Embed Size (px)
Citation preview

LOS MODELOSLOGIT Y PROBIT ENLA INVESTIGACIÓNSOCIAL
Centro de Investigación yDesarrollo (CIDE)
Lima, Agosto 2002
El caso de la Pobreza del Perúen el año 2001

2 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Preparado : Centro de Investigación y Desarrollo del Instituto Nacional deEstadística e Informática (INEI)
Impreso : Talleres de la Oficina Técnica de Administración del INEIDiagramación : Centro de Edición de la Oficina Técnica de Difusión del INEITiraje : 200 EjemplaresDomicilio : Av. General Garzón 658, Jesús María. Lima - PerúOrden de Impresión : Nº -OTA-INEIDepósito Legal Nº : 150113-2002-4014
DIRECCIÓN Y SUPERVISIÓN
Econ. Mirlena Villacorta OlazabalDirectora Técnica del CIDE
Documento Elaborado por:
Franck G. Pucutay Vásquez

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 3
Centro de Investigación y Desarrollo
Presentación
El INEI pone a disposición la investigación metodológica: "LOS MODELOSLOGIT Y PROBIT EN LA INVESTIGACIÓN SOCIAL El caso de lapobreza del Perú en el año 2001", que por su nivel de especializaciónestá dirigida principalmente a los miembros de la comunidad académica,profesionales de las oficinas de estadística y los investigadores interesadosen mantener la actualidad de sus procedimientos estadísticos.
Esta investigación metodológica tiene por finalidad, generar instrumentosy procedimientos que permitirán validar, mejorar y actualizar los procesosestadísticos. Se caracteriza por ser innovadora en su campo de aplicación,por contener un rigor científico en su desarrollo integral, por la validezde sus procesos, por la vigencia y actualidad de sus metodologías aplicadas.
En esa misma dirección, la investigación presentada desarrolla lametodología asociada a los modelos de probabilidad con variabledependiente discreta dicotómica (modelo logit y probit), en función delfenómeno de pobreza en los jefes de hogar del Perú para el año 2001.Contribuyendo a la implementación de los enfoques asociados a estosmodelos, según la viabilidad permitida por los factores de naturalezacualitativa, cuantitativa y su aporte en la probabilidad de ser pobre deljefe de hogar.
Este estudio al igual que otros de carácter metodológico, ha sido elaboradopor profesionales del Centro de Investigación y Desarrollo (CIDE), en elmarco del desarrollo y promoción de investigaciones estadísticas ysocioeconómicas que permitan elevar la calidad de la información delINEI y el SEN.
El INEI espera como resultado de esta investigación, incorporarse en elcircuito de la producción del conocimiento y elevar los estándares decalidad de sus procesos, sentando con ello las bases de la investigaciónmetodológica en la institución.
Lima, Agosto 2002
Gilberto Moncada VigoJefe del INEI

4 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 5
Centro de Investigación y Desarrollo
I N D I C EPresentación .................................................................................................. 3
Prólogo ........................................................................................................ 7
I. INTRODUCCIÓN ................................................................................... 9
II. FUNDAMENTACION DEL PROBLEMA .......................................... 112.1. Formulación del problema ........................................................................... 13
III.OBJETIVOS DE LA INVESTIGACIÓN .............................................. 153.1. Objetivo general .............................................................................................. 153.2. Objetivos específicos ...................................................................................... 15
IV. MARCO TEÓRICO ............................................................................... 174.1. Breve formulación del caso de la Pobreza del Perú. ............................... 17
4.1.1. ¿Qué es la pobreza? .............................................................................. 174.1.2. Enfoques y métodos para su medición ............................................. 17
4.2. Los modelos logit y probit con variable dependientedicotómica (VDD). ........................................................................................ 20
4.2.1. Modelos con variable dependiente dicotómica (vdd). .................... 204.2.2. Formulación del modelo logit y el modelo probit con (vdd) . .... 224.2.3. Caracterización de los modelos logit y probit aplicados
al caso de la pobreza del Perú. ............................................................ 24
V. HIPÓTESIS .......................................................................................... 33
VI. METODOS ........................................................................................... 356.1. Tratamiento de errores en la adecuación de ambos modelos. ............... 35
6.1.1. Métodos de estimación ........................................................................ 35
VII. LA ENCUESTA NACIONAL DE HOGARES - 2001 IV TRIMESTRE ................................................................................. 397.1. Características de la muestra ........................................................................ 417.2. Factores de relevancia para la explicación de la pobreza
extraídos de la ENAHO IV trimestre 2001. ............................................ 43
VIII. CRITERIOS DE FORMULACIÓN DE LOS MODELOS LOGIT Y PROBIT CON VDD APLICADOS AL CASO DE LA POBREZA DEL PERÚ. .............................................................. 498.1. Estudio a nivel descriptivo y exploratorio de algunas variables
cualitativas y cuantitativas que inciden en la pobreza del Perú. .......... 498.2. Formulación y adecuación de los modelos Logit y Probit con VDD,
en función de las variables o factores explicativosmás significativos. ......................................................................................... 58
IX. CONCLUSIONES ................................................................................. 79
X. RECOMENDACIONES ...................................................................... 81
XI. BIBLIOGRAFÍA .................................................................................... 83
XII. ANEXOS .............................................................................................. 85Anexo 1 Informe metodológico ............................................................................ 87Anexo 2. Indices de ecuaciones, cuadros y gráficos ............................................. 95

6 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 7
Centro de Investigación y Desarrollo
Prólogo
Desde las aulas universitarias y siendoconocedor de la difícil tarea que significala promoción y desarrollo de la laborcientífica en una realidad caracterizadapor la escasez de recursos y lasrestricciones presupuestarias, saludo esteesfuerzo del Centro de Investigación yDesarrollo (CIDE) orientado no sólo aelevar la calidad de la informacióngenerado por el Sistema EstadísticoNacional sino también a la produccióncientífica y metodológica en nuestromedio. En este sentido, la presentepublicación: "Los Modelos Logit y Probiten la Investigación Social: El Caso de laPobreza del Perú en el Año 2001"satisface una necesidad no sólo para losconsumidores potenciales deinvestigaciones sociales o eventualesinvestigadores sino también para elpúblico interesado y universitariofamiliarizado con los elementos de laestadística.
Aunque este documento esmetodológico por naturaleza, estáorientado hacia las aplicaciones. A lo largodel estudio, se ha mantenido al mínimolas demostraciones teórico-matemáticasy se ha puesto énfasis en el desarrollo deun entendimiento claro de los resultadosteóricos usuales en los estudios socialescon este tipo de modelos, el cual estáplasmado en los objetivos planteados enel documento. De otro lado, se hace unabreve pero precisa formulación de lapobreza en el Perú cuyo análisis se basaen las variables provenientes de LaEncuesta Nacional de Hogares-2001 IVTrimestre (ENAHO). De ahí que, seincluye un capítulo que describe ladefinición de dichas variables para luegointeractuar sistemáticamente en laformulación del problema y análisis conel enfoque de los Modelos Logit y Probit.
Luis Huamanchumo de la CubaEscuela Profesional de Ingeniería
Estadística-UNI

8 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 9
Centro de Investigación y Desarrollo
La investigación metodológica juega unpapel fundamental en el desarrollo de losestándares de calidad de las oficinasestadísticas más renombradas del mundo,con el objetivo de generar informaciónrelevante para la producción delconocimiento científico y por ende la tomade decisiones. Pero ello implica lautilización y exploración de técnicasvigentes e idóneas para el análisis de suinformación sin la cual no podríanmejorarse los procesos que implican suproducción.
Muchos de los campos en los cuales sedesarrollan estas investigaciones abordandiferentes aspectos tanto de laproblemática social y económica. Aquípodemos decir que la Pobreza es uno deesos temas tan apasionantes y a la vez muydiscutidos sobre el cual se desarrollan unagran diversidad de metodologías yexplicaciones, sin ser estas concluyentesy menos aún aceptadas por todos. Desdeel punto de vista estadístico, unaexplicación a este fenómeno esampliamente beneficiada por la utilizaciónde los modelos de elección discretadicotómica-modelos logit y probit, paraobtener la cuantificación del aporte de susfactores significativos en el análisis de lapobreza.
En esa misma línea se plantea en quémedida una explicación sobre la pobrezade los jefes de hogar del Perú en el año2001, se vería beneficiada por la adopciónde un enfoque de proporciones muestrales
I. INTRODUCCION
o por un enfoque de observacionesindividuales en la utilización de losmodelos logit y probit.
Entonces diríamos que los factores denaturaleza cuantitativa como el ingreso percápita mensual del hogar, expresado através de sus deciles de ingresos, o losaños de estudios, etc; generan un modelocorrectamente ajustado a la probabilidadde ser pobre de los jefes de hogar con elenfoque de proporciones muestrales delmodelo probit.
O que los factores explicativos de lapobreza del Perú en el año 2001 denaturaleza cualitativa y cuantitativaexclusivos del jefe de hogar como el nivelde educación, el tipo de colegio dondeestudió, la categoría ocupacional, eltamaño de la firma donde labora, latenencia de otro empleo, el estado civil,su edad, su indicador de experiencialaboral; en combinación con los factoresde naturaleza cualitativa y cuantitativaexclusivos del hogar como la cantidad demiembros del hogar, la cantidad demiembros pertenecientes a la PET, elingreso per cápita mensual, el acceso aactivos públicos de agua y desagüe, si elhogar dedica un espacio físico de este ageneración de ingresos, no permitengenerar modelos correctamente ajustadosa la probabilidad de ser pobre del jefe dehogar siguiendo el enfoque deobservaciones individuales en los modeloslogit y probit.

10 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Para tal efecto, lo que se pretende esestudiar la relación entre los factoresdeterminantes de naturaleza social,económica, demográfica de la pobrezadel Perú y los enfoques de utilización delos modelos logit y los modelos probit.
Analizar el grado de afectación de losfactores de naturaleza cuantitativa sobreel enfoque de proporciones muestrales.Comparar una estimación del modelo logitcon una estimación del modelo probit enun enfoque de casos individuales, paracuantificar el aporte de los factoresexplicativos de la pobreza en los jefes dehogar.
Luego de esta suscinta introducción, elsegundo capítulo de esta investigacióndesarrolla la fundamentación del problemay su sistematización; en el tercero seformulan los objetivos de esta, mientrasque en el cuarto capítulo mostramos elmarco teórico asociado a la pobreza, cómoesta viene definida y los métodos para sumedición. Además en este se muestranla formulación teórica de los modelos logity probit con variable dependiente discreta-dicotómica, su caracterización, similitudesy diferencias, enfoques de utilización y losefectos marginales asociados a cada unode los modelos. En el quinto capítulo semuestran las hipótesis formuladas para estainvestigación, mientras que en el sextoindicamos los métodos de estimación apartir de los enfoques utilizados.
En el séptimo capítulo se muestra demanera general la Encuesta Nacional deHogares, sus objetivos y característicasespecíficas, así como los factoresrelevantes para la explicación de la pobrezade los jefes de hogar tomados en laENAHO-IV trimestre 2001. El octavocapítulo muestra los criterios de aplicación
de los modelos logit y probit aplicados alcaso de la pobreza en el Perú, partiendode un análisis descriptivo-exploratorio dealgunas variables significativas como laeducación, el estado civil, región naturalde residencia, los años de estudios, etc;para luego hacer una formulación ydesarrollo metodológico de los modelosen función a sus enfoques y factores mássignificativos, terminando con unaexplicación de los resultados obtenidos.Los siguientes capítulos hacen referenciaa las conclusiones, recomendaciones yanexos.
No quisiera terminar esta breveintroducción sin mostrar miagradecimiento al Instituto Nacional deEstadística e Informática por permitirmecolaborar a través del desarrollo de estainvestigación en avanzar más hacia elfortalecimiento de la cultura estadística enel país, y además, sentar las bases de lainvestigación metodológica en el Perú.
De la misma manera, las gracias infinitas ala señora Directora Técnica del Centro deInvestigación y Desarrollo, MirlenaVillacorta, por sus valorables aportes en eldesarrollo de esta investigación, sucompresión y constante apoyo, y porqueme muestra que cada día es posibleconstruir desde la inteligencia y lacreatividad.
Así mismo, quiero expresar mi gratitud yreconocimiento a Luis Huamanchumo,auditor de esta investigaciónmetodológica, por sus importantísimasapreciaciones y por su compromiso con lalabor de investigación estadística, desdeya reciba las gracias infinitas. Para terminarlas gracias a Dios, a mi Familia y a misseres queridos.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 11
Centro de Investigación y Desarrollo
II. FUNDAMENTACION DEL PROBLEMA
La pobreza es un fenómeno siemprepresente, en mayor o menor medida, entodas las sociedades, razón por la cual hasido objeto de estudio y se han buscadolas herramientas de política paraenfrentarla. Existen muchas definicionesrespecto a lo que debe entenderse porpobreza y ninguna de ellas es precisa niaceptada por todos, sin embargo, engeneral todas las definiciones apuntan ala situación en que se encuentran laspersonas que no disponen de los medios(de "producción", activos fijos,intelectuales, sociales, culturales,financieros y demás que permitan generarfuentes permanentes de ingresos)suficientes para satisfacer sus necesidadesbásicas definidas como tales para un gruposocial específico y en un tiempodeterminado, y que permitan su desarrollopersonal y reflejen el estilo de vida de laformación social en su conjunto. Entreestas necesidades figuran la alimentación,salud, vivienda, educación básica, accesoa servicios esenciales de información,recreación, cultura, vestido, calzado,transporte y comunicaciones, participacióne identidad en y con la comunidad, entreotras.
El Perú es uno de los países más pobresde América del Sur. Una breve mirada acualquier listado que pretenda ordenar lospaíses en función de su bienestar lodemuestra. Casi la cuarta parte de losperuanos carecen de recursos paraalimentarse adecuadamente, es decir,viven en condiciones de pobreza extrema.
La pobreza se origina en la incapacidadde la economía peruana para generarsuficientes empleos productivos. De los140 mil jóvenes que se integran cada añoa la fuerza laboral urbana, menos de untercio obtiene un empleo adecuado y casiel 40% está desempleado o trabajandoen algo que no implica capacitaciónalguna ni ofrece perspectivas de progresofuturo.
Dada la complejidad del fenómeno,existen distintas metodologías paramedirlo, tales como el método de la líneade pobreza, el método de las NBIs, elmétodo integrado, entre otros. Noobstante, tan importante como tener unacuantificación rigurosa de los niveles depobreza y las tendencias en su evolucióntemporal y espacial, es analizar lasrelaciones entre ellas y sus factoresexplicativos que podrían albergar opcionesde política para solucionarla, tales comola educación.
Debido a lo expuesto líneas antes, se estánrealizando estudios e investigacionesavanzadas, pero aún incipientes en elaspecto metodológico, sobre el rol defactores como la posesión de activosprivados, la distribución del ingreso, elacceso a activos públicos, en su explicacióndel fenómeno de la pobreza, o mejordicho sobre la adquisición de tal condición.Investigaciones que estén orientadas ypermitan un mejor diseño eimplementación de las políticas públicas y

12 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
sociales. En tal sentido queremos afirmarque el desarrollo que se viene dando enel mundo en muchos aspectos delconocimiento, entre ellos en los camposde la economía y la estadística, permitenexplicar fenómenos a través del desarrolloy análisis de enfoques cualitativos.
Con la selección del enfoque y laformulación de modelos donde la variabledependiente cualitativa es discretadicotómica (2 niveles), para efectos de estainvestigación, ser jefe de hogar pobre ojefe de hogar no pobre; y expresada através de variables o características socialesy demográficas que pueden poseer losindividuos (el estado civil, experienciaeducacional, categoría ocupacional,acceso a activos públicos, etc) y el hogar(cantidad de miembros, ingreso per cápitamensual), podemos colaborar aún más conexplicaciones razonables a este vastofenómeno de LA POBREZA, constituidoen el Perú actualmente por más de lamitad de su población.
Actualmente, en nuestro país puedenestarse aplicando inadecuadamentemodelos con estas características, debidoa la falta de un proceso de análisisadecuado que determine su correctautilización y que puede responder a undesconocimiento y una falta deapoderamiento de las metodologíasadecuadas para su implementación ycomo consecuencia directa una correctaexplicación de los fenómenos bajo estudio,en donde la pobreza no se encontraríasola, sino también otras manifestacionessociales como la situación laboral, laeducación, o en el campo de la medicinapara el caso de enfermedades como ladiabetes, etc.
En muchas de las investigaciones deíndole social y demográfica, la naturalezadel fenómeno a indagar, en este caso lacondición ser jefe de hogar pobre o jefede hogar no pobre y sus factoresdeterminantes de naturaleza social,económica y demográfica, podríandeterminar un tipo de enfoque(proporciones muestrales u observacionesindividuales) a seguir dentro de lo que seconstituyen los modelos con variabledependiente dicotómica y por lo tantoutilizar los modelos logit o probit en laexplicación de este fenómeno.
Desde la perspectiva estadística con quese enfoca al fenómeno de pobreza, sepuede evidenciar que no es aún clara laidea de optar por alguno de los dosmodelos (el modelo Logit o el modeloProbit) siguiendo el enfoque deobservaciones o casos individuales, peroque este último, permitiría saltar laslimitaciones que posee el enfoque deproporciones muestrales o de clasificaciónde casos u observaciones en función a susfactores determinantes de índole social,demográfico, económico, etc.
En tal sentido nos vemos en la necesidadde proponer una metodología de análisisy utilización de los modelos logit y probitcon variable dependiente dicotómica,valiéndonos para ello de una explicaciónde la pobreza en los jefes de hogar delPerú para el año 2001, cuantificando elaporte de sus factores determinantes entreellos el nivel de educación, los años deestudios, la experiencia laboral, lacondición ocupacional, el acceso a activospúblicos, etc; y como esta posibilita laviabilidad de los enfoques de utilizaciónde dichos modelos y un mejoracercamiento a su explicación.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 13
Centro de Investigación y Desarrollo
Para esto se analizará la informaciónrecogida por La Encuesta Nacional deHogares (ENAHO) - IV TRIMESTRECondiciones de Vida Y Pobreza, realizadapor el Instituto Nacional de Estadística eInformática en el año de 2001.
2.1 Formulación del Problema
¿En qué medida una explicación de lapobreza en los jefes de hogar del Perú severía beneficiada por la adopción de unenfoque de proporciones muestrales o porun enfoque de observaciones individuales?
Sistematización del Problema
• ¿Cómo la pobreza en los jefes dehogar del Perú a través de sus factoresdeterminantes de naturaleza social,económica y demográfica hacenfactible el enfoque de proporcionesmuestrales o el enfoque deobservaciones individuales en losmodelos logit y probit?.
• ¿En qué medida los factoresdeterminantes de índole cuantitativocomo el ingreso percápita mensual, losaños de estudios, la experiencialaboral, la cantidad de miembros en elhogar, etc, influyen sobre un enfoquede proporciones muestrales delmodelo probit y la pobreza de los jefesde hogar del Perú?.
• ¿Resulta más eficaz una estimación delmodelo logit que una estimación delmodelo probit en un enfoque deobservaciones individuales paracuantificar el aporte de los factoresexplicativos de la pobreza en los jefesde hogar?.
• ¿Qué similitudes y diferencias puedenser encontradas en ambos modelos ycómo pueden verse estos reflejados ycontrastados desde el caso de lapobreza en el Perú- año 2001?

14 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 15
Centro de Investigación y Desarrollo
III. OBJETIVOS DE LA INVESTIGACION
3.1 Objetivo General
Determinar en qué medida una explicaciónsobre la pobreza en los jefes de hogar delPerú para el año 2001 es beneficiadasiguiendo un enfoque de proporcionesmuestrales o un enfoque de observacionesindividuales.
3.2 Objetivos Específicos
• Estudiar la relación entre los factoresdeterminantes de naturaleza social,económica, demográfica de la pobrezaen los jefes de hogar y los enfoquesde utilización de los modelos logit ylos modelos probit.
• Analizar el grado de afectación de losfactores de naturaleza cuantitativa
sobre el enfoque de proporcionesmuestrales del modelo probit y lapobreza en los jefes de hogar.
• Comparar una estimación del modelologit con una estimación del modeloprobit en un enfoque de casosindividuales, para cuantificar el aportede los factores explicativos de lapobreza en los jefes de hogar.
• Analizar las similitudes y diferenciasque puedan ser encontradas en ambosmodelos y como pueden verse estosreflejados y contrastados desde el casode la pobreza en los jefes de hogardel Perú.

16 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 17
Centro de Investigación y Desarrollo
IV. MARCO TEORICO
4.1 BREVE FORMULACIÓN DEL CASO DE LA POBREZA EN EL PERÚ
4.1.1 ¿Qué es la pobreza?
La pobreza es una condición en la cualuna o más personas tienen un nivel debienestar inferior al mínimo socialmenteaceptado. En una primera aproximación,la pobreza se asocia a la incapacidad delas personas para satisfacer sus necesidadesbásicas de alimentación. Luego seconsidera un concepto más amplio queincluye la salud, las condiciones devivienda, educación, empleo, ingresos,gastos y aspectos más extensos como laidentidad, los derechos humanos, laparticipación popular, entre otros1.
En general, todas las definiciones apuntana la situación en que se encuentran laspersonas que no disponen de los medios("de producción", activos físicos,intelectuales, sociales, culturales,financieros y demás) que permitan sudesarrollo personal y reflejen el estilo devida de la formación social en su conjunto.El concepto de pobreza es evidentementerelativo y cambiante. Basta considerar lasdiferencias de aquello que define a unpobre en Suiza respecto de los satisfactoresconsiderados relevantes en el Perú, asícomo las características de la pobreza delsiglo XIX en plena revolución industrialversus la que presentan países como los
nuestros hoy en día en pleno tercermilenio.
4.1.2 Enfoques y métodos para lamedición de la pobreza
Existen 3 grandes enfoques para medir lapobreza. El primero es el enfoque de lapobreza absoluta, que toma en cuenta elcosto de una canasta mínima esencial debienes y servicios y considera como pobresa todos aquellos cuyo consumo o ingresoestá por debajo de este valor.
El enfoque de pobreza relativa consideraal grupo de personas cuyo ingreso seencuentra por debajo de un determinadonivel. Por ejemplo, en algunos países seconsidera como pobres a todos aquellosque tienen remuneraciones inferiores a lamitad del ingreso promedio (Criterioaplicado en sociedades que han logradoerradicar la pobreza absoluta)
El enfoque de la exclusión social, deabsoluta vigencia en Europa, prestaatención a las personas que no puedenacceder a determinados servicios comopor ejemplo el empleo, la educaciónsuperior, la vivienda propia, el empleo yotros.
Ahora dentro de lo correspondiente a losmétodos de medición, solo noscentraremos en el método de línea de
1/ INEI. Metodologías Estadísticas, Año 1-N°02 Metodología para la medición de la pobreza en el Perú.

