Embed Size (px)
Citation preview

Kauno technologijos universitetas
Informatikos fakultetas
Programų sistemų inžinerijos katedra
Lygiagretūs skaičiavimai
Referatas
Parengė: dokt. Tomas Neverdauskas Priėmė: prof. R. Šeinauskas
Kaunas, 2011

Turinys
Įvadas ............................................................................................................................................................... 3
Lygiagretieji skaičiavimai ................................................................................................................................. 4
Kompiuterių architektūra ................................................................................................................................ 6
Flyno klasifikacija ......................................................................................................................................... 6
Nuoseklieji kompiuteriai .............................................................................................................................. 9
Lygiagretieji kompiuteriai .......................................................................................................................... 10
Lygiagrečiųjų kompiuterių atminties tipai ................................................................................................. 11
Bendrosios atminties kompiuteriai............................................................................................................ 11
Paskirstytosios atminties lygiagretieji kompiuteriai .................................................................................. 12
Klasteriai, GRID tipo lygiagretaus skaičiavimo sistemos ................................................................................ 13
LitGrid ............................................................................................................................................................ 14
Java kalba ir lygiagretus programavimas ....................................................................................................... 17
Kitos programavimo bibliotekos lygiagrečiam programavimui ..................................................................... 20
GPGPU - bendrosios paskirties skaičiavimai pasinaudojant vaizdo procesoriumi ........................................ 22
Kas yra GPGPU? ......................................................................................................................................... 22
Bitoninio rikiavimo algoritmas ................................................................................................................... 24
Taikymas praktikoje – IBM Watson projektas ............................................................................................... 26
Išvados ........................................................................................................................................................... 29
Literatūra ....................................................................................................................................................... 30

3
Įvadas
Nuolat tobulėjant techninei įrangai, daugėjant branduolių skaičiui procesoriuose, auga ir
lygiagrečių sistemų kūrimo, tyrimo ir tokiai techninei įrangai, skirtos programinės įrangos kūrimo poreikis.
Šiame referate apžvelgiama teorinės ir praktinės priemonės lygiagrečių skaičiavimų srityje.
Tokie didieji gamintojai, kaip „Intel“, AMD ir kiti procesorių gamintojai, didindami lustų
darbo spartą, jau dabar susidūrė su energijos sąnaudų ir šilumos problemomis. Kuo sparčiau dirba
procesorius, tuo daugiau energijos jis sunaudoja ir tuo daugiau išskiria šilumos. Šiuolaikinių procesorių
šilumos tankis gali siekti 70 – 90 W kvadratiniame centimetre. O tai reiškia, kad CD dėžutės dydžio
paviršius turėtų išspinduliuoti nuo 12,4 iki 19,9 KW šilumos.
Nebegalėdamos daugiau didinti dažnio, „Intel“, AMD ir kiti gamintojai nusprendė gaminti
procesorius, kuriuose yra keletas savarankiškai veikiančių branduolių. Tokio tipo procesoriai yra
lygiagrečiųjų skaičiavimų pagrindas. Lygiagretieji skaičiavimai įvardijami, kaip kitas esminis technologijų
progreso žingsnis ir pasak „Microsoft“ bei „Intel“ jau atėjo laikas jį žengti. Tačiau pasirodė, kad galima itin
greitiems skaičiavimams pritaikyti ir vaizdo plokščių procesorius.
Lygiagretūs skaičiavimai leidžia išnaudoti techninę įranga ir kuria naujas kompiuterinių
skaičiavimų galimybes.

4
Lygiagretieji skaičiavimai
Yra sukurta daug programavimo kalbų ir įrankių, skirtų nuosekliesiems kompiuteriams. Ši
patirtis yra svarbi ir naudojant lygiagrečiuosius algoritmus. Bet lygiagretieji skaičiavimai suformuluoja
daug naujų reikalavimų. Labai svarbu kurti programinius įrankius, leidžiančius efektyviai ir taupiai
realizuoti sudarytus lygiagrečiuosius algoritmus. Siekiama, kad programas galima būtų nesunkai perkelti iš
vieno lygiagrečiojo kompiuterio į kitą. Plėtojantis patiems lygiagretiesiems kompiuteriams, keičiasi ir
tobulėja programavimo kalbos. Yra sukurti keli lygiagrečiojo programavimo standartai, skirti
populiariesiems lygiagrečiųjų kompiuterių architektūros tipams. Palyginkime nuoseklųjį ir lygiagretųjį
skaičiavimus.
Nuoseklieji skaičiavimai (serial computing):
Vykdomi viename kompiuteryje su vienu procesoriumi/vykdomuoju įrenginiu.
Problema yra išskaidoma į diskrečią instrukcijų seką.
Instrukcijos yra vykdomos viena po kitos (nuosekliai).
Bet kuriuo laiko momentu gali būti vykdoma tik viena instrukcija.
1 pav. Nuosekliųjų skaičiavimų schema
Lygiagretieji skaičiavimai (parallel computing):
Vykdomi naudojant keletą procesorių (branduolių) vienu metu.
Problema yra išskaidoma į atskiras dalis, kuriuos gali būti sprendžiamos lygiagrečiai.
Kiekviena atskira dalis yra skaičiuojama nuosekliai.

