Embed Size (px)
Citation preview

Indice
Prefazione v
1 Introduzione al progetto Meta 1
2 Le tecnologie dei metadati 5
2.1 Resource Description Framework . . . . . . . . . . . . . . . . 6
2.1.1 Il modello . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2 La sintassi . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.3 Altri elementi di sintassi . . . . . . . . . . . . . . . . . 13
2.1.4 La reificazione . . . . . . . . . . . . . . . . . . . . . . . 15
2.1.5 La grammatica formale . . . . . . . . . . . . . . . . . . 18
2.2 RDF Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.1 Classi e proprieta . . . . . . . . . . . . . . . . . . . . . 21
2.2.2 I vincoli . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.2.3 La documentazione . . . . . . . . . . . . . . . . . . . . 25
2.3 Topic Maps . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3.1 I concetti fondamentali . . . . . . . . . . . . . . . . . . 26
2.3.2 Esempi di utilizzo dei costrutti fondamentali . . . . . . 29
2.3.3 Altri elementi del modello . . . . . . . . . . . . . . . . 33
2.3.4 Published Subject Identifier . . . . . . . . . . . . . . . 40
2.3.5 Descrizione della sintassi XTM . . . . . . . . . . . . . 44
2.3.6 Vincoli di consistenza e validita . . . . . . . . . . . . . 49
3 Conversione di formati 57
3.1 Confronto fra i due paradigmi . . . . . . . . . . . . . . . . . . 58
i

3.2 Problematiche di conversione . . . . . . . . . . . . . . . . . . . 60
3.3 Confronto fra modelli: differenze e soluzioni proposte . . . . . 61
3.3.1 Identificazione di cio che e descritto . . . . . . . . . . . 61
3.3.2 Assegnazione dei nomi . . . . . . . . . . . . . . . . . . 64
3.3.3 Relazioni tra oggetti descritti . . . . . . . . . . . . . . 67
3.3.4 Attributi . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.3.5 Tipizzazione . . . . . . . . . . . . . . . . . . . . . . . . 78
3.3.6 Metainformazioni contestuali . . . . . . . . . . . . . . . 79
3.3.7 Reificazione . . . . . . . . . . . . . . . . . . . . . . . . 83
3.3.8 Schema RDF di traduzione . . . . . . . . . . . . . . . . 83
3.4 Descrizione delle soluzioni proposte in letteratura . . . . . . . 85
3.4.1 Convergenza secondo Moore . . . . . . . . . . . . . . . 85
3.4.2 Integrazione secondo Lacher . . . . . . . . . . . . . . . 86
3.4.3 Mapping secondo Ogievetsky . . . . . . . . . . . . . . . 87
4 Implementazione del convertitore 89
4.1 Strumenti utilizzati nell’implementazione . . . . . . . . . . . . 90
4.2 Problematiche di traduzione . . . . . . . . . . . . . . . . . . . 91
4.2.1 Relazioni tra documenti e schemi . . . . . . . . . . . . 93
4.2.2 Relazioni tra i modelli di RDF e di Topic Maps . . . . 94
4.3 Esempi di conversione . . . . . . . . . . . . . . . . . . . . . . 95
4.3.1 Conversione di documenti XTM in RDF . . . . . . . . 95
4.3.2 Conversione di documenti RDF in XTM . . . . . . . . 101
4.4 Architettura del sistema . . . . . . . . . . . . . . . . . . . . . 118
4.5 Dettagli di implementazione . . . . . . . . . . . . . . . . . . . 121
4.5.1 Il serializzatore RDF . . . . . . . . . . . . . . . . . . . 121
4.5.2 La fase di bootstrap . . . . . . . . . . . . . . . . . . . 122
4.5.3 I plugin . . . . . . . . . . . . . . . . . . . . . . . . . . 123
4.6 Configurazione e installazione del software . . . . . . . . . . . 126
4.6.1 Il file di configurazione . . . . . . . . . . . . . . . . . . 126
4.6.2 I driver di conversione . . . . . . . . . . . . . . . . . . 127
4.6.3 I plugin . . . . . . . . . . . . . . . . . . . . . . . . . . 130
4.6.4 Esecuzione dell’applicazione . . . . . . . . . . . . . . . 131
4.7 Possibili estensioni . . . . . . . . . . . . . . . . . . . . . . . . 131
ii

5 Editazione di documenti RDF e XTM 133
5.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
5.2 Caratteristiche generali dell’editor . . . . . . . . . . . . . . . . 134
5.2.1 Schemi per l’editazione . . . . . . . . . . . . . . . . . . 135
5.2.2 Relazioni e attributi . . . . . . . . . . . . . . . . . . . 136
5.2.3 Regole per l’applicabilita di attributi e risorse . . . . . 138
5.2.4 Indicizzazione delle risorse descritte . . . . . . . . . . . 138
5.2.5 Operazioni effettuabili . . . . . . . . . . . . . . . . . . 139
5.3 Architettura del sistema . . . . . . . . . . . . . . . . . . . . . 142
5.4 Strumenti utilizzati . . . . . . . . . . . . . . . . . . . . . . . . 143
5.5 Modello concettuale e implementazione . . . . . . . . . . . . . 145
5.5.1 Accesso ai dati: il servlet . . . . . . . . . . . . . . . . . 145
5.5.2 Il modello del documento e dello schema: l’applet . . . 146
5.5.3 Il visualizzatore di documenti . . . . . . . . . . . . . . 146
5.5.4 Diagramma delle classi . . . . . . . . . . . . . . . . . . 148
5.5.5 Interazione fra i componenti dell’editor . . . . . . . . . 150
5.5.6 Ciclo di vita dell’editor . . . . . . . . . . . . . . . . . . 156
5.5.7 Diagramma dei componenti . . . . . . . . . . . . . . . 157
5.6 Configurazione e installazione del software . . . . . . . . . . . 157
5.6.1 Configurazione del servlet . . . . . . . . . . . . . . . . 158
5.6.2 La firma dell’applet . . . . . . . . . . . . . . . . . . . . 158
5.6.3 Configurazione del client . . . . . . . . . . . . . . . . . 160
5.6.4 Installazione del software . . . . . . . . . . . . . . . . . 160
5.7 Possibili estensioni . . . . . . . . . . . . . . . . . . . . . . . . 160
6 Navigazione di documenti RDF e XTM 163
6.1 La navigazione di metainformazioni . . . . . . . . . . . . . . . 163
6.2 Caratteristiche del navigatore . . . . . . . . . . . . . . . . . . 166
6.2.1 Attributi e relazioni . . . . . . . . . . . . . . . . . . . . 166
6.2.2 Classificazione degli attributi . . . . . . . . . . . . . . 167
6.2.3 Schemi e istanze . . . . . . . . . . . . . . . . . . . . . 168
6.3 Navigazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
6.4 Architettura del sistema . . . . . . . . . . . . . . . . . . . . . 173
6.5 Strumenti utilizzati . . . . . . . . . . . . . . . . . . . . . . . . 174
iii

6.6 Modello concettuale e implementazione . . . . . . . . . . . . . 175
6.6.1 Accesso ai dati . . . . . . . . . . . . . . . . . . . . . . 175
6.6.2 Il modello del documento e dello schema . . . . . . . . 175
6.6.3 Il visualizzatore . . . . . . . . . . . . . . . . . . . . . . 176
6.6.4 Diagramma delle classi . . . . . . . . . . . . . . . . . . 178
6.6.5 Interazione fra i componenti dell’editor . . . . . . . . . 180
6.6.6 Diagramma dei componenti . . . . . . . . . . . . . . . 181
6.7 Configurazione e installazione del software . . . . . . . . . . . 182
6.8 Test di navigazione . . . . . . . . . . . . . . . . . . . . . . . . 183
6.9 Possibili estensioni . . . . . . . . . . . . . . . . . . . . . . . . 184
7 Manuale di utilizzo dei tool sviluppati 187
7.1 L’ontologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
7.2 Il convertitore . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
7.2.1 Conversione da XTM a RDF . . . . . . . . . . . . . . . 188
7.2.2 Le risorse RDF di traduzione . . . . . . . . . . . . . . 200
7.2.3 Conversione da RDF a XTM . . . . . . . . . . . . . . . 201
7.3 L’editor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
7.3.1 Lo schema per XTM . . . . . . . . . . . . . . . . . . . 210
7.3.2 Lo schema per RDF . . . . . . . . . . . . . . . . . . . 215
7.3.3 Editazione di documenti . . . . . . . . . . . . . . . . . 216
7.3.4 Differenze di editazione fra RDF e XTM . . . . . . . . 219
7.4 Il navigatore . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
7.4.1 Navigazione di documenti . . . . . . . . . . . . . . . . 220
7.4.2 Le risorse e gli PSI proprietari . . . . . . . . . . . . . . 223
8 Conclusioni 227
iv

Prefazione
Possiamo affermare che oggi, grazie al Web, siamo in grado di accedere
ad ogni genere di informazione. Gli utenti possono consultare le ultime
notizie, le previsioni del tempo, i servizi finanziari; possono inoltre affettuare
acquisti, prenotare dei biglietti aerei o un albergo, etc. Le possibilita offerte
dal Web sembrano illimitate, ma l’attuale tecnologia si deve confrontare
con un problema generato dalla natura stessa del Web. Esso infatti fu in
origine pensato per pubblicare documenti visualizzabili mediante un browser
e consultabili da utenti. Ma cosa succede se il fruitore di un servizio non e
un essere umano ma una macchina? Sebbene ogni risorsa sia leggibile da un
computer, questo non e in grado di “capirne” il significato. Una soluzione a tale
problema e data dall’uso dei metadati, mediante i quali e possibile descrivere
le informazioni contenute nel web.
I metadati, che in seguito verranno indicati anche con il termine
metainformazioni, sono “dati sui dati” (per esempio un catalogo librario e
composto da metadati, in quanto descrive dei libri) e, nello specifico, dati che
descrivono risorse accessibili dal Web. La distinzione fra i dati veri e propri
e i metadati non e assoluta, ma e dipendente dal contesto, e la stessa risorsa
puo anche essere considerata in ambedue i modi.
Attraverso l’uso dei metadati potremo passare dall’attuale Web ad uno
completamente nuovo, in cui anche le macchine potranno effettuare delle
ricerche ed interpretare (sul piano semantico) le informazioni. La capacita
di un motore di ricerca di indicizzare le pagine web mediante l’uso delle
metainformazioni reperibili in un documento HTML sembrera un concetto di
semantica molto “primitivo” se confrontato con quanto puo essere raggiunto
mediante l’utilizzo dei metadati.

Una delle caratteristiche del Web con estensioni semantiche e certamente
quella di definire una nuova struttura, in cui tutte le risorse si vedano
associare delle descrizioni, secondo formati standardizzati ed elaborabili in
modo automatico. Le due tecnologie che si sono affermate in tale campo e che
definiscono tali formati sono Resource Description Framework (RDF ) e Topic
Maps.
Dal punto di vista architetturale, il Web semantico si puo considerare
un layer che estende il Web attuale e mediante il quale sia favorita la
cooperazione fra utenti e fra calcolatori, che potranno scambiarsi informazioni
di cui comprendono il significato.
Al fine di evitare un partizionamento del Web in collezioni di metadati
incompatibili, si e sviluppato un tool da utilizzare per effettuare la conversione
fra RDF e Topic Maps, in modo tale da poter importare nella propria base di
conoscenza le informazioni descritte in un formato diverso.
Inoltre sono stati sviluppati due ulteriori strumenti: un editor di documenti
scritti in tali formati e un visualizzatore, che permette la navigazione dei
metadati associati a informazioni correlate.
La presente dissertazione e pertanto cosı articolata:
Capitolo 1 Presentazione del progetto Meta.
Capitolo 2 Descrizione e commento di RDF, RDF Schema e Topic Maps.
Capitolo 3 Viene documentata in maniera approfondita la differenza fra
RDF e Topic Maps, alla luce della creazione del tool di conversione fra
documenti scritti nei due formati.
Capitolo 4 Viene presentato il convertitore e vengono descritti i dettagli
relativi all’implementazione dello strumento di conversione.
Capitolo 5 Presentazione dell’editor di documenti scritti nei due formati.
Vengono affrontate le problematiche di editazione e viene fornita la
soluzione poi implementata.
Capitolo 6 Presentazione dello strumento atto a permettere la navigazione
nei documenti scritti nei due formati.
vi

Capitolo 7 Contiene il manuale utente relativo a gli strumenti presentati.
Infine il capitolo conclusivo riassume il lavoro svolto e presenta ulteriori
estensioni ai problemi affrontati.
vii

viii

Capitolo 1
Il progetto Meta
Le attuali problematiche relative al mondo delle metainformazioni sono di
diversa natura e legate al limitato impiego degli strumenti che ne implementano
le funzionalita, nonostante le enormi potenzialita che queste tecnologie
offrono in termini di sovrastruttura semantica associabile all’informazione non
struttura. Una parziale giustificazione di questo e da ricercarsi nella presenza
di due standard in competizione che, seppur diversi nella loro concezione,
vengono incontro alle medesime esigenze. Inoltre tali standard, essendo
relativamente giovani, non hanno ancora raggiunto una completa maturita.
A cio va aggiunta l’inerente difficolta nella creazione di documenti
metainformativi: l’estrazione automatica delle metainformazioni rappresenta
un problema di difficile soluzione, fino ad essere del tutto impraticabile in
presenza di sorgenti informative scevre di struttura. Spesso l’unico modo
per individuare i concetti semantici da descrivere e mediante l’intervento
umano, ossia tramite la lettura e la catalogazione delle risorse, e la
susseguente creazione manuale dei documenti. Inoltre, l’utilizzo effettivo delle
metainformazioni, benche potenzialmente vario ed esteso a varie branche del
settore informatico, non e stato tutt’oggi approfonditamente esplorato.
I modelli di specifica di metainformazioni cui si fa riferimento nel progetto
sono lo standard RDF, edito dal W3C, e lo standard Topic Maps, sviluppato
dall’ISO. Entrambe le tecnologie si prestano all’impiego nel settore del
Semantic Web, e, piu in generale, ad ogni contesto applicativo nel quale si
possa trarre beneficio dall’utilizzo di tecniche standard per la formalizzazione

2 Capitolo 1. Introduzione al progetto Meta
della semantica presente in insiemi di risorse. Entrambi inoltre prevedono la
possibilita di serializzare i modelli in documenti XML, con una sintassi propria
a ciascuno di essi.
Il progetto Meta descritto in questa dissertazione cerca di soddisfare le
esigenze di questo campo applicativo attraverso l’implementazione di tre
strumenti atti a facilitare la gestione dei documenti di metainformazioni, e
ad indagare sulle potenzialita offerte da RDF e da Topic Maps al loro stato
attuale di evoluzione.
I problemi a cui il progetto cerca di offrire risposta sono:
• La divergenza dei linguaggi di specifica.
• La necessita di uno strumento per la gestione automatica dei documenti
che consenta la loro creazione e modifica senza obbligare l’utente ad
affrontare le complicazioni dovute ai dettagli sintattici.
• L’utilizzo delle metainformazioni come supporto informativo supplemen-
tare per l’utente, nell’ambito della navigazione delle risorse.
Sono stati implementati pertanto tre strumenti: un convertitore di
documenti da e per entrambi i formati, un editor per la creazione e la
modifica di documenti basati su schema, e un navigatore di documenti di
metainformazioni che mettesse in luce l’utilita di queste tecnologie in termini
di descrizione, catalogazione, e interconnessione semantica delle risorse.
Relativamente al primo degli strumenti implementati, la ragione che
ha spinto la ricerca di tecniche di conversione di documenti espressi nei
diversi formati, e rappresentata dal fatto che fondamentalmente entrambi
i modelli sono pensati per descrivere relazioni tra entita dotate di
identita. La mappatura reciproca dei costrutti definiti da i due paradigmi,
implementata dallo strumento di conversione, offre un primo supporto alla
loro interoperabilita. Indagando sulle differenze tra RDF e Topic Maps si e
cercato di far luce sulle rispettive capacita espressive, aprendo la strada alle
possibili sinergie ottenibili dall’uso di entrambe le tecnologie, nell’ottica di
poter trarre il meglio da entrambi i mondi.
Per le necessita di editazione dei documenti metainformativi, sono state
esplorate le caratteristiche, proprie ad entrambi gli standard, di tipizzazione

3
delle entita, e le possibilita da essi offerte in termini di creazione di tesauri
su cui basare le descrizioni semantiche delle risorse. Il supporto all’editazione
e stato cosı esteso dalla semplice astrazione sintattica ottenibile sfruttando
DTD o schemi XML, propria alla maggior parte degli editor gia esistenti, ad
un livello di astrazione basato sugli schemi semantici, che sia RDF che Topic
Maps rendono possibili. Lo strumento di editing, basato su interfaccia HTML,
implementa tale funzionalita sfruttando queste caratteristiche, rendendo
uniforme la visione di entita e relazioni, rispetto al reale formato del
documento.
Il terzo strumento del progetto implementa un navigatore di metainfor-
mazioni, anch’esso basato sull’idea di offrire uniformita di visione fra i due
formati. Attraverso il sistema di tipizzazione e di correlazione introdotto
dagli schemi semantici, il navigatore permette all’utente di prendere visione
delle caratteristiche associate alle entita. La navigazione avviene attraverso
un’interfaccia che separa le metainformazioni in base al ruolo, e rende
navigabili i riferimenti ad altre entita, al sistema dei tipi e ad eventuali
riferimenti Web propri a ciascuna entita. Lo strumento mostra come l’utilizzo
di queste tecnologie possa da un lato automatizzare l’implementazione di
sistemi di ricerca gerarchici, e dall’altro arricchire l’espressivita dei sistemi
di indicizzazione, sia quando le entita sono rappresentate da risorse Web, sia
nel caso in cui siano concetti semantici astratti caratterizzati da eventuali
riferimenti a documenti reperibili online.

4 Capitolo 1. Introduzione al progetto Meta

Capitolo 2
XML e metadati:
un’introduzione
Di solito i metadati vengono definiti come “dati sui dati”. Infatti essi possono
rappresentare dati su qualunque cosa; ma cio che li caratterizza e lo scopo
e l’utilizzo che se ne fa piuttosto che il loro contenuto o struttura. Spesso
i metadati vengono utilizzati per fornire un aiuto, sia ad esseri umani che a
programmi, nell’individuare e raccogliere informazioni.
I metadati hanno di solito una struttura semplice, e, sorprendentemente,
ogni persona li usa spesso nell’arco di una giornata. Ad esempio, supponiamo
di essere i proprietari di una collezione di DVD; se ogni custodia fosse
semplicemente nera, per cercare un particolare film dovremmo vedere il
contenuto (anche solo parzialmente) di ogni disco. Ma basta apporre
un’etichetta su ogni custodia per sveltire sensibilmente il processo di ricerca.
Se la nostra collezione fosse molto vasta, si potrebbe creare anche un indice o
un elenco dei DVD.
Se invece di una semplice collezione di DVD pensiamo ad una biblioteca
o al Web, e chiaro che la complessita del problema cresce enormemente. La
soluzione, comunque, e la stessa: fornire dei cataloghi e indici che permettano
di effettuare delle ricerche sulle informazioni che ci interessano.
Le tecnologie usate per esprimere i metadati cercano di risolvere questi
problemi, al fine di fornire a chi naviga sul Web lo stesso servizio che avrebbe
camminando per i corridoi di una libreria ben organizzata.

6 Capitolo 2. Le tecnologie dei metadati
I metadati possono essere espressi in varie forme: inclusi nello stesso
documento cui si riferiscono o contenuti in un documento esterno. In questo
caso, la risorsa che descrivono viene referenziata mediante il proprio URI o
mediante un’espressione XPath [CD99].
Esistono vari tipi di metadati, in base al problema affrontato:
Annotazioni - Sono note aggiunte al documento per uno scopo specifico;
sono usate solo da alcuni lettori ma in tempi diversi e per motivi diversi.
Un esempio e dato dalle note o dai commenti aggiunti in un testo
letterario.
Cataloghi - Associano delle coppie proprieta-valore a cio che descrivono. Ad
esempio un catalogo librario associa ad ogni libro il titolo, l’autore,
l’editore.
Indici - Permettono di accomunare delle informazioni per argomento e
definirne le eventuali relazioni che intercorrono fra esse. Ad esempio
un indice per argomenti dei libri di una biblioteca o una pagina Web che
contiene dei collegamenti a delle risorse, suddivise per argomento.
Riferimenti incrociati - Permettono di definire dei collegamenti fra risorse
che si ritengono correlate. Questi riferimenti possono avere un significato
particolare, ad esempio “vedi anche” o “sostituito da”.
In questo capitolo verranno presentate le due tecnologie che si sono imposte
nella definizione dei metadati. In seguito si faranno inoltre notare i pro ed i
contro nell’adottare le soluzioni proposte da tali tecnologie.
2.1 Resource Description Framework
La soluzione proposta dal W3C in [LS99] per elaborare i metadati usati nella
descrizione delle risorse presenti nel Web consiste nell’utilizzo del Resource
Description Framework (da ora in avanti RDF ).
Fra gli obiettivi che il W3C si e proposto di raggiungere con la definizione
di RDF possiamo considerare: interoperabilita fra applicazioni e sviluppo di
applicazioni automatizzate per il trattamento delle risorse del Web in modo

2.1 Resource Description Framework 7
semplice. RDF potra essere utilizzato in svariate aree applicative, come, ad
esempio, la catalogazione di risorse facenti parte di un sito Web o di una libreria
digitale, descrivendone il contenuto e le relazioni esistenti; rendere piu efficienti
le indicizzazioni effettuate dai motori di ricerca; aiutare la condivisione e lo
scambio di informazioni da parte di agenti software intelligenti.
In questo paragrafo verra introdotto il modello usato per rappresentare
RDF e la sintassi usata per codificare e trasportare i metadati cosı espressi.
Tale codifica verra effettuata in modo da massimizzare l’interoperabilita
e l’indipendenza dai server che forniranno i metadati e dai client che
usufruiranno di tali servizi. La sintassi presentata fara uso di XML [BPSMM].
Inoltre bisogna sottolineare come l’obiettivo di RDF sia quello di definire
un meccanismo per descrivere risorse che non fa assunzioni su un particolare
dominio applicativo, ne definisce a priori la semantica per uno specifico
dominio. La definizione di tale meccanismo sara quindi indipendente dal
campo di applicazione e permettera la descrizione di informazioni relative ad
ogni dominio.
2.1.1 Il modello
RDF si basa su un modello per rappresentare proprieta e valori ad esse
associati. Le proprieta possono essere pensate come attributi di risorse e
corrispondono ad una coppia attributo-valore. Inoltre mediante le proprieta si
possono rappresentare le relazioni fra le risorse e quindi il modello di RDF puo
essere visto come uno schema entita-relazione. Per usare la terminologia della
programmazione object-oriented, le risorse possono essere viste come oggetti
e le proprieta come variabili d’istanza.
Il modello e composto da tre tipi di oggetti:
Risorse: tutto cio che viene descritto da RDF e detto risorsa. Una risorsa puo
essere una pagina Web, una parte di essa (identificata da un particolare
elemento HTML o XML) o un intero sito Web. L’identificatore di ogni
risorsa e il proprio URI [BLFIM98] e pertanto una risorsa puo anche
essere un oggetto non direttamente accessibile dal Web.
Proprieta: una proprieta e una caratteristica, un attributo o una relazione

8 Capitolo 2. Le tecnologie dei metadati
utilizzata per descrivere una risorsa. Ogni proprieta ha un significato
specifico, definisce i valori che puo assumere e i tipi di risorse a cui puo
essere associata. Questo aspetto verra trattato nel paragrafo 2.2.
Asserzioni: una risorsa con una proprieta ed un valore ad essa associato e
un’asserzione. Gli oggetti che prendono parte a questa associazione sono
detti, rispettivamente: il soggetto, il predicato e l’oggetto. L’oggetto puo
essere una risorsa o un letterale.
Esempio 2.1 La frase: “Mario Rossi e l’autore della risorsa identificata
dall’URL http://www.myhost.org/˜mrossi” e composta dagli elementi elencati
nella tabella seguente.
Soggetto (risorsa) http://www.myhost.org/˜mrossi
Predicato (proprieta) Autore
Oggetto (letterale) “Mario Rossi”
Tabella 2.1: Componenti della frase dell’esempio 2.1
Questa frase puo anche essere rappresentata mediante un grafo in cui i nodi
(gli ovali) rappresentano le risorse e gli archi rappresentano le proprieta. I
nodi che rappresentano invece dei letterali sono disegnati come rettangoli.
http://www.myhost.org/˜mrossi Mario RossiAutore
Figura 2.1: Grafo corrispondente alla frase dell’esempio 2.1
Esempio 2.2 L’oggetto della frase: “La persona di nome Mario Rossi e
con email [email protected] e autore della pagina identificata dall’URL
http://www.myhost.org/˜mrossi” e questa volta non piu un letterale, ma
un’entita strutturata, rappresentata da un’altra risorsa.

2.1 Resource Description Framework 9
Nome
http://www.myhost.org/˜mrossi
Autore
Mario Rossi [email protected]
Figura 2.2: Grafo corrispondente alla frase dell’esempio 2.2
2.1.2 La sintassi
In questo paragrafo verranno presentati due tipi di sintassi per codificare
un’istanza del modello di RDF:
La sintassi di serializzazione: permette di esprimere il modello di RDF in
maniera regolare.
La sintassi abbreviata: estende la sintassi precedente, fornendo altri
costrutti che permettono una scrittura piu compatta del modello.
Queste sintassi hanno comunque lo stesso potere espressivo.
Ogni proprieta assegnata ad una risorsa viene elencata dentro un elemento
rdf:Description. Questo elemento permette di identificare la risorsa
mediante l’attributo rdf:about, contenente l’URI di tale risorsa. Se invece
la risorsa non ha un URI, questo puo essere fornito usando l’attributo rdf:ID;
in questo modo viene creata una risorsa che fa da proxy per quella originaria.
Le proprieta cosı specificate corrispondono ad archi diversi di un grafo
relativo al documento RDF. Ad ogni proprieta deve inoltre essere assegnato
uno schema. Questo puo essere fatto aggiungendo ad ogni proprieta il

10 Capitolo 2. Le tecnologie dei metadati
namespace in cui viene definito l’elemento che rappresenta la proprieta stessa.
Si puo pensare ad uno schema come ad un dizionario, che definisce i termini
che verranno usati e vi associa un particolare significato.
Esempio 2.3 La frase dell’esempio 2.1: “Mario Rossi e l’autore della risorsadefinita dall’URI http://www.myhost.org/˜mrossi” puo essere rappresentatain RDF/XML come:
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Autore>Mario Rossi</s:Autore>
</rdf:Description>
</rdf:RDF>
Nei casi in cui sia preferibile usare una forma piu compatta si utilizza
la forma abbreviata. Ne esistono tre forme, utilizzabili solo in particolari
condizioni:
1. Si puo utilizzare nel caso in cui non ci siano proprieta ripetute piu volte
entro l’elemento rdf:Description e i valori di tali proprieta siano dei
letterali. In questo caso le proprieta possono essere scritte come attributi
dell’elemento rdf:Description.
Esempio 2.4 Il documento scritto nell’esempio 2.3 diventa:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi"
s:Autore="Mario Rossi"/>
</rdf:RDF>
2. Questa forma e applicabile quando l’oggetto di un’asserzione e un’altra
risorsa le cui proprieta sono definite nel documento stesso ed i cui valori
sono dei letterali. In questo caso i predicati della risorsa referenziata
diventano attributi del predicato che referenzia la risorsa stessa.

2.1 Resource Description Framework 11
Esempio 2.5 La frase: “La persona di codice 1375 si chiama MarioRossi e ha email [email protected]; la risorsa definita dall’URIhttp://www.myhost.org/˜mrossi e stata creata da costui” puo esserescritta come:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Autore rdf:resource="http://www.myhost.com/people/1375"/>
</rdf:Description>
<rdf:Description
rdf:about="http://www.myhost.com/people/1375">
<s:Nome>Mario Rossi</s:Nome>
<s:Email>[email protected]</s:Email>
</rdf:Description>
</rdf:RDF>
Usando la seconda forma abbreviata, si ottiene:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Autore rdf:resource="http://www.myhost.com/people/1375"
s:Nome="Mario Rossi"
s:Email="[email protected]"/>
</rdf:Description>
</rdf:RDF>
3. Questa forma abbreviata si applica quando l’elemento rdf:Description
contiene rdf:type. Questo elemento definisce il tipo della risorsa. Per
ulteriori approfondimenti si rimanda al paragrafo 2.1.4. In questo caso
il tipo viene usato direttamente come proprieta della risorsa.

12 Capitolo 2. Le tecnologie dei metadati
Esempio 2.6 Se si volesse rappresentare il fatto che la risorsa“http://www.myhost.com/people/1375” e un oggetto di tipo “Persona”,la frase dell’esempio 2.5 diventa:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Autore>
<rdf:Description
rdf:about="http://www.myhost.com/people/1375">
<rdf:type rdf:resource="http://schema.org/Persona"/>
<s:Nome>Mario Rossi</s:Nome>
<s:Email>[email protected]</s:Email>
</rdf:Description>
</s:Autore>
</rdf:Description>
</rdf:RDF>
Usando la terza forma abbreviata si ottiene:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Autore>
<s:Persona rdf:about="http://www.myhost.com/people/1375">
<s:Nome>Mario Rossi</s:Nome>
<s:Email>[email protected]</s:Email>
</s:Persona>
</s:Autore>
</rdf:Description>
</rdf:RDF>

2.1 Resource Description Framework 13
2.1.3 Altri elementi di sintassi
Quando si assegna un valore ad una proprieta, puo essere importante
qualificare tale valore, ad esempio specificando l’unita di misura o la valuta in
cui si sta esprimendo il valore. A tal fine si ricorre all’uso di rdf:value. Un
valore cosı espresso e rappresentato da un’entita strutturata.
Esempio 2.7 Quando si afferma che il peso di una persona e 85,l’informazione data non e completa, in quanto e necessario specificare anchel’unita di misura usata.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/"
xmlns:u="http://www.nist.gov/units/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Peso rdf:parseType="Resource">
<rdf:value>85<rdf:value>
<u:units rdf:resource="http://www.nist.gov/units/Kilos"/>
</s:Peso>
</rdf:Description>
</rdf:RDF>
Un altro elemento di uso comune e rappresentato dai contenitori, ovvero
delle strutture che permettono di contenere collezioni di risorse. Mediante
queste strutture si ha cosı la possibilita di riferirsi ad insiemi di risorse in
maniera semplice.
Per utilizzare un contenitore basta definire una risorsa rdf:Description
la cui proprieta rdf:type ha come valore l’URI del contenitore stesso. Le
risorse elencate in tale contenitore sono identificate da rdf: n (con n ∈ N+).
Esempio 2.8 La frase “I nipoti di Paperino sono Qui, Quo e Qua”corrisponde al seguente documento RDF. La risorsa piu interna rappresentaun Bag, cioe un lista non ordinata in cui sono ammessi duplicati.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">

14 Capitolo 2. Le tecnologie dei metadati
<rdf:Description rdf:about="http://www.disney.it/paperino">
<s:Nipote>
<rdf:Description>
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="http://www.disney.it/qui"/>
<rdf:_2 rdf:resource="http://www.disney.it/quo"/>
<rdf:_3 rdf:resource="http://www.disney.it/qua"/>
</rdf:Description>
</s:Nipote>
</rdf:Description>
rdf:Bag
rdf: 1
rdf: 2
http://www.disney.it/paperino
rdf: 3
http://www.disney.it/qui
http://www.disney.it/quo
http://www.disney.it/qua
s:Nipote rdf:type
Figura 2.3: Grafo corrispondente alla frase dell’esempio 2.8
Oltre al contenitore rdf:Bag, il modello RDF definisce altri due tipi:
1. rdf:Sequence: definisce un contenitore il cui ordine degli elementi e
significativo;
2. rdf:Alternative: in cui gli elementi contenuti rappresentano
alternative del valore della proprieta.

2.1 Resource Description Framework 15
In [LS99] era stato definito un modo sintatticamente diverso a quello qui
presentato, ma ormai obsoleto. Quanto discusso in questo paragrafo, invece,
si rifa all’ultimo aggiornamento delle specifiche di RDF (vedi [Bec02]).
2.1.4 La reificazione
Finora abbiamo visto RDF come uno strumento per fare asserzioni su delle
risorse Web. Ma RDF puo anche essere utilizzato per fare asserzioni di livello
piu alto, cioe asserzioni fatte su altre. Per effettuare questo tipo di asserzioni
il modello RDF definisce le seguenti proprieta:
rdf:subject - identifica la risorsa su cui si vuole effettuare l’asserzione di alto
livello;
rdf:predicate - identifica la proprieta associata alla risorsa;
rdf:object - identifica l’oggetto dell’asserzione originaria;
rdf:type - definisce il tipo dell’asserzione di alto livello. Il modello RDF
assegna a tali asserzioni il tipo rdf:Statement, definito nello schema di
RDF stesso.
Questo processo e formalmente detto reificazione e l’asserzione su cui viene
effettuato tale procedimento e detta asserzione reificata. La risorsa che
contiene le quattro proprieta descritte rappresenta l’asserzione reificata.
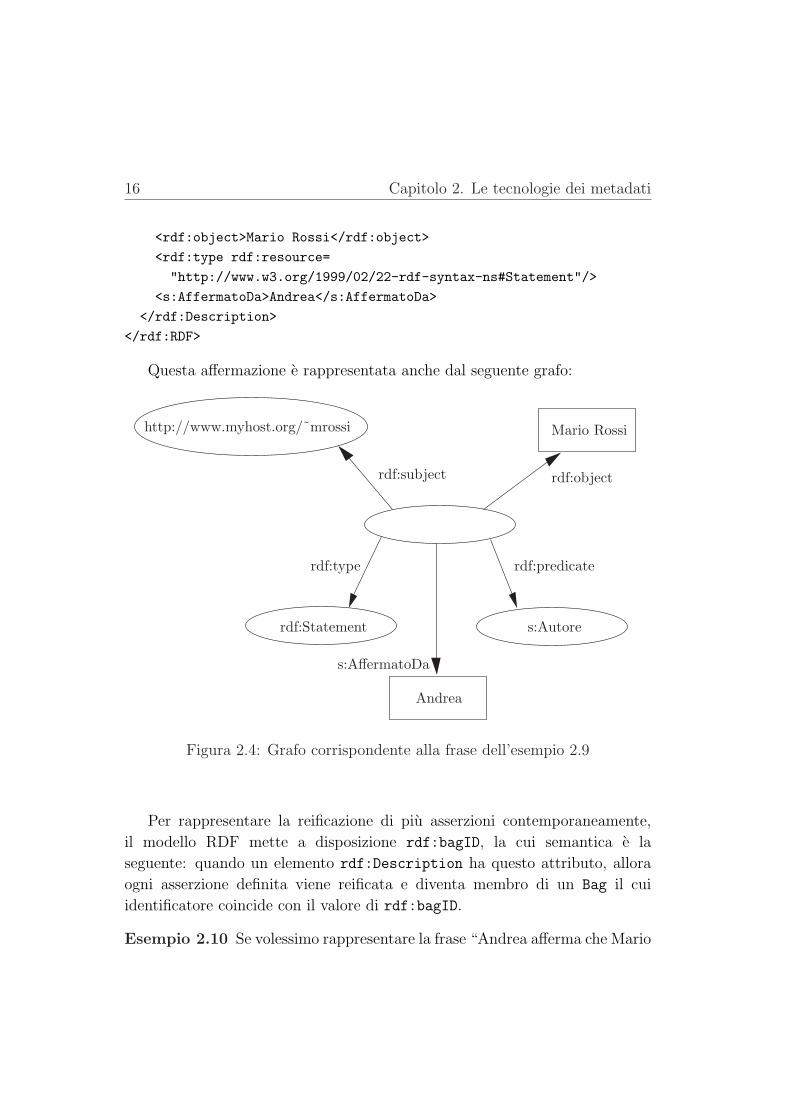
Esempio 2.9 Se volessimo rappresentare la frase “Andrea afferma che MarioRossi e l’autore della risorsa http://www.myhost.org/˜mrossi”, non dovremmopiu definire la risorsa “http://www.myhost.org/˜mrossi”, ma dovremmoesprimere il fatto che Andrea sta facendo un’affermazione. Definiamo quindila seguente asserzione reificata:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description>
<rdf:subject rdf:resource="http://www.myhost.com/~mrossi"/>
<rdf:predicate rdf:resource="http://schema.org/Autore"/>
16 Capitolo 2. Le tecnologie dei metadati
<rdf:object>Mario Rossi</rdf:object>
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement"/>
<s:AffermatoDa>Andrea</s:AffermatoDa>
</rdf:Description>
</rdf:RDF>
Questa affermazione e rappresentata anche dal seguente grafo:
rdf:Statement
http://www.myhost.org/˜mrossi Mario Rossi
rdf:type rdf:predicate
rdf:subject rdf:object
Andrea
s:Autore
s:AffermatoDa
Figura 2.4: Grafo corrispondente alla frase dell’esempio 2.9
Per rappresentare la reificazione di piu asserzioni contemporaneamente,
il modello RDF mette a disposizione rdf:bagID, la cui semantica e la
seguente: quando un elemento rdf:Description ha questo attributo, allora
ogni asserzione definita viene reificata e diventa membro di un Bag il cui
identificatore coincide con il valore di rdf:bagID.
Esempio 2.10 Se volessimo rappresentare la frase “Andrea afferma che Mario
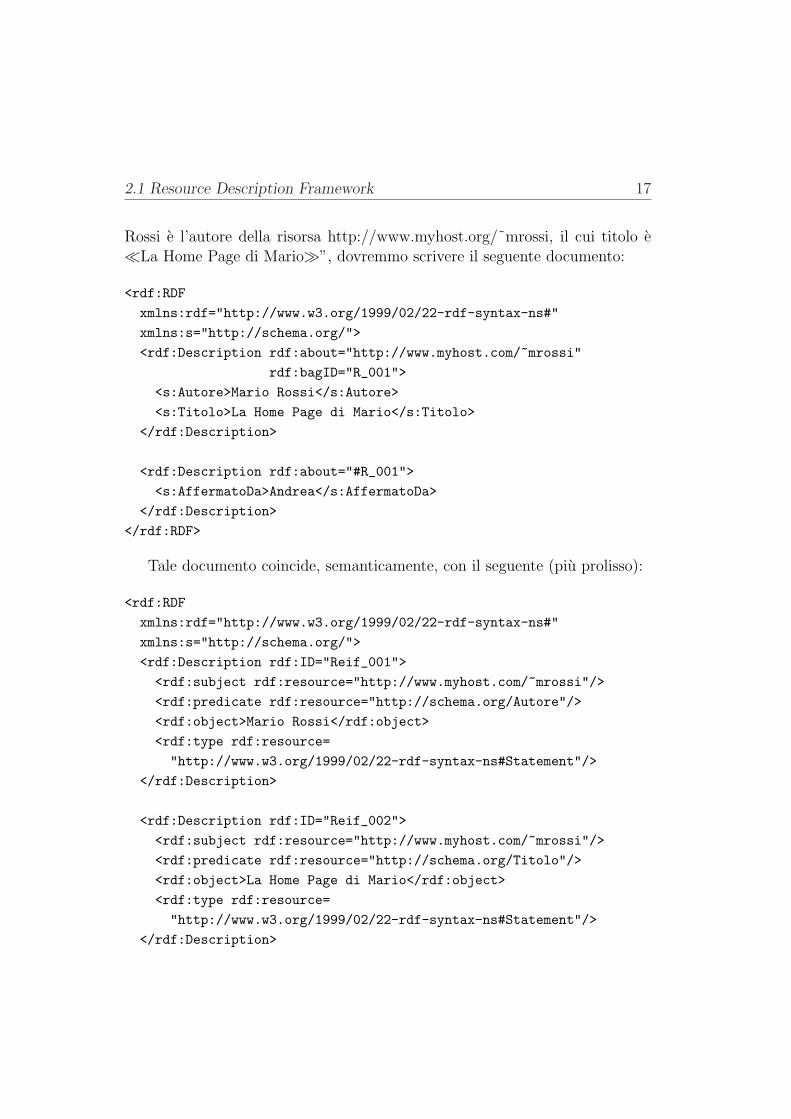
2.1 Resource Description Framework 17
Rossi e l’autore della risorsa http://www.myhost.org/˜mrossi, il cui titolo e¿La Home Page di MarioÀ”, dovremmo scrivere il seguente documento:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:about="http://www.myhost.com/~mrossi"
rdf:bagID="R_001">
<s:Autore>Mario Rossi</s:Autore>
<s:Titolo>La Home Page di Mario</s:Titolo>
</rdf:Description>
<rdf:Description rdf:about="#R_001">
<s:AffermatoDa>Andrea</s:AffermatoDa>
</rdf:Description>
</rdf:RDF>
Tale documento coincide, semanticamente, con il seguente (piu prolisso):
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://schema.org/">
<rdf:Description rdf:ID="Reif_001">
<rdf:subject rdf:resource="http://www.myhost.com/~mrossi"/>
<rdf:predicate rdf:resource="http://schema.org/Autore"/>
<rdf:object>Mario Rossi</rdf:object>
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement"/>
</rdf:Description>
<rdf:Description rdf:ID="Reif_002">
<rdf:subject rdf:resource="http://www.myhost.com/~mrossi"/>
<rdf:predicate rdf:resource="http://schema.org/Titolo"/>
<rdf:object>La Home Page di Mario</rdf:object>
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement"/>
</rdf:Description>

18 Capitolo 2. Le tecnologie dei metadati
<rdf:Description rdf:ID="R_001">
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="#Reif_001"/>
<rdf:_2 rdf:resource="#Reif_002"/>
</rdf:Description>
<rdf:Description rdf:about="#R_001">
<s:AffermatoDa>Andrea</s:AffermatoDa>
</rdf:Description>
</rdf:RDF>
2.1.5 La grammatica formale
Qui di seguito vengono presentate e commentate le produzioni grammaticali
che definiscono il modello RDF. E da notare, comunque, che la grammatica
qui definita e in parte differente da quanto era stato formalizzato nelle prime
specifiche dal W3C (in [LS99]), a causa degli emendamenti recentemente
effettuati dal working group in [Bec02].
1. RDF ::= "<rdf:RDF>" description* "</rdf:RDF>"
| description
2. description ::= "<rdf:Description" idAboutAttr? bagIdAttr?
propAttr* "/>"
| "<rdf:Description" idAboutAttr? bagIdAttr?
propAttr* ">" propertyElt*
"</rdf:Description>"
| typedNode
3. idAboutAttr ::= idAttr | aboutAttr
4. idAttr ::= "rdf:ID=/"" IDsymbol "/""
5. aboutAttr ::= "rdf:about=/"" URI-reference "/""
6. bagIdAttr ::= "rdf:bagID=/"" IDsymbol "/""

2.1 Resource Description Framework 19
7. propAttr ::= typeAttr
| propName "=/"" string "/""
8. typeAttr ::= "rdf:type=/"" URI-reference "/""
9. propertyElt ::= "<" propName idAttr? ">" value
"</" propName ">"
| "<" propName idAttr? parseLiteral ">"
literal "</" propName ">"
| "<" propName idAttr? parseResource ">"
propertyElt* "</" propName ">"
| "<" propName idRefAttr? bagIdAttr?
propAttr* "/>"
10. typedNode ::= "<" typeName idAboutAttr? bagIdAttr?
propAttr* "/>"
| "<" typeName idAboutAttr? bagIdAttr?
propAttr* ">" propertyElt* "</" typeName ">"
11. propName ::= Qname
12. typeName ::= Qname
13. idRefAttr ::= idAttr | resourceAttr
14. value ::= description | string
15. resourceAttr ::= "rdf:resource=/"" URI-reference "/""
16. Qname ::= NSprefix ":" name
17. URI-reference ::= string, interpreted per [BLFIM98]
18. IDsymbol ::= (any legal XML name symbol)
19. name ::= (any legal XML name symbol)
20. NSprefix ::= (any legal XML namespace prefix)
21. string ::= (any XML text, with "<", ">", and "\" escaped)

20 Capitolo 2. Le tecnologie dei metadati
22. parseLiteral ::= "rdf:parseType=/"Literal/""
23. parseResource ::= "rdf:parseType=/"Resource/""
24. literal ::= (any well-formed XML)
Ogni propertyElt e di un elemento rdf:Description corrisponde ad una
tripla (p, r, v), in cui (vedi produzione 9):
• p e il risultato della concatenazione del namespace a cui appartiene e
con il nome stesso di e;
• r rappresenta:
– una risorsa identificata dal valore dell’attributo rdf:about di
rdf:Description (se presente);
– una nuova risorsa, il cui identificatore e data dal valore dell’attributo
rdf:ID, se presente, oppure una nuova risorsa senza identificatore.
• v rappresenta:
– la risorsa il cui identificatore e dato dal valore dell’attributo
rdf:resource di e (se presente);
– un letterale, nel caso in cui sia presente l’attributo rdf:parseType
con valore Literal o nel caso in cui il contenuto di e sia del testo
XML;
– una risorsa, nel caso in cui sia presente l’attributo rdf:parseType
con valore Resource;
– la risorsa il cui identificatore e ottenuto dal valore dell’attributo (an-
che implicito) rdf:about o rdf:ID dell’elemento rdf:Description
contenuto in e.
Quando in un elemento rdf:Description e specificato l’attributo
rdf:about, l’asserzione si riferisce alla risorsa identificata dal valore
dell’attributo. Se invece e presente rdf:ID o rdf:bagID, la tripla stessa
rappresenta una risorsa, il cui URI e dato dalla concatenazione dell’URI del
documento in cui e definita la tripla con il valore dell’attributo stesso.

