Embed Size (px)
Citation preview

Gestao e Tratamento da InformacaoWeb Data Extraction:
Wrapper Induction
Departamento de Engenharia InformaticaInstituto Superior Tecnico
1o Semestre2008/2009
Slides baseados nos slides oficiais do livro “Web Data Mi-ning” c©Bing Liu, Springer, December, 2006.

Outline
Introduction
The Data Model and HTML Encoding
Wrapper Induction

Outline
Introduction
The Data Model and HTML Encoding
Wrapper Induction

Introduction
◮ A large amount of information on the Web is contained inregularly structured data objects
◮ often data records retrieved from databases
◮ Such Web data records are important:◮ lists of products and services;◮ Applications: e.g., comparative shopping, meta-search,
meta-query, etc.
◮ To process this data implies extracting it from semi-structuredweb pages and converting it to structured information
◮ This is done by using wrappers

Wrappers
◮ Wrappers are small applications or scripts capable ofextracting information from semi-structured sources, such asHTML
◮ Wrappers can be built manually◮ E.g., using regular expressions, XSLT, ...
◮ Or automatically◮ Using machine learning techniques

Web Data Pages
There are two types of data rich pages:
◮ List pages◮ Each such page contains one or more lists of data records◮ Each list in a specific region in the page◮ Two types of data records: flat and nested
◮ Detail pages◮ Each such page focuses on a single object◮ But can have a lot of related and unrelated information

A List Page

A Detail Page

Extraction Results
Chomsky On Anarchism Noam Chomsky, ... $11.53 4
Manufacturing Consent Edward S. Herman, ... $11.78 4
11 de septiembre... Noam Chomsky $8.95 3.5
Imperial Grand Strategy... Noam Chomsky $17.99 5

Outline
Introduction
The Data Model and HTML Encoding
Wrapper Induction

The Data Model
◮ Most Web data can be modeled as nested relations◮ typed objects allowing nested sets and tuples
◮ An instance of a type T is simply an element of the domain ofT
Definition
◮ Let B = {B1, B2, . . . ,Bk} be a set of basic types◮ Each Bi is atomic and of domain dom(Bi )
◮ If T1, T2, . . . ,Tn are types, then [T1, T2, . . . ,Tn] is a tupletype of domaindom([T1, T2, . . . ,Tn]) = {[v1, v2, . . . , vn]|vi ∈ dom(Ti )}
◮ If T is a tuple type, then {T} is a set type with domaindom({T}) = 2dom(T )

An Example Nested Tuple
◮ Classic flat relations are of un-nested or flat set types
◮ Nested relations are of arbitrary set types
An example type
tuple book (title: string;author: set (name: string);prices: set (tuple price (use: string;
price:number;))
An example tuple
[’Manufacturing Consent’,
{’Edward S. Herman’, ’Noam Chomsky’},
{[’used’, 4.78], [’new’, 8.95]}]

Type Trees
Definition
◮ A basic type Bi is a leaf
◮ A tuple type [T1, T2, . . . ,Tn] is a tree rooted at a tuple nodewith n sub-trees, one for each Ti
◮ A set type {T} is a tree rooted at a set node with onesub-tree
We introduce a labeling of a type tree, which is defined recursively:
◮ If a set node is labeled Φ, then its child is labeled Φ.0
◮ If a tuple node is labeled Φ, then its n children are labeledΦ.1, . . . ,Φ.n

An Example Type Tree
tuple (book)
string (title) set (author)
string (name)
set (prices)
tuple (price)
string (use) number (price)
Note: attribute names are not part of the type tree.

