Embed Size (px)
Citation preview

Design Principles for Sparse Matrix Multiplicationon the GPU
European Conference on Parallel and Distributed Computing
Carl Yang1,3, Aydın Buluc2,3 and John D. Owens1
1 University of California, Davis2 University of California, Berkeley
3 Lawrence Berkeley National Laboratory
August 30, 2018
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 1 / 58

Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 2 / 58
Problem
Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 3 / 58

Problem
What’s in common?
(a) Social network analysis (b) Bioinformatics
(c) Computer forensics (d) Recommender systems
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 4 / 58

Problem
What’s in common?
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 5 / 58

Problem
Problem: Why high-performance?
0Van Den Heuvel, Martijn P., and Olaf Sporns. “Rich-club organization of thehuman connectome.” Journal of Neuroscience 31.44 (2011): 15775-15786.CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 6 / 58

Problem
Solution: Graph frameworks
CPU: Pregel, GraphLab, Cyclops, GraphX, Powergraph, GoFFish, Blogel,Gremlin, Haloop, Apache Giraph, Apache Hama, GPS, Mizan, Giraphx,Seraph, GiraphUC, Pregel+, Pregelix, Apache Tinkerpop, LFGraph, Gelly,Trinity, Ligra, ...
GPU: Gunrock, Medusa, Totem, Frog, VertexAPI2, MapGraph, CuSha, ...
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 7 / 58

Problem
Problem: What are the right primitives?
1 Concise
2 Portable
3 High-performance
4 Expressible
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 8 / 58

Problem
Thesis statement
Linear algebra is the right way to think about graph algorithms.
Graph primitives based in linear algebra are superior to ones based onexisting vertex-centric graph frameworks in conciseness, portability,performance and expressibility.
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 9 / 58

Problem
Graph traversal is sparse matrix multiplication
1Denes Konig, 1931CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 10 / 58

Problem
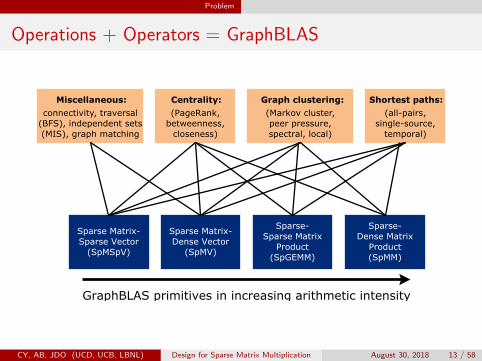
Ingredient 1: Operations
(a) SpMVYang et al., ICPP ’18
(b) SpMMYang et al., EuroPar ’18
(c) SpMSpVYang et al., IPDPSW ’15, ICPP ’18
(d) SpGEMM
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 11 / 58

Problem
Ingredient 2: Operators
Semiring notation: (Add, Multiply, Domain)
Add: How to combine edges
Multiply: How to combine vertex with incident edges
Domain: Vertex/edge attributes
Name Semiring Application
Real field {+,×,R} Classical numerical linear algebraBoolean {|,&, {0, 1}} Graph connectivityTropical {min,+,R ∪ {∞}} Shortest pathMax-plus {max,+,R} Graph matchingMin-times {min,×,R} Maximal independent set
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 12 / 58
Problem
Operations + Operators = GraphBLAS
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 13 / 58

Related work
Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 14 / 58
Related work
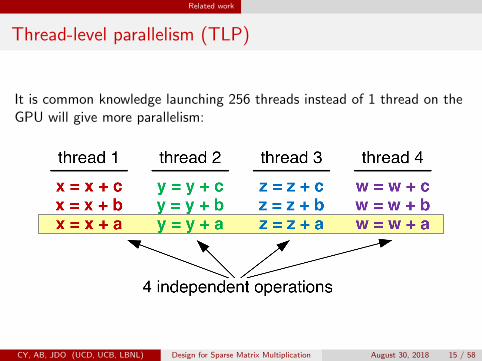
Thread-level parallelism (TLP)
It is common knowledge launching 256 threads instead of 1 thread on theGPU will give more parallelism:
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 15 / 58

