Embed Size (px)
Citation preview

Appunti per il orso di`Statisti a per l'Analisi Organizzativa'B. S arpaAA 2006/07
0Questi appunti si riferis ono al orso indi ato sopra per la dell'Università ommer iale�L.Bo oni�, e sono destinati ad es lusiva ir olazione interna. È vietata la ir olazione diquesto materiale al di fuori dell'ambito indi ato. Questo materiale non ostituis e il librodi testo del orso, ma solo una parte dei materiali segnalati agli studenti.

does money really matter?Il dibattito sull'equità nelle spese della s uola pubbli a in USAle diseguaglianze nelle spese per la s uola� è ragionevole pensare he la quantità di soldi disponibili per una s uolasia una misura della qualità dell'insegnamento, o quantomeno della apa ità di fornire agli studenti le risorse ne essarie per imparare bene.� è omprensibile he le omunità più ri he he pagano più tasse per�nanziare le s uole non vedano di buon o hio le omunità più povere he re lamano una sistema di maggiore equità� ad esempio nel Vermont (USA) è in vigore una legge he usa un ap-pro io alla Robin Hood: ra oglie le tasse nelle ittà più ri he, e isoldi ri avati li spende per migliorare le s uole nelle aree più povere.� a parte le disquisizioni ideologi he, i si hiede: ma davvero avere piùsoldi migliora la s uola? (does money really matter?)� la riti a maggiore è legata al on etto he intuitivamente, non sono isoldi in se he ambiano la s uola, ma ome vengono spesi . . .
B. S arpa, 2006-07 56 (19 ottobre 2006)

dal Washington Postdel 12 Settembre 1993�. . . [T℄he 10 states with the lowest per pupil spending in luded four − Nor-th Dakota, South Dakota, Tennessee, Utah − among the 10 states with thetop SAT s ores. Only one of the 10 states with the highest per pupil ex-penditures − Wis onsin − was among the 10 states with the highest SATs ores. New Jersey has the highest per pupil expenditures, an astonishing$10,561, whi h tea hers' unions elsewhere try to use as a negotiating ben- hmark. New Jersey's rank regarding SAT s ores? Thirty-ninth. . . The fa tthat the quality of s hools. . . [fails to orrelate℄ with edu ation appropria-tions will have no e�e t on the tea her unions' insisten e that money is the ru ial variable. The publi edu ation lobby's rumbling last line of defenseis the misedu ation of the publi .� G. Will
� per Will (e altri) il messaggio è hiaro: sempli emente i soldi non sono orrelati on l'e ellenza nell'edu azione...� In USA è d'uso ri hiedere per entrare all'università o alla �ne del-le s uole superiori di a�rontare un test standardizzato he misurail livello di preparazione degli studenti. SAT è il più di�uso e ilpiù ri hiesto nelle università più importanti.B. S arpa, 2006-07 57 (19 ottobre 2006)

l'evidenza empiri ai dati� per apire qual osa di piu' del problema, estraiamo un insieme di datidal 1997 Digest of Edu ation Statisti s, una pubbli azione annualedel U.S. Department of Edu ation.� i dati sono aggregati per stato. La prima variabile indi a quindi ilnome dello stato� i sono altre variabili he indi ano fattori he potrebbero in�uenzare irisultati degli studenti. Ad esempio� spese medie annuali per studente� rapporto studenti/insegnanti� salario medio annuale per insegnante in ogni stato� in�ne i sono 3 variabili he misurano la performan e degli studentiusando il test SAT:� punteggio medio totale per stato� punteggio per le materie �verbali�� punteggio per le materie �matemati he�B. S arpa, 2006-07 58 (19 ottobre 2006)
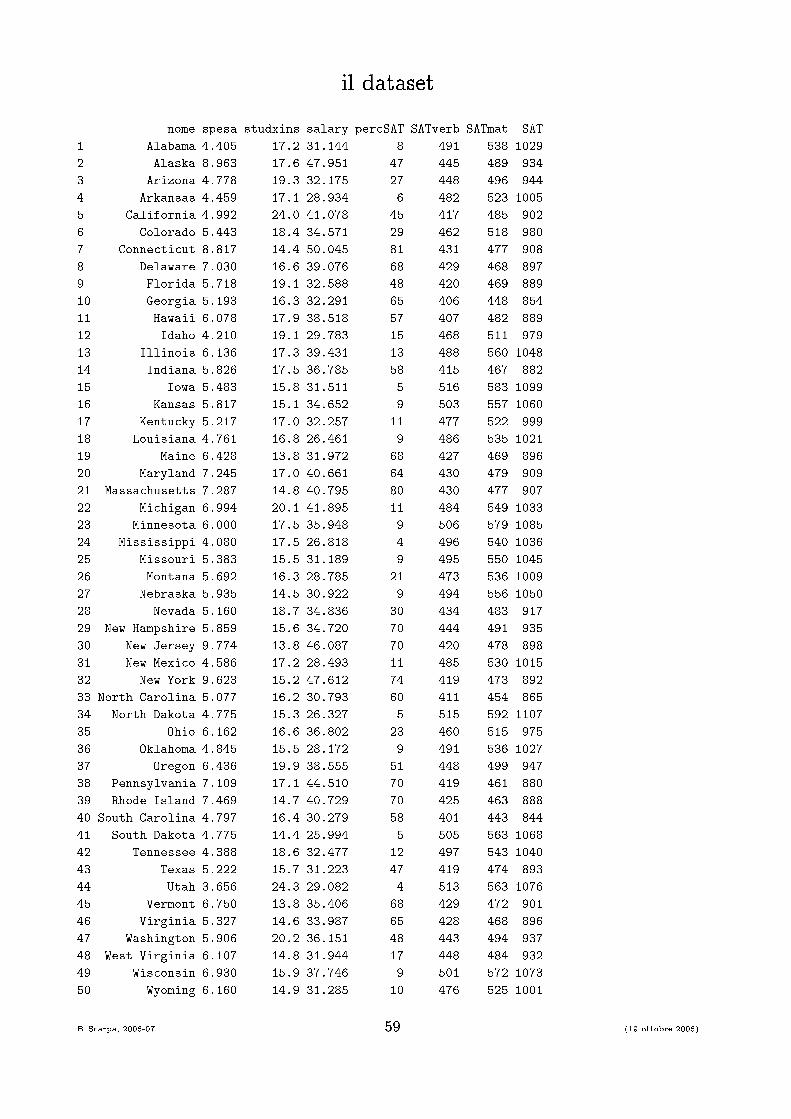
il datasetnome spesa studxins salary per SAT SATverb SATmat SAT1 Alabama 4.405 17.2 31.144 8 491 538 10292 Alaska 8.963 17.6 47.951 47 445 489 9343 Arizona 4.778 19.3 32.175 27 448 496 9444 Arkansas 4.459 17.1 28.934 6 482 523 10055 California 4.992 24.0 41.078 45 417 485 9026 Colorado 5.443 18.4 34.571 29 462 518 9807 Conne ti ut 8.817 14.4 50.045 81 431 477 9088 Delaware 7.030 16.6 39.076 68 429 468 8979 Florida 5.718 19.1 32.588 48 420 469 88910 Georgia 5.193 16.3 32.291 65 406 448 85411 Hawaii 6.078 17.9 38.518 57 407 482 88912 Idaho 4.210 19.1 29.783 15 468 511 97913 Illinois 6.136 17.3 39.431 13 488 560 104814 Indiana 5.826 17.5 36.785 58 415 467 88215 Iowa 5.483 15.8 31.511 5 516 583 109916 Kansas 5.817 15.1 34.652 9 503 557 106017 Kentu ky 5.217 17.0 32.257 11 477 522 99918 Louisiana 4.761 16.8 26.461 9 486 535 102119 Maine 6.428 13.8 31.972 68 427 469 89620 Maryland 7.245 17.0 40.661 64 430 479 90921 Massa husetts 7.287 14.8 40.795 80 430 477 90722 Mi higan 6.994 20.1 41.895 11 484 549 103323 Minnesota 6.000 17.5 35.948 9 506 579 108524 Mississippi 4.080 17.5 26.818 4 496 540 103625 Missouri 5.383 15.5 31.189 9 495 550 104526 Montana 5.692 16.3 28.785 21 473 536 100927 Nebraska 5.935 14.5 30.922 9 494 556 105028 Nevada 5.160 18.7 34.836 30 434 483 91729 New Hampshire 5.859 15.6 34.720 70 444 491 93530 New Jersey 9.774 13.8 46.087 70 420 478 89831 New Mexi o 4.586 17.2 28.493 11 485 530 101532 New York 9.623 15.2 47.612 74 419 473 89233 North Carolina 5.077 16.2 30.793 60 411 454 86534 North Dakota 4.775 15.3 26.327 5 515 592 110735 Ohio 6.162 16.6 36.802 23 460 515 97536 Oklahoma 4.845 15.5 28.172 9 491 536 102737 Oregon 6.436 19.9 38.555 51 448 499 94738 Pennsylvania 7.109 17.1 44.510 70 419 461 88039 Rhode Island 7.469 14.7 40.729 70 425 463 88840 South Carolina 4.797 16.4 30.279 58 401 443 84441 South Dakota 4.775 14.4 25.994 5 505 563 106842 Tennessee 4.388 18.6 32.477 12 497 543 104043 Texas 5.222 15.7 31.223 47 419 474 89344 Utah 3.656 24.3 29.082 4 513 563 107645 Vermont 6.750 13.8 35.406 68 429 472 90146 Virginia 5.327 14.6 33.987 65 428 468 89647 Washington 5.906 20.2 36.151 48 443 494 93748 West Virginia 6.107 14.8 31.944 17 448 484 93249 Wis onsin 6.930 15.9 37.746 9 501 572 107350 Wyoming 6.160 14.9 31.285 10 476 525 1001B. S arpa, 2006-07 59 (19 ottobre 2006)
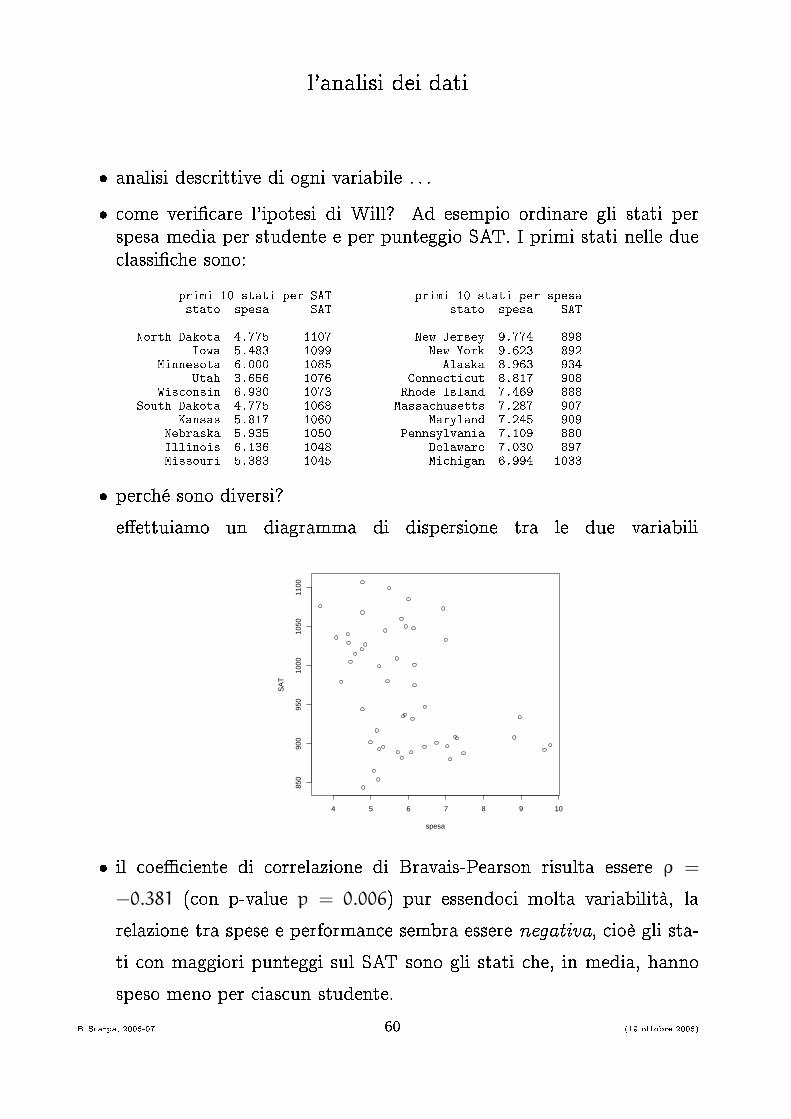
l'analisi dei dati� analisi des rittive di ogni variabile . . .� ome veri� are l'ipotesi di Will? Ad esempio ordinare gli stati perspesa media per studente e per punteggio SAT. I primi stati nelle due lassi� he sono:primi 10 stati per SAT primi 10 stati per spesastato spesa SAT stato spesa SATNorth Dakota 4.775 1107 New Jersey 9.774 898Iowa 5.483 1099 New York 9.623 892Minnesota 6.000 1085 Alaska 8.963 934Utah 3.656 1076 Conne ti ut 8.817 908Wis onsin 6.930 1073 Rhode Island 7.469 888South Dakota 4.775 1068 Massa husetts 7.287 907Kansas 5.817 1060 Maryland 7.245 909Nebraska 5.935 1050 Pennsylvania 7.109 880Illinois 6.136 1048 Delaware 7.030 897Missouri 5.383 1045 Mi higan 6.994 1033� per hé sono diversi?e�ettuiamo un diagramma di dispersione tra le due variabili
4 5 6 7 8 9 10
850
900
950
1000
1050
1100
spesa
SA
T
� il oe� iente di orrelazione di Bravais-Pearson risulta essere ρ =
−0.381 ( on p-value p = 0.006) pur essendo i molta variabilità, larelazione tra spese e performan e sembra essere negativa, ioè gli sta-ti on maggiori punteggi sul SAT sono gli stati he, in media, hannospeso meno per ias un studente.B. S arpa, 2006-07 60 (19 ottobre 2006)