18 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
pobreza. Una explicación al por qué de suelección se dará a continuación.
EL METODO DE LA LÍNEA DEPOBREZA-LP
Este método centra su atención en ladimensión económica de la pobreza yutiliza el ingreso o el gasto como medidasdel bienestar. Al determinar los niveles depobreza, se compara el valor per cápitade ingreso o gasto en el hogar con el valorde una canasta mínima denominada líneade pobreza.
Cuando se utiliza el método de línea depobreza por el consumo, se incorpora elvalor de todos los bienes y servicios queconsume el hogar, indistintamente de laforma de adquisición o consecución. Lautilización del gasto de consumo tiene laventaja de que es el mejor indicador paramedir el bienestar porque se refiere a loque realmente consume un hogar y no alo que potencialmente puede consumircuando se mide por el ingreso. Otroaspecto favorable es que el consumo esuna variable más estable que el ingreso,lo que permite una mejor condición de latendencia del nivel de pobreza.
Así como existen enfoques y métodos paramedir la pobreza, existen definiciones quenos permitirán centrar aún mejor la ideade nivel de pobreza que puede tener unapersona y/o un hogar en particular.
Pobreza Absoluta:Comprende a las personas cuyos hogarestienen ingresos o consumo per cápitainferiores al costo de una canasta total debienes y servicios mínimos esenciales.Línea de Pobreza Absoluta (LPA): Es elcosto de una canasta mínima debienes(incluido los alimentos) y servicios.
Pobreza Absoluta:Consumo Hogar < Costo Canasta BásicaConsumo (LPA)
Pobreza Extrema:Comprende a las personas cuyos hogarestienen ingresos o consumos per cápitainferiores al valor de una canasta mínimade alimentos.Línea de Pobreza Extrema (LPE): Es el costode una canasta mínima de alimentos.
Pobreza Extrema:Consumo Hogar < Costo Canasta BásicaAlimenticia (LPE)
Después de mostrar, a modo general,algunos enfoques y a grosso modométodos de medición de pobreza, que sibien es cierto no es uno de los objetivosexplícitos de esta investigación medirla,pretendemos con ello guiar al lector haciala concepción y formulación de unavariable que permita clasificar a unindividuo de acuerdo a su nivel depobreza, en otras palabras, si este poseeo no la condición de pobreza.
Según Sen (1992) la medición de pobrezarequiere realizar dos ejercicios distintospero interrelacionados: la identificación delos pobres por un lado y la agregación porotro. Este último es el usado para obtenerindicadores resumen del nivel(incidencia)de la pobreza. Para el caso de estainvestigación solo realizaremos en algunamedida el primer ejercicio.
Esto quiere decir que necesitaríamos deun método de identificación para construirlo que será la variable dependiente de lasestimaciones y es allí donde entra a tallarel MÉTODO DE LÍNEA DE POBREZA(LP),definido anteriormente. Con lo cual sedefine específicamente los valores que

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 19
Centro de Investigación y Desarrollo
podría tomar la variable en estudio: iguala 1 si es un hogar pobre y 0 si es un hogarno pobre, y como vamos a trabajar a nivelde individuos, tomamos, 1 si fuese un Jefede Hogar(JH) que pertenece a un hogarpobre y 0 si fuese un JH que no pertenecea un hogar pobre.
Obviamente, al trabajar con esta variabledependiente no se podrá conocer laintensidad de la pobreza2. Esta limitaciónpuede ser resuelta mediante el uso de lasmedidas FGT(Foster et al., 1984), quesurgen de la siguiente expresión:
* ( )i i
i
z yFGT H
z
α
α−= ∑ ECUACIÓN IV.1
Donde: Yi es el ingreso de la i-ésimafamilia u hogar, Zi es la línea de pobrezade ese hogar y a el parámetro de aversióna la pobreza.
Entonces, si a = 0 obtenemos, elporcentaje de pobres .
Si a = 1,obtenemos lo concerniente aBrecha de Pobreza.
1
1
* ( )i i
i
z yFGT H
z
−= ∑
Este es el denominado poverty gap deprofundidad o intensidad de la pobreza.A diferencia del anterior, esta medidamuestra la brecha existente entre elingreso de los hogares pobres y la líneade pobreza.
Si a = 2, arroja un indicador de severidadde la pobreza y que puede ser interpretadocomo la suma de dos componentes: labrecha de pobreza y la desigualdad entrelos pobres.
De acuerdo con lo anterior es posibleasignar a cada hogar un valor de intensidady de severidad de pobreza dado por lossupuestos acerca del parámetro a dedichas medidas. Esta forma de procederrequiere de métodos de estimacióndiferentes3, que no es motivo de estudioen este trabajo.
LOS ACTIVOS DE LOS POBRES EN ELPERÚ4
Tanto la distribución del ingreso como losniveles de pobreza han registradoimportantes modificaciones a lo largo delas últimas cuatro décadas en el Perú. Másallá de las diferencias metodológicasasociadas al cálculo de estos indicadores,la evidencia sugiere que en los últimos 40años se habría reducido la dispersión en ladistribución del ingreso. Asimismo, sehabría producido una importante reducciónen los niveles de pobreza.
De otro lado, un análisis de la distribuciónde activos durante los últimos 10 añosrevela en general una continuación de lastendencias de largo plazo. El niveleducativo medio sigue aumentando y ladesigualdad en el acceso a educación escada vez más baja. En cambio, en el casode los servicios públicos, si bien el acceso
2/ En términos de Sen (Sen, 1976), ante la necesidad de obtener una medida agregada de la pobreza, H, ocurre que no sesatisfacen los axiomas de monotonicidad y transferencia. El primero establece que toda medida de pobreza bien conformadadebe reflejar las variaciones del ingreso de los hogares situados por debajo de la LP. El segundo, que la medida de pobrezadebe ser sensible a las transferencias de ingresos entre pobres y no pobres.
3/ Paz, Jorge. La pobreza en Argentina: una comparación entre regiones disímiles. Unas, 2001.4/ Escobal, Javier; Saavedra, Jaime; Torero, Máximo. Los Activos de los pobres en el Perú. GRADE. 1998.
1N
1N

20 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
medio ha ido aumentando, los niveles dedesigualdad siguen siendo muy elevados.Asimismo, el acceso al crédito es muydiferenciado según los quintiles de gasto,mientras que el ahorro y los bienesfinancieros durables, que son activos quepueden fungir como colaterales, estánentre los activos peor distribuidos.Asimismo, reducciones en el tamaño dela familia tienen un impacto positivo ysignificativo sobre los activos privados. Enese sentido, la concepción que un mayortamaño de la familia implica un aumentode los recursos productivos de la familia,y por lo tanto un mayor bienestar, noencuentra sustento teórico.
Debido a la multidimensionalidad de lapobreza, su análisis a través de los jefesde hogar en función a sus factores deíndole cualitativo y cuantitativo, en elprimer caso reflejado a través de posesiónde activos privados como su nivel deeducación, su condición ocupacional ytamaño de la empresa donde trabaja, siposee algún otro empleo, y la influenciade aquellos factores inseparables de suhogar y también de naturaleza cualitativa,como el acceso a activos públicos comoagua y desagüe dentro de la vivienda, sialgún lugar dentro de la vivienda esdestinada para obtener ingresos juega unpapel fundamental.
Dentro de factores de naturaleza cualitativatambién resulta importante considerar laregión y área natural de procedencia deljefe de hogar como factor preponderantepara su condición de pobreza.
Con respecto a los factores de naturalezacuantitativa propios del jefe de hogar sonconsiderados los años de estudios, su
indicador proxy de experiencia laboral ysu edad como aquellos que puedendeterminar su condición. En la misma línea,factores correspondientes al hogar son lacantidad de miembros en el hogar, ingresoper cápita mensual, la cantidad de personasen edad de trabajar, serían aquellos quedeterminan una mayor probabilidad de serpobre.
4.2. LOS MODELOS LOGIT Y PROBITCON VARIABLE DEPENDIENTEDICOTÓMICA (VDD)
4.2.1.Modelos con VariableDependiente Dicotómica (VDD).
En muchas situaciones, el fenómeno quequeremos estudiar no es continuo, sinodiscreto. Por ejemplo, cuando queremosmodelar la participación del mercado detrabajo, la condición de pobreza de un Jefede Hogar, la decisión sobre si se hace unacompra o no. En el caso de la condiciónde pobreza existen estudios que sugierenque factores como la educación, la edad,el número de hijos y ciertas característicaseconómicas, sociales, demográficas, etc;que podrían ser relevantes para explicar siun individuo Jefe de Hogar está másafecto a adquirir la condición de pobreza.Pero, obviamente, algo falta si se aplicaen este caso el mismo tipo de modelo deregresión que utilizábamos para analizarel consumo o los costes de producción, oalgún otro fenómeno de naturalezacuantitativa.
Vamos a analizar algunos modelosconocidos como modelos de respuestacualitativa (RC), y lo que podemosmencionar es que tienen en común que

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 21
Centro de Investigación y Desarrollo
su variable dependiente es discreta, esdecir puede tomar valores como "no" o"sí" que pueden ser codificados como "0"ó "1"; o quizás más valores "0", "1", "2"según sus categorías, para representar losresultados cualitativos respectivos.
Pero reflejemos esto en ejemplosconcretos, el tipo de variable dependientey el fenómeno en estudio:
• Participación en el mercado detrabajo: Donde 0 es "no" y 1 significa"sí", donde la participación es Var.Dependiente nominal dicotómica, y serepresenta con 0 y 1 por comodidad.
• Opinión sobre cierto tipo delegislación: Donde0 sería "totalmente opuesto"1 para "opuesto"2 para "indiferente"3 para " a favor"4 para "totalmente a favor"Aquí vemos que se ordenan lasrespuestas no en función a su valorcuantitativo, sino por una cuestión degrado en la respuesta, en donde laOPINIÓN es Var. DependienteOrdinal.
• Área de trabajo escogida por unindividuo: Donde 0 es representar alvendedor, 1 para ingeniero, 2 paraabogado, 3 para político, y asísucesivamente, y es de allí quepodemos mencionar que AREA DETRABAJO es Var. Dependientenominal politómica5.
En ninguno de estos casos parece posible,en principio, utilizar el análisis de regresiónclásico. Sin embargo, en todos ellos esposible construir modelos que enlacen elresultado o la decisión a tomar a través desu aporte en la probabilidad de larealización del fenómeno bajo estudio; conun conjunto de factores, con la mismafilosofía que en regresión. Entonces lo quese hace es analizar cada uno de estosmodelos dentro de un marco general deLOS MODELOS DE PROBABILIDAD.
Pr(Ocurre suceso j) = Pr(Y=j) =F(efectos relevantes: parámetros)
Resulta conveniente agrupar estosmodelos en dos grandes clases: aquellosque siguen un enfoque binomial, esdecir, si el resultado o fenómeno dependede la elección o la situación en dosalternativas. Para ello podemos mencionaral respecto; que si tenemos a cada unode N individuos, casos u objetos quepueden ser clasificadosindependientemente en 1 de 2 categoríascomplementarias, ejemplo de ello puedeser cara o sello de un lanzamiento demonedas, pacientes curados o no curados,personas por sobre o debajo de un nivelde ingreso, etc. En este caso se tiene quecada individuo tiene la misma probabilidadp de estar en una de las dos categorías,por ejemplo si el Jefe de Hogar es pobre(0 £ p £ 1); y la prob. 1-p de encontrarseen la otra categoría complementaria, esdecir, si el Jefe de Hogar no es pobre.
Entonces la probabilidad de que X de losN individuos sean pobres es:
5/ Variable nominal politómica, es aquella que en sus categorías no denota ningún tipo de ordenamiento ni grado específico,otro ejemplo de ello lo constituye el estado civil (soltero, casado, viudo, conviviente, etc).

22 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Donde x=0,1,2,3...N.
[ ] (1 )N
x N x
x
P X x p p − = = − ECUACIÓN IV.2
Así como existen en los modelos elenfoque binomial, existe asimismo elenfoque multinomial, que es aquel quedepende de una elección o resultado demás de 2 alternativas y que puedenreflejarse en algunos de los ejemplosmencionados líneas antes y que resultanen algunos aspectos novedosos pero queson, en su mayor parte, extensiones delos casos binomiales.
Queremos dejar en claro aquí que en estainvestigación el enfoque que seguirá elmodelo será de tipo binomial, porqueplantear uno de tipo multinomialimplicaría, que los diversos niveles decondición de pobreza (no pobre, pobre ypobreza extrema), se encontrarían a unmismo nivel de selección, vale decir, queen el caso de pobreza absoluta y pobrezaextrema tendrían que considerarse comogrupos excluyentes uno del otro, lo cualno se da en este caso, pues la pobrezaextrema es una condición mucho másprecaria en todo aspecto que la pobrezaabsoluta . Es este entonces nuestro puntode partida para poder determinar ycuantificar el aporte de las variables ofactores que inciden sobre la probabilidadque un jefe de hogar se encuentre encondición de pobreza. En tal sentido losmodelos que más se adecuan en esta líneason el modelo logit con variabledependiente discreta dicotómica (a partirde ahora, VDD) y el modelo probit conVDD.
4.2.2. Formulación del modelo logity el modelo probit con variabledependiente dicotómica (VDD)
Empezaremos esta formulación a partir dela suposición de un modelo deprobabilidad de condición de pobreza paraJefes de Hogar (JH), donde:
Y=1 El JH se encuentra en condición depobreza
Y=0 El JH no se encuentra en condiciónde pobreza.
Vamos a suponer que un vector devariables explicativas o conjunto defactores que expliquen este fenómenovenga dada por:
X= Nivel de Educación, Analfabetismo,Dominio Geográfico, Experiencia,Estado Civil, Categoría Ocupacional,etc.
Podemos imaginar que la primera ideaintuitiva que gira alrededor del fenómenode la condición de pobreza es que estapodría ser explicada a través del conjuntode factores mencionados, y cuánto es queestos contribuyen individual y en formaconjunta a dicho fenómeno.
Entonces, autores como Green planteanla siguiente idea:
Sea:La probabilidad de que el Jefe de Hogarsea pobre:
[ 1] ( , )P Y F X β= =
ECUACIÓN IV.3

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 23
Centro de Investigación y Desarrollo
Y la probabilidad de que el Jefe de Hogarno sea pobre:
[ 0] 1 ( , )P Y F X β= = −
Donde el vector de parámetros(b) reflejael aporte o impacto que X (vector de var.explicativas) tiene como parte de la funciónde distribución acumulada sobre laprobabilidad. Por ejemplo uno de losfactores que podría interesarnos sería verel efecto que el nivel de educación tienesobre la probabilidad de ser pobre.
A partir de este punto la incógnita caesobre el lado derecho de dicha ecuacióny sobre cómo plantear un modeloadecuado para este.
Una solución a ello puede darse en unmodelo de regresión lineal.
( , ) ´F X Xβ β=ECUACIÓN IV.4
Tenemos que:
( / ) 0*Pr( 0) 1*Pr( 1)E Y X Y y= = + =( / ) ( , )E Y X F X β=
A partir de lo anterior podemos construir:Y = y = E[y/x] + [y-E[y/x]]
= F(x,b) + e
Y = b´X + eModelo de Probabilidad Lineal. ECUACIÓN IV.5
Pero este modelo de probabilidad linealpresenta algunos incovenientes:
(i) e presenta heterocedasticidad quedepende de b, esto es si:
Y= 0 -> b´X + e=0 -> e= -b´X , donde p(y=0)= 1-F
Y= 1 -> b´X + e=1 -> e= 1-b´X, donde p(y=1)= F
Entonces tendríamos queV(e) = (-b´X) (1-b´X)
ECUACIÓN IV.6
(ii) El incoveniente más serio es que nose puede asegurar que las prediccionesparezcan verdaderas probabilidades. Nose puede restringir b´X al intervalo[0,1], lo cual origina tanto varianzasnegativas como probabilidadesimposibles.
Entonces para un vector de regresoresdado, esperaríamos que [Gráfico IV.1]:
Gráfico IV.1
´ Pr( 1) 1xLim Yβ −>+∞ = =
´ Pr( 1) 0xLim Yβ −>−∞ = =
1
b´X
y

24 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Analizando el gráfico anterior, vemos quepara los requisitos especificadosanteriomente, en principio bastaría trabajarcon una Función de DistribuciónAcumulada definida sobre la recta real, ental sentido las funciones idóneas para talefecto vienen a ser la Normal y la Logística.
Es natural ahora preguntarse ¿Cuál de lasdos debe usarse?, la respuesta a esapregunta y otras que se han empezado aformar, van a ir siendo resueltas en lamedida de lo posible en la seccionessiguientes.
Supongamos ahora que en vez de utilizarla función lineal de probabilidad de X paracaracterizar esta condición, utilizamos unafunción monótona [F(b´x )] creciente delproducto b´x, es decir, variables explicativasy aportes. Esta formulación es más generalque la del modelo lineal de probabilidady, en consecuencia, el procedimiento deestimación de los parámetros así como laforma en que dichos valores debeninterpretarse, es ahora diferente.
- Al usar esta transformación, podemosver que basta tomar una función real Facotada entre 0 y 1 para que elproblema que se originaba sobre elrango de las probabilidadesdesaparezca. En efecto, ahora vemosque P = F(b´x) está siempre entre 0 y1, con independencia de los valoresque toman los factores explicativos ysus efectos marginales. Es por ello quelas funciones de distribución devariables aleatorias son candidatosimportantes a ser elegidas para estastransformaciones.
- Suponga que existe un indicador quedepende de las características
individuales: Ii=b´x , que determinala decisión tomada para cada individuoo la condición que este posee frente aun fenómeno dado. Es decir, elindividuo toma la decisión o seencuentra en el estado Yi=1 si el valorde su indicador es superior a un ciertovalor crítico I*, y la decisión contrariao se encuentre en el otro estado siYi=0. Es decir, el indicador Ii refleja elsentimiento del decisor frente a laopción indicada Yi=1, de modo quesi su predisposición, indicada por Ii essuficientemente grande (mayor queIi*), escoge dicha opción, y si no,elegirá la opción alternativa.
Por ser desconocido, consideramos elvalor crítico I* del indicador para cadaindividuo como una variable aleatoria.Entonces de acuerdo con estainterpretación, la probabilidad de queel individuo i-ésimo elija o posea lacondición Yi=1 viene dada por:
*( 1) ( ) ( ´ )i i i iP P Y P I I F xβ= = = ≤ =ECUACIÓN IV.7
Donde F es la distribución deprobabilidad de la variable aleatoria I*.
4.2.3. Caracterización de los modeloslogit y probit aplicados al casode la pobreza en el Perú.
4.2.3.1. El Modelo Logit
Supongamos el siguiente ejemplo, se tieneque Y (1 = jefe de hogar pobre, 0 = jefede hogar no pobre) en función al ingresofamiliar X(S/.) para un conjunto de familias.Se tiene la siguiente representación de lacondición de pobreza:

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 25
Centro de Investigación y Desarrollo
1 2( )
1( 1/ )
1 XPi E y Xi
e β β− += = =+
ECUACIÓN
IV.8
Para facilidad de la exposición, se escribe[ECUACIÓN IV.8] como:
1 2( )
1( 1/ )
1 XPi E y Xi
e β β− += = =+
donde iZ = 1 2( )Xβ β+
ECUACIÓN IV.9
La [ECUACIÓN IV.9] representa lo quese conoce como función de distribuciónlogística (acumulativa). Es fácil verificar quea medida que Zi se encuentra dentro deun rango de - ∞ a + ∞ , Pi se encuentradentro de un rango 0 a 1 y que Pi no estálinealmente relacionado con Zi (es decircon Xi), satisfaciendo así requerimientosque son considerados. Pero parece que alsatisfacer estos requerimientos se hacreado un problema de estimación porquePi es no lineal no solamente con X sinotambién en los β , como puede verseclaramente a partir de la [ECUACIÓNIV.8]. Esto significa que no se puede utilizarel procedimiento familiar MCO paraestimar los parámetros. Pero este problemaes más aparente que real porque la[ECUACIÓN IV.8] es intrínsecamentelineal, lo cual puede verse de la siguientemanera.
Si Pi, la probabilidad de ser jefe de hogarpobre, está dada por la [ECUACIÓN IV.9]entonces (1 - Pi), la probabilidad de jefede hogar no pobre.
11
1 ZiPi
e− =
+ ECUACIÓN IV.10
Por consiguiente, se puede escribir
1
1 1
ZiZi
Zi
Pi ee
Pi e−
+= =− + ECUACIÓN IV.11
Ahora Pi / (1-Pi) es sencillamente la razónde probabilidades (´Odds Ratio´) a favorde ser jefe de hogar pobre- la razón de laprobabilidad de que un jefe de hogar seapobre a la probabilidad de que no seapobre. Así, si Pi = 0.8, significa que lasprobabilidades son 4 a 1 a favor de que eljefe de hogar sea pobre.
Ahora, si se toma el logaritmo natural de[ECUACIÓN IV.11], se obtiene unresultado muy interesante, a saber,
1 2ln1
PiLi Zi X
Piβ β = = = + −
ECUACIÓN IV.12
es decir, Li, el logaritmo de la razón deprobabilidades no es solamente lineal enXi, sino también (desde el punto de vistade estimación) lineal en los parámetros, Les llamado Logit y de aquí el nombremodelo LOGIT para modelos como la[ECUACIÓN IV.12].
Obsérvense estas características delmodelo Logit:
(a) A medida que P va de 0 a 1 (es decir,
a medida que Z varía de -∞ a +∞ , elLogit L va de -∞ a +∞ ). Es decir,aunque las probabilidades (pornecesidad) se encuentran entre 0 y 1,los Logit no están limitados en esaforma.
(b) Aunque L es lineal en X, lasprobabilidades en sí mismas no lo son.

26 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Esta propiedad hace contraste con elmodelo de MPL, en donde lasprobabilidades aumentan linealmentecon X.
(c) La interpretación del modelo Logit es
el siguiente: 2β , la pendiente, mide
el cambio en L ocasionado por uncambio unitario en X, es decir, dicecomo el logaritmo de lasprobabilidades a favor de ser jefe dehogar pobre cambia a medida que elingreso cambia en una unidad, por
ejemplo de S/. 100. El intercepto 1βes el valor del logaritmo de lasprobabilidades a favor de ser jefe dehogar pobre si el ingreso es cero.
(d) Dado un nivel determinado deingresos, por ejemplo, X, si realmentese desea estimar la probabilidad mismade ser jefe de hogar pobre, y no lasprobabilidades a favor de ser jefe dehogar pobre , esto puede hacersedirectamente a partir de la[ECUACIÓN IV.8], una vez que se
disponga de las estimaciones de 1β y 2β .
(e) Mientras que el MLP supone que Piestá linealmente relacionado con Xi,el modelo Logit supone que ellogaritmo de la razón de probabilidadesestá relacionado linealmente con X.
4.2.3.2. EL MODELO PROBIT
Si se elige como función F la función dedistribución f de una variable normal (0,1),se tiene:
( / ) ( 1/ ) [ * ] ( ´ )P E y x P Y x P I I xβ= = = = ≤ =ΦECUACIÓN IV.13
De modo que:
1´ ( )x Pβ −= Φ
La probabilidad correspondiente a unvector X de factores que contribuyen aexplicar un fenómeno, como el de lapobreza es ahora:
2´
21
2
xt
P e d tβ
π−
− ∞
= ∫
ECUACIÓN IV.14
Como se ha podido apreciaranteriormente, para explicar elcomportamiento de una variabledependiente dicotómica, es preciso utilizaruna FDA seleccionada apropiadamente. Elmodelo Logit utiliza la función distribuciónlogística acumulativa. Pero esta no es laúnica FDA que se puede utilizar. Enalgunas aplicaciones, la FDA normal se haencontrado útil. El modelo de Estimaciónque surge de una FDA normal escomúnmente conocido como el modeloProbit, aunque algunas veces también esconocido como el modelo normit. Enprincipio, se puede sustituir la FDA normalpor la FDA logística y proceder de acuerdoal modelo Logit. Pero en lugar de seguireste camino se presentará el modelo probitbasado en la teoría de utilidad o de laperspectiva de selección racional con baseen el comportamiento, según el modelodesarrollado por McFadden.
Para motivar el modelo Probit supóngaseel ejemplo de condición de pobreza, laposesión del i-ésimo jefe de hogar de lacondición de pobreza o de no poseerla,medida a través de un índice imperfecto

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 27
Centro de Investigación y Desarrollo
de conveniencia Ii que está determinadopor una o varias variables explicativas, porejemplo, el ingreso Xi, de tal manera queentre mayor sea el valor del índice, mayorserá la probabilidad de que el jefe de hogarsea pobre. Se expresa el índice Ii, como:
1 2i iI Xβ β= +ECUACIÓN IV.15
¿Cómo se relaciona el Ii, índice imperfectode conveniencia con la condiciónespecífica de ser pobre? Sea Y=1 si esjefe de hogar pobre y Y=0 si no es. Ahorabien, es razonable suponer que para cadaindividuo hay un nivel crítico o umbraldel índice, que se puede denominar Ii*,tal que si Ii excede a Ii*, el jefe de hogares pobre, de lo contrario no lo es. El nivelcrítico Ii*, al igual que Ii, no es observable,y se supone que está distribuidonormalmente con la misma media yvarianza, y por lo tanto es posible nosolamente estimar los parámetros delíndice, sino también obtener algunainformación sobre el índice imperfecto de
la cual depende nuestra variableobservable.
Dado el supuesto de normalidad, laprobabilidad de que Ii* sea menor o igualque Ii, puede ser calculada a partir de laFDA normal estándar como:
*Pr( 1) Pr( ) ( )i i i iP Y I I F I= = = ≤ = =
2 21 2
2 21 1
2 2
ii XI t t
e dt e dtβ β
π π
+− −
−∞ −∞
= =∫ ∫
ECUACION IV.16
donde t es una variable normalestandarizada, es decir, t® N(0,1).
Puesto que Pi representa la probabilidadde que ocurra un evento, en este caso laprobabilidad de poseer la condición depobreza, ésta se mide por el área de lacurva normal estándar de -¥ a Ii, como semuestra en la figura siguiente [GRAFICOIV.2]:
*Pr( )i iI I≤Pi
1 2iI Xβ β= +
Pi
1( )i iI F P−=
Gráfico IV.2

28 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Ahora, para obtener información sobre Ii,el índice de utilidad, lo mismo que paralos coeficientes estimados se toma lainversa de [ECUACIÓN IV.7] para obtener:
1 21( )i iI F Pi Xβ β−= = +
ECUACIÓN IV.17
Donde 1F − es la inversa de la FDA
normal. El significado de todo esto puedeaclararse con la figura anterior [GRÁFICOIV.2], donde en la figura del lado izquierdose obtiene (de la ordenada) la probabilidad(acumulada) de ser jefe de hogar pobredado Ii* menor o igual que Ii, mientrasque en la parte derecha (de la abcisa) se
obtendría el valor de Ii, dado el valor dePi, es decir, evaluar la probabilidad en lainversa de la FDA Normal.
4.2.3.3. Similitudes y diferencias enambos modelos
Podemos ver que la distribución logística :es similar a la distribución normal, exceptopor sus colas, (la distribución Logística separece más a la distribución t con sietegrados de libertad).
Analicemos la siguiente gráfica [GRÁFICOIV.3], que compara ambas funciones dedistribución.
Gráfico IV.3
La FDA Normal es aquella gráficaalrededor(______) de la recta real másgruesa y la recta de segmentos (--------)viene a ser la FDA Logística y el eje verticalse desplaza entre 0 y 1.
De aquí podemos empezar a analizar cadauna de las 3 regiones formadas:
-20 -10 0 10 20
1
• La PRIMERA REGIÓN, la inferiorizquierda, muestra que para elfenómeno en estudio Y=1, porejemplo: si el Jefe de Hogar es pobre,las estimaciones del modelo Logitproducirían mayores contribucionespara la probabilidad de ser pobre enfunción a sus factores explicativos, queel modelo probit.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 29
Centro de Investigación y Desarrollo
• La SEGUNDA REGIÓN, la central,muestra que las 2 distribucionesgeneran estimaciones similares, es másautores como Amemiya dan unintervalo de variación para dichasestimaciones similares < -1.2, 1.2 >.
• La TERCERA REGIÓN, la superiorderecha, muestra que el modelo probitgeneraría mejores estimaciones de losaportes de las variables en laprobabilidad de ser pobre que elmodelo Logit.
Debemos hacer énfasis en que ambosmodelos presentan muchas similitudescon respecto a su representación deprobabilidad, visiblemente apreciable enla gráfica anterior, y con respecto a susestimaciones en la mayoría de aplicacionesparece que se llega a los mismos resultadospartiendo de una aplicación u otra.
Es de conocimiento que cabe esperar quelos 2 modelos originen predicciones oaportes diferentes en los factores si lamuestra contiene:
• Pocas respuestas afirmativas (Y=1), esdecir, pocas observaciones para JH(Jefe de Hogar) en condición depobreza; y del mismo modo, pocasrespuestas para (Y=0), vale decir,pocas observaciones para JH en statusde no pobreza
• Gran variación en una variableindependiente de importancia,especialmente si se cumple lomencionado en el párrafo anterior, porejemplo: presentar una variaciónconsiderable con respecto a los nivelesde educación de los JH de la poblaciónen estudio.
Por sencillez de cálculo pueden existirrazones prácticas para preferir una u otradistribución; pero desde el punto de vistateórico resulta difícil justificar esta elección.Amemiya (1981) analiza varios aspectosrelacionados con esta cuestión pero, entérminos generales, puede decirse queeste problema no se ha resuelto aún.
Los efectos marginales en ambosmodelos
Hay que considerar que el modelo deprobabilidad es un modelo de regresión:
E[y/x] = 0*[1-F(b´X)] + 1*[F(b´X)]= [F(b´X)]
Y que sea cual fuere la distribución quese utilice, es importante observar que losparámetros (b´X) del modelo, como losde cualquier modelo de regresión nolineal, no son necesariamente los efectosmarginales comunes analizados.
[ / ] ( ´ )( ´ )
( ´ )
E y x dF xf x
x d x
β β β ββ
∂ = = ∂ ECUACIÓN IV.18
Donde f(.) es la función de densidadasociada a la Función de distribución F(.).
Para la distribución normal:
[ / ]( ´ )
E y xx
xφ β β∂ =
∂ECUACIÓN IV.19
Siendo f (b´x) la función densidad normalestándar.
Para el caso de la distribución logística:
´
´ 2
[ ´ ]
( ´ ) (1 )
x
x
d x e
d x e
β
ββ
βΛ =
+ECUACIÓN IV.20

