Embed Size (px)
Citation preview

C++ język, nauka
• Czas nauczenia się programowania w c++ zależy od stopnia zaawansowania jaki się chce osiągnąć oraz opanowania technik towarzyszących. Zwykle 1 rok intensywnej nauki!
• Dwa sposoby na naukę: podglądać styl pracy kogoś doświadczonego, studiować dobre przykłady kodu w c++
• Pisać samodzielnie jak najwięcej kodu!• Być dociekliwym i sprawdzać nabytą wiedzę!
• Wszystkie poprzednie pytania egzaminacyjne dostępne na stronie przedmiotu.

C++ historia, współczesność, przyszłość
Język C++ jest wieloparadygmatowym językiem programowania. Stworzony w latach osiemdziesiątych XX wieku przez Bjarne Stroustrupa
•C++98 ISO/IEC 14882:1998•C++03 ISO/IEC 14882:2003•C++11 ISO/IEC 14882:2011•C++14 ISO/IEC 14882:2014

C++14 – dlaczego standard jest ważny?
Standard to brak zależności od• rodzaju kompilatora• systemu operacyjnego• CPUStandard odwołuje się / opisuje działanie abstrakcyjnej maszyny.Kompilator ma za zadanie zrealizować ten opis na konkretnym sprzęcie.
C++98/C++03 – abstrakcyjna maszyna była jednowątkowaC++11/C++14– abstrakcyjna maszyna zaprojektowana jako wielowątkowa– model pamięci (organizacja pamięci i sposoby dostępu do pamięci)– na niskim poziomie gwarantowane operacje atomowe
w określonej kolejności

C++ podstawowe cechy
• Główne cechy języka: • język kompilowalny, ogólnego przeznaczenia, określany
jako język „średniego poziomu” – dokument opisujący standard C++14 ma 1366 stron
• silna (statyczna) kontrola typów podczas kompilacji: pewna forma weryfikacji poprawności kodu, pozwalająca na wczesne wykrycie błędów lub niezamierzonego działania
• język swobodnego formatu, rozmieszczenie znaków na stronie nie ma znaczenia, ale każda instrukcja musi być zakończona średnikiem ;
• C++ nie wspiera własności specyficznych dla danej platformy lub niebędących własnościami ogólnego przeznaczenia

C++ style programowania
• C++ nie narzuca żadnego stylu, daje programiście możliwość wyboru.
• programowanie proceduralne: organizowanie kodu w postaci procedur, wykonujących ściśle określone operacje, dane nie powiązane z procedurami, jako parametry wywołania procedur
• programowanie obiektowe: zbiór obiektów komunikujących się pomiędzy sobą w celu wykonywania zadań, obiekt to element łączący stan (dane) i zachowanie (metody)… programowanie funkcjami wirtualnymi
• programowanie uogólnione: kod programu bez wcześniejszej znajomości typów danych, szukanie i systematyka abstrakcyjnych reprezentacji efektywnych algorytmów, struktur danych i innych elementów programowych… programowanie szablonami

C++ literatura (1) – kanon literatury
International Standard (można kupić – cena zaporowa)ISO/IEC 14882:2014(E)
C++14 Final Documentwww.open-std.org/jtc1/sc22/wg21/draft N3797(2013-10-13)
Bjarne Stroustrup• Język C++ (Wyd. IV)• Programowanie. Teoria i praktyka
z wykorzystaniem C++ (Wyd. II popr.)

C++ literatura (2) – „stare ale jare” (niestety, nie C++11)
Bruce EckelThinking in C++, vol. I i II (po angielsku – on-line)
Jerzy Grębosz• Symfonia C++ Standard (C++03)• Pasja C++ (niestety stare)
Uw
aga:
pow
staj
e no
wa
wer
sja…

C++ literatura (3)
Nicholas A. Solter, Scott J. KleperC++ Zaawansowane programowanie
Wydanie III po angielsku
Stephen PrataJęzyk C++. Szkoła programowania. Wydanie VI
Siddhartha RaoC++. Dla każdego. Wydanie VII

C++ literatura (4)
D. Ryan StephensC++ Receptury(O’Reilly)
Anthony WilliamsJęzyk C++ i przetwarzanie współbieżne w akcji
David Vandevoorde, Nicolai M. JosuttisC++ szablony. Vademecum profesjonalisty
Aktualizacja w roku 2017
Nicolai M. JosuttisC++. Biblioteka standardowa. Podręcznik programisty Wyd. II

C++ literatura (5)
Scott Meyers – „C++ 50 efektywnych sposobów na udoskonalenie Twoich programów”
– „Język C++ bardziej efektywny”– „STL w praktyce: 50 sposobów efektywnego wykorzystania”– „Skuteczny nowoczesny C++. 42 sposoby lepszego
posługiwania się językami C++11 I C++14”
Herb Sutter
– „Wyjątkowy język C++ 47 łamigłówek…”– „Wyjątkowy język C++ 40 nowych łamigłówek…” – „Niezwykły styl języka C++ 40 nowych łamigłówek…”– „Język C++ Standardy kodowania 101 zasad…”
(współautor: Andrei Alexandrescu)
KURSY DOSTĘPNE ON-LINEKarol „Xion” Kuczmarski – Kurs C++ (Megatutorial)Sektor van Skijlen – C++ bez cholesteroluPiotr Białas, Wojciech Palacz – Zaawansowane C++pl.wikibooks.org/wiki/C++ – niekompletny jeszcze…Frank B. Brokken – C++ Annotations Ver. 10.1.x

C++ literatura anglojęzyczna (1)
Marc Gregoire, N.A. Solter, S.J. KleperProfessional C++ 3rd Edition
Scott MeyersOverview of The NewC++ (C++11/14)Effective Modern C++
Wywiady,prezentacje… http://channel9.msdn.com
Wikipedia (EN, PL)• hasło C++11, C++14
(także C++0x)
Forum stackoverflow(tagi C++11,C++14)
http://stackoverflow.com/

C++ literatura anglojęzyczna (2)
S. B. Lippman et al.C++ Primer5th Edition
Nicolai M. JosuttisThe C++ Standard Library - A Tutorial and Reference, 2nd Edition
S. Meyers, H. SutterAndrei AlexandescuC++ and Beyond 2010-14
Stephen PrataC++ Primer Plus6th Edition
Alex KorbanC++11 Rocks(VS2013 & gcc version)

C++ literatura anglojęzyczna (3)
Herb SchildtC++ ProgrammingCookbook (2008)
Harvey M. Deitel,Paul J. DeitelC++ How to Program10th Edition
Walter Savitch• Absolute C++ (5th Edition)• Problem Solving with C++
(9th Edition)

C++ informacje, materiały wideo, konferencje
www.isocpp.org
CPPCON 2014 (Bellevue, WA)
www.youtube.com/user/CppCon

Kompilator
• Używanie gcc zamiast g++– GCC (GNU Compiler Collection) kompiluje różne języki (C, C++,
Objective-C, Objective-C++, Java, Fortran, Ada). gcc rozpoznaje kod źródłowy C++ po rozszerzeniach:
– gcc nie konsoliduje skompilowanego kodu z biblioteką standardową c++
– jeśli użyjesz gcc to będziesz musiał podać ręcznie ścieżkę do plików nagłówkowych oraz do biblioteki standardowej!
• Kompilator g++ – tłumaczy kod źródłowy na język assembler lub rozkazy komputera
• Konsolidator g++ (linker) – dopasowuje odwołania symboli do ich definicji
• Najnowsze wersje całkowicie wspierają standard C++14 (wersja 5.3)
.C, .cc, .cpp, .CPP, .c++, .cp, .cxx
Nie utrudniajmy sobie życia i używajmy g++

Kompilator – wsparcie nowego standardu
Kompilowanie kodu według nowego standarduWsparcie kompilatora dla standardu C++11 (C++14) wymaga dodatkowej opcji (flagi):
Przykładowo (linux):Program jest w katalogu /usr/binPliki nagłówkowe w katalogu /usr/include/c++/5.3Biblioteki w katalogu /usr/lib/gcc/i486-linux-gnu/5.3
Na pracowni komputerowej w chwili obecnej kompilator g++ 4.9.2 jest dostępny tylko pod windows, np. poprzez środowisko Dev-C++ ale po ustawieniu odpowiednich ścieżek oraz opcji –std=c++14 Pod linuxem na razie jest niewystarczający kompilator w wersji 4.7.2
g++ -std=c++11 …
g++ -std=c++14 …

Kompilowanie i linkowanie (konsolidacja)
Prosty program o nazwie myprog z pliku prog1.cc
Plik obiektowy (bez konsolidacji do programu)
Konsolidacja do programu wykonalnego
Uruchomienie programu (linux)
gdzie „ . ” (kropka) oznacza pełną nazwę ścieżki, chyba że ścieżka do katalogu z programem jest w zmiennej PATH
g++ -std=c++14 -o myprog prog1.cc // to samo: g++ -std=c++14 prog1.cc -o myprog
g++ -std=c++14 -c -o prog1.o prog1.cc
g++ -std=c++14 -o myprog prog1.o
./myprog

Kompilatory – kilka uwag
Można mieć zainstalowane kilka wersji g++ oraz biblioteki standardowej. Napisz: i postukaj „tab” (pokażą się wszystkie programy zaczynające się na g++)
Zwykle g++ to link symboliczny do jednej z wersji. Sprawdzenie wersji:
Inne kompilatory warte uwagi:
Kompilowanie plików nagłówkowych• niektóre kompilatory pozwalają na prekompilowanie plików nagłówkowych,
w dużych projektach znacznie może to przyspieszyć proces kompilacji• g++ kompilując plik .h tworzy plik z rozszerzeniem .h.gch• prekompilowany plik jeśli znaleziony, może być brany jako pierwszy przed plikiem .h• student robi to zwykle przez pomyłkę, niepotrzebnie umieszczając na liście plików źródłowych
do kompilowania również pliki .h (może to prowadzić do zaskakujących problemów w stylu „edytuję plik .h i nic się nie dzieje”)
g++ -v // lub: g++ --version
g++
clang ver. 3.9, Intel C++ ver. 16, Microsoft Visual Studio C++ 2015

Pierwszy program
Program wymaga napisania funkcji:
lub
W kodzie – tylko jedna funkcja main. Uwaga: dawniej (przed rokiem 1998) dopuszczano postać funkcji zwracającej void (tzn. „nic”), teraz musi zwracać int.
Paradoksalnie, jest to jedyna funkcja, w której (skoro „coś” zwraca) nie trzeba pisać instrukcji „return”. Można (ale nie trzeba) jawnie napisać:
int main() { }
int main() {return 0;
}
auto main() -> int { }

Nawiasy, komentarze
void fun() {// komentarz jednolinijkowy – do końca linii/* komentarz większego obszaru,
nie można zagnieżdżać… */}void fun2(){
// takie nawiasy // czytelniejsze?...
}
Niektóre instrukcjenie wymagają pary nawiasów:
if ( true )zawszeWykonaj();
Łatwiej jednak coś dopisaći nie pomylić się, zawszestosując nawiasy!
if ( true ) {zawszeWykonaj();latwoDopisz();
}

Pierwszy program: średnik
Uważaj na średnik – są miejsca, w których średnik jest konieczny, a są, w których jest zbędny lub nieprawidłowy.
Nie musimy stawiać średnika za nawiasem kończącym definicję funkcji – jest niepotrzebny (ale nie jest błędem)
Średnik na końcu dyrektywy preprocesora – to jest błąd! (w przykładach jak obok)
Średnik konieczny jest na końcu definicji klasy!
Przykład kompilującego siękodu, w którym przez pomyłkę mamy niezamierzone działanie…
#include "mojplik.h";#define FLAGA;
class Klasa { } ;
int fun3() {return 2;
} ;
for (int i=0; i<10; ++i);// tutaj instrukcja, którą może ktoś// zamierzał wykonać 10 razy…
; ; ; Seria średników jest legalna, bo pusty średnikoznacza pustą instrukcję.

#include <iostream>using namespace std;
int main() {cout << "I am Jan B. " << "za zycia napisalem ponad " << 100<< " ksiazek!\n";cout << "A Ty ile napisales: ";int liczba;cin >> liczba;if (liczba < 100) cout << "\n…Tak malo!";return 0; // return EXIT_SUCCESS
}
Pierwszy program – który coś robi
#include <iostream.h> // NIE UŻYWAĆczasem implementowane tak:
#include <iostream> using namespace std;
w nowych kompilatorach ostrzeżenia, a nawet może się nie skompilować
Można wskazać na konkretną deklarację użycia:using std::cout;using std::cin;Można pisać std::cout oraz std::cin- tak się robi w plikach nagłówkowych .h, w których nie piszmy dyrektywy użycia całej przestrzeni nazw std
Biblioteki z C:#include <cstdlib>#include <cstdio>#include <cassert>

Pierwszy program „wielowątkowy” ( C++11/14 )
Bez join() główny wątek nie czekałby na zakończenie wątków podrzędnych, jeśli te nie zakończą się, nastąpi terminate()
#include <iostream>#include <thread>#include <chrono>#include <atomic>
void moja_funkcja() { // static unsigned licznik;static std::atomic_uint licznik; // typy atomowestd::this_thread::sleep_for( std::chrono::seconds( 1 ) );std::cout << "Jestem watek nr " << ++licznik << "!\n";
}int main() {
std::thread t1(moja_funkcja);std::thread t2(moja_funkcja);std::thread t3(moja_funkcja);t1.join();t2.join();t3.join();std::cout << "Glowny watek!\n";
}Kolejność wykonywania wątków przypadkowa!
std::thread
”Główny wątek!\n”
narzutzwiązanyz tworzeniemwątku
”Jestem z wątku…”
wątekzablokowany
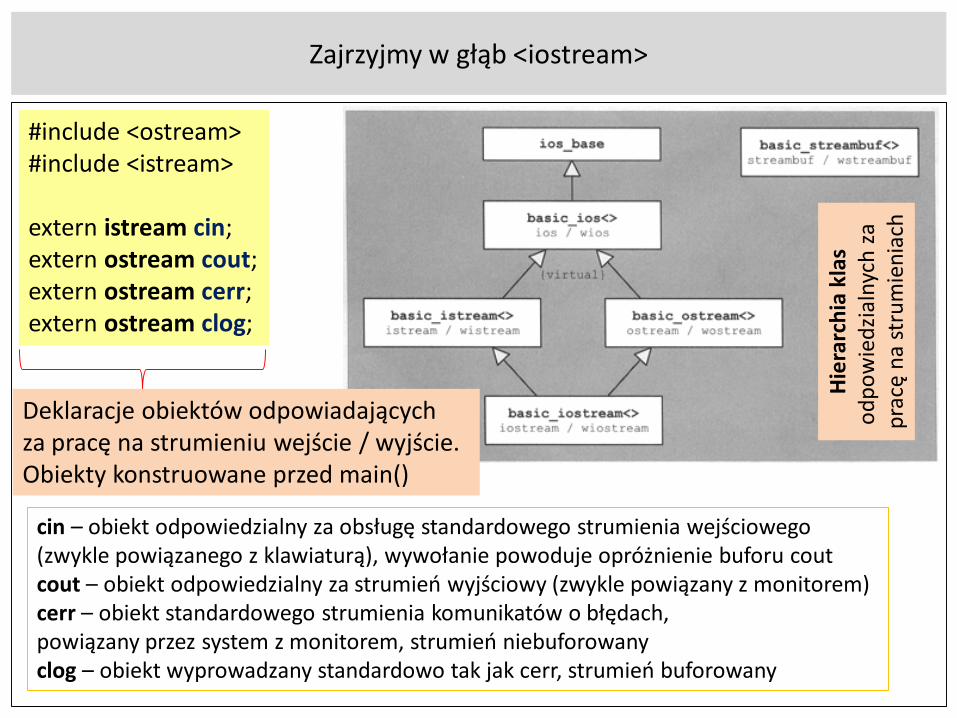
Zajrzyjmy w głąb <iostream>
#include <ostream>#include <istream>
extern istream cin;extern ostream cout;extern ostream cerr;extern ostream clog;
Deklaracje obiektów odpowiadającychza pracę na strumieniu wejście / wyjście.Obiekty konstruowane przed main()
Hier
arch
ia k
las
odpo
wie
dzia
lnyc
h za
pr
acę
na st
rum
ieni
ach
cin – obiekt odpowiedzialny za obsługę standardowego strumienia wejściowego (zwykle powiązanego z klawiaturą), wywołanie powoduje opróżnienie buforu coutcout – obiekt odpowiedzialny za strumień wyjściowy (zwykle powiązany z monitorem)cerr – obiekt standardowego strumienia komunikatów o błędach, powiązany przez system z monitorem, strumień niebuforowanyclog – obiekt wyprowadzany standardowo tak jak cerr, strumień buforowany

Operatory, manipulatory, znaki specjalne
operator<< oraz operator>> są to operatory przesunięcia bitowego, jednak dla obiektów strumienia są przeciążone i stają się „operatorami wejścia/wyjścia”
Co lepiej na końcu: std::endl czy \n ?MANIPULATORY ( tak naprawdę funkcje)endl – dodaje do buforu znak ’\n’ orazwykonuje flush – opróżnienie buforuends – wkłada znak kończący łańcuch znakowy, czyli symbol zerowy ’\0’ flush – opróżnia buforws – czyta i ignoruje białe znakiKod dla guru (przykład):
ostream& ostream::operator<<( ostream& (*op) (ostream&) ) {
return (*op) (*this); }std::ostream& std::endl (std::ostream& s) {
s.put('\n'); s.flush(); return s;
}
Można tak: std::cout << std::endl;lub tak: std::endl ( std::cout );
ZNAKI SPECJALNE (stałe znakowe)\n nowa linia\r powrót do początku linii\t pozioma tabulacja\a alarm dźwiękowy\0 symbol zerowy (koniec łańcucha)MNIEJ UŻYWANE\v pionowa tabulacja\b powrót o jedną pozycję\f nowa strona (drukarka)\? znak zapytaniaKONIECZNE W ŁAŃCUCHU ZNAKOWYM\\ lewy ukośnik\’ apostrof\” cudzysłów

Deklaracja – co to jest?
Deklaracja – to wprowadzenie w danej jednostce translacji (pliku) nazwy (lub nazw), albo redeklaracja nazw wprowadzonych poprzednimi deklaracjami.Deklaracje generalnie określają jak mają być rozumiane dane nazwy.Deklaracja może być też definicją, chyba że (i wtedy są to tylko deklaracje):• deklarujemy funkcję bez definiowania jej ciała
• deklaracja poprzedzona jest specyfikatorem extern, w znaczeniu obiektu zdefiniowanego w innym pliku
• deklaracja z użyciem extern jako sposób konsolidacji (linkowania) kodu
void fun( double d, short n, int );
gdy chcemy „zlinkować” z kodem z innego języka, musimy zadeklarować nazwy obiektów tam zdefiniowanych
extern ”C” int fun ( float );extern ”C” { /* tutaj lista deklaracj */ }
deklarujemy, że w innym pliku będzie zdefiniowana zmienna typu double o nazwie d. UWAGA: jeśli użyjemy specyfikatora extern oraz inicjalizujemy zmienną, np. extern double d = 3.14; to oznacza to już definicję a nie deklarację!
extern double d;
nie ma definicji (ciała) funkcji, czyli części ujętej w nawiasy { } to jest to tylko deklaracja

Deklaracje (2)
• deklarujemy statyczną składową w definicji klasy
• deklarujemy nazwę klasy (bez jej definiowania):• deklarujemy (silny) typ wyliczeniowy (C++11/14)
Deklaracjami nazywamy również:• deklarację z użyciem typedef
• deklarację użycia using lub dyrektywę using
class Foo;
zmienna statyczna w definicji klasy to dopiero jej deklaracja – jak się później dowiemy, taką zmienną definiuje się dopiero poza ciałem klasy
using std::cout;using namespace std;
class Foo {static int n;
};
„klasa wyliczeniowa” (albo „silny typ wyliczeniowy”) pozwala na uprzednią deklarację wraz ze specyfikacją typy danych wyliczeniowych (typ musi być całkowity)
enum class EColor;enum struct EShape : char;
deklaracja użycia czegośdyrektywa użycia którejś przestrzeni nazw
typedef int Calkowity, *PtrCalkowity;Calkowity n1; PtrCalkowity ptr1;
n1 jest typu int, zaś ptr1 jest typu „wskaźnik do int”

Definicje – reguła jednej definicji (One Definition Rule)
Jedna definicja – żadna jednostka translacji (plik) nie może zawierać więcej niż jednej definicji jakiejkolwiek zmiennej, funkcji, klasy, typu wyliczeniowego lub szablonu.
Definicja może się znajdować w programie, zewnętrznej bibliotece (standardowej, użytkownika).Definicja klasy konieczna jest w danym pliku, gdy typ klasy używany jest w sposób wymagający znajomości kompletnej definicji.
One ring to rule them all, one ring to find them,
One ring to bring them all and in the darkness bind them.
class Foo;struct Foo* ptr1;Foo *ptr2;
w tych przypadkach nie ma konieczności znajomości definicji klasy, wystarczy deklaracja jej nazwy
Czasami definicja może się „powtórzyć” w różnych plikach. Dotyczy to klasy, typu wyliczeniowego, funkcji inline (extern inline), szablonu klasy, statycznej zmiennej oraz metody składowej w szablonie klasy, niestatycznego szablonu funkcji, specjalizacji szablonu… (C++14 §3.2.6) – wszystko to pod pewnymi warunkami! (zasadniczo jest to powtórzenie tego samego kodu z ew. dopisanymi wartościami domyślnymi funkcji)

Definicje – przykłady ( C++11 §3.1.2)
int a; extern const int c = 1; int f (int x) { return x+a; }class S { int a; int b; }; struct X {
int x; static int y; X(): x(0) { }
};int X::y = 1; enum { up, down }; namespace N { int d; }namespace N1 = N; X anX;
definiuje zmienną a typu int - całkowitego
definiuje stałą c typu int (bo inicjalizacja!)
definiuje funkcję f i zmienną lokalną x
definiuje klasę S i zmienne składowe a i b
początek definicji struktury X
definicja konstruktora struktury X
deklaracja statycznej składowej y
definicja niestatycznej składowej x
definicja składowej statycznej X::y
definiuje up i down (typ wyliczeniowy)
definiuje przestrzeń nazw N i składnik d
definiuje przestrzeń nazw N1 (jako „alias”)
definiuje obiekt anX typu X

Organizacja kodu (header guard)
DEKLARACJE zmienny, funkcji nie-inline lub DEFINICJE funkcji inlineDEFINICJE klas, DEFINICJE szablonówplik nagłówkowy ( .h )Wielokrotne włączenie tego samegonagłówka (#include) – wielokrotna definicja – pogwałcenie reguły ODR – błąd!
Aby temu zapobiec, w plikach nagłówkowych zawsze korzystamyz dyrektyw preprocesora (blokada, tzw. header guard)
DEFINICJE zmiennych, funkcji, metod klasplik źródłowy ( .cc / .cpp )
Cytat z „Megatutorial-u” Karola Kuczmarskiego(Państwa niewiele starszego kolegi…)
Dyrektywa #include jest głupia jak cały preprocesor.
Dyrektywa
#pragma once• pierwotnie działała tylko w niektórych
kompilatorach, np. MS Visual C++• pragma nie jest polecana przez twórców gcc
jako dyrektywa z definicji „zależna od implementacji”, choć działa w g++ od ver. 3.4
#ifndef FIGURA_H#define FIGURA_H
// tutaj cała zawartość pliku
#endif // FIGURA_H

Pułapki myślenia o blokadach
header guard (czyli zestaw #ifndef #define … #endif) nie chroni przed problemem podczas konsolidacji plików, jeśli w pliku nagłówkowym, włączonym do tych różnych plików, zdefiniowaliśmy coś, co pogwałci ODR. Skompiluje się, ale linker zgłosi „multiple definition”header guard chroni jeden dany plik źródłowy przed wielokrotnym włączeniem (i kompilacją) tego samego pliku nagłówkowego, wielokrotne włączenie może nastąpić również nie wprost, przez inne włączane pliki
#ifndef H2_H#define H2_H#include ”h1.h”
// coś jeszcze#endif
#ifndef H1_H#define H1_H
void fun() { }#endif
#include ”h2.h” void fun2() { fun(); }
#include ”h1.h”#include ”h2.h”int main() {
fun();}
g++ main.cc test.cc –o prog/tmp/cccOPU18.o: In function `fun()':test.cc:(.text+0x0): multiple definition of `fun()'/tmp/ccGypJJH.o:main.cc:(.text+0x0): first defined herecollect2: ld returned 1 exit status
plik h2.h plik main.ccplik test.ccplik h1.h

Typy danych – typy wbudowane (§18.3.1)
• standard nie określa z ilu bitów składa się dany typ• określa minimalną i maksymalną wartość danego typu
Powyższe wyrażenia to metody lub składowe statyczne,zwracające wyrażenie stałe (constexpr – nowość C++11), np.
• nagłówki <climits>, <cfloat> takie same jak standardowe nagłówki z C o nazwie limits.h, float.h z definicjami preprocesorowymi, np.
#include <limits> // jest tu szablon numeric_limitsnumeric_limits<double>::min(); // 2.22507e-308numeric_limits<int>::max(); // 2147483647numeric_limits<float>::round_error(); // 0.5numeric_limits<short>::is_specialized; // true
static constexpr T min() noexcept; // „noexcept” – nie zgłosi wyjątku
#define INT_MAX <#if expression >= 32,767>#define LONG_MAX <#if expression >= 2,147,483,647>#define LLONG_MAX <#if expression >= 9,223,372,036,854,775,807> [added with C99]

Typy danych oraz specyfikatory
Podstawowe typy wbudowane:
wchar_t – rozszerzony typ znakowy (wielkość zależna od implementacji)char16_t i char32_t – do reprezentacji znaków standardu UnicodeSpecyfikatory (rozszerzają lub zawężają, ze znakiem lub bez znaku)
• short int (inaczej: short), int, long int (inaczej: long), long long int(inaczej: long long) oficjalnie w C++11 ze wzg. na zgodność z C99
• float, double, long doubleTyp(dwa stany logiczne: true, false – to są stałe)
char, int, float, double
short – long, signed – unsigned
bool
• operatory: && || ! < > <= >= == !=• komendy sterujące: if, for, while, do, ? :• kompilator przekształca int w bool
true – odpowiednik wartości całkowitej 1 false - odpowiednik wartości całkowitej 0
nie nadawać stanu logicznego za pomocą operacji arytmetycznej (+ lub -)→ niejawna konwersja typów

typedef, using
typedef – synonim typu istniejącego (nie żadna nowa definicja), najczęściej używany do uproszczenia zapisu (wiele razy w bibliotece standardowej) np.
using – może być użyte zamiennie jako typedef
typedef basic_fstream<char> fstream; // w nagłówku fstreamtypedef basic_string<char> string; // w nagłówku string
typedef std::vector<int>::iterator It;using It = std::vector<int>::iterator; // te dwie linie robią to samo
typedef const char* (*Fptr)( double );using Fptr = const char* (*) (double); // wskaźnik do funkcji,
też to samo co wyżej

Typy danych – zakres, bajty, precyzja
* można zobaczyć wartość typu char po wykonaniu rzutowania na int, np. -128, 127Możliwość określenia typu „ze znakiem” (signed – domyślny) oraz „bez znaku” (unsigned) dotyczy tylko typów całkowitych. Typy zmiennoprzecinkowe są signed.
typ minimum maksimum bajty precyzja
bool false true 1 -
char (*) całe ASCII całe ASCII 1 -
short intunsigned
-32768 327672
-
0 65535
int, long intunsigned
-2147483648 21474836474
-
0 4294967295
long longunsigned
-9223372036854775808 92233720368547758078
-
0 18446744073709551615
float 1.17549e-38 3.40282e+38 4 7 cyfr
double 2.22507e-308 1.79769e+308 8 15 cyfr
long double 3.3621e-4932 1.18973e+4932 10 19 cyfr

Zasięg zmiennych
• zmienne można definiować w dowolnym miejscu• często tuż przed użyciem, w obrębie wyrażeń sterujących
(pętla for i while), instrukcja if, selektor switch
zmienne globalne• na zewnątrz ciał wszystkich funkcji, dostępne dla wszystkich części programu,
czas życia == czas życia programu, w wielu plikach, można je zadeklarować (extern), można też (static) ograniczyć do jednego pliku, inicjalizowane zerem
zmienne lokalne• w obrębie jakiegoś zasięgu (od definicji do klamry zamykającej dany blok),
zmienne tymczasowe (kiedyś określane jako auto) – giną po wyjściu z zasięgu• zmienne zagnieżdżone zasłaniają zmienne wyżej położone• bez inicjalizacji wartość zmiennej lokalnej nieokreślona (śmieci)
nie można odseparować definicji / inicjalizacji za pomocą nawiasów
while ( char c = cin.get() ) // ok, ale to zawsze będzie truewhile ( ( char c = cin.get() ) ) // błąd – nie można obłożyć tego nawiasamiwhile ( char c = cin.get() != ’q’ ) // działa, ale != ważniejsze niż = więc…while ( ( char c = cin.get() ) != ’q’ ) // no właśnie, tak nie można! więc…char c; while ( ( c = cin.get() ) != ’q’ ) // teraz działa

Zasięg zmiennych, przesłanianie – przykład
int a = 1; // zmienna globalnanamespace mojeKlocki
{ int a = 7; int b = 8; }namespace { int c = 99;
// int a = 3; spowodowałoby kolizję ze zmienną globalną}
int main() {int a = 2;{
int a = 3, c = 100;for (int i=0; i<10; ++i); // nic nie robi, bo uwaga - gdzie kończy się instrukcjacout << "a lokalne = "<< a <<endl; // 3using namespace mojeKlocki;cout << "a lokalne = "<< a <<endl; // 3cout << "a z mojeKlocki = "<< mojeKlocki::a <<endl; // 7cout << "b z mojeKlocki = "<< b <<endl; // 8int b = 12;cout << "b lokalne = "<< b <<endl; // 12cout << "a nielokalne = "<< ::a <<endl; // 1cout << "c z nienazwanej przestrzeni " << ::c << endl; // 99, to też jest zmienna globalna
}cout << "a lokalne = "<< a <<endl; // 2
}
zakomentowanie globalnej zmiennej i próbaodwołania się do niej spowoduje błąd kompilacji

Rodzaje obiektów i ich cechy (static – global)
Obiekt globalny – istnieje przez cały czas wykonania programu– domyślnie łączony zewnętrznie– deklaracja extern – można użyć w innych plikach źródłowych– deklaracją static zasięg można ograniczyć do pliku
wystąpienia definicji (bez kolizji nazw)– lepszy sposób na „łączenie wewnętrzne” – użycie
nienazwanej przestrzeni nazw (namespace)– jeśli const, to zachowuje się jak static (chyba że extern const)– domyślnie inicjowany wartością zera
Statyczny obiekt lokalny – istnieje przez cały czas wykonania programu– deklaracja z modyfikatorem static– wartość takiego obiektu przetrwa między kolejnymi
wywołaniami funkcji– zasięg ograniczony jest do bieżącego kontekstu– w klasie – jeden egzemplarz dla wszystkich obiektów klasy– domyślnie inicjowany wartością zera
pam
ięć
stat
yczn
a

Obiekty globalne i statyczne (globalne) – przykłady
// w przestrzeni nazw lub przestrzeni globalnejint i; // domyślnie łączenie zewnętrzneconst int ci = 0; // domyślnie globalny const jest static (łączony wewnętrznie)extern const int eci; // jawna deklaracja łączenia zewnętrznegostatic int si; // jawnie static
// podobnie funkcje – uwaga – nie ma globalnych funkcji stałych (const)int foo(); // domyślnie łączenie zewnętrznestatic int bar(); // jawna deklaracja static
// nienazwana przestrzeń nazw jako polecany sposób na ograniczenie zakresu// widzialności nazw do danej jednostki translacjinamespace {
int i; // mimo łączenia zewnętrznego niedostępne // w innych jednostkach translacji
class niewidoczna_dla_innych { };}

Rodzaje obiektów i ich cechy (stack, heap)
Obiekt automatyczny – obiekt lokalny– przydział pamięci następuje automatycznie w chwili
wywołania funkcji– czas trwania obiektu kończy się wraz z zakończeniem bloku,
w którym został zaalokowany– zasięg ograniczony jest do bieżącego kontekstu– należy uważać na wskaźniki i referencje do obiektów
lokalnych– obiekt domyślnie nie jest inicjalizowany
Obiekt z czasem trwania określanym przez programistę– obiekt z pamięcią przydzielaną dynamicznie (operator new)– czas życia – do usunięcia operatorem delete– obiekt bez nazwy– identyfikowany pośrednio przez wskaźnik– zawieszony wskaźnik - wskazujący na nieobsługiwany obszar
pamięci (wskaźnik zwisający)– wyciek pamięci - obszar pamięci przydzielany dynamicznie na
który nie wskazuje żaden wskaźnik
stos
st
erta

Stałe dosłowne (literały całkowite i zmiennoprzecinkowe)
Stałe dosłowne są niemodyfikowalne (tzw. r-values)Literały całkowite• liczby dziesiętne (domyślnie)• ósemkowe – zaczynają się od 0• szesnastkowe – zaczynają się od 0x lub 0X• binarne – zaczynają się od 0b lub 0B (C++14)
Literały zmiennoprzecinkowe• liczba zmiennoprzecinkowa (system dziesiętny)• opcjonalnie może być z wykładnikiem:
e lub E oraz „+” (opcjonalnie) lub „–” i liczba
dopuszczalne przyrostkif, F – floatl, L – long double
• literał zmiennoprzecinkowy bez przyrostka jest rozumiany jako typ double• przyrostkiem można określić typ, np.: 3.14f jest typu float
dopuszczalne przyrostkiu, U – unsignedl, L – longll, LL – long long
• liczbę 12 można więc zapisać jako: 12, 014, 0xC, 0b1100• literał całkowity bez przyrostka jest rozumiany jako typ int• przyrostkiem można określić typ, np.: 12uL jest typu unsigned long

Manipulatory i std::bitset
W nagłówku <ios> oraz wszystkich pochodnych (czyli <iostream> też) zdefiniowane są manipulatory std::dec, std::oct i std::hex (nie ma std::bin), dzięki którym można w locie wypisać konwersję do danego systemu:
A co z systemem binarnym? Można skorzystać z szablonu klasy (konieczny nagłówek <bitset>) reprezentującego bity o zadanym rozmiarze N, std::bitset<N> a następnie wykonać rzutowanie dowolnej liczby:
Udogodnienia czytelności zapisu liczb (w dowolnym systemie) w C++14:
cout << hex << 12; // c szesnastkowocout << oct << 12; // 14 ósemkowocout << dec << 0b1100 // 12 dziesiętnie
cout << bitset<8>(12); // 00001100 binarnie na 8 bitachcout << (bitset<16>)0xc; // 00000000001100 na 16 bitachcout << static_cast<bitset<4>>(014); // 1100 na 4 bitach
1'000'000; 0xa'a'c'f; 0'123'123; // separujące apostrofy ' są ignorowane

Stałe dosłowne (literały znakowe)
Literały znakowe• jeden znak (lub więcej) ujęty w pojedynczy cudzysłów, 'x', może być
poprzedzony przedrostkiem u, U, L, na przykład: u'x', lub U'y', lub L'z'• znaki specjalne (już były): \' \" \? \\ \a \b \f \n \r \t \v• znaki specjalne ósemkowe \ooo (jedna, dwie lub trzy cyfry)• znaki specjalne szesnastkowe \xNNN (nie ma limitu na liczbę cyfr N)
– koniec znaku ósemkowego lub szesnastkowego następuje po napotkaniu pierwszej liczby spoza systemu ósemkowego / heksadecymalnego
• typ wchar_t służy do obsługi rozszerzonego typu znakowego (bez wskazania na rodzaj kodowania), typ char16_t służy reprezentowaniu kodowania w UTF-16, typ char32_t kodowaniu w UTF-32 (C++11)
• zwykły literał znakowy zawierający jeden znak jest typu char oraz wartość zgodną z ASCII• literał wieloznakowy jest typu int, a jego wartość zależy od implementacji• literał z prefiksem u jest typu char16_t, z U – typu char32_t, z L – typu wchar_t

Wsparcie standardu unicode
Dwa nowe typy znakowe: char16_t i char32_t• char16_t dla UTF-16 // potomek uint_least16_t• char32_t dla UTF-32 // potomek uint_least32_t
– Odpowiadające im literały: przedrostek u / U
• Istnieją odpowiadające im łańcuchy znakowe– u"lancuch znakowy 16-tek" // składowe typu char16_t w UTF-16– U"lancuch znakowy 32-jek" // składowe typu char32_t w UTF-32– "zwykly lanuch znakowy" // składowe typu char– u8"wsparcie dla UTF-8" // składowe typu char w UTF-8
• Pojedyncze znaki osiągalne poprzez swoje kody \unnnn i \Unnnnnnnn:– u8"Klucz wiolinowy: \U0001D11E" // (tu powinien być klucz, ale czcionka…)– U"czaszka i kosci: \u2620" // ☠
• zwykły literał znakowy zawierający jeden znak jest typu char oraz wartość zgodną z ASCII• literał wieloznakowy jest typu int, a jego wartość zależy od implementacji• literał z prefiksem u jest typu char16_t, z U – typu char32_t, z L – typu wchar_t

Stałe dosłowne (literały napisowe i inne)
Literały napisowe (łańcuchy znakowe)• sekwencja znaków zamknięta w podwójny cudzysłów, "napis",
opcjonalnie poprzedzony przedrostkiem R, u8, u8R, u, uR, U, UR, L lub LR jak np. R" (…) ", u8"…", u8R"**(…)**", u"…", uR"*~(…)*~", U"…", UR"zzz(…)zzz", L"…", LR" (…) "
Literały logiczne• dwa słowa kluczowe, true i false, będące typu boolLiterały wskaźnikowe (C++11)• słowo kluczowe nullptr (jest typu std::nullptr_t, to nie jest typ int)
autonomiczny typ na określenie wskaźnika zerowego
f(0); // wywołane f(int)f(nullptr); // wywołane f(char*)g(nullptr); // błąd: nullptr to nie intint i = nullptr; // błąd: jak wyżej
char* ptr1 = nullptr;int *ptr2 = 0; //nadal działavoid f(int); // tu argument intvoid f(char*); // tu argument char*void g(int);

Stałe (const) a preprocesor
• za pomocą preprocesora
od miejsca zdefiniowana do końca pliku
• modyfikator const
zasięg taki jak zasięg zmiennej, typ musi być określony, stała musi być zainicjalizowana (chyba że piszemy deklarację z extern)
• stałej zdefiniowanej za pomocą preprocesora nie można śledzić – bo polega na zamianie jednego symbolu na np. podaną wartość, zdecydowanie definiujmy stałe jako zmienne danego typu
• preprocesor można czasem użyć jako sprytnej makrodefinicji, np. wypisywania kontrolnego zmiennych (za Bruce Eckelem):
wtedy gdzieś w kodzie: PRINT("wartosc", a );
#define PI 3.1415
const float pi = 3.1415;
#define PRINT (STR, VAR) cout << STR " = " << VAR << endl#define PR (x) cout << #x " = " << x << " \n "

constexpr – gwarantowane wyrażenie stałe (C++11)
constexpr – uogólnione i gwarantowane wyrażenie stałe (nowe słowo kluczowe w C++11) – funkcje, konstruktory klas, także zmienne• pozwala na budowanie wyrażenia stałego przy użyciu typów
zdefiniowanych przez użytkownika• sposób gwarantujący, że inicjalizacja zachodzi podczas kompilacji• Zmienne (muszą być zainicjalizowane ale tylko literałem, inną wartością
constexpr lub wartością zwracaną przez funkcję constexpr)
• constexpr implikuje const ale nie na odwrótint a = 3; const int b = a; // a nie jest wyrażeniem stałymconstexpr int c = b; // błądconst int d = 7; // jest wyrażeniem stałymconstexpr int f = d; // ok
constexpr auto liczba = 3;constexpr auto pi = 3.14;constexpr auto nazwa = "stalowyrazeniowy ciag";

constexpr – funkcje
• funkcja constexpr musi mieć (C++11) jedną instrukcję return (często używa się operatora trójargumentowego do sprawdzenia warunków), w C++14 poluzowano warunki, może być więcej return, lokalne zmienne, if, switch, for, while, do-while (g++ od wersji 5.0)
• standard nie gwarantuje ewaluacji funkcji constexpr podczas kompilacji, chyba że występuje ona jako wyrażenie stałe (np. przypisanie do const)
• dozwolone wyrażenia ewaluowane podczas kompilacji:using, typedef, static_assert
• można wywoływać rekurencyjnie
• można użyć do wyliczenia wartości pól typu enum
• dramatyczna różnica w czasie obliczenia wartości funkcji constexprpodczas kompilacji i podczas wykonania
constexpr long long fibonacci( int n ) {return n < 1 ? -1 : ( n==1 || n==2 ? 1 : fibonacci(n-1) + fibonacci(n-2) );
}
enum Fibonacci {drugi = fibonacci(2);czternasty = fibonacci(14);
};
Można też obliczyć „w locie” (strumień):cout << fibonacci(21) << endl;ale może się okazać, że wtedy kompilator wybierzewariant obliczania podczas wykonania programu.

