Embed Size (px)
Citation preview

Exploring Wakeup-Free Instruction Scheduling
Jie S. Hu, N. Vijaykrishnan, and Mary Jane IrwinMicrosystems Design LabThe Pennsylvania State University

2
Outline
Motivation Case study: Cyclone Towards high-performance wakeup-
free scheduler A general model Employing pre-check scheme A segmented issue queue
Conclusions and future work
3
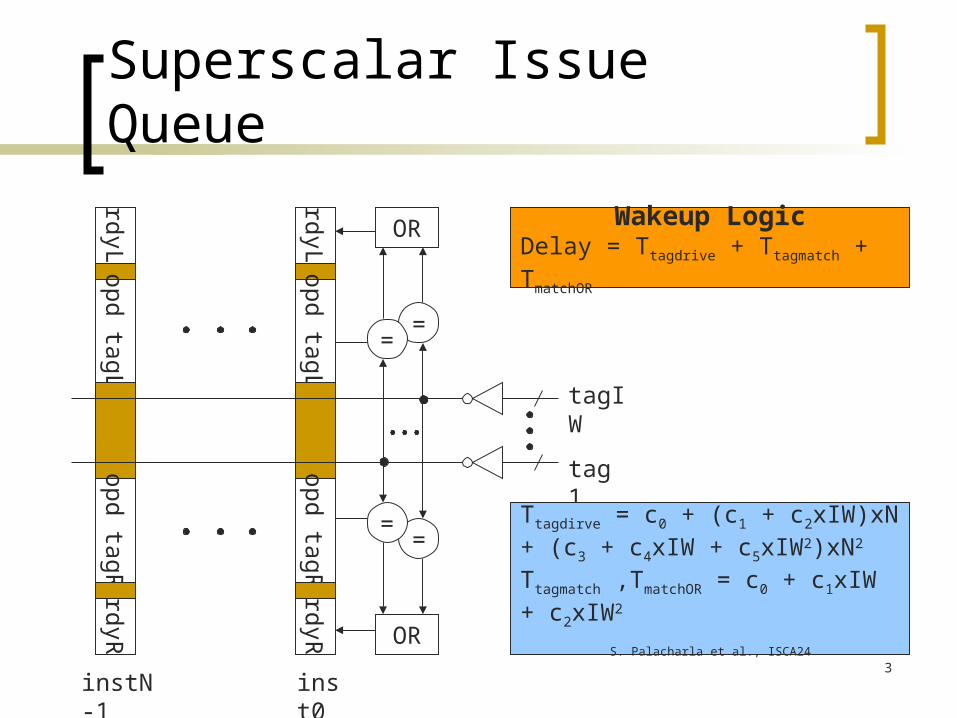
Superscalar Issue Queue
rdyLopd tagL
opd tagRrdyR
rdyLopd tagL
opd tagRrdyR
==
==
OR
OR
tag1
tagIW
instN-1 inst0
Wakeup LogicDelay = Ttagdrive + Ttagmatch + TmatchOR
Ttagdirve = c0 + (c1 + c2xIW)xN + (c3 + c4xIW + c5xIW2)xN2
Ttagmatch ,TmatchOR = c0 + c1xIW + c2xIW2
S. Palacharla et al., ISCA24

4
Superscalar Issue Queue
Selection LogicTselection = c0 + c1xlog4N
S. Palacharla et al., ISCA24
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
Issue Queue
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
enb
from/to other subtrees
root cell

5
Challenges in Dynamic Instruction Scheduling
Broadcast-based dynamic scheduler Higher complexity Power hungry A major limiter to clock frequency: increasing issue queue size, issue
width, wire delay, and shorten logic levels per pipeline stage Complexity Effective Issue
Speculative wakeup [Stark et.al.] Dependency chain based ordering [Canal/Gonzalez ICS 00//01;
Michaud/Seznec HPCA01; Segmented Issue queue [Raasch et.al. ISCA 2002] Wakeup-free dynamic scheduler [Ernst ISCA 2003 et.al.]
Lower complexity Lower power consumption Better scalability Have to trade performance loss

