Embed Size (px)
Citation preview

DELIS Kickoff, March 18-19, 2004 1
Outline1 Overriding Goals & Structure2 Background on P2P3 Background on Search Engines4 P2P SE Architecture5 Research Challenges & Opportunities
DELIS SP6: Data Management, Search, and Mining on
Internet-scale Dynamically Evolving Peer-to-Peer Networks
Gerhard Weikum (MPII)

DELIS Kickoff, March 18-19, 2004 2
1) Overriding Goals and Structure of SP6Vision: Decentralized „Ultimate Google“ + Collaborative data mining on evolving large-scale data
Challenges:• Self-organizing P2P system with unlimited scalability• Leveraging intellectual input from millions of peers (bookmarks, link evolution, click streams, etc.) for better search quality
Layered approach:
P2P Web Search Engine
Enhanced DHT
DisseminationIncentives
MiningCollaboration
SP1, SP2 SP3 SP4SP5 ...

DELIS Kickoff, March 18-19, 2004 3
2) Peer-to-Peer (P2P) Architectures
Decentralized, self-organizing, highly dynamicloose coupling of many autonomous computers
Applications:• Large-scale distributed computation (SETI, PrimeNumbers, etc.)• File sharing (Napster, Gnutella, KaZaA, etc.)• Publish-Subscribe Information Sharing (Marketplaces, etc.)• Collaborative Work (Games, etc.)• Collaborative Data Mining• (Collaborative) Web Search
Goals:• make systems ultra-scalable and completely self-organizing• make complex systems manageable and less susceptible to attacks• break information monopolies, exploit small-world phenomenon

DELIS Kickoff, March 18-19, 2004 4
Unstructured P2P: Example Gnutella
1) contact neighborhood and establish virtualtopology (on-demand + periodically): Ping, Pong
2) search file: Query, QueryHit3) download file: Get or Push (behind firewall)
1
1
2
22
2
2
all forward messages carry a TTL tag (time-to-live)
3
3
3
33

