Embed Size (px)
Citation preview

EENG449b/SavvidesLec 15.1
3/22/05
March 22, 2005
Prof. Andreas Savvides
Spring 2005
http://www.eng.yale.edu/courses/eeng449b
EENG 449bG/CPSC 439bG Computer Systems
Lecture 15
Instruction Level Parallelism I

EENG449b/SavvidesLec 15.2
3/22/05
Instruction Level Parallelism
• Reading for this lecture: Chapter 3, pages 172 – 192
• Chapter 3: ILP in hardware• Recall
stalls Control stalls hazard Data stalls Structural CPI pipeline Ideal CPI Pipeline
ILP tries to minimize these termsthrough the overlapped execution
of instructions

EENG449b/SavvidesLec 15.3
3/22/05
Recap
• So far we discussed pipelining as a basic form of ILP
• Now we will see some more advanced topics
• Trend: – Dynamic approaches mostly dominate
desktops (hardware implementation)– Static scheduling approaches (Chap. 4)
more popular in embedded systems.

EENG449b/SavvidesLec 15.4
3/22/05
Where is the maximal gain in ILP?
• Basic block – a straight line code sequence with no branches in it except the entry and the exit point
• Limited amount of parallelism within a basic block
– Instructions depend on each other so they cannot be reordered
– In typical MIPS programs dynamic branch frequency between 15 – 25% ( 4 – 7 ) instructions between a pair of branches
• Need to exploit parallelism across multiple basic blocks

EENG449b/SavvidesLec 15.5
3/22/05
Loops : an example for parallelism
for (i=1; i <= 1000; i=i+1)
x[i] = x[i] + y[i];
• Loop iterations can overlap – loop level parallelism
• Main technique – loop unrolling– Can be done either in hardware or software
• So what kind of dependencies do we need to worry about?

EENG449b/SavvidesLec 15.6
3/22/05
Data Dependences & Hazards
• An instruction i is data depended on instruction j if:
– Instruction i produces a result used by instruction j
– Instruction j is data dependent on instruction k, and instruction k is data depended on instruction i

EENG449b/SavvidesLec 15.7
3/22/05
Data Dependences
Data dependencies are properties of programs
Detection of hazards and stalls are properties of the pipeline organization
A dependence can be overcomed by:• Maintaining the dependence and
avoiding the hazard• Transforming the code to eliminate
the dependence

EENG449b/SavvidesLec 15.8
3/22/05
Detecting Data Dependences
• Data values can flow through registers or memory
• Data dependences that flow through registers are easy to detect
– Register names are the same so it is easy to check
– More complicated when branches intervene
• Data dependences are harder to detect in memory
100(R4) and 20(R6) may point to the same memory location!!
Crucial aspect to consider in compiler techniques

EENG449b/SavvidesLec 15.9
3/22/05
Name Dependences
• Name dependence: two instructions use the same register or memory, without any flow of data that is actually associated with that register or memory location
Types of name dependences• Antidependence (WAR) – instruction j writes a
register that instruction i reads• Output dependence (WAW) – instruction i and
instruction j write the same memory location or register
Name dependences are not real dependences • Just change the names – register renaming –
can be done by the hardware or the compiler

EENG449b/SavvidesLec 15.10
3/22/05
Data Hazards & Dependences
Changes the access to the operand ordering
Read After Write (RAW) – j tries to read a source before i writes it – program order must be reserved
Write After Write (WAW) – j tried to write an operand before it is written by i – output dependence. Can only happen in pipelines that write in more than one stage or let an instruction to proceed when another instruction is stalled
Write After Read (WAR) – j tries to write an instruction before it is read by i – antidependence – mostly occurs when instructions write results early in the pipeline, or when instructions are reordered

EENG449b/SavvidesLec 15.11
3/22/05
Control Dependences
• Control dependences control the ordering of instructions with respect to branch instructions
– Instructions should execute in correct program order
– Ex. Should not execute instructions from the then clause of an if statement if not needed
• Control dependence constraints– Instructions control dependent on a branch cannot
be moved before a branch» E.g an instruction from the then component of
a statement cannot be move before the if component
– An instruction that is not control dependent on a branch cannot be moved after the branch so that is execution is depended on the branch