2.2 RDF Schema 21
2.2 RDF Schema
Nel paragrafo precedente e stato presentato il modello di RDF come un mezzo
per rappresentare metadati e una sintassi RDF/XML come trasporto di tale
modello. In questo modo si e reso possibile associare delle coppie nome-valore
a delle risorse o URI. Ma spesso questo non basta.
Ad esempio nel caso in cui si ha una proprieta che si riferisce ad uno
scrittore, sarebbe semanticamente scorretto associarla ad una macchina o a
un’abitazione. Oppure nel caso in cui si ha una proprieta che rappresenta
un compleanno e importante vincolarne i valori a delle date (e non numeri
generici o caratteri). Il modello di RDF non permette di effettuare validazione
di un valore o restrizione di un dominio di applicazione di una proprieta.
Questo compito e svolto, invece, da RDF Schema. Pero, a differenza di XML
Schema o di un DTD, RDF Schema non vincola la struttura del documento,
ma fornisce informazioni utili all’interpretazione del documento stesso. In
seguito il namespace di RDF Schema sara indicato con rdfs; quello di RDF
semplicemente con rdf.
2.2.1 Classi e proprieta
In questo paragrafo sono presentate le classi principali e le proprieta che fanno
parte del vocabolario definito da RDF Schema. Le classi permettono di definire
i tipi base di ogni risorsa che verra descritta in RDF; le proprieta sono lo
strumento utilizzato per esprimere le relazioni fra esse.
rdfs:Resource Tutto cio che viene descritto in RDF e detto risorsa. Ogni
risorsa e istanza della classe rdfs:Resource.
rdfs:Literal Sottoclasse di rdfs:Resource, rappresenta un letterale, una
stringa di testo.
rdf:Property Rappresenta le proprieta, cosı come sono state definite nel
paragrafo 2.1.1. E sottoclasse di rdfs:Resource.
rdfs:Class Corrisponde al concetto di tipo e di classe della programmazione

22 Capitolo 2. Le tecnologie dei metadati
object-oriented. Quando viene definita una nuova classe, la risorsa che la
rappresenta deve avere la proprieta rdf:type impostata a rdfs:Class.
rdf:type Indica che una risorsa e membro di una classe, e cioe istanza di una
specifica classe. Il valore di rdf:type deve essere una risorsa che e istanza
di rdfs:Class (o sua sottoclasse). In pratica permette di specificare il
tipo di una risorsa.
rdfs:subClassOf Specifica la relazione di ereditarieta fra classi. Questa
proprieta puo essere assegnata solo a istanze di rdfs:Class. Una classe
puo essere sottoclasse di una o piu classi (ereditarieta multipla).
rdfs:subPropertyOf Istanza di rdf:Property, e usata per specificare che
una proprieta e una specializzazione di un’altra. Ogni proprieta puo
essere la specializzazione di zero o piu proprieta.
rdfs:seeAlso Specifica una risorsa che fornisce ulteriori informazioni sul
soggetto dell’asserzione. Cio che rappresenta questa risorsa comunque
non puo essere specificato, ed e a carico dell’applicazione specifica la sua
interpretazione.
rdfs:isDefinedBy E sottoproprieta di rdfs:seeAlso e indica una risorsa
che definisce il soggetto di un’asserzione. L’uso piu comune di questa
proprieta e di fornire un URI che identifichi lo schema in cui e stata
definito il soggetto.
rdfs:Container Rappresenta la classe base da cui sono derivati i contenitori
di RDF.
rdfs:ContainerMembershipPropriety E la classe da cui derivano i
membri rdf: 1, rdf: 2, etc. dei contenitori.
Esempio 2.11 Qui di seguito verra adottata la sintassi abbreviata; sonoquindi equivalenti le seguenti due scritture, che definiscono una classe di tipoTipo.
<rdf:Description rdf:about="http://schema.org/Tipo">
<rdf:type

2.2 RDF Schema 23
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdfs:Class rdf:about="http://schema.org/Tipo"/>
Definiamo ora la classe Persona, la sua sottoclasse Politico e la classe
Candidato, che e sottoclasse di Politico. Infine istanziamo la classe
Candidato.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdfs:Class rdf:about="http://schema.org/Persona"/>
<rdfs:Class rdf:ID="Politico">
<rdfs:subClassOf rdf:resource="http://schema.org/Persona"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Candidato">
<rdfs:subClassOf rdf:resource="#Politico"/>
</rdfs:Class>
<rdf:Description rdf:about="http://politics.org/mrossi">
<rdf:type rdf:resource="#Candidato"/>
</rdf:Description>
</rdf:RDF>
2.2.2 I vincoli
Le specifiche di RDF Schema definiscono un vocabolario che permette di
effettuare delle asserzioni vincolando le proprieta e le risorse che prendono
parte all’associazione.
rdfs:ConstraintResource Sottoclasse di rdfs:Resource, le sue istanze
rappresentano costrutti di RDF Schema utilizzati per esprimere vincoli.
Lo scopo di questa classe e fornire un mezzo ai parser RDF per

24 Capitolo 2. Le tecnologie dei metadati
riconoscere i costrutti che rappresentano vincoli. Non e pero possibile
indicare al parser come utilizzare i vincoli cosı identificati.
rdfs:ConstraintProperty Sottoclasse di rdf:Property e rdf:Constraint-
Resource, le sue istanze sono proprieta usate per specificare dei vincoli.
Sia rdfs:domain che rdfs:range sono sue istanze.
rdfs:range Usato come predicato di una risorsa r, indica le classi di cui devono
essere membri le risorse a cui verra applicata r.
rdfs:domain Usato come predicato di una risorsa r, indica le classi valide che
saranno soggetto di un’asserzione che ha come predicato r.
Esempio 2.12 Riprendendo l’esempio precedente, definiamo delle proprieta,
vincolandole ai tipi definiti in precedenza. Quando reistanziamo un oggetto
di tipo Candidato, possiamo comunque applicarvi i predicati definiti per le
superclassi da cui discende.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:s="http://schema.org/">
<rdf:Property rdf:about="http://schema.org/Nome">
<rdfs:domain rdf:resource="http://schema.org/Persona"/>
<rdfs:range
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Literal"/>
</rdf:Property>
<rdf:Property rdf:about="http://schema.org/DataNascita">
<rdfs:domain rdf:resource="http://schema.org/Persona"/>
<rdfs:range
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Literal"/>
</rdf:Property>
<rdf:Property rdf:ID="Membro">
<rdfs:domain rdf:resource="#Politico"/>

2.3 Topic Maps 25
<rdfs:range rdf:resource="#Partito"/>
</rdf:Property>
<rdf:Class rdf:about="http://schema.org/Partito"/>
<rdf:Description rdf:about="http://politics.org/parties#labour">
<rdf:type rdf:resource="http://schema.org/Partito"/>
</rdf:Description>
<rdf:Description rdf:about="http://politics.org/mrossi">
<rdf:type rdf:resource="#Candidato"/>
<s:Nome>Mario Rossi</s:Nome>
<s:DataNascita>08 Ottobre, 1968</s:DataNascita>
<epx:Membro
rdf:resource="http://www.ePolitix.com/parties#labour"/>
</rdf:Description>
</rdf:RDF>
2.2.3 La documentazione
Le proprieta che seguono forniscono il supporto per una semplice
documentazione e per la visualizzazione di risorse descritte in RDF in
applicativi specifici.
rdfs:label In alcune situazioni puo essere necessario fornire una descrizione
in forma leggibile (da parte di un essere umano) ad una risorsa, ad
esempio per visualizzare tale risorsa in un’applicazione. A tal fine basta
aggiungere questo predicato alla risorsa.
rdfs:comment Permette di aggiungere un commento ad una risorsa.
2.3 Topic Maps
Oltre al W3C, anche l’ISO (International Standard Organization) ha
formalizzato uno standard per definire i metadati. Tale standard prende

26 Capitolo 2. Le tecnologie dei metadati
il nome di Topic Maps (ISO/IEC 13250) [fS00] e si pone, come obiettivi
principali:
• La standardizzazione di una notazione per la rappresentazione di
metadati, applicabili a qualunque tipo di risorsa.
• Favorire l’interoperabilita fra applicazioni che gestiscono queste le
informazioni.
• Facilitare la navigazione attraverso grandi volumi di dati.
L’approccio seguito dall’ISO al problema della definizione di metadati
consiste nell’offrire uno strumento che fornisca la necessaria potenza espressiva
per permettere l’indicizzazione di qualsiasi tipo di struttura informativa,
fornendo nel contempo un potente strumento per la navigazione automatica.
Al pari di RDF, quindi, Topic Maps si rende utile nell’ottica del World Wide
Web, offrendo la possibilita di una ricerca piu efficiente delle informazioni,
sfruttando la caratterizzazione semantica attribuita loro. Da qui l’appellativo
di “GPS (Global Positioning System) dell’universo informativo” con cui questo
standard viene spesso referenziato.
L’architettura di Topic Maps e stata inoltre definita con l’intento di
facilitare la fusione di piu mappe aventi intersezioni nelle strutture informative
indicizzate, in modo tale da non richiedere modifiche od operazioni di copia
tra documenti.
Al fine di evitare ambiguita, d’ora in poi ci riferiremo allo standard Topic
Maps ISO/IEC 13250 usando le maiuscole, mentre con il termine “mappe” o
“topic maps” intenderemo un generico documento, istanza del modello di dati
definito dallo standard.
2.3.1 I concetti fondamentali
Lo standard definisce dei costrutti fondamentali per la rappresentazione di
meta informazioni, sufficientemente complessi e generici da poter modellare
qualsiasi tipo di base informativa. I concetti cardine su cui si basa il modello
di Topic Maps sono i topic, le associazioni e le occorrenze.

2.3 Topic Maps 27
I topic
Un topic e il piu generico concetto che possa essere espresso. Secondo la
descrizione dello standard “puo essere qualsiasi cosa, indipendentemente dal
fatto che esista o meno, e che abbia qualsiasi tipo di caratteristica”. Il ruolo che
hanno i topic e quindi paragonabile a quello che hanno le risorse nel modello
RDF, ma con due sottili ma importanti differenze:
• Un topic puo essere completamente scorrelato da qualsiasi riferimento a
risorse esterne.
• Un topic puo essere considerato la reificazione di un oggetto del mondo
reale, cioe un “sinonimo” o “rappresentante”, nella mappa, dell’effettiva
essenza di cio a cui si riferisce.
Ad ogni topic possono essere associati uno o piu nomi, ognuno con diverse
funzioni, in base all’utilizzo che si deve fare del topic stesso. Ad esempio,
e possibile assegnare dei nomi alternativi al fine di fornire supporto alle
applicazioni che dovranno effettuare l’ordinamento e la visualizzazione delle
mappe contenenti tali topic. Per un approfondimento su questi concetti di
rimanda all’esempio 2.18.
Cosı come in RDF un elemento rdf:Description poteva essere istanza
di una o piu classi, in Topic Maps un topic puo essere istanza di zero o
piu topic types. I topic types rappresentano dei particolari topic, utilizzabili
per tipizzarne altri. Pertanto i topic types forniscono uno strumento per
definire relazioni di tipo classe-istanza, e quindi possono essere utilizzati per
la creazione di ontologie.
Le occorrenze
Un topic puo essere correlato ad una o piu risorse o, piu generalmente, a
strutture informative, considerate rilevanti ai fini della descrizione del topic
stesso.
Esempi di occorrenze di un topic sono: un articolo o una pagina web in cui
si parli della materia oggetto del topic; un libro che lo descriva o che faccia
riferimento ad esso; un’immagine che lo ritragga; una breve descrizione interna
alla mappa stessa.

28 Capitolo 2. Le tecnologie dei metadati
Le occorrenze possono essere caratterizzate da un “ruolo”, l’occurrence
role, che deve essere opportunamente tipizzato da un topic type. Secondo la
nomenclatura dello standard, questo prende il nome di occurrence role type.
Se ad esempio l’occorrenza o consiste in una pagina web che contiene
citazioni relative al topic di riferimento, si puo definire un occurrence role
type “pagina web” ed associarlo ad o. In questo modo si afferma che o e
un’occorrenza di tipo “pagina web” per il topic che la contiene.
In realta, per essere piu formali, si dovrebbe affermare che un’istanza di
“pagina web” viene associata ad o, in maniera analoga a quanto avviene tra
topic e topic types.
Le associazioni
Le associazioni rappresentano una relazione tra due o piu topic. Analogamente
ai precedenti costrutti, le associazione possono essere caratterizzate da un tipo,
ossia possono essere o meno istanza di un topic type. Nel caso specifico il topic
type assume il nome di association type.
Per meglio definire l’associazione, ciascun topic all’interno di essa puo essere
caratterizzato da un ruolo, l’association role, che anche in questo caso non e
altro che un topic type. A differenza del concetto matematico di relazione le
associazioni sono inerentemente simmetriche: se A e in associazione con B, B
e necessariamente in associazione con A.
E da notare come la relazione tra i topic type e topic “regolari” da essi
tipizzati potrebbe essere ugualmente espressa da una associazione tra la classe
e l’istanza, cosı come le occorrenze potrebbero essere viste come associazioni
tra i topic e le risorse che le descrivono. Pertanto sia la tipizzazione di un topic
che le occorrenze di topic possono essere considerate delle forme implicite di
associazioni. La ridondanza semantica dei costrutti offerti espone al rischio
di errori progettuali nella realizzazione di una mappa, ma viene giustificata
da una maggiore flessibilita fornita dallo standard, soprattutto nell’ottica di
fusioni tra topic map diverse.

2.3 Topic Maps 29
2.3.2 Esempi di utilizzo dei costrutti fondamentali
Gli esempi che seguono sono basati sul modello XTM (XML Topic Maps)
versione 1.0, che e stato recentemente adottato come standard per la
serializzazione di mappe, sebbene il modello Topic Maps, in maniera analoga
a RDF, si presti anche ad essere espresso in termini di grafo. Tali specifiche
rielaborano le direttive dello standard ISO/IEC 13250, formalizzando i concetti
con una sintassi XML. La sintassi utilizzata per il linking e XLink versione
1.0. Nel seguito verra descritta la semantica degli elementi che compongono
la specifica mediante vari esempi. Per una descrizione piu formale della
grammatica mediante il DTD si rimanda al paragrafo 2.3.5.
In seguito, inoltre, si ricorrera all’uso di grafi per rappresentare, in modo
simile a quanto fatto per RDF, i documenti XTM definiti. In un grafo, i
nodi, se ovali, corrispondono ai vari topic; se rettangolari rappresentano dei
letterali. Le associazioni fra topic sono rappresentate da rombi. Gli altri
elementi del modello XTM sono definiti dagli archi. A differenza di RDF, la
rappresentazione mediante grafi non e stata mai specificata, pertanto quanto
presentato in seguito e stato definito per l’occasione e naturalmente non ha
riferimenti bibliografici.
Esempio 2.13 Per esprimere il concetto “Mario Rossi e una persona”,
definiamo il topic Persona con identificatore tt-person ed il topic Mario Rossi
come istanza di Persona. La doppia t iniziale usata nella definizione del primo
topic rappresenta una notazione sintattica atta ad evidenziare che il topic e
un topic type. Si noti inoltre che per aver modo di referenziare i vari topic
all’interno del documento, ciascuno di essi viene definito mediante una stringa
univoca, che rappresenta un’ancora nella mappa.
<topic id="tt-person">
<baseName>
<baseNameString>Persona<baseNameString>
<baseName>
</topic>
<topic id="mario_rossi">
<instanceOf>

30 Capitolo 2. Le tecnologie dei metadati
<topicRef xlink:href="#tt-person"/>
</instanceOf>
<baseName>
<baseNameString>Mario Rossi</baseNameString>
</baseName>
</topic>
Esempio 2.14 Per aggiungere l’informazione “Mario Rossi e l’autore della
pagina web http://www.myhost.com/˜mrossi” definiamo prima il topic type
per la pagina web.
<topic id="tt-web_page">
<baseName>
<baseNameString>Web Page</baseNameString>
</baseName>
</topic>
Definiamo quindi il topic che identifica la pagina web come istanza del tipo
tt-web page. Maggiori dettagli su subjectIdentity verranno forniti nel paragrafo
2.3.3; per ora basti sapere che questo elemento permette di referenziare una
risorsa che definisce l’oggetto rappresentato dal topic.
<topic id="WebPage001">
<instanceOf>
<topicRef xlink:href="#tt-web_page">
</instanceOf>
<subjectIdentity>
<subjectIndicatorRef
xlink:href="http://www.myhost.com/~mrossi"/>
</subjectIdentity>
<baseName>
<baseNameString>Home Page di Mario Rossi</baseNameString>
</baseName>
</topic>
Dopo aver definito tutti i topic che rappresentano le entita che si vogliono
modellare, definiamo l’associazione fra di essi. Come primo passo si crea un

2.3 Topic Maps 31
topic con funzione di association type. Tale topic verra utilizzato per tipizzare
l’associazione autore di.
<topic id="at-author">
<baseName>
<baseNameString>Autore</baseNameString>
</baseName>
</topic>
Infine, creiamo l’associazione. Questa e istanza del tipo at-author, definito
precedentemente, ed ha come membri i topic che rappresentano Mario Rossi e
la pagina web. Per ciascun membro viene specificato il ruolo assunto all’interno
dell’associazione.
<association id="Association001">
<instanceOf>
<topicRef xlink:href="#at-author">
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#tt-web_page"/>
</roleSpec>
<topicRef xlink:href="#WebPage001"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#tt-person"/>
</roleSpec>
<topicRef xlink:href="#mario_rossi"/>
</member>
</association>
Come si nota, e possibile associare un identificatore univoco anche alle
associazioni in modo tale da potersi riferire ad esse.

32 Capitolo 2. Le tecnologie dei metadati
at-author
mario rossi
topicRefroleSpec
Persona
tt-person
Mario Rossi
tt-web page
WebPage001
Association001
http://www.myhost.org/˜mrossi
roleSpec
membermember
instanceOf instanceOf
baseName baseName
baseNamebaseName
Web Page
Mario RossiHome Page di
topicRef
subjectIdentity
Autore
baseName
instanceOf
Figura 2.5: Grafo corrispondente al documento dell’esempio 2.14
Esempio 2.15 Il modello Topic Maps permette di differenziare, per ogni
risorsa informativa, il ruolo di soggetto di un topic da quello di risorsa che
faccia semplicemente riferimento ad esso, cosı come avviene nelle occorrenze.
Nell’esempio precedente, la pagina web e stata rappresentata nella mappa
attraverso un topic, di cui quindi rappresenta il soggetto. In questo esempio
verra presentato il caso in cui una risorsa e l’occorrenza di un topic.
Supponendo che la risorsa “http://www.anagrafe.it/rossi.html” descriva i
dati anagrafici di Mario Rossi, potremmo estendere la definizione del topic
relativo alla persona di Mario Rossi, affermando che in tale risorsa “si parla”
proprio di Mario Rossi. Si aggiunge pertanto a tale topic un riferimento a

2.3 Topic Maps 33
questa pagina.
Viene inoltre specificato il ruolo dell’occorrenza mediante l’elemento
instanceOf di occurrence: in questo caso si e scelto l’occurrence role type
ort-anagrafe.
<topic id="ort-anagrafe">
<baseName>
<baseNameString>Dati Anagrafici</baseNameString>
</baseName>
</topic>
<topic id="mario_rossi">
<instanceOf>
<topicRef xlink:href="#tt-person"/>
</instanceOf>
<baseName>
<baseNameString>Mario Rossi</baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#ort-anagrafe"/>
</instanceOf>
<resourceRef xlink:href="http://www.anagrafe.it/rossi.html"/>
</occurrence>
</topic>
2.3.3 Altri elementi del modello
Come si e visto, un topic puo talvolta essere visto come la reificazione di
un’entita o di un concetto che rappresenta. Di qui la possibilita di associare
al topic un attributo di identita (subjectIdentity) che abbia come valore un
riferimento al soggetto che si vuole reificare.
L’attributo subjectIdentity permette quindi di distinguere le differenti
situazioni in cui una risorsa rappresenti una semplice occorrenza del topic
(come visto nell’esempio 2.15) o sia il soggetto stesso del topic (esempio 2.14).

34 Capitolo 2. Le tecnologie dei metadati
mario rossi
Persona
tt-person
Mario Rossi
instanceOf
baseName
occurrence
instanceOf
http://www.anagrafe.it/rossi.html
resourceRefbaseName
Dati Anagrafici
ort-anagrafe
Figura 2.6: Grafo corrispondente al documento dell’esempio 2.15
La possibilita di poter accedere a qualsiasi cosa sia referenziabile, e quindi
anche ad altri topic o associazioni, rende possibile la loro stessa reificazione.
Secondo il modello Topic Maps se due topic diversi reificano uno stesso
soggetto vengono considerati semanticamente equivalenti al singolo topic
ottenuto unendo le caratteristiche di entrambi.
Esempio 2.16 Se volessimo reificare l’asserzione dell’esempio 2.14, specifi-cando che tale affermazione e stata compiuta da Andrea, potremmo definire untopic che abbia come subjectIdentity un riferimento all’associazione da reificaree quindi creare un’associazione (opportunamente tipizzata) tra questo topic edil topic che definisce Andrea.
<topic id="andrea">
<instanceOf>
<topicRef xlink:href="#tt-person"/>
</instanceOf>
<baseName>
<baseNameString>Andrea</baseNameString>
</baseName>
</topic>
<topic id="tt-reified_statement">

2.3 Topic Maps 35
<baseName>
<baseNameString>Reified Statement</baseNameString>
</baseName>
</topic>
<topic id="Reif001">
<instanceOf>
<topicRef xlink:href="#reified_statement"/>
</instanceOf>
<subjectIdentity>
<subjectIndicatorRef xlink:href="#Association001"/>
</subjectIdentity>
</topic>
<topic id="at-affermato_da">
<baseName>
<baseNameString>Affermato da</baseNameString>
</baseName>
</topic>
<association id="Association002">
<instanceOf>
<topicRef xlink:href="#tt-affermato_da"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#tt-reified_statement"/>
</roleSpec>
<topicRef xlink:href="#Reif001"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#tt-person"/>
</roleSpec>
<topicRef xlink:href="#andrea"/>
</member>

36 Capitolo 2. Le tecnologie dei metadati
</association>
Per reificare l’associazione “Association001” potrebbe sembrare piu ovvio
referenziare direttamente tale associazione da “Association002”, ma il modello
Topic Maps non permette di utilizzare un’associazione come membro di
un’altra associazione. Per sopperire a questa mancanza e stata sufficiente
la creazione del topic “Reif001” il cui soggetto, espresso mediante l’elemento
subjectIdentity, e l’associazione “Association001”, quella si vuole reificare.
Sara poi questo topic ad essere uno dei membri di “Association002”. Come si
vedra in seguito, una possibile alternativa per esprimere lo stesso concetto in
Topic Maps sara la creazione di uno scope, ossia di un contesto, entro il quale
vincolare la validita dell’associazione da reificare.
L’attributo scope serve, come il nome stesso suggerisce, a limitare la validita
di alcune definizioni, specificandone il contesto di riferimento. In particolare,
e possibile assegnare degli scope ai seguenti costrutti:
• nomi dei topic (baseName);
• occorrenze;
• associazioni.
In questo modo ciascuno di questi concetti viene considerato valido solamente
in riferimento allo scope specificato, se ve n’e uno, o globalmente valido
altrimenti. Gli scope sono definiti in termini di temi (definiti themes nello
standard), ossia di topic specificamente creati per essere usati come valori di
scope.
Esempio 2.17 Applicando degli scope a elementi baseName di topic,
possiamo assegnare loro i nomi espressi in piu lingue, ad ognuna delle quali
corrispondera un tema.
<topic id="language">
<baseName>
<baseNameString>Language</baseNameString>
</baseName>

2.3 Topic Maps 37
</topic>
<topic id="italiano">
<instanceOf>
<topicRef xlink:href="#language"/>
</instanceOf>
<baseName>
<baseNameString>Italiano</baseNameString>
</baseName>
</topic>
<topic id="inglese">
<instanceOf>
<topicRef xlink:href="#language"/>
</instanceOf>
<baseName>
<baseNameString>English</baseNameString>
</baseName>
</topic>
Volendo assegnare un nome diverso alla pagina web definita in precedenza,
a seconda della lingua, possiamo vincolare il baseName allo scope determinato
dai precedenti temi linguistici.
<topic id="WebPage001">
<instanceOf>
<topicRef xlink:href="#tt-web_page">
</instanceOf>
<subjectIdentity>
<subjectIndicatorRef
xlink:href="http://www.myhost.com/~mrossi"/>
</subjectIdentity>
<baseName>
<baseNameString>Nome di default</baseNameString>
</baseName>
<baseName>
<scope><topicRef xlink:href="#italiano"/></scope>

38 Capitolo 2. Le tecnologie dei metadati
<baseNameString>
Home Page di Mario Rossi
</baseNameString>
</baseName>
<baseName>
<scope><topicRef xlink:href="#inglese"/></scope>
<baseNameString>Mario Rossi’s Home Page</baseNameString>
</baseName>
</topic>
In maniera analoga all’esempio precedente, associazioni e occorrenze
possono essere contestualizzate. All’interno degli elementi occurrence e
association puo comparire l’elemento scope con riferimento ad uno o piu topic-
theme o ad una risorsa, che viene in questo caso interpretata come tema. Uno
scope puo essere l’unione di un numero arbitrario di temi, nel qual caso la
validita e estesa a ciascuno di essi.
Un elemento baseName permette di assegnare un nome al topic cui fa
parte. Entro tale elemento e anche possibile specificare degli elementi variant,
mediante i quali si possono assegnare al topic degli ulteriori nomi. A differenza
del nome espresso dall’elemento baseName, quelli espressi per mezzo di un
elemento variant hanno significato solo entro uno specifico contesto.
Esempio 2.18 Supponendo che un’applicazione abbia la necessita di ordinare
alfabeticamente la base di dati a cui Mario Rossi appartiene, potremmo
aggiungere la stringa “rossi, mario”, da utilizzare in questa situazione. I
valori dell’elemento parameters determinano i casi di utilizzo di questo “nome
alternativo” aggiunto.
<topic id="mario_rossi">
<instanceOf>
<topicRef xlink:href="#tt-person"/>
</instanceOf>
<baseName>
<baseNameString>Mario Rossi</baseNameString>
<variant>
<parameters>

2.3 Topic Maps 39
tt-web-page
scope
Italiano
baseName baseName
instanceOf
http://www.myhost.org/˜mrossi
Nome di default
baseNamebaseName
subjectIdentity
baseName
scope baseNameString
italiano
baseName
instanceOf instanceOf
baseNameString
WebPage001
Mario Rossi’sHome Page
Home Page diMario Rossi
language
English
inglese
Language
Figura 2.7: Grafo corrispondente al documento dell’esempio 2.17
<topicRef xlink:href="#ordinamento"/>
</parameters>
<variantName>
<resourceData>rossi, mario</resourceData>
</variantName>
</variant>
</baseName>
</topic>
Nello standard ISO e stato definito anche attributo facet, pensato per
assegnare, in maniera diretta, metadati di tipo proprieta-valore alle risorse
informative che costituiscono le occorrenze nelle definizioni di topic, svolgendo
pertanto un compito molto simile ad un’asserzione RDF. Inoltre tale attributo

40 Capitolo 2. Le tecnologie dei metadati
potrebbe essere usato per filtrare le risorse referenziate dipendentemente dal
valore della proprieta.
Tuttavia i facet non sono stati inclusi nella specifica XTM. La semantica di
tale costrutto e d’altronde piuttosto ridondante rispetto a quanto gia definito,
soprattutto in relazione agli scope. Infatti essa e riproducibile aggiungendo alle
occorrenze del topic dei riferimenti che rappresentino i valori delle proprieta.
Esempio 2.19 Se si volesse aggiungere all’occorrenza interna del topic Mario
Rossi l’informazione “la pagina web e in italiano”, (corrispondente alla
coppia proprieta-valore lingua-italiano), potremmo specificare uno scope che
rappresenta il valore del facet.
<topic id="mario_rossi">
<instanceOf>
<topicRef xlink:href="#tt-person"/>
</instanceOf>
<baseName>
<baseNameString>Mario Rossi</baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#ort-anagrafe"/>
</instanceOf>
<scope><topicRef xlink:href="#italiano"/></scope>
<resourceRef xlink:href="http://www.anagrafe.it/rossi.html"/>
</occurrence>
</topic>
2.3.4 Published Subject Identifier
A differenza dello standard RDF, incentrato sulle risorse, lo standard Topic
Maps, spesso definito come “topic centrico”, non pone alcun vincolo alla
referenziazione a documenti reali. In questo modo si rende possibile sia la
descrizione di risorse accedibili da Web, organizzate gerarchicamente, sia la
creazione di topic maps puramente dichiarative, senza alcun link a risorse
esterne.

2.3 Topic Maps 41
In generale non esiste una distinzione sintattica tra la parte dichiarativa e
quella descrittiva di una mappa, il che puo rendere difficile l’interpretazione
della mappa stessa. Sono quindi stati creati i cosiddetti topic-template, che
permettono una definizione sistematica dei topic da utilizzare come tipi base
nella creazione di ulteriori mappe.
I topic-template sono definiti mediante PSI (Published Subject Identifier),
il cui URI puo essere utilizzato per referenziarli. Nonostante allo stato attuale
il numero dei PSI definiti sia piuttosto limitato, il loro utilizzo permette di
riferirsi a tipi standard, la cui semantica e nota, senza avere in questo modo
la necessita di ridefinire gli stessi concetti in ogni mappa.
La specifica XTM 1.0 descrive i seguenti tipi:
topic - Classe generica che tipizza tutti i topic, se non altrimenti specificato.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#topic
occurrence - Classe generica che tipizza tutte le risorse utilizzate come
occorrenze, se non altrimenti specificato.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#occurrence
association - Classe generica che tipizza tutte le associazioni, se non
altrimenti specificato.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#association
class-instance - Classe delle associazioni atte a rappresentare relazioni di
classe-istanza tra topic. Associazioni di questo tipo sono semanticamente
equivalenti all’uso dell’elemento instanceOf nella descrizione di un topic.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#class-instance
class - Classe per la tipizzazione del ruolo di classe nei membri di associazione
di tipo class-instance.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#class
instance Classe per la tipizzazione del ruolo di istanza nei membri di
associazione di tipo class-instance.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#instance

42 Capitolo 2. Le tecnologie dei metadati
superclass-subclass Classe delle associazioni atte a rappresentare relazioni
di superclasse-sottoclasse tra topic.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass
superclass Classe per la tipizzazione del ruolo di superclasse nei membri di
associazione di tipo superclass-subclass.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#superclass
subclass Classe per la tipizzazione del ruolo di sottoclasse nei membri di
associazione di tipo superclass-subclass.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#subclass
sort Topic utile alla definizione di nomi per l’ordinamento, pensato per essere
usato come scope degli elementi variant.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#sort
display Topic utile alla definizione di nomi per l’ordinamento, pensato per
essere usato come scope degli elementi variant.
URI: http://www.topicmaps.org/xtm/1.0/core.xtm#display
Topic Maps, come si e visto, permette in maniera diretta di definire
relazioni di tipo classe-istanza tra topic, senza l’overhead della dichiarazione
esplicita dell’associazione. Facendo a meno di questi meccanismi di
tipizzazione, e possibile comunque creare gerarchie di classi definendo una
sottoclasse come istanza di una superclasse.
Esempio 2.20 Si definisce Candidato come sottoclasse di Politico, e
quest’ultimo come sottoclasse di Persona nel modo seguente.
<topic id="tt-politico">
<instanceOf>
<topicRef xlink:href="#tt-person"/>
</instanceOf>
<baseName>
<baseNameString>Politico</baseNameString>
</baseName>
</topic>

2.3 Topic Maps 43
<topic id="tt-candidato">
<instanceOf>
<topicRef xlink:href="#tt-politico"/>
</instanceOf>
<baseName>
<baseNameString>Candidato</baseNameString>
</baseName>
</topic>
Mediante PSI e tuttavia possibile specificare direttamente la relazione
classe-sottoclasse. Limitandoci alle classi Politico e Candidato, l’esempio
precedente potrebbe essere riformulato nel seguente modo.
<topic id="tt-politico">
<baseName>
<baseNameString>Politico</baseNameString>
</baseName>
</topic>
<topic id="tt-candidato">
<baseName>
<baseNameString>Candidato</baseNameString>
</baseName>
</topic>
<association>
<instanceOf>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass"/>
</roleSpec>
<topicRef xlink:href="#tt-politico"/>

44 Capitolo 2. Le tecnologie dei metadati
</member>
<member>
<roleSpec>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#subclass"/>
</roleSpec>
<topicRef xlink:href="#tt-candidato"/>
</member>
</association>
2.3.5 Descrizione della sintassi XTM
A causa dell’iniziale assenza nello standard ISO/IEC 13250 di specifiche
per la serializzazione di Topic Maps, il consorzio indipendente denominato
TopicMaps.org ([PM01]), formato dalle maggiori aziende interessate allo
sviluppo del paradigma, ha redatto le specifiche di XTM 1.0, con l’intento di
creare uno standard de facto per la rappresentazione e lo scambio di documenti
topic maps.
Tra gli obiettivi progettuali dichiarati dagli autori della specifica XTM
sono:
• Massimizzare la semplicita di utilizzo nel Web;
• Minimizzare le funzionalita opzionali;
• Facilitare la creazione e la manipolazione di mappe;
• Rendere ragionevolmente leggibili i documenti.
Negli esempi finora presentati sono stati presentati tutti i costrutti definiti
in XTM, ma nulla e stato esposto sui vincoli della grammatica, definita da un
apposito DTD, che riportiamo per completezza. E strano che le specifiche di
RDF siano state invece definite mediante produzioni grammaticali [Dum]...
<!ELEMENT topicMap
( topic | association | mergeMap )*
>

2.3 Topic Maps 45
<!ATTLIST topicMap
id ID #IMPLIED
xmlns CDATA #FIXED ’http://www.topicmaps.org/xtm/1.0/’
xmlns:xlink CDATA #FIXED ’http://www.w3.org/1999/xlink’
xml:base CDATA #IMPLIED
>
<!ELEMENT topic
( instanceOf*, subjectIdentity?, ( baseName | occurrence )* )
>
<!ATTLIST topic
id ID #REQUIRED
>
<!-- instanceOf: Points To a Topic representing a class -->
<!ELEMENT instanceOf ( topicRef | subjectIndicatorRef ) >
<!ATTLIST instanceOf
id ID #IMPLIED
>
<!-- subjectIdentity: Subject reified by Topic -->
<!ELEMENT subjectIdentity
( resourceRef?, ( topicRef | subjectIndicatorRef )* )
>
<!ATTLIST subjectIdentity
id ID #IMPLIED
>
<!-- topicRef: Reference to a Topic element -->
<!ELEMENT topicRef EMPTY >
<!ATTLIST topicRef
id ID #IMPLIED
xlink:type NMTOKEN #FIXED ’simple’
xlink:href CDATA #REQUIRED

46 Capitolo 2. Le tecnologie dei metadati
>
<!-- subjectIndicatorRef: Reference to a Subject Indicator -->
<!ELEMENT subjectIndicatorRef EMPTY >
<!ATTLIST subjectIndicatorRef
id ID #IMPLIED
xlink:type NMTOKEN #FIXED ’simple’
xlink:href CDATA #REQUIRED
>
<!-- baseName: Base Name of a Topic -->
<!ELEMENT baseName ( scope?, baseNameString, variant* ) >
<!ATTLIST baseName
id ID #IMPLIED
>
<!-- baseNameString: Base Name String container -->
<!ELEMENT baseNameString ( #PCDATA ) >
<!ATTLIST baseNameString
id ID #IMPLIED
>
<!-- variant: Alternate forms of Base Name -->
<!ELEMENT variant ( parameters, variantName?, variant* ) >
<!ATTLIST variant
id ID #IMPLIED
>
<!-- variantName: Container for Variant Name -->
<!ELEMENT variantName ( resourceRef | resourceData ) >
<!ATTLIST variantName

2.3 Topic Maps 47
id ID #IMPLIED
>
<!-- parameters: Processing context for Variant -->
<!ELEMENT parameters ( topicRef | subjectIndicatorRef )+ >
<!ATTLIST parameters
id ID #IMPLIED
>
<!-- occurrence: Resources regarded as an Occurrence -->
<!ELEMENT occurrence
( instanceOf?, scope?, ( resourceRef | resourceData ) )
>
<!ATTLIST occurrence
id ID #IMPLIED
>
<!-- resourceRef: Reference to a Resource -->
<!ELEMENT resourceRef EMPTY >
<!ATTLIST resourceRef
id ID #IMPLIED
xlink:type NMTOKEN #FIXED ’simple’
xlink:href CDATA #REQUIRED
>
<!-- resourceData: Container for Resource Data -->
<!ELEMENT resourceData ( #PCDATA ) >
<!ATTLIST resourceData
id ID #IMPLIED
>
<!-- association: Topic Association -->

48 Capitolo 2. Le tecnologie dei metadati
<!ELEMENT association
( instanceOf?, scope?, member+ )
>
<!ATTLIST association
id ID #IMPLIED
>
<!-- member: Member in Topic Association -->
<!ELEMENT member
( roleSpec?, ( topicRef | resourceRef | subjectIndicatorRef )* )
>
<!ATTLIST member
id ID #IMPLIED
>
<!-- roleSpec: Points to a Topic serving as an Association Role -->
<!ELEMENT roleSpec ( topicRef | subjectIndicatorRef ) >
<!ATTLIST roleSpec
id ID #IMPLIED
>
<!-- scope: Reference to Topic(s) that comprise the Scope -->
<!ELEMENT scope ( topicRef | resourceRef | subjectIndicatorRef )+ >
<!ATTLIST scope
id ID #IMPLIED
>
<!-- mergeMap: Merge with another Topic Map -->
<!ELEMENT mergeMap (topicRef | resourceRef | subjectIndicatorRef)* >
<!ATTLIST mergeMap
id ID #IMPLIED

2.3 Topic Maps 49
xlink:type NMTOKEN #FIXED ’simple’
xlink:href CDATA #REQUIRED
>
2.3.6 Vincoli di consistenza e validita
Benche sia chiara la necessita di un meccanismo per la definizione di
vincoli semantici sulla struttura delle mappe, al momento della stesura di
questa dissertazione non e stato ufficializzato nessuno standard in proposito.
La possibilita di definire schemi di mappe e una necessita stringente per
molte applicazioni basate sul linguaggio, soprattuto, come vedremeo, per
gli strumenti di authoring. L’ISO sta elaborando TMCL (Topic Map
Constraint Language), [Ste01] un linguaggio che permettera la definizione
di “schemi” mediante i quali sara possibile specificare vincoli strutturali sui
topic, consentendo la validazione delle mappe. Il documento di specifica finora
pubblicato riguardante lo sviluppo di tale linguaggio ne descrive i requisiti
e fornisce, a scopo propositivo una prima bozza di specifica di TMCL, che
permette la definizione dei piu comuni vincoli auspicabilmente esprimibili da
uno schema. Tale specifica e stata pubblicata con l’intento di rappresentare un
punto di partenza per le discussioni sulle esigenze del linguaggio, in particolare
sulle potenzialita espressive che tale linguaggio dovra possedere.
Requisiti di TMCL
I principali requisiti riconosciuti dal draft ISO per il linguaggio di specifica di
vincoli sono riassumibili in:
• Un supporto per definire topic con funzioni di classe, utilizzabili solo per
tipizzare rispettivamente altri topic, associazioni e occorrenze, e ruoli di
associazioni.
• Vincoli sulla presenza di attributi dalla struttura predefinita (quali nomi,
soggetto e occorrenze) che devono essere specificati per topic di un dato
tipo.

