Embed Size (px)
Citation preview

Learning From Observation and Practice Using Primitives
Darrin C. Bentivegna1,2, Christopher G. Atkeson1,3, and Gordon Cheng1,2
1ATR Computational Neuroscience Laboratories, Department of Humanoid Robotics andComputational Neuroscience,Kyoto, Japan2Computational Brain Project, ICORP, Japan Science and Technology Agency, Kyoto, Japan3 Robotics Institute, Carnegie Mellon University, Pittsburgh, PA, USA
Abstract
We explore how to enable robots to rapidly learn from watch-ing a human or robot perform a task, and from practicing thetask itself. A key component of our approach is to use smallunits of behavior, which we refer to as behavioral primitives.Another key component is to use the observed human behav-ior to define the space to be explored during learning frompractice. In this paper we manually define task appropriateprimitives by programming how to find them in the train-ing data. We describe memory-based approaches to learninghow to select and provide subgoals for behavioral primitives.We demonstrate both learning from observation and learn-ing from practice on a marble maze task, Labyrinth. Usingbehavioral primitives greatly speeds up learning relative tolearning using a direct mapping from states to actions.
IntroductionWe are exploring how primitives, small units of behavior,can speed up robot learning and enable robots to learn dif-ficult dynamic tasks in reasonable amounts of time. Primi-tives are units of behavior above the level of motor or mus-cle commands. There have been many proposals for suchunits of behavior in neuroscience, psychology, robotics,artificial intelligence, and machine learning (Arkin 1998;Schmidt 1988; Russell & Norvig 1995; Barto & Mahadevan2003). (Bentivegna 2004) presents a more complete surveyof relevant work, and provides additional detail on the workdescribed in this paper.
There is a great deal of evidence that biological systemshave units of behavior above the level of activating individ-ual motor neurons, and that the organization of the brainreflects those units of behavior. There is evidence fromneuroscience and brain imaging that there are distinct areasof the brain for different types of movements. Developinga computational theory that explains the roles of primitivesin generating behavior and learning is an important step to-wards understanding how biological systems generate be-havior and learn. A difference between work on behavioralprimitives in biology and in robotics is that in biology theemphasis is typically on finding behavioral primitives thatare used across many tasks, while in robotics the emphasis
Copyright c° 2004, American Association for Artificial Intelli-gence (www.aaai.org). All rights reserved.
is typically on primitives that are only appropriate for a sin-gle task or a small set of closely related tasks.
In robotics, behavioral units or primitives are a way tosupport modularity in the design of behaviors. Primitives arean important step towards reasoning about behavior, abstrac-tion, and applying general knowledge across a wide rangeof behaviors. We believe that restricting behavioral optionsby adopting a set of primitives is a good way to handle highdimensional tasks. We believe the techniques described inthis paper will apply to many current challenges in robot-ics, such as grasping with an anthropomorphic hand, whereobject shape and pose can be used to select a grasping primi-tive. In manipulating deformable objects, such as putting onclothes, the task is quite complex, but simple actions such aspushing an arm through a sleeve or using gravity to orientthe clothing are useful primitives to select from. We believeeveryday tasks such as cooking, cleaning, and repair can beperformed by robots using a library of primitives for spe-cific behaviors and a learned primitive selection algorithmand subgoal generator.
Our current research strategy is to focus on how to bestutilize behavioral primitives. Therefore, we manually defineprimitives. We are deferring the question of how to inventnew primitives until we better understand how primitives arebest used. Because of our emphasis on learning from ob-servation, the definition of primitives is largely perceptual:the robot must know how to detect the use of a primitive intraining data. Other aspects of the primitive, such as how toactually do it, can be learned.
We are exploring a three part framework for primitive use(Figure 1). A classifier selects the type of primitive to usein a given context. A function approximator predicts theappropriate arguments or parameters for the selected prim-itive (subgoal generation). Another function approxima-tor predicts the necessary commands to achieve the subgoalspecified by the parameters for the primitive (action gener-ation). This framework supports rapid learning. The avail-ability of subgoal information decouples action generationlearning from the rest of the problem and will allow what islearned at the action level to be reused every time a primi-tive of the corresponding type is used. In what follows wedescribe our approach to learning how to select primitivesand generate subgoals.
We have used two tasks to develop our thinking, the mar-

Primitive Selection
Action Generation
SubgoalGeneration
Learning from Observation
Learning from Practice
Primitive Selection
Action Generation
SubgoalGeneration
Learning from Observation
Learning from Practice
Figure 1: Three part framework for learning using primi-tives.
