Embed Size (px)
Citation preview

Diseño de un sistema para la recolección de datos de riego de cultivos: Aplicado al cultivo de
la caña de azúcar
Ana María Cabrera Agudelo, [email protected]
Jose Daniel Angarita Mejía, [email protected]
Trabajo de Grado para optar al título de Ingeniero (a) Multimedia otorgado por Universidad
de San Buenaventura Colombia
Asesor (a): Sandra Patricia Cano Mazuera, Doctora (PhD) en Ciencias de la Electrónica
Universidad de San Buenaventura Colombia
Facultad de Ingeniería
Ingeniería Multimedia
Santiago de Cali
2017

1
Citar/How to cite: [1]
Referencia/Reference:
Estilo/Style:
IEEE (2014)
A. M. Cabrera Agudelo y J. D. Angarita Mejía,
“Diseño de un sistema para la recolección de datos de
riego de cultivo: Aplicado a la caña de azúcar”,
Trabajo de grado Ingeniería Multimedia, Cali,
Facultad de Ingeniería, 2017.
Bibliotecas Universidad de San Buenaventura
Biblioteca Digital (Repositorio)
http://bibliotecadigital.usb.edu.co
● Biblioteca Fray Alberto Montealegre OFM - Bogotá.
● Biblioteca Fray Arturo Calle Restrepo OFM - Medellín, Bello, Armenia, Ibagué.
● Departamento de Biblioteca - Cali.
● Biblioteca Central Fray Antonio de Marchena – Cartagena.
Universidad de San Buenaventura Colombia
Universidad de San Buenaventura Colombia - http://www.usb.edu.co/
Bogotá - http://www.usbbog.edu.co
Medellín - http://www.usbmed.edu.co
Cali - http://www.usbcali.edu.co
Cartagena - http://www.usbctg.edu.co
Editorial Bonaventuriana - http://www.editorialbonaventuriana.usb.edu.co/
Revistas - http://revistas.usb.edu.co/

2
Dedicatoria
A mi papá, Mario Alfredo Angarita sin su indispensable ayuda nada habría sido posible. - J.A.
Agradecimientos
Cenicaña
Ingeniero Mario Alfredo Angarita
Ingeniero Pedro Ivan Bastidas

3
TABLA DE CONTENIDO
RESUMEN 14
ABSTRACT 14
I. INTRODUCCIÓN 16
II. PLANTEAMIENTO DEL PROBLEMA 18
A. Antecedentes 18
III. JUSTIFICACIÓN 21
IV. OBJETIVOS 22
A. Objetivo General 22
B. Objetivos Específicos 22
V. METODOLOGÍA 23
VI. MARCO TEÓRICO 25
Recolección de datos 25
Interoperabilidad 25
SOA: Arquitectura Orientada al Servicio 27
Servicios Web 27
Estándares 29
Seguridad 36
Sockets 39
Descripción del Recurso (en inglés, Resource Description) 39
Servicio de Descubrimiento (en inglés, Discovery Service) 39
Representación (en inglés, Representation) 40
Patrones de diseño 40
Patrón de diseño Timestamp Transfer [54] 41
Flyweight 43

4
Factory Method 45
Singleton 46
Template Method 47
Arquitectura de Software 49
Estilos y patrones de Arquitectura 49
Objetivos de la Arquitectura de Software 50
JavaScript frameworks 52
Microprocesador y Sistemas embebidos 53
Microprocesadores 53
Microprocesadores en el riego 54
Sistemas embebidos 55
Sistemas de riego de cultivos industriales 55
Tipos de riego 55
Tipos de Suelo 56
Variables de estudio 58
Dependencias entre variables 61
Cultivo de la Caña de Azúcar 62
Sensores profesionales 63
Tarjetas para la adquisición o captura de datos 66
Sensores académicos 68
VII. ANÁLISIS Y DESARROLLO 72
Análisis de otros sistemas de recolección de datos de riego de cultivo 72
Captación de datos 72
Visualización de reportes 73
Configuración inicial de un cultivo o lote 73
Comparación de estilos de arquitectura de servicios web 75
SOAP y la colección WS-* 75

5
REST 76
REST vs SOAP 77
Análisis de estilos de arquitectura de servicios web 88
Requisitos del sistema 90
Requisitos de usuario 90
Requisitos de hardware 92
Requisitos de software 93
Propuesta de Diseño del Sistema 97
Formas de captación del sistema 97
Tipos de Usuario (Perfiles) 98
Componentes del sistema 99
Arquitectura del sistema 100
Navegador web 100
Aplicación móvil 101
Arduino 101
Sensores 102
Modulo wifi 102
Servicio web 102
Base de datos 103
Diseño del sistema 105
Casos de uso 105
Diagramas de secuencias 117
Diagramas de procesos 121
Modelo de datos 122
Patrones de Diseño 134
Identificación de recursos, diseño de URI 134
Descripción de métodos 135

6
Listado de respuestas 136
Descripción del servicio y documentación 137
Descubrimiento del servicio 140
Diseño de Hardware 141
Características del sistema 144
Implementación del Sistema 145
Trigger Lote 145
Trigger Variable 145
Añadir Variable 146
VIII. PRUEBAS Y RESULTADOS 148
Pruebas manuales 148
Pruebas automatizadas 153
IX. CONCLUSIONES 158
X. RECOMENDACIONES 160
REFERENCIAS 161
ANEXOS 169

7
LISTA DE TABLAS
Tabla 1: Seguridad al nivel de aplicación. Tomado de [63]
Tabla 2: Estilos y patrones de arquitectura. Tomado de [92]
Tabla 3: Objetivos de la Arquitectura de Software. Tomado de [92]
Tabla 4: Popularidad de JavaScript frameworks en Github
Tabla 5: Tipos de suelo
Tabla 6: Dependencia de variables
Tabla 7: Comparación captación de datos de sistemas existentes
Tabla 8: Comparación visualización de reportes en sistemas existentes
Tabla 9: Comparación de configuración de cultivo o lote en sistemas existentes
Tabla 10: Comparación de Principios. Tomado de [36]
Tabla 11: Comparación conceptual. Tomado de [36]
Tabla 12: Comparación tecnológica. Tomado de [36]
Tabla 13: Resultados de rendimiento de servicios web SOAP y REST en la computación
móvil. Tomado de [58]
Tabla 14: Diferencias percibidas. Tomado de [61]
Tabla 15: Idoneidad para casos de uso. Tomado de [61]
Tabla 16: Directrices para la elección de una arquitectura de servicios. Tomado de [61]
Tabla 17: Requisitos de Capacidad de usuario del sistema
Tabla 18: Requisitos de restricciones impuestas al usuario en el sistema
Tabla 19: Requisitos de hardware
Tabla 20: Requisitos funcionales del sistema
Tabla 21: Requisitos de interfaz e interacciones
Tabla 22: Requisitos de operación
Tabla 23: Requisitos de recursos
Tabla 24: Requisitos de seguridad
Tabla 25: Flujo de eventos - Iniciar sesión
Tabla 26: Flujo de eventos - Crear cuenta
Tabla 27: Flujo de eventos - Añadir cuenta
Tabla 28: Flujo de eventos - Eliminar cuenta
Tabla 29: Flujo de eventos - Listar usuarios de la compañía

8
Tabla 30: Flujo de eventos - Salir de la plataforma
Tabla 31: Flujo de eventos - Añadir Cultivo
Tabla 32: Flujo de eventos - Actualizar Cultivo
Tabla 33: Flujo de eventos - Eliminar Cultivo
Tabla 34: Flujo de eventos - Añadir sensor a una variable de un cultivo
Tabla 35: Flujo de eventos - Cambiar sensor de un cultivo a otro
Tabla 36: Flujo de eventos - Eliminar sensor de un cultivo
Tabla 37: Flujo de eventos - Eliminar Cultivo
Tabla 38: Flujo de eventos - Eliminar valor a una variable de un cultivo
Tabla 39: Flujo de eventos - Buscar Cultivo por nombre
Tabla 40: Flujo de eventos - Comparar valores de variables en dos gráficas
Tabla 41: Flujo de eventos - Consultar un cultivo específico
Tabla 42: Campos del Cultivo
Tabla 43: Campos del Lote
Tabla 44: Campos de variables
Tabla 45: Campos de valor captado
Tabla 46: Perfiles del sistema
Tabla 47: Campos de sensor
Tabla 48: Campos de Variables del sistema
Tabla 49: Capos de Variables del sistema y personalizadas
Tabla 50: Campos de usuarios
Tabla 51: CRUD correspondiente con HTTP métodos
Tabla 52: Catálogo de respuestas HTTP habituales
Tabla 53: Tiempos de respuesta solicitud ‘Crear un nuevo cultivo’
Tabla 54: Tiempos de respuesta solicitud ‘Editar un cultivo existente’
Tabla 55: Tiempo de respuestas solicitud ‘Seleccionar 10 cultivos’
Tabla 56: Tiempos de respuesta solicitud ‘Eliminar Cultivo’
Tabla 57: Tiempos de respuesta solicitud ‘Eliminar Cultivo’
Tabla 58: Tiempos de respuesta solicitud ‘Editar una variable’
Tabla 59: Tiempos de respuesta solicitud ‘Obtener una variable’
Tabla 60: Tiempos de respuesta solicitud ‘Crear una variable’
Tabla 61: Tiempos de respuesta solicitud ‘Modificar o agregar campos a una variable’
Tabla 62: Pruebas con Arduino, sensor humedad suelo, lluvia y módulo WiFi

9
LISTA DE FIGURAS
Figura 1: Funcionamiento de los servicios web usando SOAP. Tomada de [5]
Figura 2: Arquitectura SOAP. Tomado de [3]
Figura 3: Arquitectura de los mensajes SOAP. Tomado de [5]
Figura 4: Arquitectura de REST. Tomado de [62]
Figura 5: Ejemplo de documento XML, Tomado de [50]
Figura 6: Ejemplo 2-4 definición de interfaz. Tomado de [51]
Figura 7: Relación entre UDDI y WSDL. Tomado de [53]
Figura 8: Modelo Orientado al Recurso. Tomado de [33]
Figura 9: Representación visual del patrón ‘Timestamp Transfer’. Tomado de [54]
Figura 10: Diagrama UML del patrón Flyweight. Tomado de [42]
Figura 11: Diagrama UML del método de fábrica. Tomado de [42]
Figura 12: Diagrama UML del patrón Singleton. Tomado de [42]
Figura 13: Diagrama UML del método de modelado (Template Method). Tomado de [42]
Figura 14: Tendencia de uso de librerías JavaScript del 2009 a 2017, sacado de google trends
compara: Angular, React, Ember y Polymer
Figura 15: Diagrama simplificado de un microprocesador. Tomado de [97]
Figura 16: Componente de un sistema embebido [99]
Figura 17: Tensiometro. Tomado de [82]
Figura 18: Sonda de neutrones. Tomado de [85]
Figura 19: Tarjeta Goblin 2. Tomado de [79]
Figura 20: Tarjeta Arduino UNO. Tomado de [76]
Figura 21: Sensor Humedad Suelo/Módulo HL-69. Tomado de [86]
Figura 22: Sensor de lluvia/Módulo YL-83. Tomado de [87]
Figura 23: Sensor de temperatura para Arduino
Figura 24: Reporte Wisecrop. Tomado de www.wisecrop.com
Figura 25: Percepción de Accesibilidad al Aprendizaje. Tomado de [61]
Figura 26: Percepción de facilidad de aprendizaje. Tomado de [61]
Figura 27: Tendencia de uso de lenguajes de SW entre: NodeJs, Laravel, Java EE 6, Django,
Ruby and rails. Tomado de Google Trends.
Figura 28: Tendencia de uso de frameworks Node.JS que contiene un conjunto de sólidas
características para las aplicaciones web entre: Express.js, koa.js, hapi.js y reatify,js. Tomado

10
de Google Trends
Figura 29: Arquitectura del sistema
Figura 30: Casos de uso aplicaciones
Figura 31: Inicio de sesión y permanecer logueado
Figura 32: Crear cuenta con compañia nueva
Figura 33: Consultar un cultivo específico
Figura 34: Consultar una variable de un cultivo específico
Figura 35: Muestra dos gráficas con diferentes meses
Figura 36: Añadir valor a una variable de un cultivo específico de forma manual
Figura 37: Añadir un sensor a una variable de un cultivo específico
Figura 38: Diagrama de procesos crear, editar y eliminar cultivo
Figura 39: Diagrama de procesos crear, eliminar, editar variable y añadir, eliminar y
modificar sensor
Figura 40: Diagrama de procesos inicio de sesión y crear cuenta
Figura 41: Esquema base de datos
Figura 42: Estructura Cultivo
Figura 43: Estructura Lote
Figura 44: Estructura Variables
Figura 45: Estructura valor captado
Figura 46: Esquema de Perfiles del sistema
Figura 47: Estructura de un sensor
Figura 48: Estructura variables del sistema
Figura 49: Estructura de una variable del sistema
Figura 50: Estructura Usuarios
Figura 51: Almacenamiento de información, actualización, proceso de detección y
eliminación de información. Tomado de [66]
Figura 52: Módulo WiFi ESP8266
Figura 53: Diagrama de conexión de sensor humedad de suelo al Arduino UNO. Tomado de
[88]
Figura 54: Diagrama de conexión sensor de lluvia al Arduino UNO. Tomado de [87]
Figura 55: Diagrama de conexión de módulo WiFi ESP8266 al Arduino UNO. Tomado de
[89]
Figura 56: Trozo del trigger lote

11
Figura 57: Trozo del trigger variable
Figura 58: Trozo añadir variable al sistema
Figura 59: Prueba Arduino - Sensor Humedad del Suelo
Figura 60: Prueba Arduino - Sensor de Lluvia

12
LISTA DE ACRÓNIMOS
API → Application Programming Interface (Interfaz de programación de aplicaciones)
CE → Conductividad Eléctrica
CRUD → Create, Read, Update and Delete (Crear, Leer, Actualizar y Borrar)
DDD → Domain Driven Design (Diseño orientado al dominio)
EFX → Efficient XML (XML Eficiente)
FAO → Food Agriculture Organisation (Organización de Agricultura y Alimentación)
HTTP → Hypertext Transfer Protocol (Protocolo de Transferencia de Hypertexto)
HTTPS → Hypertext Transfer Protocol Secure (Protocolo Seguro de Transferencia de
Hypertexto)
IoT → Internet of Things (Internet de las Cosas)
JSON → JavaScript Object Notation
LARA → Lámina Rápidamente Aprovechable
MIME → Multipurpose Internet Mail Extensions
QoS → Quality of Service (Calidad de Servicio)
REST → Representation State Transfer
ROM → Resource Oriented Model (Modelo Orientado a Recurso)
RPC → Remote Procedure Call (Llamada a Procedimiento Remoto)
SOA → Service Oriented Architecture ( Arquitectura Orientada al Servicio)
SOAP → Simple Object Access Protocol
SOC → System-on-chip (Sistema-en-chip)
SSL → Secure Socket Layer
SW (WS) → Servicio Web (Web Service)
TAG → Grupo Técnico de Arquitectura
TCP → Transmission Control Protocol (Protocolo de Control de Transmisión)
TDR → Time Domain Reflectometry (Reflectómetro de dominio de tiempo)

13
TLS → Transport Layer Security
UDDI → Universal Description, Discovery and Integration
UDP → User Datagram Protocol (Protocolo de datagramas de usuario)
URI → Uniform Resource Identifier (Identificador uniforme de recursos)
USDA → United States Department of Agriculture (Departamento de agricultura de los
Estados Unidos)
W3C → World Wide Web Consortium (Consorcio de la World Wide Web)
WADL → Web Application Description Language
WSDL → Web Services Description Language
XML → Extensible Markup Language

14
RESUMEN
El presente proyecto tiene como objetivo diseñar un sistema para la recolección de datos de
riego de cultivo aplicado al cultivo de la caña de azúcar.
Sirve para recolectar información del sistema de riego aplicado en el cultivo de caña de azúcar
por medio de sensores y/o usuarios que registren el estado del cultivo diariamente, este
procura satisfacer una necesidad, en este caso poder recolectar información sin importar que
el sistema sea utilizado con dispositivos de diferentes marcas. Ahora bien la industria podrá
obtener los datos del riego que está buscando por medio de múltiples opciones.
Para que el objetivo del proyecto sea cumplido requiere un funcionamiento uniforme de todas
las partes que lo componen, este funciona a través de aplicaciones que permiten el ingreso de
datos al sistema, concede añadir nuevas variables de cultivo y sensores, además ofrece reporte
de la información obtenida de las variables existentes, dicha información facilita el análisis
del estado del cultivo. No obstante, cuenta con la integración de elementos de hardware para
emular el envío de datos al Servicio Web desde un lote perteneciente al cultivo, empleando un
Arduino UNO con módulo wifi y sensores académicos.
Palabras claves: Irrigación, Diseño de Sistema, Cultivo, Recolección de datos
ABSTRACT
The present project aims to design a system for the collection of crop irrigation data applied to
the cultivation of sugarcane.
It is used to collect information about the irrigation system applied in the sugarcane
cultivation by means of sensors and / or users that record the state of the crop daily, this seeks
to satisfy a need, in this case to be able to collect information regardless of whether the
system is Used with devices of different brands. Now the industry can get the irrigation data
you are looking for through multiple options.

15
In order for the objective of the project to be fulfilled requires a uniform operation of all its
component parts, it works through applications that allow the input of data to the system, adds
new crop variables and sensors, and also provides information reporting obtained from the
existing variables, this information facilitates the analysis of the state of the crop. However, it
has the integration of hardware elements to emulate the sending of data to the Web Service
from a lot belonging to the crop, using an Arduino UNO with wifi module and academic
sensors.
Keywords: Irrigation, System Design, Cultivation, Data Collection

16
I. INTRODUCCIÓN
Un sistema para la recolección de datos es una herramienta que permite la centralización de la
información para así facilitar el acceso a ésta desde múltiples puntos autenticados. Mediante
un servicio web, sensores de fenómenos físicos, la red y aplicaciones de usuario se logra una
exitosa exposición y comunicación de los datos relevantes que alimentan el sistema. Estos
servicios cumplen unas acciones y tareas específicas que pueden ser integradas en
aplicaciones externas y así permitir a un usuario hacer uso de éstas. La necesidad de
involucrar un sistema de recolección de datos se puede aplicar en prácticamente todas las
industrias y/o aspectos de la vida, ya que la tendencia global es que el acceso a la información
sea cada vez más ubicua.
Por otro lado, los sistemas orientados a cultivos por riego son sistemas relacionados con el
medio ambiente y la inclusión de las tecnologías de la información, dentro de estos sistemas
se está expandiendo de manera rápida con el propósito de capturar datos capaz de ofrecer
información que le permita al usuario final tomar una decisión más rápida.
Este fenómeno no es diferente para la industria del riego, los sistemas de visualización de
variables físicas que los traducen en muchos casos a señales eléctricas, es decir, los sensores,
aportan un mecanismo de control y monitoreo para dicha industria. Este crecimiento en
adquisición de información ha tenido como consecuencia una extensa cantidad de datos
heterogéneos, lo cual ha generado a su vez una necesidad de procesamiento y análisis de esta
misma para poder convertirla en información útil para facilitar el proceso de toma de decisión
del usuario final.
En este trabajo se presenta un sistema de recolección de datos que le permite a una máquina
externa enviar datos relevantes por medio de un servicio web durante el proceso de riego de
cultivos, o por medio de recolección de información a través de sensores de lluvia o humedad
para medir el comportamiento e impacto en el suelo. Este sistema se aplicará a un caso de
estudio en el cultivo de la caña de azúcar para que dichos datos puedan ser almacenados, y
posteriormente accedidos.

17
Los sistemas de comunicación inalámbricos como radio, bluetooth, wifi, etc han evolucionado
mucho a lo largo de los años apoyados en el progreso e interconexión de la internet. Este
cambio no ha sido ajeno para el ambiente empresarial. En la industria del riego de cultivos se
ha realizado mucho avance para el monitoreo y sensado de estos. Sin embargo hay un vacío
en un sistema que ofrezca un lugar centralizado para el almacenamiento de los datos que estos
sistemas de monitoreo pueden obtener para poder ser accedido desde cualquier dispositivo,
ejecutando cualquier sistema operativo en cualquier ubicación que sea requerido.

18
II. PLANTEAMIENTO DEL PROBLEMA
Los servicios web permiten una comunicación y acceso a la información desde cualquier
lugar con acceso a internet, como lo mencionan en [69] “El principal objetivo de un Servicio
Web es brindar interoperabilidad entre aplicaciones que han sido construidas en sistemas
diferentes, con tipos diferentes de middleware, utilizando diferentes almacenes de datos”. Los
sistemas de recolección físicos tienen el inconveniente de que en su gran mayoría son
desarrollados por privados que manejan protocolos y métodos de comunicación particulares
para acceder a estos, dificultando así la integración de estos a sistemas para una visualización
comprensiva de estos datos.
Se hace necesario un sistema con una base de datos para centralizar todos los datos que son
recolectados y así poder ser consumidos por múltiples clientes autorizados para obtener estos;
Por lo que se propone diseñar un sistema de recolección de datos que permita realizar un
almacenamiento de variables físicas capturadas en el proceso del riego de un cultivo y así
poder ser accedidos por cliente (s) externo (s) y habilitar una obtención, visualización y/o
manipulación de estos mismos.
A. Antecedentes
Un sistema de recolección de datos es un conjunto de componentes, aplicaciones y/o
tecnologías que intercambian datos entre sí con el objetivo de ofrecer unos servicios o
resultados específicos. Estos sistemas proporcionan mecanismos de comunicación estándar
entre diferentes aplicaciones, que interactúan entre sí para presentar información dinámica al
usuario. Por medio de un servicio web y elementos físicos como sensores para capturar
información se presenta una buena herramienta para centralizar y exponer los datos del
sistema.
Se han realizado investigaciones relacionados con el diseño de servicios web, como el trabajo
presentado por Lozano [67], donde describe el uso de un servicio web para el control remoto
de aparatos electrónicos por medio de teléfonos inteligentes para los sistemas operativos
Android. En este trabajo los autores propusieron un servicio web de tipo REST elegido por
ser muy sencillo e intuitivo y además, por su característica de ser más rápido en la

19
comunicación entre aplicaciones, que interactúan entre sí. Así mismo, usaron sockets con el
protocolo UDP, los cuales se caracterizan por no necesitar establecer una conexión, ya que
tanto el servidor como el cliente escucha en un puerto y en cualquier momento cualquiera de
ellos puede enviar un mensaje al otro. El autor desarrolló una aplicación que simula el
funcionamiento de una bombilla por medio de un servicio web, el cual envía datos al servidor
a través de sockets, usando mensajes de control. Con este trabajo concluyeron que el uso de
dispositivos móviles para el control remoto de aparatos electrónicos ayuda al ahorro de
energía en el hogar.
Por otro lado, un trabajo propuesto por Johnsrud Lars [68], presenta un análisis de tipos de
compresión de documentos XML para la efectividad de los servidores en dispositivos
móviles. En este documento se estudian dos tipos de compresión el zLIB (biblioteca de
compresión de datos XML de software libre) y EFX, los autores demuestran que estos dos
presentan casi el mismo tiempo de respuesta, siendo el EFX ligeramente mejor. Sin embargo,
estos formatos les toma la mitad de tiempo de respuesta de un documento XML sin
compresión. Con este experimento lograron concluir que el uso de compresores de XML hace
que la transmisión de datos sea más rápida en los servidores web que prestan servicios a
dispositivos móviles y además, sugieren usar el EFX pues proporciona mejor rendimiento y es
aconsejado por W3C.
También se han desarrollado diversas herramientas para monitorear los sistemas de riego,
como Ranch Systems Internet Software [71], es un software de recolección de datos de un
sistema de riego. En esta aplicación se puede monitorear el estado de la humedad del suelo,
temperatura, bombas de agua. Éste funciona con un dispositivo en el campo, el cual se
encarga de recolectar datos de sensores integrados con el sistema de riego, que luego enviará
a un servidor que se encargará de almacenar y analizar los datos de cada variable que
posteriormente se podrán visualizar en una aplicación web en un ordenador o si los datos
lanzan una alerta se enviará un mensaje de texto al celular del operador. Para poder tener o
usar este software el sistema de riego debe ser de Ranch Systems.
Otra herramienta ClimateMinder Technology [72], es un software de recolección de datos
para sistemas de riego. Con el que se puede recolectar datos de la humedad del suelo,
temperatura, concentración de sal en el suelo. Éste funciona en tres partes, primero se tiene

20
los sensores y controladores los cuales contienen integrado el ClimateMinder Wireless
Network para comunicarse con un dispositivo con ClimateMinder Mobile Software, el cual se
encarga de enviar datos determinados de los sensores y controladores a un servidor al mismo
tiempo de recibir órdenes del servidor para cambiar los estados de los controladores. El
servidor se encarga de almacenar, leer, actualizar, analizar y enviar datos y respuestas, para
visualizar los datos se debe tener un dispositivo con acceso a internet e ingresar a la
aplicación web. Para poder usar esta herramienta, todo el sistema de riego (estaciones
meteorológicas, sensores, etc.) debe ser ClimateMinder.
Las herramientas mencionadas anteriormente, pueden ser muy útiles para la recolección de
datos en los sistemas de riego en un cultivo, pero estos programas requieren para su
funcionamiento que el sistema de riego sea de su misma compañía para poder interactuar con
los traductores que envían los datos a los servidores. En Colombia la mayoría de los
agricultores no tienen los recursos económicos para solventar todo un sistema de riego de una
misma compañía, por lo que las herramientas no son usadas y emplean el monitoreo
tradicional por medio de plantillas. Por lo que, una alternativa podría tener una aplicación
móvil que pueda almacenar y visualizar los datos, el cual sea un medio de apoyo tecnológico.
Aclaración: En la sección Análisis de otros sistemas de recolección de datos de riego de
cultivo, se extiende en los antecedentes y se realiza un análisis de la captación de datos,
visualización de reportes y configuración inicial de un cultivo o lote de sistemas existentes.

21
III. JUSTIFICACIÓN
El sistema de recolección de datos tiene como beneficio el desacoplamiento de las interfaces
de las implementaciones, consideraciones de plataforma y facilidad de acceso, brindando así
la capacidad de realizar un enlace de servicio dinámico y acercarse cada vez más a una
interoperabilidad entre lenguajes y entre plataformas.
Colombia es un país privilegiado, en cuanto a la oferta del recurso hídrico. La precipitación
media supera ampliamente los estándares de Suramérica y del mundo. Pero el problema de la
disponibilidad del agua para las plantas es que está muy mal distribuida moviéndose entre
épocas de exceso y época de déficit extremos, lo cual implica que una producción agrícola
exitosa necesita de un buen sistema de riego.
Dichos sistemas de riego pueden ser optimizados mediante el monitoreo y control, a través de
estos se pueden obtener datos para ser analizados posteriormente por agricultores u otros
perfiles involucrados en esa industria. Con la construcción de un Servicio Web que brinde un
acceso ubicuo, remoto y accesible se puede brindar una herramienta para facilitar el trabajo en
la industria del riego y cultivos en general.
Un sistema de bajo costo, basado en sensores de fácil reemplazo, software libre y con un
servicio de fácil acceso para cualquier sistema operativo, lenguaje o arquitectura con
capacidad de conexión a internet brinda beneficios para agricultores en Colombia ya que
puede ser usado para la optimización y eventual automatización de todo el sistema de riego.

22
IV. OBJETIVOS
A. Objetivo General
Diseñar un sistema para la recolección de datos de riego de cultivo aplicado al cultivo de la
caña de azúcar.
B. Objetivos Específicos
● Identificar y seleccionar las variables más representativas para los sistemas de riego en
el cultivo de caña de azúcar.
● Analizar las diferentes tecnologías que existen para la creación de un sistema para la
recolección de datos de riego de cultivo.
● Identificar los diferentes aspectos que deben considerarse para soportar las diferentes
formas de recolección de datos de un sistema de riego de cultivo.
● Implementar el diseño de recolección de datos para cultivos de riego.
● Evaluar el diseño a través de un prototipo funcional aplicado a un caso de estudio en
Colombia con el cultivo de la caña de azúcar.

23
V. METODOLOGÍA
Este proyecto basa su metodología principalmente en el método científico ya que para
identificar y seleccionar las variables más representativas en los sistemas de riego, analizar las
diferentes tecnologías existentes para la recolección de datos e identificar los diferentes
aspectos involucrados en los sistemas de riego se requiere de una profunda investigación
bibliográfica para poder cumplir cada uno de estos objetivos.
Para identificar y seleccionar las variables más representativas para los sistemas de riego en el
cultivo de la caña de azúcar, se investigará en textos académicos y profesionales de la
industria del riego sobre cuales son las variables involucradas en el proceso de riego del
mencionado cultivo y en base a otros estudios se identificarán las más representativas para ser
incluidas en el diseño del sistema.
Para el análisis de tecnologías existentes y los aspectos involucrados en la recolección de
datos de sistemas de riego de cultivo, se realizará una investigación de las diferentes opciones
existentes para llevar a cabo el diseño del sistema, posteriormente se hará una comparación
entre estás, seguido de un análisis y final decisión de cual tecnología usar en cada componente
del sistema.
La implementación del diseño se llevará a cabo siguiendo los patrones de diseño pertinentes
para cada caso específico, estos se definirán realizando una investigación de cada uno y
posterior análisis para establecer el mejor uso de cada patrón en los componentes del sistema.
Debido a la naturaleza de este proyecto, la evaluación del sistema se llevará a cabo mediante
el método empírico - análitico, el cual se basa en la experimentación y lógica empírica. La
razón de ser de esta investigación es ofrecer a la industria con un sistema que sea flexible,
escalable, usable e integrable a cualquier sistema existente, por lo cual se realizarán pruebas
de este alimentando el mismo con datos reales obtenidos de profesionales de la industria. De
igual manera se llevará a cabo un experimento con una tarjeta programable y sensores de
fenómenos físicos para evaluar el sistema con el ingreso automático de datos en tiempo real.

