Embed Size (px)
Citation preview

Informe de Proyecto de Fin de Curso
Tratamiento Estadístico de Señales
iie.�ng
Seguimiento de Información Melódica
usando Filtro de Kalman
Haldo Spontón
4.017.891-6
5 de abril de 2010

Índice general
1. Introducción 4
2. Contexto del Problema 6
2.1. Archivos de Entrada . . . . . . . . . . . . . . . . . . . . . . . 6
2.2. Salida de la Primera Etapa . . . . . . . . . . . . . . . . . . . 6
3. Filtro de Kalman 11
3.1. Planteo Original de Filtro de Kalman . . . . . . . . . . . . . . 11
3.2. Resumen (Pseudo-código) del �ltrado de Kalman . . . . . . . 14
3.3. Adaptación al Seguimiento de Altura de Melodía Principal . . 15
3.3.1. Variables del Problema . . . . . . . . . . . . . . . . . . 16
3.3.2. Modelado del Ground Truth . . . . . . . . . . . . . . . 17
4. Algoritmo de Seguimiento 19
4.1. Inicialización . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2. Determinación de Punto de Arranque . . . . . . . . . . . . . . 19
4.3. Seguimiento hacia Adelante y hacia Atrás . . . . . . . . . . . 20
1

4.4. Condiciones de Parada . . . . . . . . . . . . . . . . . . . . . . 21
4.5. Resumen (Pseudo-código) del Algoritmo de Seguimiento . . . 22
5. Análisis de Resultados 23
5.1. Análisis de Ejemplo: daisy4.wav . . . . . . . . . . . . . . . . 24
5.2. Análisis de Ejemplo: pop1.wav . . . . . . . . . . . . . . . . . 24
2

Índice de �guras
2.1. Señal de audio e información tiempo-frecuencia asociada, archi-vo daisy4.wav. . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2. Señal de audio e información tiempo-frecuencia asociada, archi-vo pop1.wav. . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3. Resultados de estimación local de candidatos a frecuencia fun-damental, archivo daisy4.wav. . . . . . . . . . . . . . . . . . . 8
2.4. Resultados de estimación local de candidatos a frecuencia fun-damental, archivo pop1.wav. . . . . . . . . . . . . . . . . . . . 10
4.1. Evaluación de la saliencia en el archivo daisy4.wav. . . . . . . 20
4.2. Evaluación de la saliencia en el archivo pop1.wav. . . . . . . . 21
5.1. Análisis grá�co de resultados, archivo daisy4.wav. . . . . . . 25
5.2. Análisis grá�co de resultados 1, archivo pop1.wav. . . . . . . 26
5.3. Análisis grá�co de resultados 2, archivo pop1.wav. . . . . . . 27
3

Capítulo 1
Introducción
Este proyecto se enmarca en la tesis de grado en la que estoy trabajando.La idea principal de la misma es hacer un sistema punta a punta que, dadauna pieza musical, extraiga la información de altura de la melodía princi-pal en la misma. Por melodía principal se denomina a la melodía que másdestaque sobre el resto de la instrumentación de la pieza, que en ciertos ca-sos puede ser voz, y en otros simplemente un instrumento líder o un sonidosintetizado.
Dado lo amplio del problema, se decidió dividir el mismo en varias etapasde análisis/desarrollo:
Detección local de frecuencia fundamental:
Se divide la pieza musical en frames solapados para el estudio localde la frecuencia fundamental. Para cada frame, se calcula la Trans-formada de Fourier en tiempo corto, y usando un algoritmo basadoen la suma de amplitudes de los distintos parciales de cada frecuenciafundamental, se extraen hasta 5 candidatos de frecuencia fundamentalpara dicho frame.
Extracción y evaluación de características:
Una vez que se disponen de los candidatos a frecuencia fundamentalpara cada frame de audio, se plantean y evalúan diferentes caracterís-
4

ticas para los mismos que tengan un comportamiento de interés a lahora de dar coherencia temporal a los resultados.
Seguimiento temporal:
En este punto se centra este trabajo. Se aplican técnicas de seguimien-to usando Filtro de Kalman para mejorar el resultado de la estimaciónlocal de frecuencia fundamental.
Aplicación:
Por último la aplicación será un software capaz de mostrar de maneraintuitiva y amigable al usuario los resultados del proyecto.
El proyecto se desarrolla de manera que la salida de cada etapa es laentrada a la siguiente. Este trabajo se centra en la etapa de SeguimientoTemporal o �tracking�, por lo que primero se muestran algunos resultadosprevios en el siguiente capítulo.
5

