Embed Size (px)
DESCRIPTION
Exploiting Content Localities for Efficient Search in P2P Systems. Lei Guo 1 Song Jiang 2 Li Xiao 3 and Xiaodong Zhang 1 1 College of William and Mary, USA 2 Los Alamos National Laboratory, USA 3 Michigan State University, USA. Network manager. Don’t be so greedy, the Internet - PowerPoint PPT Presentation
Citation preview

Exploiting Content Localities for Efficient Search in P2P Systems
Lei Guo1 Song Jiang2 Li Xiao3 andXiaodong Zhang1
1College of William and Mary, USA2Los Alamos National Laboratory, USA
3Michigan State University, USA

Peer-to-Peer Search
• Two Performance Objectives – Individual peer: improve the search quality– Internet management: minimize the search cost
Fast, fast, fast, andthe more the better!
P2P user
Don’t be so greedy, the Internet is shared by all the people!
Network manager

Existing Solutions
• Generally aim to one of the two objectives and have performance limits to the other
• Flooding:– Most effective for user’s experience– Least efficient for network resource utilization
• Random walk:– Traffic efficient, but– Long response time and limited number of search
results

Super-Node Architecture
• Super-node– Index server for its leaf nodes
• Problems– Index based search has limits
• Hard for full-text search• Impossible for encrypted content search
– Not responsible for the content quality of its leaf nodes – The structure becomes large and inefficient.
• A leaf node has to connect to multiple super-nodes to avoid single point failure
• Generating an increasingly large number of super-nodes

Gnutella Population in One Day (2003)
number of peers
number of super peers
One super node only connects to 3-4 peers in average!

Outline
• Our Measurement Study
• CAC: Constructing Content Abundant Cluster
• SPIRP: Selectively Prefetching Indices from Responding Peers
• CAC-SPIRP: Combining CAC and SPIRP
• Performance Evaluation
• Conclusion

Our Measurement Study
• Existing measurement studies– A small percentage of popular files account for most
shared storage and transmissions in P2P systems– A small amount of peers contribute majority number
of files in P2P. – They are only the indirect evidence of content locality
• Some files may be never accessed, or accessed rarely
• Our purpose– Fully understand the localities in the peer community
and individual peers– Get first-hand traces for our simulation study

Trace Collection
• Four-day crawling on the Gnutella network– Open source code of LimeWire Gnutella– Session based collection (for the whole life time of
peers)
• Query sending traces by different peers– 25,764 peers– 409,129 queries
• Content indices of different peers– Full indices of 18,255 peers– 37% free riders

Top Content Providers (in percentage)Que
ries
Rep
lied
by T
op Q
uery
Res
pond
ers
(%)
Res
ults
Rep
lied
by T
op R
esul
t Pro
vide
rs (
%)
100
80
60
40
20
0
100
80
60
40
20
00 20 40 60 80 100
Content Locality in the Peer Community
A small group of peers can reply nearly all queries and provide most of resultsA small group of peers can reply nearly all queries and provide most of results
Number of Queries100 101 102 103 104
Pe
rce
nta
ge
of
Pe
ers
(%
)100
80
60
40
20
0
Pe
rce
nta
ge
of
Pe
ers
(%
)
Number of Results100 102 104 106
100
80
60
40
20
0

The Localities of Search Interests of Individual Peers
• A peer can get search results from a small number of its top query responders: they share the same search interests
• Similar to the idea in Locality of Interest scheme, but our conclusion is based on real P2P systems
Top Query Responders Top Result Providerstop 1 top 10 top 5% top 10% top 20% top 1 top 10 top 5% top 10% top 20%
Que
ry C
ontr
ibut
ions
(%
)
Res
ult
Con
trib
utio
ns (
%)
100
80
60
40
20
0
50
40
30
20
10
0
60

Reorganizing the P2P Management Structure
• Clustering those small number of content abundant peers
• Prefetching indices from those top query responders

CAC: Constructing Content Abundant Cluster
• Objectives– Clustering those small number of content abundant
peers in P2P overlay– Providing high quality and fast service
• Content Abundant Cluster– An overlay on top of P2P network– Self-evaluate, self-identify, and self-organize– Persistent public service for all peers in the system– Strong content-based (not index-based)

ClusteringLeveling
CAC: System Structure
C A CC A C
0
00 0
0
0 0
11
1
1 1
1
1
1
22
22
2
2
2
2
2
2 2
2
3
3
3
3
3
3
4
X
3
3
2
Dynamic Update

CAC: Search Operations
• Queries are sent to CAC first– Up-flowing operation– Flooding in CAC
• Unsatisfied queries are propagated from CAC to the whole system– Down-flooding operation– Propagated from low levels to high levels

Up-flowing
C A CC A C
0
00 0
0
0 0
11
1
1 1
1
1
1
22
22
2
2
2
2
2
2 2
2
3
3
3
3
3
3
4

Down-flooding
C A CC A C
0
00 0
0
0 0
11
1
1 1
1
1
1
22
22
2
2
2
2
2
2 2
2
3
3
3
3
3
3
4
Unused links