Roll Off WallRoll To Corner
Guide Roll From Wall
Corner
Figure 2: Left: The hardware marble maze setup. Right:Marble maze primitives (top view).
ble maze game Labyrinth (Figure 2) and air hockey (Ben-tivegna, Atkeson, & Cheng 2003; Bentivegna et al. 2002).We selected these tasks because 1) they are challenging dy-namic tasks with different characteristics and 2) robots havebeen programmed to do both tasks, so they are doable, andto the extent there are published descriptions, there are otherimplementations to compare to. The marble maze task issimilar to parts orientation using tray tilting (Erdmann &Mason 1988). The marble maze task will allow us to ex-plore generalization across different board layouts, while airhockey will allow us to explore generalization across differ-ent opponents. We have developed versions of these gamesto be played by simulated agents and by actual robots. Al-though hardware implementations necessarily include realworld effects, we can collect useful training data from thesimulations without the cost of running the full robot setups,and can perform more repeatable and controllable experi-ments in simulation.
This paper describes some of our work using the mar-ble maze. In the marble maze a player controls a marblethrough a maze by tilting the board that the marble is rollingon. The actual board is tilted using two knobs and the simu-lated board is controlled with a mouse. There are obstacles,in the form of holes and walls. The primitives we have man-ually designed for the marble maze game are based on ourobservations of human players. The following primitives arecurrently being explored and are shown in Figure 2:• Roll To Corner: The ball rolls along a wall and stops when
it hits another wall.• Corner: The ball is moved into a corner and the board is
then almost leveled, so that the next primitive can movethe ball out of the corner.
• Roll Off Wall: The ball rolls along a wall and then rollsoff the end of the wall.
• Roll From Wall: The ball hits, or is on, a wall and then ismaneuvered off it.
• Guide: The ball is rolled from one location to anotherwithout touching a wall.
Learning From ObservationIn learning from observation the robot observes a human oranother robot performing a task, and uses that information todo the task. In learning from observation without primitives,the robot learns desired states or state trajectories and cor-responding low level actions or action sequences (Atkeson& Schaal 1997). It is difficult to generalize much beyondthe state trajectories or reuse information across tasks. Itis also difficult to reason about what the demonstrator wastrying to do at any time during the observation. Primitivesprovide a way to generalize more aggressively, and to reuseinformation more effectively. Furthermore, selecting the ap-propriate primitive can be interpreted as selecting a subgoalin that point of the task, a simple form of reasoning.
Finding Primitives In The Observation DataIn learning from observation using behavioral primitives, itis necessary to segment the observation (or training data)into instances of the primitives. The example tasks, mar-ble maze and air hockey, have been chosen to some extentbecause it is relatively easy to segment an observation intodistinct primitives. We use a strategy based on recognizingcritical events. Examples of critical events for air hockeyinclude puck collisions with a wall or paddle, in which thepuck speed and direction are rapidly changed. In marblemaze initiating and terminating contact with a wall are ex-amples of critical events (Figure 3). A combination of geo-metric knowledge (proximity of the ball to walls) and viola-tions of dynamic models (the ball does not accelerate in thedirection of board tilt, sudden changes in ball velocity) areused to infer wall contact. Primitives are defined by creatingalgorithms that automatically segment the observed primi-tives by searching for sequences of critical events. Parame-ters or subgoals are estimated by observing the state of thetask at the transition to the next observed primitive. In mar-ble maze, the task state is given by the marble position andvelocity, and the board tilt angles. There are cases where aprimitive can not be identified in the training data (gaps inthe figure).
Learning to Select Primitives and Choose SubgoalsIn learning from observation using primitives the learnerlearns a policy of which primitive type and subgoal to usein each task state. The segmented observation data can beused to train this mechanism. There are many classifiersand function approximators we could have used. We havetaken a memory-based approach, using a nearest neighborscheme for the classifier that selects primitives, and kernelbased regression for the function approximator that providessubgoals. This provides us with one mechanism, the dis-tance function, that can be used to improve performance in

0 5 10 15 20 250
5
10
15
20
Start position
Goal location
+Y
+X0 5 10 15 20 25
0
5
10
15
20
Start position
Goal location
+Y
+X
+Y
+X
Figure 3: Top Left: Raw observed data. Top Right: Wallcontact identified by thick line segments. Bottom: Symbolsshow the start of recognized primitives: °-Roll To Corner,¤-Roll Off Wall, ♦-Guide, ∗-Roll FromWall, ×-Corner.
both primitive selection and subgoal generation. Our sys-tem learns by modifying the calculated distances between aquery and the stored experiences in memory. Memory-basedapproaches have a number of other benefits, such as rapidlearning, low interference, and control over forgetting (Atke-son, Moore, & Schaal 1997).
Each time a primitive is observed in the training data acorresponding data point is stored in a database that is in-dexed by the state of the task at the time the primitive wasperformed. In marble maze, the state is six dimensional,including the marble position (mx,my), marble velocity(mx, my), and board tilt angles (bx, by). During execution,the current state is used to look up in the database the clos-est or most similar primitive, which determines which kindof primitive to use. Distance is computed using a weightedEuclidean metric:
d(x,q) =Xj
wj(xj − qj)2 (1)
x is a stored experience, q is the query to the data base, andj indexes components or dimensions. Each dimension isscaled to range from -1 to 1 based on all the data in the data-base, and then the following weights are applied: a weightof 100 on marble positions, 10 on marble velocities, and 1on board angles. We will discuss the sensitivity to these pa-rameters in a later section.
