Embed Size (px)
Citation preview

MSC Software Confidential
GPU Enhancements for Noise, Vibration
and Harshness (NVH) Analysis
Dr. Ted Wertheimer

MSC Software Confidential MSC Software Confidential
20 Million DOF - 3.9 M elements
2 3/20/2013

MSC Software Confidential MSC Software Confidential
• This model extracted many modes:
• up to 1500 Hz structure -> ~26500 modes
• up to 1500 Hz fluid -> ~3200 modes
• Large frequency range: 0 to 1024 Hz in 2048 frequency steps
20 Million DOF
3 3/20/2013
# Nodes DMP SMP Elapsed Time
4 16 * 4 4:58:09

MSC Software Confidential MSC Software Confidential
94 Million DOF
4 3/20/2013

MSC Software Confidential MSC Software Confidential
• Automated Component Modal Synthesis
(ACMS)
• MSC Nastran model is automatically divided
into N domains
• Executes in parallel using Distributed Memory
Parallel (DMP)
– Shared Memory Parallel (SMP) provides additional
speedup
ACMS

MSC Software Confidential MSC Software Confidential
1 2 3 4 6 7 8 9 10 11 12 13 14 15 16
0
25
21 23 22 24
26
20 19 18 17
30
28 27
Master
Slave 2
Slave 1
Slave 3
29
Example with DMP=4
ACMS Domain Decomposition
5

MSC Software Confidential MSC Software Confidential
• Multi-CPU, multi-core parallel scalability
• 2X performance increase from 2010
MSC Nastran ACMS – Automotive Models
0
200
400
600
800
serial 12 CPUs serial 12 CPUs serial 12 CPUs serial 12 CPUs
Case 1 Case 2 Case 3 Case 4
ACMS)
2010
2011.1
2011.22012

MSC Software Confidential MSC Software Confidential
• Up to 3X faster for exterior acoustics
– Exterior acoustics
– Brake squeal
– Friction
– Rotordynamics
Nonsymmetric Solver Performance
0
200
400
600
800
1000
1200
1400
1600
1800
2000
fr resp total job
Case 3
Exterior acoustics
2011.1
2011.22012

MSC Software Confidential MSC Software Confidential
Improved Performance for Acoustics
• Efficient Participation Factor
3 Times Faster
MSC Nastran 2012 MSC Nastran 2010

MSC Software Confidential MSC Software Confidential
• Nastran direct equation solver is GPU accelerated – Sparse direct factorization (MSCLDL, MSCLU)
• Real, Complex, Symmetric, Un-symmetric
– Handles very large fronts with minimal use of pinned host memory • Lowest granularity GPU implementation of a sparse
direct solver; solves unlimited sparse matrix sizes
– Impacts several solution sequences: • High impact (SOL101, SOL108), Mid (SOL103), Low
(SOL111, SOL400)
MSC Nastran 2013
10

MSC Software Confidential MSC Software Confidential
• Support of multi-GPU and for Linux and Windows – With DMP> 1, multiple fronts are factorized
concurrently on multiple GPUs; 1 GPU per matrix domain
– NVIDIA GPUs: Tesla K20/K20X, Tesla M2090, Tesla
C2075, Quadro 6000 – CUDA 5.0
MSC Nastran 2013
11

MSC Software Confidential MSC Software Confidential
Direct sparse solver workflow
in MSC Nastran (MSCLDL, MSCLU)
3/20/2013
In a proper order, do the
following at each node.
Assembly
Pivoting
Block factorization:
from Global Stiffness &
contribution blocks
11
9 10
8
6 7
5
3 4
1 2
Most time-consuming matrix update operations on GPU
Off-diagonal
update
Diagonal
decomposition Schur Complement
Trailing matrix update