EENG449b/SavvidesLec 15.12
3/22/05
Control Dependence
• Control dependence is not the critical property to preserve
– May be willing to execute extra instructions if that does not compromise program correctness
• Need to preserve– Exception behavior – the way exceptions raise in
a program should not be altered– Data flow – flow of data among instructions that
produce results and those that consume them

EENG449b/SavvidesLec 15.13
3/22/05
Potential Control Hazard Issue
DADDU R1, R2, R3BEQZ R4, LDSUBU R1, R5, R6
L: ….OR R7, R1, R8
R1 in the OR instruction depends on both the ADD and the SUB instruction.
Data dependence is not enough. Data flow must also be preserved.
Speculation will be used to avoid this:• Idea builds on dynamic scheduling concepts.
Bet the outcome of a branch and start executing under the provision that the result could be invalidated.

EENG449b/SavvidesLec 15.14
3/22/05
Dynamic Scheduling
• Statically scheduled pipelines– When a data dependence cannot be hidden with
bypassing or forwarding, the processor stalls until the data is cleared
• Dynamic scheduling– Hardware reorders instructions to reduce the
stalls while maintaining data flow and instruction behavior
• Advantages– Handles dependences not known at compile time
» Simplifies compiler design– Allows code compiled for one pipeline to run
efficiently on another
• Disadvantage – hardware complexity

EENG449b/SavvidesLec 15.15
3/22/05
Dynamic Scheduled Pipelines
• Simple pipelines result in hazards that require stalling.
• Static scheduling – compilers rearrange instructions to avoid stalls.
• Dynamic scheduling – processor executes instructions out-of-order to minimize stalls
• Dynamic scheduling requires splitting the ID stage into stages:
– Issue – Decode instructions, check for structural hazards
– Read operands – Wait until there are no data hazards, then read operands
– Also need to know when each instruction begins and ends execution
• Requires a lot more bookkeeping!

EENG449b/SavvidesLec 15.16
3/22/05
Examples
DIV.D F0, F2, F4ADD.D F10, F0, F8SUB.D F12, F8, F14
• SUB.D cannot execute because of antidependence of ADD.D on DIV.D
• The only reason that SUB.D cannot execute before is the in-order execution requirement
• Split ID stage in 2 parts– Check for stuctural hazards – Check for the absence of data hazards

EENG449b/SavvidesLec 15.17
3/22/05
Lookout for WAR and WAW hazards
DIV.D F0, F2, F4
ADD.D F6, F0, F8
SUB.D F8, F10, F14
MUL.D F6, F10, F8
Both hazards can be avoided with register renaming
Antidependence
Potential WAW Hazard

EENG449b/SavvidesLec 15.18
3/22/05
Preserving Exception Behavior
• Out-of-order completion must also preserve exception behavior.
• No instruction can raise an exception until the processor knows that the instruction will be executed
– Pipeline may have completed instructions that are later in the program order
– Pipeline may have not yet completed instructions earlier in the program that may case exceptions when executed

EENG449b/SavvidesLec 15.19
3/22/05
ID-Stage Changes
• Split the ID stage in two parts
1. Issue – Decode instructions and check for structural hazards
2. Read operands – wait until no data hazards, read operands
Need to distinguish between when an instruction begins execution and when it completes execution.
Pipeline allows instructions to be in execution at the same time – this allows for dynamic optimizations
All instructions enter the issue stage in order, but may bypass each other in the second stage

EENG449b/SavvidesLec 15.20
3/22/05
Scoreboarding
Scoreboarding – a technique that allows out-of-order execution when resources are available and there are no data dependencies – originated in CDC6600 in the mid 60s.
• Scoreboard fully responsible for instruction execution and hazard detection
– Requires changes in # of functional units and latency of operations
– Needs to keep track of status of all instructions in execution

EENG449b/SavvidesLec 15.21
3/22/05
Scoreboarding II

EENG449b/SavvidesLec 15.22
3/22/05
Tomasulo’s Algorithm
• Hardware based technique for ILP– Tracks when operands are available to avoid
RAW hazards– Introduces register renaming to avoid WAW and
WAR hazards» What does this mean?
• More sophisticated approach than the scoreboard from Appendix A
• Initially designed for the IBM 360/91– Designed in the late 60s– Scoreboarding + register renaming– 4 FP registers, long memory access delays, long
FP times – compiler level optimizations were limited

EENG449b/SavvidesLec 15.23
3/22/05
Register Renaming
DIV.D F0, F2, F4
ADD.D F6, F0, F8
S.D F6, 0(R1)
SUB.D F8, F10, F14
MUL.D F6, F10, F8
Where is the antidependence (WAR)?

