Embed Size (px)
Citation preview

Integration and Performance of New Technologies
in the CMS Simulation
Kevin Pedro (FNAL)on behalf of the CMS Collaboration
November 5, 2019

• High Luminosity LHC will have an instantaneous luminosity of5–7.5×1034 cm-2s-1 → more data, more radiation, more pileup
• CMS detector will be upgraded to cope with these conditions
o Including High Granularity Calorimeter (HGCal)in the endcap region
• Simulating HGCal requires 10× more geometryvolumes → 40–60% increase in simulation time
• HGCal also requires more accurate physics liststo simulate precisely-measured particle showers
• Reconstruction scales with pileup, requires more complex algorithms→ larger fraction of total CPU usage in Run 4 vs. Run 2
Run 4 simulation needs to provide more accuracy in more complicated geometry… w/ smaller fraction of total CPU usage vs. Run 2
Simulation Challenges
2CHEP 2019 Kevin Pedro (FNAL)
CE-HCE-E

• CMS currently uses a modified physics list FTFP_BERT_EMM: o Simplified multiple scattering model for most regions (not HCAL, HGCal)o Brings ~15% reduction in simulation CPU usage vs. default FTFP_BERT
Accurate simulation of showers in HGCal requires more involved models• Test case: custom physics list FTFP_BERT_EMN: o Goudsmit-Saunderson model for e+e– multiple scattering below 100 MeVo Angular generator for bremsstrahlungo More accurate Compton scattering model
Simulation takes 2–3× longer w/ new physics list
Simulating HGCal Physics
3CHEP 2019 Kevin Pedro (FNAL)
Run 2 Run 4 (range)Minimum Bias FTFP_BERT_EMM 1.00 1.18 1.24(10.5.ref08) FTFP_BERT_EMN 1.06 2.01 2.15ttbar FTFP_BERT_EMM 1.00 1.64 1.75(10.5.ref08) FTFP_BERT_EMN 1.14 2.97 3.25

A. Gheata
• CMS constantly tests technical improvements and physics-preserving approximations to speed up simulation
Led to 4–6× faster simulation vs. Geant4 default settings
o Major contributions: Russian Roulette algorithm, forward shower libraries, specific cuts/models per detector region
o New products like VecGeom also important (7–14% speedup)
• However, even this will not suffice for the demands of HL-LHC
• Enter GeantV: Vectorized Transport Engine
o Track-level parallelism& basketization of similar tracks
o Better usage of modern CPUregisters by improving data locality
Single instruction, multiple data (SIMD) vectorization
Simulation R&D
4CHEP 2019 Kevin Pedro (FNAL)

• Important to test R&D products in experiment software framework:
1. Engage in co-development between R&D team and experiments to prevent divergences or incompatibilities
2. Measure any potential CPU penalties from running in full software framework
3. Estimate human cost for experiments to adapt to new interfaces when considering migrating to new, backward-incompatible tools
Tests of GeantV integration have met these goals
• Not currently planning to migrate CMS simulation to GeantV
o These tests should be viewed as a demonstrator of feasibility
o Also provide independent measurements of any speedup
GeantV compared to Geant4 w/ VecGeom (“moving target”)
Testing GeantV in CMSSW
5CHEP 2019 Kevin Pedro (FNAL)

Generate events in CMSSW framework, convert HepMC to GeantV format Build CMSSW geometry natively and pass to GeantV engineo Currently using TGeo; could be improved with DD4hep
• Using constant magnetic field, limited EM-only physics list Calorimeter scoring adapted Run GeantV using CMSSW ExternalWork feature:o Asynchronous, non-blocking, task-based processing
Hits output in CMS format, immediately suitable for digitization etc.
Elements of GeantV Integration
6CHEP 2019 Kevin Pedro (FNAL)
External processing
CMSSW thread acquire()
GeantV
produce()(other work)

• Sensitive detectors and scoring trickiest to adapt
o Necessary to test “full chain” (simulation → digitization → reconstruction)
o Significantly more complicated than multithreaded Geant4
• Duplicate scoring class objects per event per thread, then aggregate→ 4 streams, 4 threads = 16 objects
o GeantV TaskData supports this approach
Geant4 vs. GeantV Scoring
7CHEP 2019 Kevin Pedro (FNAL)
Event Geant4 SDSDSDParticles Hits
Event Geant4 SDSDSDParticles Hits
Geant4 shares memory, but each event processed in separate thread
EventGeantV
SDSDSDHits
Event SDSDSD
Each event processed in multiple threads, mixed in with other events
?