Operatory
• zwracają wartości na podstawie argumentów (argumentu)• 18 poziomów ważności – nie uczyć się wszystkiego! raczej używać
nawiasów ( ) do czytelnego oddzielenia; niektóre zapamiętać• operatory =, ++, -- dodatkowo zmieniają wartość argumentu
(skutek uboczny, ang. side effect)• operator przypisania = kopiuje p-wartość do l-wartości• operatory matematyczne +, -, *, /, %
• można połączyć z operatorem przypisania +=, -=, *=, /=, %=• zatem np. b %= 4; równoważne jest b = b % 4;• operator % (modulo) tylko z liczbami typu całkowitego
• operatory relacji <, >, <=, >=, ==, != zwracają wartość logiczną• operatory logiczne && (iloczyn), || (suma)• operatory bitowe & (koniunkcja), | (alternatywa), ^ (różnica
symetryczna), ~ (bitowy operator negacji)

Operatory – ciąg dalszy
• operatory przesunięć <<, >>jeśli po lewej liczba ze znakiem, to przesunięcie >> nie musi być operacją logiczną• można łączyć z operatorem przypisania <<=, >>=• bity przesunięte poza granicę są tracone
• operatory jednoargumentowe ! (negacji logicznej), -, +• operatory adresu &, wyłuskania *, -> i rzutowania
• rzutowanie: float a = 3.14; int b = (int)a; albo int b = int(a);
• operatory alokacji i usuwania: new, delete• operator trójargumentowy ? :
co się stanie:
• operator , zwraca wartość ostatniego z wyrażeń• operator sizeof
int a = --b ? b : (b = -10); // jeśli b=1, to a=-10
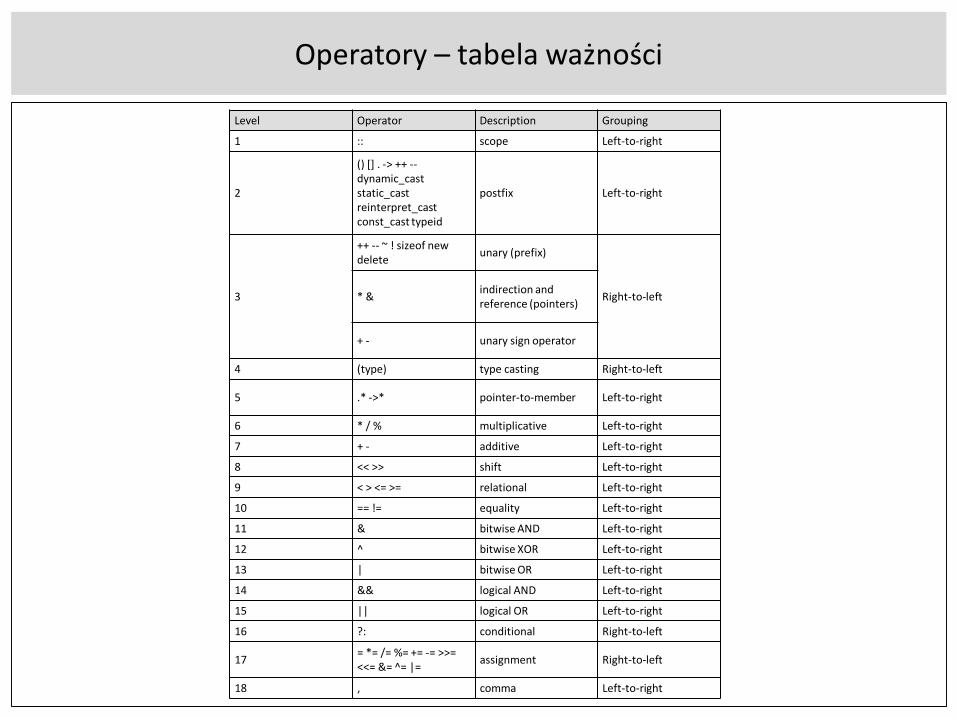
Operatory – tabela ważności
Level Operator Description Grouping
1 :: scope Left-to-right
2
() [] . -> ++ --dynamic_cast static_cast reinterpret_cast const_cast typeid
postfix Left-to-right
3
++ -- ~ ! sizeof new delete unary (prefix)
Right-to-left* & indirection and reference (pointers)
+ - unary sign operator
4 (type) type casting Right-to-left
5 .* ->* pointer-to-member Left-to-right
6 * / % multiplicative Left-to-right
7 + - additive Left-to-right
8 << >> shift Left-to-right
9 < > <= >= relational Left-to-right
10 == != equality Left-to-right
11 & bitwise AND Left-to-right
12 ^ bitwise XOR Left-to-right
13 | bitwise OR Left-to-right
14 && logical AND Left-to-right
15 || logical OR Left-to-right
16 ?: conditional Right-to-left
17 = *= /= %= += -= >>= <<= &= ̂ = |= assignment Right-to-left
18 , comma Left-to-right

Operatory – rzutowanie
• static_cast (konwersje niejawne, zawężające, zmieniające typ – podczas kompilowania) int b = static_cast<int>(a);void *vp; int *num = static_cast<int*>(vp);
• const_cast (od typów z modyfikatowem const lub volatiledo takich samych typów bez modyfikatora lub w drugą stronę)
• reinterpret_cast (pełna odpowiedzialność użytkownika, bez kontroli)
• dynamic_cast (rzutowanie "w dół" od abstrakcyjnego typu ogólnego do typu pochodnego – zajdzie gdy operacja taka ma sens – podczas wykonywania programu)

Referencje – lewe ( T &, const T & )
Terminologia wprowadzająca
Referencja ( T & ) „zwykła” to jakby „przezwisko” na coś.„Przezwisko” nie może istnieć samo, bez powiązania z tym, co określa. Zatem referencja w momencie definicji musi być zainicjalizowana i nie może być przestawiona na coś innego.
Niestała referencja ( T & ) może wskazywać na l-wartość. Stała referencja ( const T & lub T const & ) może wskazywać na l-warość i p-wartość. W roli p-wartości może wystąpić obiekt, który nie musi być stały, jak i obiekt, którego nie wolno modyfikować (np. tymczasowy). Do tej pory nie można było rozróżnić, na co pokazuje stała referencja.
l-value (lewa-wartość, l-wartość) coś, co można zmodyfikować, np. poprzez przypisanie (stoi po lewej stronie = )r-value (prawa-wartość, p-wartość) coś, co stoi po prawej stronie operacji przypisania, często rozumiana jako niemodyfikowalne
Nie istnieją:• referencje do referencji• tablice referencji• wskaźniki do referencji

Referencje – zakazane cv, prawe ( T && ) (C++11)
Kwalifikatory cv dla referencji, są niedopuszczalne. Wprowadzone przez typedef, albo argument szablonu, są zignorowane.
Przykład
C++11 wprowadza referencję „p-wartości” ( && ), która ma służyć wskazywaniu na p-wartości, ale w rozumieniu takim, że można je modyfikować. Służyć to ma budowaniu semantyki (składni) „przenoszenia”. Pojawiają się dzięki temu „konstruktory przenoszące” (move constructors) i „przenoszące operatory przypisania” (moveassignment operator). Więcej o tym – w dalszej części wykładu.
pamiętajmy, że w c++ funkcjonuje pojęcie kwalifikatora cv, czyli const i/lub volatile, zatem to co piszemy o const, dotyczy też volatile
Nie istnieje:T & const
int a = 3;typedef int& RINT;const RINT aref = a;aref = 4; // teraz ma wartość 4
wbrew pozorom, aref jest referencją „l-wartości” do int, a nie do const intnapisanie const RINT tu oznacza nie const int&a próbę int& const – coś takiego jest ignorowane
albo innymi słowy: referencja musi być zadeklarowana z const, potem tego const nie można dołożyć na zasadzie zmiany typu deklarowanej referencji

glvalues, prvalues, xvalues… ( C++11 )
Kategoryzacja typów wyrażeń w nowym standardzie
generalized lvalue
pure rvalue
expiring value
obiekt bliski końca czasu swojego życiajego zasoby mogą być przeniesionema swoją tożsamość• funkcja zwracająca T&&• rzutowanie na T&&• wyrażenie zwracające lvalue (np. throw)
Dwie cechy obiektów• mają (nie mają) tożsamość(i) – adres, nazwę…• mogą (nie mogą) być przenoszone – oryginał w stanie „wyzerowanym”
jego zasoby mogą być przeniesionenie ma swojej tożsamości• funkcja nie zwracająca T&&• rzutowanie nie na T&&• literały 12, 7.3e5, true• musi być ustalonego typu

lewe-wartości, prawe-wartości ( C++11 )
Jak odróżnić l-wartości od p-wartości?l-wartości: mają nazwę, mają adres, który możemy użyć
p-wartości: nie mają nazwy, zwykle obiekty tymczasowe
this – mimo, że ma nazwę, jest definiowany jako p-wartośćliterały – też są p-wartościami, ale nie posiadają operacji przenoszeniaReferencje do l-wartości ( T& ) i p-wartości ( T&& ):• l-wartości mogą być pokazane przez T&• p-wartości mogą być pokazane przez T const&
(stają się l-wartościami, bo referencja to też nazwa… ma nazwę? jest więc…)• p-wartości mogą być pokazane przez T&& (C++11)• l-wartości nie mogą być pokazane przez T&& (C++11)
size_t fun( string s ); // to co zwraca fun jest p-wartościąfun( ”word” ); // tymczasowy string inicjalizowany ”word” jest p-wartością
int i; // i jest l-wartościąint& fun(); fun() = 7; // fun() też jest l-wartością

Wskaźniki
Wskaźniki – zawierają adres i informację o typie (wyjątek: void*)T* – zwykły wskaźnik (do typu T)const T*, T const* – wskaźnik do stałego obiektu („gwarancja nietykalności”)
T* const – wskaźnik stały („gwarancja nieprzesuwalności”)
const T* const, T const* const – stały wskaźnik do stałego obiektuPonownie uwaga na typedef:
typedef int* pointer;typedef const pointer const_pointer;
const_pointer jest typu int* const,a nie typu const int*
const int ci = 10, *pc = &ci, *const cpc = pc, **ppc;int i, *p, *const cp = &i;
pc – wskaźnik na stały int, cpc – stały wskaźnik na stały int, ppc – wskaźnik do wskaźnika na stały int, p – wskaźnik na int, cp – stały wskaźnik na int

Wskaźniki – własności i arytmetyka
• wskaźnik jak tablica
można nimi operować jakby były tablicą, vInt[2] to samo co n[2]
• operacje ++ lub - -– są one inteligentne, tzn. na podstawie typu wskaźnika kompilator
wie o ile bajtów ma przeskoczyć• operacje + lub – ograniczone
– można dodawać lub odejmować liczby całkowite (operacja inteligentna tzn. z wykorzystaniem wiedzy na temat wskazywanego typu)
– nie można dodawać dwóch wskaźników– można odjąć dwa wskaźniki – wynikiem jest liczba elementów danego typu
znajdujących się pomiędzy nimi:
int *vInt = n; // wcześniej int n[10];vInt = &n[0]; // to samo
vInt – to adres początku tablicy (pierwszego jej elementu)vInt + 1 – to adres drugiego elementu tablicy*(vInt + 2) – to zawartość wskazywana pod adresem vInt + 2
* tu jakooperatorwyłuskaniazmiennejze wskaźnika
int tab[] = { 1, 2, 5, 7 }; int *p1 = tab; int *p2 = &tab[3];cout << p2 – p1 << endl; // 3

Wskaźniki – przykłady
• można dokonać zmian…
•
• nie wszystkie zmiany możliwe…nie można usunąć przydomka const z żadnego obiektu (można tylko rzutować)
double f1 = 0.;const double pi = 3.14;double *vZmienna = &f1;const double *vStala1 = πconst double *vStala2; // wskaźnik do stałego obiektu, jeszcze nie ustawionyvStala2 = vZmienna;*vZmienna = 25.;double * const vStalyZmienna = const_cast<double * const>( vStala1 );vZmienna = vStalyZmienna;
T & * - takie coś nie istnieje!
przydaje się jako argument funkcji,wtedy wskaźnik – argument, możnawewnątrz funkcji przestawić na inny adres
T * & - referencja do wskaźnika na typ T

Typy złożone w c++ (litania)
Poprzez złożone typy w języku c++ rozumie się:• tablice obiektów danego typu• funkcje, mające parametry danego typu, a zwracające void lub referencje
lub obiekty danego typu• wskaźniki do void lub obiektów, lub funkcji danego typu (włączając w to
statyczne składniki klasy)• referencje do obiektów lub funkcji (tzw. referencje lewej wartości i
referencje prawej wartości)• klasy, zawierające obiekty różnych typów oraz metody składowe, wraz z
odpowiednimi ograniczeniami dostępu• unie, które są rodzajem klasy, mogącej zawierać obiekt różnych typów, w
różnych chwilach czasu• typy wyliczeniowe, zawierające listę nazwanych stałych wartości• wskaźniki do niestatycznych składowych klasy

enum – typ wyliczeniowy „konwencjonalny”
enum – autonomiczny typ wyliczeniowy
poważne mankamenty• możliwa niejawna konwersja z enum do int (może prowadzić
do błędów, jeśli ktoś takiej konwersji nie chce)
• „wyciekanie” identyfikatorów do zewnętrznego zakresu względem miejsca zdefiniowania typu wyliczeniowego (np. enum zdefiniowany w przestrzeni globalnej eksportuje nazwy wszędzie… kolizja nazw)
• nie można określić typu, na jakim zbudowane sa identyfikatory• niemożliwa jest uprzedzająca deklaracja typu wyliczeniowegonienazwany enum – ma sens właśnie przez to, że jego identyfikatory (z listy wyliczeniowej) są widziane na zewnątrz jako stałe (całkowite):
enum EPozycja {eAsystent, // 0eAdiunkt, // 1eProfesor // 2
};
definiowanie zmiennych podobnie jak dla typu wbudowanego:
EPozycja pracownik = eAsystent;
można też zadać wartośćenum EPozycja {
eAsystent = 5,eAdiunkt = eAsystent + 2,eProfesor
}; nie można robić inkrementacji: pracownik++;
int a = eAsystent; // ok, konwersja!pracownik = 3; // bez rzutowania to jest błąd
enum { jeden = 1, dwa = 2, cztery = 4 };
sizeof( EPozycja ) = ?… pewnie 4 ale… może być mniej

enum – silny typ wyliczeniowy (C++11)
• nazwy z listy wyliczeniowej nie wyciekają na zewnątrz• nie następuje niejawna automatyczna konwersja na int
• można (opcjonalnie) zdefiniować typ (musi być całkowity), na którym zbudwany jest nowy enum (domyślnie – int) i dzięki temu kontrolować wielkość
• możliwa jest deklaracja wyprzedzająca
enum class nazwa { lista identyfikatorów };
enum Alert { green, yellow, election, red }; // standardowy, stary typ wyliczeniowyenum class Color { red, blue }; // nowy, silny, identyfikatory nieznane na zewnątrzenum struct TrafficLight { red, yellow, green }; // jak widać, nie koliduje z niczymAlert a = 7; // błąd: zwykły przypadek, nie ma konwersji z int na enumColor c = 7; // błąd: nie ma konwersji int->Colorint a2 = red; // ok: możliwa konwersja Alert::red->intint a3 = Alert::red; // błąd w C++98, ok w C++11int a4 = blue; // błąd: blue nieznane w tym zakresieint a5 = Color::blue; // błąd: brak konwersji Color->intColor a6 = Color::blue; // ok
enum class Color : char; // deklaracjavoid foo(Color* p); // teraz można już użyć
zamiast class może być struct
enum class Color : char { red, blue }; // sizeof( Color ) taki sam jak sizeof( char )

Tablice
tablica - sekwencyjny zbiór zmiennej danego typu (nie void)• dopuszczalne są typy podstawowe, wskaźniki, wskaźniki do
składowych, klasy, typy wyliczeniowe i inne tablice (z nich konstruuje się tablice wielowymiarowe)
• tablica wielkości N posiada ciągły zbiór niepustych elementów, numerowanych od 0 do N-1
• deklaracje, definicje:
typ nazwa[ stała ( lub constexpr )opcj ];…można utworzyć tablicę wskaźników do void:void * tablica[10]; // sizeof(tablica) równy 10*4
int tabl1[5], *tabl2[4]; // tablica int-ów oraz tablica wskaźników do intMojaKlasa tabl3[2];typedef float A[5];typedef const A CA; // CA – typ: tablica 5-elementowa const float
extern int tab[4]; // można też: extern int tab[]; // wtedy w definicji trzeba rozmiar podać
int tab[]; // ok, bo w deklaracji podano rozmiarclass Klasa { static int tab2[4]; /* static, więc to tylko deklaracja */ };int Klasa::tab2[]; // tu definicja – ok, bo rozmiar podano w deklaracji

Tablice – cechy, inicjalizacja
• dostęp do dowolnej pozycji bardzo szybki • wielkość (statycznej) tablicy trzeba z góry zdefiniować• z nazwy tablicy nie wiemy nic o jej wielkości• elementy tablicy są przechowywane w pamięci jeden za drugim• nazwa tablicy: adres (stały) początku tablicy• inicjalizacja:
• wyzerować tablicę można też za pomocą funkcji std::memsetznajdującą się w nagłówku <cstring>
char literki[100] = { 'a', 'b', 'c' }; // reszta zeramistd::string slowa[] = { "Windows", "Linux" };const int stale[4] = { 1, 2, 3, 4 }; // inicjalizacja konieczna
void *memset(void *s, int c, size_t n); // s – adres, c – wartość, n – rozmiarmemset ( literki, 0, sizeof(literki) ); // można jako drugi arg podać też char

std::array – tablica na miarę naszych czasów (C++11)
• łączy w sobie szybkość zwykłej C-tablicy z zaletami bycia kontenerem standardowym, czyli np. „wie jaki ma rozmiar”
• zawiera w sobie agregat; potrzebny nagłówek <array>• wielkość i przetrzymywany typ trzeba z góry określić
• można używać jak tablicę, albo odpytać daną pozycję metodą at(n), można zapytać o pierwszy – front() i ostatni – back() element
• metody empty() – true gdy pusta czyli… zrobiona tak: array<int, 0> a;• size() – rozmiar tablicy, max_size() – hipotetyczny maksymalny rozmiar• fill( const T& val ) – wypełnienie wszystkich elementów wartością val
array<int, 3> a = { 1, 3, 7 }; // znak = opcjonalny, ale…array<string, 2> b { { string("Windows"), "Linux" } }; // powyższe zagnieżdżenie to inicjalizacja wewnętrznego agregatu// ten zapis nie jest przejawem „uniwersalnej inicjalizacji” poprzez// initializer_list<T> ponieważ array nie ma napisanego konstruktora
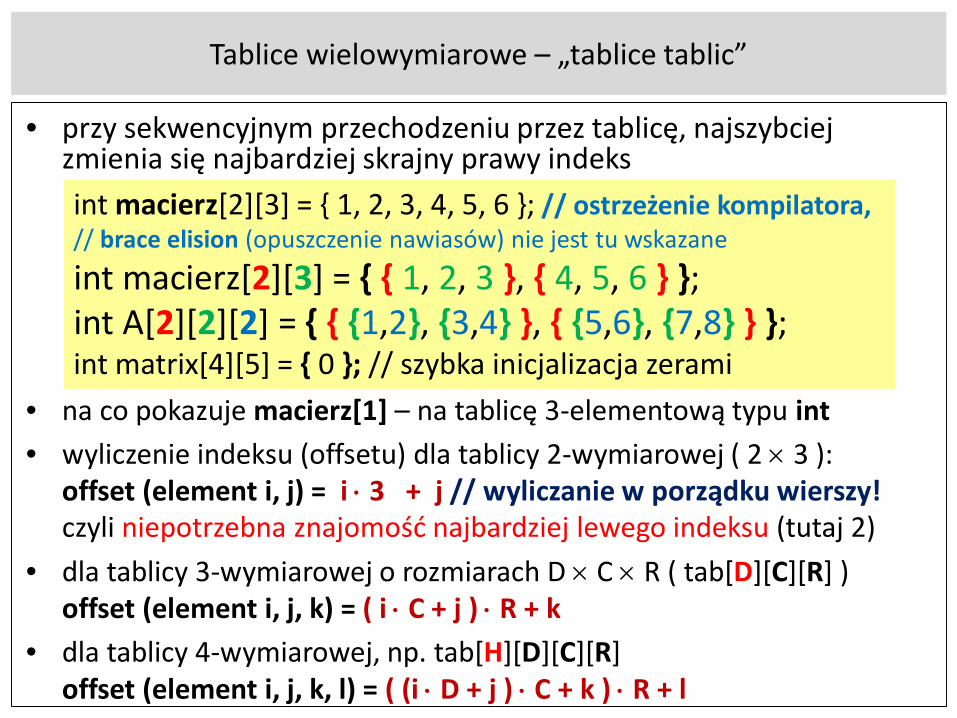
Tablice wielowymiarowe – „tablice tablic”
• przy sekwencyjnym przechodzeniu przez tablicę, najszybciej zmienia się najbardziej skrajny prawy indeks
• na co pokazuje macierz[1] – na tablicę 3-elementową typu int• wyliczenie indeksu (offsetu) dla tablicy 2-wymiarowej ( 2 × 3 ):
offset (element i, j) = i ⋅ 3 + j // wyliczanie w porządku wierszy!czyli niepotrzebna znajomość najbardziej lewego indeksu (tutaj 2)
• dla tablicy 3-wymiarowej o rozmiarach D × C × R ( tab[D][C][R] )offset (element i, j, k) = ( i ⋅ C + j ) ⋅ R + k
• dla tablicy 4-wymiarowej, np. tab[H][D][C][R]offset (element i, j, k, l) = ( (i ⋅ D + j ) ⋅ C + k ) ⋅ R + l
int macierz[2][3] = { 1, 2, 3, 4, 5, 6 }; // ostrzeżenie kompilatora, // brace elision (opuszczenie nawiasów) nie jest tu wskazaneint macierz[2][3] = { { 1, 2, 3 }, { 4, 5, 6 } };int A[2][2][2] = { { {1,2}, {3,4} }, { {5,6}, {7,8} } };int matrix[4][5] = { 0 }; // szybka inicjalizacja zerami

std::array wielowymiarowe niespodzianki
• w zwykłej tablicy, ponieważ najszybciej rotuje prawy indeks, więc myślimy o prawym indeksie (rozmiar 3) jak o kolejnych pozycjach (kolumnach) w wierszu oznaczonym indeksem lewym (rozmiar 2)
• w tablicy zrobionej na bazie array jest odwrotnie! Najszybciej rotujący indeks to ten najbardziej zagnieżdżony, w zapisie matrix[i][j] lewy indeks; zatem poniżej jest odpowiednik int macierz[3][2];
• używając at() można sprawdzić czy wychodzi się poza zakres:matrix.at(0) = 1; // oczywiście źle, bo to jest próba przypisania// int do const std::array<int, 2ul>… poprawna składnia:matrix.at(0).at(0) = 1; // idźmy z prawym indeksem dalejmatrix.at(0).at(2) = 1; // terminate called after throwing // an instance of 'std::out_of_range' what(): array::at// czyli wyszliśmy poza zakres, bo prawy indeks dotyczy tej// zagnieżdżonej tablicy, zatem odwrotnie niż w statycznej tablicy
int macierz[2][3]; // 2 wiersze, 3 kolumny, 2 × 3
array< array< int, 2>, 3> matrix; // 3 wiersze, 2 kolumny, 3 × 2

std::array jednak nie takie samo jak C-array
• krytykowaną własnością std::array jest brak dedukcji rozmiaru z wielkości listy inicjalizującej, niemożliwy jest zapis:
• obejściem tego problemu jest napisanie, za pomocą szablonów o zmiennej liczbie parametrów funkcji tworzącej, co wykracza za bardzo poza ten wykład, ale oto przykładowe rozwiązanie:
template <typename ...Args> struct all_same { static const bool value = false; };template <typename S, typename T, typename ...Args> struct all_same<S, T, Args...> {static const bool value =
std::is_same<typename std::decay<S>::type, typename std::decay<T>::type>::value && all_same<T, Args...>::value;};template <typename S, typename T> struct all_same<S, T> {static const bool value =
std::is_same<typename std::decay<S>::type, typename std::decay<T>::type>::value;};template <typename T> struct all_same<T> { static const bool value = true; };
template <typename T, typename ...Args>typename std::enable_if<all_same<T, Args...>::value, std::array<T, sizeof...(Args) + 1>>::typemake_array(T && t, Args &&... args) {return std::array<T, sizeof...(Args) + 1> { std::forward<T>(t), std::forward<Args>(args)...};
}
array<int> n = { 1, 2, 3 }; // musimy podać rozmiar: array<int,3>

Tablice wielowymiarowe – czytanie typów
int tablica[2][3][4];
Jakiego typu jest:
tablica – int (*)[3][4]*tablica – int (*)[4]tablica[0] – int (*)[4]*tablica[0] – int*&tablica[0] – int (*)[3][4]tablica[0][0] – int**tablica[0][0] – int&tablica[0][0] – int (*)[4]tablica[0][0][0] – int&tablica[0][0][0] – int*
int *s[4];s – typu int** – tablica czteroelementowa wskaźników do int
int (*p)[3];p – typu int (*)[3] – wskaźnik do trójelementowej tablicy int
int mac[][3] = { {1,2,3},{4,5,6},{7,8,9} };p = &mac[1];cout << *(*(p+1)-4) << endl;
Skoro p jest „wskaźnikiem do trójelementowej tablicy int”, więc jednostką dla niego jest taka właśnie tablica: p+1 oznacza przejście o wielkość int[3] do przodu, natomiast *(p+1) jest typu int* więc operacja (*(p+1)-4) oznacza przejście wskaźnika o cztery int wstecz, by na koniec wyłuskać wartość *(*(p+1)-4), czyli 3

new i delete – tworzenie i niszczenie
malloc() oraz free() – funkcje biblioteczne, poza kontrolą kompilatora
tworzenie obiektu w C++• przydzielenie pamięci
• pamięć statyczna• stos (pamiętamy o czasie życia obiektów, ograniczonym
zakresem ich ważności)• sterta (dynamiczny przydział, czas życia dowolny, nie
ograniczony zasięgiem)• wywołanie konstruktora (specjalnej funkcji)operator new
operator delete
int *pN = new int(10); // wskaźnik pokazuje na 10double *pD = new double[*pN]; // tablica
delete pN;delete [] pD;
Stosowanie zwykłych wskaźników wymaga dużej dyscypliny w kontrolowaniu „kto odpowiada za dany zasób”, pilnowania, żeby nie utracić kontaktu z zasobem oraz usuwania go w odpowiednim momencie.

new i delete – tablice
dynamiczne tablice wielowymiarowe
dwuwymiarowa … to samo:
usunięcie jest operacją odwrotną
int (*pTabl)[3][4] = new int[zmienna][3][4]; // nawiasy ( ) bo priorytety operatorów!
int **pTablica;pTablica = new int*[5];for (int i = 0; i < 5; i++)
pTablica[i] = new int[7];
for (int i = 0; i < 5; i++)delete [] pTablica[i];
delete [] pTablica;
zwykły operator new działa w dwóch etapach, najpierw alokuje potrzebną ilość pamięci, następnie tworzy w niej obiekt i dopiero na koniec zwraca wskaźnik (odpowiedniego typu) do utworzonego obiektu
pamiętajmy, że istnieją dwie wersje operatora delete, jedna zwykła, a druga tzw. tablicowa delete []
int ** pTablica( new int*[5] );for ( size_t i(0); i != 5; ++i ) {
pTablica[i] = new int[7];}

operator new (sytuacja krytyczna)
• gdy zaalokowanie odpowiedniej ilości pamięci na stercie się nie powiedzie, wywołana zostaje funkcja obsługi operatora new (new handler)
• domyślna wersja funkcji zgłasza wyjątek typu bad_alloc• możemy zmienić sposób reagowania na brak pamięci, np. dodać informację
o okolicznościach wyczerpania się zasobów
#include <iostream>#include <cstdlib>#include <new>using namespace std;
static long i; // zmienne statyczne inicjalizowane przez 0void informacja_krytyczna(); // deklaracja wyprzedzająca
int main() {// podajemy adres funkcji która ma być wywołana w krytycznej sytuacjiset_new_handler(informacja_krytyczna);for (i; ; i++) new int[1000000]; // nieskończona pętla aż do wyczerpania
}void informacja_krytyczna() {cout << "Pamiec wyczerpana po: << i << " alokacjach.\n"; exit(1);// np. exit(42) zwraca kod wykonania programu równy 42
}

Funkcje – argumenty, wartości zwracane
• funkcja to podprogram• funkcję identyfikuje jej nazwa, trzeba ją zadeklarować – wyjątek to funkcja main• definicja funkcji jest deklaracją, niemniej
starajmy się deklarować wszystkie funkcje• deklarację funkcji można zagnieździć w innej funkcji, ale definicji funkcji nie
można zagnieżdżać w innej funkcji (nawet w main)• funkcja może przyjmować dowolne parametry i zwracać dany typ lub nic nie
zwracać (wtedy piszemy void)
• nigdy nie zwracamy adresu (referencji) do obiektu lokalnego(czas jego życia się skończył…)
• main zwraca zawsze int – z przyczyn historycznych nie musimy wołać komendy return, kompilator nie napotkawszy jej wstawia na koniec bloku tej funkcji return 0;
void fun(); // nic nie zwraca, ale można wewnątrz funkcji napisać // pustą instrukcję wyjścia return;
int fun(string, int); // deklaracja nie wymaga podania nazw zmiennych, // ale dla czytelności kodu warto je pisać
auto fun( double ) -> double; // nowa notacja C++11 ( -> trailing return type )auto fun( char ); // możliwe w C++14 ale wtedy przed wywołaniem funkcja // musi być zdefiniowana, sama deklaracja nie wystarczy bo nieznany jest typ zwracany

Funkcje – sposoby przekazania parametrów
• sposoby przekazywania parametrów do funkcjivoid fun(float f); // przez wartość, do wnętrza funkcji tworzona jest kopia// obiektu f, więc oryginału nie można zmienić (uszkodzić)void fun(const float f); // to nie ma sensu, tworzona jest kopia// i nawet tej kopii nie da się zmienić, czytelniej więc byłoby // jako argument używać float f, a w pierwsze linii funkcji np.// const float& argf = f;void fun(float& f); // przez referencję (adres), można // modyfikować obiekt podawany jako parametrvoid fun(const float& f); // przez referencję do stałego obiektu,// optymalny sposób! – nie jest tworzona kopia, a argument jest// chroniony przed zmianąvoid fun(float&& f); // przez referencję do prawej wartości, większy sens// ma dla typów złożonych, które umożliwiają operacje przenoszeniavoid fun(const float&& f); // zwykle bez sensu, bo blokuje przenoszenievoid fun(float* f); // przez wskaźnik, można modyfikowaćvoid fun(const float* f); // wskaźnik do stałego obiektu, nie można modyfikować

Funkcje – wywołanie a parametry
• jaka jest różnica pomiędzy parametrem "przez referencję" i "przez wskaźnik"? Sposób wywołania funkcji:
• na temat dedukcji typu zwracanego przez funkcję:
auto f(); // zwracany typ nieznanyauto f() { return 5; } // zwracany typ intauto f(); // redeklaracja – okint f(); // błąd – traktowane jako deklaracja inne funkcjiauto f() { return f(); } // błąd, dopóki typ zwracany jest nieznany,
// nie można wołać rekurencyjnieauto suma(int i) {
if (i==1) return i; // zwracany typ teraz znanyelse return suma(i-1) + i; // można więc dalej wołać rekurencyjnie
}// taka funkcja może mieć wiele instrukcji return ale każda zwracająca taki sam typ
float mojaLiczba = 0.;fun(mojaLiczba); // przez referencję, tak samo jak przez wartośćfun(&mojaLiczba); // przez wskaźnik, trzeba podać adres obiektu za pomocą &

Funkcje – tablice argumentami, inline
• tablice jako argumenty funkcji nie są przekazywane przez wartość
• funkcje inline (krótkie, w celu szybkiego wywoływania)• treść rozwijana w miejscu ich wystąpienia, o ile nie jest zbyt skomplikowana• dla zwykłej funkcji: deklaracja (bez specyfikatora) w nagłówku
definicja w plku źródłowym poprzedzona specyfikatorem inline
• podobnie dla metody składowej (tylko definicja ze słowem inline)• wszystkie funkcje zdefiniowane wewnątrz klas są automatycznie inline• jeśli pobierany jest adres funkcji – nie następuje rozwinięcie
(w szczególności w procesie „debugowania” – krokowego śledzenia działania programu)
void func1(int a[], int rozmiar); // musimy podać rozmiarvoid func2(int *a, int rozmiar); // array-to-pointer decayvoid func3(int (&a) [10]); // tylko 10-elementowa tablicavoid func4(int macierz[][3], int rozmiar);
void fun();
inline void fun() { /* definicja */ }

Funkcje – wartości domyślne
argumenty domniemane (od prawej do lewej) tylko w deklaracji
• deklaracja argumentu domyślnego tylko raz(w danym zakresie ważności)• w deklaracji funkcji – deklaracje można powtarzać, ale
nie z powtórzonymi w nich wartościami domyślnymivoid fun(int a); // w deklaracjach można zmieniać
// nazwy zmiennych, tylko po co…void fun(int a = 5); // tak jest dobrze
• w definicji funkcji jeśli ta jest jednocześnie jej deklaracją• obiekty lokalne nie mogą być wartościami domyślnymi• w nowym (lokalnym) zakresie ważności możliwa jest deklaracja
z innymi wartościami domyślnymi – nie jest to dobra praktyka!
void fun(int a, void*, float = 3.14, char znak= '\0');

Funkcje – wartości domyślne, przykłady
void g(int = 0, ...); // ok, bo … (wielokropek) to nie argument, tylko ich listavoid f(int, int);void f(int, int = 7); // powtórzenie deklaracji z dodaną wartością domyślnąvoid h() {
f(3); // OK, woła f(3, 7)void f(int = 1, int); // błąd: niezależne od wartości domyślnych deklaracji
// z innego – zewnętrznego – zasięgu }void m() {
void f(int, int); // nie ma wartości domyślnychf(4); // błąd: niepoprawna liczba argumentówvoid f(int, int = 5); // OKf(4); // OK, woła f(4, 5);void f(int, int = 5); // błąd: nie można redeklarować, nawet
// z taką samą wartością domyślną}void n() {
f(6); // OK, woła f(6, 7)}

Funkcje – dowolna liczba argumentów
int suma ( int liczba, … ) {va_list ap; // utworzenie zmiennej typu va_list (variable argument list)va_start( ap, liczba ); // ustawienie ap na pierwszy, jawnie podany, argumentint sum = 0;for (int i = 0; i < liczba; ++i ) {
sum += va_arg( ap, int ); // odczyt kolejnej zmiennej, sami określamy jej typ!}va_end( ap ); // porządkowanie stosu, ustawienie ap na 0return sum;
}int main() {
cout << sum(3, 1, 1, 1, 1, 1) << endl; // OK, możemy mniej liczyć, 3cout << sum(8, 1, 1, 1, 1, 1, 1) << endl; // śmieci, wyszliśmy poza listę
}
… - wielokropek umożliwia napisanie funkcji przyjmującej dowolną liczbę argumentów• Przynajmniej jeden (pierwszy) argument takiej funkcji musi być podany jawnie.• Obsługa (odczyt) takich argumentów za pomocą makr, pochodzących z języka C.• Konieczne włączenie nagłówka <cstdarg> ( lub stdarg.h )
Wady: argumenty poza kontrolą typów. Popularne przykłady z biblioteki: printf, sprintf

Funkcje – argumenty funkcji main
int main(int argc, char* argv[]) { // …to samo:
int main(int argc, char** argv) { // …
• argc – liczba argumentówpierwszym zawsze jest ścieżka i nazwa programuargv[0] – zapisana w pierwszej pozycji tej tablicy
• kolejne argumenty można konwertowaćpo włączeniu nagłówka #include <cstdlib>za pomocą funkcji: atoi(), atol(), atof()
• możemy wykorzystać obiekt klasy istringstream– klasa ta dziedziczy po klasie istream, ta zaś dziedziczy po klasie ios, zaś ta
po klasie ios_base– oznacza to, że obiekt ten "ma w sobie" wszystkie funkcje zdefiniowane
w powyższych klasach– ponadto ma zdefiniowaną własną funkcję:
void str(const string& tekst) const;string str() const;

Funkcje – odczyt argumentów funkcji main
#include <iostream>#include <sstream>using namespace std;
// wywołajmy program na przykład ze zmiennymi: Rok 2010
int main(int argc, char* argv[]) {istringstream ss(argv[1]); // tu pierwszy argument w konstruktorzestring slowo;ss >> slowo;// w tym momencie pozycja czytania strumienia doszła do jego końcaif (ss.eof()) {
// jeśli tak, to musimy "przywrócić" strumień do czytania od początkuss.clear( ss.rdstate() & ~ios::eofbit );
}// poddajemy nowy strumień obiektowi istringstream, czyli drugi argumentss.str(argv[2]); // tu drugi argument za pomocą funkcji strint rok;ss >> rok;cout << "Argument 1: "<< slowo << " Argument 2: "<< rok << endl;
}

Pomiędzy innymi typami a „łańcuchem znakowym”
#include <string>// konwertuje zmienną typu int na łańcuch znakowy std::stringstd::string to_string( int value );// taki sam, gdy działało sprintf o odpowiednio dużym buforzestd::sprintf(buf, "%d", value); // podobnie pozostałe:std::string to_string( long value );std::string to_string( long long value );std::string to_string( unsigned value );std::string to_string( unsigned long value );std::string to_string( unsigned long long value );std::string to_string( float value );std::string to_string( double value );std::string to_string( long double value );
Warto wiedzieć, że sytuacja, gdy „skazani byliśmy” na printf (sprintf) nie ma już miejsca!W nagłówku <string> dostępna jest seria przeciążonych funkcji to_string, działającychkomfortowo i bezpiecznie z punktu widzenia kontroli typów.Nie musimy się też martwić o wielkość wypełnianego buforu!