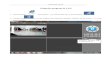
SPIRP: Selectively Prefetching Indices from Responding Peers
• Basic operations– Peer I initiates a query q
• Query hits: displays the results• Misses: sends q
– Peer R responds query q• sends query results as well as• piggybacks indices of all shared files
– Peer I receives response• Display the searching results as well as • stores piggybacked indices
• Indices updating– Active updating indices by responding peers– Updating indices demanded by requesting peers
• Replacement of file indices
Where are these files?
Pop music
Classic music
SPIRP Technique
♫♫
R1
R2
Query = “Beethoven mp3”
I

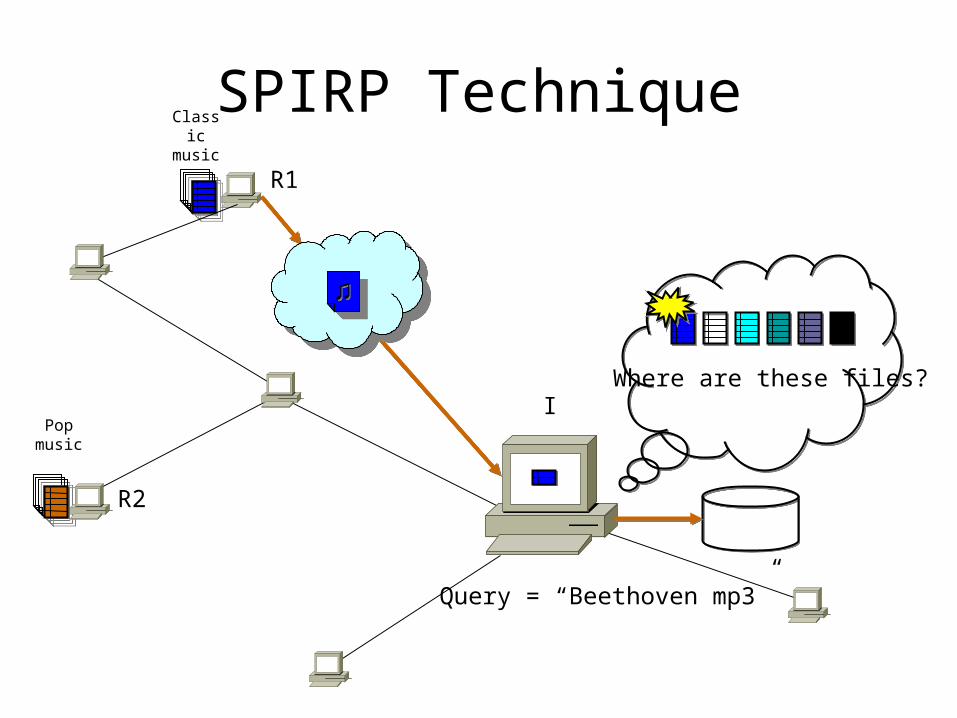
SPIRP Technique
pop
classic
NULLNULL
R1
R2
Query = “Beetle mp3”
Where are these files?I

SPIRP Techniqueclassic
pop
R1
R2
Query = “Beetle mp3”
I

SPIRP Techniqueclassic
pop
R1
R2
Query = “Beetle mp3”
No enough space tosave indicesI
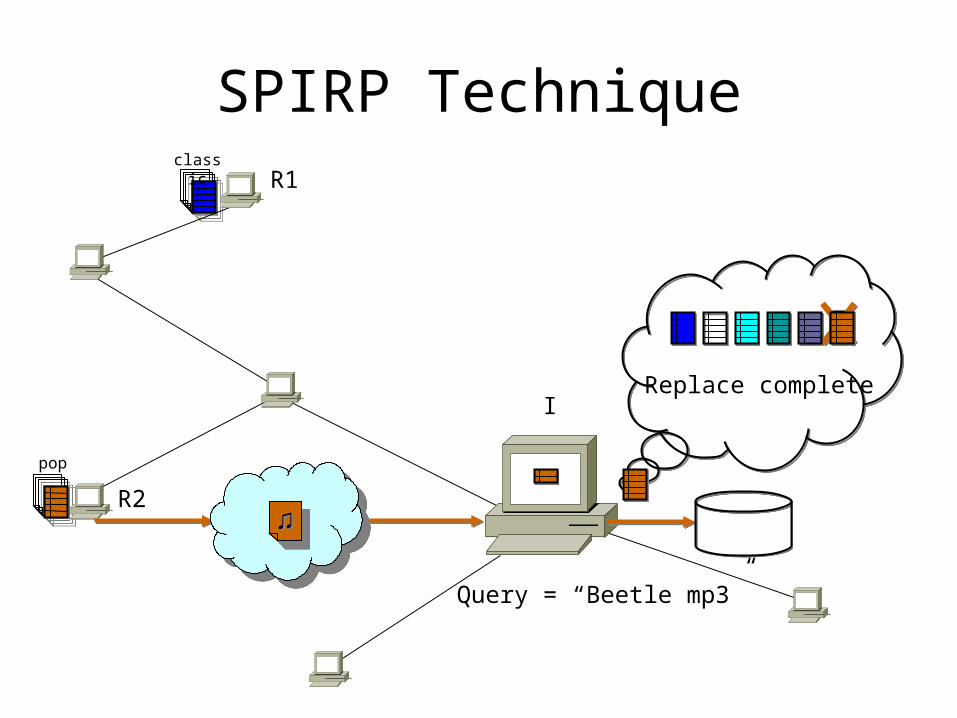
SPIRP Techniqueclassic
pop
♫♫
R1
R2
Replace completeI
Query = “Beetle mp3”