Instance Trees
Definition
◮ An instance (constant) of a basic type is a leaf
◮ A tuple instance [v1, v2, . . . , vn] forms a tree rooted at a tuplenode with n children or sub-trees representing attribute valuesv1, v2, . . . , vn
◮ A set instance {e1, e2, . . . , en} forms a set node with nchildren or sub-trees representing the set elementse1, e2, . . . , en
Note: A tuple instance is usually called a data record
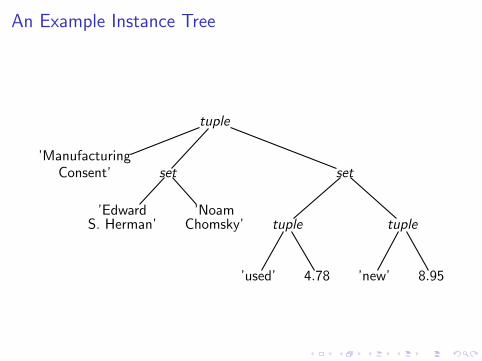
An Example Instance Tree
tuple
’ManufacturingConsent’ set
’EdwardS. Herman’
’NoamChomsky’
set
tuple
’used’ 4.78
tuple
’new’ 8.95

HTML Encoding of Data
◮ There are no designated tags for each type◮ HTML was not designed as a data encoding language◮ Any HTML tag can be used for any type
◮ For a tuple type, values (also called data items) of differentattributes are usually encoded differently to distinguish themand to highlight important items
◮ A tuple may be partitioned into several groups or sub-tuples◮ Each group covers a disjoint subset of attributes and may be
encoded differently

HTML Encoding and Type Trees
DefinitionFor leaf node of a basic type Φ, an instance c is encoded with
enc(Φ : c) = OPEN-TAGS c CLOSE-TAGS
where OPEN-TAGS is a sequence of open HTML tags andCLOSE-TAGS is a sequence of HTML close tags

HTML Encoding and Type Trees (cont.)
A tuple node of type [Φ.1, Φ.2, . . . ,Φ.n] is partitioned into hgroups:
〈Φ.1, . . . ,Φ.e〉, 〈Φ.(e + 1), . . . ,Φ.g〉, . . . , 〈Φ.(k + 1), . . . ,Φ.n〉
An instance [v1, v2, . . . , vn] is encoded with:
enc(Φ : [v .1, v .2, . . . , v .n]) =
OPEN-TAGS1 enc(v1) · · · enc(ve) CLOSE-TAGS1
OPEN-TAGS2 enc(ve+1) · · · enc(vg ) CLOSE-TAGS2
· · ·
OPEN-TAGSh enc(vk+1) · · · enc(vn) CLOSE-TAGSh

HTML Encoding and Type Trees (cont.)
For a set node labeled Φ, a non-empty set instance {e1, e2, . . . , en}is encoded with:
enc(Φ : {e1, e2, . . . , en}) =
OPEN-TAGS enc(e1), enc(e2), . . . , enc(en) CLOSE-TAGS

An Example
<p>
<h3>Manufacturing Consent</h3>
<ul>
<li>Edward S. Herman</li>
<li>Noam Chomsky</li>
</ul>
<ul>
<li>
<strong>used</strong>
<it>4.78</it>
</li> <li>
<strong>new</strong>
<it>8.95</it>
</li>
</ul>
</p>

Limitations
◮ Clearly, this mark-up encoding does not cover all cases in Webpages
◮ In fact, each group of a tuple type can be further divided
◮ In an actual Web page the encoding may not be done byHTML tags alone
◮ Words and punctuation marks can be used

Outline
Introduction
The Data Model and HTML Encoding
Wrapper Induction

Wrapper Induction
◮ Wrappers are generated by using machine learning to generateextraction rules
◮ The user marks the target items in a few training pages◮ The system learns extraction rules from these pages◮ The rules are applied to extract items from other pages
◮ There are many wrapper induction systems◮ WIEN (Kushmerick et al, IJCAI-97)◮ Softmealy (Hsu and Dung, 1998)◮ BWI (Freitag and Kushmerick, AAAI-00)◮ WL2 (Cohen et al. WWW-02)◮ We will focus on Stalker (Muslea et al. Agents-99)