24

25
VI. MARCO TEÓRICO
A continuación se definen algunos conceptos que están relacionados con la propuesta del
proyecto, en el diseño de un sistema de recolección de datos aplicado a un caso de estudio
como el cultivo de la caña de azúcar
Recolección de datos
La recopilación de datos es el proceso de recolección y medición de información sobre las
variables seleccionadas de forma sistemática y establecida, que permite responder a las
preguntas pertinentes y evaluar los resultados. El componente de recopilación de datos de la
investigación es común a todos los campos de estudio incluyendo las ciencias físicas y
sociales, humanidades y negocios. Ayuda a científicos y analistas a recolectar los puntos
principales como información recopilada. Aunque los métodos varían según la disciplina, el
énfasis en la recolección exacta y honesta sigue siendo el mismo. El objetivo de toda la
recolección de datos es capturar evidencia de calidad que luego se traduce en análisis de datos
ricos y permite construir una respuesta convincente y creíble a las preguntas que se han
planteado. [90]
Interoperabilidad
La interoperabilidad se define como la capacidad que tiene un producto o un sistema, cuya
interfaces son totalmente conocidas, para funcionar con otros productos o sistemas existentes
o futuros y eso sin restricción de acceso e implementación. [13]
En el contexto de interoperabilidad en los sistemas de información Lynch Cliford lo explica
como: “la habilidad de una máquina para interactuar provechosamente con otras máquinas
de manera casual y automática, esto sin planeación o negociación previa entre las
organizaciones que operan estas máquinas”. [13] Otras definiciones aceptadas son:
“Interoperabilidad es la posibilidad de que distintos tipos de ordenadores, redes, sistemas
operativos, y aplicaciones trabajen juntos de forma eficaz, sin comunicación previa, de tal

26
forma que puedan intercambiar información de manera útil y con sentido. Hay tres aspectos
que se deben tener en cuenta en la interoperabilidad: semántica, estructural y sintáctica”.
[46]
La interoperabilidad es la capacidad de sistemas múltiples con diversas plataformas de
hardware y de software, estructuras de datos e interfaces, para intercambiar datos con la
pérdida mínima de contenido y de funcionalidad. [13]
La interoperabilidad está relacionada con la posibilidad de que los sistemas de las
Administraciones Públicas trabajen juntos de forma satisfactoria y productiva
independientemente de la tecnología o la aplicación que se utilice, o qué proveedor ha
suministrado el sistema subyacente. [48]
De la misma forma, el El uso de metadatos en la administración electrónica española: los
retos de la interoperabilidad [70] define la interoperabilidad como “la capacidad de los
sistemas de tecnologías de la información y las comunicaciones, y de los procesos
empresariales a los que apoyan, de intercambiar datos y posibilitar la puesta en común de
información y conocimiento”. [48]
El Marco Europeo de Interoperabilidad, una iniciativa para facilitar la interoperabilidad de
servicios y sistemas a nivel pan-europeo, define la interoperabilidad como “la capacidad de
los sistemas de Tecnologías de Información y Comunicación (TIC) y de los procesos de
negocio que soportan, para intercambiar datos y compartir información y conocimientos”.
[13]
Basado en la recolección bibliográfica realizada en [13, 46, 48], se puede definir la
interoperabilidad como: “La capacidad de un sistema de información de comunicar y
compartir datos de forma efectiva (con la mínima o nula pérdida de su valor y funcionalidad),
con uno o varios sistemas de información (siendo generalmente estos sistemas completamente
heterogéneos en sus protocolos de recolección y distribución de datos además, de estar
geográficamente distantes), mediante una interconexión libre, automática y transparente, sin
dejar de utilizar en ningún momento las interfaces del sistema propio”.

27
Sin interoperabilidad no hay Servicios Web, ya que sin éste el servicio perdería su propósito.
Los Servicios Web se están convirtiendo en tecnologías para implementar SOAs. Ellos
simplifican la interoperabilidad permitiendo una mayor integración de aplicación. Proveen el
medio para presentar aplicaciones existentes para que los desarrolladores las puedan acceder a
través de lenguajes y protocolos estándar. La estandarización simplifica la interoperabilidad;
en vez de interactuar con sistemas heterogéneos, cada uno con diferentes formato de datos,
protocolos, etc., las aplicaciones pueden interactuar con sistemas más homogéneos.
SOA: Arquitectura Orientada al Servicio
Una SOA es un paradigma para organizar y utilizar capacidades distribuidas que pueden estar
bajo el control de diferentes dominios de propiedad. [30]
Es un estilo arquitectónico que es compatible con la orientación del servicio (service-
orientation). La orientación a servicios es una manera de pensar en términos de servicios el
desarrollo basado en el servicio y los resultados del servicio.
Un servicio puede definirse como:
● Una representación lógica de una actividad repetible que tiene un resultado esperado
específico.
● Es auto-contenido
● Puede estar compuesto de otros servicios
● Una “caja negra” para los consumidores del servicio [33]
El principal beneficio de la arquitectura SOA es que provee un simple paradigma escalable
para la organización de grandes sistemas que requieren interoperabilidad para realizar una
tarea. SOA es escalable porque hace el menor número de suposiciones sobre la red y
minimiza suposiciones de confianza que se hacen a menudo de manera implícita en los
sistemas de menor escala. [30]
Servicios Web
Los servicios web son un conjunto de protocolos y estándares que sirven para intercambiar
datos entre aplicaciones, además permite utilizar distintas aplicaciones software desarrolladas

28
en lenguajes de programación diferentes y ejecutadas desde cualquier plataforma para
intercambiar datos.
Un servicio web es un método de comunicación entre dos dispositivos electrónicos a través de
una red, también es definido en [1] como un sistema de software diseñado para soportar
interacciones interoperables máquina a máquina a través de una red.
Esta tecnología utiliza un conjunto de protocolos y estándares que le permiten intercambiar
datos entre aplicaciones sin importar el lenguaje o las características físicas del sistema donde
se ejecuta cada aplicación, entre estos estándares encontramos a SOAP1. De igual manera
aunque todavía no ha sido estandarizado, se encuentra REST2 . Ambos servicios permiten que
las máquinas tengan un lenguaje en común, por el cual puedan comunicar información
permitiendo a través de acciones como obtener, poner, borrar, entre otras.
Estos protocolos de servicios funcionan exponiendo diferentes acciones, ya sean de entrada o
salida mediante estándares web W3C [5], como se observa en la Figura 1, el cual muestra el
funcionamiento de un servicio web, aplicado a diferentes contexto de uso.
Figura 1: Funcionamiento de los servicios web usando SOAP. Tomada de [5]
1 SOAP: http://www.w3.org/TR/soap/
2 REST: http://www.w3.org/TR/ws-arch/#relwwwrest

29
La Figura 1, muestra un usuario (que juega el papel de cliente dentro de los Servicios Web), a
través de una aplicación, solicita información sobre un viaje que desea realizar haciendo una
petición a una agencia de viajes que ofrece sus servicios a través de Internet. La agencia de
viajes ofrecerá a su cliente (usuario) la información requerida. Para proporcionar al cliente la
información que necesita, esta agencia de viajes solicita a su vez información a otros recursos
(otros Servicios Web) en relación con el hotel y la compañía aérea. La agencia de viajes
obtendrá información de estos recursos, lo que la convierte a su vez en cliente de esos otros
Servicios Web que le van a proporcionar la información solicitada sobre el hotel y la línea
aérea. Por último, el usuario realizará el pago del viaje a través de la agencia de viajes que
servirá de intermediario entre el usuario y el servicio Web que gestionará el pago.” [2]
En el proceso descrito se observa que se incluyen un conjunto de tecnologías, las cuales hacen
posible la comunicación entre dos sistemas. El estándar SOAP [3] es usado para que el
servicio web sea aplicado a diferentes contextos, como: hotel, agencia de viajes, entre otros.
Estándares
SOAP
En la Figura 2, se observa la arquitectura de la colección WS-* con los estándares actuales y
especificaciones Web emergentes que IBM, Microsoft y otras compañías importantes de TI
han desarrollado. SOAP proporciona un sobre para el envío de mensajes de servicios web a
través de Internet.

30
Figura 2: Arquitectura SOAP. Tomado de [3]
Como se observa en la Figura 3, el sobre SOAP contiene dos partes: Una cabecera opcional
que proporciona información de autenticación, codificación de los datos o como se debe
procesar el mensaje. y el cuerpo del mensaje que puede definirse usando WSDL.
Figura 3: Arquitectura de los mensajes SOAP. Tomado de [5]
Es un protocolo simple y ligero para la comunicación, en un entorno distribuido o
descentralizado. Las operaciones son definidas como puerto WSDL. La comunicación (Figura

31
3) se realiza mediante mensajes codificados en XML y transportado un protocolo de
transporte HTTP. SOAP se define como un mecanismo para el intercambio de información,
estructurada y tipada, entre pares de aplicaciones en un entorno distribuido. [11] Es posible
ver a SOAP desde distintos puntos de vista [49]:
● Como un mecanismo para invocar métodos en servidores, servicios, o componentes,
para lo cual se define en la especificación una metodología para encapsular e
intercambiar invocaciones RPC, en los mensajes, usando la extensibilidad y
flexibilidad que proporciona XML.
● Como un protocolo para intercambio de mensajes (sincrónicos o asincrónicos).
● Como un formato para intercambio de documentos XML.
REST
Es un estilo de arquitectura como se muestra en la Figura 4, creado por el TAG del consorcio
W3C en paralelo con HTTP/1.1. Esta arquitectura fue diseñada especialmente para la
comunicación entre navegadores y servicios web cuyo término fue acuñado por Roy Thomas
Fielding. Al ser REST un estilo de arquitectura, lo cual se define como un conjunto
coordinado de restricciones que controlan el funcionamiento y las características de los
elemento de la arquitectura y permiten las relaciones de unos elementos con otros. [12]
La mayoría de APIs REST están basadas en protocolo de transporte HTTP, lo que infiere que
todo el control de transmisión de información se hace a través de las acciones POST, GET
PUT, DELETE, que sirven para enviar, obtener, reemplazar y eliminar. Este estándar puede
usar tanto XML como JSON como formato de intercambio de mensajes, siendo JSON el más
rápido y entendible para el humano de los dos.

32
Figura 4: Arquitectura de REST. Tomado de [62]
Los servicios web se pueden basar en SOAP o REST. SOAP es un estilo estandarizado
además, de ser más seguro que REST pero el uso de este requiere mayor tiempo de desarrollo
debido a su nivel de complejidad. Por tanto en el desarrollo de aplicaciones ágiles se emplean
servicios web basados en REST para mostrar cantidad de datos masivos. Esto también se debe
al uso de mensajes en formato XML (usados en SOAP) los cuales son complejos comparados
con los de tipo JSON (usados en REST), razón por lo que muchos de los servicios de redes
sociales hacen uso del protocolo REST-JSON.
JSON
JSON es un formato de intercambio de datos ligero, es fácil de leer y escribir para los seres
humanos, al igual que fácil de interpretar y generar para las máquinas. Se basa en un
subconjunto del lenguaje de programación JavaScript, estándar ECMA-262. JSON se basan
en dos estructuras: [6]
● Una colección de pares (nombre —> valor). En varios lenguajes esto se realiza como
un objeto, estructura, mapa, lista con clave o una matriz.
● Una lista ordenada de valores. En la mayoría de lenguajes esto se realiza como una
lista.

33
XML
Es un lenguaje de etiquetado extensible. La W3C lo define como un formato que permite la
lectura de datos a través de diferentes aplicaciones. [50] Este lenguaje sirve para estructurar,
almacenar e intercambiar información. El XML tiene una estructura como se puede ver en la
Figura 5.
Figura 5: Ejemplo de documento XML, Tomado de [50]
XML es un metalenguaje que usa la sintaxis para definir otros lenguajes de etiquetas
estructurados, como DTD, XSL y XLL:
● DTD (Document Type Definition)
Una definición de tipo de documento (DTD) define los bloques de construcción legales de un
documento XML. La declaración de tipo de documento XML contiene o apunta a
declaraciones del marcado que proporcionan una gramática para una clase de documentos.
Esta gramática se conoce como una definición de tipo de documento o DTD. [59]
● XSL (Extensible Stylesheet Language)
XSL es el lenguaje para expresar hojas de estilo. Es un archivo que describe cómo visualizar
un documento añadiendo características avanzadas de estilo, expresadas por un tipo de
documento XML que define un conjunto de elementos llamados ‘Formato de los objetos’ y
atributos. [59]
● XLL (Extensible Linking Language)

34
La especificación XLL, conocida inicialmente como XLink [4], establece tres estructuras
diferentes que pueden ser añadidas a documentos XML: Links “Simples”, Links “Extendidos”
y “Grupos” de Links.
Los Links “Simples” se asemejan a los enlaces HTML que utilizan la etiqueta de elemento A,
estos se diferencian principalmente por referirse a un único recurso remoto, por lo tanto
contiene toda la información en una única etiqueta. Los Links “Extendidos” difieren de los
simples en cuanto a que se puede conectar a múltiples recursos y que son frecuentemente
fuera-de-línea3.
WSDL
Es un lenguaje de descripción de servicios basado en XML. Permite que un servicio y un
cliente establezcan un acuerdo en los que se refiere a los detalles de transporte de mensajes y
contenido, por medio de un documento procesable por dispositivos. El WSDL se usa a
menudo en combinación con SOAP y XML Schema. Como se ha mencionado anteriormente
un programa cliente que se conecta a un servicio web puede leer el WSDL para determinar
qué funciones están disponibles en el servidor. Un documento WSDL se observa en la Figura
6, en el que se visualiza un ejemplo de una definición de interfaz usando WSDL [5]:
Figura 6: Ejemplo 2-4 definición de interfaz. Tomado de [51]
UDDI
Lo definen como uno de los estándares básicos de los servicios Web cuyo objetivo es ser
accedido por los mensajes SOAP y dar paso a documentos WSDL, en los que se describen los
requisitos del protocolo y los formatos del mensaje solicitado para interactuar con los
servicios Web del catálogo de registros. [52] UDDI tiene dos funciones [53]:
3 out-of-line: https://www.w3.org/TR/1998/WD-xlink-19980303#dt-outofline

35
● Un protocolo basado en SOAP que define cómo se comunican los clientes UDD con
registros
● Un conjunto en particular de registros duplicados globalmente
En el registro de un servicio intervienen cuatro tipos de estructuras de datos principales:
● El tipo de datos businessEntity contiene información sobre la empresa que tiene un
servicio publicado.
● El tipo de datos businessService es una descripción de un servicio Web.
● El tipo de datos bindingTemplate contiene información técnica para determinar el
punto de entrada y especificaciones de construcción para invocar un servicio Web.
● El tipo de datos tModel proporciona un sistema de referencia que ayuda a descubrir
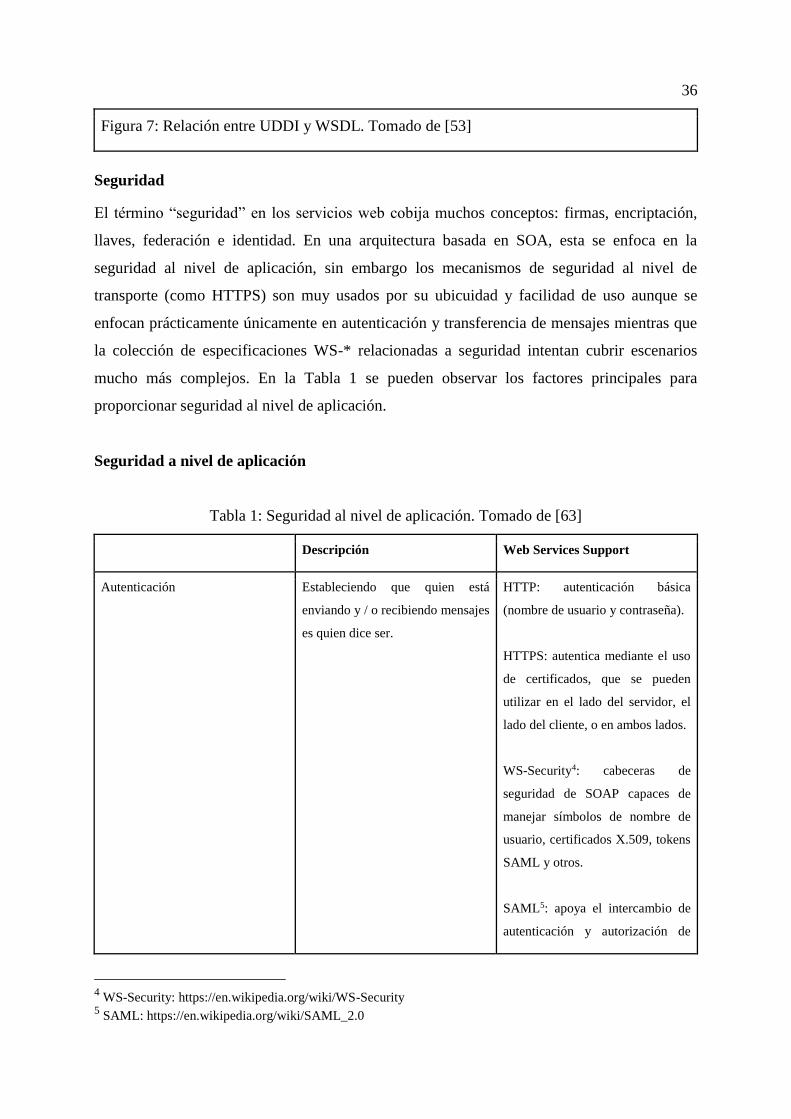
servicios Web y actúa como una especificación técnica de un servicio Web
En la Figura 7 se puede ver la relación entre UDDI y WSDL con referencia a los 4 tipos de
estructura que se pueden encontrar en el UDDI
36
Figura 7: Relación entre UDDI y WSDL. Tomado de [53]
Seguridad
El término “seguridad” en los servicios web cobija muchos conceptos: firmas, encriptación,
llaves, federación e identidad. En una arquitectura basada en SOA, esta se enfoca en la
seguridad al nivel de aplicación, sin embargo los mecanismos de seguridad al nivel de
transporte (como HTTPS) son muy usados por su ubicuidad y facilidad de uso aunque se
enfocan prácticamente únicamente en autenticación y transferencia de mensajes mientras que
la colección de especificaciones WS-* relacionadas a seguridad intentan cubrir escenarios
mucho más complejos. En la Tabla 1 se pueden observar los factores principales para
proporcionar seguridad al nivel de aplicación.
Seguridad a nivel de aplicación
Tabla 1: Seguridad al nivel de aplicación. Tomado de [63]
Descripción Web Services Support
Autenticación Estableciendo que quien está
enviando y / o recibiendo mensajes
es quien dice ser.
HTTP: autenticación básica
(nombre de usuario y contraseña).
HTTPS: autentica mediante el uso
de certificados, que se pueden
utilizar en el lado del servidor, el
lado del cliente, o en ambos lados.
WS-Security4: cabeceras de
seguridad de SOAP capaces de
manejar símbolos de nombre de
usuario, certificados X.509, tokens
SAML y otros.
SAML5: apoya el intercambio de
autenticación y autorización de
4 WS-Security: https://en.wikipedia.org/wiki/WS-Security
5 SAML: https://en.wikipedia.org/wiki/SAML_2.0

37
información entre dominios de
seguridad.
OAuth6: Proporciona a los clientes
un "acceso seguro delegado" a los
recursos del servidor en nombre
del propietario de un recurso.
Autorización El control del acceso a los
recursos, incluyendo servicios
Web individuales en función de la
identidad del usuario o rol.
SAML: apoya el intercambio de
autenticación y autorización de
información entre dominios de
seguridad.
XACML: proporciona un lenguaje
de políticas de control de acceso
para especificar las reglas sobre
quién puede hacer qué y cuándo, y
un protocolo para hacer solicitudes
de acceso.
OAuth: en él se especifica un
proceso para los propietarios de
recursos para autorizar el acceso
de terceros a sus recursos de
servidor sin compartir sus
credenciales.
Privacidad y Encriptación de los
datos
Asegura que los datos en el
mensaje es sólo visible para las
partes previstas.
HTTPS: proporciona cifrado de
nivel de transporte; encripta todo
el documento.
WS-Security: el cifrado de XML
proporciona privacidad al mensaje
SOAP; cifrado a nivel de
elemento.
Integridad de los datos y la firma
digital
Detecta cuando los datos en el
mensaje es modificado durante la
HTTPS: proporciona firma digital
de nivel de transporte; firma todo
6 OAuth: https://en.wikipedia.org/wiki/OAuth

38
transmisión. el documento.
WS-Security: la firma XML
proporciona integridad de
mensajes SOAP; firma a nivel de
elemento.
No repudio Permite a una parte para probar
que un mensaje fue enviado o
recibido, o que se ha producido
una transacción. Utilizado por un
tercero para resolver los
desacuerdos.
WS-Security: mensaje no repudio
se proporciona mediante el
aprovechamiento de la Firma
XML.
Inicio de sesión único Permite a un solicitante de servicio
ser autenticado una vez y luego
tener acceso a los recursos
autorizados a través de dominios
de seguridad.
SAML: estándar para el
intercambio de autenticación y
autorización de información entre
sistemas y apoya inicio de sesión
único para ambas interacciones
automáticas y manuales entre los
sistemas.
Registro de auditoría de seguridad
de nivel de servicio
Mantener un registro de todas las
invocaciones de servicio para que
los problemas de seguridad pueden
ser revisados después del hecho.
Personalizado
Seguridad al nivel de transporte
SSL, también conocido como TLS, el Grupo de Trabajo de Ingeniería de Internet (IETF)
oficialmente estandarizada versión de SSL, es el protocolo de nivel de transporte de datos de
comunicación más utilizado que proporciona: [64]
● Autenticación (se establece la comunicación entre dos partes de confianza).
● Confidencialidad (los datos intercambiados son encriptados).
● Integridad del mensaje (se comprueban los datos por posible corrupción).
● Intercambio de claves segura entre el cliente y el servidor.

39
Sockets
Un socket es un punto final de un enlace de comunicación bidireccional entre dos programas
que se ejecutan en la red. [10] Los sockets se crean y se utilizan con un sistema de peticiones
o de llamadas de función a veces llamados API para la familia de protocolos TCP, al cual está
enlazado a un número de puerto.
Los sockets usan dos tipos de protocolos de comunicación, TCP y UDP:
Sockets UDP: Permiten el envío de datagramas a través de la red sin que se haya establecido
previamente una conexión, ya que el propio datagrama incorpora suficiente información de
direccionamiento en su cabecera. Debido a que se desconoce de la conexión los datagramas
pueden llegar en desorden o duplicarse. [55]
Sockets TCP: Son orientados a conexión, esto hace se garantice la transmisión de todos los
octetos sin errores ni omisiones. Además, de que todos los octetos llegarán en el orden en el
que fueron enviados. [55]
Websocket
Websocket es [91] un protocolo que permite establecer una conexión bidireccional, entre un
navegador y servidor web. Los websockets son usualmente usados para hacer streaming y/o
aplicaciones en tiempo real.
Descripción del Recurso (en inglés, Resource Description)
“Una descripción del recurso es cualquier maquina de datos legibles que pueden permitir que
los recursos sean descubiertos. Todas las descripciones de recursos deben contener el
identificador de recursos”. [33]
Servicio de Descubrimiento (en inglés, Discovery Service)
“Un servicio de descubrimiento es un servicio que permite a los agentes recuperar las
descripciones de recursos relacionados con el servicio Web”. [33] Es un servicio, que es
usado para publicar descripciones y buscar descripciones de recursos.

40
Representación (en inglés, Representation)
“Una representación es una pieza de información que describe un estado de recursos”. [33]
Figura 8: Modelo Orientado al Recurso. Tomado de [33]
En la Figura 8 se puede observar que un recurso tiene un URI, una descripción y un dueño,
puede no tener, tener una o múltiples representaciones, es descubierto por un agente y se le
puede aplicar una norma/política (en inglés, policy). El agente interactúa con el
descubrimiento del servicio y descubre recursos.
Patrones de diseño
Un patrón se define como un modelo de muestra que sirve para obtener un resultado esperado.
[54] En el campo de la informática el concepto de patrones de diseño de software es definido
por Nicolás Tedeschi como “Esqueletos que brindan una solución ya probada y documentada
a problemas de desarrollo de software que están sujetos a contextos similares. [37]”, al igual
Cristian Giovanni y Martínez Rodríguez en “Aplicación de patrones de diseño en el diseño de
arquitecturas” lo definen como “Soluciones probadas a una serie de circunstancias
particulares que definen un escenario en el que se puede aplicar esa solución [38]”.
En el desarrollo de aplicaciones o en este caso el diseño de un sistema de recolección de datos
aunque puede que este sea un sistema único, tendrá partes comunes con otros sistemas, como
es el caso del acceso a datos, almacenamiento de información, entre otras. En lugar de buscar

41
una forma de resolver cualquiera de esos problemas recurrentes, se puede encontrar la
solución al problema implementando algún patrón, ya que son soluciones probadas y
documentadas por multitud de programadores. Además, al utilizar patrones de diseño permite
tener control de cohesión y acoplamiento o reutilización de código.
Patrón de diseño Timestamp Transfer [54]
Intención: En un evento de sincronización, sólo las partes del conjunto de datos han cambiado
desde la última sincronización se transfieren entre el dispositivo móvil y el sistema remoto
utilizando un último cambio de marca de tiempo.
Problema: Con el tema de la velocidad de la red y ancho de banda en los dispositivos
móviles, la cantidad de datos transferidos a conciliar conjuntos de datos entre un dispositivo y
un sistema remoto deben reducirse al mínimo. residuos transferencia completa demasiados
recursos y el conjunto de datos no se ajusta a los requisitos más estrictos para la transferencia
de Matemática (descrito más adelante). Todavía es imperativo para sincronizar los datos, pero
se necesita otro método para reducir al mínimo la transferencia de datos.
Aplicabilidad
El conjunto de datos de una aplicación puede ser descargado / cargado de piezas específicas.
● Una aplicación con datos versionados que se almacena en un servicio en línea, que
podría elegir archivos específicos.
● Piezas de datos para cargar o descargar basan en una comparación de la última
actualización de la fecha y hora dispositivo y la fecha y hora de creación/modificación
en el archivo o datos.
Las piezas de datos deben tener un campo para almacenar una marca de tiempo que indica la
última vez que se modificó.
● Si una aplicación y su correspondiente servicio en línea se sincronizan las tablas de
información, cada tabla debe tener una columna de marca de tiempo para facilitar las
comparaciones necesarias para una transferencia de marca de hora.

42
Figura 9: Representación visual del patrón ‘Timestamp Transfer’. Tomado de [54]
Vista representativa
Este diagrama de flujo muestra el aumento de la lógica de una transferencia de marca de hora.
El cliente inicia una solicitud y adjunta una fecha y hora de la solicitud, la cual es procesada
por el servidor para determinar si debe o no devuelve ningún dato.
Solución
Una indicación de la hora proporcionada por el sistema remoto desde la última actualización
satisfactoria se lía con una solicitud de cambio datos. El sistema remoto devuelve sólo los
datos que se ha añadido o cambiado después de esa fecha y hora. Para la presentación de los
datos, el dispositivo sólo presenta datos que se han añadido o modificado desde la última
presentación con éxito.
Beneficios
Menor utilización de ancho de banda que la transferencia completa.
● Mediante la comparación de una marca de tiempo "última actualización" presentada
por una aplicación a un servicio, sólo los datos creado o modificado desde esa fecha y
hora debe ser enviado de nuevo al dispositivo. Del mismo modo, si una aplicación
almacena la fecha y hora de la última vez que se cargan los datos, entonces pueden

43
decidir sobre el siguiente evento de sincronización de sólo los datos de carga de la
meta aún no ha visto.
Compromisos
se debe dar atención cuidadosa a la fuente de las marcas de tiempo.
● Es importante mantener la fuente de las marcas de tiempo consistentes, como la
sincronización puede convertirse incoherente si se utilizan diferentes marcas de
tiempo. Es común el uso de la marca de tiempo a distancia para cualquier los datos
transferidos y la marca de tiempo para cualquier dispositivo de datos cargados.
Puede que no sea evidente cómo manejar la eliminación de datos.
● Una marca de tiempo no va a hacer ningún bien si se eliminan los datos en un sistema
remoto y un dispositivo de intentos Transferencia de marca de tiempo, ya que los
datos borrados no existe para una comparación de marca de tiempo. Una común
solución a este problema es añadir un campo booleano en cada pieza de datos para
indicar si es o no ha sido eliminado.
Flyweight
Intención: Compartir atributos de un objeto que soporta varios objetos teniendo el mismo
valor del atributo. [73] Lo que quiere decir crear sólo un objeto intermedio para cada entidad
concreta como se muestra en la Figura 31. Este patrón comparte estados para soportar un gran
número de objetos pequeños aumentando la eficiencia en espacio. [74]

44
Figura 10: Diagrama UML del patrón Flyweight. Tomado de [42]
Motivación
El motivo no es otro que permitir que sea el objeto que implementa este patrón el que gestione
la separación entre la parte “común” (denominada intrínseca) y la parte “privada”
(denominada extrínseca), centralizando el proceso y evitando así que perdamos referencias
por el camino si realizamos el proceso de una forma un poco más artesanal. [75]
Por lo tanto, dentro de un patrón Flyweight, se distingue entre estos dos tipos de datos:
● Intrínsecos: son los datos compartidos por todos los objetos de un subtipo
determinado. Por norma general, son datos que no cambiarán a lo largo del tiempo, y
si cambian, alterarán el estado de todos los objetos que hagan uso de ellos.
● Extrínsecos: se calculan “al vuelo” fuera del objeto Flyweight. Este cálculo suele
realizarse a partir de los datos intrínsecos y de los parámetros recibidos por los
métodos del objeto Flyweight. La idea detrás de los datos extrínsecos radica en que, o
bien sean calculados a partir de los datos intrínsecos o bien ocupe una cantidad de
memoria mínima en comparación a éstos.
Aplicabilidad
La efectividad de este patrón depende de cómo y cuándo es utilizado, por eso es importante
implementarlo siempre que todas las siguientes situaciones se cumplan:
● Una aplicación usa un gran número de objetos.
● El coste de almacenamiento es alto debido al excesivo número de objetos.

45
● La gran mayoría de los estados de los objetos puede hacerse extrínseco.
● Al separar el estado extrínseco, muchos grupos de objetos pueden reemplazarse por
unos pocos objetos compartidos.
● La aplicación no depende de la identidad de los objetos, pues el patrón se basa en el
compartimento de objetos.
Implementación
● Asegurarse que la sobrecarga de objeto es un tema que necesita atención y el cliente
de la clase es capaz y está dispuesto a absorber la responsabilidad de reajuste.
● Dividir la clase de estado de destino en: Estado compartible (intrínseco) y estado no
compartible (extrínseco).
● Quitar el estado no compartible de los atributos de clase y agregarlo como argumento
de llamada a la lista de métodos afectados.
● Crear un Factory que pueda almacenar en caché y reutilizar instancias de clases
existentes.
● El cliente debe usar el Factory en lugar del operador new.
● El cliente (o un tercero) debe observar o calcular el estado no compartible y
suministrar el estado a través de métodos de clase.
Factory Method
Intención: Crear objetos sin saber que tipo son, siendo otras subclases las encargadas de
decidirlo tal como se puede ver en la Figura 32 en donde se muestra de forma gráfica la idea
de este patrón. [41]
Problema
El sistema tiene un tipo de componentes que se repite numerosas veces, y las instancias tienen
una serie de características en común. Se quiere optimizar el tamaño en memoria que ocupa
para sacar el máximo partido al sistema y no desaprovechar los recursos con datos
redundantes.