5
Skirtingų dalių instrukcijos yra vykdomos skirtinguose CPU tuo pačiu metu t.y. keletas procesorių
kartu tuo pačiu metu sprendžia vieną problemą
2 pav. Lygiagrečiųjų skaičiavimų schema
Šiuolaikinė lygiagrečioji sistema privalo būti integruota sistema, kurią sudaro procesorių
aibė (jos aparatūra), atminties sistema (bendra, paskirstyta, laikinoji atmintis), ryšių (komutacijos)
sistema, sisteminė programinė įranga (OS, kompiliatoriai) bei taikomosios programos.
Uždaviniai lygiagretiesiems skaičiavimams:
Sukurti lygiagrečiuosius kompiuterius (daug procesorių, gerai organizuota atmintis, ryšiai).
Sukurti efektyvius lygiagrečiuosius algoritmus (svarbiausios uždavinių klasės, pritaikymas įvairių tipų
kompiuteriams, užduočių paskirstymo tarp procesorių uždavinys, teoriniai lygiagrečiųjų algoritmų
sudėtingumo modeliai, leidžiantys įvertinti algoritmų efektyvumą ir t.t.).
Sukurti “lygiagrečiąsias” kalbas.
Sukurti lygiagretaus programavimo įrankius.
Sukurti metodus ir priemones lygiagrečių skaičiavimų efektyvumui įvertinti.
Užtikrinti lygiagrečių programų pernešamumą.
Lygiagrečiųjų skaičiavimų taikymo sritys:
Orų prognozė ir klimato pokyčiai.

6
Branduolinės ir cheminės reakcijos.
Kosmologija, geologija, seismologija.
Žmogaus genomas, genų inžinerija.
Raketų, lėktuvų, automobilių projektavimas.
Vaizdų generavimas, grafika.
Finansinis, ekonominis modeliavimas.
Diskrečiojo optimizavimo uždavinių klasė (tvarkaraščių sudarymas oro bendrovėse,
krovinių pervežimo maršruto optimizavimas, skirtingos formos detalių taupus išdėstymas dideliuose
ruošiniuose, mikroschemų projektavimas). Norėdami rasti tokių uždavinių sprendinius, turime patikrinti
labai daug leistinų variantų, o tikrinant kiekviena variantą irgi reikia atlikti nemažai aritmetinių veiksmų.
Todėl dažnai tenkinamasi apytiksliu sprendiniu, kuris randamas patikrinus tik dalį leistinų variantų.
Gautasis sprendinio artinys bus tuos tikslesnis, kuo daugiau variantų sugebėsime patikrinti. Šiuo principu
yra sukurtos visos kompiuterinės šachmatų žaidimo programos.
Kompiuterių architektūra
Kai norime sudaryti efektyvius lygiagrečiuosius algoritmus riekia būti susipažinusiems su
svarbiausiais lygiagrečiųjų kompiuterių tipais. Reikia išsiaiškinti kaip lygiagretieji kompiuteriai yra sudaryti
ir kaip jie veikia.
Flyno klasifikacija
M.Flynas (Michael Flynn) 1972 metais pasiūlė įvairias kompiuterių architektūras
klasifikuoti remiantis komandų (I) ir duomenų (D) srautų skaičiumi. Taip skiriamos 4 klasės:

7
Lentelė 1. Flyno klasifikacija
Single Instruction Multiple Instruction
Single Data SISD MISD
Multiple Data SIMD MIMD
SISD - vienas komandų srautas ir vienas duomenų srautas:
3 pav. SISD
SIMD - vienas komandų srautas ir daug duomenų srautų:
4 pav. SIMD
MISD - daug komandų srautų ir vienas duomenų srautas:

8
5 pav. MISD
MIMD - daug komandų srautų ir daug duomenų srautų:
6 pav. MIMD
SISD - tai paprasti vienprocesoriniai kompiuteriai. Gali būti konvejerizuoti, turėti kelis FĮ
(koprocesorius, grafikos procesorius (įtaisus), vektorinius įtaisus).
SIMD - tai vektoriniai kompiuteriai, turintys skaliarinius ir vektorinius procesorius. Viską
valdo vienintelis centrinis VĮ, kuris valdymo signalus transliuoja visiems procesoriams (PE).
MISD klasės mašinose gali būti:
tas pats duomenų srautas eina per linijinį procesorių masyvą, kurio elementai vykdo skirtingus
komandų srautus. Ši architektūra taip pat žinoma sistolinių masyvų (systolic arrays) vardu. Jie
realizuoja specifinius algoritmus konvejerio principu.
tie patys duomenys paduodami į visus procesorius, tačiau kiekvienas iš jų vykdo savo programą.
SIMD ir MISD modeliai tinka tik specialiems uždaviniams spręsti. Tikrieji lygiagretūs
kompiuteriai programas vykdo MIMD režimu.

9
Nuoseklieji kompiuteriai
Dauguma šiuolaikinių senesnių personalinių procesorių ir darbo stočių yra sukurti
remiantis Neumano (John von Neumann) modeliu. Svarbiausios tokio kompiuterio dalys yra procesorius,
kurį sudaro valdymo įrenginys (VĮ, control unit), skaičiavimo įrenginys (SĮ, processing element) ir atminties
blokas (AB, storage unit arba memory) Ši schema pavaizduota 12 pav.
7 pav. Nuosekliojo kompiuterio schema
Visos šio skaičiavimo modelio operacijos vykdomas nuosekliai viena po kitos, vienu metu
aritmetiniai ir loginiai veiksmai atliekami tik su vienu duomenų rinkiniu. Flyno pasiūlytoje kompiuterių
klasifikacijoje nuoseklieji kompiuteriai sudaro SISD grupę.
Kompiuterio skaičiavimo greitis priklauso nuo dviejų svarbiausių veiksnių: procesoriaus
taktinio greičio, bei nuo greičio, kuriuo renginys keičiasi duomenimis su atmintimi. Nė vienas kompiuterio
veiksmas negali būti atliktas greičiau už vieno takto trukmę. Todėl kuo didesnis procesoriaus taktinis
greitis, tuo greičiau bus atliekami visi veiksmai.
Tačiau daugeliu atvejų kompiuterio spartą riboja duomenų pasikeitimo tarp skaičiavimo
įrenginio ir atminties greitis. Todėl stengiamasi šį laiką sutrumpinti hierarchiškai organizuojant atmintį.
Skiriame labai greitą, bet labai brangią registrinę atmintį. Joje saugomi tik kelių artimiausių operacijų
operandai. Skaičiai į registrinę atmintį patenka iš gana greitos operatyvios buferinės atminties.
Dauguma duomenų yra saugoma išorinėje standžiųjų diskų atmintyje. Tačiau duomenų
keitimasis tarp išorinės ir operatyviosios atminčių sąlygiškai yra lėtas.
Kurdami efektyvius algoritmus, turime stengtis:
Minimizuoti duomenų judėjimą tarp skirtingų atminties lygių, stengtis kuo greičiau skaityti duomenis,
esančius išorinėje atmintyje;