Stalker: A Hierarchical Wrapper Induction System
◮ Hierarchical wrapper learning◮ Extraction is isolated at different levels of hierarchy◮ This is suitable for nested data records
◮ Each item is extracted independently of others
◮ The extraction is done using a tree structure called theEC tree (embedded catalog tree)
◮ The EC tree is based on the type tree of the data
◮ To extract each target item (a node), the wrapper needs arule that extracts the item from its parent

Extraction Rules
◮ Each extraction is done using two rules◮ a start rule and an end rule
◮ The start rule identifies the beginning of the node and the endrule identifies the end of the node.
◮ This strategy is applicable to both leaf nodes (which representdata items) and list nodes
◮ For a list node, list iteration rules are needed to break the listinto individual data records (tuple instances)

Landmarks
◮ The extraction rules are based on the idea of landmarks◮ A landmark is a sequence of consecutive tokens
◮ Landmarks are used to locate the beginning and the end of atarget item
◮ Rules use landmarks to extract the items

An Example
<p>Seller Name:<b>Good Books Inc.</b><br><br>
<li>321 Red Street, <i>Mullen</i>, Phone 0-<i>485</i>-3463-1766</li>
<li>62 Blue Street, <i>Finner</i>, Phone (621) 2176-2771</li>
<li>543 Yellow Street, <i>Pitsher</i>, Phone 0-<i>788</i>-3452-4638</li>
<li>321 Orange Street, <i>Kingston</i>, Phone: (333)-6755-7891</li></p>
◮ To extract the seller name, rule R1 can identify the beginning:
R1: SkipTo(<b>)
◮ This rule means that the system should start from thebeginning of the page and skip all the tokens until it sees thefirst <b> tag.
◮ <b> is a landmark
◮ Similarly, to identify the end of the seller name, we use:
R2: SkipTo(</b>)

An Example (cont.)
◮ A rule may not be unique. For example, we can also use thefollowing rules to identify the beginning of the name:
R3: SkiptTo(Name Punctuation HtmlTag )
or
R4: SkiptTo(Name) SkipTo(<b>)
◮ R3 means that we skip everything untill the word”Name”followed by a punctuation symbol and then a HTMLtag.
◮ In this case, “Name Punctuation HtmlTag ” together is alandmark
◮ Punctuation and HtmlTag are wildcards

Learning Extraction Rules
Stalker uses sequential covering to learn extraction rules for eachtarget item
◮ In each iteration, it learns a perfect rule that covers as manypositive examples as possible without covering any negativeexample
◮ Once a positive example is covered by a rule, it is removed
◮ The algorithm ends when all the positive examples arecovered.
◮ The result is an ordered list of all learned rules

The Stalker Algorithm
Algorithm LearnRules(examples)
1. rule ← ∅
2. while examples 6= ∅ do
2.1 disjunct ← LearnDisjunct(examples)2.2 remove all items in examples covered by disjunct2.3 add disjunct to rule
3. return rule

The Stalker Algorithm (cont.)
Algorithm LearnDisjunct(examples)
1. seed ← the shortest example
2. candidates ← GetInitialCandidates(seed)
3. while candidates 6= ∅ do
3.1 D ← BestDisjunct(candidates)3.2 if D is a perfect disjunct then
3.2.1 return D
3.3 remove D from candidates3.4 candidates ← candidates ∪ Refine(D, seed)
4. return D

The Stalker Algorithm (cont.)
GetInitialCandidates(seed)
Return tokens t that immediately precede the example or wildcardsthat match t
BestDisjunct(candidates)
Return candidates that have
◮ more correct matches
◮ fewer false positives
◮ fewer wildcards
◮ longer landmarks
Refine(D, seed)
Specialize D by adding more terminals