Related work
Instruction-level parallelism (ILP)
It is less well-known that you can also use parallelism among instructionsin a single thread:
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 16 / 58
Related work
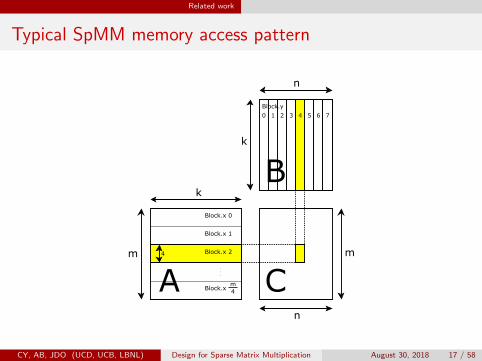
Typical SpMM memory access pattern
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 17 / 58
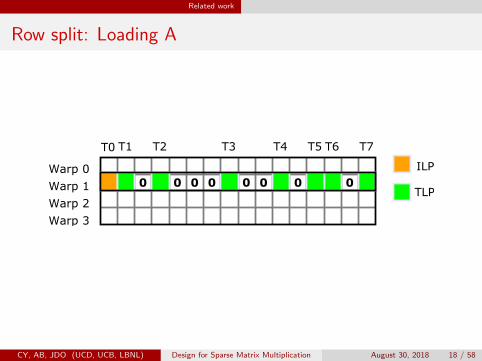
Related work
Row split: Loading A
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 18 / 58

Related work
Row split: Loading B is dependent on A
(a) Sparse matrix A (b) Dense matrix B
memory accesses not coalescedILP: 1 (non-existent)
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 19 / 58

Related work
Anything wrong with this?
(a) Sparse matrix A (b) Dense matrix B
memory accesses not coalescedILP: 1 (non-existent)CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 20 / 58

Related work
Load-balancing can be an issue
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 21 / 58

Related work
Can we do better?
Row split
Use ILP that naturally exists in SpMM
Merge-based
Address load-balancing issue
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 22 / 58

Row split
Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 23 / 58

Row split
A new SpMM memory access pattern
4
A
B
C
32
m
k
n
k
m
n
Block.x 0
Block.x 1
Block.x 2
Block.x
Block.y 1Block.y 0
m4
.
.
.
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 24 / 58
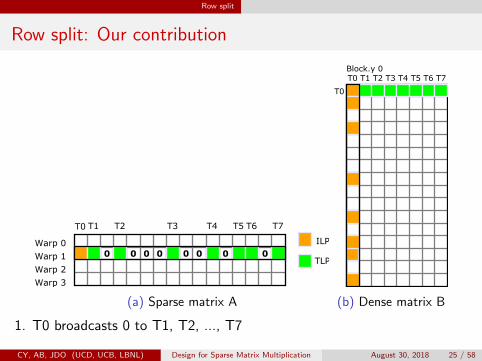
Row split
Row split: Our contribution
(a) Sparse matrix A (b) Dense matrix B
1. T0 broadcasts 0 to T1, T2, ..., T7
2. T0, T1, T2, ..., T7 do coalesced memory access for row 0
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 25 / 58

Row split
Row split: Our contribution
(a) Sparse matrix A (b) Dense matrix B
1. T0 broadcasts 0 to T1, T2, ..., T72. T0, T1, T2, ..., T7 do coalesced memory access for row 0CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 26 / 58
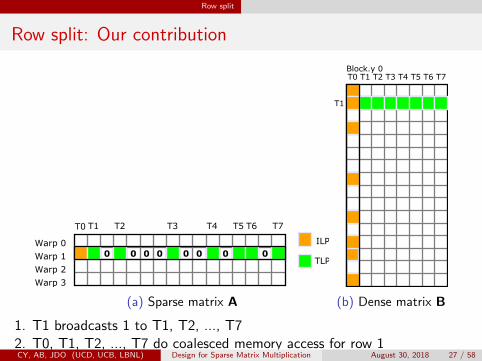
Row split
Row split: Our contribution
(a) Sparse matrix A (b) Dense matrix B
1. T1 broadcasts 1 to T1, T2, ..., T72. T0, T1, T2, ..., T7 do coalesced memory access for row 1CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 27 / 58