MSC Software Confidential
Block LU Decomposition
Direct solves are (typically) performed using Block LU
decomposition
Spend most of their time computing the Schur Complement
Compute bound / low hanging fruit
A11 A12
A21 A22
0
L21 I
I 0
0 A22 –
L21U12 0
= * *
U12
I
L11 U11
DGEMM
DTRSM DPOTRF DPOTRF
DTRSM
L11 U11 = A11
L11 U12 = A12
L21 U11 = A21
MSC Software Confidential
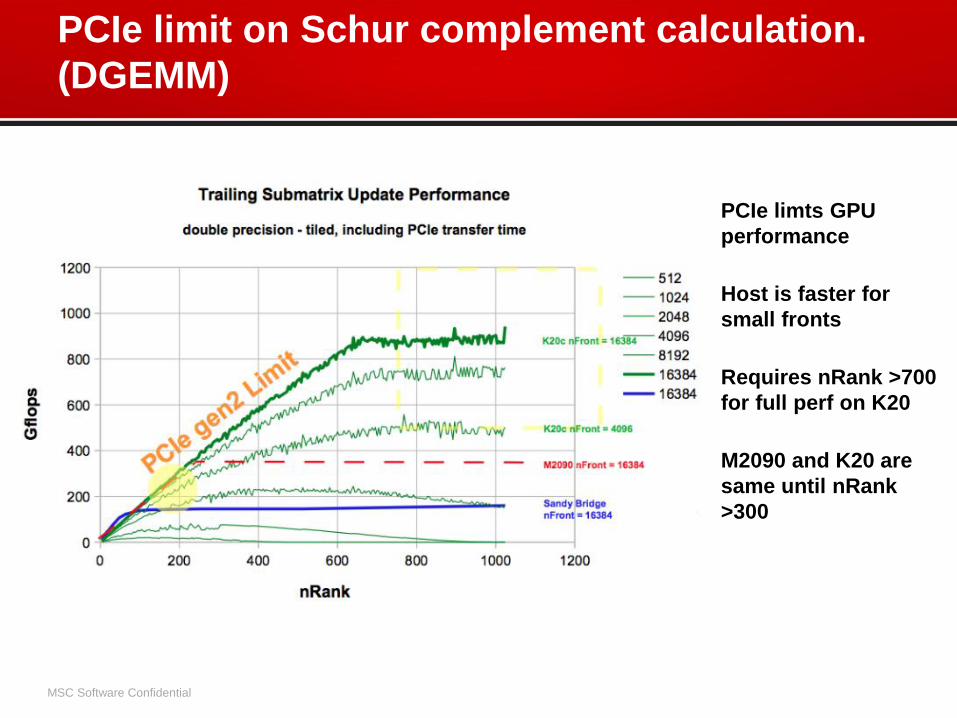
PCIe limit on Schur complement calculation.
(DGEMM)
• PCIe limts GPU
performance
• Host is faster for
small fronts
• Requires nRank >700
for full perf on K20
• M2090 and K20 are
same until nRank
>300
MSC Software Confidential MSC Software Confidential
0
1.5
3
4.5
6
SOL101, 2.4M rows, 42K front SOL103, 2.6M rows, 18K front
serial 4c 4c+1g
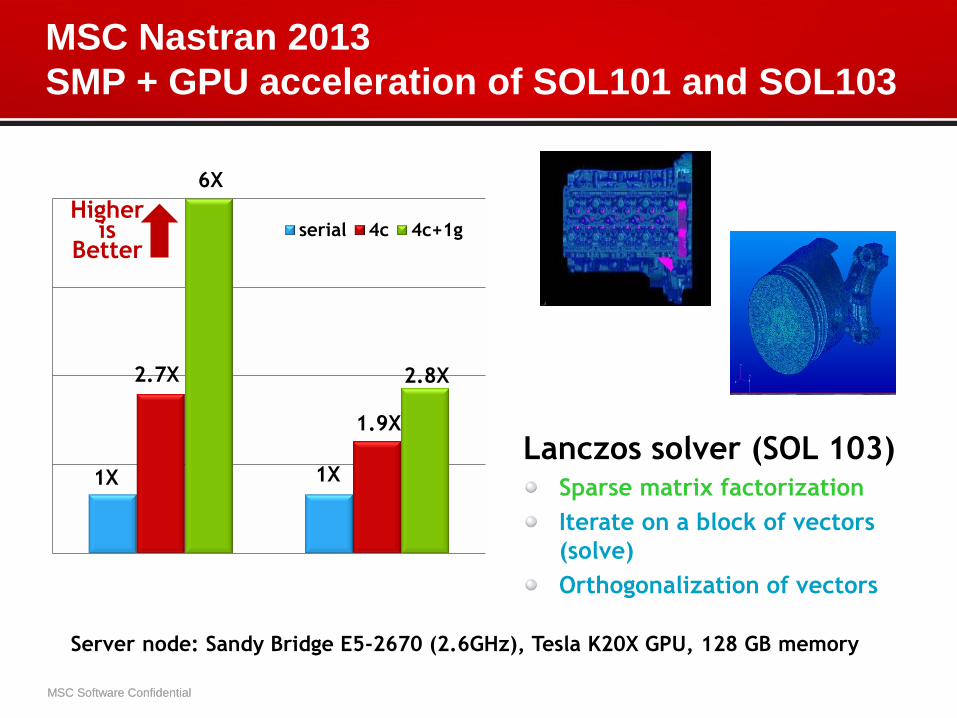
MSC Nastran 2013
SMP + GPU acceleration of SOL101 and SOL103
Higher is
Better
Server node: Sandy Bridge E5-2670 (2.6GHz), Tesla K20X GPU, 128 GB memory
1X 1X
2.7X
1.9X
6X
2.8X
Lanczos solver (SOL 103) Sparse matrix factorization
Iterate on a block of vectors
(solve)
Orthogonalization of vectors