30 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Lo que es sumamente práctico. Así en elmodelo logit.
[ / ]( ´ )[1 ( ´ )]
E y xx x
xβ β β∂ = Λ − Λ
∂ECUACIÓN IV.21
Para interpretar el modelo estimado,resulta útil calcular estos efectosmarginales en varios valores de x: porejemplo en las medias de los regresoreso en otros puntos que puedan resultar deinterés.
Los modelos de variable dependientediscreta aparecen con frecuencia comomodelos con función índice, es decir,interpretamos el resultado de una eleccióndiscreta como un reflejo de una regresiónsubyacente. Pero el significado de esto loentenderemos a través de un ejemplo:
Supongamos que tenemos que tomar unadecisión para hacer una compraimportante.
Teoría: Consumidor hace cálculo Beneficiomarginal - Coste marginal : Obtener unautilidad y tomar una decisión..
Gráfico IV.4
DECISIÓN COMPRA
IMPORTANTE
BENEFICIO
COSTE
UTILIDAD
EMPLEA DINERO
OTRA COSA
REALIZA COMPRA
Podemos apreciar que el beneficiomarginal es evindentemente no observable(no tangible), modelizamos la diferenciaentre beneficio y coste con una variableno observable y cumple.
* ´y xβ ε= +ECUACIÓN IV.22
Suponemos que la distribución de(0,1)Nε → ó Logística, entonces, no
se observa el beneficio neto de la compra,sólo si esta se hace o no.
Y=1 si Y*>0 (*)Y=0 si Y*£0
Donde b´X, recibe el nombre de funcióníndice.
Cabe recalcar que se deben consideraralgunos aspectos en la construcción de (*):
• Primero: La hipótesis de varianzaunitaria es una normalización que nojuega ningún papel importante.Supongamos que la varianza de ε esen realidad 2σ y multipliquemosentonces los coeficientes por σ .Nuestros datos observados no varían:y es 0 ó 1, dependiendo únicamente

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 31
Centro de Investigación y Desarrollo
del signo de y*, no de la escala enque se midan los datos.
• Segundo: La hipótesis de que elumbral es 0, tampoco juega ningúnpapel si el modelo contiene términoconstante6.
La probabilidad del suceso Y=1, jefe dehogar pobre, se puede ver como sigue:
Pr( * 0) Pr( ´ 0)y xβ ε⟩ = + ⟩ =Pr( ´ ) 1 ( ´ )x F xε β β⟩ − = − −
Si la distribución es simétrica7, como loson la normal y la logística.
Pr( * 0) Pr( ´ ) ( ´ )y x F xε β β⟩ ⟨= =
De este modo se habría obtenido unmodelo estructural para la probabilidad ycomo esta depende de la FDA Normal oLogística.
Análisis de datos a través deproporciones muestrales
Cuando se analizan respuestas binarias, losdatos vendrán dados de una de las dosformas siguientes: o bien, tal y como seha considerado hasta ahora, de formaindividual (es decir, cada observación estáformada por la respuesta del individuo yun vector de regresores asociados a él[Yi, Xi ]), O bien de forma agrupada (esdecir, los datos consisten en proporcioneso recuentos de observaciones). Los datosen forma agrupada se obtienen
observando la respuesta de ni individuos,todos ellos con la misma xi. La variabledependiente observada será la proporción(P
i) de los ni individuos ij para los cuales
yij = 1. Una observación es por tanto [ ni,Pi, xi], i = 1,...,N. Los datos electoralesconstituyen un ejemplo típico8. En el casode datos dados en forma agrupada, puedenanalizarse la relación entre Pi y xi no sóloutilizando los estimadores de máximaverosimilitud, sino también métodos deregresión. La proporción observada Pi, esun estimador de la cantidad poblacional
( ´ )i iF xπ β= . Si consideramos esta
igualdad como un sencillo problema demuestreo en una población Bernoulli,utilizando los resultados básicos deestadística obtenemos que:
( ´ )i i i i iP F xβ ε π ε+= + = , siendo
( ) 0iE ε = , (1 )
( )i i
i
i
Varn
π πε −=
Este formato de regresión heterocedásticasugiere que los parámetros podríanestimarse utilizando una regresión demínimos cuadrados ponderados nolineales. Para no detallar más podemosdecir que este análisis y su estimacióncorrespondiente será abordada en lassecciones posteriores de estainvestigación. Lo que podemos mencionarpor ahora es que en la práctica surgen doscomplicaciones con respecto a los erroresen este enfoque. Primero, cuando laproporción se calcula utilizando unamuestra de gran tamaño, la varianza delestimador puede llegar a ser sumamentepequeña. Ello originará que en la regresión
6/ Ha no ser que haya poderosas razones, los modelos binomiales deben incluir constante (Green)7/ En distribuciones simétricas se tiene que: 1 - F(b´X) = F(-b´X)8/ Los estudios iniciales sobre modelos probit se desarrollaron en laboratorios. Cada observación consistía en n
i individuos que
recibían una cierta dosis xi, la proporción P
i respondían al tratamiento. Véase Finney (1971) y Cox (1970).

32 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
de mínimo chi-cuadrado los erroresestándar sean inverosímilmente pequeñosy los estadísticos t enormemente grandes.Por desgracia, todo esto es consecuenciade la estructura del modelo. A los mismosresultados se llega si se estima por máximaverosimilitud con datos de proporciones.
Segundo, es imposible obtener tanto elestimador de máxima verosimilitud comoalgún otro relacionado, si una de las dosproporciones es 0 ó 1. Se han sugeridovarias posibles soluciones específicas paraeste caso, la que con más frecuencia se
utiliza consiste en sumar o restar un valorconstante pequeño, por ejemplo, 0.001,al valor observado cuando éste sea 0 ó 1.
De lo anteriormente expresado, en estainvestigación se tratará de desarrollar unametodología que permita cuantificar elaporte de los factores asociados a lapobreza con su correspondienteprobabilidad de ser pobre para el jefe dehogar en los modelos Logit y Probit convariable dependiente dicotómica,utlizando criterios de enfoque a nivelteórico y práctico.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 33
Centro de Investigación y Desarrollo
V. HIPOTESIS DE INVESTIGACIÓN
• Los factores de naturaleza cuantitativacomo el ingreso per cápita mensual delhogar expresado a través de sus décilesde ingreso, los años de estudios deljefe hogar, etc, generan un modelocorrectamente ajustado a laprobabilidad de ser pobre de los jefesde hogar expresado a través de suestadístico de bondad de ajustepearson c 2 dejando de lado laslimitaciones del tamaño de muestra,en el enfoque de proporcionesmuestrales del modelo probit.
• Los factores explicativos de la pobrezaen los jefes de hogar de naturalezacualitativa y cuantitativa exclusivos deestos como el nivel de educación, eltipo de colegio de estudio, la categoríaocupacional, el tamaño de la firma
donde labora, la tenencia de otroempleo, el estado civil, su edad, suindicador de experiencia laboral; encombinación con los factores denaturaleza cualitativa y cuantitativaexclusivos del hogar como el indicadorde si el hogar dedica un espacio delhogar a generación de ingresos, lacantidad de miembros en el hogar, lacantidad de miembros pertenecientesa la PET, el ingreso per cápita mensual,el acceso a activos públicos de agua ydesagüe, no permiten generar modeloscorrectamente ajustados a laprobabilidad de ser pobre del jefe dehogar siguiendo el enfoque deobservaciones individuales o noclasificación en los modelos logit yprobit.

34 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 35
Centro de Investigación y Desarrollo
VI. METODOS
6.1 Tratamiento de Errores en laadecuación de ambos modelos,análisis de factores explicativosobservables y no observables
Casi todos los modelos de elección binaria,excepto el modelo de probabilidad lineal,se estiman habitualmente por el métodode máxima verosimilitud. Cadaobservación se considera como realizaciónindividual de una variable aleatoria condistribución Bernoulli (es decir, binomialcon n=1). La probabilidad conjunta ofunción de verosimilitud, de un modelocon probabilidad de éxito F(b´X) yobservaciones independientes es:
1 1, 2 2, ...,Pr( )n nY y Y y Y y= = = =1 , 2 , ..., ..,Pr( 1 0 1, 0)i nY Y Y Y= = = =
0 1
[1 ( ´ )] ( ´ )i i
i iy y
F x F xβ β= =
= −∏ ∏ECUACIÓN VI.1
Podemos reescribir la fórmula anteriorcomo:
1
1
[ ( ´ )] [1 ( ´ )]i in
y y
i
L F x F xβ β −
=
= −∏ECUACIÓN VI.2
Esta es la función de verosimilitud para unamuestra de n observaciones.
1
ln [ ln ( ´ ) (1 )ln(1 ( ´ ))]i i i i
n
i
L y F x y F xβ β=
= + − −∑
Las condiciones de primer orden delproblema de maximización requieren que
1
ln(1 ) 0
(1 )
i i i
i i
i i
n
i
L y f fy x
F Fβ =
∂ −= + − = ∂ − ∑
ECUACIÓN VI.3
En la ecuación anterior y en lo que sigue,se utilizará el subíndice i para indicar quela función se evalúa en b´X, es decir, enel conjunto de factores explicativos alfenómeno. Al seleccionar una formaconcreta para Fi se obtiene un modeloempírico.
A menos que se utilice el modelo deprobabilidad lineal, las ecuacionescontenidas en la fórmula anterior serán nolineales y habrán de resolverse de modoiterativo.
6.1.1 Los métodos de estimaciónsegún enfoques
MODELO PROBIT
Estimación de mínimos cuadrados conenfoque de proporciones muestrales
El modelo original relaciona las frecuenciasobservadas pi, con las probabilidades (Pi)que resultan de las clasificaciones de losfactores explicativas, por ejemplo elingreso per cápita mensual, por medio de:
9
9/ Como vimos hace un momento en distribuciones simétricas 1-F(b´x)=F(-b´x). Definiendo q=2y-1, entonces lnL=SlnF(qb´x).

36 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
ip = ( )i iP u+
por lo que1 1( ) ( )i i ip P u− −Φ = Φ +
De aquí esta expresión pude aproximarsepor:
1 ``
1( )
( )i i i
i
p X uf X
ββ
−Φ → +
El modelo probit puede por tantoestimarse de modo aproximado por unaregresión de los llamados "probits"
muestrales 1( )ip−Φ sobre el vector Xi.
Se trata de calcular las frecuencias
muestrales pi, obtener los valores 1( )ip−Φa partir de la tablas de la distribución N(0,1)y estimar la regresión descrita.
Ahora bien, los residuos tienenheterocedasticidad, puesto que:
` ` 2
(1 )var( )
( ) [ ( )]
i i i
i i i
u P P
f X n f Xβ β−=
ECUACIÓN VI.4
Por lo que habrá que utilizar mínimoscuadrados generalizados.
1 1 1( ` ) `X X Xβ π− − −= Σ Σ
Con una matriz Σ diagonal, conelementos genéricos dados por [Ecuaciónvi.4] donde π es el vector de probitsmuestrales. Como la matriz Σ esdesconocida, hay que estimarla, para loque se podría utilizar: a) las frecuenciasobservadas pi, o bien b) las prediccionesPi obtenidas a partir de un modelo deprobabilidad lineal previamente estimado.
Estimación de máxima verosímilitudpara observaciones individuales
El procedimiento de estimación MV espreciso cuando no es posible agrupar lasobservaciones según los valores del vectorXi. En tal situación, carece de sentido hablarde proporciones muestrales. En dichoscasos, la estimación por MV evita losproblemas ya citados acerca de laestimación MCG del modelo lineal deprobabilidad. Por otra parte el estimadorde MV es eficiente, y se calcula sobre elmodelo original, sin necesidad de ningunaaproximación.
En el caso del MODELO PROBIT, lafunción de verosimilitud sería:
Reemplazando [Ecuación iv.9] en[Ecuación vi.1]
1
1
[ ( ´ )] [1 ( ´ )]i iN
y yL x xβ β −= Φ − Φ∏
Nótese que para cada individuo i eltérmino correspondiente en la función de
verosimilitud es simplemente ( ´ )xβΦ o
1 ( ´ )xβ− Φ , dependiendo de si Y=1,
jefe de hogar pobre, ó Y=0, jefe de hogarno pobre.
Por tanto la función logaritmo de laverosimilitud se obtiene del logaritmo dela expresión anterior, y tomando sus
derivadas con respecto al vector β se
tienen las k condiciones necesarias deoptimalidad:
1 1
(1 ) 01
i i
i i i i k
i i
N N
Y x Y xφ φ−+ − =Φ − Φ∑ ∑
ECUACIÓN VI.5
ó
,,
, ,

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 37
Centro de Investigación y Desarrollo
1
( ´ )( ) ( ´ ) 0
( ´ )[1 ( ´ )]i
i
N Y xS x x
x x
ββ φ ββ β
−Φ= =Φ −Φ∑
ECUACIÓN VI.6
donde S(b) denota el vector gradiente dela función de verosimilitud. Si derivamosde nuevo en la expresión anterior conrespecto al vector b, se obtiene la matrizHessiana, y tomando esperanza en esta ycambiando de signo se obtiene finalmentela matriz de información, I(b):
2
1
[ ( ´ ) ]( ) ´
( ´ ) [1 ( ´ )]i i
N xI x x
x x
φ βββ β
=Φ − Φ∑
ECUACIÓN VI.7
Conviene hacer hincapié en que en lasexpresiones anteriores N denota elnúmero total de observaciones, por lo queprescindiendo de clasificaciones, hay queconsiderar un sumando para cadaobservación muestral. En particular, enestos problemas es más sencillo utilizar elmétodo del scoring10, razón por la quehemos calculado directamente la matrizde información a partir de la matriz dederivadas segundas de la función deverosimilitud con respecto al vector b. Lainversa de la matriz de información seráademás la matriz de covarianzas delestimador de MV del vector b. Elprocedimiento de estimación de MVutilizaría:
2
1
[ ( ´ ) ]( ) ´
( ´ ) [1 ( ´ )]i i
N xI x x
x x
φ βββ β
=Φ − Φ∑
ECUACIÓN VI.8
que proporciona la corrección que hay queintroducir en el estimador del vector b encada iteración. Al sustituir las expresiones
de I(b) y S(b) antes obtenidas puede versefácilmente que si se hace el cambio devariables:
* ( ´ )
( ´ )(1 ( ´ ))
ij
ij
x xx
x x
φ ββ β
=Φ −Φ ,
j=1,2,....,K ECUACIÓN VI.9
que forma, para cada observación i, unvector de dimensión k, e:
* ( ´ )
( ´ )(1 ( ´ ))
i
iy x
yx x
ββ β
− Φ=Φ − Φ
ECUACIÓN VI.10
entonces la corrección a introducir en el
estimador 1nβ −
∧ coincide con los
coeficientes estimados por mínimos cuadradosordinarios en una regresión que utilizase yi*como variable a explicar, y xi* como vectorde variables explicativas, utilizando los
1nβ −
∧ para calcular *
ijx y yi*.
MODELO LOGITEstimación de máxima verosímilitudpara observaciones individuales.
La función de verosimilitud muestral es:Reemplazando [ECUACION IV.4] en[ECUACION VI.1]
1 0
( ´ ) [1 ( ´ ) ]Y i Y i
L F x F xβ β= =
= − =∏ ∏
1
( ( ´ ) )
´
1
[1 ]
N
Y i x
Nx
e
e
β
β
∑
+∏
o, lo que es lo mismo:
´
1 1ln ( ' ) ln(1 )i
N N xL Y x eββ= − + =∑ ∑ ∑10/ Especialmente diseñado para el caso en que se pretende obtener el EMV, este algoritmo se basa en la propiedad de que
la esperanza matemática de la matriz hessiana de la función de verosimilitud (es decir, la matriz de información cambiadade signo). Así se ha sugerido como aproximación, sustituir la matriz de derivadas segundas por la matriz de información,
teniéndose el llamado algoritmo de "scoring" 1 1 11[ ( )] ln ( )n n n nI Lθ θ θ θ− − −
∧ ∧ ∧ ∧−= + ∇

38 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
´
1 1( ´) ln(1 )i i
N N xYx eββ − +∑ ∑ECUACIÓN VI.11
y denotando por 1
´ ´i i
Nz Yx= ∑ un vector
fila 1 x k se tiene:
´
1ln ´ ln[1 ]
N xL z eββ= − +∑y
´
´1
ln( ) 0
1
i
k
xN
x
L e xS z
e
β
βββ
∂= = − =∂ +∑
ECUACIÓN VI.12
y este sistema de k ecuaciones no linealesdebería, en principio, resolverse porprocedimientos numéricos, para obtenerel vector de estimaciones b. La matriz deinformación es:
´
´1 1
´( ) (1 ) ´
1
i i
i i i i
xN N
x
e xxI xP P x
e
β
ββ = = −+∑ ∑
ECUACIÓN VI.13
Para estimar el valor b por el algoritmo del"scoring" se comienza de un estimador boy se actualiza por medio de:
1 0 0 01[ ( )] ( )I Sβ β β β−= +
En realidad, la matriz S(b) puede escribirsetambién:
´1 1 1( ) ( )
1
i
i i i i i
N N N
x
xS Y x Y P x
e ββ −= − = −+∑ ∑ ∑
donde ´
1
1i
ixP
e β−=+ , por lo que el
algoritmo puede describirse como sigue:
1. A partir de un estimador inicial 0β∧
,
calcular (1 )i iP P∧ ∧
− .
2. Transformar las variables:
* (1 )i i I ix x P P∧ ∧
= − ECUACIÓN VI.14
* ( )
(1 )
i i
i
i i
Y PY
P P
∧
∧ ∧
−=−
ECUACIÓN VI.15
y el cambio a introducir en el vector 0β∧
viene dado por los coeficientes estimadospor mínimos cuadrados ordinarios en unaregresión Yi* sobre el vector xi*.
El algoritmo se itera hasta conseguir suconvergencia, y se utiliza la inversa de lamatriz de información evaluada en elúltimo estimador obtenido comoestimación de la matriz de covarianzas deb. Por otra parte, los métodos de inferenciaque consideran esta matriz de covarianzasson válidos, ya que el estimador máximoverosímil resultante tiene distribuciónnormal asintótica. Las probabilidades deque un individuo con características Xiescoja la acción o se situe dentro delestado que hemos catalogado como Yi=1,(estar en condición de pobreza) se estimanmediante la expresión:
´
´1i
x
x
eP
e
β
β
∧=
+
Luego de mostrar como la teoría estadísticade ambos modelos propone su desarrollo,es aquí donde empezamos el trabajo deestudio empírico del fenómeno depobreza en su conjunto. Las variables aconsiderar fueron recopiladas de unseguimiento de investigaciones las cualesexisten en abundancia acerca del temade la pobreza11.
11/ La metodología desarrollada para la inclusión de variables se encuentra en el anexo metodológico al final de estainvestigación.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 39
Centro de Investigación y Desarrollo
VII. LA ENCUESTA NACIONAL DE HOGARES
La Encuesta Nacional de Hogares(ENAHO), es un programa continuo deencuestas, que inició el Instituto Nacionalde Estadística e Informática (INEI) a travésde la Dirección Nacional de Censos yEncuestas el año 1995.
A partir del año 1997, el INEI ha puestoen ejecución el Programa deMejoramiento de Encuestas y de laMedición de las Condiciones de Vida(MECOVI), bajo el auspicio financiero ytécnico del Banco Interamericano deDesarrollo (BID), Banco Mundial (BM) y laComisión Económica para América Latinay el Caribe (CEPAL), con el propósitocentral de fortalecer y mejorar el Sistemade Encuestas de Hogares, constituido porun conjunto de encuestas que se vienenrealizando trimestralmente, y querepresentan una de las principales fuentesde información para el análisis, evaluacióny seguimiento de la realidad demográfica,social y económica de la poblaciónperuana.
El Empleo y el Ingreso son módulos deseguimiento en todos los trimestres, puesson considerados los pilares para explicarlos cambios en las condiciones de vida.
En el segundo y cuarto trimestre seefectúan las Encuestas Panel con el fin deestudiar los cambios en las característicasde la población en el tiempo.
En el marco de los nuevos lineamientosde política de gestión para identificar lademanda real de información y encoordinación con los usuarios el INEI haidentificado la necesidad de contarprincipalmente con indicadores de empleoy condiciones de vida que permitancumplir con su principal misión.
OBJETIVOS
Objetivos Generales:
La encuesta del cuarto trimestre del 2001tiene los objetivos generales siguientes:
i. Generar indicadores anuales, quepermitan conocer la evolución de lapobreza, el bienestar y las condicionesde vida de los hogares.
ii. Efectuar diagnósticos (anuales) sobrelas condiciones de vida y pobreza dela población.
iii. Medir el alcance de los programassociales en la mejora de las condicionesde vida de la población.
iv. Servir de fuente de información ainstituciones públicas y privadas, asícomo a investigadores.
v. Permitir la comparabilidad coninvestigaciones similares en relación alas variables investigadas.

40 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Objetivos Específicos
Los objetivos específicos de la ENAHO2001 del cuarto trimestre son lossiguientes:
i. Determinar el grado de acceso aservicios básicos de la vivienda y delhogar y de los programas socialesorientados a la vivienda segúndiferentes estratos socio-económicos.
ii. Obtener indicadores de riesgo desalud debido al hacinamiento y lascondiciones sanitarias de los hogaressegún diferentes estratos socio-económicos.
iii. Caracterizar las estructurasdemográficas, según diferentes estratossocio-económicos, con el fin de medirla evolución y el impacto demográficode los programas sociales.
iv. Determinar el nivel educativo segúndiferentes estratos socio-económicos.
v. Determinar el grado de acceso a laeducación y el alcance de losprogramas sociales, según diferentesestratos socio-económicos.
vi. Caracterizar los niveles de empleo,según diferentes estratos socio-económicos.
vii. Determinar la estructura del ingreso delos hogares, teniendo en cuenta losingresos provenientes de los propioshogares y el efecto redistributivo delos programas sociales.
viii.Cuantificar el gasto de consumo de loshogares diferenciando el aporte de los
programas sociales según diferentesestratos socio-económicos.
ix. Obtener información sobre morbilidady acceso a los servicios de salud.
x. Evaluar el grado de conocimiento yutilización de los Programas Sociales yProyectos de Inversión Social.
xi. Caracterizar a los hogares en pobrezaextrema, pobres y no pobres enfunción a variables demográficas,educativas, otras sociales y económicasy el grado de acceso a los servicios
TEMAS A INVESTIGAR
- Módulo de Vivienda- Características de los miembros del
hogar- Módulo básico de Educación- Módulo básico de Salud- Módulo básico de empleo- Sistema de Pensiones- Uso de Computadora e Internet en el
Trabajo- Ingresos del sector formal e informal- Gastos- Módulo básico de Programa Social- Módulo Comunal para Informantes
Calificados- Módulo de Opinión
CARACTERISTICAS
La Investigación se desarrollará sobre labase de una muestra de hogares siendolos niveles de inferencia del diseñomuestral: Nacional, Urbano Nacional, RuralNacional, Resto Costa, Sierra, Selva y elArea Metropolitana de Lima y Callao.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 41
Centro de Investigación y Desarrollo
Los cuestionarios a emplearse serán losmismos del Cuarto Trimestre de 2000,además de un módulo de opinión.
Los informantes serán todos los residenteshabituales de 12 años y más de edad queconforman el hogar entrevistado.
La Unidad de Investigación: es el hogar,el cual está constituido por: 1) losintegrantes del hogar familiar, 2) lostrabajadores del hogar con cama adentro,reciban o no pago por sus servicios, 3) losintegrantes de una pensión familiar quetienen como máximo 9 pensionistas, y 4)las personas que no son miembros delhogar familiar pero que estuvieronpresentes en el hogar los últimos 30 días.
No serán investigados: 1) los integrantesde una pensión familiar que tiene de 10 amás pensionistas, y 2) los trabajadores delhogar con cama afuera.
7.1. CARACTERISTICAS DE LAMUESTRA
Población y Cobertura
El universo cubierto por la muestra de laENAHO es todo el territorio nacional. Esdecir, la población está definida como elconjunto de todas las viviendas particularesy sus ocupantes residentes del área urbanay rural del país.
Se excluye del estudio a la poblaciónresidente en viviendas tipo colectivascomo hospitales, cuarteles, comisarías,hoteles, centros de reclusión, etc.
Niveles de Inferencia de Resultados
A efectos de permitir el estudio de loscambios en las características de la
población en el tiempo, se ha consideradoque en la ENAHO 2001 Cuarto Trimestrese trabaje con una muestra del tipo Panely una muestra No Panel.
La muestra panel estará conformada porlos hogares entrevistados en la ENAHO2000 - Cuarto Trimestre. En el caso de lamuestra no panel, esta será totalmentenueva.
Muestra panel: El principal objetivo deluso de una muestra panel en una encuesta,es realizar un seguimiento de las unidadesde investigación, en este caso los hogaresy los miembros que habitan en ella en undeterminado período. Asimismo, estamuestra permite obtener estimaciones delas características socio-demográficas dela población para diferentes áreas, estratoso dominios de interés, paraposteriormente realizar comparaciones delas unidades investigadas con referencia ala anterior investigación.
Muestra no panel: A través de la muestraNo Panel, se puede obtener estimacionesde las características socio-demográficasde la población de estudio para diferentesáreas, estratos o dominios de interés.Además, esta muestra incluye las nuevasunidades estadísticas que se incrementanen el marco inicial de selección.
Metodología de Estimación
La metodología de estimación paraprocesar los datos de la ENAHO, involucrael uso de un peso o factor de expansiónpara cada registro que será multiplicadopor todos los datos que conforman elregistro correspondiente.
El factor final para cada registro tiene doscomponentes:

