Embed Size (px)
Citation preview

EENG449b/SavvidesLec 16.1
3/30/04
March 30, 2004
Prof. Andreas Savvides
Spring 2004
http://www.eng.yale.edu/courses/eeng449bG
EENG 449bG/CPSC 439bG Computer Systems
Lecture 16
Software ILPHardware Support for Compile-time ILP and
Itanium Architecture

EENG449b/SavvidesLec 16.2
3/30/04
Last Time
• Loop Unrolling• Software Pipelining• Trace scheduling - incurs cost to the less
frequent paths• Trace selection: Identify a sequence of basic
blocks and put their operations in a smaller set of instructions
– Can be done with loops and conditional statements for which some static branch prediction is available
– Disadvantage – there is a single entry point and a single exit point to the trace – high overhead
• Superblocks: Single entry point but multiple exit points
– Reduces the overhead of mis-prediction but may result in larger code sizes than trace scheduling

EENG449b/SavvidesLec 16.3
3/30/04
HW Support for Exposing ILP at Compile Time
• Loop unrolling, software pipelining and Trace scheduling and superblock scheduling – good when braches can be predicted at compile time
• What if branches are not predictable?– One solution – extend instruction set to include
predicated instructions
• Predicated Instructions – an instruction refers to a condition as part of instruction execution
– Execute if condition is true, treat the instruction as a no-op if the condition is false.
– Predication transforms control dependences to data dependences

EENG449b/SavvidesLec 16.4
3/30/04
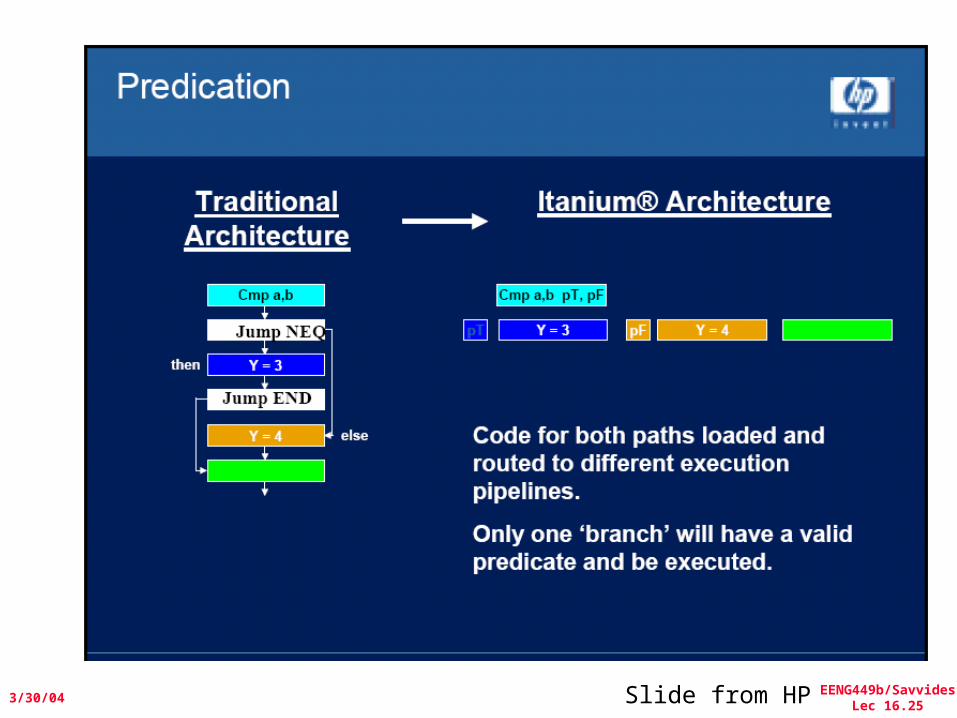
Conditional or Predicated Instructions
Example:if (A==0) {S=T};
Assume that A, S, T are stored in R1, R2, R3The assembly code would be:
BNEZ R1,LADDU R2, R3, R0
L:
The new instruction would use a conditional move if the third operand is equal to zero
CMOVZ R2,R3,R1
Limitation: Inefficient when trying to eliminate branches that guard the execution of large blocks of code.

EENG449b/SavvidesLec 16.5
3/30/04
Full Predication
• The execution of all instructions is controlled by a predicate
• Assume we have a 2-issue architecture• First instruction slot Second instruction
slotLW R10,40(R2) ADD R3,R4,R5
ADD R6,R3,R7
BEQZ R10,L
LW R8,0(R10)
LW R9,0(R8)
• Waste slot since 3rd LW dependent on result of 2nd LW
IdleSlot
Stall

EENG449b/SavvidesLec 16.6
3/30/04
Hardware Support for Exposing More Parallelism at Compile-
Time
• Use predicated version load word (LWC)? – load occurs unless the third operand is 0
• First instruction slot Second instruction slot
LW R10,40(R2) ADD R3,R4,R5
LWC R8,20(R10),R10 ADD R6,R3,R7
BEQZ R10,L
LW R9,0(R8)
• If the sequence following the branch were short, the entire block of code might be converted to predicated execution, and the branch eliminated