46
Figura 11: Diagrama UML del método de fábrica. Tomado de [42]
Consecuencias:
Positivas:
● Simplifica el uso de sistemas complejos con tareas redundantes
● Oculta al cliente la complejidad real del sistema
● Reduce el acoplamiento entre el subsistema y los clientes
Negativas
● Aumenta la complejidad de los objetos
● Aumenta el número de clases del sistema
Singleton
Se usa el patrón Singleton cuando por alguna razón se necesita que exista sólo una instancia
(un objeto) de una determinada Clase. [42] Como se ve en la Figura 33, dicha clase se creará
de forma que tenga una propiedad estática y un constructor privado, así como un método
público estático que será el encargado de crear la instancia (cuando no exista) y guardar una
referencia a la misma en la propiedad estática (devolviendo ésta).
Intención
Garantiza que una clase sólo tenga una instancia y proporciona un punto de acceso global a
ella.
Problema

47
Varios clientes distintos precisan referenciar a un mismo elemento y se quiere asegurar de que
no hay más de una instancia de ese elemento. [40]
Aplicabilidad
● Debe haber exactamente una instancia de una clase y ésta deba ser accesible a los
clientes desde un punto de acceso conocido.
● La única instancia debería ser extensible mediante herencia y los clientes deberían ser
capaces de utilizar una instancia extendida sin modificar su código.
● Consecuencias
● Acceso controlado a la única instancia. Puede tener un control estricto sobre cómo y
cuando acceden los clientes a la instancia.
● Espacio de nombres reducido. El patrón Singleton es una mejora sobre las variables
globales.
● Permite el refinamiento de operaciones y la representación. Se puede crear una
subclase de Singleton.
● Permite un número variable de instancias. El patrón hace que sea fácil cambiar de
opinión y permitir más de una instancia de la clase Singleton.
● Más flexible que las operaciones de clase (static en C#, Shared en VB .NET).
Figura 12: Diagrama UML del patrón Singleton. Tomado de [42]
Template Method
Este sencillo patrón resulta útil en casos en los que se puede implementar en una clase
abstracta el código común que será usado por las clases que heredan de ella, permitiéndoles
que implementan el comportamiento que varía mediante la reescritura (total o parcial) de
determinados métodos. [39]

48
La diferencia con la forma común herencia y sobreescritura de los métodos abstractos estriba
en que la clase abstracta contiene un método denominado 'plantilla' que hace llamadas a los
que han de ser implementados por las clases que hereden de ella así como se ve ilustrado en la
Figura 34.
Figura 13: Diagrama UML del método de modelado (Template Method). Tomado de
[42]
Consecuencias
● La principal: los métodos de plantilla sirven para la reutilización de código.
● Inversión de control: es la clase padre quien llama a las operaciones de los hijos.
● Los métodos de plantilla pueden llamar a los siguientes tipos de operaciones:
Operaciones concretas de las subclases o de otras clases, operaciones concretas en la
propia clase base abstracta, operaciones primitivas (es decir, abstractas), métodos de
fabricación (o también llamados factorías) y también operaciones de enganche (hook).
● Las operaciones de enganche proporcionan comportamiento predeterminado que las
subclases pueden redefinir si es necesario. Normalmente, la implementación
predeterminada no hace nada.
Aplicaciones
● Se quiera implementar las partes de un algoritmo que no cambian y dejar que las
subclases implementan aquellas otras que puedan variar.
● Por motivo de factorizar código, cuando movemos cierto código a una clase base
común evitar código duplicado.

49
● Para controlar el modo en que las subclases extienden la clase base. Haciendo que solo
sea a través de unos métodos de plantilla datos.
Arquitectura de Software
La arquitectura de software [93] es un conjunto de reglas para desarrollar un sistema de
software para una tarea específica. Se refiere a unas estructuras de alto nivel, la disciplina para
crear dichas estructuras y la documentación de estas.
La arquitectura de software se trata decisiones fundamentales de estructura y diseño las cuales
se debe evitar cambiar durante el desarrollo, ya que esto conlleva un alto costo. El objetivo
principal de la arquitectura de software sobre un sistema es categorizar el mayor número de
componentes del sistema para identificar las relaciones entre estos y categorizarlos
acordemente, estos componentes son conglomerados usando conectores los cuales brindan
una relación entre los componentes. Los conectores juegan un rol esencial para distinguir
entre un estilo de arquitectura y otro, de igual manera tienen un efecto importante en las
características de cada estilo particular. [92]
Estilos y patrones de Arquitectura
El entendimiento de estilos de arquitectura provee un lenguaje común con oportunidades para
conversaciones que son independientes de la tecnología, estos pueden ser agrupados por su
área de interés [92], la Tabla 2 lista las mayores áreas de enfoque
Tabla 2: Estilos y patrones de arquitectura. Tomado de [92]
Categoría Estilo de Arquitectura
Comunicación SOA, Mensaje de Bus
Despliegue Cliente/Servidor, Nivel-N, Nivel-3
Dominio Diseño orientado al dominio
Estructura Basado en Componentes, Orientado a objetos,
Arquitectura por capas
Estilo cliente/servidor

50
Este estilo es un tipo de sistema distribuido que involucra una relación entre cliente y
servidor. Puede tener diferentes sistemas de cliente y servidor conectados mediante una red.
[92]
Estilo nivel-3, nivel-N
Este estilo explica la separación de funcionalidades en múltiples partes. Cada segmento es un
nivel que puede ser encontrado en diferentes computadores. Involucra la descomposición
funcional de componentes de servicio, sus aplicaciones y despliegue distribuido. [92]
Estilo basado en componentes
Este estilo describe un enfoque al diseño de sistemas y desarrollo. Involucra la
descomposición del diseño en componentes individuales lógicos o funcionales . Estos
componentes ofrecen unos estándares bien definidos de comunicación, propiedades y eventos.
[92]
Estilo orientado al diseño (DDD)
Este estilo está enfocado a los objetos. Es basado en dominio de sistema, sus componentes, la
forma como se comportan y la relación entre estos. [92]
Estilo orientado a objetos
Este estilo es un prototipo de diseño basado en la división de tareas de una aplicación o
sistema en individuales objetos autosuficientes reusables. Cada objeto contiene los datos y su
comportamiento. [92]
Estilo por capas
Este estilo es más adecuado para aplicaciones que comprenden distintas clases de servicos las
cuales pueden ser organizadas jerárquicamente. Se enfatiza en el agrupamiento de funciones
relaciones en una aplicación en una única pila vertical de capas, la comunicación entre capas
es explícita y ligeramente acoplada. [92]
Objetivos de la Arquitectura de Software
La Tabla 3 lista los diferentes objetivos de la Arquitectura de Software con su correspondiente
descripción.

51
Tabla 3: Objetivos de la Arquitectura de Software. Tomado de [92]
Objetivo Descripción
Plataforma
independiente
La arquitectura del software no dependerá de una plataforma de hardware específica.
Esto ayudará a ejecutar software en cualquier sistema embebido o computadoras
personales con las especificaciones mínimas proporcionadas.
Modularidad de
Hardware
Los componentes de hardware deben dividirse en unidades pequeñas y comunicarse
entre sí a través de un medio cableado o inalámbrico. La arquitectura de software debe
definir reglas y marco para la comunicación entre los diferentes módulos de hardware.
Esto proporcionará al sistema la capacidad de extensión de la característica sin mucho
esfuerzo.
Productividad
Incrementada
La estructura del software debe estar bien definida, por lo que será más fácil agregar
nuevas características.
Mantenimiento de
código
El código debe ser modular y bien estructurado, por lo que será más fácil de refinar y
mantener.
Testabilidad El software estructurado debe proporcionar una función bien definida interfaces para el
usuario final, esto facilita la capacidad de prueba de un módulo en particular.
Diagnóstico y
depuración
También es fácil identificar los errores o los agujeros del lazo dentro de un código bien
estructurado y modular. Las arquitecturas de software deben integrar funciones de
diagnóstico y depuración al diseñar un sistema de software. Así, el usuario final puede
interactuar directamente con los módulos para las funciones de diagnóstico.
Apto para equipo
grande
Cada desarrollador o probador debe ser capaz de trabajar en módulos independientes
paralelamente. Esto es posible debido a la naturaleza modular y estructurada del sistema
de software definido por la arquitectura del software.
Simplicidad El mantenimiento y la implementación de la arquitectura del software debe ser de la
manera fácil de usar.
Disponibilidad Define la proporción de tiempo que el sistema es funcional y operativo. Se puede medir
como el porcentaje del tiempo de inactividad total del sistema durante un período
predefinido. Se ve afectado por problemas de sistema, problemas de organización,
ataques maliciosos y carga del sistema.
Seguridad Capacidad de un sistema para hacer frente a ataques maliciosos desde el exterior o dentro
del sistema.

52
Desempeño Aumentar la eficiencia del sistema con respecto al tiempo de respuesta, rendimiento,
utilización de los recursos y atributos que normalmente entran en conflicto entre sí.
Concurrencia La concurrencia es propiedad del sistema en la que se ejecutan varias tareas
simultáneamente y que interactúan entre sí. Estas tareas pueden ejecutarse en los
múltiples núcleos en el mismo chip.
Escalabilidad Es la capacidad del sistema para manejar un aumento en la carga del sistema.
Costo El costo de construir, mantener y operar el sistema.
Tiempo de vida El período de tiempo en que el producto está activo antes de la jubilación.
Usabilidad La usabilidad incluye la cuestión de la satisfacción de los usuarios de usar el sistema
JavaScript frameworks
Las páginas web han sido estáticas con algún contenido dinámico. Los archivos HTML se
construían una vez por página, este paradigma ha cambiado durante los años, principalmente
por la introducción de algunas librerías, frameworks y tecnologías JavaScript.
jQuery [1] hace sencillo la manipulación del HTML DOM y dinámica actualización de partes
de la página con obtención de datos del servidor. Con AJAX y jQuery es posible crear páginas
interactivas, pero nada como “single-page applications (SPA’s)” que hoy vemos. En jQuery
manualmente se tiene que encontrar el elemento a modificar y definir las acciones a proceder
con el mismo.
Esto lleva que el tipo “client-side JavaScript framework (JSF’s)” se hace popular hoy en día,
[1] con su llegada en el 2009. JSF’s proporciona una extensa librería que le importa la unión
entre el HTML y JavaScript, en lugar de actualizar un elemento explícito del DOM como es
con jQuery. Hoy JSF’s hacen sencillo la obtención de información haciendo uso de peticiones
HTTP y manejo de “route” en el framework. [1] Los “Route” muestra la vista del contenido
de la página web en la barra de direcciones, sin cambiar realmente la página como en las
aplicaciones web clásicas (SPA’s).

53
Figura 14: Tendencia de uso de librerías JavaScript del 2009 a 2017, sacado de google
trends compara: Angular, React, Ember y Polymer
La comunidad de desarrolladores hace uso de Angular, React, Ember, Polymer con más
regularidad que otros JSF’s existentes en el momento. La figura 1 se muestra la tendencia de
los programadores en el uso de JSF’s siendo los más populares en la comunidad React y
Angula, este último más popular, con una mínima diferencia de uso con respecto a React a
diferencia con la popularidad de estos mismos en Github, la tabla 1 enseña que React es el
más preferido por los desarrolladores almacenados en la plataforma.
Tabla 4: Popularidad de JavaScript frameworks en Github
Github
Watch Start Fork
Angular 4,359 55,944 27,929
React 4,465 67,950 12,607
Ember 1,016 17,904 3,720
Polymer 1,044 17,702 1,751
Microprocesador y Sistemas embebidos
Microprocesadores

54
Se define como microprocesador [97] como un circuito integrado digital que es capaz de
realizar múltiples funciones. Está diseñado para ejecutar una serie de instrucciones que se le
dará en una lista, de acuerdo con lo que se necesita. Esa lista se le llama programa y las
instrucciones serán ejecutadas una a una por el microprocesador. Al ser un sistema
programado se puede lograr que el circuito realice tareas distintas con tan solo cambiar el
programa que se ejecuta.
Figura 15: Diagrama simplificado de un microprocesador. Tomado de [97]
En la figura 15 se aprecia un diagrama simplificado de un microprocesador, el cual cuenta con
un contador de programa (PC), el cual es un contador que inicia del cero y se va
incrementando.
Microprocesadores en el riego
Los microprocesadores en el riego se emplean con los controladores los cuales pueden llegar
a cumplir el papel de realizar tareas tales como [98] la secuencia cíclicas de tiempos de
entrega y cortes de agua desde pocos segundos a varias horas, coordinando un conjunto de
válvulas.

55
Sistemas embebidos
[99] Un sistema embebido en principio está formado por un microprocesador o por un
microcontrolador y un software que tiene que ser almacenado en localidades de memoria de
tipo RAM para luego ser ejecutado por el procesador. La figura 16 representa un componente
de un sistema embebido, implementado en una propuesta de diseño de un sistema domótico
de riego.
Figura 16: Componente de un sistema embebido [99]
Sistemas de riego de cultivos industriales
Tipos de riego
Las lluvias generalmente no están bien distribuidas, se concentran en épocas cuando su aporte
es excesivo, mientras que en otras épocas hay un déficit total, es por ello que el sistema de
riego debe de suplir en forma oportuna, las deficiencias de humedad en el perfil del suelo de
donde las raíces puedan extraer la humedad.

56
En el Valle del Cauca se utilizan diferentes sistemas de riego, el riego por gravedad
(43.095%), multicompuertas (50%), aspersión (15%), goteo (1%), pivote central y
autopropulsado frontal (0,05%). [15] Cada sistema posee una eficiencia diferente, que es
respectivamente del 25%, 55%, 65%,98% y 90%. [22]
Riego por gravedad
Este sistema depende mucho del trabajo manual con la pala, la eficiencia está entre el 20% al
25%, generalmente se riega cada 15 días y se aplican 2.000 m3 /Ha., en caso de que se
presente alguna lluvia intermedia, se trabaja con el balance hídrico. [23]
Riego por multicompuertas
Su eficiencia está entre el 55% al 60%, se aplican aproximadamente 1.000 m3 /Ha y su ciclo
sigue siendo de 15 días. [24]
Riego por aspersión
La eficiencia está alrededor del 65% y los ciclos de riego generalmente son de 10 días,
dependiendo del tipo de suelo.[25]
Riego por goteo
Su eficiencia es del 98%, el ciclo de riego puede ser diario o semanal. Este tipo de riego,
permite mantener buena oxigenación radicular lo cual junto con la fertigación (fertilización a
través del sistema de riego) aumentan la producción del cultivo.[26]
Tipos de Suelo
Los suelos de la parte plana, donde se ubican los cultivos de la caña de azúcar, en su mayoría
son aluviales, y algunos de los del piedemonte son de origen coluvio-aluviales, predominan
los suelos franco-arcillosos con un PH entre 5.5 y 7.0, el contenido de materia orgánica está
entre 2 y 4%, el fósforo disponible es superior a los 10 mg/Kg y el contenido de potasio K,
superior a 0,2 cmol/Kg de suelo. La relación de Ca/Mg intercambiables es adecuada y los
contenidos de éstos nutrientes en el suelo son altos. La mayoría de los suelos son molisoles y
vertisoles. [16]

57
La clasificación más utilizada en Colombia, es la de la FAO y la Sociedad Americana de
Suelos de USDA (Soil Survey Staff), así como la taxonomía de suelos de USDA. [17] En la
Tabla 2, se describen los tipos de suelo más conocidos a los cuales se les indican su tipo de
textura y una breve descripción.
Tabla 5: Tipos de suelo
Alfisoles
Textura arcillosa. Suelos de regiones húmedas la mayor parte del año.
Andisoles
Textura franco arenosa
Suelo de depósitos volcánicos, regiones húmedas,
buena acumulación de humus. Productividad natural
alta.
Aridisoles
Textura franco arenosa.
Suelos de zonas desérticas, suelos poco lixiviados,
pobres en materia orgánica. Generalmente
enriquecidos con CaCO3 (carbonato de calcio), PH
entre neutro y básico, pueden tener problemas de
presencia de Na (Sodio).[18]
Entisoles
Textura franco arenosa.
Tienen un 30% de fragmentos rocosos, formados tras
aluviones de los cuales dependen mineralmente (Nilo).
Pobres en materia orgánica. En Colombia se presentan
en la Orinoquia, amazonía, áreas de la región andina y
del Caribe.
Espodosoles
Textura franco limoso arenoso.
Suelos de climas aluviales, húmedos , a partir de
materiales parentales asociados a cenizas volcánicas y
a materiales arenosos. PH ácido, fertilidad baja.
Histosoles
Suelos orgánicos. Se desarrollan en ambientes de
condiciones húmedas y frías. Suelo liviano, se forman
en zonas depresionales de los páramos.
Inceptisoles
Textura desde arcillo arenosa hasta franco arenosa.
Suelos orgánicos, de PH ácido, acumulan arcillas
amorfas. Iniciaron como suelos volcánicos,
predominan en la cordillera de los Andes, presentes en
las vegas de los ríos Caquetà, Guaviare, Putumayo y
Amazonas. [19]
Molisoles
Textura franco limosa.
Suelos de zonas de pastizales(Pradera), marcados en
climas templados, húmedos y semiáridos. Suelos

58
oscuros, con buena descomposición de materia
orgánica, bien estructurados, de alta fertilidad,
dominancia de arcillas.[20]
Oxisoles
Textura franco arcillosa.
Suelos tropicales ricos en sesquióxido de hierro y
aluminio. Proporción de arcilla 1:1 Relacionados con
climas húmedos de alta precipitación, suelos lavados
de escasa fertilidad, en Colombia se encuentran en la
Amazonía.
Ultisoles
Suelos de textura arcillosa.
Suelos de horizonte argílico, de poco espesor,
vegetación arbórea, de color pardo rojizo oscuro, no
muestran presencia de saturación hídrica.
Vertisoles
Suelos muy ricos en arcilla, que se quiebran en
estación seca, formando grietas de 1 cm de ancho.
Suelos con fuerte expansión al humedecerse y
contracción al secarse y que pueden romper raíces..
Característicos de zonas de pantano. [21]
Variables de estudio
El registro de la humedad del suelo y de las variables que lo afectan son los que determinan
cuánto y cómo regar. También hay que tener en cuenta constantes tales como: Capacidad de
campo del suelo, LARA, y punto de marchitez permanente.
La evapotranspiración y el Uso consuntivo son dos conceptos que generalmente se confunden,
la evapotranspiración depende de la evaporación diaria y del uso consuntivo en ese momento
del desarrollo de la planta, por ejemplo una evaporación de 5 mm y un Uso consuntivo de 0.7,
al multiplicar estos factores nos da una evapotranspiración de 3.5 mm. El valor de la
evaporación lo obtenemos de las estaciones meteorológicas. [7]
La evaporación es el agua que se evapora directamente del suelo, la evapotranspiración es la
cantidad de agua utilizada por las plantas para realizar sus funciones y termina evaporándose
a través de los estomas.
La cantidad de agua que necesita un cultivo para desarrollarse, puede expresarse en términos
de volumen por unidad de área, m3/ha, o como lámina en mm (lt/m2). Cuando se expresa que

59
un cultivo requiere de 1mm, quiere decir que el cultivo absorberá uniformemente distribuido
sobre toda el área del campo. [8]
Para calcular las necesidades de riego de los diferentes cultivos, se utilizan las mismas
variables, la diferencia radica únicamente en el Kc, el factor de cultivo.[9]
El Kc va aumentando de acuerdo a la edad del cultivo, la necesidad de agua aumenta en forma
constante desde la germinación hasta alcanzar su máximo durante la floración y formación de
frutos, una vez formado el fruto se reduce el requerimiento de agua, por ejemplo la caña
inicia en 0,4, sube paulatinamente a los 10 meses a 0,8, luego desciende a los 12 meses a 0,3.
[28]
El Kc no es universal, la mayoría de las tablas están hechas para zonas no tropicales y para la
época cuando los días son más largos, éstas tablas se pueden utilizar aplicando una reducción
del 20%, así en E.U. se habla de un Kc máximo para el maíz de 1,0 pero en el trópico es de
0,8, en Colombia otros valores a manera de ejemplo son: frutales 0,7, plátano 1,1, palma
0.65, tomate 0,85. [29]
Existen factores como la luminosidad, la velocidad del viento, la humedad relativa del aire
que inciden sobre la evaporación, es decir ya están contenidos en el valor de la evaporación,
así como la capilaridad y la percolación inciden en la humedad del suelo y si se tiene éste
valor no hay necesidad de conocer los otros. [29]
Por lo cual tenemos como variables de estudio:
● Cultivo
○ LARA
○ Capacidad de campo
○ Tipo de riego (Eficiencia del riego, Aplicación/ciclo)
○ Variedad del cultivo
○ Área del cultivo
○ Periodo de agostamiento. (Contado desde la fecha de siembra)
○ Geolocalización
● K del cultivo (Factor de Cultivo)

60
● Evaporación
● Evapotranspiración
● Precipitación efectiva
● Riego efectivo
● Humedad del suelo (Balance hídrico)
Aclaración: En el capítulo 3 sección Diseño del servicio web centralizado: Modelo de
datos en el esquema de base de datos en el objeto variables, objeto cultivo y objeto lote se
puede encontrar el uso de estas variables en el sistema desarrollado para el proyecto, cabe
anotar.
Ev. Evaporación
La evaporación, al igual que la lluvia o la cantidad de riego, se mide en mm, 1 mm es el
equivalente de distribuir 1 litro por cada m2, o lo que es igual 10 m3 en 1 hectárea. La
evaporación depende de la temperatura, es dada por estaciones meteorológicas, se puede
tomar un valor promedio, que en el Valle del Cauca es de 5,5 mm. [27]
Kc. Factor del cultivo
Es una constante para el tipo de cultivo, se halla en las tablas diseñadas experimentalmente
por ingenieros agrícolas como apoyo al diseño de sistemas de riego. Estos valores son
diferentes para las zonas tropicales en comparación a las zonas templadas. Depende de la
variedad y de la edad del cultivo, para caña este valor se halla entre 0,4 y 0,8. [95]
En cuanto al periodo vegetativo, existen diferencias entre variedades, la tendencia es que de
18 meses se ha reducido a 13 meses, algunas son más resistentes a la sequía y el Ka de cultivo
puede llegar a reducirse hasta en un 30%., básicamente esta es la única diferencia que es
muy importante para tener en cuenta como variable de riego. [27]
Transpiración - Evapotranspiración
La transpiración es la cantidad de agua medida en mm, que la planta absorbe desde el suelo
para utilizarla en sus procesos biológicos y para devolver parte a la atmósfera por los estomas
de las hojas, durante el proceso de respiración. Es el resultado de multiplicar la evaporación

61
por el factor de cultivo, por ejemplo con una evaporación de 5,5 mm y un factor de cultivo de
0,6 tenemos una transpiración de 3,3 mm. [27]
LARA – Lámina rápidamente aprovechable
El agua útil en realidad no está fácilmente disponible para las plantas, debido a que el suelo
hace resistencia y la tensión de succión que deben realizar las raíces es muy alta por eso existe
otro concepto que es la lámina de riego rápidamente aprovechable,
LARA que se toma experimentalmente y en el Valle del Cauca ha resultado ser el 50% de la
capacidad de campo. [28]
Agostamiento
Periodo en que no se riega al final del cultivo, obligando a que la planta devuelva nutrientes
desde las hojas hacia el tallo, buscando que el azúcar se concentre en el tallo, para la caña de
azúcar el periodo es de 2 a 3 meses.
Dependencias entre variables
En la Tabla 6 se observa las variables básicas involucradas en un sistema de riego de un
cultivo con su respectiva (s) dependencia (s).
Tabla 6: Dependencia de variables
Variable Depende de
LARA Tipo de suelo
Capacidad de campo Tipo de suelo
Evaporación
Temperatura
Luminosidad
Viento
K de cultivo Variedad de cultivo
Edad del cultivo
Evapotranspiración Evaporación
K de cultivo

62
Periodo de agostamiento Fecha inicial de cultivo
Balance hídrico (Humedad del suelo)
Precipitación efectiva
Riego efectivo
Evapotranspiración
Aclaración: Las variables usadas en el sistema se pueden encontrar en la sección Modelo de
datos apartado Objeto Variables. En el cual se da una explicación de las variables usadas y
las que se capturan por medio de sensores, además de la posibilidad de añadir más variables si
así lo desa el cliente y estas pueden ser tanto calculadas por el sistema como sensada o
ingresada por un usuario.
Cultivo de la Caña de Azúcar
El cultivo de la caña de azúcar en el Valle de cauca es altamente tecnificado y el de mayor
área sembrada (248.0000 Hectáreas, de las 265.000 Totales), alcanza aproximadamente el
1,5% de la producción mundial de azúcar, se obtienen los rendimientos más altos del mundo,
120 toneladas de caña por hectárea, con una concentración de azúcar promedia de 13%, el
mayor costo de la producción está precisamente en la adquisición de sistemas de riego y su
aplicación. Además es un sector que genera 25.000 empleos directos e indirectos, con una
contribución al PIB nacional del 10,3% anual. [14]
En Colombia se cosecha todos los días, sin importar el clima, y esto se hace de día y de
noche, en otros países solo se realiza durante los tres meses de verano, Colombia es de los
pocos sitios en el mundo en el que las fábricas extractoras de azúcar no paran en ningún
momento del año.
Balance hídrico
No toda el agua que recibe la caña de azúcar proviene del riego, pues las lluvias tienen un
aporte importante. El balance hídrico es el resultado de sumas y restas entre las necesidades,
lo disponible y el faltante (o excedentes), de ese resultado sabremos cuánta agua es necesaria
para llegar a la LARA. [28]

63
El balance hídrico es similar a una contabilidad de agua, en el suelo que permite comparar las
ganancias y las pérdidas de humedad.
Variedades
La caña de azúcar es originaria de la India, pero a lo largo de la zona tropical en el mundo se
han desarrollado variedades que para los especialistas revisten de grandes diferencias, aunque
para un observador no especializado esas diferencias generalmente pasan desapercibidas.
En Colombia existen más de 350 variedades, muchas de las cuales son producto del trabajo de
entidades colombianas, pero en el Valle del Cauca predominan 5, la entidad encargada de la
creación de nuevas variedades y de su divulgación es Cenicaña. El desarrollo de una variedad
exige más de 10 años de trabajo. [94]
Medición de necesidad de riego y componentes involucrados
El agricultor necesita tomar dos decisiones importantes referente al riego, cuándo y cuánto
regar, para ello debe conocer algunas variables, pero de todas ellas la más importante es la
humedad del suelo. Para saber cuál es la humedad disponible en el suelo para la planta, hay
varios métodos, unos son directos y otros indirectos.
El agua que absorbe la planta, la toma del suelo a través de sus raíces en contra de las fuerzas
de fijación de la tierra [78], la capacidad de acumulación máxima de agua del suelo es la
llamada capacidad de campo (CC), y es diferente para cada suelo, dependiendo de su textura,
un suelo arcilloso tiene más capacidad de acumulación que uno franco y mucho más que uno
arenoso, el agua se acumula en los poros del suelo, por medio de la fuerza de capilaridad.
A medida que el agua acumulada empieza a utilizarse la humedad baja por debajo de la
capacidad de campo y progresivamente la tensión que se ejerce sobre el sistema de raíces es
mayor hasta un punto crítico cuando la planta ya no es capaz de absorber agua del suelo y
muere, se llama punto de marchitez permanente. (PMP).
Sensores profesionales
Existen diferentes métodos para medir la humedad del suelo. Todos los métodos usan una
propiedad física que cambia con la humedad. Algunas de estas propiedades son:

64
El peso de suelo La tensión del agua dentro del suelo
La humedad del aire dentro del suelo La dispersión de la radiación que entra al
suelo
La atenuación de la radiación que entra al
suelo
La constante dieléctrica del suelo
La resistencia eléctrica del suelo La textura del suelo
La energía para cambiar la temperatura del
suelo
Entre los métodos se encuentran: gravimétrico, por resistencia eléctrica, reflectometría, entre
otros los cuales usan componentes como:
● Tensiómetros
● Sonda de neutrones
● Termómetros de luz infrarroja
Resistencia eléctrica
Algunos dispositivos como los bloques de yeso, nylon o fibra utilizan la resistencia eléctrica
para medir la humedad del suelo. El principio físico es que la humedad del suelo se puede
determinar por la resistencia al paso de la corriente entre dos electrodos en contacto con el
suelo, entre más agua haya en la tierra, más baja la resistencia. [79]
Para medir la humedad del suelo, los bloques se entierran a una profundidad deseada con las
terminales eléctricas extendiéndose hasta la superficie del suelo. Las terminales se conectan a
un medidor y se toma la lectura. [80]
Reflectometría
La reflectometría se basa en la relación que existe entre el contenido de humedad del suelo y
su constante dieléctrica El agua tiene una constante dieléctrica mucho más alta que la del

65
suelo, por lo que la constante dieléctrica del suelo húmedo dependerá principalmente de su
contenido de humedad. La constante dieléctrica del suelo se mide aplicando al suelo una onda
electromagnética de alta frecuencia y midiendo la velocidad de propagación mediante un
reflectómetro de dominio de tiempo. [81]
Tensiometro
La tensión del suelo al fijar el agua es aprovechada por el sistema más antiguo de medición de
la humedad [78], el tensiómetro, es al mismo tiempo el más utilizado, también se pueden
integrar con equipos de lectura electrónica.
Los tensiómetros miden la intensidad de la fuerza con la que el suelo retiene el agua. La
mayoría de los tensiómetros tienen una punta de cerámica o porosa, conectada a una columna
de agua, los tensiómetros se pueden instalar a la profundidad que se desee e instalar varios, lo
que puede ayudar a monitorear no solo la humedad en la zona radicular sino el movimiento
del nivel freático.
Figura 17: Tensiometro. Tomado de [82]
Sonda de neutrones
La sonda de neutrones se ha empleado extensamente en trabajos de investigación para la
medición de humedad del suelo. Una sonda de electrones contiene una unidad radioactiva,

66
que envía una cierta cantidad de neutrones rápidos. Estos neutrones son de un tamaño similar
a los átomos de hidrógeno que hacen parte del agua.
Cuando los neutrones chocan contra los átomos de hidrógeno, se vuelven más lentos, un
detector dentro de la sonda mide la proporción de neutrones rápidos que salen y los lentos que
regresan. [83]
Figura 18: Sonda de neutrones. Tomado de [85]
Termómetros de luz infrarroja
De forma similar al proceso de reducción de la temperatura del cuerpo humano cuando se
suda, las plantas regulan su temperatura a medida que transpiran a través de los estomas, pero
cuando hay escasez de agua en el suelo las plantas cierran sus estomas y empiezan a aumentar
la temperatura de sus hojas, en ese momento la capacidad de campo está agotada y se debe de
regar de forma inmediata, usando un termómetro de luz infrarroja se puede medir este nivel
de temperatura. [84]
Tarjetas para la adquisición o captura de datos
Existen tarjetas programadoras para controlar y usar los componentes de la sección Sensores
académicos y crear un sistema como lo son: Arduino, Raspberry Pi o Goblin 2.
La tarjeta Goblin 2

