Embed Size (px)
Citation preview


JURNAL MASYARAKAT INFORMATIKA INDONESIA
Vol 4, No1, Tahun 2019
AHP-TOPSIS PADA SELEKSI PENERIMAAN BANTUAN PROGRAM INDONESIA PINTAR
Ari Kusuma Wardana, Rianto
MEMBANGUN APLIKASI KLASIFIKASI BAHAN PUSTAKABERDASARKAN DEWEY DECIMAL
CLASSIFICATION DENGAN MENGGUNAKAN METODE K-NEAREST NEIGHBORHOOD
Mochammad Rial Al Rasyid
PENENTUAN JENIS DAUN KOPI DENGAN PENERAPAN ALGORITMA NEURAL NETWORK
BACK PROPAGATION
Suhendri
PERANCANGAN GAME VISUAL NOVEL “THE ADVENTURE OF KABAYAN” SEBAGAI MEDIA
BELAJAR BAHASA INGGRIS UNTUK TOEFL
Rudi Kurniawan1 , Gyta Nurul Windari
SISTEM SORTASI BIJI KOPI ARABIKA BERBASIS IOT MENGGUNAKAN PENGUKURAN KADAR
AIR DAN WARNA
Endang Amalia, Ari Purno Wahyu Wibowo
SISTEM PENDUKUNG KEPUTUSAN DALAM MEMILIH E-MARKETPLACE BERDASARKAN
FITUR LAYANAN DENGAN METODE WEIGHTED PRODUCT
Deryzky Akbar, Siti Nurajizah, Sri Muryani
SISTEM INFORMASI EVALUASI KINERJA PRODUKSI PERUSAHAAN PERTAMBANGAN
BATUBARA PADA DIREKTORAT JENDERAL MINERAL DAN BATUBARA
Ajeng Shilvie Nurlatifah, Sunjana
PERENCANAAN PROYEK SISTEM INFORMASI AKADEMIK PENDEKATAN METODE EARNED
VALUE
Sunjana
ISSN: 2541-5093

Jurnal ilmiah dengan bidang ilmu teknik informatika. Terbit 3 kali dalam setahun, setiap bulan
April, Agustus dan Desember.
Ketua Redaksi
Feri Sulianta
Dewan Redaksi
Fajri Rakhmat Umbara
Agung Santoso Pribadi
Afief Dias Pambudi
Edward Daniel Maspaitella
Iqbal Yulizar
Editor Pelaksana
Farhan Ferdian Mulyadi
Vito Hafiz
Ricko Firmansyah
Reviewer
Prof The Houw Liong (Institut Teknologi Bandung)
Hengky Honggo (STMIK MDP Palembang)
Bahar Riand Passa (Nanyang Technological University)
Dwi Aryanta (ITENAS)
Eko Cahyanto (Universitas Gunadarma)
Cholid Fauzi (ST Inten)
Wawan Hendrawan (ASMTB)
Titan Halim (Universitas BINUS)
Muksin Wijaya (STMIK LIKMI)
Muhhammad Sufyan Abdurrahman (Universitas TELKOM)
SEKRETARIAT
TIM KOMUNIKA INFORMATIKA
Jl. Gatot Subroto 153 C, Bandung 40273
e-mail: [email protected] / [email protected]
website: http://www.e-jmii.org

PENGANTAR REDAKSI
Merupakan pencapaian yang luarbiasa menggembirakan bagi kami untuk
menerbitkan JURNAL MASYARAKAT INFORMATIKA INDONESIA (JMII)
yang sifatnya independen, sebagai wujud kontribusi kami kepada masyarakat
Indonesia dalam dunia edukasi. Hal inilah yang menjadi landasan esensial kami
untuk menerbitkan jurnal ini. Tujuan dari jurnal ini adalah sebagai wadah untuk
mensosialisasikan hasil penelitian dari berbagai pihak terkait ranah atau rumpun
ilmu Teknik Informatika dengan berbagai bidang kajian seperti Sistem Informasi,
Basis Data, Data Mining, Jaringan Komputer & Internet, Kecerdasan Buatan,
Komputer Forensik, Pengolahan Citra Digital, Humaniora yang melibatkan
Teknologi Informasi dan lainnya.
Kami berterima kasih pada para penulis dan peneliti yang sudah berkontribusi
dalam mengirimkan hasil penelitiannya untuk diterbitkan pada jurnal ini. Dan kami
pun mengajak masyarakat Indonesia untuk terlibat dalam terbitan konten jurnal ini
pada edisi – edisi selanjutnya.
Akhir kata, kami berkomitmen untuk terus meningkatkan kualitas jurnal ini dan
berharap agar jurnal ini dapat terus memberikan kontribusi bagi masyarakat
Indonesia dalam ranah keilmuan Informatika.
REDAKSI

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
AHP-TOPSIS PADA SELEKSI PENERIMAAN BANTUAN PROGRAM
INDONESIA PINTAR
Ari Kusuma Wardana, Rianto
Fakultas Teknik, Program Studi Teknik Informatika
Universitas PGRI Yogyakarta
Jl. IKIP PGRI I Sonosewu No.117, Kasihan, Bantul, Daerah Istimewa Yogyakarta
[email protected], [email protected]
Abstrak
Program Indonesia Pintar (PIP) merupakan sebuah
program yang digalakan pemerintah untuk menuntaskan
masalah pendidikan di Indonesia yang dimulai dari tahun
2014. Program ini memberikan bantuan pendidikan dalam
bentuk uang tunai dengan nominal yang berbeda-beda,
tergantung jenjang pendidikan dan umur dari peserta didik.
Tidak semua anak usia sekolah di Indonesia memperoleh
bantuan program Indonesia pintar, ada beberapa kriteria yang
harus dipenuhi oleh seorang anak untuk memperoleh bantuan
tersebut. Proses menentukan siapa yang berhak memperoleh
bantuan Indonesia pintar menjadi rumit dan membutuhkan
waktu lama jika proses seleksi dilakukan secara manual
dengan melakukan cek kriteria satu per satu dari sejumlah
anak atau peserta didik. Untuk itu, diperlukan sebuah metode
tertentu yang dapat digunakan untuk menyeleksi atau
menentukan siapa yang berhak menerima bantuan Program
Indonesia Pintar dengan cepat dan tepat sasaran, serta
berpedoman pada kriteria-kriteria yang sudah ditentukan.
Solusi yang ditawarkan adalah dengan memanfaatkan
metode Analytical Hierarchy Process (AHP) dan Technique
For Others References By Similarity To Ideal Solution
(TOPSIS). Gabungan metode AHP dan TOPSIS ini membantu
dalam melakukan seleksi anak-anak yang berhak menerima
bantuan program Indonesia pintar secara lebih cepat dan tepat
sasaran. Studi kasus diambil di SMP Negeri 1 Kalibening
kabupaten Banjarnegara.
Kata kunci :
Sistem Pendukung Keputusan, AHP, TOPSIS, Program
Indonesia Pintar
Abstract
Program Indonesia Pintar (PIP) is a program promoted by
the government to solve the problem of education in Indonesia
starting in 2014. This program provides educational
assistance in the form of cash in nominal amounts, depending
on the level of education and age of students. Not all school-
age children in Indonesia receive assistance from the smart
Indonesia program, there are several criteria that must be met
by a child to obtain this assistance. The process of
determining who is entitled to smart Indonesian assistance is
complicated and takes a long time if the selection process is
done manually by checking criteria one by one from a number
of children or students. For this reason, a certain method is
needed that can be used to select or determine who has the
right to receive smart Indonesian program assistance quickly
and on target, and is guided by predetermined criteria. The
solution offered is to utilize the Analytical Hierarchy Process
(AHP) and Technique for Others References By Similarity To
Ideal Solution (TOPSIS) method. This combination of AHP
and TOPSIS methods helps in selecting children who are
entitled to receive assistance from smart Indonesian programs
more quickly and on target. The case study was taken at
Kalibening 1 Public Middle School, Banjarnegara Regency.
Keywords :
Decision Support System, AHP, TOPSIS, Program Indonesia
Pintar
PENDAHULUAN
Berdasarkan pembukaan Undang-Undang Dasar Negara
Republik Indonesia tahun 1945 [1], Pemerintah Negara
Republik Indonesia diamanati untuk mencerdaskan kehidupan
bangsa. Dengan demikian, Pemerintah diwajibkan untuk
mengusahakan dan menyelenggarakan satu sistem pendidikan
nasional bagi seluruh warga negara Indonesia. Sistem
pendidikan nasional yang dimaksud harus mampu menjamin

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
pemerataan kesempatan dan peningkatan mutu pendidikan,
terutama bagi anak-anak generasi penerus bangsa Indonesia.
Pada periode pemerintahan tahun 2014 sampai 2019
salah satu wujud nyata pemerintah dalam mencerdaskan
kehidupan bangsa, menuntaskan masalah pendidikan dan
pemerataan kesempatan pendidikan adalah dengan membuat
sebuah Program Indonesia Pintar [2]. Program Indonesia
Pintar merupakan sebuah bantuan yang diberikan kepada anak
usia 6 sampai 21 tahun [3], terdaftar di sekolah, madrasah,
pondok pesantren, kelompok belajar (kejar paket A/B/C),
maupun lembaga pelatihan atau kursus. Penerima bantuan
Program Indonesia Pintar berhak mendapatkan bantuan
pendidikan dalam bentuk uang tunai dengan nominal yang
berbeda-beda, tergantung jenjang pendidikan dan umur anak
tersebut.
Tidak semua anak usia sekolah di Indonesia memperoleh
bantuan Program Indonesia Pintar, ada beberapa kriteria yang
harus dipenuhi oleh seorang anak untuk memperoleh bantuan
tersebut. Proses menentukan siapa yang berhak memperoleh
bantuan Indonesia pintar menjadi rumit dan membutuhkan
waktu lama jika proses seleksi dilakukan secara manual
dengan melakukan cek kriteria satu per satu dari sejumlah
anak.
Untuk itu, diperlukan sebuah metode tertentu yang dapat
digunakan untuk menyeleksi atau menentukan siapa yang
berhak menerima bantuan Program Indonesia Pintar dengan
cepat dan tepat sasaran, serta berpedoman pada kriteria-
kriteria yang sudah ditentukan.
Solusi yang ditawarkan adalah dengan memanfaatkan
metode Analytical Hierarchy Process (AHP) dan Technique
For Others References By Similarity To Ideal Solution
(TOPSIS). Metode AHP pada penelitian ini digunakan untuk
memberi nilai bobot tiap kriteria [4] yang digunakan untuk
proses seleksi anak-anak yang sekiranya berhak menerima
bantuan Program Indonesia Pintar. Sedangkan metode
TOPSIS digunakan sebagai metode perangkingan daftar anak-
anak yang berhak menerima bantuan Indonesia pintar
berdasarkan nilai bobot yang dihasil dari metode AHP.
Gabungan metode AHP dan TOPSIS ini nantinya akan
membantu dalam melakukan seleksi anak-anak yang berhak
menerima bantuan program Indonesia pintar secara lebih cepat
dan tepat sasaran. Studi kasus diambil di SMP Negeri 1
Kalibening kabupaten Banjarnegara.
KAJIAN LITERATUR
Penelitian ini berfokus pada bagaimana metode AHP dan
TOPSIS dapat membantu menyelesaikan masalah seleksi
penerima bantuan Program Indonesia Pintar. Dalam
penelitian-penelitian sebelumnya ada yang telah melakukan
kajian tentang seleksi penerima bantuan Program Indonesia
Pintar, namun belum ada yang melakukan penelitian tentang
bagaimana metode AHP dan TOPSIS membantu
menyelesaikan masalah seleksi penerima bantuan Progam
Indonesia Pintar. Beberapa penelitian terdahulu yang terkait
dengan penerima bantuan pernah dilakukan, penelitian-
penelitian tersebut diambil sebagai tinjauan pustaka dalam
penelitian ini.
Penelitian yang pertama [5] tantang sistem pendukung
keputusan yang menggunakan metode weight product untuk
mengukur kelayakan pada penerimaan bantuan beras bagi
masyarakat miskin di wilayah Karikil, Mangkubumi,
Tasikmalaya. Penelitian ini dilakukan untuk menyeleksi calon
penerima bantuan beras miskin dengan tujuan keakuratan dan
kecepatan dalam proses seleksi. Metode weighted product
digunakan untuk menyelesaikan masalah multi atributte
decision making (MADM) dalam penelitian ini.
Penelitian yang kedua [6] tentang pemilihan karyawan
baru dengan menggunakan metode AHP. Metode AHP dalam
penelitian ini digunakan untuk pembobotan terhadap kriteria
dari para pelamar. Pembobotan yang dihasilkan oleh AHP
menurut penelitian ini dapat digunakan untuk menentukan
rekomendasi karyawan baru.
Penelitian yang ketiga [7] melakukan penelitian tentang
salah satu sistem pendukung keputusan pada penerimaan
Kartu Indonesia Pintar dengan metode yang digunakan yaitu
simple additive weighting. Penelitian ini dilakukan karena
sering kali pendistribusian bantuan Program Indonesia Pintar
tidak tepat sasaran. Penyebabnya adalah penerima bantuan
pada priode sebelumnya masih dilakukan secara manual dan
tidak menggunakan komputer. Demi mempermudah pekerjaan
pengambil keputusan dan menghindari kesalahan, maka
penelitian ini dilakukan. Tujuannnya adalah tidak lain untuk
mempermudah pekerjaan pengambil keputusan untuk
menyeleksi penerima bantuan kartu Indonesia Pintar menjadi
tepat sasaran.
Penelitian yang keempat [8] yaitu sistem pendukung
keputusan yang digunakan untuk memililih prioritas calon
penerima Program Indonesia Pintar yang dilakukan di Sekolah
Menengah Pertama menggunakan metode TOPSIS. Peneltian
ini dilakukan karena implementasi Program Indonesia Pintar
masih terdapat banyak kendala yang mengakibatkan tidak
tepat sasaran dalam pemberian program bantuan pendidikan
tersebut. Untuk itu sistem yang dihasilkan melalui penelitian
ini diharapkan dapat membantu menyeleksi anak yang
memang benar-benar membutuhkan bantuan pendidikan
Program Indonesia Pintar. Sistem yang dibangun
menambahkan beberapa kriteria yang lebih mendasar, yaitu
Status Aktif Siswa, Surat Keterangan Miskin, Kondisi Yatim
Piatu, Gaji Orang Tua, dan Presentasi Absensi.
Penelitian yang kelima [9] melakukan penelitian tantang
seleksi penerima bantuan sosial berdasarkan sistem
pendukung keputusan dalam upaya mengurangi siswa rawan
putus sekolah. Sulitnya memilih siswa yang benar-benar
membutuhkan bantuan sosial merupakan alasan dilakukannya

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
penelitian ini. Sistem yang dihasilkan memberikan
rekomendasi keputusan yang tepat melalui perhitungan
dengan metode TOPSIS. Sehingga sistem ini memberikan
kemudahan bagi pihak pengambil keputusan dalam memilih
anak yang berhak menerima bantuan sosial.
Penelitian yang keenam [10] melakukan penelitian yang
menggunakan metode Simple Additive Weighting (SAW) dan
TOPSIS untuk menentukan siapa yang berhak mendapatkan
beras miskin. Metode TOPSIS dalam penelitian ini digunakan
untuk melakukan perangkingan terhadap kriteria dan alternatif
yang sudah ditentukan. Sedangkan metode SAW digunakan
untuk melakukan perhitungan bobot. Hasil dari penelitian ini
dapat digunakan dengan baik, cepat dan efisien saat
menentukan siapa yang berhak menerima beras miski di
tengah masyarakat.
Dari beberapa tinjauan pustaka yang di jelaskan di atas,
penelitian yang akan dilakukan ini memiliki perbedaan, di
mana penelitian ini akan mengimplementasikan metode
Analytical Hierarchy Process (AHP) dan TOPSIS untuk
memilih atau menyeleksi penerima bantuan program
Indonesia pintar di lingkungan SMP Negeri 1 Kalibening agar
bantuan bisa disalurkan ke pihak yang memang
membutuhkan.
ANALISIS DAN PERANCANGAN
Penelitian ini merupakan jenis penelitian deskripsi
kuantitatif. Penelitian ini dimulai dengan mengumpulkan data
yang menggambarkan fakta di lapangan dan informasi yang
ada. Selanjutnya data kuantitatif yang didapatkan, digunakan
sebagai tolok ukur kajian penelitian.
Metode AHP dan TOPSIS digunakan untuk membantu
pengambilan keputusan pada penelitian ini. Metode ini
diharap mampu membantu para pengambil keputusan memilih
penerima bantuan Program Indonesia Pintar di lingkungan
SMP Negeri 1 Kalibening agar bantuan bisa disalurkan ke
pihak yang memang membutuhkan. Pada penelitian ini
menggunakan tahapan-tahapan yang terlihat pada Gambar 1.
Merancang Kriteria
Gambar 1. Alur Penelitian
Penelitian dimulai dengan terlebih dahulu melakukan
observasi dan wawancara di lokasi obyek penelitian,
wawancara dan observasi yang dilakukan bertujuan untuk
memperoleh data kriteria-kriteria dalam menyeleksi penerima
bantuan Program Indoneia Pintar.
Kriteria yang didapatkan dari hasil observsi dan
wawancara menjadi acuan untuk digunakan dalam merancang
kriteria-kriteria yang digunakan dalam metode AHP dan
TOPSIS. Tahap selanjutnya adalah mengimplementasikan
metode AHP dan TOPSIS untuk menyeleksi penerima bantuan
Indoneisa pintar. Microsoft excel digunakan untuk
mengimplemtasikan metode AHP dan TOPSIS. Perhitungan
metode AHP dan TOPSIS dengan kriteria-kriteria yang sudah
didapatkan dilakukan dengan memasukkan rumus-rumus
matematika di microsoft excel.
Setelah rumus matematika dituliskan pada microsoft
excel yang disesuaikan dengan metode AHP dan TOPSIS,
langkah selanjutnya adalah melakukan uji coba. Uji coba
dilakukan dengan menggunakan data siswa kelas VII SMP
Negeri 1 Kalibening tahun ajaran 2018/2019. Jika hasil
berjalan sesuai dengan keinginan, maka metode AHP dan
TOPSIS sudah bisa berjalan sesuai dengan rancangan yang
sudah dibuat. Namun, jika hasil tidak berjalan sesuai dengan
yang direncanakan, maka proses perbaikan akan dilakukan
sampai hasil yang didapatkan sesuai dengan rancangan.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Metode AHP yaitu salah satu metode yang biasa
digunakan dalam proses pengambilan keputusan. Dalam hal
ini metode AHP dapat digunakan untuk memecahkan suatu
permasalahan yang kompleks dan semi-terstruktur. Didalam
metode AHP terdapat bagian yang biasa disebut dengan
susunan hiraki dan memberi nilai berupa angka dengan
pertimbangan yang subjektif berdasarkan kepentingan tiap
bagiannya. Mensitasi dari beberapa hal yang dipertimbangkan
untuk menetapkan nilai prioritas, kriteria mana yang
mempunyai prioritas paling tinggi yang akan berdampak pada
perolehan hasil [11]. Metode AHP bisa dilakukan dengan
langkah-langkah sebagai berikut [12] :
Menjumlahkan setiap kolom pada matriks perbadingan
berpasangan.
11 12 13
21 22 23
31 32 33
C C C
C C C
C C C (1)
Menormalisasi nilai matriks perbandingan berpasangan
menggunakan persamaan (2).
1
ij
ij n
i
CX
Cij (2)
Menencari nilai bobot masing-masing kriterian dengan
menggunakan persamaan (3).
1
n
j ij
ij
XW
n (3)
Setelah nilai bobot untuk tiap kriteria diperoleh, maka nilai
dari bobot tersebut harus dilakukan pengujian terlebih
dahulu untuk memastikan nilai dari Consistent Ratio (CR)
kurang dari 0.1 atau 10%. Akan tetapi sebelum mencari
nilai CR, harus dicari terlebih dahulu nilai dari eigen, yaitu
dengan mengalikan nilai yang diperoleh dari masing-
masing kriteria dengan nilai bobot masing-masing kriteria.
Untuk rumus dapat dilihat pada persamaan (4).
11 12 13 11 11
21 22 23 21 21
31 3131 32 33
*
C C C W Cv
C C C W Cv
W CvC C C
(4)
Dari hasil yang diperoleh pada persamaan (4) maka dapat
didapatkan nilai max dengan menggunakan rumus
persamaan (5).
max 1 n
i ijCv (5)
Setelah nilai dari max diperoleh, langkah berikutnya
menghitung nilai Consistency Index (CI) menggunakan
rumus persamaan (6) dan Consistency Ratio (CR)
menggunakan rumus persamaan (7).
max
1
nCI
n (6)
CI
CRRCI
(7)
Pada tahap pengujian nilai CR, apabila diperoleh nilainya
kurang dari 0.1 atau 10% maka nilai konsistensi terhadap
nilai bobot untuk masing-masing kriteria dapat disetujui
dan tahap berikutnya yaitu menggunakan metode TOPSIS.
Pada tahap kedua adalah menggunakan metode TOPSIS,
metode ini digunakan untuk memilih alternatif yang ada.
Technique For Others References by Similarity to Ideal
Solution (TOPSIS) adalah suatu metode pengambilan
keputusan yang memiliki solusi ideal positif dan solusi ideal
negatif. Solusi ideal positif didefinisikan sebagai jumlah dari
seluruh nilai terbaik yang dapat dicapai untuk setiap atribut,
sedangkan solusi ideal negatif adalah seluruh nilai terburuk
yang dapat dicapai untuk setiap atribut [8]. Berikut adalah
tahapan-tahapan pada metode TOPSIS [12] :
Membuat sebuah matriks keputusan ternormalisasi dari
data yang telah terkumpul. Matriks ter-normalisasi diperoleh
dengan menggunakan persamaan (8).
2
ij m
iji
Xijr
X
(8)
Membuat matriks normalisasi terbobot menggunakan
persamaan (9). Untuk mendapatkan nilai matriks normalisasi
terbobot adalah dengan mengalikan nilai matriks
ternormalisasi dengan bobot yang diperoleh dari metode AHP.
ij j ijy w r (9)
Setelah didapat data matriks normalisasi terbobot,
selanjutnya menetukan solusi ideal positif (A+) dan solusi
ideal negatif (A-). Untuk menentukan solusi ideal, ditentukan
terlebih dahulu atribut disetiap kriteria, seperti atribut
keuntungan (benefit) atau atribut biaya (cost).
1 2 , , , nA y y y (10)
1 2 , , , nA y y y (11)
Dimana:
;
;
i ij
i i
max y jika j adalahbenefity
min y jika j adalahcost
;
;
i ij
i i
min y jika j adalahbenefity
max y jika j adalahcost

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
n 1 2 3 4 5 6 7 8 9 10
RI 0.00 0.00 0.58 0.90 1.12 1.24 1.32 1.41 1.46 1.49
Selanjutnya persamaan (12) dan persamaan (13)
digunakan untuk menentukan (jarak antara nilai alternatif
ke i dengan solusi ideal positif) dan (jarak antara nilai
alternatif ke i dengan solusi ideal negatif).
2
1
n
i j ij
j
D y y (12)
2
1
n
i ij j
j
D y y (13)
Menggunakan persamaan (14) untuk menentukan nilai
preferensi (vi) dari setiap alternatif. Nilai preferensi ini
menunjukkan nilai alternatif yang memiliki nilai terbesar dari
alternatif yang lainnya.
ii
i i
Dv
D D (14)
Setelah nilai vi diperoleh, maka selanjutnya dilakukan
proses perankingan alternatif berdasarkan urutan nilai vi.
Alternatif terbaik ialah yang memiliki nilai vi terbesar.
Pengujian metode AHP dan TOPSIS pada penelitian ini
diujikan pada data siswa atau peserta didik di SMP Negeri 1
Kalibening kelas VII tahun ajaran 2018/2019. Metode AHP
digunakan untuk menentukan bobot masing-masing kriteria,
sedangkan metode TOPSIS digunakan pada proses
perankingan alternatif, dalam hal ini para peserta didik atau
siswa. Gambar 2 adalah struktur hirarki pada model pengujian.
Kriteria yang digunakan adalah Dampak Bencana Alam,
Kelainan Fisik, Keluarga Terpidana, Pemegang
PKH/KPS/KKS, Siswa Miskin, Yatim Piatu, Penghasilan
Orang Tua, dan Daerah Konflik.
Tujuan
Kriteria
Alternatif
Dampak Bencana
AlamKelainan Fisik
Keluarga
Terpidana
Pemegang PKH/
KPS/KKSSiswa Miskin Yatim Piatu
Penghasilan
Orang TuaDaerah Konflik
Afifah Pramudita Anang KasironSinggih Ragil Rio
RomandaniElisa Fai Ruzul Ma'tuf
Seleksi Peserta
Didik
Gambar 2. Struktur Hirarki Pengujian Model
Data alternatif dan kriteria pada penelitian ini diambil
dari data yang didapatkan pada saat wawancara dan observasi
dengan pihak SMP Negeri 1 Kalibening. Pada tabel 1 adalah
data alternatif yang telah dikumpulkan.
Tabel 1. Daftar Data Nilai Alternatif
Afifah Pramudita 7 1 1 1 8 1 600000 1
Anang Kasiron 7 1 1 9 8 1 600000 1
Singgih Ragil Rio Romandani 3 1 1 1 1 5 1600000 1
Elisa 6 1 1 9 7 1 750000 1
Fai Ruzul Ma'tuf 1 1 1 9 1 1 1700000 1
YP POT DK
Siswa Kandidat Penerima
Bantuan Program Indonesia
Pintar
DBA KF KT P PKH/KPS/KKS SM
Pada tabel 1 adalah nilai yang didapatkan pada saat
wawancara dan observasi dengan pihak SMP Negeri 1
Kalibening, Dampak Bencana Alam = DBA,
Kelainan Fisik = KF, Keluarga Terpidana = KT, Pemegang
PKH/KPS/KKS = P PKH/KPS/KKS, Siswa Miskin = SM,
Yatim Piatu = YP, Penghasilan Orang Tua = POT, dan Daerah
Konflik = DK. Data alterntif pada table 1 akan digunakan pada
saat masuk ke metode TOPSIS.
Tabel 2. Matrik Perbandingan Berpasangan
KRITERIA DBA KF KT P PKH/KPS/KKS SM YP POT DK
Dampak Bencana Alam 1,00 1,00 1,00 1,00 1,00 1,00 2,00 1,00
Kelainan Fisik 1,00 1,00 2,00 1,00 1,00 1,00 1,00 1,00
Keluarga Terpidana 1,00 0,50 1,00 1,00 1,00 0,50 1,00 1,00
Pemegang PKH/KPS/KKS 1,00 1,00 1,00 1,00 1,00 1,00 2,00 1,00
Siswa Miskin 1,00 1,00 1,00 1,00 1,00 1,00 2,00 1,00
Yatim Piatu 1,00 1,00 2,00 1,00 1,00 1,00 2,00 1,00
Penghasilan Orang Tua 0,50 1,00 1,00 0,50 0,50 0,50 1,00 1,00
Daerah Konflik 1,00 1,00 1,00 1,00 1,00 1,00 1,00 1,00
Pada table 2 adalah matrik perbandingan berpasangan,
dimana nilai tersebut diperoleh dengan membandingkan
tingkat kepentingan dari masing-masing kriteria. Dari
perbandingan berpasangan dilakukan perhitungan dengan
membagi tiap sel dengan jumlah tiap kolom menggunakan
persamaan (2) dan menghasilkan matriks ter-normalisasi
seperti yang tertera pada tabel 3.
Tabel 3. Bobot Kepentingan Masing-Masing Kriteria
KRITERIA DBA KF KT P PKH/KPS/KKS SM YP POT DK
Dampak Bencana Alam 0,13 0,13 0,10 0,13 0,13 0,14 0,17 0,13
Kelainan Fisik 0,13 0,13 0,20 0,13 0,13 0,14 0,08 0,13
Keluarga Terpidana 0,13 0,07 0,10 0,13 0,13 0,07 0,08 0,13
Pemegang PKH/KPS/KKS 0,13 0,13 0,10 0,13 0,13 0,14 0,17 0,13
Siswa Miskin 0,13 0,13 0,10 0,13 0,13 0,14 0,17 0,13
Yatim Piatu 0,13 0,13 0,20 0,13 0,13 0,14 0,17 0,13
Penghasilan Orang Tua 0,07 0,13 0,10 0,07 0,07 0,07 0,08 0,13
Daerah Konflik 0,13 0,13 0,10 0,13 0,13 0,14 0,08 0,13
Pada tabel 3 adalah bobot kepentingan dari masing-
masing kriteria. Untuk mencari bobot tiap kriteria dilakukan
perhitungan menggunakan persamaan (3), dimana hasil
perhitungan dapat dilihat pada table 4. Pada table 4 tersebut
dapat diperoleh bobot dari Dampak Bencana Alam = 0.13,
Kelainan Fisik = 0.14, Keluarga Terpidana = 0.11, Pemegang
PKH/KPS/KKS = 0.13, Siswa Miskin = 0.13, Yatim Piatu =
0.15, Penghasilan Orang Tua = 0.09, dan Daerah Konflik =
0.12.
Tabel 4. Nilai Bobot Kriteria
WC1 WC2 WC3 WC4 WC5 WC6 WC7 WC8
0,13 0,14 0,11 0,13 0,13 0,15 0,09 0,12