10
Keistis kuo didesniais duomenų kiekiais;
Kuo ilgiau naudoti duomenis, jau esančius atminties registre bei sparčiojoje atmintyje.
Sudarydami algoritmus dažniausiai darome prielaidą, kad naudojame virtualią atmintį,
kurios resursai yra pakankami, o kiekvieną atminties ląstelę pasiekiame nurodydami jos adresą bendrame
adresų sąraše. Duomenų kopijavimo uždavinį paliekame spręsti operacinei kompiuterio sistemai.
Algoritmai, kuriuose naudojama standžiųjų diskų atmintis, vadinami išoriniais algoritmais.
Juose daugiausia dėmesio skiriama ne aritmetiniams veiksmams minimizuoti, o efektyviai pasikeisti
duomenimis.
Lygiagretieji kompiuteriai
Nuoseklieji kompiuteriai turi tik vieną skaičiavimo ir valdymo įrenginį. Konstruodami
lygiagretųjį kompiuterį, galime naudoti daugiau procesorių arba didinti tik skaičiavimo įrenginių skaičių.
Jeigu kompiuteryje yra tik vienas valdymo įrenginys ir keli skaičiavimo įrenginiai, tai
vykdant programą visi šie skaičiuokliai arba atlieka tokią pačią operaciją su skirtingais duomenimis, arba
nevykdo jokių veiksmų. Toks skaičiavimo modelis yra vadinamas SIMD tipo (6 pav a). Tokie lygiagretieji
kompiuteriai dar vadinami matriciniais kompiuteriais, nes jie efektyvūs kai atliekami veiksmai su
matricomis.
8 pav. SIMD tipo lygiagretieji kompiuteriai
SIMD architektūros kompiuteriams priklauso ir vektoriniai procesoriai, juose ta pati
operacija atliekama daugeliu operandų.
Jeigu kompiuteryje yra keli procesoriai, galintys vykdyti skirtingas operacijas, tai turime
MIMD tipo skaičiavimo modelį (14 pav.). Tokiu kompiuteriu galime realizuoti daug bendresnių algoritmų,
tačiau sunkiau sinchronizuoti procesorių darbą.

11
9 pav. MIMD tipo lygiagretieji kompiuteriai
Lygiagrečiųjų kompiuterių atminties tipai
Sudarydami lygiagrečiuosius algoritmus sprendžiame kelis pagrindinius uždavinius, tarp jų
svarbiausias – uždavinio skaidymas į mažesnes užduotis, jų paskirstymas procesoriams ir duomenų
persiuntimas tarp procesorių. Būtent duomenų persiuntimo algoritmai esmingai priklauso nuo
kompiuterio atminties architektūros. Skiriamos dvi didelės lygiagrečiųjų kompiuterių grupės:
bendrosios atminties kompiuteriai;
paskirstytosios atminties kompiuteriai.
Bendrosios atminties kompiuteriai
Visi procesoriai atlieka veiksmus su tam tikrais duomenimis, kuriuos perskaito ir užrašo į
jiems skirtas atminties ląsteles. Bendrosios atminties lygiagretieji kompiuteriai turi tik vieną atminties
bloką ir visi procesoriai gali tiesiogiai pasiekti visas atminties vietas (13 pav.).

12
10 pav. Bendrosios atminties lygiagretieji kompiuteriai
Jeigu visų procesorių bet kokių duomenų persiuntimo greitis yra vienodas , tai sakome, jog
turime kompiuterį su tolygiai pasiekiama bendrąja atmintimi(UMA – uniform memory acces).
Tačiau daugelio procesorių grupė techniškai sunkiai realizuoja tokią sąlygą, todėl dažnai
atmintis skirstoma į dalis, kurios priklauso skirtingiems procesoriams. Ir šiuo atveju išlieka bendras
atminties adresavimas, bet procesoriai greičiau pasiekia duomenis, esančius lokalioje atminties dalyje, nei
duomenis, esančius kituose procesoriuose. Turime kompiuterius su netolygiai pasiekiama bendrąja
atmintimi (NUMA – nonuniform memory acces).
Kadangi kiekvienas procesorius gali tiesiogiai perskaityti ir užrašyti duomenis, esančius
kito procesoriaus atmintyje, tai UMA ir NUMA tipo kompiuteriai dar vadinami pasidalintosios atminties
lygiagrečiaisiais kompiuteriais
Paskirstytosios atminties lygiagretieji kompiuteriai
Tokio tipo kompiuteriai priklauso MIMD tipui. Tačiau dabar vienas procesorius gali
tiesiogiai perskaityti ir įrašyti tik duomenis, esančius jo lokalioje atmintyje (14 pav).

