Embed Size (px)
Citation preview

T-110.5121 Mobile Cloud Computing
Datacenter hardware and networking
by Andrey Lukyanenko
Aalto University, Finland
10.10.2014

Outline
1. Architecture
2. Network
3. Resources
4. Conclusion

Architecture

Datacenter planSureTech datacenter as an example

Datacenter planServer rooms –production area
Rack

Datacenter planNetwork operation center (NOC)
24x7x365

Datacenter planCore networks room

Datacenter planElectrical switchgear and power distribution

Datacenter planDatacenter UPS system
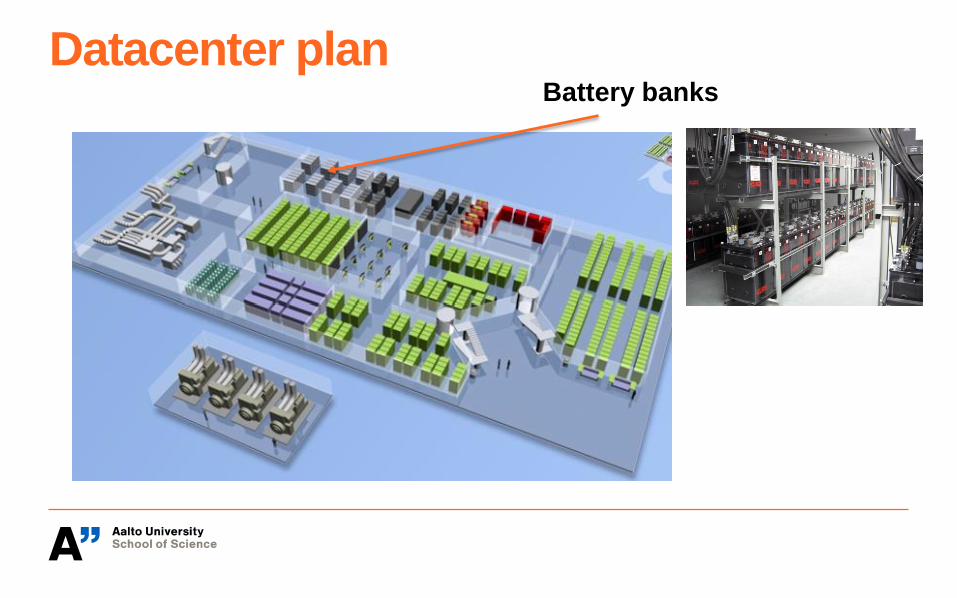
Datacenter planBattery banks

Datacenter planDiesel generators

Datacenter planFire suppression

Datacenter planRedundant HVAC cooling system

Datacenter plan
10.10.2014
14
Another example (pretty much the same)

Rack
10.10.2014
15

Wires
10.10.2014
16

Electricity in datacenter
10.10.2014
17
Reduction of energy wastes on cooling, by constructing
datacenters in frigid climate:
• Facebook at Lulea, Sweden;
• Google at Hamina, Finland.
http://blog.opower.com/tag/data-centers/

Cooling in Datacenter
10.10.2014
18

Cooling in Datacenter
10.10.2014
19
Legend:
75F = 24C,
70F = 21C,
65F = 18C

Cooling in datacenter
10.10.2014
20

Costs in datacenter (another source)
10.10.2014
21
“Assuming a PUE of 1.7, a reasonable utility
price of $.07 per KWH, 50,000 servers with
each drawing on average 180W (servers
draw as much as 65% of peak when idle),
the total cost comes to 50,000*180/1000*
1.7*$0.07*24*365 = $9.3 million a year. Out
of each watt delivered, about 59% goes to
the IT equipment, 8% goes to power
distribution loss, and 33% goes to cooling.”
Greenberg, Albert, et al. "The cost of a cloud: research problems in data center networks." ACM SIGCOMM computer communication review 39.1 (2008): 68-73.
Power Usage Efficiency (PUE) as PUE =
(Total Facility Power)/(IT Equipment Power).
A state of the art facility will typically attain a
PUE of ∼1.7, which is far below the average
of the world’s facilities but more than the
best. Inefficient enterprise facilities will have
a PUE of 2.0 to 3.0
For example, assuming 50,000 servers, a relatively aggressive price
of $3000 per server, a 5% cost of money, and a 3 year amortization,
the amortized cost of servers comes to $52.5 million dollars
per year.

Modular datacenter
10.10.2014
22

Network & beyond

Topology: hierarchy vs fat-tree (clos)
10.10.2014
24
Al-Fares, Mohammad, Alexander Loukissas, and Amin Vahdat. "A scalable, commodity data center network architecture." ACM SIGCOMM Computer Communication Review. Vol. 38. No. 4. ACM, 2008.
Oversubscription!!!