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Setelah bobot untuk tiap kriteria diperoleh, langkah
berikutnya adalah melakukan pengujian terhadap nilai dari
bobot masing-masing kriteria, dalam hal ini harus dilakukan
pengujian terhadap nilai dari CR, dimana nilai terebut harus
lebih kecil dari 0.1 atau 10%.
Sebelum mencari nilai CR, terlebih dahulu harus
menghitung nilai eigen dari masing-masing kriteria
menggunakan persamaan (4) dan menjumlahkan nilai dari
lamda tersebut untuk memperoleh nilai dari max dengan
menggunakan persamaan (5).
Perhitungan dibawah adalah perolehan nilai eigen dari
masing-masing kriteria yang dihitung dengan menggunakan
persamaan (4).
Tabel 5. Nilai Eigen Masing-Masing Kriteria
Cv 11 Cv 21 Cv 31 Cv 41 Cv 51 Cv 61 Cv 71 Cv 81
1,09 1,11 0,86 1,09 1,09 1,19 0,73 1,00
Setelah dipeoleh nilai eigen untuk masing-masing
kriteria maka harus mencari nilai max, dengan menggunakan
persamaan (5).
max = 1.09 + 1.11 + 0.86 + 1.09 + 1.09 + 1.19 + 0.73
+ 1.00 = 8.15
Nilai dari max telah didapatkan, tahap berikutnya
mencari nilai Consistency Index (CI) dengan menggunakan
persamaan (6).
CI = = 0.02
Nilai dari CI telah diperoleh yaitu 0.02, tahap berikutnya
adalah mencari nilai Consistency Ratio (CR) dengan
menggunakan persamaan (6). Pada persamaan (6) terdapat
RCI dimana RCI adalah Random Consistency Index yang
dapat di lihat pada table 6.
Tabel 6. Tabel Random Consistency Index
CR = = 0.02
Dari perolehan nilai CR adalah 0.02 sehingga lebih kecil
dari 0.1 atau 10%, maka konsistensi nilai terhadap bobot untuk
masing kriteria dapat disetujui dan diakui.
Pada tahap ini, metode AHP telah selesai dan konsistensi
untuk setiap bobot masing-masing kriteria sudah dapat
dipertanggungjawabkan, maka langkah selanjutnya adalah
melakukan peringkingan dengan menggunakan metode
TOPSIS.
Dengan Mengambil nilai yang terdapat pada table 1,
yaitu tabel nilai data alternative dari masing-masing peserta
didik yang diperoleh dari SMP Negeri 1 Kalibening. Dimana
nilai data yang dimaksud adalah Dampak Bencana Alam,
Kelainan Fisik, Keluarga Terpidana, Pemegang
PKH/KPS/KKS, Siswa Miskin, Yatim Piatu, Penghasilan
Orang Tua dan Daerah Konflik. Sebelum normalisasi, maka
harus mencari nilai pembagi untuk masing masing kriteria
dengan melakukan perkalian akar kuadrat untuk masing-
masing kolom kriteria, dimana hasil perkalian akar kuadrat
dari masing-masing kolom adalah sebagai berikut:
C1 = = 12.00
C2 = = 2.24
C3 = = 2.24
C4 = = 15.65
C5 = = 13.38
C6 = = 5.39
C7 = =
2594706.15
C8 = = 2.24
Dengan menggunakan rumus persamaan (8) maka dapat
mencari nilai dari matrik keputusan ternormalisasi. Potongan
hasil perhitungan untuk normalisasi matrik adalah sebagai
berikut:
C11 = = 0.58
C21 = = 0.58
C31 = = 0.25
C41 = = 0.50
C51 = = 0.08
Pada tabel 7 adalah hasil perhitungan keseluruhan dari
Matrik keputusan ternormalisasi yang dikerjakan dengan
menggunakan persamaan (8).
Tabel 7. Matriks Keputusan Ternormalisasi
C1 C2 C3 C4 C5 C6 C7 C8
0,58 0,45 0,45 0,06 0,6 0,19 0,23 0,45
0,58 0,45 0,45 0,57 0,6 0,19 0,23 0,45
0,25 0,45 0,45 0,06 0,07 0,93 0,62 0,45
0,5 0,45 0,45 0,57 0,52 0,19 0,29 0,45
0,08 0,45 0,45 0,57 0,07 0,19 0,66 0,45

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Setelah nilai dari matrik keputusan ternormalisasi
diperoleh, tahap berikutnya adalah mencari matrik normalisasi
terbobot dengan menggunakan persamaan (9). Pada tahap ini
nilai bobot masing-masing kriteria yang diperoleh pada tabel 4
dikalikan dengan nilai dari matrik keputusan ternormalisai
yang terdapat pada tabel 7.
Potongan dari hasil perhitungan matrik normalisasi
terbobot pada kriteria Dampak Bencana Alam adalah sebagai
berikut:
C11 = = 0.0779
C21 = = 0.0779
C31 = = 0.0334
C41 = = 0.0667
C51 = = 0.0111
Hasil secara keseluruhan untuk perhitungan dari matrik
normalisasi terbobot pada masing-masing kriteria dapat dilihat
pada table 8.
Tabel 8. Matriks Normalisasi Terbobot
C1 C2 C3 C4 C5 C6 C7 C8
0,0779 0,0606 0,0473 0,0085 0,0798 0,0271 0,0206 0,055
0,0779 0,0606 0,0473 0,0768 0,0798 0,0271 0,0206 0,055
0,0334 0,0606 0,0473 0,0085 0,01 0,1355 0,055 0,055
0,0667 0,0606 0,0473 0,0768 0,0698 0,0271 0,0258 0,055
0,0111 0,0606 0,0473 0,0768 0,01 0,0271 0,0584 0,055
Setelah diperoleh nilai matriks normalisasi terbobot,
selanjutnya menentukan nilai solusi ideal positif (A+) dan
solusi ideal negatif (A-) menggunakan persamaan (12) dan
persaman (13) dengan memperhatikan atribut kriteria, seperti
atribut keuntungan (benefit) atau atribut biaya (cost) yang
dapat dilihat pada tabel 9.
Tabel 9. Nilai Atribut Kriteria
Kriteria Nama Kriteria Atribut
C1 Dampak Bencana Alam Benefit
C2 Kelainan Fisik Benefit
C3 Keluarga Terpidana Benefit
C4 Pemegang
PKH/KPS/KKS
Benefit
C5 Siswa Miskin Benefit
C6 Yatim Piatu Benefit
C7 Penghasilan Orang Tua Cost
C8 Daerah Konflik Benefit
Sebelum mencari nilai dari solusi ideal positif dan solusi
idel negative, maka harus dicari terlebih dahulu nilai terbesar
dan nilai terkecil dari masing-masing kriteria. Untuk mencari
nilai max dan nilai min pada tiap kriteria dapat menggunakan
persamaan (10) dan persamaan (11). Apabila kriteria tersebut
bersifat benefit maka nilai yang diambil adalah nilai yang
paling besar dari nilai seluruh kolom kriteria, sedangkan
kriteria bersifat cost maka nilai yang diambil adalah nilai yang
paling kecil dari nilai seluruh kolom kriteria. Dari pernyataan
tersebut maka diperoleh nilai max dan nilai min untuk masing-
masing kriteria yang dapat dilihat pada tabel 10.
Tabel 10. Solusi Ideal Positif Dan Negatif
A+ 0,0779 0,0606 0,0473 0,0768 0,0798 0,1355 0,0206 0,055
A- 0,0111 0,0606 0,0473 0,0085 0,01 0,0271 0,0584 0,055
Tabel 11 adalah nilai dari Di (jarak antara nilai
alternatif ke i dengan solusi ideal positif) dan Di (jarak
antara nilai alternatif ke i dengan solusi ideal negatif), dimana
nilai tersebut diperoleh dari table 8 dan table 10 dengan
menggunakan rumus persamaan (12) dan (13).
Tabel 11. Jarak Antara Nilai Setiap Matriks Di dan
Di
D+ D-
0,1281 0,1037
0,1084 0,1242
0,1127 0,1107
0,1096 0,1113
0,1501 0,0682
Pada tabel 12 adalah nilai preferensi yang dilambangkan
dengan vi yang diperoleh dengan menggunakan rumus
persamaan (14). Nilai yang diperoleh tersebut merupakan nilai
perangkingan untuk masing-masing peserta didik.
Perhitungan dari nilai preferensi dengan persamaan (14)
adalah sebagai berikut:
Afifah Pramudita = 0,1037
0,1037+0,1281 = 0.4474
Anang Kasiron = 0,1242
0,1242+0,1084 = 0.5338
Singgih Ragil Rio Romandani = 0,1107
0,1107+0,1127 = 0.4957
Elisa = 0,1113
0,1113+0,1096 = 0.5040
Fai Ruzul Ma'tuf = 0,0682
0,0682+0,1501 = 0.3125
Pada tabel 12 adalah nilai hasil keseluruhan preferensi
untuk setiap alternatif.
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
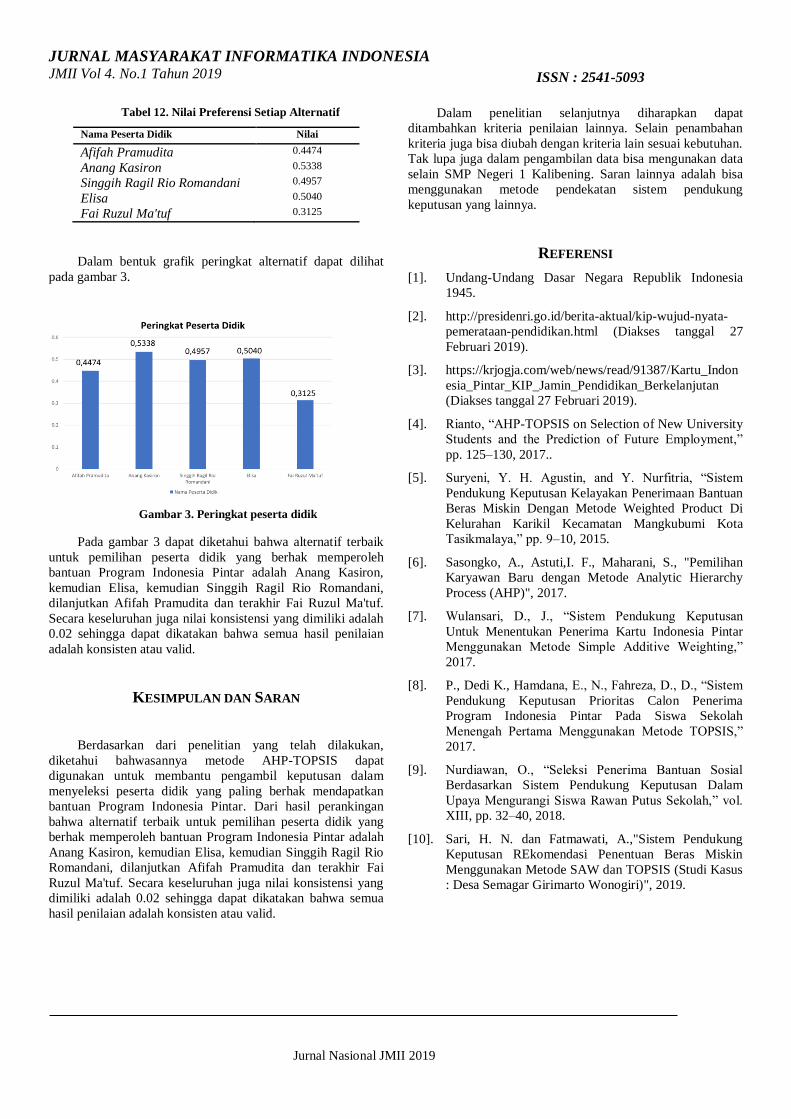
Tabel 12. Nilai Preferensi Setiap Alternatif
Nama Peserta Didik Nilai
Afifah Pramudita 0.4474
Anang Kasiron 0.5338
Singgih Ragil Rio Romandani 0.4957
Elisa 0.5040
Fai Ruzul Ma'tuf 0.3125
Dalam bentuk grafik peringkat alternatif dapat dilihat
pada gambar 3.
Gambar 3. Peringkat peserta didik
Pada gambar 3 dapat diketahui bahwa alternatif terbaik
untuk pemilihan peserta didik yang berhak memperoleh
bantuan Program Indonesia Pintar adalah Anang Kasiron,
kemudian Elisa, kemudian Singgih Ragil Rio Romandani,
dilanjutkan Afifah Pramudita dan terakhir Fai Ruzul Ma'tuf.
Secara keseluruhan juga nilai konsistensi yang dimiliki adalah
0.02 sehingga dapat dikatakan bahwa semua hasil penilaian
adalah konsisten atau valid.
KESIMPULAN DAN SARAN
Berdasarkan dari penelitian yang telah dilakukan,
diketahui bahwasannya metode AHP-TOPSIS dapat
digunakan untuk membantu pengambil keputusan dalam
menyeleksi peserta didik yang paling berhak mendapatkan
bantuan Program Indonesia Pintar. Dari hasil perankingan
bahwa alternatif terbaik untuk pemilihan peserta didik yang
berhak memperoleh bantuan Program Indonesia Pintar adalah
Anang Kasiron, kemudian Elisa, kemudian Singgih Ragil Rio
Romandani, dilanjutkan Afifah Pramudita dan terakhir Fai
Ruzul Ma'tuf. Secara keseluruhan juga nilai konsistensi yang
dimiliki adalah 0.02 sehingga dapat dikatakan bahwa semua
hasil penilaian adalah konsisten atau valid.
Dalam penelitian selanjutnya diharapkan dapat
ditambahkan kriteria penilaian lainnya. Selain penambahan
kriteria juga bisa diubah dengan kriteria lain sesuai kebutuhan.
Tak lupa juga dalam pengambilan data bisa mengunakan data
selain SMP Negeri 1 Kalibening. Saran lainnya adalah bisa
menggunakan metode pendekatan sistem pendukung
keputusan yang lainnya.
REFERENSI
[1]. Undang-Undang Dasar Negara Republik Indonesia
1945.
[2]. http://presidenri.go.id/berita-aktual/kip-wujud-nyata-
pemerataan-pendidikan.html (Diakses tanggal 27
Februari 2019).
[3]. https://krjogja.com/web/news/read/91387/Kartu_Indon
esia_Pintar_KIP_Jamin_Pendidikan_Berkelanjutan
(Diakses tanggal 27 Februari 2019).
[4]. Rianto, “AHP-TOPSIS on Selection of New University
Students and the Prediction of Future Employment,”
pp. 125–130, 2017..
[5]. Suryeni, Y. H. Agustin, and Y. Nurfitria, “Sistem
Pendukung Keputusan Kelayakan Penerimaan Bantuan
Beras Miskin Dengan Metode Weighted Product Di
Kelurahan Karikil Kecamatan Mangkubumi Kota
Tasikmalaya,” pp. 9–10, 2015.
[6]. Sasongko, A., Astuti,I. F., Maharani, S., "Pemilihan
Karyawan Baru dengan Metode Analytic Hierarchy
Process (AHP)", 2017.
[7]. Wulansari, D., J., “Sistem Pendukung Keputusan
Untuk Menentukan Penerima Kartu Indonesia Pintar
Menggunakan Metode Simple Additive Weighting,”
2017.
[8]. P., Dedi K., Hamdana, E., N., Fahreza, D., D., “Sistem
Pendukung Keputusan Prioritas Calon Penerima
Program Indonesia Pintar Pada Siswa Sekolah
Menengah Pertama Menggunakan Metode TOPSIS,”
2017.
[9]. Nurdiawan, O., “Seleksi Penerima Bantuan Sosial
Berdasarkan Sistem Pendukung Keputusan Dalam
Upaya Mengurangi Siswa Rawan Putus Sekolah,” vol.
XIII, pp. 32–40, 2018.
[10]. Sari, H. N. dan Fatmawati, A.,"Sistem Pendukung
Keputusan REkomendasi Penentuan Beras Miskin
Menggunakan Metode SAW dan TOPSIS (Studi Kasus
: Desa Semagar Girimarto Wonogiri)", 2019.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
[11]. Ilham, D., N., Mulyana, S., “Sistem Pendukung
Keputusan Kelompok Pemilihan Tempat PKL
Mahasiswa dengan Menggunakan Metode AHP dan
Borda,” vol. 11, no. 1, pp. 55–66, 2017.
[12]. Sari, D.,R., Windarto, A.,P., Hartama, D.,
Solikhun,"Sistem Pendukung Keputusan untuk
Rekomendasi Kelulusan Sidang Skripsi Menggunakan
Metode AHP-TOPSIS", vol. 6, no. November 2017,
pp. 1–6, 2018.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
MEMBANGUN APLIKASI KLASIFIKASI BAHAN
PUSTAKABERDASARKAN DEWEY DECIMAL
CLASSIFICATION DENGAN MENGGUNAKAN METODE K-
NEAREST NEIGHBORHOOD
Mochammad Rial Al Rasyid
Program Studi Informatika, Fakultas Teknik, Universitas Widyatama Bandung
Jalan Cikutra No. 204 A Bandung 40125
Telp. 62.22.7275855- Fax. 62.22.7274010 http://www.widyatama.ac.id
E-mail: [email protected]
Teknik klasifikasi ditujukan untuk
mengelompokan atribut yang memiliki beberapa
ciri yang sama dan memisahkan atribut yang tidak
sama. Dalam konteks perpustakaan, klasifikasi
adalah kegiatan mengelompokan bahan pustaka
berdasarkan kesamaan subjek atau topiknya
dengan berpedoman pada metode atau sistem yang
akan dibuat. Teknik klasifikasi ditujukan untuk
mengelompokan atribut yang memiliki beberapa
ciri yang sama dan memisahkan atribut yang tidak
sama. Dalam konteks perpustakaan, klasifikasi
adalah kegiatan mengelompokan bahan pustaka
berdasarkan kesamaan subjek atau topiknya
dengan berpedoman pada metode atau sistem yang
akan dibuat.
Penelitian ini akan membahas tentang
klasifikasi nomor panggil otomatis yang
mengklasifikasikan bahan pustaka sesuai dengan
sistem klasifikasi Dewey Decimal Classification
(DDC) dengan metode K-Nearest Neighborhood
(KNN). Dalam penelitian ini juga diterapkan
metode Text Mining sebagai cara untuk
menentukan subjek utama sebuah bahan pustaka.
Sistem yang dibangun ini bertujuan untuk
membantu seorang pustakawan dalam
mengklasifikasi buku di perpustakaan yang
berguna sebagai pengelompokan buku yang
nantinya akan disimpan pada rak rak buku
sehingga mampu memberikan informasi tata letak
buku dan memudahkan pengunjung dalam
mencari buku berdasarkan kategorisasi nomor
yang telah ditentukan oleh seorang pustakawan.
Kata kunci : klasifikasi, pustaka,
perpustakaan, pustakawan, dewey decimal
classification, k-nearest neighborhood, text mining
I. PENDAHULUAN
Perpustakaan adalah salah satu institusi
dalam suatu lembaga pendidikan yang
menyediakan berbagai macam sumber daya
informasi baik buku, e-book maupun learning
content lainnya serta menyediakan layanan yang
penting dalam mendukung proses pembelajaran,
penelitian, dan pengembangan pengetahuan bagi
setiap anggotanya.
Penggunaan sistem informasi
perpustakaan saat ini sudah tidak asing lagi, banyak
perpustakaan mulai menggunakan sistem informasi
perpustakaan sebagai bagian penting untuk
meningkatkan kinerja staf perpustakaan dan
organisasi perpustakaan. Sistem informasi
perpustakaan pun berkembang sedemikian pesat
baik yang disediakan secara gratis atau tidak
sampai dengan sistem yang dikembangkan sendiri
oleh perpustakaan. Perpustakaan diberi kebebasan
untuk memilih sistem informasi perpustakaan yang
paling baik dan sesuai dengan kebutuhan
perpustakaan. Pemilihan sistem informasi menjadi
pertaruhan bagi perpustakaan dalam menghadapi
globalisasi informasi dan perkembangan teknologi
informasi. Perpustakaan harus dapat menentukan
sistem informasi yang mampu terimplementasi
dengan baik dan mampu diterima penggunanya.
Dalam perpustakaan seorang pustakawan
mempunyai kewajiban menenukan nomor
klasifikasi atau nomor panggil buku tersebut ketika
menerima sebuah bahan pustaka atau buku baru.
Karena sering kali buku baru yang masuk tidak
memiliki nomor klasifikasi dan belum
teridentifikasi, maka tugas pustakawan adalah
menentukan nomor klasifikasi atau nomor panggil
buku tersebut. Pada perpustakaan klasifikasi
mempunyai pengertian penyusunan sistematis
terhadap bahan pustaka berdasarkan subyek,
sebagai ciri untuk pemustaka mencari suatu buku
tertentu. Salah satu cara dalam mennentukan

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
klasifikasi bahan pustaka adalah dengan
menggunakan sistem Dewey Decimal
Classification (DDC). Problem yang sering
ditemukan oleh pustakawan salah satunya adalah
Sulit membedakan klasifikasi buku yang sangat
banyak sekali, maka dari itu pengklasifikasian buku
menggunakan DDC, dan problem nya lainnya yang
sering ditemui oleh pustakawan adalah saat
mencari buku diantara ribuan bahkan jutaan dari
database buku.
Dewey Decimal Classification (DDC) atau
yang biasa disebut Sistem Desimal Dewey,
merupakan suatu aturan pengklasifikasian buku
yang sering di gunakan secara umum di semua
perpustakaan, baik di perpustakaan lokal maupun
internasional. Pemakain sistem klasifikasi ini
bertujuan untuk memudahkan pengorganisasian
serta pencarian bahan pustaka tersebut kedalam
kelompoknya. Didalam DDC dituliskan dalam tiga
digit angka, angka pertama menunjukan kelas
utama, angka kedua menunjukan kelas divisi dan
angka ketiga menunjukan kelas section. Setiap
dokumen yang perpustakaan yang diolah
menggunakan sistem DDC akan dimasukan
kedalam satu kelas yang ada pada sistem DDC.
Hasil observasi yang ada menunjukan
bahwasannya pustakawan dalam proses
pengklasifikasian masih menggunakan. cara
manual yaitu pertama pustakawan menentukan
subyek terdekat bahan pustaka. Kemudian mencari
klasifikasi yang tepat berdasarkan subyek yang
sudah ditentukan sebelumnya secara manual dan
menentukan angka klasifikasi berdasarkan buku
panduan DDC. Tentu saja hal ini kurang efektif dan
efisien, belum lagi pustakawan harus bekerja
dengan menentukan angka klasifikasi bahan
pustaka dan menginputkan angka klasifikasi
kedalam sistem yang ada.
Metode text mining merupakan
pengembangan metode data mining yang dapat
diterapkan untuk mengatasi masalah tersebut.
Algoritma dalam text mining tersebut tercipta
untuk dapat mengenali data yang sifatnya semi
terstruktur seperti judul buku, subjek buku serta
modul dewey decimal classification. Oleh karena
itu pada penelitian kali ini akan dikembangkan
sebuah solusi baru untuk mengklasifikasikan bahan
pustaka berdasarkan DDC secara otomatis
menggunakan teknik text mining.
Salah satu solusi dalam pencarian buku
tersebut digunakanlah metode dalam proses
klasifikasi pada text mining yakni Algotitma K-
Nearest Neighborhood (KNN) yang merupakan
pendekatan untuk mencari kasus dengan
menghitung kedekatan antara kasus baru dengan
kasus lama, yaitu berdasarkan pada pencocokan
bobot dari sejumlah fitur yang ada.
Sebagai sistem pendukung keputusan yang
banyak peneliti pakai. Hal ini digunakan untuk
memberikan alternattip rekomendasi berdasarkan
kedekatan untuk membantu dalam pengambilan
keputusan/kebijakan terhadap data yang diolah
berdasarkan data data latih / data buku sebelumnya
sehingga masalah yang ada dapat diselesaikan
dengan bijak. Pada intinya metode KNN untuk
mengklasifikasikan objek baru terhadap atribut dan
data latih yang pendekatannya untuk mencari kasus
dengan menghitung nilai kedekatan antara kasus
baru atau data yang akan diuji dengan kasus lama
atau data yang sudah ada, dengan mencocokkan
nilai bobot dari sejumlah fitur yang ada.
Maka dari itu metode K-Nearest
Neighborhood (KNN) lebih cocok di pakai untuk
pembuatan aplikasi perpustakaan karena
menggunakan klasifikasi Dewey Decimal
Classification (DDC) dan untuk optimasi pencarian
agar lebih tepat dan akurat disaran kan
menggunakan metode KNN ini. Oleh karena itu
pada penelitian kali ini dipilih metode K-Nearest
Neighborhood (KNN) dengan alasan lebih
sederhana tetapi memiliki tingkat akurasi yang
tinggi dan tingginya kecepatan dalam proses
pelatihan dan klasifikasi. Dengan demikian dapat
disimpulkan bahwasannya pengklasifikasian
menggunakan metode KNN ini memberikan hasil
yang cukup akurat dengan presentasi keberhasilan
sebesar 71,58 % sampai dengan 83,2 %.
II. METODOLOGI PENELITIAN
Metode penelitian digunakan untuk dapat
membantu menyelesaikan permasalahan sehingga
hasil yang didapat lebih sistematis dan terarah.
a. Tahap Pengumpulan Data
Pengumpulan data dilakukan dengan cara
mengambil data secara langsung dengan instansi
terkait sebagai pendukung utama dalam analisis dan
perancangan sistem yang akan dibuat.
b. Tahap Data Pre Processing
Dalam tahapan ini akan dilakukan
transformasi data mentah kedalam format yang
sesuai dengan analisis dan perancangan yang dibuat.
terdapat beberapa aktifitas seperti data integration
dan data cleaning dan terdiri dari proses seleksi
fitur, reduksi dimensionalitas, normalisasi dan
subsetting data.
c. Tahap Pengolahan Data