13
11 pav. Paskirstytosios atminties lygiagretieji kompiuteriai
Jeigu vykdant algoritmą reikalingi duomenys, saugomi kitame procesoriuje, tai antrasis
procesorius turi nusiųsti pirmajam pranešimą su reikalinga informacija. Pranešimo perdavimo
mechanizmas toks: vienas procesorius siunčia pranešimą, o kitas procesorius, kuriam reikalingi duomenys,
laukia, kol ateis pranešimas. Duomenų persiuntimu turi pasirūpinti pats programuotojas, nurodydamas,
kas, kam ir kada turi siųsti ar gauti pranešimą. Toks duomenų siuntimas tampa ir algoritmo vykdymo
sinchronizavimo tašku.
Taigi duomenų mainai paskirstytosios atminties lygiagrečiuose kompiuteriuose yra
sudėtingesni, nei bendrosios atminties kompiuteriuose. Tačiau šiuo atveju nesusiduriame su svarbia
problema, kuri egzistuoja bendrosios atminties kompiuteriuose, kai keli procesoriai vienu metu bando
skaityti ir/arba rašyti tą pačią atminties vietą.
Klasteriai, GRID tipo lygiagretaus skaičiavimo sistemos
Anksčiau aukščiausio našumo augimas buvo siejamas su superkompiuteriais, tačiau juos
naudojant atsirado trūkumai:
• superkompiuterių kaina yra aukšta,
• jų plėtimo galimybės ribotos
• elementų bazė greitai keičiasi ir superkompiuterių konstravimas nespėja su tuo
• superkompiuteriai greitai “sensta” našumo požiūriu
Klasteris – lygiagrečioji arba paskirstytoji sistema, kurią sudaro keli tarpusavyje susieti
kompiuteriai, naudojama kaip vieningas unifikuotas kompiuterinis resursas. Kiekviename klasterio mazge
veikia sava OS kopija. Mazgas gali būti paprastas kompiuteris arba multiprocesorinis kompiuteris, klasterį

14
sudarantys kompiuteriai gali turėti skirtingas konfigūracijas (skirtingą procesorių skaičių, skirtingos talpos
atmintis ir diskus). Klasterio mazgai gali būti sujungiami naudojant įprastas jungimo į tinklą priemones
(Ethernet, FDDI, Fibre Channel) arba specialius nestandartinius sujungimus (pvz. Memory Channel). Tokie
sujungimai įgalina mazgus bendrauti tarpusavyje nepriklausomai nuo išorinio tinklo tipo.
Sudarydami lygiagrečiuosius algoritmus, turime atsižvelgti į dvi svarbias kompiuterių
klasterių savybes. Pirma, lokaliojo tinklo (juo labiau – Ethernet tinklo) greitis yra daug mažesnis už
duomenų perdavimo greitį MIMD tipo paskirstytosios atminties kompiuteriuose. Todėl algoritmų,
kuriuose tenka dažnai keistis duomenimis, gali būti nedidelis, kai juos realizuojame vistualiuoju
lygiagrečiuoju kompiuteriu. Antra, kompiuterio klasterį gali sudaryti skirtingo tipo kompiuteriai. Be to kai
kurie iš kompiuterių patys gali turėti kelis procesorius. Todėl visuose algoritmuose turi būti numatyta
galimybė įvertinti procesorių heterogeniškumą. Pažymėtina, kad procesorių heterogeniškumas atsiranda
ir todėl, kad kai kurie klasterio kompiuteriai tuo pačiu metu yra naudojami kelių vartotojų ir jų apkrova
svyruoja net ir tada, kai visi kompiuteriai yra vienodi.
Gridas – paskirstytų procesorių pajėgumų ir paskirstytų informacijos laikymo sistemų
panaudojimo metodas, išpopuliarėjęs dėl schemų, leidžiančių panaudoti neužimtus skaičiavimo resursus,
išdėstytus visame pasaulyje. Gridas – bet kurios globalios paskirstytų skaičiavimų sistemos infrastruktūra,
tinkama plačiam taikomųjų uždavinių ratui – elektroninio verslo, paskirstytosios gamybos, duomenų
analizės, aukšto našumo informacijos apdorojimo, paskirstytųjų superskaičiavimų.
LitGrid
12pav. LitGrid schema

15
LitGrid funkcionavimas apima:
Grid infrastruktūros ir e-paslaugų grid infrastruktūros diegimą, palaikymą ir atnaujinimą
„Cloud computing“ technologijų analizę, projektavimą, eksperimentinį diegimą
Mokslo tyrimų ir mokslo plėtros darbų, reikalaujančių intensyvių skaičiavimų, mokymo uždavinių ir
/arba e-paslaugų, naudojant grid technologijas vystymą, aptarnavimą, naujų naudotojų paiešką, jų
mokymą
LitGrid CA sukūrimą ir jos palaikymo įdiegimą
LitGrid veiklos ir galimybių pateikimą visuomenei, potencialiems naudotojams, viešojo sektoriaus ir
verslo struktūroms, potencialių naujų grid projektų analizę
Santykius su slėniais, branduoliais, viešuoju sektoriumi
LitGrid pasiekti rodikliai:
institucijų (partnerių) skaičius – 13 (VU, KTU, VGTU, VDU, KU, ŠU - universitetai, FI, MII, PRI, TFAI -
institutai, Alytaus, Marijampolės, Panevėžio - kolegijos), LitGrid infrastruktūra taip pat naudojosi
Lietuvos energetikos institutas, Biochemijos institutas, VU fizikos fakultetas, kt.
mokslininkų ir specialistų skaičius – 93
taikomųjų tyrimų krypčių skaičius – 23
taikomųjų uždavinių skaičius – 44
procesorių skaičius - 495
norm. val. skaičius – apie 900 000 val.
mokslo projektų, programų, slėnių aptarnavimas, suteikiant skaičiavimų resursus ir paslaugas
numatomi grid technologijų pristatymai verslui
įjungimas į European Grid Initiative