un modello di regressione ome veri� are queste evidenze visive?� un modello di regressione sempli e potrebbe essere:SAT = α + βSPESA + ε on ε un errore assunto WN(0, σ2). La stima ai minimi quadrati portaai seguenti risultatiα = 1089.293718 (se = 44.38995020)
β = −20.892174 (se = 7.32820865)� si può e�ettuare un test di signi� atività per veri� are se β èsigni� ativamente diverso da zero.� nelle usuali ipotesi la statisti a del test sarà toss = −2.85 (t48;0.975 =
2.01, si ri�uta quindi l'ipotesi di uguaglianza a zero) e il livello disigni� atività osservato (p-value) sarà di p = 0.0064, he indi a laforte signi� atività del parametro� la relazione appare pare hio forte: ogni dollaro di aumento nella spesaper studente all'anno è asso iato on un alo di ir a 21 punti nel pun-teggio medio SAT dello stato, e tale stima raggiunge ogni onvenzionalelivello di signi� atività statisti a (p < 0.01)� è possibile valutare la apa ità espli ativa del modello ad esempio attra-verso il al olo dell'R2 he risulta R2 = 0.144808. Il test F sull'adattabi-lità omplessiva del modello risulta pari a Foss = 8.13 (F1;47;0.975 = 5.36) on p-value pari a p = 0.0064.Eser izi� e�ettuare un'analisi dei residui e un'analisi più ompleta dell'adatta-mento del modelloB. S arpa, 2006-07 61 (19 ottobre 2006)
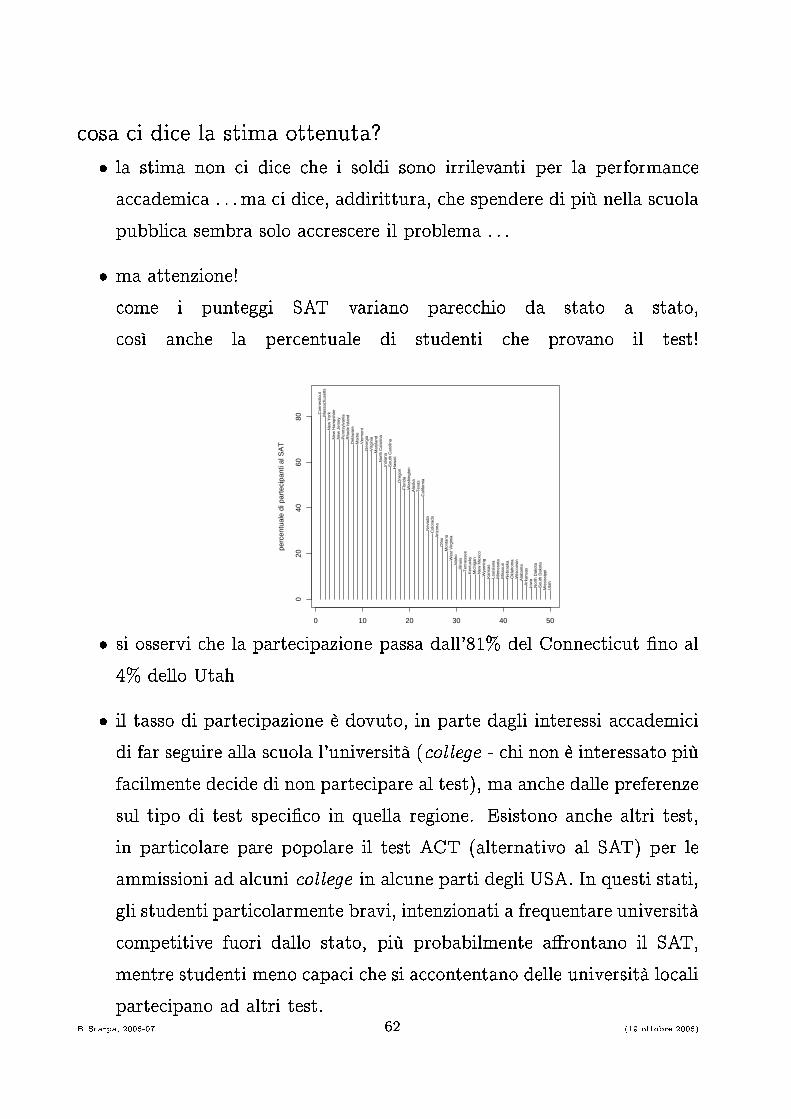
osa i di e la stima ottenuta?� la stima non i di e he i soldi sono irrilevanti per la performan ea ademi a . . .ma i di e, addirittura, he spendere di più nella s uolapubbli a sembra solo a res ere il problema . . .� ma attenzione! ome i punteggi SAT variano pare hio da stato a stato, osì an he la per entuale di studenti he provano il test!
0 10 20 30 40 50
020
4060
80
perc
entu
ale
di p
arte
cipa
nti a
l SA
T
Con
nect
icut
Mas
sach
uset
tsN
ew Y
ork
New
Ham
pshi
reN
ew J
erse
yP
enns
ylva
nia
Rho
de Is
land
Del
awar
eM
aine
Ver
mon
tG
eorg
iaV
irgin
iaM
aryl
and
Nor
th C
arol
ina
Indi
ana
Sou
th C
arol
ina
Haw
aii
Ore
gon
Flo
rida
Was
hing
ton
Ala
ska
Tex
asC
alifo
rnia
Nev
ada
Col
orad
oA
rizon
aO
hio
Mon
tana
Wes
t Virg
inia
Idah
oIll
inoi
sT
enne
ssee
Ken
tuck
yM
ichi
gan
New
Mex
ico
Wyo
min
gK
ansa
sLo
uisi
ana
Min
neso
taM
isso
uri
Neb
rask
aO
klah
oma
Wis
cons
inA
laba
ma
Ark
ansa
sIo
wa
Nor
th D
akot
aS
outh
Dak
ota
Mis
siss
ippi
Uta
h� si osservi he la parte ipazione passa dall'81% del Conne ti ut �no al4% dello Utah� il tasso di parte ipazione è dovuto, in parte dagli interessi a ademi idi far seguire alla s uola l'università ( ollege - hi non è interessato piùfa ilmente de ide di non parte ipare al test), ma an he dalle preferenzesul tipo di test spe i� o in quella regione. Esistono an he altri test,in parti olare pare popolare il test ACT (alternativo al SAT) per leammissioni ad al uni ollege in al une parti degli USA. In questi stati,gli studenti parti olarmente bravi, intenzionati a frequentare università ompetitive fuori dallo stato, più probabilmente a�rontano il SAT,mentre studenti meno apa i he si a ontentano delle università lo aliparte ipano ad altri test.B. S arpa, 2006-07 62 (19 ottobre 2006)
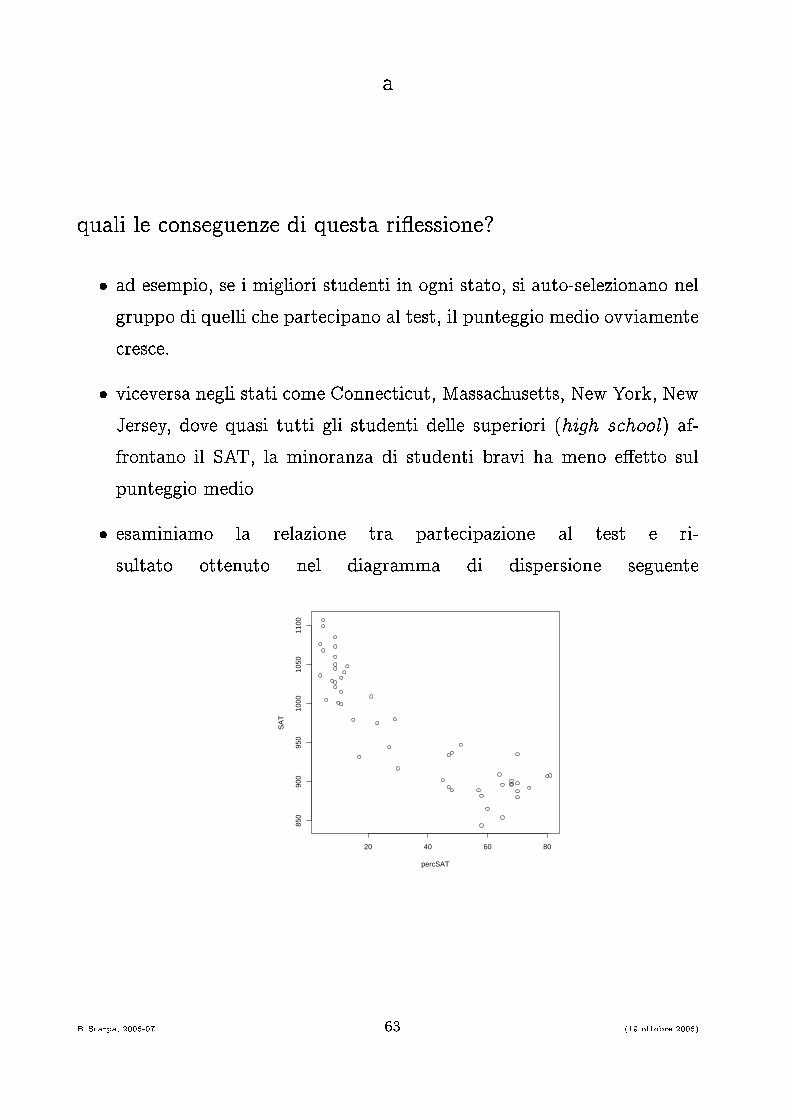
aquali le onseguenze di questa ri�essione?� ad esempio, se i migliori studenti in ogni stato, si auto-selezionano nelgruppo di quelli he parte ipano al test, il punteggio medio ovviamente res e.� vi eversa negli stati ome Conne ti ut, Massa husetts, New York, NewJersey, dove quasi tutti gli studenti delle superiori (high s hool) af-frontano il SAT, la minoranza di studenti bravi ha meno e�etto sulpunteggio medio� esaminiamo la relazione tra parte ipazione al test e ri-sultato ottenuto nel diagramma di dispersione seguente
20 40 60 80
850
900
950
1000
1050
1100
percSAT
SA
T
B. S arpa, 2006-07 63 (19 ottobre 2006)

la orrelazione parzialela � omposizione� dei parte ipanti al test, può in�uenzare lanostra domanda iniziale sulla relazione tra le spese per la s uolae i risultati degli studenti?� er hiamo di ostruire un indi atore (e un modello) he tenga ontodella parti olare omposizione dei parte ipanti al test, per poter osìveri� arne l'e�etto.� in parti olare i interessa misurare l'e�etto della spesa per la s uolasulla performan e degli studenti al netto dell'e�etto sulla performan edovuto alla auto-selezione nella parte ipazione al test.per essere più generali . . .� il problema esaminato può essere visto in maniera un po' più generale:� si ha una variabile risposta Y e (almeno) una variabile espli ativa X1.� si ha a disposizione an he (almeno) un'altra variabile X2 he è(potenzialmente) legata sia alla Y sia alla X1.� la domanda è quella di trovare un modo per ottenere un indi atore hemisura la relazione tra X1 e Y eliminando l'e�etto dovuto alla variabileX2� o in altre parole, senza tener onto di quella parte della relazione traX1 e Y he non è attribuibile direttamente a X1 ma he vi eversa viene olta (e giusti� ata e . . . ausata) da X2 la quale in�uis e sia su X1 maan he (direttamente, non in maniera vei olata da X1) sulla stessa Y
B. S arpa, 2006-07 64 (19 ottobre 2006)