After it has been decided which type of primitive to use,the parameters of that primitive are also specified by the
database of prior observations. The closest N stored ex-periences that involved the same primitive type are used tocompute the subgoal for the primitive to be performed. Wecompute the parameters using kernel regression:
θ(q) =
PNi=1 θi ·K(d(xi,q))PNi=1K(d(xi,q))
(2)
xi is the ith stored experience, K(d) is the kernel functionand is typically e−d
2/s. As can be seen, the estimate θ de-pends on the location of the query point, q. We typicallyused the 4 closest experiences of the appropriate type tocompute the subgoal, but N can range from 2 to 6 with littleeffect.
Results on Learning From ObservationFigure 4 shows the training data and performance using thetraining data on the hardware marble maze setup. Figure 5shows the effect of the number of observed games on learn-ing from observation for a large number of simulation runs.In the simulations we turn failures (falling into a hole) into atime penalty: if the marble falls into a hole or does not makeprogress for 15 seconds it is moved forward in the maze andthe player is given a 10 second penalty. One to five gameswere randomly selected from a database of 50 human gameswith no failures and playing times of 20-26 seconds.
Learning from observation using this memory-based ap-proach seems to work well. It became clear to us that learn-ing from observation alone had several problems, however.Even under ideal conditions the learner just learns to imi-tate the performance of the teacher, not to do better than theteacher. In general, the learner did not match the teacher’sperformance. The same mistakes tend to be made over andover. To improve further, it became clear to us that additionallearning mechanisms were necessary, such as the ability tolearn from practice in addition to learning from watchingothers perform.
Learning From PracticeIn order to learn from practice, the system needs to have away to evaluate performance, or have a defined task objec-tive function or criterion. This information is used to up-date primitive selection, and subgoal and action generation.A tough question is where the task criterion comes from.Ideally, it should be learned from observation. The learnershould infer the intent of the teacher. This is very difficult,and we defer addressing this question by manually specify-ing a task criterion.
Our system learns from practice by changing the distancefunction used in the nearest neighbor lookup done in bothselecting primitives and generating subgoals. Let’s considerthe simplest case, where a nearest neighbor classifier is usedto select the primitive used in the experience most similarto the current context. If the closest primitive actually leadsto bad consequences, we want to increase the apparent dis-tance, so that a different experience becomes the “closest”and a different primitive is tried. If the closest primitiveleads to good consequences, we want to decrease the ap-parent distance. In the nearest neighbor case, decreasing the

Figure 4: Top: The 3 observed games played by the hu-man teacher. Middle: Performance on 10 games based onlearning from observation using the 3 training games. Themaze was successfully completed 5 times, and the circlesmark where the ball fell into holes. Bottom: Performanceon 10 games based on learning from practice after 30 prac-tice games. There were no failures.
1 2 3 4 50
10
20
30
40
50
60
Number of games observed
Aver
age
Tim
e to
Rea
ch th
e G
oal (
sec.
)
Observation OnlyTableLWPR
Figure 5: Performance in simulation based on one to fivetraining games: learning from observation using one to fivegames (left bars), learning from observation and practice us-ing tables (middle bars), and learning from observation andpractice using LWPR (right bars). 30 trials using differentrandomly selected training games were averaged and the er-ror bars are standard deviations of the results. The learningfrom practice results are based on practicing 300 games.
distance to the closest point has no effect, but in kernel re-gression it increases the weighting of that subgoal.
Let us continue to consider the simplest case, a near-est neighbor approach. We use an estimate of the valuefunction, or actually a Q function, to represent the conse-quences of choosing a particular primitive in the current taskstate (Watkins & Dayan 1992). A Q function takes as ar-guments the current task state and an action. In our case,the task state is the query q to the database, and the actionis choosing to use information from stored point xi, so wehave Q(q,xi). We use this Q value as a scale factor appliedto the distance, where C is a normalizing constant (version1 of the scale factor):
d = d(xi,q) ∗ C
Q(q,xi)(3)
This scale factor will have the effect of moving a stored ex-perience in relationship to the query point. Scale factorsC/Q greater than 1.0 will have the effect of moving the datapoint farther away from the query point and scale factorsless then 1.0 have the effect of moving the data point closerto the query point. For example, if the marble falls into ahole after a selected primitive is performed, the scale fac-tors associated with the set of data points that voted for thatprimitive selection or contributed to the subgoal generationcan be increased. The next time the agent finds itself in thesame state, those data points will appear further away andwill therefore have less effect on the chosen action. We havealso explored using an alternative form of the scale factor(version 2):
d = d(xi,q) ∗ exp((C −Q(q,xi))/β) (4)

Version 2 of the scale factor will allow the Q values to bezero or negative and the influence of the Q value on the mul-tiplier can be controlled by β (typically 20,000).