16
LitGrid tolimesnėje veikloje numatoma:
kurti, palaikyti ir vystyti e-Infrastruktūrą: grid, cloud computing, HPC, virtualius repozitoriumus, kitus
duomenų rinkinius
aptarnauti: akademinę aplinką, viešąjį sektorių, verslo poreikius, užsakymus iš užsienio partnerių
suteikti funkcionalumą: skaičiavimų resursus, modeliavimo paslaugas, virtualių repozitoriumų ir
duomenų rinkinių saugojimą bei naudojimą
teikti „on demand“: skaičiavimus, duomenų repozitoriumus, susijusias e-paslaugas, kt.
vienyti ir sinchronizuoti veiklą: institucijų turimos kompiuterinės įrangos veiklą (administravimo,
funkcionalumo, organizaciniu požiūriais)
įsisavinti ir naudoti technologijų naujoves ar naujas technologijas, dalyvaujant projektuose: PRACE,
EGI, kituose
skatinti Lietuvos mokslininkų ir specialistų bendradarbiavimą su žymiais mokslo centrais (CERN, kitais)

17
Java kalba ir lygiagretus programavimas
Java kalba – viena iš nedaugelio programavimo kalbų, kurios pilnai palaiko
konkurencinį/lygiagretų skaičiavimą (concurent/parallel computing). Skirtumą tarp konkurencinio ir
lygiagretaus skaičiavimo gerai atvaizduoja žemiau pateikta diagramą.
13 pav. Lygiagretus skaičiavimas
Tam kad skaičiavimai vyktų tikrai lygiagrečiai reikia, kad kompiuteris turėtų kelis CPU ir
lygiagrečiam darbui pritaikytą architektūrą. Tuo tarpu paprastame asmeniniame kompiuteryje dažniausiai
yra vienas CPU, todėl užduotys konkuruoja dėl CPU laiko.
Java konkurencinio/lygiagretaus darbo mechanizmas realizuotas gijomis (angl. threads) ir
sinchronizacijos mechanizmu bei virtualios mašinos struktūra. Didžiausia dalis konkurencinio/lygiagretaus
darbo palaikymo yra klasėje Thread. Šios klasės egzemplioriai (angl. instances) ir yra virtualūs procesai
(gijos). Tik vienas Thread objektas gali būti vykdomas vienam CPU tuo pačiu laiku kiti Thread objektai tuo
metu yra įvairiose laukimo būsenose: laukia resursų, laukia CPU laiko, miega, yra laikinai sustabdytas ar
pabaigtas. Svarbiausi Thread metodai:
start() – užregistruoja giją gijų planuotojuje (angl. thread scheduler), kuris ir nuspręs, kada gija gaus
CPU laiko ir bus vykdoma
run() – metodas, kuris yra vykdomas, kada gija gauna CPU laiko. Kai šitas metodas pabaigiamas, t.y. iš
jo išeinama, gija laikoma pabaigta (angl. dead) ir daugiau nebegali būti vykdoma. Šis metodas neturi

18
būti kviečiamas tiesiogiai – gijai užtenka iššaukti start() metodą, kuris užregistruoja ją gijų
planuotojuje, kuris iššauks metodą run(), kai gija bus suplanuota vykdymui.
yield() – perveda einamu metu vykdomą giją į laukimo būseną ir atiduoda laiką kuriai nors iš
pasiruošusių gijų. Jeigu tokių nėra, tuomet gija vykdoma toliau. Visgi daug kas čia priklauso ir nuo gijų
planuotojo – dauguma jų ignoruoja mažesnio prioriteto gijas ir toliau vykdo einama giją.
sleep(int milliseconds) – užmigdo einamu metu vykdomą giją nurodytam laiko tarpui. Reikia pastebėti,
kad, baigus miegojimo laikui, gija nebūtinai bus vykdoma – gali būti kad jinai gaus CPU laiko tiktai
vėliau, dėl to, kad tuo metu CPU vartos kitos suplanuotos gijos.
suspend() – laikinai sustabdo giją, kol jai nebus iššauktas metodas resume(). Bet šitas metodas yra
laikomas pasenusiu ir nerekomenduojamas naudoti – iš vėlesnių Java versijų jis bus išmestas. Taip
padaryta todėl, kad naudojant jį labai lengva patekti į aklavietę, jeigu programuotojas neapgalvos visų
galimų situacijų.
resume() – atgaivina laikinai sustabdytą giją. Šis metodas taip pat pasenęs.
stop() – sustabdo giją. Šis metodas taip pat pasenęs, nes, naudojant jį, gija iškart nutraukiama
sisteminėmis priemonėmis, o tai labai lengvai gali baigtis neatlaisvintų nebenaudojamų resursų
palikimu.
setPriority(int priority) – nustato gijos prioritetą. Prioritetų traktavimas yra JVM ir gijų planuotojo
reikalas, nėra tiesiogiai pasakyta kaip jie turi būti interpretuojami.
getPriority() – grąžina gijos prioritetą.
Galimos gijų būsenos pavaizduotos žemiau esančiame paveiksle (13 pav.).

19
14 pav. Perėjimai tarp gijų būsenų Java kalboje
Kitas dalykas, aktualus programuojant yra gijų sinchronizacija ir kritinių sričių valdymas.
Sinchronizacija yra realizuota kalbos struktūroje: jai dedikuotas raktinis žodis synchronized. Šis raktinis
žodis gali būti taikomas metodui arba kodo fragmentui. Jo esmė – išskirti kritines sritis, kuriose esant
vienai gijai kitos gijos negali įeiti į kritines sinchronizuojamo objekto sritis. Tai realizuota monitorių
būsenomis: kiekvienas objektas turi savo monitorių ir kiekviena gija, įeidama į kritinę objekto kodo sritį,
monitoriaus užraktą pasiima; kitos gijos, norinčios įeiti į to objekto kritinę sritį, turi laukti kol pirmoji gija
išeis iš kritinės srities ir užraktą atiduos.
Object klasė, kuri yra visų Java kalbos klasių viršklasė, taip pat turi kelis metodus, kurie gali
būti kviečiami tiktai kritinėse srityse, t.y. synchronized metoduose ar kodo fragmentuose:
wait() – šis metodas grąžina objekto raktą iš einamos gijos ir perleidžia CPU kitoms gijoms. Einama gija
yra pervedama į laukimo būseną.
notify() – pažadina vieną iš laukiančių gijų.
notifyAll() – pažadina visas laukiančias gijas paeiliui.

