Embed Size (px)
DESCRIPTION
Extrakce informac í z webových stránek pomocí extrakčních ontologií. Diserta ční práce. Obor: Informatika Školitel: Prof. Ing. Petr Berka, CSc. Martin Labsk ý Vysoká škola ekonomická v Praze Fakulta informatiky a statistiky Katedra inf. a znalostního inženýrství [email protected]. Agenda. - PowerPoint PPT Presentation
Citation preview

Vysoká škola ekonomická v Praze
Extrakce informací z webových stránek pomocí extrakčních ontologií
Martin LabskýVysoká škola ekonomická v PrazeFakulta informatiky a statistikyKatedra inf. a znalostního inženýrství[email protected]
Disertační práce
Obor: InformatikaŠkolitel:Prof. Ing. Petr Berka, CSc.

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 2
Agenda
Extrakce informací Motivace, cíle a obsah disertační práce Rozšířené extrakční ontologie
– kombinace tří typů extrakčních znalostí– návrh jazyka EOL a implementace interpretu– algoritmy extrakčního procesu
Popis experimentů– oznámení o seminářích– kontaktní informace z webových stránek– popisy produktů
Závěry

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 3
Extrakce informací – příklady aplikací
Nalézt v dokumentech údaje předem definovaného sémantického typu
Seminář
místo ?řečník ?
začátek ?konec ?
Extrakce informací

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 4
Extrakce informací – příklady aplikací
Extrakce informací

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 5
Využití extrakce informací
Strukturované vyhledávání– hledání dle parametrů (např. výrobku)– disambiguace při vyhledávání (Jaguar, Johnsson)
Urychlení navigace v dokumentech– zvýraznění relevantních informací pro určitou úlohu
Automatické zodpovídání otázek– jaké je hlavní město...
Podpora automatického překladu– identifikace a nepřekládání jmen (Jan Kovář)
Podpora posuzování kvality webových stránek– např. zda medicínské stránky splňují formální kritéria jako je
uvedení kontaktních informací
Extrakce informací

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 6
Automatická extrakce informací
Alternativou je ruční anotace dokumentů jejich autory– např. FOAF (Friend Of A Friend)– k dispozici pouze výjimečně, navíc nemusí obsahovat potřebné
informace– anotace může být (i záměrně) nepravdivá
Automatická extrakce informací– rychlé pokrytí velkého počtu dokumentů– využívá různé typy extrakčních znalostí– spolehlivost závisí na obtížnosti úlohy, zvolených algoritmech a jimi
využitých extrakčních znalostech
Extrakce informací

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 7
Agenda
Extrakce informací Motivace, cíle a obsah disertační práce Rozšířené extrakční ontologie
– kombinace tří typů extrakčních znalostí– návrh jazyka EOL a implementace interpretu– algoritmy extrakčního procesu
Popis experimentů– oznámení o seminářích– kontaktní informace z webových stránek– popisy produktů
Závěry

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 8
Motivace
Manuální přístupy– řízení báze znalostí o mnoha extrakčních pravidlech je pro člověka
obtížné– není snadné využít případná trénovací data
Trénované přístupy– často vyžadují velké množství trénovacích dat, která typicky nejsou
pro specifickou úlohu dostupná– po sběru trénovacích dat je obtížné měnit extrakční schéma
Wrappery– využitelné jen pro dokumenty s pevnou formátovací strukturou
(např. katalog zboží konkrétní website)– nelze spoléhat na známou formátovací strukturu konkrétních
website pro úlohy, kde množina zpracovávaných website není předem dána
Motivace, cíle a obsah disertační práce

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 9
Cíle a přínosy disertační práce
Využít tři různé typy znalostí pro extrakci informací z dokumentů– pravidla zadané expertem,– znalosti indukované z trénovacích dat,– pravidelné formátování dokumentů.
Navržení metody extrakčních ontologií a jazyka pro jejich reprezentaci– rychlé prototypování extrakčních aplikací– postupné zlepšování přesnosti a pokrytí přidáním dalších znalostí– snadné změny extrakčního schématu
Implementace prakticky využitelného extrakčního nástroje Ex Rozšíření extrakce textových položek o extrakci obrázků
Motivace, cíle a obsah disertační práce

