soft SVD (next slide), with costper soft SVD O[(m + n) · r + |Ω|] where r is rank of solution.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 11/ 27

Soft-Impute: Path Algorithm
1 Initialize Z old = 0 and create a decreasing grid Λ of valuesλ0 > λ1 > . . . > λK > 0, with λ0 = λmax(PΩ(X ))
2 For each λ = λ1, λ2, . . . ∈ Λ iterate 2a-2b till convergence:
(2a) Compute Znew ← Sλ(PΩ(X ) + P⊥Ω (Z old))
(2b) Assign Z old ← Znew and go to step (2a)
(2c) Assign Zλ ← Znew and go to 2
3 Output the sequence of solutions Zλ1 , . . . , ZλK .
This is an MM algorithm for solving the nuclear-norm regularizedproblem
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 12/ 27

Soft-Impute: Path Algorithm
1 Initialize Z old = 0 and create a decreasing grid Λ of valuesλ0 > λ1 > . . . > λK > 0, with λ0 = λmax(PΩ(X ))
2 For each λ = λ1, λ2, . . . ∈ Λ iterate 2a-2b till convergence:
(2a) Compute Znew ← Sλ(PΩ(X ) + P⊥Ω (Z old))
(2b) Assign Z old ← Znew and go to step (2a)
(2c) Assign Zλ ← Znew and go to 2
3 Output the sequence of solutions Zλ1 , . . . , ZλK .
This is an MM algorithm for solving the nuclear-norm regularizedproblem
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 12/ 27

Soft-Impute : Computational Bottleneck
Obtain the sequence Zk of guesses
Zk+1 = argminZ
12‖PΩ(X ) + P⊥Ω (Zk)− Z‖2
F + λ‖Z‖∗
Computational bottleneck — soft SVD requires (low-rank) SVD ofcompleted matrix after k iterations:
Xk = PΩ(X ) + P⊥Ω (Zk)
Trick:
PΩ(X ) + P⊥Ω (Zk) = PΩ(X )− PΩ(Zk) + Zk
Sparse Low Rank
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 13/ 27

Computational tricks in Soft-Impute
I Anticipate rank of Zλj+1based on rank of Zλj , erring on
generous side.
I Compute low-rank SVD of Xk using orthogonal QR iterationswith Reitz acceleration (Stewart, 1969, Hastie, Mazumder,Lee and Zadeh 2014 [arXiv]).
I Iterations require left and right multiplications U ′Xk andXkV . Ideal for Sparse + Low-Rank structure.
I Warm starts: Sλ(Xk) provides excellent warm starts (U andV ) for Sλ(Xk+1). Likewise Zλj for Zλj+1
.
I Total cost per iteration O[(m + n) · r + |Ω|].
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 14/ 27

Computational tricks in Soft-Impute
I Anticipate rank of Zλj+1based on rank of Zλj , erring on
generous side.
I Compute low-rank SVD of Xk using orthogonal QR iterationswith Reitz acceleration (Stewart, 1969, Hastie, Mazumder,Lee and Zadeh 2014 [arXiv]).
I Iterations require left and right multiplications U ′Xk andXkV . Ideal for Sparse + Low-Rank structure.
I Warm starts: Sλ(Xk) provides excellent warm starts (U andV ) for Sλ(Xk+1). Likewise Zλj for Zλj+1
.
I Total cost per iteration O[(m + n) · r + |Ω|].
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 14/ 27

Computational tricks in Soft-Impute
I Anticipate rank of Zλj+1based on rank of Zλj , erring on
generous side.
I Compute low-rank SVD of Xk using orthogonal QR iterationswith Reitz acceleration (Stewart, 1969, Hastie, Mazumder,Lee and Zadeh 2014 [arXiv]).
I Iterations require left and right multiplications U ′Xk andXkV . Ideal for Sparse + Low-Rank structure.
I Warm starts: Sλ(Xk) provides excellent warm starts (U andV ) for Sλ(Xk+1). Likewise Zλj for Zλj+1
.
I Total cost per iteration O[(m + n) · r + |Ω|].
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 14/ 27

