Embed Size (px)
Citation preview

Latent Sector Errors Latent Sector Errors In Disk DrivesIn Disk Drives
Ahmet Salih BÜYÜKKAYHAN2007706435 - 2009 Spring

OUTLINEOUTLINEMotivationIntroductionDisk ErrorsError HandlingEvaluationConclusion

MotivationMotivation
90% of all new information produced in the world is being stored on magnetic media mostly hard disk drives
This study analyzes data collected from production storage systems over 32 months across 1.53 million disks◦ storage system has a built-in, low-overhead
mechanism to log important system events back to a central repository
This study can shed light on disk fault prevention, fault tolerance and fault forecasting researches

Introduction - Disk DrivesIntroduction - Disk DrivesMechanical and
electronic components
Disk Controller◦ Electronic component◦ Convert serial bit
stream to block of bytes
◦ perform error correction as necessary

Introduction - Disk DrivesIntroduction - Disk DrivesSectors: the smallest
addressable unit of data access, usually 512 bytes in size ◦ Error correcting codes
Linear array of equal sized blocks each identified by a logical block number (LBN).

IntroductionIntroductionFactors other than complete disk
failures influence the reliability of data and expressed as mean time to data loss (MTTDL)
Disk drives do not report any latent sector error until the particular sector is accessed.

DiskDisk DDrivesrives Failure Failure PatternPattern
Bad sector errors: manufactoring defectsSeek errors: head can not be positioned in the
right track◦ The disk head needs to be recalibrated
Data Corruption◦ Lost writes : not write but completion is reported◦ Misdirected writes: write to the wrong disk block◦ Torn writes: partially write but completion is reported

Disk ErrorsDisk ErrorsLatent Sector Errors: disk sector cannot be
read or written, or uncorrectable ECC error. ◦ Any data previously stored in the sector is lost.◦ Requires higher-level mechanisms such as RAID
reconstructionNot-Ready-Condition Errors: Disk drive is
not ready to handle a command from the host. ◦ waiting and retrying.
Recovered Errors: Access to a sector required disk-level retry or error-correction.

Error HandlingError Handling
Some disks able to re-map automaticallyOS can handle bad sectors by re-mapping
tables◦ Constructs a list of bad sectors◦ Both allocated and free blocks tested

Proactive Error DetectionProactive Error DetectionMedia scrubs use a SCSI Verify
command to validate a disk sector’s integrity. (ECC)◦ check of the sector’s content within the disk
A data scrub: to detect data corruption.◦ read operations for each disk sector,
computes a checksum over its data, ◦ compares the checksum to the on-disk 8-
byte checksum◦ reconstructs the sector from other disks in
the RAID group if the checksum fails◦ Latent sector errors discovered by data
scrubs appear as read errors.

System System ArchitectureArchitecture
Store, verify block ID (Inode X, offset Y)
Detect identity discrepancy Lost or misdirected writes
WAFL® File Sys
RAID layer
Storage layer
Disk drives
Aut
osup
port
Client IFace (NFS)
Parity generation Reconstruction on failure Data scrubbing
o Read blocks, verify parityo Detect parity
inconsistencyo Lost or misdirected writes,
parity miscalculations
Store, verify checksumo Detect checksum
mismatcho Bit corruptions, torn writes

12
RAIDRAID – I/O Parallelism – I/O ParallelismRAID is a set of disks with a single RAID controller
◦ Improve the fault tolerance and performance ◦ Reduce costs
The disks in RAID appear as a single disk to the OS
There are six different RAID organizations (0…5)
RAID level 0 : Strips of size “k-sectors” partitioned into individual disks in round robin fashiono There is no redundant data storage in this
approacho No performance gain if the requests are one
sector at a time!

13
RAIDRAID
RAID level 1: Duplicates all the disks.◦ Every strip is written twice!
◦ Either of the two copies could be read!
Write performance is the same Read performance can be twice as goodFault tolerance is excellent
o Recovery is easy, buy a new drive, and replace it with the one that crashed

14
RAIDRAID
RAID level 2: granularity striping with hamming code for error detection and correction.
Disk drives must be synchronized
RAID level 3: simplified version of level 2, where only parity is stored.
Single disk crash?