In our memory based approach, we associate the Q values,Qi(q,xi), with our experiences, xi. In order to support in-dexing the Q values with the query q, we actually associatea table of Q values with each stored experience, and use thattable to approximateQi(q,xi). This also solves the problemthat from one query point state the chosen experiences maybe appropriate, but from a different query point, these ex-periences may not work very well. With a table associatedwith each stored experience, we can handle this effect. Inthe marble maze environment the state space is six dimen-sional. Each dimension is quantized into five cells. Eachstored experience in the database has a table of size 56. Forany query point in the state space, its position relative to thedata point is used to find the cell that is associated with thatquery point. Since we expect only a small fraction of thecells to be used, the tables are stored as sparse arrays andonly when the value in a cell is initially updated is the cellactually created. The size of the cells associated with a datapoint were chosen manually through trial and error with thecells near the center being smaller then those further away.To eliminate the need to specify a large number of parame-ters and to allow the agent to learn its own discretization ofthe state space we also explored the use of LWPR models toencode the Q values.
The Q values are initialized with C and then updated us-ing a modified version of Q learning. For each of the datapoints chosen in the subgoal computation the Q-values areupdated as follows:
Q(qt,xm)← Q(qt,xm)+α · [r + γQ(q, x)−Q(qt,xm)](5)
• α is the learning rate. Since multiple points are used, the weight-ing given by K(d(xm,qt))
Ni=1
K(d(xi,qt))is used as the learning rate. This
weighting has the effect of having points that contributed themost toward selecting the subgoal having the highest learningrate.
• r is the reward observed after the primitive has been performed.• γ is the discount factor (typically 0.8).
• Q(q, x) is the future reward that can be expected from the newstate q and selecting the data points x at the next time step. Thisvalue is given by a weighted average:
Q(q, x) =
PNi=1Q(q, xi)K(d(xi, q))PN
i=1K(d(xi, q))(6)
When each primitive ends the reward function is com-puted as the sum of the following terms:• Moving through the maze: the distance in centimeters from the
beginning of the primitive to the end location along the path (theline drawn on the board) toward the goal.
• Taking up time: −10× the amount of time in seconds from thetime the primitive started to the time it ended.
• Not making any progress during the execution of the primitive:−50, 000.
• Not completing the execution of the primitive within 4 seconds:−20, 000. Primitive execution is terminated after 4 seconds.
• Rolling into, and being stable in, a corner: 30, 000. When acorner is reached, learning stops and restarts from the cornerlocation. The playing agent only gets a reward the first time itgoes to a corner. Subsequent visits to the same corner will alsoreset learning, but will result in no reward. This prevents theagent from returning to corners just to get high rewards.
• Falling into a hole: −50, 000, the Q-value of the hole state is0. When the playing agent falls into a hole, learning is stoppedand restarted from the location the marble is placed at when thegame begins again.
• Reaching the goal location in the maze: 10, 000.
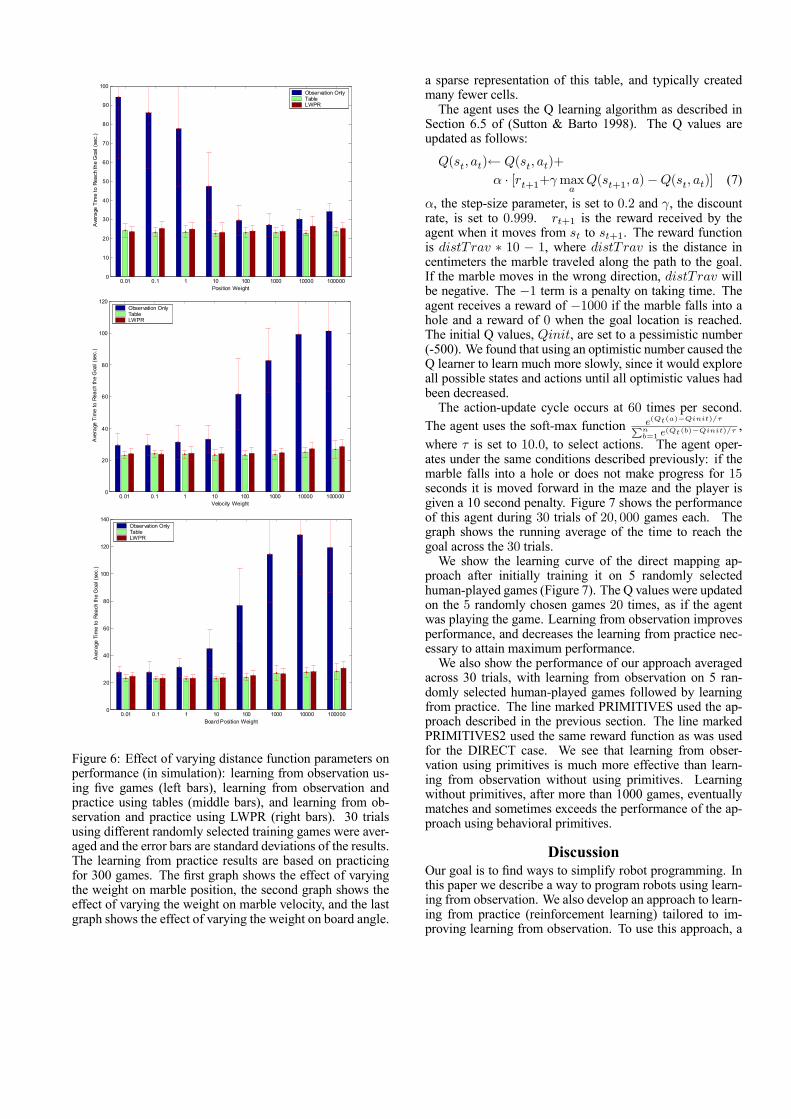
After learning from observation, the system now learnsfrom practice using either tables or LWPR models to alterthe distance function. Figure 4 shows individual games onactual hardware after learning from practice (using version1 of the distance function scale factor and tables to representthe distance function). Figure 5 shows a more comprehen-sive set of simulation experiments exploring using version2 of the distance function modification formula and eitherlocal tables or LWPR models to alter the distance function.Performance of learning from practice using local tables andLWPR models are about the same. Practice improves perfor-mance to human levels and also reduces variability. Figure 6shows the effect of varying the distance function in simula-tion. The marble position is clearly the most important factorin learning from observation. However, after learning frompractice, performance is relatively independent of the origi-nal distance function. The adjustment of the distance scalefactors in learning from practice can compensate for poorselections of the original distance function.