. . . il mondo e' lineare
� per sempli ità (ma senza perdere molto in generalità, almeno on et-tuale) i poniamo in un ontesto in ui i migliori modelli he possiamopensare sono lineari e la realtà bene si adatta a tali modelli� ome abbiamo detto le variabili Y e X1 subis ono simultaneamentel'in�uenza della variabile X2. L'uso quindi dell'indi e di orrelazione ρtra Y e X1 può fornire indi azioni s orrette (di solito si di e spurie)� un modo per `eliminare' l'e�etto lineare della variabile X2 si ottieneutilizzando i residui
B. S arpa, 2006-07 65 (19 ottobre 2006)

il oe� iente di orrelazione parziale� si stima ioè l'e�etto (lineare) di X2 sulle due variabili di interesse,adattando i modelli
Y = α0 + α1X2 + εY
X1 = β0 + β1X2 + εX1suppondendo he le εY e le εX1sono variabili WN(0, σ2
Y) e WN(0, σ2X1
);si determinano le stime di α1, α2, β1 e β2 se ondo il prin ipio deiminimi quadrati.� si ottengono ora i residui dei due modelliZY = Y − α0 + α1X2
ZX1= X1 − β0 + β1X2 he misurano quanto della variabile Y e X1 rispettivamente non è statospiegato dalla variabile X2. Quanto ioè resta da spiegare dopo avertolto l'e�etto della variabile X2.� a questo punto è ragionevole utilizzare la orrelazione tra queste duenuove variabili ZY e ZX1
ome indi azione della relazione tra Y e X1 alnetto dell'e�etto di X2 su entrambe...ρZY ,ZX1
= ov(ZY, ZX1
)√var(ZY)
√var(ZX1)� questo indi atore viene hiamato oe� iente di orrelazione parzialetra Y e X1 `al netto' dell'e�etto lineare della variabile X2 e spesso vieneindi ato on ρYX1;X2
B. S arpa, 2006-07 66 (19 ottobre 2006)

� la orrelazione tra spesa e performan e senza tener onto dellaparte ipazione dal test abbiamo visto era di -0.381 (p = 0.006).� una misura della orrelazione parziale della relazione tra spesa e per-forman e ma al netto dell'e�etto su entrambe della autoselezione de-gli studenti nella de isione di parte ipare al test risulta essere pari a+0.391.Come valutare la signi� atività di questa misura?� abbiamo già visto nel aso della regressione sempli e he esiste unarelazione deterministi a tra oe� iente di orrelazione ρ e oe� ientedi determinazione R2:R2 = ρ2� per veri� are la signi� atività di R2 (e quindi an he di ρ) abbiamo fattoriferimento alla statisti a F =(
R2
1−R2
)
(
n−kk−1
) he sappiamo distribuirsi ome una F di Snede or.� sulla s orta di tali risultati er hiamo un risultato analogo an he peril nostro ρYX1;X2.� si può mostrare, infatti, he il quadrato del nostro oe� iente di or-relazione parziale ρYX1;X2
può essere s ritto in una forma simile a quella he abbiamo trovato per R2. In quel aso ri ordiamo heR2 =
varianza spiegatavarianza totale = 1 −varianza residuavarianza totale
B. S arpa, 2006-07 67 (19 ottobre 2006)

� onsiderando inve e ρYX1;X2possiamo s rivere he
ρ2YX1;X2
= 1 −varianza residua del modello on X1 e X2varianza residua del modello on solo X2 he è molto simile a iò he abbiamo per R2, infatti a denominatoreabbiamo in entrambi i asi una misura della variabilità he resta unavolta utilizzato il �migliore� modello a disposizione �no ad ora (nel asodi R2 il �migliore� modello era la media, nel aso di ρYX1;X2
il �migliore�modello è il modello di regressione he onsidera solo la variabile X2). Anumeratore inve e abbiamo una misura della variabilità he è spiegataspe i� amente dalla variabile X1. Possiamo s rivere infattiρ2
YX1;X2=
varianza res. mod. on solo X2− varianza res. mod. on X1 e X2varianza residua del modello on solo X2� questa nuova interpretazione di ρYX1;X2 i permette di muover i an he inquesto aso ome avevamo fatto nel aso di R2 e osì possiamo de�nirela statisti a test
Foss =
ρ2YX1;X2
2−1
1−ρ2YX1 ;X2
n−2
=
(
ρ2YX1;X2
1 − ρ2YX1;X2
)
(
n − 2
2 − 1
)
he si distribuis e ome una F di Snede or on 2 − 1 gradi di libertà anumeratore e n − 2 a denominatore.� Si osservi he an he in questo aso la Foss è il rapporto tra media deiquadrati degli s arti �spiegati� dalla variabile X1 (al netto della X2) emedia dei quadrati degli s arti �residui�.� Possiamo ora quindi utilizzare tale strumento per veri� are l'ipotesi he la orrelazione parziale ottenuta tra spesa e performan e al nettodell'autoselezione (+0.391) sia diversa da zero. Tale test porta a unlivello di signi� atività osservato (p-value) inferiore a 0.0001B. S arpa, 2006-07 68 (19 ottobre 2006)

ome stimare un nuovo modello per il SAT?� il oe� iente di orrelazione parziale he abbiamo stimato i di e quan-to il punteggio SAT è legato alla spesa, depurando questa relazionedall'e�etto dovuto all'autoselezione degli studenti nell'a�rontare il testSAT.� vogliamo ora er are di stimare un modello he i aiuti a �spiegare�il punteggio SAT utilizzando sia la variabile spesa, sia la variabileautoselezione� er hiamo, ioè, di stimare un modello del tipoSAT = β0 + β1SPESA + β2
( per entuale di studenti he a�rontano il SAT )
+ ε on ε un errore assunto WN(0, σ2).� è importante osservare he stimare un modello di questo tipo non èla stessa osa he stimare due modelli he mettano in relazione ilpunteggio SAT on spesa e on la per entuale di parte ipazione altest.� in quel aso infatti stimeremmo gli e�etti �marginali� della relazio-ne on il punteggio SAT, ma non rius iremmo a dire se 'è l'e�etto� ongiunto� delle due variabili spesa e autoselezione ontemporanea� il modello nuovo inve e dovrebbe ogliere l'e�etto ongiunto delle duevariabili, fornendo i delle misure di quanto ias una variabile in�uis esingolarmente sul SAT se onsiderata insieme all'altra variabileB. S arpa, 2006-07 69 (19 ottobre 2006)

Minimi quadrati� per essere più generali, ome abbiamo già fatto pre edentemente, hia-miamo la variabile risposta (il punteggio SAT) Y e le due variabiliespli ative X1 (la spesa pro apite) e X2 (per entuale di studenti hea�rontano il SAT). Il modello sarà quindi
Y = β0 + β1X1 + β2X2 + ε on ε variabile asuale degli errori he soddisfa alle usuali ipotesi(Eser izio: quali?).� per stimare i valori dei parametri β0, β1 e β2 è ragionevole adottare un riterio analogo a quello adottato nel aso in ui avevamo a disposizioneun'uni a variabile.� in questo aso però le variabili sono due, dovremo quindi onsiderareuno spazio tridimensionale. Nello spazio tridimensionale (Y, X1, X2)l'equazione del modello disegna un piano ( ome nel aso bidimensionaledisegnava una retta).� vogliamo er are di al olare β0, β1 e β2 in modo tale he la formulaβ0 + β1x1 + β2x2 fornis a buone �previsioni� sull'insieme dei dati os-servato. Quel he vorremmo è trovare dei valori per i parametri tali he
y1 ≈ β0 + β1x1,1 + β2x2,1
y2 ≈ β0 + β1x1,2 + β2x2,2...yn ≈ β0 + β1x1,n + β2x2,n
B. S arpa, 2006-07 70 (19 ottobre 2006)

� an ora una volta per rendere �operativo� questo insieme di equazio-ni, dobbiamo de idere in he senso interpretiamo gli ≈ s ritti e ome ombiniamo tra loro le varie formule s ritte. La soluzione più usa-ta, an he in questo aso si on retizza nello s egliere i tre parametriminimizzandos2(β0, β1, β2) =
n∑
i=1
(yi − β0 − β1x1,i − β2x2,i)2ovvero s egliendo β0, β1 e β2 in maniera tale he
s2(β0, β1, β2) ≤ s2(β0, β1, β2)per qualsivoglia β0 ∈ R, β1 ∈ R e β2 ∈ R . Ciò he stiamo er andoè quindi il piano he minimizza la somma dei quadrati delle distanzeparallele all'asse Y (analogamente a quanto avevamo nel aso bidimen-sionale). Il riterio he abbiamo adottato è an ora una volta quello deiminimi quadrati.� An he in questo aso, se sono noti β1 e β2 la soluzione del nostroproblema rispetto a β0 la troviamo in orrispondenza diβ0(β1, β2) =
1
n
n∑
i=1
(yi − β0 − β1x1,i − β2x2,i) = y − β1x1 − β2x2dove y, x1 e x2 indi ano rispettivamente la media delle yi, quella dellex1,i e quella di x2,i
B. S arpa, 2006-07 71 (19 ottobre 2006)

� an he in questo aso, dalla de�nizione di β0(β1, β2) segue he, perqualsiasi β0, β1 e β2,s2(β0, β1, β2) ≥ s2(β0(β1, β2), β1, β2).� quindi β1 e β2 possono essere er ati risolvendo il problema diottimizzazione (ri er a del minimo)inf
β1∈R,β2∈Rs2(β0(β1, β2), β1, β2)mentre
β0 = β0(β1, β2)� ora,s2(β0(β1, β2), β1, β2) =
n∑
i=1
[yi − y − β1(x1,i − x1) − β2(x2,i − x2)]2derivando rispetto a β1 e β2 e ponendo uguali a zero le due derivatesi ottiene il sistema di equazioni (per β1 e β2)
{
−2∑n
i=1(x1,i − x1)[yi − y − β1(x1,i − x1) − β2(x2,i − x2)] = 0
−2∑n
i=1(x2,i − x2)[yi − y − β1(x1,i − x1) − β2(x2,i − x2)] = 0 he può essere ris ritto (eser izio) ome{ ov(x1, y) = β1sqm(x1) + β2 ov(x1, x2) ov(x2, y) = β1 ov(x2, x1) + β2sqm(x2)� le equazioni ottenute per determinare β1 e β2 assieme a quella perottenere β0 sono dette equazioni normali
B. S arpa, 2006-07 72 (19 ottobre 2006)

� E' fa ile ora espli itare le soluzioni sotto la ondizione (detta di regola-rità) sqm(x1)sqm(x2)− ov2(x1, x2) > 0 he unite alla soluzione per β0già trovata pre edentemente fornis ono il seguente sistema di soluzioni
β1 = ov(x1,y)sqm(x2)− ov(x2,y) ov(x1,x2)sqm(x1)sqm(x2)− ov2(x1,x2)
β2 = ov(x2,y)sqm(x1)− ov(x1,y) ov(x1,x2)sqm(x1)sqm(x2)− ov2(x1,x2)
β0 = y − β1x1 − β2x2� nel nostro esempio a partire dalle medie, dalle varianze e dalle ova-rianze delle variabili di SAT, spesa e di per entuale di studenti hea�rontano il SAT var(y) = 5598.11592var(x1) = 1.857242var(x2) = 716.22694 ov(x1, x2) = −38.801816 ov(x1, y) = −1776.34776 ov(x2, y) = 21.61430si possono quindi fa ilmente ottenere le stime dei parametri
β0 = 993.832
β1 = 12.287 (spesa)β2 = −2.851 (per entuale SAT)
B. S arpa, 2006-07 73 (19 ottobre 2006)

la notazione matri iale� L'utilizzo dell'algebra delle matri i, sempli� a di molto la presentazio-ne (e la memorizzazione) dei al oli appena in ontrati. Infatti, uti-lizzando la notazione matri iale, possiamo s rivere il nostro modellolineare ome un modello di matri i. Consideriamo un modello lineare on k − 1 variabili espli ative.� Sia y il vettore n × 1 delle osservazioni della variabile risposta, ε unvettore n×1 di determinazioni della variabile aleatoria degli errori, β ilvettore k×1 dei k parametri da stimare (k parametri uno per ias unavariabile + 1 parametro β0 per l'inter etta), e sia X la matri e n × k on le osservazioni delle variabili espli ative dalla se onda alla k−esima olonna e ome prima olonna un vettore di 1:
X =
1 x1,1 x2,1 · · · xk−1,1
1 x1,2 x2,2 · · · xk−1,2
. . . . . . . . . . . . . . .
1 x1,i x2,i . . . xk−1,i
. . . . . . . . . . . . . . .
1 x1,n x2,n . . . xk−1,n
dove x1,1, x1,2, · · · , x1,n sono le osservazioni della variabilex1,x2,1, x2,2, · · · , x2,n le osservazioni della variabile x2 e ...� on questa notazione il modello lineare può essere s rittoy = Xβ + ε on ε un vettore di variabili aleatorie di media 0 e varianza σ2 in or-relate tra loro (la matri e di varianze ovarianze di ε è diagonale ontutti gli elementi sulla diagonale uguali a σ2).B. S arpa, 2006-07 74 (19 ottobre 2006)