50 Capitolo 2. Le tecnologie dei metadati
• Vincoli sulla presenza di associazioni a cui topic di un dato tipo devono
partecipare.
• Possibilita di vincolare la struttura delle associazioni in base al loro tipo,
in modo da permettere la sola presenza di membri di un dato tipo.
• Vincoli di cardinalita sugli attributi associabili ai costrutti, sia per
quanto riguarda i topic (numero minimo e massimo di nomi, occorrenze
etc..), sia per le associazioni (numero dei membri e dei partecipanti a
ciascun membro).
Un ulteriore importante requisito relativo al linguaggio riconosciuto dal
draft ISO e la sua esprimibilita attraverso la sintassi XTM. Cio infatti
permetterebbe alle applicazioni di gestire ogni documento di schema alla
stregua delle proprie istanze, consentendo il riutilizzo degli strumenti di parsing
finora sviluppati.
Proposta ISO di TMCL
La prima istanza di specifica di TMCL fa ricorso essenzialmente al meccanismo
dei PSI per la definizione delle classi e l’estensione semantica dei costrutti di
Topic Maps. In particolare non viene aggiunto alcun nuovo tag per la sintassi
XTM.
Il meccanismo di applicabilita dei vincoli espressi dallo schema consiste
essenzialmente nel matching tra i tipi di topic e delle associazioni nel
documento istanza e la definizione degli stessi nel documento che descrive
lo schema: ogni topic o associazione tipizzata con un topic-type definito nello
schema e soggetto ai vincoli ivi espressi. I concetti necessari al sistema di
vincoli descritti dal draft di specifica vengono identificati attraverso dei PSI,
rappresentati da URL ancora provvisori ed indicati a scopo illustrativo, e
servono a rappresentare i seguenti concetti:
topic type - Classe di un topic con funzioni di tipizzazione per topic: ogni
topic dello schema tipizzato con tale PSI potra essere usato per la
tipizzazione dei topic di documenti conformi allo schema.

2.3 Topic Maps 51
occurrence type - Classe di un topic con funzioni di tipizzazione per
occorrenze.
association type - Classe di un topic con funzioni di tipizzazione per
associazioni.
association role type - Classe di un topic con funzioni di tipizzazione per
ruoli di associazioni.
theme - Classe di un topic con funzioni di tipizzazione per temi.
template - Un topic template e riconosciuto come un tema utilizzabile per
specificare, attraverso uno scope, il ruolo di schema del costrutto che
contestualizza. Se ad esempio viene indicato nello scope di un’occorrenza
di un topic-type dello schema, ogni topic di un documento conforme allo
schema, che sia istanza di tale topic-type, dovra presentare un’occorrenza
strutturalmente identica a quella dello schema (salvo la presenza del tema
template stesso nello scope).
Esempio 2.21 La definizione seguente definisce un topic-type e fornisce deitemplate per nomi e occorrenze specificabili in topic istanza di questo tipo.
<topic id="country">
<instanceOf>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#topic-type"/>
</instanceOf>
<baseName>
<baseNameString>country</baseNameString>
</baseName>
<baseName>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
<topicRef xlink:href="#en"/>
</scope>
<baseNameString>English name</baseNameString>

52 Capitolo 2. Le tecnologie dei metadati
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#map"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>
<resourceRef xlink:href="http://www.maps.com/"/>
</occurrence>
</topic>
Per essere conforme a questo schema un topic di tipo “country” deve avereun nome con scope “en”, atto ad indicare il nome in lingua inglese, deve avereoccorrenze di tipo “map”, localizzabile tramite un riferimento a risorsa il cuiURI inizi con “http://www.maps.com/”. Il seguente topic ne e un esempio:
<topic id="norway">
<instanceOf>
<topicRef xlink:href="#country"/>
</instanceOf>
<baseName>
<scope>
<topicRef xlink:href="#en"/>
</scope>
<baseNameString>Norway</baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#map"/>
</instanceOf>
<resourceRef xlink:href="http://www.maps.com/norway.jpg"/>
</occurrence>
</topic>
Esempio 2.22 La seguente definizione descrive un template di associazione
tra persone e citta, utile a specificare il luogo di nascita.

2.3 Topic Maps 53
<topic id="#born-in">
<instanceOf>
<topicRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#association-type"/>
</instanceOf>
</topic>
<topic id="#person-role">
<instanceOf>
<topicRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#association-role-type"/>
</instanceOf>
</topic>
<topic id="#place-role">
<instanceOf>
<topicRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#association-role-type"/>
</instanceOf>
</topic>
<topic id="#person">
<instanceOf>
<topicRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#association-role-type"/>
</instanceOf>
</topic>
<topic id="#city">
<instanceOf>
<topicRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#association-role-type"/>
</instanceOf>
</topic>
<association>

54 Capitolo 2. Le tecnologie dei metadati
<instanceOf>
<topicRef xlink:href="#born-in"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>
<member>
<roleSpec>
<topicRef xlink:href="#person-role"/>
</roleSpec>
<topicRef xlink:href="#person"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#place-role"/>
</roleSpec>
<topicRef xlink:href="#city"/>
</member>
</association>
Ogni definizione di associazione istanza conforme a questo template, ossia
di tipo “born-in” dovra possedere come membri due topic, il primo di tipo e
“person” con ruolo “person-role” ed il secondo di tipo “city” con ruolo “place-
role”. Il seguente frammento di documento XTM e conforme allo schema
precedente:
<topic id="riccardo">
<instanceOf>
<topicRef xlink:href="#person"/>
</instanceOf>
</topic>
<topic id="pesaro">
<instanceOf>
<topicRef xlink:href="#city"/>

2.3 Topic Maps 55
</instanceOf>
</topic>
<association>
<instanceOf>
<topicRef xlink:href="#born-in"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#person-role"/>
</roleSpec>
<topicRef xlink:href="#riccardo"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#place-role"/>
</roleSpec>
<topicRef xlink:href="#pesaro"/>
</member>
</association>
In generale, in presenza di uno schema esistono due modi di considerare
la validazione dei documenti, ossia con interpretazione lasca o stringente. Nel
primo caso i vincoli espressi nello schema vengono considerati validi solo nelle
condizioni in cui sono applicabili ed ogni definizione che esuli dalle condizioni
espresse dai vincoli dello schema e accettata. Nel secondo caso i documenti
sono validi solo se tutti gli elementi in esso definiti sono tipizzati e in accordo
allo schema definito.
Questa proposta di specifica sembra soddisfare la maggior parte delle
necessita di utilizzo per vincolare mappe. Lo stesso documento di specifica
indica quella descritta come una soluzione tra il 60/40 e l’80/20 in termini di
esigenze di casi d’uso.
Le potenzialita espressive di questa versione di TMCL sono tuttavia solo
una parte dell’insieme dei requisiti che lo standard si prefigge di raggiungere
nella futura versione definitiva. In particolare, le limitazioni piu stringenti
riconosciute da questo primo draft sono:

56 Capitolo 2. Le tecnologie dei metadati
1. Impossibilita di imporre che topic appartenenti ad una certa classe di
tipi debbano partecipare a determinate associazioni, in un determinato
ruolo.
2. Impossibilita di esprimere vincoli di cardinalita sul numero degli attributi
associati ai vari costrutti, ad esempio sull’esatto numero (o intervallo di
validita) dei membri di una associazione di un determinato tipo.
3. Impossibilita di definire le valide combinazioni di temi che possono
costituire uno scope valido per i costrutti che lo prevedono.
OSL: Ontopia Schema Language
Un altra specifica di linguaggio di schema per documenti Topic Maps
e rappresentata dal linguaggio di “constraint” sviluppato in maniera
indipendente da Ontopia Inc. [Ont]. Presentato nel novembre scorso col nome
di OSL (Ontopia Schema Language), tale linguaggui ha l’obiettivo di fornire
un supporto concreto, funzionale ed efficiente al problema della definizione
di schemi per documenti XTM, in attesa che l’ISO ufficializzi una versione
definitiva del linguaggio TMCL ufficiale. OSL ha anche un valore propositivo
nei confronti di TMCL, racchiudendo in se parte delle funzionalita auspicate
ma non ancora definite dallo stesso.
Tuttavia, OSL ha lo svantaggio di essere frutto di una iniziativa del tutto
independente di una azienda interessata allo standard Topic Maps, e pertanto
legata alle volonta di un’unica azienda. Un ulteriore caratteristica negativa
di OSL e l’estensione della sintassi XTM utilizzata per definire gli schemi. Il
vantaggio di OSL rispetto al “low bar proposal” di TMCL sta nella piu fine
granularita con cui e possibile controllare la struttura dei documenti, ma al
prezzo di avere schemi che non sono documenti XTM validi.

Capitolo 3
Conversione fra RDF e Topic
Maps
Gli standard RDF e Topic Maps, presentati nel capitolo precedente,
definiscono due diverse tecnologie che forniscono supporto per lo stesso dominio
applicativo: la specifica di metadati.
Ma, come dice un adagio in uso nell’informatica, “il bello degli standard
sta nella possibilita di poter scegliere fra i tanti”. Pertanto il problema che si
pone in presenza di piu standard riguardanti lo stesso contesto applicativo e
l’interoperabilita fra le applicazioni che ne implementano le specifiche.
L’intento che ci si e proposti, pertanto, e quello di capire le differenze
sostanziali tra i due modelli ed i problemi derivanti dalla necessita di
rappresentare tutti i concetti esprimibili secondo un modello nei termini
dell’altro. A tal fine, per tutti i costrutti di entrambi i modelli, verranno
commentati gli approcci di traduzione descritti nei lavori in materia finora
pubblicati.
Verranno inoltre proposti e argomentati gli schemi di traduzione scelti e
implementati.

58 Capitolo 3. Conversione di formati
3.1 Confronto fra i due paradigmi
Sebbene le due tecnologie condividano il dominio applicativo della descrizione
di metadati, i differenti contesti in cui si sono evoluti hanno comportato
un diverso approccio alla formulazione dei costrutti di base da cui sono
composti. In generale, entrambi gli standard sono volti all’utilizzo nel settore
del knowledge management, in tutte le accezioni attribuibili al termine, anche
se l’idea ispiratrice della loro creazione ha posto l’accento su un diversi aspetti.
Topic Maps e nato con l’intento di risolvere il findability problem, ossia di
creare uno strumento che permetta un’efficiente ricerca di argomenti sulla base
della loro semantica. Tali argomenti possono rappresentare concetti astratti o
possono essere documenti reali. La loro ricerca viene effettuata mediante un
complesso meccanismo di indicizzazione e caratterizzazione, grazie al quale e
possibile fornire alle applicazioni un modo standard di trattare le informazioni,
in particolare se esse sono risorse web.
RDF e stato sviluppato come strumento di base per la creazione del
Semantic Web [Mil01], pensato per essere un’estensione del Web di oggi,
in cui sia possibile associare ad ogni risorsa pubblicata un insieme di
metainformazioni, atte ad esprimerne la semantica. I vantaggi che si possono
trarre in questo modo permetterebbero, in prima istanza, una piu efficiente
ricerca e interpretazione automatica di tali risorse.
Nonostante cio, comunque, entrambi i paradigmi cercano di raggiungere i
rispettivi obiettivi mediante concetti comuni:
• definizione di entita, astratte (ossia che modellano un concetto e non
rappresentano risorse fisiche) o concrete;
• definizione di relazioni di varia natura tra entita;
• rappresentazione del modello mediante grafo con archi etichettati;
• definizione di una sintassi di serializzazione per rendere pratico
l’interscambio dei metadati attraverso la rete.
Nella stesura dei rispettivi paradigmi, benche fossero pressoche analoghe le
finalita, sono state prese scelte implementative significativamente diverse, che

3.1 Confronto fra i due paradigmi 59
hanno portato un maggiore potere espressivo per i costrutti di base di Topic
Maps. Questo aspetto verra discusso spesso in seguito, specialmente quando
si dovra effettuare la conversione verso RDF.
Come e stato evidenziato nel precedente capitolo, il livello di specifica
raggiunto nei due casi non e a tutt’oggi uniforme. Nel caso di RDF il lavoro
della comunita interessata si spinge su piu fronti:
• e in corso la stesura di standard a supporto con funzionalita di constraint
e di estensione semantica, quali RDFS stesso, DAML e OIL ([dam02] e
[oil02]), che forniranno il supporto di meccanismi inferenziali a sistemi
deduttivi;
• sono gia disponibili le prime proposte (gia implementate e funzionali) di
meccanismi di query come RQL (RDF Query Language, vedi [oCS01]),
RDQL (vedi [rdq02]) e Sesame (vedi [ses02]);
• sono ancora in fase di aggiornamento alcune delle specifiche di base: il
documento che descrive le specifiche sintattiche [Bec02] si trova tutt’ora
allo stato di Working Draft.
Per quanto riguarda Topic Maps, benche lo standard ISO 13250 appaia
ormai stabilmente consolidato, i linguaggi di quering (TMQL: Topic Maps
Query Language [Han01]) e le specifiche di validazione (TMCL: Topic Maps
Constraint Language [Ste01]) attendono ancora una prima stesura, sebbene
se ne avverta la necessita impellente. Il loro stato di avanzamento inoltre
appare strettamente legato alle (ancore poche) compagnie che supportano
questa tecnologia.
I limiti delle potenzialita espressive di entrambi i meta linguaggi sono a
tutt’oggi poco definiti. I reciproci sostenitori dichiarano che l’uno sia in grado
di coprire qualsiasi contesto applicativo dell’altro. Tra l’altro, non si conoscono
analisi critiche comparative che dimostrino in maniera imparziale la superiorita
di uno dei due, o che ne abbiano evidenziato le possibili sinergie.

60 Capitolo 3. Conversione di formati
3.2 Problematiche di conversione
Per offrire interoperabilita tra i due paradigmi e necessario poter rendere le
applicazioni RDF in grado di gestire ed interrogare documenti nella specifica
Topic Maps e viceversa, attraverso la conversione dei documenti da un formato
all’altro. Esistono fondamentalmente due approcci alternativi al problema
della conversione.
• Il primo consiste nella descrizione dei costrutti di base di un paradigma
mediante gli strumenti dell’altro.
Nel caso RDF si puo definire uno schema che descriva topic, associazioni,
occorrenze, etc. attraverso predicati e risorse astratte.
Viceversa, in Topic Maps e possibile descrivere attraverso una serie di
topic-templates i ruoli dei costituenti delle asserzioni RDF.
Un simile approccio e plausibile, ma risolve solo parzialmente il problema
dell’interoperabilita, poiche le applicazioni sviluppate per uno dei due
paradigmi sono costrette a conoscere i concetti dell’altro per gestire
correttamente i metadati cosı espressi.
Inoltre i documenti prodotti da tale conversione assumono una forma
poco leggibile e sono molto lontani da quelli scritti in forma nativa.
• Il secondo approccio risolve il problema ad un livello piu alto, e consiste
nell’individuazione, ove possibile, delle equivalenze semantiche tra i
costrutti dei due modelli. In questo modo si evitano gli svantaggi della
prima metodologia di traduzione, ma la diversa natura dei due standard
non sempre rende agevole e praticabile questa strada.
In generale, possiamo riassumere gli aspetti peculiari di uno schema di
conversione in:
• grado di completezza semantica: quanta della semantica dei rispettivi
modelli viene conservata nella traduzione;
• produzione di documenti tradotti quanto piu vicini possibile ad una
forma nativa, e quindi diretta e leggibile, dell’altro standard;

3.3 Confronto fra modelli: differenze e soluzioni proposte 61
• riproducibilita del documento originale applicando una nuova conversio-
ne al documento prodotto dalla traduzione.
Come vedremo, a causa delle inerenti diversita concettuali dei due modelli,
difficilmente tutti questi requisiti possono essere soddisfatti.
Al fine di affrontare tali problematiche e stato sviluppato un framework,
atto a fornire un supporto alla traduzione automatica fra i documenti scritti nei
due formalismi. Uno degli obiettivi proposti e stato rendere tale procedimento
il piu possibile flessibile.
Poiche e ragionevole supporre che l’utente manipoli documenti relativi
ad un particolare contesto applicativo, questi potrebbe avere la necessita
di effettuare delle conversioni mirate. L’implementazione fornita opera
una traduzione dei modelli, e pertanto e relativamente generica. Il
framework, comunque, consente la riscrittura delle metodologie di conversione
in maniera agevole, anche se limitatamente all’espressione di relazioni fra
entita, permettendo in questo modo di considerare casi non prevedibili a priori.
3.3 Confronto fra modelli: differenze e
soluzioni proposte
In questo paragrafo verranno confrontati i modelli di RDF e di Topic Maps,
mettendo alla luce ed approfondendo le similitudini e le diversita adottate nella
descrizione dei metadati.
3.3.1 Identificazione di cio che e descritto
In RDF ciascuna risorsa che si descrive e rappresentata da un URI univoco:
• se la risorsa fa riferimento ad un documento indirizzabile, l’URI sara
quello del documento stesso (definito dall’attributo rdf:about);
• per oggetti astratti l’URI sara un identificatore simbolico (definito
dall’attributo rdf:ID).

62 Capitolo 3. Conversione di formati
La natura della risorsa descritta puo essere ulteriormente dettagliata attraverso
RDFS, che definisce il predicato rdfs:isDefinedBy, che ha come oggetto una
qualsiasi risorsa atta a definire il soggetto dell’asserzione.
In Topic Maps la “cosa” che si descrive (cio che il topic reifica) viene
indicata mediante il subjectIdentity. La sua identificazione e piu raffinata;
vengono distinti i casi in cui il soggetto e:
• una risorsa indirizzabile (elemento resourceRef);
• un altro topic utile per descrizioni incrementali unificabili mediante
regole di merging (elemento topicRef);
• un URI utile ad indicare all’applicazione quale sia il soggetto descritto
(elemento subjectIndicatorRef);
• un insieme di questi ultimi due. Possono essere ripetuti piu volte gli
elementi topicRef e subjectIndicatorRef
In linea di massima la corrispondenza diretta esistente e topic-risorsa,
tuttavia le differenze fra le due rappresentazioni necessitano di una traduzione
piu raffinata, che vedremo essere non banale.
La soluzione qui proposta consiste in:
Traduzione da Topic Maps a RDF - Si possono distinguere i seguenti
casi:
• Il topic ha l’elemento resourceRef, figlio di subjectIdentity, che punta
ad un documento. In questo caso viene creata una risorsa RDF con
attributo rdf:about e valore posto all’URI del documento stesso.
• Se l’elemento resourceRef non e presente viene creata una nuova
risorsa il cui identificatore (rdf:ID) e funzione del nome del topic
stesso.
• Se il topic non ha nemmeno un nome la nuova risorsa avra come
identificatore una stringa generata randomicamente.

3.3 Confronto fra modelli: differenze e soluzioni proposte 63
Inoltre il SubjectIndicatorRef del topic viene mappato con il predicato
rdfs:isDefinedBy. Infatti, secondo le specifiche di RDFS [BG00], tale
elemento “indica la risorsa che definisce il soggetto della descrizione”.
Il topicRef, invece, viene ignorato, in quanto funzionale solo alla fusione
fra mappe.
Esempio 3.1 Il topic WebPage001 indica la home page di Mario Rossi,
identificata dall’URL http://www.myhost.com/˜mrossi. Viene tradotto
in una risorsa RDF il cui soggetto rdfs:about e dato proprio dall’URL.
<topic id="WebPage001">
...
<subjectIdentity>
<resourceRef
xlink:href="http://www.myhost.com/~mrossi"/>
</subjectIdentity>
</topic>
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
...
</rdf:Description>
Traduzione da RDF a Topic Maps - In maniera analoga, una risorsa
astratta (rdf:ID) viene mappata in un topic che ha per baseName
l’identificatore della risorsa stessa. Le stesse considerazioni valgono per
la traduzione dell’elemento rdfs:isDefinedBy in subjectIndicatorRef.
Nel caso la risorsa sia identificata da un URI, questo diventa
immediatamente il valore dell’elemento resourceRef di subjectIdentity del
topic.
Utilizzando tale metodologia si ottiene biunivocita semantica e chiarezza
espressiva.
Esempio 3.2 Si suppone che l’URL http://www.anagrafe.it/rossi.html
contenga i dati anagrafici che distinguano univocamente Mario Rossi. Pertanto
si puo affermare che la risorsa mario rossi sia definita da tale URL.

64 Capitolo 3. Conversione di formati
<rdf:Description rdf:ID="mario_rossi">
...
<rdfs:isDefinedBy
rdf:resource="http://www.anagrafe.it/rossi.html"/>
</rdf:Description>
<topic id="mario_rossi">
...
<baseName>
<baseNameString>mario_rossi</baseNameString>
</baseName>
<subjectIdentity>
<subjectIndicatorRef
xlink:href="http://www.anagrafe.it/rossi.html"/>
</subjectIdentity>
</topic>
3.3.2 Assegnazione dei nomi
Uno dei concetti in cui RDF e Topic Maps maggiormente differiscono e
l’assegnazione dei nomi alle risorse descritte. RDF non gestisce l’uso di nomi
(utilizzabili ai fini di visualizzazione di tali risorse), ma fa uso dell’elemento
rdfs:label, definito nelle specifiche di RDFS. Topic Maps, invece, fornisce
un supporto avanzato a tale funzionalita: oltre all’elemento baseName, che
permette di assegnare un insieme di nomi a ciascun topic, e previsto l’uso di
elementi variant. Il loro valore fornisce una forma alternativa ai baseName,
ottimizzata per un particolare fine computazionale, come, ad esempio, la
visualizzazione o l’ordinamento. E compito dell’applicazione valutare tali
elementi in base al valore degli elementi parameter ad essi associati.
Poiche i variant rappresentano una struttura informativa complessa, la
loro semantica non e direttamente riproducibile mediante un’asserzione RDF,
ma e necessario adottare una soluzione piu articolata. Pertanto si e scelto
di creare una risorsa astratta contenente le informazioni corrispondenti a
quelle contenute nell’elemento variant. Il solo modo per potere aggiungere
questo potere espressivo anche ad RDF consiste nel creare ulteriori predicati,

3.3 Confronto fra modelli: differenze e soluzioni proposte 65
assegnando loro lo stesso tipo di semantica. Come vedremo in seguito, questo
approccio verra seguito anche in altre situazioni in cui RDF non fornisce un
supporto nativo ai concetti di Topic Maps.
Esempio 3.3 Il topic mario rossi ha nome “Mario Rossi”. Sono pero presenti
entro il baseName due elementi variant, che in questo caso definiscono il
comportamento delle applicazioni nel manipolare il topic. Nello specifico,
questo topic viene visualizzato con il letterale “Rossi, Mario” e per
l’ordinamento viene usata la stringa “rossi mario”. Queste informazioni sono
espresse mediante l’utilizzo di parametri che si riferiscono a particolari topic
definiti nella specifica XTM 1.0.
<topic id="mario_rossi">
...
<baseName>
...
<baseNameString>Mario Rossi</baseNameString>
<variant>
<parameters>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm\#display"/>
</parameters>
<variantName>
<resourceData>Rossi, Mario</resourceData>
</variantName>
</variant>
<variant>
<parameters>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm\#sort"/>
</parameters>
<variantName>
<resourceData>rossi mario</resourceData>
</variantName>
</variant>
</baseName>

66 Capitolo 3. Conversione di formati
</topic>
Non e possibile convetire le informazioni contenute negli elementi variant
in modo diretto, ma e necessaria la creazione di strutture astratte, atte a
modellare queste informazioni complesse. A tal fine vengono definiti i seguenti
predicati RDF, definiti in uno schema apposito identificato dal prefisso tm2rdf:
tm2rdf:baseName poiche un topic puo avere un numero indefinito di
elementi baseName, si usa questo predicato per referenziare la struttura
usata per mappare ognuno di questi elementi;
tm2rdf:variant punta alla risorsa astratta contenente tutte le informazioni
contenute nell’elemento variant del baseName;
tm2rdf:parameter punta alla risorsa che modella il parametro usato;
tm2rdf:variantName puo assumere forme diverse in base alla struttura del
topic:
• se entro l’elemento variantName e stato usato resourceRef, allora
punta alla risorsa che contiene le informazioni relative al nome del
variant;
• se entro l’elemento variantName e stato usato resourceData,
contiene il letterale che rappresenta il nome del variant.
<rdf:Description rdf:ID="mario_rossi">
...
<tm2rdf:baseName rdf:resource="#bn1_mario_rossi">
</rdf:Description>
<rdf:Description rdf:ID="bn1_mario_rossi">
...
<rdfs:label>Mario Rossi</rdfs:label>
<tm2rdf:variant rdf:resource="#v11_mario_rossi"/>
<tm2rdf:variant rdf:resource="#v12_mario_rossi"/>
</rdf:Description>

3.3 Confronto fra modelli: differenze e soluzioni proposte 67
<rdf:Description rdf:ID="v11_mario_rossi">
<tm2rdf:parameter rdf:resource="#param1"/>
<tm2rdf:variantName>Rossi, Mario</s:variantName>
</rdf:Description>
<rdf:Description rdf:ID="v12_mario_rossi">
<tm2rdf:parameter rdf:resource="#param2"/>
<tm2rdf:variantName>rossi mario</s:variantName>
</rdf:Description>
Esempio 3.4 A causa della gestione minimale del nomi da parte del modello
RDF, la conversione di un elemento rdfs:label e semplice. Si e pensato
di farlo coincidere, in Topic Maps, con un baseName, il cui valore letterale
coincide con quello dell’elemento RDF.
<rdf:Description rdf:ID="mario_rossi">
...
<rdfs:label>Mario Rossi</rdfs:label>
</rdf:Description>
<topic id="mario_rossi">
...
<baseName>
<baseNameString>Mario Rossi</baseNameString>
</baseName>
</topic>
3.3.3 Relazioni tra oggetti descritti
In RDF attraverso l’uso dei predicati possiamo stabilire una relazione tra
coppie di risorse o possiamo definire una coppia attributo-valore associata alla
risorsa descritta. Quest’ultimo e il caso in cui l’oggetto del predicato sia un
letterale.
In Topic Maps, mediante il concetto di associazione, vengono messi in
una relazione (determinata dal tipo dell’associazione) un arbitrario numero

68 Capitolo 3. Conversione di formati
di topic, per ognuno dei quali puo anche essere specificato il ruolo all’interno
dell’associazione stessa.
Le differenze in questo contesto sono evidenti e difficilmente conciliabili e
sono dovute alla natura piu primitiva di RDF nei confronti di Topic Maps.
RDF mette in una relazione ordinata e non commutativa due risorse, mentre
Topic Maps crea relazioni n-arie, non ordinate, tra topic, permettendo anche di
specificare il tipo di coinvolgimento (il ruolo) di ciascun topic nell’associazione.
Una conversione a livello di modello, nel caso generico, benche complessa
e artificiosa, e comunque possibile, al prezzo di snaturare RDF nel modo di
esprimere relazioni: e possibile tradurre una generica associazione n-aria in un
rdf:Bag che abbia come elementi le risorse astratte corrispondenti ai membri
dell’associazione. Per ciascuna di tali risorse si utilizzano i seguenti predicati:
• rdfs:isDefinedBy, con oggetto la risorsa relativa al membro
dell’associazione;
• rdf:type, atto ad indicare il ruolo del membro.
Tale risorsa astratta e referenziata dalla risorsa che modella l’associazione
mediante il predicato tm2rdf:association.
Esempio 3.5 Ricordando l’esempio 2.14, si definisce l’associazione di tipo“at-autore di” fra i topic “mario rossi” e “WebPage001”, in cui si afferma cheMario Rossi e autore della propria home page.
<association id="Association001">
<instanceOf>
<topicRef xlink:href="#at-autore_di">
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#tt-pagina_web"/>
</roleSpec>
<topicRef xlink:href="#WebPage001"/>
</member>
<member>
<roleSpec>

3.3 Confronto fra modelli: differenze e soluzioni proposte 69
<topicRef xlink:href="#tt-person"/>
</roleSpec>
<topicRef xlink:href="#mario_rossi"/>
</member>
</association>
Viene prima modellata la risorsa che rappresenta l’associazione, assegnan-
dole il tipo at-autore di.
<rdf:Description rdf:ID="Association001">
<rdf:type rdf:resource="#at-autore-di"/>
<tm2rdf:association rdf:resource="#members_Association001"/>
</rdf:Description>
I membri dell’associazione vengono inclusi un un rdf:Bag.
<rdf:Description rdf:ID="members_Association001">
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="#WebPage001_Association001"/>
<rdf:_2 rdf:resource="#mario_rossi_Association001"/>
</rdf:Description>
Viene descritto ogni membro con il proprio ruolo, relativo alla specifica
associazione. In questo modo vengono vincolate le descrizioni dei membri alle
singole associazioni.
<rdf:Description rdf:ID="WebPage001_Association001">
<rdf:type rdf:resource="#tt-pagina_web"/>
<rdfs:isDefinedBy rdf:resource="#WebPage001"/>
</rdf:Description>
<rdf:Description rdf:ID="mario_rossi_Association001">
<rdf:type rdf:resource="#tt-person"/>
<rdfs:isDefinedBy rdf:resource="#mario_rossi"/>
</rdf:Description>

70 Capitolo 3. Conversione di formati
Esempio 3.6 Il predicato di supporto tm2rdf:association permette di
aggiungere un po di leggibilita al documento prodotto. Comunque, si
potrebbero far coincidere la risorsa astratta usata per modellare i membri
dell’associazione e l’associazione stessa, eliminando in questo modo la necessita
di usare questo predicato. L’associazione descritta nell’esempio precedente puo
pertanto essere modellata come segue.
<rdf:Description rdf:ID="Association001">
<rdf:type rdf:resource="#at-autore-di"/>
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="#WebPage001_Association001"/>
<rdf:_2 rdf:resource="#mario_rossi_Association001"/>
</rdf:Description>
<rdf:Description rdf:ID="WebPage001_Association001">
<rdf:type rdf:resource="#tt-pagina_web"/>
<rdfs:isDefinedBy rdf:resource="#WebPage001"/>
</rdf:Description>
<rdf:Description rdf:ID="mario_rossi_Association001">
<rdf:type rdf:resource="#tt-person"/>
<rdfs:isDefinedBy rdf:resource="#mario_rossi"/>
</rdf:Description>
Una traduzione alternativa potrebbe essere quella, sotto certi aspetti piu
naturale, di far corrispondere i concetti di predicato e di associazione. Il
problema di fondo sta nella natura inerentemente binaria e unidirezionale dei
predicati RDF: se da un lato passare da un predicato RDF ad una associazione
binaria Topic Maps non pone problemi, una generica associazione n-aria
dovrebbe tradursi nell’inserimento di n-1 predicati nella descrizione di ciascuno
dei membri dell’associazione. Tali predicati dovrebbero corrispondere al tipo
dell’associazione e dovrebbero avere per oggetto ciascuno degli altri membri.
Si perderebbe comunque l’informazione relativa al ruolo di ciascun membro,
nonche, come vedremo, quella relativa al possibile scope dell’associazione.

3.3 Confronto fra modelli: differenze e soluzioni proposte 71
Esempio 3.7 L’associazione “the clash band” associa la band dei Clash conciascuno dei suoi componenti.
<association id="the_clash_band">
<instanceOf>
<topicRef xlink:href="#at-member_of"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#tt-band"/>
</roleSpec>
<topicRef xlink:href="#the_clash"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#tt-vocalist"/>
</roleSpec>
<topicRef xlink:href="#joe_strummer"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#tt-guitarist"/>
</roleSpec>
<topicRef xlink:href="#mick_jones"/>
</member>
...
</association>
Viene definito il predicato “at-member of”, relativo al tipo dell’asso-
ciazione. Vengono poi descritte le risorse relative ad ogni membro di
“the clash band”. Da notare che vengono persi i ruoli di ogni membro.
<rdf:Property rdf:ID="at-member_of"/>
<rdf:Description rdf:ID="the_clash">
...
<at-member_of rdf:resource="#joe_strummer"/>

72 Capitolo 3. Conversione di formati
<at-member_of rdf:resource="#mick_jones"/>
</rdf:Description>
<rdf:Description rdf:ID="joe_strummer">
...
<at-member_of rdf:resource="#the_clash"/>
<at-member_of rdf:resource="#mick_jones"/>
</rdf:Description>
<rdf:Description rdf:ID="mick_jones">
...
<at-member_of rdf:resource="#the_clash"/>
<at-member_of rdf:resource="#joe_strummer"/>
</rdf:Description>
Un ulteriore raffinamento a tale approccio potrebbe consistere nel definire
predicati diversi per ogni ruolo ricoperto dai membri. In questo modo
verrebbero mantenute tutte le informazioni, comprese quelle espresse dai ruoli.
<rdf:Property rdf:ID="at-member_of_tt-band"/>
<rdf:Property rdf:ID="at-member_of_tt-vocalist"/>
<rdf:Property rdf:ID="at-member_of_tt-guitarist"/>
<rdf:Description rdf:ID="the_clash">
...
<at-member_of_tt-vocalist rdf:resource="#joe_strummer"/>
<at-member_of_tt-guitarist rdf:resource="#mick_jones"/>
</rdf:Description>
<rdf:Description rdf:ID="joe_strummer">
...
<at-member_of_tt-band rdf:resource="#the_clash"/>
<at-member_of_tt-guitarist rdf:resource="#mick_jones"/>
</rdf:Description>
<rdf:Description rdf:ID="mick_jones">
...

3.3 Confronto fra modelli: differenze e soluzioni proposte 73
<at-member_of_tt-band rdf:resource="#the_clash"/>
<at-member_of_tt-vocalist rdf:resource="#joe_strummer"/>
</rdf:Description>
Come si puo notare il numero dei predicati definiti per ciascuna associazione
aumenta con il numero dei ruoli ricoperti dai membri.
RDF e RDFS permettono di associare solo un “primo livello” di semantica
a questi predicati, ad esempio usando:
• rdfs:subPropertyOf per specificare che il predicato e una specializza-
zione di un’altro;
• rdfs:range e rdfs:domain per definirne i vincoli di applicabilita.
Poiche tali predicati vengono generati automaticamente non e possibile
usare gli strumenti forniti da RDF/RDFS per poter assegnare loro la semantica
necessaria ad una corretta interpretazione. Sarebbe neccessario utilizzare un
meta linguaggio dal maggiore potere espressivo. Non essendo cio possibile
la logica necessaria all’interpretazione dovrebbe essere spostata a livello
applicativo.
L’approccio presentato nell’esempio 3.5, invece, non ha questo limite,
poiche e sufficiente che l’applicazione che dovra manipolare il documento RDF
prodotto sia a conoscenza dell’unico schema usato nella traduzione.
Viceversa, per effettuare la conversione di un predicato appartenente ad un
generico schema di RDF in costrutti di Topic Maps, e possibile far coincidere
tale predicato con un topic la cui funzione e di association type. L’asserzione
RDF puo quindi essere mappata con un’associazione di questo tipo, i cui
membri siano i topic corrispondenti al soggetto e all’oggetto.
Esempio 3.8 Per esprimere l’asserzione RDF in XTM si crea l’associazione
di tipo “Autore” avente come membri il soggetto e l’oggetto della descrizione.
<rdf:Description rdf:about="http://www.myhost.com/~mrossi">
<s:Autore rdf:resource="#mario_rossi"/>
</rdf:Description>

74 Capitolo 3. Conversione di formati
<topic id="Autore">
...
</topic>
<topic id="rnd001">
...
<subjectIdentity>
<resourceRef
xlink:href="http://www.myhost.com/~mrossi"/>
</subjectIdentity>
</topic>
<association>
<instanceOf>
<topicRef xlink:href="#Autore"/>
</instanceOf>
<member>
<topicRef xlink:href="#rnd001"/>
</member>
<member>
<topicRef xlink:href="#mario_rossi"/>
</member>
</association>
Tuttavia, come si vedra nel paragrafo 3.3.4, nonostante questo approccio
rappresenti una buona soluzione generica, puo essere preferibile, in certi
contesti, applicare altri tipi di conversione. Se si conoscesse la semantica
associata al predicato RDF, sarebbe possibile trovare un equivalente costrutto
di Topic Maps piu appropriato rispetto ad una generica associazione. In questo
modo il documento prodotto rispecchierebbe meglio la forma di un documento
scritto nativamente in Topic Maps.