6
Our Goals
Explore the predictability of instruction issue latency
Identify the performance impediments in wakeup-free architectures
Design high-performance wakeup-free schedulers
7
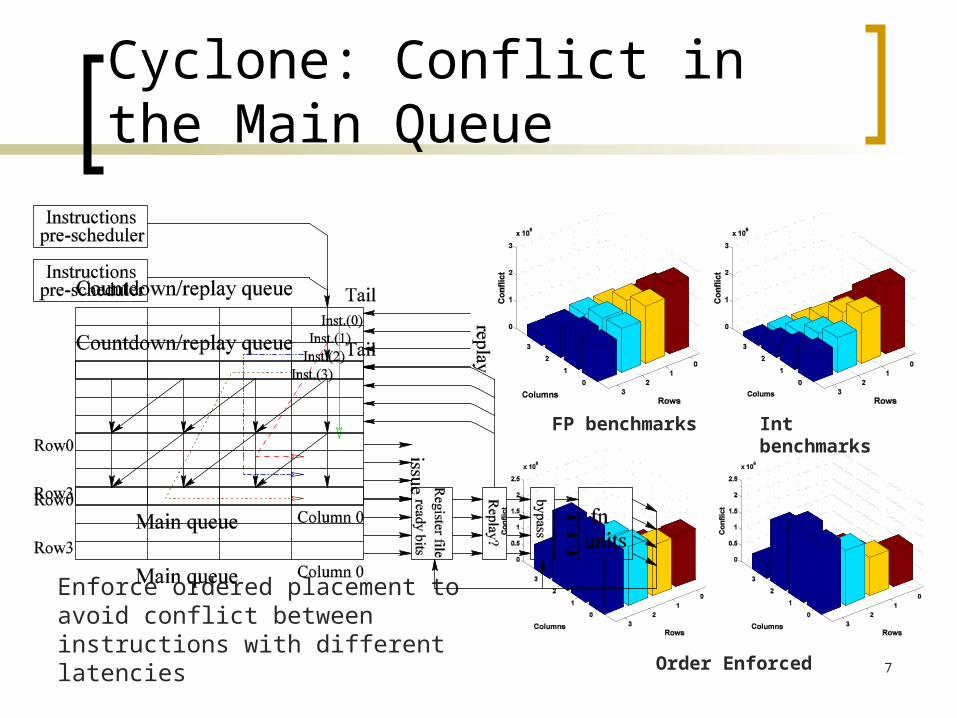
Cyclone: Conflict in the Main Queue
FP benchmarks Int benchmarks
Order Enforced
Enforce ordered placement to avoid conflict between instructions with different latencies

8
Possible Structural Problems
Instruction promotion/forwarding incurs conflict along the path
Very limited instruction pool for selection Only entries in column 0 in the main queue can be issued Ready instructions (not in column 0) are delayed due to
conflict Limited number of issue ports has less tolerance to
mispredicted ready instructions Waste issue port Prevent ready instruction from issue Complete with newly decoded instructions due to replay