� è possibile s rivere quindi il riterio dei minimi quadrati omes2(β) = (y − Xβ)T(y − Xβ)� è fa ile mostrare he le equazioni normali, ioè le equazioni he permet-tono di trovare il minimo in β della funzione s2 possono essere s rittein forma matri iale ome XTXβ = XTy he si risolve fa ilmente, basta premoltipli are per (XTX)−1 ottenendo
(XTX)−1XTXβ = (XTX)−1XTy he dal momento he (XTX)−1XTX = I fornis eβ = (XTX)−1XTy� la formula appena s ritta è la soluzione del problema ai minimi quadra-ti, in una situazione molto generale (qualunque sia il numero di righee soprattutto di olonne, ioè di variabili espli ative, della matri e X)� I valori stimati si ottengono fa ilmente attraverso la relazioney = Xβ
B. S arpa, 2006-07 75 (19 ottobre 2006)

La s omposizione della varianza� nel aso della regressione sempli e abbiamo visto ome la varianzatotale di y poteva essere s omposta nella somma di due parti, una heavevamo hiamato varianza spiegata dal modello e un'altra he dettavarianza residua.� an he in questo aso otteniamo una s omposizione analoga. Per sem-pli ità (in modo da non dover tener onto ogni volta di n o dei gradidi libertà) onsideriamo solo il numeratore della varianza ( he spessoviene detta devianza o somma dei quadrati di . . . ).� possiamo s rivere quindi (dimostrarlo per eser izio)
n∑
i=1
(yi − y)2 =
n∑
i=1
(yi − y)2 +
n∑
i=1
(yi − yi)2dove ∑
(yi − y)2 viene detta somma dei quadrati degli s arti dallamedia (SST), o devianza totale (è il numeratore della varianza di y),∑
(yi − y)2 è la devianza spiegata dal modello o la somma dei quadratidegli s arti dalla regressione (SSR); in�ne ∑
(yi − yi)2 è la devianzaresidua detta an he somma dei quadrati degli s arti residui o dell'errore(SSE).� an he i gradi di libertà sono s omponibili nella somma di due valori:gdl totali = gdl della regressione + gdl dei residui he nel aso di regressione multipla on k variabili espli ative sarà
(n − 1) = (k) + (n − k − 1)
B. S arpa, 2006-07 76 (19 ottobre 2006)

� on il nostro modello y = Xβ+ε e le nostre stime y = Xβ, utilizzandola notazione matri iale possiamo s rivereSST =
n∑
i=1
(yi − y)2 = yTy − ny2
SSR =
n∑
i=1
(yi − y)2 = βTXTy − ny2
SSE =
n∑
i=1
(yi − yi)2 = yTy − βTXTy� Possiamo fa ilmente ottenere la statisti a R2 in forma matri iale.
R2 =(βTXTy − ny2)
(yTy − ny2) ome sempre, il oe� iente di determinazione (R2) è ottenuto omeper entuale di varianza totale spiegata dal modello he in questo asosarà la somma degli e�etti lineari delle diverse variabili. An he inquesto aso, R2 sarà un numero ompreso tra 0 e 1 e assumerà il valoreminimo quando il nostro modello non spiegherà nulla della variabilitàdella y, assumerà valore massimo, al ontrario, quando i nostri datisono perfettamente sul piano des ritto dal modello.� Possiamo onsiderare quindi R2 un indi atore di adattamento globaledel nostro modello ai dati, non essendo spe i� amente legato ad unasingola variabile, ma a tutte le variabili onsiderate ongiuntamente(si osservi he il modello onsidera le variabili solo e uni amente nellaloro relazione lineare on la variabile risposta).B. S arpa, 2006-07 77 (19 ottobre 2006)

Inferenza per il modello di regressione multiplala matri e di varianze- ovarianze di β� analogamente a quanto visto per il aso di una x e una y, i hiediamose i risultati ottenuti dalla pro edura di stima possono essere attribuitial aso o vi eversa sono davvero spiegati dalle variabili onsiderate.� un primo passo onsiste nell'ottenere le varianze degli stimatori deidiversi β0, . . . , βk−1. Tali varianze possono essere raggruppate nellamatri e delle varianze e ovarianze del vettore β e he può essere s ritta ome Var(β) = (XTX)−1σ2dove σ2 è la varianza (s alare) di ias una εi. Naturalmente σ2 non ènota (è un parametro ignoto) ma può essere stimato, esattamente omenel aso della regressione sempli e on s2, he è la somma dei quadratidei residui divisa per n−k−1 (si fa ia riferimento alla dis ussione suigradi di libertà dei residui fatta nel aso della regressione sempli e).In notazione matri iale la stima della varianza dei residui può esseres ritta ome
s2 =1
n − k − 1(yTy − βTXTy)per ui la stima della varianza dei parametri saràVar(β) = (XTX)−1s2
B. S arpa, 2006-07 78 (19 ottobre 2006)

Il test di signi� atività globale� Veri� are l'ipotesi globale he il nostro modello non sia per nulla utileper spiegare la variabile risposta y ontro l'alternativa he almeno aqual osa serva, signi� a veri� are l'ipotesi he tutti i parametri delnostro modello siano nulli, ioè
{ H0 : β1 = β2 = . . . = βk = 0H1 : almeno un βj 6= 0 j = 1, . . . , k� per veri� are quest'ipotesi possiamo utilizzare an ora una volta unatrasformata dell'R2 (il oe� iente di determinazione era un indi- e des rittivo he di eva esattamente quanto le variabili espli ativespiegavano la variabile risposta), he analogamente al aso bivariatosaràFoss =
R2
k
1−R2
n−k−1
=R2
1 − R2
n − k − 1
k� an he in questo aso la statisti a Foss può essere vista ome rapportotra la media dei quadrati degli s arti �spiegati dall'intero modello� e la orrispondente media dei quadrati degli s arti residui. CioèFoss =
media dei quadrati degli s arti �spiegati�media dei quadrati degli s arti �residui�=
∑ni=1(yi − y)2/(k)
∑ni=1(yi − yi)2/(n − k − 1)La F è osì il rapporto tra due varianze, a numeratore la varianzaspiegata dalla regressione, a denominatore la varianza residua.
B. S arpa, 2006-07 79 (19 ottobre 2006)

� in genere, per omodità, si ra olgono le informazioni riguardanti las omposizione della devianza in una tabella detta di analisi dellavarianza, del tipogradi somma erroreFonte di dei quadrati o F Plibertà quadrati (SS) medio (MS)Regressione k βTXTy − ny2 SSRk
MSRMST
p-valueResidui n − k − 1 yTy − βTXTy s2 = SSEn−k−1Totale n − 1 yTy − ny2
B. S arpa, 2006-07 80 (19 ottobre 2006)

�
B. S arpa, 2006-07 81 (19 ottobre 2006)

previsioni dei prezzi delle ase a Boston� stima� modello di regressione lineare multipla� tabella di analisi della varianza� test F
B. S arpa, 2006-07 82 (19 ottobre 2006)

I dati� Si ha a disposizione un insieme di informazioni su ias uno dei 506distretti in ui è divisa l'area metropolitana di Boston. Per ias undistretto è registrato il prezzo medio delle ase, e siamo interessati a apire quali ondizioni so iali ed e onomi he sono legate a tale prezzo.� A osa bisogna fare riferimento per apire dove le ase valgono di più?� quali informazioni sono positivamente e quali negativamente legate alvalore delle ase?� è possibile pensare di prevedere il prezzo medio delle ase in undistretto non ompreso tra quelli a disposizione?� per ias un distretto sono state osservate le seguenti informazioni:1. tasso di rimine pro apite per ittà2. proporzione di appezzamenti residenziali per lotti ogni 25000 piedi quadrati3. proporzione di zone industriali (a ri)4. Variabile dummy: adia enza (1) o meno (0) del �ume Charles5. on entrazione di ossido nitri o (parte per 10 milioni)6. numero medio di stanze per dimora7. proporzione di ase o upate dai padroni ostruite prima del 19408. distanze pesate dai 5 entri lavorativi di Boston9. indi e di a essibilità alle autostrade radiali10. per entuale di tasse di proprietà (ogni 10000 dollari)11. rapporto studenti/insegnanti12. misura della presenza di neri(1000 · (Bk − 0.63)2) dove Bk è la proporzione di neri.13. per entuale di bassi strati della popolazione14. valore mediano delle ase o upate dal proprietario (migliaia di dollari)
B. S arpa, 2006-07 83 (19 ottobre 2006)
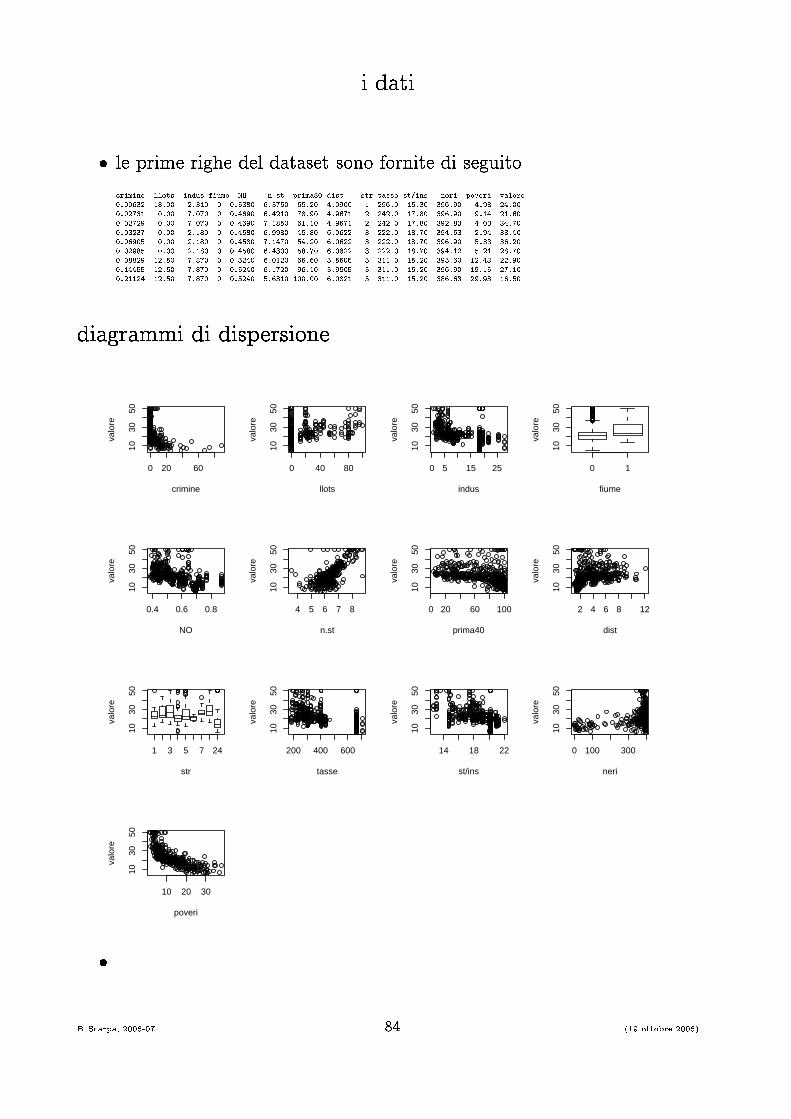
i dati� le prime righe del dataset sono fornite di seguito rimine llots indus fiume NO n.st prima80 dist str tasse st/ins neri poveri valore0.00632 18.00 2.310 0 0.5380 6.5750 65.20 4.0900 1 296.0 15.30 396.90 4.98 24.000.02731 0.00 7.070 0 0.4690 6.4210 78.90 4.9671 2 242.0 17.80 396.90 9.14 21.600.02729 0.00 7.070 0 0.4690 7.1850 61.10 4.9671 2 242.0 17.80 392.83 4.03 34.700.03237 0.00 2.180 0 0.4580 6.9980 45.80 6.0622 3 222.0 18.70 394.63 2.94 33.400.06905 0.00 2.180 0 0.4580 7.1470 54.20 6.0622 3 222.0 18.70 396.90 5.33 36.200.02985 0.00 2.180 0 0.4580 6.4300 58.70 6.0622 3 222.0 18.70 394.12 5.21 28.700.08829 12.50 7.870 0 0.5240 6.0120 66.60 5.5605 5 311.0 15.20 395.60 12.43 22.900.14455 12.50 7.870 0 0.5240 6.1720 96.10 5.9505 5 311.0 15.20 396.90 19.15 27.100.21124 12.50 7.870 0 0.5240 5.6310 100.00 6.0821 5 311.0 15.20 386.63 29.93 16.50diagrammi di dispersione0 20 60
1030
50
crimine
valo
re
0 40 80
1030
50
llots
valo
re
0 5 15 25
1030
50
indus
valo
re
0 1
1030
50
fiume
valo
re
0.4 0.6 0.8
1030
50
NO
valo
re
4 5 6 7 8
1030
50
n.st
valo
re
0 20 60 100
1030
50
prima40
valo
re
2 4 6 8 12
1030
50
dist
valo
re
1 3 5 7 24
1030
50
str
valo
re
200 400 600
1030
50
tasse
valo
re
14 18 22
1030
50
st/ins
valo
re
0 100 300
1030
50
neri
valo
re
10 20 30
1030
50
poveri
valo
re
�B. S arpa, 2006-07 84 (19 ottobre 2006)