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Tahapan pengolahan data dengan proses
data mining yang bertujuan untuk menentukan pola
atau informasi penting didalam sekumpulan data.
Metode yang digunakan dalam pengolahan data ini
adalah K-Nearest Neighborhood (KNN) yang
melakukan pengklasifikasian berdasarkan Dewey
Decimal Classification (DDC).
d. Tahap Data Post Processing
Pada tahap ini akan dilakukan data post
processing yang terdiri dari proses interpretasi,
visualisasi, dan evaluasi terhadap pola atau
informasi yang terlah dihasilkan dari tahap
pengolahan data. Data post processing bertujuan
untuk menjamin bahwasanya hasil yang didapat dari
proses data mining telah diintegrasikan pada sistem
penunjang keputusan dengan hasil yang benar benar
valid.
e. Tahap Analisis Hasil
Pada tahapan ini akan dilakukan analisis
terhadap pengolahan data yang telah dilakukan
dalam kebutuhan sistem penelitian yang dibuat
berdasarkan tahapan pengumpulan data, data pre
processing, pengolahan data, dan data post
processing. Maka akan didapat hasil dari proses
analisis dan perancangan pengklasifikasian pada
metode K-Nearest Neighborhood (KNN).
III. LANDASAN TEORI
A. Perpustakaan
Perpustakaan adalah tempat untuk
mengembangkan informasi dan pengetahuan yang
dikelola oleh suatu lembaga pendidikan, sekaligus
sebagai sarana edukatif untuk membantu
memperlancar cakrawala pendidik dan peserta
didik dalam kegiatan belajar mengajar.
B. Data Mining
Data mining adalah proses menemukan
sesuatu yang bermakna dari suatu korelasi baru,
pola dan tren yang ada dengan cara memilah-milah
data berukuran besar yang disimpan dalam
repositori, menggunakan teknologi pengenalan pola
serta teknik matematika dan statistik.
C. Text Mining
Menurut Milkha Harlian Ch, (2006) text
mining merupakan menambang data yang berupa
teks dimana sumber data biasanya didapatkan dari
dokumen dan tujuannya adalah mencari kata-kata
yang dapat mewakili isi dari dokumen sehingga
dapat dilakukan analisa keterhubungan antar
dokumen.
Gambar 1 Tahapan Text Mining
1. Tahap case folding adalah merubah
huruf kapital menjadi huruf kecil.
2. Tahap Tokenizing adalah tahap
pemotongan string input berdasarkan
tiap kata yang menyusunnya.
3. Tahap filtering adalah tahap mengambil
kata-kata penting dari hasil token.
Algoritma yang digunakan adalah
algoritma stoplist (membuang kata
yang kurang penting) atau wordlist
(menyimpan kata penting).
4. Tahap matching, adalah proses
pencocokan kata hasil dari filtering
dengan data yang ada pada modul
DDC.
5. Tahap analizing merupakan tahap
penentuan seberapa jauh keterhubungan
antara kata-kata antar dokumen yang
ada. Tahap ini menggunakan algoritma
frekuensi term (TF), invers document
frequency (IDF) dan kombinasi
perkalian antara keduanya (TFxIDF).
D. K-NEAREST NEIGHBORHOOD
(KNN)
Algoritma k-nearest neighbor (KNN)
adalah sebuah metode untuk melakukan
klasifikasi terhadap objek berdasarkan data
pembelajaran yang jaraknya paling dekat dengan
objek tersebut. KNN termasuk algoritma
supervised learning dimana hasil dari query
instance yang baru diklasifikan berdasarkan
mayoritas dari kategori pada KNN. Nanti kelas
yang paling banyak muncul yang akan menjadi
kelas hasil klasifikasi.
Gambar 2 K Nearest Neighborhood

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Tujuan dari algoritma ini adalah
mengklasifikasikan obyek baru bedasarkan atribut
dan training sample. Classifier tidak
menggunakan model apapun untuk dicocokkan dan
hanya berdasarkan pada memori. Diberikan titik
query, akan ditemukan sejumlah k obyek atau (titik
training) yang paling dekat dengan titik query.
Klasifikasi menggunakan voting terbanyak diantara
klasifikasi dari k obyek.. algoritma k-nearest
neighbor (KNN) menggunakan klasifikasi
ketetanggaan sebagai nilai prediksi dari query
instanceyang baru.
Gambar 3 Flowchart KNN
E. Dewey Decimal Classification (DDC)
Sistem pengelompokkan buku paling
umum di pakai di setiap perpustakaan yaitu sistem
klasifikasi DDC. Sistem pengelompokkan Dewey
Decimal Classification atau biasa disingkat DDC
merupakan sebuah sistem yang paling banyak
digunakan di perpustakaan di seluruh dunia.
Penciptanya adalah Melvil Dewey atau nama
lengkapnya adalah Melvil Louis Kassuth Dewey
(1851-1931). Keunggulan DDC ini karena sistem
ini direvisi secara terus-menerus sesuai dengan
perkembangan ilmu. Hal ini menyebabkan sistem
ini selalu dalam keadaan up to date sehinga subjek-
subjek baru terakomodasi dengan lengkap.
Kemutakhiran isi DDC bisa terjaga karena sistem
ini mempunyai lembaga khusus yang mengawasi
dan mendukung penerbitannya adalah Forest Press.
Kedua badan tersebut memeriksa usulan revisis dan
mengajukan saran perbaikan kepada Forest Press.
Terbagi menjadi 10 kelas utama dengan
masing masing kelasnya terdapat anak kelas dari
kelas utama, berikut 10 kelas utama dari DDC :
000 Karya Umum
100 Filsafat
200 Agama
300 Ilmu Sosial
400 Bahasa
500 Ilmu Pengetahuan Murni
600 Ilmu Pengetahuan Terapan
700 Kesenian dan Olah Raga
800 Kesusastraan
900 Sejarah, Geografi
IV. ANALISIS SISTEM
Analisis sistem yang sedang berjalan
Perpustakaan masih menerapkan sistem
pengklasifikasian buku secara manual membuat
proses pengklasifikasian buku tidak efektif dan
tidak efisien bagi seorang pustakawan
1) Data buku yang terdapat pada perpuatakaan
dispusibda jabar bersumber dari internal dan
eksternal. Internal itu diperoleh dari
pembelian buku yang dilakukan oleh
dispusibda, dan untuk ekternal buku tersebut
berasal dari pemberian atau sumbangsih
penerbit ataupun penulis yang bersangkutan.
2) Buku yang masuk tersebut didata oleh
pustakawan, dari mulai judul buku sampai
dengan subjek buku yang kemudian disimpan
pada dokumen data buku yang tersedia.
3) Setelah didata buku tersebut telah siap untuk
diklasifikasi dengan modul Dewey Decimal
Classification (DDC). Diberi nomor buku
sesuai dengan kelasnya masing masing. Yang
manual dilakukan oleh seorang pustakawan
4) Proses selanjutnya buku dikelompokan sesuai
dengan jenis serta kesamaan nomor nya dan
di catat pada dokumen klasifikasi buku.
5) Laporan semua hasil rekap diberikan kepada
manajer. Setelahnya pustakawan akan
membuat bahwa proses tersebut telah
disetujui oleh manajer dengan membuat tanda
terima buku. Proses pun selesai dilakukan.
Analisis Metode
A. Text Preprocessing
Tahapan selanjutnya adalah
preprocessing. Langkah langkah yang akan
dilakukan adalah case folding, kemudian akan

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
dilakukan proses tokenizing, filtering, matching
sampai dengan analyzing.
a. Case folding
Case folding adalah mengubah semua
huruf dalam dokumen menjadi huruf kecil.
Sistem akan menerima huruf “a” sampai dengan
“z”.
b. Tokenizing
Tahap tokenizing adalah tahap
pemotongan string input bedasarkan dari tiap kata
yang menyusun kata tersebut.
c. Filtering
Tahap mengambil kata kata penting dari
hasil token. Algoritma yang digunakan adalah
algoritma stoplist atau artinya membuang kata kata
yang kurang penting atau wordlist yang artinya
menyimpan kata penting.
d. Matching
Proses mining yang digunakan sebagai
mekanisme dalam pengambilan data dengan
mengasumsikan bahwasannya terdapat tingkat
variabel prediktor yang ideal yang mana hal ini
harus dipenuhi oleh subjek yang diteliti. Dalam hal
ini yang dicocokan pada proses matching ialah
pencocokan kata hasil kategorisasi dengan master
DDC.
e. Analyzing
Tahap penentuan seberapa jauh
keterhubungan antara kata kata antara dokumen
yang ada. Perhitungan pada tahapan ini
menggunakan term, dan term yang digunakan
adalah Term Frequency (TF), Invert Document
Frequency (IDF) dan kombinasi perkalian antara
keduanya (TFxIDF).
Gambar 4 Text Processing
B. Global Block Diagram
Setiap data tentunya harus terlebih dahulu
di proses sedemikianrupa sehingga dapat
menghasilkan data yang nantinya dapat digunakan
dalam proses mining. Sama hal nya dengan sistem
yang nantinya akan dibangun dan dijalankan pada
perusahaan, tahapan tahapan tersebut dibagi
kedalam 3 bagian yaitu input atau masukan, lalu
ada proses dari pada data tersebut diolah dan
menghasilkan output yang nantinya merupakan
hasil dari pada keseluruhan proses yang telah
diolah dan dilakukan pemrosesan data.
Gambar 5 Global Block Diagram
C. INPUT Block Diagram
Pada Input Block Diagram dijelaskan,
bahwa input berasal dari data buku, data subjek dan
data DDC yang mana akan langsung diteruskan
pada proses data preprocessing yang didalamnya
terdapat case folding dan tokenizing. Case folding
yakni merubah huruf besar menjadi huruf kecil.
Dan tokenizing ial lah memotong kata penyusun
dari judul buku yang ada. Setelah proses tersebut
selesai dilakukan, barulah muncul data
preprocessing yang nantinya akan diproses pada
tahapan berikutnya.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Gambar 6 Input Block Diagram
D. PROCESS Block Diagram
Pada proses yang terlihat pada gambar
block diagram proses, bahwasannya daa buku dan
data subjek dijadikan sebagai masukan data dari
luar menuju kedalam sistem. Yang mana halnya
dalam proses ini, data akan langsung diproses
dengan DDC, yang didalamnya terdapat masing
masing proses yang berguna untuk mengolah data
setelahnya data akan disimpan pada temporary
database sementata pada masing masing database
berdasarkan proses nya. Setelah proses DDC
selesai dilanjutkan pada proses KNN, yang
bertujuan untuk mencari nilai kemiripan yang
melandasi nomor kedekatan klasifikasi buku.
Gambar 7 Process Block Diagram
E. OUTPUT Block Diagram
Gambar 8 Output Block Diagram
Pada tahapan output KNN berperan
penting sebagai algoritma yang merupakan metode
yang dipakai untuk menentukan nomor klasifikasi
buku. Buku masukan di tes serta diuji pada KNN
setelah itu dilanjutkan pada tahapan hasil
klasifikasi DDC KNN, yang mana pada tahapan ini
klasifikasi buku pada proses sebelumnya serta
temporary data pula turut menjadi data yang
menjadi masukan untuk pengimpelentasian nomor
klasifikasi DDC dan mencari kedekatan dengan
algoritma KNN dan hasilnya selanjutnya akan
menjadi strategi penyimpanan buku pada rak rak
buku berdasarkan ketentuan yang berlaku.
Algoritma KNN
Dalam proses pengkalsifikasian buku pada
aplikasi yang dibangun sudah pasti melibatkan
perhitungan algoritma KNN didalamnya, adapun
tahapannya sebagai berikut :
1. Menghitung Text Mining
Pada setiap klasifikasi DDC persentasi
setiap judul buku dengan menggunakan term
frequency (tf) berdasarkan dari isi dokumen 1 (D1)
sampai dengan dokumen berikutna (Dn). Seperti
terlihat pada gambar berikut :
Gambar 9 Dokumen yang terlibat
Untuk menentukan kesamaan kata pada
setiap klasifikasi DDC subjek presentase terbesar
tiap judul buku,

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Gambar 10 Perhitungan Text Mining
2. Menghitung TF-IDF
Berfungsi untuk menentukan DDC yang
mempunyai persentase diatas nol persen atau nol.
Dapat terlihat pada gambar dibawah bahwasannya
dokumen yang memiliki angka akan dihitung
menggunaan rumus :.
Gambar 11 Perhitungan TF-IDF
3. Perkalian Skalar
Pada bagian ini dihitung Perkalian skalar
(antara dokumen sebanyak Dn dengan dokumen
lainnya) dan Panjang Vektor. Berfungsi sebagai
pengujian untuk memperkuat data uji dari dokumen
judul buku.
Gambar 12 Perhitungan Perkalian Skalar
4. Cosine Similarity
Pada bagian ini dihitung cosine similarity
yang merupakan hasil nilai kedekatan dari KNN
serta pada hal ini dokumen yang terlibat adalah D1
sampai dengan Dn
Gambar 13 Perhitungan Cosine
Similarity
5. Kesimpulan
Nomor DDC akan direpresentasikan
bersama judul buku lengkap dengan persentase
nya.
Gambar 14 Kesimpulan
Dan ini adalah nilai KNN dengan 3
kedekatan nomor klasifikasi
Gambar 14 Nilai K = 3
Jadi pengujian klasifikasi untuk nilai DDC
nya lebih dari 0 itulah yang menjadi acuan nomor
klasifikasi buku dengan metode DDC dan mencari
nilai kedekatan dengan KNN
V. PERANCANGAN SISTEM
A. Data Flow Diagram
Berikut rancangan DFD yang berjalan
pada sistem yang dibangun :
Gambar 15 Data Flow Diagram
Level 1
Proses menginputkan data buku sampai
dengan proses penampilan nomor yang telah di
klasifikasi oleh sistem, yang secara keseluruhan
mencakup data buku, data subjek, data DDC, data
pengujian dan data hasil klasifikasinya.
B. Entity Relationship Diagram
Diagram kelas tahap analisis merupakan
diagram untuk membantu dalam menggambarkan
struktur kelas-kelas pada sistem yang akan dibuat.
Setiap tahapan yang ada di scenario use case akan

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
digambarkan pada diagram kelas tahap analisis
sehingga penggambaran sistem dibuat akan lebih
jelas. Berikut ini adalah gambar diagram kelas
tahap analisis :
Gambar 16 Entity Relationship Diagram
Maksud dari gambar 16 adalah BUKU
memiliki kode_buku, sebagai primary key
untuk menginputkan data buku. MST_SUBJEK
memiiliki primary key id yang mewakili atribut
yang ada pada entitas mst_Subjek. Lalu Entitas
MST_DDC memiliki primary key kode_ddc
yang menerangkan kode yang ada pada modul
DDC. Berikutnya Entitas TEMP_DDC
mempunyai id_buku sebagai primary key
sebagai tempat sementara ketika
pengklasifikasian buku diproses. Hal serupa
pula terjadi pada entitas TEMP_KLASIFIKASI
dengan primary key id_buku sebagai identitas
dari entitas yang dipakai untuk tempat
pemrosesan data sementara dan bersifat
temporary / sementara. Terakhir yakni entitas
MST_SUBJEKDDC yang mempunyai primary
key id, entitas ini perannya juga sangat sentral
karena sebagai alternatif penghubung antara
subjek dengan DDC untuk menentukan
pengklasifikasian buku.
A. Flowchart Hasil Klasifikasi
Flowchart adalah Bagan-bagan yang
mempunyai arus yang menggambarkan langkah-
langkah penyelesaian suatu masalah. Flowchart
merupakan cara penyajian dari suatu algoritma.
Gambar 17 Flowchart Hasil Klasifikasi
VI. IMPLEMENTASI SISTEM
A. Tampilan Halaman Home
Inilah tampilan awal dari aplikasi
klasifikasi bahan pustaka yang ada di perpustakaan
provinsi jawa barat
Gambar 18 Antarmuka Halaman Home
B. Tampilan Halaman Buku
Di bawah ini merupakan menu buku yang
didalamnya terdapat data buku, terdapat opsi
menambhakan, merubahs sampai menghapus data
buku.
Gambar 19 Antarmuka Halaman Buku
C. Tampilan Haaman Subjek
Di bawah ini merupakan seluruh data
subjek yang telah dihimpun. Terdapat pula opsi

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
untuk menambah, mengubah serta menghapus data
subjek.
Gambar 20 Antarmuka Halaman Subjek
D. Tampilan Halaman DDC
Di bawah ini merupakan tampilan modul
DDC yang berjumlah 1000, dimulai dari kelas 000
sampai dengan 999.
Gambar 21 Antarmuka Halaman DDC
E. Tampilan Halaman Hasil Klasifikasi
KNN
Di bawah ini merupakan hasil klasifikasi
dari semua buku yang telah
diklasisfikasi.menggunakan perhitungan KNN
berdasarkan modul DDC.
Gambar 22 Antarmuka Halaman Data Hasil
Klasifikasi
F. Tampilan Halaman Hasil Klasifikasi K
= 3
Di bawah ini merupakan hasil klasifikasi
yang menunjukan 3 nilai kedekatan, persentase
terbesar itulah yang menjadi nomor klasifikasi
buku tersebut.
Gambar 23 Antarmuka Halaman Hasil
Klasifikasi per Buku
B. Pengujian
Pada bagian ini akan menjelaskan mengenai
hasil pengujian dari sistem aplikasi yang buat.
Pengujian yang dilakukan menguji sitem ini adalah
metode pengujian black-box. Black box testing
adalah pengujian yang dilakukan hanya mengamati
hasil eksekusi melalui data uji dan memeriksa
fungsional dari perangkat lunak.
VII. PENUTUP
A. Ksimpulan
Berdasarkan hasil dari pelaksanaan tugas
akhir “Membangun Aplikasi Klasifikasi Bahan
Pustaka Berdasarkan Dewey Decimal
Classification Dengan Metode K Nearest
Neighborhood”, dapat diambil beberapa
kesimpulan, diantaranya :
1. Untuk membuat sistem informasi di
perpustakaan maka disiapkanlah terlebih
dahulu informasi data dari buku sebagai pokok
bahan aplikasinya. Lalu referensi DDC yang
akan dijadikan klasifikasi terhadap penomoran
pada buku serta referensi subjek..untuk
membantu dalam menentukan klasifikasi buku
berdasarkan metode KNN. Maka dapat
dibangun sebuah sistem algoritma
menggunakan metode KNN yang dapat
membantu pustakawan untuk menggunakan
sebuah sistem tersebut sehingga dapat
membantu mempermudah bagi pustakawan
dalam menentukan proses penentuan
klasifikasi masing masing buku berdasarkan
nama judul dan jenis subjeknya sehingga
mempermudah dalam pencatatan dan
pengelolaan buku.
2. Dari hasil penelitian klasifikasi bahan pustaka
berdasarkan DDC dengan menggunakan
metode KNN dapat disimpulkan bahwa
metode KNN dapat digunakan untuk
klasifikasi bahan pustaka berdasarkan DDC,
karena mempunyai akurasi kecocokan kelas
sebenarnya dengan kelas prediksi KNN yang
cukup tinggi terhadap akurasinya. Aplikasi
dapat menentukan masing maisng buku

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
klasitikasinya dari DDC dengan cara
mengkelompikkan judul buku dan subjek
dengan cara memilah milah kata kata pada
judul buku berdasarkan kelompok wilayah,
kesusteraan, bentuk bahasa, ras, etnik, budaya,
bahasa, standar. Yang nantinya akan
menghasilkan presentasi kedekatan. Hasil
klasifikasi berdasarkan KNN tersebut akan
memberikan output jika sesuai syarat
algoritmanya yaitu harus ada data buku, subjek
serta referensi DDC.
3. Pengukuran akurasi dilakukan dengan cara
klasifikasi berdasarkan judul buku dan subjek.
Dan harus terdapat data latih yang ada pada
data buku. Jika tidak ada maka akan terbantu
dengan referenai beberapa DDC dari subjek
yang telah ditentukan.
B. Saran
Penulis menyadari bahwa tugas akhir yang
dibuat ini belumlah sempurna, sehingga perlu
adanya peneyempurnaan secara berlanjut sesuai
kebutuhan. Oleh karenanya maka penulis
menyarankan beberapa saran agar penelitian ini
dapat disempurnakan :
1. untuk tahap penyempurnaan dan
pengembangan berikutnya buku dapat
dilengkapi dengan pengarang, penerbit,
tahun tetbit serta posisi rak dimana dia
disimpan. Sehingga memudahkan dalam
mencari buku.
2. pada sistem yang ada pula dapat untuk
menambahkan fitur hak akses pengguna
dan model aplikasi berbasis mobile
android yang dapat diakses menggunakan
device smartphone sehingga dapat diakses
dimana dan kapanpun secara online.
VIII. DAFTAR PUSTAKA
[1]. Milkha Harlian Ch, Text
Mining,2006.http://kesehatankerja.depkes.
go.id/downloads/
[2]. Kusrini, Emha Taufiq Luthfi,
“Algoritma Data Mining” Yogyakarta:
Andi, 2009
[3]. Kusrini, Emha Taufiq Luthfi. 2009.
Algoritma Data Mining. Yogyakarta: Andi
[4]. Tawa P. Hamakonda, Mls & J. N. B
Tairas, “Pengantar Klasifikasi
Persepuluhan Dewey”, Cetakan ke -18,
Jakarta, 2008
[5]. Zhou Yong, “An Improved K-NN Text
Classification Algorithm Based on
Clustering” 2009
[6]. Heri Kurniawan, Rizal Fathoni Aji.
2006.Otomatisasi Pengelompokkan
Koleksli Perpustakaan Dengan
Pengukuran Cosine imilarity Dan
Euclidean Distance, [Online]
Journal.uii.ac.id/index.php/Snati/article/vi
ew/15 99/1374. [diunduh: anggal 15
januar 2018]

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
PENENTUAN JENIS DAUN KOPI DENGAN PENERAPAN
ALGORITMA NEURAL NETWORK BACK PROPAGATION
Suhendri
Program Studi Teknik Informatika STMIK ”AMIKBANDUNG”
Jln. Jakarta No. 28 Bandung 40272 INDONESIA
Abstrak. Membedakan jenis daun dari jenis
pohon satu spesies kopi sangat sulit dibedakan
secara fisik. Kopi memiliki beberapa jenis seperti
robusta, arabika, brazil dan lain-lain, dimana
hampir semua jenis memiliki kesamaan bentuk
fisik daun. Pada usia tertentu jenis kopi tersebut
sulit dibedakan, karena secara fisik semua jenis
pohon kopi hampir sama baik dari tinggi pohon,
warna maupun bentuk daunnya. Menentukan jenis
daun kopi ini sangat penting terutama pada masa
tanam, sehingga bila tanaman kopi tercampur
jenisnya akan mempengaruhi kualitas rasa kopi.
Jika dalam populasi Robusta terdapat jenis Arabika
maka hal ini tidak masalah karena citarasa Robusta
akan terbawa baik. Tetapi jika dalam populasi
Arabika terdapat jenis Robusta maka akan
menurunkan kualitas kopi Arabika tersebut.
Melalui pengolahan data digital citra daun
kopi, diperoleh dataset yang terdiri dari atribut-
atribut GLCM (Gray Level Co-Occurence Matrix),
yang selanjutnya diolah dengan menerapkan
Algoritma Backpropagation Neural Network
(BPNN) berhasil mengklasifikasi jenis daun kopi
dengan akurasi sebesar 77,78%, dengan Naïve
Bayes sebesar 61,11%, dan dengan Decision Tree
71,11%. Data ini membuktikan bahwa Algoritma
Neural Network dapat mengklasifikasi jenis daun
kopi dengan baik jika dibandingkan dengan kedua
algoritma pengklasifikasi lainnya.
Keyword: Daun kopi, Neural Network
Backpropagation, image processing
I. Pendahuluan
Secara umum benda mudah dikenali
melalui warna. Namun ada juga benda yang susah
dikenali karena dari warnanya yang tumpang
tindih[1], atau justru memiliki warna yang mirip
dengan benda yang lainnya, sehingga sulit
dibedakan. Atribut yang paling sederhana untuk
membedakan benda adalah bentuk dan ukuran
benda. Namun jika memiliki kesamaan ukuran dan
bentuk yang mirip maka digunakan atribut lain
untuk membedakannya seperti warna, kecerahan
dan lain-lain.
Kopi memiliki jenis yang berbeda-beda.
Dari semua jenis kopi tersebut yang paling tumbuh
subur di Indonesia adalah Robusta. Namun citarasa
dari jenis kopi ini masih kalah oleh jenis kopi
Arabika, sehingga Arabika di pasar kopi dunia
masih tetap paling banyak diminatioleh masyarakat
internasional (International Coffee Organization).
Sebagian besar karya-karya tersebut menggunakan
teknik pengenalan bentuk untuk model dan
mewakili bentuk kontur daun, namun selain itu,
warna dan tekstur daun juga telah dipertimbangkan
untuk meningkatkan akurasi[2].
Jenis kopi yang digunakan sebagai sampel
penelitian ini adalah dari jenis kopi Arabika, Brazil
dan Dwarf (jenis kopi hasil perkawinan silang
antara keduanya). Ketiga jenis kopi ini memiliki
rata-rata ukuran daun yang sama dan bentuk mirip
pula. Sehingga secara fisik sulit dibedakan. Dalam
pemilahan benih tanaman kopi di usia tanam muda
ini sangat diperlukan cara komputerisasi untuk
mengklasifikasikan sesuai jenisnya. Ketiga jenis
kopi ini baru bisa dibedakan ketika sudah berbuah,
karena ketiga jenis kopi ini memiliki bentuk dan
warna buah yang berbeda.
Berdasarkan penelitian sebelumnya, dalam
pengklasifikasian yang telah dilakukan hanya
menggunakan empat fitur (Contras, Energy,
Homogenity dan Entrophy). Dalan penelitian ini
ditambahkan fitur-fitur yang ada dalam proses
prepocessing menjadi delapan fitur yaitu
Correlation, Cluster Prominence, Entropy,
Homogeneity, Sum Average, Contrast dan Varian)
diharapkan hasil pengklasifikasian lebih akurat.
Dalam penulisan ini disusun dengan
Sistematika Penulisan sebagai berikut: Bagian
Pendahuluan, memaparkan tentang latar belakang
penelitian, mengidentifikasi permasalahan,
merumuskan permasalahan dan menentukan
metode pemecahan masalah yang akan digunakan.
Bagian kedua yaitu Landasan Teori, mencari
referensi penelitian sejenis, formula-formula serta
teori-teori yang mendukung. Bagian ketiga adalah