EENG449b/SavvidesLec 15.24
3/22/05
Register Renaming
DIV.D F0, F2, F4
ADD.D F6, F0, F8
S.D F6, 0(R1)
SUB.D F8, F10, F14
MUL.D F6, F10, F8
Where is the output dependence (WAW)?

EENG449b/SavvidesLec 15.25
3/22/05
Register Renaming
DIV.D F0, F2, F4
ADD.D F6, F0, F8
S.D F6, 0(R1)
SUB.D F8, F10, F14
MUL.D F6, F10, F8
Where are the true data dependences (RAW)?

EENG449b/SavvidesLec 15.26
3/22/05
Getting Rid of Name Dependencies
• Assume we have 2 temporary registers S and T the code sequence can be re-written as:
DIV.D F0, F2, F4 DIV.D F0, F2, F4ADD.D F6, F0, F8 ADD.D S, F0, F8S.D F6, 0(R1) S.D S, 0(R1)SUB.D F8, F10, F14 SUB.D T, F10, F14MUL.D F6, F10, F8 MUL.D F6, F10, T
• Any subsequent uses of F8 should be replaced with register T
– Requires sophisticated compiler analysis since intervening branches may change the meaning of F8
– Tomasulo’s algorithm can handle renaming across branches

EENG449b/SavvidesLec 15.27
3/22/05
Tomasulo’s Scheme for Avoiding Name Dependences
• Use Reservation Stations & Issue Logic– Buffer the operands of instructions waiting to issue– Buffers the operand as soon as it is available,
eliminating the need to get an operand from a register
– Operands are renamed to the names of the reservation station, avoiding register name conflicts
– There are more reservation stations than registers» Eliminates more hazards than the compiler
• Pending instructions designate the reservation station that will provide their input

EENG449b/SavvidesLec 15.28
3/22/05
Advantages of Tomasulo’s Algorithm
• Hazard Detection and Execution Control are distributed
– The information held in each functional unit will determine when an instruction is ready to execute
• Reservation stations buffer pass the results directly to functional units
– Do not have to go through registers

EENG449b/SavvidesLec 15.29
3/22/05
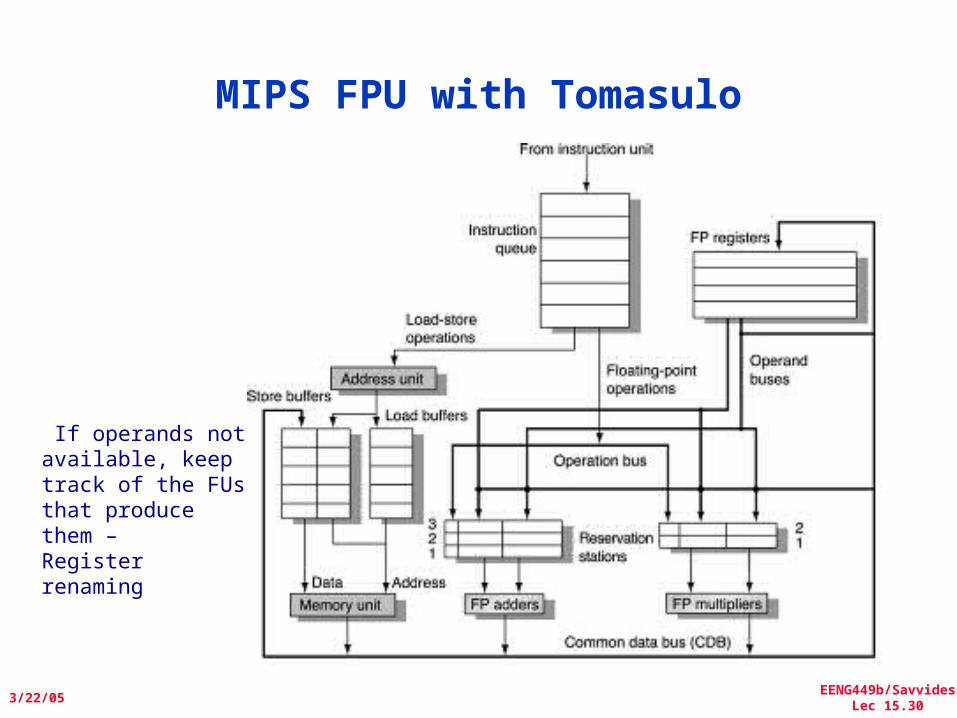
MIPS FPU with Tomasulo
Issue: In order instructions to Preserve correct data flow• If there is an empty reservation station issue the instruction with operands• Else stall –stuctural hazard
EENG449b/SavvidesLec 15.30
3/22/05
MIPS FPU with Tomasulo
If operands not available, keep track of the FUs that produce them –Register renaming