9
A General Model: WF-Replay
lat lat lat
Wakeup-FreeIssue Queue
lat lat lat
register file ready bits
replay?
Rename
Pre-schedule
From
decoder
Timing Table
to FU
s
Selection Logic
from FUs
Collapsing issue queue without
promotion. Conventional random selection logic
Given much wider issue width
How to relax the structural constraints?
Instruction is removed if no
replay is needed
10
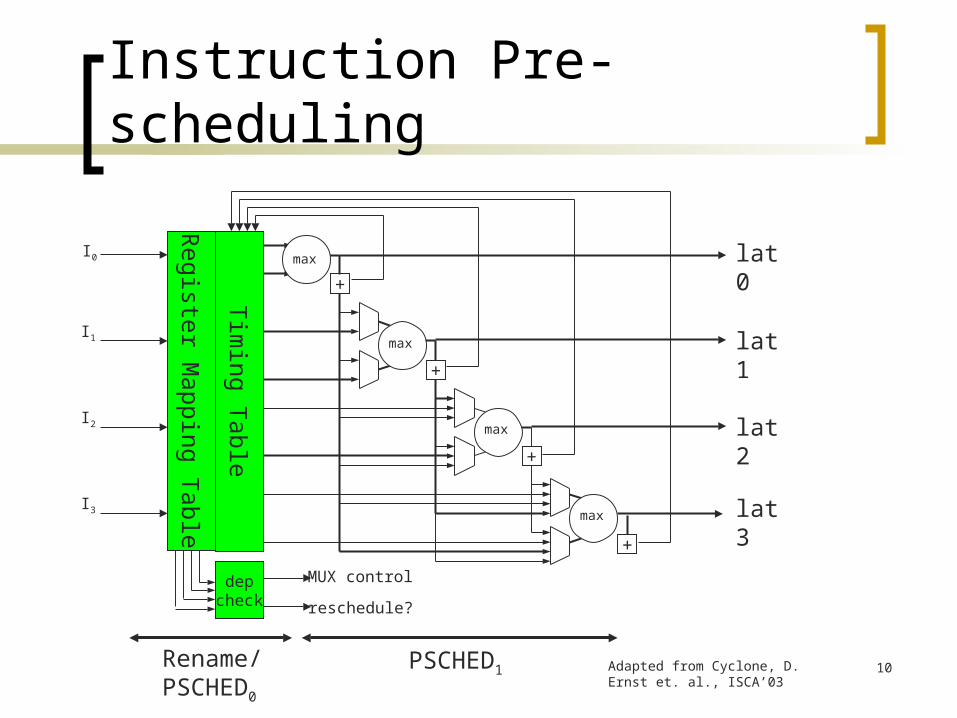
Instruction Pre-scheduling
I0
I1
I2
I3
Rename/PSCHED0
max
max
+
reschedule?
Tim
ing Table
PSCHED1
max
+
max
+
depcheck
MUX control
Register M
apping Table
+
lat0
lat1
lat2
lat3
Adapted from Cyclone, D. Ernst et. al., ISCA’03
11
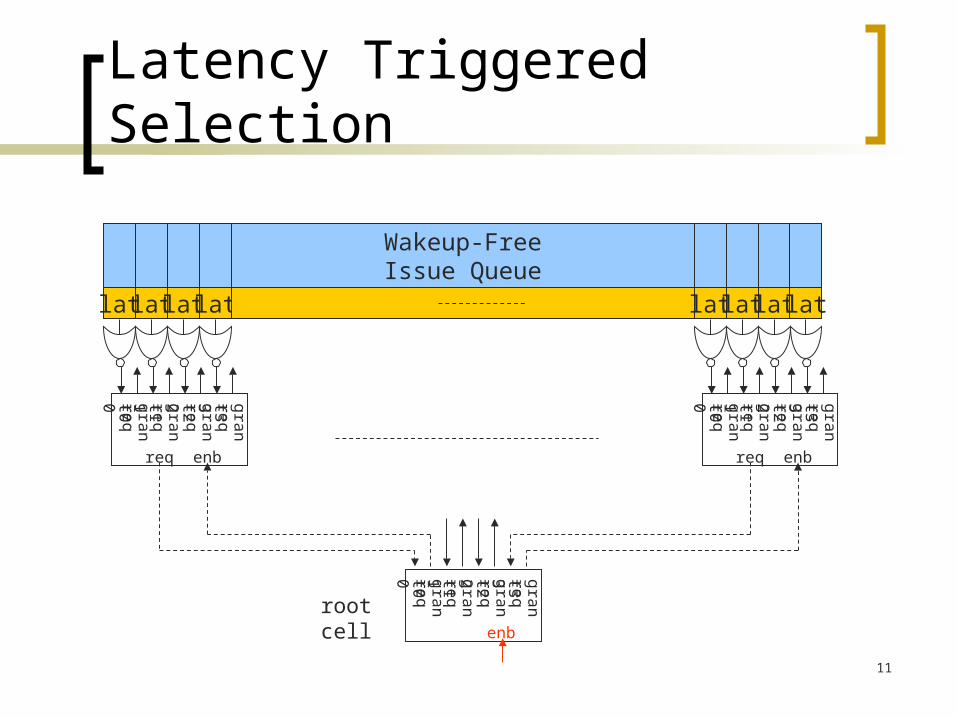
Latency Triggered Selection
lat lat lat
Wakeup-FreeIssue Queue
lat lat latlat
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