20
15 pav. Sichronizacijos įtaką gijų vykdymui
Kitos programavimo bibliotekos lygiagrečiam programavimui
Yra daug populiarių programavimo kalbų, kuriomis užrašome nuosekliuosius algoritmus,.
Pirmiausia, reikia nuspręsti, ar realizuodami lygiagrečiuosius algoritmus kursime naujas programavimo
kalbas, ar užteks papildyti jau egzistuojančias. Į šį klausimą galėsime atsakyti tik tada, kai nustatysime,
kokių papildomų priemonių mums reikia, jei norime užrašyti bet kokį lygiagretųjį algoritmą. Taigi buvo
suburta specialistų grupė, kuri sudarė paskirstytųjų skaičiavimų standartą ir rekomendavo jį naudoti
paskirstytosios atminties lygiagrečiuosiuose kompiuteriuose. Ši duomenų persiuntimo sąsaja buvo
pavadinta MPI (angl. Message Parsing Interface). Ją sudarant buvo pasitelkta kitų programavimo
bibliotekų (PVM, Chameleon, PARMACS) ypatybės bei įvertinti naujausi teoriniai siūlymai. Svarbiausios
MPI ypatybės:
MPI yra biblioteka, o ne nauja programavimo kalba. Ji tik apibrėžia paprogramių vardus, parametrus
ir jų funkcinę paskirtį. Šias paprogrames galima naudoti Fortran 77 ir C kalbomis parašytose
programose; parengtos paprogramių Fortran 95 ir C++ versijos. Vartotojas programą rašo
standartine programavimo kalba tik kompiliuodamas prijungia MPI biblioteką.

21
MPI realizuotas išreikštinis duomenų siuntimo modelis. Apibrėžtos ne tik būtinosios priemonės, be
kurių negalime užrašyti lygiagrečiojo algoritmo, realizuojamo paskirstytosios atminties lygiagrečiuoju
kompiuteriu, bet ir daug papildomų paprogramių, lengvinančių algoritmo realizaciją arba padidinančių
algoritmo efektyvumą. MPI leidžia atlikti skaičiavimus su heterogeniškais kompiuteriais.
MPI standartas apibrėžia tik funkcinę paprogramės paskirtį, be nereglamentuoja jos realizacijos. Todėl
skirtingų tipų kompiuterių gamintojai gali šias paprogrames realizuoti efektyviausiu šiam kompiuteriui
būdu.
MPI standartu parašyta programa be pakeitimų gali būti perkelta iš vieno tipo kompiuterio į kito tipo
kompiuterį. Tai ypač svarbu kuriant matematinių algoritmų bibliotekas.
OpenMP yra vienas iš bandymų suformuluoti programavimo standartą, skirtą
lygiagretiesiems algoritmams realizuoti bendrosios atminties kompiuteriuose. Siekiama sudaryti nedidelį
rinkinį programavimo konstrukcijų, leidžiančių efektyviai realizuoti lygiagretųjį algoritmą. Kadangi
OpenMP yra skirtas kompiuteriams, naudojantiems bendrąją atmintį, tai programuotojui nereikia pačiam
rūpintis duomenų pasikeitimu tarp skirtingų procesorių. Pagrindinis jų tikslas – išskirti tas algoritmo(ar
juos realizuojančios programos) dalis, kurios gali būti vykdomos vienu metu.
22
GPGPU - bendrosios paskirties skaičiavimai pasinaudojant
vaizdo procesoriumi
Kas yra GPGPU?
GPGPU angliškai reiškia General-Purpose computation on GPUs. Verčiant pažodžiui -
Bendros Paskirties Skaičiavimai su GPU. Dėl galimybės programuoti vaizdo procesorius ir didelės jų galios
jie sudomino įvairių sričių specialistus. Priversti procesorių dirbti galima pasinaudojant įvairiomis
bibliotekomis. Dvi pagrindinės ir šiuo metu populiariausios: Direct3D, kuri turi HLSL (angl. „High Level
Shading Language“), ir OpenGL su GLSL (angl. „OpenGL Shading Language“). Taip pat NVIDIA pristatė
CUDA (angl. „Compute Unified Device Architecture“) programavimo įrankį, kuris leidžia
programuoti vaizdo procesorius kalba, panašia į populiariąją C kalbą.
Duomenys vaizdo atmintyje laikomi tekstūrų arba atminties blokų (buferių), į kuriuos
surašomos viršūnių erdvėje koordinatės, pavidalu. Tekstūra – tai vienmatis, dvimatis ar trimatis
paveiksliukas. Tekstūroje galime laikyti duomenis, kurių reikės atlikti skaičiavimams ir išvesti į ją
skaičiavimo rezultatus.
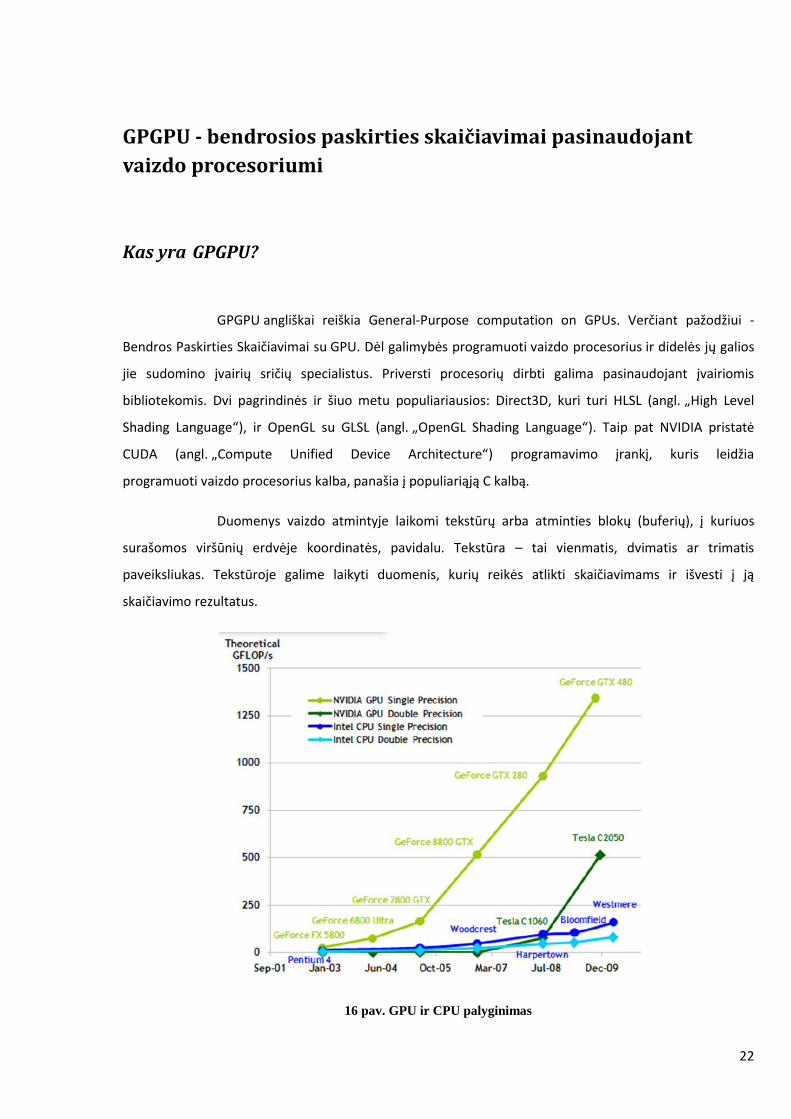
16 pav. GPU ir CPU palyginimas