CAC-SPIRP
• CAC: application level infrastructure– Significantly reducing bandwidth consumption– Good response time when queries success in CAC– Long response time when queries fail in CAC
• SPIRP: client-oriented and overlay independent– Significantly reducing response time– Small traffic when queries can be satisfied in cache– Same traffic as flooding when cache misses
• CAC-SPIRP– Easy to combine the two techniques– Consider the trade-off between the two performance objectives– Has both merits of search quality and search cost

Simulation Environment
• Content trace and query trace– 4 day Gnutella crawling in our measurement
• Overlay topology– Traces by Clip2 Distributed Search Solutions
• Session duration– Pareto distribution fitted from measurement
results
P(x) = 14.5311 * x -1.8598

Evaluation Metrics
• Query success rate– CAC: success rate in CAC (normalized to flooding)– SPIRP: success rate in local cache (normalized to flooding)
• Overall network traffic– accumulated communication traffics for all queries, responses,
and index transferring (normalized to flooding)
• Average response time– use the number of routing hops (normalized to flooding)
Evaluate for different query satisfactions– 1, 10, 50 results, representing different user demands

Performance Evaluation for CAC
0 10 20 30 40 50Cluster Size (In Percentage of P2P Network Size)
5% top content abundant peers are good enough for cluster construction
Ove
rall
Tra
ffic
(Nor
mal
ized
)
1
0.8
0.6
0.4
0.2
0
0 10 20 30 40 50Cluster Size (In Percentage of P2P Network Size)
0 10 20 30 40 50Cluster Size (In Percentage of P2P Network Size)
Su
cce
ss R
ate
in C
AC
(n
orm
aliz
ed
)
1
0.8
0.6
0.4
0.2
0
Avg
Re
spo
nse
Tim
e
(No
rma
lize
d)
2
1.5
1
0.5
0
Minimum Results = 1Minimum Results = 10Minimum Results = 50
Minimum Results = 1Minimum Results = 10Minimum Results = 50
Minimum Results = 1Minimum Results = 10Minimum Results = 50
0 10 20 30 40 50Cluster Size (In Percentage of P2P Network Size)

CAC Member Selection
0 0.01 0.02 0.03 0.04Success Response Rate of Content-Abundant Peers
Suc
cess
Rat
e in
CA
C (
norm
aliz
ed) 1
0.8
0.6
0.4
0.2
0
Minimum Results = 1Minimum Results = 10Minimum Results = 50
Avg
Re
spo
nse
Tim
e (
No
rma
lize
d)
Ove
rall
Tra
ffic
(N
orm
aliz
ed
)
0 0.01 0.02 0.03 0.04Success response rate of CAC Peers
1
0.8
0.6
0.4
0.2
0
0 0.01 0.02 0.03 0.04Success Response Rate of CAC Peers
2
1.5
1
0.5
0
Minimum Results = 1Minimum Results = 10Minimum Results = 50
Minimum Results = 1Minimum Results = 10Minimum Results = 50
• Overall traffic is not sensitive to CAC member quality• Traffic can be significantly reduced even for
randomly selected CAC members CAC down flooding is very efficient

CAC-SPIRP Overall PerformancePeers having 1 to 5 queries satisfiedPeers having 10 to 20 queries satisfiedPeers having 30 to 40 queries satisfiedPeers having at least 50 queries satisfied
Peers having 1 to 5 queries satisfiedPeers having 10 to 20 queries satisfiedPeers having 30 to 40 queries satisfiedPeers having at least 50 queries satisfied
Query Satisfaction = 1Query Satisfaction = 10Query Satisfaction = 50
0 2 4 6 8 10Size of Incoming Index Set Buffer (in M Bytes)
Ave
rage
Res
pons
e T
ime
(Nor
mal
ized
)
2
1.6
1.2
0.8
0.4
0
Su
cce
ss R
ate
in L
oca
l Ca
che
1
0.8
0.6
0.4
0.2
Ove
rall
Tra
ffic
(N
orm
aliz
ed
)
1
0.8
0.6
0.4
0.2
0 2 4 6 8 10Size of Incoming Index Set Buffer (in M Bytes)
0
0 2 4 6 8 10Size of Incoming Index Set Buffer (in M Bytes)
0
CAC-SPIRP reduces both the overall trafficand response time significantly

Conclusion
• CAC-SPIRP fundamentally addresses the P2P search problem by a re-organization.– Exploiting organizational content locality
• CAC: a content abundant cluster provides high quality and fast services.
– Exploiting user content locality• SPIRP: a client prefetching technique to speed up
search by avoiding unnecessary queries