Embed Size (px)
Citation preview

Experiences and lessons learnt from bootstrapping random-
effects predictions
Robert GrantSenior Research Fellow,
Kingston University & St George’s

Topics
• The problem: quality of stroke care• Predictions from random effects• Bootstrapping do-file• Spotting errors from xtmelogit postestimation

The problem: quality of stroke care
• National clinical audit of stroke• 203 hospitals provide data• 10,617 patients from the 2008 data analysed• 26 binary quality indicators used in scoring

The problem: quality of stroke care
• National clinical audit of stroke• 203 hospitals provide data• 10,617 patients from the 2008 data analysed• 26 binary quality indicators used in scoring• Is inter-hospital variation adequately
summarised?• Can we depict uncertainty around scores /
ranks of hospitals?

“Multilevel principal components analysis”
• Run mixed-effects models to adjust each indicator
• Get predictions of each hospital’s performance as BLUPs (level-2 residuals)
• Summarise by principal components analysis• Rank the scores on the component(s)• Bootstrap to capture correlation between
indicators

Predictions from random effects
• Logistic model
• BLUPs – predictions of individual ui
• Random effect distribution (mean 0, SD estimated) acts as empirical Bayes prior
• Data in each cluster provide likelihood• BLUP can be mode (xtmelogit) or mean (gllamm)
of the posterior distribution

Predictions from random effects
• Profile likelihood for the cluster effects
Stata 11 [XT] manual, p. 277

Predictions from random effects• xtmelogit outcome covariate1 covariate2 || hospital:• predict mode_blup, reffects
• gllamm outcome covariate1 covariate2, i(hospital) family(binomial) link(logit) adapt
• gllapred mean_blup, u
• xtmelogit...• predict offset, xb• statsby mle=_b[_cons], by(hospital) saving(ml): logit
outcome, offset(offset)

Bootstrapping do-file
• Program with bsample / bstat• Save individual resample and ‘parameters’• Can be broken into, run on multiple machines

Do-file• Assemble your observed values as a single matrix
pca mode1 mode2 mode3 mode4 mode5 mode6 mode7 mode8 mode9 mode10 mode11 mode12 mode13 mode14 mode15 mode16 mode17 mode18 mode19 mode20 mode21 mode22 mode23 mode24 mode25 mode26 if pickone, covariance components(1)
matrix obsload=e(L)forvalues i=1/26 {
scalar obsload`i'=obsload[`i',1]}scalar obsload27=e(rho)matrix obspca=(obsload1,obsload2,obsload3,obsload4,obsload5,obsload6,obsload7,
obsload8,obsload9,obsload10,obsload11,obsload12,obsload13,obsload14, obsload15,obsload16,obsload17,obsload18,obsload19,obsload20,obsload21, obsload22,obsload23,obsload24,obsload25,obsload26,obsload27)
predict obsscore if pickone, scoremkmat obsscore if pickonematrix define obs=obspca,obsscore'