3.3 Confronto fra modelli: differenze e soluzioni proposte 75
3.3.4 Attributi
In RDF non esiste, a livello di modello, una classificazione degli attributi
o delle meta informazioni associate ad una risorsa. Al di fuori delle poche
proprieta definite dal modello RDF, lo schema RDFS, attraverso la definizione
di ulteriori predicati con semantica predeterminata:
• permette una classificazione piu dettagliata di alcuni attributi;
• fornisce gli strumenti semantici per la descrizione di ulteriori schemi,
permettendo la definizione e la caratterizzazione di predicati e risorse.
Nel modello Topic Maps esiste invece il concetto di occorrenza.
Un’occorrenza e inerentemente associata ad un topic, a cui permette di
associarvi come attributi una risorsa o un letterale. E inoltre possibile
assegnare all’occorrenza un tipo, permettendone cosı una classificazione.
Una conversione da RDF a Topic Maps piu accurata rispetto a quanto
proposto nel paragrafo precedente puo essere eseguita nel caso in cui si sappia
che la semantica del predicato che si vuole tradurre coincida con quello di
occurrence di Topic Maps. In questo caso si possono eseguire i seguenti passi:
• si fa coincidere il predicato con un topic con funzione di occurrence role
type;
• si crea un’occorrenza all’interno del topic che rappresenta il soggetto
dell’asserzione RDF;
• si pone tale occorrenza istanza del tipo definito.
Naturalmente tale procedimento non e automatizzabile, in quanto non e in
generale noto a priori lo schema utilizzato.
Esempio 3.9 Viene effettuata la traduzione del predicato RDF s:homepage,
che indica la home page relativa al soggetto dell’asserzione. Tale predicato e
assimilabile a un elemento occurrence di Topic Maps.
<rdf:Property rdf:ID="homepage"/>

76 Capitolo 3. Conversione di formati
<rdf:Description rdf:ID="mario_rossi">
<s:homepage rdf:resource="http://www.myhost.com/~mrossi"/>
</rdf:Description>
<topic id="homepage">
...
</topic>
<topic id="mario_rossi">
...
<occurrence>
<instanceOf>
<topicRef xlink:href="#homepage"/>
<instanceOf>
<resourceRef xlink:href="http://www.myhost.com/~mrossi"/>
</occurrence>
</topic>
Nel caso in cui l’oggetto dell’asserzione fosse stato un letterale, si sarebbe
utilizzato un elemento resourceData al posto di resouceRef.
Nel caso di traduzione di Topic Maps verso RDF e possibile adottare
l’approccio inverso:
• si definisce un predicato (di tipo rdf:Property) corrispondente al topic
utilizzato per tipizzare l’occorrenza;
• si usa tale predicato in una nuova asserzione RDF;
• si usa la risorsa referenziata dall’occorrenza come oggetto dell’asserzione
RDF.
Tuttavia, e possibile che all’interno dell’elemento occurrence sia presente
uno scope. In questo caso la traduzione e piu complessa e non automatizzabile
nel modo presentato. Inoltre, poiche in Topic Maps non vi e una separazione
netta fra i ruoli che puo ricoprire un topic, l’approccio presentato potrebbe

3.3 Confronto fra modelli: differenze e soluzioni proposte 77
portare a definire in RDF, per lo stesso topic, delle risorse astratte che
sarebbero descritte sia come proprieta che in altro modo.
Per questi motivi la soluzione proposta, adatta nel caso piu generale, fa
ricorso al predicato rdfs:seeAlso, la cui semantica e quella di “specificare
una ulteriore risorsa che possa fornire informazioni addizionali sulla risorsa
soggetto”. Si crea quindi una risorsa astratta usata per includere tutte
le informazioni riguardanti l’occorrenza e la si lega alla risorsa mediante il
predicato rdfs:seeAlso.
Per una discussione piu approfondita della traduzione dell’elemento scope
si rimanda al paragrafo 3.3.6.
Esempio 3.10 Il topic “mario rossi” occorre nell’URL http://www.my-host.com/office/1375. Tale occorrenza ha validita solo nel contesto definitodal topic “ufficio”. Viene creata la risorsa astratta “oc1 mario rossi”, atta amodellare l’occorrenza.
<topic id="mario_rossi">
...
<occurrence>
...
<scope>
<topicRef xlink:href="#ufficio"/>
</scope>
<resourceRef xlink:href="http://www.myhost.com/office/1375"/>
</occurrence>
</topic>
<rdf:Description rdf:ID="mario_rossi">
...
<rdfs:seeAlso rdf:resource="#oc1_mario_rossi"/>
</rdf:Description>
<rdf:Description rdf:ID="oc1_mario_rossi">
...
<rdfs:isDefinedBy
rdf:resource="http://www.myhost.com/office/1375"/>

78 Capitolo 3. Conversione di formati
<s:scope rdf:resource="#anagrafe"/>
</rdf:Description>
3.3.5 Tipizzazione
I due standard presentano entrambi meccanismi per la creazione di relazioni
di tipo classe istanza e per la creazione di ontologie tra i concetti descritti.
RDF mette a disposizione la proprieta rdf:type che crea la relazione
classe-istanza tra soggetto e oggetto dell’asserzione.
RDFS aggiunge la semantica necessaria per specificare relazioni di tipo
superclasse-sottoclasse mediante il predicato rdfs:subClassOf.
In Topic Maps, invece, tale dipendenza e esprimibile a livello di modello:
per ciascun topic e ciascuna associazione e prevista la specifica del tipo o dei
tipi che li caratterizzano.
In RDF la relazione superclasse-sottoclasse si realizza mediante la
combinazione della proprieta rdf:type e di rdfs:subClassOf entro la stessa
descrizione. Tali predicati sono usati, rispettivamente:
• per dichiarare la natura di classe della risorsa (viene posto a valore
rdfs:Class).
• per specificare la superclasse da cui la risorsa discende.
In Topic Maps non esiste al momento un metodo standard per dichiarare la
natura di tipo di un certo topic: il dominio dei topic con funzione di tipizzazione
non e necessariamente disgiunto da quello dei topic istanza. La natura del topic
e quindi dipendente dal contesto.
La specifica XTM prevede la possibilita di poter distinguere la relazione di
tipo classe-istanza da quella di superclasse-sottoclasse. Il primo caso e espresso
nel topic istanza con il costrutto instanceOf); nel secondo caso e previsto un
tipo di associazione identificato da un URI (PSI superclass-subclass).
Esempio 3.11 Rifacendoci all’esempio 2.11, la conversione della risorsa
“politico”, sottoclasse di “persona” e diretta.
<rdfs:Class rdf:ID="politico">

3.3 Confronto fra modelli: differenze e soluzioni proposte 79
...
<rdfs:subClassOf rdf:resource="#persona"/>
</rdfs:Class>
<topic id="politico">
...
</topic>
<association>
<instanceOf>
<topicRef xlink:link=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass"/>
</roleSpec>
<topicRef xlink:href="#persona"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#subclass"/>
</roleSpec>
<topicRef xlink:href="#politico"/>
</member>
</association>
3.3.6 Metainformazioni contestuali
Nel definire meta informazioni puo essere utile poter limitare le definizioni
dei concetti descritti ad un determinato contesto. Topic Maps prevede questa
possibilita attraverso il meccanismo degli scope. E possibile contestualizzare
tali meta informazioni nei seguenti costrutti:

80 Capitolo 3. Conversione di formati
• occorrenze;
• associazioni;
• nomi associati ai topic (baseName).
Il modello RDF non permette di descrivere in maniera esplicita il concetto di
contesto di validita delle asserzioni.
In questo caso quindi il problema della convergenza si pone soltanto in un
senso.
L’unico modo per far fronte a questa mancanza e probabilmente la
definizione di proprieta RDF aggiuntive che incorporino questa semantica.
Un modo poco elegante per farlo potrebbe essere quello di definire piu
predicati RDF in modo di legare oggetto e soggetto in un certo contesto.
Ognuno di questi predicati potrebbe essere specializzato in modo da indicare
come ulteriore tipo il predicato di base, privo di contesto.
Esempio 3.12 Viene effettuato il mapping di elementi baseName, contenenti
uno scope, in due risorse astratte con funzione di predicati RDF. Queste risorse
vengono definite di tipo tm2rdf:baseName.
<topic id="mario_rossi">
...
<baseName>
<scope>
<topicRef xlink:href="#matricola"/>
</scope>
<baseNameString>1375</baseNameString>
</baseName>
<baseName>
<scope>
<topicRef xlink:href="#nickname"/>
</scope>
<baseNameString>Homer</baseNameString>
</baseName>
</topic>

3.3 Confronto fra modelli: differenze e soluzioni proposte 81
<rdf:Property rdf:ID="baseName_matricola">
<rdf:type
rdf:resource="http://cs.unibo.it/schemas/tm2rdf#baseName"/>
</rdf:Property>
<rdf:Property rdf:ID="baseName_nickname">
<rdf:type
rdf:resource="http://cs.unibo.it/schemas/tm2rdf#baseName"/>
</rdf:Property>
<rdf:Description rdf:ID="mario_rossi">
...
<nome_matricola>1375</nome_matricola>
<nome_nickname>Homer</nome_nickname>
</rdf:Description>
Si noti che sarebbe scorretto definire questi predicati “contestualizzati”
usando il predicato rdfs:subPropertyOf posto a valore uguale al predicato
privo di contesto, in quanto, secondo le specifiche RDFS, rimarrebbe valida
anche la proprieta di tipo base (senza contesto), che e proprio cio che si vuole
evitare.
Inoltre questo approccio presenta ulteriori problemi: il numero dei predicati
“contestualizzati” creati e pari al numero degli scope utilizzati. In questo modo
vengono definiti numerosi predicati con la stessa semantica, ma con diversi
vincoli di validita. Questa non rappresenta una soluzione ottimale, in quanto
si preferirebbe un unico predicato, con una determinata semantica, e vincolato
mediante altri predicati.
Un’altra soluzione potrebbe essere quella di creare, per ciascun predicato
soggetto a scope, uno statement di reificazione, in modo potersi riferire ad essi
come risorse e potervi quindi associare dei vincoli di validita.
Sarebbe comunque necessaria l’introduzione di predicati a cui attribuire
la semantica di “scope”, non essendo questa prevista in nessun costrutto
RDF/RDFS.

82 Capitolo 3. Conversione di formati
La soluzione proposta fa effettivamente ricorso alla definizione di un
predicato RDF tm2rdf:scope che incorpora la semantica di contestualizza-
zione. Esso viene applicato alle risorse astratte create per modellare elementi
baseName, occurrence e association. In particolare ciascun tema presente nello
“scope” di questi costrutti sara l’oggetto di un predicato tm2rdf:scope nella
descrizione della risorsa astratta.
Esempio 3.13 Rifacendosi all’esempio 3.5, si puo limitare la validitadell’associazione ponendo entro l’elemento association un elemento scope.L’associazione risultante e definita come segue.
<association id="Association001">
<instanceOf>
<topicRef xlink:href="#at-autore_di">
</instanceOf>
<scope>
<topicRef xlink:href="#web_design"/>
<scope>
<member>
<roleSpec>
<topicRef xlink:href="#tt-pagina_web"/>
</roleSpec>
<topicRef xlink:href="#WebPage001"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#tt-person"/>
</roleSpec>
<topicRef xlink:href="#mario_rossi"/>
</member>
</association>
La traduzione produce le stesse risorse RDF definite nell’esempio 3.5.
L’unica risorsa ad essere modificata e la seguente, in cui viene utilizzato anche
il predicato atto a mappare l’elemento scope di XTM.
<rdf:Description rdf:ID="Association001">

3.3 Confronto fra modelli: differenze e soluzioni proposte 83
<rdf:type rdf:resource="#at-autore-di"/>
<tm2rdf:scope rdf:resource="#web_design"/>
<tm2rdf:association rdf:resource="#members_Association001"/>
</rdf:Description>
3.3.7 Reificazione
In Topic Maps non esistono costrutti espliciti per la reificazione, a differenza di
RDF, il quale definisce i predicati rdf:subject, rdf:object, rdf:predicate
per la descizione di un’asserzione da reificare, e rdf:bagID per riferirsi ad un
insieme di asserzioni.
Come detto nel paragrafo 2.3.3, reificare un’associazione “A” in Topic
Maps puo essere visto come rendere “A” membro di un’altra associazione
“B”, la quale permette di esprimere affermazioni ulteriori su “A”. Per fare
cio e sufficiente creare un topic che abbia come subjectIdentity l’URI di “A” e
usarlo come membro di “B”. Si rimanda all’esempio 2.16.
I due modelli in questo caso non presentano grosse differenze a livello
concettuale. La traduzione in ambedue i versi non pone particolari problemi,
ma la rappresentazione sintattica e sensibilmente diversa.
In particolare, nel caso della traduzione da XTM a RDF, se si considera
l’alternativa esposta nell’esempio 3.5 per la traduzione delle associazioni, non
occorre aggiungere altre regole di traduzione. Viceversa il secondo modello di
traduzione da associazioni (vedi esempio 3.7), presenta ulteriori complicazioni:
se si traduce una associazione reificata in un predicato RDF, non si ha piu la
possibilita di riferirsi ad esso e quindi poter effettuare affermazioni su di esso.
3.3.8 Schema RDF di traduzione
Si presenta in questo paragrafo lo schema contenente i predicati utilizzati per
la traduzione da Topic Maps.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
xmlns:xtm2rdf="http://cs.unibo.it/schemas/xtm2rdf#">

84 Capitolo 3. Conversione di formati
<rdf:Property baseName>
<rdfs:comment>Indica la risorsa astratta
che contiente le informazioni sulla denominazione
del soggetto
</rdfs:comment>
</rdf:Property>
<rdf:Property variant>
<rdfs:comment>Indica la risorsa astratta
che contiente le informazioni sulle denominazioni
alternative del soggetto
</rdfs:comment>
</rdf:Property>
<rdf:Property parameter>
<rdfs:comment>Indica la risorsa astratta
che contiente le informazioni sul contesto
di validita della denominazione alternativa del
soggetto
</rdfs:comment>
</rdf:Property>
<rdf:Property variantName>
<rdfs:comment>Indica la risorsa astratta
che contiente la denominazione alternativa
del soggetto
</rdfs:comment>
</rdf:Property>
<rdf:Property association>
<rdfs:range rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdfs:comment>Indica la risorsa astratta di tipo
rdf:Bag che contiene i riferimenti ai membri di
una associazione
</rdfs:comment>
</rdf:Property>
<rdf:Property scope>
<rdfs:comment>Indica una risorsa astratta che serve

3.4 Descrizione delle soluzioni proposte in letteratura 85
a contestualizzare il soggetto
</rdfs:comment>
</rdf:Property>
<rdf:RDF>
3.4 Descrizione delle soluzioni proposte in
letteratura
Prima di scendere nel dettaglio della soluzione proposta verranno mostrati i
lavori presentati per risolvere tali problematiche e verranno discussi alla luce
delle considerazioni fatte nei paragrafi precedenti.
3.4.1 Convergenza secondo Moore
La prima proposta per integrare RDF e Topic Maps e stata presentata
in [Moo01]. In questo articolo per prima cosa viene descritto un modo
per rappresentare il modello RDF mediante topic map. Tale conversione e
effettuata in maniera molto semplice: vengono definiti i subject indicators per
ogni componente del modello RDF, cioe per le asserzioni, i predicati, i soggetti
e gli oggetti. Cosı ogni asserzione RDF diventa un’associazione di tipo RDF
statement, in cui il soggetto, il predicato e l’oggetto hanno ruoli definiti dai
subject indicators.
In questo modo la rappresentazione di un documento RDF mediante mappe
e diretta, ma ancora non vengono affrontate varie problematiche. Ad esempio,
le risorse RDF probabilmente vengono convertite in topic, ma non e specificato
cosa accade ai loro URI: diventano il valore dell’elemento resourceRef o
dell’elemento subjectIndicatorRef? La differenza potrebbe sembrare sottile, ma
in realta la loro semantica e molto diversa. Per un ulteriore approfondimento
si rimanda al paragrafo 3.3.1. C’e da dire, comunque, che Moore afferma che lo
scopo propostosi nello scrivere il proprio articolo e mostrare che le mappe sono
un strumento abbastanza flessibile da permettere di modellare RDF, senza
volere fornire una soluzione esaustiva al problema.
Successivamente viene mostrato come modellare Topic Maps mediante

86 Capitolo 3. Conversione di formati
documenti RDF. Anche in questo caso la soluzione proposta e semplice: per
quasi ogni costrutto di Topic Maps vengono definiti dei predicati RDF, a cui
viene attribuita una semantica che permette un mapping diretto. Il modello
presentato, comunque, non e completo, poiche manca il mapping per gli
elementi variant e non viene affrontato il problema di come gestire gli elementi
resourceRef e subjectIndicatorRef. Comunque, anche qui, Moore afferma di
voler semplicemente mostrare come RDF permetta di rappresentare mappe.
In seguito viene affrontato il problema di come effettuare il mapping fra i
due modelli. In questa sezione vengono confrontati il modello RDF con quello
Topic Maps e i topic con le risorse. Gli URI delle risorse RDF diventano
valore degli elementi subjectIndicatorRef dei topic, ma non viene affrontato il
problema di quando mappare certi URI di risorse con elementi resourceRef.
Infine le asserzioni RDF vengono confrontate con le associazioni di Topic
Maps. Ogni asserzione viene mappata con un’associazione in cui:
• Il predicato diventa il tipo dell’associazione.
• I ruoli di soggetto e oggetto dell’associazione sono definiti da topic gia
prefissati, definiti per tale tipo di mapping.
Il lavoro proposto da Moore sembra interessante, anche se ad uno stadio
ancora non maturo, ma, in fondo, egli stesso afferma che e “solo un articolo
introduttivo”.
3.4.2 Integrazione secondo Lacher
Un altro articolo interessante e stato proposto in [LD01]. In questo lavoro
viene presentato un metodo per effettuare il mapping di Topic Maps in RDF
secondo il data model definito in [NB01], in cui viene spiegato il significato della
sintassi XTM. Infatti l’approccio qui descritto fa uso di uno schema RDF in cui
vengono definiti varie asserzioni RDF, atte a mappare i costrutti commentati
in [NB01]. Questo metodo e completo e reversibile, ma il documento RDF
risultante dal mapping e difficilmente rappresentabile.
Inoltre Lacher non fornisce alcun esempio di serializzazione di un
documento RDF cosı prodotto e pertanto risulta in parte difficoltoso valutare
completamente il suo lavoro. Comunque vari punti sono chiari:

3.4 Descrizione delle soluzioni proposte in letteratura 87
• Il mapping fa uso di uno schema RDF, pertanto per manipolare i
documenti prodotti e necessario che le applicazioni siano in grado di
capire lo schema utilizzato.
• Il documento RDF e di difficile comprensione; ad esempio, per ottenere
il valore dell’elemento baseName di un topic e necessario effettuare delle
query tutt’altro che banali sul documento RDF.
• Il problema degli elementi resourceRef e subjectIndicatorRef non e
affrontato.
• Non viene proposto il mapping da RDF verso Topic Maps.
3.4.3 Mapping secondo Ogievetsky
Anche in [Ogi01] viene seguito un approccio simile al precedente: Ogievetsky
si basa su [NB01], e introduce uno schema RDF molto diverso da quello
presentato in [LD01]. Vi sono svariati aspetti interessanti:
• Se un topic ha un elemento resourceRef, questo diventa l’URI della
risorsa RDF corrispondente (attributo rdf:about), in caso contrario
viene generato un identificatore univoco e viene posto come valore
dell’attributo rdf:ID. I campi subjectIndicatorRef diventano proprieta
della risorsa, anche se in RDF la semantica di risorsa e di soggetto che
costituisce la risorsa non e chiara.
• La relazione classe-istanza tra topic e rappresentata usando rdf:type.
• Le associazioni diventano risorse, i cui predicati rappresentano i topic
facenti parte dell’associazione.
• I nomi e le occorrenze di un topic diventano risorse.
• Lo scope e rappresentato da uno specifico predicato.
La proposta di Ogievetsky per il mapping da Topic Maps a RDF e
praticamente completa, ma il mapping inverso non e stato affrontato. Inoltre,
i documenti RDF prodotti sono in una forma molto complessa.

88 Capitolo 3. Conversione di formati

Capitolo 4
Implementazione degli
strumenti di conversione
In questo capitolo verra descritto lo strumento implementato per la
realizzazione della conversione di documenti di meta informazioni espressi nei
formati RDF e Topic Maps.
Le motivazioni da cui nasce la necessita di un simile strumento sono
da ricercarsi nella possibilita di poter importare, in una base di dati di
metainformazioni espressa in uno dei due formati, dei documenti espressi
nell’altro formato e permettere alle applicazioni specializzate nella gestione
di solo RDF o solo XTM di poter trattare in modo trasparente i documenti
risultanti dalle conversioni. Cio consente di raggiungere un elevato grado di
interoperabilita tra le applicazioni che gestiscono meta-informazioni, senza che
sia necessario doverle modificare o aggiunger loro ulteriori funzionalita. In
particolare, ci si aspetta che le funzionalita di ricerca presenti in entrambi
gli ambiti, e implementati da linguaggi in via di standardizzazione quali
TMQL [Han01] e RQL [oCS01], possano essere utilizzati per interrogazioni
su documenti in qualsiasi formato, senza previa eventuale traduzione.

90 Capitolo 4. Implementazione del convertitore
4.1 Strumenti utilizzati nell’implementazione
Il convertitore e stato implementato con il linguaggio di programmazione
Java, nella versione 1.4. Non sono state utilizzate estensioni proprietarie al
linguaggio e come unico strumento di sviluppo si e utilizzato l’SDK fornito
gratuitamente da Sun [jav02a].
Per la manipolazione dei documenti RDF e Topic Maps si e pensato
di utilizzare delle librerie che consentissero la creazione dei Document
Object Model relativi ad entrambi i linguaggi, e che quindi permettessero
la manipolazione dei modelli attraverso comode API, rendendo del tutto
trasparenti i dettagli relativi al parsing e alla serializzazione dei documenti.
Per la gestione di documenti in formato XTM si e utilizzato il framework
TM4J [tm402] nella versione 0.6.5, Questo e un progetto individuale ancora in
fase di sviluppo ma allo stato attuale sufficientemente evoluto da permettere
una gestione del documento in memoria piu agevole rispetto a quella
offerta dalla mera interfaccia DOM dell’XML. Il livello di astrazione creato
dall’insieme delle interfacce esposte all’utente permette di agire in maniera
diretta sugli elementi della sintassi XTM. Tuttavia, come testimonia il numero
della versione, la scarsa maturita del pacchetto ha richiesto, oltre ad una buona
dose di lavoro per la correzione dei numerosi bachi segnalati di volta in volta
all’autore, la scrittura di numerose funzioni di utilita non ancora supportate
per una manipolazione dei documenti piu agevole. La natura Open Source del
progetto ha facilitato in questo senso le correzioni e la riscrittura del codice
necessario.
La scelta di questo framework, operata anche per l’implementazione
degli altri strumenti oggetto di questa dissertazione, e stata dettata dal
linguaggio di programmazione, comune alla scelta progettuale effettuata per
l’implementazione, dall’assenza di valide alternative, e dalla prevalenza che lo
strumento ha ottenuto in ambito scientifico.
Per la gestione di documenti in formato RDF, si e optato per il framework
Jena, nella versione 1.3.2, edito dal gruppo di ricerca Hewlett-Packard attivo
nel campo del Semantic Web [jen02]. Si tratta in questo caso di un framework
maturo e ampiamente utilizzato in ambito scientifico, completo delle piu
comuni funzionalita auspicabili. Al pari del precedente, viene offerto un

4.2 Problematiche di traduzione 91
insieme di interfacce che permettono un piu elevato livello di astrazione rispetto
alla rappresentazione XML del documento. In questo caso, data la natura piu
primitiva del modello RDF rispetto a Topic Maps, l’astrazione creata permette
la gestione del modello attraverso la manipolazione delle terne soggetto,
predicato e oggetto degli statement di cui e composto. Va sottolineato che
anche in questo caso si tratta di un prodotto Open Source, liberamente
scaricabile da rete ed utilizzabile in ambito sia privato che commerciale.
Entrambi questi framework si appoggiano a loro volta su vari altri diffusi
strumenti Open Source, tra cui in primis il parser XML Xerces dell’Apache
Software Fondation [xer02], usato da entrambi per il parsing dei documenti.
4.2 Problematiche di traduzione
L’ambito teorico del problema puo essere collocato a meta strada fra la
trasformazione di documenti XML e la traduzione tra programmi espressi in
due diversi linguaggi di programmazione. Tuttavia, gli approcci seguiti in
letteratura nella risoluzione di simili problemi sono difficilmente applicabili al
contesto di conversione tra documenti RDF e Topic Maps. Le trasformazioni di
documenti XML in diversi formati sono spesso limitate alla mera trasposizione
sintattica di semplici strutture informative e, benche sia possibile costruire
un foglio di stile che trasformi ogni singola istanza di documento RDF in
un documento XTM (e viceversa) nel modo che piu si ritiene adatto, la
generalizzazione del problema rende difficilmente praticabile questa strada.
Per quanto visto nel capitolo precedente spesso la conversione e fortemente
dipendente dalla natura semantica dei concetti descritti nei documenti,
difficilmente catturabile nella logica di un foglio di stile XSL. Oltre a cio,
un simile approccio renderebbe problematica anche la parametrizzazione della
conversione sulla base delle reali esigenze dell’utente.
Come e stato fatto notare nei precedenti capitoli, il livello semantico
raggiungibile da un documento in termini di caratterizzazione delle risorse
descritte e del tutto arbitrario per entrambi i modelli. Cio lascia ampia liberta
in fase di creazione dei documenti e rende gli standard flessibili senza limitarne

92 Capitolo 4. Implementazione del convertitore
l’estendibilita. Il compito di vincolare le strutture dei documenti espressi in
entrambi i formati e in effetti lasciato a livelli di specifica superiori:
• RDF Schema e successive estensioni nel caso di RDF.
• TMCL per Topic Map se e quando uno standard definitivo verra
finalmente redatto.
In assenza di schemi vincolanti, i documenti di entrambi i modelli possono
rivelarsi perfettamente corretti sintatticamente e coerenti alle poche regole
imposte dal modello stesso, ed essere al tempo stesso ambigui e difficilmente
interpretabili, se non completamente privi di significato reale. Considerando
ad esempio RDF, si pensi al sistema di tipizzazione definito dalle specifiche
RDF Schema [BG00]. Benche introduca concetti quali quelli di classe, di
proprieta e di tipo, non pone barriere alla definizione di una risorsa come classe
e proprieta allo stesso tempo, o come sottoclasse e al tempo stesso istanza di
un’altra classe. Non esistono cioe sufficienti distinzioni concettuali tra gli stessi
costrutti primitivi del linguaggio per poter pensare di assimilare il problema
della traduzione nel caso generico all’ambito dei linguaggi di programmazione,
come siamo comunemente abituati ad intenderli. Su questo fronte, le stesse
problematiche si presentano per Topic Maps, il quale ha gia insito un sistema
di tipizzazione con le stesse caratteristiche di potenziale ambiguita. In effetti,
il valore aggiunto che TMCL si propone di apportare in termini di espressivita
consiste nella possibilita di vincolare l’applicabilita dei costrutti Topic Maps
sulla base dei tipi loro assegnati.
L’assenza di vincoli strutturali di questo tipo e le inerenti potenziali
ambiguita proprie ai modelli, ostacolano l’applicabilita di metodi di traduzione
automatica ma non ne pregiudicano la possibilita. In effetti, le considerazioni
fatte ci permettono di classificare il problema della traduzione nel caso generico
come appartenente alla cosiddetta classe GIGO, acronimo di Garbage In
Garbage Out: se i dati in input sono privi di coerenza, cosı saranno i dati
in output. Il problema che ci si e posto e quindi quello di riuscire ad ottenere
documenti tradotti che ricalchino la semantica contenuta in quelli di partenza,
nella misura in cui quest’ultimi siano sufficientemente coerenti e non ambigui,
rifacendoci alle convenzionali regole in uso nella redazione di documenti per

4.2 Problematiche di traduzione 93
entrambi gli standard. In particolare, non ci si e preoccupati dei risultati
ottenibili da documenti redatti al di fuori di queste assunzioni.
4.2.1 Relazioni tra documenti e schemi
Come e stato ampiamente descritto nel capitolo precedente, il problema della
traduzione tra RDF e Topic Maps e piu compiutamente affrontabile se si
considera RDF affiancato ad un layer semantico, quale appunto RDF Schema:
in questo modo, nonostante i differenti approcci seguiti dai due standard, e
stato possibile proporre delle equivalenze di costrutti. RDF Schema svolge nei
confronti di RDF un doppio ruolo: oltre ad offrire un sistema di tipizzazione,
permette di definire vincoli sull’applicabilita delle Property definite. Spesso
i documenti RDF fanno riferimento a schemi pubblici (si pensi al Dublin
Core) o comunque definiti esternamente al documento stesso. Per consentire
un’operazione di traduzione di tipo batch, sono stati ignorate problematiche
derivanti dal recupero di informazioni esterne al documento oggetto della
traduzione. Poiche tali informazini sono comunque necessarie per la corretta
interpretazione semantica del documento, lo strumento sviluppato necessita,
per traduzione da RDF a XTM, di un unico documento nel quale siano presenti
sia la parte dichiarativa, cioe l’insieme delle classi e delle proprieta utilizzate
e definibili con RDF Schema, sia la parte descrittiva rappresentata dalle
asserzioni che associano metainforamzioni alle risorse. Inoltre viene assunta
la validazione del documento RDF di origine relativamente ai vincoli RDFS
applicabili.
Considerazioni simili valgono nel caso opposto di traduzione, ossia da XTM
a RDF. Come e stato descritto in precedenza, l’ambito della definizione di
schemi per Topic Maps e ancora poco definito. Tuttavia il linguaggio possiede
gia gli strumenti per la definizione di sistemi di tipi che prescindono da qualsiasi
schema. Infatti, attraverso i Published Subject Indicators introdotti da XTM
1.0 e possibile sia specificare il ruolo di classe, di tipo di associazione, di tipo di
occorrenza che possono avere i vari topic, sia specificare esplicite associazioni
di tipo superclasse e sottoclasse. Sebbene anche in questo caso possa essere
considerata pratica comune la separazione in file diversi del sistema di tipi e
del documento istanza, lo strumento di traduzione assume per semplicita la

94 Capitolo 4. Implementazione del convertitore
presenza di tutte le definzioni necessarie all’interno del documento XTM di
origine.
4.2.2 Relazioni tra i modelli di RDF e di Topic Maps
Come ampiamente argomentato nel precedente capitolo, attuare delle
conversioni di documenti tra i due formati in modo da preservare la semantica
del documento originario, produrre allo stesso tempo un documento convertito
semanticamente autocontenuto e quanto piu vicino possibile ad una forma
nativa dello stesso, rappresenta un’operazione difficilmente automatizzabile
nel caso generico.
Si e scelto pertanto di permettere all’utente di pilotare la conversione
attraverso delle regole basate sul matching dei vari costrutti, in modo da offrire
la possibilita di produrre documenti quanto piu possibile conformi alle reali
esigenze dell’utente stesso.
I modelli di conversione discussi nel precedente capitolo rappresentano la
base per la traduzione di documenti tra i due formati, utile per l’ottenimento
di modelli che conservino il contenuto meta-informativo secondo una struttura
coerente alle caratteristiche dei due linguaggi. La difficolta nel discernere, nel
caso generico, il reale significato delle relazioni esistenti tra risorse e meta-
informazioni ad esse associate, ha suggerito l’introduzione di un semplice
meccanismo che permetta di stabilire in che modo mappare i vari tipi di
relazioni.
In particolare, nel caso di conversione da modelli XTM a modelli RDF, e
possibile stabilire quali tipi di associazioni e quali tipi di occorrenze debbano
essere rappresentati come predicati RDF.
Abbiamo visto infatti che a causa dei diversi livelli semantici di associazioni
e occorrenze rispetto a predicati RDF preservare completamente i contenuti
informativi di una generica associazione XTM (potenzialmente composta da
piu di due membri, varie occorrenze e scope) e piuttosto complicato. E
necessario creare una insieme di classi e proprieta RDF che costringono le
applicazioni a conoscere il significato di tali definizioni.
Cio puo comportare la necessita di estendere le funzionalita di applicazioni
gia esistenti, cosa non sempre possibile, e puo non essere la soluzione

4.3 Esempi di conversione 95
migliore in piu situazioni. Non sempre infatti e desiderabile complicare la
struttura delle informazioni nell’intento di volerne conservare il piu possibile.
Spesso la priorita puo essere rivolta ad una maggiore conformita alle comuni
regole redazionali di un documento RDF, e soprattuto all’ottenimento di un
documento semanticamente autocontenuto e privo di riferimenti a strutture di
schema artificiose e dipendenti dall’applicazione.
Nel caso delle conversioni da modelli RDF a modelli XTM, lo stesso
problema si ripropone a parti invertite: predicati generici definiti dal
documento di origine possono essere riconoscibili piu adatti ad essere
rappresentati come associazioni o occorrenze di Topic Maps in maniera
inequivocabile solo conoscendo il significato del predicato, difficilmente
estrapolabile automaticamente dal contesto, senza una descrizione corretta di
dominio e codominio del predicato stesso. Per questi motivi l’implementazione
qui descritta fa uso di un sistema di traduzione che consente la specifica
di regole per pilotare le conversioni in entrambe le direzioni in maniera piu
appropriata. Un insieme di regole vuoto porta la traduzione al caso generico
come descritta nel precedente capitolo. Queste regole sono definibili per
ciascun verso di conversione mediante un file XML che verra descritto in
seguito.
4.3 Esempi di conversione
Il framework di conversione realizzato ha un meccanismo di funzionamento
diverso a seconda del modello cui appartiene il file di partenza, in linea con la
struttura del formato.
4.3.1 Conversione di documenti XTM in RDF
Nel caso della conversione da XTM a RDF, la mappa di partenza viene
inizialmente parsata al fine di ottenere la rappresentazione in memoria del
documento. Il modello di scansione e simile a quello realizzato dai parser
XML di tipo SAX.
Per ciascun elemento definito nella sintassi XTM e stato definita la routine
di gestione che riceve come parametri tutte le informazioni necessarie per

96 Capitolo 4. Implementazione del convertitore
la generazione degli statement RDF di traduzione. Le funzioni di gestione
per gli elementi innestati vengono invocate direttamente dagli elementi che li
contengono.
In maniera iterativa vengono elaborati prima tutti i topic e quindi tutte
le associazioni. Per ciascun topic e ciascuna associazione vengono invocate le
rispettive funzioni di traduzione, che a loro volta invocheranno le funzioni per
la traduzione degli elementi innestati presenti nel modello del documento in
memoria.
Le modalita di traduzione sono quelle descritte nel precedente capitolo,
ossia orientate all’utilizzo di uno schema RDF che descrive le classi e le
proprieta necessarie a conservare interamente il contenuto informativo del
documento XTM di origine.
Come anticipato, la traduzione di occorrenze e associazioni e parametrizza-
bile rispetto alle regole definibili mediante un opportuno file di configurazione
in XML.
E cosı possibile specificare che tutte le associazioni e tutte le occorrenze
tipizzate nello stesso modo devono essere tradotte con proprieta la cui struttura
e definita nel file di configurazione.
Per le associazioni e inoltre possibile specificare quali ruoli devono essere
considerati come dominio e quali come codominio della proprieta, offrendo cosı
la possibilita di risolvere il problema risultante dalla multidirezionalita delle
associazioni Topic Maps, discusso precedentemente nel paragrafo 3.3.3.
Esempio 4.1 Riprendendo e ampliando alcuni degli esempi gia visti nei
capitoli precedenti, consideriamo il seguente esempio:
<?xml version="1.0" encoding="ISO-8859-1"?>
<topicMap
xmlns="http://www.topicmaps.org/xtm/1.0/"
xmlns:xlink="http://www.w3.org/1999/xlink">
<topic id="at-autore-di">
<baseName>
<baseNameString>Autore Di</baseNameString>
</baseName>

4.3 Esempi di conversione 97
</topic>
<topic id="art-autore"/>
<topic id="art-website"/>
<topic id="ort-age"/>
<topic id="mario_rossi">
<baseName>
<baseNameString>Mario Rossi</baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#ort-age"/>
</instanceOf>
<resourceData>25</resourceData>
</occurrence>
</topic>
<topic id="mario_rossi_web_site">
<subjectIdentity>
<resourceRef xlink:href="http://www.mariorossi.com/"/>
</subjectIdentity>
</topic>
<association id="assoc">
<instanceOf>
<topicRef xlink:href="#at-autore-di"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#art-autore"/>
</roleSpec>
<topicRef xlink:href="#mario_rossi"/>
</member>
<member>
<roleSpec>

98 Capitolo 4. Implementazione del convertitore
<topicRef xlink:href="#art-website"/>
</roleSpec>
<topicRef xlink:href="#mario_rossi_web_site"/>
</member>
</association>
</topicMap>
Le impostazioni di default, cosı come descritte nel precedente capitolo,
producono il seguente documento RDF:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:xtm2rdf="http://cs.unibo.it/meta/tmschema.rdf#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdf:Description rdf:ID="membro_2">
<rdf:type rdf:resource="#art-website"/>
<rdfs:isDefinedBy rdf:resource="http://www.mariorossi.com/"/>
</rdf:Description>
<rdf:Description rdf:ID="membro_1">
<rdf:type rdf:resource="#art-autore"/>
<rdfs:isDefinedBy rdf:resource="#mario_rossi"/>
</rdf:Description>
<rdf:Description rdf:ID="assoc">
<xtm2rdf:association rdf:resource="#members_assoc"/>
<rdf:type rdf:resource="#at-autore-di"/>
</rdf:Description>
<rdf:Description rdf:ID="at-autore-di">
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Class"/>
<rdfs:label>Autore Di</rdfs:label>
</rdf:Description>

4.3 Esempi di conversione 99
<rdf:Description rdf:ID="members_assoc">
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="#membro_1"/>
<rdf:_2 rdf:resource="#membro_2"/>
</rdf:Description>
<rdf:Description rdf:ID="dataOccurrence_643">
<rdf:type rdf:resource="#ort-age"/>
<rdfs:label>25</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="mario_rossi">
<rdfs:label>Mario Rossi</rdfs:label>
<rdfs:seeAlso rdf:resource="#dataOccurrence_643"/>
</rdf:Description>
</rdf:RDF>
La natura binaria dell’associazione tra l’autore del sito ed il sito stesso,
puo suggerire una traduzione mediante proprieta associabile all’autore e con
oggetto la risorsa che rappresenta il sito o, viceversa, come una proprieta
associata al sito e che ha per oggetto il suo autore.
Analogamente, l’occorrenza di tipo age che associa a Mario Rossi la sua
eta puo essere interpretata, senza perdita di informazioni, come una proprieta
della persona. Pertanto si e reso possibile un simile comportamento mediante
la specifica delle seguenti regole:
<?xml version="1.0"?>
<xtm2rdf>
<property_associations>
<li id="at-autore_di">
<domain_role id="art-autore"/>
<range_role id="art-website"/>
</li>
</property_associations>

100 Capitolo 4. Implementazione del convertitore
<property_occurrences>
<li id="ort-age"/>
</property_occurrences>
</xtm2rdf>
Ossia, si specificano gli identificatori dei tipi di associazione e dei tipi
di occorrenze che si desidera tradurre come proprieta. Per le associazioni e
possibile stabilire anche quali occurrence role types devono essere considerati
soggetto e quali oggetto della proprieta relativa. Con l’aggiunta di queste
regole si ottiene il seguente documento RDF:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:NS0="http://cs.unibo.it/test.rdf#">
<rdf:Description rdf:ID="at-autore_di">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:label>Autore Di</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="ort-age">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<rdf:Description rdf:ID="mario_rossi">
<rdfs:label>Mario Rossi</rdfs:label>
<NS0:ort-age>25</NS0:ort-age>
<NS0:at-autore_di rdf:resource="http://www.mariorossi.com/"/>
</rdf:Description>
</rdf:RDF>
Va sottolineato come cio comporti la perdita delle eventuali informazioni di

4.3 Esempi di conversione 101
scope relative alle associazioni ed occorrenze mappate a proprieta. Tuttavia,
estendendo il meccanismo ad ogni tipo di associazione e di occorrenza, si
ottiene l’indipendenza del documento prodotto dallo schema di traduzione.
4.3.2 Conversione di documenti RDF in XTM
Consideriamo ora la conversione in senso opposto a quello appena esaminato,
ossia da documenti RDF a documenti XTM. La struttura XML della
serializzazione RDF e priva di livelli innestati. In effetti, benche le sintassi
abbreviate possono portare, attraverso descrizioni anonime, ad un arbitrario
livello di “nesting”, il modello risultante e comunque rappresentabile in forma
“lineare”, ovvero in una forma che elenca le descrizioni di risorse di primo
livello.
Inoltre, il modello in memoria successivo al parsing e costituito dalla lista
di statement che il documento RDF rappresenta.
Quindi, l’analisi del documento RDF di origine avviene mediante una
scansione dell’elenco di statement, e procede sulla base del tipo di predicato
esaminato.
In questo modo si attua una sorta di verifica sulla struttura del grafo diretto
che il modello rappresenta.
Il procedimento equivale, in effetti, ad esaminare tutti gli archi uscenti
da ciascun nodo del grafo e ad applicare l’opportuna funzione di conversione,
basata sulla natura dell’arco e dei nodi ai suoi estremi.
Per ciascun predicato definito, vengono applicate le regole di conversione
viste nel capitolo precedente. In particolare, per i predicati non appartenenti
alle specifiche RDF e RDFS, e possibile, come nel caso precedente, specificare
la modalita di conversione attraverso un file XML.
Vengonono riportati qui di seguito alcuni possibili esempi di conversione.
Esempio 4.2 Consideriamo un esempio di documento RDF comprendente lo
schema Dublin Core [dc01] ed una descrizione di risorsa relativa alla pagina
iniziale del sito stesso e da esso linkata. Per brevita si e preferito eliminare
le parti non essenziali dello schema, comprendenti commenti e proprieta non
significative per l’esempio.