Comparison: Learning Without BehavioralPrimitives.
We also implemented learning from observation and prac-tice using as direct a mapping from states to actions as wecould practically implement. We implemented standard Qlearning based on the description of Section 6.5 of (Sutton& Barto 1998). The Q function was represented as a ta-ble. We note that this table represents a different kind ofbehavioral primitive rather than no primitive at all, becausethe same action is used within each cell. We roughly opti-mized the size of the cells to maximize the learning rate, andthe cell sizes were as follows: marble position cell width:0.01m, marble velocity cell width: 0.1m/sec, board rota-tion cell width: 0.01radians, and three possible actions ineach state, which change the rotation angle of the boardby (−0.01radians, 0, 0.01radians). With cells of this sizeand a board of size 28cm × 23.5cm, a maximum velocityof 0.5m/sec and maximum board rotation of 0.14 radiansthere were (28 ∗ 24) ∗ (10 ∗ 10) ∗ (28 ∗ 28) = 52, 684, 800states. This results in 52, 684, 800 ∗ (3 ∗ 3) = 474, 163, 200state-action pairs or Q values. Since many parts of the boardare inaccessible due to walls and holes the actual numberof possible Q values is smaller than this number. We used
0.01 0.1 1 10 100 1000 10000 1000000
20
40
60
80
100
120
140
Board Position Weight
Ave
rage
Tim
e to
Rea
ch th
e G
oal (
sec.
)
Observation OnlyTableLWPR
0.01 0.1 1 10 100 1000 10000 1000000
10
20
30
40
50
60
70
80
90
100
Position Weight
Ave
rage
Tim
e to
Rea
ch th
e G
oal (
sec.
)Observation OnlyTableLWPR
0.01 0.1 1 10 100 1000 10000 1000000
20
40
60
80
100
120
Velocity Weight
Ave
rage
Tim
e to
Rea
ch th
e G
oal (
sec.
)
Observation OnlyTableLWPR
Figure 6: Effect of varying distance function parameters onperformance (in simulation): learning from observation us-ing five games (left bars), learning from observation andpractice using tables (middle bars), and learning from ob-servation and practice using LWPR (right bars). 30 trialsusing different randomly selected training games were aver-aged and the error bars are standard deviations of the results.The learning from practice results are based on practicingfor 300 games. The first graph shows the effect of varyingthe weight on marble position, the second graph shows theeffect of varying the weight on marble velocity, and the lastgraph shows the effect of varying the weight on board angle.
a sparse representation of this table, and typically createdmany fewer cells.
The agent uses the Q learning algorithm as described inSection 6.5 of (Sutton & Barto 1998). The Q values areupdated as follows:
Q(st, at)← Q(st, at)+
α · [rt+1+γmaxa Q(st+1, a)−Q(st, at)] (7)
α, the step-size parameter, is set to 0.2 and γ, the discountrate, is set to 0.999. rt+1 is the reward received by theagent when it moves from st to st+1. The reward functionis distTrav ∗ 10 − 1, where distT rav is the distance incentimeters the marble traveled along the path to the goal.If the marble moves in the wrong direction, distTrav willbe negative. The −1 term is a penalty on taking time. Theagent receives a reward of −1000 if the marble falls into ahole and a reward of 0 when the goal location is reached.The initial Q values, Qinit, are set to a pessimistic number(-500). We found that using an optimistic number caused theQ learner to learn much more slowly, since it would exploreall possible states and actions until all optimistic values hadbeen decreased.
