Embed Size (px)
Citation preview

EECC722 - ShaabanEECC722 - Shaaban#1 lec # 10 Fall 2006 10-25-2006
Data/Thread Level Speculation(TLS) in the Stanford Hydra Chip Multiprocessor (CMP)
Hydra ia a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software support for Data/Thread Level Speculation (TLS) to extract parallel speculated threads from sequential code (single thread) augmented with software thread speculation handlers.
(Primary Hydra papers: 4, 6)
Stanford Hydra, discussed here, is one TLS architecture example.Other TLS Architectures include:
- Wisconsin Multiscalar- Carnegie-Mellon Stampede- MIT M-machine

EECC722 - ShaabanEECC722 - Shaaban#2 lec # 10 Fall 2006 10-25-2006
Motivation for Chip Multiprocessors (CMPs)• Chip Multiprocessors (CMPs) offers implementation benefits:
– High-speed signals are localized in individual CPUs– A proven CPU design is replicated across the die (including SMT
processors, e.g IBM Power 5)
• Overcomes diminishing performance/transistor return problem (limited-ILP) in single-threaded superscalar processors (similar motivation for SMT)– Transistors are used today mostly for ILP extraction– CMPs use transistors to run multiple threads (exploit thread level
parallelism, TLP):• On parallelized (multi-threaded) programs• With multi-programmed workloads (multi-tasking)
– A number of single-threaded applications executing on different CPUs
• Fast inter-processor communication eases parallelization of code (Using shared L2 cache)
• Potential Drawback of CMPs: High power/heat issues using current VLSI processes.
But slower than logical processor communication in SMT
Results in reduced CMP clock rate

EECC722 - ShaabanEECC722 - Shaaban#3 lec # 10 Fall 2006 10-25-2006
Stanford Hydra CMP Approach Goals• Exploit all levels of program parallelism.
• Develop a single-chip multiprocessor architecture that simplifies microprocessor design and achieves high performance.
• Make the multiprocessor transparent to the average user.
• Integrate use of parallelizing compiler technology in the design of microarchitecture that supports data/thread level speculation (TLS).
Within a single CPU core
On multiple CPU cores withina single CMP or multiple CMPs
On multiple CPU cores withina single CMP using Thread LevelSpeculation (TLS)
CoarseGrain
FineGrain

EECC722 - ShaabanEECC722 - Shaaban#4 lec # 10 Fall 2006 10-25-2006
Hydra Prototype Overview
• 4 CPU cores with modified private L1 caches.• Speculative coprocessor (for each processor core)
– Speculative memory reference controller– Speculative interrupt screening mechanism– Statistics mechanisms for performance evaluation and to
allow feedback for code tuning• Memory system
– Read and write buses– Controllers for all resources– On-chip shared L2 cache– L2 Speculation write buffers.– Simple off-chip main memory controller– I/O and debugging interface
EECC722 - ShaabanEECC722 - Shaaban#5 lec # 10 Fall 2006 10-25-2006
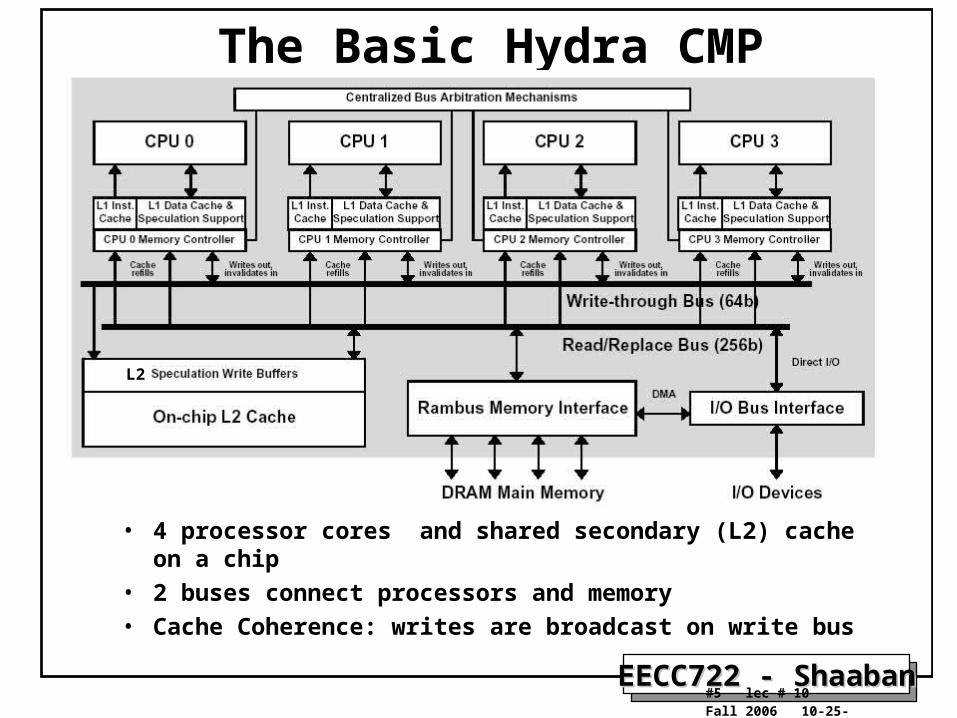
The Basic Hydra CMP
• 4 processor cores and shared secondary (L2) cache on a chip
• 2 buses connect processors and memory
• Cache Coherence: writes are broadcast on write bus
L2
EECC722 - ShaabanEECC722 - Shaaban#6 lec # 10 Fall 2006 10-25-2006
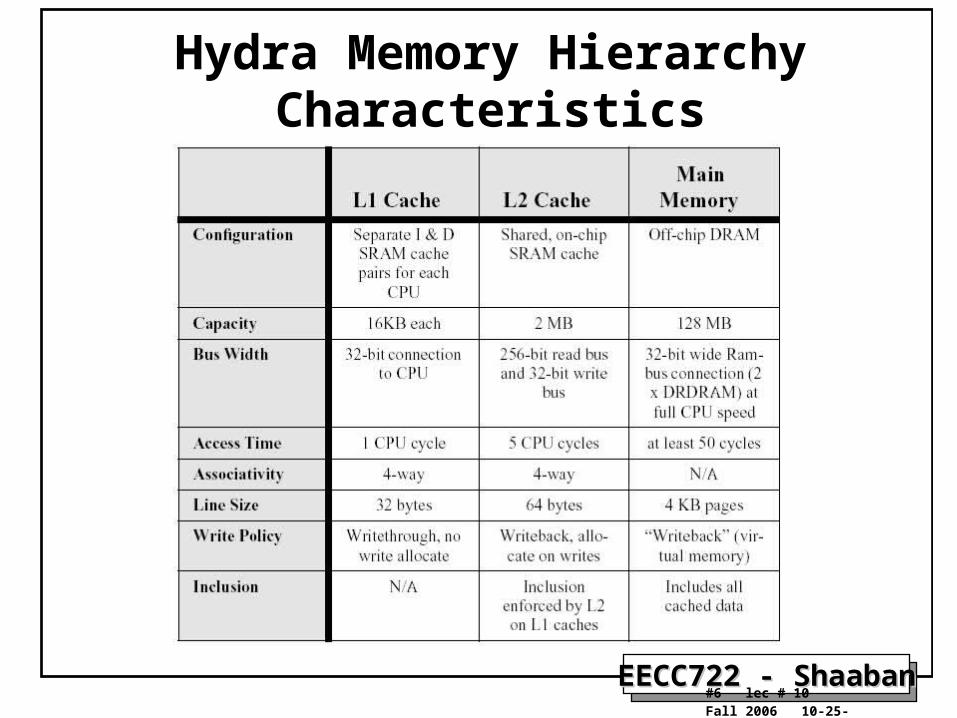
Hydra Memory Hierarchy Characteristics