102 Capitolo 4. Implementazione del convertitore
<?xml version="1.0"?>
<!--
RDF Schema declaration for the Dublin Core Element Set 1.1
2001/08/14 comments, etc. to webteam <[email protected]>
-->
<!DOCTYPE rdf:RDF [
<!ENTITY rdfns ’http://www.w3.org/1999/02/22-rdf-syntax-ns#’>
<!ENTITY rdfsns ’http://www.w3.org/2000/01/rdf-schema#’>
<!ENTITY dcns ’http://purl.org/dc/elements/1.1/’>
]>
<rdf:RDF xmlns:rdf="&rdfns;"
xmlns:rdfs="&rdfsns;"
xmlns:dc="&dcns;">
<!-- Begin: Title Declaration -->
<rdf:Property rdf:about = "&dcns;title">
<rdfs:label>Title</rdfs:label>
<rdfs:comment>A name given to the resource.</rdfs:comment>
</rdf:Property>
<rdf:Property rdf:about = "&dcns;contributor">
<rdfs:label>Contributor</rdfs:label>
<rdfs:comment>
An entity responsible for making contributions to the
content of the resource.
</rdfs:comment>
</rdf:Property>
<rdf:Property rdf:about = "&dcns;description">
<rdfs:label>Description</rdfs:label>
<rdfs:comment>
An account of the content of the resource.
</rdfs:comment>
</rdf:Property>

4.3 Esempi di conversione 103
<rdf:Property rdf:about = "&dcns;date">
<rdfs:label>Date</rdfs:label>
<rdfs:comment>
A date associated with an event in the life cycle of
the resource.
</rdfs:comment>
</rdf:Property>
<rdf:Property rdf:about = "&dcns;format">
<rdfs:label>Format</rdfs:label>
<rdfs:comment>
The physical or digital manifestation of the
resource.
</rdfs:comment>
<rdfs:isDefinedBy rdf:resource = "&dcns;" />
</rdf:Property>
<rdf:Property rdf:about = "&dcns;language">
<rdfs:label>Language</rdfs:label>
<rdfs:comment>
A language of the intellectual content of the
resource.
</rdfs:comment>
<rdfs:isDefinedBy rdf:resource = "&dcns;" />
</rdf:Property>
<!-- esempio di descrizione basata su schema Dublin Core -->
<rdf:Description rdf:about="http://dublincore.org/">
<dc:title>
Dublin Core Metadata Initiative (DCMI) Home Page
</dc:title>
<dc:description>
The Dublin Core Metadata Initiative is an open
forum engaged in the development of interoperable

104 Capitolo 4. Implementazione del convertitore
online metadata standards that support a broad
range of purposes and business models. DCMI’s
activities include consensus-driven working
groups, global workshops, conferences, standards
liaison, and educational efforts to promote
widespread acceptance of metadata standards and
practices.
</dc:description>
<dc:date>2001-01-16</dc:date>
<dc:format>text/html</dc:format>
<dc:language>en</dc:language>
<dc:contributor>
Dublin Core Metadata Initiative
</dc:contributor>
</rdf:Description>
</rdf:RDF>
Quello riportato qui di seguito e il documento tradotto in XTM.
Anche in questo caso sono state eliminate per brevita le parti poco
significative e sono stati resi piu leggibili gli identificatori dei costrutti
normalmente costiuite da stringhe esadecimali.
<?xml version="1.0" encoding="UTF-8"?>
<topicMap xmlns="http://www.topicmaps.org/xtm/1.0/"
xmlns:xlink="http://www.w3.org/1999/xlink">
<topic id="occ-type">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#occurrence"/>
</subjectIdentity>
</topic>
<topic id="ass-type">
<subjectIdentity>

4.3 Esempi di conversione 105
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#association"/>
</subjectIdentity>
</topic>
<topic id="topic-type">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#class"/>
</subjectIdentity>
</topic>
<topic id="format">
<instanceOf>
<topicRef xlink:href="#occ-type"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://purl.org/dc/elements/1.1/format"/>
</subjectIdentity>
<baseName>
<baseNameString>Format</baseNameString>
</baseName>
<occurrence>
<resourceData>
The physical or digital manifestation of the resource.
</resourceData>
</occurrence>
</topic>
<topic id="title">
<instanceOf>
<topicRef xlink:href="#occ-type"/>
</instanceOf>
<subjectIdentity>
<resourceRef

106 Capitolo 4. Implementazione del convertitore
xlink:href="http://purl.org/dc/elements/1.1/title"/>
</subjectIdentity>
<baseName>
<baseNameString>Title</baseNameString>
</baseName>
<occurrence>
<resourceData>A name given to the resource.</resourceData>
</occurrence>
</topic>
<topic id="language">
<instanceOf>
<topicRef xlink:href="#occ-type"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://purl.org/dc/elements/1.1/language"/>
</subjectIdentity>
<baseName>
<baseNameString>Language</baseNameString>
</baseName>
<occurrence>
<resourceData>
A language of the intellectual content of the resource.
</resourceData>
</occurrence>
</topic>
<topic id="contributor">
<instanceOf>
<topicRef xlink:href="#occ-type"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://purl.org/dc/elements/1.1/contributor"/>
</subjectIdentity>

4.3 Esempi di conversione 107
<baseName>
<baseNameString>Contributor</baseNameString>
</baseName>
<occurrence>
<resourceData>
An entity responsible for making contributions
to the content of the resource.
</resourceData>
</occurrence>
</topic>
<topic id="date">
<instanceOf>
<topicRef xlink:href="#occ-type"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://purl.org/dc/elements/1.1/date"/>
</subjectIdentity>
<baseName>
<baseNameString>Date</baseNameString>
</baseName>
<occurrence>
<resourceData>
A date associated with an event in the life
cycle of the resource.
</resourceData>
</occurrence>
</topic>
<topic id="description">
<instanceOf>
<topicRef xlink:href="#occ-type"/>
</instanceOf>
<subjectIdentity>
<resourceRef

108 Capitolo 4. Implementazione del convertitore
xlink:href="http://purl.org/dc/elements/1.1/description"/>
</subjectIdentity>
<baseName>
<baseNameString>Description</baseNameString>
</baseName>
<occurrence>
<resourceData>
An account of the content of the resource.
</resourceData>
</occurrence>
</topic>
<topic id="dublinCoreHomePage">
<subjectIdentity>
<resourceRef xlink:href="http://dublincore.org/"/>
</subjectIdentity>
<occurrence>
<instanceOf>
<topicRef xlink:href="#language"/>
</instanceOf>
<resourceData>en</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#format"/>
</instanceOf>
<resourceData>text/html</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#contributor"/>
</instanceOf>
<resourceData>Dublin Core Metadata Initiative</resourceData>
</occurrence>
<occurrence>
<instanceOf>

4.3 Esempi di conversione 109
<topicRef xlink:href="#description"/>
</instanceOf>
<resourceData>
The Dublin Core Metadata Initiative is an
open forum engaged in the development of
interoperable online metadata standards that support
a broad range of purposes and business models.
DCMI's activities include consensus-driven working
groups, global workshops, conferences, standards
liaison, and educational efforts to promote
widespread acceptance of metadata standards and practices.
</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#title"/>
</instanceOf>
<resourceData>
Dublin Core Metadata Initiative (DCMI) Home Page
</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#date"/>
</instanceOf>
<resourceData>2001-01-16</resourceData>
</occurrence>
</topic>
</topicMap>
Come si puo notare il modello prodotto esprime i concetti del documento
originale, identificando propriamente i ruoli delle proprieta RDF come tipi di
occorrenze, istanziate poi nel topic corrispondente alla risorsa a cui le proprieta
si riferiscono.
Si noti come l’identifcazione della parte dichiarativa della mappa faccia

110 Capitolo 4. Implementazione del convertitore
riferimento ai Published Subject Indicators per descrivere il sistema di
tipizzazione di XTM.
Esempio 4.3 A complemento dell’esempio precedente presentiamo la tradu-
zione di un documento RDF che definisce una semplice ontologia, presente nel
documento di specifica di RDF Schema. Esso definisce un insieme di classi che
modellano autoveicoli associabili ai proprietari.
<?xml version=’1.0’ encoding=’ISO-8859-1’?>
<!DOCTYPE rdf:RDF [
<!ENTITY rdf ’http://www.w3.org/1999/02/22-rdf-syntax-ns#’>
<!ENTITY rdfs ’http://www.w3.org/TR/1999/PR-rdf-schema-19990303#’>
<!ENTITY mv ’http://targetnamespace/vehicle-onthology#’>
]>
<rdf:RDF xmlns:rdf="&rdf;"
xmlns:rdfs="&rdfs;">
<rdfs:Class rdf:about="&mv;MiniVan">
<rdfs:subClassOf rdf:resource="&mv;PassengerVehicle"/>
<rdfs:subClassOf rdf:resource="&mv;Van"/>
</rdfs:Class>
<rdfs:Class rdf:about="&mv;MotorVehicle">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdfs:Class rdf:about="&mv;PassengerVehicle">
<rdfs:subClassOf rdf:resource="&mv;MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:about="&mv;Truck">
<rdfs:subClassOf rdf:resource="&mv;MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:about="&mv;Van">

4.3 Esempi di conversione 111
<rdfs:subClassOf rdf:resource="&mv;MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:about="&mv;Person">
<rdfs:subClassOf rdf:resource="&rdfs;Resource"/>
</rdfs:Class>
<rdf:Property rdf:about="&mv;name">
<rdfs:domain rdf:resource="&mv;Person"/>
<rdfs:range rdf:resource="&rdfs;Literal"/>
</rdf:Property>
<rdf:Property rdf:about="&mv;rearSeatLegRoom">
<rdfs:domain rdf:resource="&mv;MotorVehicle"/>
<rdfs:range rdf:resource="&rdfs;Literal"/>
</rdf:Property>
<rdf:Property rdf:about="&mv;registeredTo">
<rdfs:domain rdf:resource="&mv;MotorVehicle"/>
<rdfs:range rdf:resource="&mv;Person"/>
</rdf:Property>
</rdf:RDF>
Il documento tradotto in XTM e quello che segue. Si noti che il documento
di origine definisce solamente un sistema di tipi senza introdurre alcuna risorsa
istanza, e che pertanto utilizza solamente proprieta di RDF Schema.
La tipizzazione dei topic di traduzione fa ricorso ai Subject Indicators di
XTM.
I rapporti di tipo superclasse sottoclasse tra topic sono definiti mediante
un’apposita associzione che esplicita i ruoli.
Anche in questo caso, per facilitare la leggibilita del documento si sono
sostituiti gli idetificatori.
<?xml version="1.0" encoding="UTF-8"?>
<topicMap xmlns="http://www.topicmaps.org/xtm/1.0/"

112 Capitolo 4. Implementazione del convertitore
xmlns:xlink="http://www.w3.org/1999/xlink">
<topic id="tt-class">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#class"/>
</subjectIdentity>
</topic>
<topic id="tt-association">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#association"/>
</subjectIdentity>
</topic>
<topic id="tt-occurrence">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#occurrence"/>
</subjectIdentity>
</topic>
<topic id="at-superclass-subclass">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass"/>
</subjectIdentity>
</topic>
<topic id="ort-superclass">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass"/>
</subjectIdentity>
</topic>

4.3 Esempi di conversione 113
<topic id="ort-subclass">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#subclass"/>
</subjectIdentity>
</topic>
<topic id="motorVehicle">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://vehicle-onthology/MotorVehicle"/>
</subjectIdentity>
</topic>
<topic id="passengerVehicle">
<instanceOf>
<topicRef xlink:href="#x1gmot94il-1b"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://vehicle-onthology/PassengerVehicle"/>
</subjectIdentity>
</topic>
<topic id="rearSeatLegRoom">
<instanceOf>
<topicRef xlink:href="#tt-occurrence"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://vehicle-onthology/rearSeatLegRoom"/>
</subjectIdentity>

114 Capitolo 4. Implementazione del convertitore
</topic>
<topic id="registeredTo">
<instanceOf>
<topicRef xlink:href="#tt-association"/>
</instanceOf>
<subjectIdentity>
<resourceRef
xlink:href="http://vehicle-onthology/registeredTo"/>
</subjectIdentity>
</topic>
<topic id="person">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://vehicle-onthology/Person"/>
</subjectIdentity>
</topic>
<topic id="van">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://vehicle-onthology/Van"/>
</subjectIdentity>
</topic>
<topic id="name">
<instanceOf>
<topicRef xlink:href="#tt-occurrence"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://vehicle-onthology/name"/>

4.3 Esempi di conversione 115
</subjectIdentity>
</topic>
<topic id="miniVan">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://vehicle-onthology/MiniVan"/>
</subjectIdentity>
</topic>
<topic id="truck">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://vehicle-onthology/Truck"/>
</subjectIdentity>
</topic>
<association>
<instanceOf>
<topicRef xlink:href="#at-superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#ort-subclass"/>
</roleSpec>
<topicRef xlink:href="#passengerVehicle"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#ort-superclass"/>
</roleSpec>
<topicRef xlink:href="#motorVehicle"/>

116 Capitolo 4. Implementazione del convertitore
</member>
</association>
<association>
<instanceOf>
<topicRef xlink:href="#at-superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#ort-subclass"/>
</roleSpec>
<topicRef xlink:href="#truck"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#ort-superclass"/>
</roleSpec>
<topicRef xlink:href="#motorVehicle"/>
</member>
</association>
<association>
<instanceOf>
<topicRef xlink:href="#at-superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#ort-subclass"/>
</roleSpec>
<topicRef xlink:href="#miniVan"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#ort-superclass"/>
</roleSpec>
<topicRef xlink:href="#passengerVehicle"/>

4.3 Esempi di conversione 117
</member>
</association>
<association>
<instanceOf>
<topicRef xlink:href="#at-superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#ort-subclass"/>
</roleSpec>
<topicRef xlink:href="#van"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#ort-superclass"/>
</roleSpec>
<topicRef xlink:href="#motorVehicle"/>
</member>
</association>
<association>
<instanceOf>
<topicRef xlink:href="#at-superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#ort-subclass"/>
</roleSpec>
<topicRef xlink:href="#miniVan"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#ort-superclass"/>
</roleSpec>
<topicRef xlink:href="#van"/>

118 Capitolo 4. Implementazione del convertitore
</member>
</association>
</topicMap>
Come si nota, la convenzione adottata per la referenziazione a soggetti
pubblici e quella di definire topic stub che rappresentino i PSI per poter
ottenere riferimenti locali.
Questo approccio, oltre ad essere sintatticamente corretto, facilita le
operazioni di manipolazione del documento in fase di creazione.
4.4 Architettura del sistema
L’implemetazione del convertitore e stata pilotata dall’idea di produrre un
software quanto piu modulare possibile. Questa scelta e stata dettata, oltre
dalle regole di buona programmazione, anche dall’esigenta di rendere tale
software il piu configurabile possibile, persino da parte di un utente che sia
poco avvezzo alle problematiche di conversione e di manipolazione di metadati.
Pertanto, come si puo notare dal seguente class diagramm, si possono
individuare i seguenti componenti:
Meta Il cuore dell’applicazione. Richiama tutti i componenti necessari al fine
di eseguire la conversione richiesta.
ConfEngine Si occupa di leggere i file di configurazione. Per una descrizione
del formato di tali file di rimanda la paragrafo 4.6.
PluginEngine Permette il caricamento dinamico dei moduli (o plugin) usati
per la conversione. Nel paragrafo 4.6 verra mostrato come installare
correttamente tali componenti. Si possono notare inoltre le classi:
ClassLoader Si occupa dell’effettivo caricamento dei plugin.
ConversionTable Pilota la conversione usando i parametri letti nei file
di configurazione e i moduli prima caricati.

4.4 Architettura del sistema 119
InputParser Legge il file di cui si vuole effettuare la conversione e le crea il
modello il memoria.
OutputSerializer Al termine della conversione questo componente si occupa
di serializzare il modello risultante, salvandolo cosı nel file specificato.
ConfigurationManager
ConfEngine
ClassLoaderConversionTable
PluginEngine
InputParser
Meta
OutputSerializer
Figura 4.1: Il class diagram concettuale del covertitore
Proseguendo con la specifica dei componenti si e reso necessario suddividere
le funzionalita di lettura e di salvataggio di un file in base al verso di traduzione:
da Topic Maps verso RDF o viceversa.
Nel primo caso (vedi figura 4.2) i componenti InputParser e Out-
putSerializer sono stati sostituiti da una gerarchia di classi un po’ piu
complicata:
XTMDocParser Effettua il caricamento del documento XTM da convertire.
Ne crea il modello usando MyXTMBuilder, che implementa l’interfaccia
TopicMapHandler definita nelle API del pacchetto TM4J.

120 Capitolo 4. Implementazione del convertitore
RDFProducer E la classe astratta, che in seguito verra specificata, che si
occupa di creare il modello RDF corrispondente al documento XTM
prima caricato. Infine il modello verra serializzato in XML.
TopicMapHandler
ConfigurationManager
MyXTMBuilder
ConfEngineXTMDocParser
RDFProducer
Meta
ClassLoaderConversionTable
XTMPlugin
PluginEngine
Figura 4.2: Il class diagram per la traduzione da Topic Maps verso RDF
Nel caso di traduzione da RDF verso Topic Maps (vedi figura 4.3), i
componenti InputParser e OutputSerializer sono stati sostituiti dalle seguenti
classi:
RDFDocParser Effettua il caricamento del documento RDF da convertire
e ne crea il modello.
XTMProducer Crea il modello del documeto XTM risultante dalla
conversione. A tal fine usa la classe MyTopicMapWalker, che permette
la navigazione del modello stesso. La serializzazione, infine, e effettuata
mediante MyXTMWriter.

4.5 Dettagli di implementazione 121
TopicMapWriter
MyXTMWriter
MyTopicMapWalker
ConfigurationManager
RDFDocParser
XTMProducer
ConfEngine ClassLoaderConversionTable
MetaRDFPlugin
PluginEngine
Figura 4.3: Il class diagram per la traduzione da RDF verso Topic Maps
4.5 Dettagli di implementazione
In questo paragrafo verranno trattati tutti gli aspetti di implementazione
necessari a comprendere la particolare organizzazione in classi del convertitore;
verranno mostrati i passi compiuti durante la traduzione ed infine verra
commentata l’achitettura a plugin utilizzata.
4.5.1 Il serializzatore RDF
Come anticipato nel paragrafo precedente, i costituenti del componente atto
alla serializzazione del documento nel caso di traduzione da XTM verso RDF
sono rappresentati nella figura 4.4. Si noti il supporto fornito a due insiemi
di API: Jena, di cui e gia stato discusso prima, e le cosidette Stanford RDF
API, prodotte dall’Universita di Stanford, il cui ultimo aggiornamento risale
agli inizi del 2001.
A tal fine sono state definite due classi, JenaRDFProducer e W3CRDFPro-
ducer (entrambe implementano RDFProducer), che si occupano di serializzare

122 Capitolo 4. Implementazione del convertitore
il documento RDF mediante, rispettivamente, JenaRDFXMLWriter e
MySerializer.
RDFXMLWriter
Comparator RDFSerializer
RDFFactoryImpl
MySerializer
MyRDFFactoryImpl
W3CRDFProducer
RDFProperty
RDFStatementRDFResource
RDFLiteral
RDFProducer
JenaRDFXMLWriter
JenaRDFProducer
Figura 4.4: Il class diagram per il serializzatore RDF
4.5.2 La fase di bootstrap
Dopo aver definito nei paragrafi precedenti le dipenze fra i componenti che
compongono il convertitore, a causa del loro gran numero e necessario chiarire
anche l’ordine in cui essi interagiscono.
Nel sequence diagram di figura 4.5 vengono mostrati i messaggi scambiati
fra i vari componenti del convertitore durante la fase di bootstrap. Si possono
notare i seguenti passi salienti:
1. Il componene principale, Meta, ottiene un’istanza del lettore del file
di configurazione, che usa per inizializzare i parametri dell’applicazione
(initConfig()).
2. Viene richiesto al PluginEngine di caricare i plugin installati e quindi di
inizializzarli.

4.5 Dettagli di implementazione 123
3. Viene iniziato il parsing del documento da convertire. Nell’esempio e
mostrato il parsing di un file XTM, e pertanto vengono chiamati i metodi
startTopicGeneration() e startAssociationGeneration().
4. Alla fine della conversione il modello viene serializzato (writeRDF()).
m : Meta ce : ConfEngine
pe : PluginEngine
dp : XTMDocParser
rp : JenaRDFProducer
getInstance( )
initConfig( )
initPlugins( )
identifyFile( )
loadPlugin( )
registerPlugins( )
initParsing( )
startTopicGeneration( )
startAssociationGeneration( )
writeRDF( )
writeRDF( )
Figura 4.5: Fase di bootstrap del convertitore
4.5.3 I plugin
L’alto grado di configurabilita richiesto e stato soddisfatto realizzando due
strumenti che permettono di pilotare la traduzione:
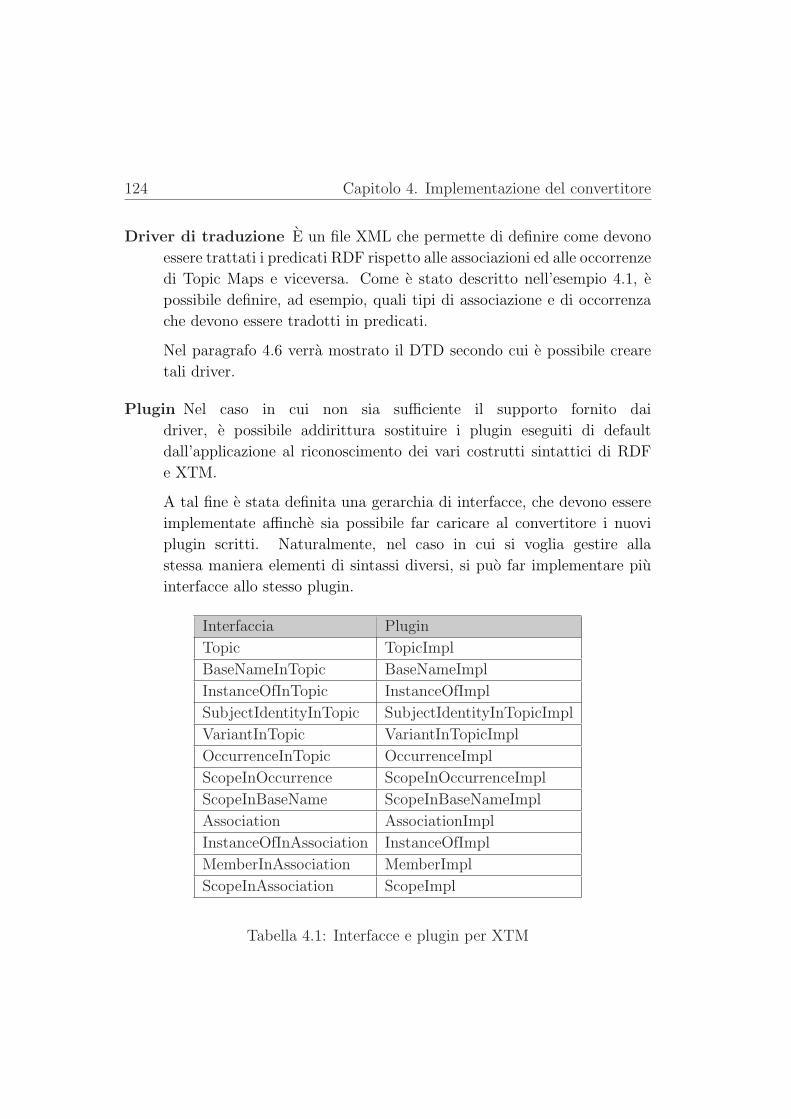
124 Capitolo 4. Implementazione del convertitore
Driver di traduzione E un file XML che permette di definire come devono
essere trattati i predicati RDF rispetto alle associazioni ed alle occorrenze
di Topic Maps e viceversa. Come e stato descritto nell’esempio 4.1, e
possibile definire, ad esempio, quali tipi di associazione e di occorrenza
che devono essere tradotti in predicati.
Nel paragrafo 4.6 verra mostrato il DTD secondo cui e possibile creare
tali driver.
Plugin Nel caso in cui non sia sufficiente il supporto fornito dai
driver, e possibile addirittura sostituire i plugin eseguiti di default
dall’applicazione al riconoscimento dei vari costrutti sintattici di RDF
e XTM.
A tal fine e stata definita una gerarchia di interfacce, che devono essere
implementate affinche sia possibile far caricare al convertitore i nuovi
plugin scritti. Naturalmente, nel caso in cui si voglia gestire alla
stessa maniera elementi di sintassi diversi, si puo far implementare piu
interfacce allo stesso plugin.
Interfaccia Plugin
Topic TopicImpl
BaseNameInTopic BaseNameImpl
InstanceOfInTopic InstanceOfImpl
SubjectIdentityInTopic SubjectIdentityInTopicImpl
VariantInTopic VariantInTopicImpl
OccurrenceInTopic OccurrenceImpl
ScopeInOccurrence ScopeInOccurrenceImpl
ScopeInBaseName ScopeInBaseNameImpl
Association AssociationImpl
InstanceOfInAssociation InstanceOfImpl
MemberInAssociation MemberImpl
ScopeInAssociation ScopeImpl
Tabella 4.1: Interfacce e plugin per XTM

4.5 Dettagli di implementazione 125
Nella tabella 4.1 e possibile notare le relazioni esistenti fra i plugin e le
interfacce definite nel caso della traduzione da XTM verso RDF.
Si noti che:
• Ogni interfaccia estende la classe XTMPlugin.
• In nome di ogni interfaccia e nella forma NomeElemento-In-
NomeGenitore, dove NomeElemento indica l’elemento XTM che
ha generato la chiamata al plugin corrispondente, e NomeGenitore
indica l’elemento che contiene NomeElemento.
• Come si e potuto notare dal sequence diagram di figura 4.5, la
traduzione inizia scandendo prima tutti i topic ed in seguito tutte
le associazioni. E compito di questi plugin invocare gli altri, in base
agli elementi contenuti in Topic e in Association.
Interfaccia Plugin
Default DefaultImpl
RDFDescription RDFDescriptionImpl
RDFSLabel RDFSLabelImpl
RDFType RDFTypeImpl
RDFSSubClassOf RDFSSubClassOfImpl
RDFSSubPropertyOf RDFSSubPropertyOfImpl
RDFSRange RDFSRangeImpl
RDFSDomain RDFSDomainImpl
RDFSIsDefinedBy RDFSIsDefinedByImpl
RDFSSeeAlso RDFSSeeAlsoImpl
RDFListItem RDFListItemImpl
RDFReif RDFReifImpl
RDFSComment RDFSCommentImpl
Tabella 4.2: Interfacce e plugin per RDF
Nella tabella 4.2 e possibile notare le relazioni esistenti fra i plugin e le
interfacce definite nel caso della traduzione da RDF verso XTM. Si noti
che ogni interfaccia estende RDFPlugin.

126 Capitolo 4. Implementazione del convertitore
La traduzione e questa volta pilotata dal tipo di predicato trovato
durante il parsing. In particolare:
Default Indica tutti i predicati che non fanno parte del namespace di
RDF e di RDFS.
RDFListItem Indica i predicati rdf: 1, rdf: 2, etc. racchiusi in un
contenitore RDF.
RDFReif Indica i predicati RDF usati per identificare un costrutto di
reificazione: rdf:subject, rdf:predicate, rdf:object.
4.6 Configurazione e installazione del software
In questi paragrafo verra discusso come configurare il convertitore, ponendo
particolare attenzione alla scrittura del file di configurazione ed al driver di
conversione. Infine verra mostrato come installare i plugin, nel caso in cui non
si vogliano usare quelli forniti.
4.6.1 Il file di configurazione
Il file di configurazione dell’editor si chiama config.xml ed e contenuto nella
directory conf. Esso e composto dalle seguenti sezioni:
general Contiene le impostazioni generali del converitore. Consta delle
proprieta:
convType Il tipo di conversione. Puo assumere i valori xtm2rdf e
rdf2xtm.
inFile Il nome del file da convertire, comprensivo di eventuale path.
outFile Il file che dovra contenere il risultato della conversione.
parser Il parser XML da usare.
Di solito coincide con org.apache.xerces.parsers.SAXParser.
xtm Contiene le impostazioni relative alla manipolazione dei documenti
XTM. E composto da:

4.6 Configurazione e installazione del software 127
baseURL URL, anche fittizio, del documento da convertire.
XTMSchema URL dello schema XTM.
pluginsPath Directory contenente i plugin utilizzati per la conversione
da XTM verso RDF.
driverFile Nome del driver di conversione, comprensivo di eventuale
path, oppure none.
rdf-api Nome del pacchetto di API usato per la manipolazione di
documenti RDF. Puo assumere i valori jena o w3c.
rdf Contiene le impostazioni relative alla manipolazione dei documenti RDF.
Include:
pluginsPath Directory contenente i plugin utilizzati per la conversione
da RDF verso XTM.
driverFile Nome del driver di conversione, comprensivo di eventuale
path, oppure none.
4.6.2 I driver di conversione
Il driver permette di ottenere una traduzione molto accurata, poiche permette
di specificare come trattare ogni tipo presente nel documento da convertire.
Nel caso di conversione da XTM:
• Permette di elencare, attraverso gli elementi property associations,
gli identificatori dei tipi di associazione che devono essere tradotte
direttamente come predicati RDF, senza l’uso delle risorse astratte
necessarie alla conversione di associazioni generiche. Permette inoltre
di definire quali membri dell’associazione devono essere considerati
soggetto e quali oggetto della proprieta RDF risultante. In particolare,
ogni qualvolta il motore di conversione dovra convertire un’istanza
di associazione tipizzata con il topic che ha per identificatore quello
specificato, verranno inseriti nel documento RDF degli statement cosı
fatti:

128 Capitolo 4. Implementazione del convertitore
– Hanno per soggetto le risorse corrispondenti ai topic tipizzati con
il topic-type il cui identificatore e indicato come attributo id in un
elemento domain role;
– Hanno come oggetto le risorse corrispondenti ai topic il cui topic-
type ha identificatore corrispondente all’attributo id di un elemento
range role.
Si noti che vengono creati automaticamente tutti gli statement nei quali
e possibile specificare come soggetto un membro con ruolo di dominio e
come oggetto un membro con ruolo di codominio.
• Permette di elencare gli identificatori delle occorrenze che devono
essere tradotte direttamente in predicati RDF. In particolare, tutte le
occorrenze tipizzate con un topic (che ha identificatore corrispondente
all’attributo id di un elemento li innestato in property occurrences)
verranno tradotte con proprieta della risorsa relativa al topic che contiene
l’occorrenza, aventi per oggetto il link o il testo dell’occorrenza.
Il DTD del driver per la coversione da XTM verso RDF e il seguente:
<!ELEMENT xtm2rdf
( property_associations | property_occurrences )*
>
<!ELEMENT property_associations
( li )*
>
<!ELEMENT li
( domain_role, range_role )*
>
<!ATTLIST li
id ID #REQUIRED
>

4.6 Configurazione e installazione del software 129
<!ELEMENT domain_role
EMPTY
>
<!ATTLIST domain_role
id ID #REQUIRED
>
<!ELEMENT range_role
EMPTY
>
<!ATTLIST range_role
id ID #REQUIRED
>
<!ELEMENT property_occurrences
( li )*
>
Nel caso di conversione da RDF, il driver di conversione:
• Permette di elencare, attravero gli elementi predicate innestati in
association predicates i predicati non standard, cioe non appartenenti
ai namespace normalmente indicati con rdf e rdfs, che devono essere
trasformati in associazioni Topic Maps. L’identificazione del predicato
avviene mediante specifica del suo namespace e del suo identificatore.
Poiche in RDF non e definito il concetto di ruolo in una associazione,
essendo implicito in quello di soggetto e oggetto di un predicato, tali
informazioni non vengono specificate nell’associazione creata.
• Permette di elencare, attravero gli elementi predicate innestati in
occurrence predicates, i predicati non standard che devono essere
trasformati in occorrenze Topic Maps. Analogamente al caso precedente,
l’identificazione del predicato avviene mediante specifica del suo
namespace e del suo identificatore.

130 Capitolo 4. Implementazione del convertitore
Il DTD del driver per la coversione da XTM verso RDF e il seguente:
<!ELEMENT rdf2xtm
( association_predicates | occurrence_predicates )*
>
<!ELEMENT association_predicates
( predicate )*
>
<!ATTLIST association_predicates
nameSpace CDATA #IMPLIED
predicateId CDATA #REQUIRED
>
<!ELEMENT occurrence_predicates
( predicate )*
>
<!ATTLIST occurrence_predicates
nameSpace CDATA #IMPLIED
predicateId CDATA #REQUIRED
>
<!ELEMENT predicate
EMPTY
>
4.6.3 I plugin
I plugin, indieme al driver, rappresentano uno dei mezzi atti a configurare la
traduzione. Nel paragrafo 4.5.3 e stato mostrata la gerarchia di classi definita
dai plugin; in questo paragrafo verra mostrato come installare ulteriori plugin
rispetto a quelli gia forniti.
Il file di configurazione conf.xml definisce due proprieta di nome
pluginsPath, che rappresentano le directory in cui risiedono tali plugin.

4.7 Possibili estensioni 131
I plugin di sistema sono contenuti nelle directory plugins e plugins2. Ogni
classe ivi definita dichiara inoltre appartenere al package plugins o plugins2.
Affinche il PluginEngine carichi nuovi plugin e pertanto necessario effettuare
i seguenti passi:
• Aggiornare il file di configurazione, inserendo le directory in cui si trovano
i plugin.
• Scrivere il plugin in modo che appartenga al package il cui nome coincida
con quello della directory in cui e contenuto e che implementi l’opportuna
interfaccia.
• Compilare tutto mediante lo script build.xml, eseguibile mediante il tool
Ant [ant02]. E sufficiente eseguire ant install dalla directory che
contiene i sorgenti.
Se tutto e stato eseguito correttamente, durante la fase di avvio verra
mostrato un messaggio che notifica il caricamento del nuovo plugin.
4.6.4 Esecuzione dell’applicazione
A causa del gran numero di librerie a cui il convertitore fa riferimento, lo
script build.xml fornisce anche il supporto all’avvio dell’applicazione. Pertanto
e sufficiente eseguire ant run dalla directory che contiene i sorgenti.
4.7 Possibili estensioni
Come abbiamo visto, affrontare il problema della traduzione nel caso generico
e un compito particolarmente difficile. Cio e dovuto al fatto che la “migliore”
traduzione di un documento e fortemente vincolata dal contesto, da quali
informazioni si vogliono preservare e da come tali informazioni debbano essere
rappresentate.
Lo strumento fornito cerca di risolvere il problema generando una
traduzione corretta ma che puo ovviamente non coincidere con la “migliore”
ottenibile.

132 Capitolo 4. Implementazione del convertitore
Il supporto fornito alla risoluzione di questo problema consiste nella
personalizzazione della traduzione mediante gli opportuni file di configurazione
che sono stati descritti nei paragrafi precedenti.

Capitolo 5
L’editor
Come si e visto nei capitoli precedenti, attraverso RDF e Topic Maps e possibile
descrivere risorse associando loro metainformazioni. Dopo aver esaminato
entrambi i modelli ed aver mostrato le caratteristiche sintattiche delle
rispettive grammatiche di serializzazione, vediamo quali sono le problematiche
relative alla creazione guidata di documenti nei due formati, nell’ottica di
automatizzare il processo di scrittura e portarlo ad un livello di astrazione che
nasconda all’utente i dettagli sintattici.
5.1 Introduzione
Gli indubbi vantaggi dell’utilizzo di XML come formato per documenti di
qualsiasi genere si scontrano spesso con le difficolta di editazione che essi
presentano. In generale, il problema dell’editazione puo essere affrontato con
strumenti piu sofisticati di un semplice editor di testo, in modo che i dettagli
sintattici del documento siano resi trasparenti all’utente.
In alcuni casi, il documento XML e il prodotto di un processo
completamente automatico, conseguente alla serializzazione di un modello di
dati editati o estratti da sorgenti informative di tutt’altra natura. Si pensi ad
esempio all’XML data binding di oggetti Java.
In altri casi, quando cioe la struttura dell’XML e esposta all’utente, gli
strumenti di editazione utilizzano il DTD o lo schema XML di riferimento per

134 Capitolo 5. Editazione di documenti RDF e XTM
permettere all’utente, tra le altre cose, di sapere quali elementi e necessario
inserire e quali valori siano consentiti per gli elementi e gli attributi definiti.
La creazione e l’editazione di documenti di metainformazioni nei formati
presi in esame in questa dissertazione e sicuramente piu vicino al secondo
di questi casi. In effetti, gli strumenti per la creazione di documenti RDF
e XTM a tutt’oggi disponibili sono essenzialmente editor XML basati sulla
grammatica dei due formati, definita da un DTD nel caso di Topic Maps e
da una specifica in EBNF per RDF. Tuttavia, sebbene strumenti di questa
natura facilitino la creazione, il grado di trasparenza che offrono all’utente e
molto limitato. In particolare l’utente e costretto a conoscere i concetti propri
a ciascuno dei due paradigmi per essere in grado di inserire metainformazioni
su qualsiasi tipo di risorsa. In questo modo, inoltre, non viene posta alcuna
distinzione tra le risorse che formano il sistema di tipizzazione del modello e
quelle che rappresentano le reali metainformazioni.
5.2 Caratteristiche generali dell’editor
L’idea alla base dello strumento di editazione che qui viene presentato e quella
di sfruttare le informazioni semantiche, rappresentate dalle ontologie e dai
vincoli definiti in appositi documenti di schema, per guidare l’utente alla
creazione di documenti validi e significativi, in maniera del tutto trasparente.
In questo modo si sposta il livello di astrazione dei modelli ad un livello
piu elevato rispetto al mero sistema di vincoli imposto dalla sintassi.
In effetti, se si pensa al sistema di tipi e all’insieme di vincoli di relazioni
introdotti da un’istanza di RDF Schema, si nota come queste informazioni
possano essere utilizzate come supporto alla creazione di documenti validi e
conformi allo schema, rendendo il processo di creazione rapido e sistematico.
In particolare, l’idea e quella di consentire la creazione di risorse descrittive
tipizzabili sulla base delle classi definite nello schema, e quindi, in base al tipo
specificato, consentire l’inserimento solo degli attributi e delle relazioni con le
altre risorse previste dallo schema stesso.

5.2 Caratteristiche generali dell’editor 135
5.2.1 Schemi per l’editazione
In virtu dell’approfondita indagine sulle analogie tra i due standard, l’obiettivo
che ci si e posti per la creazione dell’editor e stato quello di rendere del tutto
omogenea la visione dei modelli percepita dall’utente in relazione al linguaggio
di specifica. Il problema principale in questo senso e rappresentato dall’assenza
di uno standard ufficiale per la specifica di schemi in Topic Maps che permetta
di esprimere vincoli sulle relazioni possibili tra le risorse, simile a RDF
Schema. Pertanto, piuttosto che introdurre arbitrariamente un meccanismo
che consentisse di parificare i due standard sotto questo aspetto, si e optato
per l’implementazione di un sistema di vincoli analogo a quello introdotto
dalla versione propositiva di TMCL, pubblicata dalla ISO nel primo draft di
specifica [Ste01]. In effetti la potenzialita espressiva raggiunta da questa prima
istanza del linguaggio raggiunge il livello necessario agli scopi del progetto.
Interpretazione di schemi XTM
La caratteristica essenziale degli schemi esprimibili in questa versione di TMCL
e la definizione di tipi attraverso template. In particolare per esprimere
l’applicabilita di tipi di occorrenze ai topic si elencano tali occorrenze nel
template. Vediamo un esempio:
Esempio 5.1<topic id="ort-birthday">
<instnceOf>
<topicRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#occurrence-type"/>
</instanceOf>
<baseName>
<baseNameString>Data di nascita</baseNameString>
</baseName>
</topic>
<topic id="person">
<instnceOf>
<topicRef

136 Capitolo 5. Editazione di documenti RDF e XTM
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#topic-type"/>
</instanceOf>
<baseName>
<baseNameString>Persona</baseNameString>
</baseName>
<occurrence>
<instnceOf>
<topicRef xlink:href="#ort-birthday"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>
<resourceData></resourceData>
</occurrence>
</topic>
In questo caso si e definito un template di persona per il quale si e specificata
l’applicabilita dell’occorrenza di tipo ort-birthday.
Come si e accennato nel primo capitolo, l’interpretazione di uno schema
Topic Maps puo essere di due tipi: stringente (strict) o lasca (loose). Nel
primo caso, l’occorrenza dell’esempio precedente, cioe la data di nascita della
persona, verrebbe considerata necessaria per ogni topic istanza della classe
persona, mentre nel secondo caso sarebbe considerata solo facoltativamente
applicabile. Il diverso modo di interpretazione si riflette ovviamente nello
strumento di editazione guidata.
Come si e visto, la filosofia di RDF Schema e quella di definire proprieta
specificando le classi delle risorse a cui possono essere applicate, e non obbligare
quindi la specifica di una proprieta per una determinata risorsa. Quindi, poiche
si e voluta offrire la trasparenza del linguaggio utilizzato per i documenti
editati, si e scelta l’interpretazione lasca.
5.2.2 Relazioni e attributi
Le caratteristiche semantiche di RDF e Topic Maps rendono possibile la
creazione di strumenti che permettono di uniformare la visione dei modelli

5.2 Caratteristiche generali dell’editor 137
di metainformazioni.
Nei precedenti capitoli si e fatto spesso notare come una delle
caratteristiche che li differenzia maggiormente sia il modo in cui vengono
associati attributi alle cose descritte ed il modo in cui queste vengono messe
in relazione.
Nel caso di RDF si utilizzano in entrambi i casi delle proprieta che associano
alle risorse dei valori letterali o altre risorse, opportunamente tipizzate.
L’approccio di Topic Maps e quello di dividere tali informazioni in
occorrenze e associazioni. Il diverso ruolo di queste informazioni e in effetti
evidente.
Per questo motivo, per raggiungere un sufficiente grado di trasparenza, sie scelto di esporre attraverso l’editor tale diversita. In particolare vengonoidentificati come attributi le proprieta RDF che lo schema definisce concodominio di tipo Literal. Ad esempio:
<rdf:Property rdf:ID="birthday">
<rdfs:domain rdf:resource="#Persona"/>
<rdfs:range
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Literal"/>
</rdf:Property>
Per Topic Maps, sono considerati attributi tutti i tipi di occorrenze definite
nello schema TMCL, come visto nell’esempio precedente.
Viceversa, vengono considerate relazioni tutte le proprieta RDF che
specificano una classe dello schema quale codominio, mentre per Topic Maps
sono relazioni tutti i tipi di associazioni.
Un ruolo particolare all’interno dell’editor e svolto dagli attributi di nome e
di tipo. In effetti entrambi gli standard hanno definito dei meccanismi built-in
per la specifica di tali informazioni.
Attorno alla scelta del tipo di una risorsa ruota tutto il meccanismo
di inserimento delle metainformazioni ad essa attribuibili, secondo le
impostazioni dettate dallo schema associato al documento.