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Metode yang Diusulkan dan bagaimana tahapan-
tahapan penelitian yang dilakukan. Bagian keempat
adalah Pengujian, dataset yang sudah didapatkan
dari tahapan prepocessing diuji dan selanjutnya
akan didapatkan hasil akurasi. Bagian kelima,
Kesimpulan yaitu berisi tentang hasil yang
didapatkan berupa nilai akurasi dari
pengklasifikasikasian.
II. Penelitian Terkait
Untuk kebutuhan penelitian ini penulis
mengumpulkan beberapa referensi untuk dijadikan
acuan penelitian yaitu dari para peneliti
sebelumnya. Dewasa ini telah banyak
dikembangkan berbagai metode dalam pengenalan
bentuk image, klasifikasi image dengan
pemanfaatan Algoritma Neural Network seperti
yang dilakukan oleh Andi Wahju Rahardjo
Emanuel dan Arie Hartono, dengan mengambil
judul “Pengembangan Aplikasi Pengenalan
Karakter Alfanumerik dengan Menggunakan
Algoritma Neural Network Three-Layer
Backpropagation”. Beliau menyimpulkan hasil
penelitiannya adalah bahwa semakin tinggi jumlah
layer yang dipakai akan semakin meningkatkan
akurasi pengenalan karakter alfanumerik yang
diinginkan[3]. Ini berarti bahwa semakin banyak
melakukan percobaan maka kemungkinan akan
didapatkan hasil yang semakin baik.
Ranjan Parekh dan Jyotismita Chaki
dalam penelitiannya, ”Plant Leaf Recognition
using Shape based Features and Neural Network
classifiers”, dengan algoritma yang sama berhasil
mengklasifikasi jenis daun. Data yang digunakan
sebanyak 180 image, dan menghasilkan akurasi
diatas 90%[4]. Ini menunjukkan bahwa algoritma
yang dipakai adalah sesuai dengan objek penelitian.
III. Metode Yang Diusulkan
Metode yang diusulkan dalam penelitian ini
adalah algoritma Neural Network Back
Propagation dengan skema yang diusulkan
sebagaimana terlihat pada gambar 1 sebagai
berikut:
Daun kopi yang digunakan sebagai sampel adalah
dari tiga jenis daun kopi yaitu daun kopi Arabika,
Brazil dan Dawrf/ Kate, yang masing-masing
berjumlah 30 buah daun atau berjumlah
keseluruhan 90 sampel daun kopi. Jenis Robusta
tidak disertakan dalam pengujian, karena daun kopi
ini jenis secara fisik sudah bisa dibedakan. Untuk
lebih jelasnya keempat jenis daun kopi bisa dilihat
seperti di bawah berikut ini:
(a)
(b)
(c) (d)
(a) daun Arabika; (b) daun Brazil; (c) daun
Kate; (d) daun Robusta
Pada gambar di atas, dengan ukuran latar/
background yang sama jelas sekali daun Robusta
lebih besar ukurannya dan cenderung bulat
dibanding ketiga jenis yang lainnya juga lebih
cerah warna hijaunya sehingga cirri-ciri tersebut
sudah sangat cukup untuk membedakannya.
Sedangkan ketiga jenis daun yang lainnya secara
fisik belum bisa dibedakan.
Gambar 1. Usulan Metode Penelitian
Gambar 2. Daun Kopi

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Gambar 3. Teknik Pengambilan sampel Citra
Daun
Pada kegiatan pengumpulan data,
pengambilan citra daun kopi menggunakan kamera
digital, Fuji FinePix S2980 12MP Digital Camera
with 18x Optical Dual Image Stabilized Zoom.
Jarak kamera dengan objek daun 30cm,
pengambilan citra secar vertikal. Setting kamera
diset default, tanpa zoom, tanpa blitz. Untuk
mengurangi goncangan kamera diikatkan pada
tiang penyangga (kayu) berbentuk meja. Alas
background Gambar berukuran 35 x 25 cm.
Pengambilan gambar dari arah atas agar semua
sampel mendapatkan perlakuan pencahayaan yang
relatif sama.
I.1 Pre Processing
Secara umum pengolahan image
processing pada Neural Network terdiri dari dua
kategori yaitu rekontruksi citra dan restorasi
citra[7]. Citra tidak bisa dijadikan langsung sebagai
data untuk algoritma Neural Network
Backpropagation walaupun pada Matlab sebuah
image bisa langsung dibaca menjadi sebuah
matriks. Hal ini disebabkan karena nilai-nilai
matriks tersebut masih bergabung dengan image
backround yang tidak kita perlukan dalam proses.
Gambar yang masih tercampur atau kurang jelas
objeknya adalah objek tidak baik. Dengan
demikian latar dan objek harus bisa dipisahkan,
karena bila masih tercampur akan berpengaruh
pada hasil yang tidak diinginkan[3].
I.2 Menghapus Background Gambar
Pengolahan data imagepre processing
semua dilakukan melalui coding program termasuk
menghilangkan warna background, tidak
‘menyentuh’ langsung dengan cara edit manual.
Agar background terhapus semua maka harus
diketahui terlebih dahulu nilai RGB kelompok
warna yang membedakan antara background
dengan objek.
I.3 Features Extraction
Tahapan ini adalah tahap menganalisis
tekstur daun dengan metode GLCM. Ada sebanyak
23 feature yang yang terdapat pada metode GLCM
ini yaitu: Autocorelation, Contrast, Corelation
Matlab, Corelation, Cluster Prominence,
Disimiality, Cluster Shade, Energy, Homogenity,
Maximum Probability, Sum of Squares, Sum
Average, Sum Enthropy, Difference variance,
Difference Enthropy, Information Measure of
Coorelation 1, Information Measure of Coorelation
2, Inverse Difference is homon,Inverse Difference
Normalized dan Inverse Difference Moment
Normalization. Dalam penelitian kali ini dipakai
delapan fitur.
I.3.1 1.CORRELATION. DALAM GLCM
SEBUAH MATRIKS MERUPAKAN
NOMOR DARI KOLOM DAN BARIS
YANG MENGGAMBARKAN
KEDALAMAN NILAI G
(GRAYSCALE) DALAM SEBUAH
CITRA[13]. BERIKUT ADALAH
ATRIBUT UNTUK MEMPEROLEH
NILAI FITUR-FITUR DALAM
PROSES IMAGE PROCESSING[17].
I.3.2 2.CLUSTER PROMINENCE, ADALAH
UNTUK MENCARI CLUSTER-
CLUSTER YANG UNGGUL,
DENGAN RUMUS:
I.3.3 3. CLUSTER SHADE, YAITU UNTUK
MELINDUNGI CLUSTER-CLUSTER
DALAM IMAGE DENGAN RUMUS
PERHITUNGAN:
I.3.4 4. ENTROPY, MENYATAKAN
UKURAN KETIDAK-TERATURAN
ARAS KEABUAN DIDALAM CITRA.
NILAINYA TINGGI JIKA ELEMEN-
ELEMEN GLCM MEMPUNYAI
NILAI YANG RELATIF SAMA, DAN
NILAINYA RENDAH JIKA
ELEMEN-ELEMEN GLCM DEKAT
DENGAN NILAI 0 ATAU 1. RUMUS
UNTUK MENGHITUNG ENTROPI:
I.3.5 5. HOMOGENEITY, YAITU
MERUPAKAN UKURAN
HOMOGENITAS/KESAMAAN
CITRA DIHITUNG DENGAN
RUMUS:

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
I.3.6 6. SUM AVERAGE, UNTUK
MENJUMLAHKAN NILAI RATA-
RATA DALAM CITRA, DENGAN
RUMUS:
I.3.7 7. CONTRAST, MERUPAKAN
UKURAN KEBERADAAN VARIASI
ARAS KEABUAN PIKSEL CITRA
DIHITUNG DENGAN RUMUS:
I.3.8 8.VARIAN, UNTUK
MEMPERLIHATKAN NILAI
PERBEDAAN DALAM CITRA
DENGAN RUMUS:
Segmentasi
Pemrosesan citra digital memerlukan satu
proses pre processing yang selanjutnya akan
digunakan untuk proses yang lain. Proses tersebut
adalah segmentasi yang merupakan langkah
pertama dan menjadi kunci yang penting dalam
suatu pengenalan objek (object recognition). Proses
segmentasi merupakan suatu proses untuk
memisahkan antara satu obyek dengan obyek
lainnya. Dengan proses segmentasi masing-masing
obyek pada citra dapat diambil secara terpisah
sehingga dapat digunakan sebagai masukan proses
yang lain atau proses pembagian citra ke dalam
wilayah (region) yang mempunyai kesamaan fitur
antara lain : tingkat keabuan (grayscale), teksture
(texture), warna (color), gerakan (motion)[15].
Segmentasi wilayah merupakan
pendekatan lanjutan dari deteksi tepi. Dalam
deteksi tepi segmentasi citra dilakukan melalui
identifikasi batas-batas objek (boundaries of
object). Batas merupakan lokasi dimana terjadi
perubahan intensitas. Dalam pendekatan didasarkan
pada wilayah, maka identifikasi dilakukan melalui
wilayah yang terdapat dalam objek tersebut. Salah
satu cara untuk mendefinisikan segmentasi citra
adalah sebagai berikut. Sekumpulan wilayah {
R1,R2,…} merupakan suatu segmentasi citra R ke
dalam n wilayah jika[15] :
Analisis citra digital atau Digital Image
Analys (DIA) dapat direkomendasikan untuk
pembedaan yang lebih rinci[2].
I.4 Klasifikasi
Hasil dari proses ekstraksi berupa nilai
akhir dari sebuah fitur dari tekstur daun. Kemudian
data tersebut diolah lagi untuk ke proses akhir yaitu
klasifikasi. Jenis algoritma klasifikasi yang dipakai
adalah Neural Network Backpropagation.
IV. Pengujian
Pada tahap pengujian terhadap metoda
yang diusulkan dengan dataset fitur-fitur daun kopi
yang sudah dikonversi menjadi file excel. Fitur-
fitur tersebut ada sembilan (Correlation, Cluster
Prominence, Cluster Shade, Entropy, Homogeneity,
Sum Average, Contrast, Varian), dimana setiap
fitur menghasilkan dua buah nilai (x1 dan x2). Data
terdiri dari tiga kelompok jenis daun kopi yaitu
Arabika, Brazil dan Kate/Dawrf, dimana setiap
jenis daun kopi terdapat 30 sampel. Dengan
demikian ukuran matriks yang akan diproses dalam
Neural Network: 9 x 2 x 90 = 1620 dataset.
Gambar 4 Data Retrieve
Pada RapidMiner dataset daun kopi
dihubungkan dengan model Neural Network.
Sebagai Label pada database tersebut atribut Nama
Kopi yang digunakan, karena label harus memiliki
format /type text/ character.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Gambar 5. Improved Neural Net
Dari data 90 image daun menjadi 19
inputan, 13 hidden dan 3 output.
Dengan masing-masing menggunakan 30
buah sampel data daun, hasil perhitungan
menggunakan algoritma Neural Network
menunjukkan bahwa: data jenis kopi Arabika
terdeteksi sebagai jenis Arabika sebanyak 19 data
dan sisanya (11) termasuk jenis Kate, atau data ini
terklasifikasi sebesar 63.33%.
Kopi Brazil terdeteksi dengan baik, semua
data terdefinisi sebagai jenis kopi Brasil (sebanyak
30 data) atau sebesar 100% terklasifikasi dengan
baik. Sedangkan pada jenis Kate, sebanyak 9 data
terdefinisi sebagai kopi Arabika, dan terdefinisi
sebagai Kate sebanyak 21 data atau sebesar 70%
terklasifikasi dengan cukup baik. Secara
keseluruhan didapatkan akurasi sebesar 77,78%.
Dengan cara yang sama, peneliti mencoba
menggunakan algoritma pembanding yaitu Naïve
Bayes dan Decision Tree. Hasilnya adalah sebagai
berikut: dengan algoritma Naive Bayes didapatkan
hasil lebih variatif. Penyebaran data ini justru
menunjukkan ketidak-akuratan data, sulit
terdefinisi, akurasi keseluruhannya hanya sebesar
61,11%
Dengan menggunakan Decision Tree ternyata
akurasinya lebih rendah dibandingkan dengan
kedua algoritma sebelumnya, yaitu hanya 17.78%.
V. Kesimpulan
Setelah dilakukan proses pengklasifikasian
dengan tiga algoritma didapatkan bahwa Jaringan
Syaraf Tiruan (JST) propagasi balik dengan fungsi
aktivasi kontinyu dapat memberikan performansi
yang cukup baik untuk mengklasifikasi jenis kopi
tertentu berdasarkan faktor korelasi.
AlgoritmaBackpropagation Neural Network
mampu mengklasifikasi dengan baik dan
didapatkan akurasi sebesar 77,78%. Sedangkan
klasifikasi dengan Naïve Bayes didapatkan akurasi
sebesar 61,11%, dan dengan Decision Tree
didapatkan akurasi sebesar 71,11%.
VI. REFERENSI
[1] Kendule and Mukane, "Flower
Classification Using Neural Network Based
Image," IOSR Journal of Electronics and
Communication Engineering (IOSR-JECE),
vol. 7, no. 3, 2013.
[2] J. Chaki and R. Parekh, "Plant Leaf
Recognition using Shape based Features
and Neural Network classifiers," (IJACSA)
International Journal of Advanced
Computer Science and Applications, vol. 2,
no. 10, 2011.
[3] A. W. R. Emanuel and A. Hartono,
"Pengembangan Aplikasi Pengenalan
Karakter Alfanumerik dengan
Menggunakan Algoritma Neural Network
Three-Layer Backpropagation," Jurnal
Informatika, vol. 4, no. 1, pp. 49-58, 2008.
[4] Kumar, A. Ehsanirad and Sharath,
"Leaf Recognition for Plant Classification
Using," Oriental Journal of Computer
Science & Technology, vol. 3, no. 1, pp. 31-
36, 2010.
[5] Ahmadia, Zoeja, Ebadia and
Mokhtarzadea, "The Application Of Neural
Networks, Image Processing And Cad-
Based Environments Facilities In Automatic
Road Extraction And Vectorization from
High Resolution Satellite Images," The
International Archives of the
Photogrammetry, Remote Sensing and
Spatial Information Sciences, vol. XXXVII,
2008.
[6] Hermantoro, "Aplikasi Pengolahan
Citra Digital dan Jaringan Syaraf Tiruan
untuk Prediksi Kadar Bahan Organik Dalam
Tanah," 2007.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
[7] He, Z. Shi and Lifeng, "Application of
Neural Networks in Medical Image
Processing," Proceedings of the Second
International Symposium on Networking
and Network Security (ISNNS ’10), 2010.
[8] Kadir and Susanto, Teori dan Aplikasi
Pengolahan Citra, Yogyakarta: Andi
Yogyakarta, 2012.
[9] Gadkari and Dhanashree, "Image
Quality Analysis Using GLCM," 2004.
[10] Sarwono, "Pengendalian Penyakit
Karat Daun Hemileia Vastatrix b. Et. Br
pada Tanaman Kopi Arabika dengan Bubur
Bordo Berdasarkan Ambang Kendali,"
2013.
[11] Trisanto and Agus, "Program Jaringan
Syaraf Tiruan Dengan Scilab 5.1".
[12] Mohanaiah, Sathyanarayana and
GuruKumar, "Image Texture Feature
Extraction Using GLCM Approach,"
International Journal of Scientific and
Research Publications, vol. 3, no. 5, 2013.
[13] Pawar, N. Zulpe and Vrushsen,
"GLCM Textural Features for Brain Tumor
Classification," IJCSI International Journal
of Computer Science Issues, vol. 9, no. 3,
2012.
[14] R. Yulianto, "Identifikasi Pengenalan
Bentuk Bangun Datar Dua Dimensi
Menggunakan Neural Network
Backpropagation," Proceeding Thesis
Jurusan Teknik Elektro FTI-ITS , pp. 1-6,
2009.
[15] A. H. Murinto, "Segmentasi Citra
Menggunakan Watershed dan Itensitas
Filtering Sebagai Prepocessing," Seminar
Nasional Informatika, 2009.
[16]
[17]
M. N. A. Khan, Sheraz and Naveed,
"Gender Classification with Decision Tree,"
International Journal of Signal Processing,
Image Processing and Pattern Recognition,
vol. 6, no. 1, 2013.
https://support.echoview.com/WebHel
p/Windows_and_Dialog_Boxes/Dialog_Bo
xes/Variable_properties_dialog_box/Operat
or_pages/GLCM_Texture_Features.htm,
tanggal akses 22/05/2019; pkl.09:21 WIB

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
PERANCANGAN GAME VISUAL NOVEL “THE ADVENTURE OF
KABAYAN” SEBAGAI MEDIA BELAJAR BAHASA INGGRIS UNTUK
TOEFL
Rudi Kurniawan1 , Gyta Nurul Windari2
STMIK ”AMIKBANDUNG”
Jln. Jakarta No. 28 Bandung 40272 INDONESIA 1 [email protected], [email protected]
Media pembelajaran yang disampaikan melalui suatu
permainan diharapkan dapat memberikan dan
meningkatkan wawasan yang baru bagi Pembelajar. Dalam
kasus ini diambil objek pelajaran Bahasa Inggris yang
ditujukan untuk peningkatan TOEFL. Dengan
menitikberatkan struktur Bahasa Inggris, pembangunan
media belajar yang berbentuk game visual novel ini dapat
dijadikan sebagai suatu media bermain sambil belajar.
Dengan mengangkat tokoh lokal daerah Sunda yang
sudah terkenal yaitu Kabayan dimaksudkan untuk
menyampaikan budaya tradisional khususnya Jawa Barat
yang disesuaikan dengan era globalisasi. Metode yang
digunakan untuk pengembangan sistem adalah waterfall
model dengan tahapan meliputi (i) analisis sistem
menggunakan Unified Model Language (UML), (ii)
pembuatan algoritma alur cerita, (iii) pendefinisian
karakter, (iv) perancangan background, (v) penentuan
skenario, dan merancang antarmuka sistem.
Pada tahap pengujian digunakan metode black box
dengan maksud hanya untuk mengobservasi keluaran
eksekusi dari data uji yang ditetapkan dan memeriksa
fungsional pada perangkat lunak berdasarkan skenario
pengujian yang telah ditetapkan dan pada tahap pengujian
beta dilibatkan para pengguna aplikasi sebagai responden
dengan menggunakan kuesioner untuk menilai tingkat
kepuasan terhadap aplikasi game. Hasil dari penelitian ini
adalah terbentuknya aplikasi permainan jenis Visual Novel
yang berunsur edukasi dan dapat memberikan wawasan
Bahasa Inggris terutama struktur dalam TOEFL untuk
Pengguna.
Kata kunci : Visual Novel, Visual Novel Bejalar
TOEFL, Game Pembelajaran Bahasa Inggris, Media
Belajar TOEFL
1. PENDAHULUAN
Game adalah produk teknologi yang
perkembangannya semakin pesat dan disukai oleh
hampir semua kalangan. Diperkirakan game akan terus
diminati selama mengikuti kedinamisan dunia dan
manusianya itu sendiri. Pada saat ini, kehadiran game
dengan jenis-jenisnya telah banyak dimanfaatkan untuk
berbagai kebutuhan[8]. Baik itu sebagai hiburan, pengisi
waktu luang, atau media belajar, termasuk Bahasa
Inggris. Meskipun Bahasa Inggris tergolong bahasa yang
paling sering dipelajari di Indonesia, namun tidak semua
pembelajar berakhir mahir dalam Bahasa Inggris.
Pembelajaran yang dilakukan di kelas selama ini relatif
tidak cukup. Hal tersebut salah satunya karena waktu
belajar yang singkat[10].

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Ada berbagai jenis permainan yang mampu
menyisipkan pengetahuan Bahasa Inggris kepada
pemain. Salah satunya adalah visual novel. Jenis
game ini dikategorikan Adventure Game yang mana
fokusnya pada bagian penceritaan dengan
menampilkan visualisasi gambar diam, teks dan
suara. Pemain diarahkan untuk memilih bagian pada
pilihan-pilihan yang disediakan agar dapat
melanjutkan ke jalan cerita berikutnya, pada pilihan
yang diambil oleh pemain akan mempengaruhi alur
cerita yang sedang dimainkan[7]. Jenis permainan
visual novel ini cukup populer dikalangan pengguna
karena keunggulannya dari sisi storytelling dan
diberikan nilai sebagai genre game dengan
storytelling terbaik, seperti yang disampaikan Josiah
Lebowitz dan Chris Clug[1].
Penelitian yang telah dilakukan mengenai
perancangan dan pembangunan permainan visual
novel, mayoritas masih berisi cerita-cerita populer
yang diadaptasi dari cerita atau film tokoh-tokoh
Disney atau cerita fiksi dan klasik populer dunia
lainnya seperti dari buku cerita H.C. Anderson.
Sehingga relatif masih sedikit yang berisikan cerita
mengenai pembelajaran suatu muatan materi dengan
mengangkat kearifan budaya lokal[9]. Metoda dan
teknik penelitian yang digunakan mayoritas dengan
cara menyusun alur cerita secara langsung berupa
flowchart serta perolehan datanya didapat dari hasil
pengamatan langsung melalui kuisioner ataupun
forum grup diskusi dan wawancara terhadap pelaku
industri permainan. Sehingga produk yang dihasilkan
lebih berorientasi terhadap bisnis atau popularitas
game semata. Dan untuk produksi permainan yang
berbentuk media pembelajaran masih dianggap relatif
kurang peminatnya sehingga tidak akan laku
dipasaran[6].
Berdasarkan uraian tersebut maka Penulis
merancang permainan visual novel yang tujuannya
dapat difungsikan sebagai sarana belajar Bahasa
Inggris untuk TOEFL. Pada visual novel ini alur
cerita ditentukan dengan menyediakan pilihan-pilihan
cerita di mana pada setiap cerita yang dipilih telah
disisipkan kalimat-kalimat dalam Bahasa Inggris dan
bentuk kalimat tersebut disesuaikan dengan jalan
cerita yang telah dipilih sebelumnya dengan
mengikuti pola struktur bahasa Inggris baku. Produk
permainan inipun dapat dimanfaatkan sebagai media
hiburan sekaligus pembelajaran oleh masyarakat luas
sehingga diharapkan menjadi pemicu untuk
dikembangkan oleh para pelaku industri permainan
yang ada saat ini.
Penulis membatasi masalah kepada hal-hal: 1)
Permainan ini dimainkan secara offline. 2) Narasi
yang dirancang sebagian besar menggunakan Bahasa
Indonesia. 3) Interaksi dengan pengguna berisi tujuh
akhir cerita. 4) Tokoh utama yaitu Kabayan dengan
menggunakan sudut pandang orang ketiga. 5) Sasaran
pemain adalah para pelajar dan masyarakat umum
yang berminat bermain game sambil belajar bahasa
Inggris terutama TOEFL. 6) Muatan Bahasa Inggris
yang muncul dalam game ini menitikberatkan pada
structure.
Maksud dari penelitian ini yaitu merancang
permainan visual novel yang bergenre petualangan
dengan tokoh budaya lokal Kabayan di mana
tujuannya diharapkan dapat menambah jenis jumlah
permainan berupa media pembelajaran yang tidak
saja menghibur, namun dapat meningkatkan
kemampuan Bahasa Inggris khususnya pada tingkat
pengetahuan struktur dalam Bahasa Inggris.
Secara menyeluruh, makalah ini diorganisasikan
ke dalam enam bagian yaitu bagian 2 akan
menjelaskan mengenai studi literatur yang mendasari
penelitian ini. Bagian 3 membahas metoda dan
arsitektur system yang di usulkan. Bagian 4 berisi
analisa dan pembahasan hasil dari metoda yang
diusulkan. Bagian 5, berisi pengujian dari metoda
yang diusulkan. Bagian 6 menyajikan sebuah
ringkasan dari hasil penelitian.
2. STUDI LITERATUR
Studi literatur yang akan dijelakan meliputi
pengertian visual novel dan visual storytelling. Untuk
memperjelas diberikan pula contoh-contoh tampilan
gambar dari produk visual novel populer. Di bagian
akhir dituliskan aturan-aturan untuk membuat visual
storytelling yang harus diikuti oleh para perancang
alur cerita.
Menurut Josiah Lebowitz dan Chris Klug
(2011:193) visual novel adalah jenis permainan yang
dalam banyak hal mirip dengan membaca buku.
Kisahnya diceritakan melalui sebagian besar teks dan
umumnya ditulis dalam sudut pandang orang
pertama[1]. Tidak seperti e-book, visual novel berisi
latar belakang gambar yang berubah berdasarkan