MSC Software Confidential MSC Software Confidential
0
200
400
600
800
1000
serial 1c + 1g 4c (smp) 4c + 1g 8c(dmp=2)
8c + 2g(dmp=2)
NVH with MSC Nastran 2013
Coupled Structural-Acoustics simulation with SOL108
1X
Lower is Better
Europe Auto OEM 710K nodes, 3.83M elements
100 frequency increments
(FREQ1)
Direct Sparse solver
4.8X
2.7X
5.2X 5.5X
11.1X
Server node: Sandy Bridge 2.6GHz, 2x 8 core, Tesla 2x K20X GPU, 128GB memory
Ela
psed
Tim
e in M
inu
tes

MSC Software Confidential
MSC Nastran 2013:
Solution Price-Performance Gain
MSC Software Confidential MSC Software Confidential
0
20
40
60
80
serial smp 4c smp 4c+1g(x1 node)
dmp 4c+1g(x2 nodes)
dmp 4c+1g(x3 nodes)
Elap
sed
Tim
e in
Ho
urs
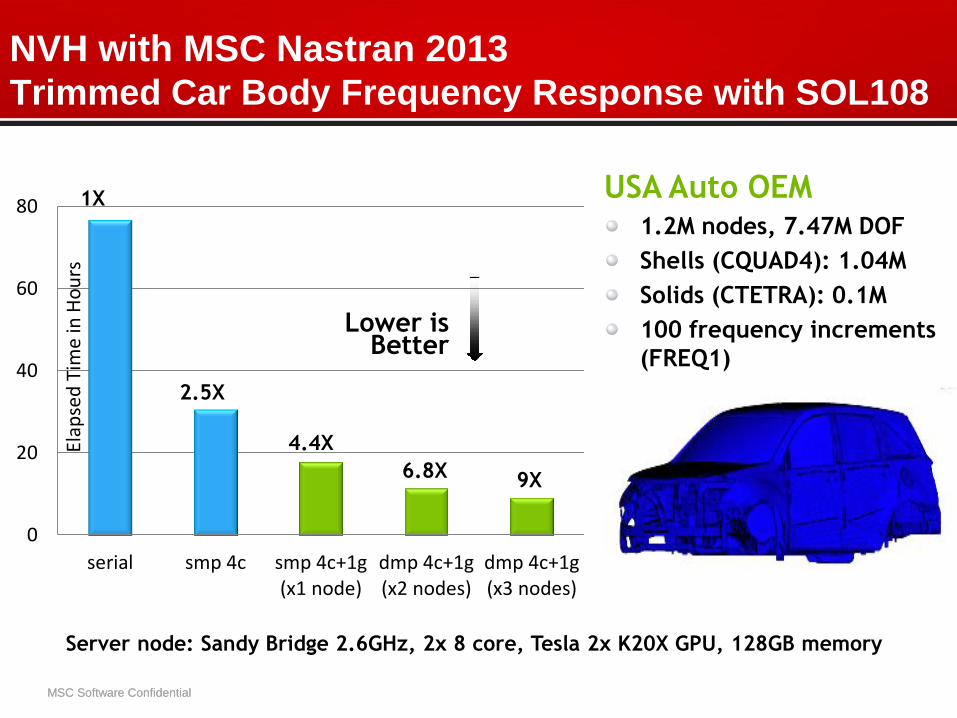
NVH with MSC Nastran 2013 Trimmed Car Body Frequency Response with SOL108
Server node: Sandy Bridge 2.6GHz, 2x 8 core, Tesla 2x K20X GPU, 128GB memory
1X
2.5X
Lower is Better
USA Auto OEM 1.2M nodes, 7.47M DOF
Shells (CQUAD4): 1.04M
Solids (CTETRA): 0.1M
100 frequency increments
(FREQ1)
4.4X
6.8X 9X

