Embed Size (px)
Citation preview

Large Scale Matrix-Free
Topology Optimization on the GPU
Krishnan Suresh
Associate Professor
Mechanical Engineering

What is Topology Optimization?
2

Topology Optimization (2D)
Reduce weight, but keep it stiff
Structure problem Optimal topologies
10% reduction in weight
2% loss in stiffness
D
50% reduction in weight
12% loss in stiffness
Topology optimization is the systematic generation of such structures
3

TopOpt (SIMP)
0 1 : ' Density' e
r< £
SIMP: Most popular TopOpt method
4

Topology Optimization (3D)
40% reduction in weight
10% loss in stiffness
50% reduction in weight
30% loss in stiffness
5
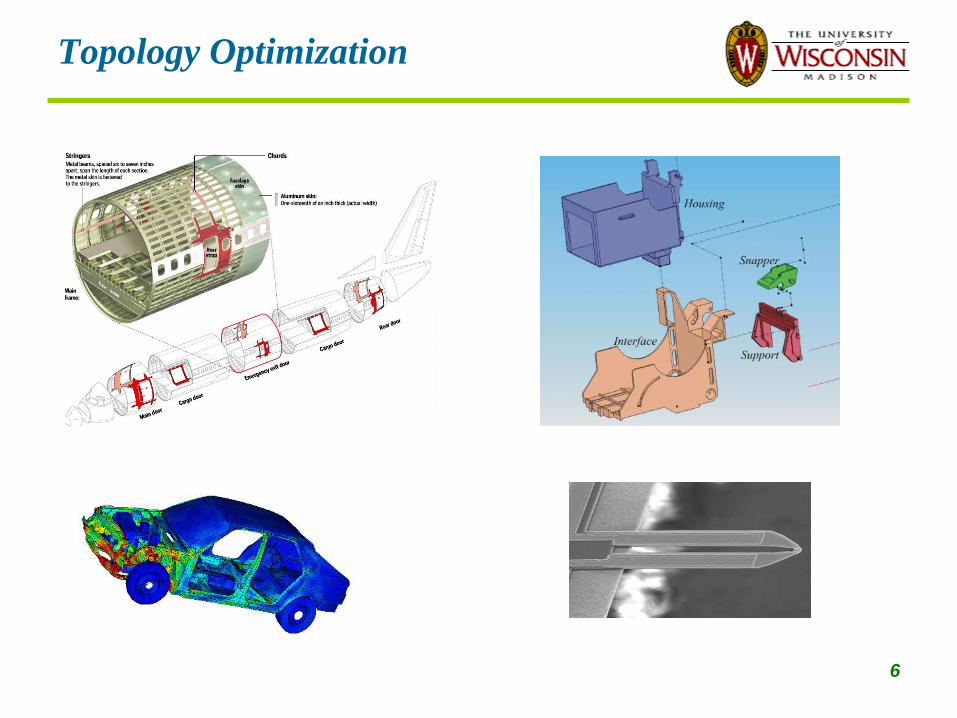
Topology Optimization
6