67
Es “es una tarjeta de desarrollo disenada para ser autonoma, cuenta con un modulo para
controlar la carga de una bateria de Li-ion de 3.7V a 4.2V, versatil en conectividad y lista
para comunicacion remota. Integra conectividad por protocolo RS-485 y voltajes de salida de
24V, 5V y 3.3V ideal para sensores industriales o sensores con senales analogicas/digitales.
Su diseno para el internet de las cosas es gracias al SIM5320A que incorpora y asi poder
tener la conectividad con servidores web mediante alguna red celular. ” [77]
De esta tarjeta se puede resaltar que cuenta con módulos integrados como el SIM5320A que
le permite una conexión a internet a través de una red celular lo cual puede ser muy práctico
para la conexión a un Servidor Web en lugares remotos o de difícil acceso.
Figura 19: Tarjeta Goblin 2. Tomado de [79]
La tarjeta Arduino UNO
Es “una placa electrónica basada en el ATmega328P. Cuenta con 14 pines digitales de
entrada / salida (de los cuales 6 se podrán utilizar como salidas PWM), 6 entradas
analógicas, un cristal de cuarzo de 16MHz, una conexión USB, un conector de alimentación,
una cabecera ICSP y un botón de reinicio. Contiene todo lo necesario para apoyar el
microcontrolador; basta con conectarlo a un ordenador con un cable USB o la corriente con
un adaptador de CA a CC o una batería para empezar.” [76]
Esta tarjeta no cuenta con módulos integrados, por cual cualquier funcionalidad que se quiera
suplir, como conexión a internet, captura de humedad

68
Figura 20: Tarjeta Arduino UNO. Tomado de [76]
Sensores académicos
Existen sensores de uso académico que pueden hacer las veces de su homólogo profesional
Algunos de los fenómenos físicos, pero no limitado a estos, que pueden ser capturados por
sensores de Arduino son:
● Temperatura
● Humedad de suelo
● Lluvia
● Presión atmosférica
● Luminosidad
Sensor humedad suelo
El sensor de Humedad de Suelo es usado para determinar el nivel de humedad alrededor del
sensor indicada por el nivel de resistencia en el mismo.
Un higrómetro de suelo HL-69 [86] es un sensor que mide la humedad del suelo. Es un sensor
que mide la humedad del suelo por la variación de su conductividad. El HL-69 se distribuye

69
con una placa de medición estándar que permite obtener la medición como valor analógico o
como una salida digital, activada cuando la humedad supera un cierto umbral.
Figura 21: Sensor Humedad Suelo/Módulo HL-69. Tomado de [86]
Los valores obtenidos van desde 0 (sumergido en agua), a 1023 en el aire. La salida digital se
dispara cuando el valor de humedad supera un cierto umbral, el cual se ajusta mediante el
potenciómetro. Esto quiere decir, que se obtiene una señal LOW cuando el suelo no está
húmedo, y HIGH cuando la humedad supera el valor programado. [86]
Sensor de lluvia
El sensor de lluvia permite determinar un nivel de humedad sobre la placa mediante la
resistencia que esté presente, a menor resistencia significa menor presencia de agua y
viceversa.
“Este módulo consiste en una serie de pistas conductoras impresas sobre una placa de
baquelita. La separación entre las pistas es muy pequeña. Lo que este módulo hace es crear un
corto circuito cada vez que las pistas se mojan. El agua hace que se cree un camino de baja
resistencia entre las pistas con polaridad positiva y las pistas conectadas al GND. La corriente
que fluye a través de estas pistas se ve limitada por resistencias de 10K en cada conductor, lo
que impide que el cortocircuito que se genera cuando se moja la placa vaya a estropear el
micro controlador.” [87]

70
Figura 22: Sensor de lluvia/Módulo YL-83. Tomado de [87]
Al igual que el sensor de humedad de suelo, los valores obtenidos van desde 0 (sumergido en
agua), a 1023 en el aire completamente seco.
Sensor de temperatura
El LM35 “es un sensor de temperatura digital. A diferencia de otros dispositivos como los
termistores en los que la medición de temperatura se obtiene de la medición de su resistencia
eléctrica, el LM35 es un integrado con su propio circuito de control, que proporciona una
salida de voltaje proporcional a la temperatura.”
El LM35 es un sensor de temperatura con una precisión de 1 ºC. Su rango de medición va
desde -55 ºC hasta 150 ºC, cada grado Celsius equivale a 10 mV, lo cual quiere decir que:
150 º𝐶 = 1500 𝑚𝑉
−55 º𝐶 = −550 𝑚𝑉

71
Figura 23: Sensor de temperatura para Arduino

72
VII. ANÁLISIS Y DESARROLLO
Análisis de otros sistemas de recolección de datos de riego de cultivo
Existen múltiples sistemas de captación y visualización de información del riego de cultivos.
Algunos de estos sistemas son: Wisecrop, AquaDaia, Instacrops, Flower Power, Appgro.
Esta sección se divide en los siguientes análisis: Captación de datos, Visualización de
reportes, Configuración inicial de un cultivo o lote.
Captación de datos
Es la forma en la que el sistema adquiere los datos que posteriormente serán reportados de
forma visual a un usuario. En la Tabla 7 se distribuyen los sistemas por captación de sensores
y/o por usuario.
Tabla 7: Comparación captación de datos de sistemas existentes
Sensores Wisecrop, Instacrop, Flower Power
Usuario AquaDaia, Appgro
Los sistemas que usan sensores son aquellas que distribuyen dispositivos de producción para
agricultores como son: sensores y controladores. Estos dispositivos no pueden ser consumidos
por terceros para almacenar y visualizar la información captada. En la página de Wisercrop se
puede encontrar la frase “Recuerde que la inversión en una estrategia de riego adecuada se
puede traducir en un aumento de hasta el 30% de la productividad en comparación con las
estrategias empíricas de riego.”7 con lo cual se puede interpretar que el uso de sensores y
controladores es la mejor forma de manejar la productividad en el cultivo. Pero esto no es del
todo cierto si el sensor usado no es de una buena calidad los datos obtenidos son subjetivos.
7 "Riego - Wisecrop." https://www.wisecrop.com/es/apps/riego1. Accessed 20 Apr. 2017.

73
En conclusión el mejor sistema de captación de información es el uso de sensores siempre y
cuando estos sean de buena calidad. Pero si el usuario no puede costear estos también es útil
contar con un sistema que permita al usuario ingresar los valores y/o que este calcule el valor
para obtener resultados en unidad de medida no subjetiva.
Visualización de reportes
Es la forma en cómo el sistema presenta la información captada en una vista que puede
acceder un usuario. En la tabla 8 se divide por visualización gráfica y/o tabla.
Tabla 8: Comparación visualización de reportes en sistemas existentes
Grafica Wisecrop, Instacrop, Flower Power, AquaDaia
Tabla tipo excel Wisecrop, Appgro
El uso de gráficas para exponer la información es la más usada en estos sistemas, siendo esta
la más legible para el usuario. Pero el uso de tablas es al igual que la gráfica un complemento
para procesar mejor la información. Se observa que Wisecrop hace uso de los dos tipos de
visualización como se puede ver en la figura 24.
En conclusión el uso de gráfica y tabla es la mejor propuesta de los sistemas ya que se puede
ver información relevante con solo mirar la tabla que contendrá estos datos ya analizados y al
mismo tiempo ver los cambios de la variable en el transcurso del tiempo.
Configuración inicial de un cultivo o lote
En este apartado se quiere analizar las forma en que se hace la configuración inicial de un
cultivo o lote, teniendo en cuenta geolocalización, información básica del cultivo,
información sobre el cultivo por medio de la base de datos del cultivo y toma de foto del
cultivo. En la tabla 9 se presenta el uso o no de los anteriores puntos a evaluar.
Tabla 9: Comparación de configuración de cultivo o lote en sistemas existentes
Sistemas Geolocalización Información Básica Información DB
Sistema
Foto

74
Wisecrop Si Si No No
Instacrop Si Si No No
Flower Power No Si Si Si
AquaDaia No Si No No
Appgro Si Si No No
Estos sistemas le dan una gran importancia a la información básica del cultivo o lote a sensar
siendo esta requerida en todos los sistemas evaluado, además es también importante poder
ubicar el lote en un mapa de la finca en estos sistemas.
En conclusión la configuración inicial de un cultivo debe contar con un formulario que
contenga la información básica del mismo y para una mejor experiencia de usuario ubicar este
en un mapa.
Figura 24: Reporte Wisecrop. Tomado de www.wisecrop.com
En conclusión un sistema de recolección de datos de riego debe contar con captadores
humanos tanto como con sensores para abarcar más usuarios, además de contar con
controladores que puedan ser controlados a distancia. Por el lado de la visualización es ideal
brindar al usuario información analizada y gráfica de la fluctuación de los datos. También al
configurar un cultivo es vital solicitar toda la información básica de este como es el LARA,

75
Área, Tipo de suelo, Fecha de inicio, Humedad inicial del suelo, Tipo de riego, Capacidad de
campo y Variedad de cultivo. Al igual de pedirle que ubique su cultivo en un mapa.
Comparación de estilos de arquitectura de servicios web
Existen múltiples estilos que pueden ser usados para la integración y comunicación de
aplicaciones o sistemas empresariales o de consumo general. La elección entre confiar en una
base de datos compartida, una transferencia de archivos, llamar procedimientos/métodos
remotos, o intercambiando mensajes de manera asincrónica es una decisión de arquitectura
que puede llegar a tener un gran impacto en los requisitos de todo el sistema. [31]
La colección de servicios web de tecnología (SOAP, WSDL, WS-Addressing, WS-
ReliableMessaging, WS-Security, etc.) [31, 32, 33] ofrece interoperabilidad para ambos: RPC
y estilos de integración de mensajes. [34] Los servicios web RESTful [35] también ofrecen
una posibilidad para implementar sistemas de llamada a procedimiento remoto a través de la
Web.
Para definir la arquitectura correcta para cada aplicación o sistema que se planee crear, se
vuelve necesario tomar una decisión de diseño, integración y tecnología basado en
argumentos técnicos y comparaciones justas de las capacidades y características ofrecidas por
cada alternativa.
SOAP y la colección WS-*
Pese a su percibida complejidad, el formato de los mensajes SOAP y el lenguaje de definición
de la interfaz WSDL han obtenido una adopción generalizada como las tecnologías que
permiten una verdadera interoperabilidad entre sistemas de middleware. Entre sus ventajas se
encuentra la transparencia e independencia de protocolo. El protocolo de transporte puede
cambiar en el transcurso de la comunicación del mensaje, pero siendo declarados como
cabeceras SOAP, los aspectos de QoS, tales como encriptación y transferencia confiable
pueden ser independientes del transporte usado.
El contrato WSDL provee una descripción procesable para la máquina de la sintaxis y
estructura correspondiente a los mensajes de solicitud y respuesta. Usando WSDL para

76
describir una interfaz del servicio ayuda a abstraer detalles de la plataforma de
implementación, protocolos de comunicación y detalles de serialización.
Pueden existir problemas de interoperabilidad cuando tipos de datos nativos y construcciones
del lenguaje de la implementación del servicio se encuentran en su interfaz. Dada la
expresividad de los estándares de la colección de WS-* hubo muchos problemas de este tipo
en las primeras implementaciones, las cuales se atribuyen principalmente a la falta de
coordinación entre XML y lenguajes (orientados a objetos) de programación existentes. [54,
55]
REST
El estilo REST está basado en 4 principios:
● Identificación de recursos a través de URI
● Interfaz uniforme
● Mensajes auto descriptivos
● Interacciones con estado a través de hipervínculos
Los servicios web RESTful son percibidos como sencillos debido a que operan sobre
estándares conocidos (HTTP, XML, URI, MIME). Una infraestructura tan liviana es muy
fácil de adoptar, el esfuerzo necesario para construir un cliente hacía un servicio RESTful es
muy pequeño para los desarrolladores, tan simple como probarlo desde un navegador sin
necesidad de ningún desarrollo. Dado a la posibilidad de trabajar con formatos livianos como
JSON o si se desea hasta con texto plano, REST tiene más cabida para optimizar el
rendimiento del Servicio Web.
Al no estar estandarizado hay confusión entre las mejores prácticas para construir servicios
RESTful. Algunas recomendaciones se han establecido no formalmente, existen defensores de
usar los 4 verbos (GET, POST, PUT, DELETE)8 y el uso de URIs “bonitas”, al igual que
existen otros que se basan en el mínimo denominador común y recomiendan usar solo 2
verbos (GET para solicitudes que no generan ningún cambio y POST para todo lo demás),
8 En HTTP 1.1 se hace referencia a 8 verbos: GET, POST, PUT, DELETE, HEAD, TRACE, OPTIONS,
CONNECT.

77
esto debido a las restricciones que puedan tener proxies y firewalls sobre las conexiones
HTTP.
REST vs SOAP
En esta sección realizaremos un análisis cualitativo basado en el trabajo realizado en [36, 61],
y el cuantitativo realizado en [58] de cada servicio y seguidamente una comparación de estos,
dividida en 5 secciones: Comparación de principios, comparación conceptual, comparación
tecnológica, comparación de rendimiento y comparación de preferencias de desarrollo en los
cuales se tienen en cuenta los siguientes factores:
1. Comparación de principios
1.1. Capas de protocolo
1.2. Acoplamiento débil
2. Comparación conceptual
2.1. Estilo de integración
2.2. Diseño de los contratos
2.3. Representación/Modelado de
recursos
2.4. Patrones de intercambio de
mensajes
3. Comparación tecnológica
3.1. Protocolo de transporte
3.2. Formato de carga útil
3.3. Identificación del servicio
3.4. Descripción del servicio
3.5. Fiabilidad, seguridad,
transacciones
4. Comparación de rendimiento
4.1. Tiempo total de respuesta
4.2. Tamaño de paquetes
5. Comparación de preferencias de
desarrollo
5.1. Diferencias percibidas
5.2. Accesibilidad y facilidad de
aprendizaje
5.3. Idoneidad para casos de uso
Comparación de principios
Un Servicio Web tiene como objetivo la comunicación de información, y esto lo hace a través
de unos principios definidos, los cuales determinan cómo el estilo arquitectónico, por ejemplo
REST, maneja las necesidades y objetivos del diseño. En la Tabla 10 se muestra la
comparación de principios que se han establecido entre REST y SOAP. Se comparan las
capas de protocolo y el acoplamiento débil, obteniendo que REST opera sobre HTTP en el
nivel de aplicación y transporte mientras SOAP solo en el nivel de transporte. En cuanto a

78
acoplamiento débil se observa que en SOAP se puede soportar mientras en REST no es
posible.
Tabla 10: Comparación de Principios. Tomado de [36]
Principio y Aspectos de la
Arquitectura REST SOAP
Capas de protocolo 2 1
HTTP: nivel de aplicación Si
HTTP: nivel de transporte Si Si
Acoplamiento débil 1 2
Tiempo/Disponibilidad Si
Ubicación Si Si
Capas de protocolo
Para REST la Web es vista como un medio para publicar información accesible globalmente,
cada aplicación se convierte en parte de la Web usando URIs para identificar los recursos que
ofrecen, usando los verbos de HTTP para exponer operaciones o recursos.
Para SOAP, la Web es vista como un medio para transportar mensajes, los cuales son
intercambiados entre diferentes ‘endpoints’ de los servicios Web. Esto quiere decir, que
utilizan la Web para tener la habilidad de interactuar entre sí, pero no hacen parte de esta.
Acoplamiento débil
Un aspecto importante del acoplamiento débil tiene que ver con la habilidad de los
consumidores de interactuar con el proveedor del servicio hasta cuando este no está
disponible [36], evitando así que los clientes sean afectados cuando el servicio sufre de
problemas temporales.
Debido a que en SOAP existe la capacidad para implementar sistemas basados en mensajes
(No RPC), SOAs, el bus de mensajes hace posible llegar a tal grado de acoplamiento débil,
dado que los mensajes pueden ser transferidos usando colas fiables y persistentes. Dado que
los servicios Web RESTful se enfocan exclusivamente en interacciones de la forma RPC, en
esta tecnología no puede llegar a implementarse un sistema que soporte dicho acoplamiento,

79
cuando el servidor está caído todos los clientes se ven afectados y deben prever este
escenario.
Comparación conceptual
En la Tabla 11 se realiza una comparación conceptual de las decisiones requeridas para
desarrollar el servicio web usando alguno de los dos estilos. En los cuatro aspectos
comparados, para el estilo REST no es necesario tomar una decisión, debido a su simplicidad
solo hay una opción mientras que para SOAP, por su complejidad, presenta opciones en tres
de los cuatro.
Adicionalmente a estos aspectos hay que tener en cuenta para el estilo REST: la identificación
de recursos (de que objeto del mundo real fueron abstraídos), el diseño del URI (cada URI
debe ser “bonita” [43]), la semántica de la interacción de recursos (decidir qué verbos se
deben usar) y la relación de estos.
Tabla 11: Comparación conceptual. Tomado de [36]
Decisiones de Arquitectura REST SOAP
Estilo de integración 1 2
Base de datos compartida
Transferencia de archivos
Llamada a procedimiento remoto Si Si
Mensajería Si
Diseño de los contratos 1 2
Contrato de primera Si
Contrato de última Si
Contrato de menos Si
Representación de datos 1 1
Régimen XML Opcional Si
Hazlo tu mismo Si
Patrones de intercambio de 1 2

80
mensajes
Solicitud – Respuesta Si Si
Un sentido Si
Diseño de los contratos
Contrato de primera hace referencia a iniciar el desarrollo de un servicio a partir de la
especificación de su interfaz, mientras que el contrato de ultima un servicio existente es
publicado con un contrato generado automáticamente. En REST no es necesario tomar una
decisión sobre cuáles son las operaciones disponibles (Contrato de menos). Es recomendable
enfocarse en definir los recursos expuestos.
Representación/Modelado de datos
El content-type9 de cada recurso debe ser seleccionado de la lista de formatos estándar, si se
escoge una representación basada en XML no es necesario.
Patrones de intercambio de mensajes
Determinar si cada operación actúa de manera sincrónica o asincrónica.
Comparación tecnológica
En la Tabla 12, se muestra un comparación entre los dos estilos REST y SOAP, la cual
destaca que SOAP tiene una mayor cobertura de protocolos para realizar el transporte
mientras REST solo funciona sobre HTTP. Por otro lado, REST posee múltiples formatos
para la carga o transferencia de datos mientras que SOAP solo trabaja en XML, mientras que
SOAP posee servicios complementarios (opcionales) que le brindan alternativas en temas
como Identificación de recursos, Confiabilidad, Seguridad, Transacciones y Descubrimiento
del servicio. Claramente SOAP es un estilo más completo y estandarizado, pero esto a su vez
significa que tiene mayor grado de complejidad para el desarrollo tanto del servicio como tal,
como de las aplicaciones que lo consumen.
Tabla 12: Comparación tecnológica. Tomado de [36]
Decisiones de Arquitectura REST SOAP
9 Content-type: Tiene como objetivo describir la información contenida en el cuerpo de una solicitud.
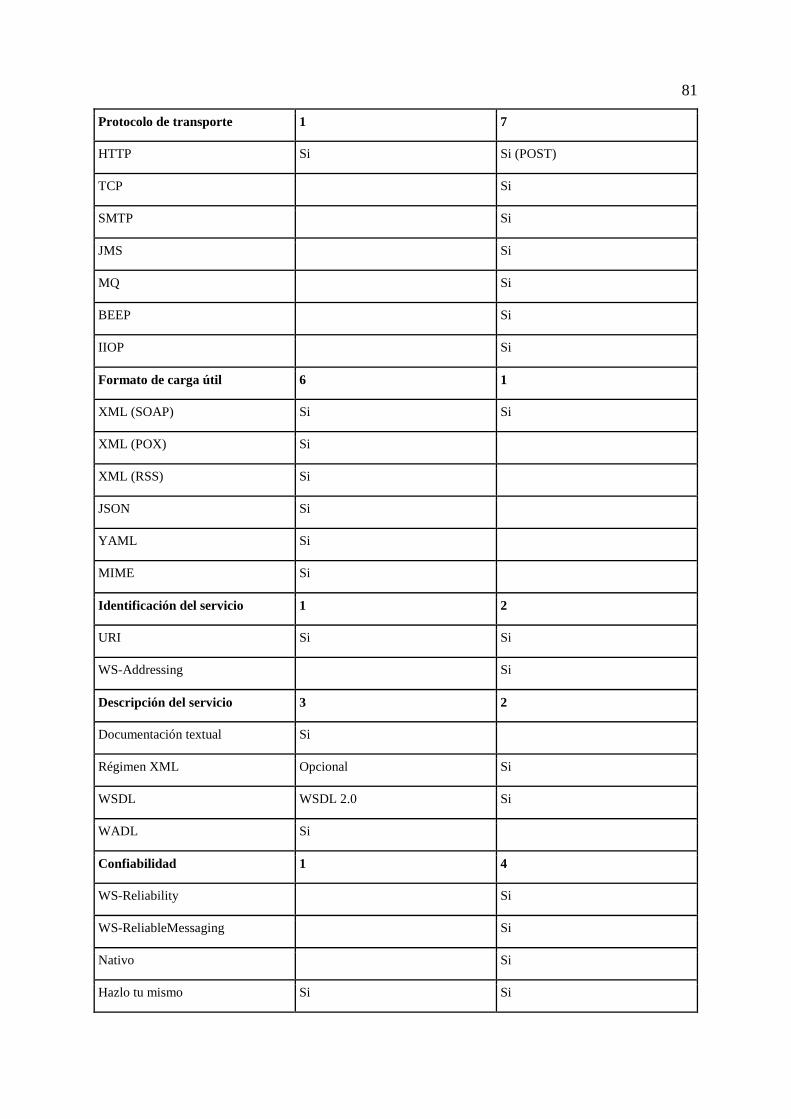
81
Protocolo de transporte 1 7
HTTP Si Si (POST)
TCP Si
SMTP Si
JMS Si
MQ Si
BEEP Si
IIOP Si
Formato de carga útil 6 1
XML (SOAP) Si Si
XML (POX) Si
XML (RSS) Si
JSON Si
YAML Si
MIME Si
Identificación del servicio 1 2
URI Si Si
WS-Addressing Si
Descripción del servicio 3 2
Documentación textual Si
Régimen XML Opcional Si
WSDL WSDL 2.0 Si
WADL Si
Confiabilidad 1 4
WS-Reliability Si
WS-ReliableMessaging Si
Nativo Si
Hazlo tu mismo Si Si

82
Seguridad 1 2
HTTPS Si Si
WS-Security Si
Transacciones 1 3
WS-AT, WS-BA Si
WS-CAF Si
Hazlo tu mismo Si Si
Protocolo de transporte
La Web está construida sobre el protocolo HTTP, para construir servicios RESTful no hay
elección alguna dado que solo se comunica mediante éste. SOAP es independiente y se puede
transferir mediante múltiples protocolos, a través del WSDL se define el protocolo adecuado
de transporte, en la Tabla 12 se muestran algunas opciones de protocolos disponibles, los
mensajes se pueden transportar usando el protocolo más adecuado para cada caso.
Formato de carga útil
Servicios web RESTful no poseen un único formato para representar los recursos, por el
contrario pueden escoger de la variedad de tipos de documento MIME, esto puede llegar a
complicar la comunicación ya que el cliente debe conocer de antemano cómo va a recibir la
información para poder tratarla acorde. Mientras que SOAP solo es presentado en XML, sin
embargo, en la experiencia en desarrollo de servicios web (al igual que en [36]) el beneficio
de trabajar con JSON en vez de XML puede superar el costo de mantenimiento y
complicaciones en la interoperabilidad que puede llegar a presentar REST.
Identificación del servicio
Servicios Web RESTful operan sobre el estándar URI para el nombramiento de la dirección
de los recursos, lo cual permite encapsular toda la información sobre el recurso en este
mismo, adicionalmente pueden ser referenciados fácilmente, compartidos y dada su
legibilidad hasta usados para publicidad. [44]
Descripción del servicio

83
Mientras que el Servicio Web SOAP se basan en una estandarizada, fuertemente-tipado
interfaz (WSDL), los RESTful han adoptado una más orientada al humano, con descripciones
textuales dando a los desarrolladores extensa documentación del API proveído. En general,
tener una buena documentación ayuda enormemente a reducir el tiempo de prueba y error
pero no puede reemplazar el uso de un compilador de una descripción interfaz de lenguaje.
Para atacar esta limitación se ha presentado el WADL [45] al igual que el WSDL 2.0 se puede
aplicar para describir servicios Web RESTful
Fiabilidad, Seguridad y Transacciones
Ambos estilos soportan HTTP y HTTPS, garantizando así una seguridad básica usada
ampliamente en el ambiente web.
La colección de servicios WS-* contiene especificaciones opcionales para cubrir las
propiedades de QoS respecto al intercambio de mensajes, aportando así una calidad en la
comunicación independiente del protocolo de transporte.
Comparación de rendimiento
Debido a que ya se han realizado numerosos estudios [56,57,58,59,60] en cuanto al
rendimiento de SOAP y REST, y comparaciones entre estos; en esta sección nos basaremos
en experimentos ya realizados y publicados para realizar una comparación de rendimiento
entre estos dos estilos.
La comunicación SOAP genera un mayor tráfico en la red, mayor latencia y retardos de
procesamiento, como una alternativa a estas implicaciones se usa la arquitectura RESTful. En
[60] se concluye que el uso de mensajes SOAP requiere un gran ancho de banda,
“codificación y descodificación de mensajes SOAP basado en XML consume recursos”. Por
lo cual se prefiere usar servicios web RESTful para obtener mejor rendimiento. En [58] se
evalúa el rendimiento de ambos servicios web en el ambiente de la computación móvil. Dos
puntos de referencia están implementados basados en parámetros de tipo float10 y string11, el
cliente de servicio corre en un emulador móvil, los resultados se capturan para ambos estilos
en términos de tiempo total de respuesta y tamaño del mensaje, la Tabla 8 muestra que el
10
Float: https://msdn.microsoft.com/es-co/library/b1e65aza.aspx 11
String: https://docs.oracle.com/javase/7/docs/api/java/lang/String.html

84
tamaño de los mensajes en el estilo REST es de 9 a diez veces menor que el tamaño de los
mensajes basados en SOAP. De igual manera, el tiempo requerido para el procesamiento y
transmisión es de 5 a 6 veces menor que servicios web basados en SOAP.
Tabla 13: Resultados de rendimiento de servicios web SOAP y REST en la computación
móvil. Tomado de [58]
Número de
elementos de la
matriz
Tamaño del mensaje (byte) Tiempo (Milisegundos)
SOAP/HTTP REST (HTTP) SOAP/HTTP REST (HTTP)
Referencia #1: Concatenación de texto
2 351 39 781 359
3 371 48 828 344
4 395 63 828 359
5 418 76 969 360
Referencia #2: Adición de números flotantes
2 357 32 781 359
3 383 36 781 407
4 409 35 922 375
5 435 39 1016 359
Comparación de preferencias de desarrolladores
Existen numerosos estudios para comparar REST y la colección WS-* en cuanto a
rendimiento (ver sección Comparación de rendimiento) y características, sin embargo se ha
dejado de lado un aspecto que se considera importante al momento de decidir por un estilo
arquitectónico para la construcción de un Servicio Web. En [61], 69 desarrolladores novatos
aprendieron ambas tecnologías e implementaron aplicaciones de telefonía móvil que
recuperan información de datos de sensores, en ambas arquitectura de servicio RESTful y
WS-*.
Diferencias percibidas

85
En la Tabla 14, se observan unas diferencias cualitativas de ambos estilos. REST fue
percibido “muy fácil de entender, aprender e implementar, ligero y escalable”, mientras que
SOAP “permite operaciones más complejas, provee alta seguridad y un mayor nivel de
abstracción”.
Tabla 14: Diferencias percibidas. Tomado de [61]
REST ( N = 69 ) #
Fácil de entender, aprender e implementar 36
Ligero 27
Fácil de usar por los clientes 25
Más escalable 21
No se requieren librerías 17
Accesible en navegadores 14
Re usa funcionalidades http 10
WS-* ( N = 69 ) #
WSDL permite publicar una interfaz WS-* 31
Permite operaciones más complejas 24
Ofrece mejor seguridad 19
Provee un nivel más alto de abstracción 11
Tiene más características 10
Accesibilidad y facilidad de aprendizaje
Los resultados de la encuesta realizada en [61] mostraron que REST es estadísticamente más
fácil y rápido de aprender que SOAP. Justificando que los Servicios Web RESTful son más
fáciles de aprender debido a que se basan en tecnologías tales como HTTP y HTML, las
cuales son muy conocidas y familiares para personas involucradas en tecnología.
Como se observa en la Figura 25, se percibe una mayor accesibilidad para el aprendizaje de
servicios RESTful sobre WS-*, alrededor de 40 personas consideran la velocidad de
aprendizaje ‘no rápida’ y 25 ‘para nada rápida’, mientras sobre 40 encuestados consideran la

86
velocidad de aprender servicios REST como ‘rápida’ y alrededor de 25 la consideran ‘muy
rápida’.
Figura 25: Percepción de Accesibilidad al Aprendizaje. Tomado de [61]
Como se observa en la Figura 26, los encuestados perciben que la curva de aprendizaje es
mucho menor para servicios RESTful, alrededor de 45 encuestados perciben que los servicios
RESTful tienen un nivel de facilidad ‘fácil’ mientras menos de 10 lo consideran así para
servicios basados en SOAP.
Figura 26: Percepción de facilidad de aprendizaje. Tomado de [61]

87
Idoneidad para casos de uso
En la Tabla 15, se observa los casos de uso donde cada estilo es recomendado, REST es
percibido como adecuado para aplicaciones simples, mientras que SOAP para aplicaciones
donde la seguridad es importante.
Tabla 15: Idoneidad para casos de uso. Tomado de [61]
REST ( N = 37 ) #
Para aplicaciones simples, con funcionalidad atómica 23
Para las aplicaciones web y aplicaciones web híbridas 14
Si la seguridad no es un requisito básico 8
Para las aplicaciones centradas en el usuario 6
Para entornos heterogéneos 6
WS-* ( N = 37 ) #
Para aplicaciones seguras 20
Cuando se necesitan contratos en formatos de
mensajes
16
Directrices para la elección de una arquitectura de servicios
Aunque el estudio realizado en [61] es enfocado al internet de las cosas IoT, se considera que
las recomendaciones y directrices son muy pertinentes para el presente proyecto debido a su
naturaleza móvil. En la Tabla 16, se muestran una serie de directrices para elegir una
arquitectura de servicios, es decir, que forma de comunicación elegir entre REST y SOAP,
dependiendo del (de los) requisito (s) de cada servicio se puede decidir por la arquitectura con
mayor recomendación (+).
Tabla 16: Directrices para la elección de una arquitectura de servicios. Tomado de [61]
Requisito REST SOAP Justificación
Móvil y Embebido + - Ligero, Soporte IP/HTTP
Facilidad de uso ++ - Fácil de aprender
Fomenta la adopción de ++ - Fácil de prototipar

