Embed Size (px)
Citation preview

Data Warehousing and Data MiningData Warehousing and Data Mining
Winter Semester 2009/10Free University of Bozen, Bolzano
DW Lecturer: DM Lecturer:
Johann [email protected]
Mouna [email protected]
http://www.inf.unibz.it/dis/teaching/DWDM/index.html

OrganizationL tLecturesTuesday & Thursday From 10:30 To 12:30. Rooms are dynamicOffice hours Dr. Kacimi: Thursday From 14:00 to 17:00
(appointment by email) (appointment by email) ProjectsLab hours Tuesday From 14:00 to 16:00. Room is dynamicRequirements: obtain at least 18 points in each of the followingRequirements: obtain at least 18 points in each of the followingProject: - use & implement algorithms
- write a project report- present the project present the project
Exam: - have knowledge about the course- be able to present it
TextbooksTextbooks• Jiawei Han and Micheline Kamber, “Data Mining: Concepts and
Techniques”, Second Edition, 2006• Pang-Ning Tan, Michael Steinbach, and Vipin Kumar, "Introduction to
Data Mining" Pearson Addison Wesley 2008 ISBN: 0-32-134136-7Data Mining , Pearson Addison Wesley, 2008, ISBN: 0 32 134136 7• Margaret H. Dunham, “Data Mining: Introductory and Advanced
Topics”, Prentice Hall, 2003

D t Mi iData Mining

Outline
Introduction to Data Mining Part I: Introduction
Data Analysis and Uncertainty
Part I: Introduction & Foundations
Classification & Prediction
Cluster Analysis
Part II: Supervised Learning
Part III: Unsupervised Cluster Analysis
Applications
Part III: Unsupervised Learning
Part IV: Summary & Open problems& Open problems

Chapter I: Introduction & Foundations
1.1 Introduction 1.1.1 Definitions & Motivations 1.1.2 Data to be Mined1.1.3 Knowledge to be discovered 1.1.4 Techniques Utilized 1 1 5 Applications Adapted1.1.5 Applications Adapted1.1.6 Major Issues in Data Mining
1.2 Getting to Know Your Dataj i1.2.1 Data Objects and Attribute Types
1.2.2 Descriptive Data Summarization1.2.3 Measuring Data Similarity and Dissimilarity
1.3 Basics from Probability Theory and Statistics 1.3.1 Probability Theory1 3 2 Statistical Inference: Sampling and Estimation 1.3.2 Statistical Inference: Sampling and Estimation 1.3.3 Statistical Inference: Hypothesis Testing and Regression

1.1 Definitions & MotivationsWh D t Mi i ?
Explosive Growth of Data: from terabytes to petabytesData Collections and Data Availability
Why Data Mining?
Data Collections and Data Availability Crawlers, database systems, Web, etc.
Sources
Business: Web, e-commerce, transactions, etc.
Science: Remote sensing, bioinformatics, etc.
S i t d Y T b t Society and everyone: news, YouTube, etc.
Problem: We are drowning in data, but starving for knowledge!
Solution: Use Data Mining tools for Automated Analysis of Solution: Use Data Mining tools for Automated Analysis of massive data sets

What is Data Mining?
Data mining (knowledge discovery from data) Extraction of interesting (non-trivial, implicit, previously unknownand potentially useful) patterns or knowledge from huge amount p y ) p g gof dataData mining: a misnomer?
Gold Mining Not Stone MiningStone
Alternative names
Knowledge Knowledge Mining?Data
Alternative namesKnowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging information harvesting business intelligence etcdredging, information harvesting, business intelligence, etc.