An Example: Extracting Area Codes
E1:<li>321 Red Street, <i>Mullen</i>, Ph 0-<i> 485 </i>-3463-1766</li>
E2:<li>62 Blue Street, <i>Finner</i>, Ph ( 621 ) 2176-2771</li>
E3:<li>543 Yellow Street, <i>Pitsher</i>, Ph 0-<i> 788 </i>-3452-4638</li>
E4:<li>321 Orange Street, <i>Kingston</i>, Ph: ( 333 )-6755-7891</li></p>
◮ The following candidate disjuncts are generated:
D1: SkipTo(( )
D2: SkipTo( Punctuation )
◮ D1 is selected by BestDisjunct
◮ D1 is a perfect disjunct
◮ The first iteration of LearnRule() ends◮ E2 and E4 are removed

An Example (cont.)
E1:<li>321 Red Street, <i>Mullen</i>, Ph 0-<i> 485 </i>-3463-1766</li>
E3:<li>543 Yellow Street, <i>Pitsher</i>, Ph 0-<i> 788 </i>-3452-4638</li>
◮ Two candidates are then generated:
D3: SkipTo(<i>)
D4: SkipTo( HtmlTag )
◮ Both candidates match early in the uncovered examples, E1and E3. Thus, they cannot uniquely locate the positive items
◮ Refinement is needed

Refinement
◮ To specialize a disjunct by adding more terminals to it◮ A terminal means a token or one of its matching wildcards
◮ We hope the refined version will be able to uniquely identifythe positive items in some examples without matching anynegative item in any example
◮ Two types of refinement:◮ Landmark refinement◮ Topology refinement

Landmark Refinement
Landmark refinement: increase the size of a landmark byconcatenating a terminal
E1:<li>321 Red Street, <i>Mullen</i>, Ph 0-<i> 485 </i>-3463-1766</li>
E3:<li>543 Yellow Street, <i>Pitsher</i>, Ph 0-<i> 788 </i>-3452-4638</li>
D5: SkipTo(-<i>)
D6: SkipTo( Punctuation <i>)

Topology Refinement
Topology refinement: Increase the number of landmarks by adding1-terminal landmarks
E1:<li>321 Red Street, <i>Mullen</i>, Ph 0-<i> 485 </i>-3463-1766</li>
E3:<li>543 Yellow Street, <i>Pitsher</i>, Ph 0-<i> 788 </i>-3452-4638</li>
D7 SkipTo(321)SkipTo(<i>)
D8 SkipTo(Red)SkipTo(<i>)
D9 SkipTo(Street)SkipTo(<i>)
D10 SkipTo(,)SkipTo(<i>)
D11 SkipTo(<i>)SkipTo(<i>)
...
D19 SkipTo( Numeric )SkipTo(<i>)
D20 SkipTo( Punctuation )SkipTo(<i>)

Final Results
E1:<li>321 Red Street, <i>Mullen</i>, Ph 0-<i> 485 </i>-3463-1766</li>
E2:<li>62 Blue Street, <i>Finner</i>, Ph ( 621 ) 2176-2771</li>
E3:<li>543 Yellow Street, <i>Pitsher</i>, Ph 0-<i> 788 </i>-3452-4638</li>
E4:<li>321 Orange Street, <i>Kingston</i>, Ph: ( 333 )-6755-7891</li></p>
◮ Using BestDisjunct, D5 is selected as the final solution as ithas longest last landmark
D5: SkipTo(-<i>)
◮ Since all the examples are covered, LearnRule() returns thedisjunctive (start) rule: either D1 or D5
R7: either SkipTo(( ) or
SkipTo(-<i>)

Wrapper Maintenance
◮ Wrapper verification: if the site changes, does the wrapperknow the change?
◮ Wrapper repair: if the change is correctly detected, how toautomatically repair the wrapper?
◮ One way to deal with both problems is to learn thecharacteristic patterns of the target items
◮ These patterns are then used to monitor the extraction tocheck whether the extracted items are correct
◮ These tasks are extremely difficult◮ often needs contextual and semantic information to detect
changes and to find the new locations of the target items
◮ Wrapper maintenance is still an active research area

Questions?





