The action-update cycle occurs at 60 times per second.The agent uses the soft-max function e(Qt(a)−Qinit)/τ
nb=1 e
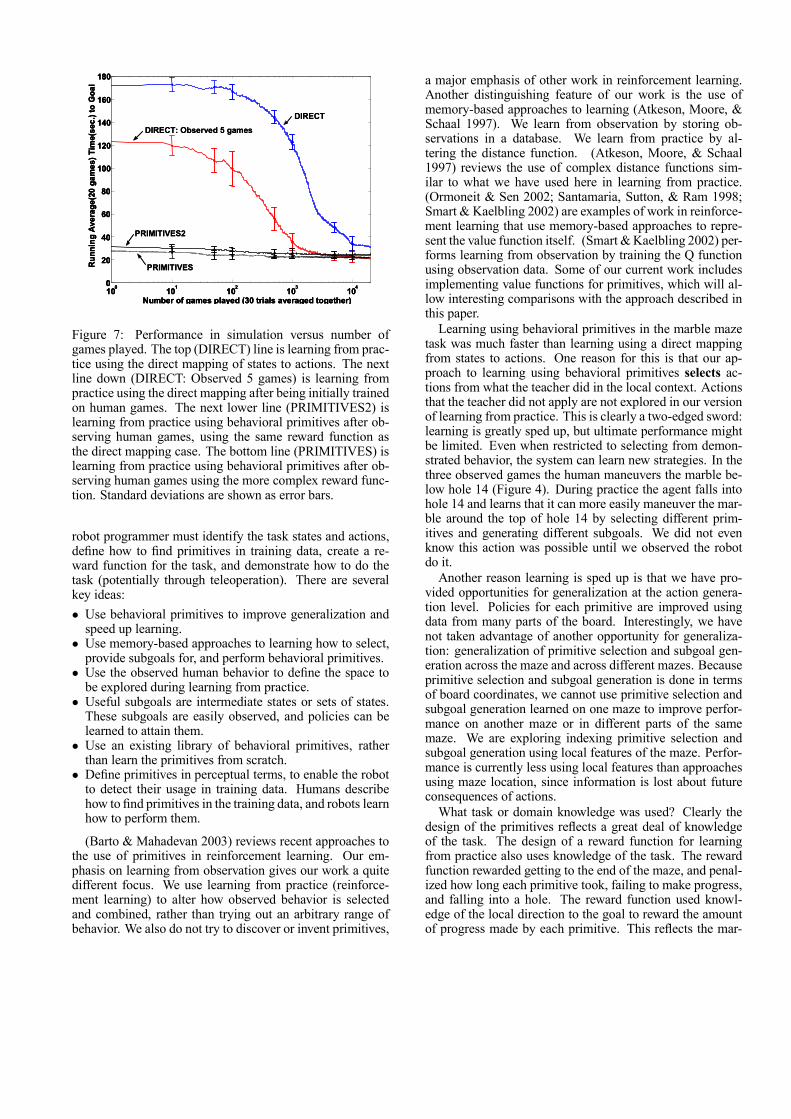
(Qt(b)−Qinit)/τ ,where τ is set to 10.0, to select actions. The agent oper-ates under the same conditions described previously: if themarble falls into a hole or does not make progress for 15seconds it is moved forward in the maze and the player isgiven a 10 second penalty. Figure 7 shows the performanceof this agent during 30 trials of 20, 000 games each. Thegraph shows the running average of the time to reach thegoal across the 30 trials.
We show the learning curve of the direct mapping ap-proach after initially training it on 5 randomly selectedhuman-played games (Figure 7). The Q values were updatedon the 5 randomly chosen games 20 times, as if the agentwas playing the game. Learning from observation improvesperformance, and decreases the learning from practice nec-essary to attain maximum performance.
We also show the performance of our approach averagedacross 30 trials, with learning from observation on 5 ran-domly selected human-played games followed by learningfrom practice. The line marked PRIMITIVES used the ap-proach described in the previous section. The line markedPRIMITIVES2 used the same reward function as was usedfor the DIRECT case. We see that learning from obser-vation using primitives is much more effective than learn-ing from observation without using primitives. Learningwithout primitives, after more than 1000 games, eventuallymatches and sometimes exceeds the performance of the ap-proach using behavioral primitives.
DiscussionOur goal is to find ways to simplify robot programming. Inthis paper we describe a way to program robots using learn-ing from observation. We also develop an approach to learn-ing from practice (reinforcement learning) tailored to im-proving learning from observation. To use this approach, a
100 101 102 103 1040
20
40
60
80
100
120
140
160
180
Number of games played (30 trials averaged together)
Run
ning
Ave
rage
(20
gam
es) T
ime(
sec.
) to
Goa
l
DIRECT: Observed 5 games DIRECT
PRIMITIVES2
PRIMITIVES
100 101 102 103 1040
20
40
60
80
100
120
140
160
180
100 101 102 103 1040
20
40
60
80
100
120
140
160
180
Number of games played (30 trials averaged together)
Run
ning
Ave
rage
(20
gam
es) T
ime(
sec.
) to
Goa
l
DIRECT: Observed 5 games DIRECT
PRIMITIVES2
PRIMITIVES
Number of games played (30 trials averaged together)
Run
ning
Ave
rage
(20
gam
es) T
ime(
sec.