Knowledge Discovery (KDD) ProcessK l dView from typical database
systems and data warehousing communities
Evaluation & Presentation
Knowledge
Data MiningPatterns
Task-relevantData
Selection& transformation
Data Warehouse
& transformation
Data Cleaning
& Integration
Data Warehouse
Data mining plays an essential role in the knowledge di
Databases
discovery process

Knowledge Discovery (KDD) ProcessData Cleaning Data Cleaning
Remove noise and inconsistent dataData Integration
Combine multiple data sources Combine multiple data sources Data Selection
Data relevant to analysis tasks are retrieved form the data
Data transformationTransform data into appropriate form for mining (summary, aggregation, etc.)
Data mining Extract data patterns
Pattern EvaluationIdentify truly interesting patterns
Knowledge representation Use visualization and knowledge Use sua a o a d o edge representation tools to present the mined data to the user

Typical Architecture of a Data Mining System
Knowledge BaseGuide the searchEvaluate
Pattern Evaluation
User Interface
Knowledge
interestingness of the results
Include
Data Mining Engine
gBaseConcept
hierarchies User believes
Database or Data Warehouse Server
Constraints, thresholds, metadata, etc.
Data cleaning, Integration and selection
DatabaseData
WarehouseWorld Wide
WebOther InfoRepositories

Confluence of Multiple Disciplines
Database Technology StatisticsTechnology
Data MiningMachineLearning
Visualization
Patterni i OtherRecognition
AlgorithmOther
Disciplines

Why Confluence of Multiple Disciplines?
Tremendous amount of dataScalable algorithms to handle terabytes of data (e.g., Flickr had 3.6 billion images in June, 2009)
High dimensionality of dataData can have tens of thousands of features (e,g., DNA microarray)
High complexity of dataData can be highly complex, can be of different types, and can include different descriptors p
Images can be described using text and visual features such as color, texture, contours, etc. Videos can be described using text, images and their descriptors, g g paudio phonemes, etc.Social networks can have a complex structure...
New and sophisticated applicationsApplications can be difficult (e.g., medical applications).

Different Views of Data Mining
Data View
Kinds of data to be mined
Knowledge view
Kinds of knowledge to be discovered
Method view
Kinds of techniques utilized q
Application view
Kinds of applications

1.1.2 Data to be Mined
In principle, data mining should be applicable to any data repository
This lecture includes examples about:
Relational databasesRelational databasesData warehousesTransactional databasesAd d d t b tAdvanced database systems

