Embed Size (px)
Citation preview

Knowledge Discovery in Databases
Chung-Chian Hsu
National Yunlin University of Science and Technology

From Data Mining to Knowledge Discovery: An Overview
U. Fayyad, G. Piatetsky-Shapiro, and P. Smyth
Advances in Knowledge Discovery and Data Mining, pp.1-36, 1996

3
Knowledge Discovery in Databases
Non-trivial process of identify valid, novel, potentially useful, and ultimately understandable patterns in data

4
Related Research Fields
• Machine Learning
• Pattern Recognition
• Databases
• Statistics
• Artificial Intelligence
• Knowledge Acquisition for Expert Systems
• Data Visualization
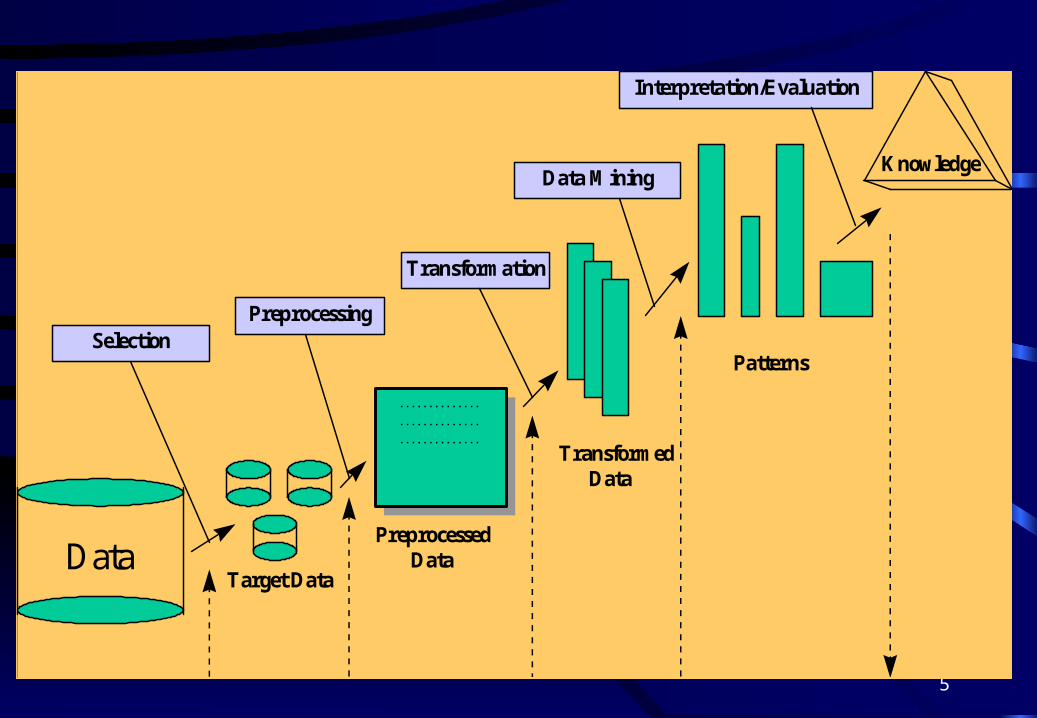
5
DataTarget Data
Preprocessed Data
Transformed Data
Patterns
Knowledge
SelectionPreprocessing
Transformation
Data Mining
Interpretation/Evaluation

6
The KDD Process
• Interactive and iterative, involving numerous steps with many decisions being made by the user– Selection– Preprocessing: noise, missing data, error– Transformation: reduction, projection– Data mining– Interpretation and evaluation

7
An Overview of Data Mining Methods
• Data Mining– a step in KDD process consisting of particular data
mining algorithms that, under some acceptable computational efficiency limitations, produces a particular enumeration of patterns
– involves fitting models to, or determining patterns from observed data
Note: a pattern can be thought of as instantiation of a modele.g. f(x)= 3x2 + x is a pattern whereas f(x) = x2+ x
is considered a model