EENG449b/SavvidesLec 16.7
3/30/04
Exception Behavior Support
• Several mechanisms to ensure that speculation by compiler does not violate exception behavior
– For example, cannot raise exceptions in predicated code if annulled
– Prefetch does not cause exceptions

EENG449b/SavvidesLec 16.8
3/30/04
Summary#1: Hardware versus Software Speculation
Mechanisms• To speculate extensively, must be able to
disambiguate memory references– Much easier in HW than in SW for code with pointers
• HW-based speculation works better when control flow is unpredictable, and when HW-based branch prediction is superior to SW-based branch prediction done at compile time
– Mispredictions mean wasted speculation
• HW-based speculation maintains precise exception model even for speculated instructions
• HW-based speculation does not require compensation or bookkeeping code

EENG449b/SavvidesLec 16.9
3/30/04
Summary#2: Hardware versus Software Speculation Mechanisms
cont’d• Compiler-based approaches may benefit
from the ability to see further in the code sequence, resulting in better code scheduling
• HW-based speculation with dynamic scheduling does not require different code sequences to achieve good performance for different implementations of an architecture
– may be the most important in the long run?

EENG449b/SavvidesLec 16.10
3/30/04
Summary #3: Software Scheduling
• Instruction Level Parallelism (ILP) found either by compiler or hardware.
• Loop level parallelism is easiest to see– SW dependencies/compiler sophistication determine if compiler
can unroll loops– Memory dependencies hardest to determine => Memory
disambiguation– Very sophisticated transformations available
• Trace Sceduling to Parallelize If statements• Superscalar and VLIW: CPI < 1 (IPC > 1)
– Dynamic issue vs. Static issue– More instructions issue at same time => larger hazard penalty– Limitation is often number of instructions that you can
successfully fetch and decode per cycle

EENG449b/SavvidesLec 16.11
3/30/04
Intel/HP IA-64 “Explicitly Parallel Instruction Computer
(EPIC)”• IA-64: instruction set architecture; EPIC is type
– EPIC = 2nd generation VLIW?
• Itanium™ is name of first implementation (2001)– Highly parallel and deeply pipelined hardware at 800Mhz
– 6-wide, 10-stage pipeline at 800Mhz on 0.18 µ process
– Targeted for servers and high end computers
• 128 64-bit integer registers + 128 82-bit floating point registers
– Not separate register files per functional unit as in old VLIW
• Hardware checks dependencies (interlocks => binary compatibility over time)
• Predicated execution (select 1 out of 64 1-bit flags) => 40% fewer mispredictions?

EENG449b/SavvidesLec 16.12
3/30/04
IA-64 Registers• The integer registers are configured to help
accelerate procedure calls using a register stack – mechanism similar to that developed in the Berkeley RISC-I
processor and used in the SPARC architecture. – Registers 0-31 are always accessible and addressed as 0-31– Registers 32-128 are used as a register stack and each
procedure is allocated a set of registers (from 0 to 96)– The new register stack frame is created for a called
procedure by renaming the registers in hardware; – a special register called the current frame pointer (CFM)
points to the set of registers to be used by a given procedure
• 8 64-bit Branch registers used to hold branch destination addresses for indirect branches
• 64 1-bit predict registers

EENG449b/SavvidesLec 16.13
3/30/04
IA-64 Registers
• Both the integer and floating point registers support register rotation for registers 32-128.
• Register rotation is designed to ease the task of allocating of registers in software pipelined loops
• When combined with predication, possible to avoid the need for unrolling and for separate prologue and epilogue code for a software pipelined loop
– makes the SW-pipelining usable for loops with smaller numbers of iterations, where the overheads would traditionally negate many of the advantages