88
terceros
Escalabilidad ++ + Mecanismos Web
Integración Web +++ + Web es RESTful
Negocios + ++ QoS y seguridad
Contratos de servicio + ++ WSDL
Seguridad - +++ WS-Security
Como se observa REST se recomienda en los aspectos de facilidad de uso, integración web,
escalabilidad, móvil y embebido, pero a diferencia de SOAP no se considera ideal para la
implementación de sistemas donde la seguridad toma una vital importancia.
Análisis de estilos de arquitectura de servicios web
Después de haber realizado una recopilación bibliográfica [32, 36, 56, 57, 58, 59, 60, 61]
sobre las ventajas y desventajas de cada protocolo (SOAP y REST), se ha encontrado que
SOAP es un protocolo basado en mensajes que están escritos en XML, mientras que REST es
un protocolo más simple.
REST tiene ventajas comparadas con SOAP, como por ejemplo, requiere de poca
infraestructura de apoyo sobre HTTP ya que están soportados por la mayoría de los lenguaje
de programación, sistemas operativos y servidores. Aunque a diferencia de SOAP, éste sólo
soporta el protocolo HTTP, lo cual puede ser una desventaja, ya que SOAP permite la
transmisión de mensajes XML sobre HTTP y permite trabajar con protocolos de capa de
transporte. Sin embargo, en muchos casos una transferencia sobre HTTP es suficiente para
satisfacer una necesidad específica, como se puede considerar el caso de este proyecto
aplicado a los sistema de riego.
SOAP es tradicionalmente un enfoque basado en estándares, pero la mayoría de Servicios
Web con API públicas ofrecen interfaces REST, mientras que algunos ofrecen ambos SOAP y
REST. Dos gigantes del ámbito empresarial, Salesforce12 y Amazon13, ofrecen ambos SOAP
12
Salesforce: https://www.salesforce.com 13
Amazon Web Services: https://aws.amazon.com/

89
y REST, aunque para el caso de AWS en su blog oficial14 han resaltado un consumo de 80%
para REST sobre 20% para SOAP. Por otro lado, SOAP es muy usado en software
empresarial, por ejemplo, Google implementa todos sus servicios usando SOAP, con la
excepción de Blogger que usa XML-RPC. [56]
Mientras que SOAP proporciona una manera estandarizada para acceder y manipular objetos
remotamente, REST se enfoca en las operaciones que pueden ser ejecutadas sobre los
recursos que expone. Dado que REST hereda operaciones de HTTP, es la opción más
acertada para crear un Web API abierta.
Comunicando información de objetos de ida y vuelta puede consumir mucho ancho de banda,
que puede ser limitada en ambientes donde la conexión es escasa o costosa, por ejemplo en un
cultivo de caña de azúcar en una ubicación remota, una API consumida por una aplicación
móvil es uno de los casos más comunes donde se debe evitar el uso de SOAP debido a su
mayor complejidad de mensajes y consumo de recursos.
El requisito principal de la computación móvil es la conexión del sistema móvil a un ambiente
de computación distribuido convencional. [60] Debido a que los posibles clientes que estarían
consumiendo el servicio web que se desarrolla en este proyecto pueden llegar a tener un
componente grande de computación móvil (debido a la ubicación, en algunos casos, remota
de los cultivos de caña de azúcar) y por las consideraciones mencionadas en este análisis se
considera que el estilo RESTful brinda unas ventajas sobre SOAP para el desarrollo del
Servicio Web. Sin embargo, considerando que el ámbito del enfoque de este proyecto es
empresarial la seguridad toma una importancia alta, por esto se considera que para los
potenciales clientes puede ser importante contar con ambas opciones de diseño estructural,
por cuestiones de tiempo y simplicidad el alcance de este proyecto se concentrará en el
desarrollo del servicio RESTful dejando explícito la necesidad de un desarrollo de servicio
SOAP para futuros trabajos.
14
https://aws.amazon.com/blogs/aws/rest_vs_soap/

90
Requisitos del sistema
Requisitos de usuario
Esta sección describe los requisitos de usuario del sistema de recolección de datos. La
especificación de requisitos de usuario se divide en requisitos de capacidad y requisitos de
restricción impuestos al sistema por el usuario.
La especificación de los requisitos se hace en una tabla con las siguientes propiedades:
● Identificador: Identificador único del requisito.
● Descripción: Descripción del requisito.
● Necesidad: Importancia del requisito para el usuario. (Esencial, Deseable)
● Prioridad: Indica la prioridad establecida para el requisito siendo el valor alto el de
mayor prioridad y baja el de menor prioridad. (Alta, Media, Baja)
● Estabilidad: Indica si el requisito está sujeto a modificaciones. (Estable, No estable)
● Fuente: Indica la procedencia de la especificación del requisito. (Cliente, Dev
(Programador) )
Requisito de capacidad
Los siguientes requisitos hacen referencia a la capacidad de usuario del sistema.
Tabla 17: Requisitos de Capacidad de usuario del sistema
ID Descripción Necesidad Prioridad Estabilidad Fuente
UR01 El sistema debe mostrar la información
en la interfaz en base al usuario
logueado
Esencial Alta Estable Cliente
UR02 El sistema debe soportar el ingreso de
variables personalizadas indicadas por
un usuario
Esencial Alta Estable Cliente
UR03 El sistema debe permitir al usuario
ingresar sensores en los lotes creados
Esencial Alta Estable Dev
UR04 El sistema debe poder alterar el estado Esencial Alta Estable Dev

91
de los elementos almacenados en el
mismo
UR05 El sistema debe proveer al usuario una
interfaz de ingreso al sistema
Esencial Media Estable Cliente
UR06 El sistema debería incluir el método de
recuperación de contraseña a un usario
que se ha olvidado de ella
Deseable Baja No estable Dev
UR07 El sistema debe bloquear determinadas
acciones a usuarios que no cuenten con
los permisos necesarios
Esencial Alta Estable Dev
UR08 El sistema debe ser capaz de captar
datos recuperados por sensores que
estén incluidos en el mismo
Esencial Alta Estable Cliente
UR09 El sistema debe ser capaz de localizar el
cultivo y/o lote en el mapa de la finca
Deseable Baja No estable Cliente
UR13 El sistema debe brindar
retroalimentación a los usuarios de las
acciones que estos implementen en el
sistema
Deseable Media No estable Dev
Requisito de restricción
Los siguientes requisitos hacen referencia a las restricciones impuestas al usuario en el
sistema.
Tabla 18: Requisitos de restricciones impuestas al usuario en el sistema
ID Descripción Necesidad Prioridad Estabilidad Fuente
UR10 El sistema debe proveer ingreso a el
desde cualquier lugar del mundo
Esencial Alta Estable Cliente
UR11 El sistema debe poder ser accedido
desde cualquier dispositivo móvil
Esencial Media No estable Cliente
UR12 El sistema debe poder ser accedido Esencial Alta Estable Dev
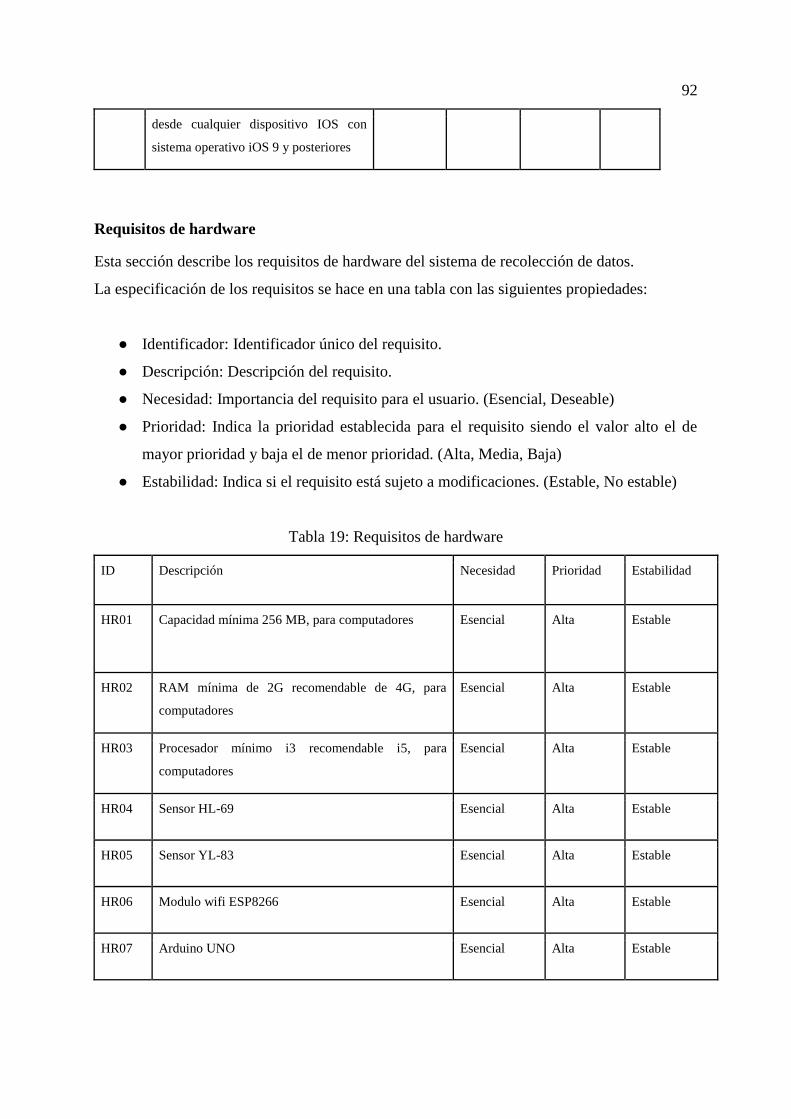
92
desde cualquier dispositivo IOS con
sistema operativo iOS 9 y posteriores
Requisitos de hardware
Esta sección describe los requisitos de hardware del sistema de recolección de datos.
La especificación de los requisitos se hace en una tabla con las siguientes propiedades:
● Identificador: Identificador único del requisito.
● Descripción: Descripción del requisito.
● Necesidad: Importancia del requisito para el usuario. (Esencial, Deseable)
● Prioridad: Indica la prioridad establecida para el requisito siendo el valor alto el de
mayor prioridad y baja el de menor prioridad. (Alta, Media, Baja)
● Estabilidad: Indica si el requisito está sujeto a modificaciones. (Estable, No estable)
Tabla 19: Requisitos de hardware
ID Descripción Necesidad Prioridad Estabilidad
HR01 Capacidad mínima 256 MB, para computadores Esencial Alta Estable
HR02 RAM mínima de 2G recomendable de 4G, para
computadores
Esencial Alta Estable
HR03 Procesador mínimo i3 recomendable i5, para
computadores
Esencial Alta Estable
HR04 Sensor HL-69 Esencial Alta Estable
HR05 Sensor YL-83 Esencial Alta Estable
HR06 Modulo wifi ESP8266 Esencial Alta Estable
HR07 Arduino UNO Esencial Alta Estable

93
HR08 Ipad con sistema apple A7 o posteriores Esencial Alta Estable
HR09 Ipad con memoria mínima de 1024 MB LPDDR3
RAM
Esencial Alta Estable
HR10 Ipad con “storage” mínimo de 16GB Esencial Alta Estable
HR11 Ipad con gráfica Quad-core PowerVR G6430 Esencial Alta Estable
HR12 Ipad con CPU mínima de 1.3 GHz dual-core Apple
Cyclone
Esencial Alta Estable
HR13 Ipad con conectividad mínima de Wi-Fi802.11
a/b/g/n @ 2.4 GHz and 5GHz
Esencial Alta Estable
Requisitos de software
Esta sección describe los requisitos de software del sistema de recolección de datos. La
especificación de requisitos de software se divide en requisitos funcionales, requisitos no
funcionales de interfaz y requisitos no funcionales de operación que especifican cómo debe de
llevarse a cabo.
La especificación de los requisitos se hace en una tabla con las siguientes propiedades:
● Identificador: Identificador único del requisito.
● Descripción: Descripción del requisito.
● Necesidad: Importancia del requisito para el usuario.
● Prioridad: Indica la prioridad establecida para el requisito siendo el valor alto el de
mayor prioridad y baja el de menor prioridad.
● Estabilidad: Indica si el requisito está sujeto a modificaciones.
● Fuente: Indica la procedencia de la especificación del requisito.
Requisitos funcionales
Los requisitos funcionales que a continuación se detallan definen qué hace el sistema.

94
Tabla 20: Requisitos funcionales del sistema
ID Descripción Necesidad Prioridad Estabilidad Fuente
SR01 El sistema debe mostrar la información
proveída por el usuario en la interfaz
Esencial Alta Estable UR01
SR02 El sistema debe ser capaz de captar
datos tanto ingresados por un usuario
humano como por un controlador
(Arduino)
Esencial Alta Estable UR02
SR03 El sistema debe ser capaz de permitir a
usuarios autorizados eliminar, crear,
actualizar y/o modificar cultivos y lotes
Esencial Alta Estable UR04
UR07
UR06
SR10 El sistema debe ser capaz de enviar
notificaciones al usuario de cambios en
el cultivo y/o lote
Deseable Bajo No estable UR04
SR11 El sistema debe permitir la
geolocalización el cultivo en el mapa
Deseable Medio No estable UR09
Requisitos de interfaz
Los requisitos de interfaz definen el modo en que interactúan y se comunican las interfaces y
diferentes módulos del sistema.
Tabla 21: Requisitos de interfaz e interacciones
ID Descripción Necesidad Prioridad Estabilidad Fuente
SR12 El sistema debe ser capaz de ser
accedido desde cualquier explorador
web que esté soportado: Chrome 21.0,
Safari 10.0, Mozilla 18.0, Safari 6.1 y
Opera 17.0
Esencial Alta Estable UR10
SR13 Els sistema debe permitir descarga en
dispositivos iOS con sistema operativo
iOS 9 o superiores
Esencial Media Estable UR11
UR12
SR14 El sistema debe tener una comunicación Esencial Alta Estable HR01

95
entre los pares por medio de HTTPS HR07
SR15 El sistema debe tener una comunicación
con sensores por medio de
controladores (Arduino)
Esencial Alta Estable HR01
HR02
HR03
HR04
Requisitos de operación
Los requisitos de operación definen cómo debe de operar del sistema.
Tabla 22: Requisitos de operación
ID Descripción Necesidad Prioridad Estabilidad Fuente
SR16 El sistema debe retroalimentar al usuario
después de que este realice alguna
acción en el sistema.
Esencial Alta Estable UR13
SR17 El sistema debe solicitar confirmaciones
en operaciones de alto riesgo como la
eliminación de un cultivo.
Deseable Media No estable UR13
SR18 El sistema debe generar reportes de
forma gráfica con charts y/o tablas
Deseable Alta Estable UR13
UR04
Requisitos de recursos
Los requisitos de recursos definen los recursos mínimos para que la aplicación pueda ponerse
en marcha.
Tabla 23: Requisitos de recursos
ID Descripción Necesidad Prioridad Estabilidad Fuente
SR20 El sistema debe contener un servicio
web con operaciones de CRUD e
implementaciones de funciones a
realizar después, antes o mientras de
algún cambio, creación o eliminación
Esencial Alta Estable UR04
UR08

96
SR21 El sistema requiere que los dispositivos
que se conecten estén conectados a una
red. Si se usa en un lugar sin conexión a
internet y la red sea la misma en la que
está corriendo el servicio.
Esencial Alta Estable UR12
UR13
UR14
UR15
SR22 El sistema requiere de un dispositivo
que sea capaz de hacer entender la
recolección de datos que obtienen los
sensores como es el caso de un Arduino
para este diseño
Esencial Alta Estable HR01
SR23 El sistema requiere de sensores
compatibles con la unidad de control
que estén conectados y se comunique
con el SW
Esencial Alta Estable HR02
HR03
HR04
Requisitos de seguridad
Los requisitos de seguridad definen las características de seguridad del sistema.
Tabla 24: Requisitos de seguridad
ID Descripción Necesidad Prioridad Estabilidad Fuente
SR19 El sistema requiere que cualquier
operación de un usuario humano se
debe ser enviado headers de
autorización para ello
Esencial Alta Estable UR04
SR09 El sistema requiere que los usuarios se
conecten por usuario y contraseña
Escencial Medio Estable UR05
SR24 El sistema requiere tener un tiempo de
vencimiento de la autorización
alrededor de los 15 min
Escencial Medio Estable UR04

97
Propuesta de Diseño del Sistema
Se propone el diseño de un sistema que permita captar variables de un sistema de riego y
generar gráfica por variable con los valores obtenidos de la misma con información básica del
lote.
Las variables soportadas en primera instancia son: Factor de cultivo, Riego efectivo,
Precipitación efectiva, Precipitación efectiva real, Evaporación, Evapotranspiración,
Humedad del suelo y Humedad del suelo real. Las anteriores variables soportadas se capturan
de diferente forma en el sistema.
Formas de captación del sistema
A continuación se presenta las formas de captación del sistema y las variables que soportan
los mismos.
Ingresada por el usuario
Estas son las variables que el usuario ingresa manualmente en el sistema por medio de algún
dispositivo de entrada (plataforma web o móvil), las cuales son: Factor de cultivo, Riego
efectivo, Precipitación efectiva, Evaporación.
Calculada por el sistema
Estas son las variables que el sistema calcula en base a una fórmula estipulada en el mismo,
las cuales son: Evapotranspiración (cálculo: El producto de Evaporación por Factor de
cultivo) y Humedad de suelo (cálculo: Humedad de suelo anterior menos la suma de
Evapotranspiración con Precipitación efectiva y Riego efectivo ).
Captada por sensor
Estas son las variables que son obtenidas por medio de un sensor que es controlado por una
tarjeta programada Arduino y por el mismo hace peticiones de almacenamiento de estas, las
cuales son: Humedad del suelo real y Precipitación efectiva real.

98
Tipos de Usuario (Perfiles)
Este sistema cuenta con manejo de usuarios, por lo tanto cumplen un roles específico los
cuales son: Visitante, Registrador y Administrador. A continuación exponemos el rol que
cumple cada uno en el sistema:
Visitante
Estos usuarios solo pueden ver la información de cultivos, lotes, sensores y variables. No
tienen permitido ver el listado de usuario y al igual que no pueden modificar, crear o eliminar
ningún elemento del sistema (cultivo, lotes, sensores, usuarios o variables).
Registrador
Estos usuarios pueden hacer lo mismo del visitante además de poder ver el listado de usuarios
y poder crear y modificar los elementos usuarios, cultivo y lotes. No tienen permitido crear y
modificar sensores y variables y tampoco pueden eliminar usuarios, cultivos, lotes, sensores o
variables

99
Administrador
Estos usuarios pueden hacer lo mismo que el registrador además de crear y modificar
sensores y variables personalizadas y también pueden eliminar usuarios, cultivos, lotes,
sensores o variables personalizadas
Componentes del sistema
El sistema cuenta con tres clientes, dos de visualización y captación de datos manuales y
calculados y uno de captador de datos por sensores. Estos clientes son:
Plataforma virtual
Se puede acceder a esta por medio de un explorador moderno preferiblemente Chrome para
una mejor experiencia. Desde esta se puede visualizar todos los elementos del sistema
almacenados tales como los cultivos, lotes, variables, usuarios y sensores. En la misma el
usuario puede interactuar creando, modificando y eliminado algunos elementos del sistema
que tienen permitido interactuar. Esta plataforma cuenta con mayor información visible para
los usuarios y no importa si el usuario accede desde un computador o un dispositivo móvil.
Dispositivo móvil
Se puede acceder a esta por medio de un dispositivo iOS 9 o posteriores y esta solo para iPad.
Desde esta se puede visualizar todos los elementos del sistema. En la misma el usuario puede
interactuar creando y modificando elementos así esté en modo offline.
Tarjeta programada Arduino
Este cliente es el comunicador de sensores al sistema. Desde la tarjeta se obtienen los valores
captados por los sensores conectados a unos de los pines que en el mismo instante que se
obtiene el valor este envía al servicio el dato o datos recolectados. Este solo puede actualizar y
añadir valores a las variables representativa del sensor.
El sistema es capaz de hacer CRUD en la base de datos (NoSQL) realizando operaciones de
creación, lectura, actualización y eliminado de datos dependiendo del cliente y acción
solicitada. Así mismo se activan operaciones que escuchan eventos de creación, eliminación y

100
actualización que modifican valores del elemento o elementos relacionados. Las operaciones
que soporta el sistema son:
● CRUD Cultivo
● CRUD Lote
● CRUD Usuario
● Leer Variable
● CRUD Sensor
● Trigger Variable
● Trigger Sensor
● Trigger Cultivo
● Trigger Lote
● CRUD Variable personalizada
Arquitectura del sistema
Se propone posteriormente una arquitectura para el diseño propuesto. Los módulos que
componen este son: navegador web, aplicación móvil, Arduino, sensores, modulo wifi,
servicio web y base de datos.
Navegador web
El navegador web representa el cliente que se conecta al sistema por medio de un explorador
tal como Chrome, Safari entre otros. Su comunicación con el servicio web es por medio de
peticiones HTTP preferiblemente HTTPS por más seguridad en el envío de datos.
ReactJS con redux son las tecnologías a usar en la implementación del cliente. Pero también
se puede hacer uso de otras tecnologías como es Angular, Ember, Polymer u otras populares o
usadas en el momento de la intención de uso de este diseño. El cliente contiene una
integración directa con el servidor de almacenamiento de información con el fin de enseñar la
información a almacenar de forma instantánea (real-time-database) en todos los dispositivos
conectados. Este debe contener un generador de reportes por ello se hace uso de tecnologías
de generación de gráficas haciendo uso de Google Charts para esta implementación, pero en
la comunidad se pueden encontrar otras librerías tales como ChartsJs, D3js, Recharts,
Graphics.
El cliente web se necesita para tener una interfaz entendible, de visualización e ingreso de
datos para un usuario y que se integre con el servicio web que interopera con los demás

101
clientes conectados por medio de un mismo cliente web u otro cliente los cual puede ser un
controlador en el sistema de riego o aplicación móvil.
Aplicación móvil
La aplicación móvil representa el cliente que se conecta al sistema por medio de un aplicativo
nativo o híbrido. Su comunicación con el servicio web es por medio de peticiones HTTPS.
El aplicativo dependiendo del tipo de dispositivo se pondrá en funcionamiento con las
tecnologías pertinentes, en el caso de este diseño se usará un dispositivo con sistema operativo
iOS con soporte desde iOS 9 y posteriores que soportan Swift 3.0. El cliente se integra con
“Firebase real time database” en el uso de lectura de datos aprovechando la funcionalidad
“real-time” que ofrece. Para la visualización de reportes de la información almacenada se
hace uso de Charts 3.0.
La aplicación móvil se es necesaria en el caso de uso de un cliente sin computador y apartado
de la finca y con conexión a internet el cual desea estar pendiente del estado de su cultivo.
Arduino
La tarjeta programable Arduino hacer representación de un controlador de riego, la cual
obtiene y distribuye la información capturada por sensores, al mismo tiempo que con la
integración de un sistema embebido asignar tareas a bombas y/o dispositivos de riego en el
lote (hectárea controlada). En el diseño planteado la función del Arduino se limita a la
captación y envío de datos al servicio web haciendo uso de un módulo wifi con el cual pude
hacer peticiones HTTPS.
La tarjeta programable se necesita para tener un dispositivo que emule la captación y envío de
información para ser probado el sistema planteado. Se aconseja que si es para uso industrial
hacer consultas de integración de sistemas embebidos por controladores a servicios por
motivos de protocolos únicos de cada dispositivo.

102
Sensores
Los sensores captan la información “real” del suelo, en este diseño se emplean sensores
académicos para la precipitación efectiva (lluvia) y humedad del suelo. Se usan por
demostración de captación de información. Estos se comunican únicamente con el Arduino
por medio de los pines del mismo. Se usan los sensores HL-69 para la humedad de suelo y
YL-83 para lluvia
Modulo wifi
El módulo wifi se emplea para darle conectividad al arduino con la red, el módulo
implementado en el diseño es el Wifi ESP8266.
Servicio web
El servicio web (SW) hace referencia a la parte lógica que se comunica con el servicio de
almacenamiento para crear y actualizar datos. Este diseño hace uso de una base de datos
NoSQL no contiene funcionalidad de triggers como es en el caso de las SQL, debido a hello si
se decide por este sistema de almacenamiento el servicio debe contener funciones que hagan
de triggers y realicen operaciones necesarias para las funcionalidades de variables
personalizadas, campos formulan, promedio y/o cálculo de valores numéricos como son el
LARA, capacidad de campo entre otros del cultivo o algún otro método necesario que se
aplique a más de un elemento después, antes o durante la eliminación, actualización o
creación de elementos en el sistema.
Figura 27: Tendencia de uso de lenguajes de SW entre: NodeJs, Laravel, Java EE 6,
Django, Ruby and rails. Tomado de Google Trends.

103
En el diseño propuesto se hace uso de Node.Js como lenguaje del SW siendo uno de los más
populares en la comunidad hoy en día, la figura 27 se aprecia las tendencias de uso de los
lenguajes al lado de SW: Laravel, Node.Js, Django, Java EE 6 y Ruby and rails de las cuales
la preferida por la comunidad de programadores es Laravel seguida por Node.Js siendo este
último JavaScript al lado del SW. Se usan los módulos Express que [96] proporciona un
conjunto sólido de características para las aplicaciones web, la figura 28 las tendencias de los
programadores están en usar Hapi.js o Express.js para ser implantados como complemento de
Node.Js . Para el servicio de almacenamiento el cual es por Firebase el usado en este diseño se
usa el módulo firebase-admin.
El SW se almacena para hacer el hosting en una instancia EC215 de AWS16 con sistema
operativo Linux, de tipo t2.small, en la zona eu-west-1a. Se instala dentro de esta Forever17 y
Node.Js 6.10.3 para correr el código del SW y la aplicación web .
Figura 28: Tendencia de uso de frameworks Node.JS que contiene un conjunto de sólidas
características para las aplicaciones web entre: Express.js, koa.js, hapi.js y reatify,js.
Tomado de Google Trends
Base de datos
Módulo de gestión de almacenamiento del sistema, se usa en el diseño Firebase para esta
funcionalidad. Se usa la tecnología NoSQL se define esta por la ventaja de ser ejecutada en
15
Elastic Compute Cloud (EC2): https://aws.amazon.com/ec2/ 16
Amazon Web Services (AWS): https://aws.amazon.com/ 17
Forever: https://github.com/foreverjs/forever

104
maquinas de pocos recursos viendo siendo útil en el ámbito de los sistemas embebidos. En el
desarrollo se implanta Firebase más que todo por su característica de “real-time” pero existen
otras opciones de este tipo de bases de datos tales como: Dynamodb, Cassandra, Mongodb.
El sistema se construyó usando una base de datos NoSQL documental a la cual se le hace
CRUD por medio de un servicio web desarrollado en NodeJS18 debido a que esta es una base
de datos sin triggers en el servicio se desarrolló unas funciones que se encargan de hacer
operaciones específicas al terminar de crear, actualizar o eliminar información de la base de
datos en algunos métodos. En la Figura 15 se representa la arquitectura donde se puede
apreciar la interacción del servicio web con firebase.
Los clientes del sistema pueden ser de visualización y/o recolección como se aprecia en la
Figura 29 los clientes web y móvil recolectan datos por medio de un usuario que ingresa
información y el mismo puede ver la información organizada, estos se comunican con el
servicio web por medio de http y headers de autenticación.
El cliente arduino solo recolecta datos de los sensores conectados al mismo y los envía
haciendo uso del módulo wifi por medio de http como los otros clientes a diferencia del web y
el móvil este no envía headers de autenticación pero para poder hacer modificaciones en la
base de datos los sensores deben estar configurados antes en el sistema.
18
Node.js: https://nodejs.org

105
Figura 29: Arquitectura del sistema
El Servicio Web proporciona un medio estándar de interoperabilidad entre distintas
aplicaciones de software que se pueden ejecutar en plataformas diferentes y ser construidas en
múltiples lenguajes de programación.
El Servicio Web es diseñado con un ROM19 ilustrado en la Figura 8, este modelo se concentra
en los aspectos de la arquitectura que se relacionan a los recursos20. Los recursos representan
cualquier cosa que puede tener un identificador único para poder ser referenciado
posteriormente, de igual manera pueden tener un dueño y unos controles definidos y puede
llegar a tener más de una representación.
Diseño del sistema
Casos de uso
19
The Resource Oriented Model: https://www.w3.org/TR/ws-
arch/#resource_oriented_model#resource_oriented_model 20
RFC 2396: http://ietf.org/rfc/rfc2396.txt
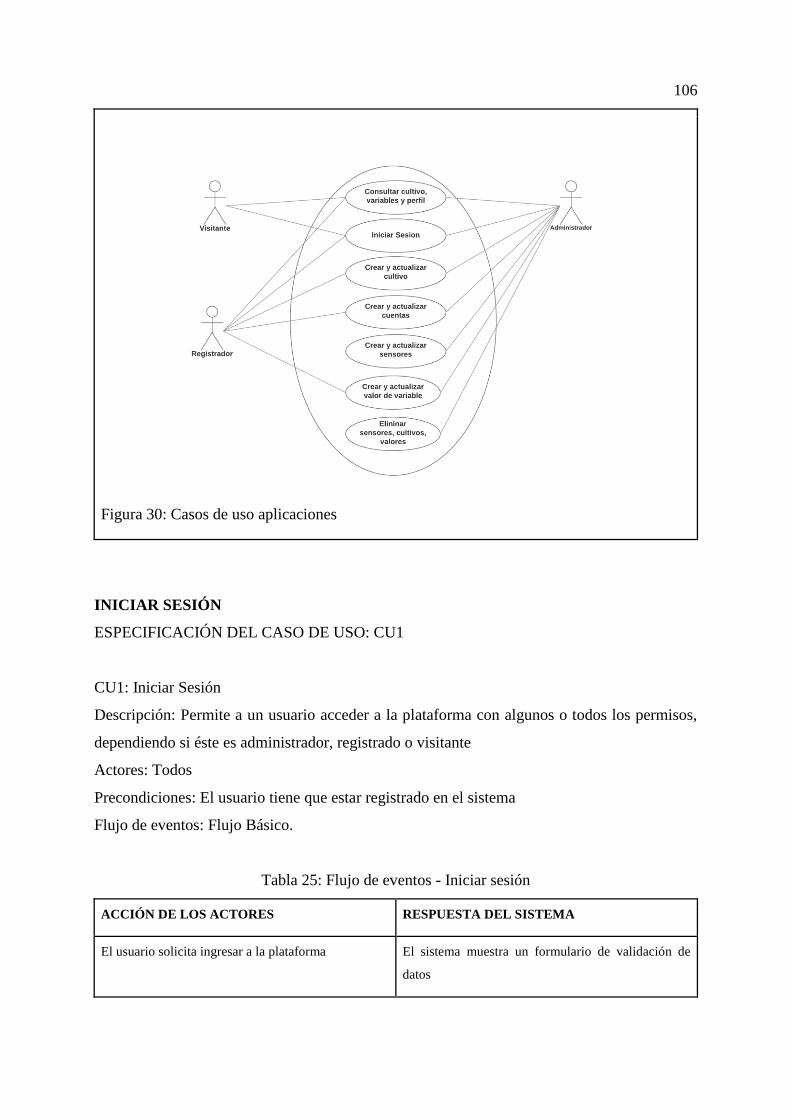
106
Figura 30: Casos de uso aplicaciones
INICIAR SESIÓN
ESPECIFICACIÓN DEL CASO DE USO: CU1
CU1: Iniciar Sesión
Descripción: Permite a un usuario acceder a la plataforma con algunos o todos los permisos,
dependiendo si éste es administrador, registrado o visitante
Actores: Todos
Precondiciones: El usuario tiene que estar registrado en el sistema
Flujo de eventos: Flujo Básico.
Tabla 25: Flujo de eventos - Iniciar sesión
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita ingresar a la plataforma El sistema muestra un formulario de validación de
datos

107
El usuario ingresa correo electrónico y contraseña El sistema valida los datos y de ser correctos permite
que el usuario vea la plataforma según sea sus
privilegios
Flujo alternativos: Usuario incorrecto
Acción 3: Si los datos no son correctos, se le avisara al actor de ello, permitiéndole volver a
ingresar los datos.
Flujo alternativos: Entrar a páginas sin logueo (Solo aplicación web)
Acción 1: El usuario entra a una dirección sin haberse identificado, se le cargará en la
dirección el formulario de iniciar sesión, permitiéndole ingresar el correo electrónico y
contraseña.
Flujo alternativos: Usuario no recuerda la contraseña
Acción 3: Si no recuerda la contraseña, se le avisara al actor de solicitar que le envíen una
recuperación de contraseña al correo.
CREAR CUENTA
ESPECIFICACIÓN DEL CASO DE USO: CU2
CU2: Crear cuenta
Descripción: Permite a un usuario con compañía no registrada crear una cuenta
Actores: Todos
Precondiciones: La compañía no debe existir en la base de datos
Flujo de eventos: Flujo Básico.
Tabla 26: Flujo de eventos - Crear cuenta
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita crear una cuenta en la plataforma El sistema muestra un formulario de ingreso de datos
El usuario ingresa correo electrónico, contraseña,
empresa, nombre, apellido
El sistema valida los datos y de ser correctos crea la
cuenta y permite que el usuario vea la plataforma con
todos los privilegios

108
Flujo alternativos: Empresa existente
Acción 3: Si la compañía existe, se le avisara al actor de la existencia y que solicite a la
empresa que lo agregue a la plataforma.
Flujo alternativos: Correo electrónico en uso
Acción 3: El usuario entra un correo electrónico en uso, se le avisa al actor de que ya existe el
correo y además de darle la opción de recuperar contraseña.
Flujo alternativos: Información ingresada nula
Acción 3: El usuario no ingresa todos los campos, se le avisara al actor que todos los campos
del formulario son requeridos para la creación de una cuenta padre.
AÑADIR CUENTA
ESPECIFICACIÓN DEL CASO DE USO: CU3
CU3: Añadir cuenta
Descripción: Permite a un usuario añadir una cuenta a la lista de cuentas de la compañía
Actores: Administrador
Precondiciones: El usuario debe estar logueado y ser administrador
Flujo de eventos: Flujo Básico.
Tabla 27: Flujo de eventos - Añadir cuenta
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita añadir una cuenta en la plataforma El sistema muestra un formulario de ingreso de datos
El usuario ingresa correo electrónico, contraseña,
nombre, apellido, perfil
El sistema valida los datos y de ser correctos crea la
cuenta y permite que el usuario vea la nueva cuenta
en la lista de cuentas
Flujo alternativos: Correo electrónico en uso
Acción 3: El usuario entra un correo electrónico en uso, se le avisa al actor de que ya existe el
correo y además de darle la opción de ver el usuario.

