Embed Size (px)
Citation preview

DIMACS Working Group on Data Mining and Epidemiology

What are the challenges for mathematical scientists in the defense against disease?
This question led DIMACS, the Center for Discrete Mathematics and Theoretical Computer Science, to launch a “special focus” on this topic.

DIMACS Special Focus on Computational and Mathematical
Epidemiology 2002-2005
Anthrax
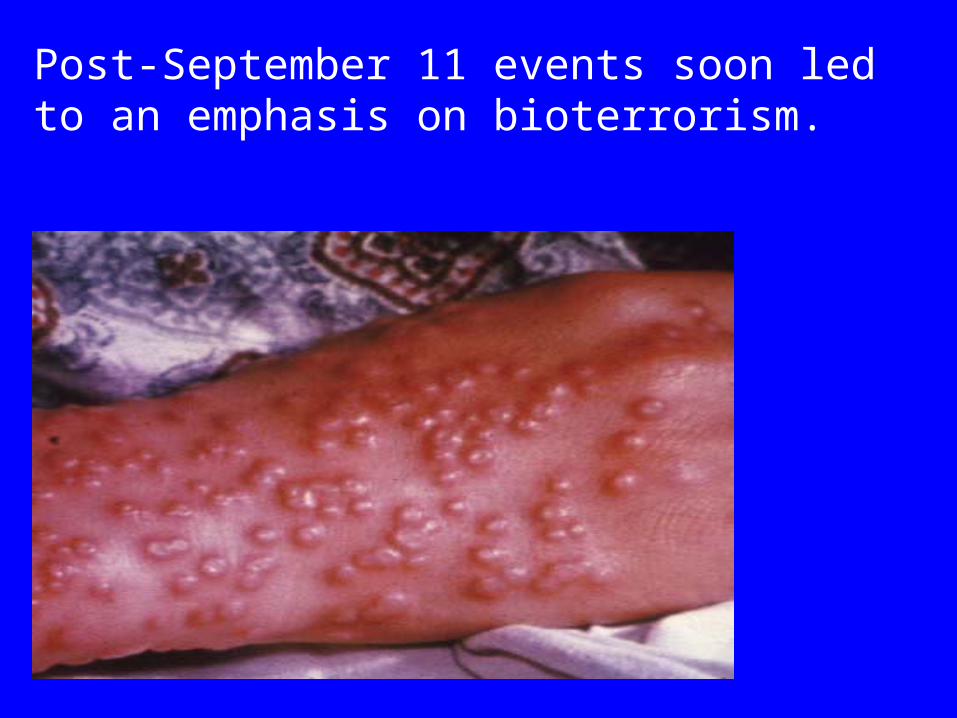
Post-September 11 events soon led to an emphasis on bioterrorism.
smallpox

Working Groups

Working Groups Continued
•Interdisciplinary, international groups of researchers.
•Come together at DIMACS.
•Informal presentations, lots of time for discussion.
•Emphasis on collaboration.
•Return as a full group or in subgroups to pursue problems/approaches identified in first meeting.
•By invitation; but contact the organizer.
•Junior researchers welcomed. Nominate them.

Working GroupsWG’s on Large Data Sets:
•Adverse Event/Disease Reporting, Surveillance & Analysis.
•Spin-off: Health Care Data Privacy and Confidentiality
•Data Mining and Epidemiology.

WG’s on Analogies between Computers and Humans:
•Analogies between Computer Viruses/Immune Systems and Human Viruses/Immune Systems
•Distributed Computing, Social Networks, and Disease Spread Processes

WG’s on Methods/Tools of TCS•Phylogenetic Trees and Rapidly Evolving Diseases
•Order-Theoretic Aspects of Epidemiology

WG’s on Computational Methods for Analyzing Large Models for Spread/Control of Disease
•Spatio-temporal and Network Modeling of Diseases
•Methodologies for Comparing Vaccination Strategies

WG’s on Mathematical Sciences Methodologies
•Mathematical Models and Defense Against Bioterrorism
•Predictive Methodologies for Infectious Diseases
•Statistical, Mathematical, and Modeling Issues in the Analysis of Marine Diseases

Data Mining and Epidemiology
–Interest sparked in part by availability of large and disparate computerized databases on subjects relating to disease

• Early warning is critical in public health
• This is a crucial factor underlying government’s plans to place networks of sensors/detectors to warn of a bioterrorist attack
• Sensors will be a source of huge amounts of data
The BASIS System

The DIMACS Bioterrorism Sensor Location Project

Data Mining and Epidemiology: Some Research Issues:

1. Streaming Data Analysis:
•When you only have one shot at the data
•Widely used to detect trends and sound alarms in applications in telecommunications and finance
•AT&T uses this to detect fraudulent use of credit cards or impending billing defaults
•Columbia has developed methods for detecting fraudulent behavior in financial systems
•Uses algorithms based in TCS
•Needs modification to apply to disease detection

Research Issues:•Modify methods of data collection, transmission, processing, and visualization•Explore use of decision trees, vector-space methods, Bayesian and neural nets•How are the results of monitoring systems best reported and visualized?•To what extent can they incur fast and safe automated responses?•How are relevant queries best expressed, giving the user sufficient power while implicitly restraining him/her from incurring unwanted computational overhead?

2. Cluster Analysis
•Used to extract patterns from complex data
•Application of traditional clustering algorithms hindered by extreme heterogeneity of the data
•Newer clustering methods based on TCS for clustering heterogeneous data need to be modified for infectious disease and bioterrorist applications.

3. Visualization
•Large data sets are sometimes best understood by visualizing them.

3. Visualization (continued)
•Sheer data sizes require new visualization regimes, which require suitable external memory data structures to reorganize tabular data to facilitate access, usage, and analysis.
•Visualization algorithms become harder when data arises from various sources and each source contains only partial information.

4. Data Cleaning
•Disease detection problem: Very “dirty” data:

4. Data Cleaning (continued)
•Very “dirty” data due to –manual entry–lack of uniform standards for content and formats–data duplication–measurement errors
•TCS-based methods of data cleaning–duplicate removal–“merge purge”–automated detection

5. Dealing with “Natural Language” Reports
•Devise effective methods for translating natural language input into formats suitable for analysis.
•Develop computationally efficient methods to provide automated responses consisting of follow-up questions.
•Develop semi-automatic systems to generate queries based on dynamically changing data.

6. Cryptography and Security
•Devise effective methods for protecting privacy of individuals about whom data is provided to biosurveillance teams -- data from emergency dept. visits, doctor visits, prescriptions
•Develop ways to share information between databases of intelligence agencies while protecting privacy?

6. Cryptography and Security (continued)
•Specifically: How can we make a simultaneous query to two datasets without compromising information in those data sets? (E.g., is individual xx included in both sets?)
•Issues include:–insuring accuracy and reliability of responses–authentication of queries–policies for access control and authorization

7. Spatio-Temporal Mining of Sensor Data
• Sensors provide observations of the state of the world localized in space and time.
• Finding trends in data from individual sensors: time series data mining.
• Detecting general correlations in multiple time series of observations.
• This has been studied in statistics, database theory, knowledge discovery, data mining.
• Complications: proximity relationships based on geography; complex chronological effects.






