EECC722 - ShaabanEECC722 - Shaaban#7 lec # 10 Fall 2006 10-25-2006
Hydra Prototype Layout
250 MHz clock rate target
SharedL2
L2SpeculationWriteBuffers
Circa ~ 1999
D-L1
D-L1 D-L1
D-L1
I-L1 I-L1
I-L1 I-L1
PrivateSplitL1 cachesPer core
EECC722 - ShaabanEECC722 - Shaaban#8 lec # 10 Fall 2006 10-25-2006
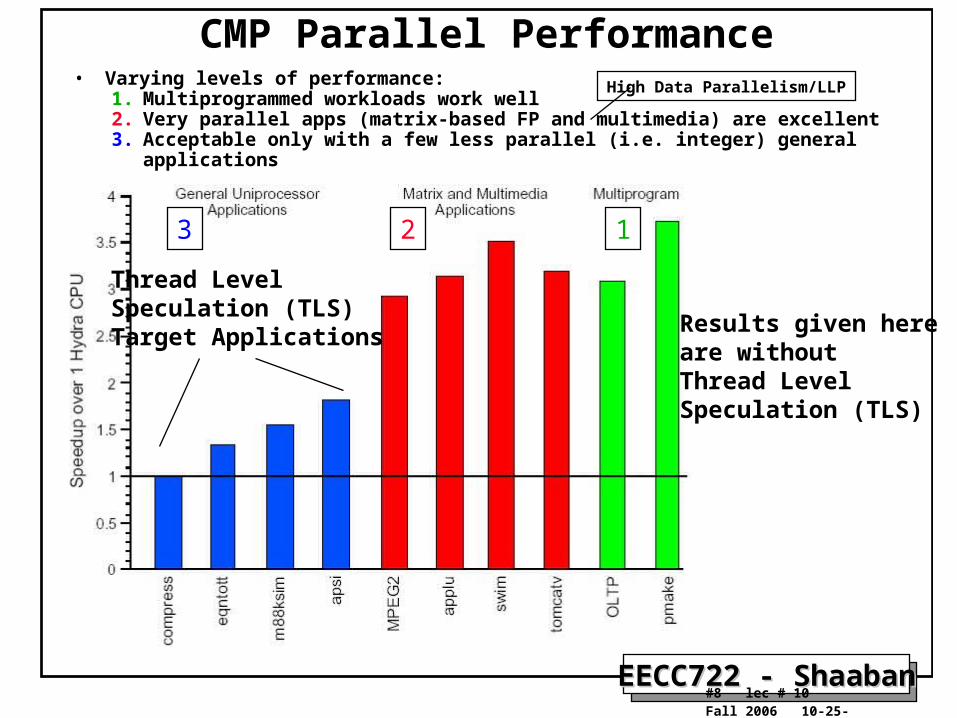
CMP Parallel Performance• Varying levels of performance:
1. Multiprogrammed workloads work well2. Very parallel apps (matrix-based FP and multimedia) are excellent3. Acceptable only with a few less parallel (i.e. integer) general applications
Results given here are withoutThread LevelSpeculation (TLS)
Thread LevelSpeculation (TLS)Target Applications
High Data Parallelism/LLP
3 2 1

EECC722 - ShaabanEECC722 - Shaaban#9 lec # 10 Fall 2006 10-25-2006
The Parallelization Problem • Current automated parallelization software (parallel compilers) is limited
– Parallel compilers are generally successful for scientific applications with statically known dependencies (e.g dense matrix computations).
– Automated parallization of general-purpose applications provides poor parallel performance especially for integer applications due to ambiguous dependencies resulting from:
• Significant pointer use: Pointer aliasing (Pointer disambiguation problem)• Dynamic loop limits• Complex control flow• Irregular array accesses • Inter-procedural dependencies
– Ambiguous dependencies limit extracted parallelism/performance:• Complicate static dependency analysis• Introduce imprecision into dependence relations • Force conservative performance-degrading synchronization to safely handle potential dependencies.
Parallelism may exist in algorithm, but code hides it.
• Manual parallelization can provide good performance on a much wider range of applications:
– Requires different initial program design/data structures/algorithms– Programmers with additional skills.– Handling ambiguous dependencies present in general-purpose applications may still force
conservative synchronization greatly limiting parallel performance
• Can hardware help the situation?
High Data Parallelism/LLP
Hardware Supported Thread Level Speculation