138 Capitolo 5. Editazione di documenti RDF e XTM
5.2.3 Regole per l’applicabilita di attributi e risorse
L’applicabilita di attributi e la specifica di relazioni tra risorse e vincolata dal
tipo specificato per ciascuna risorsa.
Si e fatto precedentemente notare come entrambi gli standard supportino
la tipizzazione multipla: una risorsa RDF (o un topic) puo in generale essere
caratterizzata da un numero arbitrario di tipi. Tuttavia appare casisticamente
improbabile la necessita di ricorre alla specifica multipla di tipi per le istanze.
In effetti, seguendo la metafora delle gerarchie di classi nei linguaggi di
programmazione ad oggetti, l’ereditarieta multipla (laddove sia possibile) e
limitata al sistema di classi: gli oggetti (le istanze) sono tipizzabili con un’unica
classe, ed eventualmente e possibile effettuare il casting a classi imparentate
con quella di appartenenza.
Pertanto la necessita di poter trattare una stessa istanza con due diversi
tipi si deve riflettere nella costruzione di gerarchie di classi che consentano il
casting dell’istanza.
Per gli attributi vale la regola di ereditarieta: ogni attributo applicabile
alle istanze di una classe A, diventa applicabile a tutte le istanze di quelle
classi che hanno A fra i propri superiori (ancestors) nella gerarchia. Lo stesso
vale per le relazioni.
5.2.4 Indicizzazione delle risorse descritte
La gestione dei documenti che vengono elaborati presenta spesso caratteristi-
che simili a quelle di comuni basi di dati di tipo relazionale. L’implementazione
prevede che il repository dei modelli sia semplicemente una directory che
contiene tutti i documenti editabili. Tuttavia, il modello di dati costituito da
ogni singolo documento presenta delle analogie con un database, relativamente
alle operazioni di ricerca, modifica e cancellazione delle risorse descritte.
In un documento di metainformazioni, sia esso espresso in RDF o XTM,
ogni cosa descritta puo essere referenziata in vari modi, e pertanto a ciascuna
di esse e associato un identificatore univoco interno al documento.
In RDF, il ruolo di identificazione della risorsa descritta puo essere
ricoperto dall’URI della risorsa stessa, e ci si riferisce ad essa senza utilizzare
identificatori interni al documento di metainformazioni. E comunque possibile

5.2 Caratteristiche generali dell’editor 139
specificare un identificatore interno al documento per riferirsi alle varie risorse
RDF.
Nel normale modo di operare per Topic Maps tutti i topic del documento
hanno il proprio identificatore e, nel caso la risorsa descritta abbia un URI,
lo si specifica mediante il tag subjectIdentity. Per raggiungere univocita
di rappresentazione, si e scelto quindi di utilizzare anche per RDF un
identificatore interno al documento per ciascuna risorsa descritta, e si utilizza
eventualmente il predicato di sistema rdf:subject per specificare l’URI della
risorsa nel caso esista.
Negli esempi fin qui presentati si e preferito utilizzare degli identificatori
che aiutassero la leggibilita. Nei normali casi d’uso e in particolar modo
nei casi di generazione automatica dei documenti come quello qui descritto,
tale identificatore e spesso costituito da stringhe esadecimali incrementali e,
avendo principalmente un utilizzo interno, non possono essere esposte a livello
di interfaccia utente. Il problema della reperibilita delle risorse descritte
all’interno del documento e stato risolto attraverso l’esposizione dei nomi ad
esse associati, ossia ai baseName dei topic di XTM e alle rdf:label delle
risorse RDF. Ovviamente, per entrambi gli standard non esiste nessuna regola
che obblighi la specifica di un attributo di nome univoco a tutto cio che e
descritto. E altrettanto vero che e necessario poter avere un’informazione
leggibile che abbia funzione di chiave per dare all’utente la possibilita di
referenziare ogni singola risorsa. Pertanto, la specifica di nomi univoci
internamente al documento e lasciato come onere all’utente.
Come si vedra nel paragrafo 5.5.3, per risolvere casi di ambiguita dovuti a
possibili omonimie, e possibile la specifica di nomi in numero arbitrario. La
sidebar dell’editor che elenca le risorse contenute del documento specifichera
l’insieme dei nomi per ciascuna risorsa, mentre i SELECT di HTML che
elencano le risorse per l’istanziazione di relazioni tra esse fanno ricorso
semplicemente al primo dei nomi definiti.
5.2.5 Operazioni effettuabili
L’avvio dell’applicazione, che consiste nel caricamento della pagina iniziale
dell’editor dal browser, consente la scelta del file da editare dall’elenco di quelli

140 Capitolo 5. Editazione di documenti RDF e XTM
disponibili, oppure la creazione di un nuovo file sulla base di uno schema tra
quelli selezionabili. Il formato del documento creato, trasparente all’utente,
sara dipendente dal formato dello schema prescelto, che e constatabile
dall’estensione del file di schema associato.
Creazione e modifica di una nuova entita
E questa l’operazione fondamentale per l’editor. L’area di editazione principale
consente la definizione di un’entita tipizzabile, per la quale, indipendentemente
dal tipo prescelto, e possibile specificare uno o piu nomi, un commento per la
sua descrizione e l’attributo che consiste nell’URL che rappresenta l’eventuale
soggetto. La specifica di questo e degli altri eventuali attributi specificabili
in funzione del tipo prescelto, e facoltativa. Si e scelta l’applicabilita
incondizionata dell’attributo soggetto ad ogni tipo di entita in considerazione
del prevalente ruolo di descrizione di risorse online o con riferimenti Web che
e ricoperto dalle metainformazioni.
Essendo il sistema di editazione guidata essenzialmente basato sui tipi,
la modifica del tipo di un’entita ha ripercussioni sia sugli attributi che sulle
relazioni definite per essa. Alla modifica del tipo, gli attributi, salvo l’eventuale
commento, vengono cancellati, non essendo piu garantita la compatibilita fra
questi e la nuova classe che tipizza l’entita.
Creazione e modifica delle relazioni
Contestualmente alla creazione, o alla modifica di un’entita, e possibile
specificare, in numero arbitrario, le eventuali relazioni dell’entita corrente con
altre gia definite. I possibili tipi di relazioni specificabili dipendono dal tipo
dell’entita corrente, poiche almeno uno dei ruoli dell’associazione deve essere
compatibile con la classe d’appartenenza dell’entita. Scelto il tipo di relazione
da aggiungere, vengono mostrate le entita istanze che hanno tipi compatibili
con gli altri ruoli previsti dal tipo di relazione. In caso di relazioni n-arie
viene indicato anche il ruolo di ogni altro membro da specificare. In effetti la
presenza di piu di due membri per una relazione e possibile solo nel caso in
cui si stia creando un modello Topic Maps, essendo le association di natura
n-aria e le Property inerentemente binarie.

5.2 Caratteristiche generali dell’editor 141
Un’ulteriore differenza tra i due paradigmi si ha nell’interpretazione
unidirezionale delle relazioni per documenti RDF e in quella multidirezionale
per quelle di Topic Maps. Cio significa che per RDF i tipi di relazione possibili
per le entita istanza di una determinata classe corrispondono alle sole Property
per le quali e specificata come dominio (attraverso rdfs:domain) la stessa
classe o una classe genitrice. Viceversa, per XTM, i tipi di relazione possibili
sono tutte le associazioni che prevedono tra i propri membri un elemento che
e istanza della classe dell’entita corrente, o di una delle sue superclassi. Per
questo motivo sono necessarie delle linee guida nella costruzione di schemi
Topic Maps, in particolare:
• anche se puo sembrare un banale problema di nomenclatura, onde evitare
che l’utente rimanga confuso, e appropriato che si scelgano dei nomi per
i tipi di relazioni che non esprimano direzionalita laddove la relazione
non sia inerentemente biunivoca;
• per tipi di relazioni non biunivoche che coinvolgono entita della stessa
classe o di classi con rapporti di discendenza e appropriata una modifica
alla gerarchia che disambigui la relazione. Ad esempio, un tipo di
relazione padre di tra due entita istanze della classe persona in Topic
Maps e ambigua, non essendo chiari i ruoli nell’associazione. Tuttavia,
creando due classi, padre e figlio, entrambe sottoclassi di persona e
possibile esplicitare il tipo di relazione indicando con la classe padre
l’istanza che deve avere ruolo di padre e con classe figlio l’istanza che
deve avere ruolo di figlio. Proseguendo l’esempio, nel caso in cui si
preveda che una stessa istanza possa essere nella stessa relazione con
altre entita ricoprendo potenzialmente sia il ruolo di figlio che di padre e
possibile creare un tipo che erediti da entrambi. In questo caso l’editor
si accorgera della possibile ambiguita della relazione ed esplicitera i ruoli
della relazione nel form.
Eliminazione delle entita
L’eliminazione di un’entita e possibile previa selezione dell’entita stessa. Come
si e detto, nel caso dell’eliminazione si presentano problemi di integrita del

142 Capitolo 5. Editazione di documenti RDF e XTM
documento. Vengono risolti con la contemporanea eliminazione di tutte le
relazioni in cui l’entita partecipa.
Ricerca di entita
La ricerca che e necessaria per poter selezionare le entita che si vogliono
modificare. Con l’aumentare delle entita definite nello stesso documento,
finisce per essere difficoltoso il loro reperimento nell’editor. Per questo motivo
viene offerta una funzione di ricerca basata sul pattern matching del nome.
Salvataggio
Il salvataggio del documento corrente consta nell’invio al server del
modello XML serializzato e quindi nella risincronizzazione di client e server
relativamente al documento in questione.
5.3 Architettura del sistema
Il software sviluppato fornisce le funzionalita di manipolazione ed editazione
di documenti RDF e XTM. L’editor e composto da vari layer, ognuno dei
quali fornisce un particolare supporto all’accesso ed alla manipolazione dei
documenti.
Esso consta essenzialmente di due componenti, la cui comunicazione e
descritta mediante architettura client server.
Il primo componente risiede su un server remoto, e fornisce l’accesso ai
documenti ivi memorizzati. E composto da due sotto-componenti:
Data Layer Permette il reperimento dei documenti contenuti nel database.
Document Layer Rende remotamente disponibili i documenti presenti.
Il secondo componente risiede sul client, e permette l’interazione fra l’utente
ed il documento stesso. Quest’ultimo componente e a sua volta composto da
altri sotto-componenti:
Model Layer Il gestore del modello rappresentativo del documento e dello
schema ad esso associato.

5.4 Strumenti utilizzati 143
Rendering Layer Il motore di rendering del documento, che fornisce
la visualizzazione su schermo del documento caricato, permettendo
all’utente la sua editazione.
Rendering Layer
Database
ClientServer
Data Layer Model Layer
Document Layer
Figura 5.1: La composizione in layer dell’editor
Nella figura 5.2 e mostrata l’interazione fra l’utente, l’editor ed il server
remoto. Si notino le funzionalita direttamente offerte all’utente: caricamento,
creazione e salvataggio di un documento, e l’editazione e visualizzazione dello
stesso. Le fasi di gestione del documento implicano una comunicazione con
il server, al fine di ottenere la lista dei documenti disponibili o di salvare i
documenti modificati.
5.4 Strumenti utilizzati
Per l’implementazione di questo progetto sono state scelte due tecnologie
differenti:
• Il linguaggio Java, in versione 1.4.
• Il linguaggio di scripting Javascript, nell’implementazione fornita da
Internet Explorer 6.

144 Capitolo 5. Editazione di documenti RDF e XTM
Load DocumentCreate New Document
Save Current Document
Fornisce le funzionalità di editazione
Visualizza il documento su schermo
DocumentsDatabase
Remote Server
<<uses>>
Render Document
Manage Document
<<include>>
<<include>>
<<include>>
<<communicate>>
Edit Document
<<uses>>
<<communicate>>
<<communicate>>
User
Figura 5.2: L’use case dell’editor; i servizi forniti
Il componente che risiede sul server remoto e stato implementato come un
servlet [jav02c], ed e quindi stato installato in un application server.
Il componente residente sul client fa uso di entrambe le tecnologie. Il
gestore del documento caricato e stato implementato come un applet; il motore
di rendering, invece, fa largo uso di Javascript per trasformare il documento
caricato in oggetti HTML visualizzabili da Internet Explorer e manipolabili
mediante la loro rappresentazione DOM fornita dal browser.
La comunicazione fra Javascript e l’applet e stata implementata sfruttando
la tecnologia LiveConnect [liv02], prodotta da Netscape, ma da tempo inclusa
anche nel browser di casa Microsoft.
Inoltre, poiche Internet Explorer fornisce anche il supporto per i CSS
(livello 1) [css99], sono stati definiti numerosi stili, al fine di rendere piu
elegante l’aspetto dell’applicazione prodotta.

5.5 Modello concettuale e implementazione 145
5.5 Modello concettuale e implementazione
In questo capitolo verranno trattati gli aspetti concettuali che hanno guidato
la scrittura dell’editor e verra commentata l’architettura del sistema.
5.5.1 Accesso ai dati: il servlet
Il servlet e il mezzo per accedere da remoto ai documenti disponibili. Esso
fornisce i seguenti servizi, in base ai parametri che vengono passati:
• L’interfaccia web verso il database contenente i documenti RDF e XTM,
se invocato con parametro task=init (figura 5.3).
Figura 5.3: Risposta del servlet alla richiesta dei documenti disponibili
• Il caricamento del documento specificato, se invocato con parametri
task=load e filename con il nome del documento che si vuole caricare.
• Il caricamento dello schema associato al documento, se invocato con
parametri task=loadschema e filename con il nome del documento di
cui si richiede lo schema.

146 Capitolo 5. Editazione di documenti RDF e XTM
• Il salvataggio di un documento, se invocato con parametri task=save,
filename con il nome del file da salvare, filedesc con una sua eventuale
descrizione, schemaname con il nome dello schema ad esso associato e
filecontent con la serializzazione del documento da salvare.
Ad esclusione del primo caso, tutti questi servizi vengono richiamati
dall’applet, su richiesta dell’utente. Per una trattazione piu approfondita
dell’interazione fra il servlet e l’applet si rimanda al paragrafo 5.5.5.
5.5.2 Il modello del documento e dello schema: l’applet
In seguito alla richiesta di caricamento di un documento l’applet effettua
una richiesta remota al servlet, che si occupa di fornirlo al richiedente. Una
volta ricevuto tale documento, l’applet stesso ne effettua il parsing, creando il
modello corrispondente in memoria. Da questo momento in poi ogni modifica
al documento coincidera con una modifica al modello.
Quando verra richiesto il salvataggio del documento, l’applet si occupera
di serializzare il modello in RDF o XTM e di inviare il risultato al servlet, al
fine di memorizzare le modifiche apportate.
5.5.3 Il visualizzatore di documenti
Questo componente, interamente scritto in Javascript, si occupa di visualizzare
sullo schermo i costituenti del documento caricato. Un costituente rappresenta
un topic di Topic Maps o una risorsa di RDF.
Il modulo non e a conoscenza di cosa sia un documento RDF o XTM, ma
si occupa solo di effettuare il rendering degli oggetti che gli vengono forniti
dall’applet.
La GUI dell’editor (figura 5.4) e composta essenzialmente da una pagina
HTML, divisa in tre aree, implementate come tre IFRAME, adibite a ruoli
diversi:
Toolbar Contiene la bottoniera per accedere alle funzionalita di editazione.
Comprende le icone relative all’apertura ed al salvataggio di un
documento.

5.5 Modello concettuale e implementazione 147
SideBar Contiene l’elenco degli elementi definiti nel documento corrente.
Cliccando su ognuno di essi di ottengono le informazioni relative
all’elemento selezionato.
Figura 5.4: La GUI dell’editor: visualizzazione di un elemento
Workbench E l’area in cui si effettua l’editazione di ogni elemento. E
composta da tre sezioni, ognuna delle quali permette l’editazione di una
parte delle informazioni relative all’elemento selezionato.
• La prima sezione contiene le informazioni generali, comuni ad ogni
tipo di elemento: i suoi nomi, il tipo ed un eventuale commento.
• La seconda sezione permette di editare le relazioni in cui l’elemento
prende parte. Dopo aver selezionato una relazione vengono mostrati
gli altri membri che possono partecipare alla relazione stessa. Nel
caso in cui l’elemento corrente possa ricoprile piu ruoli entro la
relazione selezionata, verra aggiunto nell’elenco dei membri anche
un segnaposto per l’elemento attuale, con nome Current Element.

148 Capitolo 5. Editazione di documenti RDF e XTM
• L’ultima sezione permette di editare gli attributi dell’elemento.
Un attributo rappresenta una coppia proprieta-valore, in cui il
valore e un letterale. Fra gli attributi di ogni elemento e sempre
presente il Subject URL, che indica l’eventuale risorsa che e soggetto
dell’elemento che si sta editando.
5.5.4 Diagramma delle classi
In questo paragrafo verra fornito un modello concettuale dettagliato per
l’editor. Verra mostrato il class diagram che definisce la struttura statica
del modello.
Si occupa di effettuare il rendering del documento
Applet
HttpServlet
XTMAppletEngine RDFAppletEngine
DocumentsDatabase
(from Use Case View)
MetaServlet<<Http Servlet>>...>>
Permettel'editazione di documentiscritti in XTM
Permettel'editazione di documentiscritti in RDF
Definisce un'interfaccia comune fra gli applet e la libreria javascript
Rende disponibili i documenti remoti e ne permette il caricamento e salvataggio
SchemaInterface
JS Library
Figura 5.5: Il class diagram dell’editor

5.5 Modello concettuale e implementazione 149
Si puo notare come siano stati specificati i componenti definiti nei paragrafi
precedenti:
Data Layer e Document Layer Sono stati collassati in un’unica entita,
MetaServlet.
Model Layer Questo componente invece e stato suddiviso in due classi,
XTMAppletEngine e RDFAppletEngine, che si occupano cosı di
manipolare rispettivamente i documenti scritti in XTM e in RDF. E
stata inoltre creata l’interfaccia SchemaInterface allo scopo di definire le
funzionalita comuni che devono implementare i due applet.
Rendering Layer E stato implementato mediante la libreria JS Library.
Da questo class diagram si possono inoltre notare le relazioni di dipendenza
fra i vari componenti:
• Il motore di rendering fa uso degli applet per accedere alle porzioni dei
documenti caricati. La comunicazione fra l’applet e il visualizzatore
avviene mediante lo scambio di codice XML.
• Gli applet, come gia specificato, possono accedere all’archivio dei
documenti solo mediante il servlet. La comunicazione fra tali componenti
e stata implementata mediante il protocollo HTTP. In pratica, quando
e necessario caricare un documento viene effettuata una GET all’url
del servlet, specificando il file richiesto, secondo la sintassi definita nel
paragrafo 5.5.1. Nel caso in cui sia necessario salvare un file, viene invece
effettuata una POST, contenente la serializzazione del documento che si
vuole memorizzare.
Il seguente class diagram mostra i dettagli di implementazione per l’applet
XTMAppletEngine. Si possono notare le seguenti classi:
• MyXTMBuilder: si occupa di leggere il documento richiesto al server.
• MyXTMWriter: permette la serializzazione del modello del documento
caricato in memoria. Questa classe viene usata al momento di salvare il
documento.

150 Capitolo 5. Editazione di documenti RDF e XTM
• MyTopicMapWalker: classe di utilita che permette di navigare il modello
in memoria.
• MyIDGeneratorFactory e MyIDGenerator: e la factory e il “prodotto
concreto” [GHJV95] relativi al generatore di identificatori assegnati ai
vari topic.
TopicMapHandler
SchemaInterface
TopicMapWriterWalkerHandler
MyIDGenerator
MyXTMBuilder
MyIDGeneratorFactory
MyXTMWriter
XTMAppletEngine
MyTopicMapWalker
Figura 5.6: Il class diagram per l’applet XTMAppletEngine
5.5.5 Interazione fra i componenti dell’editor
In questo paragrafo verranno mostrate alcune delle fasi salienti nell’utilizzo
dell’editor. Per dettagliare meglio tali situazioni si fara uso dei sequence
diagram.
Caricamento di un documento Quando viene richiesto il caricamento di
un documento, viene chiamata la funzione loadDocument, che si occupa

5.5 Modello concettuale e implementazione 151
di effettuare la chiamata remota al server. In risposta si ottiene
il documento richiesto, di cui viene creata una rappresentazione in
memoria. A questo punto viene preparata l’interfaccia grafica principale
dell’editor, creando la ToolBar, la SideBar (con l’elenco degli elementi
presenti nel modello) e il Workbench vuoto.
js : JS Library applet : SchemaInter...
ms : MetaServlet
ie : Browser
loadDocument( )loadDocument( )
service( )
Richiesta del documentoselezionato
cleanPage( )
getToolBar( )
getItemsList( )
getWorkbench( )
getElementsInModel( )
getElementsInModel( )
Elenco degli elementi istanza presenti nel documento caricato
Figura 5.7: Caricamento di un documento

152 Capitolo 5. Editazione di documenti RDF e XTM
Creazione di un nuovo elemento In seguito alla richiesta di creazione di
un elemento viene prima inizializzato il Workbench (resetPage), che
viene poi aggiornato aggiungendovi i campi per i nomi, il tipo e il
commento dell’elemento. I tipi assegnabili all’elemento sono visualizzati
in un SELECT di HTML, riempito mediante la chiamata alla funzione
getTypesInSchema.
js : JS Library applet : SchemaI...
ie : Browser
newItem( )
resetPage( )
createNameInput( )
createTypeInput( )
getTypesInSchema( )
Figura 5.8: Creazione di un nuovo elemento

5.5 Modello concettuale e implementazione 153
Aggiunta delle relazioni Quando si vuole introdurre una nuova relazione
per l’elemento corrente, viene invocata la getRelationsInSchema, che si
occupa di creare un nuovo SELECT contenente tutte le relazioni che
sono compatibili con il tipo assegnato all’elemento stesso. Una volta
selezionata una specifica relazione, vengono creati tanti SELECT quanti
sono i membri che possono partecipare alla relazione scelta (funzione
getRelationMembers).
Si noti che prima della chiamata alla getRelationsInSchema viene
effettuato un salvataggio preventivo dell’elemento, affinche l’applet sia
in grado di selezionare solo le relazioni compatibili con esso.
js : JS Library applet : SchemaI...
ie : Browser
getRelationsInSchema( )
saveElement( )
getRelationsInSchema( )
getRelationMembers( )
getRelationMembers( )
Figura 5.9: Aggiunta delle relazioni

154 Capitolo 5. Editazione di documenti RDF e XTM
Aggiunta degli attributi Un attributo e una coppia proprieta-valore, dove
il valore e un letterale. Alla richiesta degli attributi relativi all’elemento
corrente vengono creati tanti campi di testo quanti sono gli attributi
compatibili con il tipo selezionato.
js : JS Library applet : SchemaI...
ie : Browser
getAttributesInSchema( )
saveElement( )
getAttributesInSchema( )
Figura 5.10: Aggiunta degli attributi

5.5 Modello concettuale e implementazione 155
Modifica di un elemento E possibile effettuare la modifica di un elemento
semplicemente cliccando su di esso, nella SideBar. Viene cosı chiamata
la funzione resetPage, che si occupa di reinizializzare il Workbench.
Successivamente vengono richieste all’applet tutte le informazioni
associate all’elemento selezionato, che vengono poi visualizzate su
schermo.
ie : Browser applet : SchemaI...
js : JS Library
modifyItem( )
resetPage( )
getElement( )
createNameInput( )
createTypeInput( )
getTypesInSchema( )
getRelationsInSchema( )
getRelationMembers( )
getAttributesInSchema( )
Figura 5.11: Modifica di un elemento
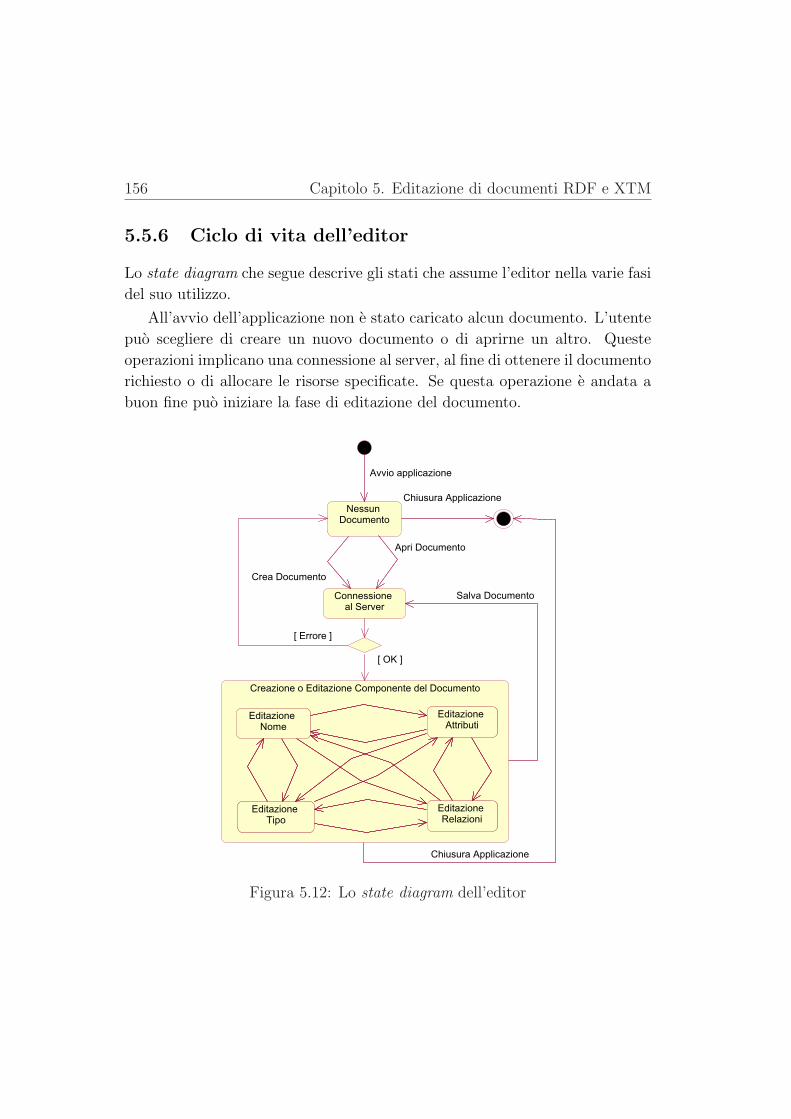
156 Capitolo 5. Editazione di documenti RDF e XTM
5.5.6 Ciclo di vita dell’editor
Lo state diagram che segue descrive gli stati che assume l’editor nella varie fasi
del suo utilizzo.
All’avvio dell’applicazione non e stato caricato alcun documento. L’utente
puo scegliere di creare un nuovo documento o di aprirne un altro. Queste
operazioni implicano una connessione al server, al fine di ottenere il documento
richiesto o di allocare le risorse specificate. Se questa operazione e andata a
buon fine puo iniziare la fase di editazione del documento.
NessunDocumento
Connessioneal Server
Avvio applicazione
Chiusura Applicazione
Creazione o Editazione Componente del Documento
EditazioneNome
EditazioneTipo
EditazioneRelazioni
EditazioneAttributi
EditazioneNome
EditazioneTipo
EditazioneRelazioni
EditazioneAttributi
Crea Documento
Apri Documento
[ OK ]
Salva Documento
Chiusura Applicazione
[ Errore ]
Figura 5.12: Lo state diagram dell’editor

5.6 Configurazione e installazione del software 157
5.5.7 Diagramma dei componenti
Per quanto detto sinora, la rappresentazione dei componenti costituenti l’editor
e mostrata nella figura seguente. Si possono notare due package, relativi al
lato server ed al lato client dell’applicazione. Il Client Package rappresenta
il browser dell’utente, contenente l’applet e la libreria Javascript. Il Server
Package rappresenta invece Tomcat, il servlet container in cui e in esecuzione
il MetaServlet.
Client Package<<Browser>>
Server Package<<Servlet Container>>
DocumentsEditor
<<Applet>>
JS Library<< Javascript Lib >>
DocumentsSupplier
<<Servlet>>
Documents Database
Richiesta remota dei documenti. Usa HTTP.
Figura 5.13: I componenti principali dell’editor
5.6 Configurazione e installazione del software
In questo capitolo verra descritto come configurare l’editor e come installarlo
in un application server conforme alle specifiche prodotte da Sun in [jav02d].

158 Capitolo 5. Editazione di documenti RDF e XTM
In seguito verra usato Tomcat [tom02], progetto open source di “The Jakarta
Project” di Apache.
5.6.1 Configurazione del servlet
La configurazione del servlet avviene mediante il file web.xml, in cui sono stati
definiti due parametri:
fileDir Indica il percorso assoluto in cui si trova il database dei documenti
RDF e XTM.
webDir Indica l’URL della web application che contiene l’editor.
Questi parametri dovranno essere modificati in base alle caratteristiche della
macchina in cui e installato il web server ed in base alla configurazione di
Tomcat.
5.6.2 La firma dell’applet
Poiche parte delle librerie java utilizzate necessitano di accedere alle risorse di
sistema si e reso necessario firmare l’applet con un certificato RSA. E stato
seguito quanto specificato in [sig02].
Il primo strumento utilizzato, fornito dal JDK, e il keytool. Mediante di
esso e stato possibile generare una coppia di chiavi, pubblica e privata, ed il
certificato ad esse associato. Questi oggetti vengono memorizzati nel keystore,
e sono accessibili mediante la definizione di opportuni alias univoci. Infine
e stato utilizzato il jarsigner, anch’esso incluso nel JDK, mediante il quale
sono state firmate le librerie usate dall’applet.
Sono stati eseguiti i seguenti passi:
1. keytool -genkey -alias meta -keypass <pwd> -keystore metastore
Viene creata la coppia di chiavi, pubblica e privata, con alias meta.
Queste chiavi vengono memorizzate nel keystore di nome metastore. La
password pwd sara necessaria, in seguito, per accedere a tali chiavi.
All’esecuzione di tale comando verra prima richiesta la password da
associare al keystore ed in seguito verranno richieste delle informazioni

5.6 Configurazione e installazione del software 159
relative all’identita del proprietario delle chiavi. Dopo aver risposto ad
ogni domanda verra creato il keystore contenente le chiavi.
2. keytool -export -alias meta -keystore metastore -file meta.cer
Viene creato il certificato meta.cer usando le informazioni contenute nel
keystore. E necessario inserire la password che e stata ad esso associata
al passo precedente. Questo certificato verra in seguito installato nel web
server, rendendolo di fatto disponibile all’applet.
Figura 5.14: La richiesta di esecuzione dell’applet firmato
3. jarsigner -keystore metastore -signedjar <siglib.jar> <lib.jar>
meta
Si effettua la firma della libreria lib.jar usando il keystore metastore e
l’alias definito al primo punto. La libreria, cosı firmata, viene salvata in
siglib.jar. Sono state firmate le seguenti librerie:
• Jena, che fornisce le API per manipolare i documenti RDF.
• TM4J, che fornisce le API per manipolare i documenti XTM.
• Xerces, il parser XML.
• Meta, che contiene l’applet vero e proprio.

160 Capitolo 5. Editazione di documenti RDF e XTM
5.6.3 Configurazione del client
Per una corretta installazione dell’applet nel browser dell’utente e necessario
che sia stato preventivamente installato il JRE versione 1.4. Al primo avvio
dell’applet verra scaricato il certificato ad esso associato e verra richiesto se
estendere i normali diritti dell’applet. Per un corretto funzionamento sara
necessario fornire un accesso alle risorse di sistema. Fatto cio verranno caricate
le librerie necessarie.
5.6.4 Installazione del software
Per automatizzare l’installazione del software e stato fornito uno script,
build.xml, eseguibile mediante il tool Ant [ant02]. In questo script vengono
definite due variabili (o property):
tomcatdir Definisce la directory di installazione di Tomcat.
webxml Il nome del file di configurazione del servlet.
Una volta modificati tali valori sara sufficiente eseguire ant install dalla
directory che contiene i sorgenti dell’editor e tutte le librerie verranno installate
ove necessario.
5.7 Possibili estensioni
Dal punto di vista dell’usabilita, lo strumento sviluppato e sicuramente
estendibile con le piu moderne funzionalita comuni agli ambienti di sviluppo
piu diffusi. Il lavoro svolto, benche pratico, funzionale ed usabile, e stato
mirato principalmente a suggerire un nuovo modo di interpretare l’editazione
per le metainformazioni, basato su un piu elevato livello di astrazione e
orientato all’utilizzo da parte di un’utenza potenzialmente ignara di qualsiasi
nozione sui formati di metainformazioni.
Particolare attenzione e stata posta nell’offrire un’interfaccia comune per i
due standard. In questo modo tuttavia si e dovuto rinunciare ad alcune delle
caratteristiche peculiari di ciascuno dei due linguaggi. Si pensi a funzionalita
quali la specifica di scope per i costrutti Topic Maps, o all’utilizzo di strutture

5.7 Possibili estensioni 161
complesse quali i containers nello standard RDF, che difficilmente potrebbero
trovare una convergenza nell’altro paradigma senza artificiose estensioni.
L’architettura client-server rende inoltre lo strumento particolarmente
adatto ad un utilizzo su rete locale. Tuttavia manca il supporto per la gestione
della concorrenza nell’accesso ai documenti, essendo questa una problematica
di natura prettamente pratica e di corredo allo strumento.
L’editazione vincolata allo schema definito astrae il modello di me-
tainformazioni dal formalismo. Tuttavia la presenza di uno schema e
necessaria per poter usufruire della creazione guidata. La presenza di
uno schema sintatticamente corretto e semanticamente significativo e la
condizione necessaria per poter usufruire delle potenzialita dello strumento.
La costruzione degli schemi necessita di conoscenze teoriche sia dal punto di
vista dei formalismi, sia da quello del disegno di tesauri che abbiano requisiti di
coerenza ed espressivita. Sarebbe possibile in questo senso pensare di estendere
la creazione guidata anche agli schemi, creando una sorta di meta-schema,
ossia uno schema per schemi, per entrambi i formati. L’utilita di una simile
funzionalita consisterebbe nel dispensare l’utente dall’editazione manuale del
documento di schema, ma non presenterebbe vantaggi sostanziali a supporto
della progettazione concettuale delle ontologie.
Un file di schema, inoltre, a differenza dei documenti istanza, ha una natura
prettamente statica. Le modifiche apportate ad uno schema in riferimento
al quale siano stati creati uno o piu documenti istanza puo pregiudicare la
loro consistenza, e quindi renderli non piu validi. In particolare e possibile
aggiungere nuove classi e nuovi tipi di relazioni e attributi senza compromettere
la validita delle istanze, mentre e decisamente rischiosa la modifica di classi,
tipi di relazioni e attributi gia definiti.