Capítulo 2
Contexto del Problema
2.1. Archivos de Entrada
Para desarrollar y probar el algoritmo, se tiene una base de archivos deaudio con su correspondiente información de frecuencia fundamental de lamelodía principal (de ahora en adelante, �Ground Truth�). La mayoría de losarchivos de audio están muestreados a 22050Hz; cuando esto no es así se re-muestrea el audio de manera de tener una fs = 22050Hz, ya que hay algunosparámetros del problema que dependen de dicha frecuencia de muestreo.
En la �gura 2.1 se puede ver la forma de onda de uno de los archivos deaudio utilizados, junto con su información de tiempo - frecuencia fundamen-tal de la melodía principal. En este caso la melodía principal nunca se corta,pero se puede ver en la �gura 2.2 un caso en el que si pasa1.
2.2. Salida de la Primera Etapa
La salida del algoritmo de estimación local de frecuencia fundamental esuna matriz donde se guardan 5 candidatos de frecuencia fundamental paracada frame de audio junto con la información temporal de los frames. Dada
1En los datos de tiempo-frecuencia, frecuencia 0 indica que no hay meoldía en esaporción de tiempo.
6

Figura 2.1: Señal de audio e información tiempo-frecuencia asociada, archivodaisy4.wav.
Figura 2.2: Señal de audio e información tiempo-frecuencia asociada, archivopop1.wav.
7

la forma de obtención de los distintos candidatos a frecuencia fundamental,hay casos en los que ninguno de los 5 candidatos es el correcto.
En las �guras 2.3 y 2.4 se pueden ver los resultados de la estimación de 5candidatos por frame de audio para los ejemplos mostrados en el capítulo 1.Se ve de fondo el espectrograma del audio, en líneas contínuas la informaciónetiquetada de tiempo-frecuencia de la base de datos de cada archivo, en líneaspunteadas un margen de 3% alrededor de dicha información etiquetada,y en puntos de diversos colores los candidatos de frecuencia fundamentalobtenidos.
Figura 2.3: Resultados de estimación local de candidatos a frecuencia fun-damental, archivo daisy4.wav.
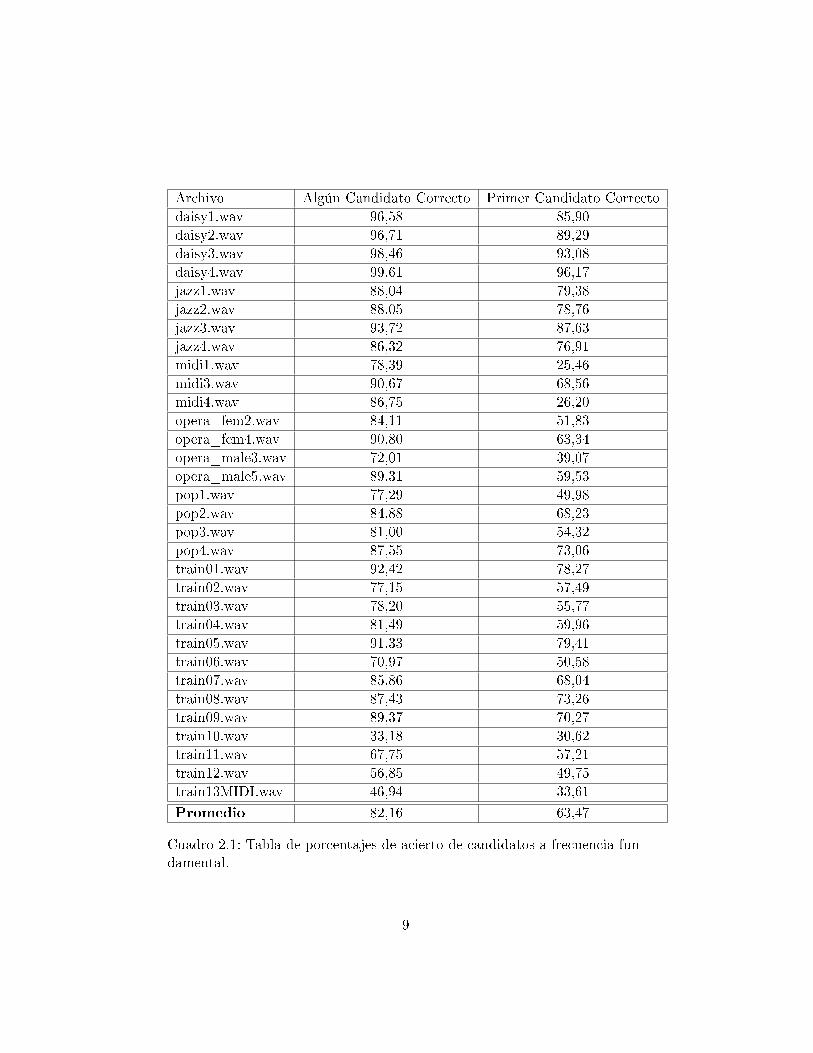
Para los distintos archivos de audio de la base de datos de prueba, seobtuvieron los resultados2 que se muestran en la tabla 2.1.
Una vez que se dispone de la información de candidatos a frecuencia fun-damental de la melodía principal para cada frame, la idea es dar coherenciatemporal a dicha estimación. El primer objetivo con esto es mejorar cuan-titativamente los resultados del sistema, de manera de encontrar un can-
2Un candidato es correcto cuando di�ere en menos de 3% con el Ground Truth.
8
Archivo Algún Candidato Correcto Primer Candidato Correcto
daisy1.wav 96,58 85,90
daisy2.wav 96,71 89,29
daisy3.wav 98,46 93,08
daisy4.wav 99,61 96,17
jazz1.wav 88,04 79,38
jazz2.wav 88,05 78,76
jazz3.wav 93,72 87,63
jazz4.wav 86,32 76,91
midi1.wav 78,39 25,46
midi3.wav 90,67 68,56
midi4.wav 86,75 26,20
opera_fem2.wav 84,11 51,83
opera_fem4.wav 90,80 63,34
opera_male3.wav 72,01 39,07
opera_male5.wav 89,31 59,53
pop1.wav 77,29 49,98
pop2.wav 84,88 68,23
pop3.wav 81,00 54,32
pop4.wav 87,55 73,06
train01.wav 92,42 78,27
train02.wav 77,15 57,49
train03.wav 78,20 55,77
train04.wav 81,49 59,96
train05.wav 91,33 79,41
train06.wav 70,97 50,58
train07.wav 85,86 68,04
train08.wav 87,43 73,26
train09.wav 89,37 70,27
train10.wav 33,18 30,62
train11.wav 67,75 57,21
train12.wav 56,85 49,75
train13MIDI.wav 46,94 33,61
Promedio 82,16 63,47
Cuadro 2.1: Tabla de porcentajes de acierto de candidatos a frecuencia fun-damental.
9