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 10
Obsah disertační práce
1. Úvod
2. Současný stav extrakce informací
3. Klasifikace obrázků pro účely extrakce informací z webu
4. Extrakce informací pomocí skrytých markovských modelů
5. Rozšířené extrakční ontologie
6. Případové studie s využitím extrakčních ontologií
7. Závěr
Motivace, cíle a obsah disertační práce

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 11
Agenda
Extrakce informací Motivace, cíle a obsah disertační práce Rozšířené extrakční ontologie
– kombinace tří typů extrakčních znalostí– návrh jazyka EOL a implementace interpretu– algoritmy extrakčního procesu
Popis experimentů– oznámení o seminářích– kontaktní informace z webových stránek– popisy produktů
Závěry

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 12
Rozšířené extrakční ontologie
Termín extrakční ontologie zavedl (D.W. Embley, 2002)– metoda pro extrakci strukturovaných záznamů z internetu na bázi
ručně zadaných regulárních výrazů Navržené rozšířené extrakční ontologie
– bohatší jazyk pro manuální zadání extrakčních znalostí– využívají navíc trénovací data a nesupervizované rozpoznání
pravidelné formátovací struktury– kombinují extrakční znalosti na základě pravděpodobnostního
modelu– reprezentovány navrženým a implementovaným jazykem Extraction
Ontology Language (EOL) v rámci vyvinutého opensource nástroje Ex
Rozšířené extrakční ontologie
(ISMIS 2008), (KCAP 2007), (ESWC workshop 2006)

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 13
Zapojení extrakčních znalostí v extrakční ontologii
...
z trénovacích datnesupervizovanéextrakční indiciejiné znalosti
manuální
p r
příznaky značky v místech kde byl atribut klasifikovánw1, w2,...
příznaky
Rozšířené extrakční ontologie

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 14
Kombinace extrakčních indicií
Každá indicie E je vybavena 2 odhady pravděpodobností vzhledem k předpovídanému atributu A:– přesnost indicie p = P(A|E) ... míra postačitelnosti
– pokrytí indicie r = P(E|A) ... míra nutnosti Každému atributu je přiřazena apriori pravděpodobnost výskytu P(A) označuje množinu indicií definovaných pro A Předpokládáme podmíněnou nezávislost indicií v rámci :
Pomocí Bayesova vzorce určíme P(A | hodnoty indicií ve ) takto:
kde
AA
A
Rozšířené extrakční ontologie