• Each ScoringClass object has instance of sensitive detector class
o Some memory overhead from duplicated class members (can be minimized)
• Merged ScoringClass output copied to cache attached to Event object
o Cache used by CMSSW to write output
GeantV Data Aggregation
8CHEP 2019 Kevin Pedro (FNAL)
RunManager
threads
TaskDataDataPerThread
TaskDataDataPerThread
events
ScoringClass ScoringClass ScoringClass ScoringClass
1 2 1 2
A BUserApplication
TaskDataHandle
EventScoringCache
merge

Goal: use exact same scoring code for Geant4 and GeantV
• Problem: totally incompatible APIs
o Example: G4Step::GetTotalEnergyDeposit() vs. geant::Track::Edep()
• Solution: template wrappers with unified interfacese.g. StepWrapper<T>::getEnergyDeposit()
o Scoring code only calls accessors of wrapper, which stores pointer to T
o No branching or virtual table → minimize overhead
o Wrappers for Run, Event, Step, Volume → collected in single Traits class
• Scoring class templated on Traits class
Preserve 1000s of lines of scoring code
o Wrappers & data aggregation approach make integration straightforward
Path to Integration
9CHEP 2019 Kevin Pedro (FNAL)
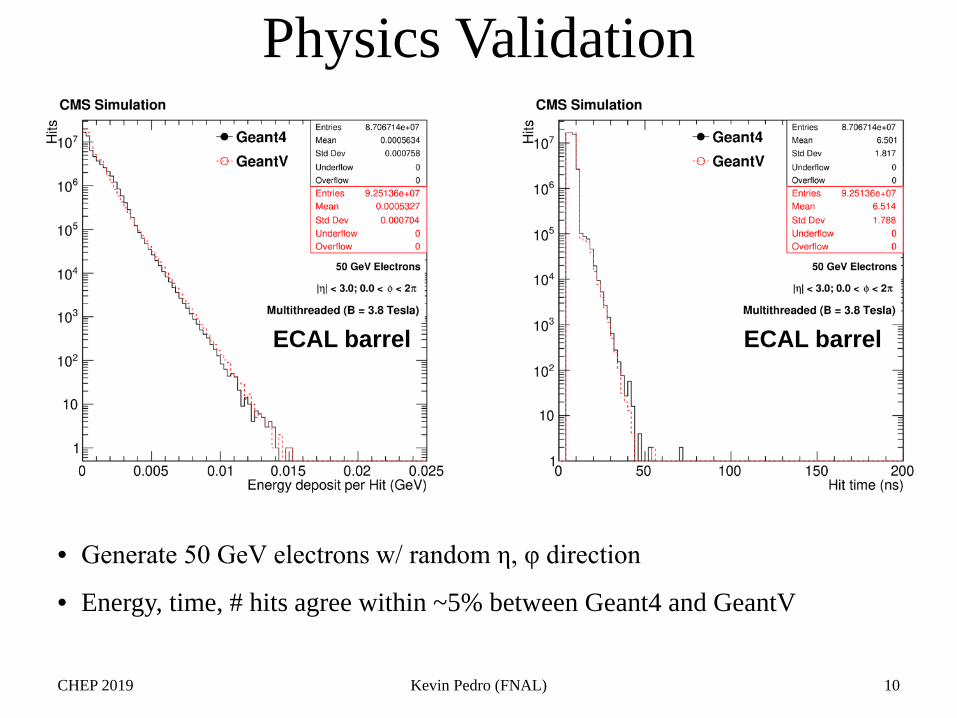
• Generate 50 GeV electrons w/ random η, φ direction
• Energy, time, # hits agree within ~5% between Geant4 and GeantV
Physics Validation
10CHEP 2019 Kevin Pedro (FNAL)
ECAL barrel ECAL barrel

• Settings:o GeantV pre-beta-7+ (63468c9b) w/ vectorized multiple scattering, fieldo Generate & reuse 500 events w/ 2 electrons, E = 50 GeV, random η & φo Keep # events / thread constant, keep unused threads busy, disable outputo CMS 2018 (Run 2) geometry, calorimeter scoring enabled
• Machine: Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz, 35840 KB cache, 28 cores, sse4.2 instructions (from CERN OpenLab)
• Track wall clock time & memory with CMSSW TimeMemoryInfo toolo Measures VSIZE, RSS per evento Calculate throughput and speedup from wall timeo Multithreaded jobs are necessary for efficient use of computing grids
• To characterize CMSSW performance results, first run built-in GeantV FullCMS standalone test (single thread, settings as similar as possible)o GeantV: 526.796s, Geant4: 842.76s
→ 1.6× speedup (standalone)
Performance Tests
11CHEP 2019 Kevin Pedro (FNAL)

speedup
• speedup = throughput(threads=N)/throughput(threads=1)• G4 has better scaling w/ # threads than GV
Time Performance
12
• GV 1.7× faster than G4 single thread, still ~1.3× faster in multithreaded• GV single track mode similar to basketized version
CHEP 2019 Kevin Pedro (FNAL)
throughput [evt/s] throughput GV/G4