EENG449b/SavvidesLec 16.14
3/30/04
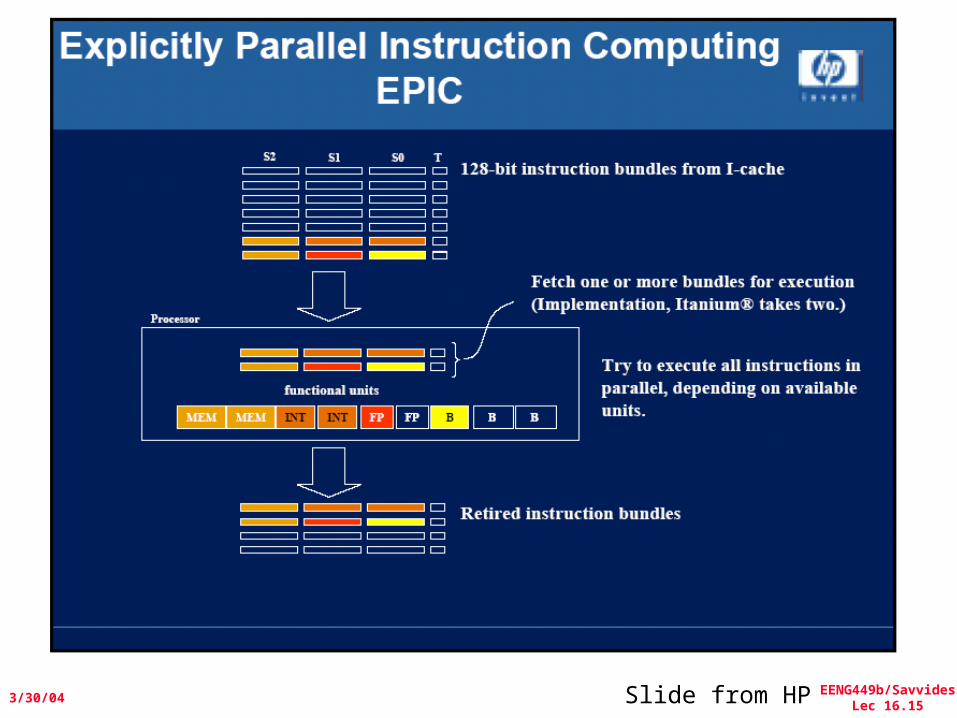
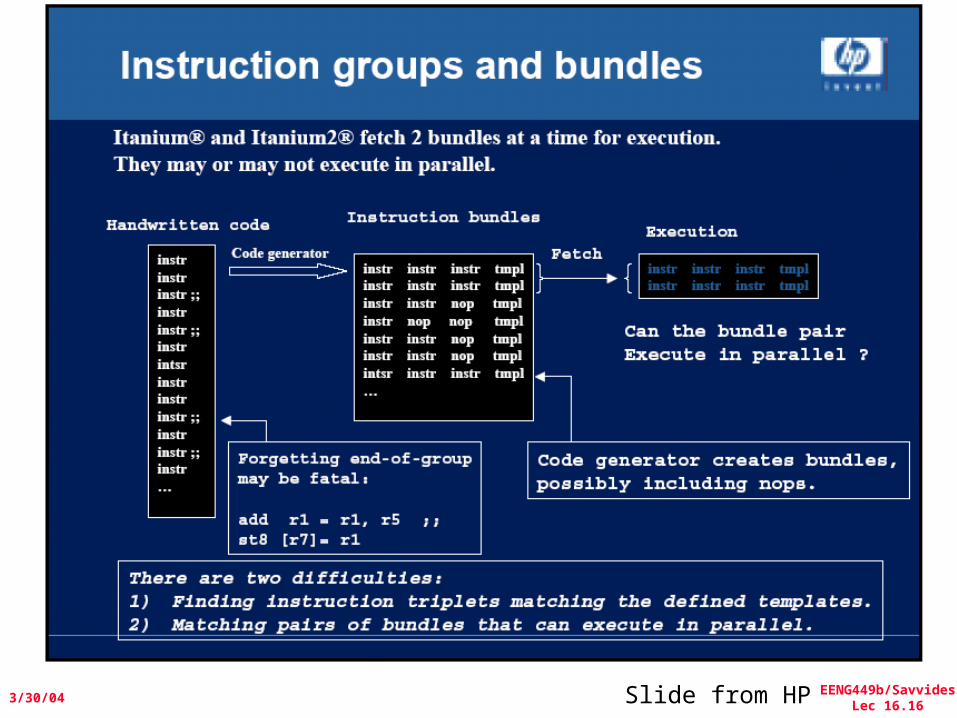
Intel/HP IA-64 “Explicitly Parallel Instruction Computer
(EPIC)”• Instruction group: a sequence of consecutive
instructions with no register data dependences– All the instructions in a group could be executed in parallel, if
sufficient hardware resources existed and if any dependences through memory were preserved
– An instruction group can be arbitrarily long, but the compiler must explicitly indicate the boundary between one instruction group and another by placing a stop between 2 instructions that belong to different groups
• IA-64 instructions are encoded in bundles, which are 128 bits wide.
– Each bundle consists of a 5-bit template field and 3 instructions, each 41 bits in length
• 3 Instructions in 128 bit “groups”; field determines if instructions dependent or independent
– Smaller code size than old VLIW, larger than x86/RISC– Groups can be linked to show independence > 3 instr
EENG449b/SavvidesLec 16.15
3/30/04 Slide from HP
EENG449b/SavvidesLec 16.16
3/30/04 Slide from HP