Computational Challenge?
7
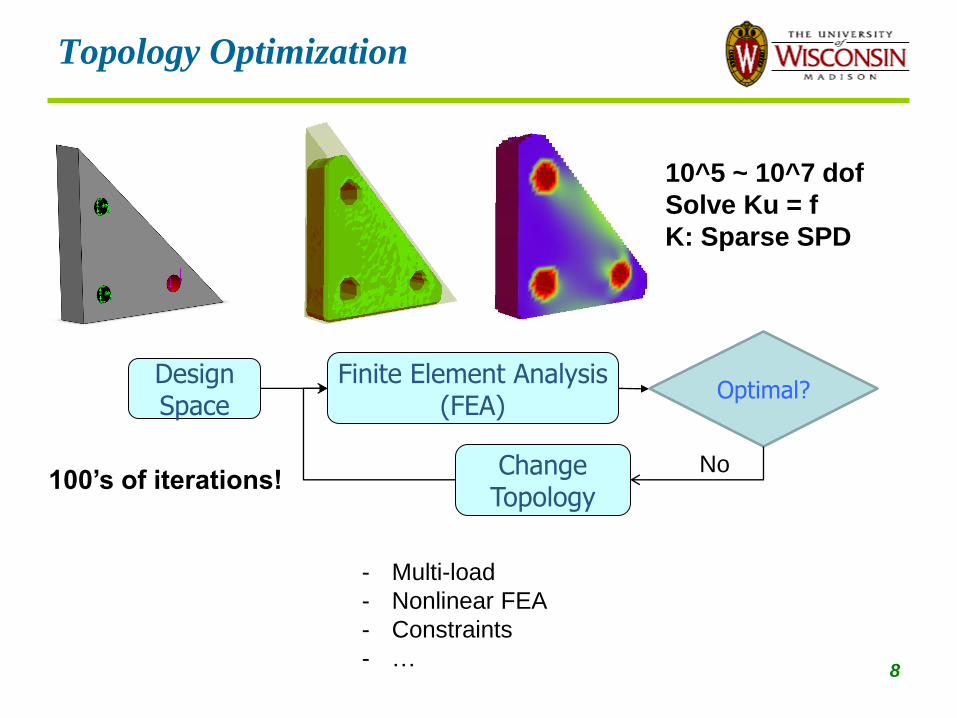
Topology Optimization
Design Space
Finite Element Analysis (FEA)
Optimal?
Change Topology
No
10^5 ~ 10^7 dof
Solve Ku = f
K: Sparse SPD
100’s of iterations!
- Multi-load
- Nonlinear FEA
- Constraints
- … 8

Topology Optimization Cost
Size DOF [Wang]
Medium (84,28,14) 107,184 2.4 hours
Large (180,60,30) 1,010,160 45.7 hours
AMD Opteron TM252 2.6GHz
64-bit processor, with 8GB RAM
9

Solve Ku=f
10
Method
• Direct
• Iterative
Precision
• Single
• Double

Iterative Solve Ku = f on GPU
11

Iterative Solve Ku = f
Two Goals:
1. Minimize #iterations
2. Minimize cost of K*u (SpMv)
1 ( )
: Preconditioner of K
i i iu u B f Ku
B
12

13
SpMV on GPU
Double precision real world SpMv
100,000 to 1 Million degrees of freedom
GPU (GTX 280): 2~6 increase in flop-rate

14
Iterative Ku = f (GTC 2012)
Fine-grained Parallel Preconditioners …(Wed)
CULA (Wed)
MAGMA (Wed)
Accelerating Iterative Linear Solvers (Wed)
Efficient AMG on Hybrid GPU Clusters (Wed)
Preconditioning for Large-Scale Linear Solvers (Thu)
…

Iterative Solve Ku=f in TopOpt:
Unique Challenges
15
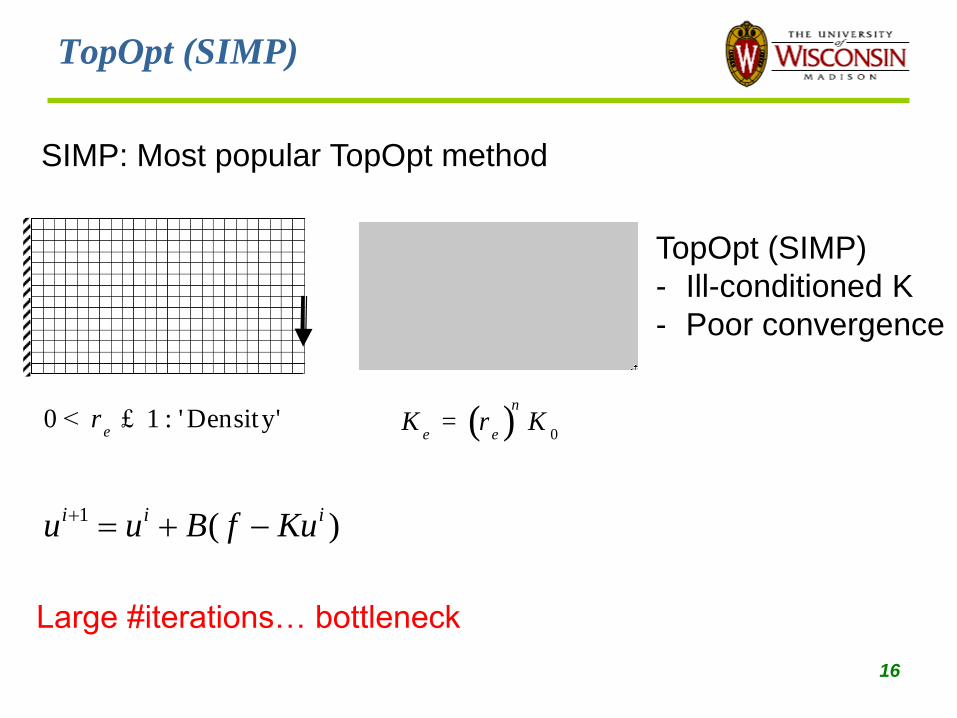
TopOpt (SIMP)
0 1 : ' Density' e
r< £
TopOpt (SIMP)
- Ill-conditioned K
- Poor convergence
SIMP: Most popular TopOpt method
( ) 0
n
e eK Kr=
Large #iterations… bottleneck
16
1 ( ) i i iu u B f Ku