Do-file• The `iteration’ macro lets you see how many
resamples the computer has done. • Define your bootstrap program
global iteration=1capture: program drop myboot_modeprogram define myboot_mode, rclass
display as result "Now running resample number $iteration"global iteration=$iteration + 1preservebsample, strata(hospital) capture: drop pickoneegen pickone=tag(hospital)* save bsample_$iteration.dta, replace
* Code then follows for the models, the PCA etc etc.
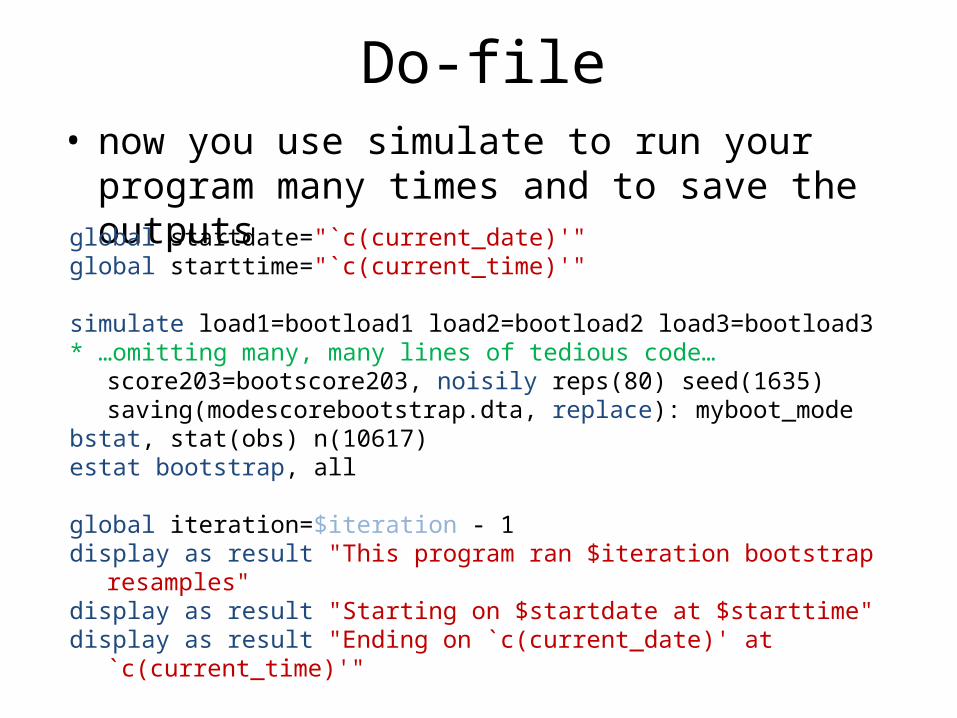
Do-file• now you use simulate to run your program many
times and to save the outputsglobal startdate="`c(current_date)'"global starttime="`c(current_time)'"
simulate load1=bootload1 load2=bootload2 load3=bootload3* …omitting many, many lines of tedious code…
score203=bootscore203, noisily reps(80) seed(1635) saving(modescorebootstrap.dta, replace): myboot_mode
bstat, stat(obs) n(10617)estat bootstrap, all
global iteration=$iteration - 1display as result "This program ran $iteration bootstrap resamples"display as result "Starting on $startdate at $starttime"display as result "Ending on `c(current_date)' at `c(current_time)'"

Spotting errors
• xtmelogit is faster than gllamm because mode doesn’t require full integration
• A few extremely large BLUPs arise from non-convergence of the profile likelihood
• Can pick them out and draw up bootstrap confidence intervals from the remainder (may not be so easy in every situation?)

Spotting errors: original data-2
02
4ra
ndo
m e
ffec
ts f
or id
: _c
ons
-2 -1 0 1 2 3Inverse Normal

Spotting errors: original data-1
01
23
4M
odal
BLU
P
0 .2 .4 .6 .8 1Proportion of Yes responses

Spotting errors: problematic resample-1
00
-50
050
ran
dom
eff
ects
for
id:
_con
s
-60 -40 -20 0 20 40Inverse Normal

Spotting errors: problematic resample-8
0-6
0-4
0-2
00
Mod
al B
LUP
0 .2 .4 .6 .8 1Proportion of Yes responses

Spotting errors: PCA0
.2.4
.6.8
1Lo
adin
g
0 5 10 15 20 25Quality indicator

Spotting errors
• Consider multivariate outliers which may not be univariate ones
• Methods suggested by Gnanadesikan & Kettenring (Biometrics 1972; 28(1): 81-124.)
• Mahalanobis distances• Minor principal component scores

Confidence intervals-1
0-5
05
101s
t prin
cip
al c
om
pone
nt s
core
bas
ed
on m
ean
BLU
Ps
0 50 100 150 200Rank of hospital
050
100
150
200
Boo
tstr
ap 9
5% C
I fo
r ra
nks
0 50 100 150 200Hospital median rank

Confidence intervals
• Normal approximate confidence intervals were often inappropriate
• Percentile, bias-corrected (BC) and Bca confidence intervals often disagreed
• Sometime degenerate to a point• The problem is mostly in the ranks• Because of an implicitly discontinuous
transformation – no Edgeworth expansion?

Alternatives
• Multivariate AND multilevel modelling (SEM?) in a single step
• Goldstein, Bonnet & Rocher. J Educ Behav Stat (2007); 32: 252
• runmlwin (MCMC)• Fully Bayesian specification

Acknowledgements
• Thanks to Kristin MacDonald & colleagues at StataCorp for looking into the xtmelogit postestimation errors
• Thanks to former colleagues at the Royal College of Physicians for supplying the stroke audit data
• Thanks to Chris Frost & Rebecca Jones at LSHTM for guidance on the early versions of these analyses which went into my MSc.