42 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
El factor básico de muestreo y los factoresde ajuste por la no entrevista.
El factor básico de expansión para cadahogar muestral es determinado por eldiseño de la muestra. Equivale al inversode su probabilidad final de selección, elmismo que es el producto de lasprobabilidades de selección en cada etapa.
El diseño de la muestra de la ENAHO,involucra hasta 3 etapas de muestreodonde las unidades son seleccionadas conprobabilidades proporcionales al tamaño(ppt) excepto la última etapa. En la últimaetapa se seleccionará un número deviviendas para cada conglomeradoteniendo en cuenta un intervalo deselección.
Errores de Muestreo
Trimestralmente, en la Encuesta Nacionalde Hogares se calculan los errores demuestreo de las estimaciones de lasprincipales variables investigadas en laencuesta.
El paquete estadístico utilizado en laENAHO para el cálculo de las varianzas esel CENVAR (Sistema de Cálculo deVarianzas), el cual provee los estimadoresde variabilidad muestral para parámetrospoblacionales, como: totales, medias ,razones y proporciones para los diferentesdominios de estimación.
Para cada parámetro especificado ydominio de estimación, CENVAR produceun cuadro de salida con los indicadoressiguientes:
- El valor estimado del parámetro(estimación puntual)
- El error estándar
- El coeficiente de variación (CV)- El intervalo con 95 por ciento de
confianza- El efecto del diseño (DEFT)- El número de observaciones sobre el
cual se basa la estimación
El algoritmo usado por el CENVAR se basaen el método de los estimadores de lavarianza de los conglomerados últimos.
Cuestionarios
Se emplearán 6 tipos de cuestionarios:
ENAHO 01. Cuestionario individual paraser llenado con información del jefe delhogar y con entrevista directa a losinformantes individuales. Comprende lascaracterísticas de la vivienda, del hogar yde los miembros del hogar, Gastos delHogar, Programas Sociales y OtrasTransacciones.
ENAHO 01A. Cuestionario individual paraser llenado con información del jefe delhogar y con entrevista directa a losinformantes individuales, investiga lascaracterísticas de Educación, Salud, Empleoe Ingreso, Sistema de Pensiones y Usode Computadora e Internet en el Centrode Trabajo.
ENAHO 01B. Cuestionario individual quees llenado por entrevista directa coninformación del Jefe del hogar, en esteMódulo de Opinión se investiga Nivel deVida/Situaciones Adversas, Participaciónciudadana, Percepción sobre lacomunidad, Seguridad y Violencia,ETNIA/RAZA y Educación de los Padres.
ENAHO 02. Cuestionario individual quees llenado por entrevista directa con cadaproductor agropecuario que conduce una

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 43
Centro de Investigación y Desarrollo
unidad agropecuaria. Se investiga losingresos del productor agropecuario, elrégimen de tenencia de las tierras, laposesión de títulos de propiedad, el destinode la producción y crianza, los gastosrealizados en la actividad agropecuaria yel crédito agropecuario.
ENAHO 03. Cuestionario aplicado ainformantes calificados del área rural oáreas periféricas de las ciudades, investigaacerca del acceso a servicios y programassociales, así como a los organismos quefinancian dichos programas.
ENAHO 04. Ingreso del TrabajadorIndependiente (Sector Informal).
7.2. Factores de relevancia para laexplicación de la pobrezaextraídos de la ENAHO IVtrimestre 2001
Variable dependiente
[CONDICIÓN DE POBREZA]pobreza PobrezaEscala Nominal Categórica
Codificación: 1 Pobre Extremo, 2 PobreNo extremo, 3 No PobreBase de datos: Sumaria
Esta variable es recodificada en una nuevavariable EpobreEscala Nominal DicotómicaCodificación: 0 No Pobre, 1 Pobre
Variables independientesCaracterísticas Sociodemográficas delJefe de Hogar
[NIVEL DE EDUCACIÓN]p301 Nivel educativo que aprobó
Conocer el grado de educación más altoaprobado por cada persona dentro delnivel educativo que alcanzó.Escala Ordinal
Base de datos: Educación (CAP. 300)Codificación: 1 Sin nivel, 2 Inicial, 3Primaria incompleta, 4 Primaria completa,5 Secundaria incompleta, 6 Secundariacompleta, 7 Sup. No Univ. Incompleta, 8Sup. No Univ. Completa, 9 Sup. Univ.Incompl., 10 Sup. Univ. Completa, 11Post-grado Universitario, 99 Missing value
La variable nivel educativo que aprobó(p301) fue recodificada en la variableadnivedu-Nivel Educativo aprobado.Escala ordinal.Codificación: 1 Sin nivel, 2 Primaria, 3Secundaria, 4 Sup. No Univ., 5 Sup. Univ.6 Post- Grado Univ.
Se creó la variable aest-Años de Estudiostotales. Para su construcción se considerólas variables p301 y p301b(años de estudiosque aprobó). Como es evidente,dependiendo del grado aprobado y losaños que aprobó, se generan la cantidadtotal de años estudiados. Ejem: Si es unjefe de hogar que llegó solo a secundariaincompleta (3 años aprobados), entonceslos años de estudios totales (aest = 6(primaria completa) + 3 (secundariaincompleta)).
[CENTRO DE ESTUDIOS]p301d Centro de EstudiosDeterminar si el colegio de procedenciadonde se estudio es de régimen estatal oparticular.Escala nominalBase de datos: Educación (CAP. 300)Codificación: 1 Estatal, 2 No estatal, 9Missing value

44 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
[EDAD]p208a Edad en añosDeterminar el período transcurrido entrela fecha de nacimiento de la persona y eldía de la entrevista.Variable cuantitativaBase de Datos: Características de losmiembros del hogar (CAP. 200)
[GÉNERO]p207 SexoDeterminar el sexo de los entrevistados.Identificados como hombre o mujer.Escala Nominal DicotómicaBase de Datos: Características de losmiembros del hogar (CAP. 200)Codificación: 1 Hombre, 2 Mujer
[ESTADO CIVIL]p209 Estado conyugalInvestigar sobre la naturaleza de laparticipación de la población en materiade comportamiento conyugal en especialdurante el período de madurez.Escala Nominal CategóricaBase de Datos: Características de losmiembros del hogar (CAP. 200)Codificación: 1 Conviviente, 2 Casado(a),3 Viudo(a), 4 Divorciado(a) ,5 Separado(a),6 Soltero(a)
[DOMINIO GEOGRÁFICO]dominio Dominio GeográficoEscala Nominal CategóricaBase de Datos: Identificador presente entodas las bases de datosCodificación: 1 Costa Norte , 2 CostaCentro, 3 Costa Sur, 4 Sierra Norte, 5 SierraCentro, 6 Sierra Sur, 7 Selva, 8 LimaMetropolitana
[GRANDES DOMINIOS ]gdomini Grandes Dominios Geog.Escala Nominal CategóricaCodificación: 1 Costa , 2 Sierra, 3 Selva, 4Lima Metropolitana
[ESTRATO]estrato Estrato GeográficoDeterminar la cantidad de viviendasalbergadas en cada estrato geográfico.Escala Nominal CategóricaBase de Datos: Identificador presente entodas las bases de datosCodificación: 1 Mayor de 100,000viviendas, 2 De 20,001 a 100,000viviendas, 3 De 10,001 a 20,000viviendas, 4 De 4,001 a 10,000 viviendas,5 De 401 a 4,000 viviendas, 6 Menos de400 viviendas, 7 AER compuestos, 8 AERsimples.
[AREA]urb_ru Área urbano-ruralEsta variable resulta de recodificar lavariable estrato cuyas 5 primeras categoríasproceden a conformar el área urbana y lascategorías de 6 a la 8 conformarían el árearural.Escala Nominal DicotómicaCodificaciòn: 1 Área Urbana, 2 Área Rural
[DOMINIO URBANO RURAL]domur_ru Grandes dominios por áreaurb o ru.Esta variable resulta del cruce de lasvariables gdomini (Costa, Sierra, etc) y área(urbano, rural).Escala Nominal categóricaCodificación: 11 Costa Urbana, 12 CostaRural, 21 Sierra Urbana, 22 Sierra Rural,31 Selva Urbana, 32 Selva Rural, 41 LimaUrbana
Características de la inserciónocupacional del JH
[EXPERIENCIA LABORAL]exper1 Indicador proxy de exper.laboralEste indicador resulta de restar a la edaddel jefe de hogar los años de estudios,

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 45
Centro de Investigación y Desarrollo
aunque no considera si el jefe de hogarha trabajado y estudiado a la vez, seaproxima en buena medida a laexperiencia laboral del jefe de hogar. Seresta "6" al final del indicador, pues es a laedad en que debería empezar el colegio.Variable cuantitativaPor ejemplo, un jefe de hogar con 45 añosy secundaria completa, tendrá:Exper1 = p208a - aest - 6 = 45 - (6+5) -6 = 28 años de experiencia laboral
[CATEGORÍA OCUPACIONAL]p507 Cargo en Centro Ocupacional.Conocer la relación del trabajador con suempleo, es decir, la forma que tienen lostrabajadores de insertarse en el mercadolaboral. Una primera distinción básica essi se trabaja en forma dependiente oindependiente, ya que en ambos casos sonmuy diferentes las relaciones económicasy laborales involucradas.Escala Nominal Categórica
Base de datos: Empleo e Ingresos (Cap.500)Codificación: 1 Empleador o patrono, 2Trabajador independiente, 3 Empleado, 4Obrero, 5 Trabajador Familiar noremunerado, 6 Trabajador del Hoga, 7Otro.
[TAMAÑO DE LA FIRMA]p512a Tamaño de la empresaDisponer de información sobre el volumende la fuerza de trabajo según el tamañodel establecimiento, el mismo queconjuntamente con otras características,son útiles para determinar el volumen dela población del sector informal.Escala OrdinalBase de datos: Empleo e Ingresos (Cap.500)
Codificación: 1 menos de 100 personas,2 De 100 a 499 personas, 3 De 500 y màspersonas.
[TRABAJO ADICIONAL]p514 Ocupación secundariaDeterminar el número de ocupados quetienen actividad secundaria, quedesarrollan simultáneamente con laactividad principal en la semana dereferencia, ya sea en forma dependienteo independiente.Escala Nominal DicotómicaBase de datos: Empleo e Ingresos (Cap.500)Codificación: 1 Si , 2 No
Características del hogar
[NUCLEOS EN EL HOGAR]nuchoga Cant. de núcleos en hogarDeterminar el número de núcleospresentes en cada hogar para intentarcaptar a cuántos hogares se alberga fueradel propio hogar del jefe de hogar, dentrode la misma vivienda.Variable cuantitativa
Base de datos: Generada a partir decaracterísticas de los miembros del hogar(cap.200)
[HIJOS EN EL HOGAR]hijxhog Cant. de hijos del jhDeterminar la cantidad de hijos presentesen el hogar.Variable cuantitativaBase de datos: Generada a partir decaracterísticas de los miembros del hogar(cap.200)
[MIEMBROS EN EL HOGAR]mieperhog Cant. de miembros en hogarDeterminar la cantidad de miembrospertenecientes al hogar, se excluyen a las

46 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
trabajadoras del hogar que nopermanecen más de 30 días en el hogar.Variable CuantitativaBase de Datos: Sumaria
[PERCEPTORES EN HOGAR]percephog Cant. de preceptores enhogar.Determinar la cantidad de preceptoresdentro de cada hogar.Variable CuantitativaBase de Datos: Sumaria
[INGRESO NETO TRIMESTRAL]inghog2d Ingreso neto trimestralTrimestralizar la información de ingresos,llevándola a un mismo período deinvestigación.Variable CuantitativaBase de Datos: Sumaria
[INGRESO PER CÁPITA M]ingperho Ingreso per cápita mens.del hogarDeterminar el ingreso per cápita mensualde los hogares.Variable CuantitativaBase de datos: Generada a partir deSumaria.
[ACCESO LUZ]p112 Tipo de alumbrado en su hogarDeterminar si el hogar dispone o no dealumbrado eléctrico. Asimismo seconocerá la cantidad de hogares quecarecen de servicio y permitirá establecerla relación que existe entre padecimientosrespiratorios y algunas formas de alumbradocomo el uso de kerosene y vela.Asimismo, las deficiencias en al agudezavisual, también pueden estar en relaciónal uso de alumbrado no eléctrico.Escala Nominal Categórica
Base de datos: Características de lavivienda y el hogar. (cap. 100)Codificación: 1 Electricidad, 2 kerosene(mechero/lamparin), 3 Petróleo/gas(lampara), 4 Vela, 5 Generador, 6 Otro.
[ACCESO AGUA]p110 Abastecimiento agua en hogarConocer la cantidad de personas y lugaresdonde se carece de este líquido vital, loque será de utilidad para la ejecución deprogramas de saneamiento.Escala Nominal CategóricaBase de datos: Características de lavivienda y el hogar. (cap. 100)Codificación: 1 Red pública, dentro de lavivienda, 2 Red pública, fuera de lavivienda, 3 Pilón de uso público, 4 Camión-cisterna u otro similar, 5 Pozo, 6 Río,acequia, manantial o similar, 7 otro.
[ACCESO A RED SANITARIA]p111 El servicio higiénico estaconectadoConocer si el hogar dispone o no deservicio higiénico, su ubicación y formade eliminación de los residuos humanos.Permitirá tener una apreciación másgeneral respecto a la calidad de vida delos habitantes; y es un componenteelemental en la determinación delbienestar social. Además permitiráconocer las posibilidades de contaminaciónen la comunidad en general y las causasque producen la hepatitis y la tifoidea.Escala Nominal CategóricaBase de datos: Características de lavivienda y el hogar. (cap. 100)Codificación: 1 Red pública dentro de lavivienda, 2 red pública fuera de la vivienda,3 pozo séptico, 4 pozo ciego o negro/letrina, 5 río, acequia o canal, 6 no tiene

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 47
Centro de Investigación y Desarrollo
Si se desea obtener más información sobreotras variables de medición de condicionesde vida y pobreza, se puede consultar"Variables investigadas en la ENAHO-2001IV TRIMESTRE .INEI - MECOVI"
VARIABLES INDICADORAS
Se generaron variables indicadoras paratrabajar sobre los modelos de probabilidaddel jefe de hogar y poder captar el efectode las categorías de las variables en escalasnominales sobre sus categorías base . Elmismo proceder se efectuó para lasvariables en escalas ordinales.
En tal sentido el nivel educativo agrupadofue dividido en 5 indicadoras, donde lacategoría que está fuera de riesgo es elPost-Grado Univ.
• DSINNIV = 1Si JH no tiene nivel educativo y 0 enotro caso
• DPRIM = 1Si JH tiene primaria y 0 en otro caso
• DSECUND = 1Si JH tiene secundaria y 0 en otro caso
• DSUPNU = 1Si JH tiene educ. sup no univ. y 0 enotro caso
• DSUPUN = 1Si JH tiene educ. sup. Univer. y 0 enotro caso
Variable indicadora de colegio estatal.
• DCOLEGIO = 1Si JH a estudiado en colegio estatal y 0en otro caso
La variable categoría ocupacional generaría4 variables categóricas, donde se considera
que la categoría empleador o patrono esla categoría base.
• DINDEP = 1Si JH es trabajador independiente y 0en o.c.
• DEMPLEADO = 1Si JH es empleado y 0 en o.c.
• DOBRERO = 1Si JH es obrero y 0 en otro caso
• DOTRO = 1Si JH se encuentra en otra situaciónocupacional
Se generan variables indicadoras paradominio en área urbana y rural.
• DCORU = 1Si JH habita en Costa urbana y 0 enotro caso
• DSIEUR = 1Si JH habita en Sierra urbana y 0 enotro caso
• DSELUR = 1Si JH habita en Selva urbana y 0 enotro caso
La variable en escala ordinal Tamaño de lafirma genera dos variables indicadoras,tomando como categoría base el tamañode la firma de 500 y más personas.
• DME100 = 1Si JH trabaja empresa con menos de100 personas y 0 o.c.
• DME499 = 1Si JH trabaja empresa con 100 a 499personas y 0 o.c.
Variable indicadora de si el JH tiene ejerceuna actividad secundaria

48 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
• DOEMP = 1Si JH tiene otro trabajo y 0 en otro caso
De igual manera el estado civil generaría5 variables indicadoras, donde tomaríamoscomo categoría base cuando el jefe dehogar es soltero.
• DCONVI = 1Si JH es conviviente y 0 en otro caso
• DCASAD = 1Si JH es casado y 0 en o.c.
• DVIUDO = 1Si JH es viudo y 0 en o.c.
• DDIVOR = 1Si JH es divorciado y 0 en o.c.
• DSEPAR = 1Si JH es separado y 0 en o.c.
Generamos variables indicadoras cuandoel hogar tiene conexión de servicioshigiénicos a red pública dentro devivienda.
• DSHDV = 1Si SS.HH. hogar - conectados a redpública dentro de vivienda y 0 en o.c.
De la misma manera, se generan unavariable indicadora cuando el hogar notiene ss.hh. dentro del hogar.
• DSHNO = 1Si hogar no tiene SS.HH. dentro dehogar y 0 en o.c.
Para el caso de abastecimiento de aguadentro de la vivienda a través de redpública, generamos la variable indicadora.
• DAGUDV = 1Si abastecimiento de agua es través dered pública dentro de vivienda
Variable indicadora que defina si elalumbrado público en la vivienda es travésde kerosene.
• P1122 = 1Si el tipo de alumbrado en la viviendaes a través de kerosene
Variable indicadora que define si se utilizaespacio de la vivienda que destine ingresospara el hogar.
• P115 = 1Si se utiliza espacio en la vivienda quedestine ingresos al hogar.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 49
Centro de Investigación y Desarrollo
VIII. CRITERIOS DE APLICACIÓN DE LOS MODELOSLOGIT Y PROBIT CON VDD APLICADOSAL CASO DE LA POBREZA EN EL PERÚ
8.1 Estudio a nivel descriptivo yexploratorio de variablescualitativas y cuantitativas queincidan en la pobreza en el Perú12
Empezaremos esta parte de nuestrainvestigación describiendo aquellasvariables que nos brindan posiblesexplicaciones de la pobreza en un marcogeneral y de los individuos Jefe de Hogaren este caso en particular. Entre ellas seencuentran aquellas de caráctersociodemográfico como el género, laedad, el estado civil, el nivel de educación,el alfabetismo (variables de naturalezacualitativa), medidas en algunos casos enescala nominal - dicotómica como el sexodel jefe de hogar (Hombre-Mujer) y enotros casos nominal - politómica como elestado civil (Soltero-Casado-Conviviente-etc).
En otro tipo de escalas se encuentranaquellas que denotan un orden ascendenteen sus categorías como lo es el nivel deeducación (Sin Nivel- Educación Primaria-etc.) alcanzado por el Jefe de Hogar.
Además encontramos variables denaturaleza cuantitativa como lo constituyen
la edad y el indicador proxy de experiencialaboral , que no considera aquel caso enel que el Jefe del Hogar, ha estudiado ytrabajado, sino solo aquel tiempo en elcual el Jefe de Hogar solo trabaja.
Uno de los objetivos que perseguimos yque esta implícito dentro de estainvestigación es dejar en claro queestamos trabajando con variables adiferentes escalas, mencionadas comoejemplos líneas antes, y que dependiendode estas escalas determinarán laimplementación y ejecución de lasmetodologías que sirvan de herramientaspara una explicación de la pobreza en elPerú en particular.
EDUCACIÓN
Una de las características de la pobreza esque esta se encuentra asociada a nivelesbajos de educación alcanzados por el Jefede Hogar. Podemos ver [Cuadro VIII.1]como dentro de aquellos Jefes de Hogarsin nivel educativo y nivel educativoprimario, el 72.5% y el 61.3% seencuentran en condición de pobreza,respectivamente.
72.5% 61.3% 40.0% 19.3% 8.2% .2% 46.8%
27.5% 38.7% 60.0% 80.7% 91.8% 99.8% 53.2%100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0%
pobre
no pobre
estado pobreza
Total
sin nivel primaria secundaria sup. no univ. universitaria post univers.
Nivel Educativo Agrupadoa
Total
Porcentage de columnasa.
12/ Debemos de recordar que si bien el objetivo de nuestra investigación gira en torno a los modelos logit y probit, vemos que nopodemos ser ajenos a aquellos previos fundamentales de análisis descriptivo para poder seguir avanzando sobre niveles de análisismás complejos, como lo podrían constituir el análisis multivariado y los modelos de probabilidad con enfoques binomial.
Cuadro VIII.1 Perfil del Jefe de Hogar según Nivel Educativo y Estado pobreza

50 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
En el caso de los que tienen nivel educativosecundaria, se aprecia que el estado depobreza se encuentra repartido para susdos categorías, con 40% para el caso dejefes de hogar pobres y con 60% para elcaso de no pobreza. Un panoramadiferente y en sentido opuesto se da enlos niveles superiores donde en el casode jefes de hogar con nivel educativosuperior no universitario el 80.7% seencuentran en estado de no pobreza. Enuna tendencia creciente mucho mayor yestado de no pobreza se encuentranaquellos jefes de hogar que tiene nivelescomo el universitario y el post-grado, con91.8% y 99.8% para la primera y segundarespectivamente.
En función del comportamiento entre elestado de pobreza y el nivel educativo deljefe de hogar nos toca ahora analizar elgrado de relación que estas tienen, ydefinir más aún este comportamiento anivel poblacional. Analizando el cuadroque muestra el Test Chi-Square [CUADROVIII.2] podemos ver que la hipótesis denulidad que supone independiente elnivel educativo y la condición de pobrezadel jefe de hogar es rechazada para unvalor de c2 = 859730.5 y un nivel designificancia (p-valor =0.000), por lo tantoa medida que el jefe de hogar vaadquiriendo un mayor nivel de educación,éste obtiene mas capacidades para irabandonando la condición de pobreza,más aún si tiene niveles de educaciónsuperiores.
859730.5 5 .000954693.3 5 .000
842469.1 1 .000
5834837
Pearson Chi-SquareLikelihood RatioLinear-by-LinearAssoc iation
N of Valid Cas es
Value dfAsymp. Sig.
(2-sided)
Cuadro VIII.2 Chi-Square Test
Una respuesta a la pregunta de ¿cual es elgrado de asociación? Se puede apreciaren el cuadro [CUADRO VIII.3] SymmetricMeasures donde los Coeficientes decorrelación de Spearman (0.375), Gamma(0.567) y Kendall´s tau-c (0.409) denotanun fuerte grado de asociación, pues nos
dan la idea de la asociación que debe darseentre el nivel socioeconómico y el niveleducativo, hablando de la población en suconjunto. Debemos de tomar en cuentaque estamos aislando en alguna medida elfenómeno de pobreza y poniéndolo soloen términos del nivel educativo.
Cuadro VIII.3 Symmetric Measures
. 346 .000
. 409 .000
. 567 .000
. 375 .0005834837
Kendall's tau-bKendall's tau-c
GammaSp earman Correlation
Ordinal byOrdinal
N of Valid Cases
Value Ap prox. Sig .

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 51
Centro de Investigación y Desarrollo
ESTADO CIVIL - SEXO DEL JEFE DEHOGAR
A continuación analizaremos elcomportamiento y la relación existenteentre el sexo del jefe de hogar y el estadocivil que posee. Se puede apreciar[CUADRO VIII.4] que dentro de lacondición de pobreza, los jefes de hogarhombres constituyen el 96.4% del estado
civil conviviente, en igual sentido seencuentra los jefe de hogar casados quevienen a estar constituidos en un 97.7%por los hombres. La figura cambia para lasotras categorías de estado civil, donde parael estado civil viuda, divorciada, separaday soltera, las mujeres constituyen el76.36%, el 70.86%, el 84.13% y el 50.48,para cada categoría y en ese ordenrespectivamente.
0
10
20
30
40
50
60
70
80
90
100
Sin Nivel Prim aria Secundaria Superior No
Universitaria
Universitaria Post -Grado
Pobre
N o Pobre
Gráfico VIII.1Perfil del Nivel Educativo según estado de pobreza del jefe del hogar
Cuadro VIII.4Perfil de jefe de hogar según género y estado civil o conyugal en estado de pobreza
96.4% 97.7% 23.6% 29.1% 15.9% 49.5% 81.2%3.6% 2.3% 76.4% 70.9% 84.1% 50.5% 18.8%
100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0%
HombreMujer
Sexo
Total
estadopobrezapobre
Conviviente Casado Viudo Divorciado Separado SolteroCual es su estado civil o conyugal
a
Total
Porcentage en columnasa.
Resultado de la incorporación de losefectos de diseño vemos [CUADROVIII.5] que según el Chi-Square Tets,obtenemos el coeficiente Pearson c² (5)= 1685365 y un p-valor=0.000, nos
permite rechazar la hipótesis que formulala independencia de ambas variables, esdecir, que existe relación significativa entreel estado civil y el sexo del jefe de hogaren condición de pobreza.
PORC
ENTA
JE
NIVEL EDUCATIVO

52 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
El grado de asociación del cual estamoshablando lo podemos observar en el cuadrosiguiente Symetric Measures [CUADROVIII.6], donde coeficientes como el decontingencia (CC) con un valor de 0.615, el Phi = 0.781 y el Cramer´s V=.781denotan un alto grado de asociación13, locual nos muestra que la pobreza afectaen todos los estados civiles sean estos en
condición de pareja (casado-conviviente),como sería en el caso de los jefes de hogarhombres. En aquellas situaciones en lasque la mujer tiene que responder comojefe de hogar y "no tendría pareja" (Viuda-Divorciada-Soltera-etc.), podría motivar unmayor riesgo para la adquisición de lacondición de pobreza.
1685365 5 .0001478553 5 .000
2764186
Pearson Chi-SquareLikelihood Ratio
N of Valid Cases
estado pobrezapobre
Value dfAsymp. Sig.
(2-sided)
Cuadro VIII.5 Chi-Square Test
Cuadro VIII.6 Symmetric Measures
.781 .000
.781 .000
.615 .0002764186
PhiCramer's VContingency Coefficient
NombyNom
N of Valid Cases
estadopobrezapobre
Value Approx. Sig.
Al analizar las mismas variables para losjefes de hogar no pobres, podemosobservar [CUADRO VIII.7] uncomportamiento parecido al de los jefesde hogar en estado de pobreza. Es decir,para los jefes de hogar con estado civil deconvivencia y casado, los hombres
constituyen el 94.1% y el 97.2% dentrode cada categoría respectivamente. Paralos jefes de hogar en los estados civilesviudo, divorciado y separado, las mujeresconstituyen el 67.8%, el 60.2% y el67.8% de cada categoría y en ese ordenrespectivamente.
Cuadro VIII.7Perfil de jefe de hogar según género y estado civil o conyugal en estado de no pobreza
94.1% 97.2% 32.2% 39.8% 32.2% 62.1% 78.2%5.9% 2.8% 67.8% 60.2% 67.8% 37.9% 21.8%
100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0%
HombreMujer
Sexo
Total
estadopobrezanopobre
Conviviente Casado Viudo Divorciado Separado SolteroCual es su estado civil o conyugal
a
Total
Porcentage de Columnasa.
13/ Debemos de considerar que si bien estos coeficientes nos confirman los grados de asociación de variables estos poseenlimitaciones como el caso del coeficiente de contingencia, que a pesar que nos puede expresar que un valor de ceroconfirma la no asociación de variables, no posee la propiedad en el caso extremo de un grado de asociación total, es decir,igual a 1. Para más detalle consultar Siegel , Sidney.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 53
Centro de Investigación y Desarrollo
Se confirma la relación significativa ydiferente de cero existente entre el sexoy el estado civil del jefe de hogar, esto enel Chi-Square Test [CUADRO VIII.8], através de los coeficientes de Pearson c²(5)=1356731, el c ² de la razón deverosimilitud (likelihood ratio)= 1327980
con resultados en el mismo sentido debidoal tamaño de la población. A través de susignificancia (0.000) que permite rechazarla hipótesis que sostiene la independenciadel sexo y el estado civil del jefe de hogardentro de cada categoría de pobreza.
Cuadro VIII.8 Chi-Square Test
1356731 5 .000
1327980 5 .000
3144673
Pearson Ch i-Squar e
Likelihood Ratio
N of Valid Cases
estado pobrezano pobre
Value dfAsymp. Sig.
(2-sided)
De lo explicado anteriormente, resultainteresante ver que a pesar que exista unarelación entre el sexo del jefe de hogar ysu correspondiente estado civil, la pobrezade los jefes de hogar del Perú ya no solo
capta a los hogares con jefes de hogarmujeres sin pareja, ahora en el año 2001ya ha captado a los jefes de hogar conpareja, ya sea formal o informal.
Cuadro VIII.9 Symmetric Measures
.657 .000
.657 .000
.549 .000
3144673
Phi
Cramer's V
ContingencyCoefficien t
Nom byNom
N of V alid Cases
estado pobrez ano pobre
Value Appro x. Sig .
0
20
40
60
80
100
CONVIVIE NT E CAS ADO VIUDO DIVOR CIADO SE PAR ADO S OLT E R O
Mujer
Hombre
PORC
ENTA
JE
ESTADO CIVIL
Gráfico VIII.2Perfil del Jefe de Hogar según Género y Estado Civil
condición de no pobreza