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
lokasi saat setiap karakter berbicara. Masing-masing
karakter memiliki pose untuk menunjukan karakter
bereaksi secara tepat dengan situasi. Teks dan visual
dalam visual novel dilengkapi dengan set lengkap
efek suara dan latar belakang musik, bahkan dalam
beberapa game terdapat juga voice acting.
Permainan Visual novel memiliki lebih dari satu
alur cerita. Di mana alur cerita yang akan
ditampilkan tergantung pada pilihan-pilihan yang
ditetapkan oleh pemain. Pada permainan
dimunculkan alur cerita yang berbeda-beda pada saat
pengguna melakukan pilihan menu sesuai
keinginannya. Dari pilihan hal tersebut akan
dihasilkan akhir cerita yang berbeda pula sesuai
pilihan yang telah ditentukan[5].
Contoh tampilan suatu permainan visual novel
ditunjukkan seperti tampak pada gambar 1 berikut.
Gambar 1. Bentuk tampilan dalam Visual Novel
[7]
Seorang master visual storytelling bernama
Eisner (2008:3) memaparkan bahwa semua cerita
memiliki struktur. Cerita memiliki awal, akhir dan
benang cerita yang diletakkan pada kerangka.
Kerangka dalam sebuah cerita akan selalu sama
apapun media penyampaiannya. Namun gaya
bercerita dapat dipengaruhi oleh media[3].
Bentuk cerita dapat diibaratkan sebagai
kendaraan untuk menyampaikan informasi sehingga
mudah diserap. Teknologi sekarang ini telah
memberikan banyak kendaraan transmisi dalam
bercerita. Akan tetapi pada dasarnya hanya ada dua
cara utama yaitu, kata (lisan atau tertulis) dan gambar
atau gabungan dari keduanya. Dalam visual
storytelling gambar digunakan sebagai alat narasi dan
biasanya menggunakan simbol yang membentuk
stereotip. Eisner mendefinisikan stereotip itu sendiri
sebagai suatu ide atau karakter yang dibakukan dalam
bentuk konvensional, tanpa individualitas. Pembaca
akan menerima pesan dari gambar stereotip[4].
Tony Capputo (1996) mendefinisikan visual
storytelling sebagai seni bercerita untuk hiburan,
pendidikan atau komersialisme, melalui penggunaan
citra sekuensial. Visual storytelling juga dapat
dikatakan sebagai informasi yang diproyeksikan ke
dalam bingkai. Salah satu contoh dari visual
storytelling adalah komik yang penceritaannya
menggunakan gambar atau ilustrasi berututan dari
satu panel ke panel lain. Alan Male (2007:10)
berpendapat ilustrasi adalah cara lain untuk memberi
tahu dan mendidik kita, memberikan kita hiburan dan
cerita [5]. Jay Leno (Tony Capputo, 1996: Chapter :
3 memperjelas peran dari ilustrasi itu sendiri adalah
untuk menjelaskan naskah.
Dalam buku visual storytelling, Tony Capputo
(1996: Chapter 10) menjelaskan aturan dalam visual
storytelling, yaitu: 1) Clarity, menciptakan visual
yang mudah dipahami, sehingga isi pesan, emosi
serta tindakan yang sedang terjadi di dalam cerita
dapat ditangkap oleh Pembaca. 2) Realism, rasa nyata
yang diciptakan untuk membuat seorang pengguna
merasakan secara langsung seolah cerita tersebut
terjadi di kehidupan nyata dengan benar. Rasa nyata
dalam visual storytelling dapat dicapai dengan
menambahkan simbol-simbol yang bisa ditemukan
dalam kenyataan. 3) Dynamic, rasa dinamik dicapai
dengan menggunakan efek-efek khusus yang
ditujukan untuk melebih-lebihkan atau menambahkan
penekanan terhadap suatu pesan dengan dramatis dan
unik. Penambahan efek khusus dimaksudkan sebagai
bentuk pelayanan dalam bercerita. 4) Continuity,
penyajian cerita melalui visual setiap adegan harus
ada kesamaan gaya, karakter, dan elemen lainnya
sehingga Pembaca dapat berpikir bahwa setiap
adegan memang merupakan satu kesatuan dalam
cerita. 5) Intuity, pembentukan visual storytelling
tahapannya selalu dimulai dari intuisi atau perasaan
dan representasi perseorangan secara pribadi[4].
3. METODA YANG DIUSULKAN
Metoda yang diusulkan meliputi arsitektur dalam
bentuk use case diagram, perancangan alur cerita,
dan perancangan struktur Bahasa Inggris.
Sedangakan teknik untuk pengumpulan data dalam
penelitian ini terdiri dari Studi Literatur, Observasi,
dan penyebaran kuesioner. Model pengembangan
sistem memakai waterfall model. Untuk proses
perancangan permainan, menggunakan metode user

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
experience dari David Armano dengan tahapan
proses 1) Uncover, merupakan langkah pencarian
sesuatu yang mendasar dari motivasi dan kepentingan
pengguna. 2) Define, merupakan langkah perumusan
strategi pembentukan pengalaman pengguna. 3)
Ideate, merupakan tahap kolaborasi dan eksplorasi.
4) Build, merupakan tahap mengolah gagasan atau
ide yang telah ada melalui cara yang tepat dan sesuai
dengan tujuan. 5) Design, merupakan proses
finalisasi dan eksekusi.
Use Case Diagram yang terlihat pada Gambar 2
memperlihatkan boundary sistem beserta fungsi-
fungsi utamanya dan untuk menggambarkan fungsi
dari sistem tersebut dari sudut pandang pengguna.
Cara use case bekerja yaitu dengan
mendeskripsikan jenis interaksi antara aktor di
sebuah sistem dengan sistemnya itu sendiri
melalui sebuah proses bagaimana sebuah sistem
dipergunakan. Proses yang dapat dipilih oleh aktor
terdiri dari Start, Load, Preference, About, Help dan
Quit.
Gambar 2. Use case game VN
Yang dimaksudkan dengan alur cerita yaitu
susunan cerita yang terbentuk melalui tahapan-
tahapan peristiwa yang ditentukan sehingga akan
terjalin suatu cerita yang ditampilkan oleh para
subjek atau tokoh yang ada di dalamnya. Adapun alur
cerita dalam Visual Novel The Adventure of Kabayan
yang memiliki 7 (tujuh) akhir cerita seperti terlihat
pada gambar 3. Alur cerita tersebut terdiri dari lima
cerita dan masing-masing cerita terdapat ending
cerita sesuai dari cerita yang sebelumnya telah dipilih
oleh Pengguna.
Gambar 3. Alur Cerita
I.4.1
Perancangan Struktur Bahasa Inggris dalam
perancangan game Visual Novel The Adventure of
Kabayan ini, diterapkan pada sebagian skenario
cerita yang menggunakan Bahasa Inggris dan dititik
beratkan pada struktur. Adapun struktur yang akan
digunakan adalah beberapa tenses yang meliputi
berikut ini. 1) Simple present tense dipakai untuk
mendeklarasikan suatu kebiasaan, fakta, dan kejadian
yang terjadi pada saat sekarang. 2) Present
Continuous Tense digunakan untuk membicarakan
aksi yang sedang berlangsung sekarang. 3) Present
Perfect Tense dipakai untuk menyatakan suatu
kejadian atau aktivitas di masa lampau dan telah
selesai di suatu titik waktu tertentu atau masih
berlanjut sampai sekarang. 4) Present Perfect
Continuous Tense dipakai untuk mengungkapkan
kejadian atau aktivitas yang telah selesai pada suatu
titik tertentu di masa lampau atau aksi yang telah
dimulai di masa lalu dan masih berlanjut hingga
sekarang. Biasanya aksi tersebut memiliki durasi
waktu tertentu dan ada hubungannya dengan masa
sekarang. 5) Simple past tense digunakan untuk
menunjukkan suatu kejadian atau kegiatan yang
terjadi di masa lampau. 6) Past continuous tense
dipakai pada saat menyatakan suatu peristiwa atau
kegiatan yang sedang terjadi di masa lampau. 7)
Simple future tense dipakai untuk menyatakan
kejadian yang akan terjadi di masa depan, baik secara
spontan atau terencana.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
4. HASIL DAN PENGUJIAN
Pada bagian ini disampaikan implementasi hasil
perancangan antarmuka, dan pengujian terhadap
produk permainan Visual Novel “The Adventure of
Kabayan”. Implementasi antarmuka yang dibangun
terdiri dari antarmuka halaman utama seperti yang
tampak pada gambar 4, di mana pada antarmuka ini
difungsikan sebagai pembuka permainan dan
informasi awal untuk Penguna. Pada layar ini
ditampilkan bentuk visualisasi dari tokoh-tokoh yang
ada pada cerita dengan menggunakan tokoh lokal
yang digambar mengikuti gaya populer gambar
manga Jepang.
Gambar 4. Antarmuka Halaman Utama
Antarmuka pada gambar 5, merupakan halaman
state awal yang menampilkan pengenalan tokoh-
tokoh yang terlibat dalam permainan. Dengan
demikian melalui tampilan ini Pengguna akan
mengenal dan mengikuti serta memilih alur cerita
dengan baik. Dalam gambar diperlihatkan tokoh
Kabayan yang sedang menyapa Pengguna dengan
memperlihatkan latar belakang di sebuah pantai.
Gambar 5. Antarmuka Halaman Game State
Awal
Pada gambar 6 merupakan implementasi hasil
perancangan antarmuka pilihan state awal dengan
dua pilihan cerita yang berbeda. Pilihan tersebut
berupa menu jalan cerita yang mengikuti tokoh Peter
atau jalan cerita apabila Kabayan kembali ke laut.
Dari dua pilihan cerita ini Pengguna akan
mendapatkan hasil cerita yang berbeda pula.
Gambar 6. Antarmuka Halaman Game Opsi State
Awal
Untuk pengaturan permainan yang terkait dengan
ukuran tampilan gambar, kecepatan tampilan teks,
pengaturan suara diperlihatkan pada menu Preference
seperti terlihat pada gambar 7. Pada menu ini
Pengguna dapat mengatur bentuk tampilan pada layar
apakah berupa window atau secara penuh. Pengaturan
kecepatan kemunculan teks dan waktu dapat diatur
melalui baris Text Speed. Demikian pula keras atau
tidaknya suara dan musik atar dapat diatur melalui
slider pada Music, Sound dan Voice.
Gambar 7. Antarmuka Halaman Preferences
Pengguna baru dapat melihat penjelasan dan
aturan permainan pada antarmuka Help seperti
terlihat pada gambar 8. Penggunaan navigasi akan
membantu Pengguna untuk mengetahui tombol-
tombol yang digunakan untuk mengatur jalannya

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
cerita. Dengan alat navigasi pintas Pengguna dapat
mendengar cerita dan dialog sebelum atau
sesudahnya.
Gambar 8. Antarmuka Halaman Help
Pengguna dapat menampilkan cerita yang
diinginkan sesuai pilihannya melalui antarmuka Load
seperti terlihat pada gambar 9. Dengan memilih
cerita yang diinginkan maka Pengguna secara bebas
meilih cerita yang menarik. Alur cerita yang
ditampilkan dibuat per halaman, dan setiap halaman
terdiri dari bagian-bagian cerita (chapter).
Gambar 9. Antarmuka Halaman Load
Pada tahap pengujian produk digunakan metode
black box dengan maksud untuk mengamati dan
mengetahui hasil eksekusi terhadap data uji yang
telah ditentukan dan untuk melakukan pemeriksaan
fungsional dari perangkat lunak yang didasarkan
kepada skenario pengujian yang telah disusun seperti
terlihat pada tabel 1. Tahap pengujian berikutnya
dilakukan terhadap engujian beta dengan melibatkan
para pengguna aplikasi game sebanyak 20 (dua
puluh) responden dengan menggunakan media
kuesioner dengan maksud untuk menilai tingkat
kepuasan para pengguna terseut terhadap aplikasi
game yang telah dibangun. Untuk penilaian hasil
pengujian digunakan metode kuantitatif berdasarkan
data dari pengguna dengan menetapkan tujuh kriteria
yaitu 1) Tampilan antarmuka, 2) Pemahanan Menu 3)
Alur cerita dan Karakteristik tokoh 4) Tampilan
visualisasi 5) Peningkatan minat belajar 6)
Penambahan wawasan 7) Peningkatan hasil berlajar
untuk TOEFL.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Tabel 1. Hasil Pengujian
Dari hasil jawaban para responden terhadap
kuesioner yang telah disebarkan, menghasilkan
penilaian sebagai berikut: 1) Secara umum tampilan
perancangan aplikasi game visual novel “The
Adventure of Kabayan” sudah baik (82%). 2) Akses
terhadap menu-menu yang ditawarkan pada game ini
pun sudah baik dan mudah dipahami (userfriendly)
(86%). 3) Alur cerita dan karakteristik tokoh-tokoh
yang ada pada visual novel ini cukup menarik,
meskipun harus digali lagi supaya cerita semakin
kokoh dan apik (74%). 4). Skenario atau naskah
visual novel ini cukup baik, meskipun harus lebih
dikembangkan supaya lebih menarik (74%). 5) Cerita
yang dibuat pada visual novel ini cukup mampu
meningkatkan antusiasme responden untuk belajar
Bahasa Inggris (79%). 6) Cerita yang dibuat pada
visual novel ini cukup membantu responden dalam
meningkatkan wawasan Bahasa Inggris terutama
untuk TOEFL (79%). 7) Visual novel ini perlu dibuat
lebih kompleks dari berbagai segi, seperti pada segi
cerita, kedalaman Bahasa Inggris, dan fitur-fitur
tambahan guna membuatnya lebih baik (81%).
5. KESIMPULAN
Dari pemaparan dan uraian yang telah
disampaikan, maka Penulis menyimpulkan bahwa
permainan visual novel “The Adventure of Kabayan”
telah dapat menyajikan permainan yang cukup
menyenangkan dengan menu yang relatif mudah
dipahami. Fungsi sebagai media bermain sambil
belajar Bahasa Inggris dengan menyisipkan kalimat-
kalimat Bahasa Inggris dalam alur cerita dapat
meningkatkan minat dan wawasan Bahasa Inggris
terutama untuk TOEFL. Dengan mengangkat tokoh
utama yang berasal dari cerita budaya lokal,
diharapkan secara tidak langsung permainan ini juga
dapat turut melestarikan budaya bangsa.
Produk yang dibangun masih harus
disempurnakan dan pengembangan dapat dilakukan
pada skenario atau naskah cerita yang dibuat lebih
bervariasi yang beragam. Alur cerita yang
digambarkan dalam bentuk pohon alur cerita dapat
dibuat lebih kompleks dan penyajian pembelajaran
Bahasa Inggris dapat disesuaikan dengan suatu
kurikulum pembelajaran di sekolah formal agar
pelajaran Bahasa Inggris menjadi lebih lengkap. Dari
sisi tampilan grafis seperti karakter dan background
cerita dapat pula ditingkatkan kualitas dan
penambahan tokoh antagonis serta protagonis.
DAFTAR PUSTAKA
[1] C. K. Josiah Lebowitz, (2011), Interactive
Storytelling Video Games, USA: Elsevier.
[2] Sloan, Robin J.S. (2015), Virtual Character
Design for Games and Interactive Media, CRC
Press, Taylor & Francis Group, London, New
York.
[3] Cavallaro, Dani (2010), Anime and the Visual
Novel. Narrative Structure, Design and Play at
the Crossroads of Animation and Computer
Games, McFarland & Company, Inc., North
Carolina.
[4] Kusnawi dan Firmansyah, R. (2015), Game
Hybrid Visual Novel sejarah Dengan Metode
Sistem Pakar “Twist Majapahit”, Prosiding
Seminar Nasional Teknologi Informasi dan
Multimedia 6-8 Februari 2015, hal 5.7-5,
STMIK AMIKOM, Yogyakarta.
[5] E. Z. Katie Salen, Rules of Play: Game Design
Fundamental, MIT Press, 2003.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
[6] STIKI Malang, Lppm & Triatmaja Permana
Sadewa, Arief. (2016). Perancangan Game
Visual Novel Menggunakan Ren’py. J-Intech
vol.04 no.01 th 2016. 04. 26-32.
[7] Visual Novel,
https://en.wikipedia.org/wiki/Visual_novel
[8] Lukman. (2014). Laporan: 30 juta pengguna
internet di Indonesia adalah remaja.
http://id.techinasia.com/laporan-30-juta-
pengguna-internet-di-indonesia-adalah-remaja/
[Akses: 21/05/19].
[9] Estidianti, Brigitta Rena dan Lakoro,
Rahmatsyam (2014), Perancangan Karakter
Game Visual Novel “Tikta Kavya” dengan
Konsep Visual Bishonen. Jurnal Sains dan Seni
Pomits, Vol. 3 No. 2, hal. 49, Institut Teknologi
Sepuluh November, Surabaya.
[10] Gunawan, Adi W. (2006), Genius Learning
Strategy. Petunjuk Praktis Untuk Menerapkan
Accelerated Learning, Jakarta: PT Gramedia,
Cetakan II, hal 334.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
SISTEM SORTASI BIJI KOPI ARABIKA BERBASIS IOT
MENGGUNAKAN PENGUKURAN KADAR AIR DAN WARNA
Endang Amalia
Fakultas Teknik, Jurusan Sistem Informasi
Universitas Widyatama
Jl Cikutra No 204A Sukapada Cibeunying Kidul, Bandung, Indonesia
Ari Purno Wahyu Wibowo
Fakultas Teknik, Jurusan Teknik Informatika
Universitas Widyatama
Jl Cikutra No 204A Sukapada Cibeunying Kidul, Bandung, Indonesia
Abstrak
Biji kopi yang baik serta pengolahan biji kopi
yang tepat sangat mempengaruhi kualitas hasil akhir
kopi yang akan diseduh. Riset ini kami lakukan untuk
mendapatkan biji kopi yang baik adalah dengan
melakukan sortir biji kopi, yang dikelompokan
menjadi 3 kelompok berdasarkan tiga warna biji kopi
yaitu merah, hijau, dan kuning dengan
menggunankan sensor TCS 3200 dan penambahan
teknik computer vision, langkah selanjutnya adalah
pemilihan biji kopi berdasarkan parameter
pengukuran kadar air dengan menggunakan soil
mosture sensor dengan sistem sortasi menggunakan
teknologi IOT dan bisa membantu petani untuk
mendapatkan biji kopi terbaik yang sangat
mempengaruhi nilai harga jual dipasaran.
Kata kunci:
Biji kopi, sistem sortasi, IOT, Sensor TCS 3200,
Computer vision, Kadar Air
Abstract
From choosing the right coffee varieties from the
very first step until deliberating over irrigation
methods and crop management, coffee growers make
hundreds of small decisions that affect to the quality
of the coffee they ready to be harvested and ready to
be served on the table. Our research is about offering
two best ways to produce the best coffee beans, first,
we choose the best coffee beans based on colour
classification by divided into 3 categories based on
the colours of red, green and yellow beans by using
TCS 3200 and computer vision technique, and second
step is sorting coffee beans by monitor the soil water
content using soil moisture sensor through IoT to
help farmers to harvest the best coffee beans because
it affects the value of market price.
Keywords:
Coffee beans, Sortation, IoT, TCS 3200, Computer
Vision, Soil Mousture
PENDAHULUAN
Biji kopi berasal dari biji di dalam ceri kopi
yang tumbuh di sepanjang cabang pohon kopi dan
dibutuhkan bertahun-tahun untuk pohon kopi tumbuh
dewasa [6]. Ada sepuluh langkah dalam menyiapkan
secangkir kopi mulai dari biji-bijian yang langkah-
langkahnya meliputi penanaman, memanen buah ceri,
memproses ceri, mengeringkan kacang, menggiling
biji, mengekspor biji kopi, mencicipi kopi,
memanggang kopi, menggiling kopi dan pembuatan
brewing kopi [6]. Semua proses memiliki dampak
besar pada kualitas kopi jika ada kesalahan yang
dibuat selama proses.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Kopi ceri adalah buah mentah dari tanaman
kopi, yang terdiri dari dua biji kopi yang ditutupi oleh
perkamen tipis seperti kulit dan selanjutnya
dikelilingi oleh pulp. Ceri ini biasanya dipanen
setelah 5 tahun perkebunan pohon kopi dan ketika
bear fruit berubah menjadi merah [1]. Proses inisiasi
kopi dengan konversi ceri kopi menjadi biji kopi
hijau, dan dimulai dengan penghilangan pulp dan hull
menggunakan metode basah atau kering [9]. Metode
kering, yang biasa digunakan untuk Robusta, dan
metode basah, yang umumnya digunakan untuk biji
kopi Arabika. Dalam proses kopi basah, ampas dan
hull dihilangkan sementara ceri masih segar. Proses
ini melibatkan beberapa tahap yang terdiri dari
sejumlah besar air dan juga termasuk langkah
fermentasi mikroba untuk menghilangkan lendir yang
masih menempel pada kacang [4][5].
Riset ini bertujuan untuk membantu petani
memanin biji kopi terbaik berdasarkan warna dan
kadar air berbasis IoT dengan menggunakan sensor
TCS 3200 dan teknik computer vision.
KAJIAN LITERATUR
A. Coffee Arabica
Awalnya kopi disebut qahwah (qahwain)
berasal dari bahasa Turki atau disebut kahven.
Adapun istilah kopi untuk tiap negara berbeda-beda,
yaitu kaffe (Jerman), coffee (Inggris), cafe
(Peramcis), koffie (Belanda), dan kopi (Indonesia).
Tanaman kopi arabika (Coffee arabica) berasal dari
Afrika, yaitu dari daerah pegunungan di Etiopia.
Kopi arabika baru dikenal secara luas oleh
masyarakat dunia setelah tanaman tersebut
dikembangkan diluar daerah asalnya, tanaman
tersebut dikembangkan di daerah Yaman dibagian
selatan jazirah Arab. Melalui perdagangan, kopi
menyebar kedaerah lainnya. Awalnya hasil dari
tanaman kopi yaitu buah kopi hanya dikonsumsi
sebagai tambahan energi, seiring berkembangnya
teknologi dan pengetahuan buah kopi dimanfaatkan
menjadi minuman kopi seperti saat ini[10].
Tanaman kopi arabika sendiri dibudidayakan di
Indonesia tahun 1696. Tanaman kopi arabika dapat
tumbuh baik di daerah yang sejuk dan dingin di
ketinggian 600-2000 meter diatas permukaan laut
dikarenakan kopi arabika rentan terhadap penyakit
karat daun. Suhu tumbuh optimalnya adalah 18-26
derajat celcius. Proses dari berbunga hingga menjadi
buah siap panen adalah 9 bulan dan akan
menghasilakan buah siap panen berwarna hijau
hingga merah gelap[2].
Kopi sendiri merupakan sebuah minuman yang
berasal dari proses pengolahan dan ekstraksi biji
kopi. Kopi arabika sendiri menguasai 70 persen pasar
kopi dunia [2].
B. Colour Classification
Pengolahan citra adalah pemrosesan citra atau
image processing, khususnya dengan menggunakan
komputer menjadi citra yang kualitasnya lebih baik.
Dengan kata lain pengolahan citra adalah kegiatan
memperbaiki kualitas citra agar mudah diinterprestasi
oleh manusia atau mesin[8].
Tahap pengolahan citra ini menggunakan
metode GLCM. Metode GLCM (Gray Level Co-
Occurrence Matrix) menurut Xie [12] merupakan
suatu metode yang melakukan analisis terhadap suatu
piksel pada citra dan mengetahui tingkat keabuan
yang sering terjadi. Metode ini juga untuk tabulasi
tentang frekuensi kombinasi nilai piksel yang muncul
pada suatu citra. Untuk melakukan analisis citra
berdasarkan distribusi statistik dari intensitas
pikselnya, dapat dilakukan dengan mengekstrak fitur
teksturnya [7].
GLCM merupakan suatu metode untuk
melakukan ekstraksi ciri berbasis statistikal,
perolehan ciri diperoleh dari nilai piksel matrik, yang
mempunyai nilai tertentu dan membentuk suatu sudut
pola [12]. Untuk sudut yang dibentuk dari nilai piksel
citra menggunakan GLCM adalah 00, 450, 900,
1350[3], untuk sudut yang terbentuk terlihat pada
Gambar dua gambar dibawah:
Gambar 1. Piksel dengan berbagai sudut

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 2. Ilustrasi matriks co-ocurensi[3]
C. Soil Moisture
Salah satu faktor yang mempengaruhi proses
pengeringan biji kopi adalah kadar air. Pengeringan
bertujuan untuk mengurangi kadar air bahan
sehingga menghambat perkembangan organisme
pembusuk. Kadar air suatu bahan berpengaruh
terhadap banyaknya air yang diuapkan dan lamanya
proses pengeringan[11].
METODE PENELITIAN
Gambar 3. Metode Sortasi
Tahapan metode pada penelitian ini adalah
seperti yang terdapat pada gambar diatas,
penjelasannya adalah sebagai berikuts:
1. Pengukuran kadar air
Kopi yang bagus adalah kopi yang memiliki
kadar air yang rendah, pada proses pemetikan kadar
air bisa mencapai 20% ,dan bisa berkurang hingga 13
dan 11 % , proses pengeringan menggunakan green
house saat ini sudah cukup membantu untuk
mengurangi kelembaban dan kadar air pada biji kopi,
rasa pada kopi dipengaruhi rasa pada saat proses
pengeringan, sistem yang dibuat menggunakan alat
soil mouture yang akan ditempatkan pada sampel
greenbean dan akan ditampilkan melalui LCD, jika
kadar air di bawah 12% maka greenbean siap untuk
di-roasting.
2. Sortasi Warna
Pada umumnya kopi yang bagus adalah kopi
yang ketika dipetik berwarna merah, dan harus proses
sortasi sendiri oleh petani dan kadang masih terbawa
kopi yang mentah atau berwarna hijau yang akan
mempengaruhi kualitas warna, proses sortasi tersebut
bisa menggunakan bantuan teknik IOT (internet of
things) dengan komponen tcs3200 dan 2300 dengan
mangambil data inputan photo dioda yang berkerja
dengan cara menangkap gelombang warna yang
dipantulakan dari LED dan ditangkap oleh
photodioda.
IMPLEMENTASI DAN PENGUJIAN
Pada pengujian ini penulis menggunakan
beberapa sampel biji kopi (cherry) yang diambil pada
petani derah manglayang diambil beberapa sampel
kopi matang, kopi setengah matang dan mentah.
Gambar 4. Biji Kopi Yang Sudah Matang
Pada gambar 4 adalah data sampel yang diambil
dari biji kopi yang sudah matang yang diambil dari
beberapa petani dan siap diuntuk diproses.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 5. biji kopi yang sudah matang
Pada gambar 5 adalah proses pengambilan biji
kopi yang belum matang dan terbawa kopi tersebut
memiliki rasa yang pahit karena masih banyak
mengandung getah.
Gambar 6. biji kopi yang sudah matang
Pada gambar 6 adalah biji kopi setangah matang
terlihat dari warna yang masih hijau dan sedikit
berwarna merah, biji kopi ini paling sulit untuk
dipisahkan dan masuk pada kategori biji kopi mentah
Pada pengujian sistem kali ini proses pengujian
dilakukan dengan tiga tahapan pertama sortasi kopi
berdasarkan warna dari biji kopi yang berwana merah
atau disebut juga dengan kopi cherry, sensor yang
dipakai pada sistem ini menggunakan sensor warna
TCS2300 dan 3200, sistem tersebut berguna sebagai
proses penyortiran awal biji kopi yang merah
sebelum masuk ketahap pencucian.
Tabel 1 script pada sistem sortasi #include <Servo.h>
# definisi PIN S0 2
# definisi PIN S1 3
# definisi PIN S2 4
# definisi PIN S3 5
# definisi PIN keluaran sensor 6
Servo bagian atas ;
Servo bagian bawah ;
int frekwensi = 0;
int warna =0;
void setup() {
modePIN (S0, OUTPUT);
modePIN (S1, OUTPUT);
modePIN (S2, OUTPUT);
modePIN (S3, OUTPUT);
modePIN (sensorOut, INPUT);
// Setting frequency-scaling to 20%
digitalWrite(S0, HIGH);
digitalWrite(S1, LOW);
bagian atas.attach(7);
bagianbawah.attach(8);
Serial.begin(9600);
}
Pada tabel 1 adalah sebuah script yang
digunakan pada sensor photodioda yang memiliki
empat buah PIN yang definiskan dengan nomer pin
S0,S1,S2,S3, sedangkan pada sensor PIN yang
digunakan untuk kendali servo.
Servo bagianAtas;
Servo bagianBawah;
Servo digunakan sebagai penggerak atau
montorik yang akan mensortir warna biji kopi yang
belum matang dalam hal ini masih berwarna hijau
dan kuning. Servo tersebut akan memisahkan dengan
tempat yang berbeda.
Tabel 2 sortasi warna dengan foto dioda
int PembacaanData() {
// Setting red filtered photodiodes to
be read
digitalWrite(S2, LOW);
digitalWrite(S3, LOW);
// Reading the output frequency
frequency = pulseIn(sensorOut, LOW);
int R = frequency;