109
Flujo alternativos: Información ingresada nula
Acción 3: El usuario no ingresa todos los campos, se le avisara al actor que todos los campos
del formulario son requeridos para la creación de una cuenta.
ELIMINAR CUENTA
ESPECIFICACIÓN DEL CASO DE USO: CU4
CU4: Eliminar cuenta
Descripción: Permite a un usuario eliminar una cuenta a la lista de cuentas de la compañía
Actores: Administrador
Precondiciones: El usuario debe estar logueado y ser administrador
Flujo de eventos: Flujo Básico.
Tabla 28: Flujo de eventos - Eliminar cuenta
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita eliminar una cuenta en la
plataforma
El sistema muestra una alerta, advirtiendo al actor
que está apunto de eliminar un usuario
El usuario acepta eliminar la cuenta El sistema valida los datos y elimina la cuenta
seleccionada y permite ver al usuario la lista de
usuarios sin la cuenta eliminada
Flujo alternativos: El usuario no acepta eliminar la cuenta, se cierra la alerta y no se presenta
ningún cambio en el listado de usuarios
LISTAR USUARIOS DE LA COMPAÑÍA
ESPECIFICACIÓN DEL CASO DE USO: CU5
CU5: Listar usuarios de la compañía
Descripción: Permite a un usuario ver el listado de usuarios
Actores: Registrador, Administrador
Precondiciones: El usuario debe estar logueado y deben existir usuarios de la compañía en la
base de datos

110
Flujo de eventos: Flujo Básico.
Tabla 29: Flujo de eventos - Listar usuarios de la compañía
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita listar los usuarios de la compañía a
la plataforma
El sistema muestra el listado de usuarios.
SALIR DE LA PLATAFORMA
ESPECIFICACIÓN DEL CASO DE USO: CU6
CU6: Salir de la plataforma
Descripción: Permite a un usuario desloguearse de la plataforma
Actores: Todos
Precondiciones: El usuario debe estar logueado
Flujo de eventos: Flujo Básico.
Tabla 30: Flujo de eventos - Salir de la plataforma
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita salir de la plataforma El sistema borra los cookies del usuario y muestra el
formulario de inicio de sesión
AÑADIR CULTIVO
ESPECIFICACIÓN DEL CASO DE USO: CU7
CU7: Añadir cultivo
Descripción: Permite a un usuario crear un cultivo en la base de datos
Actores: Registrador, Administrador
Precondiciones: El usuario debe estar logueado
Flujo de eventos: Flujo Básico.
Tabla 31: Flujo de eventos - Añadir Cultivo

111
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita añadir un cultivo a la plataforma El sistema muestra el formulario de registro
El usuario ingresa el nombre del cultivo, fecha de
inicio, LARA, capacidad de campo, área del campo,
tipo de cultivo, tipo de riego, adjunta una imagen del
cultivo.
El sistema valida los datos y de ser correctos crea el
nuevo cultivo y además permite ver al usuario el
nuevo cultivo.
Flujo alternativos: Información requerida nula
Acción 3: El usuario no ingresa información requerida, se le avisara al actor de que esa
información es requerida y le permite ingresar los datos nuevamente.
ACTUALIZAR CULTIVO
ESPECIFICACIÓN DEL CASO DE USO: CU8
CU8: Actualizar cultivo
Descripción: Permite a un usuario editar un cultivo de la base de datos
Actores: Registrador, Administrador
Precondiciones: El usuario debe estar logueado y el cultivo debe existir en la base de datos
Flujo de eventos: Flujo Básico.
Tabla 32: Flujo de eventos - Actualizar Cultivo
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita editar un cultivo a la plataforma El sistema muestra el formulario de edición
El usuario cambia el nombre del cultivo, fecha de
inicio, LARA, capacidad de campo, área del campo,
tipo de cultivo, tipo de riego, adjunta un nueva
imagen del cultivo.
El sistema valida los datos y de ser correctos
actualiza el cultivo y además permite ver al usuario
los cambios en el cultivo.
ELIMINAR CULTIVO
ESPECIFICACIÓN DEL CASO DE USO: CU9
CU9: Eliminar cultivo

112
Descripción: Permite a un usuario eliminar un cultivo de la base de datos
Actores: Administrador
Precondiciones: El usuario debe estar logueado y el cultivo debe existir en la base de datos
Flujo de eventos: Flujo Básico.
Tabla 33: Flujo de eventos - Eliminar Cultivo
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita eliminar un cultivo a la plataforma El sistema muestra una alerta, avisando al actor que
va a eliminar un cultivo con todo lo que esté
relacionado a el.
El usuario acepta eliminar el cultivo El sistema valida los datos y de ser correctos elimina
el cultivo.
AÑADIR SENSOR A UN CULTIVO
ESPECIFICACIÓN DEL CASO DE USO: CU10
CU10: Añadir sensor a un cultivo
Descripción: Permite a un usuario añadir un sensor a la base de datos
Actores: Registrador, Administrador
Precondiciones: El usuario debe estar logueado y el cultivo debe existir en la base de datos
Flujo de eventos: Flujo Básico.
Tabla 34: Flujo de eventos - Añadir sensor a una variable de un cultivo
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita añadir un sensor a un cultivo a la
plataforma
El sistema muestra el formulario.
El usuario ingresa el identificador único del sensor, el
tipo de envío de datos (discretos o continuos)
El sistema valida los datos y de ser correctos agrega
el sensor a la variable del cultivo.
CAMBIAR SENSOR DE UN CULTIVO A OTRO
ESPECIFICACIÓN DEL CASO DE USO: CU11

113
CU11: Cambiar sensor de un cultivo a otro
Descripción: Permite a un usuario cambiar un sensor de una variable a otra variable de otro
cultivo
Actores: Administrador
Precondiciones: El usuario debe estar logueado y el sensor debe de existir
Flujo de eventos: Flujo Básico.

114
Tabla 35: Flujo de eventos - Cambiar sensor de un cultivo a otro
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita cambiar un sensor de cultivo a la
plataforma
El sistema muestra el formulario pertinente.
El usuario ingresa el id del cultivo al cual se cambia
el sensor
El sistema valida los datos y de ser correctos borra el
sensor del cultivo actual y crea el sensor en el nuevo
cultivo.
ELIMINAR SENSOR DE UN CULTIVO
ESPECIFICACIÓN DEL CASO DE USO: CU12
CU12: Eliminar sensor de un cultivo
Descripción: Permite a un usuario eliminar un sensor de la base de datos
Actores: Administrador
Precondiciones: El usuario debe estar logueado y el sensor debe de existir
Flujo de eventos: Flujo Básico.
Tabla 36: Flujo de eventos - Eliminar sensor de un cultivo
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita eliminar un sensor a la plataforma El sistema muestra una alerta, avisando al actor que
va a eliminar un sensor del cultivo.
El usuario acepta eliminar el sensor El sistema valida los datos y de ser correctos elimina
el sensor.
AÑADIR VALOR A UNA VARIABLE DE UN CULTIVO
ESPECIFICACIÓN DEL CASO DE USO: CU13
CU13: Añadir valor a una variable de un cultivo
Descripción: Permite a un usuario añadir un valor de nivel a una variable
Actores: Registrador, Administrador
Precondiciones: El usuario debe estar logueado y el cultivo debe existir en la base de datos

115
Flujo de eventos: Flujo Básico.
Tabla 37: Flujo de eventos - Eliminar Cultivo
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita añadir un valor a una variable de
un cultivo a la plataforma
El sistema muestra el formulario correspondiente
El usuario ingresa el valor del nivel, la fecha a la cual
pertenece y el tipo de dato (para aproximar con el
valor actual o para colocar como valor del dia)
El sistema valida los datos y de ser correctos crea el
valor del nivel a una variable del cultivo.
ELIMINAR VALOR A UNA VARIABLE DE UN CULTIVO EN UNA FECHA
ESPECÍFICA
ESPECIFICACIÓN DEL CASO DE USO: CU14
CU14: Eliminar valor a una variable de un cultivo en una fecha específica
Descripción: Permite a un usuario eliminar un valor de nivel a una variable en una fecha
específica
Actores: Administrador
Precondiciones: El usuario debe estar logueado y el valor de nivel en la fecha debe existir en
la variable
Flujo de eventos: Flujo Básico.
Tabla 38: Flujo de eventos - Eliminar valor a una variable de un cultivo
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita eliminar un valor de una variable El sistema muestra un calendario
El usuario selecciona la fecha de la valor que desea
eliminar
El sistema muestra una alerta, informando al actor
que está apunto de eliminar un valor de la variable
El usuario acepta eliminar el valor de la variable El sistema valida los datos y de ser correctors elimina
el valor de la variable
BUSCAR CULTIVO POR NOMBRE

116
ESPECIFICACIÓN DEL CASO DE USO: CU15
CU15: Buscar cultivo por nombre
Descripción: Permite a un usuario consultar un cultivos por su nombre
Actores: Todos
Precondiciones: El usuario debe estar logueado y el cultivo debe existir en la base de datos
Flujo de eventos: Flujo Básico.
Tabla 39: Flujo de eventos - Buscar Cultivo por nombre
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario ingresa un nombre de un cultivo y solicita
el cultivo
El sistema muestra un listado de cultivos que
contienen las palabras ingresadas
COMPARAR VALORES DE VARIABLE EN DOS GRÁFICAS
ESPECIFICACIÓN DEL CASO DE USO: CU16
CU16: Comparar valores de variables en dos gráficas
Descripción: Permite a un usuario comparar los niveles en etapas diferentes del cultivo por
medio de dos tablas filtradas por meses
Actores: Todos
Precondiciones: El usuario debe estar logueado y la variable debe tener más de un mes con
información
Flujo de eventos: Flujo Básico.

117
Tabla 40: Flujo de eventos - Comparar valores de variables en dos gráficas
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita comparar niveles de un variable a
la plataforma
El sistema muestra dos tablas, una con la información
estandarizada por el usuario y otra nueva con el
último mes de información
El usuario selecciona el mes que desea ver en cada
tabla
El sistema valida los datos y despliega la gráficas en
el mes solicitado
CONSULTAR UN CULTIVOS ESPECÍFICO
ESPECIFICACIÓN DEL CASO DE USO: CU17
CU17: Consultar un cultivo específico
Descripción: Permite a un usuario ingresar a un cultivo conocido por la plataforma
Actores: Todos
Precondiciones: El usuario debe estar logueado y el cultivo debe existir en la base de datos
Flujo de eventos: Flujo Básico.
Tabla 41: Flujo de eventos - Consultar un cultivo específico
ACCIÓN DE LOS ACTORES RESPUESTA DEL SISTEMA
El usuario solicita ver un cultivo específico a la
plataforma
El sistema muestra la vista del cultivo
Diagramas de secuencias
Este apartado presenta los diagramas de secuencia del módulo web del sistema. Cada
diagrama de secuencia muestra la secuencia de comunicación mediante mensajes entre
objetos necesarios para la realización del caso de uso.

118
Figura 31: Inicio de sesión y permanecer logueado
Figura 32: Crear cuenta con compañia nueva

119
Figura 33: Consultar un cultivo específico
Figura 34: Consultar una variable de un cultivo específico

120
Figura 35: Muestra dos gráficas con diferentes meses
Figura 36: Añadir valor a una variable de un cultivo específico de forma manual

121
Figura 37: Añadir un sensor a una variable de un cultivo específico
Diagramas de procesos
Este apartado presenta los diagramas de procesos del módulo web del sistema. Cada diagrama
de procesos muestra la secuencia de acciones necesarias para realización de los casos de uso.
Figura 38: Diagrama de procesos crear, editar y eliminar cultivo

122
Figura 39: Diagrama de procesos crear, eliminar, editar variable y añadir, eliminar y
modificar sensor
Figura 40: Diagrama de procesos inicio de sesión y crear cuenta
Modelo de datos
En esta sección se describe el modelo de datos propuesto para la plataforma. Debido a que se
hizo uso de una base de datos NoSQL y optado por el método de documentación. En la figura
41 se puede observar la estructura del modelo de datos.

123
Figura 41: Esquema base de datos
Objeto Crops ( Cultivos )
En este objeto se encuentra toda la información que se obtiene del cultivo. En la figura 42 se
puede observar la estructura del cultivo.
Figura 42: Estructura Cultivo
En la tabla 44 se puede encontrar una descripción de todos los campos que pertenecen al
cultivo.
Tabla 42: Campos del Cultivo
Campo Descripción

124
Area Es el área en la que se encuentra todo el cultivo este valor por defecto es en
hectáreas, este valor puede ser ingresado por el usuario o si el usuario colocó
isCalculate esta es la suma de todas las áreas de los lotes.
CropVariety Es la variedad del cultivo esta debe ser ingresada por el usuario.
FieldCapacity Es la capacidad de campo, esta puede ser ingresada por el usuario o si el usuario
colocó isCalculate esta es el promedio de la capacidad de campo de los lotes.
IrrigationType Es el tipo de riego implementado en el cultivo, esta debe ser ingresada por el
usuario.
Lara Es el lara del cultivo puede ser ingresada por el usuario o si el usuario colocó
isCalculate esta es el promedio del LARA de los lotes.
StartDate Es la fecha en la que se empezó a sembrar, esta debe ser ingresada por el usuario.
IsCalculate Es el condicional para saber si se calculan algunas variables del cultivo con
relación a lo que se encuentra en los lotes o si el usuario ingresa los valores que
deben tener esas variables.
Lotes Es un listado de todos los lotes que componen el cultivo. Su estructura la se
puede encontrar en Campo Cultivo: Lotes
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.

125
Campo Cultivo: Lotes
En este campo se encuentra toda la información que se obtiene de los lotes. En la figura 39 se
puede ver la estructura del lote, donde keyLot es el identificador único del lote generado por
el sistema.
Figura 43: Estructura Lote
En la tabla 43 se puede encontrar una descripción de todos los campos que pertenecen al lote.
Tabla 43: Campos del Lote
Campo Descripción
Area Es el área en la que se encuentra todo el cultivo este valor por defecto es en
hectáreas, este valor debe ser ingresado por el usuario.
CropVariety Es la variedad del cultivo esta debe ser ingresada por el usuario.
FieldCapacity Es la capacidad de campo, esta debe ser ingresada por el usuario.
IrrigationType Es el tipo de riego implementado en el cultivo, esta debe ser ingresada por el
usuario
Lara Es el lara del cultivo debe ser ingresada por el usuario.

126
StartDate Es la fecha en la que se empezó a sembrar, esta debe ser ingresada por el usuario.
Variables Es un listado de todas las variables de cultivo que se recolectan en el lote (por
ejemplo: Evaporación). Su estructura la se puede encontrar en Campo Lote:
Variables
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.
Campo Lote: Variables
En este campo se encuentra toda la información que se obtiene de una variable. En la figura
44 se puede observar la estructura de una variable, donde “Variable -> apiName” hace
referencia a que el identificador único de una variable es el apiName de la misma.
Figura 44: Estructura Variables
En la tabla 44 se puede encontrar una descripción de todos los campos que pertenecen a la
variable.
Tabla 44: Campos de variables
Campo Descripción
ApiName Es el nombre de la variable establecido por el sistema. Si esta es una variable
creada por un usuario terminará con las siglas “__c”.

127
Max Es el valor máximo que puede obtener la variable. Establecido por el sistema o
por el usuario si esta fue creada.
Min Es el valor mínimo que puede obtener la variable. Establecido por el sistema o
por el usuario si esta fue creada.
Values Listado de todos los valores que se han captado de esa variable. Su estructura la
se puede encontrar en Campo Variable: Values
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.
Campo Variable: Values
En este objeto se encuentra toda la información que se obtiene de un valor captado. En la
figura 45 se puede ver la estructura de un valor captado, dónde “Date String ‘YYYY-MM-
DD’” hace referencia al identificador único del valor captado en la fecha específica.
Figura 45: Estructura valor captado
En la tabla 45 se puede encontrar una descripción de todos los campos que pertenecen a un
valor captado.
Tabla 45: Campos de valor captado
Campo Descripción
Max Es el valor máximo que ha obtenido ese valor en esa fecha

128
Min Es el valor mínimo que ha obtenido ese valor en esa fecha
Values Listado de todos los valores que se han captado en esa fecha. Por ejemplo un
valor: 2017-03-19 10:30:00 = 100
Alert Es el mensaje que se muestra si el valor está por encima o por debajo del límite
LastValue El último valor obtenido de la variable
Average Promedio de todos los valores que se han obtenido en la fecha
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.
Objeto ProfileNames (Perfiles)
En este objeto se encuentra todos los perfiles existentes en el sistema. En la figura 46 se puede
ver los perfiles del sistema.
Figura 46: Esquema de Perfiles del sistema
En la tabla 46 se puede encontrar una descripción de todos los perfiles existentes.
Tabla 46: Perfiles del sistema
Campo Descripción

129
Admin Este puede crear, modificar, eliminar y ver cualquier cosa de la aplicación que se
pueda crear, modificar o ver.
Register Este puede crear, modificar y ver algunas cosa de la aplicación que se pueda
crear, modificar o ver.
Visit Este puede ver cualquier cosa de la aplicación que se pueda ver.
Objeto Sensors (Sensores)
En este objeto se encuentra toda la información que se obtiene de un sensor. En la figura 47 se
puede ver la estructura de un sensor.
Figura 47: Estructura de un sensor
En la tabla 47 se puede encontrar una descripción de todos los campos que pertenecen a un
sensor.
Tabla 47: Campos de sensor
Campo Descripción
keySensor El Id o serial obtenido por el usuario que representa al sensor
Crop Este contiene el key (identificador único) perteneciente al cultivo al cual se está
sensando

130
Lotes Listado de lotes que contiene los key (identificador único) perteneciente a los
lotes que se estan sensando. Por ejemplo: K-50PyUrtpYXoki7, K-
50PyUrtpYXoki8
Id Es el identificador único del sensor con el cual se identifica cuando hace
peticiones. En el caso del arduino se crea un ID para la tarjeta el cual se quema
con el programa y es el usado para la petición.
Name Nombre el cual el usuario quiera darle al sensor.
Status Es el estado del sensor los cuales pueden ser: active (Activado) o disabled
(Desactivado).
Varialbe Es el api name de la variable que se está obteniendo los datos.
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.
Objeto Variables (Variables del sistema)
En este objeto se encuentra todas la variables que están por defecto en el sistema. En la figura
48 se puede ver la estructura del objeto variables del sistema. Para tener más información
sobre las variables véase Variables de estudio:
Figura 48: Estructura variables del sistema
En la tabla 48 se puede encontrar una descripción de todas los variables existentes.

131
Tabla 48: Campos de Variables del sistema
Campo Descripción
CropFactor Es el factor de cultivo y es no calculada y ni se sensada por el
sistema.
EffectiveIrrigation Es el riego efectivo y es no calculada y ni se sensada por el sistema.
EffectivePrecipitation Es la precipitación efectiva y es no calculada y se sensa por el
sistema
EffectivePrecipitationReal Es la variable para la precipitación efectiva para sensores.
Evaporation Es la evaporación y es no calculada y se puede sensar. (En este
proyecto no se hace sensar esta variable), por el sistema.
EvaporationReal Es la variable para la evaporación para sensores.
Evapotranspiration Es la evapotranspiración y se calcula y no se sensa por el sistema.
SoilMoisture Es la humedad del suelo y se calcula y se puede sensar por el
sistema.
SoilMoistureReal Es la variable para la humedad del suelo para sensores.
El sistema permite crear nuevas variables que contengan el modelo de “Objeto variable” que
se describe a continuación.
Objeto Variable (Variable del sistema)
En la figura 49 se puede ver la estructura de una variable del sistema. Las variables por
defecto no se pueden cambiar sus configuraciones, solo las que contengan en el apiName
“__c” se pueden editar.

132
Figura 49: Estructura de una variable del sistema
En la tabla 49 se puede encontrar una descripción de todos los campos que puede tener una
variable.
Tabla 49: Capos de Variables del sistema y personalizadas
Campo Descripción
Alert Variable si es verdadera enseña mensajes al usuario cuando ingresa a la variable de
que se está por debajo o por encima del valor máximo o mínimo que puede
Max Contiene el valor máximo que puede tener la variable.
Min Contiene el valor mínimo que puede tener la variable.
Name Nombre al cual se referencia a la variable. Este no puede contener caracteres
especiales como por ejemplo la letra “ñ”.
Status Contiene el estado de la variable que puede ser active (Activa) o disabled
(Desactivado).
isCalculate Es la variable para la evaporación para sensores.
Formula Contiene una fórmula que sólo puede tener operadores matemáticos enlazados a un o
varios (apiName.Average o/y apiName.LastValue) o/y números. Por ejemplo:
“SoilMoisture.LastValue - (Evapotranspiration.Average +
EffectivePrecipitation.Average + EffectiveIrrigation.Average)”
Sensor Variable si es verdadera ignora el isCalculate tomando los valores solo de sensores.

133
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.
Objeto Users (Usuarios)
En este objeto se encuentra toda la información que se obtiene de un usuario. En la figura 50
se puede ver la estructura de usuarios. El keyUser es el user id que le da el sistema.
Figura 50: Estructura Usuarios
En la tabla 50 se puede encontrar una descripción de todos los campos que puede tener un
usuario.
Tabla 50: Campos de usuarios
Campo Descripción
Email Contiene el correo electrónico del usuario
FirstName Contiene el nombre del usuario.
LastName Contiene el apellido del usuario.
Name Contiene el nombre completo del usuario.
Phone Contiene el teléfono del usuario.

134
Profile Contiene el perfil del usuario.
Title Contiene el cargo que ocupa el usuario.
CreateDate
ModifyDate
CreateBy
ModifyBy
Son datos de control de usuarios.
Patrones de Diseño
En esta sección se mencionan los patrones de diseño que se implementan en el diseño del
sistema, estos son:
Template Method
Se emplea el patrón usando React que usan este patrón en su arquitectura, por ejemplo con el
uso de componentes los cuales son clases que contiene un código que se repite numerosas
veces en la aplicación.
Factory Method
Se utiliza el patón con Redux con sus clases reusables que son como una fabrica de datos de
un determinado tipo, por ejemplo la clase crop.js retorna la información dependiendo de qué
tipo de petición se realizó al servidor o acción dentro de la misma aplicación.
Flyweight Method
Se aplica en la generación de listados de objetos en la aplicación móvil en swift, cuando se
realiza un petición de los cultivos este primero crea los cultivos obtenidos crop y los añade a
un dictionary que posteriormente se recorre en un dispatchQueue.main.async para que no
colapse la memoria y se ordenan los cultivos obtenidos según la fecha de modificación.
Identificación de recursos, diseño de URI
REST depende en que el creador del servicio defina la URL de la mejor manera para describir
el recurso al cual hace referencia. Es muy importante escoger nombres representativos,
aunque no hay ninguna limitación para esto, es un buena práctica usar nombres abstraídos de
la realidad comprensibles para el ser humano.

135
Ejemplos de recursos y sus identificadores únicos:
● Una lista de estudiantes: http://university.edu/students
● La cantidad de estudiantes de ingeniería:
http://university.edu/students/engineering/quantity
● El blog mas visto: http://example.com/blogs/mostviewed
Se definen las siguientes URI del sistema usando el concepto de UPSERT el cual trata de
realizar actualizaciones o creaciones desde el mismo método y proveer identificador único del
elemento cuando se desea realizar una actualización:
1. <dominio>/upsert/crop
2. <dominio>/upsert/lote
3. <dominio>/upsert/variable
4. <dominio>/upsert/sensor
5. <dominio>/delete/crop
6. <dominio>/delete/lote
7. <dominio>/delete/value
8. <dominio>/delete/variable
9. <dominio>/delete/sensor
10. <dominio>/add/value/sensor
Descripción de métodos
Los recursos son manipulados por medio de transferencias representaciones a través de una
interfaz uniforme dirigida por el identificador de recursos.
Cada representación tiene que implementar una interfaz CRUD para lograr la interfaz
uniforme requerido por la arquitectura REST. HTTP / 1.1 protocolo define ocho métodos o
verbos, dos de los cuales permite que definen dicha interface: GET y POST. La Tabla 51
muestra la correspondencia de los métodos HTTP y acciones CRUD.
Tabla 51: CRUD correspondiente con HTTP métodos

136
Método CRUD Descripción
POST upsert (crear o actualizar),
eliminar
Crear, eliminar o actualizar un
nuevo recurso
GET Recuperar Recuperar información
Cualquier representación tiene que aceptar todos estos dos métodos, aunque esto no implica
que tienen que ponerse en práctica. Cada una de las URIs corresponde a una acción específica
si la uri contiene /delete/ esto infiere que la operación es de eliminación.
En el caso de que está sea /upsert/ la operación a seguir depende de los datos encontrados en
el “body” de la petición los casos pueden ser:
1. El body conteniendo el identificador único del elemento este se debe actualizar
2. El body sin el identificador único del elemento este es un elemento nuevo
Listado de respuestas
Se debe aclarar que las posibles respuestas se pueden enviar al cliente en función de la
petición recibida. HTTP define cinco categorías de respuestas
● 1xx Informativo
● 2xx Éxito
● 3xx Redirección
● 4xx Error en el lado del cliente
● 5xx Error en el lado del servidor
Cada uno de estos grupos contiene algunos códigos HTTP predefinidas que permiten el envío
de más información en la respuesta. Las respuestas más habituales con respecto a los métodos
descritos anteriormente se muestran en la Tabla 52.
Tabla 52: Catálogo de respuestas HTTP habituales
Código Método Mensaje

137
200 GET solicitud exitosa de la petición la
representación se envía al cliente
201 POST Creado (La ubicación del nuevo
recurso está en cabecera
Location)
400 Todos Mala solicitud (mala solicitud
creada)
401 Todos No autorizado (el cliente tiene
que ser autenticado)
404 Todos No se ha encontrado (el recurso
no está en el sistema)
405 Todos Método no permitido
500 Todos Error interno del servidor (error
interno del Servidor)
Es posible definir nuevos códigos y respuestas HTTP, aunque no se recomienda. Si un cliente
recibe un código HTTP que no sabe, se lo considerará como un código de respuesta X00
(donde X es la categoría en la que se define el nuevo código HTTP).
Además de la respuesta de código HTTP y el mensaje, el servidor tiene que enviar la
representación adecuada en el caso de peticiones GET o la dirección URL del recurso creado
(en el campo de cabecera Location) para peticiones POST. Es obligatorio para los servidores
que utilizan correctamente los códigos de respuesta HTTP. Los clientes deben comprender al
menos las respuestas de código descritas en la Tabla 52
Descripción del servicio y documentación
La solución propuesta por la plataforma presentada en este documento implementa un registro
de servicios centralizada. Se utiliza para proporcionar capacidades de publicación /
despublicación / actualización de las descripciones de servicio aplicaciones. Este servicio
tiene dos representaciones: una representación JSON que se utiliza por las aplicaciones que
desean publicar sus servicios, una representación HTML que proporciona, para cada servicio
registrada, una documentación. La plataforma ofrece registro de servicios centralizados para

138
asegurar misma 'apariencia' para la documentación de todos los servicios, apoyando de este
modo la integración a nivel de interfaz de usuario.
Cada servicio debe proporcionar una documentación que contenga al menos la siguiente
información:
● Grupo al que pertenece
● Nombre y una breve descripción
● URL que lo identifica
● El API name
● Versión
● Para cada representación:
○ Headers
■ Nombre de la cabecera
■ Tipo de la cabecera
■ Descripción de la cabecera
○ Parámetros si contiene campos (JSON)
■ Nombre del campo
■ Tipo del campo
■ Descripción del campo
○ Método disponible
■ El método y lo que hace.
■ URL donde se aplica
■ Código de respuesta y mensaje
El registro de servicios contiene por defecto todos los servicios proporcionados por la
plataforma de integración. Su nombre es "servicios" y la URL para acceder a ella se
determina por el dominio del servidor donde la plataforma está desplegado, por ejemplo:
http://www.domain.com/doc/servicio

139
Las capacidades de edición, Anulación de la publicación y actualización de los servicios
registrados se muestran en la Figura 35. Estas capacidades se describen de la siguiente manera
Paso 1
Para almacenar una nueva información o crear una nueva tabla variable o columna de tablas
editables, los desarrolladores deben lanzar una petición POST en esa dirección URL con un
JSON en sus solicitudes corporales que contienen la información detallada anteriormente. Tal
JSON debe tener la estructura definida para la petición realizada. Encabezado de autorización,
ubicación de la respuesta, en caso de un código de respuesta 201, la URL donde se encuentra
la API del servicio.
Paso 2
Para actualizar una información, tabla o columna, los desarrolladores pueden actualizar su
API de servicio, el lanzamiento de una solicitud PUT en la dirección URL a la que pertenece.
Limitarse a proporcionar el mismo JSON que se utiliza para registrar el servicio más las
actualizaciones necesarias es suficiente.
Paso 3
Para desechar, eliminar información, tablas personalizadas o columnas personalizadas, los
desarrolladores pueden eliminar su API de servicio, el lanzamiento de una solicitud DELETE
en la dirección URL a la que pertenece. El encabezado de autorización y permisos de
administrador.