8
Primary Goals of Data Mining
• Prediction– Using some variables or fields in database to predict
unknown or future values of other variables of interest
e.g. education, job, sex and salary
• Description– Finding human-interpretable patterns describing the
data
e.g. mean, variance, mode, distribution

9
Primary Tasks of Data Mining -1
• Classification:– Learning a function that classify a data item into one of
several predefined classes
• Regression– Learning a function that maps a data item to a real-valued
predication variable
• Clustering– Identify a finite set of categories or clusters to describe the
data
• Summarization– Finding a compact description for a subset of data

10
Primary Tasks of Data Mining -2
• Dependency Modeling– Finding a model which describes significant
dependencies between variables
• Change and Deviation Detection– Discovering the most significant changes in the data
from previously measured or normative values

11
Components of Data Mining Algorithms -1
• Model Representation– Describing discoverable patterns
• Search Method– Parameter search:
• Search for parameters optimizing model evaluation criteria given observed data and a fixed model representation
– Model search: • Model representation is changed so that a family of models are
considered.
• For each specific model representation, parameter search method is instantiated to evaluate the quality of that particular model

12
Components of Data Mining Algorithms -2
• Model Evaluationestimates how well a particular pattern meet the
criteria of the KDD process

13
Popular Data Mining Methods
• Decision trees and rules // propositional logic power
• Nonlinear regression methods; e.g. Neural network
• Example-based methods: e.g. nearest-neighbor classification, regression algorithms, cas
e-based reasoning
• Probabilistic graphical dependency modelse.g. baysian network
• Genetic algorithms• Inductive logic programming // first-order logic power

14
Day Outlook Temperature Humidity Wind PlayTennisD1 Sunny Hot High Weak NoD2 Sunny Hot High Strong NoD3 Overcast Hot High Weak YesD4 Rain Mild High Weak YesD5 Rain Cool Normal Weak YesD6 Rain Cool Normal Strong NoD7 Overcast Cool Normal Strong YesD8 Sunny Mild High Weak NoD9 Sunny Cool Normal Weak YesD10 Rain Mild Normal Weak YesD11 Sunny Mild Normal Strong YesD12 Overcast Mild High Strong Yes
D13 Overcast Hot Normal Weak YesD14 Rain Mild High Strong No