lat
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
enb
root cell
12
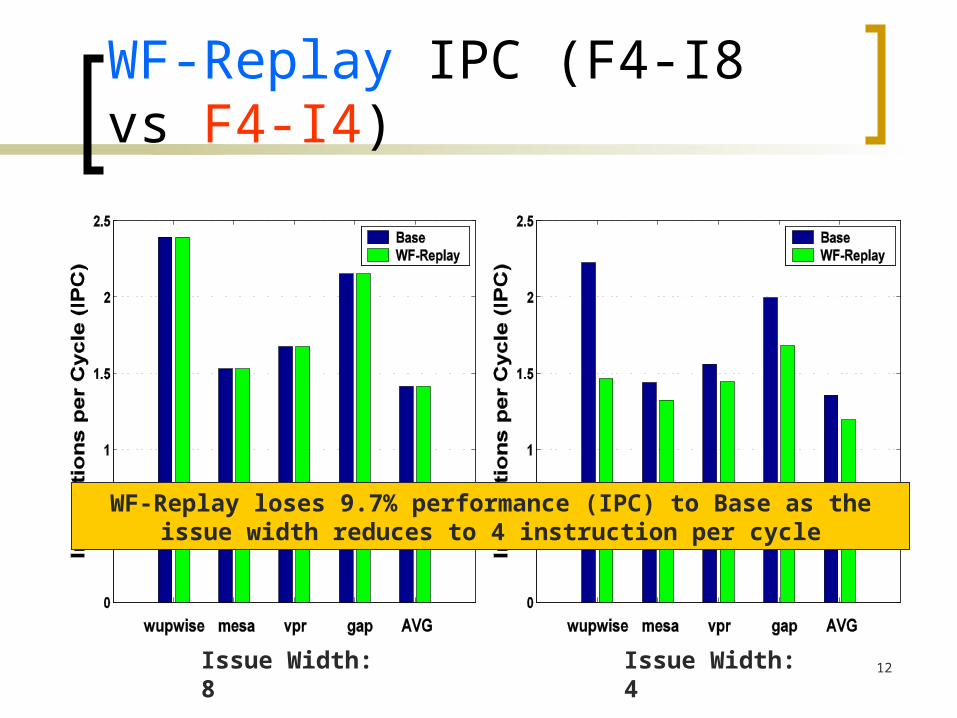
WF-Replay IPC (F4-I8 vs F4-I4)
Issue Width: 8 Issue Width: 4
WF-Replay loses 9.7% performance (IPC) to Base as the issue width reduces to 4 instruction per cycle
13
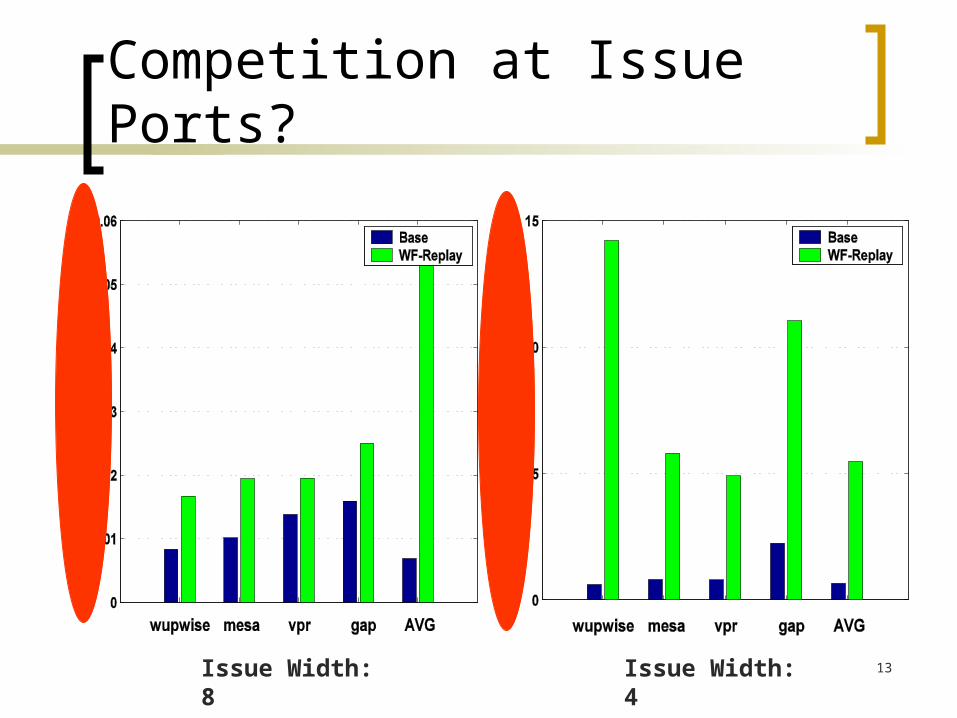
Competition at Issue Ports?
Issue Width: 8 Issue Width: 4