Pomiędzy „łańcuchem znakowym” a innymi typami
#include <string>// konwertuje łańcuch znakowy std::string na typ całkowityInt stoi( const std::string& str, size_t *pos = 0, int base = 10 );long stol( const std::string& str, size_t *pos = 0, int base = 10 );long long stoll( const std::string& str, size_t *pos = 0, int base = 10 );unsigned long stoul( const std::string& str, size_t *pos = 0, int base = 10 );unsigned long long stoull( const std::string& str, size_t *pos = 0, int base = 10 );
// konwertuje łańcuch znakowy std::string na typ zmiennoprzecinkowyfloat stof( const std::string& str, size_t *pos = 0 );double stod( const std::string& str, size_t *pos = 0 );long double stold( const std::string& str, size_t *pos = 0 );
Podobnie w drugą stronę, jeśli mamy łańcuchy znakowe (np. parametry programu), możemyteraz skorzystać z następujących funkcji konwersji. Działają one następująco: opuszczają białe znaki, czytają cyfry (tak wiele ile jest poprawne dla ustawionej bazy base, resztę ignorują), jeśli podstawi się jako drugi parametr niezerowy wskaźnik, to wpisane w niego zostaje adres pierwszego nieskonwertowanego znaku oraz jego indeks.

Wskaźniki do funkcji
nazwa funkcji jest zarazem jej adresem• wskaźnik do funkcji bez argumentów i nie zwracającej żadnej
wartościprzeczytajmy to:
bardziej skomplikowane deklaracje
spróbujmy to przeczytać:pFun1() – pFun1 jest bezarg. funkcją…*(pFun1()) – …zwracającą wskaźnik do…(*(pFun1()))[10] – …10-elementowej tablicy…(*(*(pFun1()))[10]) – …zawierającej wskaźniki do…(*(*(pFun1())[10])() – …funkcji bezargumentowych…int (*(*(pFun1())[10])() – …zwracających int
void (*pFun)();
*pFun – pFun jest wskaźnikiem do…(*pFun)() – …bezargumentowej funkcji…void (*pFun)() – …zwracającej void (czyli nic)
Co by się stało, gdyby przestawić jeden z nawiasów, np. tak:int (*(*(pFun1()) [10] ))();… byłby błąd: deklaracja funkcji zwracającej tablicę
int (*(*(pFun1()))[10])();

Wskaźniki do funkcji – przykład dla…
• typedef znacznie upraszcza zapis (czasem jest wręcz konieczny)
to też spróbujmy przeczytać:(*pFun2) – pFun2 jest wskaźnikiem do…(*pFun2)() – …bezargumentowej funkcji…(*(*pFun2)()) – …zwracającej wskaźnik do…(*(*pFun2)())[10] – …10-elementowej tablicy…(*(*(*pFun2)())[10]) – …zawierającej wskaźniki do…(*(*(*pFun2)())[10])(void (*(tab[]))()) – …funkcji, która jako argument ma…
tab[] – …tablicę… (*(tab[])) – …wskaźników do…void (*(tab[]))() – …bezargumentowej funkcji nic nie zwracającej…
double (*(*(*pFun2)())[10])(void (*(tab[]))()) - …a zwraca typ double• normalny przykład użycia – tablica wskaźników do funkcji
typedef double (*(*(*pFun2)())[10])(void (*(tab[]))());pFun2 mojaZmienna;
void glos1(); void glos2(); void glos3();// … gdzieś dalej w funkcji mainvoid (*tablica[3])() = { glos1, glos2, glos3 }; // 3-elementowa tablica wskaźników do…tablica[0](); // wywołanie funkcji glos1(*tablica[2])(); // wywołanie funkcji glos3

Funkcje – przeładowanie (przeciążenie)
• przeładowanie (przeciążenie) ma miejsce, gdy w danym zakresie ważności dostępne są więcej niż jedna funkcja o tej samej nazwie
• rozróżnienie funkcji następuje poprzez listę parametrów funkcji, która musi się różnić, ewentualnie modyfikator metody const
• typ zwracany przez funkcję nie ma znaczenia• to nie jest żadna technika obiektowa, kompilator buduje sobie nazwę funkcji
poprzez doklejanie do nazwy różnych przyrostków opisujących argumenty (ang.: name mangling – „dekorowanie”)
• „dekorowanie” nazw nie jest określone w standardzie (zależne od kompilatora)void fun(int); // _Z3funiint fun(int, double); // _Z3funidchar fun(char, short int, float*); // _Z3funcsPfdouble* fun(int&, const double&, char*); // _Z3funRiRKdPc
• jeżeli chcemy skonsolidować nasz kod z kodem skompilowanym w innym języku (C, Fortran) w którym nie ma „dekorowania”, musimy użyć specyfikatora extern "C"
extern "C" void mojaZewnFun(int, double);extern "C" { /* można też więcej w nawiasach */
#include "myHeader.h" // można włączyć nagłówek}

Funkcje – przeładowanie (szczegóły)
• użycie typedef (albo using) nie powoduje zmiany typutypedef int calkowity;void fun(int);void fun(calkowity); // nie wolno, ta sama funkcja
• enum to już zupełnie inny typ, mimo iż oparty na wielkościach całkowitych, podobnie short int to inny typ niż int
enum EPozycja { eAsystent = 1, eAdiunkt, eProfesor };void fun(int);void fun(short); // OKvoid fun(EPozycja); // OK
• o możliwości przeładowania decyduje wygląd inicjalizatora, jeżeli parametr, z którym jest wywołana funkcja wygląda tak samo, to przeładowanie niemożliwe
void fun(int tablica[]); void fun(int* ptrTab); // obie funkcje można wywołać z takim samym // argumentem, np. nazwą tablicy int tab[5];
• jeśli parametrem jest tablica, to pamiętajmy o nieznaczeniu najbardziej lewego indeksu do rozróżnienia typów
void fun(int tab1[10]);void fun(int tab2[5]); // tab1 i tab2 nierozróżnialnevoid fun(int tab3[6][3]);void fun(int tab4[6][2]); // tab3 i tab4 rozróżnialne

Funkcje – przeładowanie (c.d.)
• identyczność T oraz T& – void fun(T) i void fun(T&)są nierozróżnialne, bo wywoływane z tym samym parametrem
• identyczność T, const T, volatile T – podobnie, inicjalizator takich argumentów wygląda tak samo, nie da się rozróżnić funkcji
• rozróżnialność T*, const T*, volatile T*w przypadku takich argumentów inicjalizatory muszą być różne
• rozróżnialność T&, const T&, volatile T&podobnie, takie funkcje o takich argumentach mogą być przeładowane
• wskaźnik do funkcji pokazujący na przeciążoną nazwę funkcji – wskaźnik jest ściśle określony, więc nie ma problemu z przeciążeniem (niezależnie od tego czy wskaźnik jest argumentem lub typem zwracanym przez funkcję)
• dwie przestrzenie nazw mogą doprowadzić do przeciążenia funkcji o tej samej liście parametrów, ale tylko do chwili wywołania (niejednoznaczność sygnalizowana przez kompilator – ale tylko jeśli jest takie wywołanie, więc taka niejednoznaczność może pozostać niezauważona)namespace A { void fun(int) { cout << "Jestem z A /n"; } }namespace B { void fun(int) { cout << "Jestem z B /n"; } }using namespace A;using namespace B;fun(5); // wywołanie funkcji niejednoznaczne, błąd kompilatoraA::fun(5); // w takim wypadku trzeba jawnie podać kwalifikator

Funkcje – dopasowanie argumentów (1)
• dokładne (parametry dokładnie pasują do argumentów)• dopasowanie z tzw. trywialną konwersją
T → T&, T& → T, T[] → T*, T(arg) → (*T)(arg), T → const T, T →volatile T, T* → const T*, T* → volatile T*
• dopasowanie z konwersją bezstratną (tzw. „promocja”) float → double, char (signed char, unsigned char, short int, unsigned short int) →int lub unsigned int (wybiera ten typ, który nie obetnie danych!)bool → intwchat_t (enum) → int lub unsigned int lub long lub unsigned longpola bitowe → int lub unsigned int (ten, który nie obetnie!)
nie należy mylić tego z przeciążonymi wersjami funkcjamitu mówimy o dopasowaniu konkretnych argumentów do argumentów z deklaracji funkcji

Funkcje – dopasowanie argumentów (2)
• dopasowanie za pomocą konwersji standardowych (może być stratna)int → unsigned int, unsigned int → int, double → float, zmiennoprzecinkowy → całkowity, całkowity →zmiennoprzecinkowy, konwersje arytmetyczne, konwersje wskaźników (0 na wskaźnik do adresu zerowego), wskaźnik nie-const i nie-volatile na void*, wskaźnik klasy pochodnej na wskaźnik klasy podstawowej, referencja do klasy pochodnej na referencję do klasy podstawowej
• dopasowanie z użyciem konwersji zdefiniowanych przez użytkownika (dopuszczalna tylko jedna)
• do funkcji z wielokropkiem void fun(…) – jeśli taka jest• wskaźniki – tylko dosłownie!• jeśli funkcja z kilkoma argumentami, to wybierane najlepiej
dopasowane

std::function – uogólnienie wskaźnika na funkcję (C++11)
Wskaźnik na funkcję mógł pokazywać tylko funkcję.std::function może pokazywać na wszystko, co można wywołać: funkcje, obiekty funkcyjne, wyrażenia lambda, wyrażenia bind, wskaźniki na metody składowe.
Nowa składnia też możliwa, np.: std::function<auto(int)->void> f;Jeśli obiektu std::function nie ustawi się na coś i spróbuje wywołać, zgłoszony zostanie wyjątek: std::bad_function_callUżycie std::function jest zwykle kosztowniejsze (w sensie czasu wykonania) niż użycie auto, ale nie zawsze auto jest dozwolone:
void fun(int i) { cout << "to ja " << i << endl; }std::function<void(int)> f = fun; // f pokazuje na funkcję funf(7); // wywołanie
void useIt(auto func); // błądvoid useIt(std::function<bool(long)> func); // okclass Klasa { auto func; // błąd…class Klasa { std::function<bool(long)> func; // ok…
Nagłówek: <functional>

auto – dedukcja typu (C++11)
auto – dawniej oznaczało tylko zmienną lokalną (automatyczną)• dedukcji typu w oparciu o typ inicjalizatora
lub typu zwracanego przez funkcję
• dedukcja odbywa się tak jak w szablonach, z wyjątkiem rozpoznawania listy { a, b, c }, którą auto widzi jako std::initializer_list<T> (gdzie T to typ a, b, c)
auto i = 7; // typ intauto x = wyrażenie // x będzie typu zwracanego przez wyrażenie
template<class T> // to samo co: template<typename T>int whatever(T t) {
T x; // równoważne do auto x poza szablonem};

auto – dedukcja typu (C++11)
• korzystne gdy typ bardzo długi (szablony…)
• czasem wręcz bardzo pomocne, gdy typy nieustalone•
• może prowadzić do nowych nawyków
template<class T> void printall(const vector<T>& v) { for (typename vector<T>::const_iterator p = v.cbegin(); p != v.cend(); ++p)
cout << *p << "\n"; for (auto p = v.cbegin(); p != v.cend(); ++p)
}
auto i = MyClass(); // zamiast poniższegoMyClass i;
template<class T, class U> void (const vector<T>& vt, const vector<U>& vu) { // ... auto tmp = vt[i]*vu[i]; // ...
}

auto – zastosowania ( C++11 )
• przykłady
• działa również z operatorem new
• szczególnie wygodne do dedukcji typów iteratorów
• uwaga na przyszłość: (C++14) auto działa również wewnątrz wyrażeń lambda, np. [ ] ( auto param ) { };
for( auto i = m.begin(); i != m.end(); ++i ) .. // niech m jest typu map<int,string>const auto& y = m; // y jest typu const std::map<int, std::string>&
auto a = 0; // a jest typu intconst auto *ptr = &a, b = 5; // ptr typu const int*, b typu const intstatic auto d = 3.14; // d typu doubleauto x = { 1, 2, 3 }; // x typu std::initializer_list<int>
new auto(1); // alokowanym typem jest intauto z = new auto('a'); // alokowanym typem jest char, z jest typu char*

auto – zastosowania ( C++11/14 )
• niektóre rzeczy są (C++14) już możliwe, a niektóre nadal nie:
• możliwe jest
• uwagaauto s = "hello world"; // jest typu const char*auto& s = "hello world"; // jest typu referencja do const char[12] czyli tablicy
void fun( auto arg ) { } // autodedukcja typu argumentu możliwa w C++14class Foo {
auto m = 1; // źle: autodedukcja typu zwykłej składowej klasy niemożliwa// bo np. auto m = f(); wprowadzałoby spory problem w szukaniu // właściwej interpretacji tego czym jest f()};auto tablica[5]; // źle: autodedukcja typu z którego zbudowana jest tablica
class Foo {static const auto n = 0; // jeśli static to tylko const inicjalizowany i również auto
};

auto – nowe metody w kontenerach, nowa pętla for ( C++11 )
W kontekście auto przydatne są nowe metody kontenerów:• zwracają jawnie stałe iteratory: cbegin(), cend(), crbegin(), crend()
Nowa składnia dla pętli for (tzw. range-based loop)
Można przebiegać po tablicach, kontenerach oraz dowolnych typach wyposażonych w iteratory, zwracane przez begin() i end()
short tablica[5];for ( auto& t : tablica ) { t = -t; } std::unordered_multiset<std::shared_ptr< T >> obj;for ( const auto& r : obj ) cout << r; // wypisuje wskaźnik// pytanie: czemu powyższe przez referencję?
auto ci = m.cbegin(); // ci typu std::map<int, std::string>::const_iterator
vector<int> v { 1,2,3,4,5 };for ( int i : v ) cout << i << endl; // i bezpośrednio każdym elementem wektorafor ( auto i : v ) cout << i << endl; // to samo co powyżejfor ( int& i : v ) cout << ++i; // może być też referencją i zmieniać zawartość!for ( auto& i : v ) cout << ++i; // to samo co powyżejfor (const int i : v ) jakasMetoda( i ); // const/volatile też możliwe
w C++11 nie ma problemu zagnieżdżonychnawiasów szablonów, nie
trzeba rozdzielać spacją

auto – referencje, modyfikatory ( C++11 )
Dla zmiennych nie zadeklarowanych wprost jako referencje, modyfikatory const/volatile na najwyższym poziomie są ignorowane:
Podobnie (tak jak działa dedukcja w szablonach) referencje ignorowane:
Referencje do prawych-wartości:
Wskaźniki i modyfikatory:
const vector<int> w;auto v1 = w; // v1 typu vector<int>, const zignorowaneauto& v2 = w; // v2 typu const vector<int>& - ale jeśli przez referencję, to ok
int a; int& r = a;auto b1 = r; // b1 typu intauto& b2 = r; // b2 typu int&
int a; int& r = a;auto&& c1 = r; // c1 typu int& ponieważ r jest „lewą-wartością” więc: && → &auto&& c2 = 7; // c2 typu int&& gdyż 7 jest „prawą-wartością”
int a; const int* const pcc = &a; const int* pc = &a; int* p = &a;auto d1 = pcc; // d1 typu const int* czyli const wskaźnika zignorowaneauto d2 = pc; // d2 typu const int*auto d3 = p; // d3 typu int*

auto – referencje, modyfikatory ( C++11 )
W przypadku „referencji do p-wartości” zwracanej przez funkcję:
Tablice i nazwy funkcji redukują się do wskaźników:
Jeżeli const/volatile nie na najwyższym poziomie, to zostają:
Za pomocą auto można deklarować więcej zmiennych w linii:auto zmienna = s, *ptr_zmienna = &s; // dedukcja typu inicjalizatora – ten sam typauto i = 3, d = 3.14; // błąd – rożne typy inicjalizatorów
int&& fun();auto f1 = fun(); // f1 jest typu int
double tablica[5];auto t1 = tablica; // t1 typu double* - to się nazywa ”array decay to pointer”auto& t2 = tablica; // t2 typu double(&)[5] – właściwy typ tylko jeśli przez referencję
auto i = 10; map<int, string> m;const auto *pi = &i; // pi jest typu const int*const auto& pm = m; // pm typu const map<int, string>&

decltype ( C++11 )
decltype – służy do określenia typu w czasie kompilacji
int a, *p;struct K { float f; } *ptr;decltype(a) m; // m jest typu intdecltype(p) mp; // mp jest typi int*size_t s = sizeof( decltype( ++m ) ); // s = sizeof(int), m nie jest ewaluowana (powiększona)
decltype(ptr->f) x; // x jest typu floatdecltype(K::f) y; // y jest typu floatvector<int> v;decltype (v[0]) z; // z jest typu int&decltype(v) v2; // v2 jest typu vector<int>decltype(v)::iterator it; // vector<int>::iterator
decltype – głownie po to, żebyokreślić typy zwracane w szablonach,zależne od typów parametrów
template <typename X, typename Y>auto mnożenie(X x, Y y) -> decltype(x*y) {
return x*y;}
template <typename X, typename Y>decltype(x*y) mnożenie(X x, Y y) {
return x*y;} // składnia z auto na początku jest // konieczna, powyższe jest błędne bo// x i y jeszcze „nie zaistniały”

decltype i decltype(auto) ( C++14 )
Podwójny nawias względem wyrażenia decltype:
W standardzie C++14 decltype w połączeniu z auto:
Niespodzianki:
int&& f();auto var1 = f(); // var1 jest typu intdecltype( f() ) var2 = f(); // var2 jest typu int&&
decltype ((a)) m2 = a; // int a; m2 jest typu int& - wymaga inicjalizacji// jeśli: const int a; wtedy m2 jest typu const int&
decltype(auto) var3 = f();
decltype(auto) f1() {int x = 0;return x; // decltype(x) jest int, więc f1 zwraca int
}decltype(auto) f2() {
int x = 0;return (x); // decltype((x)) jest int&, więc f2 zwraca int& …do obiektu lokalnego!
}
Trzeba uważać na nawiasy!

auto i decltype ( C++14 ) kilka przykładów na podsumowanie
Przykłady:int a;int&& fun();auto k1 = a; // k1 jest typu intdecltype(auto) k2 = a; // k2 jest typu intauto k3 = (a); // k3 jest typu intdecltype(auto) k4 = (a); // k4 jest typu int&auto k5 = fun(); // k5 jest typu intdecltype(auto) k6 = fun(); // k6 jest typu int&&auto k7 = { 1, 2, 3 }; // k7 jest typu std::initializer_list<int>decltype(auto) k8 = { 1, 2, 3 }; // błąd: {1, 2, 3} nie jest wyrażeniemauto *k9 = &a; // k9 jest typu int*decltype(auto) *k10 = &a; // błąd: to jest niepoprawne wyrażenieW standardzie C++17 nastąpią pewne zmiany, np.:auto k11 { 7 }; // k11 będzie int, (w C++14) jest std::initializer_list<int>

Para obiektów – std::pair
Czasem przydaje się pojedynczy obiekt, ale reprezentujący więcej niż jeden typ. Dwa obiekty dowolnego typu można zamknąć w szablonie std::pair
Utworzenie pary (wprost albo za pomocą std::make_pair):
Para zawiera dwa pola, jej składowe nazwano first i second:
int tab[] = { 1, 2, 3, 4 };pair<int, double> p1( 3, 3.14 );auto p2 = make_pair( tab[2], 3.14 ); // z dedukcją typu: int, doubleauto p3 = make_pair( ref( tab[0] ), tab); // jeśli chcemy referencję// to możemy opakować w std::ref z nagłówka <functional>, drugie pole int*pair< int, double > p4 = { 3, 2.45 }; // dostępne w C++11
#include <utility> // typ std::pair w tym nagłówku
template < typename T1, typename T2 > class pair;
cout << p1.first << ", " << p1.second; // 3, 3.14cout << p3.first << ", " << *(p3.second+3); // 1, 4

std::tuple i std::get ( C++11 )
Uogólnienie std::pair na dowolny zbiór wielkości różnego typu (heterogeniczny), ale o stałej wielkości (jak w deklaracji).
Można zainicjalizować inną tuplę:
Dostęp do elementów tupli poprzez get:
Indeks (argument szablonu get) jest wygenerowany podczas kompilacji, nie można więc podstawić zmiennej!Dla lepszej czytelności, można użyć etykiet z typu wyliczeniowego itp.Pętle for/do/while po argumentach tuple niemożliwe.
std::tuple< Nazwisko, Adres, Data > info( pracownik ( n ) );
#include <tuple> // związane również z <utility>
std::tuple< Nazwisko, Adres, Data > pracownik( unsigned id );
std::get<0>(info);std::get<1>(info);std::get<2>(info);

std::tie ( C++11 )
Zamiast wiele razy wołać std::get można użyć std::tie
Jeśli chcemy odczytać tylko niektóre pola, można użyć std::ignore
std::tie można użyć też z std::pair ponieważ std::tuple akceptuje std::pair jako argument konstruktora (jednego z wielu...):
std::tie( n1, a1, std::ignore ) = pracownik( m ); // nie chcemy datystd::tie( std::ignore, a1, std::ignore ) = pracownik( m );
// chcemy tylko adres... chyba łatwiej użyć tutaj std::get
Nazwisko n1; Adres a1; Data d1;std::tie( n1, a1, d1 ) = pracownik( m ); // w nagłówku <tuple>
std::pair<Nazwisko, Adres> czytajNazwAdr(unsigned n);std::tie(n1, a1) = czytajNazwAdr(i);

Typy abstrakcyjne – klasa i obiekt
• Z myślenia w kategoriach "jak to zrobić" przechodzimy do myślenia bezpośredniego nad zagadnieniem, czyli "co zrobić"
• Odwrócona kolejność tworzenia: opis danych, przepływ danych, algorytmy
• Najważniejsze są dane, na których operujemy
• klasa– matryca, "plan" według którego powstaje obiekt (opisana zawartość,
a także sposób utworzenia – konkretyzacji)– nowy typ danych zawiera w sobie składniki danych innego typu oraz funkcje
(metody) – enkapsulacja (kapsułkowanie)• obiekt
– obiekt to egzemplarz klasy– samodzielna, ograniczona jednostka posiadająca zespół cech i zachowań– każdy obiekt ma własną kopię atrybutów (wyjątek: dane statyczne),
metody (ich implementacja) są wspólne– obiekty współpracują ze sobą, działanie jest "na rzecz" jakiegoś obiektu

Kiedy klasa jest dobra?
• klasa – reprezentuje wspólne właściwości grupy obiektów– czy istnieje potrzeba tworzenia więcej niż jednego
egzemplarza klasy? (są specjalne wyjątki – singleton)– jeśli nie ma różnić pomiędzy egzemplarzami klasy:
prawdopodobnie taka klasa powinna być wartością– nie jest tylko pojemnikiem na dane, które mogą być
modyfikowane przez funkcje– udostępnia uproszczony obraz złożonego bytu, określa
dopuszczalne do wykonania czynności
• co nie jest (dobrą) klasą– zgrupowanie kilku funkcji– kontener na dane (typu struktura w C) tylko
z funkcjami typu set i get)

Cele klasy
• cel klasy
– powinien być dobrze zdefiniowany, a klasa łatwa do zrozumienia i prosta w użyciu
– nie należy dodawać do klasy metod zupełnie z nią nie związanych, tylko po to aby zaspokoić oczekiwania grupy klientów
– jeśli klient po zetknięciu z klasą nie jest pewien do czego ona służy, projekt może być słaby i niepoprawny
– wielkość klasy: jeśli liczba metod przekracza 15-25, to warto się zastanowić czy nie należałoby z jednej "wielkiej" klasy zrobić kilka mniejszych, czytelniejszych
Czy potrafisz określić cel klasy w jednym zdaniu?

Obiekt – własności
• obiekt – powołuje klasę do życia– stan obiektu jest sumą wszystkich statycznych i dynamicznych
wartości jego właściwości, właściwość jest niepowtarzalną cechą obiektu
– stan obiektu określają typy proste lub złożone– to, jak obiekt reaguje na nasze polecenia i co robi z innymi obiektami,
zależy od jego stanu– stan obiektu kontrolują metody, zwykle metody wywoływane są
przez klienta (wyjątek to metody np. do obsługi błędów, przerwań)• zachowanie obiektu
– sposób, w jaki obiekt działa i reaguje na komunikaty– komunikat może zmienić stan obiektu, może też spowodować
wysłanie komunikatów do innych obiektów– metody stałe: takie, które (gwarantują, że) nie zmieniają stanu
obiektu– wszystko co nie powinno być dostępne dla normalnego klienta,
powinno być ukrywane

Model obiektowy
• model obiektowy– w uproszczeniu: można myśleć o klasach jak o rzeczownikach,
a o ich metodach jak o czasownikach– kluczowe elementy modelu obiektowego
• abstrakcja danych• hermentyzacja• hierarchia
abstrakcja danychwynik definiowania klas, koncentrujemy się na zewnętrznym wyglądzie obiektu i oddzielamy ważne zachowania od wewnętrznych szczegółów implementacji
hermetyzacja (ukrywanie danych)wynik ukrywania wewnętrznych szczegółów implementacji, istotna w momencie rozpoczęcia implementacji
hierarchiasposób tworzenia wzajemnych relacji pomiędzy abstrakcjami danych

Typy hierarchii
"jest-czymś", realizowane poprzez dziedziczenie, umoż-liwia stosowanie relacji ogólne-specyficzne
"ma-coś", budowanie z elementów składowych, wprowadza stosunek część-całość
RACHUNEK BANKOWY
ROR LOKATA
jest:
SAMOCHÓD ma:
silnik siedzenie
koło kierownica

Zalety modelu obiektowego
• zachęca do tworzenia systemów, które mogą podlegać zmianom, systemy są elastyczne i stabilne
• myślenie w kategoriach (klas i) obiektów jest naturalne dla człowieka
• oddzielenie klienta i programisty (hermetyzacja danych)
• wielokrotne wykorzystanie prostych klas, unikanie replikacji kodu
• rozszerzalność projektów (np. poprzez dziedziczenie), czyli zachęta do ponownego wykorzystywania istniejącego oprogramowania

Interfejs i implementacja
• interfejs to punkt widzenia użytkownika na to, jak obiekt wygląda i co można z nim zrobić
• klient używa klasy bez wgłębiania się w jej wewnętrzne działanie, dobrze zaprojektowany interfejs spełnia wymagania użytkownika
• specyfikacja interfejsu – w plikach nagłówkowych• implementacja określa w jaki sposób coś jest
wykonywane, model obiektowy pozwala na ochronę implementacji (przed klientem)
• model obiektowy pozwala na zmienianie implementacji podczas gdy interfejs pozostaje niezmieniony

Klasa
KLASApodstawowa jednostka
abstrakcji danych w języku C++
• posiada trzy regiony dostępu: prywatny, chroniony i publiczny
• zawiera sygnatury – metod niestatycznych i statycznych – deklaracje danych składowych zwykłych i statycznych
• może zawierać deklarację (definicję) innej klasy – zagnieżdżonej
Nazwy deklarowane w klasie = zakres ważności to obszar całej klasy. Domyślna etykieta dostępu (odwrotnie niż w strukturze) private

Dostęp do składników klasy
class MojaKlasa {
int nr_pokoju;std::string etykieta;
public:
int getNr();string getName();
};
dane składowe są w części prywatnej!
Dostęp do składników klasy:
MojaKlasa mojObiekt;MojaKlasa *mojWskaznik = &mojObiekt;MojaKlasa &mojaReferencja = mojObiekt;
mojObiekt.getNr();mojWskaznik->getNr();mojaReferencja.getNr();
Skąd zwykła (niestatyczna) metoda wie, na jakim komplecie danych (na jakim obiekcie) pracuje?
Otrzymuje niejawnie specjalny wskaźnik: this
zawiera adres konkretnego obiektu danego typu

this is it (kilka słów o „tym” wskaźniku)
(stały) wskaźnik this – niejawnie zdefiniowana składowakażdej (niestatycznej) metody klasy, zawiera adres obiektu
this przekazywany jest jako parametr (niejawny) niestatycznym metodom klasy, aby znały adres obiektu, na którego zmiennych działają
typ wskaźnika this zależy od atrybutów metody (const, volatile), jeśli metoda jest const (volatile), to podobnie wskaźnik this (wtedy jest stałym wskaźnikiem do stałego obiektu)
void Prostokat::ustawParam(double x, double y) {this->bokX = x; // można jawnie zapisać, ale nie trzebathis->bokY = y;
}

przypadki użycia wskaźnika this
• jawne użycie this – w przypadku kopiowania obiektu, sprawdzenie żeby obiekt się nie chciał sam na siebie skopiować (jak zobaczymy później: standardowe w operatorze przypisania =)
• nie wolno używać this do usuwania obiektu (np. deletethis), za wyjątkiem sytuacji specjalnych – np. obiekt konstruujemy na stercie, ale klasa ma zablokowany destruktor, wtedy „ręcznie” sterujemy destrukcją obiektu
void Prostokat::kopiuj(const Prostokat& figura) {if (this != &figura) { // tu sprawdzamy czy nie to samo
bokX = figura.bokX; bokY = figura.bokY;
} }

Klasa – prawa dostępu
public: protected: private:
public• dostęp bez
ograniczeń (z wnętrza i poza zakresem klasy)
• tutaj jest interfejs• składniki to funkcje
protected• tak jak private,
plus dostęp dla klas pochodnych(dziedziczenie) private
• dostęp tylko z wnętrza klasy (z zewnątrz dla klas lub fukcji - przyjaciół)
• tutaj szczegóły implementacji
w dowolnej kolejności
etykiety mogą się powtarzać
domyślny

Jak ukryć implementację? Za pomocą „uchwytu”!
Technika prywatnej implementacji (idiom pimpl: PrivateIMPLementation), nazywana: „z uchwytem” (handle), „kompilowany firewall”, technika „kota z Cheshire” –przesunąć prywatne składowe klasy do zewnętrznej klasy, w pierwotnej klasie zostawiając tylko wskaźnik.
class Handle { private:
struct CheshireCat; // deklaracjaCheshireCat *smile; // uchwyt
public: // publiczny interfejsvoid init();int read();
};
struct Handle::CheshireCat {// coś ukrytegoint i;
};void Handle::init() {
simle = new CheshireCat;smile->i = 0;
}int Handle::read() {
return smile->i;}tyle potrzebne do użycia,
użytkownik zna tylko częśćpubliczną - interfejs
plik nagłówkowy
plik źródłowy
en.wikipedia.org/wiki/Opaque_pointer

Wady i zalety pimpl
Zalety
Wady
• zmiany w części prywatnej (wydzielonej) nie pociągają za sobą konieczności rekompilacji interfejsu → szybsza kompilacja
• w pliku z definicją klasy interfejsowej nie trzeba włączać nagłówków wymaganych w implementacji → szybsza kompilacja
• silniejsza forma enkapsulacji
• więcej pracy przy implementacji• nie nadaje się dla składników części chronionej• trudniejsze studiowanie kodu• pogorszenie wydajności działania – wołanie przez
pośredni wskaźnik (zwłaszcza funkcje wirtualne)

Klasa – zasłanianie i zagnieżdżanie
class A {public:
class B { };};
// zagnieżdżony typ B jest osiągalny tak:
A::B objB;
• funkcji nie można definiować lokalnie wewnątrz innych funkcji (w tym main) i innych bloków
• klasy można zagnieżdżać• klasa zagnieżdżona jest niewidoczna
poza obszarem klasy zewnętrznej, ale poprzez odpowiedni kwalifikator zakresu, o ile zdefiniowana została w części publicznej, jest do niej dostęp:
// zmienna globalnastring rechot = "hue hue…";
class Glos {class Krtan {
public:void getStruny();
};class Przelyk;public:
void rechot();};
void Glos::rechot() {float rechot;rechot(); // błąd, zasłonięte!Glos::rechot(); // okcout << ::rechot; // globalna
}void Glos::Krtan::getStruny() { /*…*/ }class Glos::Przelyk {
// ciało klasy …};

Klasa – zagnieżdżanie a prywatność
class A {// część prywatna Aint a;
class B; // ta deklaracja wyprzedzająca// jest potrzeba jeśli chce się użyć B// ale gdy już jest, to mamy dostęp// do tego co w definicji, ale tylko do// części publicznej !void foo( B* ptr ) { ptr->b2 = 0; }
class B {// część prywatna Bint b;
// klasa B ma dostęp do części // prywatnej klasy A i to w całym// zakresie void foo( A *ptr ) { ptr->a = ptr->a2; }public:
int b2; // ciąg dalszy klasy B};
int a2; // ciąg dalszy klasy A};
• C++03: zagnieżdżenie nie narusza prywatności, obiekt jednej klasy nie ma dostępu do danych prywatnych drugiej klasy
• C++11/14: zagnieżdżony typ jest traktowany tak jak każdy inny składnik klasy, czyli:
• klasa zagnieżdżona ma dostęp do całości klasy nadrzędnej, również jej części prywatnych (cały zakres klasy)
• jednak klasa nadrzędna nie ma dostępu do części prywatnych klasy zagnieżdżonej, co więcej, jeśli chcemy użyć klasy zagnieżdżonej przed jej definicją, to potrzebna jest deklaracjawyprzedzająca, potem można użyć