DELIS Kickoff, March 18-19, 2004 5
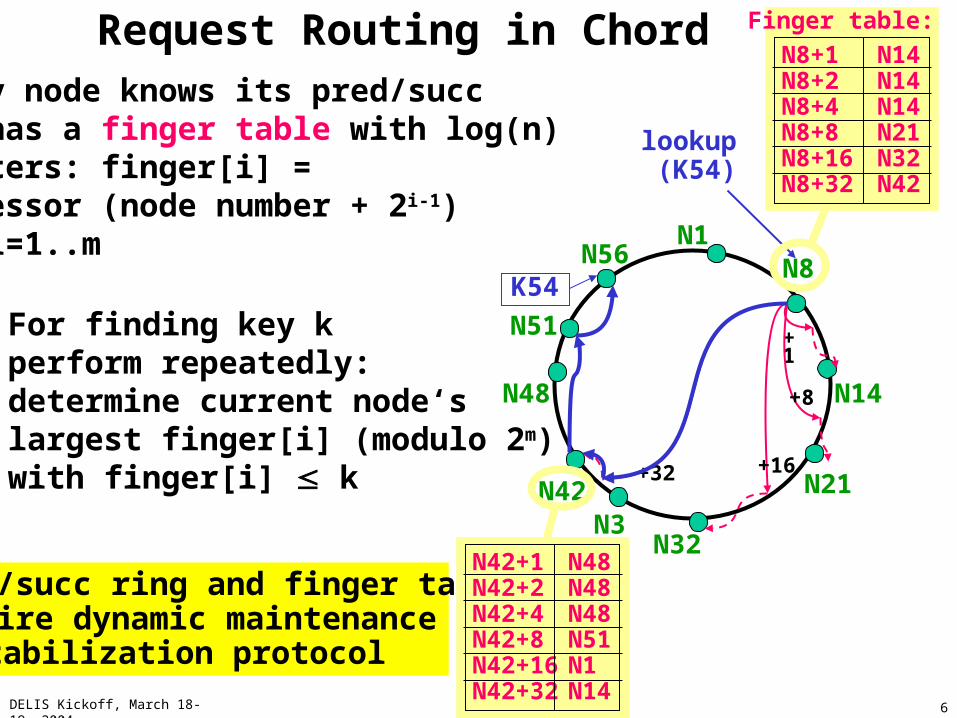
Structured P2P: Example Chord
Properties & claims:Unlimited scalability (> 106 nodes)O(log n) hops to target, O(log n) state per nodeSelf-stabilization (many failures, high dynamics)
Distributed Hash Table (DHT):map strings (file names, keywords) and numbers (IP addresses)onto very large „cyclic“ key space 0..2m-1, the so-called Chord Ring
Key k (e.g., hash(file name))is assigned to the node withkey n (e.g., hash(IP address))such that k n and there isno node n‘ with k n‘ and n‘<n
N1
N8
N14
N21
N32N38
N42
N48
N51
N56
K10
K24
K30K38
K54
DELIS Kickoff, March 18-19, 2004 6
Every node knows its pred/succ and has a finger table with log(n)pointers: finger[i] = successor (node number + 2i-1) for i=1..m
Request Routing in Chord
For finding key kperform repeatedly:determine current node‘slargest finger[i] (modulo 2m)with finger[i] k
pred/succ ring and finger tablesrequire dynamic maintenance stabilization protocol
N48
N1N8
N14
N21
N32N38
N42
N51
N56K54
lookup (K54)
+1
+8
+16+32
N42+1 N48N42+2 N48N42+4 N48N42+8 N51N42+16 N1N42+32 N14
N8+1 N14N8+2 N14N8+4 N14N8+8 N21N8+16 N32N8+32 N42
Finger table:
DELIS Kickoff, March 18-19, 2004 7
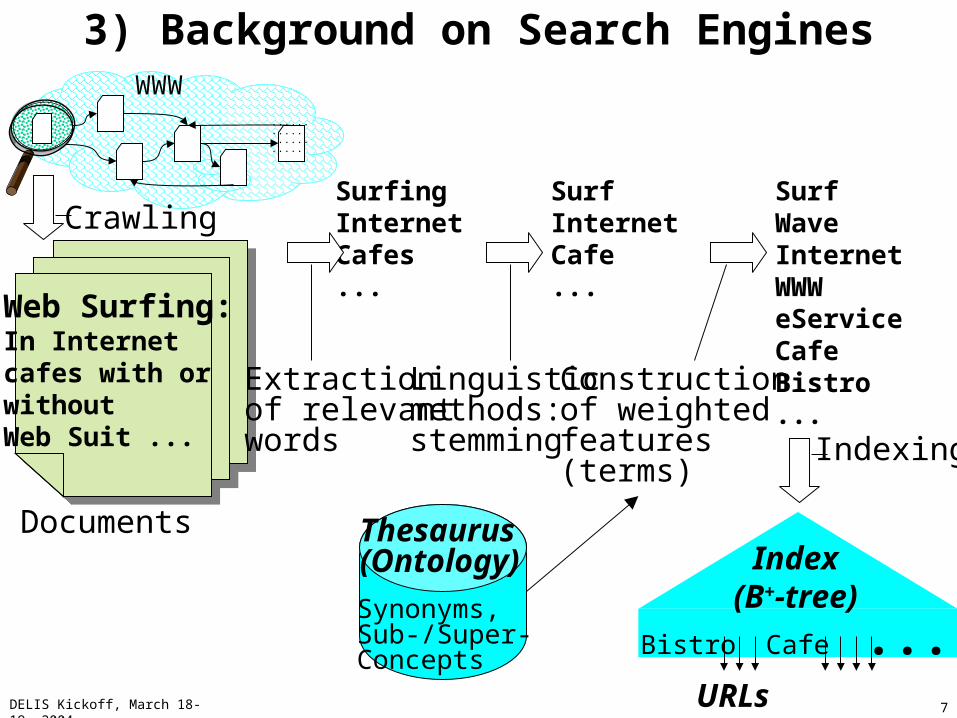
3) Background on Search Engines
Documents
Web Surfing:In Internet cafes with or withoutWeb Suit ...
SurfingInternetCafes...
Extractionof relevantwords
SurfInternetCafe...
Linguisticmethods:stemming
SurfWaveInternetWWWeServiceCafeBistro...
Constructionof weightedfeatures(terms)
Index(B+-tree)
Bistro Cafe ...URLs
Indexing
Thesaurus(Ontology)
Synonyms,Sub-/Super-Concepts
WWW......................
Crawling