14
Precheck to Avoid Competition
Competition at issue port may delay ready (predictive) instructions
Delayed instructions may again compete with instructions dependent on them
Causing more instructions falsely ready or to be delayed
Wider issue port can avoid unnecessary competition at cost of higher complexity
Solution: preventing falsely ready instructions from selection by pre-checking register ready bits
15
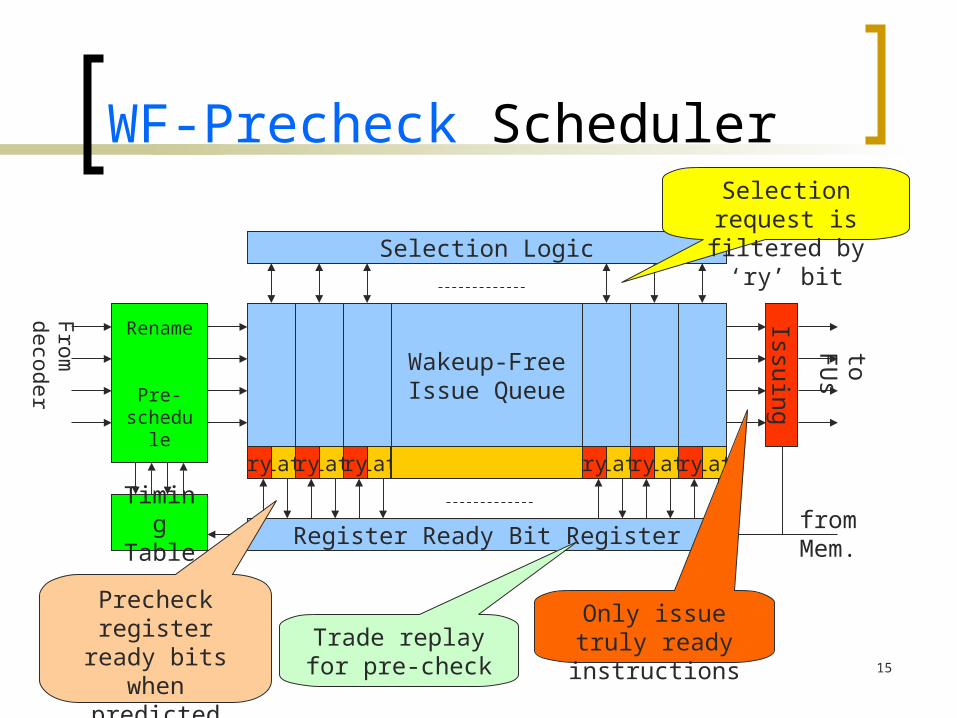
WF-Precheck Scheduler
lat
Wakeup-FreeIssue Queue
Issuing
Rename
Pre-schedule
From
decoder
Timing Table
to FU
s
Register Ready Bit Registerfrom Mem.
Selection Logic
ry latry latry latry latry latry
Precheck register ready bits when predicted latency
reaches 0
Selection request is filtered by ‘ry’ bit
Trade replay for pre-check
Only issue truly ready instructions
16
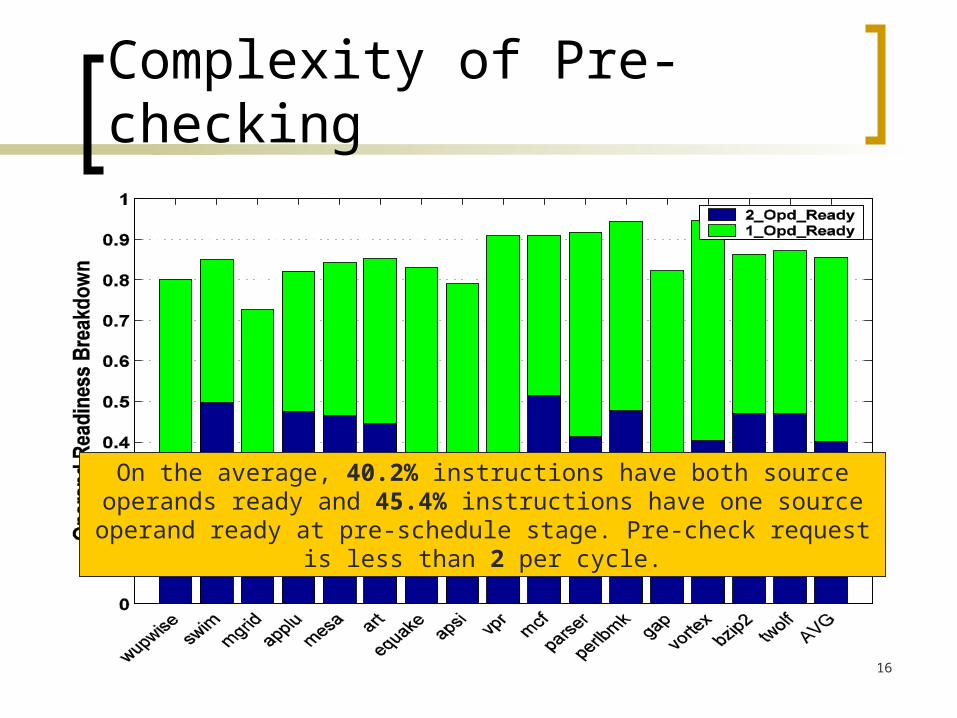
Complexity of Pre-checking
On the average, 40.2% instructions have both source operands ready and 45.4% instructions have one source operand ready at pre-schedule stage.
Pre-check request is less than 2 per cycle.