Relational Databases
Database System Collection of interrelated data, known as databaseA set of software programs that manage and access the datap g g
Relational Databases (RD)A collection of tables. Each one has a unique nameA table contains a set of attributes (columns) & tuples (rows) A table contains a set of attributes (columns) & tuples (rows). Each object in a relational table has a unique key and is described by a set of attribute values. Data are accessed using database cust Id Name age income
Costumers
Data are accessed using databasequeries (SQL): projection, join, etc.Data Mining applied to RD
cust_Id Name age income152...
Anna...
27...
24000 €...
trans Id cust Id method AmountPurchases
Search for trends or data patternsExample:
predict the credit risk of costumers based on their income, age and
trans_Id cust_Id method AmountT156...
152...
Visa...
1357 €...
expenses.
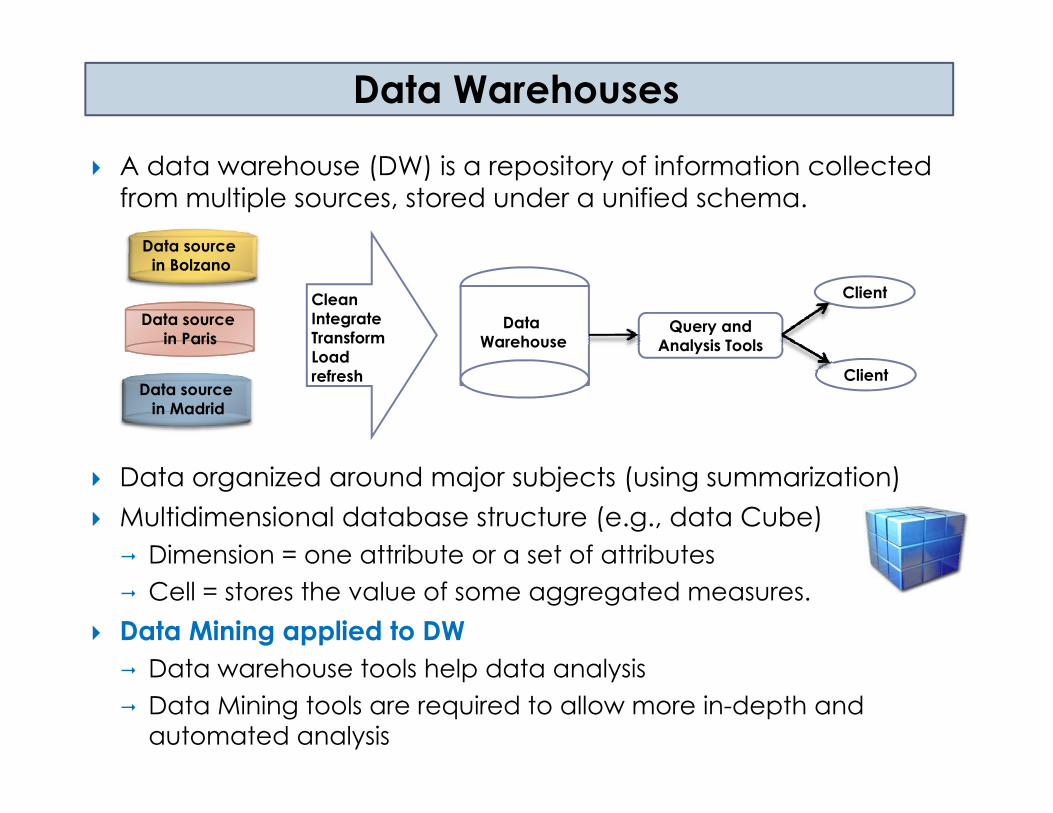
Data Warehouses
A data warehouse (DW) is a repository of information collected from multiple sources, stored under a unified schema.
Data sourcein Bolzano
Data sourcein Paris
Data Warehouse
CleanIntegrateTransformLoad
Query and Analysis Tools
Client
Data sourcein Madrid
Loadrefresh Client
Data organized around major subjects (using summarization)Multidimensional database structure (e.g., data Cube)
Dimension = one attribute or a set of attributesDimension one attribute or a set of attributesCell = stores the value of some aggregated measures.
Data Mining applied to DWD t h t l h l d t l iData warehouse tools help data analysisData Mining tools are required to allow more in-depth and automated analysis

Transactional Databases
A transactional database (TD) consists of a file where each record represents a transaction. A transaction includes a unique transaction identifier (trans_id) and a list of the items making the transaction. A transaction database may include other tables containing other information regarding the sale trans_Id List of items_IDsg g(customer_Id, location, etc.)Basic analysis (examples)
Show me all the items purchased by David Smith?
T100 I1,I3,I8,I16
T200 I2,I8
... ...
Show me all the items purchased by David Smith?How many transactions include item number 5?
Data Mining on TDPerform a deeper analysisExample: Which items sold well together?Basically, data mining systems can identify frequent sets in transactional databases and perform market basket data analysis.

Advanced Database Systems(1)
Advanced database systems provide tools for handling complex data
Spatial data (e.g., maps)Engineering design data (e.g., buildings, system components)Hypertext and multimedia data (text, image, audio, and video)Time-related data (e.g., historical records)e e a ed da a (e.g., s o ca eco ds)Stream data (e.g., video surveillance and sensor data)World Wide Web, a huge, widely distributed information repository made available by Internetmade available by Internet
Require efficient data structures and scalable methods to handleComplex object structures and variable length recordsSemi structured or unstructured dataSemi structured or unstructured dataMultimedia and spatiotemporal data Database schema with complex and dynamic structures