un primo modello� adottiamo per il momento l'ipotesi di una relazione lineare. possiamoallora pensare ad un modello del tipo(valore) = β0 + β1( rimine) + β2(llots) + β3(indus) + β4(�ume) +
+ β5(NO) + β6(n.st) + β7(prima40) + β8(dist) + β9(str) +
+ β10(tasse) + β11(st/ins) + β12(neri) + β13(poveri) + (errore)dove l'ultima omponente esprime la parte delle os illazioni del valorenon legate alle variabili (o, forse più pre isamente, he una funzionelineare non ries e a spiegare)� Per e�ettuare la stima in maniera più agevole, si possono esprimere levariabili in forma matri iale.� sia y il vettore on le osservazioni della variabile risposta (valore), esia X la matri e di 506 righe he ha ome olonne le variabili heverranno utilizzate ome espli ative, oltre alla olonna di 1 per la stimadell'inter etta.� si tratta di 13 variabili, 11 ontinue e 2 dis rete. Di queste ultime, una(�ume) è di otomi a, mentre l'altra, (str) assume più modalità. Perla pre isione (str) assume 9 modalità (1,2,3,4,5,6,7,8 e 24). per poterutilizzare gli strumenti a nostra disposizione per la stima è opportunotrasformare la variabile dis reta he assume 9 modalità in 8 variabilidummies, una per ias una modalità meno una.� si s eglie ad esempio ome riferimento la modalità 1 strada, e si de-�nis ono le 8 variabili dummy in modo he ias una assuma valore 1quando si presenta una delle 8 modalità.� la matri e X avrà quindi 506 righe e 21 olonne, la prima legata all'in-ter etta, 10 relative alle variabili qualitative, una, di otomi a, per lavariabile (�ume) e 8 di otomi he an h'esse (dummies) per la variabile(strade).B. S arpa, 2006-07 85 (19 ottobre 2006)

la stima� il modello può essere quindi s ritto nella forma generaley = Xβ + ǫ� e, assumendo le usuali ipotesi di media nulla, in orrelazione e omo-s hedasti ità degli errori, si può ottenere la stima ai minimi quadratiattraverso lo stimatoreβ = (XTX)−1XTy.� i test per la veri� a di ipotesi di uguaglianza a zero dei parametri
{ H0 : βi = 0H1 : βi 6= 0possono essere veri� ati, aggiungendo l'ipotesi di normalità della distri-buzione, attraverso le statisti he test (nel nostro aso n = 506 numerodi unità statisti he e p = 21 numero di parametri da stimare)toss(βi) =
βi√
s2∑n
j=1(xij−xi)2
=βi
√
∑n
j=1(yij−yj)2/(n−p)∑n
j=1(xij−xi)2 he in forma matri iale si possono esprimere ometoss(βi) =
aT β
s√aT(XTX)−1adove a è un vettore di 21 elementi tutti 0 ad e ezione dell'i-esimo hevale 1.� La statisti a toss sotto H0 si distribuis e ome una t di Student on
n−p gradi di libertà. Con tale distribuzione andrà quindi onfrontatala toss osservata per ottenere la regione di a ettazione e di ri�uto.� per i dati sul prezzo delle ase i gradi di libertà sono quindi 506−21 =
485. Come è noto la distribuzione t on un osì elevato numero di gradidi libertà è approssimata in maniera quasi perfetta dalla Normale.B. S arpa, 2006-07 86 (19 ottobre 2006)