EECC722 - ShaabanEECC722 - Shaaban#10 lec # 10 Fall 2006 10-25-2006
Possible Limited Parallel Software Solution:Data Speculation &
Thread Level Speculation (TLS)• Data speculation and Thread Level Speculation (TLS)
enable parallelization without regard for data dependencies– Normal sequential program is broken up into speculative threads– Speculative threads are now run in parallel on multiple physical CPUs (e.g. CMP)
and/or logical CPUs (e.g. SMT). – Speculation hardware (TLS processor) architecture ensures correctness
• Parallel software implications– Loop parallelization is now easily automated– Ambiguous dependencies resolved dynamically without conservative
synchronization – More “arbitrary” threads are possible (subroutines)– Add synchronization only for performance
• Thread Level Speculation (TLS) hardware support mechanisms– Speculative thread control mechanism– Five basic speculation hardware/memory system requirements for correct
data/thread speculation
e.g Speculative thread creation, restart, termination ..
Given later in slide 21
EECC722 - ShaabanEECC722 - Shaaban#11 lec # 10 Fall 2006 10-25-2006
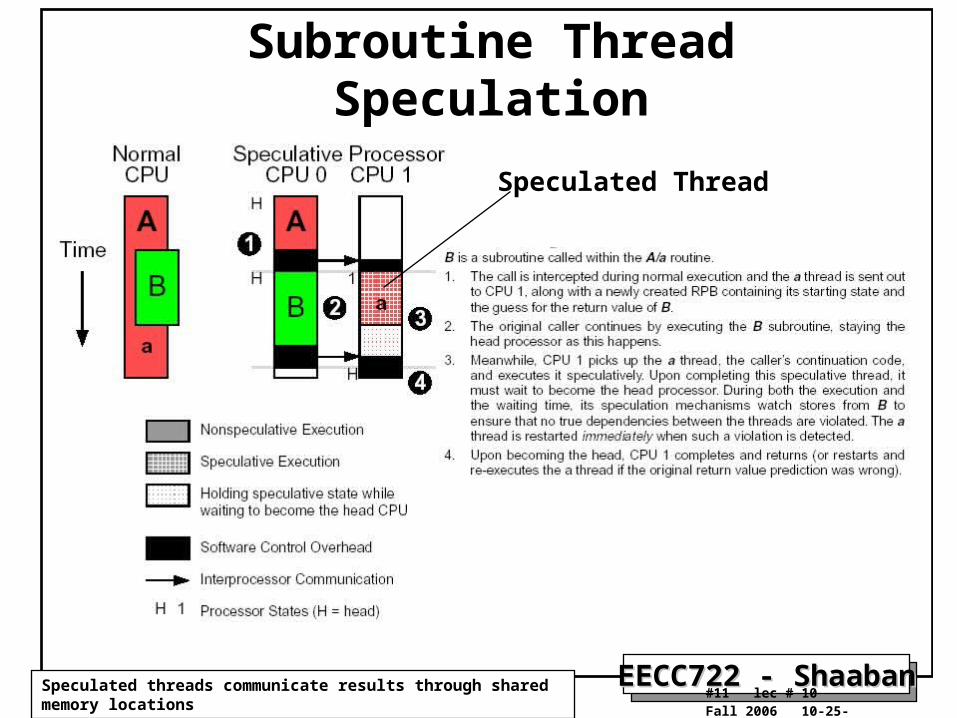
Subroutine Thread Speculation
Speculated Thread
Speculated threads communicate results through shared memory locations
EECC722 - ShaabanEECC722 - Shaaban#12 lec # 10 Fall 2006 10-25-2006
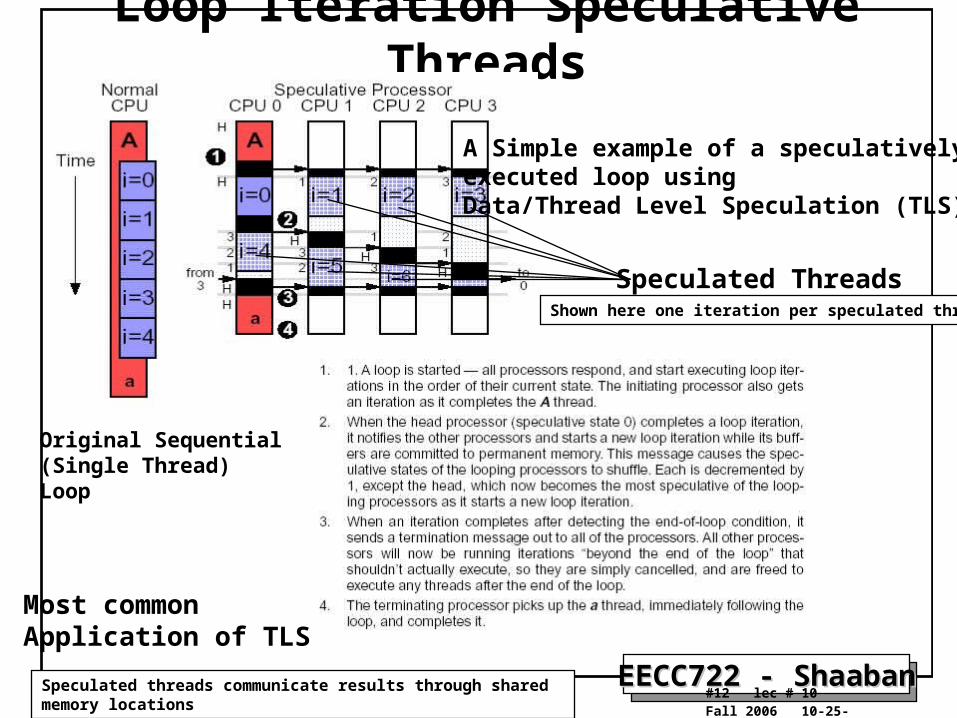
Loop Iteration Speculative Threads
A Simple example of a speculatively executed loop usingData/Thread Level Speculation (TLS)
Original Sequential(Single Thread)Loop
Speculated Threads
Most commonApplication of TLS
Shown here one iteration per speculated thread
Speculated threads communicate results through shared memory locations
EECC722 - ShaabanEECC722 - Shaaban#13 lec # 10 Fall 2006 10-25-2006
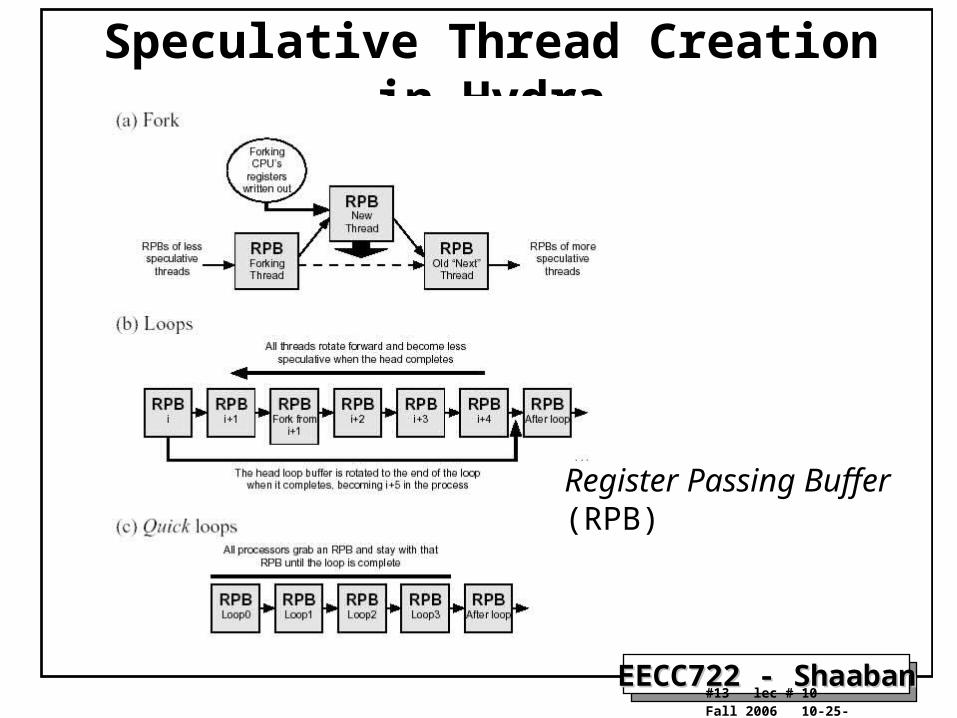
Speculative Thread Creation in Hydra
Register Passing Buffer(RPB)

EECC722 - ShaabanEECC722 - Shaaban#14 lec # 10 Fall 2006 10-25-2006
Hydra’s Data & Thread Speculation Operations
Speculated threadsmust commit results in order

EECC722 - ShaabanEECC722 - Shaaban#15 lec # 10 Fall 2006 10-25-2006
Hydra Loop Compiling for SpeculationHydra Loop Compiling for Speculation
CreateSpeculatedThreads