Figura 2.4: Resultados de estimación local de candidatos a frecuencia fun-damental, archivo pop1.wav.
didato correcto en los lugares donde no hay conociendo los candidatos ensu entorno. Por otro lado está el objetivo de mejorar cualitativamente losresultados pensando en el uso de los mismos. Por ejemplo, si se quiere sin-tetizar nuevos sonidos usando la información de frecuencia fundamental dela melodía principal obtenida, lo ideal es tener tramos de melodía continuos,sin saltos abruptos ni cortes. Esta coherencia temporal se intentará lograrcon técnicas de tracking.
10

Capítulo 3
Filtro de Kalman
3.1. Planteo Original de Filtro de Kalman
El objetivo del �ltro de Kalman es usar una serie de medidas ruidosaspara estimar el estado de un sistema.
Se suponen que se tienen medidas ruidosas de un proceso x[n] a estimar:
y[n] = x[n] + v[n] (3.1)
siendo x[n] un proceso AR(p) generado por la ecuación:
x[n] =p∑
k=1
a[k]x[n− k] + w[n] (3.2)
Entonces, si en vez de trabajar con un solo valor x[n] se pasa a trabajarcon un vector de estados de tamaño p, de�nido como:
x[n] =
x[n]
x[n− 1]...
x[n− p + 1]
Por lo que las ecuaciones 3.1 y 3.2, escritas en función del anterior vector
11