54 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
0
20
40
60
80
100
CONVIVIENT E CAS ADO VIU DO DIVOR CIADO SEPAR ADO S OLT E RO
Mujer
Hombre
AREAS DE RESIDENCIA - REGIÓNNATURAL
La pobreza en nuestros días haconquistado todos los ámbitos del vastoterritorio peruano, lo cual sumado acondiciones de focalización mal llevadasen la década pasada permitió que aquellosque se encontraban en estado de pobrezano fueran quienes recibieran la ayuda y losmedios adecuados paleativos para subsisitir.
En el año 2001, podemos ver [CUADROVIII.10] que en condición de pobreza los
jefes de hogar del área urbana constituyeel 84.3% para la región de la costa. Enun nivel porcentual menor pero igual deconsiderable, la región de la sierra estáconstituida en un 75.9% por jefes dehogar del área rural. Si bien para el árearural en la región selvática los jefes dehogar pobres son alrededor del 58% , noes tan evidente la diferencia como en elresto de regiones, debido a que en el áreaurbana se encuentra un 42.1% en estadode pobreza.
PORC
ENTA
JE
ESTADO CIVIL
Gráfico VIII.3Perfil del Jefe de Hogar según Género y Estado Civil
condición de pobreza
Cuadro VIII.10Perfil de jefe de hogar según Area y Región Natural en estado de pobreza
84.3% 24.1% 42.1% 47.4%
15.7% 75.9% 57.9% 52.6%
100.0% 100.0% 100.0% 100.0%
urbano
rural
Urbano_Rural
Total
estadopobrezapobre
costa sierra selva
regiones naturalesa
Total
Porcentage de Columnasa.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 55
Centro de Investigación y Desarrollo
Resulta dramático evidenciar cómo lacondición de pobreza afecta en mayormedida a aquellos que menos accesotienen en cuanto a activos públicos deinfraestructura, educación, salud, etc; queson justamente aquellos jefes de hogar
que se encuentran en la sierra rural delPerú, a pesar de que se sostenga enalgunas investigaciones que la brecha deacceso a estos activos se ha ido reduciendoen los últimos años.
PORC
ENTA
JE
REGION NATURAL
Gráfico VIII.4Perfil del Jefe de Hogar según Área y RegiónNatural de residencia - Condición de pobreza
0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
C OS TA SIE R R A S E LV A
U rb an o
R ur al
La relación entre estas variables essignificativa a un nivel de confianza del95%. Esto como sabemos podemosdeducirlo del rechazo de la hipótesis quesupone la independencia del área (urbanoo rural) y la región natural de residencia
del jefe de hogar [CUADRO VIII.11],ambos en escala nominal para la condiciónde pobreza, al haber obtenido valores delcoeficiente de Pearson c²(2) = 819652.7y un p-valor = 0.000, esto con unasignificancia (a) de 5%.
Cuadro VIII.11 Chi-Square Test
819652.7 2 .000
879899.6 2 .000
2764184
Pearson Chi-Square
Likelihood Ratio
N of Valid Cases
estado pobreza01pobre
Value dfAsymp. Sig.
(2-s ided)
El grado de asociación que se encuentraen estas variables se puede apreciar en elcuadro [CUADRO VIII.12] SymmetricMeasures, el cual nos muestra loscoeficientes de asociación Phi=0.545,
Cramer´s V = 0.545, y el ya conocidocoeficiente de contingencia (CC)=0 .478,que a pesar estos últimos de mostrar unalto grado de relación entre 2 variablesmedidas en una escala simple como es la

56 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
nominal, puede mostrarnos cómo vadeterminando en alguna medida suinfluencia en la condición de pobreza que
posee el jefe de hogar y cómo esta entraráa tallar dentro la probabilidad que elindividuo obtenga dicha condición.
.545 .000
.545 .000
.478 .000
2764 184
P hi
Crame r's VCon tinge ncyCoe fficient
Nom b yNom
N of Vali d Cases
estad opobrezapobre
V alu e Approx. S ig.
Cuadro VIII.12 Symmetric Measures
ANÁLISIS CUANTITATIVO
Si bien hemos mostrado relaciones convariables importantes que en principio nosmuestran panoramas independientes dela pobreza y el efecto que sobre lacondición del jefe de hogar ejercen estasvariables de naturaleza cualitativa,extrayéndolas del fenómenomultidimensional en su conjunto,podemos también detenernos porinstantes dado que no es objetivo de estainvestigación analizar como cierto tipo deactivo de capital humano se comportandentro de las distintas condiciones depobreza, entre ellos, años de estudios deljefe de hogar.
AÑOS DE ESTUDIOS DEL JEFE DEHOGAR
Uno de los indicadores que muchosconsideran de suma importancia al analizarla pobreza, es el de los años de estudiosdel jefe de hogar. Para el año 2001podemos observar [CUADRO VIII.13] queel activo de capital humano referente alos años de estudios del jefe de hogar esbajo, basta solo con observar que para el
estado de pobreza el promedio de añosde estudios se encuentra alrededor de 5,pequeño en comparación a que los jefesde hogar en condición de no pobrezatienen en promedio alrededor de 10 añosde estudios.
Dada la heterogeneidad y dispersión delas poblaciones en estudio, el tomar comovalor del promedio de años de estudioslos valores obtenidos, resulta erróneo. Ental sentido deberemos optar por lamediana como mejor medida de ajuste aesta variable. Se puede apreciar que enpromedio, el jefe de hogar pobre estaríaalcanzando el grado de primaria (6 años),diferencia sustantiva con respecto a losaños alcanzados por el jefe de hogar nopobre que podría estar alcanzando alcompletar el nivel de secundaria con los11 años en promedio de estudio que estetendría. No debemos además olvidar queestamos considerando su conducta desdela idea de un corte transversal hecho enel tiempo y deben ser consideradas susimplicancias respectivas, en caso sedecidiese, probarla con alguna otra variabley analizar su comportamiento.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 57
Centro de Investigación y Desarrollo
Más allá de que la desigualdad existenteentre los dos grupos sea evidente, esinteresante confirmar cómo a través de laprueba de diferencia de mediasconfirmamos tal. El [CUADRO VIII.14] nosmuestra en primer lugar el estadístico deLevene14, el cual nos permite rechazar laidea de igualdad de poblaciones pobre yno pobre. Como ya probamos la diferenciaexistente entre los años de estudios dejefes de hogar pobres y no pobres, con eltest de equivalencia de mediasrechazamos tal hipótesis, primero tomandola fila de varianzas diferentes, que ya hasido probada y luego podemos ver que la
diferencia de medias es distinta de cero(3.92), debido a un t = - 1026.487 y unasignificancia de 0.000, lo cualestadísticamente hablando nos permiterechazar la idea de igualdad de medias alnivel poblacional.
Probada esta diferencia de medias nos tocaahora mostrar cómo la diferencia en añosde estudios se hace cada vez más notoriaa medida que el jefe de hogar seencuentra en pobreza extrema, pobrezano extrema y no pobreza, la cual serámostrada por única vez, dado que no esfin primordial de esta investigación.
Cuadro VIII.13Cuadro de años de estudio del Jefe de Hogar según Condición de Pobreza
5.36 2.60E-03
5.17
6.00
4.30
.345 .001
-.870 .003
9.29 2.80E-03
9.38
11.00
4.93
-.298 .001
-.842 .003
Promedio
Promedio sin 5% VE
Mediana
Desviacion Std.
Asimetría
Kurtosis
Promedio
Promedio sin 5% VE
Mediana
Desviacion Std.
Asimetría
Kurtosis
Estado Pobrezapobre
no pobre
Años deestudios JH
Statistic Std. Error
57766.511 .000 -1017.677 5834834 .000 -3.92 3.86E-03
-1026.487 5834386 .000 -3.92 3.82E-03
Asumiendovarianzas iguales
Sin asumirvarianzas iguales
Años deestudiosjh
F Sig.
Levene's Test forEquality of Variances
t df Sig. (2-tailed)Mean
DifferenceStd. ErrorDifference
t-test for Equality of Means
14/ Sabemos que el estadístico de Levene es resistente a la ausencia de normalidad de una distribución analizada, en tal sentidose propone como más idóneo para medir la homogeneidad de las varianzas.
Cuadro VIII.14Prueba de Levene para igualdad de varianzas y diferencia de medias
en los años de estudios del JH
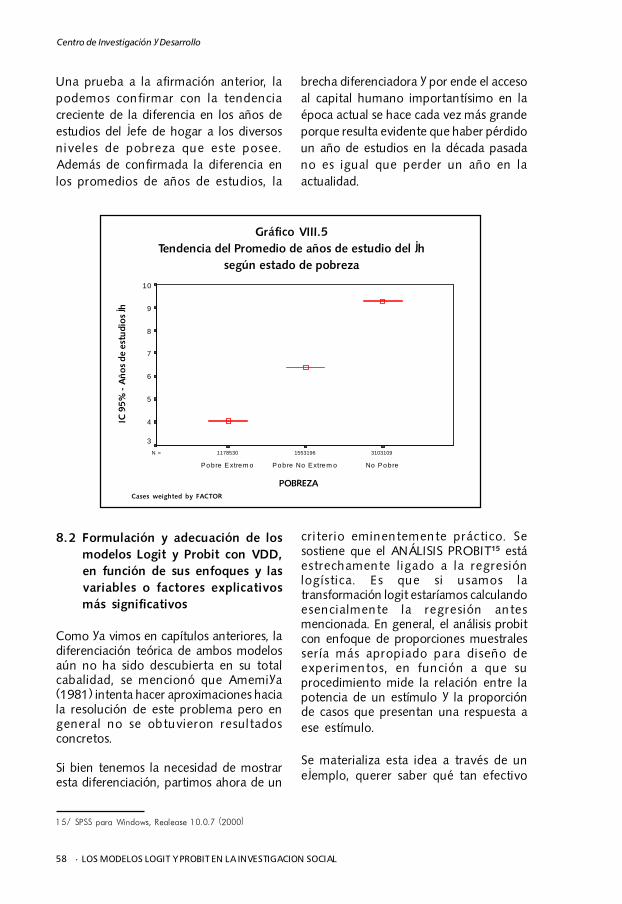
58 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
310310915531961178530N =
No PobrePobre No Extrem oPobre E xtrem o
10
9
8
7
6
5
4
3
Una prueba a la afirmación anterior, lapodemos confirmar con la tendenciacreciente de la diferencia en los años deestudios del jefe de hogar a los diversosniveles de pobreza que este posee.Además de confirmada la diferencia enlos promedios de años de estudios, la
brecha diferenciadora y por ende el accesoal capital humano importantísimo en laépoca actual se hace cada vez más grandeporque resulta evidente que haber pérdidoun año de estudios en la década pasadano es igual que perder un año en laactualidad.
IC 9
5% -
Año
s de
est
udio
s jh
POBREZA
Gráfico VIII.5Tendencia del Promedio de años de estudio del jh
según estado de pobreza
Cases weighted by FACTOR
8.2 Formulación y adecuación de losmodelos Logit y Probit con VDD,en función de sus enfoques y lasvariables o factores explicativosmás significativos
Como ya vimos en capítulos anteriores, ladiferenciación teórica de ambos modelosaún no ha sido descubierta en su totalcabalidad, se mencionó que Amemiya(1981) intenta hacer aproximaciones haciala resolución de este problema pero engeneral no se obtuvieron resultadosconcretos.
Si bien tenemos la necesidad de mostraresta diferenciación, partimos ahora de un
criterio eminentemente práctico. Sesostiene que el ANÁLISIS PROBIT15 estáestrechamente ligado a la regresiónlogística. Es que si usamos latransformación logit estaríamos calculandoesencialmente la regresión antesmencionada. En general, el análisis probitcon enfoque de proporciones muestralessería más apropiado para diseño deexperimentos, en función a que suprocedimiento mide la relación entre lapotencia de un estímulo y la proporciónde casos que presentan una respuesta aese estímulo.
Se materializa esta idea a través de unejemplo, querer saber qué tan efectivo
15/ SPSS para Windows, Realease 10.0.7 (2000)

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 59
Centro de Investigación y Desarrollo
es un nuevo pesticida para liquidarinsectos, ¿cual sería la concentración letalefectiva a usar? Uno podría diseñar unexperimento en el cual se exponenmuestras de insectos a diferentesconcentraciones del insecticida, es decir,tener el número de insectos expuestos endicha concentración y entonces determinarel número de insectos muertos bajo talefecto. Aplicando un análisis probit a estosdatos, uno puede determinar la potenciade la relación entre la muerte de losinsectos y la dosis de pesticida adecuadoy determinar cuál es el grado deconcentración apropiado del insecticidaque me permitiría estar seguro de mataral 95% de los insectos expuestos.
Como resulta evidente, se está realizandoun enfoque cuantitativo, confirmado estoademás en la línea seguida por autorescomo Green o Gujarati al formular susmodelos de probabilidad. Pero comopuede apreciar se limita al hecho deinclusión de pocas variables, más aúnsiendo estas de índole cuantitativo yporque necesariamente tendría queobtener la frecuencia de observacionesque implican en primer lugar a las variablesindependientes, vale decir por ejemplocantidad de jefes de hogar dentro de losdeciles de ingreso, luego determinar lacantidad de jefes de hogar pobres dentrode cada décil, para poder saber la tasa derespuesta a ese nivel de ingreso dentrode la variable dependiente (la condiciónde pobreza). Si se decidiera incluir másvariables independientes se tiene quetomar en cuenta que debemos obtenerlas frecuencias que resultan del cruce deestas. Imaginarse tan solo el cruce losdiversos valores del ingreso per cápita conel estado civil, la cantidad de miembrosde la familia y con los tipos de accesos aactivos públicos como la luz, agua, entreotros, empiezan a figurar la inviabilidad deesta aplicación.
Aquí es donde se producirán limitacionesen la aplicación de este enfoque debido a
que si bien se pueden obtener el crucede ellas, no esta regido a parámetros demedición exacta y continua, pues lapobreza es un fenómeno de escalamultidimensional. Sería interesante podersaber si la mezcla de escalas determinanun nivel de medición que me permitieseacceder a la probabilidad exacta de serpobre.
A parte de la condición de que lasobservaciones deben ser independientes.Si tenemos un gran cantidad de estas paralas variables independientes, la Chi-cuadrado (c²) y los estadísticos de bondadde ajuste pueden no ser válidos.
Retomando la diferenciación de ambosmodelos, podemos mencionar que laregresión logística con enfoque de casosindividuales es más apropiada para estudiosobservacionales. Usada también parasituaciones en las cuales uno quiere sercapaz de predecir la presencia o ausenciade una característica o resultado basadoen valores de un conjunto de variablespredictoras. Los coeficientes del modelologit pueden ser usados para estimar OddsRatios (`Razón de probabilidades`) paracada una de las variables independientesen el modelo. La regresión logística y porende el modelo logit, es aplicable a unrango mayor de situaciones deinvestigación. Adicionalmente, como enotras formas de regresión, lamulticolinealidad de las variablesindependientes si no es manejable puedegenerar estimadores sesgados o inflar elerror estándar.
8.2.1 Metodologías de estimación delos modelos de probabilidad
MODELO DE PROBABILIDAD DE LAPOBREZA EN EL JEFE DE HOGAR
A continuación mostramos la metodologíade estimación del modelo de probabilidaddel jefe de hogar pobre del Perú, para el
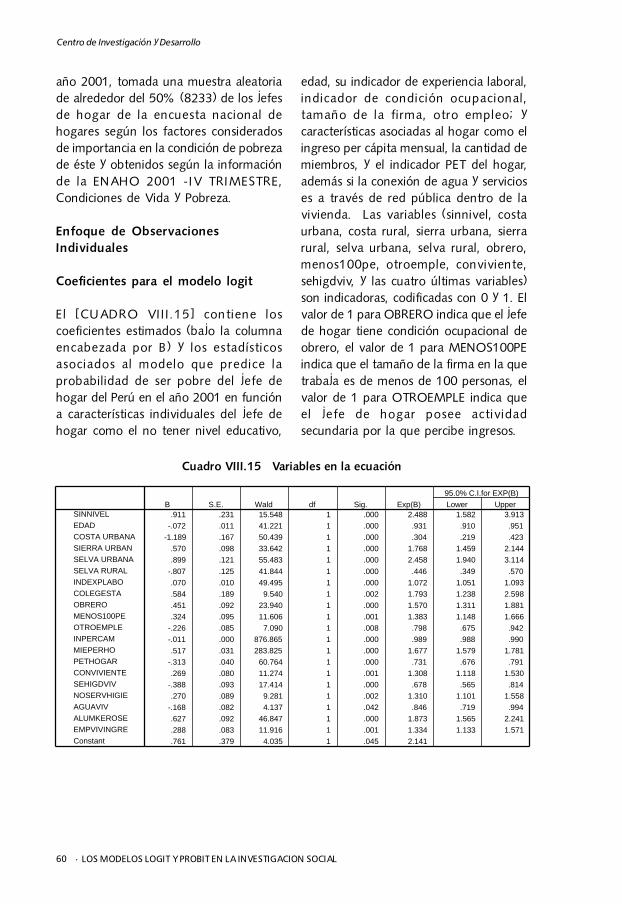
60 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
año 2001, tomada una muestra aleatoriade alrededor del 50% (8233) de los jefesde hogar de la encuesta nacional dehogares según los factores consideradosde importancia en la condición de pobrezade éste y obtenidos según la informaciónde la ENAHO 2001 -IV TRIMESTRE,Condiciones de Vida y Pobreza.
Enfoque de ObservacionesIndividuales
Coeficientes para el modelo logit
El [CUADRO VIII.15] contiene loscoeficientes estimados (bajo la columnaencabezada por B) y los estadísticosasociados al modelo que predice laprobabilidad de ser pobre del jefe dehogar del Perú en el año 2001 en funcióna características individuales del jefe dehogar como el no tener nivel educativo,
edad, su indicador de experiencia laboral,indicador de condición ocupacional,tamaño de la firma, otro empleo; ycaracterísticas asociadas al hogar como elingreso per cápita mensual, la cantidad demiembros, y el indicador PET del hogar,además si la conexión de agua y servicioses a través de red pública dentro de lavivienda. Las variables (sinnivel, costaurbana, costa rural, sierra urbana, sierrarural, selva urbana, selva rural, obrero,menos100pe, otroemple, conviviente,sehigdviv, y las cuatro últimas variables)son indicadoras, codificadas con 0 y 1. Elvalor de 1 para OBRERO indica que el jefede hogar tiene condición ocupacional deobrero, el valor de 1 para MENOS100PEindica que el tamaño de la firma en la quetrabaja es de menos de 100 personas, elvalor de 1 para OTROEMPLE indica queel jefe de hogar posee actividadsecundaria por la que percibe ingresos.
.911 .231 15.548 1 .000 2.488 1.582 3.913
-.072 .011 41.221 1 .000 .931 .910 .951
-1.189 .167 50.439 1 .000 .304 .219 .423
.570 .098 33.642 1 .000 1.768 1.459 2.144
.899 .121 55.483 1 .000 2.458 1.940 3.114
-.807 .125 41.844 1 .000 .446 .349 .570
.070 .010 49.495 1 .000 1.072 1.051 1.093
.584 .189 9.540 1 .002 1.793 1.238 2.598
.451 .092 23.940 1 .000 1.570 1.311 1.881
.324 .095 11.606 1 .001 1.383 1.148 1.666
-.226 .085 7.090 1 .008 .798 .675 .942
-.011 .000 876.865 1 .000 .989 .988 .990
.517 .031 283.825 1 .000 1.677 1.579 1.781
-.313 .040 60.764 1 .000 .731 .676 .791
.269 .080 11.274 1 .001 1.308 1.118 1.530
-.388 .093 17.414 1 .000 .678 .565 .814
.270 .089 9.281 1 .002 1.310 1.101 1.558
-.168 .082 4.137 1 .042 .846 .719 .994
.627 .092 46.847 1 .000 1.873 1.565 2.241
.288 .083 11.916 1 .001 1.334 1.133 1.571
.761 .379 4.035 1 .045 2.141
SINNIVEL
EDAD
COSTA URBANA
SIERRA URBAN
SELVA URBANA
SELVA RURAL
INDEXPLABO
COLEGESTA
OBRERO
MENOS100PE
OTROEMPLE
INPERCAM
MIEPERHO
PETHOGAR
CONVIVIENTE
SEHIGDVIV
NOSERVHIGIE
AGUAVIV
ALUMKEROSE
EMPVIVINGRE
Constant
B S.E. Wald df Sig. Exp(B) Lower Upper
95.0% C.I.for EXP(B)
Cuadro VIII.15 Variables en la ecuación

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 61
Centro de Investigación y Desarrollo
Dados estos coeficientes, la ecuación parala probabilidad de ser pobre del jefe dehogar se puede escribir como sigue:
Pr(Jefe de Hogar Pobre) =
1
1 ZiPi
e−=+
ECUACIÓN VIII.1
Donde:
Zi = 0.761 + 0.911(sinnivel) -0.072(edad) - 1.189(costa urbana) +0.570(sierra urbana) + 0.899(selvaurbana) - 0.807(selva rural) +0.07(indexplabo) + 0.584(colegesta) +0.451(obrero) + 0.324(menos100pe) -0.226(otroemple) -0.011(inpercam) +0.517(mieperhog) - 0.313(pethogar) +0.269(conviviente) -0.388(sehigdviv) +0.270(noservhigie) - 0.168(aguaviv) +0.627(alumkerose) + 0.288(empvivingre).
ECUACIÓN VIII.2
Aplicando esto a un jefe de hogar sin nivelde educación con 60 años de edad deLima con un indicador de experiencialaboral de 54 años, desocupado, con uningreso per cápita mensual de s/.143.00,con 4 miembros en su hogar, con 3personas en la PET , que no es conviviente,que no use el kerosene como tipo dealumbrado en su hogar, que poseeconexión a red pública dentro de lavivienda tanto de agua como dealcantarillado y no emplea parte de lavivienda para ingresos dentro del hogar.
Zi = 0.761 + 0.911(1) -0.072(60)...........-0.388(1) + 0.270(0) -0.168(1) + 0.627(0) + 0.288(0)
ECUACIÓN VIII.3
Entonces la probabilidad de ser pobre deljefe de hogar es:
Pr(Jefe de hogar pobre) = 0.65847ECUACIÓN VIII.4
Basados en este estimado, podemospredecir que el jefe de hogar con estascaracterísticas es pobre. En general, si laprobabilidad estimada del evento esmenor a 0.5, podemos decir que elevento no va a ocurrir. Si la probabilidades mejor que 0.5, podemos decir que elevento va a ocurrir y por lo tanto como enel ejemplo, que el jefe de hogar es pobre.
Prueba de hipótesis sobre loscoeficientes
Para tamaños de muestra grande, la pruebade que un coeficiente es 0 es basada enel estadístico de Wald, el cual tiene unadistribución chi-cuadrado. Cuando unavariable tiene un grado de libertad, elestadístico de Wald es el cuadrado del ratiodel coeficiente entre su error estándar. Paravariables categóricas, el estadístico deWald tiene sus grados de libertadequivalentes a uno menos el número decategorías.
Por ejemplo, en el [CUADRO VIII.15] elcoeficiente de sin nivel de educación es0.911 y su error estándar es 0.231 (en elcuadro la columna llamada S.E.). Elestadístico de Wald es (0.911/0.231)2 ó15.548. El nivel de significancia para elestadístico de Wald es mostrada en lacolumna Sig. En nuestro caso todas lasvariables obtenidas en el modelo resultanser significativamente diferentes de cero,para un nivel de significancia de 0.05.