DELIS Kickoff, March 18-19, 2004 8
Ranking bydescendingrelevance
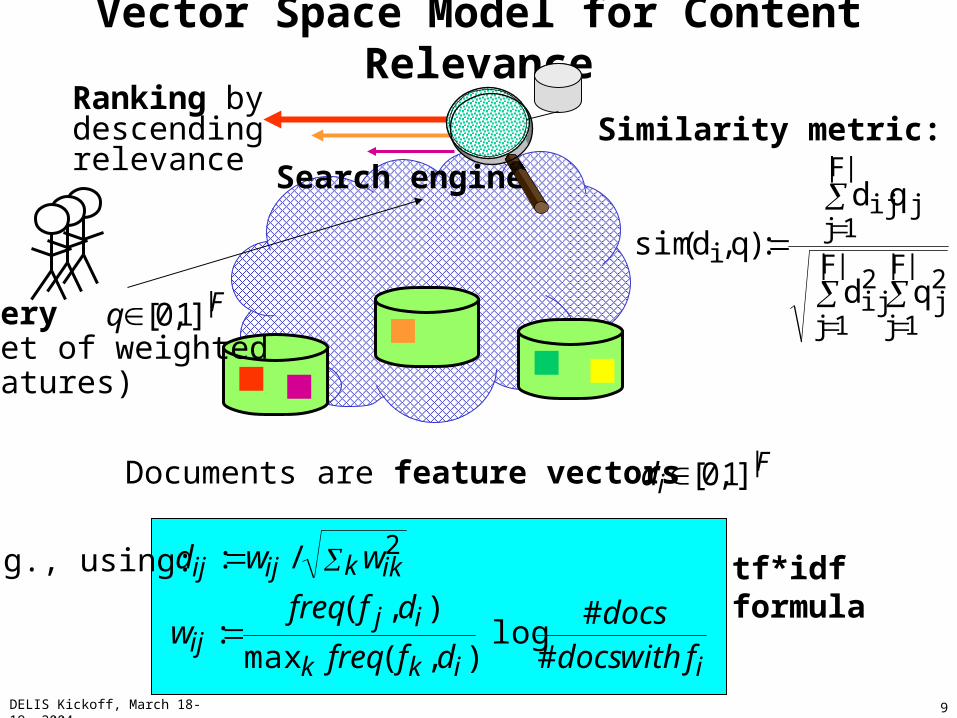
Vector Space Model for Content Relevance
Search engine
Query (set of weightedfeatures)
||]1,0[ Fid Documents are feature vectors
||]1,0[ Fq
|F|
1j
2j
|F|
1j
2ij
|F|
1jjij
i
qd
qd
:)q,d(sim
Similarity metric:
DELIS Kickoff, March 18-19, 2004 9
Vector Space Model for Content Relevance
Search engine
Query (Set of weightedfeatures)
||]1,0[ Fid Documents are feature vectors
||]1,0[ Fq
|F|
1j
2j
|F|
1j
2ij
|F|
1jjij
i
qd
qd
:)q,d(sim
Similarity metric:Ranking bydescendingrelevance
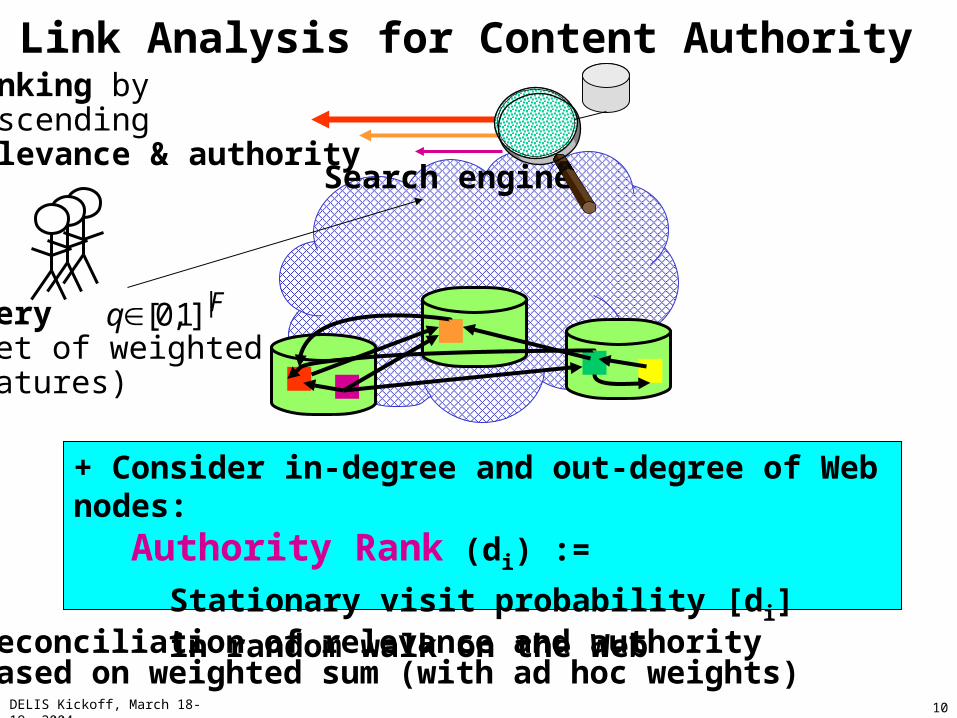
e.g., using: k ikijij wwd 2/:
iikk
ijij fwithdocs
docsdffreq
dffreqw
##
log),(max
),(:
tf*idfformula
DELIS Kickoff, March 18-19, 2004 10
Link Analysis for Content Authority
Search engine
Query (Set of weighted features)
||]1,0[ Fq
Ranking by descendingrelevance & authority
+ Consider in-degree and out-degree of Web nodes: Authority Rank (di) :=
Stationary visit probability [di]
in random walk on the WebReconciliation of relevance and authoritybased on weighted sum (with ad hoc weights)