Klasa – zagnieżdżona w funkcji
void fun() {
class Wewnetrzna {int a;
public:Wewnetrzna(int n=0) : a(n) {}~Wewnetrzna() {}// static int nieMoge;
} obiekt;
// jakaś funkcjonalność// wykorzystująca typ// Wewnetrzna
}
• klasę można zdefiniować równieżlokalnie wewnątrz funkcji!
• może to być nawet zagnieżdżony blok wewnątrz funkcji (np. nawet pętla)
• jej typ będzie znany tylko w bloku zakresie ważności funkcji – od miejsca zdefiniowania
• klasa w całości musi być zdefiniowanawewnątrz – czyli wszystkie metodysą typu inline
• dlatego taka klasa nie może zawierać składników statycznych… (bo te są tylko deklarowane w klasie, a definicja na zwenątrz – co jest zakazane)
• …ale może mieć metody statyczne
• klasa taka może korzystać z nazw typów zdefiniowanych w funkcji (typedef), typów wyliczeniowych (enum) oraz typów zadeklarowanych jako zewnętrzne (extern)

Klasa – konstruktor
class Trivia {int i; float f;
public:Trivia(int n=0);Trivia(int k, float d);~Trivia();
};
konstruktor ( c-tor )• funkcja wywołana podczas tworzenia obiektu,
po przydzieleniu (lub wskazaniu miejsca w) pamięci• nazwa taka sama jak nazwa klasy• niczego nie zwraca (ale nie piszemy void)• może występować w wielu odmianach, z różną liczbą
argumentów (przeciążone wersje)• „domyślny” – taki, który można wywołać bez podania
parametrów (czyli bezparametryczny lub z wartością/warościami domyślną/domyślnymi argumentów
Czym się różni:Trivia::Trivia(int n) { i=n; f = 0; } // tu jest przypisanie
od:Trivia::Trivia(int n) : i(n), f(0) { } // tu jest inicjalizacja
Czy można pomieszać kolejność:Trivia::Trivia(int n, float d) : f(d), i(n) { /* … */ }
„Można”, ale to wcale nie zmienia kolejności tworzenia obiektów (najpierw i, potem f), a kompilator ostrzeże o odwrotnej (niż zapisana w kodzie) inicjalizacji!
lista inicjatorów konstruktora, „miejsce”, gdzie powstają i są inicjalizowane obiekty otwarcie { oznacza skonstruowanie obiektu

Argument o tej samej nazwie
Należy unikać zapisów budzących wątpliwość i zmniejszających czytelność kodu: class K {
int n = 3; // domyślna wartość lokalnej zmiennej n w klasie Kpublic:
K(int& n) : n(n) { // konwencja: n inicjalizujące to argument, n inicjalizowane z klasy Kn = 77; // „bliższe” jest n argument i to on będzie zmienionyn = n; // przypisanie n argumentu na samego siebie// jeśli chcemy użyć n z klasy K, napiszmy this->n, na przykład this->n = 77;
}void f( int& n ) {
n = 88; // tak samo jak w konstruktorze, tu zmieniany argument// jeśli chcemy zmienić n z klasy K, napiszmy: this->n = 88;
}};int main() {
int t = 7;int r = 5;K obj(r);obj.f(t);
}

Klasa – destruktor
class Trivia { // to co poprzednio~Trivia();
};
destruktor ( d-tor )• funkcja wywoływana podczas usuwania obiektu• nazwa taka jak nazwa klasy poprzedzona znaczkiem ~• jest tylko jeden destruktor, niczego nie zwraca• destruktor nie może mieć żadnych parametrów• destruktor powinien „posprzątać” wszelkie dynamicznie
zaalokowane wewnątrz klasy zasoby• operator delete najpierw woła destruktor (potem zwalnia
pamięć)• zgłoszenie wyjątku gwarantuje posprzątanie obiektów na
stosie (wywołanie ich destruktorów)• wyskok za pomocą instrukcji goto też wywołuje destruktor
Trivia::~Trivia() { cout << "Good bye" << endl; }

Konstruktor kopiujący T::T (const T&)
• służy do skonstruowana obiektu, który jest kopią innego, już istniejącego obiektu tej klasy (inicjalizator kopiujący)Foo::Foo( Foo& );
– może posiadać również argumenty domyślneFoo::Foo(Foo&, float = 3.14);
– może być w postaci Foo::Foo( const Foo& );Foo::Foo( volatile Foo& );Foo::Foo( const volatile Foo& );
• jeśli go nie ma, kompilator sam go utworzy, na zasadzie tworzenia wiernej kopii (bit po bicie)

Konstruktor kopiujący T::T (const T&)
• generowany konstruktor kopiujący bezpieczny (const) chyba że któryś składnik klasy ma swój konstruktor kopiujący bez przydomka const
• jeśli klasa zawiera obiekty abstrakcyjne, to do kopiowania wołane są ich konstruktory kopiujące
• kiedy pracuje copy constructor:– wywołanie jawne (inicjalizacja przez przypisanie)
– przekazanie jako argument funkcji przez wartość– zwrócenie wartości funkcji (obiekt tymczasowy
inicjalizowany konstruktorem kopiującym – zależy od optymalizacji kompilatora)
Foo nowy = stary; // stary też klasy FooFoo nowy = Foo(stary);// ale nie: nowy = stary; tu pracuje operator =

Konstruktor kopiujący – kiedy konieczny?
class A {// klasa bez konstruktora kopiującego
int numer;char* nazwa;
};// gdzieś w programie:// konstruktor tworzy dynamiczną tablicę, // do której kopiuje słowo "Trzy"A a1(3, "Trzy"); A a2 = a1; // a2 to wierna kopia a1a2.setNumber(4);a2.setName("Cztery");cout << "a1 nazwa: " << a1.getName(); // "Cztery" !
• Prawdziwa tragedia w chwili likwidowania obiektów, destruktory dwa razy spróbują usuwać tablicę pod tym samym adresem
• Analogiczny problem mamy gdy stosujemy operator przypisania =• Zwykle w klasie, w której występują wskaźniki,
konieczne jest napisanie konstruktora kopiującego
// funkcje z nagłówka <cstring>A::A(const A& src) :
numer(src.numer), nazwa(new char[strlen(str.nazwa)+1]) {
strcpy(nazwa, src.nazwa);} // wszystko zainicjalizowaliśmy// na liście inicjatorów konstruktora

delegowanie konstruktorów ( C++11 )
Można (wreszcie) użyć do budowy obiektu konstruktora, który użyjeinnego konstruktora pomocniczo:
Ograniczenie: konstruktor delegujący budowę obiektu do innego konstruktora nie może nic innego zrobić na swojej liście inicjatorów.Konstruktor nie może wywołać samego siebie do budowy obiektu.Nie ma ograniczeń w rodzaju – konstruktory mogą być inline, explicite, w dowolnej części klasy (public / protected / private).
class Foo { public: // klasa Foo ma różne wersje konstruktorówFoo() : Foo(0) {} // woła drugiFoo(int m) : Foo( 3.14 ) { } // woła trzeci – można więc „łańcuchowo”…Foo(double d) : Foo( 0, 3.14 ) {} // woła ostatniFoo(const Foo& s) : Foo( s.fm, s.fd ) {} // woła ostatni
private:// jakieś składniki fm, fd …Foo(int m, double d) : fm(m), fd(d) { }
};

Konwersja typów – konstruktor konwersji
• definiujemy konstruktor, który ma jeden argument – obiekt (lub referencję) innego typu, za jego pomocą kompilator dokona automatyczną konwersję typów
• klasa docelowa jest odpowiedzialna za konwersję typów
class A { /* … */ };class B { public:B(const A&) { /* … */ }
};void fun(B argb);// gdzieś w programie:A obiektA;fun(obiektA); // wymagany obiekt klasy B// kompilator wie jak przekonwertować B na AB obiektB = obiektA // zaskakujące?// działa (cc-tor klasy B) c-tor konwersji A na B

Konwersja typów – operator konwersji
• słowo operator, poprzedzające nazwę typu, do którego ma zostać dokonana konwersja (przeciążanie operatora)
• klasa źródłowa jest odpowiedzialna za konwersję typów
• tylko tak można zdefiniować konwersję z typów abstrakcyjnych do typów wbudowanych
class A { public: float r, s;char* nazwa;const char* cNazwa;A(float f1 = 1.0, float f2 = 3.14);operator B() const { return B(r); }operator char*() const { return nazwa; }operator const char*() const { returnc Nazwa;}
};class B { // …B(int n);
};void fun(B argb);// gdzieś w programie:A obiektA;fun(obiektA); // działa operator konwersji fun(22); // działa konstruktor klasy B

Konwersja typów – explicit
Konstruktor konwersji:• Jeśli nie chcemy niejawnego (automatycznego) konwertowania,
należy deklarację konstruktora poprzedzić słowem kluczowymexplicit B(const A&);
• Wtedy można tylko jawnie:fun(B(obiektA));obiektB = B(obiektA);
Operator konwersji: (C++11 – tylko w nowym standardzie)• Jeśli nie chcemy niejawnego (automatycznego) konwertowania,
należy deklarację operatora poprzedzić słowem kluczowymexplicit operator A();
• Wtedy można tylko jawnie:obiektB = B(obiektA); albo obiektB = (B)obiektA;albo obiektB = static_cast<B>( obiektA );

Konwersja typów – konflikty
class A {public:A(const B);
};class B {
public:operator A() const;
};void fun(A a);// gdzieś w programie:B b;fun(b); // niejednoznaczność
• Należy się zdecydować na jeden sposób konwersji• Konwersja jest jednostopniowa (tzn. jeśli mamy zdefiniowane B→A
i C→B, to jeśli na rzecz argumentu typu C zostanie podany argument typu A, nie nastąpi łańcuch konwersji od C do A
• Najpierw sprawdzana jest dwuznaczność, potem kontrola dostępu
"przeciążenie wyjścia"
class A { /* … */ };class B { /* … */ };class C {public:operator A() const;operator B() const;
};// tu się zaczyna problem// przeładowane wersje funvoid fun(A a);void fun(B b);// gdzieś w programie:C c;fun(c); // niejednoznaczność

T&, T const&, T&&, T const&& ( C++11 )
Teraz sprawdzimy wszystkie możliwe referencje do l-wartości i p-wartości:int main() {
string modyfikowalna_lwartosc("mut_lvalue");const string stala_lwartosc("const_lvalue");string& r1 = modyfikowalna_lwartosc; // OKstring& r2 = stala_lwartosc; // błądstring& r3 = modyfikowalna_pwartosc(); // błądstring& r4 = stala_pwartosc(); // błądconst string& cr1 = modyfikowalna_lwartosc; // OKconst string& cr2 = stala_lwartosc; // OKconst string& cr3 = modyfikowalna_pwartosc(); // OKconst string& cr4 = stala_pwartosc(); // OKstring&& pr1 = modyfikowalna_lwartosc; // błądstring&& pr2 = stala_lwartosc; // błądstring&& pr3 = modyfikowalna_pwartosc(); // OKstring&& pr4 = stala_pwartosc(); // błądconst string&& cpr1 = modyfikowalna_lwartosc; // błądconst string&& cpr2 = stala_lwartosc; // błądconst string&& cpr3 = modyfikowalna_pwartosc(); // OKconst string&& cpr4 = stala_pwartosc(); // OK
}
string modyfikowalna_pwartosc() { return "mut_pvalue"; }const string stala_pwartosc() { return "const_pvalue"; }

T const&, T&& - przeciążanie ( C++11 )
Teraz sprawdzimy jak zachowuje się przeciążanie:
Reguły:• poprawność inicjalizacji (np. wyrażenie stałe nie może inicjalizować niestałego argumentu)• l-wartości mocno preferują lewe-referencje, p-wartości preferują prawe-referencje• wyrażenia modyfikowalne raczej preferują referencje bez const
int main() {string modyfikowalna_lwartosc("mut_lvalue");const string stala_lwartosc("const_lvalue");
fun( modyfikowalna_pwartosc() ); // funkcja – string&& mut_pvaluefun( stala_pwartosc() ); // funkcja – const string& const_pvaluefun( modyfikowalna_lwartosc ); // funkcja – const string& mut_lvaluefun( stala_lwartosc ); // funkcja – const string& const_lvalue
}
void fun( const string& s ) { cout << " funkcja – const string& " << s << endl; }void fun( string&& s ) { cout << " funkcja – string&& " << s << endl; }string modyfikowalna_pwartosc() { return " mut_pvalue "; }const string stala_pwartosc() { return " const_pvalue "; }

za dużo kopiowania ( C++98 )
W niektórych sytuacjach C++98 wykonuje dużo zbędnych operacji kopiowania (na przykładzie wektora):
Przeniesienie lokalnego obiektu byłoby o wiele bardziej efektywne.Również w przypadkach dodawania kolejnych elementów do kontenera, gdy brakuje miejsca, powiększanie powoduje sporo operacji kopiowania - wystarczyłoby przenoszenie:
vec.push_back( obiektT );// właśnie zabrakło miejsca…// trzeba zaalokować nową// tablicę i skopiować do niej// poprzednią zawartość
std::vector<T> getVector(); // metoda produkująca wektor zawierający Tstd::vector<T> vec;vec = getVector(); // skopiuj wartość zwracaną, potem usuń lokalny obiekt

klasyczny przykład - swap ( C++98 – C++11 )
Operacja zamiany (swap) generuje mnóstwo niepotrzebnych kopiowań, choć tak naprawdę nie chcemy żadnego!
Korzystając z funkcji szablonowej std::move (nagłówek <utility>):template <typename T>void swap( T& a, T& b) {
T tmp( std::move(a) ); // przesuń dane obiektu a do tmpa = std::move( b ); // przesuń dane obiektu b do ab = std::move( tmp ); // przesuń tmp do b
} // usuń (pusty) obiekt tmp
template <typename T>void swap( T& a, T& b ) {
T tmp(a); // skopiuj a do tmp (mamy dwa obiekty a)a = b; // skopiuj b do a (mamy dwa obiekty b)b = tmp; // skopiuj tmp do b (mamy dwa obiekty tmp)
} // zniszcz obiekt tmp

kwestia stałości prawych-wartości, przenoszenie ( C++11 )
T const&& – poprawne, ale nie nadaje się do semantyki przenoszenia
Pojawiają się konstruktor przenoszący i operator= przenoszący:
class Foo { public:Foo( const Foo& ); // konstruktor kopiującyFoo( Foo&& ); // konstruktor przesuwającyFoo& operator=( const Foo& ); // operator przypisaniaFoo& operator=( Foo&& ); // przenoszący operator przypisania
};Foo utworzFoo(); // zwracamy obiekt przez wartośćFoo m1;Foo m2 = m1; // kopiowanie, bo z lewej-wartościm2 = utworzFoo(); // przenoszenie możliwe, bo z prawej-wartościm1 = m2; // tylko lewe-wartości, kopiowanie
void fun( const T&& ); // poprawne, ale nieużyteczneconst T fun(); // nie zwracaj stałej wartości bo nie użyjesz z T&&

operacja przenoszenia ( C++11 )
Przenoszenie wymaga trzech czynności:• pozbycie się dotychczasowej zawartości obiektu, do którego
przypisujemy (tylko dla operacji przypisania)• przeniesienia źródłowej zawartości• pozostawienie źródła w stanie do użytku (ale bez danych)
class Foo { Bar *ptr; // jakiś wskaźnik do zasobów
public:Foo( Foo&& src ) : ptr( src.ptr) { src.ptr = nullptr; }Foo& operator=( Foo&& src ) {
delete ptr; // usunięcie starej zawartościptr = src.ptr; // przeniesienie nowejsrc.ptr = nullptr; // ustawienie źródła na zeroreturn *this;
}};
• wskaźniki – łatwo• typy użytkownika –
składnik po składniku z użyciem ich konstruktorów / operatorów przesunięcia
nie wolno przenosićobiektu (kopiowanie, przypisanie) na samego siebie – ”undefined behavior”

realizacja przenoszenia ( C++11 )
Uważajmy czy rzeczywiście chcemy przenieść p-wartość:
Można przenieść również l-wartość (trzeba ukryć jej nazwę):// dla kodu podobnego jak w powyższym przykładzieBar( Bar&& src ) : Foo( std::move( src ) ), s( std::move(src.s) ) { … }Bar& operator=( Bar&& src ) {
Foo::operator=( std::move( src ) );s = std::move( src.s );return *this;
}
class Foo { string s; public:
Foo( Foo const& ); // cc-torFoo( Foo&& src ) : s( src.s ) { … } // kompiluje się ale tylko kopiuje
}; class Bar : public Foo { public:
Bar( Bar&& src ) : Foo( src ) { … } // też tylko kopiuje};
src.s oraz srcmają nazwysą więc l-wartościami
klasa std::string posiadastring::string( const string& ); // konstruktor kopiującystring::string( string&& ); // konstruktor przenoszący

klasa wyposażona lub nie w operacje przenoszenia ( C++11 )
Jeśli w klasie nie zdefiniowano konstruktora przenoszenia…
Automatyczne generowanie operacji przenoszenia uwarunkowane:• wszystkie składniki i klasy bazowe „przenaszalne”
– typy wbudowane (dla nich move oznacza copy) – większość typów biblioteki standardowej (np. kontenery)
• użytkownik nie zdeklarował operacji kopiowania / przenoszenia• użytkownik nie zdeklarował destruktora
class Foo { public: // klasa Foo nie wspiera operacji przenoszenia
Foo( Foo const& ); // cc-tor – nie wygeneruje się mvc-tor}; class Bar {
Foo w;public:
Bar( Bar&& src ) : w( move(src.w) ) { … } // nie skompiluje się// move(src.w) zwraca p-wartość do typu Foo, a ta idzie do cc-tora klasy Foo
};
trzeba zdefiniować również:Foo( Foo&& );

dlaczego destruktor blokuje autogenerowanie przenoszenia? ( C++11 )
Destruktor może wskazywać na istnienie pewnych niezmienników, których nie zachowa operacja przenoszenia (automatyczna):
Jeśli użytkownik napisał destruktor, ale nie napisał konstruktorów (czy operatorów=), to operacje przenoszenia nie zostaną wygenerowane.Można przenosić l-wartości ze świadomością konsekwencji, co się
dzieje z obiektem źródłowym (np. zostaje pozbawiony zawartości).
class Foo { vector<int> x;vector<int> y;size_t suma;
public: ~Foo() { assert( suma == x.size() + y.size() ); }
}; vector< Foo > w; Foo m; // dodajemy coś do wektorów x i yw.push_back( std::move(m) ); // x i y przeniesione, wartość suma zostawiona!// np. m dalej nie używane i asercja w destruktorze niespełniona!
zapamiętaj również:• napisanie move c-tor blokuje
automatyczne generowanie cc-tor (i odwrotnie)
• napisanie move operator= blokuje automatyczne generowanie kopiującego operator= (i odwrotnie)
default, delete ( C++11 )
Jeśli jest np. jakikolwiek konstruktor, to domyślny nie będzie generowany...Odblokowanie możliwości generowania, składnia „= default”
Można też zaznaczyć co jest wersją domyślną (w zasadzie nadmiarowe)
Blokowanie funkcji za pomocą składni „= delete”Foo(const Foo&) = delete; // blokowanie operacji kopiowaniaFoo& operator=(const Foo&) = delete; // blokowanie przypisania kopiującegovoid* operator new(std::size_t) = delete; // blokowanie kreacji obiektu na stercievoid fun( int ); // wywołanie fun z int jest ok – patrz poniżej jak inne typy blokowaćvoid fun( double ) = delete; // wywołanie fun z argumentem double – błądtemplate<typename T> void fun(T) = delete; // fun z dowolnym typem – błąd
class Foo { public:Foo( const Foo& ); // jest cc-tor, nie będzie automatycznego c-tor i mvc-torFoo() = default; // deklaracja, „proszę wygenerować w razie potrzeby”Foo(Foo&&) = default; // ditto
};
virtual ~Foo() = default; // deklarowany jako wirtualnyexplicit Foo(const Foo&) = default; // deklarowany jako explicit

friend – deklaracja przyjaźni
Klasa może zadeklarować przyjaźń względem funkcji lub innej klasy. Wtedy taka funkcja (inna klasa – jej funkcje) ma dostęp do części private(a także protected)
• przyjaźń nie jest wzajemna (w przykładzie jak wyżej: Przestepca nie jest przyjacielem Prokuratora)
• przyjaciel mojego przyjaciela nie jest moim przyjacielem (nie ma przechodniości)
class Przestepca {float pieniadze; // (domyślnie) część prywatna klasystring zycie_osobiste; // jak wyżej// miejsce deklaracji przyjaźni bez znaczenia// prokurator może zbadać całą część prywatną…friend class Prokurator; // lepiej deklarować przyjaźń tylko względem funkcji// metoda poniżej ma dostęp do privatefriend void Policjant::przeszukaj(Przestepca&); friend void ukradnij(float); // globalny przyjaciel
};

friend – szczegóły
• ponieważ kompilator musi znać deklarację obiektu w chwili deklarowania przyjaźni, więc nie da się zadeklarować przyjaźni pomiędzy dwiema funkcjami dwóch różnych klas, tylko pomiędzy całymi klasamiclass A;class B { friend class A; };class A { friend class B; };
• funkcja (klasa) może być przyjacielem więcej niż jednej klasy• funkcja zaprzyjaźniona może na argumentach jej wywołania
dokonywać konwersji zdefiniowanych przez użytkownika (w szczególności: operator<<, operator>>)
• przyjacielem może być nawet funkcja napisana w innym języku
• przyjacielem jest tylko konkretna funkcja, a nie ewentualne inne przeciążone

friend – trochę egzotyki
Można zdefiniować funkcję zaprzyjaźnioną w ciele klasy deklarującej przyjaźń
class A;
class B{public:float czytaj();float czytaj(A& a);
};
class A{float f1;static float f2;// funkcja zaprzyjaźniona nie ma wskaźnika thisfriend float B::czytaj(A& a) { return a.f1; }friend float B::czytaj() { return A::f2; }// poniżej funkcja globalna, bez uprzedniej deklaracjifriend float readGlobal() { return A::f2; }
};
float A::f2 = 3.14; // definicja zmiennej statycznej
• w deklaracji przyjaźni nie mogąsię pojawić specyfikatory:static, auto, register,extern, mutablefunkcja zdefiniowana w cieleklasy A może korzystać zobowiązujących deklaracjitypedef oraz zdefiniowanychtypów wyliczeniowych enum
• klasa A nie może być klasą lokalną (tzn. zdefiniowanąw ciele funkcji)
• jeśli konstruktor klasy A prywatnyto funkcji zaprzyjaźnionej z klasyB można użyć do utworzeniaobiektu klasy A
A propos:funkcji zaprzyjaźnionej nie jest przekazywany wskaźnik this, zatem adres danego obiektu trzeba jej przekazać jawnie jako jeden z argumentów

przeciążenie (przeładowanie) operatorów
• Możliwe jest zdefiniowanie działania operatorów dla typów abstrakcyjnych (tzn. zdefiniowanych przez użytkownika)
• Przeładowanie to definiowanie nowej (przeciążonej) wersji funkcji operatora:
operator@, gdzie @ - symbol operatora
• Operatory mogą być jednoargumentowe lub dwuargumentowe, argumenty nie mogą być domyślne
• Operatory mogą być funkcjami globalnymi lub funkcjami składowymi danego typu abstrakcyjnego
• Funkcje operatorów zwracają albo referencję do obiektu typu, na którym się wykonuje operację, albo sam obiekt –chyba że są to operatory warunkowe (zwracające wartość logiczną bool)

przeciążenie (przeładowanie) – logika, czego nie można
• Należy zachować logikę działania operatora i przeciążać go wtedy, gdy zwiększy to czytelność programu
• Można przeciążać tylko istniejące operatory (nie można definiować własnych)
• Nie można zmienić reguł dotyczących priorytetów operatorów, ani natury operatorów (tzn. operator dwuargumentowy musi być dwuargumentowy)
• Nie można przeciążyć operatora wyboru składowej (.), operatora wyłuskania wskaźnika do składowej (.*), operatora zakresu (::) i trójargumentowego operatora ?:
• Nie można też przeładować znaków dla dyrektyw preprocesora # lub ##, oraz operatora sizeof i operatorów rzutowania (w stylu C++) static_cast, dynamic_cast, reinterpret_cast, const_cast

operatory 1-argumentowe (globalne)
Operatory: +, -, ~, &, !, ++, -- w wersji funkcji globalnych
class A {int i;A* This() { return this; }public:A(int n=0) : i(n) {}// przyjaźń konieczna, tylko gdy chcemy dostać się do prywatnych składowychfriend const A& operator+(const A& a);friend const A operator-(const A& a);friend const A operator~(const A& a);friend A* operator&(A& a);friend bool operator!(const A& a);// zmienia się stan obiektu, więc już nie const ("efekt uboczny")friend const A& operator++(A& a); // przedrostkowyfriend const A operator++(A& a, int); // przyrostkowyfriend const A& operator--(A& a); // przedrostkowyfriend const A operator--(A& a, int); // przyrostkowy
};

operatory 1-argumentowe (implementacja)
const A& operator+ (const A& a) {return a; // nic nie robi więc może być zwracanie przez referencję
}const A operator–(const A& a) {
return A(–a.i); // przez wartość, bo nigdy nie zwracamy} // referencji do obiektu tymczasowegoA* operator&(A& a) {
// return &a; to by nas wpędziło w nieskończoną pętlę rekurencji !!!return a.This(); // zwraca this
}// operator przedrostkowy, zwracamy referencję do obiektu po jego inkrementacjiconst A& operator++(A& a) {
a.i++; return a;}// operator przyrostkowy, drugi nienazwany argumentconst A operator++(A& a, int) { // konieczny do odróżnienia wersji
A temp(a.i);a.i++;return temp; // zwracamy obiekt przed jego inkrementacją
} // - przez wartość, bo tymczasowy

operatory 1-argumentowe (składowe)
Operatory w wersji funkcji składowych
class A {int i;public:A(int n=0) : i(n) {}// argument funkcji staje się zbędny, operator działa na rzecz obiektuconst A& operator+() const { return *this; }const A operator-() const { return A(-i); }const A operator~() const { return A(~i); }A* operator&() { return this; }bool operator!() const { return !i; } // może czytelniej: return !this->i; const A& operator++() { ++i; return *this; }const A operator++(int) { A temp(i); ++i; return temp; }const A& operator--(); // przedrostkowy, analogicznie jak wyżejconst A operator--(int); // przyrostkowy, analogicznie
};

operatory 2-argumentowe (globalne)
Operatory : +, -, *, /, %, ^, &, |, <<, >>,+=, -=, *=, /=, %=, ^=, &=, |=, >>=, <<=,==, !=, <, >, <=, >=, &&, || w wersji funkcji globalnych
class A {int i;A* This() { return this; }public:A(int n=0) : i(n) {}// pamiętajmy, że sens ma definiowanie całych grup operatorów// czyli jeśli przeładujemy operator==, to również operator!=friend const A operator+(const A& a, const A& b); // reszta analogiczniefriend A& operator+=(A& a, const B& b);friend bool operator==(const A& a, const A& b);
};

operatory 2-argumentowe (implementacja)
const A operator+ (const A& a, const A& b) {return A(a.i + b.i); // przez wartość, bo obiekt tymczasowy
}const A operator/(const A& a, const A& b) {
if (b.i == 0) { /* coś trzeba zrobić, np. rzucić wyjątek */ }return A(a.i / b.i);
}// przypisanie modyfikujące i zwracające l-wartośćA& operator+=(A& a, const A& b) {
if (&a == &b) { /* ewentualnie zareagować na taką sytuację */ }a.i += b.i; return a;
}// operator warunkowy, zwracający true lub falsebool operator==(const A& a, const A& b) {
return a.i == b.i; }

operatory 2-argumentowe (składowe)
Operatory w wersji metod składowychclass A {
int i;public:A(int n=0) : i(n) {}const A operator+(const A& b) const { return A(i + b.i); }// przypisanie modyfikujące i zwracające l-wartość (funkcja składowa)A& operator=(const A& b) {
if (this == &b) return *this; // przypisanie do samego siebiei = b.i;return *this;
}A& operator+=(const A& b) {
if (this == &b) { /* ewentualnie zareagować na taką sytuację */ }i += b.i;return *this;
}bool operator==(const A& b) const { return i == b.i; }
};

operator przypisania: operator=
Najlepiej unikać inicjalizacji przezprzypisanie i używać do tego celuwywołanie konstruktora
A a;A b = a; // tu działa konstruktor kopiującyb = a; // tu działa operator przypisania
• Jeśli operator ten nie został zdefiniowany, zostanie automatycznie wygenerowany przez kompilator: operacja przypisania polega na wiernym (bit po bicie) przepisaniu stanu obiektu z prawej strony do obiektu po lewej stronie
• Jeśli klasa zawiera obiekty składowe, to dla każdego z nich jest wywoływany rekurencyjnie operator= (jest to przypisanie za pośrednictwem elementów składowych – memberwise assignment)
• Jeśli klasa zawiera wskaźniki, to przy braku definicji operator=przypisanie jednego obiektu do drugiego da równie katastrofalne efekty, jak w przypadku działania automatycznie wygenerowanego konstruktora kopiującego (skopiujemy adres wskaźnika, a nie wskazywaną zawartość)
• operator= nie jest dziedziczony (podobnie jak konstruktory / destruktory)• Jeśli chcemy zakazać przypisywania obiektu, to w deklaracji należy dodać
„= delete” (C++11), poprzednio realizowano to deklarując operator= jako funkcję prywatną (o ile jej nie wywołamy gdzieś w obrębie klasy – nie trzeba jej definiować)
tylko funkcja składowa

operator= (automatyczny)
Przy braku zdefiniowanej funkcji operator= nastąpi próba wygenerowania.Nie uda się jeśli:• klasa ma składnik const (bo dopuszczalna tylko inicjalizacja)• klasa ma referencję (bo też musi być zainicjalizowana)• klasa ma składnik innej klasy, w której przypisanie jest
uniemożliwione (tzn. operator= jest zablokowany)• (dot. dziedziczenia) klasa podstawowa ma operator
przypisania zablokowany
Przypomnienie:Musimy kontrolować czy przypisujemy obiekt do siebie samego, ponieważ jeśli zachodzi alokowanie pamięci w obiekcie, to zanim obiekt skopiuje "od siebie do siebie", to zniszczy kawałek siebie, wykonując inicjalizację (alokację pamięci)if (this==&source) return *this;
// standardowo pierwsza linijka

Powrót z funkcji – „copy elision”
Jak może przebiegać powrót z funkcji?return A(a.i + b.i);
• Składnia obiektu tymczasowego - "utwórz obiekt tymczasowy i go zwróć"
• Obiekt tymczasowy tworzony jest bezpośrednio w miejscu przeznaczonym na wartość zwracaną – tylko jedno wywołanie konstruktora (nie potrzeba w ogóle konstruktora kopiującego)A temp(a.i + b.i);return temp;
• Tworzony obiekt tymczasowy z wywołaniem konstruktora• Konstruktor kopiujący kopiuje wartość obiektu temp do
miejsca na zewnątrz funkcji przeznaczonego na zwracaną przez nią wartość
• Na koniec, wołany destruktor obiektu temp
Współczesne kompilatory potrafią wydajnie optymalizować nawet takie sytuacje. Niewykorzystanie cc-tor’a nie oznacza, że jego „przepis” może nie być dostępny. Musi być (lub będzie wygenerowany).
Kopiowanie płytkie i głębokie
Tablica2D obiekt_zrodlo
int szerokosc int wysokosc
TablicaKomorka**
każdy element jestwskaźnikiem bez nazwyTablicaKomorka*
każdy element jestobiektem bez nazwyTablicaKomorka
Tablica2D obiekt_kopia
int szerokosc int wysokosc
TablicaKomorka**
płytkie kopiowanie
głębokie kopiowanie
• nie tylko konstruktor kopiujący musi zadbaćo głębokie kopiowanie
• również operator przypisania =Foo& operator=(const Foo& source);(będzie o tym później)
• ponieważ konstruktor kopiujący i operator= wykonują podobne operacje, można zamknąć wspólną część w osobnej funkcji

Kopiowanie przy zapisie (Copy On Write)
obiekt1
TString
• dzielenie zasobów musi być możliwe bez dodatkowych kosztów procesora i pamięci
• powinna być możliwa identyfikacja i kontrola wszystkich ścieżek, które mogą modyfikować zasoby
• implementacja musi mieć możliwość śledzenia w każdych warunkach wielu obiektów, które dzielą zasoby
idea: współdzielić zasoby (kopiowanie płytkie) tak długo jak to możliwe, głęboką kopię tworzy się dopiero przy próbie modyfikacji – kiedy jeden z obiektów dzielących zasoby próbuje je zmieniać, tworzona jest kopia (kopiowanie głębokie)
”ALFABET”
obiekt1
TString
”ALFABET”
obiekt2
TString
kopiowanie
płytkie
obiekt1
TString
obiekt2
TString
”ALFABET””alfabet”
kopiowaniegłębokie
np. wywołana jest funkcja zmieniająca wielkość liter we współdzielonym zasobie: obiekt1.tolower();

copy on write (i zliczanie referencji)
class TString {// wiele funkcji
class StrContainer {public:char* str;unsigned refCount;unsigned length;
} *ptrStr;};
TString::TString(const TString& src) {src.ptrStr->refCount++;this->ptrStr = src.ptrStr; }
TString& TString::operator=(const TString& src) {if (this==&src) return *this;src.ptrStr->refCount++;if (--ptrStr->refCount == 0) {
delete [] ptrStr->str;delete ptrStr; }
this->ptrStr = src.ptrStr;return *this; }
TString::~TString() {if (--ptrStr->refCount == 0) {
delete [] ptrStr->str;delete ptrStr;
} }
TString& TString::tolower() {char* p;if (ptrStr->refCount > 1) {// tu kopiowanie przy zapisie
unsigned len = ptrStr->length;p = new char[len+1];strcpy(p, ptrStr->str);ptrStr->refCount--;ptrStr = new StrContainer;ptrStr->refCount = 1;ptrStr->length = len;ptrStr->str = p;
}// dalej część zmieniająca// wielkość znakówreturn *this; }
TString::TString() {ptrStr = new StrContainer;ptrStr->refCount = 1;ptrStr->length = 0;ptrStr->str = 0; }
przypisujemy nowy zasób, więc w starym musimy zmniejszyć licznik i ewentualnie skasować cały zasób, jeśli był to ostatni obiekt posiadający

Wskaźniki do składników klasy
wskaźnik – zmienna przechowująca adreswskaźnik do składowych – pokazuje na położenie elementu wewnątrz klasyadres elementu wewnątrz klasy – wymaga istnienia konkretnego obiektu, składa się z adresu tego obiektu oraz przesunięcia do danego elementu klasyelement pokazywany wskaźnikiem – dostajemy się do niego przez operację wyłuskiwania (*), teraz jednak potrzebujemy również obiektu:
(normalnie) obiekt.składowawsk_do_obiektu->składowa
(gdy mamy wsk_do_skladowej)obiekt.*wsk_do_skladowejwsk_do_obiektu->*wsk_do_skladowej

Wskaźniki do składowych
• wskaźników do składników nie można inkrementować (dekrementować), ani porównywać
• pokazują one na dane niestatyczne, bo dane statyczne istnieją pomimo obiektów i mają swój adres od chwili definicji – można na nie pokazywać zwykłym wskaźnikiem
int T::*wsk; // wskaźnik do dowolnego typu int w klasie Tclass T {
public:int a, b, c;
};// ptr tylko do pokazywania jakiegoś int w klasie Tint T::*ptr = &T::b;// tworzymy obiektT mojT;T* wskT = &mojT;mojT.*ptr = 7;ptr = &T::c;wskT->*ptr = 5;

Wskaźniki do składowych (c.d.)
• nie można ich ustawić na czymś co nie ma swojej nazwy np. 7-my element tablicy:
• na samą tablicę – można
• zwykle przydatna jest tablica wskaźników do składowych klasy
class T {public:
int kontrast;int jasnosc;float tabl[8];
};
float (T::*wsk)[8];wsk = &T::tabl; // w tym przypadku & jest obligatoryjne
int T::*tabwsk[5];tabwsk[0] = &T::kontrast;tabwsk[1] = &T::jasnosc;// … i tak dalej

Wskaźniki do składowych metod klasy
• funkcje setName w klasie T są przeciążone, ale podczas ustawiania wskaźnika o tym, na co on pokaże, rozstrzyga jego typ!
class T {public:void setName(int);void setName(string&);
};// wskaźnik do funkcji z klasy T o argumencie string&// niczego nie zwracającej (void)void (T::*fptr)(string&);// ustawienie wskaźnika na daną funkcjęfptr = &T::setName; // także tutaj & jest obligatoryjne// przykład użyciaT obiekt;T *wsk_do_obiektu = &obiekt;(obiekt.*fptr)("Joseph"); // albo:(wsk_do_obiektu->*fptr)("Jan");