EENG449b/SavvidesLec 15.31
3/22/05
MIPS FPU with Tomasulo
All the results are made available on CDC that goes everywhere.
All reservation stations have tag fields controlled bythe pipeline control

EENG449b/SavvidesLec 15.32
3/22/05
An Instruction goes through 3 basic steps
1. Issue – described in the previous slide• Instructions are issued in order from the
instruction FIFO• If there is an empty reservation station for that
operation, issue the instruction and operands to the reservation station.
• If there is no reservation station available, stall and wait for one
• If the operands are not in the registers, track the operational units that will produce the result.

EENG449b/SavvidesLec 15.33
3/22/05
Step 22. Execute – Operands placed in the
reservation tables as they become available
When all operands available the instruction is executed- this execution delay eliminates RAW hazards
Loads and stores have 2 execution steps1. Compute the effective address and place in load or store buffer2. Execute as soon as memory unit is available
No instruction is executed until all preceding branches have been determined to preserve exception behavior
• This prevents the occurrence of exceptions • Exceptions get generated only if commands
will execute.• Next lecture we will discuss speculation for
more efficient handling of branches

EENG449b/SavvidesLec 15.34
3/22/05
Step 3
3. Write result – Results written on common data bus (CDB)
» End up in corresponding registers and reservation tables
– Write data to memory also happens at this step

EENG449b/SavvidesLec 15.35
3/22/05
Things to note about Tomasulo’s Scheme
• Data structures to detect and eliminate hazards are attached to:
– Reservation stations– Register file– Load and store buffers
• Reservation stations act as a set of virtual registers
– More than FP registers so register renaming is possible

EENG449b/SavvidesLec 15.36
3/22/05
Reservation Table Fields
To track the state of the algorithm:• Op – operation to perform on source operands• Qj, Qk – the reservation stations that will
produce the operand• Vj, Vk – The value of the source operands• A – holds information on the memory address
calculation (immediate and address calculation are stored here)
• Busy – Reservation station and its accompanying functional unit is busy
The register file also contains a field• Qi – The number of the reservation station
that contains the value that should be stored in this register

EENG449b/SavvidesLec 15.37
3/22/05
Tomasulo Algorithm Example
L.D F6, 34(R2)
L.D F2, 45(R3)
MUL.D F0, F2, F4
SUB.D F8, F2, F6
DIV.D F10, F0, F6
ADD.D F6, F8, F2

EENG449b/SavvidesLec 15.38
3/22/05

EENG449b/SavvidesLec 15.39
3/22/05
Tomasulo’s Advantages
• No checking needed for WAR or WAW as registers are renamed
• Hazard detection logic is distributed • Loads and stores are treated as basic
functional units• Has larger register sets – reservation
tables• Exploits ILP well but requires more
complex hardware than scoreboarding

EENG449b/SavvidesLec 15.40
3/22/05
Next Lecture
• Tomasulo Algorithm Details• Speculation





