DELIS Kickoff, March 18-19, 2004 11
... ...
...
PageRank Authority ComputationBasic model: random surfer follows outgoing links with uniform prob.and occasionally makes random jumps
( , )/ (1 ) / ( )j i
i j Gr n r out i
with 0 < 0.25
(1 ) 'r p A r
with A‘ij = 1/out(i) or 0 and pi = 1/n
is vector of stationary prob‘s for ergodic Markov chain
compute by power iteration for principal Eigenvector
?

DELIS Kickoff, March 18-19, 2004 12
PageRank Authority ComputationBasic model: random surfer follows outgoing links with uniform prob.and occasionally makes random jumps
Research issues:• improve efficiency (recent work at Stanford and INRIA)• biased random jumps for personalized or topic-sensitive PR• biased PR based on query logs & click streams• combine PR authority with TS-based freshness measures
( , )/ (1 ) / ( )j i
i j Gr n r out i
with 0 < 0.25
(1 ) 'r p A r
with A‘ij = 1/out(i) or 0 and pi = 1/n
is vector of stationary prob‘s for ergodic Markov chain
compute by power iteration for principal Eigenvector

DELIS Kickoff, March 18-19, 2004 13
LSI: Unsupervised Learning in IR
term i
doc j
...........................
......
.....A
mn
=
mrrr rn
latenttopic t
......
......
..
U
........... ..............................
1
r0
0
V T
......
...
doc j
latenttopic t
...........................
......
.....
mn
mkkk kn
......
......
..
Uk
........ ........................1
k00
k VkT
......
.
dUd Tk
'
qUq Tk
'
'( , ) '
Tjjsim d q d q
��������������
Research issues:• improve efficiency• understand LSI alternatives and tuning options• combine latent-space similarities with explicit ontology• combine multiple, distributed LSI spaces
Latent Semantic Indexing based on SVD
*
'TT
k kj
V q
' T Tk k kA U A V

DELIS Kickoff, March 18-19, 2004 14
Top-k Query Processing with Scoring
Naive QP algorithm: candidate-docs := ; for i=1 to z do { candidate-docs := candidate-docs index-lookup(ti) }; for each dj candidate-docs do {compute score(q,dj)}; sort candidate-docs by score(q,dj) descending;
algorithm
B+ tree on terms
17: 0.344: 0.4
...
performance... z-transform...
52: 0.153: 0.855: 0.6
12: 0.514: 0.4
...
28: 0.144: 0.251: 0.652: 0.3
17: 0.128: 0.7
...
17: 0.317: 0.144: 0.4
44: 0.2
11: 0.6index lists with(DocId, tf*idf)sorted by DocId
Given: query q = t1 t2 ... tz with z (conjunctive) keywords similarity scoring function score(q,d) for docs dD, e.g.: Find: top k results with regard to score(q,d)
Google:> 10 Mio. terms> 4 Bio. docs> 2 TB index
dq
real Web search engines: heuristic pruning for score(q,d) = auth(d) + csim(q,d) with various tricks

DELIS Kickoff, March 18-19, 2004 15
TA-Sorted (Fagin, Güntzer et al., ...)scan index lists in parallel: consider dj at position posi in Li; E(dj) := E(dj) {i}; highi := si(q,dj); bestscore(dj) := aggr{x1, ..., xm) with xi := si(q,dj) for iE(dj), highi for i E(dj); worstscore(dj) := aggr{x1, ..., xm) with xi := si(q,dj) for iE(dj), 0 for i E(dj); top-k := k docs with largest worstscore; if min worstscore among top-k bestscore{d | d not in top-k} then exit;
m=3aggr: sumk=2
a: 0.55b: 0.2f: 0.2g: 0.2c: 0.1
h: 0.35d: 0.35b: 0.2a: 0.1c: 0.05f: 0.05
top-k:
candidates:
f: 0.5b: 0.4c: 0.35a: 0.3h: 0.1d: 0.1
f: 0.7 + ? 0.7 + 0.1
a: 0.95
h: 0.35 + ? 0.35 + 0.5
b: 0.8
d: 0.35 + ? 0.35 + 0.5c: 0.35 + ? 0.35 + 0.3
g: 0.2 + ? 0.2 + 0.4
h: 0.45 + ? 0.45 + 0.2
d: 0.35 + ? 0.35 + 0.3