Wskaźniki do składowych metod klasy (c.d.)
Do czego się to przyda?
class Gielda { // Date – jakiś typy abstrakcyjnypublic:double funduszPKO (Date, double);double funduszBPH (Date, double);
// … może jeszcze jakiś, teraz jeszcze nieznany …double zarobek(double money, double okres,
double (Gielda::*fp)(Date, double)) {return faktor = (this->*fp)("dziś", okres);
}};
// tworzymy obiektGielda warsawStock;warsawStock.zarobek(1000, 365, &Gielda::funduszBPH);

Wskaźniki do składowych metod klasy (c.d.)
Tworzenie menu: można wewnątrz klasy zdefiniować tablicę wskaźników do funkcji
class T {private:
int a(double) const;int b(double) const;int c(double) const;enum { ile = 3 };
// tablica wskaźników do pewnych funkcji wewnątrz klasy Tint (T::*fptr[ile])(double) const;
public:T() { // konstruktor
fptr[0] = &T::a; // mimo tego że w klasie, pełna specyfikacjafptr[1] = &T::b; fptr[2] = &T::c;
}int select(int i, double f) {
return (this->*fptr[i])(f);}
};

operator[] (indeksowy)
tylko funkcja składowa, o jednym parametrze• zwraca referencję do obiektu, żeby mógł być l-wartością
• nie musi służyć do pracy z tablicami, a parametr dowolny (nie musi być typu całkowitego – co było niedopuszczalne dla zmiennych wbudowanych)np. jeśli mamy jakieś duże tablice … tablica[1045][234]( tablica[1045] ) [234] – pierwszy operator przeładowany, drugi nieint *linia = new int[rozmiar];int* A::operator[](int wiersz) {
// wczytywanie do tablicy całego wiersza np. z bazy danychreturn linia;
} // przykład – patrz J. Grębosz (Symfonia C++ Standard)
class A {int i[10];public:
int& operator[] (unsigned int n) {// if (n < 10) … można sprawdzić zakresreturn i[n];
}};

operator() (funkcyjny)
tylko funkcja składowa• może mieć więcej niż 2 argumenty• może mieć argumenty domyślne
obiekt(arg1, … argN);obiekt.operator()(arg1, … argN);
Do czego się może przydać?• tablica wielowymiarowa tab(2, 4, 7);• nazwanie jakiejś czynności z którą obiekt jest związany
// Image Processing UnitIPU recognition; // rozpoznawanie obrazurecognition(); // oznacza wywołanie: recognition.operator()();
• konkretna czynność
poważne i częste zastosowanie:Zdecydowanie najczęściejużywa się go tworząc tzw. obiektyfunkcyjne, czyli klasy (struktury)wyposażone w przeciążony operator()na potrzeby algorytmów uogólnionych.
class Obiad;void Obiad::operator()(const char* food) {
cout << food << " jest mniam mniam\n";}// tworzymy obiektObiad domowy;domowy("rosół"); // wywołanie: domowy.operator()(const char*);

operator-> („strzałkowy”)
tylko funkcja składowa• cel: żeby obiekt naszego typu zachowywał się „jak wskaźnik”• jednoargumentowy, działa na argumencie po jego lewej stronie „wygląda”
jak wywołany na rzecz wskaźnika, ale jest wywołany dla obiektu
• na tym co zwraca funkcja obiekt.operator->() działa zwykły dwuargumentowy operator->– może zwracać wskaźnik lub– obiekt (lub referencję do obiektu) klasy,
która też ma przeładowany operator-> ale ostatecznieprzeciążony operator musi zwrócić wskaźnik
• po co?– zwykły operator-> wymaga po lewej stronie wskaźnika– teraz można go zastosować również do typu abstrakcyjnego, aby wyglądał
„jak wskaźnik”, np. możemy „opakować” wskaźnik klasą, aby uczynić go bezpiecznym
– można przy okazji wykonać jakieś dodatkowe zadania
zwykłe wywołanie: wskaznik->składnik // chcemy: obiekt->skladnikpo przeciążeniu: (obiekt.operator->())->składnik

operator-> i operator*
• operator -> nie jest automatycznie generowany, istnieje za to dla typów wbudowanych, a takim jest wskaźnik do… (czegokolwiek)
• klasyczne zastosowanie to inteligentny wskaźnik
class A { public: void funA(); /* robi cokolwiek */ };class SmartPrt {
A *fp { nullptr };A* fTable[5] { nullptr };int fUse { 0 };public:
SmartPrt(A *prt = nullptr) : fp(prt) { }A* operator->() { fTable[fUse] = fp; fUse = (++fUse) % 5; return fp; }A& operator*() { return *(operator->()); }
};// gdzieś w programieA a;SmartPrt wsk = &a; // konstruktor SmartPtrwsk->funA(); // tu działa przeciążony operator ->// przy okazji zapisuje sobie w wewnętrznej tablicy fakt użycia(*wsk).funA(); // tak też powinno się dać, zawsze przeciążajmy parami// a może warto też dodać możliwość inkrementacji/dekrementacji?

operator->*
• cel: żeby obiekt typu abstrakcyjnego mógł być użyty tak samo jak „wskaźnik do składowej”
• dwuargumentowy (zastosowanie: inteligentny wskaźnik)
• a jest obiektem klasy A, zachowuje się jak wskaźnik, a za pomocą wskaźnika możemy się przecież chcieć dostać do składowych klasy, wskazywanych przez wskaźnik na składowe, czyli właśnie użyć ->*
• musi zwracać obiekt dla którego można wywołać funkcję operator(), któremu są przekazane argumenty, z jakimi wywołano operator->*
• operator() pobiera te argumenty i wyłuskuje prawdziwy wskaźnik do składowej
• a co z operatorem wyłuskania składowej za pomocą obiektu, czyli .*Przypomnienie: nie wolno go przeładować.
// gdzieś w programie …int tablica_danych[10]; A a; // w klasie A niech będzie składowa funkcja o nazwie calcAA::FunPointer fPointer = &A::calcA; // wskaźnik na składową (patrz następny slajd)(a->*fPointer)(tablica_danych); // tu cała akcja

operator->* (przykład)
• na zwróconym obiekcie, typu MemA, wołamy następnie operator() czyli ostatecznie poprzez wskaźnik wołamy odpowiednią funkcję, przekazując jej parametr dany jako parametr do operator() – w przykładzie powyżej jest nim int* w postaci nazwy tablicy int-ów
• wywołanie operatora ->* powoduje wywołanie funkcji operator() dla wartości zwracanej przez operator->* wraz z przekazaniem jej wszystkich argumentów podanych operatorowi ->*
class A {public:double calcA(int*) const;double calcA() const;double calcB(int*) const;typedef double (A::*FunPointer)(int*) const;class MemA {A* fpA; // na potrzeby operator() zapamiętamy wskaźnik do obiektu, którego używamyFunPointer fpmem; // na potrzeby operator() zapamiętamy którą funkcję wołamy za pomocą ->*public:MemA(A *a, FunPointer p) : fpA(a), fpmem(p) { }// operator() wywoła funkcję składową klasy A pokazywaną wskaźnikiemdouble operator()(int* pn) const { return (fpA->*fpmem)(pn); }
}; // koniec zagnieżdżonej klasy MemAMemA operator->*(FunPointer p) { return MemA(this, p); }
};

operator, (przecinkowy)
• nie jest wywoływany w przypadku listy argumentów funkcji• wywoływany dla obiektu o typie, dla którego został zdefiniowany
class Figlarz {public:// operator wywołany w sytuacji: obiekt typu Figlarz, obiekt typu doubleconst Figlarz& operator,(double) { cout<< " double za mną! "; return *this; }
}// funkcja globalna dla wersji z przecinkiem przed obiektem// wywołany w sytuacji: obiekty typu int, obiekt typu FiglarzFiglarz& operator,(int, Figlarz& f) {
cout << " int przede mną! ";return f;
}
int main() {Figlarz filutek;filutek, 3.14; // wypisze na ekranie: double za mną!5, filutek; // wypisze na ekranie: int przede mną!
}

operator<< i operator>> (wstawianie i wyjmowanie)
• operator<<wstawia obiekt do strumienia (klasa ostream)dla typów wbudowanych zachowanie zdefiniowane, np.
ostream& operator<<(int);• operator>> pobiera dane ze strumienia do obiektu (klasa istream)• dla typów abstrakcyjnych chcielibyśmy korzystać z operatorów strumieniowych
tak jak dla typów wbudowanych• spróbujmy zdefiniować jako składową klasy (tylko kawałek kodu):
• poprawne rozwiązanie: musimy zdeklarować funkcje operator<< oraz operator>>jako funkcje globalne, zaprzyjaźnione z daną klasą
• funkcje-przyjaciele nie otrzymują wskaźnika this z danego obiektumusimy im zatem przekazać adres tego obiektu jako argument
class MojaKlasa { int a, b; public:
ostream& operator<<(ostream& stream) const {stream << ”a = ” << a << ” b = ” << b;return stream;
}};// w programieMojaKlasa mojObiekt;cout << mojObiekt << endl; // błąd, to nie zadziała !mojObiekt << cout << endl; // to jest ok, ale składnia wygląda… dziwnie

operator<< i >> (zaprzyjaźniona funkcja globalna)
Dla zachowania poprawnej składni operator<< i operator>>musi być zaimplementowany jako funkcja niebędąca składową.Czy można rozwiązać to lepiej, np. bez deklaracji przyjaźni? Tak i to z dodatkowymi korzyściami!
class MojaKlasa {int a, b;
public:friend
ostream& operator<<(ostream& stream, const MojaKlasa& ref);friend
istream& operator>>(istream& stream, MojaKlasa& ref);};ostream& operator<<(ostream& stream, const MojaKlasa& ref) {
return stream << ”a = ” << ref.a << ” b = ” << ref.b;}istream& operator>>(istream& stream, MojaKlasa& ref) {
// implementacja dowolna, tutaj: wczytanie dwóch liczbreturn stream;
}

operator<< i >> (funkcja globalna i składowe)
Zalety rozwiązania z dodatkowymi składowymi funkcjami przekazującymi:• zewnętrznym operatorom << i >> nie dajemy dostępu do części prywatnej (chronionej)
klasy, czyli hermetyzacja danych pod lepszą kontrolą• jeśli funkcje WyDrukuj i OdCzytaj będą wirtualne, możliwe będzie dynamiczne wiązanie
(czyli zachowanie polimorficzne przy dziedziczeniu) – coś zupełnie niedostępnego w przypadku funkcji zaprzyjaźnionej
class MojaKlasa {int a, b;
public:ostream& WyDrukuj(ostream& stream) const; // robią to samo co operatoryistream& OdCzytaj(istream& stream) const;
};ostream& operator<<(ostream& stream, const MojaKlasa& ref) {
return ref.WyDrukuj(stream);}istream& operator>>(istream& stream, MojaKlasa& ref) {
return ref.OdCzytaj(stream);}

Trzy formy operatora new (C++98)
void* ::operator new(std::size_t size) throw(std::bad_alloc);to jest „zwykły” operator new, użycie w postaci new T, operator nie ma żadnych parametrów, przydziela pamięć, a w przypadku niepowodzenia zgłasza wyjątek (typu bad_alloc), można zdefiniować własną wersję tego operatora
void* ::operator new(std::size_t size, const std::nothrow_t&) throw();wersja niezgłaszająca wyjątków, używa się go w postaci new (std::nothrow) T, a jeśli przydział pamięci zakończy się niepowodzeniem to zwraca 0, również można zdefiniować własną wersję tego operatora
void* ::operator new(std::size_t size, void* ptr) throw();wersja operatora nazywana „placement new” (we wskazanym miejscu), użycie w postaci new (ptr) T, nie alokuje pamięci dla obiektu, tylko tworzy go we wskazanym przez wskaźnik ptr miejscu – np. uprzednio przygotowanym przez inną alokację pamięci, w związku z tym że pamięć nie jest przydzielana więc operacja taka nie może się zakończyć niepowodzeniem ani wyjątek też nie będzie rzucony, nie można napisać własnej wersji tego operatora
• to samo w wersji tablicowej – gdy tworzymy tablice, działa operator new[] W C++11 zmiana: throw() na noexcept ale nadal sprawdzane dynamicznie,ponadto deklarowanie typów zgłaszanych wyjątków ma być „przestarzałe”

operator new i delete (globalne)
• można zmienić sposób przydzielania pamięci:– ogromna ilość alokacji (poprawić efektywność)– radzenie sobie w przypadku defragmentacji sterty, limitowanych zasobów
• nie możemy zmienić faktu, że po przydzieleniu pamięci rusza konstruktor
przeciążenie globalne
#include <cstdio>#include <cstdlib>using namespace std;
void* operator new(size_t sz) { // zwraca adres początku pamięciprintf("alokujemy %d bajtow\n",sz); // nie można użyć iostream// ponieważ dla obiektów globalnych np. cout jest wołany operator newvoid* mem = malloc(sz);if (!mem) puts("brak zasobów");return mem; // jeśli 0 to nie ruszy konstruktor!
}
void operator delete(void* mem) {puts ("usuwamy alokację");free(mem);
}

operator new i delete (lokalne)
przeciążenie dla danego typu • statyczna funkcja składowa (niezależnie od tego czy zadeklarujemy static)
Zawsze tworzymy i używamy parę: new i delete
class A { // najsensowniej zrobić jakiś magazyn – banki pamięci i nimi zarządzać// pierwszy argument obligatoryjnie – rozmiar typu size_tvoid* operator new(size_t rozmiar) {
// można użyć iostream – dla nich wołane globalne wersje new / deletecout << "Alokujemy " << rozmiar << " obiektów char\n";return (::new char[rozmiar]); // char ma 1 bajt, zamiast sizeof „sami robimy”
}void operator delete(void *wsk) { // argument – adres
::delete wsk; }
};
// gdzieś w programieA *ptr = new A; // konstruktor domyślny, operator new przeciążonydelete ptr;ptr = ::new A; // teraz działa wersja globalna operatora new::delete ptr; // wersja globalna operatora delete

operatory new[] i delete[]
• dotyczy wersji operatorów dla alokowania (usuwania) tablic obiektów
można też wersje globalne new[] i delete[], tak jak poprzednio:• jeśli przeładowujesz globalny operator new / delete, to tracisz dostęp do wersji oficjalnych• przeładowanie globalne obowiązuje w całym programie, również podczas tworzenia
obiektów z bibliotek standardowych (np. cin, cout, cerr…)
Skąd delete[] wie jaki rozmiar ma tablica do skasowania? Odpowiedź: zależy od implementacji w danym kompilatorze (to nie jest w standardzie języka). Może byćnp. tak, że jest to kilka bajtów poprzedzających adres podany jako początek tablicy.
// przykład operatorów dla klasy T, pracujących na wersjach globalnych class T {
// gdzieś w części publicznejvoid* operator new[](size_t sz) {
return ::new char[sz];}void operator delete[](void* m) {
::delete [] m;}
};
Gdy kompilator napotyka wywołanieoperatora new, faktycznie wywołanyzostaje T::operator new( sizeof( typ ) )a w przypadku niezdefiniowania wywołany jest globalny::operator new( sizeof( typ ) )

operator new i delete („ze wskazaniem”)
• wersje przeciążone operatora new mogą mieć więcej niż jeden argument• możemy umieścić obiekt w miejscu wcześniej dla niego przygotowanym
(np. sloty pamięci o odpowiedniej wielkości, których adresy znamy)
Operator new „z umieszczeniem” jest faktycznie tak wołany, np.T *ptr = new ( 0x0040 ) T;T *ptr = T::operator new( sizeof( T ), 0x0040 ); // lub:T *ptr = ::operator new( sizeof( T ), 0x0040 );
T *ptr = new(addr) T;// addr jest przekazany jako drugi parametr operatora new// pierwszym (tu niejawnym) jest rozmiar obiektuclass T { // gdzieś w środku klasy…
void* operator new(size_t, void* loc) {return loc; /* nic nie alokujemy, wskazujemy tylko miejsce! */ }
};// operator delete jest tylko jeden, więc usuwając obiekt z jakiegoś slotu, umieszczony tam // za pomocą powyższego operatora new musimy jawnie wywołać jego destruktorT *ptr = new(addr) T;ptr->T::~T(); // wolno tylko w takim przypadku, w którym niszcząc obiekt na stercie
// tak naprawdę nie chcemy zwrócić pamięci tylko usunąć samo istnienie obiektu

dziedziczenie [ inheritance ]
• technika definiowania nowej klasy z wykorzystaniem już istniejącej• klucz do tworzenia relacji dziedziczenia to określenie wspólnego zachowania klas• nie potrzebujemy kodu źródłowego, tylko plik nagłówkowy – możemy np. dziedziczyć z klas
bibliotecznych (które potem linkujemy)
class B : public A { /* ... */ };lista pochodzenia
A – klasa podstawowa (bazowa)B – klasa pochodna klasy A
klasa pochodna• dziedziczy wszystkie składniki klasy podstawowej (atrybuty i zachowanie)• można w niej zdefiniować
– dodatkowe dane składowe– dodatkowe funkcje składowe
• można w niej przedefiniować– składniki / funkcje już istniejące w klasie podstawowej– redefiniowany składnik zasłania składnik z klasy podstawowej

• relacja: jest – czymś• relacja: uogólnienie – uszczegółowienie
( klasa bazowa – klasa pochodna )• klasa pochodna może
– rozszerzać możliwości klasy bazowej (implementacja nowych metod)– uściślać (ponowna implementacja metod istniejących w klasie bazowej)
Klasa pochodna zawsze może być traktowanajako klasa bazowa (w dziedziczeniu publicznym), oznacza to, że:
– można wskaźnikiem (referencją) klasy bazowej pokazywać na obiekty klaspochodnych i nie jest to operacja powodująca utratę części wskazywanegoobiektu
– dziedziczenie prywatne nie jest prawdziwym dziedziczeniem
relacja dziedziczenia – znaczenie

klasa bazowa A klasa pochodna Bprivateprotected protectedpublic public
klasa bazowa A klasa pochodna Bprivateprotected protectedpublic
klasa bazowa A klasa pochodna Bprivate privateprotectedpublic
• dostęp do części prywatnej klasy bazowej A tylko przez jej interfejs
• mamy dostęp do części public i protectedz tym że protected na zewnątrz niedostępny(tak samo jak private)
public
protected
private • domyślny, niepodanie specyfikacjioznacza dziedziczenie privateclass B : A { /* ... */ };
• stosujemy gdy chcemy ukryć fakt dziedziczenia
dziedziczenie implementacji
dziedziczenie interfejsu
sposoby dziedziczenia (public, protected, private)

• umożliwia selektywne zachowanie sposobu dziedziczenia składowych• należy umieścić w wybranej części klasy pochodnej
using klasa_podstawowa::nazwa_skladnika;można również według starego przepisu (bez słowa using)
klasa_podstawowa::nazwa_skladnika;• za pomocą using można zachować (powtórzyć) zakres dostępu
z klasy bazowej lub zmienić z protected na public (i vice versa)class A {// niedostępne w klasie pochodnejint n; void getVal(int);
protected:int k;int calc();
public:int calc(int);void getVal();
};
class B : private A {protected:using A::k;using A::calc; // nie rozróżnia nazw przeciążonych
public:using A::getVal; // nie zadziała bo getVal jest też
}; // w części private• deklaracja dostępu nie może posłużyć do odsłonięcia
nazwy zasłoniętej w klasie pochodnej, również w przypadku redefinicji funkcji (wirtualnej)
• nie usuwa ew. wieloznaczności w dziedziczeniuwielokrotnym (najpierw zawsze jest rozstrzyganawieloznaczność)
deklaracja dostępu (using)

• klasa B jest dla klasy C klasą podstawową bezpośrednią, zaśklasa A – klasą podstawową pośrednią
• inicjalizowanie klasy podstawowej poprzez wywołanie jejkonstruktora
C::C(int i, float f) : B(i,f) { // ...B::B(int i, float f) : A(i) { // ...
lista inicjatorów konstruktora• wywołujemy tylko konstruktor bezpośredniej klasy podstawowej• jeśli tego nie zrobimy, użyty będzie konstruktor domyślny, kolejność
jest “od góry” (klasa A), “do dołu” (klasa C)• gwarantowane jest też wywołanie destruktorów, w kolejności
odwrotnej (czyli od C do A)
A
B
C
dziedziczenie kilkupokoleniowe i inicjalizacja

// wcześniej definiujemy klasy: MW, MX, MY, MZ oraz klasę Aclass B : public A {
MY my;MX mx;
public:B(int i) : mx(), my(), A() { /*...*/ }~B();
};class C : public B {
MW mw;MZ mz;
public:C() : mw(3.14), B(45) { /*...*/ }~C();
};
• kolejność wywołania konstruktorówelementów składowych jest związanaz kolejnością ich wystąpieniaw definicji klasy, a nie z kolejnościąna liście inicjatorów
• w przykładzie po lewej, kolejność konstrukcji:A, MY, MX, B, MW, MZ, C
• kolejność destrukcjijest dokładnie odwrotna:C, MZ, MW, B, MX, MY, A
kompozycja i dziedziczenie

• przedefiniowanie (redefining) w przypadkuzwykłych funkcji składowych klasy bazowej
• zasłanianie (overriding) w przypadku funkcji wirtualnych klasy bazowejclass A { public:int fun() const;int fun(float) const;
};class B : public A { public:int fun() const; // przedefiniowanie
};class C : public A { public:void fun() const; // zmiana zwracanego typu
};class D : public A { public:int fun(char*) const; // zmiana listy argumentów
};
we wszystkich przypadkachniewidoczne (zasłonięte) stają się również funkcjeprzeciążone w klasie bazowej,tzn. tutaj: int fun(float) const;
gdyby w klasie A była metoda prywatna, to dostępu do niej nie mamy w klasach pochodnych, ale możemy ją przedefiniować !!! tak, że będzie działać nasza nowa wersja, tak jakby była tą funkcją składową z części prywatnej A
ukrywanie nazw w klasach pochodnych

class A { public:A(const A& a);
};class B : public A { public:B(const B& b) : A(b) { /* ... */ }
};
• konstruktory (patrz C++11)
• operator=• destruktorKONSTRUKTOR KOPIUJĄCY• ten generowany automatycznie wykorzysta konstruktory kopiujące klas-przodków i
składników– chyba że któryś z tych konstruktorów kopiujących jest prywatny– uwaga: definicja jakiegokolwiek konstruktora (np. właśnie kopiującego) wyklucza
automatyczne generowanie zwykłego konstruktora• definiowany przez nas może je wywołać
• trzeba je zdefiniować samemu(lub zostaną wygenerowane automatycznie!)
• można jednak we własnych definicjach wywołać wersjez klas podstawowych do obsłużenia odziedziczonej części obiektu
jawne wywołanie konstruktorakopiującego klasy A, inaczej zostałbywywołany zwykły konstruktordomyślny klasy A
czego się nie dziedziczy (C++98)

dziedziczenie konstruktorów ( C++11 )
Deklaracja using może być użyta z konstruktorami klasy bazowej
Dziedziczone konstruktory zachowują swoją specyfikację (tzn. są np. explicit lub są wyrażeniem stałym constexpr).
class Foo { public:explicit Foo(int); // explicit jako przykład „dobrego stylu”void fun();
};class Bar : public Foo { public:
using Foo::fun; // tu nic nowego, w zasadzie niepotrzebneusing Foo::Foo; // powoduje niejawną deklarację Bar::Bar(int); // taki konstruktor zdefiniowany/wygenerowany tylko w przypadku użyciavoid fun(); // nadpisuje Foo::fun() Bar( int, int ); // tu już samemu napisany konstruktor, bez dziedziczenia
};Bar b1( 7 ); // ok w C++11 dzięki dziedziczeniu konstruktoraBar b2( 3, 5 ); // normalne wywołanie Bar::Bar(int, int);

dziedziczenie konstruktorów – dostępność, inicjalizacja składników ( C++11 )
Może się okazać, że odziedzczony konstruktor jest prywatny
Jeśli klasa potomna ma jeszcze jakieś składowe, to użycie dziedziczonego konstruktora jest ryzykowne. Składowe klasy Bar będą albo domyślnie inicjalizowane (s) albo niezainicjalizowane (x, y).Oczywiście można:
class Foo { private:explicit Foo(int);
};class Bar : public Foo { public:
using Foo::Foo; private:
string s;int x, y;
};Bar b1( 7 ); // błąd – woła Bar(int), który woła Foo(int), a ten jest niedostępny
błąd objawia sięw momencie próby użycia
string s = ”niezainicjalizowany”;int x = 0, y = 0;

OPERATOR PRZYPISANIA operator=• ten generowany automatycznie wywoła operatory= klasy-przodka i
składników– chyba, że któryś z tych operatorów jest prywatny– chyba, że są składniki const lub składniki będące referencją – bo te
wymagają inicjalizacji• definiując operator= możemy je użyć
class A { public:A& operator=(const A& a);
};class B : public A { public:
B& operator=(const B& b) {A::operator=(b);// ...return *this; }
};
musi być podany zakres ( A:: )ponieważ nowodefiniowanyB::operator= przesłania funkcjęoperatora klasy bazowej
alternatywnie mozna tak:(*this).A::operator=(b);lubA *wsk = this; // możemy wskaźnikiem klasy bazowej(*wsk) = b; // pokazać na obiekt pochodnylubA &ref = *this; // możemy referencji do klasy bazowejref = b; // przypisać obiekt klasy pochodnej
czego się nie dziedziczy

• składniki statyczne i oczywiście definiujemy je dla klasyw której są zdeklarowane– możemy je zasłaniać
class A { public:static int ca;static int getNew() { return ca; }
};class B : public A { public:
static int ca;static int getNew() { return ca; } // zasłania funkcję z klasy Astatic int getOld() { return A::ca; } // tak możemy się dostać do “starej” wartości
};int A::ca = 2;int B::ca = 5; // z powodu re-deklaracji w klasie B, musimy zdefiniować
• statyczne funkcje składowe– gdy przedefiniowane – zasłaniają funkcje z klasy podstawowej (wszystkie
przeciążone wersje), również wtedy gdy następuje zmiana sygnaturyfunkcji
co jest dziedziczone i warto wspomnieć

• operatory konwersji typów – bo w klasach pochodnych mamy kompletinformacji do wykonania konwersji
• konstruktory konwersji nie są dziedziczone, ale…
class C { public:C(int n) : c(n) {}int c;
};
class A { public:A(int n) : a(n) {}A (const C& c) : a(c.c) {}int a;
};
void fun(const A& a) { cout << "a.a = " << a.a << endl; }void fun2(const B& b) { cout << "b.a = " << b.a << endl; }
int main() {C c(11);D d(22);A a(33);B b(44);fun(c); // normalnie, wypisze 11 – konwersja typufun(b); // co wypisze? 44 czy 46?fun(d); // co wypisze? 22 czy 25? fun2(c); // błąd – bo konstr. konwersji się nie dziedziczy
}
obiekt klasy B pokazywany referencją do klasy bazowej Ajest widziany jako obiekt klasy A,więc wypisana jest częśćobiektu z klasy A (tu zasłoniętaw klasie B)
class D : public C { public:D(int n) : C(n+3), c(n) {}int c;
};
class B : public A { public:B(int n) : A(n+2), a(n) {}int a;
};
obiekt klasy D jest również obiektem typu klasy C, więc możliwa jest konwersja obiektutypu D na obiekt typu A, wypisanajest ta część obiektu z klasy C(tu zasłonięta w klasie D)
co jeszcze jest dziedziczone

• jest bezpieczne bo od typu bardziej wyspecjalizowanego przechodzimy do typu bardziej ogólnego
• jest naturalne: wskaźnikiem (referencją) typu bazowego pokazujemy na typ pochodny
class A { public: int a; };class B : public A { public: int b; };// gdzieś w programie…B b;A *wskA = &b;A &refA = b;
– poprzez wskA i refA oczywiście nie mamy dostępu do części zdefiniowanej w klasie B (tzn. int b), ale np. poprzez jawne rzutowanie (w dół !) można się tam dostać
• co jeśli przez wartość?A a = b;
– to też dopuszczalne, ale następuje nieodwracalna strata części obiektu klasy B (tu zadziała konstruktor kopiujący z klasy A, który nic nie wie o dodatkowej części z klasy B)
rzutowanie w górę (upcasting) i w dół

class A { public: void getMe() { cout << "Jestem A/n"; }
};class B : public A { public:
void getMe() { cout << "Jestem B/n"; } };class C : public B { public:
void getMe() { cout << "Jestem C/n"; } };// …gdzieś w programieB b;C c;A *ptrA = &b;A &refA = c;A a = b;ptrA->getMe(); // "Jestem A"refA.getMe(); // "Jestem A"a.getMe(); // "Jestem A"
to nas nie zadowala, boprzecież pokazywane sąobiekty klas pochodnych
chcielibyśmy, żeby wskaźnik(referencja) inteligentniereagowały na typ obiektuna który pokazują, wołającjego funkcję…
polimorfizm – czego oczekujemy?

class A { public: virtual void getMe() { cout << "Jestem A/n"; }
};class B : public A { public:
void getMe() { cout << "Jestem B/n"; } };class C : public B { public:
void getMe() { cout << "Jestem C/n"; } };// …gdzieś w programieB b;C c;A *ptrA = &b;A &refA = c;A a = b;ptrA->getMe(); // "Jestem B"refA.getMe(); // "Jestem C"a.getMe(); // "Jestem A" – nieodwracalne "przycięcie" do A
w klasie bazowej (tutaj klasie A)
musimy w deklaracjifunkcji dodać
virtual
funkcja getMe() jest wirtualna w każdejklasie pochodnej, można (ale nie trzebabo jest to mylące) dopisać "virtual"również w klasie B i C…
• ściśle rzecz biorąc polimorficzne jestwywołanie funkcji, a nie funkcja• klasa, w której jest zdefiniowana lub odziedziczona funkcja wirtualna,nazywa się klasą polimorficzną
polimorfizm - rozwiązanie

• wiązanie (binding) – połączenie wywołania funkcji z jej ciałem– wczesne wiązanie (early binding) – gdy wykonane podczas kompilacji– późne wiązanie (late binding) – gdy wykonane w trakcie wykonywania
programu na podstawie informacji o typie• polimorfizm wymaga późnego wiązania, wiąże się to z dodatkowymi kosztami
– gdy występuje funkcja wirtualna obiekt klasy jest większy o rozmiar wskaźnikado specjalnej tablicy – niezależnie od liczby funkcji wirtualnych (tablica ta nie wchodzi w skład klasy)
– tylko w tej klasie, w której pojawia się po raz pierwszy deklaracja danej funkcji wirtualnej, tworzona jest tablica do wszystkich funkcji wirtualnych o tej nazwie
– podejmowanie decyzji którą funkcję wykonać w trakcie wykonywania programu, również stanowi narzut
• tam gdzie wywołanie funkcji wirtualnej, podczas kompilowania, wstawiony kod uruchomieniowy funkcji pokazywanej przez wskaźnik schowany w którymś elemencie tablicy
• tablica wskaźników do funkcji zawierająca adresy wszystkich kolejnych wersji funkcji wirtualnej budowana dla klasy podstawowej w chwili linkowania
wiązanie – koszty

• polimorfizm działa jeśli funkcję typu virtual wywołujemy przez wskaźnik lub referencję do obiektu klasy podstawowej
• nowa definicja funkcji wirtualnej (w klasie pochodnej) musi być identyczna co do listy argumentów, zaś zwracany typ musi być identyczny lub…
• …zwracany typ może być kowariantny (covariant)wymagania – zwracany typ to wskaźnik lub referencja
– wtedy można zmienić obiekt zwracany przez funkcję wirtualną w klasie pochodnej na wskaźnik (referencję) do obiektu klasy pochodnej jednoznacznie wskazującej na klasę bazową, do której wskaźnik (referencję) zwraca funkcja wirtualna w klasie bazowej
class Partia { public:virtual Polityk* getPolityk()
{ cout << "Teraz ja!" << endl; }virtual Przewodniczący& getPrzewodniczacy()
{ cout << "RULEZ!" << endl; }};class Dlugopis : public Partia { public:
DzialaczDlugopis* getPolityk() { cout << "Beee…" << endl; }
PrezesDlugopis& getPrzewodniczacy() { cout << "Chcesz w papę?" << endl; }
};
// …gdzieś w programiePartia *ptrP = new Dlugopis;ptrP->getPolityk(); // "Beee…"ptrP->getPrzewodniczacy(); // Chcesz w papę?
Polityk
DzialaczDlugopis
Przewodniczacy
PrezesDlugopis
funkcje wirtualne – co można zmienic?