Row split
Row split: Our contribution
(a) Sparse matrix A (b) Dense matrix B
1. T2 broadcasts 3 to T1, T2, ..., T72. T0, T1, T2, ..., T7 do coalesced memory access for row 3CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 28 / 58
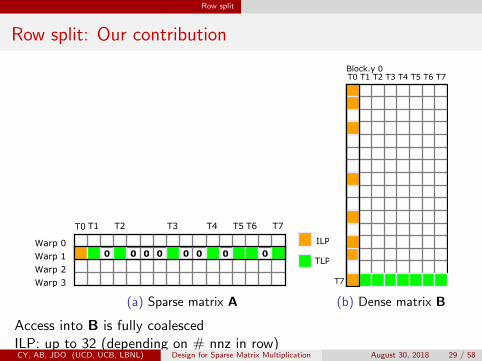
Row split
Row split: Our contribution
(a) Sparse matrix A (b) Dense matrix B
Access into B is fully coalescedILP: up to 32 (depending on # nnz in row)CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 29 / 58

Row split
Row split: Main takeaways
Thinking about TLP and ILP is the right way to think about sparsematrix multiplication
Isolate memory reads from compute from memory writes, because thisallows ILP to materialize
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 30 / 58

Merge-based
Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 31 / 58

Merge-based
Static work assignment
(a) Row split
(b) Merge based1
Merge-based SpMV has been shown superior static allocations.Will merge-based SpMM be superior too?
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 32 / 58

Merge-based
Merge-based (dynamic work assignment)
(a) Row split (b) Merge-based1
Merge-based SpMV has been shown superior static allocations.Will merge-based SpMM be superior too?
1Duane Merrill, Michael Garland. “Merge-based parallel sparse matrix-vectormultiplication”. SC ’16, IEEE: 678-689CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 33 / 58

Merge-based
Merge-based (dynamic work assignment)
(a) Row split (b) Merge-based1
Merge-based SpMV has been shown superior to row split SpMV.Is merge-based SpMM be superior too?
1Duane Merrill, Michael Garland. “Merge-based parallel sparse matrix-vectormultiplication”. SC ’16, IEEE: 678-689CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 34 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Carry-out fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 35 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Carry-out fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 36 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Carry-out fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 37 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Carry-out fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 38 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Carry-out fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 39 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Carry-out fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 40 / 58

Merge-based
Merge-based
Two-level decomposition:
1 Partition nonzeroes evenlyamongst blocks 0, 1, 2, 3
2 Global synchronization
3 Perform computation
4 Global synchronization
5 Partial sum fix-up
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 41 / 58

Evaluation
Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 42 / 58

Evaluation
Experimental setup
CPU: Intel 4-core E5-2637 v2 Xeon CPU @ 3.50GHz, 556GB RAM
GPU: NVIDIA K40c, 12GB RAM
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 43 / 58

Evaluation
Row split performance (62.5 nonzeroes per row)
StocF-
1465
ldoor
bmw3_2
bone
S10 F1
inline
_1
bone
010
audik
w_1
bmwcra
_1
crank
seg_2
Dataset
0
20
40
60
80
100
120
140
160
Perfo
rman
ce (G
Flop
s)cuSPARSE csrmmcuSPARSE csrmm2
MAGMA SELL-PProposed row-split
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 44 / 58

Evaluation
Merge path performance (7.92 nonzeroes per row)
citati
onCite
web-St
anf
wheel_
601
c-big
FullC
hip
ASIC_32
0k
Stanfo
rd ins2
neos3
circui
t5M
Dataset
0
10
20
30
40
50
Perfo
rman
ce (G
Flop
s)cuSPARSE csrmmRow-split
cuSPARSE csrmm2Proposed merge-based
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 45 / 58

Evaluation
Heuristic to switch between row split and merge path
101 102 103
Mean row length
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Spee
d-up
Row-splitMerge-based
(a) Without heuristic
101 102 103
Mean row length
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Spee
d-up
(b) With heuristic
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 46 / 58

Conclusion and Future Work
Overview
1 Problem
2 Related work
3 Row split
4 Merge-based
5 Evaluation
6 Conclusion and Future Work
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 47 / 58

Conclusion and Future Work
Comparison with GEMM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15Percentage of Nonzeroes in Matrix
0
500
1000
1500
2000
2500
3000
3500
Runt
ime
(ms)
cuSPARSE csrmmcuSPARSE csrmm2Proposed SpMMcuBLAS sgemm
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 48 / 58

Conclusion and Future Work
Typical SpMM memory access pattern
By one scan of A while adding for each non-zero entry aij the productaijbj to ci , the result matrix C is computed
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 49 / 58

Conclusion and Future Work
Future direction: Adjustment for deep learning workloads
Keep B in memory and load A
m = number of slow memory refs =√
knM
n2
M
Optimal for many nnz per row k ≥ nM
1Greiner, Gero and Riko Jacob. “The I/O Complexity of Sparse Matrix Dense MatrixMultiplication.” LATIN ’10.CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 50 / 58