EECC722 - ShaabanEECC722 - Shaaban#16 lec # 10 Fall 2006 10-25-2006
Overview of Loop-Iteration Thread Speculation• Parallel regions (loop iterations) are annotated by the compiler.
– e.g. Begin_Speculation … End_Speculation
• The hardware uses these annotations to run loop iterations in parallel as speculated threads on a number of CPU cores.
• Each CPU core knows which loop iteration it is running.
• CPUs dynamically prevent data/name dependency violations:– “later” iterations can’t use data before write by “earlier” iterations
(Prevent data dependency violation, RAW hazard)– “earlier” iterations never see writes by “later” iterations (WAW, WAR
hazards prevented): • Multiple views of memory are created by TLS hardware
• If a “later” iteration (more speculated thread) has used data that an “earlier” iteration (less speculated thread) writes before data is actually written (data dependency violation, RAW hazard), the later iteration is restarted– All following iterations are halted and restarted, also.– All writes by the later iteration are discarded (undo speculated work).
Memory Renaming
A later iteration is assigned a more speculated thread
Speculated threads communicate results through shared memory locations
How?
EECC722 - ShaabanEECC722 - Shaaban#17 lec # 10 Fall 2006 10-25-2006
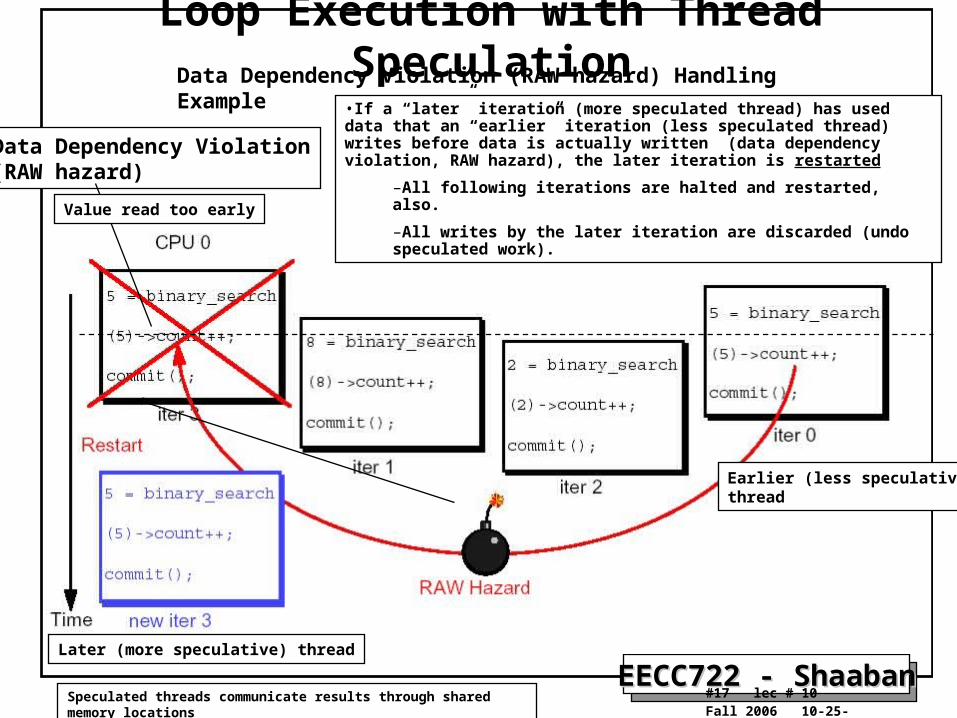
Loop Execution with Thread Speculation
Data Dependency Violation(RAW hazard)
Data Dependency Violation (RAW hazard) Handling Example
•If a “later” iteration (more speculated thread) has used data that an “earlier” iteration (less speculated thread) writes before data is actually written (data dependency violation, RAW hazard), the later iteration is restarted
–All following iterations are halted and restarted, also.
–All writes by the later iteration are discarded (undo speculated work).Value read too early
Earlier (less speculative)thread
Later (more speculative) thread
Speculated threads communicate results through shared memory locations
EECC722 - ShaabanEECC722 - Shaaban#18 lec # 10 Fall 2006 10-25-2006
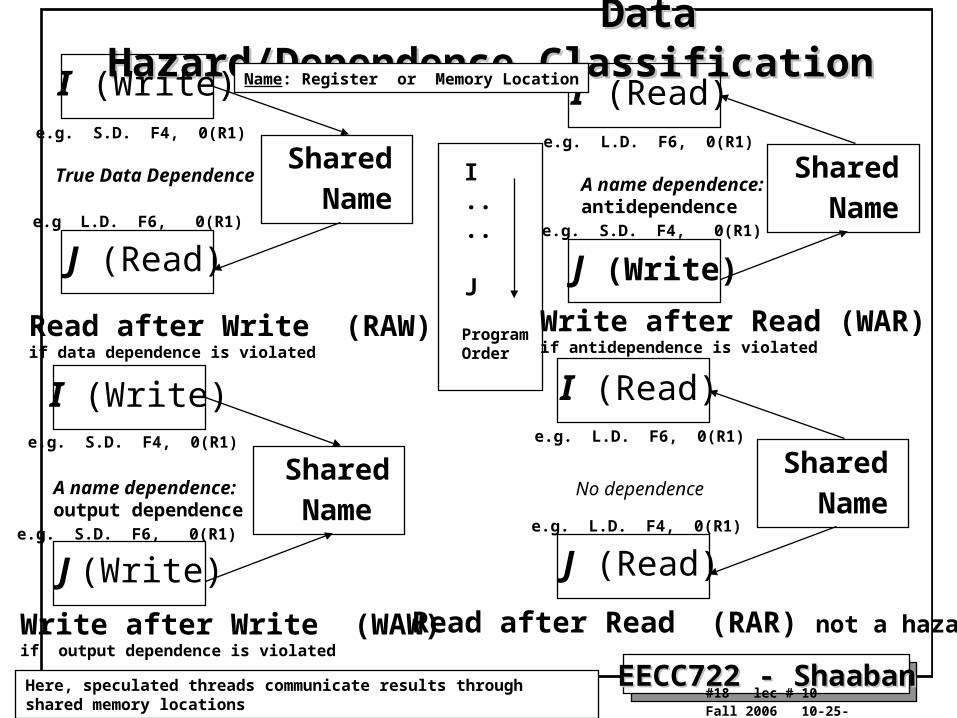
Data Hazard/Dependence ClassificationData Hazard/Dependence ClassificationI (Write)
Shared Name
J (Read)
Read after Write (RAW)if data dependence is violated
I (Read)
Shared Name
J (Write)
Write after Read (WAR)if antidependence is violated
I (Read)
Shared Name
J (Read)
Read after Read (RAR) not a hazard
I (Write)
Shared Name
J (Write)
Write after Write (WAW)if output dependence is violated
A name dependence:output dependence
A name dependence:antidependence
I....
J
ProgramOrder
No dependence
True Data Dependence
Name: Register or Memory Location
e.g. S.D. F4, 0(R1)
e.g L.D. F6, 0(R1)
e.g. S.D. F4, 0(R1)
e.g. S.D. F6, 0(R1)
e.g. L.D. F6, 0(R1)
e.g. S.D. F4, 0(R1)
e.g. L.D. F6, 0(R1)
e.g. L.D. F4, 0(R1)
Here, speculated threads communicate results through shared memory locations