DELIS Kickoff, March 18-19, 2004 16
Top-k Queries with Probabilistic GuaranteesTA family of algorithms based on invariant (with sum as aggr)
( ) ( ) ( )( ) ( ) ( )i i i
i E d i E d i E ds d s d s d high
Relaxed into probabilistic invariant
( ) ( )( ) : [ ( ) ] [ ( ) ]k i i k
i E d i E dp d P s d worst P s d S worst
( ) ( ) ( )[ ( )] : [ ]i k i ii E d i E d i E d
P S worst s d P S
where RV Si has some (postulated and/or estimated) distribution in the interval (0,highi]
f: 0.5b: 0.4c: 0.35a: 0.3h: 0.1d: 0.1
a: 0.55b: 0.2f: 0.2g: 0.2c: 0.1
h: 0.35d: 0.35b: 0.2a: 0.1c: 0.05f: 0.05
S1S2 S3
speedup > 10 onTREC-12 .GOV benchmarkwith 80 percentprecision & recallof TA-sorted
DELIS Kickoff, March 18-19, 2004 17
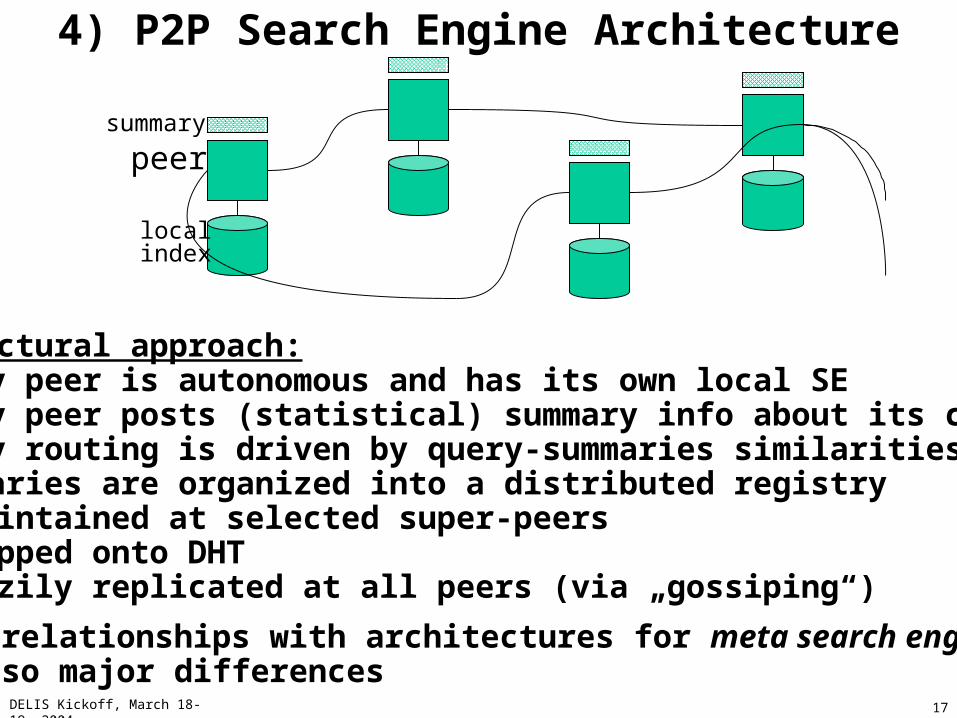
4) P2P Search Engine Architecture
Close relationships with architectures for meta search enginesbut also major differences
summary
peer
localindex
Architectural approach:• every peer is autonomous and has its own local SE• every peer posts (statistical) summary info about its contents• query routing is driven by query-summaries similarities• summaries are organized into a distributed registry
• maintained at selected super-peers• mapped onto DHT• lazily replicated at all peers (via „gossiping“)

DELIS Kickoff, March 18-19, 2004 18
P2P SE ModelData space: m terms T = {t1, ..., tm}, n docs D = {d1, ..., dn}
Peer space: p peers P = {1, ..., p}, each peer k has• index lists for terms Tk T (usually |Tk| << |T|),• bookmarks Bk D (|Bk| << |D|) or other profile info• cached docs Dk D • QoS parameters (e.g., index list lengths, score & authority distr.)
P2P system: each peer k globally posts subsets Tk‘ Tk, Bk‘ Bk, Dk‘ Dk, plus QoSinducing global mappings (directories):• systerms: T 2T with systerms(t) = {k P | t Tk‘}• sysbm: D 2T with sysbm(d) = {k P | d Bk‘}• syscd: D 2T with syscd(d) = {k P | d Dk‘}
systerms, sysbm, syscd could be organized as separate DHTs using hash1(t), hash2(d), hash3(d)