62 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Otra manera ver de este análisis, es a travésde la prueba asociada a su efecto:
Ho : b (SINNIV) = 0, lo cual quiere decirque el efecto de no tener educación esirrelevante, pero obteniendo un valor parael estadísitico Wald de 15.548 y unasignificancia de 0.000, rechazábamos esahipótesis nula afirmando que tal efecto essignificativamente distinto de cero y portal razón relevante para la probabilidad deser pobre del jefe de hogar.
De la misma manera podemos afirmar, porejemplo, con respecto a la significanciade la cantidad de miembros en el hogar,obteniendo un valor de 283.825 para elestadístico de Wald, que se obtiene deelevar al cuadrado la división delcoeficiente entre su respectivo ErrorEstándar de estimación, demás estámencionar la relevancia de esta variable yconfirmar el efecto positivo (0.517) quejuega dentro de la probabilidad de serpobre del jefe de hogar.
Desafortunadamente, el estadístico deWald posee una propiedad indeseable.Cuando el valor absoluto del coeficientede regresión llega a ser demasiado grande,el error estándar también lo es. Estoproduce que el estadístico de Wald, seamuy pequeño, por tal motivo noestaríamos rechazando la hipótesis nula deque el coeficiente es 0, cuando en realidadsí deberíamos. De allí que cuandotenemos un coeficiente grande, uno nodebería de confiar en el estadístico deWald para prueba de hipótesis. En vez deello, se debería construir un modelo conla variable y otro sin variable y basar laprueba de hipótesis en el cambio del logde la función verosimilitud. (Hauck &Donner, 1977).
Interpretación de los coeficientes
Para entender la interpretación de loscoeficientes de esta regresión,consideramos un reordenamiento de laecuación para el modelo logístico. Estepuede ser escrito como unreordenamiento en términos de lasrazones (´Odds´) de ocurrencia de unevento. (Las Odds (´razón deprobabilidades´) de ocurrencia de unevento es definido como el ratio de laprobabilidad de que ocurra un eventosobre la probabilidad de que no ocurra unevento. Por ejemplo, la odds de obtenercara en un lanzamiento de una monedasería 0.5/0.5 = 1. Similarmente, la oddsde obtener un corazón en una reparticiónde cartas será 0.25/0.75 = 1/3. No debeconfundirse este significado técnico de laodds con su uso informal de un simplepromedio de probabilidad)
Escribimos el modelo logístico en términosdel logaritmo de las odds, llamada comosabemos logit:
0 1 1 ......
Pr( )log( )
Pr( )p p
jhpobreX X
jhnopobreβ β β= + + +
ECUACIÓN VIII.5
De la ecuación anterior, el coeficientelogístico puede ser interpretado como uncambio en el log odds asociado con uncambio unitario en la variableindependiente. Por ejemplo, del[CUADRO VIII.15] podemos ver que elcoeficiente para sinnivel es 0.911. Esto nosindica que cuando el jefe de hogar noposee nivel educativo y los valores de lasotras variables independientes semantienen constantes, el log odds (razónde probabilidades) se incrementa en un0.911.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 63
Centro de Investigación y Desarrollo
La ecuación de regresión puede ser escritaen términos de los odds como:
Pr ( )
Pr ( )
ob jhpobre
ob jhnopobre=
0 1 1 ...... 0 1 1...X pXp X pXpe e e eβ β β β β β+ + + =
ECUACIÓN VIII.6
En e radica el poder de Bi, que es el factorpor el cual la razón de probabilidades(´Odds´) cambia cuando la i-ésimavariable independiente se incrementa enuna unidad. Si Bi positivo, este factor va aser mayor que 1, lo cual significa que laOdds se incrementa; si Bi es negativo, elfactor va a ser menor que uno, lo cualsignifica que la Odds decrece. Cuando Bies 0, el factor equivale a 1, lo cual significaque la odds no cambia.
En ese sentido resultó interesante vercomo al ser obrero es 1.6 veces másprobable ser pobre que no serlo, es decir,la Odds a favor de ser jefe de hogar pobrecambia positivamente en 100 (1.570 - 1)%=57% al tener condición ocupacional deobrero. De la misma manera pudimos daruna lectura parecida, pero con los criteriosadecuados del caso, al afirmar que el tenerabastecimiento de agua dentro de lavivienda a través de red pública le reducela probabilidad de ser pobre al jefe de
hogar, es decir, que su Odds se reduce ocambia negativamente en 100(0.846-1)%= 15.4%, y como mencionamosanteriormente la probabilidad de ser jefede hogar pobre sería menor con respectoa la probabilidad de ser no pobre.
Otra de las variables que resulta de interés,es la del número de miembros del hogar,donde se puede apreciar que dicha variableaumenta positivamente el logit de laprobabilidad de ser pobre con respecto ano serlo en 0.517. Es decir, que la Odds(´razón de probabilidades´) a favor de serpobre cambia posivitivamente en100(1.677-1)%= 67.7% al producirse elaumento de 1 persona en la cantidad demiembros del hogar.
Determinación de la bondad de ajustedel modelo
Existen varios caminos para determinar deun modo u otro la calidad de ajuste delmodelo a los datos.
Tabla de clasificaciónUn camino para determinar que tan biennuestro modelo ajusta los datos escomparar nuestras predicciones con losresultados observados. El [CUADROVIII.16] muestra la tabla de clasificaciónpara el modelo obtenido.
3400 701 82.9
519 3550 87.2
85.1
Observedno pobre
pobre
Estado pobreza
Overall Percentage
no pobre pobre
Estado pobreza PercentageCorrect
Predicted
El punto de corte es .50a.
Cuadro VIII.16 Tabla de Clasificación a

64 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Del cuadro anterior vemos que 3400 jefesde hogar no pobres fueron correctamenteclasificados por el modelo como jefes dehogar en estado de no pobreza.Similarmente, 3550 jefes de hogar pobresfueron correctamente clasificados enestado de pobreza. Los elementos fuerade la diagonal de la tabla nos dicen cuántosjefes de hogar fueron incorrectamenteclasificados. Un total de 1220 jefes dehogar fueron mal clasificados- 701 jefesde hogar no pobres y 519 jefes de hogarpobres. De los jefes de hogar no pobresel 82.9% fueron correctamenteclasificados. De los jefes de hogar pobresel 87.2% fueron correctamenteclasificados. Del total, el 85.1% de los8170 jefes de hogar tomados para seranalizados fueron correctamenteclasificados.
Bondad de ajuste del modelo
Observando que tan bien clasifica elmodelo los casos observados es uno delos caminos para determinar la potenciadel modelo logit y la regresión logística.
Otro camino de acceso a la bondad deajuste del modelo es examinar que tanbien los resultados de la muestra actualnos dan los parámetrosestimados. La probabilidad de los resultadosobservados, dados los parámetrosestimados, es conocida como laverosimilitud (´likelihood´). Como laverosimilitud es un número pequeñomenor que uno, se usa generalmente -2veces el logaritmo de la verosimilitud (-2LL) como una medida para verificar quetan bien el modelo estimado ajusta losdatos. Un buen modelo es aquel que tieneuna alta verosimilitud obtenida de losresultados observados. Lo cual se traduciríaen un pequeño valor para -2LL. (Si unmodelo ajusta perfectamente, laverosimilitud es 1, y -2 veces el loglikelihood es 0).
Ahora, para el modelo logit y de regresiónlogística de los jefes de hogar, un modelocon solo la constante nos da un -2LL iguala 11325.9 como se muestra en el[CUADRO VIII.17].
11325.900 -.008Iteración
1Step 0-2 Log likelihood Constant
Coefficients
Constante es incluida en el modelo.a.
Inicial -2 Log Likelihood(-2LL): 11325.900b.
Estimación terminada en iteración N° 1 porquelog-likelihood decrece en menos de .01%.
c.
Cuadro VIII.17 Historia de Iteración a,b,c
Bondad de ajuste con todas lasvariables
El [CUADRO VIII.18] nos muestra labondad de ajuste para el modelo con todaslas variables independientes [CUADROVIII.15]. Para este modelo el valor de -2LL
es 5683.192, el cual es menor que el -2LL para el modelo solo con la constante.La bondad de ajuste puede apreciarseademás en los estadísticos R2 de Cox &Snell (0.499) y de Nagelkerke (0.665), quenos explican el porcentaje de variaciónexplicada por el modelo.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 65
Centro de Investigación y Desarrollo
Existen otros estadísticos [CUADROVIII.19] que nos permiten abordar el ajustedel modelo. Ellos son llamados X2 para elmodelo, el bloque y el paso de iteración.Para el caso de los jefes de hogar, la X2del modelo es la diferencia entre -2LL parael modelo solo con la constante y -2LLpara el modelo con todas las variablesindependientes. Es decir, se prueba lahipótesis nula que sostiene que el modelocon solo la constante es mejor que elmodelo con todos los factores incluidos,es decir:
c²(20 g.l.) = -2 (LnL(solo con cte.) -LnL(con factores covariantes)) = 11325.9- 5683.192 = 5642.707, la cual frente aun c²(20 g.l., 5%)=31.41, rechaza lahipótesis nula de que el efecto de todaslas variables explicativas incluidas, excepto
la constante, es 0. De allí que podemosafirmar que este modelo es mejor ymantener L = b´X. La misma manera deproceder se realiza para una comparaciónentre diversos modelos que incluyen unacantidad diversa de factores explicativos.Este estadístico es comparable a la pruebaF para la regresión clásica. Los grados delibertad para c² modelo son la diferenciaentre el número de parámetros de los dosmodelos.
Con respecto a la c² del paso (Step), serefiere al cambio en -2LL para este últimopaso en la construcción del modelo.Probaría la hipótesis nula que el efecto deeste paso no es significativamentediferente de 0, lo cual es rechazado deacuerdo a su significancia de 0.042
5683.192 .499 .665Step20
-2 Loglikelihood
Cox & SnellR Square
NagelkerkeR Square
Cuadro VIII.18 Model Summary
Cuadro VIII.19 Omnibus Test of Model Coefficients
4.126 1 .0425642.707 20 .000
5642.707 20 .000
StepBlock
Model
Step 20Chi-square df Sig.
Con respecto a la c² del bloque sería elcambio en -2LL entre los sucesivos bloquesen la construcción del modelo. Prueba lahipótesis nula que los coeficientes para elconjunto de variables adicionadas en elúltimo paso son 0. En el caso de los jefesde hogar, consideramos solo dos modelos:el modelo solo con la constante y elmodelo con todas las variables
independientes [CUADRO VIII.15], portal motivo la c² del modelo y del bloquetienen los mismos valores. Si se consideransecuencialmente otros modelos a parte deestos dos, usando los métodos deselección de variables Fordward oBackward, las c² para el modelo y para elbloque van a ser diferentes.

66 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Métodos de diagnóstico
Cuando se construye un modeloestadístico, es importante examinar lacalidad de los resultados obtenidos. Enregresión lineal, observamos una variedadde residuales, medidas de influencia eindicadores de colinealidad. Existenherramientas valiosas, para identificarpuntos donde el modelo no puede ajustarbien, puntos que ejercen fuerte influenciasobre los coeficientes estimados, yvariables que son altamente relacionadasunas con otras. En regresión logística y elmodelo logit existen diagnósticoscomparables que deberían ser usados paradetectar problemas.
El residual es la diferencia entre laprobabilidad observada del evento y laprobabilidad predicha del evento basadoen el modelo. Por ejemplo, si predecimosque la probabilidad de ser pobre es 0.75para un jefe de hogar pobre, su residuales 1 -0.75 = 0.25.
El residual estandarizado (standardizedresidual) es el residual dividido por unestimado de su desviación estándar. En estecaso será:
(1 )
i
i
i i
residualZ
P P=
−ECUACIÓN VIII.7
Para cada observación, el residualestandarizado puede además serconsiderado una componente delestadístico de bondad de ajuste c². Si eltamaño de muestra es grande, el residualestandarizado debería aproximarse a unadistribución normal, con media 0 ydesviación estándar de 1.
Para cada observación, la deviance escalculada como:
-2*log (probabilidad calculada para elgrupo observado)
ECUACIÓN VIII.8
La deviance es calculada tomando la raízcuadrada del estadístico anterior yadicionándole un signo negativo si elevento no ocurre para dicha observación.Por ejemplo, la deviance para un jefe dehogar no pobre y una probabilidadcalculada de 0.45 de ser no pobre es
2log(0.45) 0.833Deviance= − − = −ECUACIÓN VIII.9
Valores grandes para la deviance indicanque el modelo no ajusta bien laobservación. Para tamaños de muestragrande, la deviance es aproximadamenteuna distribución normal.
El Studentized residual para cadaobservación es el cambio en la deviancedel modelo si el caso es excluido.Discrepancias entre la deviance y elstudentized residual pueden identificarcasos inusuales. Una gráfica deprobabilidad normal de los studentizedresiduals puede ser muy útil.
El logit residual es el residual para elmodelo si la predicción esta en la escalalogit.
(1 )
i
i
i i
residualLogitresid
P P=
−ECUACIÓN VIII.10
El leverage en la regresión logística es enmuchos aspectos análogo al leverage en

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 67
Centro de Investigación y Desarrollo
la regresión de mínimos cuadrados. Losvalores de leverage son siempre usadospara detectar observaciones que tienengran impacto en los valores predecidos. Adiferencia de la regresión lineal, los valoresleverage en esta regresión dependen delas puntuaciones de la variabledependiente y del diseño de la matriz. Losvalores de los leverage están restringidosentre 0 y 1. Su valor promedio es p/n,donde p es el número de parámetrosestimados en el modelo, incluyendo laconstante, y n es el tamaño de la muestra.
La Cook´s distance es la medida de lainfluencia de una observación. Nos dicecuánto afecta no solo en el residual paraesta observación, sino también sobre elresidual del resto de observacionesrestantes cuando se elimina dicho caso.La Cook´s distance (D) depende de suresidual estandarizado, así como de suleverage. Esta definido como:
*
2(1 )
i i
i
i
Z hD
h=
−ECUACIÓN VIII.11
Donde Zi es su residual estandarizado y hies su leverage.
Otra medida de diagnóstico útil es elcambio en los coeficientes del modelocuando una observación es retirada delmodelo, o DFBeta. Se puede calcular elcambio en cada coeficiente, incluyendola constante. Un ejemplo sería el cambioen el primer coeficiente cuando el caso ies borrado
( )1 1 1( )( ) iiDfBeta B B B−=
ECUACIÓN VIII.12
Donde B1 es el valor del coeficiente
cuando todas las observaciones sonincluidas en el modelo y B1(i) es el valordel coeficiente cuando la i-ésimaobservación es retirada. Valores grandesde cambio identifican observaciones quedeben ser examinadas.
Diagnósticos de gráficas
Todos los estadísticos descritos hasta ahorapueden ser grabados para este análisis enla matriz de casos/variables. Cuando seconsidere conveniente, se puedenobtener gráficas de probabilidad normalusando el procedimiento de exploracióny gráficas de diágnóstico usandoprocedimientos gráficos.
El [GRÁFICO VIII.6] muestra la gráfica deprobabilidad normal Q-Q y la gráfica Q-Q de desviaciones respecto a la normal.En el caso de la gráfica izquierda Q-Q(Quantiles reales y teóricos de unadistribución normal) de probabilidadnormal, los valores correspondientes a unadistribución normal teórica vienenrepresentados por la recta y los puntos sonlos valores de la deviance de los jefes dehogar. Como vemos estos puntos, en sumayoría, están próximos a la recta, lo cualindica que el ajuste es aceptable. Confirmaesto la suposición hecha con respecto alos tamaños de muestra grande. Para elcaso de aquellos valores de deviance muysuperiores a 2, el modelo no ajusta muybien dichas observaciones, pero se debeconsiderar que estos correspondenprobabilidades de mala clasificación de losjefes de hogar, en tal sentido, se puedeoptar por su eliminación o por el análisisde los estadísticos de Cook´s y DfBetaspara ver la influencia de dichasobservaciones.
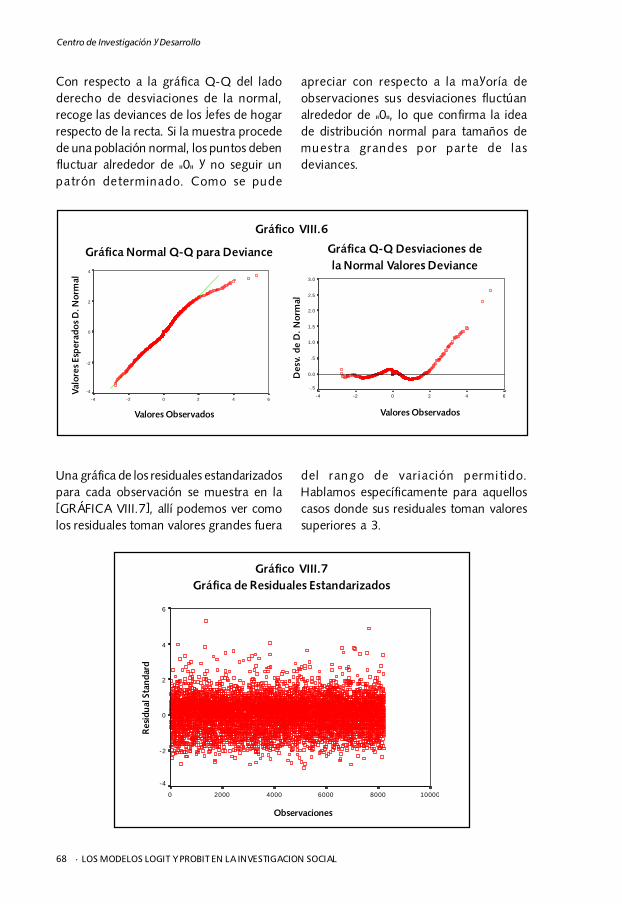
68 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Con respecto a la gráfica Q-Q del ladoderecho de desviaciones de la normal,recoge las deviances de los jefes de hogarrespecto de la recta. Si la muestra procedede una población normal, los puntos debenfluctuar alrededor de "0" y no seguir unpatrón determinado. Como se pude
apreciar con respecto a la mayoría deobservaciones sus desviaciones fluctúanalrededor de "0", lo que confirma la ideade distribución normal para tamaños demuestra grandes por parte de lasdeviances.
6420-2-4
4
2
0
-2
-46420-2-4
3.0
2.5
2.0
1.5
1.0
.5
0.0
-.5
Valores Observados
Gráfico VIII.6
Gráfica Normal Q-Q para Deviance Gráfica Q-Q Desviaciones dela Normal Valores Deviance
Valo
res
Espe
rado
s D
. Nor
mal
Valores Observados
Des
v. d
e D
. Nor
mal
Una gráfica de los residuales estandarizadospara cada observación se muestra en la[GRÁFICA VIII.7], allí podemos ver comolos residuales toman valores grandes fuera
del rango de variación permitido.Hablamos específicamente para aquelloscasos donde sus residuales toman valoressuperiores a 3.
1000080006000400020000
6
4
2
0
-2
-4
Gráfico VIII.7Gráfica de Residuales Estandarizados
Res
idua
l Sta
ndar
d
Observaciones

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 69
Centro de Investigación y Desarrollo
En la [GRÁFICA VIII.8] se muestra queno existen en general casos que tenganun valor de leverage muy diferenciadorunos de otros, cumpliéndose en primerlugar el rango de variación sobre el cualvaría, 0 y 1. En segundo lugar, si se quiere
ser estricto, el mayor valor diferenciadorque se encontró para el leverage seencuentra alrededor de 0.02, lo que nonos llevaría a afirmar que dicho caso tieneun gran impacto sobre los valorespredichos.
1000080006000400020000
.03
.02
.01
0.00
Gráfico VIII.8Gráfica de Leverage por Observación
Valo
res
Leve
rage
Observaciones
En la [GRÁFICA VIII.9] se muestra queexisten algunos casos que tienen sustancialimpacto en la estimación del coeficientede la variable indicadora sin nivel educativo( casos 4656 y 7198), los valores paraDfbeta sinnivel de estas observaciones seencuentran alrededor de -0.04 - valoresextremos. Examinando la data se revelaque el primer caso (4656), más próximo a-0.06, es un jefe de hogar sin nivel deeducación, de la selva rural, hombre de41 años, conviviente pero en estado deno pobreza, que trabaja solo en suactividad principal. En el caso de la segundaobservación (7198), valor más próximo a-0.04, es un jefe de hogar con primaria,
de la costa urbana, mujer de 50 años, enestado de pobreza no extrema, trabajadoraindependiente con solo actividad principal.Podemos ver que estos dos casos soninusuales de acuerdo a las relacionesobtenidas en el [CUADRO VIII.15].
Si retirásemos el caso 4656 del análisis, elcoeficiente de la variable sinnivel deeducación cambiaría de 0.911 a -0.04731,con lo cual se vería perjudicado, y seconvertiría en un mal predictor o variableexplicativa. Lo mismo sucede siretirásemos el caso 7198, con lo cual elcoeficiente variaría de 0.911 a -0.03660,con los efectos del caso ya conocidos.

70 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
1000080006000400020000
.04
.02
0.00
-.02
-.04
-.06
Enfoque de proporciones muestrales
Modelo probit
En primer lugar intentaremos ejemplificara qué nos referimos con la idea de tasasde respuesta o de proporciones
muestrales dentro de este análisis.Supongamos que se desea estimar lacondición de pobreza del individuo enfunción a sus deciles de ingreso, en talsentido correspondería obtener lasiguiente información [CUADRO VIII.20]
Gráfico VIII.9Gráfica de DfBeta SINNIVEL por Observación
DFB
ETA
SIN
NIV
Observaciones
Deciles deIngreso
Jefes de hogaren deciles (Ni)
Jefes de hogar pobresen deciles (ni)
Decil I 1789 1737Decil II 1811 1711Decil III 1782 1554Decil IV 1705 1211Decil V 1702 855Decil VI 1730 531Decil VII 1623 264Decil VIII 1582 154Decil IX 1498 89Decil X 1293 21
Cuadro VIII.20
Como aquí se tiene las probabilidades (Pi)o proporciones muestrales de ser jefe dehogar pobre según decil de ingreso(ninperca), obviando las limitaciones quela técnica posee en cuanto al tamaño de
observaciones que deben entrar en elanálisis, estimamos un modelo deprobabilidad de ser pobre del jefe dehogar en función al décil de ingreso.
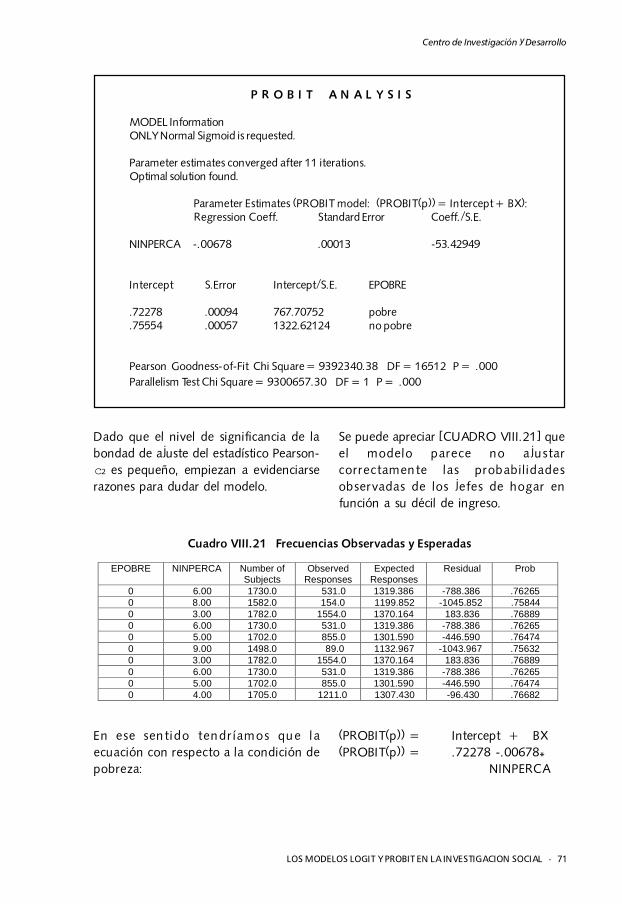
LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 71
Centro de Investigación y Desarrollo
P R O B I T A N A L Y S I S
MODEL InformationONLY Normal Sigmoid is requested.
Parameter estimates converged after 11 iterations.Optimal solution found.
Parameter Estimates (PROBIT model: (PROBIT(p)) = Intercept + BX): Regression Coeff. Standard Error Coeff./S.E.
NINPERCA -.00678 .00013 -53.42949
Intercept S.Error Intercept/S.E. EPOBRE
.72278 .00094 767.70752 pobre
.75554 .00057 1322.62124 no pobre
Pearson Goodness-of-Fit Chi Square = 9392340.38 DF = 16512 P = .000Parallelism Test Chi Square = 9300657.30 DF = 1 P = .000
Dado que el nivel de significancia de labondad de ajuste del estadístico Pearson-c² es pequeño, empiezan a evidenciarserazones para dudar del modelo.
Se puede apreciar [CUADRO VIII.21] queel modelo parece no ajustarcorrectamente las probabilidadesobservadas de los jefes de hogar enfunción a su décil de ingreso.
Cuadro VIII.21 Frecuencias Observadas y Esperadas
EPOBRE NINPERCA Number ofSubjects
ObservedResponses
ExpectedResponses
Residual Prob
0 6.00 1730.0 531.0 1319.386 -788.386 .762650 8.00 1582.0 154.0 1199.852 -1045.852 .758440 3.00 1782.0 1554.0 1370.164 183.836 .768890 6.00 1730.0 531.0 1319.386 -788.386 .762650 5.00 1702.0 855.0 1301.590 -446.590 .764740 9.00 1498.0 89.0 1132.967 -1043.967 .756320 3.00 1782.0 1554.0 1370.164 183.836 .768890 6.00 1730.0 531.0 1319.386 -788.386 .762650 5.00 1702.0 855.0 1301.590 -446.590 .764740 4.00 1705.0 1211.0 1307.430 -96.430 .76682
En ese sentido tendríamos que laecuación con respecto a la condición depobreza:
(PROBIT(p)) = Intercept + BX(PROBIT(p)) = .72278 -.00678*
NINPERCA

72 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
El resultado obtenido debe ser tomadocon cuidado en el sentido del cambio quese produciría sobre el probit de laprobabilidad de ser pobre. Ésta debe sertransformada para llegar a la cantidad sobrela cual variaría en la distribución normal(Un aumento hacia los deciles más ricosreduce el valor de la transformación probitalrededor de un 0.6%).
Resulta interesante mostrar como existeuna relación en algún sentido lineal ,presente entre las transformaciones probit(Z) en la distribución normal y lasprobabilidades de la variable respuesta, esdecir, la frecuencia relativa con respectodel jefe de hogar pobre en el decilcorrespondiente, podemos ver [GRÁFICOVIII.10] la relación inversa en el estadode pobreza de las transformaciones probity el decil de ingreso, es decir, como amedida que se da un aumento de losdéciles, por ende del nivel de ingreso per
cápita, la probabilidades de ser pobreasociadas al jefe de hogar y sutransformación probit disminuyen.
No debemos olvidar algunas de lasconsideraciones que hicimos al empezareste análisis donde se sostuvo que algunosde los estimadores pueden resultar noútiles cuando manejamos tamaños demuestra bastante grandes, en este sentidoresultaría importante el modelo logit conobservaciones individuales para este tipode condicionamientos, además si no sehubiese procedido a agrupar la muestrapor niveles o valores del estímulo (decilesde ingreso), se podría haber aplicado esteúltimo, y haber obtenido lascuantificaciones de aportes en laprobabilidad de que un jefe de hogar seaclasificado como pobre o no, en función asu nivel de educación, la cantidad de hijosque este tiene, si este accede a luz eléctricadentro de su hogar, etc.
Gráfico VIII.10Tasa de Respuesta
TRA
MSF
OR
MA
CIO
NES
PR
OBI
T
DECILES DE INGRESO
1 21 086420
3
2
1
0
-1
-2
-3
es tado pobrez a
no pobre
pobre