EECC722 - ShaabanEECC722 - Shaaban#19 lec # 10 Fall 2006 10-25-2006
Speculative Data Access in Speculated Threads i Less Speculated thread i+1 More speculated thread
WAR
RAW
WAW
i
i+1
Write by i+1Not seen by i
Access in correct program order to same memory location i before i+1
Reversed access order to same memory locationi+1 before i
Speculated threads communicate results through shared memory locations
DataDep. violation

EECC722 - ShaabanEECC722 - Shaaban#20 lec # 10 Fall 2006 10-25-2006
To provide the desired memory behavior, the data/thread
speculation hardware must provide:
1. A method for detecting true memory dependencies, in order to determine when a dependency has been violated (RAW hazard).
2. A method for backing up and re-executing speculative loads and any instructions that may be dependent upon them when the load causes a violation.
3. A method for buffering any data written during a speculative region of a program so that it may be discarded when a violation occurs or permanently committed at the right time.
Speculative Data Access in Speculated Threads
i.e RAW hazard
i.e when thread is no longer speculated and in correct program order

EECC722 - ShaabanEECC722 - Shaaban#21 lec # 10 Fall 2006 10-25-2006
Five Basic Speculation Hardware Requirements For Correct Data/Thread Speculation
1. Forward data between parallel threads (Prevent RAW). A speculative system must be able to forward shared data quickly and efficiently from an earlier thread running on one processor to a later thread running on another.
2. Detect when reads occur too early (RAW hazard occurred ). If a data value is read by a later thread and subsequently written by an earlier thread, the hardware must notice that the read retrieved incorrect data since a true dependence violation (RAW hazard) has occurred.
3. Safely discard speculative state after violations (RAW hazards). All speculative changes to the machine state must be discarded after a violation, while no permanent machine state may be lost in the process.
4. Retire speculative writes in the correct order (Prevent WAW hazards). Once speculative threads have completed successfully (no longer speculative) , their state must be added (committed) to the permanent state of the machine in the correct program order, considering the original sequencing of the threads.
5. Provide memory renaming (Prevent WAR hazards). The speculative hardware must ensure that the older thread cannot “see” any changes made by later threads, as these would not have occurred yet in the original sequential program. (i.g. Multiple views of memory)
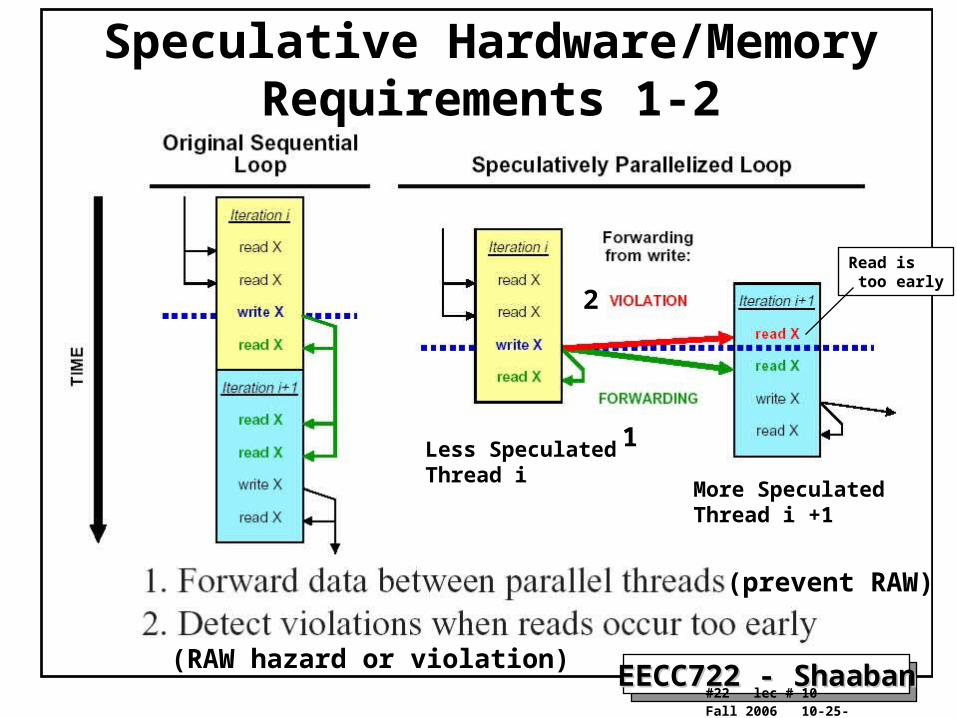
EECC722 - ShaabanEECC722 - Shaaban#22 lec # 10 Fall 2006 10-25-2006
Speculative Hardware/Memory Requirements 1-2
(prevent RAW)
(RAW hazard or violation)
1
2
More SpeculatedThread i +1
Read is too early
Less SpeculatedThread i
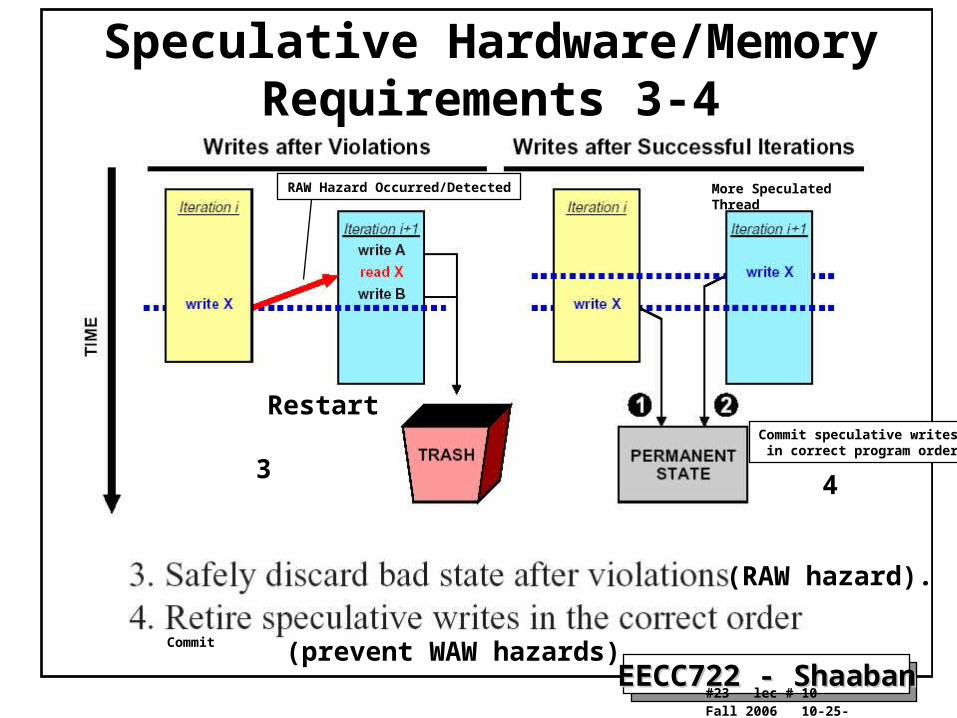
EECC722 - ShaabanEECC722 - Shaaban#23 lec # 10 Fall 2006 10-25-2006
Speculative Hardware/Memory Requirements 3-4
(RAW hazard).
(prevent WAW hazards)
Restart
34
More Speculated ThreadRAW Hazard Occurred/Detected
Commit speculative writes in correct program order
Commit
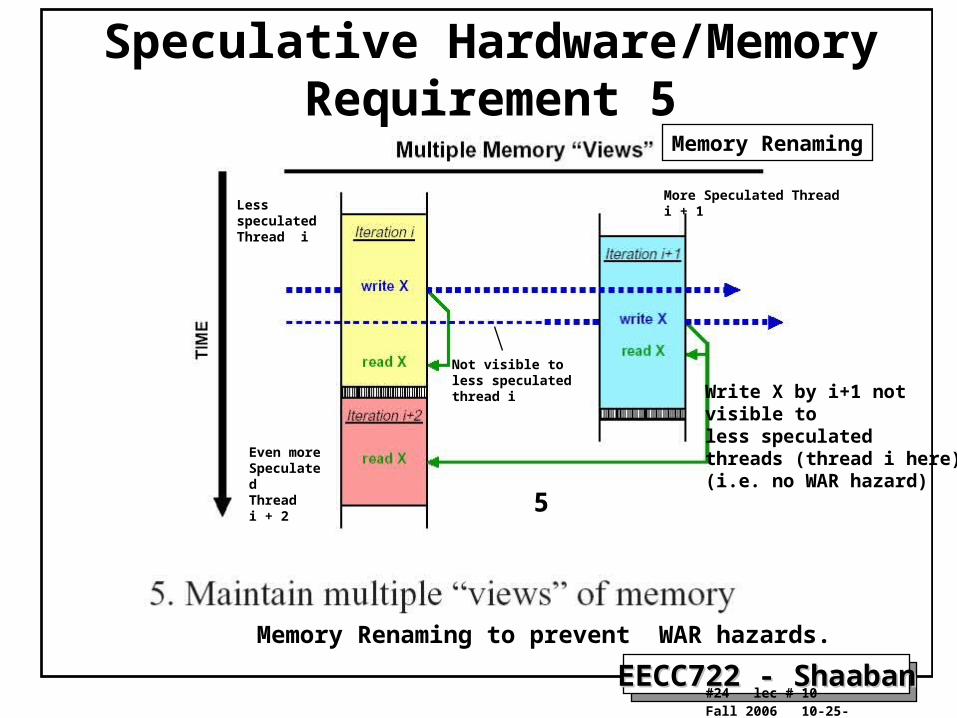
EECC722 - ShaabanEECC722 - Shaaban#24 lec # 10 Fall 2006 10-25-2006
Speculative Hardware/Memory Requirement 5
Memory Renaming to prevent WAR hazards.
Write X by i+1 not visible toless speculatedthreads (thread i here)(i.e. no WAR hazard)
Lessspeculated Thread i
More Speculated Thread i + 1
Even more Speculated Threadi + 2
Not visible to less speculated thread i
5
Memory Renaming