DELIS Kickoff, March 18-19, 2004 19
P2P Web Search
query: a b c
querying peer needs to1. determine interesting peers2. plan, run, monitor, and adapt distributed top-k algorithm3. reconcile results from different peers
objective: max. result quality
execution cost
a 95 19 14 22 73 44 ...c 88 17 44 11 ...
b 14 28 29 ...c 44 11 ...
a 73 11 27 14 ...b 92 13 11 14 ...
c 85 88 ...
DELIS Kickoff, March 18-19, 2004 20
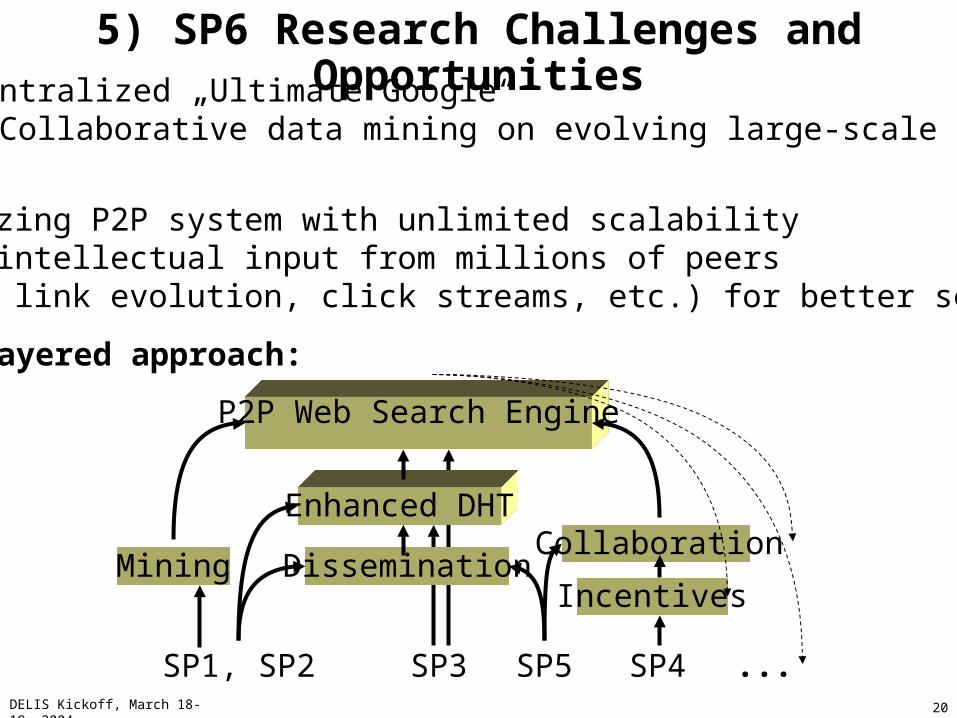
5) SP6 Research Challenges and OpportunitiesVision: Decentralized „Ultimate Google“ + Collaborative data mining on evolving large-scale data
Challenges:• Self-organizing P2P system with unlimited scalability• Leveraging intellectual input from millions of peers (bookmarks, link evolution, click streams, etc.) for better search quality
Layered approach:
P2P Web Search Engine
Enhanced DHT
DisseminationIncentives
MiningCollaboration
SP1, SP2 SP3 SP4SP5 ...

DELIS Kickoff, March 18-19, 2004 21
SP6 Work Packages and PartnersWP6.0: SP ManagementWP6.1: Collaborative Web Information SearchWP6.2: Enhanced Distributed Hash Tables for Keyword Search WP6.3: Self-Organizing Info. Dissemination & Load Sharing WP6.4: Mining Episodes and Data Streams WP6.5: Incentives for Collaborative Behaviour & Fairness Metrics WP6.6: P2P System Architecture & Testbed
UPBD
CTIGR
MPIID
UniBoI
UPCE
TU WPL
UniKaD
TelenorNO
UDRLSI
WP6.0 *WP6.1 + + *WP6.2 * + +WP6.3 * + + +WP6.4 + + + *WP6.5 * + +WP6.6 + *

DELIS Kickoff, March 18-19, 2004 22
Research Issues (1)
WP6.1: Collaborative Web Information Search• Exploit Large-scale collective intellectual input
(bookmarks, query logs, click streams, etc.)• Benefit/cost-aware query routing• Efficient distributed processing of
keyword-based top-k queries• Enhanced, distributed forms of LSI, PageRank, etc.
WP6.2: Enhanced Distributed Hash Tables for Keyword Search • DHT-style decentralized registry for
(variable-length) keyword queries• replication strategies and their properties• stability guarantees for DHTs

DELIS Kickoff, March 18-19, 2004 23
Research Issues (2)
WP6.3: Self-Organizing Info. Dissemination & Load Sharing•Dynamic, self-organizing load balancing•Replication strategies•Structured queries (e.g. range queries, string-attribute queries)•on decentralized directory (for metadata & QoS info)
WP6.4: Mining Episodes and Data Streams•Sampling on evolving Web data to learn “drifting concepts”•Temporally enabled authority analysis
WP6.5: Incentives for Collaborative Behaviour & Fairness Metrics •Statistical rewards and penalties for altruistic & egoistic peers•Incentives-enabled request/reply routing