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 73
Centro de Investigación y Desarrollo
ANÁLISIS DEL MODELO SOBRE LAPROBABILIDAD DE POBREZA EN ELJEFE DE HOGAR DEL PERÚ PARA ELAÑO 2001
EL MODELO LOGIT (Observacionesindividuales)Con respecto al cuadro siguiente, se vana analizar 3 modelos, el modelo nº 1, queno incorpora los efectos de diseño de lamuestra, con el objetivo de mostrar enque medida varían la inferencia a nivelpoblacional comparada con los modelosque sí incorporan los factores de expansión,en este caso los modelos nº 2 y nº 3, enel caso del modelo nº 2, se expande lamuestra tomada para construir lametodología (muestra aleatoria de 8233hogares) y en el caso del modelo nº3 setoma el resto de la muestra (8282 hogares)
para medir la validez y confiabilidad de laestimación realizada en la metodología.
La probabilidad de ser un jefe de hogarpobre para el año 2001 [CUADRO VIII.22]vendría a estar fuertemente ligada a laausencia de activos de capital humanocomo el de no tener nivel de educaciónalguno, contribuyendo este a elevar el logitde su probabilidad de ser pobre en un94.7% (MODELO Nº 1), creciendo hastaun 114.8% (MODELO Nº 2) yreduciéndose hasta un 78.5% (MODELON° 3). Resulta interesantísimo y no puedeser dejado de lado por su significancia,ver que ser un jefe de hogar que harecibido su educación en colegio estatalaumenta el logit de su probabilidadalrededor de un 60%, manteniendo elefecto de las demás variables constantes
E P O B RE Co ef. P > z C oe f. P > |t | C oe f. P > | t|
S IN N IV E L 0 .9 47 0.0 00 1.14 8 0 .0 00 0.78 5 0 .001
E DA D -0 .07 0.0 00 - 0.08 3 0 .0 00 - 0.06 8 0 .000
A.R U RA L -0 .996 0.0 00
S IE R R A 0 .8 52 0.0 00
S E L V A 0 .5 73 0.0 00
CO S T A U RB - 0.35 8 0 .0 04 - 0.39 2 0 .001
CO S T A R UR - 1.38 8 0 .0 00 - 1.45 6 0 .000
S IE R R A U R B 0.23 2 0 .0 94
S IE R R A R U R - 0.17 2 0 .2 77 - 0.57 1 0 .000
S E L V A R U R - 0.99 1 0 .0 00 - 1.11 3 0 .000
IN D E X P L AB 0 .0 69 0.0 00 0.07 9 0 .0 00 0.07 0 0 .000
CO L E G E S T A 0 .6 01 0.0 00 0.80 2 0 .0 00 0.50 2 0 .009
O BR E R O 0 .4 44 0.0 00 0.38 6 0 .0 01 0.48 5 0 .000
M E NO S 1 0 0 P E 0 .3 51 0.0 00 0.33 3 0 .0 11 0.23 8 0 .026
O TR O E M P L -0 .223 0.01 - 0.27 9 0 .0 19
IN P E R C AM -0 .011 0.0 00 - 0.00 9 0 .0 00 - 0.01 1 0 .000
M IE P E R H O 0 .5 15 0.0 00 0.53 9 0 .0 00 0.48 2 0 .000
P E T HO G AR -0 .318 0.0 00 - 0.32 2 0 .0 00 - 0.25 0 0 .000
CO N V IV IE N 0 .2 67 0.0 00 0.32 0 0 .0 02 0.11 6 0 .243
S E H IG D V IV -0 .416 0.0 00 - 0.36 9 0 .0 03 - 0.51 5 0 .000
NO S E HIG 0 .2 86 0.0 00 0.31 7 0 .0 10 0.22 3 0 .048
AG U AV IV -0 .139 0.0 00 - 0.23 5 0 .0 23
ALU M K E R O 0 .5 93 0.0 00 0.66 6 0 .0 00 0.63 9 0 .000
E M P V IV I -0 .284 0.0 00 - 0.14 3 0 .1 89
CO N S T 1 .2 36 0.0 00 1.12 7 0 .0 08 1.39 4 0 .000
O bs e rv a c i on e s 81 70 O bs e rv a c io n e s 8 170 O bs e rv a c io n e s 8 20 2
LR ch i-s q u a r e 5 60 4.5 Ta m . P o b la c 29 249 40 Ta m . P o b la c 2 909 895
P ro b > c h i 2 0.0 00 F( 2 1 , 2 5 9 3) 3 8.40 0 F( 1 7 , 2 60 7 ) 49.5 30
S eu do R a jus t 0.4 90 P ro b > F 0 .0 00 P ro b > F 0 .000
CC 8 4.01 0 CC 84 .1 CC 84 .6
S ig n if ica n c ia : 5 %
Fu e n te : E N AH O IV TR I M . 2 00 1 E la b o ra c ió n :C ID E
M O D E LO N ° 1 M O D E LO N° 2 M O D E LO N° 3
Cuadro VIII.22Incidencia en la probabilidad de ser pobre a nivel nacional

74 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
para el primer modelo; en el caso de losmodelos 2 y 3 , aumentan alrededor deun 80% y un 50% respectivamente.Como ya se habrá podido percibir, elposeer coeficientes positivos sobre elmodelo logit de probabilidad beneficia entérminos absolutos a la probabilidad de serpobre comparada con su complementariaen una razón de probabilidades.
En el aspecto de la situación ocupacionalen que se encuentra el jefe de hogar,podemos mencionar que estar encondición de obrero aumenta el logit desu probabilidad de ser pobre entre un 39%y un 49% en los 2 últimos modelosrespectivamente. Una situación muydistinta poseería el jefe de hogar quetendría otra ocupación, donde el efectoen el logit de su probabilidad de ser pobredesciende entre un 22% y un 27% en los2 primeros modelos, manteniendoconstante el efecto del resto de variables,mientras que en el tercero resultaría nosignificativo.
La idea de una reducción del tamaño dela familia para reducir su probabilidad deser pobre es sustentada aquí, en funcióndel hecho de que un aumento demiembros en el hogar estaríacontribuyendo entre un 52% y un 54%en los 2 primeros modelos y en un 48%en el tercer modelo, a elevar el logit desu probabilidad, siempre que se mantengael efecto del resto de variables constantes.
Con respecto a activos públicos a los quepodría acceder el hogar, la no tenencia deacceso a servicios higiénicos en suvivienda, aparte de detectar una condiciónprecaria, provoca un incremento en sulogit de probabilidad de alrededor de un29% y 32% en el primer y segundomodelo respectivamente, en el caso del
tercero, el incremento es de alrededor deun 22%; distinto el panorama y más aúnde seguro en su condición, cuando esteposee conexión a red pública dealcantarillado dentro de su vivienda,reduciendo así su logit en un 41.6%.(MODELO Nº 1), hasta un 36.9%(MODELO Nº 2) y hasta un 51.5%(MODELO N° 3), con lo cual se sigueratificando a la condición de inaccesibilidada servicios públicos como un factor muyimportante dentro de la condición depobreza que puede poseer el jefe dehogar.
Observando la parte estadística el primermodelo presenta estimaciones seudo - R²del 50% y un porcentaje de clasificaciónde 84.01%. En el caso de los modelos 2 y3, al incluir los factores de expansióntratamos con tamaños de población dealrededor de 2`924,940 y 2`909,895hogares, para el primero y segundorespectivamente; el porcentaje de correctaclasificación para estos modelos fluctúaentre un 84.1 (modelo nº2) y un 84.6(modelo nº3).
Debemos hacer hincapié en un aspectoque puede generar discusión en el sentidoteórico estadístico estricto. En el primermodelo existen influencias negativas enla probabilidad, es decir, que si el jefe dehogar pertenece al área rural suprobabilidad de ser pobre decrece en un99.6%, mientras que si este pertenece alas regiones naturales de la sierra y de laselva sus probabilidades aumentanalrededor de un 85% y un 57%. Esteresultado es producido por lamulticolinealidad existente en la relaciónentre región natural y área de residenciadel jefe de hogar, cuya relación fue probadaen la parte de análisis descriptivo[CUADRO VIII.10], Una de las medidas

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 75
Centro de Investigación y Desarrollo
tomadas para contrarrestar este efecto fueel de retirar esas variables y colocar otrasindicadoras que representan a las regionesnaturales y el área de residencia del jefede hogar, vale decir costa urbana. sierrarural, etc, por mencionar algunosejemplos; lo que sucede allí con lasprobabilidades de ser pobre es que estasse reducirían, es decir, que las otrasregiones tienen comportamientosdiferenciadores con respecto a ingresos ygastos, sueldos, salarios, condiciones deacceso muy por debajo de los que sepresentan en Lima. En tal sentido, lascaracterísticas diferenciadoras másespecificas de cada región determinanaplicaciones de modelos inherentes a cadauna.
Dadas las características de estainvestigación metodológica, no se haprofundizado aún más en la generaciónde tales modelos, pues los objetivosbuscados están más orientados hacia laparte de diferenciación de enfoques ymétodos de estimación de los modeloslogit y probit, y más específicamente haciael enfoque de proporciones individualesen estos dos últimos modelos estimados.
EL MODELO PROBIT
De la misma manera que en el modelologit, realizamos la estimación de 3modelos, donde en el primer caso no seemplean los efectos de diseñoprovenientes de la encuesta compleja quees la ENAHO. En el caso de los modelosn° 2 y n° 3, como se mencionó líneasantes, en el primero se trabaja con lamuestra aleatoria con la que se construyóla metodología (8233 hogares) y queconstituye el 50% del total deobservaciones, para que luego dichaestimación sea evaluada en cuanto a
validez y confiabilidad con el resto de casos(8282 hogares), y aplicando en cada unode ellos los factores de ponderacióncorrespondientes.
Siguiendo el enfoque de estimaciónmáximo-verosímil, procedimos a estimarel modelo de probabilidad de un jefe dehogar pobre apoyados en la suposición quela distribución de los errores sigue unadistribución normal debido a la grancantidad de observaciones manejadas.Podemos observar [CUADRO VIII.23],que no tener nivel de educación algunotiene un efecto positivo sobre laprobabilidad de ser un jefe de hogarpobre, aumentando el probit alrededor deun 53% y un 68% en los 2 primerosmodelos y en un 42.3% en el tercero.
Planteamos aquí la misma idea dediscusión del modelo logit, acerca de lamulticolinealidad con respecto al área yregiones naturales de residencia, sobre quémedida asumir, para el caso del modelon°1 sin aplicación de factores de expansión.
La dimensión regional es importante, esdecir, el hecho de vivir en zonas urbanascomo rurales de la costa sierra y selva(modelos n° 2 y n° 3), controlando por elresto de variables (algunas de las cualestratan de enfocarse en la capacidad deconsumo y de generación de ingresos delhogar), estarían reduciendo la probabilidadde ser pobre, pues los ingresos por trabajoserían superiores a los de las otras regionesy el monto de la canasta básica en zonasrurales es tremendamente menor que enzonas urbanas y sobre todo comparadascon la categoría base que sería Lima. Elloestaría explicando por qué el solo hechode vivir en la costa rural, luego de controlarel efecto por el resto de variablesindicadas, reduce el probit de la

76 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
probabilidad en un 83% en el segundomodelo y en un 80.5% en el caso deltercero.
En el caso de la sierra rural se reduciría elprobit de la probabilidad en un 11% y22.4% en el segundo y tercer modelorespectivamente, comparadas siempre conla categoría base que es Lima. Donde seestán apreciando brechas bastante notoriases en la selva rural, que comparadas conLima se estaría reduciendo el probit de suprobabilidad en 60.2% (modelo n° 2) y61.6% (modelo n°3).
Algunos resultados obtenidos en el mismosentido que en el modelo Logitanteriormente estimado recibirían igualinterpretación, como el hecho de destinar
dentro de la vivienda un espacio paraobtener ingresos, reduce el probit de suprobabilidad entre un 18.1% (modelo n°1,sin considerar factor de expansión) y11.7% (modelo n° 2, considerandofactores de expansión), pero que en el casodel tercer modelo resulta siendo nosignificativo. Además se mantiene la ideade que otro empleo para obtener ingresos,reduce su probit de probabilidad en unapequeña medida, alrededor de un 12.2%(modelo n° 1) y 15.6% (modelo n° 2).Nuevamente en el caso del tercer modeloresultaría no significativa.
Queda definitivamente claro que el accesoa activos públicos beneficia al jefe de hogary al hogar en su conjunto en una reducciónde su probabilidad de ser pobre,
E P O B R E C o e f. P > z C o e f. P > |t | C oe f . P > | t |
S IN N IV E L 0 .5 34 0 .000 0 .683 0 .0 00 0 .423 0 .00 2
E DA D -0 .0 45 0 .000 - 0.05 0 0 .0 00 - 0.04 8 0 .00 0
A .R U RA L -0 .5 40 0 .000
S IE R R A 0 .5 00 0 .000
S E L V A 0 .3 07 0 .000
C O S T A U R B - 0 .23 2 0 .0 01 - 0.23 3 0 .00 0
C O S T A R U R - 0 .83 0 0 .0 00 - 0.80 5 0 .00 0
S IE R R A U R B
S IE R R A R U R - 0 .11 1 0 .1 75 - 0.22 4 0 .01 3
S E L V A R U R - 0 .60 2 0 .0 00 - 0.61 6 0 .00 0
IN D E X P L A B 0 .0 43 0 .000 0 .048 0 .0 00 0 .048 0 .00 0
C O L E G E S T A 0 .3 33 0 .001 0 .469 0 .0 00 0 .284 0 .01 0
O B R E R O 0 .2 06 0 .000 0 .178 0 .0 08 0 .250 0 .00 0
M E NO S 1 00 P E 0 .2 43 0 .000 0 .222 0 .0 03 0 .168 0 .00 4
O TR O E M P L -0 .1 22 0 .010 - 0.15 6 0 .0 26
IN P E R C A M -0 .0 05 0 .000 - 0.00 4 0 .0 00 - 0.00 5 0 .00 0
M IE P E R H O 0 .3 04 0 .000 0 .309 0 .0 00 0 .304 0 .00 0
P E T H O G A R -0 .2 00 0 .000 - 0.19 5 0 .0 00 - 0.18 0 0 .00 0
C O N V I V IE N 0 .1 51 0 .001 0 .187 0 .0 02 0 .091 0 .12 1
S E H IG D V IV -0 .2 84 0 .000 - 0.28 2 0 .0 00 - 0.32 8 0 .00 0
N O S E H I G 0 .1 68 0 .001 0 .184 0 .0 09 0 .139 0 .03 1
A G U A V IV -0 .0 73 0 .117 - 0.10 7 0 .0 80
A LU M K E R O 0 .3 57 0 .000 0 .382 0 .0 00 0 .389 0 .00 0
E M P V IV I -0 .1 81 0 .000 - 0.07 9 0 .2 18
C O N S T 0 .5 92 0 .002 0 .595 0 .0 12 0 .590 0 .00 8
O bs e rv a c i on e s 8 170 O b se rv a c i on e s 8 170 O b se r v a c io n e s 820 2
LR ch i-sq u a r e 54 70 .3 Ta m . P o b la c 29 249 40 T am . P o bl ac 2 90 989 5
P ro b > ch i 2 0 .000 F( 20 , 2 5 94 ) 4 5 .38 0 F ( 1 7 , 2 6 07 ) 63 .940
S eu do R a jus t 0 .483 P ro b > F 0 .0 00 P r o b > F 0 .00 0
C C 8 4 .0 C C 83 .4 C C 8 4 .3
S ig n if ic a n c ia : 5%
Fu e n te : E N AH O IV TR IM . 20 0 1 E la b o rac ió n :C ID E
M O D E L O N ª 1 M O D E L O N ª 2 M O D E LO N ª 3
Cuadro VIII.23Incidencia en la probabilidad de ser pobre a nivel nacional

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 77
Centro de Investigación y Desarrollo
reduciéndola en 28.2% (MODELO N° 2)y hasta 32.8% (MODELO N° 3) cuandose tiene acceso a servicios de alcantarilladodentro de vivienda, y un 10.7%(MODELO N° 2) cuando se tieneabastecimiento de agua dentro de lavivienda del hogar, siendo no significativaesta variable en el caso del modelo n° 3.
Según lo anteriormente mostrado, laelección por alguno de los dos modelosconforme al enfoque de estimación deobservaciones individuales no esdiferenciable. Sobre todo si recalcamos laidea que la gran cantidad de observacionestratadas sesgan la idea de la distribución
normal de los errores, podría primar comocriterio para la elección del modelo probitsegún este enfoque.
Desde el punto de vista práctico, laelección del modelo logit y de lacorrespondiente regresión logísticahabilitaría una mayor cantidad deherramientas de control de la bondad deajuste del modelo estimado y por endeuna mejor validación de éste, en tal sentidose propondría como el más idóneo, parael cálculo del modelo de probabilidad deljefe de hogar pobre del Perú, en el año2001.

78 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 79
Centro de Investigación y Desarrollo
IX. CONCLUSIONES
El presenta trabajo de investigación abordalos modelos logit y probit aplicados en lainvestigación social para el caso de lapobreza en el Perú, durante el año 2001,desde la formulación de la condición dela pobreza en el Perú y algunos activospertenecientes a los jefes de hogar y alhogar que pertenece bajo esta condición.Para luego sentar las bases (enfoqueteórico) sobre los cuales se construyó losmodelos y se adaptaron a este caso enparticular; de allí que se puede concluir,desde el punto de vista práctico, queaspectos como el acceso a activos públicosbenefician al desarrollo de activos privadosde los jefes de hogar a través de undecrecimiento en su probabilidad de serpobre. Demás esta confirmar el aumentoen una gran medida sobre la probabilidadde ser pobre cuando el jefe de hogar notiene nivel de educación alguno, etc.
1. Con respecto a la hipótesis quesostiene que los factores de naturalezacuantitativa como el ingreso per cápita,a través de sus deciles de ingreso, etc;ajustarían correctamente un modelopara la probabilidad de pobreza en eljefe de hogar del Perú se rechazaría,en primer lugar, porque expresado através del estadístico de bondad deajuste Pearson X² mostraría dudasacerca de las probabilidades generadas,y por ende no se convertiría en el másidóneo sobre el cual trabajar. Ensegundo lugar, dada la naturaleza delfenómeno de la pobreza en estudio,excluirla de sus factores de naturaleza
cualitativa, los cuales no hacen posiblela viabilidad de este enfoque según losindicadores existentes, resultaríacontraproducente y por tal motivo elmodelo probit con variabledependiente dicotómica con enfoquede proporciones muestrales no es elmás adecuado para la estimación de laprobabilidad de ser pobre del jefe dehogar en función a sus factoresdeterminantes.
2. Con respecto a la hipótesis quesostiene que los factores explicativosde la pobreza de los jefes de hogardel Perú de naturaleza cualitativa ycuantitativa exclusivos del jefe dehogar como el nivel de educación, eltipo de colegio de estudio, la categoríaocupacional, el tamaño de la firmadonde labora, la tenencia de otroempleo, el estado civil, su edad, suindicador de experiencia laboral; encombinación con los factores denaturaleza cualitativa y cuantitativaexclusivos del hogar como el indicadorde si el hogar dedica un espacio delhogar a generación de ingresos, lacantidad de miembros en el hogar, lacantidad de miembros pertenecientesa la PET, el ingreso per cápita mensual,el acceso a activos públicos de agua ydesagüe, etc, no generan modeloscorrectamente ajustados seríarechazada porque, en primer lugar, lasprobabilidades de correcta clasificaciónpara los modelos estimados seencuentran alrededor del 84% en el

80 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
modelo logit y en el modelo probit,ambos con enfoque de observacionesindividuales. En segundo lugar, laobtención de efectos significativos enlos factores de naturaleza cualitativa ycuantitativa mencionados líneas antesy exclusivos al jefe y al hogar, a travésde las estimaciones de sus respectivosestadísticos de Wald y significancias
obtenidas, en el caso del modelo logit,y de sus respectivos efectos en latransformación probit, en el caso delmodelo del mismo nombre, viabilizanuna explicación del fenómeno de lapobreza en función a los determinantesantes mencionados.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 81
Centro de Investigación y Desarrollo
X. RECOMENDACIONES
• Si se estuviese interesado en el análisisprobit con variable dependientedicotómica desde el enfoque deproporciones para el estudio de lapobreza bajo ciertos factores como elnivel de educación, el área deprocedencia, acceso a ciertos tipos deactivos públicos deberían en primerlugar reducirse las cantidades deobservaciones a estudiar para no afectara los estimadores, y en segundo lugar,tratar de generar variables-estímulos(cruce de variables explicativas) quepuedan seguir un enfoque cuasi-cuantitativo, de tal manera de que sepueda determinar la medida de cambioexacto en la obtención de la condiciónde pobreza. En tal sentido y dada lalimitación de este enfoque, se puedepasar al estudio de niveles másavanzados, como los modelos probitcon variable dependiente ordinal omodelos con enfoques multinomiales.
• Si además de intentar obtener aportesde variables explicativas, estáintentando predecir un modelo declasificación idóneo a sus criterios, elmodelo logit ampliamente difundidoaporta una mayor variedad de
herramientas de validación de labondad de ajuste del modelo y nodejaría de lado su funcióndiscriminadora, beneficiosa en estecaso en el que la variable dependienteposee solo dos categorías.
• Si bien no ha sido empíricamentemostrado en esta investigación, sugierola inclusión de una mayor cantidad devariables de naturaleza cuantitativa enmodelos probit con enfoque deobservaciones individuales, pues sonvariables más idóneas a ser sometidasa pruebas de normalidad y análisis máscomplejos; además porque suparticipación en bloques nos permitiríaobtener cambios exactos a los cualesresponderían los jefes de hogarpobres. No deben dejar deconsiderarse las variables de naturalezacualitativa, pues son fundamentalespara la explicación de fenómenossociales y podrían plantearseindicadores más idóneos para captar loscambios de naturaleza cualitativa de losindividuos, y no solo expresarse enpresencia o ausencia de factores deriesgo.

82 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 83
Centro de Investigación y Desarrollo
XI. BIBILIOGRAFÍA
- �CATEGORICAL DATA ANALYSIS�,Agresti, Alan.Florida, Wiley, 1990.
- �ESTADÍSTICA MULTIVARIANTE ENLAS CIENCIAS DE LA VIDA�.Carrasco, José Luis; Hernán, MiguelAngel.CIBEST. España, Editorial Ciencia, 1993.
- �MÁS ALLÁ DE LA FOCALIZACIÓN,RIESGOS DE LA LUCHA CONTRA LAPOBREZA EN EL PERÚ�Chacaltana J., Juan.PERÚ, Consorcio de InvestigaciónEconómica y Social, 2001.
- �IMPACTO DE LOS SERVICIOSPÚBLICOS DE SALUD SOBRE LAPRODUCTIVIDAD Y LA POBREZA�,Cortez Valdivia, Rafael.Lima, INEI, 2000.
- �BIOESTADÍSTICA�.Díaz, Gabriela; Gunther, Bruno.Chile, Mediterráneo, 1994.
- �LOS ACTIVOS DE LOS POBRES ENEL PERÚ�.Escobal, Javier; Saavedra, Jaime;Torero, Máximo.Lima, GRADE. 1998.
- �EL ANÁLISIS DE DATOS ENMÉTODO DE SELECCIÓNDICOTÓMICA DE LA VARIABLECONTINGENTE�,Fasciolo, Graciela.Mendoza, 1997.
- �ANÁLISIS ECONOMÉTRICO�.Green, William H.Prentice Hall. 1998.
- �ECONOMETRÍA�,Gujarati, Damodár N.Colombia, McGraw-HILL, 1997
- �METODOLOGÍA DE LAINVESTIGACIÓN�.Hernández, Roberto; Fernández,Carlos; Baptista, Pilar.México. McGraw Hill, 1994.
- �MÉTODOS MULTIVARIADOSAPLICADOS AL ANÁLISIS DEDATOS�.Johnson,México, ITP, 2000.
- �ESTUDIO SOBRE DETERMINANTESDEL ACCESO A LOS SERVICIOS DESALUD EN EL PERÚ�,Lama More, Antonio.Lima, INEI, 2000.
- �LIMITED-DEPENDENT ANDQUALITATIVE VARIABLES INECONOMETRICS�.Maddala G. S.New York, Cambridge University Press,1996.
- �SPSS ADVANCE STATISTICS�,Majira J. Norusis.Chicago, SPSS Inc, 1994

84 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
- �METODOLOGÍA, GUÍA PARAELABORAR DISEÑOS DEINVESTIGACIÓN EN CIENCIASECONÓMICAS, CONTABLES YADMINISTRATIVAS�,Méndez Alvarez, Carlos.Colombia, Editorial McGraw -HILL.,1995.
- �MULTIVARIATE ANALYSIS:SOCIOLOGY 203�,Department of Sociology, University ofCalifornia, Riverside.
- �EVALUACIÓN DE LOS PROGRAMASDE COMPLEMENTACIÓNALIMENTARIA, GASTO ENALIMENTOS Y CONDICIONES DEVIDA EN EL PERÚ EN EL PERÍODO1998-1999�,Navarro Levano, José Carlos.Lima, INEI, 2001.
- �EL RETO 2001, COMPETIR Y CREAREMPLEO�,Ortiz de Zevallos, Felipe yKuczynski, Pedro Pablo.Lima, El Comercio, 2001.
- �LA POBREZA EN ARGENTINA: UNACOMPARACIÓN ENTRE REGIONESDISÍMILES, BUENOS AIRES, 2DAREUNIÓN ANUAL SOBRE POBREZAY DISTRIBUCIÓN DEL INGRESO-LACEA/BID/BM/�Paz, Jorge A.Universidad Torcuato Ditella, 2001.
- �POBREZA Y ECONOMÍA SOCIAL -ANÁLISIS DE UNA ENCUESTA ENNIV-1997.LA EDUCACIÓN Y LAPROBABILIDAD DE SER POBRE EN ELPERÚ DE HOY, LA APLICACIÓN DEUN MODELO PROBIT DE MÁXIMAVEROSIMILITUD�,Shack Yalta, Nelson Eduardo.Perú, DESA, 1999.
- �ANÁLISIS ESTADÍSTICO CON SPSSPARA WINDOWS�.Visauta Vinacua, B.España, Mc Graw Hill, 1998.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 85
Centro de Investigación y Desarrollo
XII. Anexos
ANEXO 1. Informe metodológico
ANEXO 2. Indices de ecuaciones, cuadros y gráficos

86 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 87
Centro de Investigación y Desarrollo
ANEXO 1 INFORME METODOLÓGICO
Fuentes de información utilizada.
Para cumplir con los objetivos de lainvestigación se tomó en consideración lainformación de la ENCUESTA NACIONALDE HOGARES 2001 - IV TRIMESTRE, aquímencionamos algunas de suscaracterísticas, que son de importanciarelevante para nuestra investigación y quenos permitiron comprobar algunas ideasreferentes a los factores determinantes dela pobreza en el Perú, y como estosbeneficiarían o afectarían, los criterios deutilización de modelos logit y probit. Paradicho propósito se analizarán variablesrelacionadas con el Jefe de Hogar, en susaspectos sociodemográficos y de inserciónocupacional.
Como sabemos, el fenómeno de lapobreza no afecta solo a los jefes de hogar, esta trae consigo una afectación alconjunto familiar, por lo tanto usar solocomo unidad de análisis al individuo y noconsiderar al hogar, puede llevar asignificativos sesgos sobrestimados alrespecto, pero que constituye un puntode partida fundamental en razón alcomportamiento de la sociedad yespecíficamente de la familia peruana, ydel rol que este juega dentro y sobre eldesarrollo de su hogar, además de teneren cuenta que estamos desarrollando unainvestigación que devela una metodologíasobre los modelos mencionadosanteriormente.
POBLACIÓN OBJETIVO: Fueron lasviviendas particulares y sus residenteshabituales (miembros permanentes delhogar), excluyéndose a los residentes en
viviendas colectivas (hoteles, cárceles,asilos, etc).
MARCO DE LA MUESTRA: La muestra esprobabilística, de áreas, estratificada,multietápica e independiente en cadadepartamento.
La muestra es probabilística porque lasunidades han sido seleccionadas mediantemétodos al azar, lo cual permite efectuarinferencias a la población en base a la teoríade probabilidades.
La muestra es de áreas, porque laprobabilidad de la población de serseleccionada, está asociada a áreasgeográficas.
La muestra es estratificada, porquepreviamente a la selección, la poblaciónse ha dividido en estratos, con el objetode mejorar su representatividad.
En la primera y segunda etapa se utiliza laselección sistemática con probabilidadproporcional al tamaño (PPT) de viviendas.
En la última etapa (selección de lasviviendas) la selección es sistemática simplecon arranque aleatorio.
COBERTURA GEOGRAFICA:Nacional, Urbana y Rural (24departamentos y la Provincia Constitucionaldel Callao).
TAMAÑO DE MUESTRA: El tamañototal de la muestra en el ámbito nacionales de 18,863 viviendas particulares, dentrode los cuales tomamos a 16515 Jefes deHogar y sus respectivos hogares.