• funkcja globalna nie może być wirtualna (bo przecież polimorficzne orientowanie ze względu na typ obiektu…)
• funkcja wirtualna nie może być statyczna• funkcja wirtualna może być przyjacielem jakiejś innej klasy, ale tylko konkretna realizacja funkcji wirtualnej
z danej klasy jest tym przyjacielem (a nie wszystkie funkcje) bo przyjaźni się nie dziedziczy• w klasie pochodnej można zasłonić funkcję wirtualną z klasy bazowej (definicja obiektu lub innej funkcji o tej
samej nazwie), ale w kolejnej klasie pochodnej (do klasy pochodnej) można ją znów zdefiniować i korzystać z polimorfizmu
• jeśli zmienia się zakres dostępu dla funkcji wirtualnej, np. w klasie bazowej funkcja ta była public, a w klasie pochodnej jest protected lub private
sposób dostępu taki jak w typie użytego wskaźnika lub referencjiclass A { public:
virtual void f() { cout << "Jestem A" << endl; }};class B : public A { private:
void f() { cout << "Jestem B" << endl; }};int main(){
A *ptrA = new B;ptrA->f(); // "Jestem B"B &refB = dynamic_cast<B&>(*ptrA);refB.f(); // błąd - virtual void B::f() is private
}
dostęp rozstrzyganyna poziomie wiedzy wyniesionej z klasybazowej A, bo pokazujemywskaźnikiem klasy bazowej
funkcje wirtualne – kilka szczegółów

• konstruktory nie są dziedziczone (C++98), nie mogą być wirtualne– żeby zadziałał polimorfizm to musi być pokazywany obiekt
danego typu (wskaźnikiem, referencją), a tego obiektu "jeszcze nie ma", jest konstruowany
• destruktor – nie jest dziedziczony, ale tak!Jeśli klasa posiada choć jedną deklarację funkcji jako virtual, jej destruktor też deklarujmy jako virtual
– wtedy destruktory klas pochodnych też będą virtual– działać będzie polimorfizm i poprawna destrukcja obiektu
konstruktor, destruktor – wirtualny

• wskaźnikiem klasy bazowej można pokazać na obiekt klasy pochodnej, ale uwaga na tablicevoid fun(A* ptr) { cout << (ptr+1)->n << endl; }class A { public: int n; };class B : public A { public: int k; };B tabB[5];// konwersja zajdzie, ale w środku funkcji wskaźnik // będzie poruszał się tak jak po obiekcie typu A !fun(tabB); // potencjalna katastrofa wewnątrz funkcji// klasa B jest rodzajem klasy A, ale // tablica klasy B nie jest rodzajem tablicy klasy A
• w przypadku wskaźnik do wskaźnika konwersja nie zajdzie (na nasze szczęście)void fun(A** ptrA);B **ptrB;fun(ptrB); // błąd
• wskaźniki na składowe klasy bazowej może zostać niejawnie zamieniony na wskaźniki na składowe klasy pochodnejint A::*calkowity = &A::n;B b;b.n = 77;cout << b.*calkowity << endl; // wypisze "77"int B::*natural = &B::n;A a;a.n = 88;// błąd, w drugą stronę nie ma niejawnej konwersji, trzeba ją samemu napisaćcout << a.*natural << endl;
dziedziczenie – a konwersje

• tworzona po to, aby być klasą bazową do dziedziczenia• będziemy korzystać z polimorfizmu (virtual)• implementacja metod niepotrzebna, deklaracja interfejsu
virtual void funkcja() = 0; // czysto wirtualna– ta wersja funkcji nigdy nie ma być wykonana, konieczność implementacji
(uściślenia) w klasie pochodnej– klasa jest abstrakcyjna gdy ma choć jedną funkcję wirtualną– dziedziczona jako czysto wirtualna, więc jeśli nie ma jej definicji w klasie
pochodnej, klasa pochodna też jest klasą abstrakcyjną– nie można stworzyć żadnego obiektu klasy abstrakcyjnej– funkcja nie może zwracać przez wartość obiektu klasy abstrakcyjnej– nie może być typem w jawnej konwersji
FUNKCJE WIRTUALNE i ich ciałavirtual void funkcja() { } // zwykła, musi mieć definicjęvirtual void funkcja() = 0; // pure virtual, bez definicji ► może mieć definicję, umieszcza się ją poza ciałem klasy→ taką funkcję można wywołać tylko wprost (z operatorem zakresu) czyli klasa::funkcja() lub
z wnętrza konstruktora (destruktora) klasy, w której jest ona czysto wirtualna→ niezdefiniowanie ciała funkcji "pure virtual" w którejś z kolejnych klas pochodnych, czyni z tej
klasy pochodnej znowu klasę abstrakcyjną
dziedziczenie – klasa abstrakcyjna

inicjalizacja dla wszystkich ( C++11 )
Domyślne wartości inicjujące składowe (niestatyczne):
Wartość nadana przez konstruktor nadpisuje powyższą inicjalizację:
Uwaga: napisanie domyślnej wartości inicjującej powoduje, że dany typ przestaje być agregatem – nie można go (bez napisania konstruktora) zainicjalizować tak jak można było agregat:
struct Bar {int m = 7; // gdyby nie wartość domyślna, ujednolicona inicjalizacja nie byłaby błędem
};Bar b { 5 }; // błąd – próba wywołania konstruktora z int, ale takiego nie ma
class Foo { int m = 3; // dopuszczalna również składnia int m { 3 };int n { 3*m }; // może zależeć od innych zmiennychstring s = getString(); // string s = { getString() }; tu znak = opcjonalnie
}; Foo w; // w.m zainicjalizowane 3, w.n 9, w.s tym co zwróci getString()
explicit Foo(int a) : m(a) {} // teraz m ma warość a, reszta jak powyżej

różne rodzaje inicjalizacji ( C++98 )
Wiele różnych sposobów inicjalizacji:
Tablice:
Proste struktury i klasy:
int a(7); // inicjalizacja bezpośredniaconst int b = 7; // inicjalizacja „kopiująca” – to nie jest przypisanie
class Para { public:
Para(int m, int n); // konstruktor};const Para p(5, 10); // inicjalizacja– wywołanie funkcji (konstruktora)Para p2 = Para(1,2); // składnia w stylu wołanie funkcji / konwersja
int tablica[] = { 1, 2, 3, 4 }; // inicjalizacja za pomocą nawiasów
struct Dane { int a, b; };const Dane d = { 5, 10 }; // inicjalizacja za pomocą nawiasów

rodzaje inicjalizacji i problemy ( C++98 )
Kontenery wymagają innych kontenerów:
Problem – nie można zainicjalizować tablic składowych klasy ani tablic tworzonych dynamicznie (na stercie):
int tab[] = { 2, 4, 6, -3, -7 }; // najpierw zwykła tablicastd::list<int> lista( tab, tab+5 ); // inicjalizacja z innego kontenera
class Tablica { const int dane[10];
public:Tablica() : /* nie da się nic zrobić z dane */ {}
};
const double* ptr = new const double[7]; // inicjalizacja niemożliwaclass Foo { // …
Foo(int n); // brak konstruktora domyślnego};Foo *ptab = new Foo[5]; // błąd! musi istnieć konstruktor domyślny!
Kłopotliwa składnia:int a(1); // definicja zmiennejint a(); // deklaracja funkcji!int a(Foo); // może być jedno// lub drugie – zależy od Foo

uogólniona (jednolita) inicjalizacja ( C++11 )
Zunifikowany sposób inicjalizowania za pomocą składni z nawiasami { }
Teraz można zainicjalizować tablice składowe klasy na liście inicjalizatorówa także tablice tworzone dynamicznie (typu prostego i abstrakcyjnego):
int a { 7 };const double b { 3.14 }; int tab[] { 0, 4, a, a+b };const Para p { 5, 10 }; // wywołanie konstruktorastd::vector<int> wektor { a, tab[3], b };
const double* ptr = new const double[3] { b, tab[3], 3.14 };class Tablica {
const int dane[2];public:
Tablica() : dane { 1.5, tab[1] } {} // konstruktor// można dodatkowe nawiasy Tablica() : dane ( { 1.5, tab[1] } ) {}
};Foo *ptab = new Foo[3] { 1, Foo(2), tab[1] }; // musi być c-tor Foo(int)

inicjalizacja – obiekt zwracany lub argument ( C++11 )
Składnia z nawiasami { } użyta w miejscu zwracania obiektu
Użycie jako listy argumentów:
agregat – tablica lub klasa bez (napisanych przez użytkownika) konstruktorów, bez (domyślnych) inicjalizacji niestatycznych składowych, bez prywatnych (bez chronionych) niestatycznych składowych, bez dziedziczenia, bez funkcji wirtualnych
Inicjalizacja agregatu – inicjalizacja składowych „od początku do końca”Inicjalizacja nie-agregatu – wywołanie konstruktoraSzczególny przypadek – unie:
Para utworzPare() { return { 0, 0 }; } // woła konstruktor klasy Para
union Unia { int a, double* p, char* c }; // definicja uniiUnia u1 = { 5 }; // tylko pierwszy element unii może być inicjalizowanyUnia u2 = { 3, 0x0 }; Unia u3 = { "tekst" }; // błąd w obu przypadkach
void fun( std::list<int>& lista ); // deklaracja funkcjifun( { a, tab[0], 3, 5 } ); // wywołanie z argumentem

inicjalizacja agregatów – szczegóły ( C++11 )
Zbyt wiele argumentów – błąd!Mniej argumentów – pozostałe obiekty inicjalizowane wartością:• typy wbudowane inicjalizowane 0• typy użytkownika (z konstruktorami) – domyślnymi konstruktorami• typy użytkownika (bez konstruktorów) – składowe inicjalizowane
wartością
Kontener std::array (tablica określonego rozmiaru) jest także agregatem:
double fun(); // ta funkcja zwraca double i za chwilę będzie użytastd::array< double, 3 > tablica = { 1, fun(), 2, 3, 5 }; // błąd// także tu za dużo inicjalizatorów
struct Dane { int a, b; }; // jak poprzednioconst Dane d = { 5 }; // to samo co { 5, 0 }const Dane d2 = { 5, 7, 9 }; // błąd – za dużo inicjalizatorów

inicjalizacja agregatów – szczegóły 2 ( C++11 )
Agregaty mogą być zagnieżdżone:
Składniki statyczne oraz anonimowe pola bitowe nie inicjalizowane:struct A {
int i;static int s;int j;int :17; // nieużywane (bo anonimowe)int k;
} a = { 1, 2, 3}; // zainicjalizowane są a.i, a.j, a.k
struct A {int x;struct B {
int i;int j;
} b;} a = { 1, { 2, 3 } };
przykład utworzenia obiektówod razu po definicji obiektów orazinicjalizacja za pomocą listy { }

inicjalizacja agregatów – szczegóły 3 ( C++11 )
Zagnieżdżony agregat bez konieczności inicjalizacji:struct S { } s; // nie posiada danych do inicjalizacjistruct A {
S s1;int i1;S s2;int i2;S s3;int i3;
} a = { { }, // nie można pominąć inicjalizacji (pustej)0, s,0
};
przykład utworzenia obiektówod razu po definicji obiektów orazinicjalizacja za pomocą listy { }

inicjalizacja nie-agregatów – szczegóły ( C++11 )
Tyle argumentów ile wymaga konstruktor!
Inicjalizacja działa również w przypadku kontenerów:
std::vector< int > w { 1, 2, a, 3, b }; // woła konstruktor wektorastd::map< std::string, long > ksiazka { { "Jan", 234567 },
{ "Anna", 456789 } }; // powyżej woła konstruktor mapystd::unordered_set< float > s { 0, 1.7, 5 }; // woła konstruktor
// unordered_set
// klasa Para jak poprzednio, ma konstruktor Para(int, int);const Para p1 { 5 }; // błąd – za mało argumentów konstruktora// A jeśli jeden z argumentów byłby domyślny?// Para( int, int = 3 );Para p11 { 5 }; // wtedy ok – równoważne z { 5, 3 }const Para p2 { 5, 7, 9 }; // błąd – za dużo argumentów

inicjalizacja – składnia z użyciem = ( C++11 )
Prawie zawsze można użyć składnię ze znakiem przypisania =
Są sytuacje, kiedy taka składnia nie działa (wszystko poniżej – błąd):const double* ptr = new const double[3] = { b, tab[3], 3.14 };class Tablica { const int dane[2];
public:Tablica() : dane = { 1.5, tab[1] } {}
};Para utworzPare() { return = { 0, 0 }; }void fun( std::list<int>& lista ); // deklaracja funkcjifun( = { a, tab[0], 3, 5 } );
int a = { 7 };const double b = { 3.14 }; int tab[] = { 0, 4, a, a+b };const Para p = { 5, 10 }; // wywołanie konstruktorastd::vector<int> wektor = { a, tab[3], b };

inicjalizacja – składnia z użyciem = bez explicit ( C++11 )
W składni z przypisaniem = nie można wołać konstruktorów „explicit”
Inicjalizacja za pomocą { } traktowana jest jako rozszerzenie możliwości języka C++. Są jednak nieliczne sytuacje, w których dotychczasowy kod będzie wymagał poprawek –wiąże się to z innym użyciem pary nawiasów – w celu zapobieżenia zaokrąglaniu (niejawnej obcinającej – stratnej konwersji) tzw. narrowing.
class Liczba {public:
explicit Liczba( int );};Liczba k1( 7 ); // ok, jawne wywołanie konstruktoraLiczba k2{ 7 }; // ok, jak wyżejLiczba k3 = 7; // błąd – składnia kopiująca: explicit c-tor nie działaLiczba k4 = { 7 }; // błąd – jak wyżej
wniosek: przyzwyczaić się raczejdo składni bez użycia znaku =

{ } w kontekście przypisania = ( C++11 )
Również w przypadku przypisania może być użyta składnia z { }int a, b;a = b = { 1 }; // oznacza a = b = 1;a = { 1 } = b; // błąd składniowyT x; // skalarny obiekt typu Tx = { a }; // tożsame z: x = T(a);x = {}; // tożsame z: x = T();
// również w przypadku operator= zdefiniowanego przez użytkownikacomplex<double> z;z = { 1, 2 }; // z.operator=( { 1, 2} );z += { 1, 2 }; // z.operator+=( { 1,2 } );

stratna (zawężająca) konwersja a sprawa inicjalizacji ( C++11 )
W języku C++ mogą się zdarzyć sytuacje stratnej konwersji:
Składnia z użyciem { } zapobiega stratnej (zawężającej) konwersji:int i { 3.5 }; // błąddouble f { i }; // też błąd – double nie reprezentuje dokładnie intunsigned u { i }; // unsigned nie reprezentuje całego intunsigned u { 34 }; // ok, kompilator wie, że unsigned może mieć 34struct Dane { int a, b; }; // jak poprzednioDane d = { 5, 7.23 }; // ok w C++98, błąd w C++11Dane d2 { 5, static_cast<int>(7.23) }; // zawsze ok
int a = 7.3;char c = 2011;int tab[] = { 1, 2, 3.14, 4, 5 };void fun1(int); fun1( 7.3 ); // bez ostrzeżeniavoid fun2(char); fun2( 2011 ); // warningvoid fun3(int[]); fun3( { 1, 2, 3, 4, 5 } ); // błąd: // niemożliwa konwersja z <brace-enclosed initializer list> do int*

stratna konwersja i różnice w inicjalizacji ( C++11 )
Ta nowa funkcja { } (blokowanie konwersji zawężającej) implikuje drobne różnice w inicjalizacji:
class Liczba { public:
Liczba(unsigned n); // konstruktor};int m;Liczba k1(m); // ok – niejawna konwersja int → unsignedLiczba k2 {m}; // błąd – bo konwersja int → unsigned zawężającaunsigned u;Liczba k3(u); // okLiczba k4 {u}; // ok – to samo co wyżej

listy inicjalizujące ( C++11 )
Typ std::initializer_list dzięki któremu możliwy jest omawiany właśnie mechanizm inicjalizacji / wstawiania:
• każda funkcja może używać listy inicjującej – także jako parametru• lista { } może konwertować na obiekt typu std::initializer_list
• w typie std::initializer_list dostępne są metody:
vector<int> v {}; // inicjalizacjav.insert( v.end(), { 3, 4, -5, -6 } ); // wstawienie wielu elementówv = { 1, 2, 3 }; // zamiana wartości w wektorze
size_t size() const; // liczba elementów w tablicyconst T* begin() const; // pierwszy elementconst T* end() const; // adres zaraz za ostatnim elementem
auto x = { 1, 2, 3 }; // x jest typu initializer_list<int>auto y = { 1 }; // y też jest typu initializer_list<int>, zmiana w C++17 na intauto z = { 1, 3.14 }; // błąd – nie można wydedukować jednego typu

listy inicjalizujące – praktyczny przykład ( C++11 )
std::initializer_list bardzo wygodne jako argument funkcji, o możliwej zmiennej liczbie argumentów (konkretnego typu):
#include <initializer_list> // potrzebny nagłówek + inne…string getName(int id); // jakaś funkcja zamieniająca int na stringclass Nazwy { public:
Nazwy( std::initializer_list<int> n ) { // konstruktornazwy.reserve( n.size() ); // możemy zarezerwować miejsce// pętla przebiegająca w całości po kontenerze (tu tablicy n)for( auto idx : n ) nazwy.push_back( getName(idx) );
}private:
vector<string> nazwy;};
// … gdzieś w programie …Nazwy m { 3, 5, 8, x, t[0] + 2 }; // wartości włożone do tablicy
Mogą być też inne argumenty:Nazwy( double x, const string& s, initializer_list<int> n );// … w programie …Nazwy m2 { 3.14, "slowo", { 1,2,3 } };// to samo co:Nazwy m2( 3.14, "slowo", initializer_list<int>({1,2,3}) );

initializer_list – rozstrzyganie przeciążenia ( C++11 )
Spośród konstruktorów w przypadku inicjalizacji przez{ } preferowany jest zawsze konstruktor z typem initializer_list:
Jeżeli dopasowanie wymaga zawężenia, wywołanie jest błędne:
class Liczby { public:Liczby(double d1, double d2); // c-tor 1Liczby(std::initializer_list<double> w); // c-tor 2
};double x, y;Liczby w1 { x, y }; // woła c-tor 2// w przypadku składni funkcyjnej – preferowany inny możliwyLiczby w2( x, y ); // woła c-tor 1
class Liczby { public:Liczby( std::initializer_list<int> );Liczby( int, int, int ); // ten c-tor nie jest brany w ogóle pod uwagę gdy argumenty { }
};Liczby w3 { 1, 3.0, 5 }; // błąd – zawężająca konwersja double → int

initializer_list – rozstrzyganie przeciążeń ( C++11 )
Kryteria dobierania kandydata na przykładzie:
class Liczby { public:Liczby(std::initializer_list<int> w); // c-tor 1Liczby(std::initializer_list<double> w); // c-tor 2Liczby(std::initializer_list<string> w); // c-tor 3Liczby(int, int , int); // jeśli argumenty jako { } to nie brany pod uwagę!
};Liczby w1 { 1, 3.14, 5 }; // niejednoznaczność: int → double, double → intLiczby w2 { 1.0f, 3.14, 5.0 }; // float → double lepsze, wołany c-tor 2string s;Liczby w3 { s, "jeden", "dwa" }; // wołany c-tor 3Liczby w4 { 1u, 2, 3 }; // też błąd bo unsigned może być int lub doubleshort k = 0;Liczby w5 { k, 2, 3 }; // wołany c-tor 1// w przypadku tablicy można użyć dowolny konstruktor inicjalizowany…Liczby *ptr = new Liczby[3] { Liczby { 1, 2, 3 }, Liczby { 1.23 }, Liczby(1,2,3) };

programowanie obiektowe grupowanie danych oraz funkcji, które nimi manipulują oddzielenie danych od kodu, który z nich korzysta, dzięki
interfejsowi w postaci funkcji działających na tych danych
hermetyzacja jest jednym z podstawowych pojęć programowania obiektowego - prawie zawsze wiąże się z ukrywaniem danych
dane składowe powinny być
zawsze prywatne!
wyjątek: proste struktury(agregaty) danych (takiejak w C) - które nie są zasadniczo klasami
dane chronione: też źle, bo pozwalająna dostęp do nich dla kodu zewnętrznegoklas pochodnych, a przecież nie stosujemyklas bazowych będących tylko prostymagregatem (strukturą) danych - wyjątkuzatem nie ma
abstrakcja danych – projetowanie obiektowe

class A { // …public:
B& getB() { return b; }protected:
C& getC() { return c; }private:
B b;C c;
};
class A { // …public:
B b;protected:
C c;};
• dostęp za pomocą funkcji inline(nie ma dodatkowych kosztów kopiowania - kompilator zoptymalizuje)• można wprowadzać dodatkowezmiany później, nie zmieniając nazwy funkcji (czyli sposobu używania)
• sztywny kod, jakakolwiek zmiana oznacza koniecznośćzmiany u wszystkich użytkowników• jeśli nawet chwilowo zostawiszgo w tej postaci, to możesz potemnie mieć okazji na zrobienie zmian,później będą one zawsze więcej kosztować niż na samym początku
najpierw dobry interfejs - resztę można poprawić później
abstrakcja danych – hermetyzacja, prosta zmiana

class A {private:
virtual void funA() {}};
int main() {A a;a.funA(); // błądusing funPtr = void (A::*)();funPtr p = &A::funA; // błądreturn (a.*p)(); // błąd wykonania
}
class B : public A {virtual void funA() {
A::funA(); // błąd}
};
składowa prywatnajej nazwa może być używana jedynie przez składowe oraz jednostki zaprzyjaźnione klasy,w której znajduje się jej deklaracja
dostęp - nie ma dostępu • ani bezpośrednio (jawne wywołanie) • ani pośrednio (przez wskaźnik na funkcję)• ani w pochodnej klasie dziedziczącej (która może przesłonić składową prywatną klasy bazowej, ale do niej dostępu nie ma)
hermetyzacja – co to znaczy składowa prywatna?

class A { public:int ai;static int si; // deklaracjaA() : ai(77) { }void getI() { cout << ai << "," << si; }
};int A::si = 88; // definicja zmiennej statycznejclass B : private A { public:using A::getI;
};class C : public B {void f();
};
void C::f() {ai = 2; // błądsi = 3; // błąd::A a; a.ai = 2; // OKa.si = 3; // OK::A::si = 4; // OK
• Klasa B dziedziczy prywatnie z klasy A, czyli wszystkie publiczne zmienne stają się prywatne
• Klasa C dziedziczy publicznie z klasy B, dostępu do pól prywatnych klasy bazowej B nie ma
• możliwy jest za to dostęp bezpośredni (lokalny obiekt, nie część odziedziczona) lub przez rzutowanie wskaźnika (do części odziedziczonej)
::A *ptrA = this; // błąd::A *ptrA2 = (::A*)this; // OKa.getI(); // 2, 4getI(); // 77, 4ptrA2->ai = 5; // OKa.getI(); // 2, 4getI(); // 5, 4
}
hermetyzacja – prywatne dziedziczenie, a dostęp

#include <complex>class Calc {
public:double Twice( double d );
private:int Twice ( int i );std::complex<float>
Twice( std::complex<float> c );};int main() {
Calc c;return c.Twice( 21 );
}
składowa prywatnajest widziana w całym kodzie,który widzi definicję klasy - oznacza to, że jej parametry muszą być zadeklarowane nawet wtedy, gdy nie są potrzebne w danej jednostce translacji (pliku)
deklaracja wyprzedzająca klasy complexkonieczna, a gdyby ta funkcja była zdefiniowanajako inline, to konieczna by była pełna definicjaklasy complex
błąd - najlepiej dopasowana funkcja Twice jest prywatnawyszukiwanie nazw - kompilator szuka zakresu, w którym znajduje się przynajmniejjeden element o nazwie Twice i tworzy listę kandydatów do wywołania, jeśli nieznajdzie to dalej szuka w klasach bazowych i przestrzeniach nazw zawierających klasę Calc, spośród kandydatów wybrana zostaje wersja najlepiej dopasowana,na koniec sprawdzenie dostępności
hermetyzacja – składowa prywatna, a widzialność

#include <string>int Twice( int i );
class Calc {private:
std::string Twice( std::string s );public:
int Test() {return Twice( 21 );
}};int main() {
return Calc().Test();}
#include <complex>class Calc {
public:double Twice( double d );
private:unsigned Twice ( unsigned i );std::complex<float>
Twice( std::complex<float> c );};
int main() {Calc c;return c.Twice( 21 );
}
przeszukiwanie kończy się gdy zostanieznaleziony przynajmniej jeden elemento odpowiedniej nazwie (dopiero potemokazuje się, że nie można go użyć - tuz powodu braku konwersji z int na string)
wybór wersji przeciążonej nie pozwalaznaleźć jednej najlepiej dopasowanejwersji funkcji na liście kandydatów(int może być przekształcony na double lub unsigned)
hermetyzacja – składowa prywatna jest widzialna

• składowa prywatna jest widziana w każdym miejscu kodu, w którym widziana jest definicja klasy
• oznacza to, że składowa ta jest brana pod uwagę w procesie wyszukiwania nazw oraz wyboru wersji przeciążonej funkcji
• dlatego składowa taka może spowodować, że wywołanie stanie się niepoprawne lub wieloznaczne
Bjarne Stroustrup mówi:kontrola za pomocą słów kluczowych public oraz privatewidzialności, a nie dostępu, powodowałaby w wyniku zmiany słowa kluczowego public na private niejawną zmianę jednej poprawnej interpretacji na inną…
[ w poprzednim przykładzie: Calc::Twice(int) na Calc::Twice(double) ]
hermetyzacja – składowa prywatna jest widzialna

class X {public:
template<class T> void f( const T& t ) { }
private:int secret;
};
namespace {struct Y { };
}template<>
void X::f( const Y& ) { secret = 2; // dostęp
}
kod, który ma dostęp do (nazwy) składowej, może go przekazać w inne miejsce, korzystając ze wskaźnika na tę składową
class Calc;typedef int (Calc::*PMember)(int);
class Calc {public:
PMember getIt() { return &Calc::Twice; }private:
int Twice( int i );};
int main() {Calc c;PMember p = c.getIt(); // dostęp do Twice(int)return (c.*p)( 21 );
}
nazwa składowej prywatnej jestdostępna jedynie dla innych składowych(włączając w to specjalizacje składowychw postaci szablonów) oraz jednostekzaprzyjaźnionych
szablon
specjalizacjaszablonu
hermetyzacja – składowa prywatna udostępniona

hermetyzacja – włamania do składowej prywatnej
class X { public:X() : secret(1) { }template<class T>
void f( const T& t ) { } int Value() { return secret; }
private:int secret;
};
reguła jednej definicjijeśli typ (tutaj X) zdefiniowany jestwięcej niż raz, jego definicje musząbyć identyczne, ale… zachowującukład danych obiektu można spróbować takie fałszerstwo
w klasie Podmieniacz układ danych ten sam co w X, większość kompilatorów pozwoli użyć utworzonej referencji do takiego oszustwa
class Podmieniacz {public:
int notSecret;};void f( X& x ) {(reinterpret_cast<Podmieniacz&>(x)).notSecret = 2;
}class X { // zamiast .h kopia całej klasy
friend ::Hijack( X& );};// funkcja włamująca się void Hijack( X& x ) { x.secret = 2; }
#define private public// teraz włączyć plik z definicją klasy X// i mamy dostęp do składowej prywatnej
nie można definiować za pomocą#define słów kluczowychto jest niedozwolone, a jednak…"działa"

Czy destruktor klasy bazowej powinien być wirtualny?Odpowiedź standardowa: destruktor klasy bazowej zawsze powinien być wirtualny!Prawidłowa odpowiedź na zagadnienie ogólne, gdzie powinny być funkcje wirtualne• publiczne - rzadko, jak najmniej• chronione - czasami• prywatne - domyślnie
staraj się tworzyć interfejsy niewirtualne
Publiczne funkcje wirtualne muszą spełniać dwa zadania• określają interfejs (są publiczne więc są częścią interfejsu)• określają szczegóły implementacji w postaci elastycznego zachowania się
Chcemy oddzielić specyfikację interfejsu od specyfikacji implementacji, która ulega zmianom
Interfejs niewirtualny(Non-virtual Interface)funkcje publiczne niewirtualne,używają prywatnych funkcji wirtualnych• w klasie bazowej istnieje możliwość pełnej kontroli interfejsu i sposób jego
działania (mniej wrażliwa na zmiany)• można kontrolować zachowanie warunków wstępnych i końcowych, dodawać
dodatkowe opcje w jednym wygodnym miejscu• rozdzielając interfejs od implementacji można każdemu z tych elementów
nadać dowolną postać
polimorfizm – funkcje wirtualne
class A {public: // stabilny niewirtualny interfejs
int process( B& ); // używa doProcess…()bool isDone(); // używa doIsDone()
private:// specjalizacja funkcji to // szczegół implementacjivirtual int doProcess1( B& );virtual int doProcess2( B& );virtual bool doIsDone();
};
• użytkownik ma dostęp do pojedynczej funkcji processjednocześnie możliwe jestelastyczne tworzenie dwóchwyspecjalizowanych wersjifunkcji (w przypadku publicznejfunkcji wirtualnej trzeba by byłoudostępnić dwie)• również samo "opakowanie"(tak jak funkcja isDone) jestopłacalne dla stabilności
Staraj się deklarować funkcje wirtualne jako prywatne, a jeśli zachodzi koniecznośćwywołania wersji z klasy bazowej w klasie pochodnej - to jako chronione
A co z destruktorem? Destruktor klasy bazowej powinien być publiczny i wirtualny (jeśli usuwanie może być wykonywane polimorficznie) - metoda interfejsu niewirtualnego nie działa - wywołanie funkcji wirtualnej z destruktora spowoduje wywołanie funkcji z klasy bazowej - obiekty pochodne przecież już nie istnieją!
polimorfizm – prywatne funkcje wirtualne, destruktor

polimorfizm – prywatne funkcje wirtualne, destruktor
chroniony i niewirtualny - np. szablon który służy jako klasa bazowa (w celu narzucenia klasom pochodnym określonych nazw definicji typu) i nie będzie usuwany polimorficznieA jeśli musimy stworzyć obiekt klasy bazowej i z niej dziedziczyć? Nie dziedzicz po klasach konkretnych. Klasy bazowe powinny być abstrakcyjne.
szablony klas z biblioteki standardowejtemplate <class Arg, class Result>struct unary_function {
typedef Arg argument_type;typedef Result result_type;
};template <class Arg1, class Arg2, class Result>struct binary_function {
typedef Arg1 first_argument_type;typedef Arg2 second_argument_type;typedef Result result_type;
};

dziedziczenie – funkcje tworzone niejawnie
class Base {public:virtual ~Base();
private:// tylko deklaracjeBase( const Base& );Base& operator=( const Base& );
};class Derived : public Base {
int i;// konstruktor domyślny - definicja się nie powiedzie// gdyż brak konstruktora domyślnego w klasie Base// konstruktor kopiujący, przypisanie kopiujące -// definicje się nie powiodą bo te z Base niedostępne
};
napisania destruktora nie da się wymusić, ale jest to mniejszy problem -destruktory są mniej podatne na wymianę na wyspecjalizowane wersje (jeden destruktor na klasę, destruktor klasy bazowej musi być wywołany)
W jaki sposób wymusićna klasie pochodnej konieczność definiowania konstruktorów, operatora przypisania, destruktora?

Jak wymusić tworzenie obiektu tylko na stosie?• zabronienie tworzenia obiektu za pomocą operatora new lub new[ ]
class X { public:X();
private:void* operator new( size_t size);void operator delete( void* addr);
};
// gdzieś w programieX objectX; // to jest okX *ptr = new X; // to się nie skompiluje// bo operator new jest prywatny
Jak wymusić tworzenie obiektu tylko na stercie?• wymuszenie tworzenia obiektu za pomocą operatora new lub new[ ]
oraz uniemożliwienie tworzenia obiektu na stosie • obiekt na stosie wymaga dostępnego konstruktora i destruktora, zatem:
class X {public:
X();void Delete() { delete this; }
private:~X(); // prywatny destruktor
}; // nie może być „= delete”
// gdzieś w programieX objectX; // to się nie skompilujeX *ptr = new X;// usuwamy jawnie za pomocą// specjalnej funkcji Delete()ptr->Delete();// delete ptr; nie skompilowałoby się
obiekty – kontrolowane tworzenie

semafor – służy do synchronizacji procesów i wątków w celu zapewnienia bezpiecznego dzielenia zasobów, kiedy proces chce użyć dzielonego zasobu, musi zapewnić wzajemne wykluczanie
void X::f() {// obiekt sam zajmujący semaforTAutoSemaphore autosem(sem);// niezbędne działania funkcjiif ( /*jakiś warunek */ ) { // coś jeszcze robimy
return;} else { // albo coś innego}// destruktor autosem sam zwalania semafor
}
class TAutoSemaphore {public:
TAutoSemaphore(TSemaphore& sem) : semaphore(sem)
{ semaphoer.acquire(); }~TAutoSemaphore() { semaphore.release(); }
private:TSemaphore& semaphore;
};
class TSemaphore { public:TSemaphore();// wywołuje klient, który chce zająć semaforbool acquire(); // wywołany, kiedy dostęp do zasobu zwolnionyvoid release();// ile zadań czeka?unsigned getWaiters() const;// blokowanie kopiowania i przenoszeniaTSemaphore(const TSemaphore&) = delete;TSemaphore(TSemaphore&&) = delete;TSemaphore& operator=(const TSemaphore&) = delete;TSemaphore& operator=(Tsemaphore&&) = delete;
};
class X { public:void f();
private:TSemaphore sem;
};void X::f() {
sem.acquire(); // zajmujemy semafor// niezbędne działania funkcjiif ( /*jakiś warunek */ ) { // coś jeszcze robimy
sem.release(); // zwolnienie zasobureturn;
} else { // albo coś innegosem.release();
}}
wada – trzeba pamiętać o zwalnianiu semaforalepsza wersja: pomocnicza klasa kontrolująca
zasoby – kontrolowany dostęp

serwer licencji – pracuje na maszynie, która udostępnia żetony licencyjne każdemu, kto chce korzystać z oprogramowania, żeton udostępniany jest wtedy, gdy liczba wydanych poprzednio jest mniejsza od liczby wykupionych stanowiskclass TLicenceToken;class TLicenceServer { public:
TLicenceServer( unsigned maxUsers );~TLicenceServer();// udostępnia nową licencję lub zwraca 0TLicenceToken* createNewLicence();// blokada kopiowania i przenoszeniaTLicenceServer( const TLicenceServer& ) = delete;TLicenceServer& operator=( const TLicenceServer& ) = delete;TLicenceServer( TLicenceServer&& ) = delete;TLicenceServer& operator=( TLicenceServer&& ) = delete;
private:unsigned numIssued;unsigned maxTokens;
};• korzystanie z aplikacji kontrolowanej przez serwer wymaga utworzenia nowego żetonu, jeśli zostaje utworzony,
serwer zwraca do niego wskaźnik• osoba, która wystawiła żądania, posiada żeton dostępu, kiedy nie chce już używać aplikacji, musi go usunąć
(wtedy serwer zmniejsza liczbę wydanych żetonów)• wada – użytkownik musi usuwać żeton, można jednak napisać implementację, w której żeton kontroluje używanie
oprogramowania i automatycznie wywołuje destruktor, jeśli oprogramowanie nie było używane przez określony okres czasu
• można użyć np. do naliczania rachunków za korzystanie z usługi (vide telewizja kablowa: pay per view)• inne rozwiązanie – żetony można duplikować, ale ich kopia traktowana jest przez serwer jako nowy żeton
(wymagana kontrola kopiowania obiektu)
Licencja udostępniana jest konkretnemu użytkownikowi – ani serwer, ani żeton nie mogą zostać zduplikowane
zasoby – kontrolowany dostęp, przykład
class TLicenceToken {public:
TLicenceToken();~TLicenceToken();// blokada kopiowania i przenoszenia
TLicenceToken( const TLicenceToken& ) = delete;TLicenceToken& operator=( const TLicenceToken& ) = delete;TLicenceToken( TLicenceToken&& ) = delete;TLicenceToken& operator=( TLicenceToken&& ) = delete;
};

• klasa może dziedziczyć bezpośrednio od więcej niż jednej klasy, można w ten sposób powiązać niezależne typy klas
• dla każdej klasy sposób dziedziczenia definiowany osobno:
• klasa bazowa może wystąpić na liście pochodzenia tylko raz• jej definicja musi być znana kompilatorowi
(deklaracja zapowiadająca to za mało)
INICJALIZACJA I DESTRUKCJA
• konstruktor klasy pochodnej w liście inicjalizacyjnej może wołać konstruktory wszystkich swoich bezpośrednich klas bazowych
• konstruktory klas bazowych wołane są w kolejności występowania na liście pochodzenia
• destrukcja odbywa się w kolejności odwrotnej
dziedziczenie wielokrotne (wielobazowe)
class D : public A, B, protected C {}; // B – (domyślnie) private

• dalsze klasy pochodne nadal dziedziczą ryzyko wieloznaczności, więc rozwiązanie go za pomocą operatora zakresu nie jest dobre
• wieloznaczna może być też funkcja wirtualna, wskazanie jej operatorem zakresu eliminuje mechanizm polimorfizmu
• w tym przypadku nadal wieloznaczność, bo najpierw rozstrzygana jest jednoznaczność,a potem prawa dostępu
• w klasach pochodnych nie ma jużwieloznaczności (można też przesłonić funkcją o tej samej nazwie)
dziedziczenie wielokrotne - wieloznaczność
class A { public: int n; };class B { public: int n; };class C : public A, public B { };// … gdzieś w programieC c;c.n = 3; // błąd wieloznacznościc.A::n = 3; // operator zakresuc.B::n = 4;
class C : public A, private B { };
class C : public A, public B {public: int n;
};
// … gdzieś w programieC c;c.n = 3; // ok – bo przedefiniowane
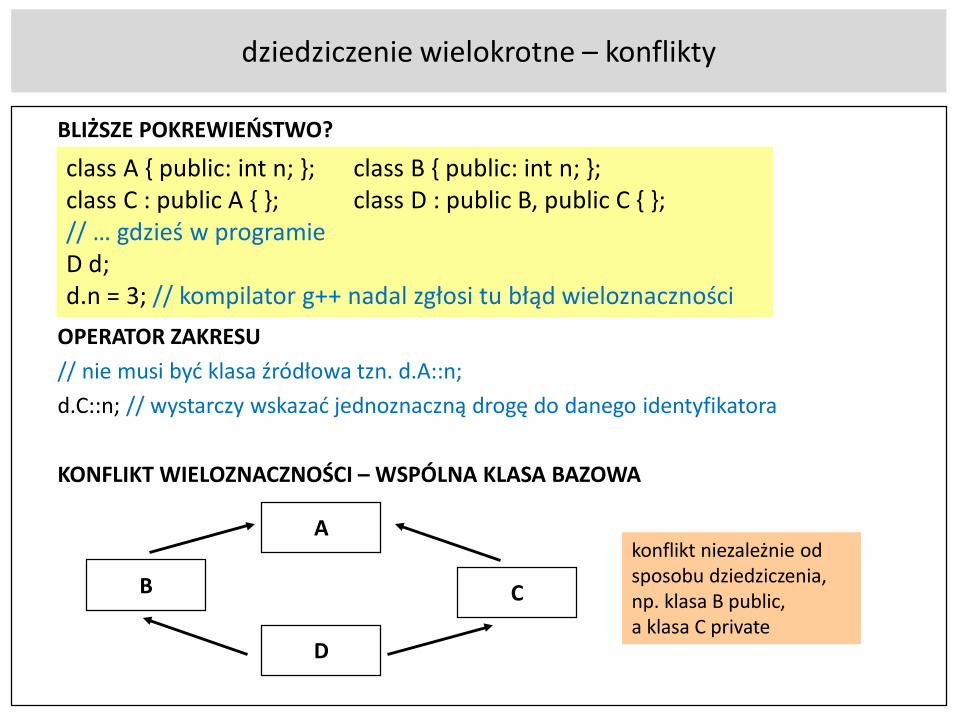
BLIŻSZE POKREWIEŃSTWO?
OPERATOR ZAKRESU // nie musi być klasa źródłowa tzn. d.A::n;d.C::n; // wystarczy wskazać jednoznaczną drogę do danego identyfikatora
KONFLIKT WIELOZNACZNOŚCI – WSPÓLNA KLASA BAZOWA
A
D
CBkonflikt niezależnie odsposobu dziedziczenia,np. klasa B public,a klasa C private
dziedziczenie wielokrotne – konflikty
class A { public: int n; }; class B { public: int n; };class C : public A { }; class D : public B, public C { };// … gdzieś w programieD d;d.n = 3; // kompilator g++ nadal zgłosi tu błąd wieloznaczności

• pośrednie dziedziczenie tej samej klasy bazowej (poprzez wielokrotne dziedzicznie od jej potomków) może doprowadzić do niejednoznaczności
• niejednoznaczność objawia się w momencie odniesienia się do zwykłego składnika klasy
• nie ma niejednoznaczności w przypadku składowych statycznych, typów wyliczeniowych i typów zdefiniowanych (zagnieżdżonych) wewnątrz klasy bazowej (w przykładzie poniżej: klasy A)
• rozwiązanie: dziedziczenie wirtualneclass A { }; // bazowaclass B : virtual public A { }; // może też być virtual private A; class C : virtual public A { }; // wystarczy że choć jedno dziedziczenie public class D : public B, public C { };
• klasa dziedzicząca wirtualnie otrzymuje tylko jeden wspólny podobiekt klasy podstawowej niezależnie od liczby wystąpień tej klasy w hierarchii dziedziczenia– nie ma ryzyka wieloznaczności, pomimo różnych dróg dojścia– składniki nie duplikują się (obiekt jest mniejszy)
• class D : public A, public B, public C { };– w takim przypadku (dziedziczenie raz normalnie, a raz wirtualnie pośrednio) znów mamy
dwa komplety danych z klasy bazowej A oraz konflikt wieloznaczności w przypadku odniesienia się do zwykłej składowej klasy A
wirtualne dziedziczenie wielokrotne