EENG449b/SavvidesLec 16.17
3/30/04
5 Types of Execution in BundleExecution Instruction Instruction ExampleUnit Slot type Description InstructionsI-unit A Integer ALU add, subtract, and, or, cmp
I Non-ALU Int shifts, bit tests, movesM-unit A Integer ALU add, subtract, and, or, cmp
M Memory access Loads, stores for int/FP regsF-unit F Floating point Floating point instructionsB-unit B Branches Conditional branches, calls L+X L+X Extended Extended immediates, stops
• 5-bit template field within each bundle describes both the presence of any stops associated with the bundle and the execution unit type required by each instruction within the bundle (see Fig 4.12 page 354)
EENG449b/SavvidesLec 16.18
3/30/04
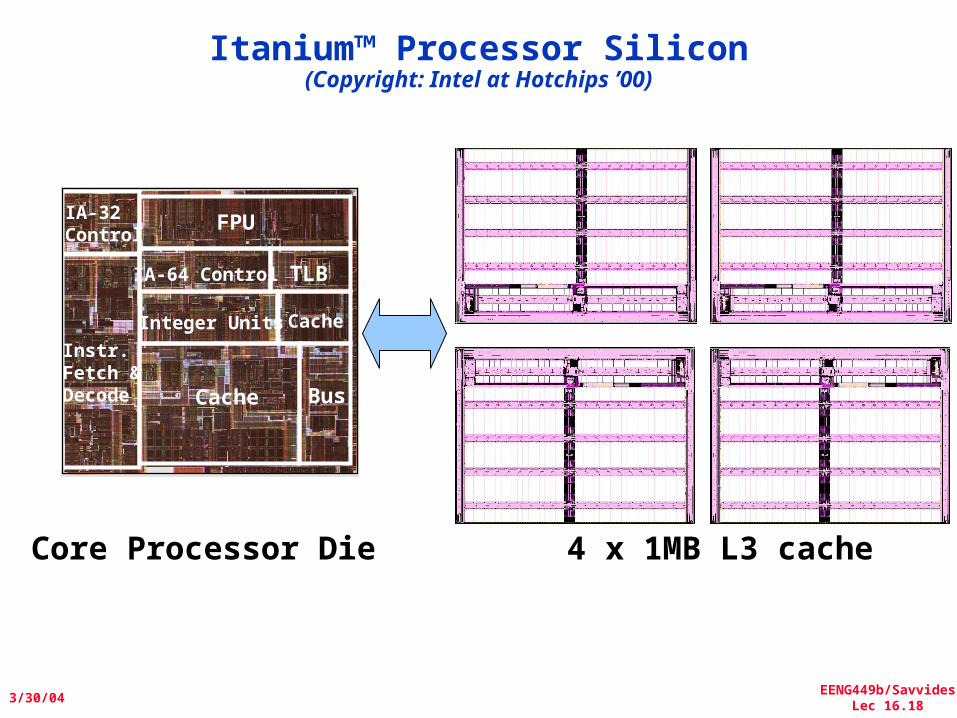
FPUIA-32Control
Instr.Fetch &Decode Cache
Cache
TLB
Integer Units
IA-64 Control
Bus
Core Processor Die 4 x 1MB L3 cache
Itanium™ Processor Silicon(Copyright: Intel at Hotchips ’00)
EENG449b/SavvidesLec 16.19
3/30/04
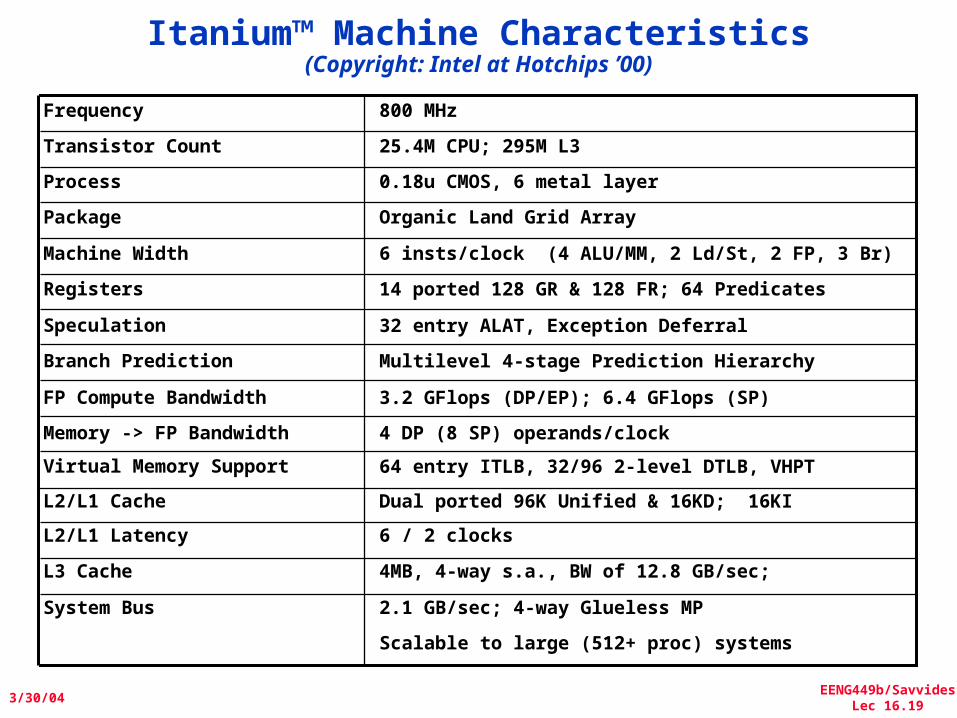
Itanium™ Machine Characteristics(Copyright: Intel at Hotchips ’00)
Organic Land Grid ArrayPackage
0.18u CMOS, 6 metal layerProcess
25.4M CPU; 295M L3Transistor Count
800 MHzFrequency
2.1 GB/sec; 4-way Glueless MPSystem Bus
4MB, 4-way s.a., BW of 12.8 GB/sec; L3 Cache
Dual ported 96K Unified & 16KD; 16KIL2/L1 Cache
6 / 2 clocksL2/L1 Latency
Scalable to large (512+ proc) systems
64 entry ITLB, 32/96 2-level DTLB, VHPTVirtual Memory Support
6 insts/clock (4 ALU/MM, 2 Ld/St, 2 FP, 3 Br)Machine Width
3.2 GFlops (DP/EP); 6.4 GFlops (SP)FP Compute Bandwidth
4 DP (8 SP) operands/clockMemory -> FP Bandwidth
14 ported 128 GR & 128 FR; 64 Predicates
32 entry ALAT, Exception DeferralSpeculation
Registers
Branch Prediction Multilevel 4-stage Prediction Hierarchy
EENG449b/SavvidesLec 16.20
3/30/04
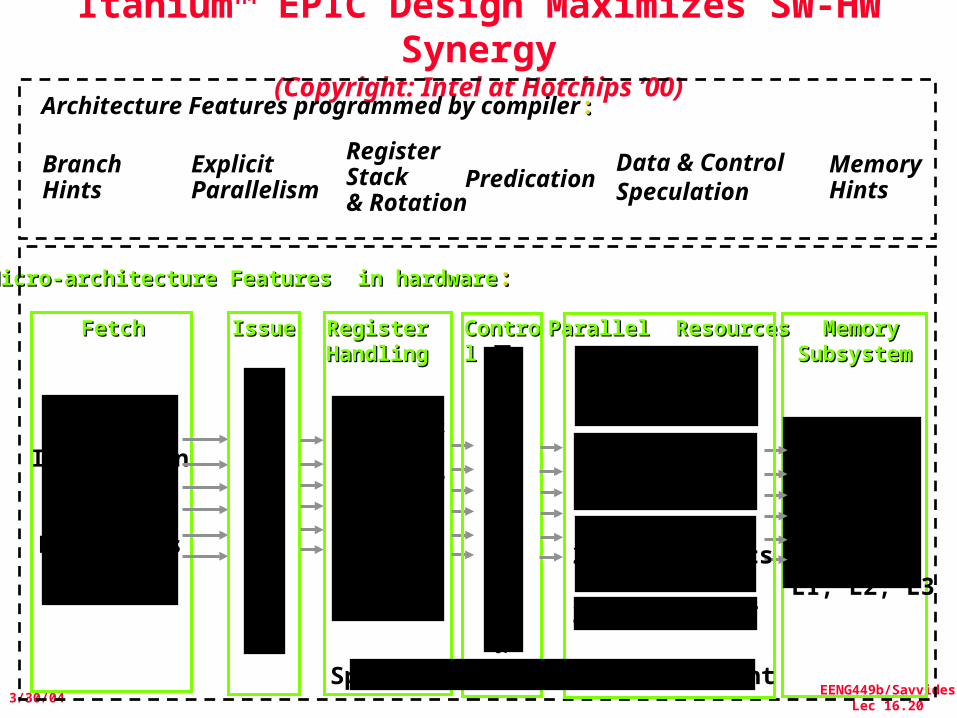