17
Issue Port Competition (F4-I4)

18
WF-Precheck IPC (F4-I4)

19
Impact of Load Related Predictions

20
How about Selection Logic?
Selection LogicTselection = c0 + c1xlog4N
S. Palacharla et al., ISCA24
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
req enb
Issue Queue
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3req enb
req
0 gra
nt
0 req
1 gra
nt
1 req
2 gra
nt
2 req
3 gra
nt
3
enb
from/to other subtrees
root cell
21
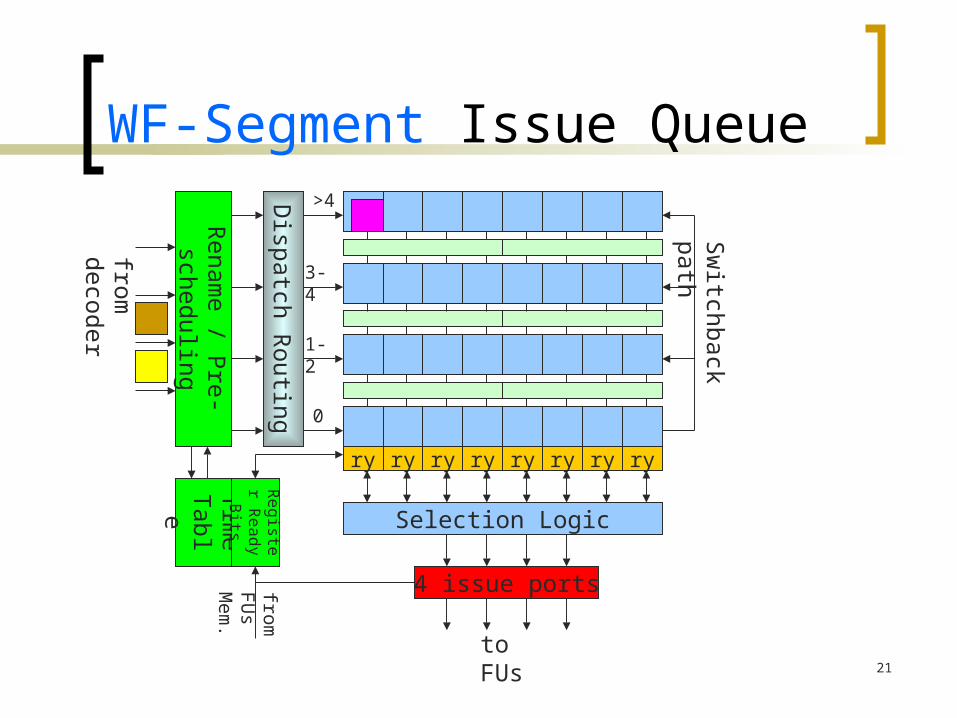
WF-Segment Issue Queue
Selection Logic
ry ry ry ry ry ry ry ry
4 issue ports
to FUsD
ispatch Routing
0
1-2
3-4
>4
Renam
e / Pre-
schedulingT
ime
Table
Re
giste
r R
ea
dy
Bits
from F
Us
Mem
.
from
decoder
Sw
itchback path
22
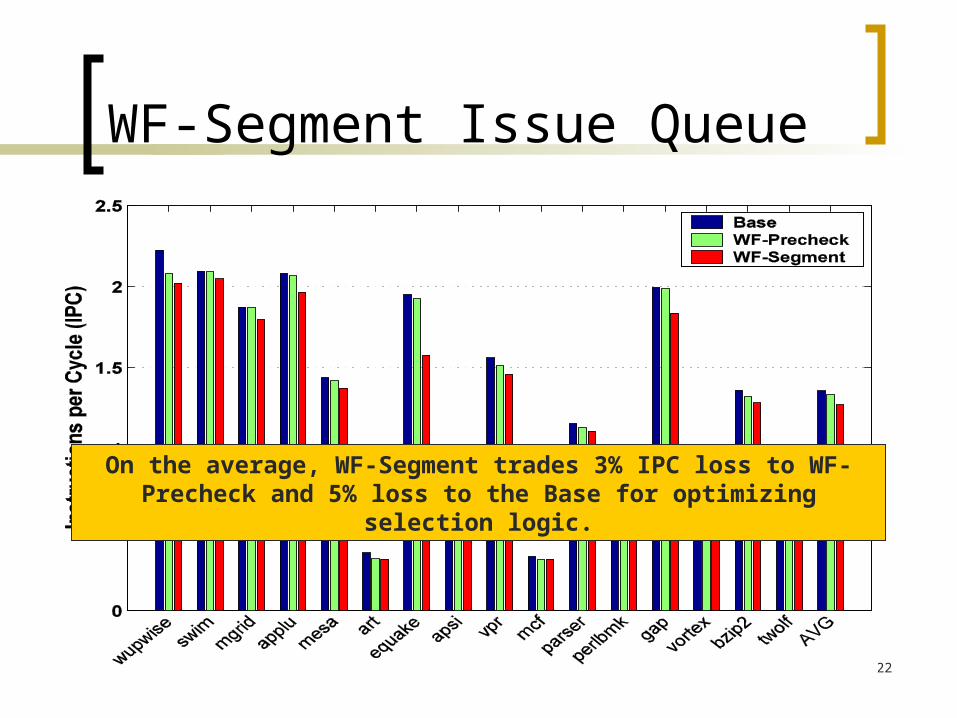
WF-Segment Issue Queue
On the average, WF-Segment trades 3% IPC loss to WF-Precheck and 5% loss to the Base for optimizing selection logic.

23
Conclusions
Explore and identify the performance impediments in wakeup-free scheduling
High-performance wakeup-free dynamic schedulers WF-Replay: eliminates structural constraints WF-Precheck: avoids unnecessary competition at
issue ports WF-Segment: optimizes selection logic for high
clock speed

24
Future Work
Routing complexity analysis in WF-Segment scheduler
Power analysis for wakeup-free schedulers
Sophisticated pre-scheduler