) to
Goa
l
DIRECT: Observed 5 games DIRECT
PRIMITIVES2
PRIMITIVES
Figure 7: Performance in simulation versus number ofgames played. The top (DIRECT) line is learning from prac-tice using the direct mapping of states to actions. The nextline down (DIRECT: Observed 5 games) is learning frompractice using the direct mapping after being initially trainedon human games. The next lower line (PRIMITIVES2) islearning from practice using behavioral primitives after ob-serving human games, using the same reward function asthe direct mapping case. The bottom line (PRIMITIVES) islearning from practice using behavioral primitives after ob-serving human games using the more complex reward func-tion. Standard deviations are shown as error bars.
robot programmer must identify the task states and actions,define how to find primitives in training data, create a re-ward function for the task, and demonstrate how to do thetask (potentially through teleoperation). There are severalkey ideas:• Use behavioral primitives to improve generalization and
speed up learning.• Use memory-based approaches to learning how to select,
provide subgoals for, and perform behavioral primitives.• Use the observed human behavior to define the space to
be explored during learning from practice.• Useful subgoals are intermediate states or sets of states.
These subgoals are easily observed, and policies can belearned to attain them.
• Use an existing library of behavioral primitives, ratherthan learn the primitives from scratch.
• Define primitives in perceptual terms, to enable the robotto detect their usage in training data. Humans describehow to find primitives in the training data, and robots learnhow to perform them.
(Barto & Mahadevan 2003) reviews recent approaches tothe use of primitives in reinforcement learning. Our em-phasis on learning from observation gives our work a quitedifferent focus. We use learning from practice (reinforce-ment learning) to alter how observed behavior is selectedand combined, rather than trying out an arbitrary range ofbehavior. We also do not try to discover or invent primitives,
a major emphasis of other work in reinforcement learning.Another distinguishing feature of our work is the use ofmemory-based approaches to learning (Atkeson, Moore, &Schaal 1997). We learn from observation by storing ob-servations in a database. We learn from practice by al-tering the distance function. (Atkeson, Moore, & Schaal1997) reviews the use of complex distance functions sim-ilar to what we have used here in learning from practice.(Ormoneit & Sen 2002; Santamaria, Sutton, & Ram 1998;Smart & Kaelbling 2002) are examples of work in reinforce-ment learning that use memory-based approaches to repre-sent the value function itself. (Smart & Kaelbling 2002) per-forms learning from observation by training the Q functionusing observation data. Some of our current work includesimplementing value functions for primitives, which will al-low interesting comparisons with the approach described inthis paper.
Learning using behavioral primitives in the marble mazetask was much faster than learning using a direct mappingfrom states to actions. One reason for this is that our ap-proach to learning using behavioral primitives selects ac-tions from what the teacher did in the local context. Actionsthat the teacher did not apply are not explored in our versionof learning from practice. This is clearly a two-edged sword:learning is greatly sped up, but ultimate performance mightbe limited. Even when restricted to selecting from demon-strated behavior, the system can learn new strategies. In thethree observed games the human maneuvers the marble be-low hole 14 (Figure 4). During practice the agent falls intohole 14 and learns that it can more easily maneuver the mar-ble around the top of hole 14 by selecting different prim-itives and generating different subgoals. We did not evenknow this action was possible until we observed the robotdo it.
Another reason learning is sped up is that we have pro-vided opportunities for generalization at the action genera-tion level. Policies for each primitive are improved usingdata from many parts of the board. Interestingly, we havenot taken advantage of another opportunity for generaliza-tion: generalization of primitive selection and subgoal gen-eration across the maze and across different mazes. Becauseprimitive selection and subgoal generation is done in termsof board coordinates, we cannot use primitive selection andsubgoal generation learned on one maze to improve perfor-mance on another maze or in different parts of the samemaze. We are exploring indexing primitive selection andsubgoal generation using local features of the maze. Perfor-mance is currently less using local features than approachesusing maze location, since information is lost about futureconsequences of actions.
What task or domain knowledge was used? Clearly thedesign of the primitives reflects a great deal of knowledgeof the task. The design of a reward function for learningfrom practice also uses knowledge of the task. The rewardfunction rewarded getting to the end of the maze, and penal-ized how long each primitive took, failing to make progress,and falling into a hole. The reward function used knowl-edge of the local direction to the goal to reward the amountof progress made by each primitive. This reflects the mar-

ble maze game, which typically has a desired path markedon the board (Figure 2). It is also easy to calculate such apath using dynamic programming or the A* algorithm, onlyconsidering marble positions and obstacle locations. The re-ward function also explicitly rewarded getting to corners, avery task specific element. Removing some of these features(corner reward, timeout penalty, and no progress penalty) re-duced performance somewhat (PRIMITIVES2 line in Fig-ure 7). In action generation learning we assume symmetry,that all corners and walls are dynamically the same. Thiscould easily not be the case. We would have to extend learn-ing to discover differences between similar situations. Inter-estingly, the only time information about wall location wasused was in recognizing primitives in the training data. Walllocation was not used by the system while playing the game.Wall and corner locations are implicit in the subgoals.