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
// Printing the value on the serial
monitor
Serial.print("R= ");//printing name
Serial.print(frekwensi);//printing
RED color frequency
Serial.print(" ");
delay(50);
// Setting pembacaan data
photodiodes to be read
digitalWrite(S2, HIGH);
digitalWrite(S3, HIGH);
// Reading the output frequency
frequency = pulseIn(sensorOut, LOW);
int G = frequency;
// print data dari serial monitor
Serial.print("G= ");//printing name
Serial.print(frequency);//printing
frekuensi data warna merah
Serial.print(" ");
delay(50);
Pada tabel 2 adalah sebuah proses sortasi warna
yang diambil dari inputan sensor TSCS 2300, dengan
level inputan PIN HIGHT, LOW, dengan hasil
kalibrasi data warna sebagai berikut:
if(R< 30 & R>20 & G<33 & G>23)
{color = 1; // kuning }
if(R<60 & R>50 & G<59 & G>49)
{color = 2; // hijau} if(R<70 & R>60 & G<10 & G>20)
{color = 3; // merah jambu }
if(R<7 & R>11 & G<21 & G>35)
{color = 4; // merah}
Inputan data tersebut akan dimasukan kedalam
sebuah sistem kerja tcs3200 yang dikoneksikan
dengan servo yang akan memilah biji kopi
berdasarkan tiga warna sebagai indikator red =
matang, green = mentah, dan pink = setengah
matang.
Tabel 3 hasil analisa tektur dengan metode GLCM
No Contrast Correlation Energy Homogeneit
y Level
1 0.0626 0.0626 0.9816 0.9816 Mature
2 0.0872 0.0892 0.9735 0.9729 Mature
3 0.0946 0.0946 0.9624 0.9624 Half Mature
4 0.0535 0.0544 0.9678 0.9673 Half Mature
5 0.0489 0.0486 0.9692 0.9694 Immature
6 0.1071 0.1059 0.9483 0.9489 Immature
Tabel 3 diatas adalah proses pembacaan biji
kopi dengan metode GLCM atau pembacaan tektur
biji kopi yang akan dijadikan sebagai data training
sebagai database uji pada aplikasi yang akan dibuat.
Gambar 7. sourcode detekti tektur menggunakan
python
Pada gambar 5 adalah sebuah function yang
digunakan untuk menganalisa tektur biji kopi dengan
computer vision dengan metode GLCM (Grey Level
Co-Occurence Matrix) dimana function berfungsi
mengawati objek dari biji kopi berdasarkan
tekturnya.
Gambar 8. Pengujian Pada Buah Matang (Merah)
Pada gambar 6 adalah proses pembacaan data
function hasil GLCM Pada biji kopi berwarna merah
dengan nilai GLCM = 0,3940** untuk buah berwarna
merah.
Gambar 9. Pengujian Pada Buah Setengah Matang
(Merah Jambu)
Pada gambar 7 adalah hasil sortasi biji kopi
menggunakan metode GLCM pada buah yang
berwarna pink dalam hal ini masuk kategori buah
mentah dengan nilai GLCM = 0,2693**.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 10. Pengujian Pada Buah Mentah (Hijau)
Pada gambar 8 hasil sortasi tektur dengan
metode GLCM Pada buah berwarna hijau yang
dimasukan kedalam kategori buah mentah dengan
nilai GLCM = 0,2848**.
Tabel 4 Pengujian Dengan Computer Vision
Gambar Keterangan
Pada gambar
disamping adalah
sample data kopi yang
merah yang akan diuji dengan metode
computer vision
Pada gambar disamping adalah
metod HUE saturation
yang mengubah
tampilan gambar kedalam mode
greyscale untuk
melihat tingkat
kematangan biji kopi
Pada gambar
disamping adalah proses validasi
saturation yang
berfungsi melihat
catcat tidaknya biji kopi pada kulit cherry
yang baru dipetik
akibat serangan hama
pada tanaman kopi terlihat warna kopi
dengan bintik gelap
Pada gambar
disamping adalah
proses pembacaan teknik computer
vision dengan
merubah warna RGB
menjadi grescale yang dikonversikan
oleh computer vision
Tabel di atas menunjukkan hasil pengujian
dengan menggunakan computer vision.
Gambar 11. sensor soil moisture
Dari gambar di atas, untuk mengetahui soil
moisture biji kopi dengan menggunakan soil moisture
sensor seperti pada gambar diatas.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 12. Testing result of soil moisture sensor
Gambar di atas menjelaskan mengenai hasil
pengukuran kadar air biji kopi Arabika yang telah
dikeringkan, kadar air normal sekitar 12%, sistem
perhitungan yang digunakan adalah kisaran 100-85 =
15% yang artinya sehingga biji kopi tersebut belum
siap untuk dikirim ke langkah selanjutnya (roasting).
Ketika biji kopi masih hijau (memiliki kadar air di
atas 12%), biji tersebut harus dikeringkan lagi untuk
mendapatkan kadar air di bawah atau sama dengan
12%. Kadar air 12% akan memudahkan proses
pemanggangan dimaksimalkan dan aroma kopi akan
lebih berkembang.
KESIMPULAN DAN SARAN
1. Kesimpulan
Penelitian ini diharapkan dapat membantu
petani menyortir ceri kopi matang menggunakan TCS
3200 dan teknik computer vision dan sensor
kelembaban tanah untuk menentukan kadar air biji
kopi yang siap dipanggang melalui aplikasi sehingga
petani dapat memanen biji kopi terbaik, tepat waktu,
efisien dan efektif.
2. Saran
Penelitian ini dapat dikembangkan lebih lanjut
dengan teknologi IoT lainnya dan juga dapat
diimplementasikan dalam bidang lain selain pertanian
dan juga bisa ditambahkan dengan modul cloud
computing.
REFERENSI
[13]. Arya, M., & Rao, J. M. (2007). An
impression of coffee carbohydrates. Critical
Reviews in Food Science and Nutrition, 47,51–
67. Retrieved June 16 2018 from
https://www.tandfonline.com/toc/bfsn20/current.
[14]. Budiman, Haryanto. 2012. Prospek Tinggi
Bertanam Kopi: pedoman meningkatkan kualitas
perkebunan kopi. penerbit pustaka baru pres.
Yokyakarta.
[15]. Eleyan, A dan Demirel,H., 2011, Co-
occurrence matrix and its statistical features as a
new approach for face recognition, Turk J Elec
Eng & Comp Sci, Vol.19, No.1,pp.97-107.
[16]. Gonzalez-Rios, O., Suarez-Quiroza, M. L.,
Boulanger, R., Barel, M.,Guyot, B., Guiraud, J.-
P., et al. (2007a). Impact of “ecological” post-
harvest processing on coffee aroma: I. Green
coffee. Journal of Food Composition and
Analysis, 20, 289–296. Retrieved June 16 2018
from
https://www.researchgate.net/publication/237295
128_Impact_of_ecological_post-
harvest_processing_on_the_volatile_fraction_of
_coffee_beans_I_Green_coffee.
[17]. Gonzalez-Rios, O., Suarez-Quiroza, M. L.,
Boulanger, R., Barel, M., Guyot, B., Guiraud, J.-
P., et al. (2007b). Impact of “ecological” post-
harvest processing on coffee aroma: II. Roasted
coffee. Journal of Food Composition and
Analysis, 20, 297–307. Retrieved June 16 2018
from http://agritrop.cirad.fr/536653/.
[18]. National Coffee Association USA. 2011.
What is coffee?.
http://www.ncausa.org/i4a/pages/index.cfm?page
id=67.
[19]. Pullaperuma PP, Dharmaratne AT. 2013.
Taxonomy of File Fragments Using Gray- Level
Co-Occurrence Matrix. DICTA.
[20]. Suprayogi, Igif Rizekiya. (2010).
Identifikasi Bentuk Kendaraan Dengan
Menggunakan Jaringan Saraf Tiruan. Malang:
Universitas Islam.
[21]. Leifa, F., Pandey, A., & Soccol, C. R.
(2001). Production of Flammulina velutipeson
coffee husk and coffee spent-ground. Brazilian
Archives of Biology and Technology, 44, 205–
212. Retrived June 16 2018 from
http://www.scielo.br/scielo.php?script=sci_arttex
t&pid=S1516-89132001000200015.
[22]. Rahardjo, Pudji. 2012. Kopi Panduan
Budidaya dan Pengolahan Kopi Arabika dan
Robusta. Jakarta: Penebar Swadaya.
[23]. Taib, G., G, Said dan S. Wiraatmadja. 1988.
Operasi Pengeringan Pada Pengolahan Hasil

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Pertanian, PT Mediatama Sarana Perkasa.
Jakarta.
[24]. Xie, L., Zhang, J., Wan, Y., Hu, D. 2010.
Identification of Colletotrichum spp. Isolated
from Strawberry in Zhejiang Province and
Shanghai City, China. J. Zhejiang University-
Science B (Biomed & Biotechnol) 11 (1): 61-70.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
SISTEM PENDUKUNG KEPUTUSAN DALAM MEMILIH
E-MARKETPLACE BERDASARKAN FITUR LAYANAN
DENGAN METODE WEIGHTED PRODUCT
Deryzky Akbar1, Siti Nurajizah2, Sri Muryani3 Program Studi Sistem Informasi STMIK Nusa Mandiri1, Program Studi Sistem Informasi Universitas Bina Sarana
Informatika2, Program Studi Teknik Informatika STMIK Nusa Mandiri3
Jl. Damai No. 8, Warung Jati Barat (Margasatwa), Pasar Minggu, RT.1/RW.1, Ragunan, Pasar Minggu, Jakarta Selatan,
125401.3, Jl. Kamal Raya No.18, RT.6/RW.3, Cengkareng., Kecamatan Cengkareng, Kota Jakarta Barat, Daerah Khusus Ibukota
Jakarta 117302
E-mail: [email protected], [email protected], [email protected]
Abstrak
Dengan adanya e-marketplace konsumen dapat
berbelanja apa saja dan dimana saja asalkan terhubung
dengan koneksi internet. Namun, dengan perkembangan e-
marketplace yang begitu pesat membuat banyaknya
bermunculan perusahaan e-marketplace baru sehingga
terkadang dapat membingungkan konsumen dalam memilih
e-marketplace yang akan digunakan untuk belanja online.
Salah satu cara untuk membantu para konsumen dalam
mengambil keputusan dalam memilih dan bertransaksi di e-
marketplace adalah dengan adanya suatu metode yang dapat
memberikan rekomendasi sebagai bahan pertimbangan
untuk pengambilan keputusan secara tepat yaitu, dengan
menerapkan metode weighted product yang dapat
menyelesaikan masalah dengan cara perkalian untuk
menghubungkan rating attribute dengan atribut bobot yang
bersangkutan. Adapun yang menjadi kriteria dalam
penelitian ini adalah pengiriman dengan bobot awal 32%,
promo 80%, produk 56%, dan pembayaran 28%.
Hasil dari penelitian ini menunjukan bahwa
rekomendasi alternatif terbaik adalah Shopee dengan nilai
vektor 0,35. Sedangkan Tokopedia 0,32 dan Bukalapak
0,33.
Kata kunci:
Sistem Pendukung Keputusan, E-Marketplace, Weighted
Product
Abstract
With the e-marketplace, consumers can shop for
anything and anywhere as long as it is connected to an
internet connection. However, with the rapid development
of e-marketplace, many new e-marketplace, companies have
emerged so that they can sometimes confuse consumers in
choosing an e-marketplaces that will be used for online
shopping.
One way to assist consumers in making decisions
in choosing and transacting in e-marketplace is by having a
method that can provide recommendations as a
consideration for appropriate decision making, namely by
applying a weighted product method that can solve
problems by multiplication for connecting the rating
attribute with the corresponding weight attribute. The
criteria in this study are shipping with an initial weight of
32%, promo 80%, produced 56%, and payment of 28%.
The results of this study indicate that the best
alternative recommendation is Shopee with a vector value of
0.35. While Tokopedia 0.32 and Bukalapak 0.33.
Keywords:
Decision Support System, E-marketplace, Weighted Product
PENDAHULUAN
Perkembangan teknologi informasi yang sangat
dramatis dalam beberapa tahun terakhir telah membawa
dampak transformational pada berbagai aspek kehidupan,
termasuk di dalamnya dunia bisnis. Setelah berlalunya era
“total quality” dan “reengineering”, kini saatnya “era

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
elektronik” yang ditandai dengan menjamurnya istilah-
istilah e-business, e-university, e-government, e-economy, e-
emtertainment, dan masih banyak lagi istilah sejenis. Salah
satu konsep yang dinilai merupakan paradigma bisnis baru
adalah e-marketplace.
Dengan adanya e-marketplace konsumen dapat
berbelanja apa saja dan dimana saja asalkan terhubung
dengan koneksi internet. Dengan begitu, konsumen dapat
menghindari kemacetan dijalan, menghindari repotnya
mencari parkiran dan repotnya berinteraksi dengan SPG.
Namun, dengan perkembangan e-marketplace yang begitu
pesat membuat banyaknya bermunculan perusahaan e-
marketplace baru sehingga terkadang dapat
membingungkan konsumen dalam memilih e-marketplace
yang akan digunakan untuk belanja online.
Contohnya saja saat kita ingin mencari suatu
barang menggunakan mesin pencari Google, hasil yang
ditampilkan akan banyak barang yang sama namun dijual
pada e-marketplace yang berbeda. Hal ini akan
membingungkan para konsumen, terlebih lagi setiap e-
marketplace mempunyai kelebihan dan kekurangan masing-
masing. Seperti pada Tokopedia dan Shopee dimana
konsumen diharuskan terdaftar diakun Tokopedia ataupun
Shopee agar dapat melakukan belanja online pada e-
marketplace tersebut. Lain halnya dengan Bukalapak yang
tidak mengharuskan konsumen terdaftar di akun Bukalapak.
Keunggulan Bukalapak ini dapat memudahkan konsumen
baru yang ingin melakukan belanja online. Promo free
ongkir Tokopedia dan Bukalapak hanya pada event tertentu
saja, sedangkan Shopee menawarkan promo gratis ongkir
hanya minimal belanja Rp.19.000,00 saja. ini menjadi
keunggulan tersediri bagi Shopee. Tampilan interface
aplikasi banyak konsumen yang memilih Tokopedia ada
juga yang lebih memilih Shopee dan Bukalapak tentunya
hal ini akan membingungkan para konsumen baru ataupun
konsumen yang ingin berpindah belanja online pada e-
marketplace lain.
Menurut (Alwafi & Magnadi, 2016) dijelaskan
permasalahan dalam penjualan online salah satunya yaitu
sulitnya membangun kepercayaan pembeli, pembeli tidak
bisa mengontrol secara pasti pemenuhan harapan ketika ia
membeli sesuatu melalui internet karena mereka tidak bisa
melihat secara langsung barang yang akan dibelinya
maupun bertemu langsung penjual yang menawarkan
produknya.
Menurut (Royanti & Yunianto, 2018) dijelaskan
“kendala yang dihadapi pada jual beli online adalah
banyaknya kasus penipuan dan tingkat kepercayaan yang
rendah dari konsumen pada pemasaran secara elektronik ini
karena tidak adanya jaminan atas transaksi yang dilakukan”.
Menurut (Fauziah & Wulandari, 2018)
“kepercayaan konsumen dalam melakukan online shopping
merupakan suatu kendala yang sulit dikendalikan karena
berhubungan dengan sikap dan prilaku konsumen sehubung
dengan online shopping agar pelaku usaha e-commerce
dapat memanfaatkan potensi yang ada di Indonesia”.
Berdasarkan pemaparan diatas diketahui bahwa
perlu adanya cara untuk membantu para konsumen dalam
mengambil keputusan dalam memilih dan bertransaksi di e-
marketplace adalah dengan adanya suatu metode yang dapat
memberikan rekomendasi sebagai bahan pertimbangan
untuk pengambilan keputusan secara tepat yaitu, dengan
menerapkan metode weighted product yang dapat
menyelesaikan masalah dengan cara perkalian untuk
menghubungkan rating attribute dengan atribut bobot yang
bersangkutan.
Penelitian ini bertujuan untuk menggunakan suatu sistem
pendukung keputusan untuk memilih e-marketplace yang
memenuhi syarat dan kriteria dengan tepat dan sesuai
dengan kebutuhan konsumen.
KAJIAN LITERATUR
2.1. Sistem Pendukung Keputusan (SPK)
Menurut (Nofriansyah & Defit, 2017) Sistem
merupakan kumpulan sub-sub sistem (elemen) yang saling
berkorelasi satu dengan yang lainnya untuk mencapai tujuan
tertentu. Sebagai contoh : Sebuah perusahaan memiliki
sistem manajerial yang terdiri dari bottom management,
middle management, dan top management yang memiliki
tujuan untuk mencapai kemampuan masyarakat. Sistem
pendukung keputusan dapat diartikan sebagai suatu sistem
yang di rancang yang digunakan untuk mendukung
manajemen di dalam pengambilan keputusan.
Menurut Litlle dalam (Sari, 2017) Sistem
pendukung keputusan (SPK) adalah suatu sistem informasi
berbasis komputer yang menghasilkan berbagai alternatif
keputusan untuk membantu manajemen dalam menangani
berbagai permasalahan yang terstruktur ataupun tidak
terstruktur dengan menggunakan data dan model. Kata
berbasis komputer merupakan kata kunci, karena hampir
tidak mungkin membangun SPK tanpa memanfaatkan
komputer sebagai alat bantu, terutama untuk menyimpan
data serta mengelola model.
Menurut Turban dalam (Setiadi & Agustia, 2019)
Sistem pendukung keputusan yaitu sistem informasi
berbasis komputer yang mengkombinasikan model dan data
untuk menyediakan dukungan kepada pengambil keputusan
dalam memecahkan masalah semi terstruktur atau masalah
ketergantungan yang melibatkan user secara mendalam.
Menurut (Hatta, Rizaldi, & Khairina, 2016) Sistem
pendukung keputusan (SPK) merupakan suatu penerapan
sistem informasi yang ditujukan untuk membantu pimpinan

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
dalam proses pengambilan keputusan. Sistem pendukung
keputusan menggabungkan kemampuan komputer dalam
pelayanan interaktif dengan pengolahan atau pemanipulasi
data yang memanfaatkan model atau aturan penyelesaian
yang tidak terstruktur. Sistem pendukung keputusan
dimaksudkan menjadi alat bantu bagi para pengambil
keputusan untuk memperluas kapabilitas mereka, namun
tidak untuk menggantikan penilaian mereka.
Menurut (Khairina, Ivando, & Maharani, 2016)
Sistem pendukung keputusan (SPK) merupakan sistem
informasi interaktif yang menyediakan informasi,
pemodelan, dan pemanipulasian data. Sistem ini digunakan
untuk membantu pengambilan keputusan dalam situasi yang
semiterstruktur dan situasi yang tidak terstruktur.
Pada dasarnya Sistem Pendukung Keputusan atau
dikenal juga dengan istilah Decision Support System (DSS)
ini merupakan pengembangan lebih lanjut dari sistem
informasi manajemen terkomputerisasi yang dirancang
sedemikian rupa sehingga bersifat interaktif dengan
pemakainya. Sifat interaktif ini dimaksudkan untuk
memudahkan integrasi antara berbagai komponen dalam
proses pengambilan keputusan seperti prosedur, kebijakan,
teknik analisis, serta pengalaman dan wawasan manajerial
guna membentuk suatu kerangka keputusan yang bersifat
fleksibel.
Menurut Simon dalam (Fahmi, 2018) mengatakan,
pengambilan keputusan berlangsung melalui empat tahap
yaitu:
a. Intelligence
b. Design
c. Choice
d. Implementasi
Secara lebih dalam beliau menegaskan bahwa,
“Intelligence adalah proses pengumplan informasi yang
bertujuan mengindentifikasi permasalahan. Design adalah
tahap perancangan solusi terhadap masalah. Biasanya pada
tahap ini dikaji berbagai macam alternatif pemecahan
masalah. Choice adalah tahap mengkaji kelebihan dan
kekurangan dari berbagai macam altenatif yang ada dan
memilih yang terbaik. Implementasi adalah tahap
pegambilan keputusan dan melaksanakannya.
Tujuan sistem pendukung keputusan (SPK)
dikemukakan oleh Peter G.W Keen dan Scott Morton
(Nofriansyah & Defit, 2017) yaitu:
1. Membantu manajer membuat keputusan untuk
memecahkan masalah semi terstruktur.
2. Mendukung penilaian manajer bukan mencoba untuk
menggantikannnya.
3. Meningkatkan efektifitas pengambilan keputusan
manajer dari pada efisiensinya.
2.2. Weighted Product
Menurut (Sari, 2017) Metode Weighted Product
merupakan bagian dari konsep multi criteria decision
making (MCDM), merupakan teknik pengambilan
keputusan dari beberapa pilihan alternatif yang ada. Metode
ini memerlukan proses normalisasi pada perhitungannya.
Dengan menggunakan metode Weighted Product,
diharapkan dapat dikembangkan software sistem pendukung
keputusan yang dapat digunakan oleh suatu instansi, yang
akan menjadi alternatif pemilihan dan memberikan nilai
bobot pada perbandingan alternatif dan kriterianya. Metode
ini mengevaluasi beberapa alternatif terhadap sekumpulan
atribut atau kriterianya, dimana setiap atribut saling tidak
bergantung satu dengan yang lainnya.
Menurut (Syafitri, Sutardi, & Dewi, 2016) Metode
Weighted Product (WP) merupakan salah satu metode yang
digunakan untuk menyelesaikan masalah MADM. WP
adalah suatu metode yang menggunakan perkalian untuk
menghubungkan rating atribut, di mana rating setiap atribut
harus dipangkatkan dulu dengan bobot yang bersangkutan.
Proses ini sama halnya dengan proses normalisasi.
Langkah-langkah penyelesaian suatu masalah yang
menggunakan multi kriteria adalah sebagai berikut:
1. Menentukan kriteria-kriteria yang akan dijadikan
acuan dalam pengambilan keputusan
2. Menentukan rating kecocokan setiap alternatif pada
setiap kriteria
3. Menentukan bobot preferensi tiap kriteria
4. Mengalikan seluruh atribut bagi sebuah alternatif
dengan bobot sebagai pangkat positif untuk atribut
keuntungan dan bobot berpangkat negatif untuk
atribut biaya.
Rumus untuk menghitung nilai preferensi
untuk alternatif Ai, diberikan sebagai berikut:
Keterangan:
Π : product
S : menyatakan preferensi kriteria yang
dianalogikan sebagai vektor S
x : menyatakan nilai kriteria
w : menyatakan bobot kriteria
i : menyatakan alternatif

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
j : menyatakan kriteria
n : menyatakan banyaknya kriteria
5. Hasil perkalian tersebut dijumlahkan untuk
menghasilkan nilai vector V untuk setiap alternatif.
Nilai vector V dapat dihitung dengan rumus :
Vi =
Keterangan:
V: menyatakan preferensi alternatif yang
dianalogikan sebagai vektor
S: menyatakan preferensi kriteria yang
dianalogikan sebagai vektor S
n : menyatakan banyaknya kriteria
6. Mencari nilai alternatif dengan melakukan langkah
yang sama seperti pada langkah satu, hanya saja
menggunakan nilai tertinggi untuk setiap atribut
tertinggi untuk setiap atribut manfaat dan nilai
terendah untuk atribut biaya.
7. Membagi nilai V bagi setiap alternatif dengan nilai
standar.
8. Mencari nilai alternatif ideal yakni dengan
merangking nilai Vektor V sekaligus membuat
kesimpulan sebagai tahap akhir.
ANALISIS DAN PERANCANGAN
3.1. Tahapan Penelitian
Pada penelitian ini melakukan beberapa tahapan.
Berikut tahapan penelitian :
1. Identifikasi masalah
Melakukan indentifikasi tentang masalah
yang dibahas pada penelitian ini, yaitu :
a. Kriteria apa saja yang memenuhi fitur layanan
yang baik.
b. Bagaimana menentukan penilaian pada setiap
kriteria e-marketplace.
c. Bagaimana menggunakan sistem pendukung
keputusan untuk menentukan e-marketplace
yang memenuhi kriteria dengan tepat dan sesuai
dengan kebutuhan konsumen.
2. Merumuskan dan membatasi masalah
Untuk lebih memusatkan penelitian yang ada
dan agar tidak menyimpang dari pokok
pembahasan, maka penulis membuat batasan
permasalahan. Dimulai dari kriteria yang penulis
uji adalah pengiriman, promo, produk dan
pembayaran. Setelah itu penulis menyebarkan
kuesioner kepada para konsumen e-marketplace di
wilayah kota Bekasi. Setelah mendapatkan
kuesioner yang telah diisi oleh konsumen
kemudian dianalisa menggunakan teknik uji
validitas dan reabilitas dan diolah menggunakan
Skala Likert dan Metode Weighted Product. Hasil
akan menentukan e-marketplace mana yang terbaik
berdasarkan fitur layanan.
3. Melakukan studi kepustakaan
Mempelajari literatur yang akan digunakan
sebagai kajian teori dalam penelitian yang akan
dibahas.
4. Merumuskan hipotesis atau pernyataan penelitian
Mengemukakan pernyataan awal tentang
faktor yang berpengaruh terhadap pemilihan e-
marketplace berdasarkan kriteria yang telah
ditentukan. Berikut hipotesis yang penulis tentukan
:
H1 : Tokopedia lebih diminati dari sisi
pembayaran dan promo
H2 : Bukalapak lebih diminati dari sisi
pengiriman dan promo
H3 : Shopee lebih diminati dari sisi promo dan
produk
5. Menentukan desain dan metode penelitian
Metode penelitian yang penulis gunakan,
yaitu :
a. Observasi
Penulis melakukan pengamatan langsung
terhadap objek penelitian di e-marketplace
terbesar di Indonesia untuk mendapatkan data
dan informasyang diperlukan untuk mengetahui
fitur layanan pada e-marketplace tersebut.
b. Wawancara
Penulis melakukan wawancara kepada
para konsumen untuk mengetahui nilai pada
setiap kriteria yang telah ditentukan.
c. Studi pustaka
Dalam metode ini penulis mendapat bahan
penulisan dan membaca buku-buku tentang
penelitian yang penulis lakukan dan bagaimana
cara mengaplikasikan dan menggunakan
metode yang akan digunakan.
6. Menyusun instrumen dan mengumpulkan data
Tahap ini adalah penentuan instrumen
penelitian yaitu dengan menggunakan kuesioner.
Kuesioner tersebut nantinya akan disebar kepada
masyarakat kota Bekasi. yang hasilnya akan
digunakan penulis sebagai bahan pengumpulan
data.
7. Menganalisis data dan menyajikan hasil