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 15
Extrakční proces 1/4
1. Předzpracování dokumentu, načtení formátovací struktury
2. Nalezení výskytů vzorů pro obsah a kontext atributů
3. Aplikace trénovaných klasifikátorů, označení jejich predikcí
4. Nalezení výskytů vzorů obsahujích reference na rozhodnutí klasifikátorů
5. Vytvoření kandidátů na hodnoty atributů (AC), nalezení možných koreferencí a skórování AC dle PAC =
6. Vytvoření svazu AC napříč dokumentem, uzly svazu jsou 3 typů: (ac) obsahují právě jeden AC, (null) prázdné, (bg) na pozadí uzel má skóre log(PAC)
Washington , DC
......
O(n)délka
dokumentu
Rozšířené extrakční ontologie
O(|AC|)
11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 16
Extrakční proces 2/4
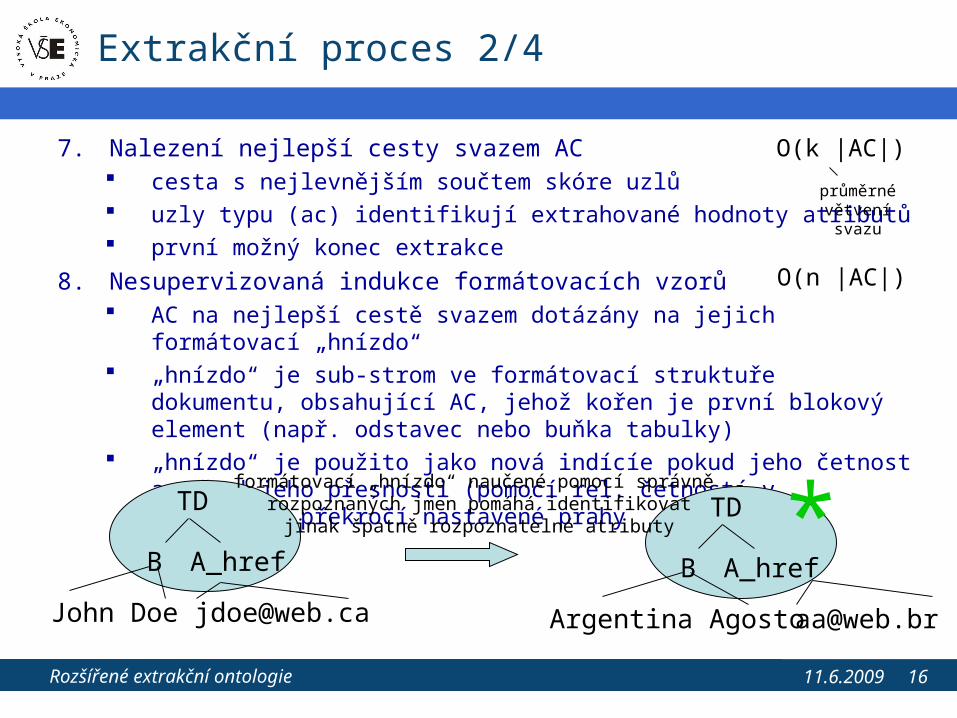
7. Nalezení nejlepší cesty svazem AC cesta s nejlevnějším součtem skóre uzlů uzly typu (ac) identifikují extrahované hodnoty atributů první možný konec extrakce
8. Nesupervizovaná indukce formátovacích vzorů AC na nejlepší cestě svazem dotázány na jejich formátovací „hnízdo“ „hnízdo“ je sub-strom ve formátovací struktuře dokumentu, obsahující AC,
jehož kořen je první blokový element (např. odstavec nebo buňka tabulky) „hnízdo“ je použito jako nová indícíe pokud jeho četnost a odhad jeho
přesnosti (pomocí rel. četností v dokumentu) překročí nastavené prahy
O(k |AC|)
TD
A_hrefB
John Doe [email protected]
TD
A_hrefB
Argentina Agosto [email protected]
formátovací „hnízdo“ naučené pomocí správně rozpoznaných jmen pomáhá identifikovat
jinak špatně rozpoznatelné atributy
O(n |AC|)
*Rozšířené extrakční ontologie
průměrné větvení svazu

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 17
Extrakční proces 3/4
9. Generování kandidátů na instance tříd (IC) zdola nahoru postupným seskupováním
jednotlivých IC s AC v jejich okolí prováděno postupně šplháním
formátovací strukturou nahoru od rozšiřovaného IC
pro rozšíření vybírán vždy nejlépe skórující IC, rozšířené IC skladovány v uspořádané frontě
řízeno a omezeno ontologií (kardinalita, axiomy a další indicie třídy) a nastavením10. Skórování IC
Skóre PIC určeno dvěma složkami – na základě skóre obsažených AC a na základě indicií třídy
kde |IC| = počet atributů v IC, ACskip = AC v rozsahu IC který není jejím členem, PAC skip = odhad pravděpodobnosti, že AC je “planý poplach”, C = množina indicií známá pro třídu C, P(C|EC) kombinuje indicie dle stejného modelu jako pro atributy
Obě skóre zkombinovány pseudo-bayesovskou funkcí známou z exp. systému Prospector:
výp. až O(n |AC|2)
Rozšířené extrakční ontologie
prost. až O(n2)