Branch Hints
Memory Hints
InstructionCache
& BranchPredictors
FetchFetch Memory Memory SubsystemSubsystem
Three levels of cache:L1, L2, L3
Register Stack & Rotation
Explicit Parallelism
128 GR &128 FR,RegisterRemap
&Stack Engine
Register Register HandlingHandling
Fast, S
imp
le 6-Issue
IssueIssue ControlControl
Micro-architecture Features in hardwareMicro-architecture Features in hardware: :
Itanium™ EPIC Design Maximizes SW-HW Synergy
(Copyright: Intel at Hotchips ’00)Architecture Features programmed by compiler::
PredicationData & ControlSpeculation
Byp
asse
s & D
ep
end
encie
s
Parallel ResourcesParallel Resources
4 Integer + 4 MMX Units
2 FMACs (4 for SSE)
2 L.D/ST units
32 entry ALAT
Speculation Deferral Management
EENG449b/SavvidesLec 16.21
3/30/04
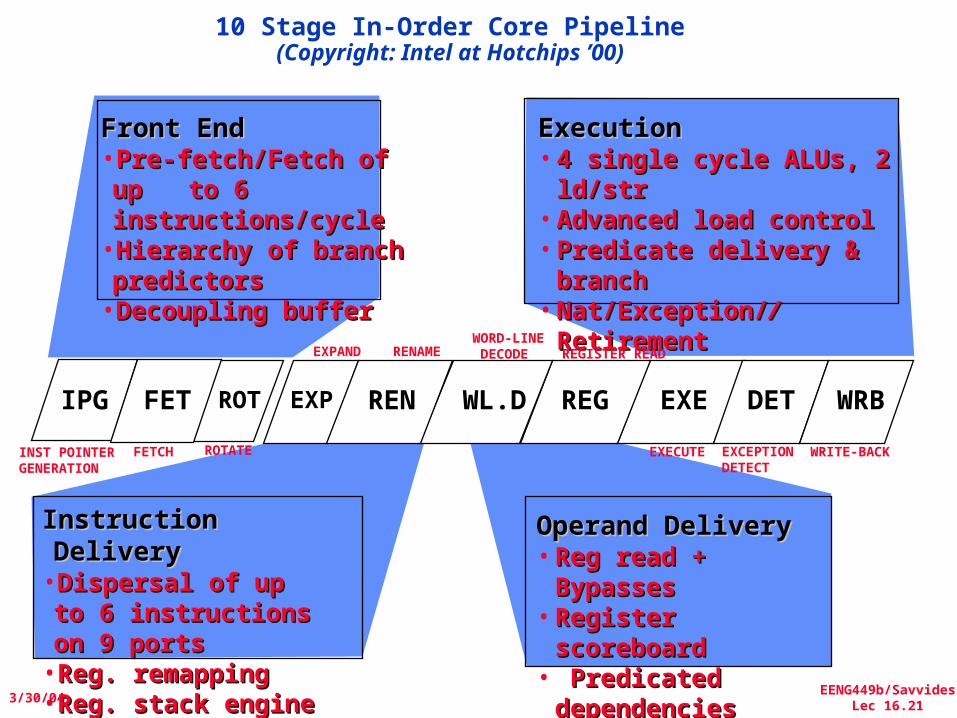
10 Stage In-Order Core Pipeline(Copyright: Intel at Hotchips ’00)
Front EndFront End•Pre-fetch/Fetch of up Pre-fetch/Fetch of up to 6 instructions/cycleto 6 instructions/cycle•Hierarchy of branch Hierarchy of branch predictorspredictors•Decoupling bufferDecoupling buffer
Instruction DeliveryInstruction Delivery•Dispersal of up to 6 Dispersal of up to 6 instructions on 9 portsinstructions on 9 ports•Reg. remappingReg. remapping•Reg. stack engineReg. stack engine
Operand DeliveryOperand Delivery• Reg read + Bypasses Reg read + Bypasses • Register scoreboardRegister scoreboard• Predicated Predicated
dependencies dependencies
ExecutionExecution• 4 single cycle ALUs, 2 ld/str4 single cycle ALUs, 2 ld/str• Advanced load control Advanced load control • Predicate delivery & branchPredicate delivery & branch• Nat/Exception/Nat/Exception///RetirementRetirement
IPG FET ROT EXP REN REG EXE DET WRBWL.D
REGISTER READWORD-LINE DECODERENAMEEXPAND
INST POINTER GENERATION
FETCH ROTATE EXCEPTIONDETECT
EXECUTE WRITE-BACK