Datacenter network
10.10.2014
25
Greenberg, Albert, et al. "VL2: a scalable and flexible data center network.“ ACM SIGCOMM Computer Communication Review. Vol. 39. No. 4. ACM, 2009.
Niranjan Mysore, Radhika, et al. "Portland: a scalable fault-tolerant layer 2 data center network fabric." ACM SIGCOMM Computer Communication Review. Vol. 39. No. 4. ACM, 2009.
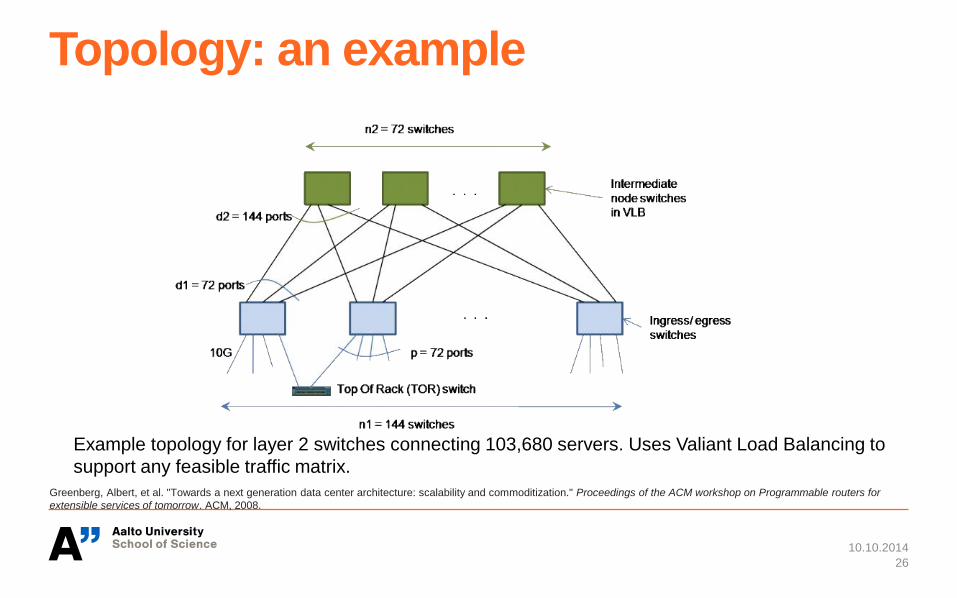
Topology: an example
10.10.2014
26
Example topology for layer 2 switches connecting 103,680 servers. Uses Valiant Load Balancing to
support any feasible traffic matrix.
Greenberg, Albert, et al. "Towards a next generation data center architecture: scalability and commoditization." Proceedings of the ACM workshop on Programmable routers for
extensible services of tomorrow. ACM, 2008.

Top of rack vs end of row
10.10.2014
27
http://www.excitingip.com/2802/data-center-network-top-of-rack-tor-vs-end-of-row-eor-design/

Layers of connectivity & clusters
10.10.2014
28
http://bradhedlund.com/2011/04/21/data-center-scale-openflow-sdn/

Network related problems of datacenter
• T-110.5111 Computer Networks II - Advanced Features P (5 cr)
Just quick recap:
• RTT is in sub millisecond level (<1ms)
• Network changes too fast; hard to control externally
• TCP is not working well, many suggestions to remove long
flows (DCTCP, D2TCP, Better never than late, etc).
New problems:
• Incast – many flows to one node, overwhelm
• ARP flooding – “which MAC has a host with IP=x.x.x.x”
10.10.2014
29

Software-defined network (SDN)
10.10.2014
30

Benefits of SDNs
10.10.2014
31
Bandwidth on demand
https://www.opennetworking.org/solution-brief-operator-network-monetization-through-openflow-enabled-sdn

Benefits of SDNs
10.10.2014
32
Bandwidth exchange
https://www.opennetworking.org/solution-brief-operator-network-monetization-through-openflow-enabled-sdn

Benefits of SDNs
10.10.2014
33
Pay for quality of service
https://www.opennetworking.org/solution-brief-operator-network-monetization-through-openflow-enabled-sdn

Benefits of SDNs
10.10.2014
34
Troubleshooting with SDN
http://www.bigswitch.com/solutions/data-center-troubleshooting-and-the-1ge-to-10ge-transition

