Embed Size (px)
Citation preview

FoggyCache: Cross-Device Approximate Computation Reuse
PeizhenGuo,BoHu,RuiLi,WenjunHu
Yale University

Emerging trend

Emerging trend

Same, popular apps run on nearby devices
Example: landmark recognition

Redundancy across nearbydevices
“Sterling Library”
Example: landmark recognition

Redundancy across nearbydevices
“Sterling Library”
Example: landmark recognition

More Examples: smart homescenarios

Can we eliminate this redundancy?

Can we eliminate this redundancy?
Reuse previous computation results

Traditional computation reuse
𝑅𝑒𝑐𝑜𝑔𝑛𝑖𝑧𝑒()
CacheKey Value
“Sterling Library”
=“Sterling Library”

Traditional computation reuse
𝑅𝑒𝑐𝑜𝑔𝑛𝑖𝑧𝑒()
CacheKey Value
“Sterling Library”
𝑅𝑒𝑐𝑜𝑔𝑛𝑖𝑧𝑒()
=
≠
“Sterling Library”
No reusable data

Ideal computation reuse
𝑅𝑒𝑐𝑜𝑔𝑛𝑖𝑧𝑒()
CacheKey Value
“Sterling Library”
𝑅𝑒𝑐𝑜𝑔𝑛𝑖𝑧𝑒()
=
≈
“Sterling Library”
“Sterling Library”

ApproximateComputation Reuse

Our goals• Algorithms for approximate computation reuse
• A system to eliminate redundancy across devices

Reuse process

Reuse process
Input data
[ , “Bass Library”] [ , “Sterling Library”] ……
Lookup computation recordswith similar input

Reuse process
Input data
[ , “Bass Library”] [ , “Sterling Library”] ……
Lookup computation recordswith similar input
Determine reuse outcome
Not reusable or “Bass Library” or “Sterling Library”

The rest of the talk…• Algorithms for approximate computation reuse
• A-LSH – fast lookup
• H-kNN – reuse with accuracy guarantee
• FoggyCache system for cross-device reuse

…
…
Handwritten digits from MNIST dataset

A-LSH: strawman
…
…
Locality sensitive Hashing (LSH)

A-LSH: strawman
h2
h1
h3…
…
More similar data stay in the same bucketwith higher probability
Locality sensitive Hashing (LSH)

LSH is not enough

LSH is not enoughh2
h1
h2
h1

LSH is not enoughh2
h1
h2
h1
Fixedbucket size

LSH is not enoughh2
h1
h2
h1
Dense data
Fixedbucket size

LSH is not enoughh2
h1
h2
h1
Dense dataIncrease lookup time
Fixedbucket size
“4”“6”
“9”

LSH is not enoughh2
h1
h2
h1
Dense dataIncrease lookup time
Sparse data
Fixedbucket size
“4”“6”
“9”

LSH is not enoughh2
h1
h2
h1
Dense dataIncrease lookup time
Sparse dataMiss actually similar records
Fixedbucket size “4”
“4”“6”
“9”

LSH is not enoughh2
h1
h2
h1
Dense dataIncrease lookup time
Sparse dataMiss actually similar records
LSH configurationis static
Data distributionis dynamic
Fixedbucket size “4”
“4”“6”
“9”

Adaptive-LSHadapt the bucket size to data distribution

Adaptive-LSH
Proper bucket setting
adapt the bucket size to data distribution

Adaptive-LSH
Step 1: Use the ratio c=R2/R1 tocharacterize input data distribution
R1
R2
adapt the bucket size to data distribution

Adaptive-LSH
Step 2: Adapt bucket sizeaccording to c and the lookup time target
R1
R2

Reuse process
Input data
[ , “Bass Library”] [ , “Sterling Library”] ……
Lookup computation recordswith similar input
Determine reuse outcome
Not reusable or “Bass Library” or “Sterling Library”

Reuse process
Input data
[ , “Bass Library”] [ , “Sterling Library”] ……
Lookup computation recordswith similar input
Determine reuse outcome
Not reusable or “Bass Library” or “Sterling Library”

H-kNN: strawman
Basic ideak Nearest Neighbor
Query input

H-kNN: strawman
“9”Basic idea
k Nearest NeighborQuery input
“4”

H-kNN: strawman
“9”
Take the result label of the largestcluster as the reuse outcome
Basic ideak Nearest Neighbor
Query input
“4”

kNN not enough

kNN not enough
Label of the largest cluster is not always thedesirable reuse result

kNN not enough
“4” “9”
Label of the largest cluster is not always thedesirable reuse result
Border

kNN not enough
kNN does not give us control over the trade-off
Need high accuracy Prefer less computation
Pill recognition Google Lens

kNN: what is needed?

kNN: what is needed?
Need to gauge dominance level of clusters
“4” “9”

Why dominance level matters?