de estados, quedan de la siguiente manera:
x[n] =
a(1) a(2) . . . a(p− 1) a(p)1 0 . . . 0 00 1 . . . 0 0...
.... . . 0 0
0 0 . . . 1 0
x[n− 1] +
10...0
w[n] (3.3)
y[n] =[1 0 . . . 0
]x[n] + v[n] (3.4)
Usando notación matricial se tiene:
x[n] = Ax[n] + w[n]
y[n] = CT x[n] + v[n] (3.5)
donde A es una matriz pxp llamada �Matriz de Trancisión de Estados�,
w[n] =[w[n] 0 . . . 0
]Tes un vector de ruido del proceso y C es un
vector unitario de largo p.
Entonces el estimador óptimo del vector de estados underlinex[n], usan-do todas las medidas hasta tiempo n, es expresado como:
x̂[n] = Ax̂[n− 1] + K(y[n]− CT Ax̂[n− 1]
)(3.6)
donde K es el vector de Ganancia de Kalman.
Una vez llegado a este resultado para un proceso estacionario AR(p),dicho resultado puede generalizarse a procesos no estacionarios.
Sea xn un vector de estados de dimensión p que evoluciona según lasiguiente ecuación en diferencias:
x[n] = A[n− 1]x[n− 1] + w[n] (3.7)
donde A es una matriz de trancisión de estados pxp, variable en el tiempo,y w[n] es un proceso de ruido blanco con media nula y con:
E{w[n]wH [n]
}=
{Q
w[n] ; k = n
0 ; k 6= n(3.8)
12

Además se tiene y[n] un vector de observaciones formado como:
y[n] = C[n]x[n] + v[n] (3.9)
donde y[n] es de largo q. C es una matriz qxp también variable en el tiempo yv[n] es un vector de proceso de ruido blanco con media nula, estadísticamenteindependiente de w[n], con:
E{v[n]vH [n]
}=
{Q
v[n] ; k = n
0 ; k 6= n(3.10)
Generalizando el resultado para procesos AR(p), se tiene que el estimadorlineal óptimo del estado x[n] se expresa como:
x̂[n] = A[n− 1]x̂[n− 1] + K[n](y[n] + C[n]A[n− 1]x̂[n− 1]
)(3.11)
Con la apropiada matriz de Ganancia de Kalman, K[n], esta recursióncorresponde al �ltro de Kalman discreto.
Asumiendo conocidas las matruces A[n], C[n], Qw[n] y Q
v[n], se puede
derivar la expresión para la matriz de Ganancia de Kalman que minimiza elerror de estimación en media cuadrática. Se obtiene:
K[n] = P [n|n− 1]CH [n](C[n]P [n|n− 1]CH [n] + Q
v[n])−1
(3.12)
con
P [n|n− 1] = A[n− 1]P [n− 1|n− 1]AH [n− 1] + Qw[n] (3.13)
donde P [n|n − 1] es la matriz de covarianza del error de la estimación x̂[n]dadas las n− 1 lecturas anteriores1.
Se puede ahora usar la lectura en tiempo n para escribir2:
x̂[n|n] = x̂[n|n− 1] + K[n](y[n]− C[n]x̂[n|n− 1]
)(3.14)
1Predicción o primer paso de Kalman.2Corrección o segundo paso de Kalman.
13

El error de esta nueva estimación tiene ahora una matriz de covarianzaque se escribe como:
P [n|n] =(I −K[n]C[n]
)P [n|n− 1] (3.15)
Ahora todo lo que se precisa para completar la recursión es de�nir laestimación y la matriz de covarianza del error en tiempo n = 0. Se realizade la siguiente manera:
x̂[0|0] = E {x[0]}
P [0|0] = E{x[0]xH [0]
}(3.16)
3.2. Resumen (Pseudo-código) del �ltrado de Kalman
Como resumen de lo visto en el punto anterior, se plantea un pseudo-código que implementa las etapas de un �ltro de Kalman discreto.
14

Ecuación de estados:
x[n] = A[n− 1]x[n− 1] + w[n]
Ecuación de observaciones:
y[n] = C[n]x[n] + v[n]
Inicialización:x̂[0|0] = E {x[0]}
P [0|0] = E{x[0]xH [0]
}Cálculo: Para n = 1, 2, . . ., calcular:
x̂[n|n− 1] = A[n− 1]x̂[n− 1|n− 1]
P [n|n− 1] = A[n− 1]P [n− 1|n− 1]AH [n− 1] + Qw[n]
K[n] = P [n|n− 1]CH [n](C[n]P [n|n− 1]CH [n] + Q
v[n])−1
x̂[n|n] = x̂[n|n− 1] + K[n](y[n]− C[n]x̂[n|n− 1]
)P [n|n] =
(I −K[n]C[n]
)P [n|n− 1]
3.3. Adaptación al Seguimiento de Altura de MelodíaPrincipal
Toda la teoría de Filtro de Kalman discreto hace referencia a señalesque tienen una evolución de estados dada y cuyas observaciones están afec-tadas por un ruido blanco de media nula y determinada matriz de covarianza.Pero las señales unidimensionales de información melódica que se quieren es-timar (Ground Truth), son señales no estacionarias, con un comportamientoen principio desconocido, y además, las observaciones de las mismas (loscandidatos obtenidos en la primer etapa del proyecto) no corresponden amuestras ruidosas del Ground Truth3.
3Las observaciones poseen comportamientos variados, y en general el ruido es fuerte-mente dependiente de la observación, como por ejemplo cuando se producen errores deoctavas.
15