EECC722 - ShaabanEECC722 - Shaaban#25 lec # 10 Fall 2006 10-25-2006
Hydra Thread Level Speculation (TLS) Hardware
SpeculationCoprocessor
L2 CacheSpeculationWrite Buffers(one per core)
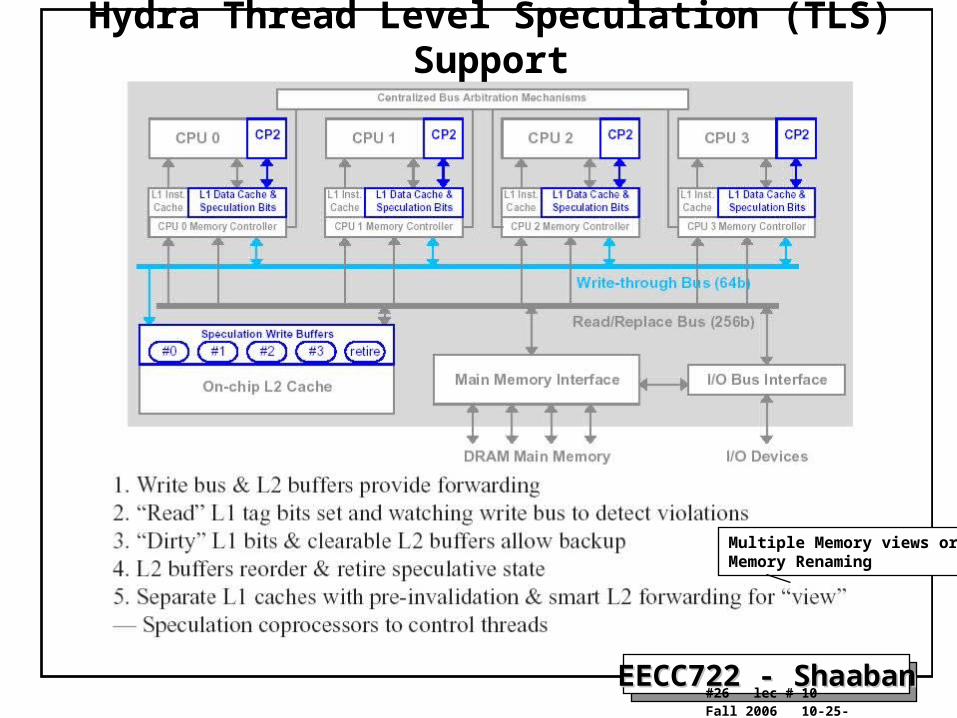
EECC722 - ShaabanEECC722 - Shaaban#26 lec # 10 Fall 2006 10-25-2006
Hydra Thread Level Speculation (TLS) Support
Multiple Memory views orMemory Renaming

EECC722 - ShaabanEECC722 - Shaaban#27 lec # 10 Fall 2006 10-25-2006
L1 Cache Tag Details
- Record writes of more speculated threads

EECC722 - ShaabanEECC722 - Shaaban#28 lec # 10 Fall 2006 10-25-2006
L2 Speculation Write Buffer Details
L2 speculation write buffers committed in L2 (which holds permanent non-speculative state ) in correct program order (when no longer speculative)
To prevent WAW hazards(basic requirement 5)