15
RAIDRAID
RAID level 4: With a strip of k bytes, an extra disk drive stores k-byte long parities constructed by XOR on the strips in each disk
RAID level 5: Like RAID 4 but parity bits are distributed over the RAID disks to reduce the risk induced by parity disk crash

16
Stable StorageStable StorageRAID deals with correct reads and
fault tolerance against crashesHow about writes?Desired Property:
◦ When a write is issued, the disk either correctly writes the data or it does nothing at all

17
Stable StorageStable Storage
Stable storage uses a pair of identical disks with the corresponding blocks form an error-free block
Stable write:◦ Write the block on drive 1◦ Read it back and verify it, if not correct repeat the
operation◦ After n consecutive failures the block is remapped to a
spare one and the operation continues◦ After the write to drive 1 succeeds, the corresponding
block on drive 2 is written and re-read until it succeeds◦ After the stable write completes, the block is successfully
written to both drives

18
Stable StorageStable Storage
Stable read:◦ First read from drive 1◦ If the ECC indicates and error, then reread◦ If after n iterations, the error occurs, then the
corresponding block is read from drive 2Crash recovery
◦ Scan both disks and compare the corresponding blocks◦ If one of the has ECC error, then the good one is written
over the bad one◦ If both have ECC good, but they are different, then the
block in drive 1 is overwritten to drive 2.

EvaluationEvaluationDisk class: Enterprise class or nearline
disk drives with respectively Fiber Channel and ATA interfaces.
Disk model: Combination of disk family and particular size ◦ Quantum Fireball EX – 6.4 GB Denoted as ‘E-1’
Disk Age: Amount of time in the field since ship date
Error disk: This term is used to refer to a disk drive that has at least one latent sector error.

EvaluationEvaluationSample Selection
◦ Model has at least 1000 disks in the field for time period being considered
◦ Model has at least 1000 disks in the field and at least 50 error disks for time being considered
◦ Disregard the very few “outlier” disks (0.2% of error disks) with more than 1000 errors to avoid the skew caused by these numbers
A-E Nearline disks, F-N Enterprise disks.E-2 have the double disk size according
to E-1

Impact of Disk AgeImpact of Disk Age
Enterprise disks Nearline disksDisk age impact varies across disk modelsNearline disk LSE grows far more rapidly
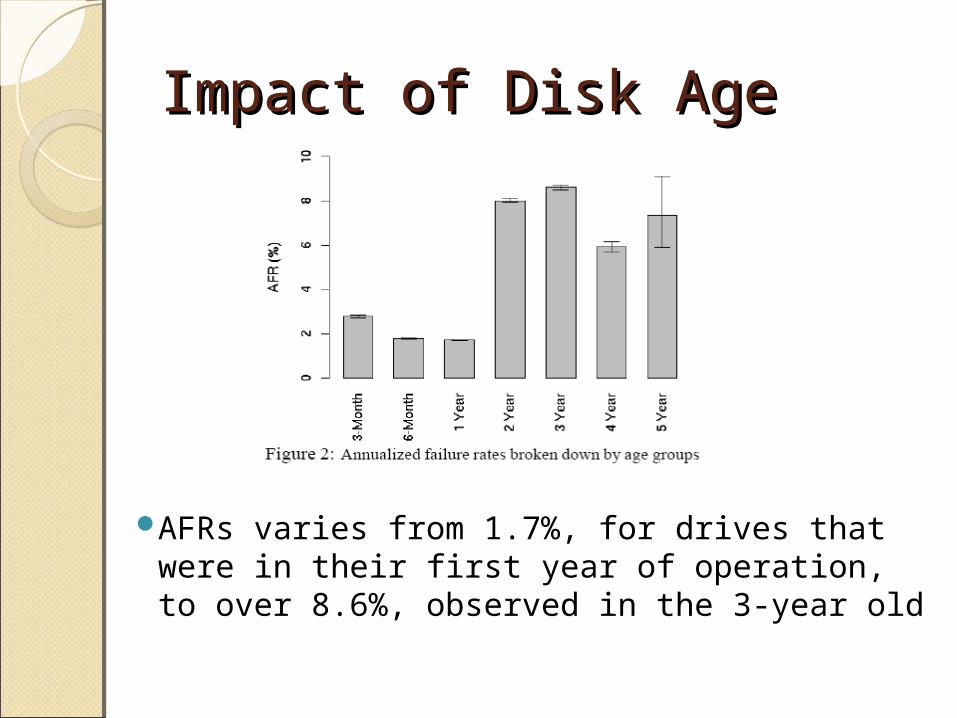
Impact of Disk AgeImpact of Disk Age
AFRs varies from 1.7%, for drives that were in their first year of operation, to over 8.6%, observed in the 3-year old
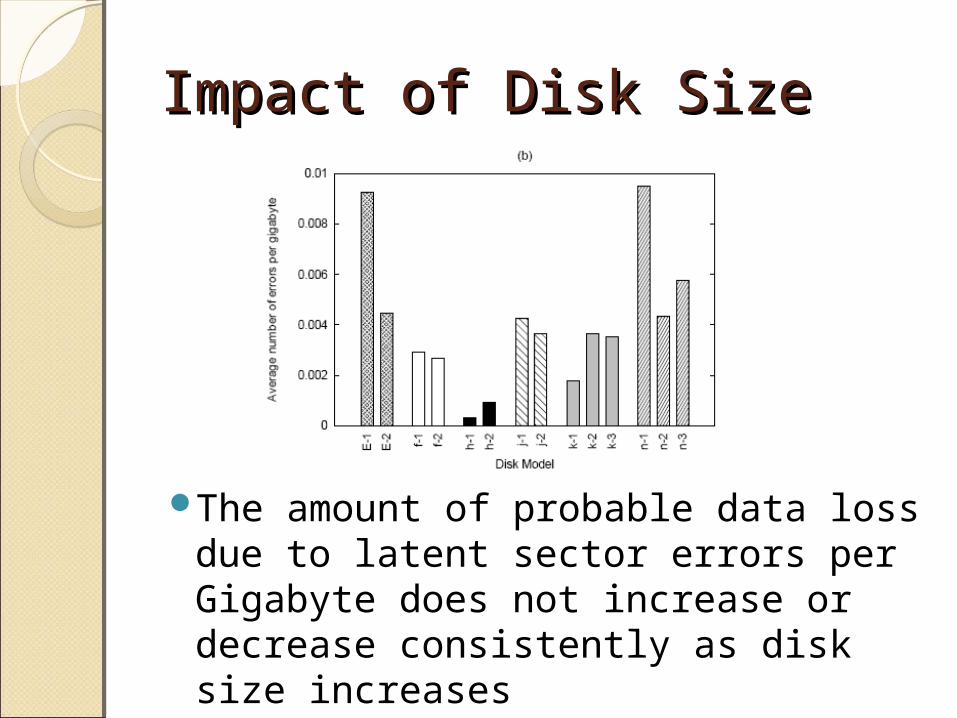
Impact of Disk SizeImpact of Disk Size
The amount of probable data loss due to latent sector errors per Gigabyte does not increase or decrease consistently as disk size increases