• Memory grows ~linearly w/ # threads (expected)
• GV uses more memory than G4 (expected)
• GV single track and basketized modes use similar memory
Memory Performance
13CHEP 2019 Kevin Pedro (FNAL)
RSS memory
RSS GV/G4

• CMS upgrade simulation for HL-LHC may be 2–3× slower than Run 2
o Driven by HGCal (increased geometry volumes, more precise physics list)
• CMS integration tests of GeantV met all goals
1. Co-development ensured compatible threading models & interfaces
2. Similar speedup measured in full experiment software framework
3. Efficient path to integration established
• GeantV prototype is a useful demonstrator:
o Benefits from rewriting/modernizing simulation code
Primary speedup from smaller instruction set → fewer cache misses
o Use of abstraction libraries for efficient code on multiple platforms
o R&D products being integrated into Geant4 (e.g. VecGeom)
Next step: GeantX project for HPCs w/ GPUs
Conclusions
14CHEP 2019 Kevin Pedro (FNAL)

• Results and R&D presented here are the products of years of work by many scientists, developers, etc. – a (multi-) team effort!
• Thanks to:o Geant4 Collaborationo GeantV R&D Teamo CMS Simulation Groupo CMS Core Software Groupo HEP Software Foundationo Support from Intel, Fermilab, and CERN OpenLab
Acknowledgements
15CHEP 2019 Kevin Pedro (FNAL)

Backup

• M. Hildreth et al., “CMS Full Simulation for Run-2”, J. Phys. Conf. Ser. 664 (2015) 072022.
• HEP Software Foundation, “A Roadmap for HEP Software and Computing R&D for the 2020s”, Comp. Soft. Big Sci. 3 (2019) 7, arxiv:1712.06982.
• HEP Software Foundation, “Detector Simulation White Paper”, HSF-CWP-2017-07, arxiv:1803.04165, October 2017.
• D. Elvira et al., “CMS Simulation in the HL-LHC Era”, HSF-CWP-011, January 2017.
• J. Apostolakis et al., “Towards a high performance geometry library for particle-detector simulations”, J. Phys. Conf. Ser. 608 (2015) 012023.
• K. Pedro, “Current and Future Performance of the CMS Simulation”, Eur. Phys. J. Web. Conf. 214 (2019) 02036.
• K. Pedro, “Integration of new simulation technologies in the experiments", Joint HSF/OSG/WLCG Workshop, JLab, March 2019.
• A. Gheata, “Design, implementation and performance results of the GeantVprototype.”, HSF meeting, October 2019.
• G. Amadio et al., “GeantV: Concurrent particle transport simulation in HEP”, in progress, for submission to Comp. Soft. Big Sci.
References
17CHEP 2019 Kevin Pedro (FNAL)

• CMSSW (GitHub/cms-sw)o CMS Offline Software, ~6 million LOC
• VecCore (GitHub/root-project)o SIMD abstraction libraryo Supports backends: Vc, UME::SIMD, CUDA
• VecMath (GitHub/root-project)o Vectorized math utilitieso Built on top of VecCore
• VecGeom (CERN/GitLab)o Vectorized geometry and navigation, multi-particle interface
• GeantV (CERN/GitLab)o pre-beta-7 tag now available!
• install-geant (GitHub/kpedro88), SimGVCore (GitHub/kpedro88)o Test repositories to install and integrate GeantV in CMSSW
Repositories
18CHEP 2019 Kevin Pedro (FNAL)

• Phase 1 upgrades began during Run 2 and will be in operation through the end of Run 3 (installation finishes during Long Shutdown 2)
• Phase 2 upgrades will be in operation during Runs 4, 5 (installation during Long Shutdown 3)
CMS & LHC Upgrade Schedule
19CHEP 2019 Kevin Pedro (FNAL)
Phase 0 Phase 1 Phase 2 (HL-LHC)
We are here