Computational tricks in Soft-Impute
I Anticipate rank of Zλj+1based on rank of Zλj , erring on
generous side.
I Compute low-rank SVD of Xk using orthogonal QR iterationswith Reitz acceleration (Stewart, 1969, Hastie, Mazumder,Lee and Zadeh 2014 [arXiv]).
I Iterations require left and right multiplications U ′Xk andXkV . Ideal for Sparse + Low-Rank structure.
I Warm starts: Sλ(Xk) provides excellent warm starts (U andV ) for Sλ(Xk+1). Likewise Zλj for Zλj+1
.
I Total cost per iteration O[(m + n) · r + |Ω|].
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 14/ 27

Computational tricks in Soft-Impute
I Anticipate rank of Zλj+1based on rank of Zλj , erring on
generous side.
I Compute low-rank SVD of Xk using orthogonal QR iterationswith Reitz acceleration (Stewart, 1969, Hastie, Mazumder,Lee and Zadeh 2014 [arXiv]).
I Iterations require left and right multiplications U ′Xk andXkV . Ideal for Sparse + Low-Rank structure.
I Warm starts: Sλ(Xk) provides excellent warm starts (U andV ) for Sλ(Xk+1). Likewise Zλj for Zλj+1
.
I Total cost per iteration O[(m + n) · r + |Ω|].
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 14/ 27

Soft-Impute on Netflix problem
rank time (hrs) RMSE % Improvement
42 1.36 0.9622 -1.166 2.21 0.9572 -0.681 2.83 0.9543 -0.3
Cinematch 0.9514 0
95 3.27 0.9497 1.8120 4.40 0.9213 3.2· · ·· · ·Winning Goal 0.8563 10
state-of-the-art convex solvers do not scale to this size
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 15/ 27

Hard-Impute
minimizerank(Z)=r
||PΩ(X )− PΩ(Z )||F
This is not convex in Z , but by analogy with Soft-Impute, aniterative algorithm gives good solutions.
Replace step:
(2a) Compute Znew ← Sλ(PΩ(X ) + P⊥Ω (Z old))
with
(2a’) Compute Znew ← Hr (PΩ(X ) + P⊥Ω (Z old))
Here Hr (X ∗) is the best rank-r approximation to X ∗ — i.e. therank-r truncated SVD approximation.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 16/ 27

Example: choosing a good rank for SVD
20 40 60 80
02
46
10−fold CV Rank Determination
Rank
Roo
t Mea
n S
quar
e E
rror
10−fold CVTrain
Truth is 200× 100 rank-50 matrix plus noise (SNR 3). Randomlyomit 10% of entries, and then predict using solutions fromSoft-Impute or Hard-Impute.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 17/ 27

Soft-Impute beats Hard-Impute on Netflix
MISSING DATA AND MATRIX COMPLETION 167
The competition identified a “probe set” of ratings, about 1.4 million ofthe entries, for testing purposes. These were not a random draw, rather moviesthat had appeared chronologically later than most. Figure 7.2 shows the rootmean squared error over the training and test sets as the rank of the SVDwas varied. Also shown are the results from an estimator based on nuclearnorm regularization, discussed in the next section. Here we double centeredthe training data, by removing row and column means. This amounts to fittingthe model
zij = αi + βj +r∑
`=1ci`gj` + wij ; (7.8)
However, the row and column means can be estimated separately, using asimple two-way ANOVA regression model (on unbalanced data).
0 50 100 150 200
0.7
0.8
0.9
1.0
Rank
RM
SE
Train
Test
0.65 0.70 0.75 0.80 0.85 0.90
0.9
50.9
60.9
70.9
80.9
91.0
0
Training RMSE
Test R
MS
E
Hard−Impute
Soft−Impute
Netflix Competition Data
Figure 7.2 Left: Root-mean-squared error for the Netflix training and test data forthe iterated-SVD (Hard-Impute) and the convex spectral-regularization algorithm(Soft-Impute). Each is plotted against the rank of the solution, an imperfect cal-ibrator for the regularized solution. Right: Test error only, plotted against trainingerror, for the two methods. The training error captures the amount of fitting thateach method performs. The dotted line represents the baseline “Cinematch” score.
While the iterated-SVD method is quite effective, it is not guaranteed tofind the optimal solution for each rank. It also tends to overfit in this example,when compared to the regularized solution. In the next section, we presenta convex relaxation of this setup that leads to an algorithm with guaranteedconvergence properties.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 18/ 27