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Mengelola data yang sudah didapat. Lalu
menganalisa hasil pengolahan data berdasarkan
hasil penelitian. Membuat kesimpulan penelitian.
3.2. Instrumen Penelitian
Instrumen penelitian yang digunakan penulis
adalah kuesioner. Merupakan Alat bantu berupa pernyataan
yang harus dijawab oleh responden. Secara singkat data
dalam penelitian ini dilakukan dengan menyebarkan
kuesioner dalam sejumlah pernyataan kepada para
responden dan hasil yang di dapatkan kemudian dianalisa
menggunakan teknik analisis uji validitas dan reabilitas
untuk mengetahui apakah data yang didapat bisa digunakan
dalam penelitian atau tidak. Pada penlitian ini terdapat
empat kriteria yang akan diteliti, yaitu pengiriman (C1),
promo (C2), produk (C3), dan pembayaran (C4).
3.3. Metode Pengumpulan Data, Populasi dan Sampel
Penelitian
3.3.1. Metode Pengumpulan Data
Metode pengumpulan data yang dilakukan, yaitu
menggunakan kuesioner. Jenis kuesioner yang digunakan
penulis adalah kuesioner tertutup. Pada kuesioner tertutup
pernyataan sudah disusun secara terstruktur. Dengan kata
lain, kuesioner terstruktur adalah kuesioner yang disajikan
sedemikian rupa sehingga responden diminta untuk memilih
satu jawaban. Kuesioner disebar menggunakan Google
Form, hasil kuesioner yang didapatkan disimpan dalam
format Microsoft Excel. Kemudian dianalisa menggunakan
teknik uji validitas dan reabilitas dan diolah menggunakan
Skala Likert dan Metode Weighted Product.
3.3.2. Populasi
Populasi yang diambil pada penelitian ini yaitu
masyarakat kota Bekasi. Menurut Badan Pusat Statistik
Kota Bekasi didapatkan data jumlah total penduduk kota
Bekasi pada tahun 2016, yaitu sebanyak 2.430.229 ribu jiwa
yang berasal dari 12 kecamatan.
3.3.3. Sampel Penelitian
Berdasarkan jumlah populasi yang diketahui. Lalu
dihitung menggunakan rumus slovin untuk menentukan
sampel yang akan diambil, yaitu 25 responden
3.4. Metode Analisis Data
Metode analisis data yang penulis gunakan, yaitu
uji validitas dan uji reabilitas.
3.5. Analisis Data
3.5.1. Data Responden
Responden yang dijadikan sampel penelitian
adalah masyarakat kota Bekasi. Secara keseluruhan jumlah
sampel 25 responden dengan 12 pernyataan dan memiliki 4
kriteria yaitu pengiriman (C1), promo (C2), produk (C3),
dan pembayaran (C4).
Dari kuesioner yang telah diisi oleh responden
didapat identitas responden, yaitu:
1. Jenis kelamin
Dari hasil perhitungan data responden
berjenis kelamin pria jumlahnya sebanyak 10
responden dari 25 total sampel. Sedangkan
responden berjenis kelamin wanita sebanyak 15
responden dari 25 total sampel.
2. Domisili di kota Bekasi
Dari hasil perhitungan data responden yang
berdomisili di kota Bekasi jumlahnya sebanyak 25
responden dengan presentase 100% dari 25 total
sampel
3.5.2.. Skala Likert
Untuk menentukan penilaian pada setiap jawaban
responden. Penulis menggunakan Skala Likert. Skala Likert
merupakan suatu skala psikometrik yang umum digunakan
dalam kuesioner dan merupakan skala yang paling banyak
digunakan dalam riset berupa survei. Biasanya dalam skala
ini rentang penilaiannya dari 1 sampai 5. Sedangkan format
pernyataan yang penulis buat dengan menggunakan format
pernyataan positif.
3.5.3. Uji Validitas
Setelah setiap jawaban responden dilakukan
penilaian dengan skala likert selanjutnya dilakukan uji
validitas. Dihetahui bahwa hasil uji validitas pada
pernyataan 1 sampai 12 valid.
3.5.4. Uji Reabilitas
Diketahui hasil uji reabilitas dengan nilai reabilitas
0,76, maka jika nilai >0,7 artinya reabilitas mencukupi
3.6. Pengujian Metode Weighted Product
3.6.1.. Penentuan Kriteria
Pada tahap ini penulis telah menentukan kriteria
yang dijadikan acuan dalam perhitungan metode weighted
product. Berikut kriteria yang dimaksud :
a) C1=pengiriman
b) C2=promo

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
c) C3=produk
d) C4=pembayaran
3.6.2. Tingkat Kepentingan
Dari hasil kuesioner dapat diketahui bahwa :
1 Pengiriman mendapatkan nilai awal bobot 32% /
0,32
2 Promo mendapatkan nilai awal bobot 80% / 0,80
3 Produk mendapatkan nilai awal bobot 56% / 0,56
4 Pembayaran mendapatkan nilai awal bobot 28% /
0,28
3.6.3. Perbaikan Bobot Kriteria
Setelah diketahui nilai bobot awal tiap-tiap kriteria.
Kemudian dilakukan perbaikan bobot sehingga ∑w = 1
dengan rumus :
𝑊𝑗 =
Keterangan : Wj = bobot atribut
∑wj = penjumlahan bobot atribut
Diperoleh :
a) W1 = 0,32 / (0,56+0,32+0,80+0,28)
= 0,16
b) W2 = 0,80 / (0,56+0,32+0,80+0,28)
= 0,40
c) W3 = 0,56 / (0,56+0,32+0,80+0,28)
= 0,28
d) W4 = 0,28 / (0,56+0,32+0,80+0,28)
= 0,14
Keterangan :
W1 = C1
W2 = C2
W3 = C3
W4 = C4
3.6.4. Penentuan Alternatif
Pada tahap ini penulis telah menentukan alternatif
yang dijadikan pilihan dalam memilih e-marketplace
berdasarkan fitur layanan. Berikut alternatif yang dimaksud
:
a) A1=Tokopedia
b) A2=Bukalapak
c) A3=Shopee
3.6.5. Penilaian Setiap Alternatif
Dari tabel diatas telah diketahui alternatif yang
dijadikan pilihan dalam memilih e-marketplace. Selanjutnya
ditentukan penilaian alternatif berdasarkan pernyataan pada
kuesioner yang telah penulis sebar.
Dari hasil kuesioner tersebut dapat diketahui nilai
dari setiap alternatif, yaitu sebagai berikut :
Tabel 4. Nilai Alternatif
No Alternatif Kriteria
C1 C2 C3 C4
1 A1 95 83 97 107
2 A2 103 95 102 80
3 A3 98 106 105 86
Keterangan :
C1 : pengiriman
C2 : promo
C3 : produk
C4 : pembayaran
A1 : Tokopedia
A2 : Bukalapak
A3 : Shopee
3.6.6. Pengujian
Setelah didapatkan bobot setiap kriteria dan nilai
setiap alternatif. Lalu dilakukan pengujian, yaitu sebagai
berikut :
Menghitung vektor S:
Diperoleh :
S1 = (950,16)(830,40)(970,28)( (1070,14)
= 84,04
S2 = (1030,16)(950,40)(1020,28)(800,14)
= 87,50
S3 = (980,16)(1060,40)(1050,28)(860,14)
= 92,36
Keterangan :
S1 = A1
S2 = A2
S3 = A3
Menghitungnilai vektor V:
Diperoleh :
V1 = 84,04 / (84,04+87,50+92,36)
= 0,32
V2 = 87,50 / (84,04+87,50+92,36)
= 0,33
V3 = 92,36 / (84,04+87,50+92,36)
= 0,35
Keterangan :
V1 = A1

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
V2 = A2
V3 = A3
Berdasarkan hasil perhitungan vektor V diketahui
bahwa nilai tertinggi (max) adalah V3 sehingga alternatif A3
atau Shopee adalah alternatif yang terpilih sebagai alternatif
terbaik.
3.7.. Uji Hipotesis
Hipotesis adalah jawaban sementara terhadap
masalah yang masih bersifat praduga karena masih harus
dibuktikan kebenarannya.
hasil dari pengujian hipotesis yaitu :
1. Hasil pengujian pada hipotesis H1 yang berisi
Tokopedia lebih diminati dari sisi pembayaran dan
promo. Hipotesis H1 ditolak dikarenakan pada
hasil penelitian dikektahui bahwa Tokopedia lebih
diminati dari sisi produk dan pembayaran.
2. Hasil pengujian pada hipotesis H2 yang berisi
Bukalapak lebih diminati dari sisi pengiriman dan
promo. Hipotesis H2 ditolak dikarenakan pada
hasil penelitian diketahui bahwa Bukalapak lebih
diminati dari sisi produk dan pengiriman.
3. Hasil pengujian pada hipotesis H3 yang berisi
Shopee lebih diminati dari sisi promo dan produk.
Hipotesis H3 diterima dikarenakan pada hasil
penelitian diketahui bahwa Shopee lebih diminati
dari sisi promo dan produk.
KESIMPULAN DAN SARAN
Berdasarkan hasil penelitian yang telah dilakukan
dapat diambil kesimpulan bahwa untuk proses pemilihan e-
marketplace berdasarkan fitur layanannya dibutuhkan
beberapa kriteria sebagai pertimbangan.
Adapun kriteria yang telah ditentukan yaitu
pengiriman, pembayaran, produk dan promo. Dari beberapa
kriteria tersebut kemudian ditentukan nilai bobot dari
masing masing kriteria dengan menggunakan kuisioner.
Lalu didapatkan hasil bahwa pertimbangan utama
masyarakat kota Bekasi dalam membeli barang secara
online adalah pada promo e-marketplace tersebut dengan
persentase 80%. Sedangkan kriteria lainnya mendapatkan
persentase produk 56%, pengiriman 32%, dan pembayaran
28%.
Dari kriteria yang telah ditemukan nilai bobotnya
kemudian dihitung dengan metode Weighted Product untuk
menghasilkan nilai terbesar yang akan terpilih sebagai
alternatif terbaik.
Hasil pengujian perhitungan dengan metode
Weighted Product menunjukkan bahwa perangkingan
vektor V yang terbesar atau tertinggi yang menjadi alternatif
pada pemilihan e-marketplace adalah Shopee dengan nilai
vektor 0,35. Sedangkan Tokopedia 0,32 dan Bukalapak
0,33.
Hasil pada pengujian hipotesis menunjukkan bahwa
hipotesis H3 dapat diterima karna sesuai dengan hasil
penelitian.
REFERENSI [1] Alwafi, F., & Magnadi, R. H. (2016). PENGARUH
PRESEPSI KEAMANAN, KEMUDAHAN
BERTRANSAKSI, KEPERCAYAAN TERHADAP
TOKO DAN PENGALAMAN BERBELANJA
TERHADAP MINAT BELI SECARA ONLINE PADA
SITUS JUAL BELI TOKOPEDIA.COM. 5(2), 1–15.
[2] Fauziah, D. N., & Wulandari, D. A. N. (2018).
Pengukuran kualitas layanan bukalapak.com
terhadap kepuasan konsumen dengan metode
webqual 4.0. Jurnal Ilmu Pengetahuan Dan
Teknologi Komputer, 3(2), 173–180.
[3] Royanti, N. I., & Yunianto, E. (2018). PEMILIHAN
E-MARKETPLACE BAGI PEDAGANG BATIK
PEKALONGAN MENGGUNAKAN METODE
FUZZY AHP-TOPSIS. 36–43.
[4] Nofriansyah, D., & Defit, S. (2017a). MULTI
CRITERIA DECISION MAKING (MCDM) PADA
SISTEM PENDUKUNG KEPUTUSAN (pertama; H.
Rahmadhani & C. M. Sartono, Eds.). Yogyakarta:
CV BUDI UTAMA.
[5] Sari, F. (2017). METODE DALAM PENGAMBILAN
KEPUTUSAN (1st ed.; D. Novidiantoko & haris ari
Susanto, Eds.). Yogyakarta: CV BUDI UTAMA.
[6] Setiadi, A., & Agustia, R. D. (2019). PENERAPAN
METODE AHP DALAM MEMILIH
MARKETPLACE E-COMMERCE BERDASARKAN
SOFTWARE QUALITY AND EVALUATION
ISO/IEC 9126-4 UNTUK UMKM. 1–10.
[7] Hatta, H. R., Rizaldi, M., & Khairina, D. M. (2016).
Penerapan Metode Weighted Product Untuk
Pemilihan Lokasi Lahan Baru Pemakaman Muslim
Dengan Visualisasi Google Maps. Jurnal Nasional
Teknologi Dan Sistem Informasi, 2(3), 85–94.
https://doi.org/10.25077/teknosi.v2i3.2016.85-94
[8] Khairina, D. M., Ivando, D., & Maharani, S. (2016).
Implementasi Metode Weighted Product Untuk
Aplikasi Pemilihan Smartphone Andorid. 8(1), 1–8.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
[9] Fahmi, I. (2018). Teori dan Teknik Pengambilan
Keputusan: Kualitatif dan Kuantitatif (3rd ed.; M. A.
Djalil, Ed.). Depok: PT Raja Grafindo Persada.
[10] Syafitri, N. A., Sutardi, & Dewi, A. P. (2016).
PENERAPAN METODE WEIGHTED PRODUCT
DALAM SISTEM PENDUKUNG KEPUTUSAN
PEMILIHAN LAPTOP BERBASIS WEB. 2(1), 169–
176.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
SISTEM INFORMASI EVALUASI KINERJA PRODUKSI
PERUSAHAAN PERTAMBANGAN BATUBARA PADA DIREKTORAT
JENDERAL MINERAL DAN BATUBARA 1Ajeng Shilvie Nurlatifah, 2Sunjana
Jurusan Teknik Informatika – Fakultas Teknik Universitas Widyatama
Jl. Cikutra Bandung - Jawa Barat, Indonesia
Email: [email protected],
Abstract— Currently, virtually no country in the world
includes Indonesia whose development is independent of the
important and strategic role of mineral and coal resources. Along
with the growing economic growth and the increasing number of
population, increasing the consumption of minerba is an
unavoidable, where the state of all activities can be ascertained
require minerba. The development of national development will
depend on the attention and efficiency of the use of minerba. The
Directorate General of Mineral and Coal as a government that
considers the minerba resources has provisions in the
management of company data and production data of mining
activities of the company. In addition, they have difficulties in
evaluating company performance. It uses the waterfall
methodology because of its development process through several
gradual processes. Odoo is used as a framework in developing
this information system with Python and XML programming
languages and PostgreSQL is used as database server. The
system can be expected to benefit the Directorate General of
Minerals and Coal in the management of the company's
production data and the assessment of performance appraisal.
Keywords— Information System, Government, Performance
Evaluation, Production, Odoo
PENDAHULUAN
Saat ini, hampir tidak ada satu pun negara di
dunia termasuk Indonesia yang pembangunannya
terlepas dari peran penting dan strategis sumber daya
mineral dan batubara (minerba). Seiring dengan
semakin berkembangnya pertumbuhan ekonomi dan
semakin bertambahnya jumlah penduduk, peningkatan
konsumsi minerba merupakan suatu hal yang tidak
dapat dihindarkan, dimana hampir seluruh aktivitas
ekonomi dapat dipastikan membutuhkan minerba.
Perkembangan pembangunan nasional akan sangat
tergantung pada ketersediaan dan efisiensi penggunaan
minerba.
Di Indonesia terdapat lebih dari 4.000 perusahaan
pertambangan batubara (Coal Mining Company) yang
memiliki ijin baik berupa Perjanjian Karya
Pengusahaan Pertambangan Batubara (PKP2B) atau
Ijin Usaha Pertambangan (IUP). Perusahaan
pertambangan batubara yang diklasifikasikan besar,
dalam arti memiliki mayoritas sumberdaya dan
cadangan batubara serta produksi batubara nasional
adalah perusahaan tambang batubara yang memegang
ijin PKP2B sejumlah kurang lebih 250 perusahaan.
Undang-Undang No. 4 tahun 2009 tentang
Pertambangan Mineral & Batubara, pada BAB XII
tentang Data Pertambangan pasal 88 menyebutkan
bahwa:
(1) Data yang diperoleh dari kegiatan usaha
pertambangan merupakan data milik Pemerintah
dan/atau pemerintah daerah sesuai dengan
kewenangannya
(2) Data usaha pertambangan yang dimiliki
pemerintah daerah wajib disampaikan kepada
Pemerintah untuk pengelolaan data pertambangan
tingkat nasional.
(3) Pengelolaan data sebagaimana dimaksud pada
ayat (1) diselenggarakan oleh Pemerintah dan/atau
pemerintah daerah sesuai dengan kewenangannya.
Dengan mengacu dasar hukum tersebut,
pemerintah berhak meminta data pertambangan dari
seluruh perusahaan tambang batubara baik itu berupa
data administratif, produksi, perijinan, operasional
maupun data yang bersifat keuangan dalam rangka
pengawasan kegiatan operasional perusahaan
pertambangan nasional.
Saat ini Dirjen Minerba secara manual melakukan
analisis terhadap data produksi pertambangan yang
dikirimkan oleh perusahaan pertambangan. Hal ini
sangat tidak efektif mengingat data yang dikirimkan
oleh perusahaan pertambangan dikirim dalam format
yang berbeda beda.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Selain itu, perlu waktu yang cukup lama bagi
Dirjen Minerba untuk merekap data yang harus
disetorkan pada pemerintah sehingga evaluasi kinerja
perusahaan hanya dinilai berdasarkan kelengkapan dan
ketepatan pengiriman laporan saja, sedangkan untuk
melakukan evaluasi kinerja produksi dibutuhkan
banyak indikator penilaian agar dapat diketahui secara
nyata bagaimana kegiatan pertambangan yang
dilakukan oleh perusahaan itu berjalan.
Menurut (Djaali, 2004 : 1) penilaian dalam bahasa
inggris dikenal dengan istilah assesment merupakan
suatu tindakan atau proses menetukan nilai sesuatu
objek. Penilaian juga merupakan suatu keputusan
tentang nilai. Penilaian dapat dilakukan berdasarkan
hasil pengukuran atau dapat pula dipengaruhi oleh
hasil pengukuran.
Menurut Buku Petunjuk Teknis Standar
Pelayanan Minimal Bidang Kesehatan (Kemenkes RI),
pengertian indikator dapat diartikan sebagai variabel
yang bisa dipakai untuk mengevaluasi
kondisi/keadaan/status serta memungkinkan
dilakukannya tindakan pengukuran terhadap berbagai
perubahan yang terjadi dari satu waktu ke waktu
lainnya.
Menurut Stufflebeam dalam Lababa (2008),
evaluasi adalah “The process of delineating, obtaining,
and providing useful information for judging decision
alternatives."
Menurut Chariri dan Ghozali, kinerja perusahaan
bisa juga diukur dengan menggunakan informasi
keuangan atau juga menggunakan informasi non
keuangan. Informasi non keuangan ini dapat berupa
kepuasan pelanggan atas pelayanan yang diberikan
oleh perusahaan. Meskipun begitu, kebanyakan kinerja
perusahaan diukur dengan rasio keuangan dalam
periode tertentu.
OpenERP (dulu bernama TinyERP, sekarang
bernama Odoo) adalah sebuah perangkat lunak
Enterprise Resource Planning (ERP) atau perangkat
lunak perencanaan sumber daya perusahaan yang
dilisensikan free/open source. OpenERP
dikembangkan dengan bahasa pemrograman Python.[1]
Tujuan dari penelitian ini adalah :
1. Untuk membangun sistem informasi yang
mampu mengelola data perusahaan
pertambangan batubara, berikut data
produksinya.
2. Untuk membangun sistem berbasis web yang
dapat mempermudah Direktorat Jenderal
Mineral dan Batubara dalam mengumpulkan
dan mendapatkan data-data pertambangan
langsung dari perusahaan pertambangan itu
sendiri yang akan dijadikan sebagai indikator
evaluasi kinerja
METODOLOGI PENGEMBANGAN SISTEM
Metodologi pengembangan sistem adalah metode-
metode, prosedur-prosedur, konsep-konsep pekerjaan,
aturan-aturan dan postulat-postulat yang akan
digunakan untuk mengembangkan suatu sistem
informasi.[2] Dalam penelitian ini, penulis
menggunakan metodologi model waterfall.
Gambar 1. Metodologi Pengembangan Sistem
Waterfall[3]
HASIL DAN PEMBAHASAN
I.5 Analisis Sistem Berjalan
1. Flowmap Pelaporan Dokumen RKAB
Dengan melihat banyaknya dokumen
yang berada di kantor minerba yaitu sekitar 63,4
m3 per perusahaan per tahun menyebabkan
penumpukan dokumen setiap tahunnya. Tidak
hanya itu, dengan pendataan seperti ini dapat
menyulitkan dalam pencarian data karena
pencarian dilakukan manual satu persatu terhadap
dokumen yang telah disimpan, hal tersebut
menyebabkan tersitanya banyak waktu.
Dalam melakukan pengumpulan laporan
RKAB Produksi dan mengevaluasi kinerja
perusahaan, saat ini Dirjen Minerba menggunakan
metode rekap data dengan menggunakan aplikasi
microsoft excel yang dikerjakan oleh tim input
mereka. Dokumen yang dikirimkan oleh
perusahaan diberikan tanda terima dokumen
sebagai bukti yang sah bahwa perusahaan tersebut
telah melaporkan kewajibannya. Berikut dibawah
ini merupakan deskripsi dan flowmap dari proses
pelaporan dokumen perusahaan :

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 2. Flowmap Pelaporan RKAB
Deskripsi Flowmap :
1. Perusahaan mendatangi kantor dirjen minerba.
2. Perusahaan menyerahkan dokumen RKAB
Produksi kepada staff minerba.
3. Staff minerba menerima dokumen RKAB
Produksi perusahaan.
4. Staff minerba membuat bukti tanda terima
penyerahan dokumen RKAB Produksi.
5. Staff minerba menyerahkan bukti tanda terima
penyerahan dokumen RKAB Produksi.
6. Perusahaan menerima bukti tanda terima
penyerahan dokumen RKAB Produksi.
7. Staff minerba menginputkan dokumen
RKAB perusahaan melalui aplikasi
microsoft excel.
8. Staff minerba menyimpan dokumen fisik
di gudang penyimpanan dokumen.
9. Proses pelaporan dokumen selesai.
2. Flowmap Evaluasi Kinerja Produksi
Format dokumen yang dikirimkan oleh
perusahaan tersebut diantaranya berupa :
Dokumen PDF dengan format narasi yang
disusun per paragraf.
Dokumen PDF dengan format tabel yang tiap
perusahaan menggunakan layout yang berbeda
beda.
Dokumen Excel dengan format tabel yang tiap
perusahaan menggunakan layout yang berbeda
beda.
Dengan adanya format laporan yang
berbeda beda maka tim input minerba harus
menerjemahkan seluruh data tersebut kedalam
sebuah format yang sama. Atas dasar kebutuhan
tersebut, maka terciptalah format excel yang
didisusun oleh dirjen minerba. Namun perusahaan
tambang batubara belum menggunakan format
tersebut karena format excel yang dibuat minerba
sendiri selalu berubah ubah.
Setiap data evaluasi yang dibutuhkan
oleh direktur minerba memerlukan waktu yang
cukup lama untuk merekapnya karena dibuat dan
dicari pada saat itu juga. Hal itu pun baru
dilaksanakan jika memang benar benar ada
permintaan dari direktur sendiri. Hal ini bukan
masalah jika hanya memerlukan 1 perusahaan
dalam 1 periode, lain halnya jika data yang harus
disajikan diambil dari rekapan dari tahun ke tahun
pasti akan memerlukan waktu yang lebih lama.
Yang lebih parahnya lagi jika dibutuhkan seluruh
data rekapan dari tahun ke tahun per perusahaan
sudah dipastikan akan membutuhkan waktu yang
jauh lebih lama. Berikut merupakan deskripsi dan
flowmap dari proses evaluasi kinerja produksi
perusaaan.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 3. Flowmap Evaluasi Kinerja
Deskripsi flowmap :
1. Direktur membutuhkan data evaluasi kinerja
produksi perusahaan tambang X.
2. Direktur minerba meminta hasil evaluasi kinerja
produksi perusahaan tambang X kepada staff
minerba.
3. Staff minerba menerima dan mencatat
permintaan hasil evaluasi kinerja produksi
perusahaan tambang X.
4. Staff minerba mencari dokumen perusahaan X
terkait dengan permintaan hasil evaluasi kinerja.
5. Staff minerba mengumpulkan dokumen RKAB
perusahaan X.
6. Staff minerba merekap evaluasi kinerja
perusahaan X menggunakan aplikasi microsot
excel.
7. Staff minerba mencatak hasil evaluasi kinerja,
kemudian menyerahkan dokumen tersebut
kepada direktur minerba.
8. Direktur minerba menerima dokumen evaluasi
kinerja perusaahaan X.
9. Proses evaluasi kinerja perusahaan selesai.
I.6 Perancangan Sistem
1. Use Case Diagram
Pemodelan Usecase sering dianggap sebagai
pandangan eksternal atau fungsional dari proses
bisnis karena menunjukkan bagaimana pengguna
melihat proses daripada mekanisme internal yang
digunakan sistem proses dan pendukungnya. Use
case dapat mendokumentasikan sistem saat ini atau
sistem baru yang sedang dikembangkan.[4] Gambar
4 Use case diagram dlampirkan.
2. Activity Diagram
Activity Diagram mengolah data RKAB via Aplikasi
Gambar 5. Activity Diagram Mengolah Data RKAB
via Aplikasi
Deskripsi activity diagram mengolah data RKAB via
Aplikasi:
a. Admin memilih menu perusahaan
b. Sistem menampilkan form perusahaan
c. Admin membuat record info tahunan tahun berjalan
d. Sistem melakukan pengecekan, jika data master
blok/pit/wda tidak ada maka admin harus mengisinya
terlebih dahulu.
e. Admin memilih sub menu produksi
f. Sistem menampilkan form sub menu produksi
g. admin mengisi data RKAB perusahaan
h. Sistem menyimpan perubahan
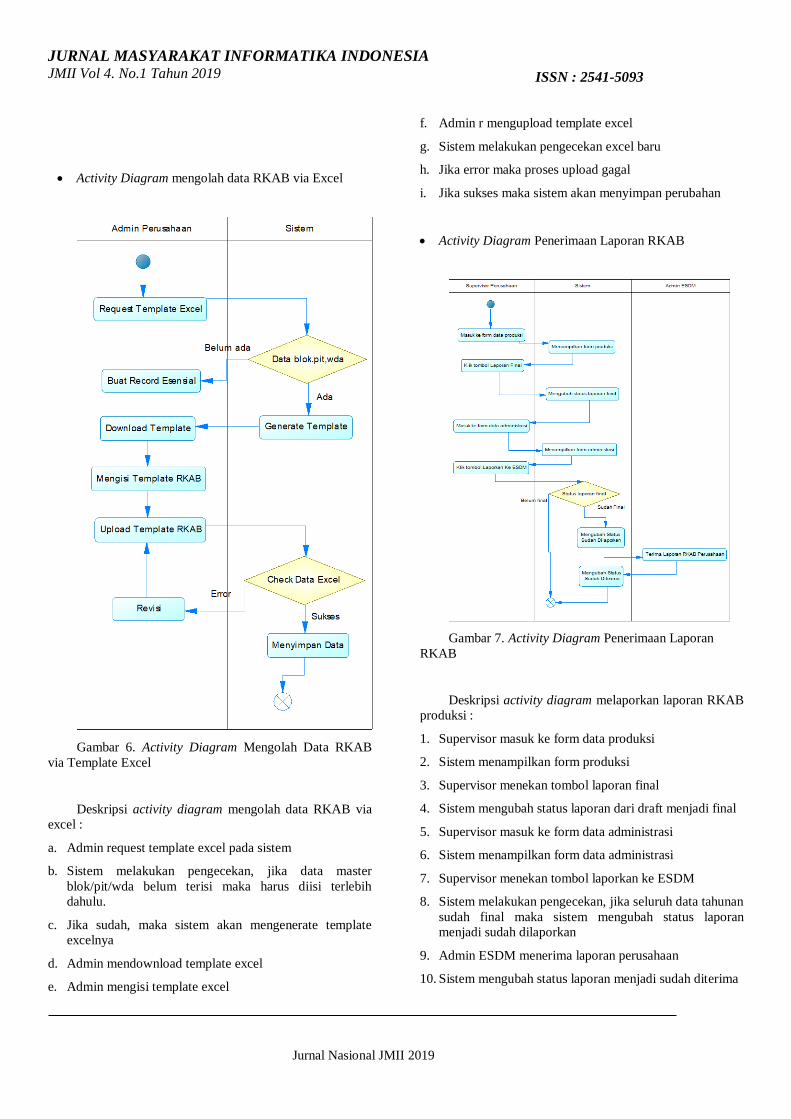
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Activity Diagram mengolah data RKAB via Excel
Gambar 6. Activity Diagram Mengolah Data RKAB
via Template Excel
Deskripsi activity diagram mengolah data RKAB via
excel :
a. Admin request template excel pada sistem
b. Sistem melakukan pengecekan, jika data master
blok/pit/wda belum terisi maka harus diisi terlebih
dahulu.
c. Jika sudah, maka sistem akan mengenerate template
excelnya
d. Admin mendownload template excel
e. Admin mengisi template excel
f. Admin r mengupload template excel
g. Sistem melakukan pengecekan excel baru
h. Jika error maka proses upload gagal
i. Jika sukses maka sistem akan menyimpan perubahan
Activity Diagram Penerimaan Laporan RKAB
Gambar 7. Activity Diagram Penerimaan Laporan
RKAB
Deskripsi activity diagram melaporkan laporan RKAB
produksi :
1. Supervisor masuk ke form data produksi
2. Sistem menampilkan form produksi
3. Supervisor menekan tombol laporan final
4. Sistem mengubah status laporan dari draft menjadi final
5. Supervisor masuk ke form data administrasi
6. Sistem menampilkan form data administrasi
7. Supervisor menekan tombol laporkan ke ESDM
8. Sistem melakukan pengecekan, jika seluruh data tahunan
sudah final maka sistem mengubah status laporan
menjadi sudah dilaporkan
9. Admin ESDM menerima laporan perusahaan
10. Sistem mengubah status laporan menjadi sudah diterima

