Embed Size (px)
Citation preview

Distributed Hash Tables
Zachary G. IvesUniversity of Pennsylvania
CIS 455 / 555 – Internet and Web Systems
April 19, 2023
Some slides based on originals by Raghu Ramakrishnan

2
Today
Recall HW1 Milestone 1 due Monday @ 11:59PM
For next time: please read the Google File System paper (Ghemawat et al.)

3
A “Flatter” Scheme: Hashing
Start with a hash function with a uniform distribution of values: h(name) a value (e.g., 32-
bit integer)
Map from values to hash buckets Generally using mod (#
buckets)
Put items into the buckets May have “collisions” and
need to chain
0
1
2
3
0
4812
…
buckets
{h(x) values
overflow chain

4
Dividing Hash Tables Across Machines
Simple distribution – allocate some number of hash buckets to various machines Can give this information to every client, or provide
a central directory Can evenly or unevenly distribute buckets Lookup is very straightforward
A possible issue – data skew: some ranges of values occur frequently Can use dynamic hashing techniques Can use better hash function, e.g., SHA-1 (160-bit
key)

5
Some Issues Not Solved withConventional Hashing
What if the set of servers holding the inverted index is dynamic? Our number of buckets changes How much work is required to reorganize the
hash table?
Solution: consistent hashing

6
Consistent Hashing – the Basis of “Structured P2P”
Intuition: we want to build a distributed hash table where the number of buckets stays constant, even if the number of machines changes Requires a mapping from hash entries to nodes Don’t need to re-hash everything if node joins/leaves Only the mapping (and allocation of buckets) needs to
change when the number of nodes changes
Many examples: CAN, Pastry, Chord For this course, you’ll use Pastry But Chord is simpler to understand, so we’ll look at it

7
Basic Ideas
We’re going to use a giant hash key space SHA-1 hash: 20B, or 160 bits We’ll arrange it into a “circular ring” (it wraps
around at 2160 to become 0)
We’ll actually map both objects’ keys (in our case, keywords) and nodes’ IP addresses into the same hash key space “abacus” SHA-1 k10 130.140.59.2 SHA-1 N12

8
Chord Hashes a Key to its Successor
N32
N10
N100
N80
N60
Circularhash
ID Space
Nodes and blocks have randomly distributed IDs Successor: node with next highest ID
k52
k30
k10
k70
k99
Node ID k112
k120
k11
k33k40
k65
Key Hash
9
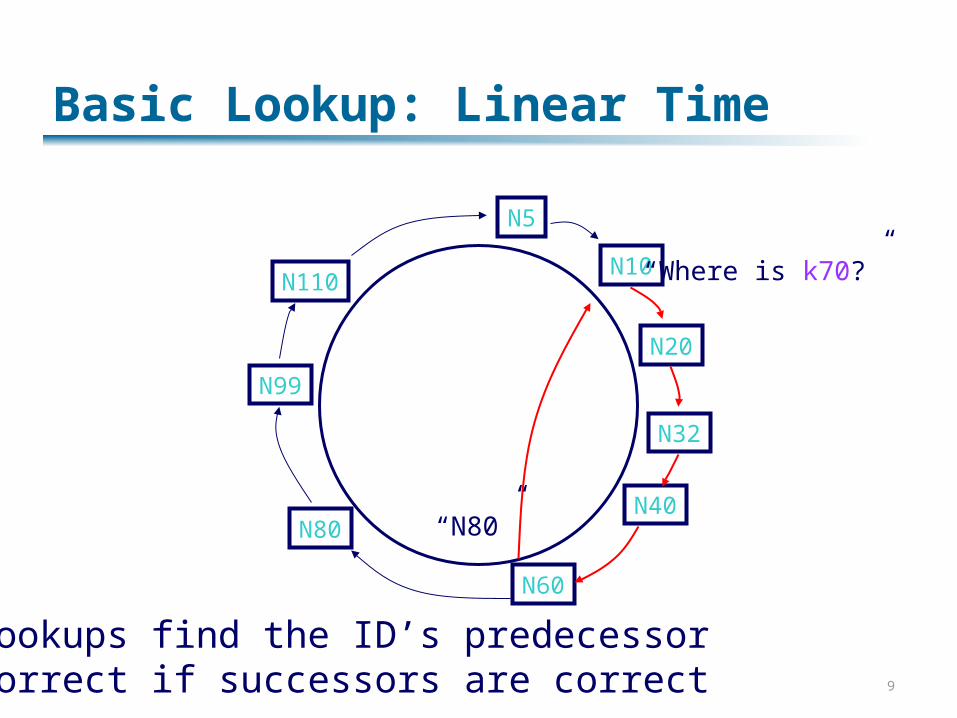
Basic Lookup: Linear Time
N32
N10
N5
N20
N110
N99
N80
N60
N40
“Where is k70?”
“N80”
Lookups find the ID’s predecessor Correct if successors are correct

10
“Finger Table” Allows O(log N) Lookups
N80
½¼
1/8
1/161/321/641/128
Goal: shortcut across the ring – binary search Reasonable lookup latency

11
Node Joins
How does the node know where to go?(Suppose it knows 1
peer)
What would need to happen to maintain connectivity?
What data needs to be shipped around?
N32
N10
N5
N20
N110
N99
N80
N60
N40
N120