Advanced Database Systems(2) Example: World Wide Web
Provide rich, worldwide, online and distributed information services.Data objects are linked togetherU t f bj t i li k t thUsers traverse from one object via links to anotherProblems
Data can be highly unstructuredDifficult to understand the semantic of web Difficult to understand the semantic of web pages and their context.
Data Mining on WWWWeb usage Mining (user access pattern) Web usage Mining (user access pattern)
Improve system design (efficiency)Better marketing decisions (adverts, user profile)
Authoritative Web page Analysis p g yRanking web pages based on their importance
Automated Web page clustering and classificationGroup and arrange web pages based on their content
Web community analysisIdentify hidden web social networks and observe their evolution

1.1.3 Knowledge to be Discovered
Data mining functionalities are used to specify the kind of patterns to be found in data mining tasksData mining tasks can be classified into two categories
Descriptive : Characterize the general properties of the dataPredictive : Perform inference on the current data to make
predictions pWhat to extract?
Users may not have an idea about what kinds of patterns in their data can be interestingdata can be interesting
What to do?Have a data mining system that can mine multiple types of patterns to handle different user and applications needs patterns to handle different user and applications needs. Discover patterns at various granularities (levels of abstraction)
CountryCityStreet Example of differentgranularities
(levels of abstraction)Allow users to guide the search for interesting patterns

Characterization and Discrimination (1)
Data can be associated with classes or conceptsExample of data from a store
Classes ConceptsClasses Concepts
printers computers Big Spenders Budget Spenders
Class/Concept descriptions: describe individual classes and concepts in summarized, concise, and precise way.
printers computers Big-Spenders Budget-Spenders
Data characterizationSummarize the data of the class under study (target class)
Data Discrimination Compare the target class with a set of comparative classes (contrasting classes)
Data characterization & Discrimination Perform both analysis

Characterization and Discrimination (2)
Data CharacterizationSummarize the general features of a target class of dataTools: statistical measures, data cube-based OLAP roll-up, etc.pOutput: charts, curves, multidimensional data cubes, etc. ExampleSummarize the characteristics • 40 50 years old
Costumers profile
Data Discrimination
Summarize the characteristics of costumers who spend more than 1000€
• 40-50 years old• Employed• excellent credit ratings
Comparison of the general features of a target class with the general features of contrasting classesOutput: similar to characterization + comparative measuresExample
Compare customers who shop for computer products regularly( more than 2 times a
Comparative profileFrequent costumers
Rare costumers
80% 60%regularly( more than 2 times a month) with those who rarely shop for such products(less then three times a year)
80% •Are between 20 and 40•Have university education
60%•Are senior or youths•Have no university degree

Frequent Patterns, Associations, Correlations
Frequent patterns are patterns occurring frequently in the data (e.g., item-sets, sub-sequences, and substructures)
Frequent item-sets: items that frequently appear together Example in a transactional data set: bred and milk
Frequent Sequential pattern: a frequently occurring subsequenceExample in a transactional data set: buy first PC, second digital p y gcamera, third memory card
Association AnalysisDerive some association rules
buys(X, “computer”) ⇒ buys (X, “software”) [support =1%, confidence=50%]age(X, “20...29” ) ∧ income(X, “20K...29K”) ⇒ buys (X, “CD player”)[support =2%, confidence=60%]
Correlation Analysis Uncover interesting statistical correlations between associated attribute-value pairsp

Classification and Prediction
Construct models (functions) based on some training examplesDescribe and distinguish classes or concepts for future predictionPredict some unknown class labelsPredict some unknown class labels
Age Income Class label
27 28K Budget-Spenders
35 36K Big-SpendersSupervised Learning
Classificationmodel (function)
Trainingexamples
65 45K Budget-Spenders examples
Class labelAge Income
[Budget Spender]
Typical methodsDecision trees naive Bayesian classification logistic regression
ClassifierNumeric value
Unlabeled datag
29 25K[Budget Spender (0.8)]
Decision trees, naive Bayesian classification, logistic regression, support vector machine, neural networks, etc.
Typical ApplicationsC dit d f d d t ti l if i b t Credit card fraud detection, classifying web pages, stars, diseases, etc.