Why dominance level matters?
“4” “9”
“4”“9”
“6”“7”

Why dominance level matters?
A more dominant cluster è more confidence of accurate reuse
“4” “9”
“4”“9”
“6”“7”

kNN: what is needed?
Need to gauge dominance level of clusters
“4” “9”
Can then customize reuse trade-off

Homogeneity factorkNN

Homogeneity factorkNN Clusters
<“6”, 1 >
<“9”, 1 >
<“4”, 3 >

Homogeneity factor
A high 𝜽 ⇒ a large dominant cluster label (i.e., “4”)⇒ a high confidence of correct reuse.
kNN Clusters
<“6”, 1 >
<“9”, 1 >
<“4”, 3 >
Homogeneity factor 𝜽
3
1 1𝛼
“6”“9”
“4”𝜽 = cos(𝛼)

Homogemized-kNN (H-kNN)
Calculate homogeneity factor 𝜽
𝜽 > 𝒕𝒉𝒓𝒆𝒔𝒉𝒐𝒍𝒅𝜽𝟎 ?Yes No
Reuse Compute

Approximate computation reuse• Algorithms for approximate computation reuse
• A-LSH – fast lookup
• H-kNN – reuse with accuracy guarantee
• FoggyCache system for cross-device reuse

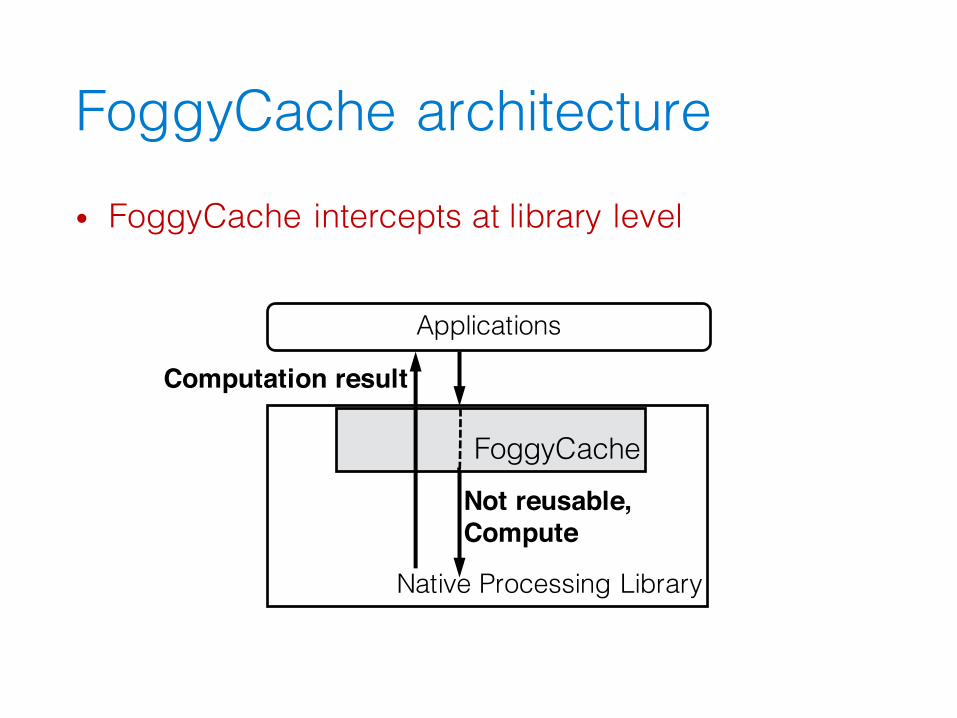
FoggyCache architecture• FoggyCache intercepts at library level
Applications
Native Processing Library
FoggyCache
Reuse result
FoggyCache architecture• FoggyCache intercepts at library level
Applications
Native Processing Library
FoggyCache
Computation result
Not reusable, Compute
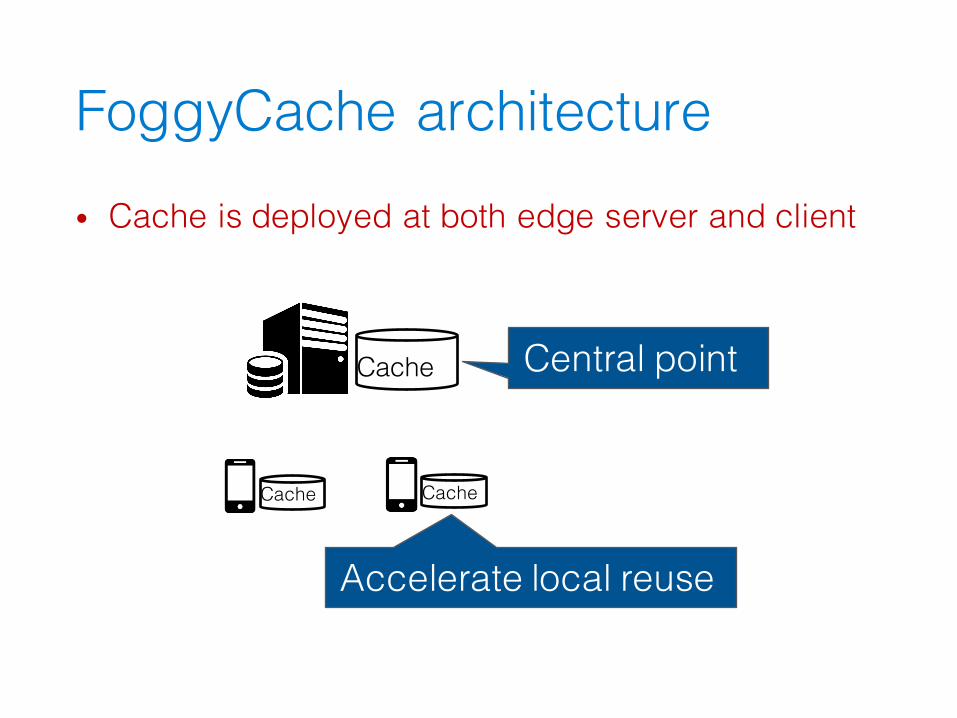
FoggyCache architecture• Cache is deployed at both edge server and client
Cache
CacheCache