12
A Graceful Exit: Node Leaves
What would need to happen to maintain connectivity?
What data needs to be shipped around?
N32
N10
N5
N20
N110
N99
N80
N60
N40

13
What about Node Failure?
Suppose a node just dies?
What techniques have we seen that might help?

14
Successor Lists Ensure Connectivity
N32
N10
N5
N20
N110
N99
N80
N60
Each node stores r successors, r = 2 log N Lookup can skip over dead nodes to find objects
N40
N10, N20, N32
N20, N32, N40
N32, N40, N60
N40, N60, N80
N60, N80, N99
N80, N99, N110
N99, N110, N5
N110, N5, N10
N5, N10, B20

15
Objects are Replicated as Well
When a “dead” peer is detected, repair the successor lists of those that pointed to it
Can take the same scheme and replicate objects on each peer in the successor list Do we need to change lookup protocol to find
objects if a peer dies? Would there be a good reason to change lookup
protocol in the presence of replication?
What model of consistency is supported here? Why?

16
Stepping Back for a Moment:DHTs vs. Gnutella and Napster 1.0
Napster 1.0: central directory; data on peers Gnutella: no directory; flood peers with requests Chord, CAN, Pastry: no directory; hashing scheme
to look for data
Clearly, Chord, CAN, and Pastry have guarantees about finding items, and they are decentralized
But non-research P2P systems haven’t adopted this paradigm: Kazaa, BitTorrent, … still use variations of the Gnutella
approach Why? There must be some drawbacks to DHTs..?

17
Distributed Hash Tables, Summarized
Provide a way of deterministically finding an entity in a distributed system, without a directory, and without worrying about failure
Can also be a way of dividing up work: instead of sending data to a node, might send a task Note that it’s up to the individual nodes to do
things like store data on disk (if necessary; e.g., using B+ Trees)

18
Applications of Distributed Hash Tables
To build distributed file systems (CFS, PAST, …) To distribute “latent semantic indexing” (U.
Rochester) As the basis of distributed data integration (U.
Penn, U. Toronto, EPFL) and databases (UC Berkeley)
To archive library content (Stanford)
It can also be used as the basis of MapReduce-like operations, as we’ll discuss next time

19
Distributed Hash Tables andYour Project
If you’re building a mini-Google, how might DHTs be useful in: Crawling + indexing URIs by keyword? Storing and retrieving query results?
The hard parts: Coordinating different crawlers to avoid redundancy Ranking different sites (often more difficult to
distribute) What if a search contains 2+ keywords?
(You’ll initially get to test out DHTs in Homework 3)

20
From Chord to Pastry
What we saw was the basic data algorithms for the Chord system
Pastry is slightly different: It uses a different mapping mechanism
Object is located at closest node in ID space, not successor node
It doesn’t exactly use a hash table abstraction – instead there’s a notion of routing messages
It allows for replication of data and finds the closest replica
It’s written in Java, not C … And you’ll be using it in your projects!

21
Pastry API Basics (v 2.1)
See freepastry.org for details and downloads Nodes have identifiers that will be hashed:
interface rice.p2p.commonapi.Id 2 main kinds of NodeIdFactories – IPNodeIdFactory for real
nodes, RandomNodeIdFactory for virtual nodes
Nodes are logical entities: can have more than one virtual node Several kinds of NodeFactories: create virtual Pastry nodes
All Pastry nodes have built in functionality to manage routing
Derive from “common API” class rice.p2p.commonapi.Application

22
Creating a P2P Network
Example code in DistTutorial.java Tutorial at http://freepastry.org/FreePastry/tutorial/ Create a Pastry node:
Environment env = new Environment();PastryNodeFactory d = new SocketPastryNodeFactory(new
RandomNodeIdNodeFactory(env), portNo, env);
// Need to compute InetSocketAddress of a host to be addrNodeHandle aKnownNode =
((SocketPastryNodeFactory)d).getNodeHandle(addr);PastryNode pn = d.newNode(aKnownNode);MyApp = new MyApp(pn); // Base class of your
application!

23
Pastry Client APIs
Based on a model of routing messages Derive your message from class
rice.p2p.commonapi.Message Every node has an Id (NodeId implementation) Every message gets an Id corresponding to its key Call endpoint.route(id, msg, hint) to send a message
(endpoint is an instance of Endpoint) The hint is the starting point, of type NodeHandle
At each intermediate point, Pastry calls a notification: app.forward(msg)
At the end, Pastry calls a final notification: app.deliver(id, msg)

24
IDs
Pastry has mechanisms for creating node IDs itself
Obviously, we need to be able to create IDs for keys
Example: use java.security.MessageDigest:MessageDigest md = MessageDigest.getInstance("SHA"); byte[] content = myString.getBytes();md.update(content);byte shaDigest[] = md.digest();
rice.pastry.Id keyId = rice.pastry.Id.build(shaDigest);

25
How Do We Create a Hash Table (Hash Map/Multiset) Abstraction?
We want the following: put (key, value) remove (key) valueSet = get (key)
How can we use Pastry to do this?

Next Time
Distributed file systems (GFS), databases (PNUTS)
26





