EECC722 - ShaabanEECC722 - Shaaban#29 lec # 10 Fall 2006 10-25-2006
The Operation of Speculative Loads
Check First On L1 miss
Check L2 Last
On local Data L1 Miss:Do Not Check: More Speculated Later writes not visible (otherwise WAR)
LessSpeculative
MoreSpeculative
L1On local Data L1 Miss:First, check own and then less speculated (earlier) Write buffers then L2 cache
This operation of speculative loads provides multiple memory views (memory renaming) where more speculative writes are not visible to less speculative threads which prevents WAR hazards (This satisfies basic speculative hardware/Memory requirement 4) and satisfies data dependencies (Requirement 1)
EECC722 - ShaabanEECC722 - Shaaban#30 lec # 10 Fall 2006 10-25-2006
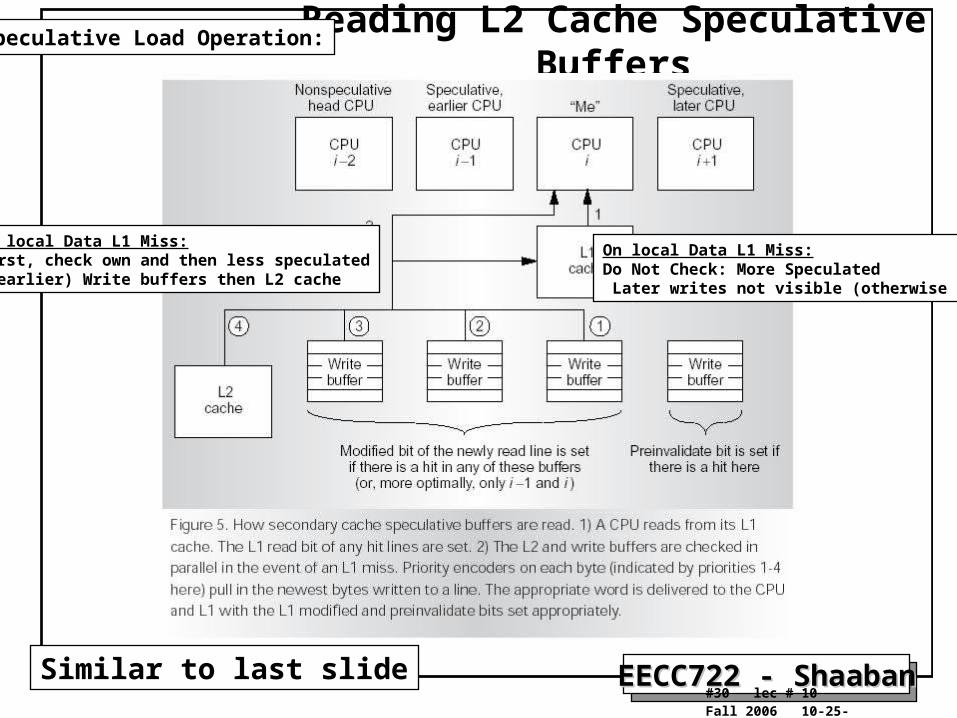
Reading L2 Cache Speculative Buffers
Similar to last slide
On local Data L1 Miss:First, check own and then less speculated (earlier) Write buffers then L2 cache
On local Data L1 Miss:Do Not Check: More Speculated Later writes not visible (otherwise WAR)
Speculative Load Operation:
EECC722 - ShaabanEECC722 - Shaaban#31 lec # 10 Fall 2006 10-25-2006
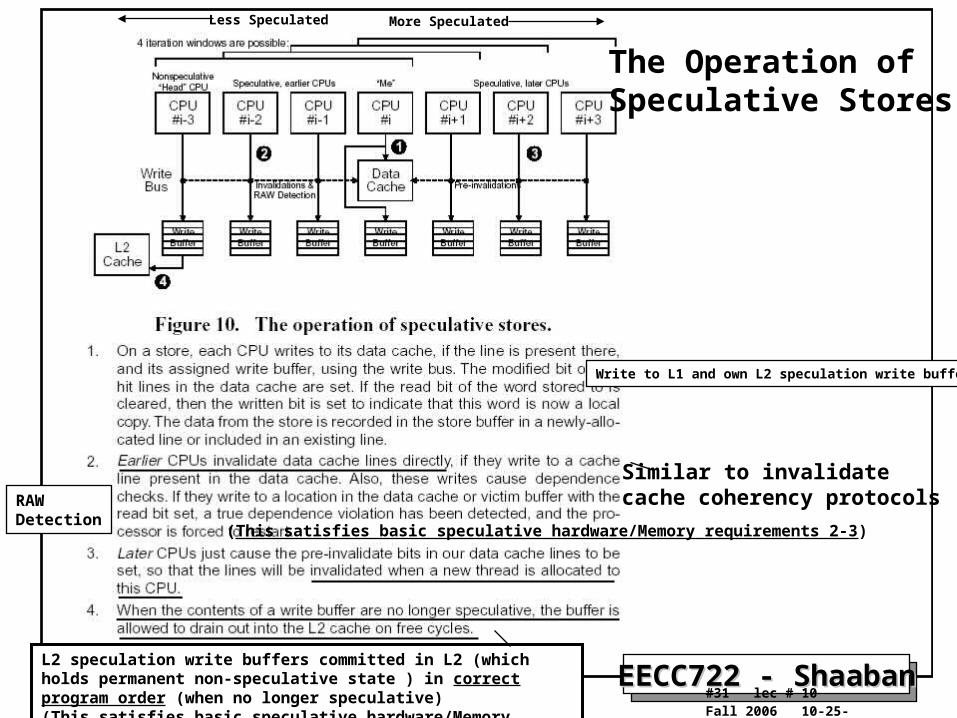
The Operation of Speculative Stores
Less Speculated More Speculated
Similar to invalidatecache coherency protocolsRAW
Detection
L2 speculation write buffers committed in L2 (which holds permanent non-speculative state ) in correct program order (when no longer speculative)(This satisfies basic speculative hardware/Memory requirement 5)
Write to L1 and own L2 speculation write buffer
(This satisfies basic speculative hardware/Memory requirements 2-3)

EECC722 - ShaabanEECC722 - Shaaban#32 lec # 10 Fall 2006 10-25-2006
Hydra’s Handling of Five Basic Speculation Hardware
Requirements For Correct Data/Thread Speculation 1. Forward data between parallel threads (RAW).
– When a speculative thread writes data over the write bus, all more-speculative threads that may need the data have their current copy of that cache line invalidated.
– This is similar to the way the system works during non-speculative operation (invalidate cache coherency protocol).
– If any of the threads subsequently need the new speculative data forwarded to them, they will miss in their primary cache and access the secondary cache.
• The speculative data contained in the write buffers of the current or older threads replaces data returned from the secondary cache on a byte-by-byte basis just before the composite line is returned to the processor and primary cache.
SpeculativeLoad
As seen earlierin slides 29-30
And own L2 write buffer and less speculated L2 buffers
In primary cache (Data L1 cache)