adattamento omplessivo del modello� l'R2 omplessivo del modello he possiamo ottenere ome
R2 = 1 −var(r1, . . . , rn)var(Y)dove r1, . . . , rn sono i residui del modello omplessivo stimato. An orauna volta in forma matri iale possiamo s rivere, espli itando il al olodella varianza totale di y e della varianza spiegata
R2 =(βTXTy − ny2)
(yTy − ny2)La signi� atività di R2 può essere valutata attraverso la statisti aFoss =
media dei quadrati degli s arti �spiegati�media dei quadrati degli s arti �residui�=
∑ni=1(yi − y)2/(p − 1)
∑ni=1(yi − yi)2/(n − p)
=(βTXTy − ny2)/(n − 1)
(yTy − ny2)/(n − p)� Sotto H0 Foss si distribuis e ome una F di Snede or on p − 1 gradi dilibertà al numeratore e n − p al denominatore.� nel aso dei prezzi delle ase i gradi di libertà sono quindi 21 − 1 = 20al numeratore e 506 − 21 = 485 al denominatore.B. S arpa, 2006-07 87 (19 ottobre 2006)
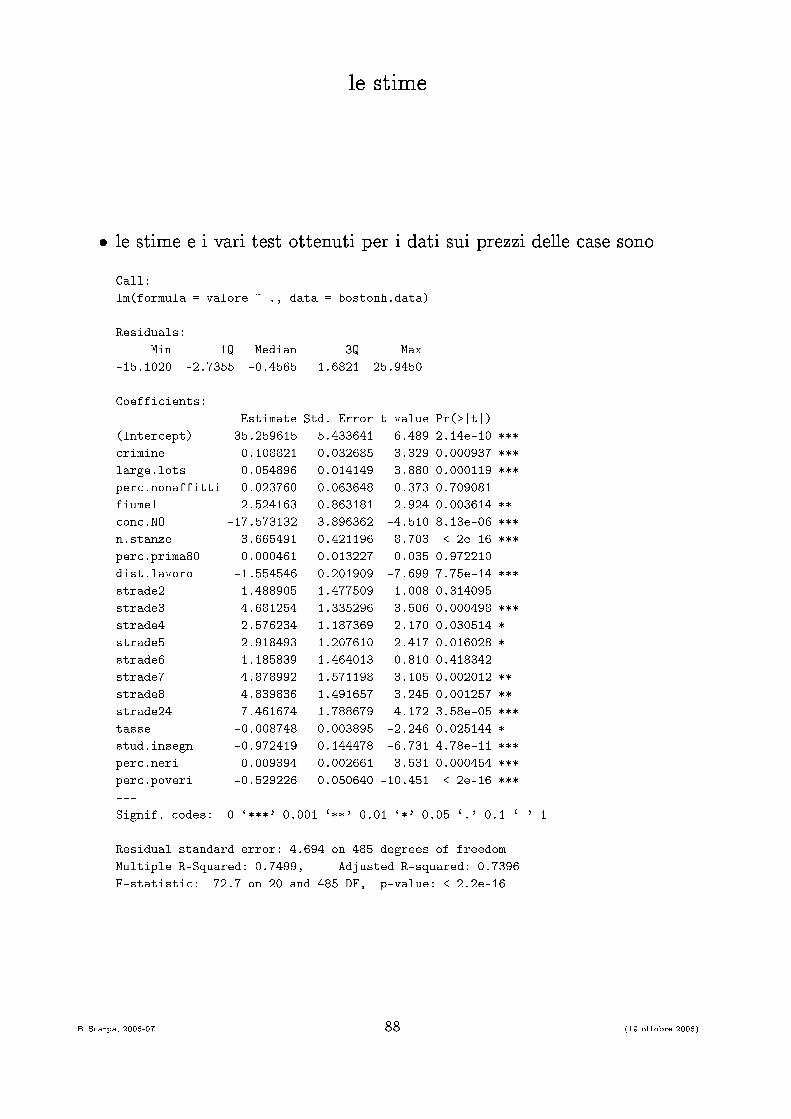
le stime� le stime e i vari test ottenuti per i dati sui prezzi delle ase sonoCall:lm(formula = valore ~ ., data = bostonh.data)Residuals:Min 1Q Median 3Q Max-15.1020 -2.7355 -0.4565 1.6821 25.9450Coeffi ients: Estimate Std. Error t value Pr(>|t|)(Inter ept) 35.259615 5.433641 6.489 2.14e-10 *** rimine -0.108821 0.032685 -3.329 0.000937 ***large.lots 0.054896 0.014149 3.880 0.000119 ***per .nonaffitti 0.023760 0.063648 0.373 0.709081fiume1 2.524163 0.863181 2.924 0.003614 ** on .NO -17.573132 3.896362 -4.510 8.13e-06 ***n.stanze 3.665491 0.421196 8.703 < 2e-16 ***per .prima80 0.000461 0.013227 0.035 0.972210dist.lavoro -1.554546 0.201909 -7.699 7.75e-14 ***strade2 1.488905 1.477509 1.008 0.314095strade3 4.681254 1.335296 3.506 0.000498 ***strade4 2.576234 1.187369 2.170 0.030514 *strade5 2.918493 1.207610 2.417 0.016028 *strade6 1.185839 1.464013 0.810 0.418342strade7 4.878992 1.571198 3.105 0.002012 **strade8 4.839836 1.491657 3.245 0.001257 **strade24 7.461674 1.788679 4.172 3.58e-05 ***tasse -0.008748 0.003895 -2.246 0.025144 *stud.insegn -0.972419 0.144478 -6.731 4.78e-11 ***per .neri 0.009394 0.002661 3.531 0.000454 ***per .poveri -0.529226 0.050640 -10.451 < 2e-16 ***---Signif. odes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1Residual standard error: 4.694 on 485 degrees of freedomMultiple R-Squared: 0.7499, Adjusted R-squared: 0.7396F-statisti : 72.7 on 20 and 485 DF, p-value: < 2.2e-16
B. S arpa, 2006-07 88 (19 ottobre 2006)
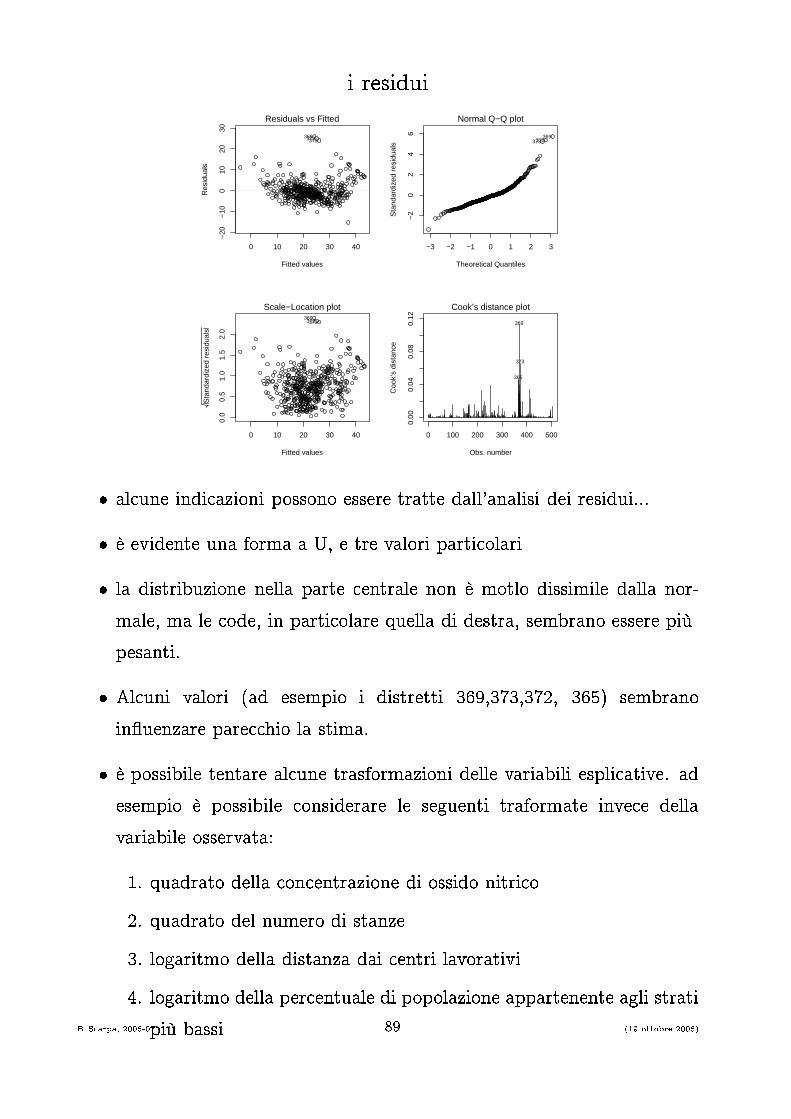
i residui0 10 20 30 40
−20
−10
010
2030
Fitted values
Res
idua
ls
Residuals vs Fitted
369372373
−3 −2 −1 0 1 2 3
−2
02
46
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
Normal Q−Q plot
369372373
0 10 20 30 40
0.0
0.5
1.0
1.5
2.0
Fitted values
Sta
ndar
dize
d re
sidu
als
Scale−Location plot369372373
0 100 200 300 400 500
0.00
0.04
0.08
0.12
Obs. number
Coo
k’s
dist
ance
Cook’s distance plot
369
373
365
� al une indi azioni possono essere tratte dall'analisi dei residui...� è evidente una forma a U, e tre valori parti olari� la distribuzione nella parte entrale non è motlo dissimile dalla nor-male, ma le ode, in parti olare quella di destra, sembrano essere piùpesanti.� Al uni valori (ad esempio i distretti 369,373,372, 365) sembranoin�uenzare pare hio la stima.� è possibile tentare al une trasformazioni delle variabili espli ative. adesempio è possibile onsiderare le seguenti traformate inve e dellavariabile osservata:1. quadrato della on entrazione di ossido nitri o2. quadrato del numero di stanze3. logaritmo della distanza dai entri lavorativi4. logaritmo della per entuale di popolazione appartenente agli stratipiù bassiB. S arpa, 2006-07 89 (19 ottobre 2006)
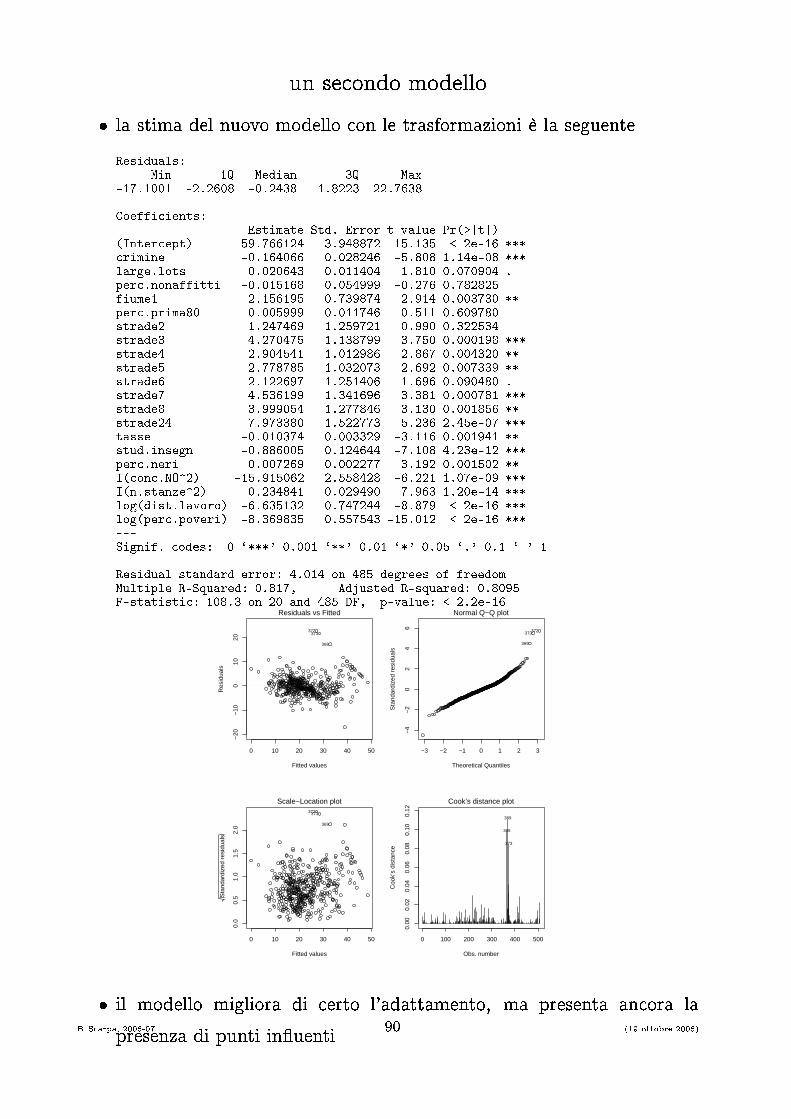
un se ondo modello� la stima del nuovo modello on le trasformazioni è la seguenteResiduals:Min 1Q Median 3Q Max-17.1001 -2.2608 -0.2438 1.8223 22.7638Coeffi ients: Estimate Std. Error t value Pr(>|t|)(Inter ept) 59.766124 3.948872 15.135 < 2e-16 *** rimine -0.164066 0.028246 -5.808 1.14e-08 ***large.lots 0.020643 0.011404 1.810 0.070904 .per .nonaffitti -0.015168 0.054999 -0.276 0.782825fiume1 2.156195 0.739874 2.914 0.003730 **per .prima80 0.005999 0.011746 0.511 0.609780strade2 1.247469 1.259721 0.990 0.322534strade3 4.270475 1.138799 3.750 0.000198 ***strade4 2.904541 1.012986 2.867 0.004320 **strade5 2.778785 1.032073 2.692 0.007339 **strade6 2.122697 1.251406 1.696 0.090480 .strade7 4.536199 1.341696 3.381 0.000781 ***strade8 3.999054 1.277846 3.130 0.001856 **strade24 7.973380 1.522773 5.236 2.45e-07 ***tasse -0.010374 0.003329 -3.116 0.001941 **stud.insegn -0.886005 0.124644 -7.108 4.23e-12 ***per .neri 0.007269 0.002277 3.192 0.001502 **I( on .NO^2) -15.915062 2.558428 -6.221 1.07e-09 ***I(n.stanze^2) 0.234841 0.029490 7.963 1.20e-14 ***log(dist.lavoro) -6.635132 0.747244 -8.879 < 2e-16 ***log(per .poveri) -8.369835 0.557543 -15.012 < 2e-16 ***---Signif. odes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1Residual standard error: 4.014 on 485 degrees of freedomMultiple R-Squared: 0.817, Adjusted R-squared: 0.8095F-statisti : 108.3 on 20 and 485 DF, p-value: < 2.2e-160 10 20 30 40 50
−20
−10
010
20
Fitted values
Res
idua
ls
Residuals vs Fitted
372373
369
−3 −2 −1 0 1 2 3
−4
−2
02
46
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
Normal Q−Q plot
372373
369
0 10 20 30 40 50
0.0
0.5
1.0
1.5
2.0
Fitted values
Sta
ndar
dize
d re
sidu
als
Scale−Location plot372373
369
0 100 200 300 400 500
0.00
0.02
0.04
0.06
0.08
0.10
0.12
Obs. number
Coo
k’s
dist
ance
Cook’s distance plot
369
365
373
� il modello migliora di erto l'adattamento, ma presenta an ora lapresenza di punti in�uentiB. S arpa, 2006-07 90 (19 ottobre 2006)
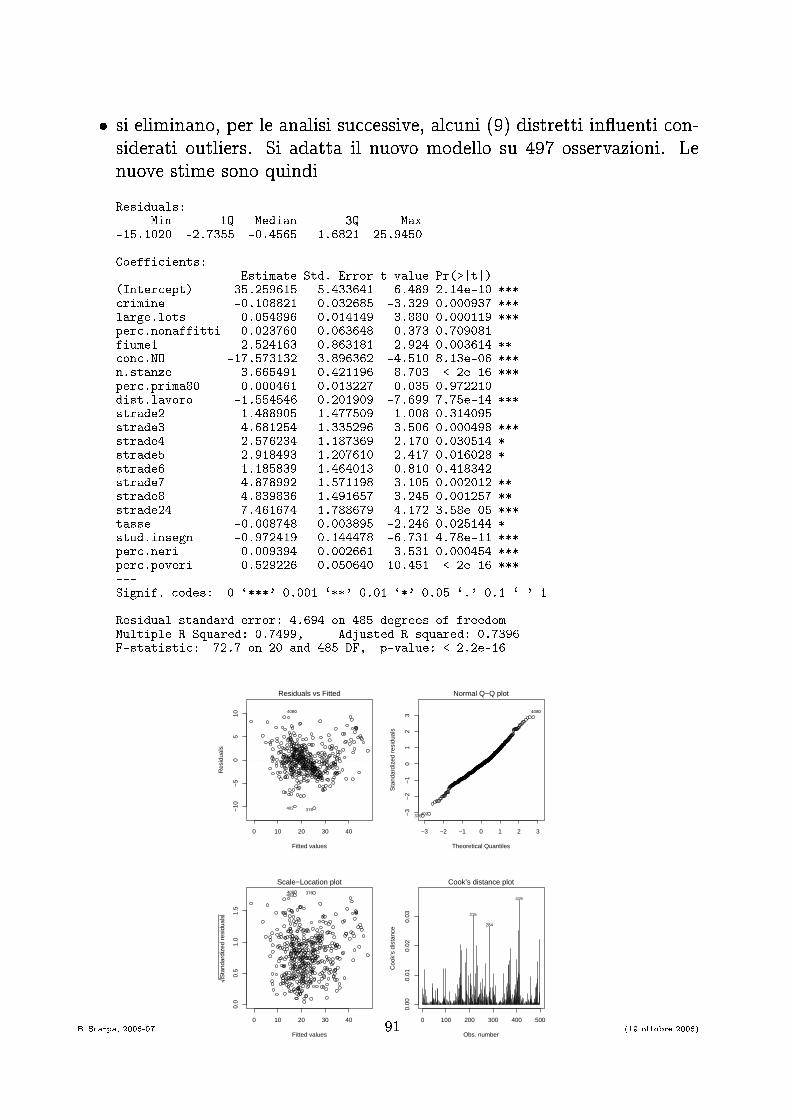
� si eliminano, per le analisi su essive, al uni (9) distretti in�uenti on-siderati outliers. Si adatta il nuovo modello su 497 osservazioni. Lenuove stime sono quindiResiduals:Min 1Q Median 3Q Max-15.1020 -2.7355 -0.4565 1.6821 25.9450Coeffi ients: Estimate Std. Error t value Pr(>|t|)(Inter ept) 35.259615 5.433641 6.489 2.14e-10 *** rimine -0.108821 0.032685 -3.329 0.000937 ***large.lots 0.054896 0.014149 3.880 0.000119 ***per .nonaffitti 0.023760 0.063648 0.373 0.709081fiume1 2.524163 0.863181 2.924 0.003614 ** on .NO -17.573132 3.896362 -4.510 8.13e-06 ***n.stanze 3.665491 0.421196 8.703 < 2e-16 ***per .prima80 0.000461 0.013227 0.035 0.972210dist.lavoro -1.554546 0.201909 -7.699 7.75e-14 ***strade2 1.488905 1.477509 1.008 0.314095strade3 4.681254 1.335296 3.506 0.000498 ***strade4 2.576234 1.187369 2.170 0.030514 *strade5 2.918493 1.207610 2.417 0.016028 *strade6 1.185839 1.464013 0.810 0.418342strade7 4.878992 1.571198 3.105 0.002012 **strade8 4.839836 1.491657 3.245 0.001257 **strade24 7.461674 1.788679 4.172 3.58e-05 ***tasse -0.008748 0.003895 -2.246 0.025144 *stud.insegn -0.972419 0.144478 -6.731 4.78e-11 ***per .neri 0.009394 0.002661 3.531 0.000454 ***per .poveri -0.529226 0.050640 -10.451 < 2e-16 ***---Signif. odes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1Residual standard error: 4.694 on 485 degrees of freedomMultiple R-Squared: 0.7499, Adjusted R-squared: 0.7396F-statisti : 72.7 on 20 and 485 DF, p-value: < 2.2e-160 10 20 30 40
−10
−5
05
10
Fitted values
Res
idua
ls
Residuals vs Fitted
408
376402
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
Normal Q−Q plot
408
376402
0 10 20 30 40
0.0
0.5
1.0
1.5
Fitted values
Sta
ndar
dize
d re
sidu
als
Scale−Location plot408 376402
0 100 200 300 400 500
0.00
0.01
0.02
0.03
Obs. number
Coo
k’s
dist
ance
Cook’s distance plot
419
215
284
B. S arpa, 2006-07 91 (19 ottobre 2006)