15
Outlook
Sunny RainOvercast
High Normal
No Yes
Strong Weak
No Yes
YesHumidity Wind

16
Decision Tree Learning (cont’d)
• Inductive rules from the previous examples
1. IF Outlook= Sunny AND Humidity= Normal,
THEN PlayTennis
2. IF Outlook= Overcast,
THEN PlayTennis
3. IF Outlook= Rain AND Wind= Weak,
THEN PlayTennis
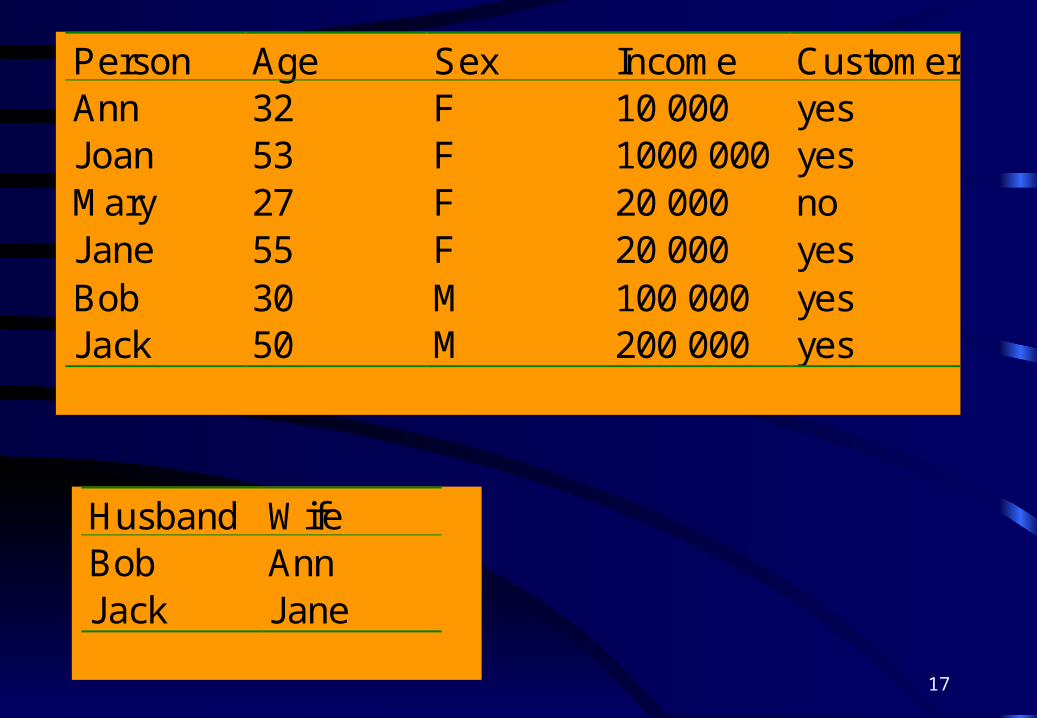
17
Person Age Sex Income CustomerAnn 32 F 10 000 yesJoan 53 F 1000 000 yesMary 27 F 20 000 noJane 55 F 20 000 yesBob 30 M 100 000 yesJack 50 M 200 000 yes
Husband WifeBob AnnJack Jane

18
Inductive logic programming
IF Married(Person, Spouse) AND Income(Person) >= 100 000
THEN Potential-Customer(Spouse)

19
Challenges for KDD -1
• Larger Databases– can’t fit in main memory at one time
– solutions: sampling, approximation methods, parallel processing, …
• High Dimensionality– increase size of search space for model induction in a combin
atorially explosive manner
– increase chances that learner will find spurious patterns that are not valid in general
– solutions: use prior knowledge to identify irrelevant variables, ...

20
Challenges for KDD -2
• Overfitting– good performance on training data, but poor performance on
real data– solutions: cross-validation, regularization, other statistical str
ategies
• Changing Data and Knowledge– changing may make previously discovered patterns invalid– solutions: incremental methods for updating the patterns, …
• Missing and Noisy Data– solutions: statistical strategies to identify hidden variables an
d dependencies

21
Challenges for KDD -3
• Complex Relationships between Fields– most of algorithms developed for simple attribute-value
records– require algorithms to deal with hierarchically structured
attributes or values, relations between attributes, ...
• Understanding of Patterns– make the discoveries more understandable by humans– solutions: graphical representations, natural language
generations, information visualization, ...
• User Interaction and Prior Knowledge– encoding domain knowledge into learning systems
• Integration with Other Systems– integration with spreadsheet, DBMS, visualization tools..

Mining Business Databases
R. Brachman, T. Khabaza, W. Kloesgen, G. Piatetsky-Shapiro, and E. Simoudis
Communication of ACM, V.39, No.11, 1996, pp.42-48

23
Goals of KDD
• Verification• Discovery
– predication• regression• classification
– description• clustering• summarization• visualization• change and deviation detection

24
Tools Supporting KDD -1
• Generic, single-task– classification
• decision-tree• neural-network• example-based• rule-discovery
• Generic, multitask– Clementine– IMACS– MLC++– MOBAL– Recon

25
Tools Supporting KDD -2
• Domain-specific– Opportunity Explorer– IBM Advanced Scout– Interactive Data Exploration and Analysis

26
Representative Applications
• Marketing
• Financial Investment
• Fraud Detection
• Manufacturing and Production
• Network Management