140
Descubrimiento del servicio
Figura 51: Almacenamiento de información, actualización, proceso de detección y
eliminación de información. Tomado de [66]
En el proceso de descubrimiento de servicios, no es necesario que los desarrolladores hayan
registrado previamente sus API del servicio, ya que el registro de servicios contiene al menos
todos los servicios proporcionados por la plataforma de integración.
En primer lugar, un usuario o una herramienta quiere buscar un servicio en el registro de
servicios. Para ello, se lanza una petición GET de recursos los "servicios" (Paso 3). La
respuesta recuperada contiene una lista de todos los servicios:
En segundo lugar, el usuario puede iterar sobre la colección hasta que encuentra el servicio
que pueda satisfacer sus necesidades (por ejemplo: mirando a nombre del servicio,
descripción, nombre de la aplicación, etc.) (Paso 4).
En tercer lugar, una vez que el usuario ha elegido el servicio, se puede:
● Recuperar API del servicio mediante el lanzamiento de una petición GET en la URL
'servicios / id', que permite el acceso a la API. Contiene información suficiente para

141
unirse e invocar el servicio: URL para acceder a ella, métodos permitidos, los cuales
están disponibles las representaciones posibles respuestas.
● Consumir el servicio mediante el lanzamiento de una petición en la URL almacenada
en la url. Se supone herramienta conoce la semántica de la estructura de recursos, ya
que es una estructura acordada. Si no es así, el desarrollador puede aprender el
significado de los recursos recuperados API (servicios tienen una representación
HTML para almacenar la documentación legible por humanos). descubrimiento de
servicio también se puede utilizar para verificar si un servicio conocido está disponible
en que el despliegue de la plataforma.
Diseño de Hardware
Usando el módulo ESP8266 para conectar el Arduino UNO a una red WiFi se accede a
internet para realizar llamados POST al servicio central enviando una cabecera de
autenticación y datos captados por los sensores en el cuerpo de la solicitud, se configura la
tarjeta para enviar información en un intervalo de tiempo determinado arbitrariamente
creando un registro nuevo en la base de datos en cada solicitud.
La tarjeta es programada para trabajar con un sensor de humedad de suelo (ver Marco
Teórico: Sensores académicos), un sensor de lluvia (ver Marco Teórico: Sensores
académicos) y el módulo de WiFi, usando una protoboard todos son conectados
simultáneamente a la tarjeta para crear un sistema de hardware de recolección de datos
relevantes en los sistemas de riego.
Módulo WiFi ESP8266
El módulo WiFi ESP8266 es un SOC auto contenido, con la colección del protocolo TCP/IP
integrada. Puede dar acceso a cualquier microcontrolador a una red WiFi.

142
Figura 52: Módulo WiFi ESP8266
Implementación
Para la implementación se conectan los dos sensores y el módulo WiFi a la tarjeta Arduino. El
Arduino se conecta a internet mediante el módulo WiFi, los sensores obtienen información en
un intervalo de tiempo predeterminado, en cada ciclo la tarjeta Arduino hace un llamado
HTTP al servicio para almacenar los datos obtenidos por el sensor.
Diagramas de conexión
Figura 53: Diagrama de conexión de sensor humedad de suelo al Arduino UNO. Tomado de
[88]

143
Figura 54: Diagrama de conexión sensor de lluvia al Arduino UNO. Tomado de [87]
Figura 55: Diagrama de conexión de módulo WiFi ESP8266 al Arduino UNO. Tomado de
[89]

144
Características del sistema
Variables personalizadas
se puede encontrar estas variables personalizadas en el objeto de variables (Objeto
Variables) y para su creación deben respetar la estructura predeterminada para las variables
explicada en “Objeto Variables”.
Campo fórmula
El campo fórmula permite al usuario general una operación matemática sencilla con la cual se
pueda calcular el valor de la variable con este campo activo. Este campo solo es permitido
para ciertas variables y no puede contener valores no numéricos o variables no existentes en el
sistema. Las operaciones matemáticas que acepta son: suma, resta, multiplicación y división.
Tarjeta programable
La tarjeta programada le da al sistema una interacción con dispositivos hardware como los
son los sensores. Esta se encarga de procesar los datos recibido por sensores y enviarlos al
servicio web, siendo estos valores de variables más exactos que los calculados o obtenidos por
un usuario.
Cálculo del LARA, capacidad de campo y área en base a los datos del lote en el cultivo
Se calcula los valores numéricos de la información inicial de un cultivo mientras este se
encuentre en el estado isCalculated como verdadero. Esta información es más exacta que la
que puede ingresar un usuario
Promedio de valor por fecha de una variable obtenida por sensores
Se realiza el promedio de los datos captados por sensores durante el día debido que en la
práctica se usa un valor por dia. La funcionalidad permite obtener un var ponderado de lo que
sucedió el día anterior.
Sincronización en tiempo real

145
Se sincronizan los valores actualizados, creados y eliminados en las plataformas virtuales con
interfaz teniendo a los usuarios con los últimos estados del cultivo .
Implementación del Sistema
En esta sección se expone algunos funcionamientos relevantes del servicio web desarrollado
para la recolección de datos.
Trigger Lote
Este método es activado cuando un lote es actualizado o creado. Su función es actualizar
campos del cultivo si el campo isCalculate igual a true. En la figura 61 se puede ver un trozo
del código que se usa para actualizar un campo del cultivo. En ese script se obtienen todos los
lotes que pertenecen al cultivo y se itera en ellos obteniendo su LARA, capacidad de campo y
área, para que posteriormente se aplique la operación pertinente para saber el valor de esos
campos en el cultivo.
Figura 56: Trozo del trigger lote
Trigger Variable
Este método es activado cuando una variable es actualizada o creada. Su función es colocar el
promedio de la fecha actualizada, añadir notificaciones a los usuarios si la variable está por

146
debajo del nivel o por encima a los usuarios. Además de hacer los cálculos de las variable que
tienen fórmula y contiene la variable modificada. En la figura 62 se puede ver un trozo del
código que se usa en este método.
Figura 57: Trozo del trigger variable
Este trozo contiene la funcionalidad de sacar el promedio y indicar si es menor o mayor que el
límite permitido para la variable
Añadir Variable
Esta operación del servicio crea nuevas variables al sistema. Su funcionalidad es añadir
nuevas variables de captación al sistema y posteriormente al lote.
En la figura 63 se puede observar un trozo del código que hace esta operación del sistema.
Este script hace el insert en la base de datos siempre y cuando la variable a crear no se
encuentre ya en el sistema. Si la operación termina de forma exitosa se llama el trigger de
variables para que añada esa nueva variable a todos los lotes existentes y si esta hace uso de
una fórmula añadir todos los valores que pueden tener hasta el momento esa variable.

147
Figura 58: Trozo añadir variable al sistema

148
VIII. PRUEBAS Y RESULTADOS
Pruebas manuales
Para validar el diseño del sistema de recolección de datos, se aplica a un caso de estudio con
datos que se han obtenido de diferentes cultivos (apéndice 1 y 2) a la vez poder consultar
estos datos y poder verlos en una interfaz amigable. Para comenzar a usar el servicio este debe
registrarse y obtener las credenciales (Id y Secret Key) que serán necesarias para la conexión
con el servicio.
Todos los datos obtenidos están registrados en milímetros (mm).
El sistema de recolección de datos planteado se ha sometido a varios casos de uso por medio
de una aplicación desarrollada de forma nativa, se hace uso del simulador de mac para
compilar la aplicación en un iPad air con iOS 9.2.1 y como consola se usó la del explorador
Safari.
Funcionalidad: Crear un nuevo cultivo
El usuario quiere crear su primer cultivo o añadir uno nuevo en la plataforma.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms). Estos tiempos se tomaron de la inspección de network de el
explorador que tomó de las acciones realizadas desde un iPad mini 2 con iOS 9.2.1 de la
aplicación desarrollada con ionic 2 y usando el módulo de angular2/http.
Tabla 53: Tiempos de respuesta solicitud ‘Crear un nuevo cultivo’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.12 111.70 2.24 0.33 4.14

149
0.12 141.93 2.79 0.30 4.82
0.12 180.19 2.28 0.31 4.21
0.11 258.60 2.29 0.29 3.16
0.12 174.67 2.26 0.28 3.42
Funcionalidad: Editar un cultivo existente
El usuario quiere modificar la información del cultivo.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).
Tabla 54: Tiempos de respuesta solicitud ‘Editar un cultivo existente’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.11 12.20 0.92 0.35 0.72
0.12 7.14 1.30 0.39 1.05
0.10 8.26 0.65 0.63 0.84
0.12 9.03 1.40 0.70 0.75
0.14 11.23 0.75 0.33 0.91
Funcionalidad: Seleccionar 10 cultivos
El cliente abre la vista “Cultivos” en la plataforma y esta debe cargar los últimos 10 cultivos
modificados. El cliente también puede colocar nuevos filtros de búsqueda para la
visualización de los cultivos
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).
Tabla 55: Tiempo de respuestas solicitud ‘Seleccionar 10 cultivos’
Petición enviada Tiempo de envío Descargar En espera Prepararse

150
(Request send) primer byte
(TTFB)
contenido (Queueing) (Stalled)
0.12 33.90 1.14 0.82 0.88
0.16 12.48 1.05 0.90 1.05
0.10 8.19 1.98 0.48 1.05
Funcionalidad: Eliminar Cultivo
El cliente desea eliminar un cultivo así que se dirige a el cultivo al cual desea eliminar y hace
clic en eliminar, este debe ser eliminado solo si el cliente que ha realizado la acción tiene
permisos de administrador.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).
Tabla 56: Tiempos de respuesta solicitud ‘Eliminar Cultivo’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.10 115.52 1.93 0.31 1.12
0.13 51.42 0.92 0.34 0.69
0.13 12.05 1.39 0.70 1.03
0.17 12.51 1.28 1.21 0.65
0.12 8.21 0.74 0.37 0.52
Funcionalidad: Añadir un nuevo valor a una variable
El cliente desea añadir los valores a las variables de un cultivo que acaba de crear así que se
dirige en al cultivo en la pestaña de variables y selecciona la variable a la cual le va agregar
los valores y le agrega los valores y guarda.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).

151
Tabla 57: Tiempos de respuesta solicitud ‘Eliminar Cultivo’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.10 111.70 2.10 0.30 4.20
0.12 121.93 2.05 0.29 4.90
0.11 110.19 2.33 0.30 4.25
0.11 100.60 2.20 0.31 3.05
0.10 110.67 2.24 0.30 3.30
Funcionalidad: Editar una variable
El cliente determina que se ha equivocado en el valor dado a una variable así que se dirige a la
variable y la edita.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).
Tabla 58: Tiempos de respuesta solicitud ‘Editar una variable’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.12 104.51 1.90 0.30 0.96
0.12 50.41 0.90 0.36 0.69
0.12 11.04 1.40 0.70 1.03
0.12 11.50 1.30 1.20 0.65
0.12 7.20 0.76 0.40 0.52
Funcionalidad: Obtener una variable
El cliente quiere ver todas las variables del cultivo y sus últimos valores con la fecha
respectiva.

152
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).
Tabla 59: Tiempos de respuesta solicitud ‘Obtener una variable’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.11 11.61 1.90 0.34 0.96
0.18 50.41 1.90 0.36 0.69
Funcionalidad: Crear una nueva variable
El cliente tiene un cultivo el cual presenta una variable la cual no existe en el sistema.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms). Después de hacer un 2 o 3 creación de una tabla el servicio
colapsa.
Tabla 60: Tiempos de respuesta solicitud ‘Crear una variable’
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.17 427.87 0.85 0.29 2.72
0.17 191.60 0.89 0.30 1.47
0.19 101.61 0.86 0.35 1.45
Funcionalidad: Modificar o agregar campos a una variable
El cliente quiere agregar y modificar campos de las variables.
Tiempos del proceso de petición de 5 cultivos siendo 2 de ellos con datos reales, los tiempos
están en milisegundos (ms).
Tabla 61: Tiempos de respuesta solicitud ‘Modificar o agregar campos a una variable’

153
Petición enviada
(Request send)
Tiempo de envío
primer byte
(TTFB)
Descargar
contenido
En espera
(Queueing)
Prepararse
(Stalled)
0.17 427.87 0.75 0.29 2.72
0.17 191.60 0.89 0.30 1.47
0.19 101.61 0.86 0.35 1.45
0.17 111.60 0.90 0.30 1.45
0.17 311.61 0.69 0.30 1.45
Pruebas automatizadas
Se realizan una serie de pruebas simulando condiciones climáticas que afectan directamente el
cultivo, usando los siguientes componentes:
● Sensor de humedad de suelo
● Sensor de lluvia
● Módulo WiFi ESP8266
● Tarjeta Arduino UNO
para enviar datos automáticamente al servicio web.
En la sección Pruebas manuales se realizaron pruebas con datos de cultivos reales en el
sistema de recolección. En esta sección se realizan pruebas de inicio-a-fin (End-to-End
testing21) del sistema planteado, el proceso ilustrado en la Figura 29: Arquitectura del sistema
es puesto a prueba con el sensor de humedad de suelo y precipitación efectiva conectados a la
tarjeta Arduino UNO, esta a su vez por medio de un módulo WiFi se conecta a internet para
poder hacer las solicitudes al servicio web y enviar los datos físicos obtenidos por los
sensores.
Cabe resaltar que a diferencia de la sección Pruebas manuales donde los datos son
manejados en mm, en las pruebas con los sensores para Arduino el dato arrojado por la
resistencia entre 0 y 1023 es numérico sin ninguna unidad de medida.
Las siguientes pruebas son realizadas usando una conexión a internet telefónica en la cual se
miden los tiempos de:
21
End-to-End Testing: https://www.techopedia.com/definition/7035/end-to-end-test

154
● Petición enviada (Request send)
La siguiente prueba de laboratorio se realiza con 220.5 cm3 de tierra, la cual en estado seco
tiene un peso de 14g y en estado de completa humedad de 32g (datos obtenido de forma
experimental).
El experimento se llevó a cabo ubicando la tierra totalmente seca (tiempo 1) en un contenedor
de plástico con rejilla en la parte inferior que no permite que la tierra traspase pero sí que el
agua escurra en un contenedor inferior. En intervalos de 1 minuto (en algunos puntos se
maneja un tiempo diferente arbitrariamente) se agregan 10 cm3 sobre la placa del sensor de
lluvia la cual escurre sobre este y llega a la tierra y se obtienen los valores de resistencia de
ambos sensores, inmediatamente son enviados al servicio para su registro y posterior análisis.
En la Tabla 62 se puede observar 30 registros tomados de la tarjeta Arduino usando los
sensores, las columnas de tiempo muestran el momento en minutos y segundos en el que es
obtenido el registro, la columna de Agua muestra la cantidad de agua que es agregada a la
tierra en cm3, las columnas de los sensores son los datos arrojados por la resistencia después
de ser expuestos a la cantidad acumulada de agua (sumatoria de agua), las columnas de
tiempos de petición muestran el tiempo que toma la solicitud para enviar el dato al Servicio
Web.
El sensor lluvia es ubicado en 3 posiciones diferentes durante la prueba, la posición 1 es
completamente horizontal sobre la tierra, la posición 2 es en un ángulo de 45º y finalmente la
posición 3 es un ángulo de 90º, esto se realiza para demostrar que este sensor tiene un alto
grado de error ya que puede variar según su ubicación.
Tabla 62: Pruebas con Arduino, sensor humedad suelo, lluvia y módulo WiFi
Tiempo
Tiempo
(seg.)
Agua
(cc)
Sensor
Lluvia
Sensor
Humedad
Suelo
Tiempo
Petición
(Lluvia)
Tiempo
Petición
(Suelo)
Comentario
s
1 0:00:00 0 0 1023 1023 71.0ms 479.00 ms
Sensor lluvia
en Posición 1

155
2 0:00:10 10 6 727 742 475.0 ms 486.00 ms
3 0:00:30 30 10 623 533 555.0ms 495.00 ms
4 0:00:50 50 10 572 515 475.0ms 496.00 ms
5 0:02:00 120 10 565 526 1010.0ms 480.00 ms
6 0:03:00 180 10 464 452 498.99ms 481.00 ms
7 0:04:00 240 10 396 370 555.0ms 484.00 ms
8 0:05:00 300 10 664 497 498.99ms 483.00 ms
Sensor lluvia
cambia a
posición 2
9 0:06:00 360 10 626 418 589.29 ms 502.00 ms
10 0:07:00 420 10 663 425 506.03 ms 505.00 ms
11 0:08:00 480 10 593 434 490.325 ms 805.00 ms
12 0:09:00 540 10 708 456 491.665 ms 487.00 ms
13 0:10:00 600 10 668 462 508.16 ms 498.00 ms
14 0:10:30 630 0 680 510 685.64 ms 821.00 ms
15 0:11:00 660 10 668 461 477.895 ms 494.00 ms
16 0:11:30 690 0 722 509 498.46 ms 480.00 ms
17 0:12:00 720 10 626 467 504.59 ms 471.00 ms
18 0:13:00 780 10 602 448 511.98 ms 488.00 ms
19 0:14:00 840 10 618 455 501.37 ms 476.00 ms
20 0:15:00 900 10 604 446 1054.1 ms 674.00 ms
21 0:16:00 960 10 642 440 915.7 ms 1365.00 ms
22 0:16:30 990 0 750 494 487.05 ms 506.00 ms
23 0:17:00 1020 10 544 435 480.365 ms 488.00 ms
24 0:18:00 1080 10 591 439 497.13 ms 479.00 ms
25 0:19:00 1140 10 706 444 485.285 ms 484.00 ms
Sensor lluvia
cambia a

156
posición 3
26 0:20:00 1200 10 709 440 483.26 ms 479.00 ms
27 0:21:00 1260 10 715 438 472.935 ms 503.00 ms
28 0:22:00 1320 10 712 438 502.69 ms 494.00 ms
29 0:23:00 1380 10 506 444 484.515 ms 910.00 ms
Sensor lluvia
cambia a
posición 1
30 0:24:00 1440 10 468 449 507.4 ms 536.00 ms
256
De la Tabla 62 se puede analizar que el total de agua suministrada fue de 256 cm3, que el
menor número arrojado por el sensor de humedad de suelo es de 370 y del sensor de lluvia de
396. De igual manera se observa una constancia en los tiempos de envíos con algunas
variaciones debido a la naturaleza de las conexiones celulares.
Figura 59: Prueba Arduino - Sensor Humedad del Suelo

157
Figura 60: Prueba Arduino - Sensor de Lluvia
De las Figuras 64 y 65 se puede observar que rápidamente los sensores de humedad de suelo y
lluvia llegan al rango de 350 - 500/400 - 750 respectivamente y se mantienen en una pequeña
oscilación en éste.
De los 256 cm3 de agua suministrados la tierra logra absorber y retener 50 cm3 y 206 cm3 son
escurridos al contenedor inferior.

158
IX. CONCLUSIONES
Este trabajo ha explorado, el diseño y desarrollo de un sistema de recolección de datos de
sistemas de riego para cultivos, con un enfoque específico al caso de cultivos de caña de
azúcar en el departamento del Valle del Cauca, Colombia. Mucho del proceso de diseño se
enfocó en Patrones de diseño, servicios webs existentes y captura de fenómenos físicos como
lluvia y humedad de suelo por medio de sensores los cuales ayudaron a un mejor
entendimiento del sistema a desarrollar, por lo cual se concluye lo siguiente:
● Debido a la naturaleza heterogénea de la industria del riego de cultivos, donde existen
múltiples cultivos y dentro de estos diferentes variedades del mismo cultivo, múltiples
empresas proveedoras de sensores, bombas de riego, programadores y otros
componentes de los Sistemas de Riego, es de vital importanci que este tipo de sistemas
sea escalable y adaptable a diferentes tipos de cultivos, sensores, programadores y
todos los componentes involucrados.
● En este proyecto se identificaron diferentes aspectos y factores involucrados en la
recolección de datos en un sistema de riego, como sensores, tarjetas programadoras,
fenómenos físicos, entre otro. Sin embargo, por el alcance del mismo en el diseño del
sistema solo se usan 2 sensores (lluvia y humedad de suelo) y una tarjeta
programadora (Arduino UNO) para la recolección de datos directamente de
fenómenos físicos, los cuales se prueban insuficientes a la hora de realizar un uso
industrial del sistema, se hace necesario tener múltiples módulos de sensores para el
envío de datos desde varios lotes.
● El diseño de un sistema de recolección de datos requiere de un proceso de
investigación, definición de estructura y servicios profundo analizando todos los casos
más comunes de uso, los cuales pueden tener varios errores que también se deben
contemplar en el diseño de este ya que muchos de esos errores pueden ser causa de un
mal funcionamiento del sistema desarrollado en base al diseño planteado.
● En este trabajo se realizó una comparación de los estándares REST y SOAP, se puede
concluir que para lograr una interoperabilidad más profunda es adecuado integrar al

159
sistema múltiples tecnologías de interconexión para así facilitar la integración de
nuevos componentes.
● Finalmente se puede concluir que se requiere una alta cantidad de pruebas en cultivos
reales para poder evaluar el diseño del sistema en un ambiente industrial.

160
X. RECOMENDACIONES
En esta tesis es explícita la necesidad de extender la construcción del Servicio para soportar
un estilo de arquitectura basado en SOAP, debido a las ventajas que SOAP ofrece en
seguridad sobre servicios RESTful y dado que este Servicio está enfocado hacia una industria
donde este puede ser un factor que cobra importancia para algún agente. Adicionalmente toda
la colección WS-* ofrece estándares en diferentes niveles que pueden ser aprovechados por
algunos agentes para integrar sus sistemas existentes al Servicio.
De igual manera, el sistema fue diseñado pensando en el desarrollo de un cliente que pueda
brindar información necesaria, ágil y útil a los agricultores sobre su (s) cultivo (s). El Sistema
puede ser extendido con variables (tablas) personalizadas para ajustarse a la necesidad de cada
agente y cada cultivo para así satisfacer cualquier necesidad que pueda presentarse y no haya
sido prevista por la versión estándar de este Sistema. Un trabajo a realizar es una aplicación
cliente que usa los datos almacenados para manejar un servicio de alerta en tiempo real sobre
exceso o déficit de agua en el cultivo.
El sistema puede extenderse para proveer diferentes opciones de visualización de los datos
recolectados, ya que en este proyecto solo se presentó una gráfica. De igual manera, se puede
añadir estándar para diferentes cultivos a la caña de azúcar debido a que la base de los
cultivos es similar.
Los componentes de hardware usados para el diseño de este sistema son enteramente
académicos y no suplen necesidades reales de la industria del riego en Colombia, por
consiguiente es necesario extender el sistema con sensores y tarjetas programables de uso
industrial para poder tener una aplicación industrial real.

161
REFERENCIAS
1. Pena, M., Pardal, J., & Villaverde, P., “Arduino y Node.js”, Moncho Pena, 2015
2. Millas, J. A., González, G., Salomon, M., & Rodríguez, Á., “Diseño de estructuras
dinámicas para ofrecer gráficos y pantallas emergentes en entorno web”, 2014
3. Weerawarana S., Curbera F., Leymann F., Storey T., & Ferguson, D, “Web Services
Platform Architecture: Soap, Wsdl, Ws-Policy, Ws-Addressing, Ws-Bpel, Ws-
Reliable Messaging and More. Prentice Hall PTR, Upper Saddle River, NJ, USA”,
2005
4. Wood, D, “Linking enterprise data. Place of publication not identified: Springer”,
2014.
5. Guía Breve de Servicios Web. Octubre 24, 2015, de W3C, 2006 [Online]
http://www.w3c.es/Divulgacion/GuiasBreves/ServiciosWeb
6. Introducing JSON, 2016 [Online] http://www.json.org/
7. Evapotranspiration and crop coefficients for coffee trees « Water .... Obtenido May 30,
2017, [Online] http://www.aguayriego.com/en/2016/02/evapotranspiracion-y-
coeficientes-de-cultivo-para-el-cafeto/
8. Races D., Smith, K, “Servicio de recursos, fomento y aprovechamiento de las aguas.
Roma: FAO”, 2006
9. Silva, J., Silva, P., Silva, T., Lúcio, J., Santos, D., & Santos, M. (), “Determinação do
Coeficiente de Cultivo (Kc) para a Cultura do Pimentão Através de Lisimetria de
Drenagem no Agreste Alagoano. Anais Do II Inovagri International Meeting - 2014”,
2014
10. Millas, J. A., González, G., Salomon, M., & Rodríguez, Á, “Diseño de estructuras
dinámicas para ofrecer gráficos y pantallas emergentes en entorno web.”, 2014
11. Michaelis, C. D., & Ames, D. P, “Web Feature Service (WFS) and Web Map Service
(WMS)”, Encyclopedia of GIS, 1-3, 2016

162
12. Chanchí, G. E., Campo, W. Y., Amaya, J. P., & Arciniegas, J. L, “Esquema de
servicios para Televisión Digital Interactiva, basados en el protocolo REST-JSON.”
Cadernos de Informática, pp.233-240, 2011
13. Spinak, E, “LA NORMA Z39. 50”, Informatio. Revista del Instituto de Información
de la Facultad de Información y Comunicación, (1), 2013
14. Cruz, R., Torres, J.S., & Besosa T.R, “Asociación de cultivadores de caña de azúcar,
de Colombia, Asocaña”, informe anual 2010- 2011, 2011
15. Viveros, C. A, “Mayor eficiencia en el uso del agua para la producción de caña de
azúcar. En Tesis doctoral en fitomejoramiento” Palmira: Universidad nacional de
Colombia. Pp.24-25, 2011
16. Roger-Estrade, J., Richard, G., Dexter, A. R., Boizard, H., De Tourdonnet, S.,
Bertrand, M., & Caneill, J, “Integration of soil structure variations with time and space
into models for crop management: a review. In Sustainable Agriculture” (pp. 813-
822). Springer Netherlands, 2009
17. “Investigación sobre el uso del suelo agropecuario en el Valle del Cauca”, DANE,
2012
18. Gisbert, J. M, “Génesis del suelo. Universidad politécnica de Valencia”, 2010
19. Ramos-Reyes, R., Sánchez-Hernández, R., & Gama-Campillo, L. M, “Análisis de
cambios de uso del suelo en el municipio costero de Comalcalco, Tabasco, México.
Ecosistemas y recursos agropecuarios” 3(8), 151-160, 2016
20. Horras, D. A., Studdert, G., & XLinzon, “Distribution properties, land use and
management of mollisols in South America”, Sci 21. Pp.511-530, 2011
21. Arévalo G., & Gauggel C, “Curso de manejo de suelos y nutrición vegetal, manual de
pràcticas. Tegucigalpa, Honduras Zamorano”. P.75, 2010
22. Cruz, R. “Necesidad de agua de la caña de azúcar Carta trimestral”, 2010 Vol. 42.
P.41, 2010
23. OLGUÍN VILLALOBOS, L. R, “Impacto de la implementación del sistema de riego
por goteo, en la rentabilidad de los cultivos de caña de azúcar, en la Empresa Sociedad
Agrícola Valle Grande SAC”, durante el período 2009-2012, 2013
24. “Proyecto subsectorial de Irrigación. Sistema de riego por multicompuertas”, Perú:
Ministerio de Agricultura - Oficina de gestión, 2014

163
25. Cavero, J., Urrego, Y., Faci, J.M., Fernández, A., & Martínez, A, “Razones
agronómicas para el riego por aspersión nocturno en maíz. Zaragoza: Departamento de
suelo y Agua. Estación experimental de aula”, Tierras 214 p.26, 2010
26. Fontela, C., Salatino, S., & Mirábile, C. “Riego por goteo en Mendoza, Argentina:
evaluación de la uniformidad del riego y del incremento de salinidad, sodicidad e
iones cloruro en el suelo”, Rev. FCA UN Cuyo, 41(1), 135-154, 2009
27. Allen, R.G, “Riego y Drenaje. Evaporación del cultivo”, Utah State University, Logan
Utah. EU, 2009
28. Cruz Valderrama, J. R, “Manejo eficiente del riego en el cultivo de caña de azúcar en
el valle geográfico del Río Cauca” (No. 633.61 C957m). CENICAÑA, 2015
29. Herrera, “Avances técnicos para la programación y manejo del riego en caña de
azúcar” México DF: Editorial Continental, 2004
30. MacKenzie, C. M., Laskey, K., McCabe, F., Brown, P. F., & Metz, R, “Reference
model for service oriented architecture” 1.0. oasis standard, 12 October 2006, 2011
31. Roshen, W, “SOA-Based Enterprise Integration: A Step-by-Step Guide to Services-
based Application”, McGraw-Hill, Inc, 2009
32. “Architecture Overview - ts - Angular 2”, 2015, [Online]
https://angular.io/docs/ts/latest/guide/architecture.html.
33. “Service Oriented Architecture : What Is SOA?”. 2016, [Online]
http://www.opengroup.org/soa/source-book/soa/soa.htm#soa_definition
34. S. Vinoski. “Putting the “Web” into Web services: Interaction models, part 1: Current
practice”, 2002
35. Hamad, H., Saad, M., & Abed, R. “Performance Evaluation of RESTful Web
Services for Mobile Devices” Int. Arab J. e-Technol., 1(3), 72-78, 2010
36. Pautasso, C., Zimmermann, O., & Leymann, F., “RESTful Web Services vs. ‘Big’
Web Services: Making the Right Architectural Decision. Beijing: Conclusiones de la
17ª”, Conferencia Internacional sobre el World Wide Web. pp. 805-812, 2008
37. Bonfè, M., Fantuzzi, C., & Secchi, C. “Design patterns for model-based automation
software design and implementation. Control Engineering Practice”, 21(11), 1608-
1619, 2013
38. “APLICACIÓN DE PATRONES DE DISEÑO EN EL DISEÑO”, 2012 [Online]:
http://biblioteca.usac.edu.gt/tesis/08/08_0584_CS.pdf.