• dziedziczenie wirtualne klasy bazowej sprawia, że mamy jeden komplet jej zwykłych składowych
• konstruktor takiej klasy będzie uruchomiony tylko raz• klasy wirtualne są konstruowane na samym początku, przed
wszystkimi innymi klasami podstawowymi, niezależnie od kolejności wpisania ich na liście inicjalizacyjnej konstruktora
• jeśli jest więcej klas dziedziczonych wirtualnie, to kolejność ich konstrukcji zgodnie z kolejnością na liście pochodzenia
• klasa najbardziej pochodna jest odpowiedzialna za konstrukcję klas dziedziczonych wirtualnie, to ona musi wywołać ich konstruktory– w zwykłym dziedziczeniu wołaliśmy tylko konstruktory bezpośrednich
klas podstawowych– teraz każda klasa dziedzicząca wirtualnie, musi wywoływać konstruktor
klasy tak dziedziczonej, ale kompilator bierze pod uwagę tylko wywołanie konstruktora przez klasę najbardziej pochodną (na dole hierarchii dziedziczenia)
inicjalizacja w dziedziczeniu wirtualnym

class B1{ };class V1 : public B1 { };class D1 : virtual public V1 { };
class B2 { };class B3 { };class V2 : public B1, public B2 { };class D2 : virtual public V2, public B3 { };
class M1 { };class M2 { };
class X : public D1, public D2 {M1 m1;M2 m2;
};
// … gdzieś w programieX x; // uwaga: w powyższym przykładzie
// dostęp do składowych klasy B1// jest niejednoznaczny
Kolejność powstawania obiektów(wywoływania ich konstruktorów)tu – wszystkie konstruktory są konstruktoram domyślnymi
• najpierw obiekty wirtualnych klas bazowych
• konstrukcja V1B1::B1(), V1::V1()
• konstrukcja V2B1::B1(), B2::B2(), V2::V2()
• następnie obiekty niewirtualnychklas bazowych
• konstrukcja D1D1::D1()
• konstrukcja D2B3::B3(), D2::D2()
• następnie powstają składowe• M1::M1(), M2::M2()
• na koniec sam obiekt x klasy X• X::X()
dziedziczenie wirtualne – kolejność inicjalizacji

sytuacje, w których należy użyć dziedziczenia wielobazowego• łączenie modułów lub bibliotek – wiele klas zostało zaprojektowanych jako klasy
bazowe, to znaczy, że ich użycie wymaga dziedziczenia• zmiana kodu biblioteki raczej niemożliwa (możemy w ogóle nie mieć dostępu
do kodu źródłowego• klasy protokołowe (interfejsowe) – najbezpieczniej dla dziedziczenia wielobazowego
jest zdefiniować klasy złożone wyłącznie z metod czysto wirtualnych, nieobecność składowych danych w klasie bazowej pozwala na unikanie największych kompliakcjiwynikających z wielodziedziczenia
• łatwość (polimorficznego) użycia – koncepcja użycia dziedziczenia celem umożliwienia innemu kodowi zastosowania obiektu pochodnego wszędzie tam, gdzie spodziewana jest klasa bazowa (np. projekt klas wyjątków)
powody dziedziczenia wielobazowego• nie tylko dlatego, że klasa pochodna "jest" typem obu klas bazowych, może chodzić
np. o dostęp do danych chronionych jednej klasy (i dziedziczyć z niej prywatnie), a z drugiej klasy dziedziczyć publicznie w celu dziedziczenia interfejsu
dziedziczenie wielobazowe – przesłanki

• RTTI (Run Time Type Identification) – identyfikacja obiektu podczas wykonywania programu
• dostępna dla obiektów klas posiadających co najmniej jedną metodę wirtualną (klasa posiadająca deklarację funkcji wirtualnej "wie" kto jest jej potomkiem – późne wiązanie)
• dynamiczne określanie typów jest mniej bezpieczne i mniej wydajne niż statyczne (podczas kompilacji)
• określenie typu obiektu, wyrażenia za pomocą operatora typeid, który zwraca obiekt klasy type_info– wymaga deklaracji pliku nagłówkowego <typeinfo>– jeśli dwa obiekty są tego samego typu, porównanie obiektów type_info zwróci
wartość true– operator typeid() działa
• dla typów polimorficznych i niepolimorficznych(ale dynamiczne rzutowanie – tylko dla typów polimorficznych)
• dla typów wbudowanych języka jak i typów abstrakcyjnych• dla nazw typów oraz dla nazw obiektów
Run Time Type Identification (definicja)

• do uzyskania nazwy danego typu (const char*) należy użyć funkcji typeid( obiekt ).name();
• porównywanie stałych, typów wbudowanych i obiektów
RTTI – przykłady
int ii = 0, *iw = ⅈcout << typeid(ii).name() << ' ' << typeid(iw).name() << '\n'; // i Pidouble dd = 0.0, *dw = ⅆcout << typeid(dd).name() << ' ' << typeid(dw).name() << '\n'; // d Pd
cout << typeid(123).name() << ' ' << typeid(3.14).name() << '\n'; // i dint ii = 0, *iw = ⅈcout << (typeid(int) == typeid(ii)); // 1cout << (typeid(int) == typeid(iw)); // 0cout << (typeid(int) != typeid(1/3)); // 0cout << (typeid(int) != typeid(1.0/3)); // 1

class A { public:virtual void met() const = 0;
};class B : public A { public:
void met() const{ cout << "metB\n";}
};class C : public A { public:
void met() const{ cout << "metC\n";}
};
void pokaz(const A& a){
cout << typeid(a).name() << ' '<< typeid(&a).name() << ' ';
a.met();}void pokaz(const A* a){
cout << typeid(a).name() << ' '<< typeid(*a).name() << ' ';
a->met();}
RTTI jest użyteczne gdy potrzebnejest rzutowanie w dół, jednak większośćoperacji związanych z typami możnarozwiązać za pomocą funkcji wirtualnych.
Nie należy pisać kodu, który bezpośredniozależy od RTTI – jest to nie tylko kosztowne, ale też powoduje, że trudniej go potem rozszerzyć.
Metody RTTI w języku C++static_cast<T>(e)const_cast<T>(e)reinterpret_cast<T>(e)dynamic_cast<T>(e)
RTTI – przykłady z typami abstrakcyjnymi
// … gdzieś w programieB b; C c;pokaz(b); // 1B PK1A metBpokaz(c); // 1C PK1A metCpokaz(&b); // PK1A 1B metBpokaz(&c); // PK1A 1C metC

• operator dynamic_cast – rzutowanie typu w trakcie wykonania programu• przekształcenie wskaźnika wskazującego na obiekt klasy we wskaźnik do obiektu
innej klasy w ramach tej samej hierarchii (ew. przekształcenie l-wartości obiektu w referencję)
• przy niepowodzeniu rzutowania dla wskaźnika zostanie zwrócony nullptr, dla referencji zgłoszony zostanie wyjątkek bad_cast
rzutowanie dynamiczne (RTTI w akcji)
class C : public A { public:C() : c(3.14) { }void met() const { cout << "metC\n";}void inna() const { cout << c << " innaC\n";}protected:
double c;};void drukuj(A* a) {
a->met();if (C* w = dynamic_cast<C*>(a)) w->inna();
}void drukujZle(A* a) {
a->met();if (C* w = static_cast<C*>(a)) w->inna();
}
// … gdzieś w programieB b; C c;drukuj(&c); // metC 3.14 innaCdrukuj(&b); // metBdrukujZle(&c); // metC 3.14 innaCdrukujZle(&b); // metB 3.83854e-308 innaC (losowa wartość)

• dziedzicz interfejsy a nie implementacje, nie sięgaj do prywatnych składowych klas bazowych, jeśli tylko możesz twórz stabilne niewirtualne interfejsy w klasach bazowych - i nigdy nie konkretyzuj klas bazowych, najlepiej więc twórz je jako klasy abstrakcyjne
• minimalizuj zależności pomiędzy klasami, osiągniesz to poprzez relację zawierania, ograniczając na ile to możliwe relację dziedziczenia, zatem asocjacja pomiędzy klasami (czy jej szczególny typ - agregacja) jest lepszym modelem niż uogólnienie (dziedziczenie)
programowanie obiektowe – najważniejsze wskazówki

• Projektując klasy ustal ich rodzaje– klasy wartości (np.. std::vector) – modelowane na wzór typów wbudowanych– klasy bazowe – fundamenty hierarchii klas– klasy cech (trait classes) – szablony niosące informacje o typach– klasy wytycznych (police classes) – najczęściej szablony implementujące fragmenty
wymienialnego zachowania obiektów– klasy wyjątków – do obsługi sytuacji wyjątkowych– klasy pomocnicze – do obsługi poszczególnych idiomów
• Lepsze są klasy niewielkie i proste – przydatne w większej liczbie rozmaitych sytuacji
• Kompozycja czy dziedziczenie– dziedziczenie to druga co do siły (po zaprzyjaźnieniu) relacja w języku C++– ścisłe powiązanie jest mało kiedy pożądane i gdzie to możliwe należy się go wystrzegać
• Nie dziedziczyć po klasach, które nie zostały przewidziane jako bazowe• Warto pomyśleć nad interfejsem abstrakcyjnym• Uważaj na udostępnianie konwersji niejawnych• Składowe klas, z wyjątkiem prostych agregatów, powinny być prywatne
projektowanie i dziedziczenie – uwagi

TOsoba
nazwiskoadresdata urodzenia
TStudent
statuswydziałkursy
TNauczyciel
funkcjakursy
TDoktorantnie może się zapisywaćna kursy podstawowe
TOsoba
nazwiskoadresdata urodzenia
TStudent
statuswydziałkursy
TNauczyciel
funkcjakursy prowadzone
TDoktorant
TDoktorantNaucz
doktorant z obowiązkiemprowadzenia zajęć
dydaktycznych
TOsoba
nazwiskoadresdata urodzenia
wielokrotne dziedziczenie spowodujezapewne pojawienie się konfliktu niejednoznaczności, np. funkcja print() odziedziczona podwójnie…
dziedziczenie kontra zawieranie – przykład uniwersytecki

class TDoktorantNaucz {private:
TNauczyciel nauczycielProxy;TDoktorant doktorantProxy;
// sporo kodu do napisania};
• funkcje składowe implementacji klasy TDoktorantNaucz muszą wywoływać odpowiednie funkcje obiektów pomocniczych nauczycielProxy i doktorantProxy
• mamy podwójne obiekty klasy TOsoba, więc trzeba zapewnić poprawne zarządzanie stanem gdy zmieniane są dane TOsoba, taka niespójność jest uciążliwa
• zalety to lepsza hermetyzacja, implementator może udostępnić jedynie te funkcje, których klient powinien używać
TNauczyciel
TDoktorant
TDoktorantNaucz
1
1
dziedziczenie wielokrotne – alternatywa 1
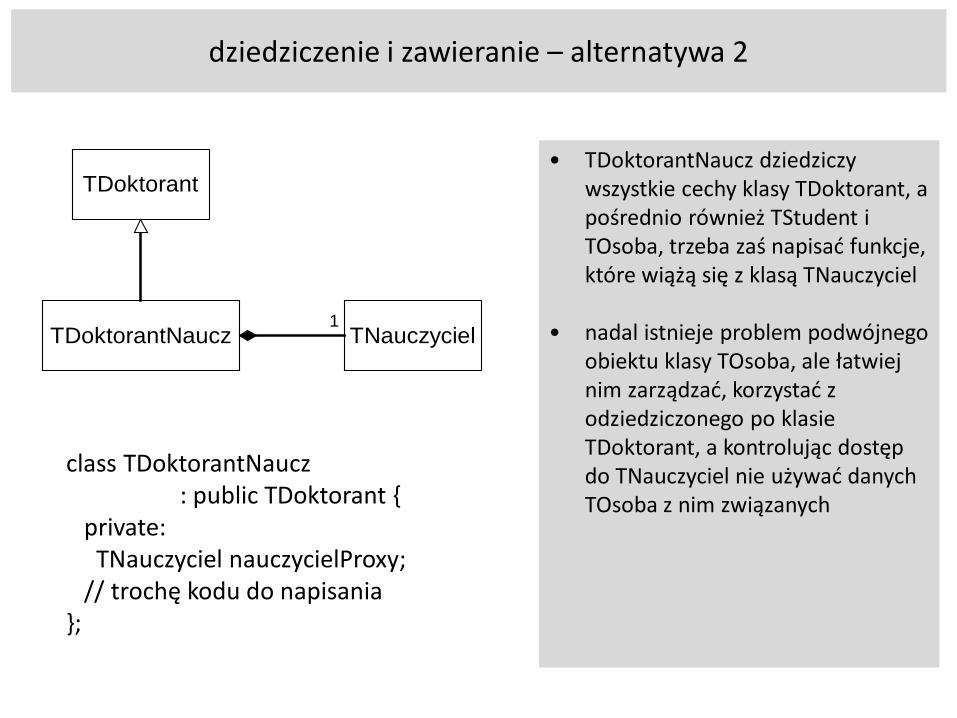
class TDoktorantNaucz : public TDoktorant {
private:TNauczyciel nauczycielProxy;
// trochę kodu do napisania};
• TDoktorantNaucz dziedziczy wszystkie cechy klasy TDoktorant, a pośrednio również TStudent i TOsoba, trzeba zaś napisać funkcje, które wiążą się z klasą TNauczyciel
• nadal istnieje problem podwójnego obiektu klasy TOsoba, ale łatwiej nim zarządzać, korzystać z odziedziczonego po klasie TDoktorant, a kontrolując dostęp do TNauczyciel nie używać danych TOsoba z nim związanych
TDoktorant
TNauczycielTDoktorantNaucz1
dziedziczenie i zawieranie – alternatywa 2

• wszystkie wirtualne klasy bazowe inicjalizuje się w konstruktorze ostatniej klasy pochodnej, czyli konstruktor klasy TOsoba trzeba wywołać przy tworzeniu obiektu klasy TDoktorantNaucz, jest to niewygodne
• jeśli konstruktor ostatniej klasy pochodnej nie wywołuje jawnie konstruktora wirtualnej klasy bazowej, kompilator próbuje wywołać domyślny konstruktor wirtualnej klasy bazowej
• łatwiej pisać kod, gdy wirtualna klasa bazowa posiada konstruktor domyślny, ale w naszym przypadku to nie ma sensu (nie ma przecież "domyślnego" nazwiska etc.)
TOsoba
nazwiskoadresdata urodzenia
TStudent
statuswydziałkursy
TNauczyciel
funkcjakursy prowadzone
TDoktorant
TDoktorantNaucz
wirtualnaklasabazowa
dziedziczenie wielokrotne – alternatywa 3
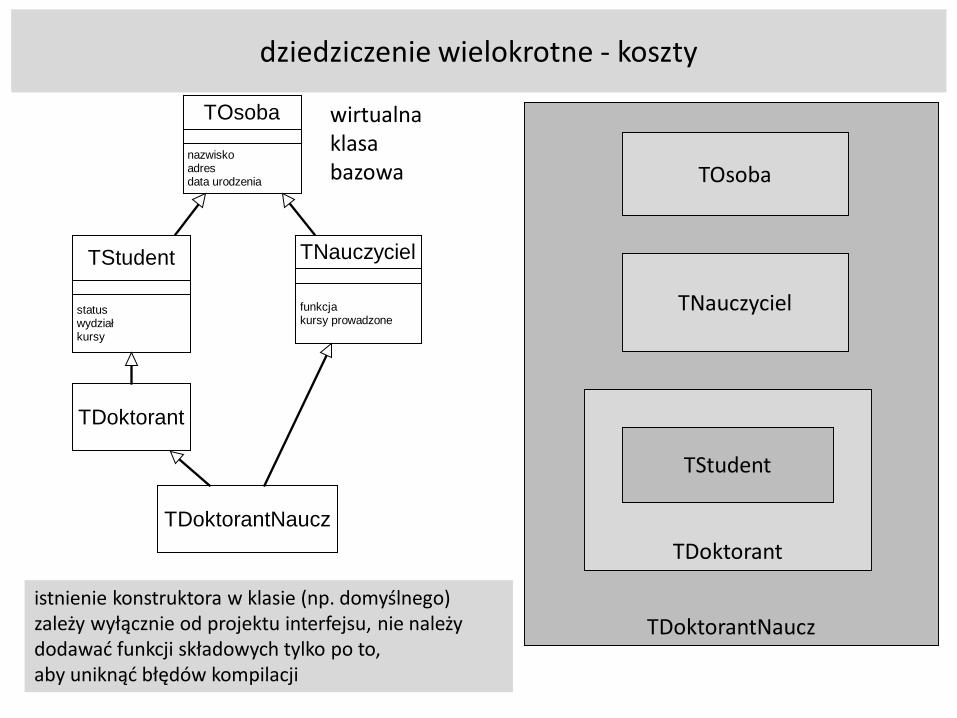
TOsoba
nazwiskoadresdata urodzenia
TStudent
statuswydziałkursy
TNauczyciel
funkcjakursy prowadzone
TDoktorant
TDoktorantNaucz
wirtualnaklasabazowa
istnienie konstruktora w klasie (np. domyślnego)zależy wyłącznie od projektu interfejsu, nie należydodawać funkcji składowych tylko po to, aby uniknąć błędów kompilacji
TDoktorantNaucz
TOsoba
TNauczyciel
TDoktorant
TStudent
dziedziczenie wielokrotne - koszty

• chcemy dodać do naszej "abstrakcji uniwersytetu" asystenta badań, nie musi on być studentem i nie musi prowadzić zajęć dydaktycznych
• co jednak zrobić jeśli TDoktorant podejmie pracę jako TAsystentBadan, nawet na innym wydziale?
• problem wynika stąd, że "prowadzenie badań" to właściwość jaką może nabyć każda osoba, nie tylko student lub wykładowca
• w wyniku złożoności relacji zachodzi tu konflikt wymagań, którego nie da się rozwiązać za pomocą dziedziczenia
• dziedziczenie jest odpowiednim mechanizmem do modelowania tych relacji między klasami, które zawsze są spełnione
TOsoba{ virtual }
TStudent TNauczyciel
TDoktorant
TDoktorantNaucz
TAsystentBadan
• dziedziczenie jest relacjąstatyczną - trudno ją zmienić• kiedy relacje między klasamizmieniają się, przydatność dziedziczenia jest ograniczona• relacje w hierarchii dziedziczeniasą określone i zakodowane na stałe
dziedziczenie – statyczna relacja
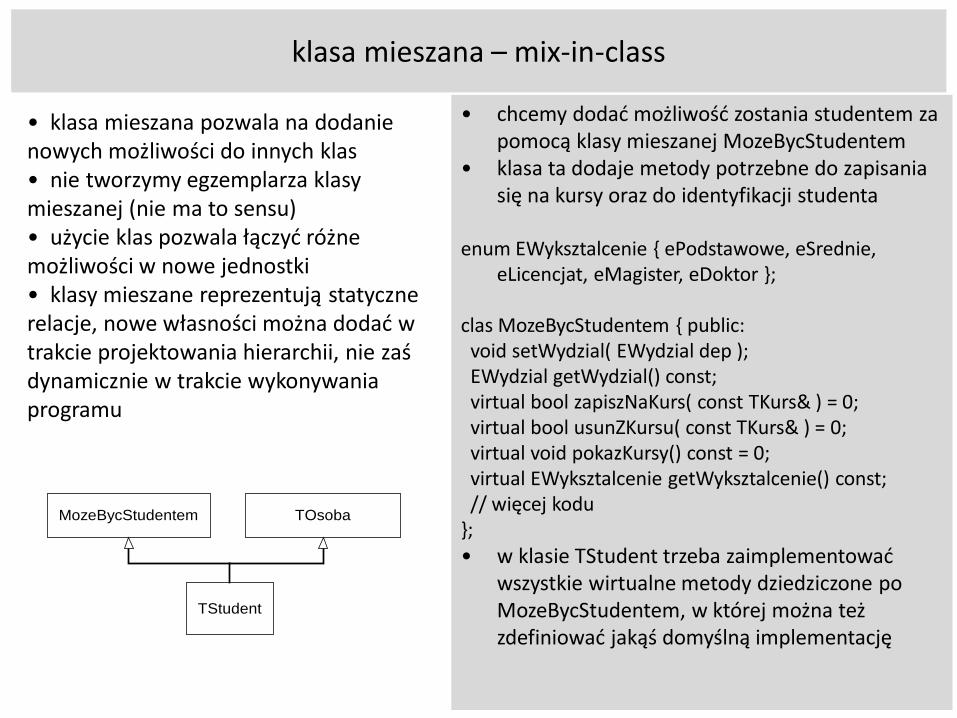
• chcemy dodać możliwość zostania studentem za pomocą klasy mieszanej MozeBycStudentem
• klasa ta dodaje metody potrzebne do zapisania się na kursy oraz do identyfikacji studenta
enum EWyksztalcenie { ePodstawowe, eSrednie, eLicencjat, eMagister, eDoktor };
clas MozeBycStudentem { public:void setWydzial( EWydzial dep );EWydzial getWydzial() const;virtual bool zapiszNaKurs( const TKurs& ) = 0;virtual bool usunZKursu( const TKurs& ) = 0;virtual void pokazKursy() const = 0;virtual EWyksztalcenie getWyksztalcenie() const;// więcej kodu
};• w klasie TStudent trzeba zaimplementować
wszystkie wirtualne metody dziedziczone po MozeBycStudentem, w której można też zdefiniować jakąś domyślną implementację
TOsoba
TStudent
MozeBycStudentem
• klasa mieszana pozwala na dodanie nowych możliwości do innych klas• nie tworzymy egzemplarza klasy mieszanej (nie ma to sensu)• użycie klas pozwala łączyć różne możliwości w nowe jednostki• klasy mieszane reprezentują statyczne relacje, nowe własności można dodać w trakcie projektowania hierarchii, nie zaś dynamicznie w trakcie wykonywania programu
klasa mieszana – mix-in-class

• klasa TOsoba nie musi już być wirtualną klasą bazową, co upraszcza zarządzanie kodem
• elastyczność i prostotę projektu uzyskuje się dzięki rozłożeniu możliwości na kilka klas
• w hierarchii z użyciem klas mieszanych można dodawać nowe możliwości bez wpływu na inne klasy w hierarchii
TOsoba
TStudent
MozeBycStudentemMozeNauczacMozeWykBadania
TNauczyciel
TAsystentBadan
TDoktorant
TDoktorantNaucz
TDoktorantBadacz
Dodajemy dalszą funkcjonalność za pomocą klas mieszanych, to znaczy klasę reprezentującą osoby z kwalifikacjami do prowadzenia kursów MozeNauczac oraz do prowadzenia badań MozeWykBadania
Kiedy klasy mieszane?1. istnieje wiele
niezależnych właściwości, które klasa może posiadać
2. trzeba wybiórczo dodać nową własność do niektórych klas w istniejącej hierarchii
klasy mieszane - dyskusja

• kiedy student kończy studia i staje się doktorantem, zmiany w obiekcie powinny dotyczyć jedynie tych części, które rzeczywiście ulegają zmianie, czyli powinna istnieć możliwość dodania do obiektu TStudent części TDoktorant
• jeśli TDoktorant staje się obiektem TNauczyciel, możliwości klasy TDoktorant powinny zostać zmienione przez możliwości klasy TNauczyciel
Wiemy już, że należy unikać niepotrzebnego powielania danych (wirtualne klasy bazowe) - bo powoduje to utratę zasobów i problemy z zarządzaniem tymi danymiWarto też do minimum ograniczyć ilość kopiowanych danych kiedy przekształcamy lub kopiujemy obiekt
Jak przekształcić TStudent w TDoktorant? • trzeba utworzyć nowy obiekt
TDoktorant i zainicjalizować go (skopiować dane) z obiektu TStudent
• ponosimy tu niepotrzebne koszty kopiowania części TOsoba, która się przecież nie zmieniaWidzimy brak elastyczności dziedziczenia
wielokrotnego w dynamicznie zmieniających sięsytuacjach - często ma miejsce w bazach danych
dynamiczna zmiana sytuacji – czyli co po studiach?
• a co jeśli osoba jest doktorantem na jednym wydziale i równocześnie asystentem badań na innym? - do zarządzania potrzeba wtedy dwóch niezależnych obiektów TDoktorant oraz TAsystentBadan, a w obu powtarzają się dane części TOsoba
• a co jeśli osoba studiuje dwa kierunki?

TOsoba
TStudent
TCzlonekUniwersytetu
TNauczyciel TBadacz
TDoktorant
0 .. n
do kogo
pełni rolęDana osoba może pełnić wiele ról, ale w konkretnym momencie pełni tylko jedną rolęKażda osoba posiada n ról jako członka uniwersytetuKażda rola należy tylko do jednej osoby (relacja "do kogo")Od każdego obiektu TCzlonekUniwersytetu można uzyskać informację o tym do kogo należy dana rolaObiekt TOsoba przechowuje listę wszystkich możliwych ról pełnionych przez daną osobę – nie powiela się danych osobowychRole są oddzielone od osoby, która je pełni, role tworzą odrębną hierarchię –do każdej osoby można przypisać dowolną liczbę ról, nawet tę samą rolę dwa razy (np. student dwóch kierunków)
Implementacja – problem określania typu• Klasy TStudent, TNauczyciel, TBadacz posiadają
różne metody ale wspólną klasę bazową TCzlonekUniwersytetu. Obiekt TOsoba zwraca za pomocą metody aktualną rolę danej osoby – ale jest to obiekt typu TCzlonekUniwersytetu
• Polimorficzne używanie obiektów tej klasy bazowej może nie być zbyt użyteczne, ponieważ nie jest możliwe uchwycenie we wspólny interfejs zachowania wszystkich klas pochodnych
• Konieczne jest poznanie rzeczywistego typu obiektu, czyli użycie mechanizmu RTTI (elastyczność kosztem złożoności kodu)
dynamiczna zmiana sytuacji – role

Niepotrzebne stają się klasy złożone, typu TDoktorantBadacz, ponieważ osobie można przypisać rolę badacza oraz rolę nauczyciela (w danej chwili pełniona jest tylko jedna z nich)
Dostęp do danych TOsoba jest teraz możliwy tylko przez metody klasy TCzlonekUniwersytetu
Obiekt TCzlonekUniwersytetu nie zależy od osoby, ale zawiera informacje potrzebne osobie do pełnienia danej roli
Można więc powiązać konkretną rolę z wieloma osobami – można np. utworzyć grupę osób prowadzących te same badania, czyli pełniących taką samą rolę…
Dwie osoby mogą prowadzić taki sam wykład (rola wykładowcy), sześć osób może prowadzić takie same ćwiczenia…
Role są przenośne
role i ich konsekwencje

Problem – gdy potrzeba wiele kombinacji różnych klas, może dojść do eksplozji kombinatorycznej
• Hierarchie dziedziczenia wielokrotnego są trudniejsze do zrozumienia od hierarchii dziedziczenia jednokrotnego, dodanie wirtualnych klas bazowych komplikuje jeszcze bardziej
TOsoba
TStudent
MozeBycStudentemMozeNauczacMozeWykBadania
TNauczyciel
TAsystentBadan
TDoktorant
TDoktorantNaucz
TDoktorantBadacz
TStudentBadacz TNauczycielDoksztalc
Klasy mieszane dodają statyczne możliwości (decyzję trzeba podjąć podczas projektowania hierarchii klas)Utworzony obiekt może odpowiadać na komunikaty będące zawarte w klasie bazowej (klasach bazowych)Klasy mieszane łatwe do zrozumienia i implementacji
Obiekty pełniące rolę to lepsze rozwiązanie w dynamicznie zmieniających się sytuacjach
Można utworzyć obiekt TOsoba bez żadnych ról, które przypisze się później
klasy mieszane vs pełnione role

Klasy mieszane dodają statyczne możliwości (decyzję trzeba podjąć podczas projektowania hierarchii klas)Utworzony obiekt może odpowiadać na komunikaty będące zawarte w klasie bazowej (klasach bazowych)Klasy mieszane łatwe do zrozumienia i implementacji
Obiekty pełniące rolę to lepsze rozwiązanie w dynamicznie zmieniających się sytuacjach
Można utworzyć obiekt TOsoba bez żadnych ról, które przypisze się później
Problem – zależność od mechanizmu RTTI lub podobnych, potrzeba napisania dodatkowego kodu do używania i konwersji obiektów TCzlonekUniwersytetu
• Klasy pochodne od klasy TCzlonekUniwersytetu trzeba określić w czasie kompilacji programu
Klasy mieszane a rolerole – lepsze gdy istnieje zbyt wiele możliwych kombinacji ról i kombinacje te mogą się zmieniać dynamicznieklasy mieszane – gdy kombinacja ról jest mała i jedna osoba może pełnić tylko jedną rolę danego rodzaju
klasy mieszane a role – przypadki zastosowań

• iteratory – uogólnione wskaźniki pozwalające na pracę z różnymi kontenerami danych w ujednolicony sposób, to gwarantuje, że funkcja pracująca na iteratorach, równie dobrze pracuje ze wskaźnikami oraz że algorytmy uogólnione potrafią operować na różnych strukturach danych
• idea: separacja rodzaju kontenera (sposobu organizacji danych – szczegół implementacji) od sposobu dostępu do niego
• wszystkie iteratory iter wspierają wyrażenie *iter, zwracające wartość klasy, typu wyliczeniowego lub typu wbudowanego (typ wartości iteratora)
• wszystkie iteratory, dla których wyrażenie (*iter).m jest zdefiniowane, wspierają również wyrażenie iter->m
• standard definiuje pięć kategorii iteratorów
input (wejściowy) output (wyjściowy)
forward (do przodu)
bidirectional (dwukierunkowy)
random access (o dostępie bezpośrednim)
odczytywanie elementu, przesuwanie do przodu o jeden, algorytmy one-pass
zapisanie elementu, przesuwanie do przodu o jeden, algorytmy one-pass
odczytywanie i zapisywanie elementu w zasobniku, przesuwanie do przodu o jeden, algorytmy wielo-przejściowe
własności iteratora do przodu z możliwością przesuwania do tyłu o jeden
własności iteratora dwukierunkowego z możliwością przesuwania o dowolną liczbę elementów do przodu i do tyłu, dostęp do dowolnego elementu
iterator – wzorzec projektowy

• kontenery standardowe obsługiwane są przez następujące iteratoryvector, deque – random accesslist, set, multiset, map, multimap – bidirectionalstack, queue, priority_queue – nie obsługują iteratorów
• działania na iteratorzeinput –• ++iter, iter++ pre- i postinkrementacja• *iter p-wartość elementu wskazywanego przez iterator• iter = iter2 przypisanie wartości innego iteratora• iter == iter2 porównanie iteratorów pod względem
równości• iter != iter2 porównanie iteratorów pod względem
nierównościoutput –• ++iter, iter++ pre- i postinkrementacja• *iter l-wartość elementu wskazywanego przez iterator• iter = iter2 przypisanie wartości innego iteratoraforward –• funkcjonalność iteratora wejściowego i wyjściowegobidirectional –• funkcjonalność iteratora do przodu (forward) • --iter, iter-- pre- i postdekrementacja
random access –• funkcjonalność iteratora dwukierunkowego• iter += i, iter -= i inkrementacja i dekrementacja o i pozycji• iter + i, iter - i wynik to iterator przesunięty o i pozycji (iter bez zmian)• iter[i] daje referencję do obiektu na pozycji iter przesuniętego o i• iter < iter2, iter <= iter2, iter > iter2, iter >= iter2 zwraca prawdę gdy relacja jest spełniona
iteratory – kontenery, rodzaje iteratorów

• kontenery mają predefiniowane iteratory do poruszania się po nich
iterator – do poruszania się do przodu (odczyt, zapis)const_iterator – do poruszania się do przodu (odczyt)reverse_iterator – do poruszania się do tyłu (odczyt, zapis)const_reverse_iterator – do poruszania się do tyłu (odczyt)
• kontenery mają też zdefiniowanevalue_type – typ elementu przechowywanego
w kontenerzereference – typ referencji do elementu przechowywanego
w kontenerzeconst_reference – typ referencji do stałego elementu
przechowywanego w kontenerzepointer – typ wskaźnika do elementu przechowywanego
w kontenerze
iteratory – kierunki iteracji

• iteratory strumieniamożna traktować strumień jako kontener, więc do poruszania się po nim dostarczone są odpowiednie iteratoryistream_iterator – dla strumienia wejściowegoostream_iterator – dla strumienia wyjściowego
Przykład:vector<int> myInt; // załóżmy, że wpisaliśmy do tego wektora jakiś zestaw liczb// użyjemy teraz copy – jednej z funkcji algorytmów uogólnionych// służącej do kopiowania w zakresie od miejsca1 do miejsca2 wskazanych // przez iterator do miejsca pokazywanego przez inny iteratorcopy( myInt.begin(), myInt.end(), ostream_iterator<int>(cout, ”\n”) );// miejscem do którego kopiujemy jest strumień wyjściowy wskazywany przez// iterator strumienia wyjściowego, ze znakiem separatora ”\n”
• A co gdybyśmy chcieli skopiować z jednego wektora do drugiego, czyli wstawić po kolei do tego drugiego elementy z pierwszego? Potrzebny do tego jest specjalny adapter.
iteratory – strumienia

• iteratory wstawiające – adaptery iteratorów specjalizowane iteratorem danego kontenera, używa się ich za pomocą pomocniczych funkcjiback_inserter() – w miejscu operatora przypisania następuje wywołanie push_back()int tab[] = { 2, 4, 6, 8}; // zwykła tablicalist<int> lista(3, 7); // lista, którą na początku wypełnimy trzema 7-kami// iterator strumienia cout z separatorem ” ”ostream_iterator<int> outIter(cout, ” ”); // wstawiamy na koniec listycopy( tab, tab+3, back_inserter(lista) ); // kopiujemy do strumienia cout czyli na ekrancopy( lista.begin(), lista.end(), outIter ); // 7 7 7 2 4 6 8
• front_inserter() – w miejscu operatora przypisania następuje wywołanie push_front()copy( tab, tab+3, front_inserter(lista) ); copy( lista.begin(), lista.end(), outIter ); // 8 6 4 2 7 7 7
• inserter() – w miejscu operatora przypisania następuje wywołanie insert()wartość iteratora zwiększa się po każdym wywołaniulist<int>::iterator itList = lista.begin();copy( tab, tab+3, inserter(lista, ++itList) );copy( lista.begin(), lista.end(), outIter ); // 7 2 4 6 8 7 7
iteratory – wstawianie do kontenerów

• metody wspólne dla wszystkich kontenerów:empty() – zwraca prawdę gdy kontener jest pustymax_size() – zwraca maksymalną liczbę elementów dla zasobnikasize() – zwraca bieżącą liczbę elementówoperator= – przypisanie kontenerówoperator<, operator<=, operator>, operator>=, operator==, operator!= - zwraca prawdę, jeśli relacja między kontenerami jest spełniona (nie obsługiwane przez priority_queue)swap – wymienia elementy dwóch zasobnikówerase – usuwa jeden lub więcej elementów zasobnikaclear – usuwa wszystkie elementy zasobnika
• na przykład dla obiektu typu string a = ””;string::npos - 4294967295, a.max_size() – 1073741820 (4 razy mniej niż npos)
• begin – zwraca iterator lub const_iterator , odwołujący się do pierwszego elementu konteneraend – zwraca iterator lub const_iterator , odwołujący się do następnej pozycji po ostatnim elemencie kontenera (element „za-ostatni”)rbegin – zwraca reverse_iterator lub const_reverse_iterator , odwołujący się do ostatniego elementu kontenerarend – zwraca reverse_iterator lub const_reverse_iterator , odwołujący się do pozycji przed pierwszym elementem kontenera (element „przed-pierwszy”)
kontenery – metody wspólne