EENG449b/SavvidesLec 16.22
3/30/04
Itanium processor 10-stage pipeline
• Front-end (stages IPG, Fetch, and Rotate): prefetches up to 32 bytes per clock (2 bundles) into a prefetch buffer, which can hold up to 8 bundles (24 instructions)
– Branch prediction is done using a multilevel adaptive predictor like P6 microarchitecture
• Instruction delivery (stages EXP and REN): distributes up to 6 instructions to the 9 functional units
– Implements registers renaming for both rotation and register stacking.

EENG449b/SavvidesLec 16.23
3/30/04
Itanium processor 10-stage pipeline
• Operand delivery (WLD and REG): accesses register file, performs register bypassing, accesses and updates a register scoreboard, and checks predicate dependences.
– Scoreboard used to detect when individual instructions can proceed, so that a stall of 1 instruction in a bundle need not cause the entire bundle to stall
• Execution (EXE, DET, and WRB): executes instructions through ALUs and load/store units, detects exceptions and posts NaTs, retires instructions and performs write-back

EENG449b/SavvidesLec 16.24
3/30/04 Slide from HP
EENG449b/SavvidesLec 16.25
3/30/04 Slide from HP

EENG449b/SavvidesLec 16.26
3/30/04 Slide from HP

EENG449b/SavvidesLec 16.27
3/30/04 Slide from HP

EENG449b/SavvidesLec 16.28
3/30/04
Comments on Itanium
• Remarkably, the Itanium has many of the features more commonly associated with the dynamically-scheduled pipelines
– strong emphasis on branch prediction, register renaming, scoreboarding, a deep pipeline with many stages before execution (to handle instruction alignment, renaming, etc.), and several stages following execution to handle exception detection
• Surprising that an approach whose goal is to rely on compiler technology and simpler HW seems to be at least as complex as dynamically scheduled processors!