It is a common belief that the most important research is-sue in primitives is how they are invented for a new task.There are several arguments against this point of view: 1)For rapid learning, especially from a single observation,there is not enough data for statistical approaches to discov-ering primitives to work. 2) Our intuition is that some formof learning based on physical reasoning (understanding whycorners and walls are useful) is key to obtaining human lev-els of learning performance. 3) Perhaps biological systemsmake use of a selection strategy as well. We are born withan existing library of biological eye movement primitivesand gaits. It may be the case that biological systems uti-lize a fixed library of motor primitives during their lifetime.4) It may be the case that we can manually create a libraryof primitives for robots that cover a wide range of everydaytasks, and that invention of new primitives is simply not nec-essary or quite rare. Hence the emphasis in this work is onexploring how to make effective use of existing primitives.It is our hope that this exploration will inform the design ofa general set of primitives.
What properties should a set of primitives have? In orderto learn from observation, primitives need to be recogniz-able from observable data. Good primitives divide learn-ing problems up, so that each individual learning problem issimplified. For example, primitives that break input/outputrelationships up at discontinuities may lead to a set of simplelearning problems with smooth input/output relationships.
There are many issues left to be worked on: How canwe intermix learning from observation and practice? In thiswork, learning from practice follows learning from observa-tion. How can we more effectively generalize across similartasks? We are currently exploring how to generalize acrossdifferent mazes. In this work we explored model-free learn-ing approaches. We are currently exploring model-based ap-proaches, which learn a model and use the learned model toaccelerate policy learning.
ConclusionsWe showed how to enable robots to rapidly learn fromwatching a human or robot perform a task, and from practic-ing the task itself. A key component of our approach is to usebehavioral primitives. Another key component is to use theobserved human behavior to define the space to be explored
during learning from practice. We developed memory-basedapproaches to learning how to select, provide subgoals for,and perform behavioral primitives. We demonstrated bothlearning from observation and learning from practice on amarble maze task, Labyrinth. Using behavioral primitivesgreatly speeds up learning relative to learning using a directmapping from states to actions.
AcknowledgmentsSupport for all authors was provided by ATR Computational Neu-roscience Laboratories, Department of Humanoid Robotics andComputational Neuroscience, and the National Institute of In-formation and Communications Technology (NiCT). It was alsosupported in part by National Science Foundation Award ECS-0325383, and the Japan Science and Technology Agency, ICORP,Computational Brain Project.
ReferencesArkin, R. C. 1998. Behavior-Based Robotics. Cambridge, MA:MIT Press.Atkeson, C. G., and Schaal, S. 1997. Learning tasks from a singledemonstration. In Proceedings of the 1997 IEEE InternationalConference on Robotics and Automation (ICRA97), 1706–1712.Atkeson, C. G.; Moore, A. W.; and Schaal, S. 1997. Locallyweighted learning. Artificial Intelligence Review 11:11–73.Barto, A., and Mahadevan, S. 2003. Recent advances in hierar-chical reinforcement learning. Discrete Event Systems 13:41–77.Bentivegna, D. C.; Atkeson, C. G.; and Cheng, G. 2003. Learn-ing from observation and practice at the action generation level. InIEEE-RAS International Conference on Humanoid Robotics (Hu-manoids 2003).Bentivegna, D. C.; Ude, A.; Atkeson, C. G.; and Cheng, G. 2002.Humanoid robot learning and game playing using PC-based vi-sion. In Proceedings of the 2002 IEEE/RSJ International Confer-ence on Intelligent Robots and Systems.Bentivegna, D. C. 2004. Learning from Observation usingPrimitives. Ph.D. Dissertation, Georgia Institute of Technology,Atlanta, GA, USA. http://etd.gatech.edu/theses/available/etd-06202004-213721/.Erdmann, M. A., and Mason, M. T. 1988. An exploration of sen-sorless manipulation. IEEE Journal of Robotics and Automation4:369–379.Ormoneit, D., and Sen, S. 2002. Kernel-based reinforcementlearning. Machine Learning 49:161–178.Russell, S. J., and Norvig, P. 1995. Artificial Intelligence: AModern Approach. Prentice Hall.Santamaria, J.; Sutton, R.; and Ram, A. 1998. Experiments withreinforcement learning in problems with continuous state and ac-tion spaces. Adaptive Behavior 6(2).Schmidt, R. A. 1988. Motor Learning and Control. Champaign,IL: Human Kinetics Publishers.Smart, W. D., and Kaelbling, L. P. 2002. Effective reinforce-ment learning for mobile robots. In IEEE International Conf. onRobotics and Automation.Sutton, R., and Barto, A. 1998. Reinforcment Learning: An In-troduction. MIT Press.Watkins, C., and Dayan, P. 1992. Q learning. InMachine Learn-ing, volume 8, 279–292.





