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 18
Extrakční proces 4/4
11. Vložení validních IC do původního AC svazu skóre validních IC finalizováno a IC prořezány dle skóre každý validní IC je reprezentován novým uzlem, obcházejícím samostatné AC a uzly reprezentující „pozadí“ skóre IC uzlu =
12. Nejlepší cesta AC+IC svazem identifikuje extrahované položky algoritmus nalezení nejlepší cesty umožňuje definovat různá omezení pro položky na cestě (min/max počet
instancí nebo atributů určitého typu) n-best
||))(log( ICICscore
IC1
IC2
O(n |IC|)
O(k (|IC|+|AC|))
Rozšířené extrakční ontologie

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 19
Agenda
Extrakce informací Motivace, cíle a obsah disertační práce Rozšířené extrakční ontologie
– kombinace tří typů extrakčních znalostí– návrh jazyka EOL a implementace interpretu– algoritmy extrakčního procesu
Popis experimentů– oznámení o seminářích– kontaktní informace z webových stránek– popisy produktů
Závěry

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 20
Experimenty: e-mailová oznámení o seminářích
485 anglických e-mailových oznámení o seminářích na Carnegie-Melon University. Manuální EO: vytvořena člověkem na základě 50 náhodně vybraných dokumentů,
testována na zbývajících 435 dokumentech. Kombinovaná EO: stejná ontologie vybavená CRF klasifikátorem. Pro atribut Location jsou
manuální indicie použity jen jako příznaky klasifikátoru, pro ostatní atributy jsou manální indicie plně zapojeny. 10-násobná křížová validace na testovací sadě 435 dokumentů.
manuální EO, testovací data kombinovaná EO, 10-CV shrnutí
atribut přesnost úplnost F-míra přesnost úplnost F-míra rozdíl F počet entit
Speaker 69.9 66.5 68.1 75.4 75.0 75.2 +7.1689
– loose 76.2 72.7 74.4 81.8 80.6 81.2 +6.8
Location 59.7 75.9 66.9 93.3 78.0 85.0 +18.1575
– loose 77.5 86.0 81.5 97.6 80.7 88.3 +6.8
Start time 96.0 88.7 92.2 98.1 93.3 95.6 +3.4881
– loose 96.4 88.9 92.5 98.1 93.3 95.6 +3.1
End time 97.8 90.3 93.9 97.0 94.4 95.7 +1.8380
– loose 97.9 90.5 94.1 97.2 94.7 96.0 +1.9
Celkem 79.1 80.0 79.6 90.4 85.0 87.6 +8.02525
– loose 85.9 84.1 85.0 93.2 87.2 90.1 +5.0
Popis experimentů
(KI 2008 – Ontology-based Information Extraction Systems Worskhop)

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 21
Experimenty: kontaktní informace z HTML
0
10
20
30
40
50
60
70
80
90
100
city country degree em ail nam e phone street zip average villa in
EN m anual com b D E m anual com b C Z m anual com b
Kolekce heterogenních webových stránek z medicínské domény ve 3 jazycích Manuální EO: vyvinuta člověkem pomocí 30 dokumentů z každé kolekce, testována na zbytku dokumentů s
využitím indukce formátovacích vzorů Kombinovaná EO: manuální EO doplněná CRF klasifikátorem, manuální indicie použity samostatně i jako
příznaky pro CRF, 10-násobná kříž. validace na testovacích dokumentech EN: 116 dokumentů, 7000 entit, 1131 instancí tříd, DE: 93/4950/768, CZ: 99/11000/2506
Villain score
hodnotí přesnost seskupování atributů
Popis experimentů
(ECAI 2008), (Datakon 2007)