En primer lugar entonces se debe determinar un modelo de las señalesa estimar que se pueda expresar como la evolución de estados que se asumeen el Filtro de Kalman. Además se debe buscar una forma de encontrar unmodelo para el ruido.
3.3.1. Variables del Problema
Consideraremos la siguiente asignación de variables.
Como vector de estados x[n] tomaremos las muestras de la señal unidi-mensional de frecuencia fundamental de la melodía principal desde tiempon−M +1 hasta tiempo n (o sea, un vector de estados de largo M , orden del�ltro de Kalman). Entonces, la ecuación de evolución de estados tomaría lasiguiente forma:
x[n] =
a(1) a(2) . . . a(M − 1) a(M)1 0 . . . 0 00 1 . . . 0 0...
.... . . 0 0
0 0 . . . 1 0
x[n− 1] (3.17)
donde se debe determinar la primer columna de esta matriz de evolución deestados.
Además se considera una lectura unidimensional y[n], que será, en prin-cipio, el candidato más cercano en tiempo n. Un estudio previo del compor-tamiento de los candidatos que se encuentran cerca del Ground Truth indicaque dichos valores se encuentran distribuidos de forma gaussiana alrededordel mismo. Este estudio implicó el estudio del histograma del error en laestimación local en los casos en que dicha estimación está cerca4 del GroundTruth.
4Se considera cerca del Ground Truth una frecuencia que se encuentre en una bandade 3% del mismo. Esto se de�ne de manera perceptual, ya que el 3% de la frecuencia deuna nota musical implica una diferencia de cuarto de tono, que es el máximo error queadmitimos en el algoritmo.
16

3.3.2. Modelado del Ground Truth
Para modelar la evolución de estados de las señales de frecuencia funda-mental a estimar, se realizó un entrenamiento de una matriz de evolución deestados de la siguiente manera; se considreraron todos los tramos continuosde información melódica contenidos en el Ground Truth. Para cada uno deestos tramos, se expresaron M valores en función del valor siguiente a ellos.Dada la evolución de estados que consideramos (ecuación 3.17), para cadauno de estos grupos de valores se tiene, para todos los puntos de estos tramoscontinuos de información melódica:
x[n] =[a(1) a(2) . . . a(M)
]
x[n− 1]x[n− 2]
...x[n−M ]
Resolviendo por mínimos cuadrados para todos los posibles casos en que
es aplicable la ecuación anterior, se obtiene la primera �la que se busca de lamatriz de evolución de estados, entrenada con señales unidimensionales deinformación melódica conocidas.
Se obtienen los siguientes resultados5:
Aforward
=
1,3405 −0,4033 0,1992 −0,1281 −0,0110
1 0 0 0 00 1 0 0 00 0 1 0 00 0 0 1 0
(3.18)
Abackward
=
1,4099 −0,5270 0,2259 −0,1002 −0,0115
1 0 0 0 00 1 0 0 00 0 1 0 00 0 0 1 0
(3.19)
5Para M = 5, orden que se tomó para los cálculos.
17

Se entrenaron dos matrices como se ve, ya que se va a realizar �ltradohacia adelante y hacia atrás, y se consideró que las señales se comportandiferente en una dirección y en la otra.
Se toman además para completar el modelo las siguientes matrices6:
Qw
=
3 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
Q
v=[3]
P [0|0] =
3 0 0 0 00 3 0 0 00 0 3 0 00 0 0 3 00 0 0 0 3
6Las elecciones de estas matrices son algo azarosas, pero se ve que el rendimiento delalgoritmo no se ve fuertemente afectado por la variación de las mismas.
18