Soft-Impute beats debiased Soft-Impute on Netflix
0.65 0.70 0.75 0.80 0.85 0.90
0.95
0.96
0.97
0.98
0.99
1.00
Training RMSE
Test
RM
SE
Hard−ImputeSoft−ImputeSoft−Impute−+
Netflix Competition Data
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 19/ 27

Alternating Least Squares
Consider rank-r approximation Z = Am×rB′n×r , and solve
minimizeA,B
||PΩ(X )− PΩ(AB ′)||2F + λ(‖A‖2F + ‖B‖2
F )
X ≈ A
B′
I Regularized SVD (Srebro et al 2003,Simon Funk)
I Not convex, but bi-convex : alternatingridge regression
Lemma (Srebro et al 2005, Mazumder et al 2010)For any matrix W , the following holds:
||W ||∗ = minA,B: W=ABT
12
(‖A‖2
F + ‖B‖2F
).
If rank(W ) = k ≤ minm, n, then the minimum above is attained at afactor decomposition W = Am×kB
Tn×k .
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 20/ 27

Connections between ALS and soft-impute
ALS : minimizeAn×r ,Bm×r
12 ||PΩ(X )− PΩ(AB ′)||2F + λ
2 (‖A‖2F + ‖B‖2
F )
soft-impute: minimizeZ
12 ||PΩ(X )− PΩ(Z )||2F + λ‖Z‖∗
I Solution-space of ALS contains solutions of soft-impute.
I For large rank r : ALS ≡ soft-impute.
−4 −2 0 2 4 6
020
4060
8010
0
Rank
k
log λ
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 21/ 27

Synthesis and New Approach
I ALS is slower than soft-impute — factor of 10.
I ALS requires guesswork for rank, and does not return adefinitive low-rank solution.
I soft-impute requires a low-rank SVD at each iteration.Typically iterative QR methods are used, exploiting problemstructure and warms starts.
Idea: combine soft-impute and ALS
I Leads to algorithm more efficient than soft-impute
I Scales naturally to larger problems using parallel/multicoreprogramming
I Suggests efficient algorithm for low-rank SVD for completematrices
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 22/ 27

New nuclear-norm and ALS results
Consider fully observed Xn×m.
Nuclear : minimizerank(Z)≤r
12 ||X − Z ||2F + λ‖Z‖∗
ALS : minimizeAn×r ,Bm×r
12 ||X − AB ′||2F + λ
2 (‖A‖2F + ‖B‖2
F )
The solution to Nuclear is
Z = UrD∗V′r ,
where Ur and Vr are first r left and right singular vectors of X , and
D∗ = diag[(σ1 − λ)+, . . . , (σr − λ)+]
A solution to ALS is
A = UrD12∗ and B = VrD
12∗
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 23/ 27

Consequences of new nuclear-norm / ALS connections
For SVD of fully observed matrix:
I Can solve reduced-rank SVD by alternating ridge regressions.
I At each iteration, re-orthogonalization as in usual QRiterations (for reduced-rank SVD) means ridge regression is asimple matrix multiply, followed by column scaling.
I Ridging speeds up convergence, and focuses accuracy onleading dimensions.
I Solution delivers a reduced-rank SVD.
For matrix completion:
I Combine SVD calculation and imputation in Soft-Impute.
I Leads to a faster algorithm that can be distributed to multiplecores for storage and computation efficiency.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 24/ 27

Consequences of new nuclear-norm / ALS connections
For SVD of fully observed matrix:
I Can solve reduced-rank SVD by alternating ridge regressions.
I At each iteration, re-orthogonalization as in usual QRiterations (for reduced-rank SVD) means ridge regression is asimple matrix multiply, followed by column scaling.
I Ridging speeds up convergence, and focuses accuracy onleading dimensions.
I Solution delivers a reduced-rank SVD.
For matrix completion:
I Combine SVD calculation and imputation in Soft-Impute.
I Leads to a faster algorithm that can be distributed to multiplecores for storage and computation efficiency.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 24/ 27