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 22
Experimenty: nabídky bicyklů z HTML
0
10
20
30
40
50
60
70
80
90
100
brake
category
chaincolo
r
discount
fork
fram
e
make
name
price
size
speedyear
average
Manual
FPI
H MM
C om bined
Kolekce 103 dokumentů / 4100 entit z různých website ve V.Británii nabízejících bicykly Manuální EO: vyvinuta člověkem pomocí 50 dokumentů, testována na zbytku FPI EO: manuální EO se zapnutou indukcí formátovacích vzorů HMM EO: využívá pouze trénovaný HMM model, datotypová omezení a axiomy Kombinovaná EO: Využívá HMM model pro všechny atributy kromě ceny a slevy
Popis experimentů
(Znalosti 2004),(ECML/PKDD 2004)
23,5%

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 23
Experimenty: HMM a extrakce obrázků
Skrytý markovský model s dedikovanými stavy pro extrahované položky a jejich kontext, inspirováno (Freitag, McCallum 2000)
Experimenty s nesupervizovaně indukovanými topologiemi
Rozšíření lexikálních distribucí stavů o n-gramové distribuce
Jediný model pro všechny extrahované položky:– 1 Background stav– 1 Target, 1 Prefix and 1 Suffix stav na 1
atribut
B
STP
S’T’P’...
Popis experimentů
Vyvinuto několik binárních klasifikátorů obrázků (bicykl ano/ne)– příznaky: rozměry, barevný histogram, počet výskytů ve stránce, podobnost k trénovací kolekci
pozitivních příkladů (Praks, 2002)– 2.6% = chybovost kombinovaného klasifikátoru (10-CV na 1600 obrázcích)
HMM model propojen s klasifikátorem obrázků tak, že lexikální distribuce stavů emitují třídy obrázků předpovídané klasifikátorem– 88% F-míra pro obrázky jako součást popisu produktu
aplikace: malý strukturovaný vyhledávač, autory webového rozhraní jsou kolegové z KEG
(RAWS 2005), (Web Intelligence 2005)

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 24
Závěry
Vyvinuta metoda rozšířených extrakčních ontologií, umožňující– volitelné využití 3 různých typů extrakční znalosti– rychlé prototypování– snadné změny extrakčního schématu
Prezentovány výsledky pro reálné domény– oznámení o seminářích, kontaktní informace, popisy bicyklů– dokumentovány výhodnost kombinace různých typů znalostí a rychlé
prototypování extrakčních úloh– vytvořeny klasifikátory obrázků, které byly úspěšně integrovány do vyvinutého
extrakčního HMM modelu Vytvořen open-source extrakční nástroj Ex
– distribuce, zdrojové kódy a příklady: http://eso.vse.cz/~labsky/ex– Java, 54000 řádků kódu
Publikace– S prací spojeno > 20 publikací na zahraničních i tuzemských konferencích a
workshopech (autor / spoluautor)