23
Šių dienų kompiuteriuose vaizdo procesorius (angl. „GPU“ – Graphics Processing Unit) yra
būtinas komponentas. Jis gali būti integruotas į motininę plokštę arba prijungtas atskirai vaizdo plokštėje.
Šis procesorius gali atlikti ypač daug operacijų, per sekundę savo galingumu kelis kartus aplenkdamas net
pačius naujausius bendrosios paskirties procesorius. Grafikas rodo, kiek apytiksliai milijardų operacijų su
slankaus kablelio skaičiais per sekundę galėjo atlikti naujausi bendrosios paskirties procesoriai (žydra
kreivė) ir vaizdo procesoriai (raudona kreivė) nuo 1998 iki 2006 metų. Vaizdo procesoriaus pagrindinė
užduotis yra manipuliuoti 3D ir 2D vaizdus, skaičiuoti erdvinių objektų pozicijas ir apšvietimą. Nuo
apytiksliai 2000 metų nauji vaizdo procesoriai gali būti programuojami vadinamųjų šešėliavimo programų
pagalba (angl. „Shaders“). Tai leido kurti dar realistiškesnę kompiuterinę grafiką ir įgyvendinti naujus
apšvietimo skaičiavimo metodus. Taip pat naujos galimybės sudomino ir kitų sričių specialistus.
Taigi duomenų apdorojimą grubiai vaizduoja sekanti diagrama. Objektai trimačiame
pasaulyje dažniausiai aprašomi trikampiais. Šių trikampių viršūnės apdorojamos vadinamosiose viršūnių
programose (angl. „Vertex shader“). Toliau iš tų viršūnių susidarantys trikampiai paverčiami į taškus ir
perduodami taškų programai (angl. „Pixel shader“). Po to šis apdorotas taškas išvedamas į ekraną arba
išsaugojamas atmintyje ir vėl iš naujo panaudojamas skaičiuojant kitas viršūnes ir taškus. Naujos kartos
vaizdo procesoriuose (palaikančiuose 10-tą Direct3D versiją) atsirado dar daugiau programuojamų
konvejerio dalių, tačiau jos nėra svarbios šiai straipsnio temai.
17 pav. GPU duomenų apdorojimo schema
Dėl tokios duomenų apdorojimo, konvejerio vaizdo procesoriuje, architektūros, duomenis
galima lengvai apdoroti lygiagrečiai. Kiekviena viršūnė nepriklauso nuo kitų apdorojamų viršūnių ir
kiekvienas taškas nepriklauso nuo kitų taškų. Todėl naujausi vaizdo procesoriai (2007m.) turi net iki 128
skaičiavimo elementų, galinčių vykdyti viršūnių ir taškų programas vienu metu. Kiekvienas skaičiavimo