� abbiamo già visto il signi� ato dei parametri stimati, ome si pos-sono e�ettuare veri� he di ipotesi su ias un β e sull'adattabilità omplessiva del modello.� L'obiettivo di questo modello onsiste nello stabilire se 'è una relazionetra l'insieme delle nostre variabili espli ative e la variabile risposta (ilprezzo delle ase), fornendo an he una misura quantitativa di questarelazione.� Ci vogliamo ora on entrare su ome veri� are se le omponenti di Xsono davvero utili per des rivere la variabilità osservata della y.� Per esempio, nel nostro esempio, abbiamo pare hie variabili he pos-sono essere disponibili per spiegare la variabilità di y, ma non tuttepossono essere di aiuto, e potrebbe essere fuorviante presentare unmodello lineare he in luda variabili super�ue.� L'obiettivo sarà quindi quello di ottenere un sottoinsieme delle variabiliespli ative X tale he:� non vengono omesse variabili utili a des rivere la variabilità di y� non vengono in luse variabili he non ontribuis ono - o on-tribuis ono molto po o - a spiegare la variabilità osservata iny� Cer hiamo un me anismo formale per determinare se una omponentesingola o un gruppo di omponenti della X possa venire eliminata dalmodello lineare senza un e�etto e essivo sulla performan e del modelloin termini di spiegazione della variabilità delle omponenti di y.B. S arpa, 2006-07 92 (19 ottobre 2006)

� Abbiamo già dis usso il me anismo per veri� are se una singola om-ponente di X possa essere eliminata dal modello, he orrispondeall'ipotesi H0 : βi = 0 e he risolviamo on la statisti a testtoss(βi) =
βi
s
√
(XTX)−1i,i
∼ tn−p� un test formale può essere e�ettuato onfrontando i valori osservati tossai quantili teori i della distribuzione tn−p.� Questa pro edura, tuttavia, è meno soddisfa iente quando onsideria-mo la possibile es lusione di diverse omponenti di X, visto he il testper ogni ompoenente assume l'in lusione di tutte le altre omponenti.� Sviluppiamo una pro edura, he prende il nome di analisi della va-rianza, he i fornirà un test per l'es lusione di un gruppo di ompo-nenti di X. Se una omponente ontribuis e solo per una pi ola partedella variabilità (varianza), allora è ragionevole pensare di eliminarladal modello.� Chiamiamo H la matri e appello: H = X(XTX)−1XT . Las omposizione di base è la seguente:SSE = (y − y)T (y − y)
= yT (In − H)T (In − H)y= yT (In − H)y= yTy − yT(XTX)−1XTy= yTy − βXTyB. S arpa, 2006-07 93 (19 ottobre 2006)

� quindi yTy = (y − y)T (y − y) + βXTye questi temini sono� SST = yTy è la somma dei quadrati totale� SSE = (y − y)T (y − y) è la somma dei quadrati degli errori� SSR = βXTy è de�nita ome la somma dei quadrati dellaregressioneabbiamo quindi l'identitàSST = SSE + SSR� si osservi he la somma dei quadrati della regressione può an he venireespressa in un altro modo. In parti olare
SSR = βXTy= β(XTX)(XTX)−1XTy= βXTXβ
= (Xβ)T (Xβ)da ui è hiaro il per hé del nome somma dei quadrati della regressio-ne. Infatti SSR può essere interpretata ome l'ammontare di variabilitàspiegata dalla regressione: se è grande rispetto a SSE la regressione staspiegando bene la variabilità delle omponenti di y.� Possiamo osì sviluppare un test formale per determinare se SSR èsu� ientemente pi olo per portar i a on ludere he il nostro modellonon si adatta bene ai dati. In altre parole un test per H0 : β = 0, ioètutte le omponenti βi sono nulle.B. S arpa, 2006-07 94 (19 ottobre 2006)

� Abbiamo già visto he E(SSE) = (n − p)σ2. Possiamo inoltre ottenerela media della somma dei quadrati della regressioneE(SSR) = E(βXTXβ)
= trE(βXTXβ)
= trE(XββXT )
= tr(X{σ2(XTX)−1 + ββT }XT )
= σ2trTp + tr(XββTXT )
= σ2p + βTXTXβ.� Così, in parti olare,se β = 0, SSR/p fornis e uno stimatore non di-storto di σ2. Se non onsideriamo β, an he SSE/(n − p) fornis e unostimatore non distorto per σ2.� Quindi la statisti aFoss =
SSR/p
SSE/(n − p)sarà vi ina a 1 se β = 0, ma sarà più grande di 1 se l'ipotesi è falsa.� sotto le ipotesi usuali di distribuzione normale, indipendenza eomos hedasti ità degli errori si ha1.SSE ∼ χ2
n−pindipendente da β.2.(β − β)TXTX(β − β) ∼ σ2χ2
pindipendente da SSE.B. S arpa, 2006-07 95 (19 ottobre 2006)

� Di onseguenzaSSR
{
σ2χ2p se β = 0
σ2χ2p(
βTXTXβσ2 ) se β 6= 0avremo quindi le seguenti pro edure test.Siano
MSR =SSR
p, MSE =
SSE
n − ple somme dei quadrati medie dovute rispettivamente alla regressione eall'errore. Allora sotto l'ipotesi nulla H0 : β = 0,F =
MSR
MSE∼
σ2χ2p/p
σ2χ2n−p/(n − p)
= Fp,n−pper l'indipendenza del numeratore e del denominatore, e per lade�nizione della distribuzione F.
B. S arpa, 2006-07 96 (19 ottobre 2006)

� La pro edura viene di solito riassunta nella osiddetta tabella ANOVAFonte SS gdl MSRegressione su β SSR = βXTy p SSR/pErrore SSE = yTy − βXTy n − p SSE/(n − p)Totale SST = yTy n
� Se onsideriamo ( ome nel nostro aso) una inter et-ta diversa da 0, la tabella sarà leggermente modi� ataFonte SS gdl MSRegress. su β1, . . . , βp−1|β0 SSR = βXTy − ny2 p − 1 SSR/(p − 1)Errore SSE = yTy − βXTy n − p SSE/(n − p)Totale SST = yTy − ny2 n − 1(Corretto)� si osservi he yTy =
∑ni=1 y2
i , mentre yTy − ny2 =∑n
i=1(yi − y)2, osìla somma dei quadrati orretta è sempli emente la somma dei quadratidei valori intorno alla media ampionaria.� nel nostro esempio dei prezzi delle ase di Boston la tabella saràFonte SS gdl MSRegress. su β1, . . . , βp−1|β0 33737.5 20 1686.9Errore 5121.6 476 10.8Totale 38859.10 496(Corretto)B. S arpa, 2006-07 97 (19 ottobre 2006)

� Di solitosiamo interessati a veri� are an he se un sottoinsieme di βpuò essere onsiderato nullo. Formalmente abbiamo il modelloy = Xβ + εdove
β =
βa
. . .
βb
=
β1...βq
. . .
βq+1...βp
e vogliamo veri� are la riduzione dal modello ompleto he non havin oli, rispetto al modello ridotto in ui βb = 0.� Pro ediamo ome segue1. Si adatti il modello ompleto per ottenere SSR(βa, βb) eSSE(βa, βb).2. Si adatti il modello ridotto per ottenere SSR(βa) e SSE(βa).3. si de�nis ano le extra SS dovute a βb dopo aver adattato βa ome
SSR(βb|βa) = SSR(βa, βb) − SSR(βa)e equivalentementeSSE(βb|βa) = SSE(βa, βb) − SSE(βa).Questi indi atori misurano la variabilità addizionale spiegata dalmodello ompleto rispetto a quanto spiegato dal modello ridotto.B. S arpa, 2006-07 98 (19 ottobre 2006)

� La tabella ANOVA viene ompletata per omprendere an he leproprietà di SSR(βb|βa). Prima al oliamo, ponendo βb = 0E(SSR(βb|βa)) = pσ2 + βXTXβ + qσ2 − qβaXTXβa
= (p − q)σ2Dall'altra parteE(SSE(βa, βb)) = (n − p)σ2 ome prima. Possiamo quindi s rivere una nuova tabella ANOVAFonte SS gdl MS
βa SSR(βa) q SSR(βa)/q
βb|βa SSR(βb|βa) p − q SSR(βb|βa)/(p − q)
βa, βb SSR(βa, βb) pErrore SSE = yTy − βXTy n − p SSE/(n − p)Totale SST = yTy n� la terza riga della tabella è ridondante, visto he raggruppa le in-formazioni delle prime due righe, ma è più fa ile valutare la se on-da riga onsiderando tutte le altre righe, ompresa la terza, e quindisottraendo.� An he in questo aso è possibile ottenere la distribuzione dellastatisti a test per veri� are l'ipotesi H0 : βb = 0Foss =
MSR(βb|βa
MSE(βb|βa) he si distribuis e sotto H0 ome una distribuzione Fp−q,n−p
B. S arpa, 2006-07 99 (19 ottobre 2006)

� E' possibile onsiderare an he in questo aso un modello in ui l'in-ter etta non viene messa in dis ussione. Avremo osì la tabelladell'ANOVA modi� ata:Fonte SS gdl MSβa SSR(βa) q SSR(βa)/q
βb|βa SSR(βb|βa) p − q − 1 SSR(βb|βa)/(p − q − 1)
βa, βb SSR(βa, βb) p − 1Errore SSE = yTy − βXTy n − p SSE/(n − p)Totale SST = yTy − ny2 n − 1(Corretto)� Il pro edimento eseguito �nora può essere reiterato più volte, nel nostromodello infatti y = Xβ + εpossiamo suddividere β in diversi sotto gruppiβ =
β1
. . .
β2
. . ....
. . .
βk
B. S arpa, 2006-07 100 (19 ottobre 2006)