Resources

Virtual machines and virtualization
• Each PC in datacenter is a physical machine.
• Machines can be virtualized to adjust resources.
• Virtualization is done using hypervisor – micro OS controlling virtual
machines (VMs).
• Type 1 hypervisor runs on top of hardware (Xen, ESXI), Type 2
hypervisor runs on top of host OS (VirtualBox)
• VMs inherit the physical machine communication capabilities but can
be limited in access rights, flow rate limiters, not only CPU/memory
limitations.
10.10.2014
36

Cloud vs Datacenter
10.10.2014
37

Cloud vs Datacenter vs Cluster
• Datacenter is a physical infrastructure described above.
• Computation cluster – is a group of interconnected machines viewed as
a single unity, resources are centrally controlled.
• Nowadays cluster is a set of VMs that have certain resources and can
perform concrete tasks.
• Controller create, migrate and initialize VMs in cluster.
• Cloud – is a virtual infrastructure that can perform computational tasks
(provide services).
10.10.2014
38

Cluster (datacenter) sharing
• Users in a datacenter/cluster called – tenant.
• A datacenter (cluster) that are utilized by multiple tenants called – multi-tenant
datacenter.
• Each tenant coming to the cluster receives own set of resources – virtual machines
(VMs) with specific CPU/Memory requirements.
• Also each tenant has own bandwidth allocations with own network topology and
traffic patterns constrains.
• Central controller needs to make decision about VM placement (there are slots,
where each VM can be run) and more.
10.10.2014
39

Resource sharing and scheduling
The core element is the sharing principle (and scheduling)
Historically, there are (fair) sharing:
1. Give 1/n to each … what if it is not needed?
2. Max-min fairness … how to utilize in multi-resource cluster?
3. Weighted max-min … how to define weights?
Properties:
1. Each get at least 1/n of resources, and less if all not needed
2. Users have no reason to lie about demands
10.10.2014
40

Multiple resources (independent)
Desirable properties:
1. Sharing incentive
2. Strategy-proofness
3. Envy-freeness
4. Pareto-efficiency
10.10.2014
41
Ghodsi, Ali, et al. "Dominant Resource Fairness: Fair Allocation of Multiple Resource Types." NSDI. Vol. 11. 2011.

Dominant resource fairness
Example:
Two users, for each task:
• User A needs <1CPU, 4GB>
• User B needs <3CPU, 1GB>
We have resources with 9 CPU and 18
GB memory.
How to organize?
10.10.2014
42

DRF algorithm
10.10.2014
43

Alternative approaches
10.10.2014
44

DRF as result
• DRF already implemented at Hadoop v2 YARN
• Many other places with multi-resource sharing benefit from DRF
• It is generalization of max-min fairness
10.10.2014
45

Network as a resource
• Unpredictable behavior
• Many applications (MapReduce) depends on slowest flow.
• Tenants organize Virtual Data Center (VDC)
10.10.2014
46
Bari, Md Faizul, et al. "Data center network virtualization: A survey. "Communications Surveys & Tutorials, IEEE 15.2 (2013): 909-928.
Ballani, Hitesh, et al. "Towards predictable datacenter networks." ACM SIGCOMM Computer Communication Review. Vol. 41. No. 4. ACM, 2011.
Li, Ang, et al. "CloudCmp: comparing public cloud providers." Proceedings of the 10th ACM SIGCOMM conference on Internet measurement. ACM, 2010.

Tenant perspective vs physical reality
10.10.2014
47

Oktopus
10.10.2014
48
Ballani, Hitesh, et al. "Towards predictable datacenter networks." ACM SIGCOMM Computer Communication Review. Vol. 41. No. 4. ACM, 2011.
Virtual cluster
Virtual oversubscribe cluster

Oktopus algorithm
10.10.2014
49

FairCloud
Requirements:
• Min-guarantee
• High-utilization
• Proportionality
10.10.2014
50
Popa, Lucian, et al. "FairCloud: sharing the network in cloud computing."Proceedings of the ACM SIGCOMM 2012 conference on Applications, technologies, architectures, and
protocols for computer communication. ACM, 2012.

FairCloud: Fundamental trade-offs
10.10.2014
51

FairCloud: Results
10.10.2014
52

ElasticSwitch
FairCloud does not provide bandwidth guarnatees
Oktopus does not provide work-conservation
ElasticSwitch tries to provide both
10.10.2014
53
Popa, Lucian, et al. "ElasticSwitch: practical work-conserving bandwidth guarantees for cloud computing." Proceedings of the ACM SIGCOMM 2013 conference on SIGCOMM.
ACM, 2013.

CoFlow: Study of applications
10.10.2014
54
Chowdhury, Mosharaf, and Ion Stoica. "Coflow: An application layer abstraction for cluster networking." ACM Hotnets. 2012.

CoFlow: New API
10.10.2014
55

Conclusions
10.10.2014
56





