Soft-Impute//
Back to matrix imputation.
1. Initialize Un×r , Vm×r orthogonal, Dr×r > 0 diagonal, andA = UD, B = VD.
2. Given U and D and hence A = UD, update B:2.a Compute current imputation:
X ∗ = PΩ(X ) + P⊥Ω (AB ′)
= [PΩ(X )− PΩ(AB ′)] + UD2V ′
2.b Ridge regression of X ∗ on A:
B ′ ← (D2 + λI )−1DU ′X ∗
= D1U′[PΩ(X )− PΩ(AB ′)] + D2V
′
2.c Reorthogonalize and update V , D and U via SVD of BD.
3. Given V and D and B = VD, update A in similar fashion.
4. At convergence, U and V provides SVD of X ∗, and henceSλ(X ∗), which cleans up the rank of the solution.
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 25/ 27
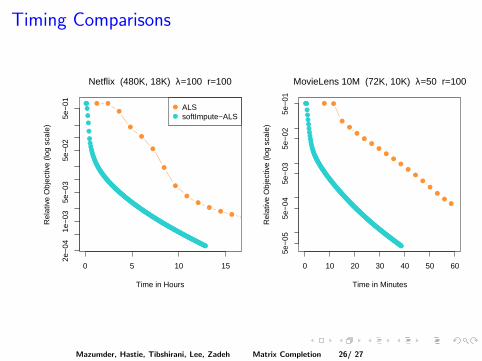
Timing Comparisonsof computing on a Linux cluster with 300Gb of ram (with a fairly liberalrelative convergence criterion of 0.001), using the softImpute package in R.
0 5 10 15
2e−
041e
−03
5e−
035e
−02
5e−
01
Time in Hours
Rel
ativ
e O
bjec
tive
(log
scal
e)
Netflix (480K, 18K) λ=100 r=100
ALSsoftImpute−ALS
0 10 20 30 40 50 60
5e−
055e
−04
5e−
035e
−02
5e−
01Time in Minutes
Rel
ativ
e O
bjec
tive
(log
scal
e)
MovieLens 10M (72K, 10K) λ=50 r=100
Figure 3: Left: timing results on the Netflix matrix, comparing ALS withsoftImpute-ALS. Right: timing on the MovieLens 10M matrix. In bothcases we see that while ALS makes bigger gains per iteration, each iterationis much more costly.
Figure 3 (left panel) gives timing comparison results for one of the Netflixfits, this time implemented in Matlab. The right panel gives timing resultson the smaller MovieLens 10M matrix. In these applications we need notget a very accurate solution, and so early stopping is an attractive option.softImpute-ALS reaches a solution close to the minimum in about 1/4 thetime it takes ALS.
6 R Package softImpute
We have developed an R package softImpute for fitting these models [3],which is available on CRAN. The package implements both softImpute andsoftImpute-ALS. It can accommodate large matrices if the number of missingentries is correspondingly large, by making use of sparse-matrix formats.There are functions for centering and scaling (see Section 8), and for making
27
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 26/ 27

Software Implementations
I softImpute package in R. Can deal with large sparsecomplete matrices, or large matrices with many missingentires (ie Netflix or bigger). Includes row and columncentering and scaling options.
I Spark cluster-programming. Uses distributed computing andchunking. Can deal with very large problems (e.g. 107 × 107,139 secs per iteration). See http://git.io/sparkfastals
with documentation in Scala.
Thank You!
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 27/ 27

Software Implementations
I softImpute package in R. Can deal with large sparsecomplete matrices, or large matrices with many missingentires (ie Netflix or bigger). Includes row and columncentering and scaling options.
I Spark cluster-programming. Uses distributed computing andchunking. Can deal with very large problems (e.g. 107 × 107,139 secs per iteration). See http://git.io/sparkfastals
with documentation in Scala.
Thank You!
Mazumder, Hastie, Tibshirani, Lee, Zadeh Matrix Completion 27/ 27

