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 25
Literatura a vybrané publikace
Embley, D.W., Tao, C., Liddle, S.W.: Automatically extracting ontologically specified data from HTML tables with unknown structure. In: Proc. ER 2002.
Karkaletsis, V., Karampiperis, P., Stamatakis, K., Labský, M., Růžička, M., Svátek, V., Polla, M., Mayer, M, Gonzales, D: Automating Accreditation of Medical Web Content. In: ECAI, Patras, IOS Press, 2008, ISBN 978-1-58603-891-5.
Labský, M., Nekvasil, M., Svátek, V.: Towards Web Information Extraction using Extraction Ontologies and (Indirectly) Domain Ontologies. In: K-CAP, Whistler, ACM, 2007, ISBN 978-1-59593-643-1.
Labský, M., Svátek, V.: Combining Multiple Sources of Evidence in Web Information Extraction. In: ISMIS, Toronto. Foundations of Intelligent Systems, Springer-Verlag, 2008, ISBN 978-3-540-68122-9.
Labský, M., Svátek, V., Nekvasil, M.: IE Based on Extraction Ontologies: Design, Deployment and Evaluation. In: KI – Ontology-based Information Extraction Systems, Kaiserslautern, CEUR-WS, 2008, ISSN 1613-0073.
Labský, M., Svátek, V.: On the Design and Exploitation of Presentation Ontologies for Information Extraction. In: ESWC/Mastering the Gap: From Information Extraction to Semantic Representation. Budva: KMI, The Open University, 2006.
Labský, M., Svátek, V., Šváb, O., Praks, P., Krátký, M., Snášel, V.: IE from HTML Product Catalogues: from Sorce Code and Images to RDF. Web Intelligence, Compiégne, IEEE, 2005, ISBN 0-7695-2415-X.
Labský, M., Svátek, V., Šváb, O.: Types and Roles of Ontologies in Web Information Extraction. In: ECML/PKDD – Knowledge Discovery and Ontologies, Pisa, 2004.
Labský, M., Vacura, M., Praks, P.: Web Image Classification for Information Extraction. In: RAWS. VŠB TU, 2005, ISBN 80-248-0864-1.
Labský, M.: Product information extraction from semistructured documents using HMMs. Znalosti, VŠB TU, 2004 Peshkin, L., Pfeifer, A.: Bayesian Information Extraction Network. In: Proc. Intl. Joint Conference on Artificial
Intelligence, 2003. Svátek, V., Labský, M., Nemrava, J., Kosek, J., Růžička, M.: Projekt MedIEQ: hodnocení zdravotnických webových
zdrojů s využitím extrakce informací. Brno 14.-17.10.2006. In: DATAKON, Brno, MU, 2006 ISBN 80-210-4102-1. Srovnání výsledků extrakčních nástrojů na úloze oznámení o seminářích: h
ttp://tcc.itc.it/research/textec/tools-resources/learningpinocchio/CMU

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 26
Děkuji za pozornost!
Otázky ?

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 27
Otázky oponentů (1/9)
Jak hodnotíte pro svoje řešení hlediska:– rychlého prototypování,– snadné změny extrakčních pravidel,– vyváženost přesnosti a potřebných nákladů (případně, času a
kvalifikace asistenta trénování).
Manuální znalosti– podporují rychlé prototypování a změny schématu, podle doporučené
metodologie se manuální znalosti vytvářejí v prvních fázích projektu Trénovací data
– pokud je třeba je pořídit, sběr probíhá v dalších fázích projektu, kdy už je extrakční schéma stabilní

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 28
Otázky oponentů (2/9)
Nakolik je řešení vázáno na daný styl webovských stránek a jak je odolné na změny.
Manuální znalosti– zda a do jaké míry je formátování přítomno v pravidlech
Indukované formátovací vzory– Adaptace na konkrétní formátování website probíhá
nesupervizovaně během vlastní extrakce– Indukované formátovací vzory se nepoužívají pro další
website extrakční ontologie nejsou závislé na konkrétním formátování

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 29
Otázky oponentů (3/9)
Jaké výsledky na daných problémech, datech dosahují veřejně dostupné prostředky?
Extrakce oznámení o seminářích je jedna z často používaných srovnávacích úloh:
Samotný CRF++ nástroj se základní množinou příznaků dosáhl pro kontakty výrazně nižší F-míry, zlepšení nastává v případě kombinace s extrakční ontologií (ve smyslu rozšíření množiny příznaků i kombinace s manuálními indiciemi)
F-míry BIEN LP2 EO SRV Rapier Whisk
Speaker 76.9 77.6 75.2 66.2 53.0 18.3
Location 87.1 75.1 85.0 79.7 73.3 66.4
Start time 96.0 99.0 95.6 94.3 95.9 92.6
End time 98.8 95.5 95.7 99.3 96.7 86.1
Overall - 89.9 87.6 - 82.6 -
Výsledky pro BIEN převzaty z (Peshkin, 2003); pro LP2, SRV, Rapier a Whisk je zdrojem http://tcc.itc.it/research/textec/tools-resources/learningpinocchio/CMU