24
elementas veikia apytiksliai 1500MHz dažniu. Dėl to jų visuma aplenkia visus bendrosios paskirties
procesorius. Šią skaičiavimo elementų didėjimo tendenciją matome ir šiandienos bendrosios paskirties
procesoriuose, kurie jau turi iki 4 branduolių. Tačiau norint panaudoti šią galią, reikia stipriai keisti
programos vykdymo eigą, priversti programą skaičiavimus vykdyti lygiagrečiai.
Bitoninio rikiavimo algoritmas
Vienas iš vaizdo procesoriaus pritaikymo būtų gali būti didelio kiekio duomenų rikiavimas.
Tai operacija, kuri dažnai atliekama realiose situacijose, pavyzdžiui, įrašų rikiavimas duomenų bazėse. Tai
galima atlikti vadinamuoju bitoninio rikiavimo algoritmu. Jis vykdomas keliomis (tiksliau log(n), kur n –
duomenų kiekis, log – dvejetainis logaritmas) pakopomis. Algoritmo vykdymo metu surikiuoti mažesni
duomenų blokai jungiami į dvigubai didesnius blokus. Šį algoritmą su vienmačiu masyvu arba vienmate
tekstūra vaizdžiai iliustruoja diagrama žemiau.
18 pav. Duomenų rikiavimo žingsniai

25
Ši diagrama vaizduoja bitoninio rikiavimo algoritmą su 8 skaičiais. Algoritmas vykdomas
trimis pakopomis. Vienos pakopos rezultatas yra sekančios pakopos duomenys. Kiekvienoje pakopoje
masyvas išdalinamas į jau surikiuotus blokus, pažymėtus raudonai ir žaliai. Gretimi blokai lyginami taip,
kaip vaizduoja rodyklės. Mažesnis elementas perkeliamas į žalią regioną, o didesnis į raudoną.
Bitoninio rikiavimo algoritmas ypatingas tuo, kad duomenų palyginimus ir sukeitimus galima atlikti
lygiagrečiai, iškart visam duomenų masyvui (tekstūrai). Taip vienu metu išnaudojami visi vaizdo
procesoriaus skaičiavimo elementai. Čia pateikiamas tik vienmačio masyvo rikiavimo algoritmas, bet
dažniausiai naudojami dvimačiai masyvai, nes vaizdo procesoriai labiau pritaikyti dirbti su dvimatėmis
tekstūromis (paveikslėliais). Taip pat šis algoritmas nėra pats našiausias lygiagretus rikiavimo algoritmas.
Lygiagretūs rikiavimo algoritmai, vykdomi vaizdo procesoriuje, greičiu konkuruoja su
algoritmais, vykdomais bendrosios paskirties procesoriuose, pavyzdžiui, greitu rikiavimu (angl. „Quick
sort“). Pigūs vaizdo procesoriai rikiuoja duomenis taip pat greit kaip žymiai brangesni bendrosios
paskirties procesoriai (lyginama tuomet kainavusi $265 NVIDIA 7800 GT vaizdo plokštė su $2200
kainavusiu 3.6 GHz Dual Xeon serveriu).

26
Taikymas praktikoje – IBM Watson projektas
Dar 1997 IBM išgarsėjo panaudoję savo super kompiuterį „Deep Blue“, kuris šachmatų
žaidime nugalėjo pasaulio čempioną G. Kasparovą. 2011 metais IBM ėmėsi kito labai ambicingo tikslo
nugalėti geriausius JAV populiariaus žaidimo „Jeopardy“ žaidėjus. Žaidimo esmė – pasakomas atsakymas,
žaidėjas turi iškelti tinkamą klausimą. Tačiau šie klausimai pateikiami žmogiška kalba (anglų), dažnai būna
labai abstraktūs ir priklausantys nuo konteksto.
Watson sudaro:
90 IBM Power 750 serverių
I/O, klasterių valdymo įrengimai
2,880 POWER7 procesorių branduoliai ir 16 terabaitų RAM
Kūrimo išlaidos – 3 mln. JAV dolerių
Kompiuterio kaina - 3 mln. JAV dolerių
19 pav. WATSON superkompiuteris

27
20 pav. Watson veikimo algoritmas
Programinė įranga panaudota kuriant sistemą:
Java ir C++ programavimo kalbos
Apache Hadoop
Apache UIMA
SUSE Linux Enterprise Server 11
Tokie skaičiavimo pajėgumai leido įveikti geriausius žaidėjus žmones ir šiam kompiuteriui
kartu su IBM mokslininkais parodyti, kad didelioms problemoms spręsti lygiagrečių algoritmų
panaudojimas yra esminis faktorius.

28

29
Išvados
1. Lygiagretūs skaičiavimai leidžia išnaudoti techninę įranga ir kuria naujas kompiuterinių
skaičiavimų galimybes.
2. Techninės įrangos tobulėjimas paralelizavimo linkme, kuria tinkamą terpę programinės įrangos,
naudojančios lygiagrečius skaičiavimus, kūrimui.
3. Lygiagretūs skaičiavimai randa vis daugiau pritaikymų namų vartotojų kompiuteriuose ir leidžia
pasiekti galingumus (naudojant GPGPU), kurių anksčiau siekdavo tik superkompiuteriai.

30
Literatūra
1. Raimondas Čiegis „Lygiagretieji algoritmai“ 2001 m., Vilnius, 226 p.
2. Darius Šilingas. Lygiagretus daugialypis integravimas su Java kalba. Prieiga internete:
http://vaidila.vdu.lt/~i5dasi/parallel/javathreads.doc *žiūrėta 2011 - 03 – 20 ]
3. The Message Passing Interface (MPI) standard. Prieiga internete:
http://www.mcs.anl.gov/research/projects/mpi/ *žiūrėta 2011 - 03 –19 ]
4. Nvidia GPU Computing Developer Home Page. Prieiga internete:
http://developer.nvidia.com/object/gpucomputing.html *žiūrėta 2011-03-21]
5. Lietuvos akademinių institucijų lygegrečiųjų ir paskirstytų skaičiavimų tinklas. Prieiga internete:
http://www.litgrid.lt/ *žiūrėta 2011-03-21]
6. JAVA - Threads and Locks, Prieiga internete:
http://java.sun.com/docs/books/jls/third_edition/html/memory.html http://www.litgrid.lt/
*žiūrėta 2011-03-20]





