Capítulo 4
Algoritmo de Seguimiento
El algoritmo de seguimiento implementado consta de varias partes:
Inicialización.
Determinación de punto de arranque.
Seguimiento hacia adelante y hacia atrás partiendo en el punto dearranque determinado.
Condiciones de parada locales y globales.
4.1. Inicialización
Se inicializan todas las matrices y parámetros del problema según se vioen la sección 3.3.2. Además se carga el archivo de audio cuya informaciónmelódica se desea estimar y se de�nen ciertos umbrales que controlan lascondiciones de parada que se de�nen más adelante.
4.2. Determinación de Punto de Arranque
Para los puntos de arranque para el tracking, se deben buscar puntosen donde se sepa con seguridad que la estimación que proviene de la primer
19

etapa del proyecto es correcta. Para esto, se evalúa en todos los puntos deinterés una característica de cada valor de frecuencia posible en cada frame,llamada �saliencia�1.
Cuando se calcula la saliencia en todos los puntos de interés de la señal2,se obtienen máximos globales en puntos seguros de arranque. Como ejemplose puede ver el comportamiento de dicha característica en las �guras 4.1 y4.2, donde en una escala de colores se tiene la saliencia en cada punto, y enlíneas negras el Ground Truth superpuesto. Se ve como los máximos localesen general caen sobre el Ground Truth.
Figura 4.1: Evaluación de la saliencia en el archivo daisy4.wav.
4.3. Seguimiento hacia Adelante y hacia Atrás
Una vez determinado un punto de arranque, se realiza el seguimientode la señal unidimensional de información de altura de la melodía principalhacia adelante (n > narranque) y hacia atrás (n < narranque).
Para ambos casos, se avanza de la siguiente manera; se toma como lec-tura el mejor candidato del frame de trabajo. En caso de que ninguno delos candidatos se encuentre en un entorno del 3% del valor anterior de es-
1No se darán detalles del cálculo de la saliencia, solo debe tenerse en cuenta su buenfuncionamiento para la determinación de puntos seguros de arranque.
2Los puntos de interés en el plano tiempo-frecuencia implica todo el tiempo de duraciónde la señal y frecuencias desde 80Hz hasta 1000Hz.
20

Figura 4.2: Evaluación de la saliencia en el archivo pop1.wav.
timación, se de�ne la lectura como el lugar donde se maximiza la salienciaen dicho entorno de 3% del valor anterior de estimación3. Una vez que setiene la lectura, se aplica el algoritmo de �ltrado de Kalman que se vio en laseccion 3.2.
4.4. Condiciones de Parada
El seguimiento hacia adelante y hacia atrás se sigue hasta que se deja decumplir alguna de las siguientes condiciones locales:
Todavía quedan lecturas (no se llegó al �nal ni al principio de la señalde audio).
La señal de salida no varía demasiado4.
La saliencia de las estimaciones no varía demasiado5.
3Esto asegura que se �inventan� candidatos en los frames en los que no hay ningunoque parezca correcto.
4Si una estimación di�ere mucho de la siguiente, no se corta el seguimiento pero semarca la señal como �cambiando�. Como condición de parada se permite un máximo decambios consecutivos.
5Si la saliencia de una estimación disminuye demasiado con respecto a la saliencia delpunto de arranque, no se corta el seguimiento pero se marca la señal como �desvanecién-dose�. Como condición de parada se premite un máximo de desvanecimientos consecutivos.
21

El algoritmo se repite (búsqueda de nuevo punto de arranque y seguimien-to hacia adelante y hacia atrás) hasta que la saliencia del nuevo máximoglobal encontrado que de�ne un nuevo punto de arranque, es menor quecierto porcentaje de la saliencia del primer punto de arranque6.
4.5. Resumen (Pseudo-código) del Algoritmo de Seguimien-to
Carga de archivos: Archivos de audio y mapa de salienciaa.
Inicialización: Matrices del modelo y parámetros del problema.
Cálculo de un punto de arranque.
Seguimiento hacia adelante y hacia atrás, hasta que se cumple algunacondición de parada en cada caso.
Extracción de lo detectadob.
Se vuelve al cálculo de un nuevo punto de arranque y se repite elalgoritmo hasta que se cumple la condición de parada global.
aDado que el cálculo de la saliencia para todos los puntos de interés es computa-cionalmente bastante costoso, se realiza previamente al seguimiento.
bSe borra del mapa de saliencia los lugares donde ya se detectó melodía principal, demanera de evitar la repetición de máximos globales.
6Condición de parada global.
22