� E' possibile quindi ostruire la tabella ANOVA seguenteFonte SS gdl MSβ1 SSR(β1) q1 SSR(β1)/q1
β2|β1 SSR(β2|β1) q2 SSR(β2|β1)/q2
β3|β1, β2 SSR(β3|β1, β2) q3 SSR(β3|β1, β2)/q3. . . . . . . . . . . .Errore SSE = yTy − βXTy n − p SSE/(n − p)Totale SST = yTy n� Appli ando questa pro edura per veri� are ogni singolo βi, dopo l'in- lusione dei termini adattati pre edentemente, si ottiene la statisti atestFoss =
MSR(βi|pre edenti omponenti di β)
MSE he sotto H0 si distribuis e ome una F1,n−p (data l'in lusione nelmodello delle pre edenti omponenti βj).� Si onsideri he l'ordine on ui vengono aggiunti termini nel modellodivente ora importante. Cioè, ad esempio, se β è partizionato in β1,β2 e β3, SSR(β3|β1) sarà in genere diverso da SSR(β3|β2), e il testo perl'in lusione di β3 potrebbe dare risultati diversi (una volta a ettare euna volta ri�utare) a se onda he β1 o β2 sia stimato prima.
B. S arpa, 2006-07 101 (19 ottobre 2006)

tabella ANOVA per i dati sui prezzi delle ase� La tabella ANOVA per il nostro dataset sui prezzi delle ase dipende, ome abbiamo visto dall'ordine on ui inseriamo i dati:� un primo ordine potrebbe essere: rimine, large.lots, indus, �u-me, per .prima40, strade, tasse, stud.insegn, per .neri, on .NO2,n.stanze2, log(dist.lavoro), log(per .poveri)� la tabella di analisi della varianza (a ui abbiamo aggiunto la statisti atest Foss e il p-value) risultagdl SS MS F Pr(>F) rimine 1 6856.0 6856.0 637.1910 < 2.2e-16 ***large.lots 1 3919.9 3919.9 364.3163 < 2.2e-16 ***indus 1 3257.0 3257.0 302.7015 < 2.2e-16 ***fiume 1 646.6 646.6 60.0937 5.525e-14 ***per .prima40 1 80.7 80.7 7.4963 0.006414 **strade 8 2754.4 344.3 31.9990 < 2.2e-16 ***tasse 1 429.1 429.1 39.8796 6.202e-10 ***stud.insegn 1 2596.6 2596.6 241.3297 < 2.2e-16 ***per .neri 1 453.2 453.2 42.1208 2.158e-10 *** on .NO^2 1 532.5 532.5 49.4856 6.992e-12 ***n.stanze^2 1 10447.6 10447.6 970.9934 < 2.2e-16 ***log(dist.lavoro) 1 616.9 616.9 57.3347 1.925e-13 ***log(per .poveri) 1 1147.1 1147.1 106.6071 < 2.2e-16 ***Errori 476 5121.6 10.8-----------------------------------------------------------Totale 496 38859.2---Codi i di Sign.: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1� ma se ambiuo l'ordine, ad esempio: rimine, �ume, tasse, stud.insegn,per .neri, on .NO2, n.stanze2, log(dist.lavoro), log(per .poveri),large.lots, indus, per .prima40, strade, si otteniene la tabellagdl SS MS F Pr(>F) rimine 1 6856.0 6856.0 637.1910 < 2.2e-16 ***fiume 1 374.2 374.2 34.7748 7.024e-09 ***tasse 1 5391.3 5391.3 501.0686 < 2.2e-16 ***stud.insegn 1 4478.7 4478.7 416.2439 < 2.2e-16 ***per .neri 1 475.4 475.4 44.1878 8.192e-11 ***I( on .NO^2) 1 1819.8 1819.8 169.1281 < 2.2e-16 ***I(n.stanze^2) 1 11887.8 11887.8 1104.8430 < 2.2e-16 ***log(dist.lavoro) 1 211.2 211.2 19.6284 1.168e-05 ***log(per .poveri) 1 1729.4 1729.4 160.7262 < 2.2e-16 ***large.lots 1 1.1 1.1 0.0980 0.75432indus 1 3.5 3.5 0.3229 0.57016per .prima80 1 59.0 59.0 5.4864 0.01958 *strade 8 450.2 56.3 5.2303 2.751e-06 ***Errori 476 5121.6 10.8-----------------------------------------------------------Totale 496 38859.2---Codi i di Sign.: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1� da ui vediamo he large.lots e indus non aggiungono nulla di nuovorispetto alle prime 9 variabiliB. S arpa, 2006-07 102 (19 ottobre 2006)

� Se voglio, inve e, ad esempio veri� are la signi� atività del modello in ui ho eliminato le due variabili he sembrano non essere legate al valore(proporzione di appezzamenti residenziali per lotti e proporzione dizone industriali) ottengo la tabella di ANOVA seguente per il onfrontotra modelliModello 1: valore ~ rimine + large.lots + indus + fiume + per .prima80 +strade + tasse + stud.insegn + per .neri + on .NO^2 +n.stanze^2 + log(dist.lavoro) + log(per .poveri)Model 2: valore ~ rimine + fiume + per .prima80 + strade + tasse + stud.insegn +per .neri + on .NO^2 + n.stanze^2 + log(dist.lavoro) + log(per .poveri)gdl-res. SSR gdl Som.quad. F Pr(>F)1 476 5121.62 478 5140.9 -2 -19.3 0.8979 0.4081� in ui abbiamo indi ato an he le di�erenze della somma dei quadratispiegata dalla regressione e quella dei gradi di libertà� Eser izio: quali sono i gradi di libertà della distribuzione F he stiamousando? Qual è la statisti a test he utilizziamo?� le stime del modello �nale saranno quindiCall:lm(formula = valore ~ rimine + fiume + per .prima40 + strade +tasse + stud.insegn + per .neri + I( on .NO^2) + I(n.stanze^2) +log(dist.lavoro) + log(per .poveri), data = bostonh.data2)Residuals:Min 1Q Median 3Q Max-10.2994 -2.0335 -0.1580 1.8775 10.5259Coeffi ients: Estimate Std. Error t value Pr(>|t|)(Inter ept) 41.667789 3.466380 12.021 < 2e-16 *** rimine -0.125589 0.023039 -5.451 8.03e-08 ***fiume1 1.378595 0.635836 2.168 0.030639 *per .prima40 -0.020355 0.009755 -2.087 0.037450 *strade2 1.268409 1.017154 1.247 0.213002strade3 4.085644 0.917607 4.452 1.06e-05 ***strade4 2.746310 0.819487 3.351 0.000868 ***strade5 2.731265 0.825163 3.310 0.001004 **strade6 1.872479 1.007511 1.859 0.063710 .strade7 3.559265 1.089735 3.266 0.001168 **strade8 3.412861 1.016632 3.357 0.000851 ***strade24 5.624553 1.230457 4.571 6.19e-06 ***tasse -0.009270 0.002465 -3.760 0.000191 ***stud.insegn -0.857986 0.096539 -8.887 < 2e-16 ***per .neri 0.009459 0.001896 4.988 8.55e-07 ***I( on .NO^2) -10.174029 2.086600 -4.876 1.48e-06 ***I(n.stanze^2) 0.410823 0.027374 15.008 < 2e-16 ***log(dist.lavoro) -4.430879 0.568248 -7.797 3.99e-14 ***log(per .poveri) -5.372402 0.516960 -10.392 < 2e-16 ***---Signif. odes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1Residual standard error: 3.279 on 478 degrees of freedomMultiple R-Squared: 0.8677, Adjusted R-squared: 0.8627F-statisti : 174.2 on 18 and 478 DF, p-value: < 2.2e-16B. S arpa, 2006-07 103 (19 ottobre 2006)
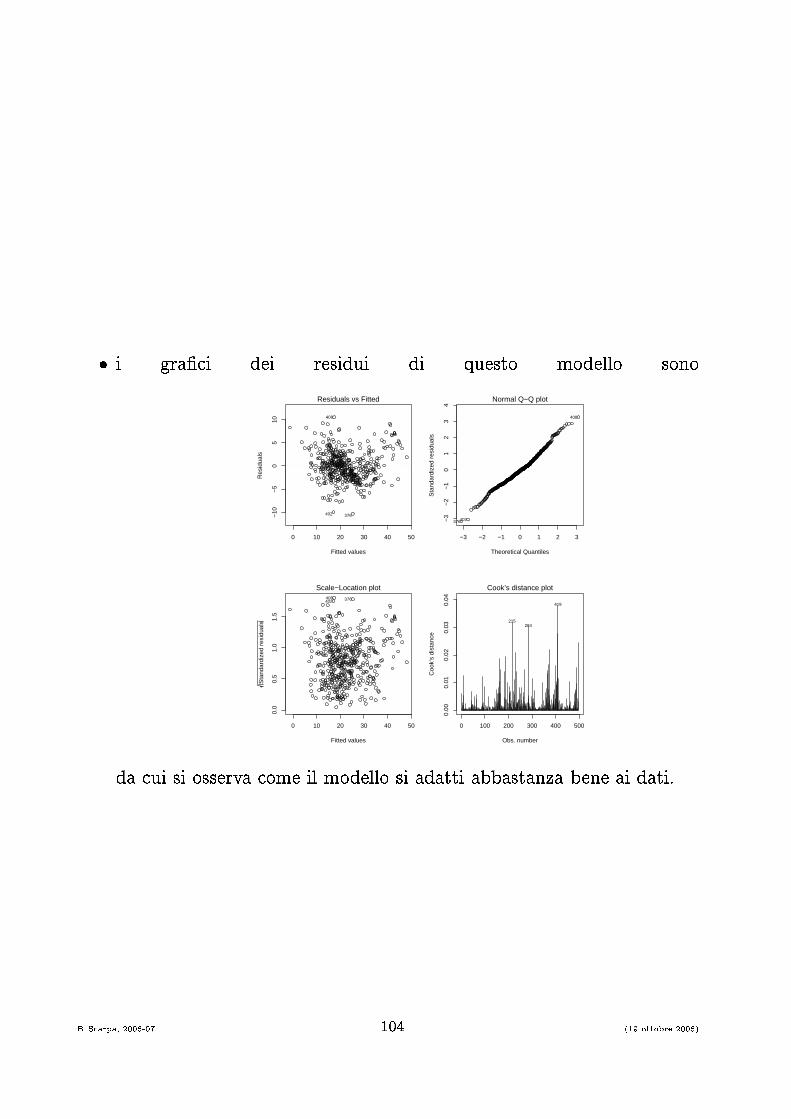
� i gra� i dei residui di questo modello sono0 10 20 30 40 50
−10
−5
05
10
Fitted values
Res
idua
ls
Residuals vs Fitted
408
376402
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
4
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
Normal Q−Q plot
408
376402
0 10 20 30 40 50
0.0
0.5
1.0
1.5
Fitted values
Sta
ndar
dize
d re
sidu
als
Scale−Location plot408 376402
0 100 200 300 400 500
0.00
0.01
0.02
0.03
0.04
Obs. number
Coo
k’s
dist
ance
Cook’s distance plot
419
215284
da ui si osserva ome il modello si adatti abbastanza bene ai dati.
B. S arpa, 2006-07 104 (19 ottobre 2006)

� la medesima pro edura può venire riutilizzata per veri� are se altrigruppi di parametri sono nulli. Ad esempio è possibile veri� are l'in- lusione di un βi singolo dopo aver in luso i termini pre edentementeinseriti Questa statisti a test sarà quindiFoss =
MSR(βi|pre edenti omponenti di β)
MSE he sotto H0 si distribuis e ome una F1,n−p
B. S arpa, 2006-07 105 (19 ottobre 2006)

g1 g2 0,5 0,75 0,90 0,95 0,99 0,9991 10 0,49 1,49 3,29 4,96 10,04 21,041 15 0,48 1,43 3,07 4,54 8,68 16,591 20 0,47 1,4 2,97 4,35 8,1 14,821 30 0,47 1,38 2,88 4,17 7,56 13,291 50 0,46 1,35 2,81 4,03 7,17 12,221 50 0,46 1,35 2,81 4,03 7,17 12,221 51 0,46 1,35 2,81 4,03 7,16 12,192 9 0,75 1,62 3,01 4,26 8,02 16,392 10 0,74 1,6 2,92 4,1 7,56 14,912 15 0,73 1,52 2,7 3,68 6,36 11,342 20 0,72 1,49 2,59 3,49 5,85 9,952 30 0,71 1,45 2,49 3,32 5,39 8,772 50 0,7 1,43 2,41 3,18 5,06 7,962 50 0,7 1,43 2,41 3,18 5,06 7,962 51 0,7 1,42 2,41 3,18 5,05 7,93�
B. S arpa, 2006-07 106 (19 ottobre 2006)

Quantili di una F di Snede or (II)g1 g2 0,5 0,75 0,90 0,95 0,99 0,9993 10 0,85 1,6 2,73 3,71 6,55 12,553 15 0,83 1,52 2,49 3,29 5,42 9,343 20 0,82 1,48 2,38 3,1 4,94 8,13 30 0,81 1,44 2,28 2,92 4,51 7,053 50 0,8 1,41 2,2 2,79 4,2 6,343 50 0,8 1,41 2,2 2,79 4,2 6,343 51 0,8 1,41 2,19 2,79 4,19 6,324 10 0,9 1,59 2,61 3,48 5,99 11,284 15 0,88 1,51 2,36 3,06 4,89 8,254 20 0,87 1,47 2,25 2,87 4,43 7,14 30 0,86 1,42 2,14 2,69 4,02 6,124 50 0,85 1,39 2,06 2,56 3,72 5,464 50 0,85 1,39 2,06 2,56 3,72 5,464 51 0,85 1,39 2,06 2,55 3,71 5,445 10 0,93 1,59 2,52 3,33 5,64 10,485 15 0,91 1,49 2,27 2,9 4,56 7,575 20 0,9 1,45 2,16 2,71 4,1 6,465 30 0,89 1,41 2,05 2,53 3,7 5,535 50 0,88 1,37 1,97 2,4 3,41 4,95 50 0,88 1,37 1,97 2,4 3,41 4,95 51 0,88 1,37 1,96 2,4 3,4 4,88
B. S arpa, 2006-07 107 (19 ottobre 2006)





