EENG449b/SavvidesLec 16.29
3/30/04
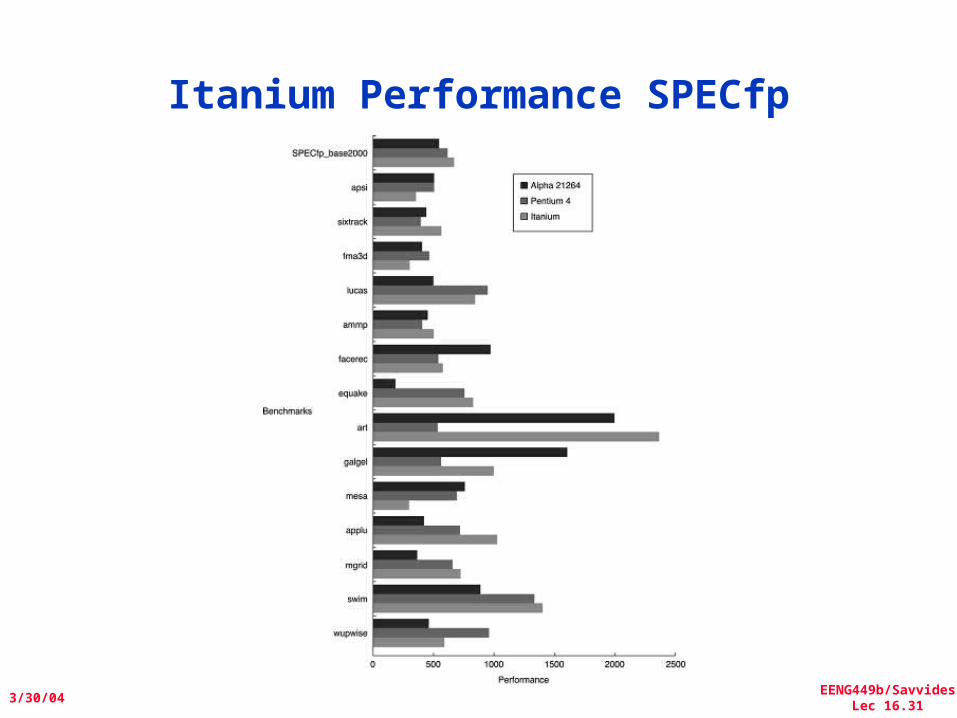
Peformance of IA-64 Itanium?
• Despite the existence of silicon, no significant standard benchmark results are available for the Itanium
• Whether this approach will result in significantly higher performance than other recent processors is unclear
• The clock rate of Itanium (733 MHz) is competitive but slower than the clock rates of several dynamically-scheduled machines, which are already available, including the Pentium III, Pentium 4 and AMD Athlon

EENG449b/SavvidesLec 16.30
3/30/04
Itanium Performace SPECint
EENG449b/SavvidesLec 16.31
3/30/04
Itanium Performance SPECfp
EENG449b/SavvidesLec 16.32
3/30/04
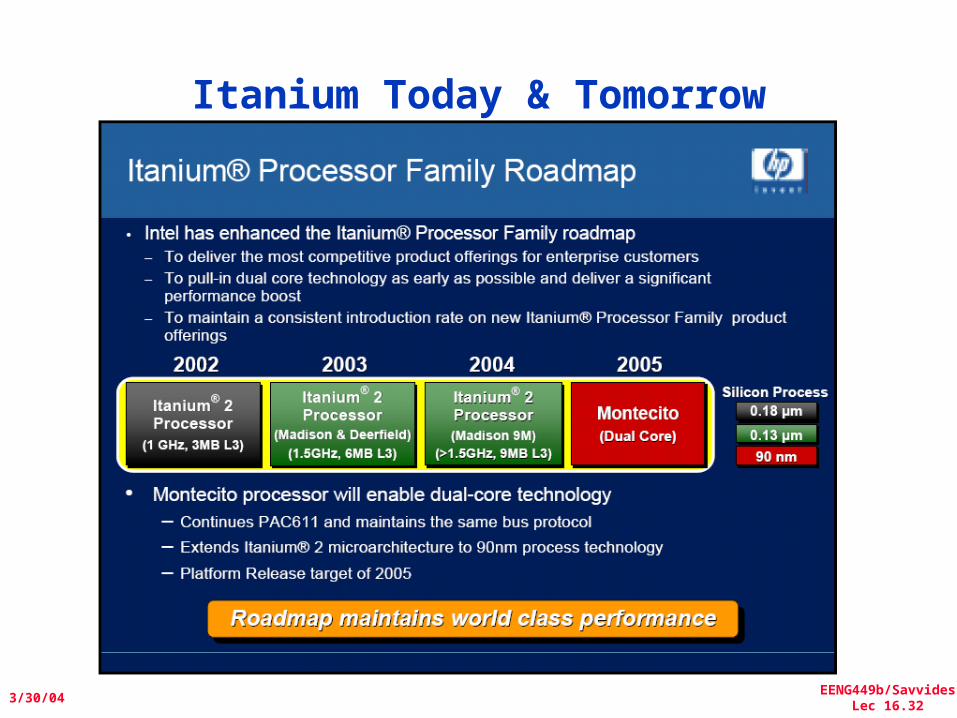
Itanium Today & Tomorrow

EENG449b/SavvidesLec 16.33
3/30/04
VLIW in Embedded Designs
• VLIW: greater parallelism under programmer, compiler control vs. hardware in superscalar
• Used in DSPs, Multimedia processors as well as IA-64
• What about code size?• Effectiveness, Quality of compilers for
these applications?

EENG449b/SavvidesLec 16.34
3/30/04
Example VLIW for multimedia:Philips Trimedia CPU
• Every instruction contains 5 operations • Predicated with single register value;
if 0 => all 5 operations are canceled• 128 64-bit registers, which contain either
integer or floating point data• Partitioned ALU (SIMD) instructions to
compute on multiple instances of narrow data
• Offers both saturating arithmetic (DSPs) and 2’s complement arithmetic (desktop)
• Delayed Branch with 3 branch slots

EENG449b/SavvidesLec 16.42
3/30/04
Transmeta Crusoe MPU
• 80x86 instruction set compatibility through a software system that translates from the x86 instruction set to VLIW instruction set implemented by Crusoe
• VLIW processor designed for the low-power marketplace
• Typical applications– Notebook: Sony, others– Compact Servers: RLX technologies