PareTO: A GPU-Friendly TopOpt Method
17

PareTO
Don’t Assign Densities!!
Compute T-Field!!
18
3 1 1 510 : ( ) ( )
2 7 5 1 2tr tr
n ns e s e
n n
é ù- -ê ú= - -ê ú- -ë û
T=
T
0.00004 A
1.36 B
T(x,y) = Stiffness-change
when hole is added @(x,y)

T-Field
19

T-Field: Level-Set
20

T-Field: Optimization

…
22

PareTO Algorithm
Design Space
FEA TopSens
Decrement Volume
Pareto-Optimal?
Yes
Recompute t No
23

Pareto Optimal Designs

PareTO
SIMP
PareTO
Now focus on GPU accelerated K*u
25
PareTO: Well-conditioned K Few CG iterations

Fast K*u on GPU
26

Approach-1: Classic
GPU thread per node ?
~100 non-zeros
1. Assemble K (CPU/GPU)
2. Push to GPU
3. Execute K*u in parallel
Coalesced memory access
challenging!

Approach-2: Matrix-Free
e
e
K K
? ...
e e e
e e
Ku K u K u

Exploit Element Congruency
20 distinct elements
120 distinct elements 1 distinct element
1.48 MB storage (vs. 384 MB)

Algorithm
Detect
Congruency
Hex-mesh
Compute Ke of templates
Push data to GPU
Assembly-free
PCG Solve
Ku = f
on GPU
30
Element: Present
or Absent
TopOpt

K*u on GPU
31

PareTO: Examples
32

Platform
CPU:
– i7, 3.2 GHz, 8 core
– 6 GB
– C Code (OpenMP)
GPU:
– GTX 480 (400 cores)
– 1.5 GB
33

Typical FEA Computing Time
34
DOF PareTO
CPU GPU
Cantilever
Beam; Edge
110K 8.3 secs 1.9 secs
Stool 2.7M 186 secs 32 secs
Point Load
Cantilever
15M 51 mins 5.73 mins
92M 12 hr -
1.5 hr on 44 core (ONR)

TopOpt Comparison
Size DOF [Wang]*
Medium (84,28,14) 107,184 2.4 hours
Large (180,60,30) 1,010,160 45.7 hours
AMD Opteron TM252 2.6GHz
64-bit processor, with 8GB RAM GTX 480
Identical results
35

Bridge Problem
36

Bridge Problem
37

Knuckle Problem
20,000 dof (Abaqus)
38

Wheel Support
39

TopOpt Computing Time
40
Name of part &
volume fraction
DOF Pub.
Data
PareTO
CPU GPU
Cantilever
Beam; Edge (0.50)
110K 2.4 hr 200 secs 45 secs
Knuckle (0.55) 20K -- 111 secs 44 secs
Bridge (0.35) 113K -- 2 mins 36.2 secs
Stool; N=96 (0.20) 2.7M 21.8 hr 1 hr, 24
mins
14 mins
Point Load
Cantilever (0.50)
783K 3.9 hr 16 mins 125 s
15M - 19hr, 28
mins
2hr, 12 mins
92M - 12 days,
2hr
-






