27
Marketing -1
• Predicting the size of TV audiences– using neural networks and rule induction– examine factors relating audience size
• Analyzing supermarket sales data– Coverstory and Spotlight: producing reports, using natural la
nguage and graphics, on the most significant changes in a particular product volume and share broken down by region, product type, etc.
– Opportunity Explorer– Management Discovery Tool
• summarization, trend analysis, change analysis, and measure and segment comparison

28
Marketing -2
• Market basket analysis– association rules
• associations between different products bought by the customer
– Lucent Technology’s NicheWorks• clustered purchases to be visualized intuitively

29
Financial Investment Management
• Fidelity Stock Selector– uses neural network to selection investments
• LBS Capital Management– uses expert systems, neural nets, and GAs to manag
e portfolios worth $600 million
• Carlberg & Associates– uses a neural network model for predicting Standard
& Poor’s 500 Index– surprisingly successful

30
Fraud Detection
• FALCON– using neural network shell– detect suspicious credit card transactions
• FAIS– detect money-laundering activity from financial
transactions
• Telecommunication– AT&T’s system detecting international calling fraud– GTE and NYNEX: detecting cellular cloning fraud

31
Manufacturing and Production
• Prospective KDD application– controlling and scheduling technical production processes
• Main advantage– high cost savings
• Key challenges– representation and exploitation of time and location as well
as model levels, such as quality, process, and control
• KDD in an Europe chemical company– assist in production process for polymeric plastics
• CASSIOPEE– diagnose and predict problems in Boeing 737

32
Network Management
• Used for– filtering redundant alarms
– locating problems in the network
– predicting severe faults
• Telecommunication Alarm Sequence Analyzer (TASA)– by University of Helsinki
– locating frequently occurring alarm episodes
– presenting them as rules
– integrating into alarm-handling software

33
Other Areas -1
• Health Care: KEFIR• determine most interesting deviations• explain key deviations• generate recommendations
• Data Quality– verify financial trading data– detect error
• NBA Basketball Games: IBM Advanced Scout– helps coaches to discover valuable patterns for
improvements in their strategy

34
Other Areas -2
• Discovery Agentsthese systems ask the user to specify a profile of interest and se
arch for related information among a wide variety of public domain and proprietary sources
– Firefly asks user their opinion of several music pieces and then suggests other music that user may like <http://www.ffly.com/>.
– NewsHound automatically search information from a wide variety of sources, including newspapers and wire services, and email relevant documents directly to user <http://www.sjmercury.com/hound/>

35
Application Development
• Practical application affected by– insufficient training– inadequate tool support– data unavailability– overabundance of patterns– changing and time-oriented data– spatially oriented data– complex data types– scalability

36
Potential for KDD Applications
• Suitable Domains– information-rich– have a changing environment– not already have existing models– require knowledge-based decisions– high payoff for the right decisions

37
References
1. Fayyad, U., G. Piatetsky-Shapiro and P. Smyth, “From Data Mining to knowledge Discovery: an Overview”, Advances in Knowledge Discovery and Data Mining, pp. 1-36, 1996.
2. Brachman, R., T. Khabaza, W. Kloesgen, G. Piatetsky-Shapiro and E. Simoudis, “Mining business Databases”, Communication of ACM, Vol. 39, No. 11, 1996.

Data Mining and Knowledge Discovery: Making Sense Out of Data
U. Fayyad
IEEE Expert, Oct. 1996, pp.20-25

39
The KDD Process
• Selection and sampling
• Preprocessing and cleaning
• Transformation and reduction
• Data mining
• Visualization and evaluation

40
Major Related Fields -1
• Statistics
• Machine Learning
• Artificial Intelligence and Reasoning With Uncertainty
• Databases
• Knowledge Acquisition
• Pattern Recognition

41
Major Related Fields -2
• Information Retrieval
• Visualization
• Intelligent Agents for Distributed and Multimedia Environments
• Digital Library
• Management Information Systems

42
Statistics
• Plays an important role in– data selection and sampling– data mining– evaluation of extracted knowledge
• Statistics focus on – evaluation of model fit to data– hypothesis testing