MSC Software Confidential MSC Software Confidential
• Japan Auto OEM – Nodes 1.4M, Elements 0.78M
• Mainly TETRA10
– Modes: 104 (2500 Hz )
– Front size: 23,718
NVH with MSC Nastran 2013
Engine Model Modal Frequency with SOL111
2848
1000
614
586
2807
901
2303
2168
0
2000
4000
6000
8000
10000
1CPU(9052sec.)
1CPU+1GPU(5116sec.)
CPU Time
Tim
e(s
ec.)
FBS+Matrix-vectorMultply
Shift+Decomposition
Sparse Decomposition
only
335 239
2856
1027
6180
4120
291
223
0
2000
4000
6000
8000
10000
12000
1CPU(9702sec.)
1CPU+1GPU(5647sec.)
Elaps Time
Tim
e(s
ec.)
Pre_Eigenvalue
Eigenvalue
Resvec
Post_Eigenvalue
1.7x speedup

MSC Software Confidential MSC Software Confidential
• Marc multi-frontal sparse solver is GPU accelerated – Marc Solver type 8
• Support of multi-GPU and for Linux and Windows – Recommend 1 GPU per DDM
Marc 2012
3/20/2013
MSC Software Confidential MSC Software Confidential
0
200
400
600
800
1000
1200
1400
1600
1800
Serial 1c + 1gpu
nps=2 nps=2, 2gpus
nps=4, 2gpus
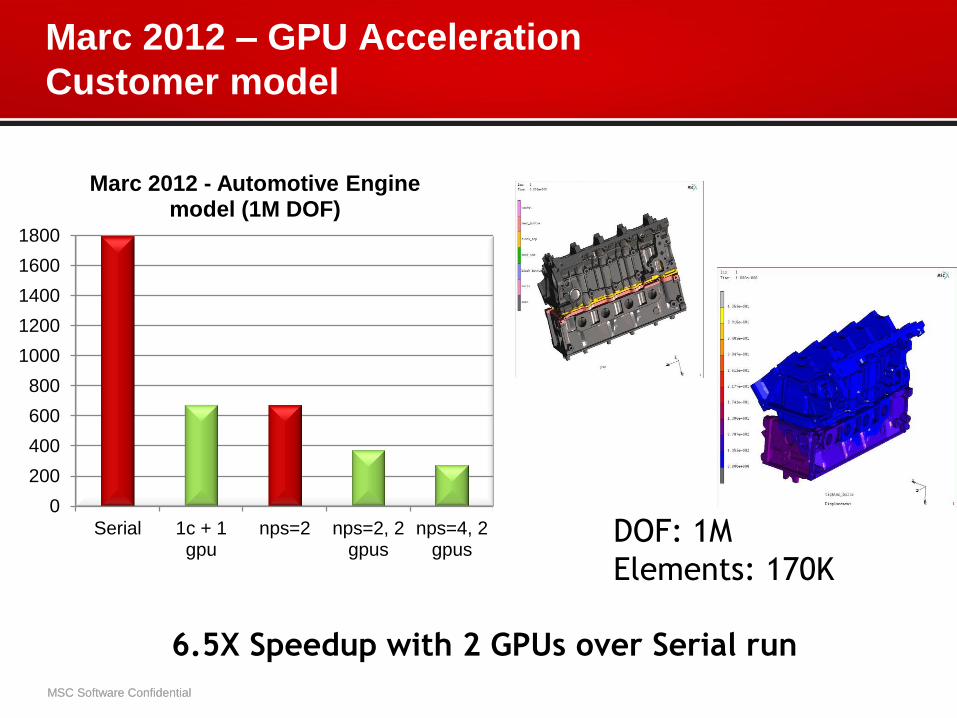
Marc 2012 - Automotive Engine model (1M DOF)
Marc 2012 – GPU Acceleration
Customer model
6.5X Speedup with 2 GPUs over Serial run
DOF: 1M
Elements: 170K

MSC Software Confidential MSC Software Confidential
Marc 2012 – GPU Acceleration of US Auto OEM
model
22 3/20/2013
Speed Up – End to End
2.5 Million Elements
10 Million DOF
Nonlinear Bolt Tightening
48 Iterations
0
0.5
1
1.5
2
2.5
3
Serial (1c) 4c 1c+1 GPU

MSC Software Confidential
Conclusions
• GPUs provide for significant performance acceleration for direct
solver intensive large jobs, ie. max front > 10000 for real data and
> 5000 for complex data models.
• Multiple GPU performance is available with DMP>1 including for
NVH SOL108 (embarrassingly parallel).
• NVIDIA and MSC continue to work together to tune BLAS and
LAPACK kernels for MSCLDL and MSCLU.
• As Models become larger the value of GPGPU becomes Greater
23

MSC Software Confidential MSC Software Confidential
Thank You
24 3/20/2013





