Conclusion and Future Work
Future direction: Implicit load-balancing
Very challenging to explicitly load-balance a sparse matrix computationand generate ILP.
What if a load-balancing library could do the hard work for you and all youhad to do was specify the computation?
What would the interface to such a library look like?
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 51 / 58

Conclusion and Future Work
Conclusion
Thinking about TLP and ILP is the right way to think about sparsematrix multiplication
Isolate memory reads from compute from memory writes, because thisallows ILP to materialize
Two-phase decomposition is especially helpful for very sparse matrices(nnz/row < 9). It is a useful building block for load-balancing library.
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 52 / 58

Conclusion and Future Work
Acknowledgments
The Gunrock team
NVIDIA
for their generous hardware support
Funding support
NSF Award # CCF-1629657DARPA XDATA program under US Army award W911QX-12-C-0059DARPA HIVE program under agreement number FA8650-18-2-7836LBNL’s DOE contract DE-AC02-05CH11231DOE’s OASCR contract DE-AC02-05CH11231NNSA and DOE’s Office of Science under the Exascale ComputingProject 17-SC-20-SC
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 53 / 58
Conclusion and Future Work
Questions?
Code is available at: https://github.com/owensgroup/merge-spmm
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 54 / 58
Conclusion and Future Work
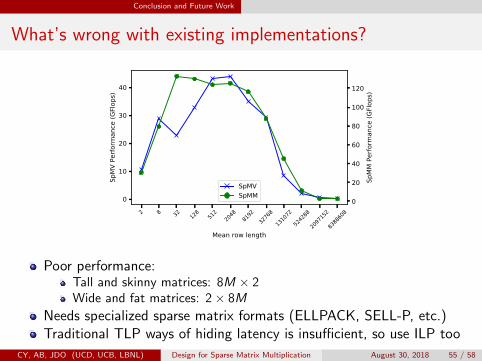
What’s wrong with existing implementations?
2 8 32 128
512
2048
8192
3276
8
1310
72
5242
88
2097
152
8388
608
Mean row length
0
10
20
30
40
SpM
V Pe
rform
ance
(GFl
ops)
SpMVSpMM
0
20
40
60
80
100
120
SpM
M P
erfo
rman
ce (G
Flop
s)
Poor performance:Tall and skinny matrices: 8M × 2Wide and fat matrices: 2× 8M
Needs specialized sparse matrix formats (ELLPACK, SELL-P, etc.)Traditional TLP ways of hiding latency is insufficient, so use ILP too
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 55 / 58
Conclusion and Future Work
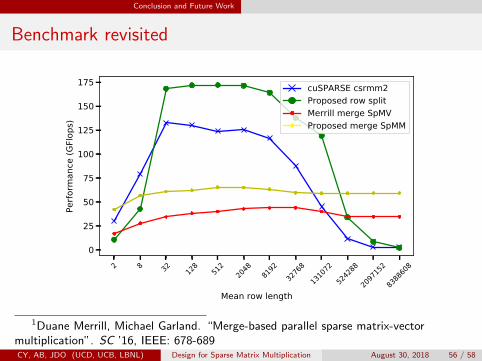
Benchmark revisited
2 8 32 128
512
2048
8192
3276
8
1310
72
5242
88
2097
152
8388
608
Mean row length
0
25
50
75
100
125
150
175Pe
rform
ance
(GFl
ops)
cuSPARSE csrmm2Proposed row splitMerrill merge SpMVProposed merge SpMM
1Duane Merrill, Michael Garland. “Merge-based parallel sparse matrix-vectormultiplication”. SC ’16, IEEE: 678-689CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 56 / 58

Conclusion and Future Work
Why merge-based underperformed
Table: Number of independent instructions per thread (ILP), register usage andoverhead. RS stands for row split. MG stands for merge-based.
SpMV SpMM
Operation RS MG RS MG
ILP: Read A.col ind and A.val 1 7 1 1ILP: Read x / Read B 1 7 0 < L ≤ 32 32ILP: Write y / Write C 1 7 1 32Register usage 2 14 64 64
Memory access overhead 0 A.nnz896 0 2A.nnz
CY, AB, JDO (UCD, UCB, LBNL) Design for Sparse Matrix Multiplication August 30, 2018 57 / 58





