164
39. Freeman, A, “The Template Method Pattern. Pro Design Patterns in Swift”, 517-524,
2014
40. The Singleton Pattern, “Pro JavaScript Design Patterns”, 65-82, 2008
41. López, R, “Análisis y Diseño Orientado a Objetos de un framework para el modelado
estadístico con MLG - TDX”, 2011 [Online]:
http://www.tdx.cat/bitstream/handle/10803/9442/trjl1de1.pdf?sequence=1.
42. A. Freeman, “The Flyweight Pattern,” Pro Design Patterns in Swift, pp. 339–356,
2014.
43. Zhou, J., & Ding, Y. “An Analysis of URLs Generated from JavaScript Code”,
IEEE/ACIS 11th International Conference on Computer and Information Science,
2012
44. Feroz, M. N., & Mengel, S, “Phishing URL Detection Using URL Ranking” 2015
IEEE International Congress on Big Data, 2015
45. Pautasso, C. “RESTful Web service composition with BPEL for REST. Data &
Knowledge Engineering”, 68(9), 851-866, 2009
46. Martorelli, S. L., Sanz, C. V., Giacomantone, J., & Martorelli, S. R, “ParasitePics: An
Animal Parasitology Image Repository Prototype for Teaching and Learning”, 2009
47. Paradiso, G, “Diario de un Consultor. Edición Especia”, 2015 [Online]:
https://books.google.com.co/books?id=xPUTCwAAQBAJ
48. Definiendo la innovación; La innovación en la Administración Pública; Transnacional:
La transformación a través de las ideas; La innovación en las Administraciones
Públicas: Una perspectiva desde la empresa y la universidad; La innovación del sector
público: Una mirada personal; La Administración Pública en Iberoamérica: Estado de
la cuestión y nuevos horizontes; Bibliografía. (n.d.). Introducción a La Innovación En
La Administración Pública. Visiones Para Una Administración Pública Innovadora,
11-104.
49. Daigneau, R, “Service Design Patterns: fundamental design solutions for
SOAP/WSDL and restful Web Services” Addison-Wesley, 2011
50. “Guía Breve de Tecnologías XML - W3C”, 2006, [Online]:
http://www.w3c.es/Divulgacion/GuiasBreves/TecnologiasXML.
51. Christensen, E., Curbera, F., Meredith, G., & Weerawarana, S, “Web services
description language (wsdl) 1.1”, 2015, [Online]: http://www. w3. org/TR/wsdl.
Accessed, 05-22.

165
52. J. Zhang, X. Yu, P. Liu, and Z. Wang, “Research on Improving Performance of
Semantic Search in UDDI,” 2009 WRI Global Congress on Intelligent Systems, 2009
53. "Relación entre UDDI y WSDL - IBM.", 2012 [Online]: http://www-
01.ibm.com/support/knowledgecenter/SS8PJ7_8.5.1/org.eclipse.jst.ws.consumption.ui
.doc.user/concepts/cwsdlud.html?lang=es
54. MCCORMICK, Z, “Data Synchronization Patterns in Mobile Application Design”,
2012 [Online]: https://www.dre.vanderbilt.edu/~schmidt/PDF/PatternPaperv11.pdf.
55. Yvonnet, J., Monteiro, E., & He, Q. C, “Computational homogenization method and
reduced database model for hyperelastic heterogeneous structures. International
Journal for Multiscale Computational Engineering”, 11(3), 2013
56. Castillo, P.A., Bernier, J.l., Arenas, M.G., Merelo, J.J., & García-Sánchez, P. (Mayo
25, 2011). “SOAP vs REST: Comparing a master-slave GA implementation”, 2013
57. Potti, P.K., Ahuja, S., Umapathy, K., & Prodanoff, Z, “Comparing Performance of
Web Service Interaction Styles: SOAP vs. REST”, University of North Florida: Actas
de la Conferencia sobre Investigación en Sistemas de Información Aplicada, 2012
58. Hamad, H., Saad, M., & ,Abed R, “Performance Evaluation of RESTful Web Services
for Mobile Devices”, Departamento de Ingeniería Informática de la Universidad
Islámica de Gaza, Palestina: Diario Árabe Internacional de e-Tecnologia, 2010
59. Parsons, M. A., Godøy, Ø., LeDrew, E., De Bruin, T. F., Danis, B., Tomlinson, S., &
Carlson, D, “A conceptual framework for managing very diverse data for complex,
interdisciplinary science”, Journal of Information Science, 37(6), 555-569, 2011
60. Mumbaikar, S., & Padiya, P. “Web Services Based On SOAP and REST Principles”,
Revista Internacional de Publicaciones científicas y de investigación, Volumen 3,
Número 5, 2013
61. Guinard, D., Ion, I., & Mayerm, S, “In Search of an Internet of Things Service
Architecture: REST or WS-*? A Developers’ Perspective. En MOBILE AND
UBIQUITOUS SYSTEMS: COMPUTING, NETWORKING, AND SERVICES”,
(pp.326-337). ETH Zurich, Suiza: Instituto de Computación Ubicua, 2012
62. Masse, M. “REST API Design Rulebook: Designing Consistent RESTful Web Service
Interfaces.", O'Reilly Media, Inc, 2011
63. Newcomer, E., & Lomow, G, “Understanding SOA with Web Services” ISBN 978-0-
321-18086-5, 2004

166
64. “Understanding Web Services Security Concepts”, 2016 [Online]:
https://docs.oracle.com/cd/E23943_01/web.1111/b32511/intro_security.htm#WSSEC
2342
65. “Custom Objects | SOAP API Developer Guide”, 2014 [Online]:
https://developer.salesforce.com/docs/atlas.en-
us.api.meta/api/sforce_api_objects_custom_objects.htm.
66. Felipe, O, “Design and development of a REST-based Web service Platform for
Applications Integration”, 2010, [Online]:
http://upcommons.upc.edu/bitstream/handle/2099.1/8553/Master%20thesis%20-
%20Luis%20Oliva.pdf.
67. Lozano, M, “Desarrollo de una aplicación móvil android para control remoto de un
servicio web”, 2012 [Online]: http://e-
archivo.uc3m.es/bitstream/handle/10016/16913/TFG_Maria_Lozano_Perez.pdf?seque
nce=1.
68. Johnsrud, L., Hadzic, D., Hafsøe, T., Johnsen, F. T., & Lund, K., “Efficient web
services in mobile networks”. En WEB SERVICES. IEEE Sixth European
Conference, 2008
69. Zheng, Z., Ma, H., Lyu, M. R., & King, I, “Wsrec: A collaborative filtering based web
service recommender system In Web Services,” 2009. ICWS 2009. IEEE International
Conference on (pp. 437-444). IEEE, 2009
70. Hernández-Pérez, T., Rodríguez-Mateos, D., Martín-Galán, B., & García-Moreno, M.
A, “El uso de metadatos en la administración electrónica española: Los retos de la
interoperabilidad”, Revista Española De Documentación Científica,32(4), 67-91, 2009
71. “Ranch Systems Internet Software”, 2015 [Online]:
http://www.ranchsystems.com/ssite/rs-internetsoftware-gettingstartedguide-1.1.pdf
72. “ClimateMinder Technology”, 2015 [Online]:
http://www.rainbird.com/ag/products/ClimateMinder/Technology.htm
73. Larman, C. “Applying UML and Patterns: An Introduction to Object Oriented
Analysis and Design and Interative Development”, Pearson Education India, 2012
74. Capítulo 4, “En PATRONES DE DISEÑO”, 2009 [Online]:
http://catarina.udlap.mx/u_dl_a/tales/documentos/lis/diaz_c_a/capitulo4.pdf.
75. Osmani, A, “Learning JavaScript Design Patterns: A JavaScript and jQuery
Developer's Guide”, O'Reilly Media, Inc, 2012

167
76. “Arduino UNO”, 2016 [Online]: https://www.arduino.cc/en/main/arduinoBoardUno
77. “Globin 2 Manual, VERSE Technology”, 2016, [Online]: http://www.verse-
technology.com/wp-content/uploads/2016/10/MANUAL-GOBLIN-ESPAÑOL.pdf
78. Bakhtiari, B., & Liaghat, A. M, “Seasonal sensitivity analysis for climatic variables of
ASCE-Penman-Monteith model in a semi-arid climate. Journal of Agricultural
Science and Technology”, 13, 1135-1145, 2011
79. Minet, J., Lambot, S., Delaide, G., Huisman, J. A., Vereecken, H., & Vanclooster, M,
“A generalized frequency domain reflectometry modeling technique for soil electrical
properties determination. Vadose zone journal”, 9(4), 1063-1072, 2010
80. Thakur, A., Roychowdhury, S., Kundu, D., & Singh, R, “Evaluation of planting
methods in irrigated rice. Archives of Agronomy and Soil Science”, 50(6), 631-640,
2004
81. Černý, R, “Time-domain reflectometry method and its application for measuring
moisture content in porous materials: A review. Measurement”, 42(3), 329-336, 2009
82. “Fundamentos de la Humedad del Suelo - IRROMETER - Básicos”, 2017 [Online]:
http://www.irrometer.com/basicssp.html
83. “Influencia de tratamiento alternativo del agua de riego en los ....” 2017 [Onlie]:
http://revistaeidenar.univalle.edu.co/revista/ejemplares/12/j.htm
84. Red Agrícola Dr. Luis Gorovich, “Desarrollo de sensores para las plantas”, Chile,
2016.
85. “American Laborayory”, 2017, [Online]:
http://media.americanlaboratory.com/m/20/article/38090-fig1.jpg
86. Luis Llamas, “Medir La Humedad Del Suelo Con Arduino E Higrómetro FC-28”,
2017, [Online]: https://www.luisllamas.es/arduino-humedad-suelo-fc-28/
87. “Arduino Rain Sensor Manual and Tutorial | Henry's Bench”, 2015. [Online]:
http://henrysbench.capnfatz.com/henrys-bench/arduino-sensors-and-input/arduino-
rain-sensor-module-guide-and-tutorial/
88. “Homeautomation, Measure soil Moisture with Arduino - Gardening”, 2017, [Online]:
http://www.homautomation.org/2014/06/20/measure-soil-moisture-with-arduino-
gardening/
89. Prometec, “ARDUINO Y WIFI” ESP8266, 2017, [Online]:
http://www.prometec.net/arduino-wifi/

168
90. Ores, J. W. S., Audet, S. A., Carney, J. K., Gottesman, J. M., Donders, A. P., &
Ujhelyi, M. R, U.S. “Patent No. 7,594,889”, Washington, DC: U.S. Patent and
Trademark Office, 2009
91. Wang, V., Salim, F., & Moskovits, P, “WebSocket Security. The Definitive Guide to
HTML5 WebSocket”, 129-147, 2013
92. Chavan, P.U., Dr. Murugan, M. y Chavan, P.P, “A Review on Software Architecture
Styles with Layered Robotic Software Architecture”, International Conference on
Computing Communication Control and Automation, 2015
93. Babu, D.K., Rajulu, G.P., Reddy R.A., Kumari A.A.N, “Selection of Architecture
Styles using Analytic Network Process for the Optimization of Software
Architecture”, International Journal of Computer Science and Information Security,
Vol. 8 No.1, 2010
94. Ramirez, J., Insuasty, O. y Viveros, C.A., “Comportamiento Agroindustrial de 10
variedades de caña de azúcar en Santander Colombia”, 183-195, 2014
95. Cruz, V.J., Torres, J.S., Besosa, T.R. y Rojas, L.R., “Resultados preliminares acerca
de la función de respuesta de la caña de azúcar al agua”, Carta trimestral 2-2010 Vol
32 Nº 3-4, 3-5., 2010
96. Mardan, A., & Gorczynski, R. “Express.js: Tworzenie aplikacji sieciowych w Node.js.
Gliwice: Helion”, 2016
97. Rossano, Víctor. Electrónica & microcontroladores PIC. USERSHOP, 2009.
98. Romay, C., L. Génova, H. Salgado, and S. M. Zabala. "RECOMENDACIONES PARA
MEJORAR LA EFICIENCIA EN EL RIEGO DISCONTINUO PROGRAMANDO LA VALVULA
AUTOMATICA." Riego y drenaje, Facultad de agronomía de Buenos Aires, Av. San Martin
4453, 2014.
99. Miniguano, Félix, Ricardo Paúl, Pacheco Chiguano, and Daniel Patricio. "Diseño e
implementación de un sistema domótico de riego de plantas controlado remotamente a través
del Internet.", 2011.

169
ANEXOS
1. Datos de riego cultivo Caña de Azúcar, datos obtenidos de Valle del río Cauca, fuente:
Cenicaña.
Cultivo: Caña de azúcar
Ubicación/Sitio de cultivo: Valle del río Cauca
Datos entregados por: Cenicaña
Constantes
Fecha de inicio Variedad de
Cultivo Tipo de riego
Capacidad de
campo LARA
01 - Junio - 2015 CC8592 Sin información 100 60
Variables
Evaporació
n
Factor de
cultivo
Evapotrans
piración
Balance Hídrico
Día Precipitaci
ón efectiva
Riego
efectivo
Humedad
del suelo
1 4,02 0,7 2,81 0 0 60
2 3,06 0,7 2,14 0 40 97,19
3 7,3 0,7 5,11 0 0 95,04
4 5,24 0,7 3,67 0 0 89,93
5 6,12 0,7 4,28 0 0 86,27
6 5,36 0,7 3,75 0 0 81,98
7 2,8 0,7 1,96 7,4 0 85,63
8 2,28 0,7 1,60 5,6 0 89,27
9 2,34 0,7 1,64 0 0 87,67
10 7,2 0,7 5,04 0 0 86,04
11 4,94 0,7 3,46 13,2 0 94,20
12 4,92 0,7 3,44 0 0 90,74
13 3,96 0,7 2,77 0 0 87,29
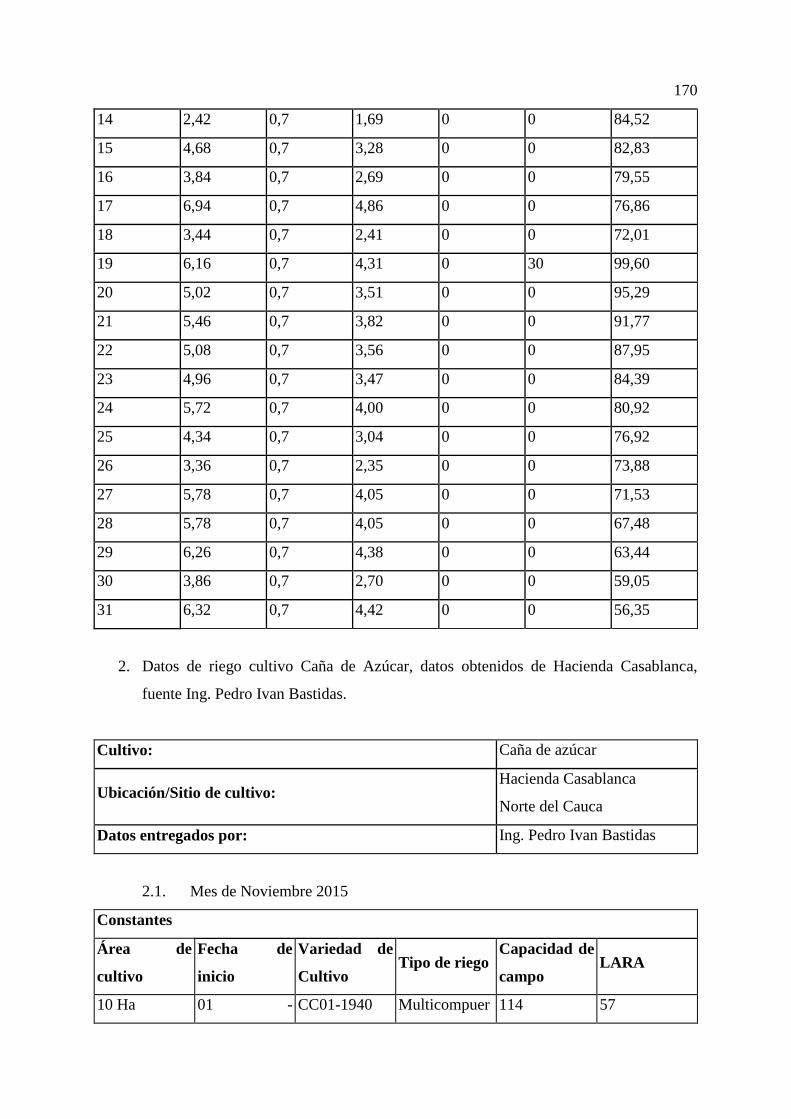
170
14 2,42 0,7 1,69 0 0 84,52
15 4,68 0,7 3,28 0 0 82,83
16 3,84 0,7 2,69 0 0 79,55
17 6,94 0,7 4,86 0 0 76,86
18 3,44 0,7 2,41 0 0 72,01
19 6,16 0,7 4,31 0 30 99,60
20 5,02 0,7 3,51 0 0 95,29
21 5,46 0,7 3,82 0 0 91,77
22 5,08 0,7 3,56 0 0 87,95
23 4,96 0,7 3,47 0 0 84,39
24 5,72 0,7 4,00 0 0 80,92
25 4,34 0,7 3,04 0 0 76,92
26 3,36 0,7 2,35 0 0 73,88
27 5,78 0,7 4,05 0 0 71,53
28 5,78 0,7 4,05 0 0 67,48
29 6,26 0,7 4,38 0 0 63,44
30 3,86 0,7 2,70 0 0 59,05
31 6,32 0,7 4,42 0 0 56,35
2. Datos de riego cultivo Caña de Azúcar, datos obtenidos de Hacienda Casablanca,
fuente Ing. Pedro Ivan Bastidas.
Cultivo: Caña de azúcar
Ubicación/Sitio de cultivo: Hacienda Casablanca
Norte del Cauca
Datos entregados por: Ing. Pedro Ivan Bastidas
2.1. Mes de Noviembre 2015
Constantes
Área de
cultivo
Fecha de
inicio
Variedad de
Cultivo Tipo de riego
Capacidad de
campo LARA
10 Ha 01 - CC01-1940 Multicompuer 114 57

171
Noviembre -
2015
tas
Variables
Evaporació
n
Factor de
cultivo
Evapotrans
piración
Balance Hídrico
Día Precipitaci
ón efectiva
Riego
efectivo
Humedad
del suelo
1 4,02 0,5 2,01 0 0 62
2 4,02 0,5 2,01 0 40 99,99
3 6,2 0,5 3,10 0 0 97,98
4 7,5 0,5 3,75 0 0 94,88
5 6,3 0,5 3,15 0 0 91,13
6 5,3 0,5 2,65 10 0 97,98
7 4,8 0,5 2,40 0 0 95,33
8 4,9 0,5 2,45 12 0 104,93
9 4,1 0,5 2,05 0 0 102,48
10 6,2 0,5 3,10 0 0 100,43
11 0,5 0,5 0,25 15 0 112,33
12 4,9 0,5 2,45 0 0 112,08
13 4,3 0,5 2,15 0 0 109,63
14 3,8 0,5 1,90 0 0 107,48
15 4,5 0,5 2,25 0 0 105,58
16 5,5 0,5 2,75 0 17 120,33
17 6,8 0,5 3,40 0 0 117,58
18 5,4 0,5 2,70 0 0 114,18
19 6 0,5 3,00 0 0 111,48
20 6,2 0,5 3,10 0 0 108,48
21 5,6 0,5 2,80 0 0 105,38
22 5,2 0,5 2,60 0 0 102,58
23 4,8 0,5 2,40 0 0 99,98
24 4,7 0,5 2,35 0 0 97,58

172
25 4,5 0,5 2,25 0 0 95,23
26 4,1 0,5 2,05 0 0 92,98
27 4 0,5 2,00 0 0 90,93
28 4,3 0,5 2,15 0 0 88,93
29 3,9 0,5 1,95 0 0 86,78
30 3,8 0,5 1,90 0 34 118,83
31
2.2. Mes de Diciembre 2015
Constantes
Área de
cultivo
Fecha de
inicio
Variedad de
Cultivo Tipo de riego
Capacidad de
campo LARA
10 Ha
01 -
Diciembre -
2015
CC01-1940 Multicompuer
tas 114 57
Variables
Evaporació
n
Factor de
cultivo
Evapotrans
piración
Balance Hídrico
Día Precipitaci
ón efectiva
Riego
efectivo
Humedad
del suelo
1 3,8 0,6 2,28 0 0 101,07
2 4 0,6 2,40 0 0 98,79
3 5,5 0,6 3,30 0 0 96,39
4 5,8 0,6 3,48 0 0 93,09
5 6,3 0,6 3,78 0 0 89,61
6 6,7 0,6 4,02 0 0 85,83
7 6,8 0,6 4,08 0 0 81,81
8 7 0,6 4,20 0 0 77,73
9 6,7 0,6 4,02 0 0 73,53
10 6,2 0,6 3,72 0 0 69,51

173
11 5,9 0,6 3,54 0 0 65,79
12 5,2 0,6 3,12 0 0 62,25
13 4,8 0,6 2,88 0 0 59,13
14 4,3 0,6 2,58 0 0 56,25
15 4,4 0,6 2,64 0 0 53,67
16 4,9 0,6 2,94 0 40 91,03
17 5,8 0,6 3,48 0 0 88,09
18 5,9 0,6 3,54 0 0 84,61
19 6 0,6 3,60 0 0 81,07
20 6,2 0,6 3,72 0 0 77,47
21 5,6 0,6 3,36 0 0 73,75
22 5,2 0,6 3,12 0 0 70,39
23 4,8 0,6 2,88 0 0 67,27
24 4,7 0,6 2,82 0 0 64,39
25 4,5 0,6 2,70 0 0 61,57
26 4,1 0,6 2,46 0 0 58,87
27 4 0,6 2,40 0 0 56,41
28 4,3 0,6 2,58 0 0 54,01
29 3,9 0,6 2,34 0 40 91,43
30 3,8 0,6 2,28 0 0 89,09
31 3,5 0,6 2,10 0 0 86,81
2.3. Mes de Enero de 2016
Constantes
Área de
cultivo
Fecha de
inicio
Variedad de
Cultivo Tipo de riego
Capacidad de
campo LARA
10 Ha 01 - Enero -
2015 CC01-1940
Multicompuer
tas 114 57
Variables
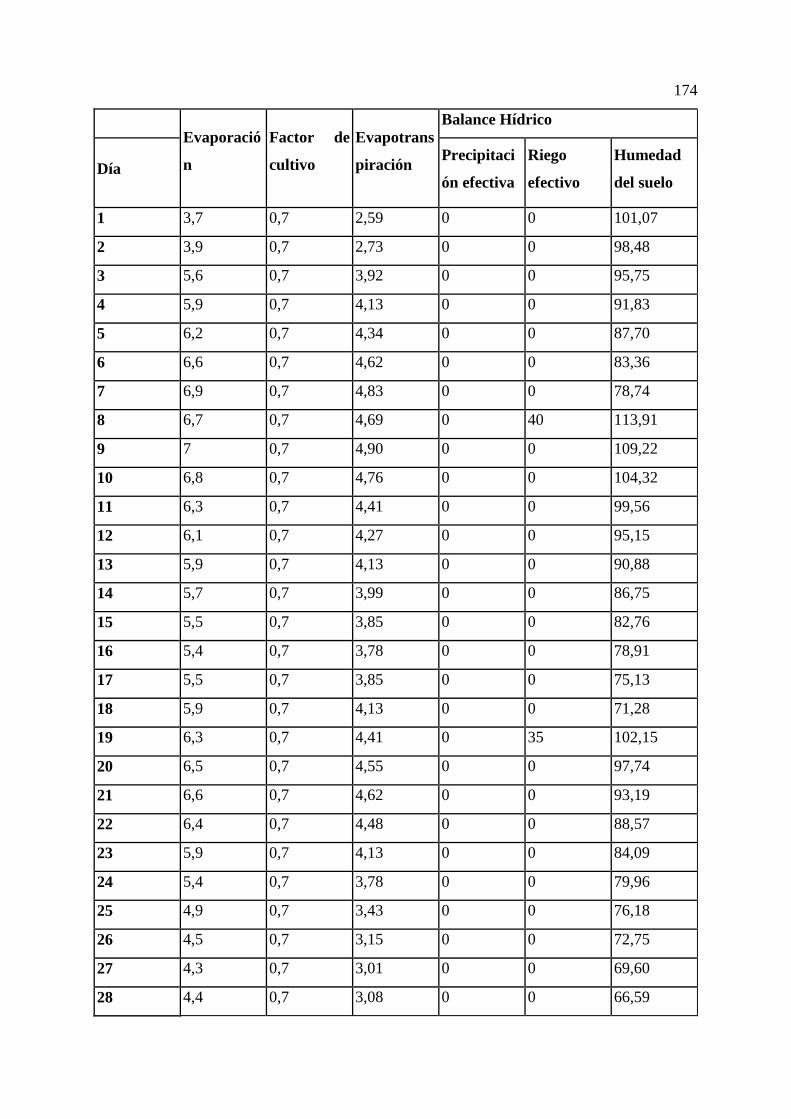
174
Evaporació
n
Factor de
cultivo
Evapotrans
piración
Balance Hídrico
Día Precipitaci
ón efectiva
Riego
efectivo
Humedad
del suelo
1 3,7 0,7 2,59 0 0 101,07
2 3,9 0,7 2,73 0 0 98,48
3 5,6 0,7 3,92 0 0 95,75
4 5,9 0,7 4,13 0 0 91,83
5 6,2 0,7 4,34 0 0 87,70
6 6,6 0,7 4,62 0 0 83,36
7 6,9 0,7 4,83 0 0 78,74
8 6,7 0,7 4,69 0 40 113,91
9 7 0,7 4,90 0 0 109,22
10 6,8 0,7 4,76 0 0 104,32
11 6,3 0,7 4,41 0 0 99,56
12 6,1 0,7 4,27 0 0 95,15
13 5,9 0,7 4,13 0 0 90,88
14 5,7 0,7 3,99 0 0 86,75
15 5,5 0,7 3,85 0 0 82,76
16 5,4 0,7 3,78 0 0 78,91
17 5,5 0,7 3,85 0 0 75,13
18 5,9 0,7 4,13 0 0 71,28
19 6,3 0,7 4,41 0 35 102,15
20 6,5 0,7 4,55 0 0 97,74
21 6,6 0,7 4,62 0 0 93,19
22 6,4 0,7 4,48 0 0 88,57
23 5,9 0,7 4,13 0 0 84,09
24 5,4 0,7 3,78 0 0 79,96
25 4,9 0,7 3,43 0 0 76,18
26 4,5 0,7 3,15 0 0 72,75
27 4,3 0,7 3,01 0 0 69,60
28 4,4 0,7 3,08 0 0 66,59

175
29 4,2 0,7 2,94 0 0 63,51
30 4,1 0,7 2,87 0 35 95,57
31 3,9 0,7 2,73 0 0 92,70
2.4. Mes de Febrero de 2016
Constantes
Área de
cultivo
Fecha de
inicio
Variedad de
Cultivo Tipo de riego
Capacidad de
campo LARA
10 Ha 01 - Febrero -
2015 CC01-1940
Multicompuer
tas 114 57
Variables
Evaporació
n
Factor de
cultivo
Evapotrans
piración
Balance Hídrico
Día Precipitaci
ón efectiva
Riego
efectivo
Humedad
del suelo
1 3,9 0,8 3,12 0 0 96,6
2 4,1 0,8 3,28 0 0 93,48
3 4,9 0,8 3,92 0 0 90,20
4 5,5 0,8 4,40 0 0 86,28
5 6 0,8 4,80 0 0 81,88
6 6,5 0,8 5,20 0 0 77,08
7 6,6 0,8 5,28 0 0 71,88
8 6,8 0,8 5,44 0 0 66,60
9 6,9 0,8 5,52 0 45 106,16
10 7 0,8 5,60 0 0 100,64
11 6,8 0,8 5,44 0 0 95,04
12 6,5 0,8 5,20 0 0 89,60
13 6,3 0,8 5,04 0 0 84,40
14 6,2 0,8 4,96 0 0 79,36
15 6,2 0,8 4,96 0 0 74,40

176
16 6,5 0,8 5,20 0 0 69,44
17 6,6 0,8 5,28 0 0 64,24
18 6,2 0,8 4,96 0 0 58,96
19 6 0,8 4,80 0 0 54,00
20 5,9 0,8 4,72 0 50 99,20
21 5,8 0,8 4,64 0 0 94,48
22 6 0,8 4,80 0 0 89,84
23 6,2 0,8 4,96 0 0 85,04
24 6,4 0,8 5,12 0 0 80,08
25 6,6 0,8 5,28 0 0 74,96
26 6,7 0,8 5,36 0 0 69,68
27 6,3 0,8 5,04 0 0 64,32
28 6 0,8 4,80 0 0 59,28
29 5,5 0,8 4,40 0 0 54,48
30
31
3. Vistazos de código fuente servicio web y aplicación móvil
3.1. Método request de clase server-api
/**
*@method request
*@param {String} uri debe ser por ejemplo: http://localhost:3010/api/crop
*@param {String} method debe ser por ejemplo: Post, el método debe tener la primera
letra en mayúscula
*@param {Obejct} body debe ser las opciones requeridas dependiendo del método que se
realice este es un JSON el cual es afectado por la función JSON.stringify()**/
request(method, uri, body, callback){
lef bodysend = JSON.stringify(body);
this.http.request(new Request({

177
method: RequestMethod[method],
url: uri,
headers : {
'access-key': this.token,
'Content-Type': 'application/json'
},
body:bodysend
})).subscribe(res => {
console.log('result', res.json())
callback(null, res.json().insertId);
}).error(err =>{
callback(err);
});
}
3.2. Método saveCrop del cliente
saveCrop(){
let newCrop = JSON.stringify({
Name : this.Name,
CropVariety: this.CropVariety,
FieldCapacity : this.FieldCapacity,
LARA: this.LARA,
CropStartDate: (new
Date(this.CropStartDate)).toISOString().substring(0,19).replace('T', ' '),
TypeIrrigation: this.TypeIrrigation,
CropArea: this.CropArea
});
Server.request(‘Post’,’/api/crops’,newCrop, function(err, result){

178
if(err){
console.log(‘error:’, err);
}
this.navParams.get('page2').saveCrop(result);
this.nav.pop();
});
}
3.3. Método listCrops del cliente
listCrops(limit){
let getCrop = JSON.stringify({
data: [ Name, LARA, CropStartDate, Id ],
limit: limit,
whereClause: “CropStartDate >= CURDATE() - INTERVAL 1 WEEK”
});
Server.request(Get,’/api/crops’,getCrop, function(err, result){
if(err){
console.log(‘error:’, err);
}
this.crops = result.data;
});
}





