162 Capitolo 5. Editazione di documenti RDF e XTM

Capitolo 6
Il navigatore
In questo capitolo vengono analizzate le possibilita offerte da RDF e
Topic Maps nell’ambito della navigazione semantica dei documenti descritti
in termini di metainformazioni. Viene inoltre descritto lo strumento
implementato quale dimostrazione delle idee espresse.
6.1 La navigazione di metainformazioni
Il Web, cosı come oggi lo conosciamo, rappresenta una tecnologia attraverso
la quale e possibile navigare agevolmente attraverso un insieme di documenti
online, arbitrariamente distribuiti, attraverso collegamenti ipertestuali. La
natura dell’associazione fra documento linkato e linkante rimane comunque
implicita, dipendente da un contesto difficilmente estrapolabile in maniera
automatica dalle applicazioni. Il Semantic Web vuole introdurre un sistema
per la rappresentazione formale dei significati dei documenti, permettendo
la classificazione dei contenuti e associando un significato non ambiguo ai
collegamenti tra le risorse.
Entrambe le tecnologie oggetto di questa dissertazione consentono la
creazione di questa nuova infrastruttura informativa, che permette la
costituzione di layer semantici al di sopra dei documenti che vengono
indicizzati, senza comunque richiedere la loro modifica. La classificazione dei

164 Capitolo 6. Navigazione di documenti RDF e XTM
contenuti delle risorse puo avvalersi di opportune ontologie che includano al
loro interno i rapporti di correlazione fra le entita definite.
Supponiamo ad esempio di definire in un’ontologia i concetti di linguaggio
di programmazione, di Java e di C++. Supponiamo inoltre che questi ultimi
due concetti siano sottoclassi di linguaggio di programmazione. Se si indicano
una serie di siti Web, attraverso i rispettivi URL, come istanze di risorse
informative relative a queste sottoclassi di argomenti, si sono realizzati dei
collegamenti semantici che creano delle associazioni di natura nota tra queste
risorse. Naturalmente queste relazioni saranno corrette solo se i contenuti dei
documenti ospitati dai siti Web avranno in comune il fatto di descrivere lo
stesso linguaggio o semplicemente di essere inerenti all’argomento linguaggi di
programmazione.
La ricerca e la navigazione di risorse Web passa spesso attraverso la
consultazione di siti ospitanti motori di ricerca, alcuni dei quali sono
organizzati in modo da catalogare le pagine web indicizzate in base al loro
contenuto, formando cosı un albero semantico che consente di raggiungere
agevolmente delle risorse relative ai contenuti di interesse.
Tale catalogazione permette la navigazione attraverso una gerarchia, ma,
oltre a richiedere un intervento umano di notevole impegno (in mancanza di
una collaborazione attiva da parte di chi espone le risorse) per esaminarne
e classificarne i contenuti, presenta lo svantaggio di permettere solo la
navigazione attraverso tipi di argomento, mascherando eventuali ulteriori
rapporti esistenti tra le risorse indicizzate. Si perde cioe la possibilita di
sfruttare tutti quei collegamenti semantici, non dettati dalla gerarchia usata
nella catalogazione, e che, come si e visto, e possibile esprimere con gli
strumenti offerti dalle due tecnologie per le metainformazioni prese in esame.
Il link alla risorsa finisce inoltre per essere il punto di uscita della
navigazione semantica, e l’utente non ha la possibilita di prendere visione
di eventuali metainformazioni utili alla ricerca delle reali informazioni di cui
necessita preventivamente alla lettura delle risorse.
Rifacendoci all’esempio precedente, per un utente risulta spesso difficile,
se non impossibile, prendere visione dell’autore o dell’editore di un tutorial
sul linguaggio Java, piuttosto che della sua data di pubblicazione, senza
accedere e leggere direttamente il documento stesso, benche esso sia stato

6.1 La navigazione di metainformazioni 165
opportunamente catalogato nella gerarchia degli argomenti. Allo stesso modo,
la lettura del documento e necessaria per poter verificare quali siano le
eventuali risorse bibliografiche linkate al suo interno. Estrapolando tutte
queste metainformazioni in un documento a corredo della risorsa reale, risulta
possibile la costruzione di un navigatore semantico molto piu ricco in termini
di contenuti informativi, e in definitiva piu utile e pratico per l’utente.
Limitandoci al caso di indicizzazione di risorse Web, dal punto di vista
dell’utente, il vantaggio ottenibile col supporto delle metainformazioni e quello
di poter usufruire di un livello intermedio aggiuntivo tra la ricerca di materiale
informativo relativo ad un determinato argomento, e la lettura dei documenti
di interesse, utile a riassumere le caratteristiche essenziali dei contenuti dei
documenti e ad offrire immediatamente dei collegamenti semantici ad altri
documenti in qualche modo correlati a questo.
Dal punto di vista dell’implementazione di strumenti che consentono
la navigazione, l’utilizzo esteso delle metainformazioni accompagnate ai
documenti rende automatico il meccanismo di catalogazione ed aumenta
notevolmente la scalabilita dei server, sia nel caso di contesti chiusi, ossia
dove le risorse hanno un’unica provenienza e sono relative ad un determinato
argomento, sia soprattutto in ambiti estremamente eterogenei, come nel caso
dei motori di ricerca gerarchici, dove le risorse sono arbitrariamente distribuite.
Va detto che affinche le tecnolgie delle metainformazioni possano avere
effettiva applicabilita in questo ambito, sarebbe necessario trovare soluzione ai
problemi di ambiguita nella definizione degli argomenti, e in generale delle
“cose” che possono essere descritte. Occorrerebbe cioe fare in modo che
le ontologie utilizzate siano standardizzate e rese pubbliche, come del resto
auspicato dal manifesto del Semantic Web [BLHL01].
E bene sottolineare che i campi di applicabilita di queste teconolgie non
sono necessariamente legati ai motori di ricerca del Web. Qualsiasi tesauro che
modelli le entita semantiche di un determinato contesto informativo, costituito
da un’insieme di documenti, e i cui contenuti abbiano riferimenti impliciti
(determinati dai tipi delle entita individuabili dal contenuto del documento)
o espliciti (dettati dal contesto descrittivo), puo beneficiare del supporto delle
metainformazioni.
In termini piu astratti e possibile pensare ai layer semantici costruiti

166 Capitolo 6. Navigazione di documenti RDF e XTM
attraverso metainformazioni come ad un meccanismo per indicizzare tutte
quelle informazioni non strutturate contenute in documenti di testo, che quindi
sfuggono al dominio applicativo delle comuni basi di dati relazionali.
Un esempio di contesto nel quale e in fase di studio l’utilizzo delle
metainformazioni in questo senso e rappresentato dal progetto NIR (Norme In
Rete) [nir02] che mira a formalizzare un formato in cui scrivere i documenti
normativi. A tal fine e stato definito un particolare DTD, atto a definire
opportuni tag XML con cui marcare porzioni rilevanti dei documenti di legge.
Ad esempio sono stati definiti tag per identificare i libri, parti, sezioni, articoli
e commi che compongono l’articolato. E evidente che gli elementi sintattici
cosı definiti hanno un ruolo semantico, in quanto rappresentano i concetti di
libro, parte, sezione, etc. e forniscono delle relazioni implicite fra di essi, come,
ad esempio, l’associazione composto-da fra l’articolato e i libri.
6.2 Caratteristiche del navigatore
L’obiettivo principale che ci si e posti per l’implementazione di un navigatore
e stato quello di offrire la possibilita di navigare all’interno di un contesto
di metainformazioni in maniera il piu possibile uniforme per entrambi gli
standard, rendendo del tutto trasparente all’utente la struttura interna delle
metainformazioni, cercando cioe di rendere possibile un’efficiente ricerca dei
contenuti senza costringere l’utente a conoscere i concetti alla base delle
tecnologie utilizzate per la specifica di metainformazioni.
Sulla base delle similarita dei due paradigmi, su cui si e indagato nei
precedenti capitoli, si e cercato pertanto di offrire all’utente un’interfaccia
univoca per la navigazione di documenti, rendendo quanto piu possibile
trasparente anche il linguaggio di specifica dei dati esposti.
6.2.1 Attributi e relazioni
Le metainformazioni associate alle entita descritte sono state suddivise in
attributi e relazioni.
I primi possono essere semplici valori letterali, oppure link a risorse utili
a sottolineare le caratteristiche dell’entita descritta, e sono quindi dati non

6.2 Caratteristiche del navigatore 167
soggetti a tipizzazione. Ad esempio, nella descrizione di opere bibliografiche
gli attribuiti possono essere informazioni come il titolo dell’opera o la data di
pubblicazione.
Le relazioni sono invece associazioni che coinvolgono due o piu entita
istanza di qualche tipo dell’ontologia di riferimento. Sia gli attributi che le
relazioni sono tipizzati, e a ciascun tipo viene associato un nome in modo che
in fase di presentazione l’utente sia in grado di discernerne la natura.
6.2.2 Classificazione degli attributi
Entrambi gli standard classificano in maniera nativa una serie di attributi, che
sono quindi considerati di prim’ordine per la caratterizzazione di un’entita.
In particolare il tipo, il nome e il link alla risorsa soggetto della descrizione
sono tipi di attributi esprimibili senza l’ausilio di schemi semantici di ulteriore
specifica. Ovvero sono esprimibili attraverso predicati predefiniti nel caso di
RDF, e attraverso costrutti base del modello di Topic Maps. L’individuazione
della natura di questi attributi e quindi immediata e puo essere sfruttata
adeguatamente in fase di presentazione.
Viceversa, attributi generici introdotti da schemi semantici necessitano
dell’interpretazione da parte dell’applicazione, in questo caso il navigatore, che
puo non conoscerne la natura. Se ad esempio per la classe Persona si definisse
mediante schema l’attributo fotografia, o allo stesso modo per la classe Libro
fosse definito l’attributo copertina, un software di navigazione che conosca
la natura di immagine dell’attributo potrebbe scegliere di recuperare il file
dell’immagine attraverso il link, ridimensionarla e collocarla adeguatamente
nel layout della pagina offerta all’utente.
Quindi, congiuntamente alla standardizzazione di ontologie, l’introduzione
di schemi pubblici per la descrizione degli attributi di entita specifiche, di
cui Dublin Core [dc01] e un (limitato) esempio, faciliterebbe la gestione dei
documenti anche dal punto di vista della presentazione.
A tale proposito, l’applicazione sviluppata fa ricorso, a titolo esemplifica-
tivo, a soggetti pubblici per la tipizzazione di attributi che hanno per oggetto
risorse con contenuti multimediali. In particolare, nel caso di RDF, il software
per la navigazione conosce gli attributi relativi alle seguenti proprieta:

168 Capitolo 6. Navigazione di documenti RDF e XTM
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [
<!ENTITY ns ’http://cs.unibo.it/meta/rdfmediaschema#’>
]>
<rdf:RDF xmlns:ns="&ns;">
<rdf:Property rdf:about="&ns;image"/>
<rdf:Property rdf:about="&ns;audio"/>
<rdf:Property rdf:about="&ns;video"/>
<rdf:Property rdf:about="&ns;flash"/>
<rdf:RDF>
6.2.3 Schemi e istanze
Il sistema di navigazione implementato attua una divisione tra parte ontologica
e parte descrittiva delle metainformazioni, associando ad ogni documento
istanza, contenente attributi e relazioni relative alle risorse descritte, un unico
schema, contenente l’ontologia e, in generale, tutto il sistema di tipizzazione
delle entita e delle relazioni tra entita.
Nel caso di RDF, l’interpretazione dello schema e quella dettata
dalle specifiche stesse dello standard. Le Property definite nello schema
rappresentano associazioni nel caso in cui nella loro descrizione sia specificata
una delle classi (risorse tipizzate come Class) appartenenti allo schema come
oggetto di un predicato range; sono considerate attributi altrimenti.
Nel caso di XTM, ogni elemento association definito nello schema
corrisponde ad una relazione fra oggetti del tipo elencato nelle sezioni member.
Ogni associazione e tipizzata con un topic di tipo association-type che definisce
il nome che verra visualizzato all’utente durante la navigazione.
Gli attributi, invece, in XTM sono stati mappati come elementi occurrence,
inclusi in ogni topic-type che necessita di ulteriori informazioni rappresentabili
semplicemente come stringhe di testo.
Ulteriori informazioni sull’interpretazioni di schemi espressi nei due formati
si rimanda al capitolo 2.

6.3 Navigazione 169
6.3 Navigazione
La navigazione ha inizio con la scelta del documento RDF o XTM del quale
si vogliono visualizzare le informazioni.
Figura 6.1: La scelta dei file su cui iniziare la navigazione
Come s’e detto, a ciascun documento istanza corrisponde uno schema, e
per la navigazione vengono esposte l’insieme delle informazioni deducibili da
entrambi i documenti.
Al caricamento del documento istanza, viene analizzata la gerarchia delle
classi, per la quale e supportata l’editarieta multipla. I rapporti gerarchici fra
le classi che tipizzano le entita sono esposti all’utente mediante link navigabili.
Le informazioni visualizzate relativamente a ciascuna classe sono:
• I percorsi dalle classi radici alla classe corrente;
• L’insieme delle entita istanza della classe corrente;
Nella figura 6.2 si possono notare la tabella che contiene i tipi radice definiti
nello schema e la tabella contenente gli elementi che sono istanza di questi tipi.
Ognuno di questi elementi e un link che permette di effettuare la
navigazione per categorie e di visualizzare i dettagli di un’istanza.
Per ogni entita che si sceglie di visionare, vengono visualizzati
separatamente relazioni e attributi. Gli attributi costituiti da URL

170 Capitolo 6. Navigazione di documenti RDF e XTM
corripondenti a risorse Web esterne al documento sono resi linkabili, e
determinano l’uscita dal navigatore, mentre per gli altri viene semplicemente
riportato il valore letterale. Nelle relazioni viene reso linkabile ogni riferimento
ad altre entita definite nel documento.
Nella figura 6.3 e mostrata un’istanza del tipo Person. Si possono notare
i nomi alternativi (Other Names), le relazioni fra l’oggetto corrente ed altre
entita (Relations), altre informazioni di tipo testuale (Attributes), il commento
(Comment), un’area riservata ad elencare delle informazioni multimediali,
come immagini, audio, etc. (Multimedia contents), ed infine un menu di
navigazione verso gli ultimi link visitati (Jump to).

6.3 Navigazione 171
Figura 6.2: La prima schermata di navigazione: categorie ed istanze

172 Capitolo 6. Navigazione di documenti RDF e XTM
Figura 6.3: Visualizzazione di un’istanza di Person

6.4 Architettura del sistema 173
6.4 Architettura del sistema
Il software sviluppato fornisce le funzionalita di navigazione di documenti RDF
e XTM. Il navigatore e composto da vari layer, ognuno dei quali fornisce un
particolare supporto all’accesso ed alla visualizzazione di tali documenti.
Presentation Layer
Database
Browser
Server Client
Data Layer
Model Layer
Figura 6.4: La composizione in layer del navigatore
Data Layer Fornisce accesso ai documenti disponibili, contenuti nel
database.
Model Layer Il gestore del modello rappresentativo del documento e dello
schema ad esso associato.
Presentation Layer Il motore di rendering, che fornisce la visualizzazione
su schermo del documento caricato, permettendo all’utente la sua
navigazione.
Browser Rappresenta il mezzo usato dall’utente per accedere alla porzione
di documento prodotto dal Presentation Layer.
Nella figura seguente e mostrata l’interazione fra l’utente, il navigatore
ed il server remoto. Si notino le funzionalita direttamente offerte all’utente:
navigazione delle categorie e delle istanze contenute nel documento.

174 Capitolo 6. Navigazione di documenti RDF e XTM
Ogni fase di navigazione implica una comunicazione con il server, al fine di
ottenere la porzione di documento interessata.
Come detto, si possono identificare, in ogni documento, particolari porzioni
di interesse al fine della navigazione: le categorie e le istanze.
Categoria Ad ogni elemento contenuto nel documento e assegnato un tipo,
che identifica cio che l’elemento e. Una categoria corrisponde proprio ad
un tipo. In questo modo e possibile fornire la navigazione fra elementi
messi in relazione da una gerarchia superclasse - sottoclasse.
Istanza Rappresenta un elemento tipizzato contenuto nel documento.
Navigate CategoriesView Instances
User Remote ServerNavigate Documents
<<include>><<include>>
<<uses>>
Figura 6.5: L’use case del navigatore: i servizi forniti
6.5 Strumenti utilizzati
L’implementazione di questo progetto e state effettuata utilizzando essenzial-
mente il linguaggio Java, in versione 1.4.
Tutti i layer concettuali sono stati definiti come componenti di un servlet
[jav02c], installato in un application server conforme alle specifiche Sun
presenti in [jav02d].
La parte client dell’applicativo necessita di un qualunque browser
compatibile con le specifiche dei CSS (livello 1) [css99].

6.6 Modello concettuale e implementazione 175
6.6 Modello concettuale e implementazione
In questo capitolo verranno trattati gli aspetti concettuali che hanno guidato
la scrittura del navigatore e verra commentata l’architettura del sistema.
6.6.1 Accesso ai dati
La funzionalita di accesso remoto ai documenti disponibili e reso possibile
dal servlet. Esso fornisce i seguenti servizi, in base ai parametri che vengono
passati:
• L’interfaccia web verso il database contenente i documenti RDF e XTM,
se invocato con parametro task=init.
• L’elenco delle categorie disponibili per il documento selezionato, se
invocato con parametro task=root e filename con il nome del
documento.
• L’elenco delle sotto categorie disponibili per la categoria selezionata, se
invocato con parametro task=type e id con l’identificatore associato
allla categoria stessa.
• I dettagli disponibili per un elemento istanza selezionato, se invocato con
parametro task=instance e id con l’identificatore dell’istanza stessa.
Ogni richiesta effettuata al servlet viene inoltrata prima al Model Layer,
che si occupera di effettuare le ricerche nel documento richiesto, e poi al
Presentation Layer, che produrra una pagina HTML contenente il risultato
della ricerca. Il gestore del modello, se necessario, sfuttera i servizi offerti dal
Data Layer per caricare il documento richiesto.
6.6.2 Il modello del documento e dello schema
In seguito alla richiesta di caricamento di un documento, il Model Layer si
occupa di crearne una rappresentazione in memoria. Da questo momento in
poi ogni richiesta verra effettuata navigando tale modello.

176 Capitolo 6. Navigazione di documenti RDF e XTM
Il risultato della ricerca nel modello e un documento XML, che verra
passato al Presentation Layer al fine di inviarlo, dopo le opportune
trasformazioni, al browser dell’utente.
6.6.3 Il visualizzatore
Questo componente, si occupa di visualizzare sullo schermo i costituenti del
documento caricato. Riceve dal Model Layer il risultato della ricerca effettuata
sul modello e si occupa di produrre una pagina HTML contenente il risultato
di tale ricerca.
Figura 6.6: Categorie, sotto-categorie e istanze
Come si nota dalla figura 6.6 l’area di navigazione e composta da varie
sezioni contenenti diverse informazioni:

6.6 Modello concettuale e implementazione 177
Categories Contiene l’elenco delle categorie disponibili, organizzate gerar-
chicamente.
Sub Categories Contiene l’elenco delle sotto categorie, ovvero dei tipi che
sono sottotipi della categoria selezionata.
Available elements Contiene l’elenco degli elementi il cui tipo coincide con
la categoria selezionata.
Ricordando la figura 6.3, in seguito al click su un link relativo ad un
elemento istanza vengono mostrate le informazioni relative all’istanza:
Other names Elenco dei nomi associati all’elemento corrente.
Relations Elenco delle relazioni a cui l’elemento partecipa. In questa sezione
sono anche presenti i nomi degli altri membri coinvolti nelle relazioni.
Ogni nome e un link verso i dettagli dell’elemento membro.
Attributes Elenco degli attributi. Questi possono essere delle semplici
stringhe di testo o dei link a risorse esterne.
Comment Eventuale commento associato all’elemento.
Multimedia contents Elenco di collegamenti a risorse multimediali esterne
messe in relazione con l’elemento.
Jump to Area di navigazione che permette di tornare agli argomenti
visualizzati in precedenza.

178 Capitolo 6. Navigazione di documenti RDF e XTM
6.6.4 Diagramma delle classi
In questo paragrafo verra fornito un modello concettuale dettagliato per il
navigatore. Verra quindi mostrato il class diagram che definisce la struttura
statica del modello.
HttpServlet
MetaLayoutManagerNavigatorServlet<<Http Servlet>>
MetaDataManager
ModelIntModelCache
RDFMediaSchema
RDFModel
NavigatorPSI
XTMModel
Figura 6.7: Il class diagram del navigatore
Si puo notare come siano stati specificati i componenti definiti nei paragrafi
precedenti:
Data Layer Corrisponde al MetaDataManager. Si occupa di chiamare il
gestore del modello appropriato in base al tipo di documento (XTM
o RDF).

6.6 Modello concettuale e implementazione 179
Model Layer La gestione dei modelli per i due tipi di documenti e
stata meglio specificata. Sono state definite due classi, RDFModel e
XTMModel, che si occupano, rispettivamente, di manipolare il modello
dei documenti RDF e XTM.
Come si puo notare dal diagramma e stata anche definita l’interfaccia
ModelInt, al fine di raggruppare le funzionalita comuni ai due modelli.
E stato inoltre definito un meccanismo di caching, al fine di evitare il
continuo caricamento dello stesso documento (con conseguente creazione
in memoria del modello) in chiamate successive effettuate al servlet.
Le classi RDFMediaSchema e NavigatorPSI, infine, contengono la
definizioni di particolari risorse atte ad identificare le informazioni che
andranno inserite nell’area Multimedia contents prodotta dal layer di
presentazione.
Presentation Layer Corrisponde alla classe MetaLayoutManager. Ogni
interrogazione al modello del documento richiesto produce una risposta
XML, passata a questo componente, che si occupa di effettuare le dovute
trasformazioni per produrre una pagina HTML visibile dal browser.
Il class diagram di figura 6.8 mostra i dettagli di implementazione per la
classe XTMModel. Si possono notare le seguenti classi:
• MyXTMBuilder: si occupa di leggere il documento richiesto al server.
• MyTopicMapWalker: classe di utilita che permette di navigare il modello
in memoria.

180 Capitolo 6. Navigazione di documenti RDF e XTM
ModelInt
NavigatorPSI
MyXTMBuilder
TopicMapHandler
WalkerHandler
XTMModel
MyTopicMapWalker
Figura 6.8: Il class diagram per la class XTMModel
6.6.5 Interazione fra i componenti dell’editor
Nel seguente sequence diagram vengono mostrate le fasi che portano alla
visualizzazione di una categoria durante la navigazione di un documento.
I dettagli della sintassi utilizzata per la richiesta di tale servizio sono stati
presentati nel paragrafo 6.6.1.
Come si nota, per prima cosa il NavigatorServlet invia la richiesta ricevuta
al MetaDataManager, al fine di effettuare le ricerche necessarie nel modello
che rappresenta il documento caricato.
Per trovare il modello necessario al completamento della richiesta viene
chiesto alla ModelCache di verificare se quanto richiesto sia gia presente in
cache. In caso affermativo viene subito ritornato il modello; in caso contrario
viene prima caricato il documento richiesto, di cui viene poi creato il modello,
che infine viene inserito in cache e restituito.
Una volta che il MetaDataManager ha ottenuto un riferimento al modello
richiesto, viene effettivamente eseguita la richiesta generata dal browser.

6.6 Modello concettuale e implementazione 181
Il risultato di questa ricerca vine quindi passato, sotto forma di un
documento XML, al MetaLayoutManager, che si occupa, infine, di effettuare
le opportune trasformazioni per produrre una pagina HTML che verra cosı
inviata al browser.
ie : Browser ns : NavigatorServlet
mdm : MetaDataManager
cache : ModelCache mi : ModelInt mlm :
MetaLayoutManager
service( )getTypes( )
getModel( )
getTypes( )
getHTMLFromTypes( )
Figura 6.9: Interazione fra i componenti dell’editor
6.6.6 Diagramma dei componenti
Per quanto detto sinora, la rappresentazione dei componenti costituenti il
navigatore e mostrata nella figura seguente.
Si possono notare due package, relativi al lato server ed al lato client
dell’applicazione. Il Client Package rappresenta il browser dell’utente. Il
Server Package rappresenta invece Tomcat, il servlet container in cui e in
esecuzione il NavigatorServlet, contenuto in Navigator. Per completezza sono
state indicate anche le librerie esterne utilizzate:
• Jena [jen02], che fornisce le API per manipolare i documenti RDF.

182 Capitolo 6. Navigazione di documenti RDF e XTM
• TM4J [tm402], che fornisce le API per manipolare i documenti XTM.
• Xerces [xer02], il parser XML.
• Log4J [log02], che fornisce funzionalita di debug per TM4J.
Server Package<<Servlet Container>>
Navigator<< Java Lib >>
Documents Database
Client Package<<Browser>>
TM4J<< Java Lib >>
Xerces<< Java Lib >>
Log4J<< Java Lib >>
Jena<< Java Lib >>
Figura 6.10: I componenti principali del navigatore
6.7 Configurazione e installazione del software
Per automatizzare l’installazione del software e stato fornito uno script,
build.xml, eseguibile mediante il tool Ant [ant02]. In questo script vengono
definite due variabili (o property):
tomcatdir Definisce la directory di installazione di Tomcat.
webxml Il nome del file di configurazione del servlet.
Una volta modificati tali valori sara sufficiente eseguire ant install dalla
directory che contiene i sorgenti dell’editor e tutte le librerie verranno installate
ove necessario.

6.8 Test di navigazione 183
6.8 Test di navigazione
Per effettuare un test intensivo del navigatore e stato necessario produrre
un’ontologia abbastanza complessa da mettere in luce tutte le caratteristiche
del prodotto. Si e scelto di utilizzare come base di partenza il materiale gia
catalogato su web e reso disponibile dai vari motori di ricerca di tipo gerarchico.
In particolare e stato scelto di utilizzare il servizio di directory fornito da
Google [goo02a]. Pero, data la vastita delle informazioni archiviate, e stata
scelta la categoria Programming [goo02b], che ad oggi raccoglie comunque piu
di 16000 risorse web.
Pertanto il primo problema e stato raccoglere una tale quantita di
informazioni. Naturalmente non e stato possibile effettuare un recupero
manuale di tutte questa pagine, ma e stato utilizzato lo spider Wget [wge02].
Una volta effettuato il download di tutte queste informazioni si e posto un
ulteriore problema: Google ritorna queste pagine in formato HTML, e pertanto
e stato necessario effettuare varie trasformazioni per ottenere dei documenti
RDF e Topic Maps.
• In primo luogo e stato scritto un semplice script Perl, googleXHTML.pl,
atto ad identificare, fra le pagine scaricate, quelle da cui estrarre le
metainformazioni necessarie.
• In seguito ogni pagina e stata trasformata in XHTML mediante il tool
HTMLTidy [htm02].
• Successivamente e stata scritta un’utility in Java atta a manipolare ogni
file XHTML prima prodotto, al fine di creare uno schema per l’ontologia
ed un file di istanze. Tale utillity viene pilotata da un altro script Perl,
googleMetadata.pl.
Ogni pagina ritornata da Google e essenzialmente composta da due
sezioni: le “Categories” e le “Web Pages”. Si e scelto di includere gli
elementi della prima sezione nello schema, creando in questo modo una
gerarchia di tipi. Le risorse elencate nella seconda sezione sono invece
state inserite nel documento delle istanze.

184 Capitolo 6. Navigazione di documenti RDF e XTM
• Come e stato fatto notare il precedenza, le metainformazioni che si
possono estrapolare dalle risorse catalogate da motori di ricerca si
riducono solo ad un insieme di relazioni di tipo class-sottoclasse fra le
categorie e ad una collezione di relazioni di tipo classe-istanza fra le
categorie e le risorse catalogate.
Pertanto, al fine di produrre un’ontologia sufficientemente complessa,
si e reso necessario un’ulteriore modifica, questa volta manuale, dei
documenti cosı prodotti.
6.9 Possibili estensioni
A supporto delle tecnologie finora descritte si stanno studiando delle specifiche
per la ricerca dei contenuti nei documenti metainformativi, largamente ispirate
al linguaggio SQL utilizzato per l’interrogazione di database relazionali.
Per RDF sono gia state implementati, in maniera indipendente, diversi
query language e diverse tecniche di mappatura dei documenti in basi di dati
relazionali, come Sesame [ses02], RDQL [rdq02] e RQL [oCS01], che sfruttano
principalmente la rappresentazione a triple dei modelli RDF.
Per Topic Maps, sebbene ancora lontano da una forma definitiva, e in fase
di standardizzazione da parte dell’ISO il linguaggio TMQL [Han01] che ha
come obiettivo quello di fornire funzionalita di ricerca all’interno di mappe
basate sul matching del contenuto dei costrutti Topic Maps.
Anche in questo caso esiste un’implementazione indipendente di un
linguaggio “SQL-like” (che fa fronte al ritardo nel rilascio dello standard) che
ha caratteristiche simili a quelli che sono ancora solo i requisiti di TMQL [tol].
L’utilizzo diretto da parte dell’utente (frontend) di linguaggi di
interrogazione di questo tipo e inerentemente improponibile in termini di
usabilita. Un sistema di navigazione user friendly non puo ovviamente
obbligare un utente a conoscere i linguaggi per il recupero delle informazioni
necessarie. Sarebbe invece interessante considerare la possibilita di permettere
delle ricerche guidate basate su pattern matching e implementate attraverso
query di questo tipo che mascherino i dettagli dei formati di specifica e
permettano ricerche contestuali, dipendentemente dallo schema.

6.9 Possibili estensioni 185
Viceversa, l’utilizzo backend del supporto di query non aggiungerebbe
funzionalita significativamente migliori in termini di praticita di utilizzo delle
API, ma potrebbe sicuramente consentire una migliore efficienza e aumentare
la scalibilita rispetto alle dimensioni dei file elaborati.
Non avendo efficienza e scalabilita tra i requisiti, e anche in considerazione
della scarsa maturita finora raggiunta da queste tecnologie, lo strumento di
navigazione implementato non fa utilizzo di questi meccanismi.

186 Capitolo 6. Navigazione di documenti RDF e XTM

Capitolo 7
Manuale di utilizzo
Per rendere piu immediato l’utilizzo dei tool presentati in questa dissertazione
si e reso necessario anche un capitolo atto a far prendere dimestichezza
all’utente con i compiti piu comuni che dovra eseguire. Per un’utilizzo avanzato
degli strumenti e per una guida all’installazione, comunque, sara necessario
studiare quanto detto nei capitoli precedenti.
7.1 L’ontologia
Nei paragrafi seguenti si fara riferimento sempre al medesimo esempio, al
fine di mettere in evidenza tutte le sfumature dell’ontologia qui presentata, e
disponibile negli schemi googleSchemaNew.xtms e googleSchemaNew.rdfs nella
directory tests/files della distribuzione.
In questa ontologia vengono definite varie risorse che modellano alcuni
linguaggi di programmazione, e vengono messe in relazione fra loro. Inoltre
viene definito il tipo Persona, contenente vari attributi, come la data di nascita,
il luogo di nascita, etc. In seguito verranno specificati i passi da seguire per
scrivere tali schemi.

188 Capitolo 7. Manuale di utilizzo dei tool sviluppati
7.2 Il convertitore
Le motivazioni da cui nasce la necessita di un convertitore sono da ricercarsi
nella possibilita di poter importare, in una base di dati di metainformazioni
espressa in uno dei due formati, dei documenti espressi nell’altro formato e
permettere alle applicazioni specializzate nella gestione di solo RDF o solo
XTM di poter trattare in modo trasparente i documenti risultanti dalle
conversioni.
Al fine di effettuare una traduzione fra documenti scritti in XTM e in RDF
non e obbligatorio definire uno schema separato dal documento delle istanze.
Basta effettuare la traduzione di un unico documento contenente la definizione
di classi, di predicati e di istanze. I passi da seguire per scrivere uno schema
verranno mostrati nel paragrafo 7.3.
7.2.1 Conversione da XTM a RDF
Per questo esempio si utilizzera il documento XTM contenuto nel file Ultima-
teGoogle.xtm della directory tests/conversion/xtm2rdf della distribuzione. In
tale documento vengono definiti vari topic:
• I topic type che rappresentano una persona, una home page e un
linguaggio di programmazione, con le relative istanze.
• Gli occurrence role type per visualizzare un’immagine e un commento
associabili ad ogni istanza. Per una definizione formale di questi topic
si rimanda ai paragrafi seguenti, in cui verra spiegato come crearli ed
utilizzarli nell’editor e nel navigatore.
• Un theme per la visualizzazione del nome di ogni istanza.
<topic id="person"/>
<topic id="display"/>
<topic id="image"/>
<topic id="birthplace"/>

7.2 Il convertitore 189
<topic id="birthday"/>
<topic id="comment"/>
<topic id="larrywall">
<instanceOf>
<topicRef xlink:href="#person"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://www.larrywall.com"/>
</subjectIdentity>
<baseName>
<scope>
<topicRef xlink:href="#display"/>
</scope>
<baseNameString>Larry Wall</baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#image"/>
</instanceOf>
<resourceRef xlink:href="http://www.photos.com/wall_l.gif"/>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#birthplace"/>
</instanceOf>
<resourceData>Boulder, Colorado</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#birthday"/>
</instanceOf>
<resourceData>21 Jan 1956</resourceData>
</occurrence>
<occurrence>
<instanceOf>

190 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<topicRef xlink:href="#comment"/>
</instanceOf>
<resourceData>The creator of Perl</resourceData>
</occurrence>
</topic>
<topic id="homepage"/>
<topic id="larryhome">
<instanceOf>
<topicRef xlink:href="#homepage"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://wall.org/~larry/ "/>
</subjectIdentity>
<baseName>
<scope>
<topicRef xlink:href="#display"/>
</scope>
<baseNameString>Larry Wall's Home Page </baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#comment"/>
</instanceOf>
<resourceData>
Official site which includes photographs, links,
his geek code block and transcripts of his speeches.
</resourceData>
</occurrence>
</topic>
<topic id="language"/>
<topic id="perl">
<instanceOf>

7.2 Il convertitore 191
<topicRef xlink:href="#language"/>
</instanceOf>
<baseName>
<scope>
<topicRef xlink:href="#display"/>
</scope>
<baseNameString>The Perl Language</baseNameString>
</baseName>
<occurrence>
<instanceOf>
<topicRef xlink:href="#comment"/>
</instanceOf>
<resourceData>
Perl: Practical Extraction and Report Language
</resourceData>
</occurrence>
</topic>
Vengono in seguito definite le seguenti relazioni:
• L’associazione ass-creator-of fra l’istanza di tipo person e l’istanza di
tipo language.
• L’associazione ass-homepage fra l’istanza di tipo person e l’istanza di
tipo homepage.
<topic id="ass-homepage"/>
<topic id="ass-creator-of"/>
<association>
<instanceOf>
<topicRef xlink:href="#ass-homepage"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#person"/>
</roleSpec>

192 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<topicRef xlink:href="#larrywall"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#homepage"/>
</roleSpec>
<topicRef xlink:href="#larryhome"/>
</member>
</association>
<association>
<instanceOf>
<topicRef xlink:href="#ass-creator-of"/>
</instanceOf>
<member>
<roleSpec>
<topicRef xlink:href="#person"/>
</roleSpec>
<topicRef xlink:href="#larrywall"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#language"/>
</roleSpec>
<topicRef xlink:href="#perl"/>
</member>
</association>
Usando la conversione standard fornita dai plugin e non utilizzando alcun
driver si ottiene una traduzione semanticamente corretta, ma non ottimizzata,
in quanto ogni occorrenza e associazione XTM viene tradotta secondo il criterio
generale presentato nei paragrafi 3.3.3 e 3.3.4. In particolare:
<!-- Classes -->
<rdf:Description rdf:ID="person">

7.2 Il convertitore 193
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="comment">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="ass-homepage">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="birthplace">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="ass-creator-of">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="birthday">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="image">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="language">
<rdf:type

194 Capitolo 7. Manuale di utilizzo dei tool sviluppati
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="homepage">
<rdf:type
rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<!-- The Perl Language -->
<rdf:Description rdf:ID="perl">
<s:name rdf:resource="#perl-name"/>
<rdf:type rdf:resource="#language"/>
<rdfs:seeAlso rdf:resource="#perl-comment"/>
</rdf:Description>
<rdf:Description rdf:ID="perl-name">
<s:scope rdf:resource="#display"/>
<rdfs:label>The Perl Language</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="perl-comment">
<rdf:type rdf:resource="#comment"/>
<rdfs:label>
Perl: Practical Extraction and Report Language
</rdfs:label>
</rdf:Description>
<!-- Larry Wall -->
<rdf:Description rdf:about="http://www.larrywall.com">
<rdf:type rdf:resource="#person"/>
<s:name rdf:resource="#larrywall-name"/>
<rdfs:seeAlso rdf:resource="#larrywall-birthday"/>
<rdfs:seeAlso rdf:resource="#larrywall-birthplace"/>
<rdfs:seeAlso rdf:resource="#larrywall-image"/>

7.2 Il convertitore 195
<rdfs:seeAlso rdf:resource="#larrywall-comment"/>
</rdf:Description>
<rdf:Description rdf:ID="larrywall-name">
<s:scope rdf:resource="#display"/>
<rdfs:label>Larry Wall</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="larrywall-birthday">
<rdf:type rdf:resource="#birthday"/>
<rdfs:label>21 Jan 1956</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="larrywall-birthplace">
<rdf:type rdf:resource="#birthplace"/>
<rdfs:label>Boulder, Colorado</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="larrywall-image">
<rdf:type rdf:resource="#image"/>
<rdfs:isDefinedBy rdf:resource="http://www.photos.com/wall_l.gif"/>
</rdf:Description>
<rdf:Description rdf:ID="larrywall-comment">
<rdf:type rdf:resource="#comment"/>
<rdfs:label>The creator of Perl</rdfs:label>
</rdf:Description>
<!-- Home Page -->
<rdf:Description rdf:about="http://wall.org/~larry/">
<s:name rdf:resource="#wall-name"/>
<rdf:type rdf:resource="#homepage"/>
<rdfs:seeAlso rdf:resource="#wall-comment"/>
</rdf:Description>

196 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<rdf:Description rdf:ID="wall-name">
<s:scope rdf:resource="#display"/>
<rdfs:label>Larry Wall's Home Page</rdfs:label>
</rdf:Description>
<rdf:Description rdf:ID="wall-comment">
<rdf:type rdf:resource="#comment"/>
<rdfs:label>
Official site which includes photographs, links,
his geek code block and transcripts of his speeches.
</rdfs:label>
</rdf:Description>
<!-- Association creator-of -->
<rdf:Description rdf:ID="generic-ass-creator-of">
<s:association rdf:resource="#members_generic-ass-creator-of"/>
<rdf:type rdf:resource="#ass-creator-of"/>
</rdf:Description>
<rdf:Description rdf:ID="members_generic-ass-creator-of">
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="#member1_generic-ass-creator-of"/>
<rdf:_2 rdf:resource="#member2_generic-ass-creator-of"/>
</rdf:Description>
<rdf:Description rdf:ID="member1_generic-ass-creator-of">
<rdf:type rdf:resource="#person"/>
<rdfs:isDefinedBy rdf:resource="http://www.larrywall.com"/>
</rdf:Description>
<rdf:Description rdf:ID="member2_generic-ass-creator-of">
<rdf:type rdf:resource="#language"/>
<rdfs:isDefinedBy rdf:resource="#perl"/>
</rdf:Description>

7.2 Il convertitore 197
<!-- Association homepage -->
<rdf:Description rdf:ID="generic-ass-homepage">
<s:association rdf:resource="#members_generic-ass-homepage"/>
<rdf:type rdf:resource="#ass-homepage"/>
</rdf:Description>
<rdf:Description rdf:ID="members_generic-ass-homepage">
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_1 rdf:resource="#member1_generic-ass-homepage"/>
<rdf:_2 rdf:resource="#member2_generic-ass-homepage"/>
</rdf:Description>
<rdf:Description rdf:ID="member1_generic-ass-homepage">
<rdf:type rdf:resource="#person"/>
<rdfs:isDefinedBy rdf:resource="http://www.larrywall.com"/>
</rdf:Description>
<rdf:Description rdf:ID="member2_generic-ass-homepage">
<rdf:type rdf:resource="#homepage"/>
<rdfs:isDefinedBy rdf:resource="http://wall.org/~larry/"/>
</rdf:Description>
<!-- Other Resources -->
<rdf:Description rdf:ID="display"/>
Per ottenere una traduzione piu accurata e necessario utilizzare ilcosiddetto driver di traduzione, cosı fatto:
<xtm2rdf>
<property_associations>
<li id="ass-homepage">
<domain_role id="person"/>
<range_role id="homepage"/>

198 Capitolo 7. Manuale di utilizzo dei tool sviluppati
</li>
<li id="ass-creator-of">
<domain_role id="person"/>
<range_role id="language"/>
</li>
</property_associations>
<property_occurrences>
<li id="comment"/>
<li id="image"/>
<li id="birthplace"/>
<li id="birthday"/>
</property_occurrences>
</xtm2rdf>
In pratica si afferma che:
• si vuole tradurre l’associazione XTM ass-homepage come una property
RDF, il cui dominio e codominio sono, rispettivamente, di tipo person e
homepage.
• si vuole tradurre l’associazione XTM ass-creator-of come una property
RDF, il cui dominio e codominio sono, rispettivamente, di tipo person e
homepage.
• si vogliono tradurre le occorrenze comment, image, birthplace e birthday
come property RDF.
Ritraducendo si ottiene pertanto un documento RDF di cui viene qui
mostrata la traduzione delle associazioni e occorrenze XTM:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:NS0="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
xmlns:s="http://cs.unibo.it/meta/tmschema.rdf#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
>

7.2 Il convertitore 199
<!-- Associations -->
<rdf:Description rdf:ID="ass-creator-of">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<rdf:Description rdf:ID="ass-homepage">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<!-- Occurrences -->
<rdf:Description rdf:ID="comment">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<rdf:Description rdf:ID="birthday">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<rdf:Description rdf:ID="birthplace">
<rdf:type rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
</rdf:Description>
<!-- Instances -->
<rdf:Description rdf:about="http://www.larrywall.com">
<s:name rdf:resource="#larrywall-name"/>
<rdf:type rdf:resource="#person"/>
<NS0:image rdf:resource="http://www.photos.com/wall_l.gif"/>

200 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<NS0:birthplace>Boulder, Colorado</NS0:birthplace>
<NS0:birthday>21 Jan 1956</NS0:birthday>
<NS0:comment>The creator of Perl</NS0:comment>
<NS0:ass-homepage rdf:resource="http://wall.org/~larry/"/>
<NS0:ass-creator-of rdf:resource="#perl"/>
</rdf:Description>
<rdf:Description rdf:ID="perl">
<s:name rdf:resource="#perl-name"/>
<rdf:type rdf:resource="#language"/>
<NS0:comment>
Perl: Practical Extraction and Report Language
</NS0:comment>
</rdf:Description>
<rdf:Description rdf:about="http://wall.org/~larry/ ">
<s:name rdf:resource="#wall-name"/>
<rdf:type rdf:resource="#homepage"/>
<NS0:comment>
Official site which includes photographs, links,
his geek code block and transcripts of his speeches.
</NS0:comment>
</rdf:Description>
...
</rdf:RDF>
7.2.2 Le risorse RDF di traduzione
Come si puo notare dalle traduzioni precedenti, sono state definite vari
predicati RDF allo scopo di catturare la semantica dei costrutti XTM piu
avanzati, difficilmente mappabili direttamente in elementi di sintassi RDF o
RDFS. In particolare:
baseName Indica la risorsa astratta che contiente le informazioni sulla

7.2 Il convertitore 201
denominazione del soggetto.
variant Indica la risorsa astratta che contiente le informazioni sulle
denominazioni alternative del soggetto.
parameter Indica la risorsa astratta che contiente le informazioni sul contesto
di validita della denominazione alternativa del soggetto.
variantName Indica la risorsa astratta che contiente la denominazione
alternativa del soggetto.
association Indica la risorsa astratta di tipo rdf:Bag che contiene i
riferimenti ai membri di un’associazione.
scope Indica una risorsa astratta che serve a contestualizzare il soggetto.
7.2.3 Conversione da RDF a XTM
Per questo esempio si utilizzera il documento XTM contenuto nel file Ultima-
teGoogle2.rdf della directory tests/conversion/rdf2xtm della distribuzione. In
questo file e stata definita la stessa ontologia usata nell’esempio precedente:
sono state create le classi person, homepage e language, con le relative istanze,
e i predicati ass-homepage, ass-creator-of, birthday, birthplace e image.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
>
<rdfs:Class rdf:ID="homepage"/>
<rdfs:Class rdf:ID="person"/>
<rdfs:Class rdf:ID="language"/>
<rdf:Property rdf:ID="ass-homepage"/>
<rdf:Property rdf:ID="ass-creator-of"/>
<rdf:Property rdf:ID="birthday"/>

202 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<rdf:Property rdf:ID="birthplace"/>
<rdf:Property rdf:ID="image"/>
<rdf:Description rdf:about="http://www.larrywall.com">
<rdfs:label>Larry Wall</rdfs:label>
<rdf:type rdf:resource="#person"/>
<image rdf:resource="http://www.photos.com/wall_l.gif"/>
<birthday>21 Jan 1956</birthday>
<rdfs:comment>The creator of Perl</rdfs:comment>
<ass-homepage rdf:resource="http://wall.org/~larry/"/>
<ass-creator-of rdf:resource="#perl"/>
</rdf:Description>
<rdf:Description rdf:ID="perl">
<rdfs:label>Perl</rdfs:label>
<rdf:type rdf:resource="#language"/>
<rdfs:comment>
Perl: Practical Extraction and Report Language
</rdfs:comment>
</rdf:Description>
<rdf:Description rdf:about="http://wall.org/~larry/">
<rdfs:label>The Perl Language</rdfs:label>
<rdf:type rdf:resource="#homepage"/>
<rdfs:comment>
Official site which includes photographs, links,
his geek code block and transcripts of his speeches.
</rdfs:comment>
</rdf:Description>
</rdf:RDF>
Se si esegue la traduzione di questo documento usando le funzionalita
standard offerte dai plugin si puo notare come la traduzione relativa alle
proprieta definite comporti la generazione di alcuni topic tipizzati sia come
association che come occurrence. Questo avviene perche sono stati definiti

7.2 Il convertitore 203
come rdf:Property e sono stati utilizzati come predicati il cui codominio e
un letterale.
<topic id="tt-class">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#class"/>
</subjectIdentity>
</topic>
<topic id="tt-assoc">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#association"/>
</subjectIdentity>
</topic>
<topic id="tt-occ">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#occurrence"/>
</subjectIdentity>
</topic>
<!-- Person -->
<topic id="person">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
</topic>
<topic id="larrywall">
<instanceOf>
<topicRef xlink:href="#person"/>
</instanceOf>

204 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<subjectIdentity>
<resourceRef xlink:href="http://www.larrywall.com"/>
</subjectIdentity>
<baseName>
<baseNameString>Larry Wall</baseNameString>
</baseName>
<occurrence>
<resourceData>The creator of Perl</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#birthday"/>
</instanceOf>
<resourceData>21 Jan 1956</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#birthplace"/>
</instanceOf>
<resourceData>Boulder, Colorado</resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#image"/>
</instanceOf>
<resourceRef xlink:href="#larryimg"/>
</occurrence>
</topic>
<!-- Language -->
<topic id="language">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
</topic>

7.2 Il convertitore 205
<topic id="perl">
<instanceOf>
<topicRef xlink:href="#language"/>
</instanceOf>
<baseName>
<baseNameString>Perl</baseNameString>
</baseName>
<occurrence>
<resourceData>
Perl: Practical Extraction and Report Language
</resourceData>
</occurrence>
</topic>
<!-- Home page -->
<topic id="homepage">
<instanceOf>
<topicRef xlink:href="#tt-class"/>
</instanceOf>
</topic>
<topic id="larryhome">
<instanceOf>
<topicRef xlink:href="#homepage"/>
</instanceOf>
<subjectIdentity>
<resourceRef xlink:href="http://wall.org/~larry/"/>
</subjectIdentity>
<baseName>
<baseNameString>The Perl Language</baseNameString>
</baseName>
<occurrence>
<resourceData>
Official site which includes photographs, links,

206 Capitolo 7. Manuale di utilizzo dei tool sviluppati
his geek code block and transcripts of his speeches.
</resourceData>
</occurrence>
</topic>
<!-- Associations and Occurrences -->
<topic id="ass-creator-of">
<instanceOf>
<topicRef xlink:href="#tt-assoc"/>
</instanceOf>
</topic>
<association>
<instanceOf>
<topicRef xlink:href="#ass-creator-of"/>
</instanceOf>
<member>
<topicRef xlink:href="#larrywall"/>
</member>
<member>
<topicRef xlink:href="#perl"/>
</member>
</association>
<topic id="ass-homepage">
<instanceOf>
<topicRef xlink:href="#tt-assoc"/>
</instanceOf>
</topic>
<association>
<instanceOf>
<topicRef xlink:href="#ass-homepage"/>
</instanceOf>
<member>

7.2 Il convertitore 207
<topicRef xlink:href="#larrywall"/>
</member>
<member>
<topicRef xlink:href="#larryhome"/>
</member>
</association>
<topic id="image">
<instanceOf>
<topicRef xlink:href="#tt-assoc"/>
</instanceOf>
</topic>
<topic id="larryimg">
<subjectIdentity>
<resourceRef xlink:href="http://www.photos.com/wall_l.gif"/>
</subjectIdentity>
</topic>
<topic id="birthday">
<instanceOf>
<topicRef xlink:href="#tt-occ"/>
</instanceOf>
<instanceOf>
<topicRef xlink:href="#tt-assoc"/>
</instanceOf>
</topic>
<topic id="birthplace">
<instanceOf>
<topicRef xlink:href="#tt-assoc"/>
</instanceOf>
<instanceOf>
<topicRef xlink:href="#tt-assoc"/>
</instanceOf>
</topic>

208 Capitolo 7. Manuale di utilizzo dei tool sviluppati
Benche la traduzione presentata sia corretta puo non essere cio che si
desidera. Per ottenere un documento XTM in cui ogni proprieta RDF sia
trattata come un elemento association o un elemento occurrence si possono
percorrere due strade:
• Si arricchisce la definizione di ogni proprieta, applicandovi i predicati
rdf:domain e rdf:range opportunamente valorizzati.
<rdf:Property rdf:ID="ass-homepage">
<rdfs:domain rdf:resource="#person"/>
<rdfs:range rdf:resource="#homepage"/>
</rdf:Property>
<rdf:Property rdf:ID="ass-creator-of">
<rdfs:domain rdf:resource="#person"/>
<rdfs:range rdf:resource="#language"/>
</rdf:Property>
<rdf:Property rdf:ID="birthday">
<rdfs:domain rdf:resource="#person"/>
<rdfs:range rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Literal"/>
</rdf:Property>
<rdf:Property rdf:ID="birthplace">
<rdfs:domain rdf:resource="#person"/>
<rdfs:range rdf:resource=
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Literal"/>
</rdf:Property>
• Si utilizza il seguente driver di traduzione, in cui si afferma che
– Si vuole tradurre in associazioni i predicati ass-homepage e
ass-creator-of.
– Si vuole tradurre in occorrenze i predicati birthday e birthplace.