43
Statistics• Dealt primarily with small data sets and addressing
small sample problems• Focused mostly on theoretical aspects of techniques
and models. Search received little emphasis.• Require
– an a priori model – significant domain knowledge of the data as well as of the
underlying mathematics for proper use and interpretation.
• Issues have only recently begun to receive attention– interfaces to databases – dealing with massive data sets– techniques for efficient data management

44
Pattern Recognition
• The major applicable techniques – classification learning– clustering
• Contributions distinguished from statistics by emphasis on– computational algorithms, – more sophisticated data structures– more search

45
Machine Learning
• Contribute to the data-mining step– representation– selection of variables
• Also focus on– discovering structure in data– empirical laws to describe observations

46
Database and Data Warehousing
• On-line analytical processing– providing new ways of manipulating and analyzing data usin
g multidimensional methods
• Data warehousing concerned with– schemes and methods of integrating legacy DBs, on-line tran
saction DBs, and nonhomogeneous RDBMSs
• Data warehousing involves– storage– data selection– data cleaning– infrastructure for updating the warehouse

Reality Check for Data Mining
E. Simoudis
IEEE Expert, Oct. 1996, pp. 26-33

48
Two Forms of Data Mining
• Verification-driven data mining– query and reporting– multidimensional analysis– statistical analysis
• Discovery-driven data mining– predictive modeling– database segmentation– link analysis– deviation detection

Data Mining: Machine Learning, Statistics, and Databases
H. Mannila
IEEE, 1996

50
The KDD Process
• Understanding the Domain
• Preparing the Data Set– could take up to 80% of the time
• Discovering Patterns (Data Mining)– efficient discovery of fairly simple patterns
• Postprocessing of Discovered Patterns
• Putting the Results Into Use

51
Data Mining, Machine Learning and Statistics -1
• Aim: locating interesting regularities, patterns or concepts form
empirical data
• Machine Learning and KDD– M.L.
• focus on learning or induction step• assume something to learn• difficult for humans to learn
– KDD• emphasis the whole process• not assume any sensible structure behind the data• analyst can do if he had the time• huge amount of data, number of attributes

52
Data Mining, Machine Learning and Statistics -2
• Statistics and KDD– Statistics
• gradually moved to model selection
• hypothesis testing
– KDD• extensive use of M.L. methods
• volume of data
• role of computational complexity issues

53
Database and Data Mining
• Association rule, rXB, where XR and BR\X
• Applications– sales data: (transactions, products)– student database: (students, courses)– publications: (publications, publications)– behavior: (measurements, conditions)
• frequency and confidence of r• Discovery of association rule
– the task of finding all rules XB such that the frequency and the confidence exceed thresholds.

54
Finding Episodes from Sequences
• A sequence of events (e, t) /* e: event, t: time• Applications
– telecommunication networks– process monitoring– quality control– user interface studies– epidemiology
• Time series data analysis in Statistics suited only for small numbers of event types
• An example: a telecommunication network alarm DB– ~ 200 events– 1000-10000 alarms per day

55
Finding Episodes from Sequences• An episode
– a partially ordered set of events– e.g. events A and B occurs before C
• A slice rt of r of width W• An episode occurs in rt
• Frequent episode– occurs in sufficiently many slices
• A generic data mining task
• A generic data mining algorithmg}interestin is and in offenly sufficient occurs |{),( pdpPpPdPI

56
Condensed Representations
• A Typical Phenomenon– evaluate other patterns closely resemble p– a solution: caching of previous results
• Condensed Representation– a data structure making queries more efficient
e.g. number of pattern occurrences, data cube

57
Some Research Directions
• Pattern Query Specification Languages and Optimization Techniques
• Condensed Representations of Patterns• Caching Strategies• Combinations of D.M. And Statistics
Techniques• Using Background Knowledge• Tools for Selecting, Grouping, and Visualizing
Discovered Knowledge





























