Embed Size (px)
Citation preview

HAWC Trigger/DAQA sketch
Dan Edmunds, Philippe Laurens,
Jim Linnemann
MSUGround-based Gamma Ray Astronomy
Workshop, UCLA
Oct 21, 2005

A Strawman Model of TDAQ
• Lay out a simple model to think aboutAssess feasibility; identify issuesTry to minimize number of meshes, boxes, layers…Start with only required inputs and outputs
Slow Control paths laterDownload, monitoring, calibration
• Look at some basic parameters

Key Trigger/DAQ Parameters
Occupancy ω = rate × sensitive time = rate / max rate
Careful: 25 kHz × 1 μs = 2.5% : significant Can we afford to trigger on all proton showers?
Mean Hits μ = # channels × ω Data rate: Bytes / hit × μ × rate(transfer)
Assuming zero suppression75x75 = 5625 tubes 4m centers: 300x300 m
perhaps another layer…

2B wide Circular Buffer (DPM?)
4B wide Circular Buffer (DPM?)
100MHz FADC
1GHz Counter
Discriminator
N=4 Majority…
N=5 Majority…
N=6 Majority…
L1 Trigger
Patch Trigger
.
.
.
Front End and Patch Trigger
Latch

TriggeringPatch level: a time input per triggering tube
won’t drive the costFixed width from tube (~ 40 ns for 3x3 patch)Fanout into several majority logic options
N=3,4,5,6…? Both layers?
Or perhaps analog sum of tube discriminator outputsDefer multiplicity cut on patch to L1; allow global multiplicityEnables risetime trigger…
L1 overall: 625 x n inputsGoal: down to within a factor of 2 of real showers
.15 MHz working figure (Too high?)
outputs of majority logics from each patchCount patches: simplest (pretrigger?)Locality in space and time may be needed

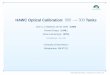
L1 Trigger
SBC
SBC
Switch625 x 100
Patches
Supervisor
625
Farm
100
Gigabit Ethernet
(full duplex)
.1 Gigabit Ethernet(full duplex)
Pull Architecture
Taccept
T(patch > n)

Switch and Farm
Farm: guess 100 nodes (scale up Milagro)~ 2K/node = 200K$
cpu may be marginal: assume same cycles on more data “12 GHz/node” Moore’s law uniprocessor unlikely
can we use multicore efficiently?need L2/3 trigger algorithm first?
Incremental processing
Cisco 6513 router: 625 in + 100 out = 72530K$ + 9K$/48 channel blades (2004 $…)12 blades/chassis (need 15, so 2 chassis)
Interconnect two, or fewer patches or concentratorsAround 250K$ or a bit less

L3 Farm HAWC Milagro D0GHz 4 2 1Processors 200 14 200Hz/processor 1000 143 7.5Instructions/event 4.00E+06 1.40E+07 1.33E+08Instructions/byte 5000 7000 533
L2 FarmGHz 1Processors 1Hz/processor 5000Instructions/event 2.00E+05Instructions/byte 67

Target Budget: 1K/channel = 10M$
SBC in a 3x3 patch: 2k$/18 = $110/channel
Farm and switch ~ .5M$/10K = $50/channel
If guess 1M$ trigger = $100/channel
So not implausible, butHV
LV, crate(?)
ADC/TDC/memory
Design scale: .3M$ (~2-3 FTE-year) = $30/channelCables
Calibration

Some Trigger Issues (R+D)L1 trigger < .15 MHz with good gamma efficiency?Complexity of inputs into L1 trigger?
Single pulse when > patch multiplicity threshold?Indication of PH? Or several multiplicity thresholds? Or analog sum proportional to tubes on? Or
digital signals? Serial?
300m cables to trigger?
A fixed time algorithm? Probably NO!Decisions in strict time order? Probably no.
Simplest data extractionBUT: Shower planes sweep through in different time order
deadtime ~20%? 1 μsec traversal time / 5 μsec/trigger: What time resolution in requests? Affects occupancy; implicit zenith angle cut
Ignore any results from trigger clustering and take all hits in 1μs?
Requiring serial order could forbid a farm in L1/2

Some DAQ Issues (R+D)What is design trigger rate? headroom? .1 -.15MHz = 10-7 μs/event!
CPU load on SBCData request handling; find, compact, ship data (SBC response)Events in blocks to reduce overheads? 7-10 μs vs. TCP ~ 15-20 μs! Choice of protocol through switch (software overhead)
Manpower costs of non-TCP
push or pull architecture Atlas experiencedoes destination ask for data?L1, or Farm supervisor broadcast/multicast to patches
telling them which data to send
Switch: Total throughput check, width, buffer memory/port100Base T limited to 100m
Need repeater(s), switch layers, or fiber? Or 2nd story?