Cluster Analysis
Unsupervised learning (i.e., Class label is unknown)Group data to form new categories (i.e., clusters), e.g., cluster houses to find distribution patternshouses to find distribution patternsPrinciple: Maximizing intra-class similarity & minimizing interclass similarity
Typical methodsHierarchical methods density based methods Grid based Hierarchical methods, density-based methods, Grid-based methods, Model-Based methods, constraint-based methods, etc.
Typical ApplicationsWWW i l t k M k ti Bi l Lib tWWW, social networks, Marketing, Biology, Library, etc.

Outlier Analysis
Outlier: A data object that does not comply with the general behavior of the data learning (i.e., Class label is unknown)Noise or exception? ― One person’s garbage could be another Noise or exception? One person s garbage could be another person’s treasure
Typical methodsOr ?
Typical methodsProduct of clustering or regression analysis, etc.
Typical ApplicationsUseful in fraud detectionExample
How to Uncover fraudulent usage of credit card?Detect purchases of extremely large amounts for a given account number in comparison to regular charges incurred by the same accountOutliers may also be detected with respect to the location and type of purchase, or the frequency.
Evolution Analysis
Evolution Analysis describes trends of data objects whose behavior changes over timeIt includesIt includes
Characterization and discrimination analysisAssociation and correlation analysisCl ifi ti d di tiClassification and predictionClustering of time–related data
Distinct features for such analysisTime-series data analysisSequence or periodicity pattern matching
e.g., first buy digital camera, then buy large SD memory cardse.g., s buy d g a ca e a, e buy a ge S e o y ca dsSimilarity-based analysis

1.1.4 Techniques Utilized
Data-intensiveData warehouse (OLAP)Machine learningMachine learningStatistics Pattern recognitionVisualizationHigh-performance...

1.1.5 Applications Adapted
Web page analysis: from web page classification, clustering to PageRank & HITS algorithms
Collaborative analysis & recommender systemsCollaborative analysis & recommender systems
Basket data analysis to targeted marketing
Biological and medical data analysis: classification, cluster Biological and medical data analysis: classification, cluster analysis (microarray data analysis), biological sequence analysis, biological network analysis
From major dedicated data mining systems/tools (e.g., SAS, MS SQL-Server Analysis Manager, Oracle Data Mining Tools) to invisible data miningg

1.1.6 Major Challenges in Data Mining
Efficiency and scalability of data mining algorithms
Parallel, distributed, stream, and incremental mining methods
H dli hi h di i litHandling high-dimensionality
Handling noise, uncertainty, and incompleteness of data
Incorporation of constraints expert knowledge and Incorporation of constraints, expert knowledge, and background knowledge in data mining
Pattern evaluation and knowledge integration
Mining diverse and heterogeneous kinds of data: e.g., bioinformatics, Web, software/system engineering, information networksnetworks
Application-oriented and domain-specific data mining
Invisible data mining (embedded in other functional modules)Invisible data mining (embedded in other functional modules)
Protection of security, integrity, and privacy in data mining

Summary of Section 1.1Data Mining is a process of extracting knowledge from dataData to be mined can be of any type
Relational Databases, Advanced databases, etc., ,Knowledge to be discovered
Frequent patterns, correlations, associations, classification, prediction cluster prediction, cluster
Techniques to be usedStatistics, machine learning, visualization, etc.
D t Mi i i i t di i li Data Mining is interdisciplinary Large amount of complex data and sophisticated applications
Challenges of data MiningEfficiency, scalability, parallel and distributed mining, handling high dimensionality, handling noisy data, mining heterogeneous data, etc.





