• CMS full simulation uses Geant4
• Run 2: Sim is 40% of total CPU time in CMS→ most expensive “step” in MC production(vs. generation, digitization, reconstruction)
• Largest contributors to CPU usage in Geant4:geometry, magnetic field, EM physics
CMS Simulation Overview
20CHEP 2018 Kevin Pedro (FNAL)
Geant4 10.0p02(similar in other versions)
~60%
~15%
~10%
Geometry/FieldEM Physics
Had.Physics
CMS user actions other

• HF shower library, Russian Roulette have largest impacts
• VecGeom, mag. field improvements entered production in past ~year
o Enabled by validating and using latest Geant4 versions
• Cumulative effects: overall, simulation is 6.2× (4.1×) faster for ( ) vs. default Geant4 settings
CMS full simulation is at least 8× faster than ATLAS
CMS Simulation Optimizations
21
Relative CPU usageConfiguration MinBias ttbarNo optimizations 1.00 1.00Static library 0.95 0.93Production cuts 0.93 0.97Tracking cut 0.69 0.88Time cut 0.95 0.97Shower library 0.60 0.74Russian roulette 0.75 0.71FTFP_BERT_EMM 0.87 0.83VecGeom (scalar) 0.87 0.93Mag. field step,track 0.92 0.90All optimizations 0.16 0.24
CHEP 2019 Kevin Pedro (FNAL)
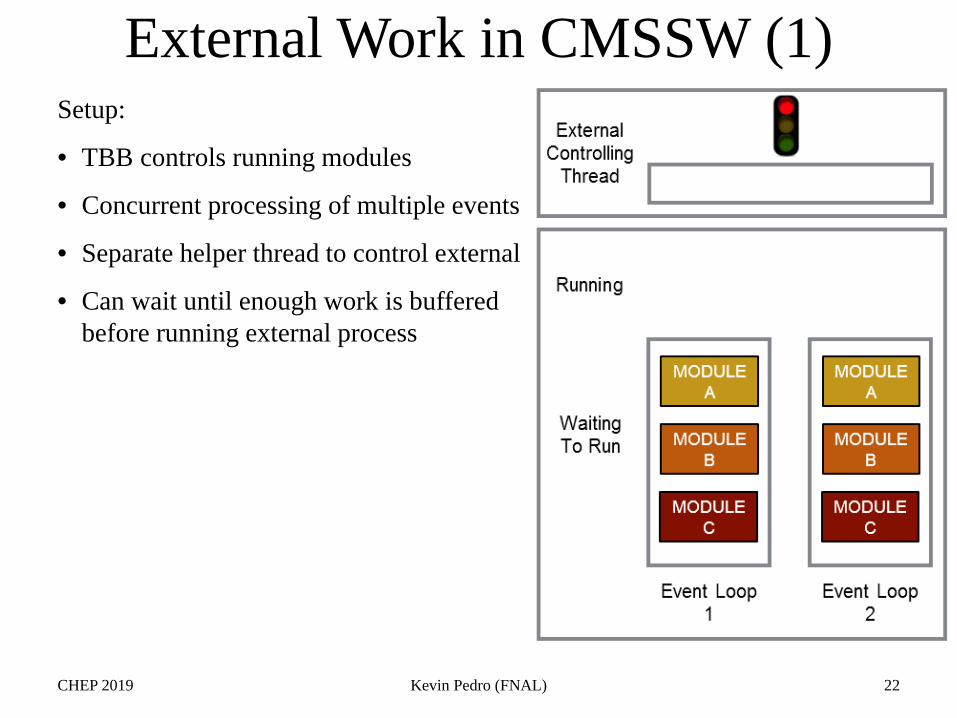
Setup:
• TBB controls running modules
• Concurrent processing of multiple events
• Separate helper thread to control external
• Can wait until enough work is buffered before running external process
External Work in CMSSW (1)
22CHEP 2019 Kevin Pedro (FNAL)