DELIS Kickoff, March 18-19, 2004 24
SP6 Next Steps
Cross-SP Collaboration & Synergies
up for discussion !
to be discussed tomorrow

DELIS Kickoff, March 18-19, 2004 25
Some Backup Slides

DELIS Kickoff, March 18-19, 2004 26
Dimensions of a Large-Scale Search Engine
• > 4 Bio. (10**9) Web docs + 1 Bio. News docs > 10 Terabytes raw data• > 10 Mio. terms > 2 Terabytes index• > 150 Mio. queries per day < 1 sec. average response time• < 30 days index freshness > 1000 Web pages per second crawled
High-end server farm:> 10 000 Intel servers each with > 1 GB memory & 2 disks, with partitioned & mirrored data, distributed across all servers,plus load balancing of queries, remote administration, etc.

DELIS Kickoff, March 18-19, 2004 27
Differences between Meta and P2P Search Engines
Meta Search Engine P2P Search Engine
small # sites (e.g., digital libraries) huge # sites
rich statistics about site contents poor/limited/stale summaries
static federation of servers highly dynamic system
each query fully executed single query may need contentat each site from multiple peers
interconnection topology highly dependent on overlaylargely irrelevant network structure

DELIS Kickoff, March 18-19, 2004 28
Fagin’s TA (PODS 01, JCSS 03)
scan all lists Li (i=1..m) in parallel: consider dj at position posi in Li; highi := si(dj); if dj top-k then { look up s(dj) in all lists L with i; // random access compute s(dj) := aggr {s(dj) | =1..m}; if s(dj) > min score among top-k then add dj to top-k and remove min-score d from top-k; }; threshold := aggr {high | =1..m}; if min score among top-k threshold then exit;
m=3aggr: sumk=2
f: 0.5b: 0.4c: 0.35a: 0.3h: 0.1d: 0.1
a: 0.55b: 0.2f: 0.2g: 0.2c: 0.1
h: 0.35d: 0.35b: 0.2a: 0.1c: 0.05f: 0.05
f: 0.75
a: 0.95
top-k:
b: 0.8
but random accesses are expensive !

DELIS Kickoff, March 18-19, 2004 29
Prob-sorted Algorithm (Conservative Variant)
Prob-sorted (RebuildPeriod r, QueueBound b):...scan all lists Li (i=1..m) in parallel: …same code as TA-sorted…
// queue management for all priority queues q for which d is relevant do insert d into q with priority bestscore(d); // periodic clean-up if step-number mod r = 0 then // dropping of queues; multiple unbounded queues if strategy = Conservative then for all priority queues q do if prob[top(q) can qualify for top-k] < then drop all elements of q; if all queues are empty then exit;

DELIS Kickoff, March 18-19, 2004 30
Prob-sorted Algorithm (Smart Variant)Prob-sorted (RebuildPeriod r, QueueBound b):...scan all lists Li (i=1..m) in parallel: …same code as TA-sorted…
// queue management for all priority queues q for which d is relevant do insert d into q with priority bestscore(d); // periodic clean-up if step-number mod r = 0 then // rebuild; single bounded queue if strategy = Smart then for all queue elements e in q do update bestscore(e) with current highi values; rebuild bounded queue with best b elements; if prob[top(q) can qualify for top-k] < then exit; if all queues are empty then exit;

DELIS Kickoff, March 18-19, 2004 31
Performance Results for .Gov Queries #
sor
ted
acc
esse
s
elap
sed
tim
e [s
] m
ax
queu
e
size
pr
ecis
ion
rank
di
stan
ce
scor
e er
ror
TA-sorted 2263652 148.7 10849 1 0 0 Prob-con 993414 25.6 29207 0.87 16.9 0.007 Prob-agg 20435 0.6 0 0.42 75.1 0.089 Prob-pro 1659706 44.2 6551 0.87 16.8 0.006 Prob-smart 527980 15.9 400 0.69 39.5 0.031
on .GOV corpus from TREC-12 Web track:1.25 Mio. docs (html, pdf, etc.) 50 keyword queries, e.g.: „Lewis Clark expedition“, „juvenile delinquency“, „legalization Marihuana“, „air bag safety reducing injuries death facts“