Capítulo 5
Análisis de Resultados
Dada la forma de salida de los resultados del algoritmo, resulta di�cilcomparar cuantitativamente los resultados del seguimiento, ya que se haceimposible comparar el seguimiento de varias líneas melódicas con respectoal Ground Truth. La solución para esto, en lo que se está trabajando, es laselección entre todas las líneas melódicas detectadas de las que correspondena la melodía principal. De todas maneras no se detallan los mecanismos paraesto, ya que escapa a las técnicas de seguimiento.
En cuanto a un análisis cualitativo de los resultados, se logra la limpiezacasi total de los errores que se tenían en la primer etapa del proyecto. Estofavorece enormemente la posibilidad de mostrar los resultados del algoritmopunta a punta de una forma más �amigable� que simplemente una grá�cao un porcentaje de acierto. Por ejemplo, el tener una estimación resultanteque es relativamente suave contribuye favorablemente a realizar la síntesis ola extracción de la melodía detectada, lo que abre una gama muy grande deposibilidades de aplicación de los resultados obtenidos.
Como ejemplo se ven en a continuación algunos sectores en donde habíaproblemas que impedían la realización de síntesis sonora, que se solucionarongracias al �ltrado con Kalman1.
1Se muestran los casos obtenidos en los mismos archivos daisy4.wav y pop1.wav quese han usado para ejemplos anteriores.
23

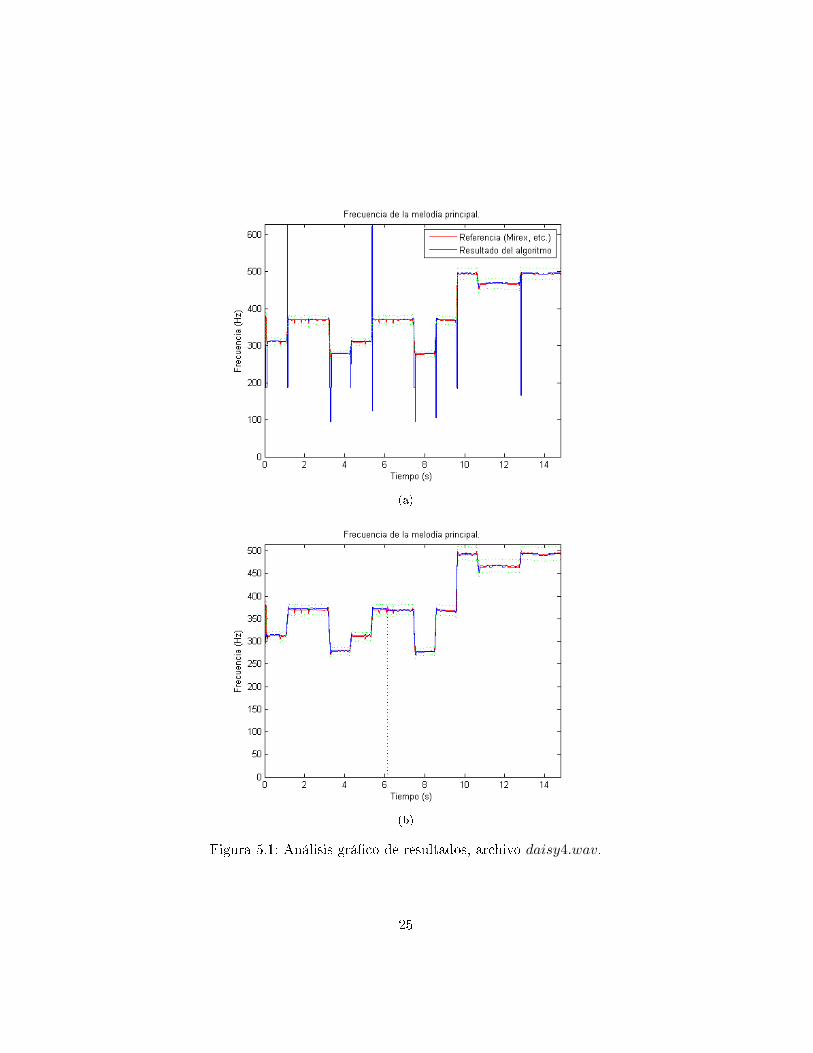
5.1. Análisis de Ejemplo: daisy4.wav
En primer lugar, se observa en la �gura 5.1 la mejora cualitativa en elresultado de la estimación antes del �ltrado y luego del �ltrado con Kalmanpara el archivo daisy4.wav. Este es un archivo sencillo pero presenta prob-lemas en la estimación local en los cambios de notas. Se ve que estos erroresson eliminados luego del �ltrado utilizando Kalman.