25

26
Wire Delay Challenges
Increasing pipeline depth for high performance
Clock period (FO4) decreases dramatically
Cross-chip wire delay will be up to 10 cycles as technology shrinks
M. S. Hrishikesh et al, ISCA29
Stephen W. Keckler et al, ISSCC’03
27
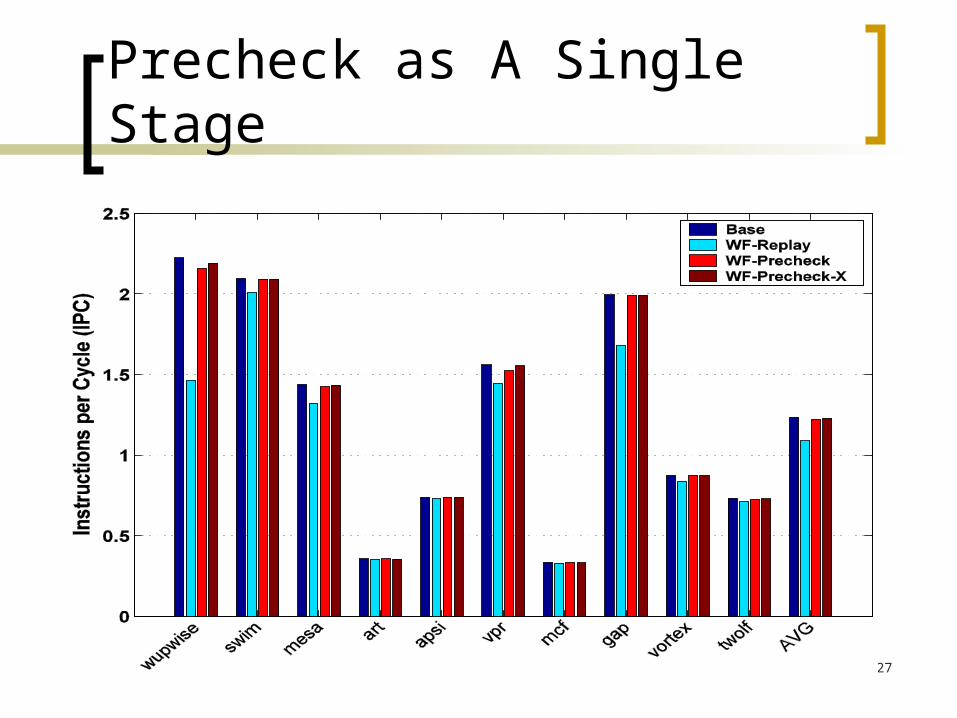
Precheck as A Single Stage
28
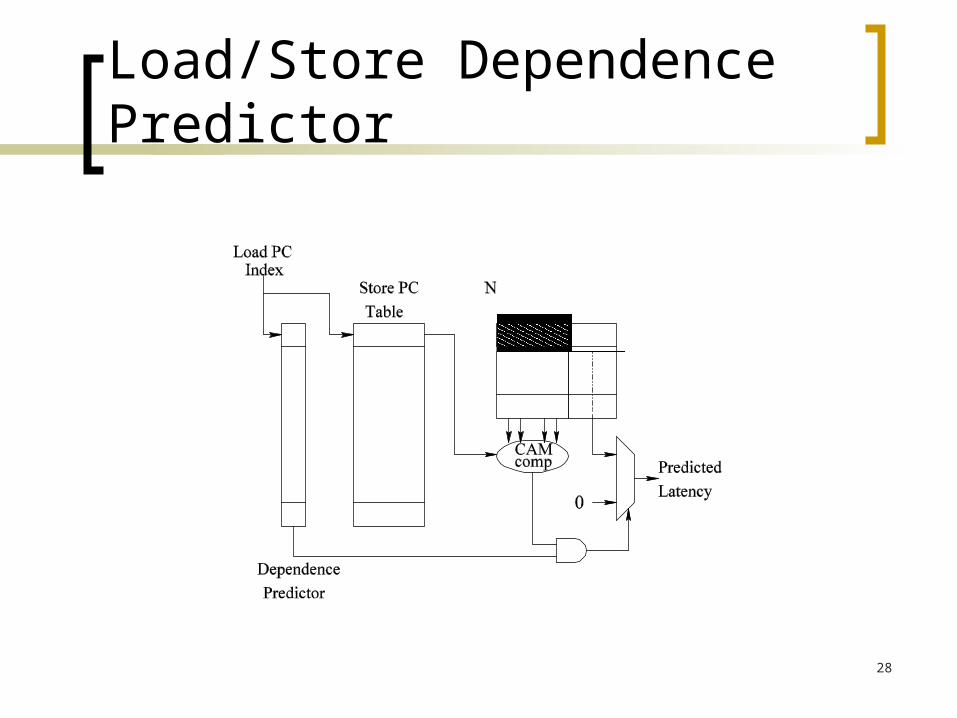
Load/Store Dependence Predictor















![Operating Systems Engineering Sleep & Wakeup [chapter #5]](https://img.dokumen.tips/doc/110x75/568162ba550346895dd3447b/operating-systems-engineering-sleep-wakeup-chapter-5.jpg)