Acquire:
• Module acquire() method called
• Pulls data from event
• Copies data to buffer
• Buffer includes callback to start next phase of module running
External Work in CMSSW (2)
23CHEP 2019 Kevin Pedro (FNAL)
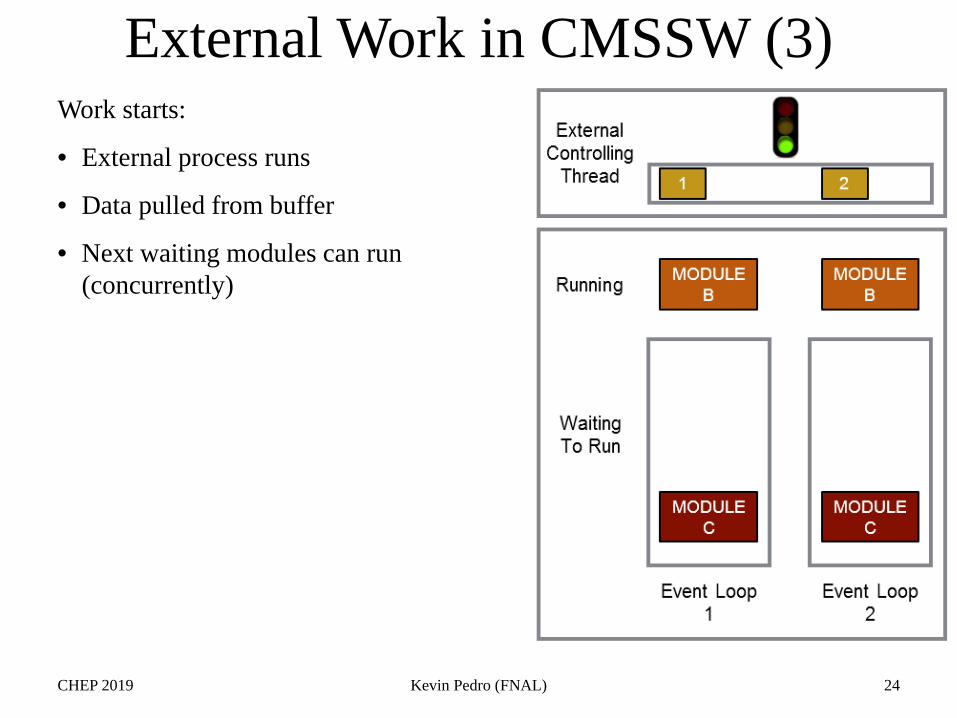
Work starts:
• External process runs
• Data pulled from buffer
• Next waiting modules can run(concurrently)
External Work in CMSSW (3)
24CHEP 2019 Kevin Pedro (FNAL)

Work finishes:
• Results copied to buffer
• Callback puts module back into queue
External Work in CMSSW (4)
25CHEP 2019 Kevin Pedro (FNAL)

Produce:
• Module produce() method is called
• Pulls results from buffer
• Data used to create objects to put into event
External Work in CMSSW (5)
26CHEP 2019 Kevin Pedro (FNAL)

• Observed speedup: 2.0 ± 0.5
o Primary source of speedup actually reduced instruction cache misses
Modern codebase → smaller compiled library
Speedup depends strongly on CPU cache size
o Vectorization gives ~15–30% depending on instruction set (sse vs. avx)
Significant portion of operations still not vectorized
Speedup for EM physics alone:1.5–3× on Haswell, 2–4× on Skylake w/ AVX2
Amdahl’s law limits overall speedup
Inconsistent support for AVX on worldwide grid
o More details in backup
GeantV Status
27CHEP 2019 Kevin Pedro (FNAL)

GeantV Basketizing Efficiency
28
CMS application benchmark• 100 GeV isotropic e-
• 100 primaries, 16 event slots• Field type: CMS map• 1 thread, performance mode
• Bad vectorization efficiency overall• Up to 10-12% depending on
platform• Large overhead, sometimes bigger
than vectorization• Dispatching to many small
basketizers (geometry) not effective
• Good use cases: field and MSC• larger % FLOP
Fractions of total scalar execution timeXeon®CPU E5-2630 [email protected] GHz ,16 core
2x32KB L1/core, 256KB L2, 20MB L3
+ Only post step sampling of physics models* Only querying distance to boundary and safetyx Only MSC position/direction correction calculationo Best configuration for vectorization (Field /Physics/MSC)
Measurement errors < 0.5%
• Overhead: Bo = (TBE – Tscalar) / Tscalar
• Observed efficiency: Be = (Tscalar – Tvector) / Tscalar
• Vectorization efficiency: Bv = Be + BoCHEP 2019 Kevin Pedro (FNAL)
A. Gheata

Basketizing Overhead vs. Arch
29
Geant4 (10.4.p03) vs. GeantV (beta)10 GeV electron x 1000 events (1-thread, 10 measurements), 16 event slots
Overhead seems to largely increase for smaller (data) cache size
CHEP 2019 Kevin Pedro (FNAL)
A. Gheata

Performance Summary
30
Geant4 (10.4.p03) vs. GeantV (beta)10 GeV electron x 1000 events (1-thread, 10 measurements)
strk (single track mode): emulation of Geant4 style tracking
CPU performance of G4/GV varies significantly over different platforms
CHEP 2019 Kevin Pedro (FNAL)
A. Gheata





