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 30
Otázky oponentů (4/9)
Metadata, např. XML schéma k extrakční ontologii?
Pro jazyk EOL je k dispozici DTD (document type definition) na doprovodném CD:– ex/models/eol.dtd

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 31
Otázky oponentů (5/9)
Není jasné kolik práce a znalostí je třeba na nastavení parametrů „vah“, nakolik je automatické a nakolik ruční.
Semináře:
Kontakty:
Bicykly:

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 32
Otázky oponentů (6/9)
Zajímalo by mě, jaké jsou možnosti aplikace popsaných metod pro web 2.0, 3.0 atd, vzhledem k tomu, že jisté části extrakce jsou vázány na technologické prvky webových stránek.
Web 2.0 – existující druhá generace technologií a designu vysoce interaktivních webových stránek a aplikací, často využívající intenzívní komunikaci mezi klientem a serverem a rozsáhlé schopnosti prohlížeče. (volně dle Wikipedie)– pro extrakci z Web 2.0 stránek lze využít API prohlížeče a jeho reprezentaci
dokumentu
– navržená metoda není v principu omezena na webové stránky, lze ji aplikovat na dokumenty bez jakéhokoliv struktury na druhé straně je možné využít i jiného hierarchického formátovaní než HTML
Web 3.0 – očekávaná další generace „sémantického webu“, kde stroje do určité míry „rozumějí“ jeho obsahu, např. jsou schopny odvozování nad prezentovanými fakty a mohou provádět operace pomocí sémanticky anotovaných webových služeb.– IE obecně je jednou z technik které by mohly „plnit“ potřebné báze znalostí

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 33
Otázky oponentů (7/9)
Jaká je časová a prostorová složitost prezentovaného řešení?
Extrakční ontologie– viz slidy 15-18 „extrakční proces“
Skryté markovské modely – nalezení nejlepší cesty Viterbi algoritmem– časová O(n s2)– prostorová O(n s)– kde n=délka analyzovaného textu, s=počet stavů
Klasifikátor obrázků– O(velikost obrázku) pro zjištění příznaků (histogram)– dále v závislosti na použitém algoritmu strojového učení

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 34
Otázky oponentů (8/9)
Jak rozsáhlé experimenty byly provedeny?
Emailová oznámení o seminářích– 485 dokumentů, 3000 pojmenovaných entit 4 typů, 1 oznámení na email
Extrakce kontaktních informací z heterogenních webových stránkek v medicínské doméně pro 3 jazyky– extrakce pojmenovaných entit 10 typů a seskupování do instancí 1 třídy
Extrakce popisů bicyklů z heterogenních webových stránek obchodů– 108 dokumentů, 4000 atributů 15 typů včetně 630 obrázků kol
– Binární klasifikace obrázků na kolekci 1600 obrázků Extrakce popisů počítačových monitorů a televizí z web. obchodů
– 500 webových stránek s monitory, 60 s televizemi
Počet dokumentů Počet entit Počet instancí tříd
EN 116 7000 1131
DE 93 4950 768
CZ 99 11000 2506

11.6.2009 Extrakce informací z webových stránek pomocí extrakčních ontologií 35
Otázky oponentů (9/9)
Bude proces extrakce ontologie dávat pro různá vstupní nastavení stejné ontologie pro danou kolekci stránek?
Extrakční ontologie zůstává během extrakce neměnná– nesupervizovaně se indukují pouze formátovací vzory, které ale nejsou persistentní a jejich působnost je omezena pouze na dokument, na základě
kterého byly indukovány Výsledky extrakce závisí na nastavení
– systém lze konfigurovat pomocí velkého množství parametrů (cca 20), např. n-best, zda generátor instancí může „přeskakovat“ AC kandidáty nevhodné pro budovanou instanci, omezení prostoru generování instancí jako abs. a rel. šířka beamu v mřížce, prahy pro minimální pravděpodobnost AC a IC
– Další „parametry“ obsahuje samotná extrakční ontologie a na ni napojené klasifikátory





