EECC722 - ShaabanEECC722 - Shaaban#33 lec # 10 Fall 2006 10-25-2006
2. Detect when reads occur too early (Detect RAW hazards). – Primary cache (Data L1) read bits are set to mark any reads that may
cause violations. – Subsequently, if a write to that address from an earlier thread (less
speculated) invalidates the address, a violation is detected, and the thread is restarted.
3. Safely discard speculative state after violations.– Since all permanent machine state in Hydra is always maintained
within the secondary cache, anything in the primary caches and secondary cache speculation buffers may be invalidated at any time without risking a loss of permanent state.
• As a result, any lines in the primary cache containing speculative data (marked with a special modified bit) may simply be invalidated all at once to clear any speculative state from a primary cache.
• In parallel with this operation, the secondary cache buffer for the thread may be emptied to discard any speculative data written by the thread.
Hydra’s Handling of Five Basic Speculation Hardware
Requirements For Correct Data/Thread Speculation
RAW hazards

EECC722 - ShaabanEECC722 - Shaaban#34 lec # 10 Fall 2006 10-25-2006
4. Retire speculative writes in the correct order (Prevent WAW hazards).– Separate secondary cache speculation buffers are maintained for each thread. As long as
these are drained (committed) into the secondary cache in the original program sequence of the threads, they will reorder speculative memory references correctly.
5. Provide memory renaming (Prevent WAR hazards). – Each processor can only read data written by itself or earlier threads (less speculated
threads) when reading its own primary cache or the secondary cache speculation buffers.– Writes from later (more speculative) threads don’t cause immediate invalidations in the
primary cache, since these writes should not be visible to earlier (less speculative) threads. – However, these “ignored” invalidations are recorded using an additional pre-invalidate
primary cache bit associated with each line. This is because they must be processed before a different speculative or non-speculative thread executes on this processor.
– If future threads have written to a particular line in the primary cache, the pre-invalidate bit for that line is set. When the current thread completes, these bits allow the processor to quickly simulate the effect of all stored invalidations caused by all writes from later processors all at once, before a new thread begins execution on this processor.
Hydra’s Handling of Five Basic Speculation Hardware Requirements For Correct Data/Thread Speculation
Multiple Memory Views
As seen earlierin speculative load operation
EECC722 - ShaabanEECC722 - Shaaban#35 lec # 10 Fall 2006 10-25-2006
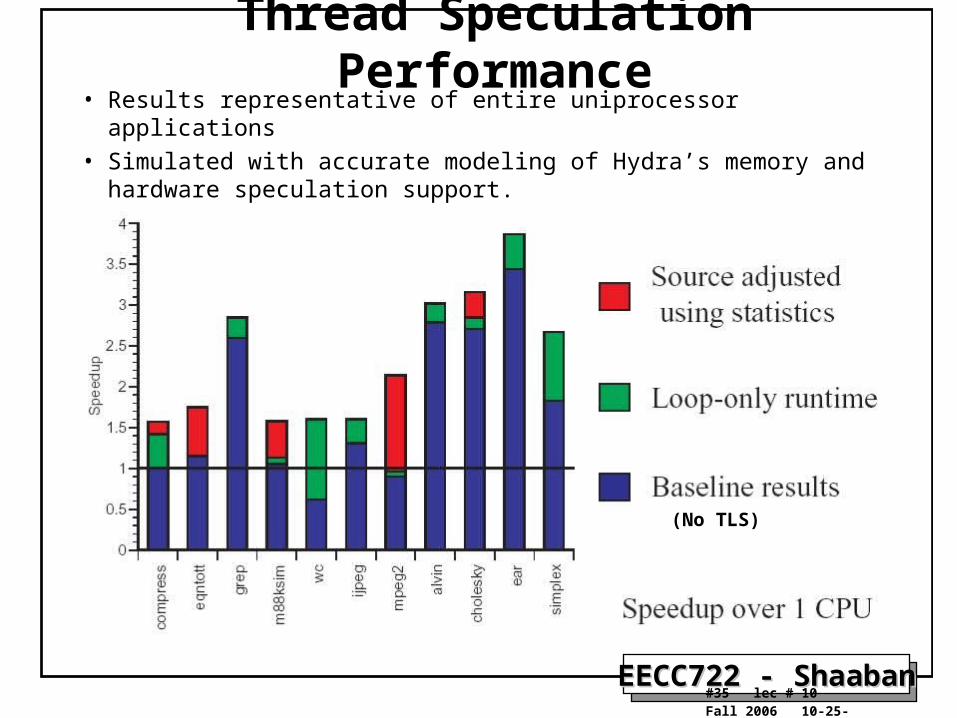
Thread Speculation Performance• Results representative of entire uniprocessor applications
• Simulated with accurate modeling of Hydra’s memory and hardware speculation support.
(No TLS)

EECC722 - ShaabanEECC722 - Shaaban#36 lec # 10 Fall 2006 10-25-2006
Hydra Conclusions
• Hydra offers a number of advantages– Good performance on parallel applications– Promising performance on difficult to parallelize sequential
(single-threaded) applications using data/Thread Level Speculation (TLS) mechanisms.
– Scalable, modular design– Low hardware overhead support for speculative thread
parallelism, yet greatly increases the number of parallel applications.

EECC722 - ShaabanEECC722 - Shaaban#37 lec # 10 Fall 2006 10-25-2006
Other Thread Level Speculation (TLS) Efforts: Wisconsin Multiscalar (1995)
• This CMP-based design proposed the first reasonable hardware to implement TLS.
• Unlike Hydra, Multiscalar implements a ring-like network between all of the processors to allow direct register-to-register communication. – Along with hardware-based thread sequencing, this type of communication
allows much smaller threads to be exploited at the expense of more complex processor cores.
• The designers proposed two different speculative memory systems to support the Multiscalar core. – The first was a unified primary cache, or address resolution buffer (ARB).
Unfortunately, the ARB has most of the complexity of Hydra’s secondary cache buffers at the primary cache level, making it difficult to implement.
– Later, they proposed the speculative versioning cache (SVC). • The SVC uses write-back primary caches to buffer speculative writes in the
primary caches, using a sophisticated coherence scheme.

EECC722 - ShaabanEECC722 - Shaaban#38 lec # 10 Fall 2006 10-25-2006
• This CMP-with-TLS proposal is very similar to Hydra,
– Including the use of software speculation handlers.
• However, the hardware is simpler than Hydra’s.
• The design uses write-back primary caches to buffer writes—similar to those in the SVC—and sophisticated compiler technology to explicitly mark all memory references that require forwarding to another speculative thread.
• Their simplified SVC must drain its speculative contents as each thread completes, unfortunately resulting in heavy bursts of bus activity.
Other Thread Level Speculation (TLS) Efforts: Carnegie-Mellon Stampede

EECC722 - ShaabanEECC722 - Shaaban#39 lec # 10 Fall 2006 10-25-2006
• This CMP design has three processors that share a primary cache and can communicate register-to-register through a crossbar.
• Each processor can also switch dynamically among several threads. (TLS & SMT??)
• As a result, the hardware connecting processors together is quite complex and slow.
• However, programs executed on the M-machine can be parallelized using very fine-grain mechanisms that are impossible on an architecture that shares outside of the processor cores, like Hydra.
• Performance results show that on typical applications extremely fine-grained parallelization is often not as effective as parallelism at the levels that Hydra can exploit. The overhead incurred by frequent synchronizations reduces the effectiveness.
Other Thread Level Speculation (TLS) Efforts: MIT M-machine





