System optimizations
Cache
CacheCache
Details in the paper

Performance

General setup
Linux desktop Google Nexus 9
Audio workloads & datasets• Speaker identification: TIMIT acoustic dataset
Devices
Visual workloads & datasets• Plant recognition: ImageNet subset• Landmark recognition: Oxford Buildings, video feeds

Reuse accuracy vs savingcomputation
20
30
40
50
60
70
80
90
100
0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1Homogeneity threshold
Time saved (%)

Reuse accuracy vs savingcomputation
20
30
40
50
60
70
80
90
100
0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1Homogeneity threshold
Accuracy (%) Time saved (%)

End-to-end performance
Application Latency (ms) Energy (mJ) Accuracyloss (%)w/o w/ w/o w/
SpeakerIdentification 13.1 4.2 30.4 9.8 3.2
LandmarkRecognition 102.4 27.9 1315 110.7 5.0
PlantRecognition 269.6 99.8 3132 901.4 4.7

End-to-end performance
Application Latency (ms) Energy (mJ) Accuracyloss (%)w/o w/ w/o w/
SpeakerIdentification 13.1 4.2 30.4 9.8 3.2
LandmarkRecognition 102.4 27.9 1315 110.7 5.0
PlantRecognition 269.6 99.8 3132 901.4 4.7

End-to-end performance
Application Latency (ms) Energy (mJ) Accuracyloss (%)w/o w/ w/o w/
SpeakerIdentification 13.1 4.2 30.4 9.8 3.2
LandmarkRecognition 102.4 27.9 1315 110.7 5.0
PlantRecognition 269.6 99.8 3132 901.4 4.7

End-to-end performance
Application Latency (ms) Energy (mJ) Accuracyloss (%)w/o w/ w/o w/
SpeakerIdentification 13.1 4.2 30.4 9.8 3.2
LandmarkRecognition 102.4 27.9 1315 110.7 5.0
PlantRecognition 269.6 99.8 3132 901.4 4.7

Conclusion• FoggyCache: cross-device approximate
computation reuse
• Effectively eliminates fuzzy redundancy
• Approximate computation reuse
• Promising new direction for optimizations
• Algorithms are applicable to other scenarios

Thank you






![Approximate Bayesian Computation for Granular and ...€¦ · reaction networks [24]. To remedy this, the Approximate Bayesian Computation (ABC) [24, 29] framework was intro-duced](https://img.dokumen.tips/doc/110x75/5ff8093d84f1a843b140a517/approximate-bayesian-computation-for-granular-and-reaction-networks-24-to.jpg)






