More DAQ Issues (R+D)• How to throttle trigger rate by declaring deadtime
– And how to monitor deadtime• Request specific patches? “Regions of Interest”
– Incompatible with blocking of event requests, and broadcasting– If data volume sustainable, look at only ROI’s in farm?
• Read out the L1 trigger data to help
• LARGE data volumes: Raw quite daunting; even reconstructed pretty big– Consequence of low trigger rejection
• Think of HAWC as a telescope? – Primary output is images, not events?
• Skymaps every 15 min? Sliced by E and gamma purity? <1Mbit/s; 4GB/day• How much reconstructed data and raw data needed?
– validation, calibration, algorithm development, reprocessing…
– Also need online short burst analysis (including triggered searches)• 1/6 TB of raw data (@ 1/6GB/s) for 15 minute lookback—ramdisk???• 6GB of reconstructed data @ 6MB/s for 15 minute lookback—maybe

Plausible, but hard• Raw Rate:
– 10MHz muons– 1MHz sensitive times (shower sweepthrough pipeline)
• Doubt L3 farm at 1MHz is plausible
• L1 trigger: – .1 to .2 MHz (showers) if can kill the muons (not trivial) curtains?
• Overlapping sensitive times at .1 MHz– Problems for reconstruction and triggering
• Must extract multiple events from 1 sensitive time• Reconstruction may need patch lists/patch times
– Do a first pass reconstruction coarsely– To ignore out of time data (for this trigger) in linear time (ROI too?)
• Real overlapping showers need to go into MC
• Proton shower rate is pushing technology– Study Atlas: L1 rate is also .1MHz
• Beware: they have lots more resources
– Below .1MHz L1 requires: • hadron rejection at trigger level• Or raise threshold to control rate: physics impact!

HAWC HAWC Milagropatches DAQ
B/channel 6 8channels 625 11,250 1,000occupancy 0.025 0.06B/event 2.70E+00 1.69E+03 4.80E+02Trigger rate (Hz) 1.60E+00 1.00E+05 2.00E+03B/sec to farm 2.70E+05 1.69E+08 9.60E+05farm nodes 100 4B/s per farm node 1.69E+06 2.40E+05network bit/s 1.00E+08 1.00E+09 1.00E+08network occupancy 2% 1% 2%recording rate (Hz) 7.50E+04 1.00E+03B/event recorded 100 24B/s recorded 7.50E+06 2.40E+04GB/day 6.48E+02 2.07E+00
reconstructed

HAWC Milagro D0 D0 Atlas Ice CubeDAQ Run 2 Run 1 2008-9
B/channel 6 8 5 5 250channels 10,000 1,000 1,000,000 250,000 5,000occupancy 0.025 0.25 0.05 0.35 0.02B/event 1.50E+03 2.00E+03 2.50E+05 4.38E+05 1.50E+06 2.50E+04Trigger rate (Hz) 1.00E+05 2.00E+03 1500 200 3.30E+03 1.50E+03B/sec to farm 1.50E+08 4.00E+06 3.75E+08 8.75E+07 4.95E+09 3.75E+07farm nodes 100 4 100 50 1000 25B/s per farm node 1.50E+06 1.00E+06 3.75E+06 1.75E+06 4.95E+06 1.50E+06network bit/s 1.00E+09 1.00E+08 1.00E+09 1.60E+08 1.00E+09 1.00E+08network occupancy 1% 8% 3% 9% 4% 12%recording rate (Hz) 7.50E+04 1.00E+03 5.00E+01 3.00E+00 2.00E+02 1.50E+03B/event recorded 100 24 3.00E+05 4.63E+05 2.00E+06 1.00E+03B/s recorded 7.50E+06 2.40E+04 1.50E+07 1.39E+06 4.00E+08 1.50E+06GB/day 6.48E+02 2.07E+00 1.30E+03 1.20E+02 3.46E+04 1.30E+02