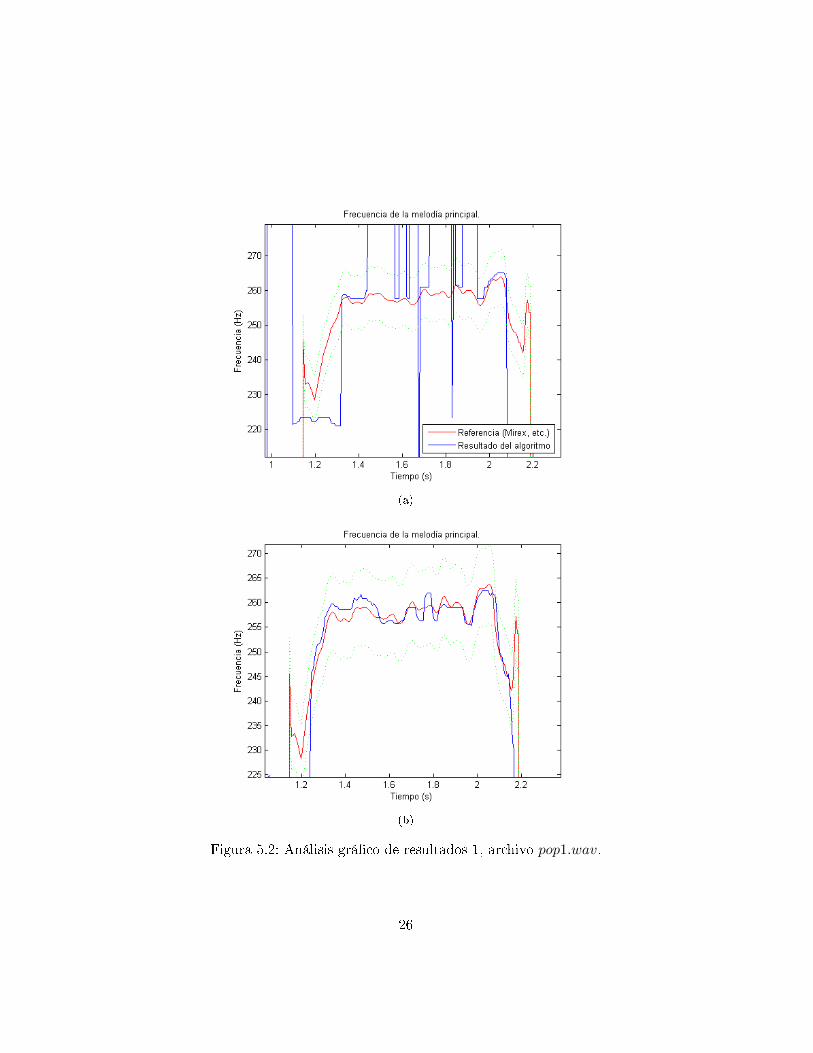
5.2. Análisis de Ejemplo: pop1.wav
Se ven a continuación en las �guras 5.2 y 5.3 dos tramos de informaciónmelódica del archivo pop1.wav2. Este archivo es bastante más complicadoque el anterior, ya que en primero lugar la melodía principal aparece de atramos, con lo que pone a prueba las condiciones de parada antes descritas,sino que además posee lugares en que la melodía principal no es la de mayoramplitud energética, con lo que se di�culta su detección por sobre esas otrasfuentes sonoras. Al igual que en el ejemplo anterior se ve la mejora sustancialde los distintos errores en detección. Estos nuevos resultados propician elbuen funcionamiento de algoritmos de síntesis sonora o de extracción de lamelodía principal.
2Corresponde a un segmento de la canción �Michelle� de The Beatles.
24
(a)
(b)
Figura 5.1: Análisis grá�co de resultados, archivo daisy4.wav.
25
(a)
(b)
Figura 5.2: Análisis grá�co de resultados 1, archivo pop1.wav.
26

(a)
(b)
Figura 5.3: Análisis grá�co de resultados 2, archivo pop1.wav.
27

Bibliografía
[1] Monson H. Hayes, Georgia Institute of Technology: Statistical DigitalSignal Processing and Modeling. Ed. John Wiley & Sons, Inc. Canada,1996.
[2] Simon Haykin: Adaptive Filter Theory, Third Edition.
[3] Steven M. Kay, University of Rhode Island: Fundamentals of StatisticalSignal Processing: Estimation Theory. Ed. Prentice Hall, New Jersey.
[4] Anssi Klapuri, Institute of Signal Processing, Tampere University ofTechnology, Finland: Multiple Fundamental Frequency Estimation bySumming Harmonic Amplitudes.
[5] Leonardo de O. Nunes & Ricardo Merched & Luiz W. P. Biscainho,Universidade Federal do Rio de Janeiro, Brasil: Recursive Least-SquaresEstimation of the Evolution of Partials in Sinusoidal Analysis.
28





