Errors per Error DiskErrors per Error Disk
ES&NL are equally likely to develop more than one error once they develop their first error.

Spatial LocalitySpatial Locality
There is significant locality in the occurrence of latent sector errors across logical sector addresses

26
Spatial LocalitySpatial Locality
Use locality radius to measure locality
Logical Block Number Space
100 block: 2/5 errors have 1 neighbor1000 block: 4/5 errors have 1 neighbor
Beginning of disk End of disk
100 Block locality radius
1000 Block locality radius

Temporal LocalityTemporal Locality
Disks that develop errors beyond the first error see most of the additional errors within one month after the first error.

Detection MethodsDetection Methods
Media scrubbing detects a large percentage of observed latent sector errors
86.6% of all LSE in NL and 61.5% of LSE in ES are discovered by verify operations

ConclusionConclusionThe fraction of disks affected by LSE
increases linearly with time for enterprise class disks and super linearly for nearline disks.
The percentage of affected disks depends on many factors, such as the disk drive model, the age of the disk drive, and the storage capacity of the drive.
A disk with a latent sector error is more likely to develop another latent sector error than a disk without an error.

ConclusionConclusionThe fraction of disks affected by
latent sector errors increases as disk capacity increases
Latent sector errors shows high spatial and temporal locality.
Latent sector errors correlate with not ready condition errors especially NL.
Latent sector errors also correlate with recovered error warnings especially ES.

ReferencesReferences [1] L. Bairavasundaram, G. Goodson, S. Pasupathy, and
J. Schindler. An Analysis of Latent Sector Errors in Disk Drives. In SIGMETRICS ’07, pages 289–300, San Diego, CA, June 2007.
[2] E. Pinheiro, W. D. Weber, and L. A. Barroso. Failure Trends in a Large Disk Drive Population. USENIX Conference on File and Storage Technologies, Feb.13–16, 2007.
[3] Bianca Schroeder and Garth Gibson. Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? In FAST ’07, pages 1–16, San Jose, CA, February 2007.
[4] Jimmy Yang and Feng-Bin Sun. A comprehensive review of hard-disk drive reliability. In 1999 Proceedings Annual Reliability and Maintainability Symposium, 1999.

ThanksThanks





