DELIS Kickoff, March 18-19, 2004 32
Performance Results for IMDB Queries
# so
rted
a
cces
ses
elap
sed
tim
e [s
]
max
qu
eue
si
ze
prec
isio
n
rank
di
stan
ce
scor
e er
ror
TA-sorted 1003650 201.9 12628 1 0 0 Prob-con 463562 17.8 14990 0.71 119.9 0.18 Prob-agg 41821 0.7 0 0.18 171.5 0.39 Prob-pro 490041 69.0 9173 0.75 122.5 0.14 Prob-smart 403981 12.7 400 0.54 126.7 0.25
on IMDB corpus (Web site: Internet Movie Database):375 000 movies, 1.2 Mio. persons (html/xml) 20 structured/text queries with Dice-coefficient-based similaritiesof categorical attributes Genre and Actor, e.g.: Genre {Western} Actor {John Wayne, Katherine Hepburn} Description {sheriff, marshall}, Genre {Thriller} Actor {Arnold Schwarzenegger} Description {robot}
DELIS Kickoff, March 18-19, 2004 33
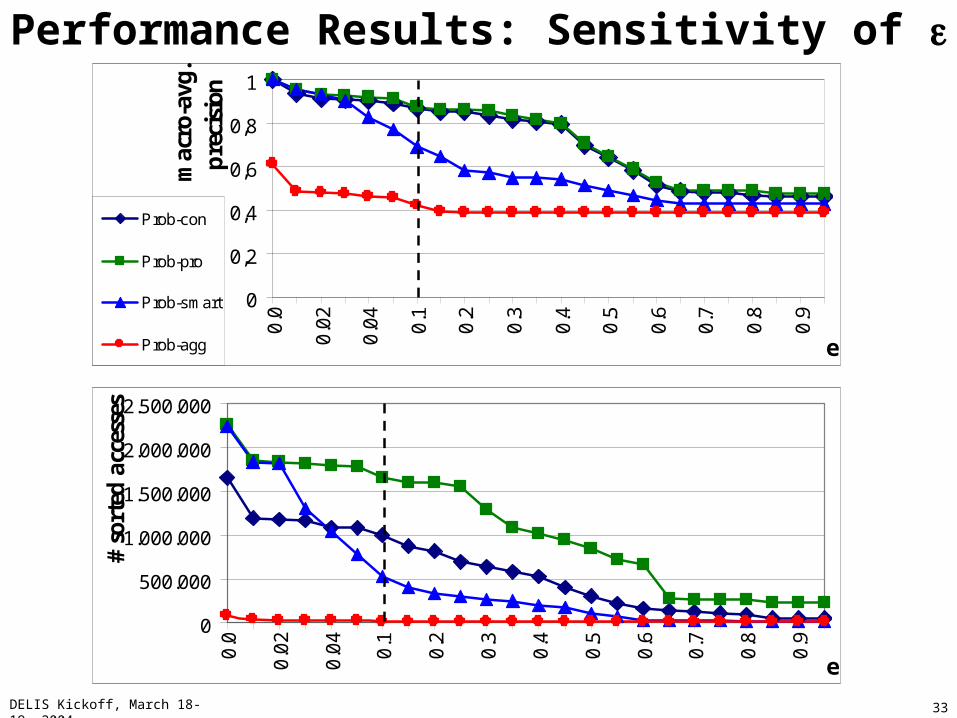
Performance Results: Sensitivity of
0
0,2
0,4
0,6
0,8
1
0.0
0.02
0.04
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
e
mac
ro-a
vg.
pre
cisi
onProb-con
Prob-pro
Prob-smart
Prob-agg
0
500.000
1.000.000
1.500.000
2.000.000
2.500.000
0.0
0.02
0.04
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
e
# so
rted
acc
esse
s

DELIS Kickoff, March 18-19, 2004 34
Exploiting Collective Human Input for Collaborative Web Search
- Beyond Relevance Feedback and Beyond Google -
• href links are human endorsements PageRank, etc.• Opportunity: online analysis of human input & behavior may compensate deficiencies of search engine
Typical scenario for 3-keyword user query: a & b & c top 10 results: user clicks on ranks 2, 5, 7
Challenge: How can we use knowledge about the collective input of all users in a large community?
top 10 results: user modifies query into a & b & c & d user modifies query into a & b & e user modifies query into a & b & NOT c top 10 results: user selects URL from bookmarks user jumps to portal user asks friend for tips
query logs, bookmarks, etc. provide• human assessments & endorsements • correlations among words & concepts and among documents




























![[XLS]Delis99 - CERNlehrausi.home.cern.ch/lehrausi/zakazky/delis/2010/DELIS... · Web viewCompute nodes for the ALICE HLT Servery pro experiment ALICE IT-3987/HR DO-28713/GS/SIS Supply](https://img.dokumen.tips/doc/110x75/5af81b2d7f8b9aac248cac76/xlsdelis99-viewcompute-nodes-for-the-alice-hlt-servery-pro-experiment-alice.jpg)