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
3. Class Diagram
Class adalah sebuah spesifikasi yang jika
diinstansiasi akan menghasilkan sebuah objek dan
merupakan inti dari pengembangan dan desain berorientasi
objek. Class menggambarkan keadaan (atribut/properti)
suatu sistem, sekaligus menawarkan layanan untuk
memanipulasi keadaan tersebut (metoda/fungsi).
Class diagram menggambarkan struktur dan
deskripsi class, package dan objek beserta hubungan satu
sama lain seperti containment, pewarisan, asosiasi, dan lain-
lain. Gambar Class Diagram dilampirkan pada Gambar 8, 9
dan 10.
I.7 Implementasi Sistem
Sistem yang dirancang dalam pengelolaan datanya
dapat melalui dua cara. Yaitu via aplikasi dan via template
excel. Template excel digunakan sebagai media semi
peralihan supaya perusahaan dapat menyesuaikan diri
dengan sistem pemerintah yang baru.
1. National Analytics
Dashboard digunakan untuk mengetahui
overview dari keadaan suatu atau beberapa
perusahaan sehingga mempermudah bagi
manajemen untuk mengambil keputusan.
Dashboard national analytics diperuntukan bagi
user dengan role Dirjen Minerba (ESDM) yang
isinya dapat melihat beberapa informasi seperti :
- Top 5 Rank
Untuk mengetahui lima perusahaan
terbaik dalam pelaporan data produksi
berdasarkan hasil evaluasi kinerja pada tahun
berjalan.
- Grafik Evaluasi Kinerja
Untuk mengetahui gambaran mengenai
evaluasi kinerja per perusahaan yang telah
melapor.
- Realisasi Ekspor Paling Tinggi
Untuk mengetahui perusahaan mana yang
paling besar melakukan ekspor keluar negeri
pada tahun berjalan.
- Realisasi DMO Paling Tinggi
Untuk mengetahui perusahaan mana yang
paling besar merealisasikan DMO (Domestic
Market Obligation) yang merupakan
kewajiban untuk memasarkan atau menjual
batubara didalam negeri.
- Perusahaan yang belum melapor
Untuk mengetahui perusahaan mana saja
yang belum melaporkan data produksinya pada
tahun berjalan.
Gambar 11. Dashboard National Analytics
2. Company Analytics
Dashboard yang hanya dapat lihat oleh
perusahaan. Dalam dashboard ini menampung
beberapa informasi mengenai :
- Status Laporan Tahun Ini
Untuk mengetahui status dari tiap item
data produksi.
- Grafik Evaluasi Kinerja Tahunan
- Untuk mengetahui progress / perkembangan
evaluasi kinerja
- Check Data Tahun Ini
Untuk mengetahui persentase
kelengkapan dari data produksi yang telah
dibuat.
Gambar 12. Company Analytics
3. Check List Data
Form check list data digunakan untuk
mengetahui progress dari setiap menu item
produksi sehingga tidak perlu melihat satu per satu
kedalam data yang terdapat dalam setiap menu.
Selain itu untuk mengetahui apakah data produksi
pada tahun itu sudah diisi atau belum, mengetahui
statusnya serta mengetahui persentase kelengkapan
datanya.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 13. Check List Data
4. Data Konfigurasi
Data konfigurasi memuat master master
data yang berhubungan dengan konfigurasi sistem.
Terdapat beberapa form konfigurasi diantaranya :
- User management
- Master Tahun
- Master Triwulan
- Master Bobot
- Kategori Indikator
- Provinsi
- Kota/Kabupaten
Gambar 14. Form User Management
5. Data Perusahaan
Menu perusahaan menampilkan kanban
view dan form view yang berisi data mengenai
perusahaan perusahaan tambang. Hanya pihak
Dirjen Minerba yang dapat membuat data
perusahaan. Setiap perusahaan yang terdaftar
dalam sistem dapat memiliki user login untuk
masuk kedalam sistem. Nantinya setiap user
perusahaan yang login hanya bisa melihat data
milik perusahaannya sendiri dan tidak dapat
melihat data milik perusahaan lain.
Gambar 15. Form Perusahaan
6. Data Administrasi
Data administrasi memuat detail
mengenai jenis komoditi dari perusahaan tambang,
kepala teknik tambang, kode wilayah, tahun
berakhirnya kontrak, luas ijin produksi, kapasitas
rencana produksi, dan lain lain. Terdapat tiga status
pada pojok kanan atas form yang bertuliskan belum
dilaporkan, sudah dilaporkan dan sudah diterima.
Ketiga status tersebut sebagai penanda status dari
data produksi pada tahun tersebut.
Gambar 16. Form Data Administrasi
7. Dokumen Triwulan dan Dokumen DMO
DMO merupakan singkatan dari
Domestic Market Obligation. Form ini digunakan
untuk menampung dokumen dokumen yang biasa
dikimkan tiap triwulan agar tidak mudah tercecer.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
Gambar 17. Form Dokumen Triwulan dan
DMO
8. Evaluasi Kinerja Produksi
Merupakan form yang digunakan untuk
mengetahui detail hasil penilaian terhadap data data
produksi yang dikirimkan atau diisi oleh
perusahaan. Perhitungan evaluasi kinerja
berdasarkan data data yang dikirimkan oleh
perusahaan seperti :
a. Data kegiatan konstruksi
b. Data operasi pengupasan overburden
c. Data biaya kegiatan penambangan
d. Data asumsi keuangan
e. Data pemasaran batubara
f. Data DMO batubara
Gambar 18. Form Evaluasi Kinerja Produksi
9. Download Excel Template
Form ini digunakan untuk request
template excel kedalam sistem. Nantinya sistem
akan men-generate template excel yang dapat diisi
oleh perusahaan yang terpilih untuk mengupdate
data pada tahun yang terpilih.
Gambar 19. Download Template Excel
10. Upload Template Excel
Form ini digunakan untuk mengupload
template excel yang telah didownload dan telah
diisi/diupdate datanya untuk kemudian disimpan
perubahannya kedalam sistem.
Gambar 20. Upload Template Excel
11. Template Excel
Template excel merupakan media
alternative untuk mengelola data perusahaan selain
melalui aplikasi secara langsung. Tetapi, template
excel ini tentunya digenerate dari sistem, kemudian
harus diupload kembali pada sistem.
Gambar 21. Template Excel
Keterangan :
- Sheet 1:
Data Administrasi.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
Jurnal Nasional JMII 2019
ISSN : 2541-5093
- Sheet 2:
Data Master Blok/Pit.
- Sheet 3 :
Rencana dan Realisasi Kegiatan
Konstruksi dan Infrastruktur Tahun Berjalan-1.
- Sheet 4 :
Rencana Kegiatan Konstruksi dan
Infrastruktur Tahun Berjalan.
- Sheet 5 :
Rencana dan Realisasi Pengupasan
Overburden (OB)/Batuan Penutup Tahun
Berjalan-1 dan Rencana Tahun Berjalan.
- Sheet 6 :
Rencana dan Realisasi Biaya
Penambangan Batubara Tahun Berjalan-1 dan
Rencana Tahun Berjalan.
- Sheet 7:
Rencana dan Realisasi Pemasaran Tahun
Berjalan-1 dan Rencana Tahun Berjalan.
- Sheet 8:
Rencana dan Realisasi Keuangan Tahun
Berjalan-1 dan Rencana Tahun Berjalan.
KESIMPULAN
Pembuatan aplikasi sistem informasi evaluasi
kinerja produksi perusahaaan pertambangan batubara ini
bertujuan untuk mengelola data perusahaan pertambangan
batubara berikut data pertambangannya. Selain itu dapat
mempermudah dirjen minerba dalam mengumpulkan dan
mendapatkan data data pertambangan langsung dari
perusahaan pertambangan itu sendiri yang akan dijadikan
sebagai indikator evaluasi kinerja.
Sistem Informasi evaluasi kinerja produksi perusahaan
pertambangan batubara di Direktorat Jenderal Mineral dan
Batubara ini memberikan efektif kerja. Secara garis besar,
berdasarkan hasil perancangan dan pembuatan aplikasi
untuk Sistem Informasi evaluasi kinerja produksi
perusahaan pertambangan batubara di Direktorat Jenderal
Mineral dan Batubara yang telah dilakukan, dapat
disimpulkan hal-hal sebagai berikut:
1. Sistem yang dirancang ini adalah sistem evaluasi
kinerja produksi perusahaan pertambangan
batubara. Sistem ini dapat memberikan beberapa
kelebihan dibandingkan dengan sistem yang sedang
berjalan saat ini, yaitu efisien dan efektif dalam
pengolahan informasi dan pengelolaan data
perusahaan serta kegiatan pertambangannya.
2. Dengan adanya sistem informasi evaluasi kinerja
produksi perusahaan pertambangan batubara ini
dapat membantu direktorat jenderal mineral dan
batubara dalam mengevaluasi kinerja perusahaan
pertambangan batubara.
REFERENSI
[1] Noprianto, Budhysantika Whisnu, Widoyo, Dasar –
Dasar OpenERP Sisi Teknikal dan Contoh Kasus,
2014
[2] Jogiyanto HM. Analisis dan Desain Sistem
Informasi: Pendekatan Terstruktur Teori dan
Praktik Aplikasi Bisnis, Andi, 2005.
[3] Pressman and Bruce R. Maxim, Software
Engineering: A Practitioner’s Approach Eighth
Edition, McGraw-Hill Education, 2015.
[4] Dennis, Wixom, and Tegarden, System Design &
Analysis With UML Version 2.0 an Object
Oriented Approach 4th Edition, John Wiley &
Sons, 2012.
[5] Rusdiana, A. (2014). Manajemen Operasi.
Bandung : Pustaka Setia.
[6] Mulyani, S. (2016). Metode Analisis dan Perancangan Sistem. Bandung : Abdi Sistematika.

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
PERENCANAAN PROYEK SISTEM INFORMASI AKADEMIK
PENDEKATAN METODE EARNED VALUE
Sunjana
Program Studi Teknik Informatika, Fakultas Teknik, Universitas Widyatama
e-mail : [email protected]
Abstrak— Pada zaman sekarang ini berbagai
macam proyek dibuat mulai dari proyek
pembangunan, pemerintahan, ataupun IT. Dalam
pembuatan proyek perlu perencanaan yang matang
agar tidak berdampak buruk dalam proses
pengerjaan suatu proyek. Biaya proyek sangat
berpengaruh dalam pelaksanaan proyek, maka dari
itu diperlukan analisis perencanaan proyek yang
tepat untuk membangun proyek sehingga proyek
dapat terselesaikan tepat waktu dan tidak over
budget. Maka dilakukan penelitian untuk
menganalisis kinerja biaya dan waktu dengan
menggunakan metode Earned Value Management
(EVM) agar manager dapat mengetahui perkiraan
biaya dan waktu dari sebuah proyek tertentu. Dari
hasil penelitian diperoleh nilai CV negatif dan nilai
SV positif, sehingga dapat ditarik kesimpulan bahwa
dari hasil perancangan biaya proyek sistem
informasi akademik di prediksi mengalami proses
pekerjaan yang lebih lambat daripada jadwal dengan
biaya yang lebih kecil dari anggaran yang dibuat.
Keywords—Biaya, Waktu, Earned Value
Management, Proyek.
I. PENDAHULUAN
Proyek merupakan serangkaian kegiatan yang
memiliki jangka waktu dan sumber daya tertentu
untuk melaksanakan tujuan yang jelas dan
keberhasilannya diikur dari perencanaan, pelaksanaan
dan pengawasan[1]. Kegiatan proyek sering tidak
sesuai dengan perencanaan awal, sehingga banyak
terjadi penyimpangan, baik pada jadwal maupun
biaya[2]. Adanya penyimpangan biaya dan waktu
yang signifikan dapat mengakibatkan pengelolaan
proyek yang buruk[3]. Oleh karena itu, perlu dibuat
perencanaan untuk mencapai efektifitas dan efisiensi
yang tinggi dari sumber daya yang akan digunakan
selama pelaksanaan proyek[4].
Konsep Earned Value adalah salah satu metode
yang bisa digunakan dalam pengelolan proyek yang
mengintegrasikan biaya dan waktu[5]. Konsep
Earned Value dapat memberikan gambaran mengenai
biaya dan jadwal proyek melalui progress pekerjaan
suatu proyek yang dijalankan. Dari segi biaya, dapat
diketahui apakah biaya sesuai perencanaan atau over
budget. Sedangkan dari segi jadwal, dapat diketahui
apakah proyek berjalan sesuai perencanaan atau
sebaliknya[6].
Tujuan penelitian ini adalah untuk menganalisa
kinerja biaya dan waktu dalam sistem informasi
akademik sehingga proyek dapat terselesaikan tepat
waktu dan tidak over budget. Proses mencapai tujuan
tersebut, terdapat tiga parameter penting bagi
penyelenggara proyek yang harus dipenuhi, yaitu
besar biaya (anggaran) yang dialokasikan, jadwal.
dan mutu. Ketiga batasan tersebut, bersifat
tarikmenarik atau saling berkaitan. Apabila ingin
meningkatkan mutu maka pada umumnya berakibat
naiknya biaya, sebaliknya jika ingin menekan biaya,
maka biasanya akan berpengaruh pada mutu dan
jadwal[4]. Hasil dari penelitian ini dapat digunakan
oleh manager proyek sebagai dasar pengambilan
keputusan untuk melakukan perbaikan agar
pelaksanaan proyek bisa sesuai perencanaan awal.
II. METODOLOGI
A. Earned Value Management (EVM)
Konsep Earned Value Management merupakan
suatu metode pengendalian biaya, dimana hasil dari

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
metode ini memberikan informasi prediksi biaya yang
dibutuhkan dan waktu penyelesaian seluruh pekerjaan.
[8].
Pada metode Earned Value terdapat
indikatorindikator yang digunakan yaitu sebagai
berikut [8,9]:
● Actual Cost (AC)
Actual Cost (AC) atau disebut juga dengan
Actual Cost of Work Performed (ACWP) merupakan
anggaran biaya yang dialokasikan berdasarkan
rencana kerja yang telah disusun terhadap waktu.
● Earned Value (EV)
Earned Value (EV) atau disebut juga
Budgeted Cost of Work Performanced (BCWP)
merupakan merupakan nilai yang diterima dari
penyelesaian pekerjaan selama periode waktu tertentu.
Earned Value ini dihitung berdasarkan akumulasi
pekerjaan pekerjaan yang telah selesai.
● Planned Value (PV)
Planned Value (PV) atau biasa disebut juga
Budgeted Cost of Work Schedule (BCWS) merupakan
anggaran biaya yang dialokasikan berdasarkan rencana
kerja yang telah disusun terhadap waktu.
I.8 ● Schedule Variance (SV)
Schedule Variance (SV) digunakan untuk
menghitung penyimpangan antara Planned Value (PV)
dengan Earned Value (EV). Nilai positif menunjukkan
bahwa paket-paket pekerjaan proyek terlaksana lebih
banyak dibanding rencana. Namun sebaliknya, nilai
negatif menunjukkan kinerja pekerjaan yang buruk
karena paket-paket pekerjaan yang terlaksana lebih
sedikit dari jadwal yang direncanakan. Berikut adalah
rumus dari Schedule Variance[3]:
I.9 ● Cost Performance Index
(CPI)
Faktor efisiensi biaya yang telah dikeluarkan
dapat diperlihatkan dengan membandingkan nilai
pekerjaan yang secara fisik telah diselesaikan Earned
Value (EV) dengan biaya yang telah dikeluarkan dalam
periode yang sama Actual Cost (AC). Berikut adalah
rumus dari Cost Performance Index[3]:
Schedule Performance Index (SPI)
Faktor efisiensi kinerja dalam menyelesaikan
pekerjaan dapat diperlihatkan oleh perbandingan antara
nilai pekerjaan yang secara fisik telah diselesaikan
Earned Value (EV) dengan rencana pengeluaran biaya
yang dikeluarkan berdasarkan Planned Value (PV).
Berikut ialah rumus untuk Schedule Performance
Index[3]:
Cost Variance (CV)
Cost Variance adalah selisih antara nilai yang
diperoleh setelah menyelesaikan paket – paket
pekerjaan dengan biaya aktual yang terjadi selama
pelaksanaan proyek. CV positif artinya pekerjaan yang
terlaksana biayanya kurang dari pada anggaran.
Sebaliknya nilai negatif menunjukan bahwa biaya
pekerjaan terlaksanaan lebih tinggi dari anggaran.
Rumus untuk Cost Variance adalah [3]:
Berikut merupakan tabel indikator SV dan CV [9].
TABLE I. INDIKATOR SV DAN CV
JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
III. ANALISIS DAN HASIL
A. Data
Penelitian ini merupakan pengembangan dari
penelitian sebelumnya, dimana pada penelitian
sebelumnya yaitu merancang proyek sistem informasi
dengan menggunakan metode Critical Path dan
Program Evaluation and Review Technic. Sehingga
diperoleh data sebagai berikut [7].
TABLE I. TASK PROYEK
ID Task Name Deskripsi
A User requirement Meneliti dan mengumpulkan data
kebutuhan pengguna pada sistem
B Identifikasi
fungsi dan tujuan
sistem
Menentukan fungsi da tujuan sistem
dibuat
C Identifikasi
anggota
pengembang
Menentukan anggota dalam
pengembangan sistem dan deskripsi
dari masing-masing anggota tim
D Identifikasi waktu
pengembangan Menentukan lamanya pengerjaan
proyek dan target yang akan dicapai
E Proses
persetujuan surat
Mengajukan surat kepada pihak
universitas
pengajuan
F Pembuatan
Software
Requirements
Spesification
(SRS)
Membuat kebutuhan selama
membangun aplikasi dan
spesifikasinya
G Analisis
kebutuhan sistem Meneliti prosedur-prosedur, data-
data dan laporan yang berhubungan
dengan sistem
H Identifikasi alur
sistem Melakukan identifikasi alur kerja
sistem
I Perancangan
DBMS Merancang basisdata yang dapat
mendukung semua operasional SIA
J Perancangan
antar muka Merancang antarmuka pengguna
sistem SIA
K Perancangan
logic Merancang logika kerja program
L Pemrograman
tahap Membuat aplikasi SIA
I
M Ujicoba sistem
tahap
I
Menguji fungsionalitas sistem
N Ujicoba sistem
dengan pengguna
tahap I
Melakukan pengujian oleh
pengguna sistem
O Pemrograman
tahap
II
Melanjutkan pembuatan program
berdasarkan masukan dari
pengguna saat uji coba sistem
P Ujicoba sistem
dengan pengguna
tahap akhir
Melakukan pengujian oleh
pengguna sistem terhadap sistem
yang telah diperiki
Q Install sistem ke
pengguna Aplikasi SIA yang telah selesai
dibuat di integrasikan dengan
sistem yang ada di Universitas
R Serah terima
sistem ke user Aplikasi diserahkan kepada pihak
Universitas
S Pelatihan system Melakukan pelatihan terhadap
civitas akademik untuk
menggunakan SIA

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Tabel I merupakan data task yang akan
dilakukan pada sebuah proyek sistem informasi
akademik. Berikut merupakan perkiraan biaya proyek
dari setiap task.
TABLE II. BIAYA PERKIRAAN SETIAP TASK
ID
Duration
(exp.
time)
Total Budget
Cost (Rp)
Budget Cost per
Week (Rp)
A 2,0 550000 275000
B 3,0 1278000 426000
C 2,0 500000 250000
D 3,0 510000 170000
E 2,0 800000 400000
F 4,0 1680000 420000
G 3,0 933000 311000
H 3,0 810000 270000
I 4,0 1384000 346000
J 3,0 576000 192000
K 4,0 1152000 288000
L 5,0 3800000 760000
M 2,0 2000000 1000000
N 2,0 924000 462000
O 5,0 2500000 500000
P 2,0 462000 231000
Q 3,0 288000 96000
R 2,0 346000 173000
S 3,0 570000 190000
Total 21063000
Dari hasil perhitungan jadwal task dengan
menggunakan metode CPM diperoleh hasil bahwa total
waktu pengerjaan proyek diperlukan sebanyak 48
minggu, seperti pada gambar dibawah ini.
Fig. 1. Hasil penjadwalan dengan menggunakan
teknik CPM.
B. Perhitungan dengan menggunnakan metode
EVM
Dari hasil pejadwalan task dengan perkiraan
biaya masing-masing task, maka selanjutnya
dilakukan perhitungan atau analisi dari peerkiraan
biaya yang sudah dibuat dengan menggunakan
metode Earned Value Management.
TABLE III. HASIL PERHITUNGAN EARNED VALUE MANAGEMENT
(EVM)

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Dari table III diperoleh hasil perhitungan sebagai
berikut:
Total Actual Cost (AC) = Rp 20,643,000
Total Planned Value (PV) = Rp 4,128,600
Total Earned Value (EV) = Rp 4,803,550
Cost Variance (CV) = EV – AC = - Rp
15,839,450
Schedule Variance (SV) = EV – PV = Rp
674,950
IV. KESIMPULAN
Dari hasil penelitian diatas diperoleh nilai CV
negatif dan nilai SV positif, sehingga dapat ditarik
kesimpulan bahwa dari hasil perancangan biaya
proyek sistem informasi akademik di prediksi
mengalami proses pekerjaan yang lebih lambat
daripada jadwal dengan biaya yang lebih kecil dari anggaran yang dibuat.
REFERENCES
[1] Pertiwi, Ayuhalinda Ekso. "Evaluasi Pengendalian
Waktu Pada Proyek Pembangunan Gedung Rawat
Inap 3 Dan 4 Rsud Suradadi Menggunakan Earned
Value Concept (The Evaluation Of Time Control
On The Development Project Of Inpatient Building
3 And 4 In Hospital Suradadi Using Earned Value
Concept)." (2018).
[2] Hartono, Widi, And Delan Suharto. "Earned Value
Method Untuk Pengendalian Biaya Dan Waktu
(Studi Kasus Proyek Pembangunan Gedung
Balaikota Surakarta)." GEMA TEKNIK Majalah
Ilmiah Teknik 10.1 (2009): 122-132
[3] Witjaksana, Budi, and Samuel Petrik Reresi.
"ALISIS BIAYA PROYEK DENGAN METODE
EARNED VALUE DALAM PROSES KINERJA
(Studi Kasus Pada Proyek Pembangunan
Universitas Katholik Widya Mandala Pakuwon

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019
Citi-Surabaya)." EXTRAPOLASI: Jurnal Teknik
Sipil 5.02 (2012).
[4] Rahman, Irfanur. Earned Value Analysis Terhadap
Biaya pada Proyek Pembangunan Gedung. Diss.
Universitas Sebelas Maret, 2010.
[5] Soemardi, Biemo W., Muhamad Abduh, And Reini
D. Wirahadikusumah Dan Nuruddin Pujoartanto.
"Konsep Earned Value untuk Pengelolaan Proyek
Konstruksi." Institut Teknologi Bandung (2006).

JURNAL MASYARAKAT INFORMATIKA INDONESIA JMII Vol 4. No.1 Tahun 2019
ISSN : 2541-5093
Jurnal Nasional JMII 2019




