88 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
METODOLOGÍA PARA LA INCLUSIÓNDE VARIABLES EN LA ESTIMACIÓN DEMODELO LOGIT DE POBREZA
En primer lugar se emplea un modelosemiautomático de selección de variables(Forward Stepwise Wald).
Block 0: Beginning Block
En el paso 0 se cuenta con un modeloconfigurado solo por el término
independiente. Sobre el se estudiará laadición o no de las demás variables, conun nivel de significación tanto de entradadel 0.05 y de salida 0.10. En [CUADROA.1] de historia de iteración obtenemosun -2 Log likelihood = 11325.900resultante de su función de verosimilitudy un valor para la constante de -0.008.
11325.900 -.008Iteration
1Step 0
-2 Loglikelihood Constant
Coefficients
Constant is included in the model.a.
Initial -2 Log Likelihood: 11325.900b.
Estimation terminated at iteration number 1 becauselog-likelihood decreased by less than .010 percent.
c.
A partir de aquí se debe comparar el valorque se obtenga en -2 Log likelihood enlos modelos con las nuevas variablesincluídas, de tal manera, que contrastemosla hipótesis nula de que el modelo sincovariables (factores de riesgo de pobreza),es tan bueno como el modelo que lascontiene. La importancia del modelo y delconjunto de variables significativas esvalidado posteriormente con el test decoeficientes del modelo (Ómnibus Test forModel Coefficients), [CUADRO A.6] en
este caso, que rechaza o no dichahipótesis.
El modelo con la constante posee una tablade clasificación del 50.2%, esto quieredecirnos que solo la constante, ya estaclasificando como pobres a 5 de cada 10,apreciable en el [CUADRO A.2]. Pero elvalor asignado al coeficiente de laconstante es de -0.008, el cual no poseeefecto significativo alguno, pues susignificancia es de 0.723 [CUADRO A.3].
Cuadro A.1 Iteration History a,b,c
4101 0 100.04069 0 .0
50.2
Observedno pobre
pobre
estado pobreza01
Overall Percentage
Step 0no pobre pobre
estado pobreza01 PercentageCorrect
Predicted
Constant is included in the model.a.
The cut value is .500b.
Cuadro A.2 Classification Table a,b

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 89
Centro de Investigación y Desarrollo
También viene acompañado de su errorestándar y el c² de Wald, que prueba eneste caso la significancia individual que enesta caso particular no se da; además demostrar el Odds Ratio (´Razón de
probabilidades´), que será fundamental enla determinación de la cantidad de vecesque un jefe de hogar puede ser más pobrecon respecto a no serlo respecto de lapresencia o no de un factor.
Cuadro A.3 Variables in the Equation
-.008 .022 .125 1 .723 .992ConstantStep 0B S.E. Wald df Sig. Exp(B)
Antes de terminar este paso y proceder alsiguiente, observemos [CUADRO A.4], serealiza un análisis de las variables todavíafuera de la ecuación a través de su p-valoro significancia, que indica la importanciarelativa que cada una de ellas tendría encaso de entrar al modelo descrito. Seseleccionará, entre las variables aquellacuya significancia se encuentre bajo elnivel 0.05, tomando también en
consideración su score, en este nuestrocaso, sería DSHDV CON P =0.000, esdecir la variable indicadora sobreabastecimiento de red de alcantarilladodentro de la vivienda.
Así finaliza el paso 0 del Forward Stepwisede Wald que se ha limitado a estudiar elmodelo de partida.
Cuadro A.4 Variables not in the Equation a
188.492 1 .000
55.014 1 .000
223.726 1 .000
.152 1 .697
15.617 1 .000
836.127 1 .000
.371 1 .542
50.785 1 .000
446.997 1 .000
8.833 1 .003
.075 1 .785
31.997 1 .000
528.833 1 .000
21.192 1 .000
860.534 1 .000
819.967 1 .000
33.780 1 .000
180.384 1 .000
1307.200 1 .000
674.480 1 .000
669.772 1 .000
1114.157 1 .000
57.575 1 .000
DSINNIV
P208A
DCOURB
DCORU
DSIEUR
DSIERU
DSELUR
DSELRU
DLIUR
EXPER1
DCOLEGIO
DOBRERO
DME100
DOEMP
INPERCAM
MIEPERHO
PETHOGAR
DCONVI
DSHDV
DSHNO
DAGUDV
P1122
P115
VariablesStep0
Score df Sig.
Residual Chi-Squares are not computed because of redundancies.a.

90 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
Block 1: Method = Forward Stepwise(Wald)
PASO 1: Variable ingresada DSHDV
Al ingresar la variable indicadora sobreabastecimiento de alcantarillado dentro dela vivienda, vemos que obtenemos un -2Log likelihood = 9973.258, ver[CUADRO A.5], obtenido este de la
función de máxima versosimilitud, menorcon respecto al modelo solo con constante(11325.900), además tenemos un Cox &Snell-R² de 0.153 y un valor de Nagelker0.203 que nos indica el grado devariabilidad explicada por el modelo, enesta caso demasiado baja, y que por eselado podemos seguir intentando buscar unmodelo más ideoneo.
Cuadro A.5 Model Summary
9973.258 .153 .203
5683.192 .499 .665
Step1
20
-2 Loglikelihood
Cox & SnellR Square
NagelkerkeR Square
Se observa en el [CUADRO A.6] siguiente(Test Omnibus) o prueba de loscoeficientes del modelo, que arrojaefectos significativos sobre el ingreso dedicha variable y por lo tanto rechazamosla hipótesis nula de que el modelo sólocon la constante es igual de bueno que el
modelo con la constante y DSHDV (tipode acceso a alcantarillado), esto en funciónde la chi-square obtenida que es de1352.641 es mayor comparada con aquellachi-square (1 g.l., 5%)=3.84, en talsentido el modelo obtenido hasta esemomento es el más adecuado.
Cuadro A.6 Omnibus Test of Model Coefficients
1352.641 1 .000
1352.641 1 .0001352.641 1 .000
4.126 1 .042
5642.707 20 .0005642.707 20 .000
Step
BlockModel
Step
BlockModel
Step 1
Step 20
Chi-square df Sig.
El modelo estimado sería: Ln (p/1-p)= ß0
+ ß1*DSHDV = 0.668 - 1.753*DSHDV,apreciable en el [CUADRO A.9], dondeya apreciamos que el tener conexión a red
pública de alcantarillado dentro de lavivienda produce un efecto negativo sobreel logit de la probabilidad de ser pobre.
21.938 8 .005
525.158 8 .000
Step2
20
Chi-square df Sig.
Cuadro A.7 Hosmer and Lemeshow Test

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 91
Centro de Investigación y Desarrollo
Si bien el Test de Hosmer y Lemershow[CUADRO A.7] deberían ser atentididosen el siguiente paso que incluye unanueva variable, este no será tratado envirtud de que el resto de procedimientosson similares en cada iteración, por esosolo nos detendremos aquí a afirmar quefrente a un valor de chi-squeare de 21.938y una significación 0.005 esta última se vareduciendo a medida que se vanaumentando más variables en el modelo.La comparación se hace respecto a unachi-square (8 g.l., 5%)=15.51 obtenidode tabla de aquí el test rechaza la hipótesisde nulidad.
Volviendo al paso 1 encontramos que estemodelo ya tiene un porcentaje declasificación general del 69.5% obtenidode su tabla [CUADRO A.8], de aquí mismola subclasificación hecha para la condiciónde pobreza de los jefes de hogar pobresobtiene un 79.8% de subclasificación.
Con respecto a los estimadores de loscoeficientes tenemos que el término
independiente 0.688 y el coeficiente delacceso a red pública de alcantarilladodentro de la vivienda -1.753 formulan elmodelo de probabilidad de pobreza[CUADRO A.9], el cual por alguna de lasrazones de índole estadística y empíricase queda corto al intentar brindarexplicaciones del fenómeno en suconjunto y proceder al análisis de lossiguientes pasos de iteración.
De la misma manera que en el paso 0, seanalizan las variables que están fuera delmodelo en este paso (1), antes deproceder al siguiente [CUADRO A.10],viendo su significancia (p-valor < 0.005),para su ingreso al modelo y además suscore, en tal sentido algunas de lascandidatas a ingresar serán MIEPERHO (0.000, 962.249), INPERCAM (0.000,561.907), P1122 (0.000, 393.466), perocomo es evidente de la ingresante en elsiguiente paso será el total de miembrosen el hogar (MIEPERHO).
Cuadro A.8 Classification Table a
2436 1665 59.4
823 3246 79.8
69.5
3400 701 82.9
519 3550 87.2
85.1
Observedno pobre
pobre
estado pobreza01
Overall Percentage
no pobre
pobre
estado pobreza01
Overall Percentage
Step 1
Step 20
no pobre pobre
estado pobreza01 PercentageCorrect
Predicted
The cut value is .500a.
El mismo análisis se realiza en cada unode los siguientes pasos de iteración, ental sentido, para ser una lectura másdinámica se presenta el primer paso deiteración y el último donde se detiene laestimación del modelo.
PASO 20: Variable ingresada DAGUDVLa variable ingresante en este paso, ver[CUADRO A.9], es si el tipo deabastecimiento de agua en la vivienda esa través de red pública. Las hipótesis acercade la validación de un adecuado modelo

92 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
frente a uno que no contiene factoressignificativos es fácil de verificar en el TestÓmnibus, ver [CUADRO A.7], y quepermite aceptar este último como mejormodelo frente a aquel que solo contieneel término constante.
Confirmada la idea anterior se puederedondear esta, es decir, confirmar elhecho de que nos encontramos frente aun modelo con un desajuste menor,además de obtener un grado declasificación general de alrededor del 85%,ver [CUADRO A.8] .
Este será el último paso ha realizarse en laestimación del modelo de probabilidad deser jefe de hogar pobre. Primero dejandoen claro que no es el único y definitivosobre el cual trabajar para estructurar
explicaciones de este fenómenomultidimensional, esto desde el punto devista empírico y porque además debemosde dejar en claro que si bien nosaproximamos en una buena medida a larealidad con la herramienta estadística estano resulta ser determinante y menosreemplazante de esta.
Segundo, que desde el punto de vistaestadístico, ninguna de las variablesrestantes tiene una significación adecuadapara ingresar al modelo [CUADRO A.10],en tal sentido, la estimación es detenida,y se empiezan a realizar los análisismostrados en capítulos anteriores en elmismo sentido de haber ingresado laprimera variable, pues este ha sido unproceso continuo durante toda la iteración.
MODELOS EN CADA PASO DE ITERACIÓN
Cuadro A.9 Variables in the Equation
-1.753 .050 1212.252 1 .000 .173 .157 .191
.668 .030 490.482 1 .000 1.950
.911 .231 15.548 1 .000 2.488 1.582 3.913
-.072 .011 41.221 1 .000 .931 .910 .951
-1.189 .167 50.439 1 .000 .304 .219 .423
.570 .098 33.642 1 .000 1.768 1.459 2.144
.899 .121 55.483 1 .000 2.458 1.940 3.114
-.807 .125 41.844 1 .000 .446 .349 .570
.070 .010 49.495 1 .000 1.072 1.051 1.093
.584 .189 9.540 1 .002 1.793 1.238 2.598
.451 .092 23.940 1 .000 1.570 1.311 1.881
.324 .095 11.606 1 .001 1.383 1.148 1.666
-.226 .085 7.090 1 .008 .798 .675 .942
-.011 .000 876.865 1 .000 .989 .988 .990
.517 .031 283.825 1 .000 1.677 1.579 1.781
-.313 .040 60.764 1 .000 .731 .676 .791
.269 .080 11.274 1 .001 1.308 1.118 1.530
-.388 .093 17.414 1 .000 .678 .565 .814
.270 .089 9.281 1 .002 1.310 1.101 1.558
-.168 .082 4.137 1 .042 .846 .719 .994
.627 .092 46.847 1 .000 1.873 1.565 2.241
.288 .083 11.916 1 .001 1.334 1.133 1.571
.761 .379 4.035 1 .045 2.141
DSHDV
Constant
Step1
a
DSINNIV
P208A
DCORU
DSIEUR
DSELUR
DSELRU
EXPER1
DCOLEGIO
DOBRERO
DME100
DOEMP
INPERCAM
MIEPERHO
PETHOGAR
DCONVI
DSHDV
DSHNO
DAGUDV
P1122
P115
Constant
Step20
t
B S.E. Wald df Sig. Exp(B) Lower Upper
95.0% C.I.for EXP(B)
Variable(s) entered on step 1: DSHDV.a.
Variable(s) entered on step 20: DAGUDV.t.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 93
Centro de Investigación y Desarrollo
VARIABLES EXCLUIDAS EN CADA PASO DE ITERACIÓN
Cuadro A.10 Variables not in the Equation
69.683 1 .000
13.868 1 .00029.125 1 .00039.325 1 .000
.985 1 .321259.136 1 .000
.699 1 .4031.023 1 .312
125.821 1 .000
8.835 1 .003.090 1 .764
13.894 1 .000206.545 1 .000
3.052 1 .081
561.907 1 .000962.249 1 .000
158.062 1 .00079.704 1 .000
107.207 1 .000
33.928 1 .000393.466 1 .000
16.562 1 .000
1.150 1 .283.005 1 .942
1.496 1 .221
DSINNIV
P208ADCOURB
DCORUDSIEURDSIERU
DSELURDSELRU
DLIUREXPER1DCOLEGIO
DOBRERODME100
DOEMPINPERCAMMIEPERHO
PETHOGARDCONVIDSHNO
DAGUDVP1122
P115
VariablesStep1
DCOURBDSIERU
DLIUR
VariablesStep20
Score df Sig.
Residual Chi-Squares are not computed because of redundancies.a.

94 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 95
Centro de Investigación y Desarrollo
ANEXO 2INDICES DE ECUACIONES, CUADROS Y GRAFICOS
INDICE DE ECUACIONES
CAPÍTULO IV
ECUACIÓN IV.1 Indicadores de Pobreza (Foster-Greer-Thordecke)ECUACIÓN IV.2 Función de Distribución BinomialECUACIÓN IV.3 Probabilidad de ser pobre del jefe de hogar en función a una FDA.ECUACIÓN IV.4 Modelo de regresión lineal asociado a una FDAECUACIÓN IV.5 Modelo de probabilidad linealECUACIÓN IV.6 Heterocedasticidad del modelo lineal de probabilidad.ECUACIÓN IV.7 Probabilidad de poseer una condición o presencia de fenómeno
asociada a una FDAECUACIÓN IV.8 Probabilidad asociada a la Función de Distribución LogísticaECUACIÓN IV.9 Transformación de la probabilidad de FDA LogísticaECUACIÓN IV.10 Probabilidad del evento complementario, Y=0, o ausencia de la
condición o fenómeno.ECUACIÓN IV.11 Razón de Probabilidades (`Odds ratio´)ECUACIÓN IV.12 Modelo Logit. Logaritmo de la razón de probabilidades en función
a factores explicativos y sus aportes.ECUACIÓN IV.13 Probabilidad asociada a la FDA Normal.ECUACIÓN IV.14 Probabilidad del evento en función a una FDA normal y su
representación matemática.ECUACIÓN IV.15 Índice imperfecto de convenienciaECUACIÓN IV.16 Probabilidad asociada al índice imperfecto de conveniencia y una
FDA Normal.ECUACIÓN IV.17 Linealidad del modelo probitECUACIÓN IV.18 Efectos marginales asociados a una FDA.ECUACIÓN IV.19 Efectos marginales para la Función de Distribución NormalECUACIÓN IV.20 Derivadas parciales respecto de los coeficientes de los factores en
la FDA Logística.ECUACIÓN IV.21 Efecto marginal para la FDA LogísticaECUACIÓN IV.22 Diferencia de beneficio-coste con una var. Observable
CAPÍTULO VI
ECUACIÓN VI.1 Probabilidad conjunta de un modelo de probabilidad .ECUACIÓN VI.2 Reformulación de la función de verosimilitud.ECUACIÓN VI.3 Condiciones de primer orden del problema de maximización.

96 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
ECUACIÓN VI.4 Heterocedasticidad de los errores en el enfoque de proporcionesmuestrales
ECUACIÓN VI.5 Condiciones necesarias de optimalidad de los coeficientes bECUACIÓN VI.6 Vector gradiente de la función de verosimilitudECUACIÓN VI.7 Matriz de información en función de la matriz Hessiana.ECUACIÓN VI.8 Método Scoring para estimación de Máxima Verosimilitud.ECUACIÓN VI.9 Transformación de la variable dependiente Xij en el modelo probitECUACIÓN VI.10 Transformación de la variable dependiente Yi en el modelo probit.ECUACIÓN VI.11 Logaritmo de la verosimilitud de "n" observaciones en el modelo
logitECUACIÓN VI.12 Vector gradiente de la verosimilitud en el modelo logitECUACIÓN VI.13 Matriz de información del modelo logit.ECUACIÓN VI.14 Transformación de la variable dependiente Xi en el modelo logit.ECUACIÓN VI.15 Transformación de la variable dependiente Yi en el modelo logit
CAPÍTULO VIII
ECUACIÓN VIII.1 Probabilidad del jefe de hogar pobre con FDA Logística.ECUACIÓN VIII.2 Estimación del modelo Logit de probabilidad en función de sus
factores explicativos.ECUACIÓN VIII.3 Análisis de un caso particular de jefe de hogar para el modelo
logit.ECUACIÓN VIII.4 Probabilidad asociada al jefe de hogar con un caso específico.ECUACIÓN VIII.5 Logit de la probabilidad de ser pobre frente a no ser pobre de
acuerdo a sus factores explicativos.ECUACIÓN VIII.6 Ecuación de regresión en términos de Odds Ratios (´Razones de
probabilidad`)ECUACIÓN VIII.7 Residual estandarizadoECUACIÓN VIII.8 Deviance de observaciones en presencia de pobreza.ECUACIÓN VIII.9 Deviance de observaciones en ausencia de pobreza.ECUACIÓN VIII.10 Logit residual del modelo de prob. de los jefes de hogar.ECUACIÓN VIII.11 Medida de influencia de cada observación.ECUACIÓN VIII.12 Cambio en el primer coeficiente al retirar la observación "i".
INDICE DE CUADROS
CAPÍTULO VIII
CUADRO VIII.1 Perfil del jefe de hogar según nivel educativo y estado de pobrezaCUADRO VIII.2 Test Chi-cuadrado (X2) de independencia entre el nivel educativo
y el estado de pobreza.CUADRO VIII.3 Cuadro de medidas simétricas sobre el grado de relación entre el
nivel educativo y el estado de pobreza.

LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL · 97
Centro de Investigación y Desarrollo
CUADRO VIII.4 Perfil del jefe de hogar según género y estado civil en condiciónde pobreza.
CUADRO VIII.5 Test Chi-cuadrado (X2) de independencia entre el género y elestado civil en condición de pobreza del jefe de hogar.
CUADRO VIII.6 Cuadro de medidas simétricas sobre el grado de relación entre elgénero y el estado civil del jefe de hogar pobre.
CUADRO VIII.7 Perfil del jefe de hogar según género y estado civil en condiciónde no pobreza.
CUADRO VIII.8 Test Chi-cuadrado (X2) de independencia entre el género y elestado civil en condición de no pobreza del jefe de hogar.
CUADRO VIII.9 Cuadro de medidas simétricas sobre el grado de relación entre elgénero y el estado civil del jefe de hogar no pobre.
CUADRO VIII.10 Perfil del jefe de hogar según área y región natural en estado depobreza
CUADRO VIII.11 Test Chi-cuadrado (X2) de independencia entre el área y la regiónnatural en condición de no pobreza del jefe de hogar.
CUADRO VIII.12 Cuadro de medidas simétricas sobre el grado de relación entre elárea y la región natural en estado de pobreza del jefe de hogar.
CUADRO VIII.13 Cuadro de los años de estudios del jefe de hogar según condiciónde pobreza
CUADRO VIII.14 Prueba de Levene para la igualdad de varianzas y diferencia demedias en los años de estudios por condición de pobreza.
CUADRO VIII.15 Cuadro de factores explicativos de la pobreza de los jefes de hogaren el modelo logit con enfoque de observaciones individuales.
CUADRO VIII.16 Tabla de correcta clasificación de Jefes de hogar.CUADRO VIII.17 Historia de IteracionesCUADRO VIII.18 Cuadro de estadísticos de bondad de ajuste del modeloCUADRO VIII.19 Cuadro de evaluación de los coeficientes del modelo.CUADRO VIII.20 Frecuencia de jefes de hogar según deciles de ingreso y jefes de
hogar pobres en cada decil de ingreso para el modelo probit conenfoque de proporciones muestrales.
CUADRO VIII.21 Frecuencias observadas y esperadas de los jefes de hogar en basea modelo probit estimado.
CUADRO VIII.22 Incidencia en la probabilidad de ser pobre a nivel nacional del jefede hogar según el modelo logit con enfoque de observacionesindividuales.
CUADRO VIII.23 Incidencia en la probabilidad de ser pobre a nivel nacional del jefede hogar según el modelo probit con enfoque de observacionesindividuales.
ANEXO
CUADRO A.1 Historia de iteración en el paso 0.CUADRO A.2 Tabla de clasificación en el paso 0.CUADRO A.3 Cuadro de variables incluidas en el paso 0 (solo cte.)

98 · LOS MODELOS LOGIT Y PROBIT EN LA INVESTIGACION SOCIAL
Centro de Investigación y Desarrollo
CUADRO A.4 Cuadro de variables excluidas en el paso 0.CUADRO A.5 Cuadro de resumen de modelos en los 1 y 20.CUADRO A.6 Cuadro de evaluación de los coeficientes de los modelos generados
en el paso 1 y el paso 20.CUADRO A.7 Cuadro de prueba de Hosmer y Lemershow en las iteraciones o
pasos 1 y 20.CUADRO A.8 Tablas de correcta clasificación de los modelos generados en los
pasos 1 y 20.CUADRO A.9 Cuadro de variables incluidas en cada paso de iteración.CUADRO A.10 Cuadro de variables excluidas en cada paso de iteración.
INDICE DE GRÁFICOS
CAPÍTULO IV
GRÁFICO IV.1 Gráfica de los límites de probabilidad asociado a la presencia delevento.
GRÁFICO IV.2 Gráfica de región asociada a su probabilidad y en función al índiceimperfecto o de utilidad.
GRÁFICO IV.3 Gráfica de comparación de la FDA Logística y Normal.GRÁFICO IV.4 Decisión de compra en base al consumidor
CAPÍTULO VIII
GRÁFICO VIII.1 Gráfica del perfil del nivel educativo según estado de pobreza deljefe de hogar
GRÁFICO VIII.2 Gráfica del perfil del jefe de hogar según género y estado civil encondición de no pobreza.
GRÁFICO VIII.3 Gráfica del perfil del jefe de hogar según género y estado civil encondición de pobreza.
GRÁFICO VIII.4 Gráfica del perfil del jefe de hogar según área y región natural encondición de pobreza.
GRÁFICO VIII.5 Gráfica de la tendencia del promedio de años de estudios del jefede hogar según estado de pobreza.
GRÁFICO VIII.6 Gráfica de distribución normal y desviaciones respecto de ladistribución normal de las Deviances obtenidas para cada JH.
GRÁFICO VIII.7 Gráfica de residuales estandarizados según observaciones.GRÁFICO VIII.8 Gráfica de Leverages obtenidos según observaciones.GRÁFICO VIII.9 Gráfica de la influencia de observaciones sobre el coeficiente del
indicador sinnivel (sin nivel de educaión).GRÁFICO VIII.10 Gráfica de transformaciones probit según deciles de ingreso





