7.2 Il convertitore 209
<rdf2xtm>
<association_predicates>
<predicate
nameSpace="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
predicateId="ass-homepage"/>
<predicate
nameSpace="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
predicateId="ass-creator-of"/>
</association_predicates>
<occurrence_predicates>
<predicate
nameSpace="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
predicateId="image"/>
<predicate
nameSpace="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
predicateId="birthday"/>
<predicate
nameSpace="http://cs.unibo.it/meta/UltimateGoogle2.rdf#"
predicateId="birthplace"/>
</occurrence_predicates>
</rdf2xtm>
In questo modo si puo ottenere la traduzione desiderata, di cui qui vengono
mostrate le differenze rispetto alla precedente.
<topic id="image">
<instanceOf>
<topicRef xlink:href="#tt-occ"/>
</instanceOf>
</topic>
<topic id="birthday">
<instanceOf>
<topicRef xlink:href="#tt-occ"/>
</instanceOf>

210 Capitolo 7. Manuale di utilizzo dei tool sviluppati
</topic>
<topic id="birthplace">
<instanceOf>
<topicRef xlink:href="#tt-occ"/>
</instanceOf>
</topic>
7.3 L’editor
L’idea alla base dello strumento di editazione e quella di sfruttare le
informazioni semantiche, rappresentate dalle ontologie e dai vincoli definiti in
appositi documenti di schema, per guidare l’utente alla creazione di documenti
validi e significativi, in maniera del tutto trasparente.
In particolare, l’idea e quella di consentire la creazione di risorse descrittive
tipizzabili sulla base delle classi definite nello schema, e quindi, in base al tipo
specificato, consentire l’inserimento solo degli attributi e delle relazioni con le
altre risorse previste dallo schema stesso.
7.3.1 Lo schema per XTM
Si vuole modellare un insieme di linguaggi. Si definisce pertanto il tipo
Language, e i tipi che corrispondono ai linguaggi prescelti, sottoclassi di
Language. Vengono utilizzati gli PSI per tipizzare questi topic e relazioni. In
questo modo si afferma che tali elementi “servono” per definire degli oggetti
di schema. In particolare:
• http://www.iso.org/iso13250/tmcl.xtm#topic-type: definizione di un
topic di tipo “classe”, che verra utilizzato per tipizzare altri topic istanze.
• http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass: de-
finizione di un’associazione di tipo superclasse-sottoclasse.
• http://www.topicmaps.org/xtm/1.0/core.xtm#superclass: identifica il
ruolo di superclasse di un membro di un’associazione.

7.3 L’editor 211
• http://www.topicmaps.org/xtm/1.0/core.xtm#subclass: identifica il
ruolo di sottoclasse di un membro di un’associazione.
<topic id="language">
<baseName>
<baseNameString>Language</baseNameString>
</baseName>
<instanceOf>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#topic-type"/>
</instanceOf>
</topic>
<topic id="functional">
<baseName>
<baseNameString>Functional Language</baseNameString>
</baseName>
<instanceOf>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#topic-type"/>
</instanceOf>
</topic>
<association>
<instanceOf>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass"/>
</instanceOf>
<member>
<roleSpec>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass"/>
</roleSpec>
<topicRef xlink:href="#language"/>
</member>
<member>

212 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<roleSpec>
<subjectIndicatorRef xlink:href=
"http://www.topicmaps.org/xtm/1.0/core.xtm#subclass"/>
</roleSpec>
<topicRef xlink:href="#functional"/>
</member>
</association>
Si definisce quindi il tipo Person, insieme ad alcuni attributi supplementari,
corrispondenti a occorrenze di XTM. Si noti come le occorrenze siano tipizzate
con dei topic occurrence role type. Anche in questo caso sono stati utilizzati
appositi PSI:
• http://www.iso.org/iso13250/tmcl.xtm#template: applicato ad un
elemento scope di un’occorrenza, permette di trattare tale occorrenza
come facente parte di uno schema.
• http://www.iso.org/iso13250/tmcl.xtm#occurrence-type: tipizza un
topic occurrence role type che verra utilizzato per tipizzare un’occor-
renza. Questi topic permettono di assegnare un nome all’attributo
corrispondente all’occorrenza.
• http://www.cs.unibo.it/meta/psi-navigator.xtm#image: questo PSI
non fa parte di quelli standard, definiti nella specifica di XTM, ma
e un’estensione proprietaria, di cui se ne avvantaggera il navigatore
al momento di visualizzare l’attributo cosı tipizzato. Per un elenco
esaustivo degli PSI proprietari si rimanda al paragrafo 7.4.2.
<topic id="person">
<baseName>
<baseNameString>Person</baseNameString>
</baseName>
<instanceOf>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#topic-type"/>
</instanceOf>
<occurrence>

7.3 L’editor 213
<instanceOf>
<topicRef xlink:href="#ort-birthday"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>
<resourceData></resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#ort-birthplace"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>
<resourceData></resourceData>
</occurrence>
<occurrence>
<instanceOf>
<topicRef xlink:href="#occ-image"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>
<resourceRef xlink:href=""/>
</occurrence>
</topic>
<topic id="ort-birthday">
<instanceOf>
<subjectIndicatorRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#occurrence-type"/>
</instanceOf>

214 Capitolo 7. Manuale di utilizzo dei tool sviluppati
<baseName>
<baseNameString>Data di nascita</baseNameString>
</baseName>
</topic>
<topic id="ort-birthplace">
<instanceOf>
<subjectIndicatorRef xlink:href=
"http://www.iso.org/iso13250/tmcl.xtm#occurrence-type"/>
</instanceOf>
<baseName>
<baseNameString>Luogo di nascita</baseNameString>
</baseName>
</topic>
<topic id="occ-image">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.cs.unibo.it/meta/psi-navigator.xtm#image"/>
</subjectIdentity>
<baseName>
<baseNameString>Image URL</baseNameString>
</baseName>
</topic>
Si vuole infine modellare il concetto secondo cui una persona ha creatoun certo linguaggio. Avendo definito prima le classi Person e Language, esufficiente creare l’associazione fra elementi di questi tipi.
<association>
<instanceOf>
<topicRef xlink:href="#ass-creator-of"/>
</instanceOf>
<scope>
<subjectIndicatorRef
xlink:href="http://www.iso.org/iso13250/tmcl.xtm#template"/>
</scope>

7.3 L’editor 215
<member>
<roleSpec>
<topicRef xlink:href="#person"/>
</roleSpec>
<topicRef xlink:href="#person"/>
</member>
<member>
<roleSpec>
<topicRef xlink:href="#language"/>
</roleSpec>
<topicRef xlink:href="#language"/>
</member>
</association>
7.3.2 Lo schema per RDF
Anche per RDF vengono espressi gli stessi concetti dei topic definiti nel
paragrafo precedente.Pertanto si crea innanzitutto una gerarchia di tipo classe-sottoclasse fra
la risorsa Language e Functional Language. Si noti che l’entita “&ns;”corrisponde al namespace relativo allo schema che si sta definendo.
<rdfs:Class rdf:about="&ns;language">
<rdfs:label>Language</rdfs:label>
</rdfs:Class>
<rdfs:Class rdf:about="&ns;functional">
<rdfs:label>Functional Language</rdfs:label>
<rdfs:subClassOf rdf:resource="&ns;language"/>
</rdfs:Class>
Viene creta poi la risorsa che modella il concetto di persona, insieme agli
stessi attributi definiti nel paragrafo precedente. Alle proprieta birthday e
birthplace, in quanto attributi, viene associato il predicato rdfs:range con
valore rdfs:Literal. La proprieta image, invece, e stata definita con il
namespace “media”, contenente la definizione di risorse proprietarie usate dal

216 Capitolo 7. Manuale di utilizzo dei tool sviluppati
navigatore al momento di visualizzare l’attributo. Per un elenco esaustivo delle
risorse ivi definite si rimanda al paragrafo 7.4.2.
L’URL del namespace e http://cs.unibo.it/meta/rdfmediaschema#.
<rdfs:Class rdf:about="&ns;person">
<rdfs:label>Person</rdfs:label>
</rdfs:Class>
<rdf:Property rdf:about="&ns;birthday">
<rdfs:label>Data di nascita</rdfs:label>
<rdfs:domain rdf:resource="&ns;person"/>
<rdfs:range rdf:resource="&rdfs;Literal"/>
</rdf:Property>
<rdf:Property rdf:about="&ns;birthplace">
<rdfs:label>Luogo di nascita</rdfs:label>
<rdfs:domain rdf:resource="&ns;person"/>
<rdfs:range rdf:resource="&rdfs;Literal"/>
</rdf:Property>
<rdf:Property rdf:about="&media;image">
<rdfs:label>Image URL</rdfs:label>
<rdfs:domain rdf:resource="&ns;person"/>
<rdfs:range rdf:resource="&rdfs;Resource"/>
</rdf:Property>
Infine si crea l’associazione fra la classe person e language come segue:
<rdf:Property rdf:about="&ns;creator-of">
<rdfs:label>Creator of</rdfs:label>
<rdfs:domain rdf:resource="&ns;person"/>
<rdfs:range rdf:resource="&ns;language"/>
</rdf:Property>
7.3.3 Editazione di documenti
Una volta installati gli schemi cosı definiti, questi compariranno fra quelli
disponibili all’editor. A questo punto sara sufficiente inserire un nome per il

7.3 L’editor 217
documento di istanze che si vuole creare, associarvi una descrizione (opzionale)
ed infine selezionare lo schema prescelto.
Figura 7.1: Caricamento e creazione di documenti RDF o XTM
A questo punto verra avviato l’editor, che mostrera un documento vuoto.
Sara necessario cliccare sull’icona “New Item” della toolbar. Verra cosı
creato un template per guidare alla creazione di un nuovo elemento di
metainformazioni.
Figura 7.2: La toolbar dell’editor
La prima sezione del template permette di inserire le informazioni comuni
ad ogni tipo di elemento: i nomi, il commento, il tipo.

218 Capitolo 7. Manuale di utilizzo dei tool sviluppati
Le informazioni inseribili nel campo relativo al tipo vengono inserite in un
SELECT di HTML, il cui contenuto coincide con le Class o i topic type definiti
nello schema selezionato.
I valori inseriti nei campi per i nomi ed i tipi vengono serializzati negli
elementi definiti nella sintassi di RDF e XTM. Cio che viene inserito nel campo
del commento viene serializzato invece come segue:
• Nel caso di XTM diventa un’occorrenza dell’elemento corrente, tipizzatacon un topic il cui soggetto e rappresentato da un altro PSI proprietario:http://www.cs.unibo.it/meta/psi-edit.xtm#comment.
<topic id="topic-with-comment">
...
<occurrence>
<instanceOf>
<topicRef xlink:href="#comment"/>
</instanceOf>
<resourceData>The comment is here!</resourceData>
</occurrence>
</topic>
<topic id="comment">
<subjectIdentity>
<subjectIndicatorRef xlink:href=
"http://www.cs.unibo.it/meta/psi-edit.xtm#comment"/>
</subjectIdentity>
</topic>
• Nel caso di RDF si sfrutta invece il predicato rdfs:comment.
<rdf:Description rdf:ID="resource-with-comment">
...
<rdfs:comment>The comment is here!</rdfs:comment>
</rdf:Description>
La seconda sezione contiene l’elenco delle relazioni definite nello schema
che sono compatibili con il tipo selezionato nella prima sezione. Mediante

7.4 Il navigatore 219
il bottone “Add Relation” e possibile aggiungere un numero arbitrario di
relazioni. Una volta selezionata una specifica relazione verranno visualizzati i
membri che possono far parte dell’associazione, cioe tutti gli elementi istanza
il cui tipo e compatibile con cio che e stato selezionato.
La terza sezione, infine, contiene tutti gli attributi compatibili col tipo
associato all’elemento corrente. Oltre agli elementi occurrence di XTM e alle
proprieta con codominio Literal di RDF che vengono definiti nello schema, e
sempre presente l’attributo “Subject URL”, il cui scopo e quello di contenere
l’url che rappresenta il soggetto dell’elemento corrente.
Una volta inserite tutte le informazioni volute, sara sufficiente cliccare
sul bottone “Save Element” per salvare localmente le modifiche apportate
al documento delle istanze. Per salvare definitivamente il documento
sara sufficiente cliccare sull’icona “Save” della toolbar. In questo modo
il documento locale verra inviato al server, che si occupera di salvarlo
permanentemente.
7.3.4 Differenze di editazione fra RDF e XTM
L’editor e stato creato con l’intento, fra gli altri, di rendere trasparente
all’utente la modifica e la creazione di documenti sia in formato RDF che
in XTM. Pertanto le differenze nell’editazione sono minime. In particolare,
XTM permette associazioni con un numero arbitrario di membri. Quindi per
ogni relazione selezionata durante l’editazione, sara possibile visualizzare un
qualunque numero di membri nel caso in cui si stiano editando documenti in
formato XTM. Nel caso di documenti RDF, invece, verra sempre visualizzato
solo un altro membro.
7.4 Il navigatore
L’obiettivo principale che ci si e posti per il navigatore e stato quello
di offrire la possibilita di navigare all’interno di un insieme di documenti
di metainformazioni in maniera il piu possibile uniforme per entrambi gli
standard, rendendo del tutto trasparente all’utente la struttura interna delle
metainformazioni, cercando cioe di rendere possibile un’efficiente ricerca dei

220 Capitolo 7. Manuale di utilizzo dei tool sviluppati
contenuti senza costringere l’utente a conoscere i concetti alla base delle
tecnologie utilizzate per la specifica di metainformazioni.
Sulla base delle similarita dei due paradigmi, su cui si e indagato nei
precedenti capitoli, si e cercato pertanto di offrire all’utente un’interfaccia
univoca per la navigazione di documenti, rendendo quanto piu possibile
trasparente anche il linguaggio di specifica dei dati esposti.
7.4.1 Navigazione di documenti
La navigazione di metainformazioni inizia con la visualizzazione dell’elenco dei
documenti disponibili da cui iniziare (figura 7.3).
Figura 7.3: Elenco dei file su cui navigare
Una volta selezionato un documento viene mostrata una pagina HTML
contenente una struttura gerarchica delle metainformazioni contenute nel file
prescelto (figura 7.4). Questa pagina e composta da due aree principali:
Categories L’elenco delle categorie disponibili, organizzate gerarchicamente.
Available instances L’elenco degli elementi disponibili, suddivisi per
categoria.
Un click su un elemento contenuto nell’area delle categorie permette
una navigazione fra la gerarchia dei tipi definita nello schema associato al
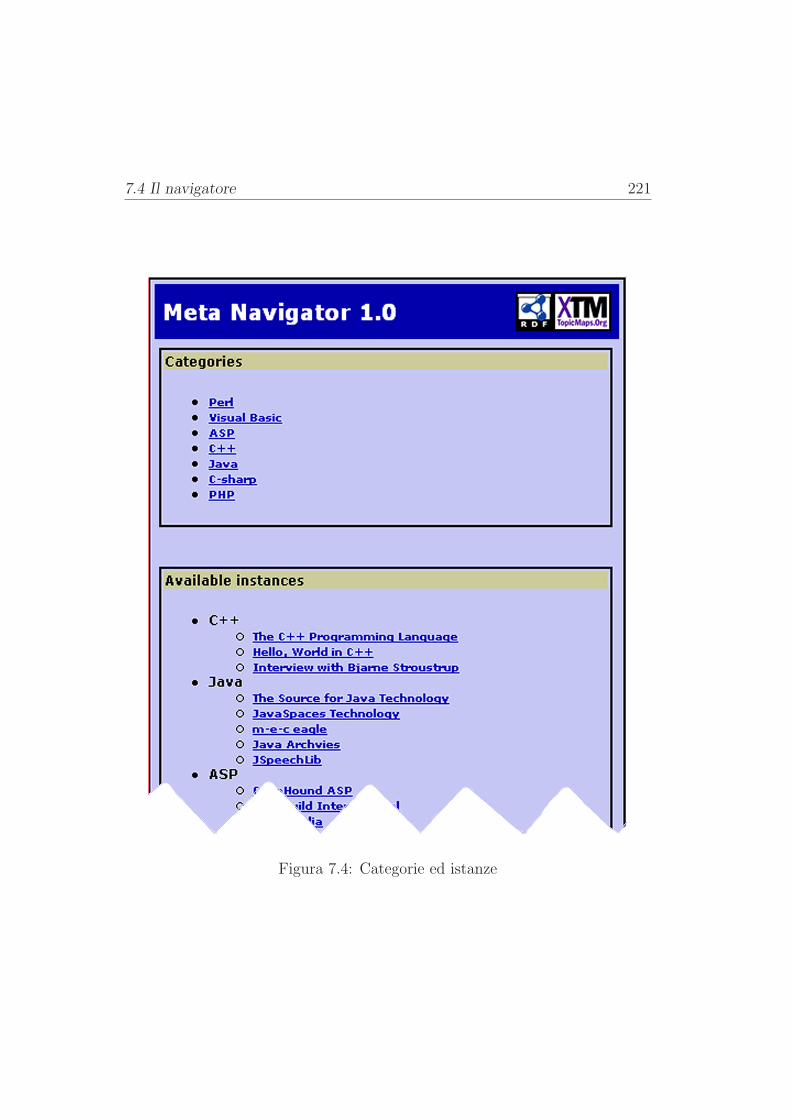
7.4 Il navigatore 221
Figura 7.4: Categorie ed istanze

222 Capitolo 7. Manuale di utilizzo dei tool sviluppati
documento. In questo modo si ottiene una nuova pagina HTML, simile alla
precedente (figura 7.5), in cui sono presenti le seguenti sezioni:
Categories Percorso di navigazione delle categorie disponibili.
Sub Categories Elenco delle sottocategorie definite per la categoria
selezionata.
Available instances L’elenco degli elementi disponibili per categoria
selezionata.
Figura 7.5: Sotto-categorie e istanze
Se si seleziona un elemento fra quelli contenuti nell’area delle istanze, viene
mostrata un’ulteriore pagina HTML contenente i dettagli relativi all’elemento

7.4 Il navigatore 223
scelto (figura 7.6). Si possono distinguere, oltre al nome ed al tipo dell’istanza
scelta, le seguenti sezioni:
Other names Elenco dei nomi associati all’elemento corrente.
Relations Elenco delle relazioni a cui l’elemento partecipa. In questa sezione
sono anche presenti i nomi degli altri membri coinvolti nelle relazioni.
Ogni nome e un link verso i dettagli dell’elemento membro.
Attributes Elenco degli attributi. Questi possono essere delle semplici
stringhe di testo o dei link a risorse esterne.
Comment Eventuale commento associato all’elemento.
Multimedia contents Elenco di collegamenti a risorse multimediali esterne
messe in relazione con l’elemento. Quest’area fa uso delle risorse RDF e
dei PSI proprietari che verranno definiti nel paragrafo 7.4.2.
Jump to Area di navigazione che permette di tornare agli argomenti
visualizzati in precedenza.
7.4.2 Le risorse e gli PSI proprietari
Come anticipato nei paragrafi precedenti, e possibile utilizzare, durante la fase
di editing, delle risorse RDF e dei PSI proprietari al fine di visualizzare in
modo diverso particolari attributi da essi tipizzati. In questo paragrafo ne
verra fornito un elenco esaustivo.
Nel caso di RDF sono state definite le seguenti risorse:
• http://cs.unibo.it/meta/rdfmediaschema#image: rappresenta un’im-
magine in un qualunque formato visualizzabile dal browser.
• http://cs.unibo.it/meta/rdfmediaschema#audio: rappresenta un con-
tributo audio, come un file wave o mp3.
• http://cs.unibo.it/meta/rdfmediaschema#video: rappresenta un fil-
mato video, come un file Real Video, AVI, Quick Time, DivX,
etc..

224 Capitolo 7. Manuale di utilizzo dei tool sviluppati
Figura 7.6: Visualizzazione di un’istanza di Person

7.4 Il navigatore 225
• http://cs.unibo.it/meta/rdfmediaschema#flash: rappresenta un fil-
mato multimediale in formato Flash di Macromedia.
Nel caso di XTM sono stati creati i seguenti PSI:
• http://www.cs.unibo.it/meta/psi-navigator.xtm#image: rappresenta
un’immagine in un qualunque formato visualizzabile dal browser.
• http://www.cs.unibo.it/meta/psi-navigator.xtm#audio: rappresenta
un contributo audio, come un file wave o mp3.
• http://www.cs.unibo.it/meta/psi-navigator.xtm#video: rappresenta
un filmato video, come un file Real Video, AVI, Quick Time, DivX, etc..
• http://www.cs.unibo.it/meta/psi-navigator.xtm#flash: rappresenta
un filmato multimediale in formato Flash di Macromedia.
• http://www.cs.unibo.it/meta/psi-edit.xtm#comment: poiche in XTM
non esiste un elemento di sintassi che rappresenti un commento, si e
creato tale PSI.

226 Capitolo 7. Manuale di utilizzo dei tool sviluppati

Capitolo 8
Conclusioni
In questa dissertazione si e visto come siano strutturate le tecnologie che
consentono l’estensione semantica del Web e che sono alla base delle tecniche
di Knowledge Representation. L’utilizzo esteso di ontologie per la condivisione
delle definizioni riguardanti le diverse aree del sapere comune, e le reti di
associazioni semantiche tra risorsce che si possono creare con queste tecnolgie,
possono portare innumerevoli benefici al mondo dell’informazione digitale,
tanto piu in considerazione dell’esplosione della quantita di informazioni, e
quindi di conoscenza, che viene resa disponibile sul Web.
La gestione automatizzata dei documenti in base ai reali contenuti rende
non piu necessario l’intervento umano relativo all’interpretazione del testo, ed
elimina il problema dell’ambiguita proprio al linguaggio naturale. Attraverso
la progressiva standardizzazione di ontologie rispetto a cui riferire i concetti
espressi o rappresentati dai documenti, e mediante le eventuali relazioni
di equivalenza esprimibili tra le definizioni di diverse ontologie, si potra
uniformare la visione delle “cose”.
I contesti applicativi in cui infrastrutture di metainformazioni possono
trovare applicazione sono numerosi, ma allo stato attuale non e ancora chiara
quale sia la migliore tecnologia da utilizzare, ne e stato determinato il modo
migliore per applicarla. Allo stato attuale servono strumenti e casi d’uso che
aprano la strada ad ulteriori estensioni e che aiutino a discernere la natura delle
problematiche che si pongono nell’ottica di un utilizzo ampio e diffuso delle
metainformazioni. Sia per RDF e le sue estensioni semantiche, che per Topic

228 Capitolo 8. Conclusioni
Maps, non e stata accumulata un’esperienza in termini di utilizzo sufficiente a
introdurre regole o specifiche, standard o convenzionali, che possano rendere
interoperabili su vasta scala le applicazioni.
Il tool di conversione tra formati sviluppato, pur nei limiti inerentemente
imposti dalla diversa filosofia di disegno dei due standard, permette di ottenere
una traduzione semantica dei modelli. Il tipo di traduzione e ragionevolmente
coerente nel caso generico, e permette una conversione pilotata per traduzione
contestuali.
L’editor dimostra come l’utilizzo di schemi semantici possa facilitare
la creazione e la modifica dei documenti e renderla semplice anche per
utenti inesperti. Inoltre, mostra come rinunciando ad alcune caratteristiche
proprie unicamente a ciascuno dei due modelli si riesca ad ottenere completa
trasparenza di formato.
Il navigatore di metainforamzioni implementa una delle funzionalita piu
interessanti introdotte dai layer semantici rappresentati dalle metainformazio-
ni, offrendo la possibilita di navigare concetti e risorse seguendo collegamenti
per cui e reso esplicito il significato.

Bibliografia
[AAB+01] Kal Ahmed, Danny Ayers, Mark Birbeckand, Jay Cousinsand,
David Doddsand, Joshua Lubelland, Miloslav Nicand, Daniel
Rivers-Mooreand, Andrew Wattand, Rob Worden, and Ann
Wrightson. Professional XML Meta Data. Wrox, 2001.
[Alt01] Anitta Altenburger. Topic Maps Tutorial, 2001.
http://topicmaps.bond.edu.au/tutorial1.
[ant02] Apache Ant, 2002. http://jakarta.apache.org/ant.
[Bec02] Dave Beckett. RDF/XML Syntax Specification (Revised), 2002.
http://www.w3.org/TR/2002/WD-rdf-syntax-grammar-2002-
0325.
[BG00] Dan Brickly and R. V. Guha. Resource Description
Framework (RDF) Schema Specification 1.0, 2000.
http://www.w3.org/TR/2000/CR-rdf-schema-20000327.
[BL00] Tim Berners-Lee. Semantic Web - XML2000, 2000.
http://www.w3.org/2000/Talks/1206-xml2k-tbl.
[BLFIM98] T. Berners-Lee, R. Fielding, U.C. Irvine, and L. Masinter.
Uniform Resource Identifiers (URI): Generic Syntax, 1998.
http://www.ietf.org/rfc/rfc2396.txt.
[BLHL01] Tim Berners-Lee, James Hendler, and Ora Lassila. The Semantic
Web, 2001. http://www.scientificamerican.com/2001/0501-
issue/0501berners-lee.html.
229

230 BIBLIOGRAFIA
[BPSMM] Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, and Eve Maler.
Extensible Markup Language (XML) 1.0.
http://www.w3.org/TR/REC-xml.
[CD99] James Clark and Steve DeRose. XML Path Language (XPath)
Version 1.0, 1999.
http://www.w3.org/TR/1999/REC-xpath-19991116.
[css99] Cascading Style Sheets, level 1, 1999.
http://www.w3.org/TR/REC-CSS1.html.
[dam02] The DARPA Agent Markup Language Homepage, 2002.
http://www.daml.org/.
[dc01] Dublin Core, 2001.
http://purl.org/dc/elements/1.1/.
[Dum] Edd Dumbill. XML Anti-Awards.
http://www.xml.com/lpt/a/2002/01/02/taglines.html.
[Fre00] E. Freese. Using Topic Maps for the representation, management
and discovery of knowledge. In Proceedings of XML Europe 2000
Conference, 2000.
[fS00] International Organization for Standardization. ISO/IEC
13250:2000 Document description and processing languages. In
Topic Maps, Ginevra, CH, 2000.
[GHJV95] Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides.
Design Patterns, Elements of Reusable Object-Oriented Software.
Addison Wesley, 1995.
[goo02a] Google Directory, 2002. http://www.google.com/dirhp?hl=en.
[goo02b] Google Directory: Computers - Programming, 2002.
http://directory.google.com/Top/Computers/Programming/.

BIBLIOGRAFIA 231
[Han01] Hans Holger Rath and Lars Marius Garshol. TMQL requirements
(1.0.0), 2001.
http://www.y12.doe.gov/sgml/sc34/document/0249.htm.
[Hay01] Patrick Hayes. RDF Model Theory, 2001.
http://www.w3.org/TR/2002/WD-rdf-mt-20020214.
[htm02] HTML Tidy Library Project, 2002.
http://tidy.sourceforge.net/.
[htt02] HTTPClient Library, 2002.
http://www.innovation.ch/java/HTTPClient.
[jav02a] JavaTM 2 Platform, Standard Edition, v 1.4.0, 2002.
http://java.sun.com/j2se/1.4.
[jav02b] JavaTM 2 Platform, Standard Edition, v 1.4.0 API Specification,
2002. http://java.sun.com/j2se/1.4/docs/api/index.html.
[jav02c] JavaTM Servlet Technology, 2002.
http://java.sun.com/products/servlet/index.html.
[jav02d] JSR-000053 JavaTM Servlet 2.3 and JavaServer PagesTM
1.2 Specifications, 2002. http://jcp.org/about-
Java/communityprocess/first/jsr053/index.html.
[jen02] HPL Semantic Web activity: Jena Toolkit, 2002.
http://www.hpl.hp.com/semweb/jena-top.html.
[Koi01] Marja-Riitta Koivunen. W3C Semantic Web Activity, 2001.
http://www.w3.org/Talks/2001/1102-semweb-fin.
[Ksi00] R. Ksiezyk. Answer is just a question [of matching Topic Maps].
In Proceedings of XML Europe 2000 Conference, 2000.
[LD01] Martin Lacher and Stefan Decker. On the integration of Topic
Map data and RDF data. In Extreme Markup Languages 2001,
2001.

232 BIBLIOGRAFIA
[liv02] LiveConnect Technology, 2002.
http://developer.netscape.com/docs/manuals/communica-
tor/jsguide4/livecon.htm.
[log02] Log4j Project, 2002. http://jakarta.apache.org/log4j.
[LS99] Ora Lassila and Ralph Swick. Resource Description Framework
(RDF) Model and Syntax Specification, 1999.
http://www.w3.org/TR/1999/REC-rdf-syntax-19990222.
[Mil01] Eric Miller. Semantic Web Activity Statement, 2001.
http://www.w3.org/2001/sw/Activity.
[Moo01] Graham Moore. An Exercise in Convergence. In XML Europe
2001, 2001.
[msd02a] MSDN: HTML and DHTML Reference, 2002.
http://msdn.microsoft.com/workshop/author/dhtml/refe-
rence/dhtml reference entry.asp.
[msd02b] MSDN: HTML Applications (HTA), 2002.
http://msdn.microsoft.com/workshop/author/hta/hta no-
de entry.asp.
[msd02c] MSDN: Internet Explorer, 2002.
http://msdn.microsoft.com/nhp/default.asp?content-
id=28000441.
[NB00] S. Newcomb and M. Biezunski. Topic Maps go XML. In
Proceedings of XML Europe 2000 Conference, 2000.
[NB01] Steven R. Newcomb and Michel Biezunski. Topicmap.net’s
Processing Model for XTM 1.0, version 1.0.2, 2001.
http://www.topicmaps.net/pmtm4.htm.
[nir02] Norme In Rete, 2002. http://www.normeinrete.it.

BIBLIOGRAFIA 233
[oCS01] FORTH Institute of Coumputer Science. The RDF Query
Language (RQL) Documentation, 2001.
http://139.91.183.30:9090/RDF/RQL/Design.html.
[Ogi01] Nikita Ogievetsky. XML Topic Maps through RDF glasses. In
Extreme Markup Languages 2001, 2001.
[oil02] The OIL Page, 2002.
http://www.ontoknowledge.org/oil/oilhome.shtml.
[Ont] Ontopia Schema Language Web Site. http://www.onto-
pia.net/omnigator/docs/schema/tutorial.html.
[oro02] Jakarta Oro, 2002. http://jakarta.apache.org/oro.
[Pep00] S. Pepper. The TAO of Topic Maps, finding the way in the age of
infoglut. XML Europe 2000, 2000.
[PM01] Steve Pepper and Graham Moore. XML Topic Maps (XTM) 1.0,
2001. http://www.topicmaps.org/xtm/1.0.
[Rat00a] H. H. Rath. Making topic maps more colourful. In Extreme
Markup 2000, 2000.
[Rat00b] H. H. Rath. Topic maps self-control. In Extreme Markup 2000,
2000.
[rdq02] HPL Semantic Web activity: Jena Toolkit, RDQL, 2002.
http://www.hpl.hp.com/semweb/jena-top.html.
[ses02] Sesame, the RDF and RDF Schema Storage and Querying service,
2002. http://www.aidministrator.nl.
[sig02] How to Sign Applets Using RSA-Signed Certificates, 2002.
http://java.sun.com/j2se/1.4/docs/guide/plugin/develo-
per guide/rsa signing.html.
[sta01] Stanford RDF API, 2001.
http://www-db.stanford.edu/~melnik/rdf.

234 BIBLIOGRAFIA
[Ste01] Steve Pepper. Draft requirements, examples, and a low
bar proposal for Topic Map Constraint Language, 2001.
http://www.y12.doe.gov/sgml/sc34/document/0226.htm.
[Swi01] Ralph Swick. Metadata Activity Statement, 2001.
http://www.w3.org/Metadata/Activity.html.
[tm402] Project TM4J: Topic Maps for Java, 2002.
http://tm4j.sourceforge.net.
[tol] Ontopia Schema Language Web Site. http://www.onto-
pia.net/omnigator/docs/query.html.
[tom02] Apache Tomcat, 2002. http://jakarta.apache.org/tomcat.
[wge02] GNU Wget, 2002. http://www.gnu.org/software/wget.
[xal02] Xalan, 2002. http://xml.apache.org/xalan-j.
[xer02] Xercer Java Parser, 2002. http://xml.apache.org/xerces-j.

Elenco delle figure
2.1 Grafo corrispondente alla frase dell’esempio 2.1 . . . . . . . . 8
2.2 Grafo corrispondente alla frase dell’esempio 2.2 . . . . . . . . 9
2.3 Grafo corrispondente alla frase dell’esempio 2.8 . . . . . . . . 14
2.4 Grafo corrispondente alla frase dell’esempio 2.9 . . . . . . . . 16
2.5 Grafo corrispondente al documento dell’esempio 2.14 . . . . . 32
2.6 Grafo corrispondente al documento dell’esempio 2.15 . . . . . 34
2.7 Grafo corrispondente al documento dell’esempio 2.17 . . . . . 39
4.1 Il class diagram concettuale del covertitore . . . . . . . . . . . 119
4.2 Il class diagram per la traduzione da Topic Maps verso RDF . 120
4.3 Il class diagram per la traduzione da RDF verso Topic Maps . 121
4.4 Il class diagram per il serializzatore RDF . . . . . . . . . . . . 122
4.5 Fase di bootstrap del convertitore . . . . . . . . . . . . . . . . 123
5.1 La composizione in layer dell’editor . . . . . . . . . . . . . . . 143
5.2 L’use case dell’editor; i servizi forniti . . . . . . . . . . . . . . 144
5.3 Risposta del servlet alla richiesta dei documenti disponibili . . 145
5.4 La GUI dell’editor: visualizzazione di un elemento . . . . . . . 147
5.5 Il class diagram dell’editor . . . . . . . . . . . . . . . . . . . . 148
5.6 Il class diagram per l’applet XTMAppletEngine . . . . . . . . 150
5.7 Caricamento di un documento . . . . . . . . . . . . . . . . . . 151
5.8 Creazione di un nuovo elemento . . . . . . . . . . . . . . . . . 152
5.9 Aggiunta delle relazioni . . . . . . . . . . . . . . . . . . . . . . 153
5.10 Aggiunta degli attributi . . . . . . . . . . . . . . . . . . . . . 154
5.11 Modifica di un elemento . . . . . . . . . . . . . . . . . . . . . 155
235

236 ELENCO DELLE FIGURE
5.12 Lo state diagram dell’editor . . . . . . . . . . . . . . . . . . . 156
5.13 I componenti principali dell’editor . . . . . . . . . . . . . . . . 157
5.14 La richiesta di esecuzione dell’applet firmato . . . . . . . . . . 159
6.1 La scelta dei file su cui iniziare la navigazione . . . . . . . . . 169
6.2 La prima schermata di navigazione: categorie ed istanze . . . 171
6.3 Visualizzazione di un’istanza di Person . . . . . . . . . . . . . 172
6.4 La composizione in layer del navigatore . . . . . . . . . . . . . 173
6.5 L’use case del navigatore: i servizi forniti . . . . . . . . . . . . 174
6.6 Categorie, sotto-categorie e istanze . . . . . . . . . . . . . . . 176
6.7 Il class diagram del navigatore . . . . . . . . . . . . . . . . . . 178
6.8 Il class diagram per la class XTMModel . . . . . . . . . . . . . 180
6.9 Interazione fra i componenti dell’editor . . . . . . . . . . . . . 181
6.10 I componenti principali del navigatore . . . . . . . . . . . . . . 182
7.1 Caricamento e creazione di documenti RDF o XTM . . . . . . 217
7.2 La toolbar dell’editor . . . . . . . . . . . . . . . . . . . . . . . 217
7.3 Elenco dei file su cui navigare . . . . . . . . . . . . . . . . . . 220
7.4 Categorie ed istanze . . . . . . . . . . . . . . . . . . . . . . . 221
7.5 Sotto-categorie e istanze . . . . . . . . . . . . . . . . . . . . . 222
7.6 Visualizzazione di un’istanza di Person . . . . . . . . . . . . . 224





