EENG449b/SavvidesLec 16.43
3/30/04
Crusoe processor: Basics
• VLIW with in-order execution • 64 Integer registers• 32 floating point registers• Simple in-order, 6-stage integer pipeline:
2 fetch stages, 1 decode, 1 register read, 1 execution, and 1 register write-back
• 10-stage pipeline for floating point, which has 4 extra execute stages
• Instructions in 2 sizes: 64 bits (2 ops) and 128 bits (4 ops)

EENG449b/SavvidesLec 16.44
3/30/04
Crusoe processor: Operations
• 5 different types of operation slots:• ALU operations: typical RISC ALU operations• Compute: this slot may specify any integer
ALU operation (2 integer ALUs), a floating point operation, or a multimedia operation
• Memory: a load or store operation• Branch: a branch instruction• Immediate: a 32-bit immediate used by
another operation in this instruction• For 128-bit instr: 1st 3 are Memory,
Compute, ALU; last field either Branch or Immediate

EENG449b/SavvidesLec 16.45
3/30/04
80x86 Compatability
• Initially, and for lowest latency to start execution, the x86 code can be interpreted on an instruction by instruction basis
• If a code segment is executed several times, translated into an equivalent Crusoe code sequence, and the translation is cached
– The unit of translation is at least a basic block, since we know that if any instruction is executed in the block, they will all be executed
– Translating an entire block both improves the translated code quality and reduces the translation overhead, since the translator need only be called once per basic block
• Assumes 16MB of main memory for cache

EENG449b/SavvidesLec 16.46
3/30/04
Exception Behavior during Speculation
• Crusoe support for speculative reordering consists of 4 major parts:
1. shadowed register file– Shadow discarded only when x86 instruction has no
exception
2. program-controlled store buffer– Only store when no exception; keep until OK to store
3. memory alias detection hardware with speculative loads
4. conditional move instruction (called select) that is used to do if-conversion on x86 code sequences

EENG449b/SavvidesLec 16.47
3/30/04
Crusoe Performance?
• Crusoe depends on realistic behavior to tune the code translation process, it will not perform in a predictive manner when benchmarked using simple, but unrealistic scripts
– Needs idle time to translate– Profiling to find hot spots
• To remedy this factor, Transmeta has proposed a new set of benchmark scripts
– Unfortunately, these scripts have not been released and endorsed by either a group of vendors or an independent entity
EENG449b/SavvidesLec 16.48
3/30/04
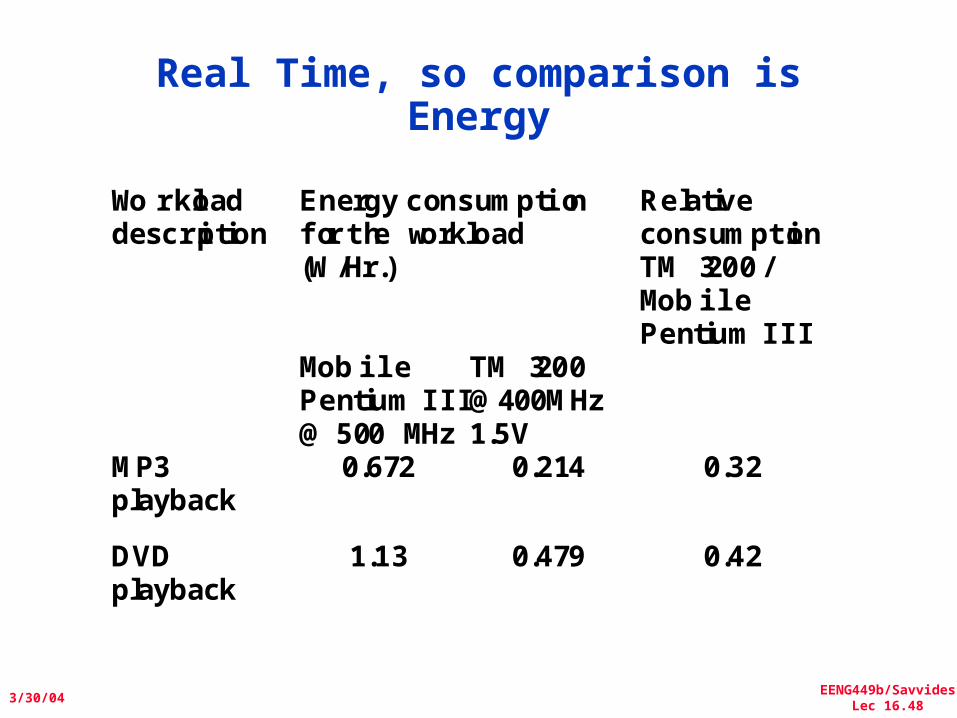
Real Time, so comparison is Energy
Workloaddescription
Energy consumptionfor the workload(W/Hr.)
RelativeconsumptionTM 3200 /MobilePentium III
MobilePentium III@ 500 MHz
MP3playback
0.672 0.214 0.32
DVDplayback
1.13 0.479 0.42

EENG449b/SavvidesLec 16.49
3/30/04
Next Time
• Memory Hierarchies – Chapter 5• Homework 2 due April 20th
• Midterm 2 April 25• Both homework 2 and midterm 2
cover class material from Chapters 3,4 and 5
• Project Presentations during finals week or reading week…





