Front EndImagine for now located at patch station
3 × 3 × 2 tubes ~ 10m signal cable
Split into time and PH paths Discriminator for time (adjustable threshold possible; multiple thresholds?)
Record 4B wide 1GHz counter into circular bufferIs 1ns least count OK?
Split/fanout to n-fold majority logic for triggering
100 MHz FADC for PH2B wide circular bufferMust be able to read out whole trace (slowly) for debugging
Independent, but strong resemblance to Ice Cube electronics
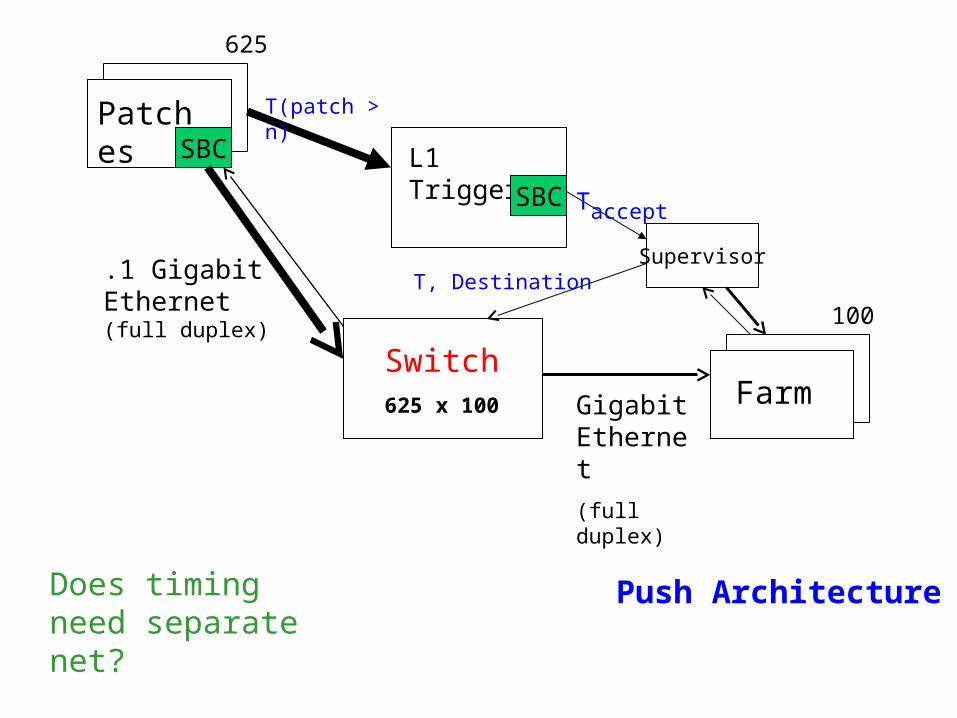
L1 Trigger
SBC
SBC
Switch625 x 100
Patches
Supervisor
625
Farm
100
Gigabit Ethernet
(full duplex)
.1 Gigabit Ethernet(full duplex)
Push Architecture
Taccept
T(patch > n)
Does timing need separate net?
T, Destination

Some MC-driven R+D:
• 1ns TDC least count OK?• L1/L2 Trigger Algorithms (select single showers)• Effect of Shower Pileup on L1 shower rate
– Overlapping smaller (>.1 MHz) showers?– How steep is spectrum?
• What is best patch size for – Triggering (local plane fit possible??)
– Readout/reconstruction granularity??• How does reconstruction cope with overlapped events• Can we ignore non-triggered patches?
– Or do a useful pre-fit on patch times» Would reduce effective sensitive time/occupancy

Big choices2 layers? Not critical for triggering; big moneyFront End in tube base, or out of water?
Ease of Commissioning, servicing vs. noise considerationsSimilar consequences if seal failsdifferent connector(s), cable complexity
L1 trigger complexity (inputs, processing) and target L1 rate!!What local processing before L1 triggering
How many tubes in a patch? How many patches?
L1 trigger in fixed time?L1 = processing of special L1 data
Hope no data movement
Readout directly to farm, or layered?Interacts with # patches, farm size, switch width (Np+Nf)And choice of protocol to event buildBlocking factor of events; accept rates; protocolSBC CPU load and latency and FE memory time
Where is L1 trigger, Farm (cable lengths)? Beside pond? 2nd story?

Some Front End Issues (R+D)• Number of TDC thresholds• FADC to PE Algorithm(s): when?
– Upon readout request? TDC hit? Patch trigger?
• Data extraction from circular buffer
• Restrict readout to triggered patches?• Single or multiple (T, PE) readouts on request
– First hit only: vulnerable to noise, prepulsing– Guess < 1% efficiency loss or more at 25kHz singles rate

Time1ns resolution goal2us range (set by pond traversal)range is then 2000 to 4000 12 bit TDCBytes/chan 2
PHdynamic range say 30000 or sominimum say .5 PEratio: 64K 16 bit adclogarithmic from 1/4 PE: bytes/chan 2 maxchannels 10000so max 4B/chan before ID 10K channels needs 2B ID40KB event before 0 suppresstypical occupancy 0.025at 6B/chan with occ 1500
Front end storagestorage time (sec) 1.00E-02
bytes rate (Hz) B/s B/channel B/patchadc 2 1.00E+08 2.00E+08 2.00E+06 3.60E+07time (1GHz) 4 1.00E+05 4.00E+05 4.00E+03 7.20E+04reduce time to 2B on t-Ttrig for readoutrollover time (s) 4.29E+00
days 4.97E-05