• metody wspólne dla kontenerów sekwencyjnych:front() – zwraca referencję do pierwszego elementu w kontenerzeback() – zwraca referencję do ostatniego elementu w kontenerzepush_back() – wstawia element do kontenera na końcupop_back() – usuwa element z ostatniego miejsca w kontenerze
• vector < T >szybki dostęp do danych przez operator indeksowaniadodawanie i usuwanie elementów na końcu sekwencji wydajneautomatyczne rozszerzenie dostępnego obszaru pamięcimetody: insert(), capacity(), resize(), reserve(), assign(), at(), operator[]
• list< T >wydajne dodawanie i usuwanie elementów w dowolnym miejscu sekwencjiimplementowany jako lista z dwukierunkowymi odnośnikami (do poprzedniego i do następnego)dostępny iterator dwukierunkowymetody: insert(), splice(), push_front(), pop_front(), remove(), unique(), merge(), reverse(), sort(), resize(), remove_if()
• deque< T >szybki dostęp do danych przez operator indeksowaniawydajne dodawanie i usuwanie elementów na początku i końcu sekwencjiautomatyczne rozszerzanie dostępnego obszaru pamięcimetody: insert(), resize(), assign(), at(), operator[], push_front(), pop_front()
kontenery sekwencyjne

typedef vector<int> Vi;Vi v;cout << v.size() << ’ ’ << v.capacity() << ’\n’; // 0 0v.push_back(12); // wkładamy na koniec wektora kilka liczbv.push_back(23);v.push_back(34);cout << v.size() << ’ ’ << v.capacity() << ’\n’; // 3 4Vi::iterator p = v.begin(); // iterator na początekcout << *p << ’\n’; // 12cout << *(p+2) << ’\n’; // 34cout << *++p << ’\n’; // 23cout << (p == v.begin()) << ’\n’; // 0cout << (p > v.begin()) << '\n'; // 1for (p = v.begin(); p != v.end(); ++p) cout << *p << ’ ’; // 12 23 34Vi::reverse_iterator q; // iterator do poruszania się do tyłufor (q = v.rbegin(); q != v.rend(); ++q) cout << *q << ’ ’; // 34 23 12v.push_back(112);v.push_back(123);v.push_back(134);cout << v.front() << ’\n’; // 12cout << v.back() << ’\n’; // 134v.pop_back(); // usuwamy ostatni element z wektoracout << v.back() << ’\n’; // 123
kontenery sekwencyjne (vector) – przykład

cout << v.size() << ’ ’ << v.capacity() << ’\n’; // 5 8v.erase(v.begin(), v.begin()+3); // usuwamy trzy pierwsze elementyostream_iterator<int> io(cout, " "); // iterator strumienia wyjściowegocopy(v.begin(), v.end(), io); // 112 123v.clear(); // usunięcie wszystkich elementówcout << v.size() << ’ ’ << v.capacity() << ’\n’; // 0 8Vi w(2, 10); // nowy wektor o rozmiarze 2 wypełniony liczbą 10cout << w.size() << ’ ’ << w.capacity() << ’\n’; // 2 2copy(w.begin(), w.end(), io); // 10 10w.resize(5); // zmieniamy rozmiar wektora, na nowe pozycje 0cout << w.size() << ’ ’ << w.capacity() << ’\n’; // 5 5copy(w.begin(), w.end(), io); // 10 10 0 0 0w.reserve(9); // zmieniamy pojemność wektora (wielkość wewn. buforu)cout << w.capacity() << ’\n’; // 9w.reserve(3); // zmieniamy, ale jako że nie powiększamy, więc bez zmiancout << w.capacity() << ’\n’; // 9w.resize(7, 6); // zmiana rozmiaru, na nowe pozycje wstawiana liczba 6cout << w.size() << ’\n’; // 7copy(w.begin(), w.end(), io); // 10 10 0 0 0 6 6
kontenery sekwencyjne (vector) – przykład

w.at(1) = 2; // kilka sposobów podstawienia wartości w danej pozycjiw[1] = 2;w.insert(w.begin()+3, 4);copy(w.begin(), w.end(), io); // 10 2 0 4 0 0 6 6w.clear();cout << ”w ” << (w.empty() ? ”pusty” : ”pełny”) << ”\n”; // w pusty
int t[] = {1, 3, 5, 7, 9, 12};Vi v1(t, t + 6); // inicjalizacja wektora tablicąVi v2(t, t + 4); // inicjalizacja wybranym zakresem z tablicyVi v3(v2); // konstruktor kopiujący tworzy v3 na wzór v2v3[2] = 4;copy(v1.begin(), v1.end(), io); // 1 3 5 7 9 12copy(v2.begin(), v2.end(), io); // 1 3 5 7copy(v3.begin(), v3.end(), io); // 1 3 4 7cout << boolalpha; // ustawienie manipulatora strumieniacout << (v1 < v2); // falsecout << (v1 > v3); // truecout << (v2 == v3); // falsecout << (v3 <= v2); // true
kontenery sekwencyjne (vector) – przykład

typedef list<int> Li;int t[] = {2, 6, 4, 8};Li w(t, t + 4); // inicjalizacja listy tablicąw.push_back(4);w.push_back(3);w.push_front(1); // można wstawić z przoduw.push_front(2);copy(w.begin(), w.end(), io); // 2 1 2 6 4 8 4 3w.sort(); // sortowaniecopy(w.begin(), w.end(), io); // 1 2 2 3 4 4 6 8w.unique(); // usuwa duplikaty pod warunkiem wcześniejszego posortowaniacopy(w.begin(), w.end(), io); // 1 2 3 4 6 8Li wi(t, t + 4);w.swap(wi); // wymiana zawartości między listą w oraz wicopy(w.begin(), w.end(), io); // 2 6 4 8copy(wi.begin(), wi.end(), io); // 1 2 3 4 6 8w.splice(w.end(), wi); // usuwanie i umieszczanie we wskazanym miejscucopy(w.begin(), w.end(), io); // 2 6 4 8 1 2 3 4 6 8copy(wi.begin(), wi.end(), io); // <pusto>wi.insert(wi.begin(), t, t+4); // wstawienie we wskazanym miejscucopy(wi.begin(), wi.end(), io); // 2 6 4 8
kontenery sekwencyjne (list) – przykład

wi.sort(); w.sort();w.merge(wi); // scalanie, w jest posortowane, wi czyszczonecopy(w.begin(), w.end(), io); // 1 2 2 2 3 4 4 4 6 6 6 8 8 8copy(wi.begin(), wi.end(), io); // <pusto>w.unique(); // usuwanie duplikatówcopy(w.begin(), w.end(), io); // 1 2 3 4 6 8w.assign(t, t+4); // wczytywanie sekwencji do istniejącego konteneracopy(w.begin(), w.end(), io); // 2 6 4 8wi.assign(5, 7); // wpisanie pięciu liczb 7copy(wi.begin(), wi.end(), io); // 7 7 7 7 7
// w.splice(w.begin()+2, wi); // błąd// error: no match for ’operator+’ in ’w. std::list<_Tp, _Alloc>::begin’// [with _Tp = int, _Alloc = std::allocator<int>]() + 2’
Li::iterator p = w.begin();p++; p++;w.splice(p, wi);copy(w.begin(), w.end(), io); // 2 6 7 7 7 7 7 4 8
// splice też w wersji // splice(cel, źródło, źródło_od)// splice(cel, źródło, źródło_od, źródło_do)
kontenery sekwencyjne (list) – przykład

w.reverse();copy(w.begin(), w.end(), io); // 8 4 7 7 7 7 7 6 2w.remove(4); // usunięcie liczby 4w.remove(7);copy(w.begin(), w.end(), io); // 8 6 2w.pop_front(); // usunięcie elementu z przoducopy(w.begin(), w.end(), io); // 6 2w.insert(w.end(), t, t+4);copy(w.begin(), w.end(), io); // 6 2 2 6 4 8// bool mniej5(int v) { return v < 5; }w.remove_if(mniej5);copy(w.begin(), w.end(), io); // 6 6 8
int t[] = {9, 3, 5};deque<int> dq(t, t + 3);for (int i = 0; i < dq.size(); ++i)cout << dq[i] << ' '; // 9 3 5dq.push_back(4);dq.push_back(3);dq.push_front(1);dq.push_front(2);copy(dq.begin(), dq.end(), io); // 2 1 9 3 5 4 3
kontenery sekwencyjne (list, deque) – przykład

• metody wspólne dla kontenerów skojarzeniowychcount() – z wartością klucza, zwraca liczbę wystąpień klucza w kontenerzefind() – zwraca iterator do elementu o podanym jako argument kluczuequal_range() – zwraca parę iteratorów ograniczających zbiór obiektów o wspólnej wartości klucza podanego jako argument (ma sens tylko dla kontenerów typu multi)lower_bound() – pierwszy element sekwencji o wartości identycznej z zadanąupper_bound() – ostatni element sekwencji o wartości identycznej z zadaną (formalnie adres za tym elementem)
• set < Key, Compare >, multiset < Key, Compare >szybkie zapamiętywanie i odzyskiwanie kluczy (dla multiset możliwe duplikaty)elementy porządkowane zgodnie z obiektem funkcji (drugi parametr szablonu to domyślnie less<T>elementy muszą obsługiwać odpowiednie operatory porównaniaobsługa iteratorów dwukierunkowych
• map < Key, Data, Compare >, multimap < Key, Data, Compare >szybkie zapamiętywanie i odzyskiwanie par wartości (klucz, wartość) (dla multimap możliwe duplikaty)elementy porządkowane zgodnie z obiektem funkcji (drugi parametr szablonu, domyślnie jest to less<T>) uwzględniającym wartość kluczaelementy muszą obsługiwać odpowiednie operatory porównaniaobsługa iteratorów dwukierunkowychdla zasobnika map dostępny jest operator[]
kontenery skojarzeniowe

ostream_iterator<int> out(cout, " ");int t[] = {6, 8, 2, 4, 8, 2};set<int> s(t, t+6); // kluczem jest int, bez duplikatów: 2 4 6 8s.insert(2); // to już jest w kontenerzecopy(s.begin(), s.end(), out); // 2 4 6 8cout << s.count(10); // 0cout << s.count(4); // 1set<int>::const_iterator q;q = s.find(6);if (q != s.end())copy(q, s.end(), out); // 6 8
typedef multiset<int> Muls;Muls ms(t, t+6); // teraz duplikaty są dopuszczalnems.insert(2);ms.insert(1);copy(ms.begin(), ms.end(), out); // 1 2 2 2 4 6 8 8cout << ms.count(2); // 3copy(ms.lower_bound(2), ms.upper_bound(4), out); // 2 2 2 4
pair<Muls::const_iterator, Muls::const_iterator> range;range = ms.equal_range(2);ms.erase(range.first, range.second);copy(ms.begin(), ms.end(), out); // 1 4 6 8 8
kontenery skojarzeniowe (set, multiset) – przykład

typedef map<int, string> Mis; // klucz int, wartość string
Mis m;m.insert(Mis::value_type(15, "Ala")); // dla map<Key, T> value_type oznacza pair<const Key, T>m.insert(pair<int, string>(11, "kota"));//m.insert(make_pair(12, "ma"));m.insert(make_pair<int, string>(12, "ma"));
// jeśli nie istnieje dany klucz jest automatycznie wstawiany do mapym[14] = "a"; m[13] = ”Jacek”;m[16] = "psa";
Mis::const_iterator p = m.begin();for(; p != m.end(); ++p)cout << p->first << ' ' << p->second << ' ';// 11 kota 12 ma 13 Jacek 14 a 15 Ala 16 psacout << m.count(90); // 0string tmp = m[90];cout << m.count(90); // 1
kontenery skojarzeniowe (map) – przykład

typedef multimap<int, string> Mulmis;
Mulmis mm(m.lower_bound(11), m.upper_bound(13));// wstawiamy raz jeszcze to samo, teraz możliwe są duplikatymm.insert(m.lower_bound(11), m.upper_bound(13));
Mulmis::iterator mp = mm.begin();for(; mp != mm.end(); ++mp)cout << mp->first << ' ' << mp->second << ' ';// 11 kota 11 kota 12 ma 12 ma 13 Jacek 13 Jacek
mp = mm.find(12); // iterator na pierwsze wystąpienie klucza 12// poniżej wstawienie w miejsce ”kota” (para przed pokazywaną przez mp)if (mp != mm.end()) (--mp)->second = "psa";
pair<Mulmis::iterator, Mulmis::iterator> r; // para iteratorówr = mm.equal_range(13);mm.erase(r.first, r.second); // wymazuje pary o kluczu 13mm.erase(12); // wymazuje wszystkie pary o kluczu 12
for(mp = mm.begin(); mp != mm.end(); ++mp)cout << mp->first << ' ' << mp->second << ' '; //11 kota 11 psa
kontenery skojarzeniowe (multimap) – przykład

• Nie dostarczają implementacji struktury danych, wykorzystują do tego zasobniki sekwencyjne.
• Nie obsługują iteratorów. • Pliki nagłówkowe <stack>, <queue>.• Wspólne metody: push(), pop()
stack<double> sdq; // domyślnie na dequestack<double, vector<double> > sdv; // może też być list
for (int i = 5; i < 10; ++i) {sdq.push(i/3.0); // ostatni wstawiony to 3.0sdv.push(i/2.0); // ostatni wstawiony to 4.5
}
template <typename T> void view_and_pop(T& v) {while (!v.empty()) {
cout << v.top() << ' '; // top() - zwraca referencję do szczytowego elementu stosu, bez zmiany // stanu stosu – można wielokrotnie odwołać się do tego elementu
v.pop(); // pop() - zdjęcie elementu ze szczytu stosu
}}
kontenery łączniki (stack, queue)

cout.setf(ios::showpoint); // flaga: pokaż przecinek w liczbiecout.precision(2); // ilość cyfr użytych po przecinku
view_and_pop(sdq); //3.00 2.67 2.33 2.00 1.67view_and_pop(sdv); //4.50 4.00 3.50 3.00 2.50
queue<double> qd; // domyślnie na dequeqd.push(1.6); qd.push(9.8); qd.push(0.8); qd.push(2.7);
cout << qd.back(); // 2.7while (!qd.empty()) {cout << qd.front() << ' '; // zwrócenie referencji do początku kolejkiqd.pop(); // usunięcie z kolejki
} // 1.60 9.80 0.800 2.70
priority_queue<double> pqd; // domyślnie na vector i z lesspqd.push(1.6); pqd.push(9.8); pqd.push(0.8); pqd.push(2.7);
view_and_pop(pqd); // 9.80 2.70 1.60 0.800priority_queue<double, deque<double>, greater<double> > pqdd;
pqdd.push(1.6); pqdd.push(9.8); pqdd.push(0.8); pqdd.push(2.7);view_and_pop(pqdd); // 0.800 1.60 2.70 9.80
kontenery łączniki (stack, queue, priority_queue) – przykład

Przegląd kontenerów – std::forward_list ( C++11 )
Jednokierunkowa lista obsługiwana przez iterator "do przodu" (forward iterator), czyli np. niemożliwa jest operacja --iter;
Cel: zerowy narzut w implementacji kodu, tak jak w zwykłej jednokierunkowej liście z C.Konsekwencja: kontener ten nie ma takich samych metod jak inne kontenery tylko:
insert_after, emplace_after, erase_after, before_begin() / cbefore_begin()
#include <forward_list>std::forward_list<int> f_lista { -5, -2, 3, 0, 4, 1 };auto iter = std::find( f_lista.cbegin(), f_lista.cend(), 4 );

std::forward_list ( C++11 )
insert_after (włóż element za wskazanym elementem) w miejsce insert - 5 przeciążonych wersjiemplace_after (skonstruuj element w miejscu za wskazanym elementem, konstruktor może otrzymać ewentualnie argumenty)
erase_after (usuń element na wskazanej pozycji lub ze wskazanego zakresu - 2 przeciążone wersje)W przypadku iteratorów oprócz begin/cbegin oraz end/cend jeszcze:before_begin() / cbefore_begin() - zwraca adres przed pierwszym elementem, ale tylko w celu użycia przez inne metody: insert_after(), emplace_after(), erase_after(), splice_after()Brak metod: size() czy push_back() bo ich obsługa powodowałaby koszt O(n)
template< class... Args >iterator emplace_after( const_iterator pos, Args&&... args );

Tablice mieszające – hash tables ( C++11 )
Potrzeba nieuporządkowanych kontenerów skojarzeniowych: operacje szukania, wstawiania i usuwania, mają średni stały koszt (niezależny od wielkości kontenera!)• W celu uniknięcia kolizji z rozwiązaniami spoza standardu, wybrano
nazwy zaczynające się przedrostkiem unordered_
oraz dodatkowa funkcjonalność zdefiniowana też w nagłówku <functional>
#include <unordered_set> // tu również unordered_multiset#include <unordered_map> // tu również unordered_multimap
Każdy kubełek (bucket) ma swój łańcuch elementów

Tablice haszujące ( C++11 )
Pełnoprawne kontenery STL, wraz z typowymi iteratorami i metodami składowymi:
iterator / const_iterator (tylko do przodu, brak reverse_iterator)begin / end, cbegin / cend (brak rbegin / rend oraz crbegin/crend)insert / erase, size, swap itd.
Są również: find, count, equal_range(jeśli nie znajdzie, zwraca parę kontener.end(), kontener.end() )
Nie ma: lower_bound, upper_boundKontener unordered_map udostępnia operator[] oraz metodę at()
Operatory relacji (zbyt kosztowne) nie są dostępne: <, <=, >=, >Dostępne są: == i != ale w oparciu o zawartość (a nie uporządkowanie)

Szablon std::hash ( C++11 )
Mieszający (haszujący) obiekt funkcyjny – dostarczony za pomocą szablonu std::hashjako drugi parametr (domyślny) kontenerów: unordered_set, unordered_multiset, unordered_map, unordered_multimapDostępny dla wszystkich typów wbudowanych oraz specjalizowany dla: string (i odmian u16string, u32string, wstring), inteligentnych wskaźników (unique_ptr, shared_ptr) oraz kilku innych (error_code, bitset, type_index, thread::id, vector<bool>)
template<class Value,class Hash = std::hash<Value>,class Pred = std::equal_to<Value>,class Alloc = std::allocator<Value>>class unordered_set { … };
template<class Key,class T,class Hash = std::hash<Key>,class Pred = std::equal_to<Key>,class Alloc = std::allocator<std::pair<const Key, T>>>class unordered_map { … };

Metody kontenerów haszujących ( C++11 )
zwraca numer kubełka (bucket) w jakim jest obiekt o kluczu keyval
zwraca liczbę kubełków
zwraca rozmiar kubełka o numerze nbucket
zwraca (float)size() / (float)bucket_count() czyli średnie obłożenie kubełków elementami
czyta lub ustawia (sugeruje) maksymalne obciążenie liczbą elementów na kubełek
wymuszenie przebudowy tablicy haszującej z liczbą kubełków (co najmniej) nbuckets
size_type bucket_count() const;
size_type bucket(const Key& keyval) const;
void rehash(size_type nbuckets);
size_type bucket_size(size_type nbucket) const;
float load_factor() const;
float max_load_factor() const;void max_load_factor(float factor);

C++11 – rdzeń i ułatwienia
override i final (nie są to słowa kluczowe) • zasłaniamy funkcję z klasy bazowej i jasno to zaznaczamy
• można też zabezpieczyć przed dziedziczeniem lub zasłonięciem
class Base final;class Derived : Base { }; // błądclass Base2 { public:
virtual void fun( float ) final;};class Derived2 : public Base2 { public:
void fun( float ); // błąd };
class Base { public:virtual void fun1( float ); // musi być wirtualna (żeby poniższe było możliwe)
};class Derived : public Base { public:
virtual void fun1( float ) override; // do wykrywania zmian w met. klasy bazowej};

wyrażenia lambda ( C++11/14 )
wyrażenie lambda = funktor, który można zdefiniować w miejscu użycia
• captures – „domknięcia”, zewnętrzne dostępne zmienne, przekazywane do wyrażenia poprzez wartość lub referencję
• params – argumenty wywołania, jeśli jest puste, to można pominąć• ret – typ zwracany, jeśli brak return lub jest jedno, można pominąć• statements – ciało wyrażenia lambda
Klasa k;// przez wartość, bez argumentuauto funktor1 = [ k ] { for ( int i=0; i<10; ++i ) fun( k ); }; funktor1(); // dzięki auto możemy łatwo przechować typ i potem wywołać// przez referencję, jest też argumentauto funktor2 = [ &k ] (const int& i) { return fun( k, i ); };int i = 12;funktor2( i );
[captures] (params)opt ->opt ret { statements; }

wyrażenie lambda – przechwycenie dopełnień ( C++11 )
Możliwe warianty „dopełnień” przejmowanych przez lambda:
Typ zwracany przez wyrażenie ->ret konieczność podania tylko, gdy występuje w wyrażeniu lambda więcej niż jedno return
vector<double> v;std::transform( v.begin(), v.end(), v.begin(),
[](double d)->double{
return std::sqrt( std::abs( d ) );}
);
[] nic nie przejmuje[=] przejmuje wszystko przez wartość (kopia)[=,&x] wszystko przez wartośc za wyjątkiem x – przez referencję[&] przejmuje wszystko przez referencję[&, x] wszystko przez referencję, za wyjątkiem x – przez wartość

wyrażenie lambda – przekazywanie składowych
Jeśli chcemy przekazać do wyrażenia którąś składową klasy, to musimy przekazać „this” (albo wprost, albo przez wartość =, albo referencję &):
class Foo {vector<int> v = { 1, 2, 3, 4 };int val = 1;public:
auto doIt() {return find_if( v.begin(), v.end(), [this](int i){ return i > val; } );
}};int main() {
Foo f;cout << *( f.doIt() ) << endl; // 2
}
Można też:[=] ( int i ) {…[&] ( int i ) {…
// można tez od razu wykonaćint result = [](int input) { return input * input; }(10);cout << result << endl;

wyrażenie lambda – przykłady ( C++11 )
[ t1, &t2 ] () { fun( t1, t2); }class Funktor {
T1 t1, T2& t2;public:
Funktor( T1 a1, T2& a2 ) : t1(a1), t2(a2) { }void operator()() { fun( t1, t2); }
};
dedukcja typu (auto) w wyrażeniu lambda działa w C++14[] ( auto p1, const auto& p2 ) { fun( p1, p2); } // w C++11 błądoczywiście typ zwracany jest też „dedukowany” ( skoro nie jest jawnie napisany w postaci ->ret )
[] ( T1 p1, const T2 & p2 ) { fun( p1, p2); }class Funktor {
public:void operator() ( T1 p1, const T2& p2 ) { fun( p1, p2); }
};

wyrażenie lambda – przykład z auto
#include<iostream>#include<complex>
int main() {// przechowaj uogólnione wyrażenie Lambda w zmiennej funcauto func = [](auto input) { return input * input; };
// Przykłady użycia:// kwadrat typu intstd::cout << func(10) << std::endl;
// kwadrat typu doublestd::cout << func(2.345) << std::endl;
// kwadrat na typie complexstd::cout << func(std::complex<double>(3, -2)) << std::endl;
}

wyrażenie lambda – przypadki ( C++11 )
int f( int i ) {int j = i*i;auto g = [&]( int k ) { return j+k; };j += 3;g( 3 ); // wywołanie lokalnej funkcji
}
Chcemy poprzez wyrażenie Lambda podać algorytm sortowania mapy:
Dzięki Lambda można zapisać „funkcję” zagnieżdżoną w innej funkcji:
Rekurencja (możliwa dzięki szablonowi function):std::function<int(int)> factorial = [&](int x) {
return (x==1) ? 1 : ( x* factorial(x-1)); }; }
auto f = [&](int x, int y) { return x > y; }map< int x, int y, decltype( f ) > m ( f ); // w konstruktorze map też
// można podać kryterium sortowania!

wyrażenie lambda – miejsca użycia ( C++11 )
Wiele algorytmów mających charakter „pętli” po zasobniku (na przykład for_each, copy, find, remove, transform), jest dobrym miejscem do efektywnego użycia wyrażeń lambda.
Kilka alternatyw do wyboru:std::string s;// pętla for ręcznie przebiegająca iteratoremfor ( auto it = s.begin(); it != s.end(); ++it ) { cout << *it << endl; }// pętla for według składni przebiegającej po całym zakresiefor ( auto w : s ) { cout << w << endl; }// za pomocą copy oraz iteratora strumienia wyjściowegocopy( s.begin(), s.end(), ostream_iterator<char>(cout, "\n") );// za pomocą for_each i wyrażenia lambdafor_each( s.begin(), s.end(), [](char& w) { cout << w << endl; } );
vector<int> v;auto it = find_if( v.cbegin(), v.cend(), [](int i){ return i>0 && i<10; } );

Można zdefiniować „własny rodzaj pętli”:
Można napisać np. tak:
wyrażenie lambda – własne pętle ( C++11 )
do_while ( [&] {// wykonuj aż…}, [] { return !wykonane(); }
);repeat_until( [&] {
// wykonuj aż…}, []{ return wykonane(); }
);
// zamiast klasycznej pętli z c++do {
// wykonuj aż…} while ( !wykonane() );

Mamy zmienną, która powinna być const, ale po drodze trzebacoś do niej przypisać:
Można oczywiście napisać funkcję, która obliczy potrzebną wartość,a potem zainicjalizuje zmienną:const int i = funkcja();Lepsze rozwiązanie:
wyrażenie lambda – const zachowane ( C++11 )
const int i = [=] {// coś liczymy i ostatecznie zwracamy jakąś wartośćreturn val;
} ();
int i = 0; // wartość początkowa// tu coś liczymy, w wyniku czego x = … nabywa jakąś wartość// teraz i już mogłoby być const…

Rozwiązanie z zachowaniem stałości:
wyrażenie lambda – const, inny przykład ( C++11 )
const int i = [=] -> int { try { // tu coś liczymy, a wartość zwracamy
return val;// … chyba że przed return nastąpi wyjątek
} catch ( TypWyjatku ) {return 0;
} ();
int i = 0; // wartość początkowatry { // tu coś liczymy, w wyniku czego x = … nabywa jakąś wartość
// chyba, że zgłoszony zostanie wyjątek} catch ( TypWyjatku ) {
i = 0;}

wyrażenie lambda – przykład z algorytmem sortowania
#include<vector>#include<numeric>#include<algorithm>
int main() {std::vector<int> V(10);// std::iota do wygenerowania sekwencji integer-ów od 1 (z krokiem „o jeden”)std::iota(V.begin(), V.end(), 1); // wypełni 1, 2, 3, …, 10
std::cout << "Oryginalne dane" << std::endl;std::for_each(V.begin(), V.end(), [](auto i) { std::cout << i << " "; });std::cout << std::endl;
// sortowanie danych z użyciem std::sort oraz lambdastd::sort(V.begin(), V.end(), [](auto i, auto j) { return (i > j); });
// drukowanie danych z użyciem std::for_each oraz lambdastd::cout << "Posortowane dane" << std::endl;std::for_each(V.begin(), V.end(), [](auto i) { std::cout << i << " "; });std::cout << std::endl;
}

Obiekty klas, w których przeciążono operator funkcyjny (wywołania funkcji)• Najczęstsze wykorzystaniejako predykaty (orzeczniki logiczne) używane w ogólnych algorytmach• Mogą zawierać dodatkowe dane potrzebne do wykonania operacji
Obiekty funkcyjne biblioteki standardowej – wzorce klasZdefiniowane w pliku nagłówkowym <functional>
arytmetyczne, relacyjne, logiczne
plus<T>minus<T>multiplies<T>divides<T>modulus<T>negate<T>
equal_to<T>not_equal_to<T>greater<T>greater_equal<T>less<T>less_equal<T>
logical_and<T>logical_or<T>logical_not<T>
obiekty funkcyjne (funktory)

multiplies<double> m;equal_to<char> e;logical_or<int> l;cout<< m(2.5, 3.1) <<” ”<< e(’a’, ’a’) <<” ”<< l(3, 1); // 7.75 1 1
int t[] = { 5, -7, 3, 1, -1, 2 };list<int> l(t, t+6); // w C++11 list<int> l {5, -7, 3, 1, -1, 2};l.sort( less<int>() );
// jest też algorytm sort( RandomIt, RandomIt, Pred );// ale działa na iteratorach „dostępu swobodnego”, a takie// nie obsługują listy – dlatego lista ma własną metodę sort (i inne)
ostream_iterator<int> out(cout, " ");copy(l.begin(), l.end(), out); // -7 -1 1 2 3 5
vector<int> v(t, t+6);sort( v.begin(), v.end(), greater<int>() );copy( v.begin(), v.end(), out ); // 5 3 2 1 -1 -7
obiekty funkcyjne – przykłady

struct intsort {bool operator() (const int& l, const int& r) { return l < r; }
};// można użyć własny funktorl.sort( intsort() ); // dzięki szablonowi można pokazać dowolny typ sekwencyjnytemplate<typename T>struct prezentuj {
prezentuj(ostream& o, string s = "") : strumien(o), separator(s) { }void operator () (const T& p) { strumien << p << separator; }
private:ostream& strumien;string separator;
};template <typename T>void view(T con) {
for_each(con.begin(), con.end(), prezentuj<typename T::value_type>(cout, " -=- "));}// w programie...view(v); view(l);
obiekty funkcyjne – przykłady

Aby umożliwić adaptorom i innym komponentom operacje na obiektach funkcyjnych, przyjmujących jeden lub dwa argumenty, wymagane jest aby funktory te dostarczały przypisanie (typedef) odpowiednich typów nazwom argument_type i result_type(dla funktorów jednoargumentowych) oraz first_argument_type, second_argument_type i result_type (dla funktorów dwuargumentowych).
Standardową procedurą ułatwiającą te definicje, jest dziedziczenie z następujących klas bazowych:
funktory – typy argumentów i zwracanych wartości
template <class Arg, class Result>struct unary_function {
typedef Arg argument_type;typedef Result result_type;
};
template <class Arg1, class Arg2, class Result>struct binary_function {
typedef Arg1 first_argument_type;typedef Arg2 second_argument_type;typedef Result result_type;
};

wzorce klas pozwalające na zmianę funkcjonalności obiektów funkcyjnychnie używa się ich bezpośrednio lecz za pomocą funkcji zwracających obiekty tych klaswiązadło (poniższe to „historyczne” wersje dla C++98)przekształca dwuargumentowy funktor w jednoargumentowy, związując jeden z argumentów z konkretną wartością
bind1st – wiąże pierwszy argument – szablon funkcji tworzący funktor typu binder1stbind2nd – wiąże drugi argument – szablon funkcji tworzący funktor typu binder2nd
– funktory te przechowują dwa argumenty, przekazane w wywołaniu bind1st() / bind2nd()
– pierwszy argument musi być dwuargumentową funkcją (lub funktorem) – operator() obiektu binder1st / binder2nd wywołuje przekazaną funkcję dwuargumentową, podając jej otrzymany argument wywołania i zapamiętaną wartość zadaną, odpowiednio jako pierwszy / drugi argument// zawartość listy: -7 -1 1 2 3 5l.remove_if(bind1st( less<int>(), 1 )); // 1 < prawy argument kolejne wyrazy z listy// z oryginalnej zawartości zostaną: -7 -1 1l.remove_if(bind2nd( less<int>(), 1 )); // lewy argument kolejne wyrazy z listy < 1// z oryginalnej zawartości zostaną: 1 2 3 5A gdyby użyć np. equal_to<int> ? Wtedy wszystko jedno czy bind1st czy bind2nd –bo argumenty operatora == są symetryczne.
adaptory obiektów funkcyjnych – wiązadła

std::bind ( C++11 ), bind1st, bind2nd – „przestarzałe”
bind1st, bind2nd – są ograniczone, wiążą tylko pierwszy lub drugi argument– nie mogą wiązać funkcji z argumentem typu „referencja do”– nierzadko wymagają adaptacji obiektów funkcyjnych
(za pomoca ptr_fun, mem_fun, mem_fun_ref)
Zastępcze obiekty pozwalają na mapowanie argumentów bind z argumentami wielkości wywoływalnej. Notacja: _n oznacza n-ty argument przekazany do obiektu funkcyjnego zwracanego przez bind.
Uwaga: zastępczy obiekt ma nazwę _1 (dla kolejnych parametrów _2 itd.)Te obiekty są formalnie umieszczone w przestrzeni nazwstd::placeholders. Jeśli widzimy błąd kompilacji, trzeba dodać jedno z:using namespace std::placeholders; // cała przestrzeń nazwusing std::placeholders::_1; // dyrektywa użycia konkretnego obiektu
obiekt_funkcyjny std::bind( wielkość_wywoływalna, 1arg, 2arg, …, Narg );
l.remove_if( bind ( less<int>(), 1, _1 )); // to samo co bind1st wcześniejl.remove_if( bind ( less<int>(), _1, 1 )); // to samo co bind2nd wcześniej

std::bind - przykłady
#include <iostream>#include <functional>using namespace std;using namespace std::placeholders;
int suma1( int n1, int n2, int& n3, int& n4 ) {n3 = 0; n4 = 0;return n1+n2+n3+n4;
}int main() {
cout << bind( suma1, 1, 2, 3, 4 )() << endl; // 3, argumenty przez wartość
int var1 = 1, var2 = 2, var3 = 3, var4 = 4;cout << bind( suma1, var1, var2, var3, var4 )() << endl; // 3, jak wyżejcout << var1 << ", " << var2 << ", " << var3 << ", " << var4 << endl; // 1, 2, 3, 4
var1 = 1, var2 = 2, var3 = 3, var4 = 4;cout << bind( suma1, var1, var2, ref(var3), var4 )() << endl; // 3cout << var1 << ", " << var2 << ", " << var3 << ", " << var4 << endl; // 1, 2, 0, 4
var1 = 1, var2 = 2, var3 = 3, var4 = 4;cout << bind( suma1, var1, _2, _1, var4 )(var2,var3) << endl; // 4 placeholders przez referencjęcout << var1 << ", " << var2 << ", " << var3 << ", " << var4 << endl; // 1, 0, 3, 4
cout << bind( suma1, _1, _2, _5, var4 )(77, var2, var3, var4, var1) << endl; }

std::bind – dalsze przykłady
void wypisz( ostream& strumien, int n ) {strumien << n << endl;
}
bind( wypisz, ref(cout), 777)();
list<int> ll { 1,2,3,4,5 };for_each( ll.begin(), ll.end(), bind(wypisz, ref(cout), _1) );
Wysłanie do strumienia:
Zabawy z initializer_list:int suma(initializer_list<int> il) {
int sum {0};for ( auto n : il ) { cout<<n<<" "; sum+=n; }return sum;
}
// w programie:// to nie działa: bind( suma, { 1, 2, 3, 4, 5 } )();int sumka = bind( suma, initializer_list<int>{ 1, 2, 3, 4, 5 } )(); // okcout << bind( suma, _1 )( initializer_list<int>{ 1, 2, 3, 4, 5 } ); // ok

negatorto funkcja, która zmienia wartość logiczną funktora na wartość przeciwną
not1 – odwraca wartość logiczną funktora jednoargumentowegonot2 – odwraca wartość logiczną funktora dwuargumentowego
adaptory obiektów funkcyjnych – negatory (C++98)
// negacja unary_functiontemplate <class Predicate>
unary_negate<Predicate> not1(const Predicate& pred);
// negacja binary_functiontemplate <class Predicate>
binary_negate<Predicate> not2(const Predicate& pred);
// zawartość listy: -7 -1 1 2 3 5l.remove_if( not1( bind1st( equal_to<int>(), 3 ) ) ); // bind nie działa… patrz dalej// z oryginalnej zawartości zostanie: 3
l.sort( not2( less<int>() ) );// to samo jak użycie do sortowania greater<int>// czyli oryginalna zawartość: 5 3 2 1 -1 -7

Zamiast samodzielnie dziedziczyć z klas unary_function czy binary_function, można użyć specjalnego adaptora ptr_fun, przyjmującego wskaźnik do funkcji i konwertującego ją do postaci obiektu funkcyjnego. Funkcje te muszą być jedno- lub dwuargumentowe (nie mogą być bezargumentowe).
adaptory wskaźników do funkcji – ptr_fun (C++98)
template <class Arg, class Result>pointer_to_unary_function<Arg, Result>
ptr_fun(Result (*f)(Arg)); // jednoargumentowa
template <class Arg1, class Arg2, class Result>pointer_to_binary_function<Arg1,Arg2,Result>
ptr_fun(Result (*f)(Arg1, Arg2)); // dwuargumentowa
Typy zwracane przez funkcję ptr_fun rzeczywiście dziedziczą z odpowiednich klas:template <class Arg, class Result>class pointer_to_unary_function :
public unary_function<Arg, Result>;
template <class Arg1, class Arg2, class Result>class pointer_to_binary_function :
public binary_function<Arg1,Arg2,Result>;

ptr_fun – przykład (i alternatywy w C++11)
#include <string>#include <iostream>#include <algorithm>#include <functional>
bool isvowel(char c) {return std::string("aeoiuAEIOU").find(c) != std::string::npos;
}
int main(){
std::string s = "Hello, world!";std::copy_if(s.begin(), s.end(), std::ostreambuf_iterator<char>(std::cout),
std::not1(std::ptr_fun(isvowel)));// C++11 alternatywy: // std::not1(std::cref(isvowel)));// std::not1(std::function<bool(char)>(isvowel)));// UWAGA: bind nie działa z not1 gdyż bind nie definiuje argument_type// jak tego oczekuje not1}

Gdy chcemy zaadaptować metodę z klasy, przekazując ją przez wskaźnik do składowej klasy, używamy adaptor mem_fun, który generuje obiekt funkcyjny. Jego metoda, która ma być docelowo użyta, jest wywołana za pomocą wskaźnika do tego obiektu. Są wersje dla metod z przydomkiem const i dla metod modyfikujących (jak poniżej):
adaptory do metod składowych – mem_fun (C++98), mem_fn (C++11)
template<class S, class T> mem_fun_t<S,T> mem_fun(S (T::*f)()); // bezargumentowa
template<class S, class T, class A> mem_fun1_t<S,T,A> mem_fun(S (T::*f)(A)); // jednoargumentowa
Tym razem zwracany typ to:template <class S, class T> class mem_fun_t : public unary_function<T*, S> { public:
explicit mem_fun_t(S (T::*p)());S operator()(T* p) const;
};template <class S, class T, class A> class mem_fun1_t : public binary_function<T*, A, S>;

Adaptor mem_fun_ref generuje obiekt funkcyjny, którego metoda jest wywoływany za pomocą referencji do obiektu (czyli bezpośrednio na rzecz danego obiektu). Są wersje dla metod z przydomkiem const i dla metod modyfikujących (poniżej bez const):
adaptory wskaźników do metod – mem_fun_ref (C++98) , mem_fn (C++11)
template<class S, class T> mem_fun_ref_t<S,T> mem_fun_ref(S (T::*f)()); // bezargumentowa
template<class S, class T, class A> mem_fun1_ref_t<S,T,A> mem_fun_ref(S (T::*f)(A)); // jednoargumentowa
Zwracany typ to:template <class S, class T> class mem_fun_ref_t : public unary_function<T, S> { public:
explicit mem_fun_ref_t(S (T::*p)());S operator()(T& p) const;
};template <class S, class T, class A> class mem_fun1_ref_t : public binary_function<T, A, S>;

const char* tab[] = {"alice", "has", "a", "cat"};replace_if( tab, tab+4,
not1(bind2nd(ptr_fun(strcmp), ”alice”)),”jarek” );// przykład ryzykowny, jeśli łańcuch ”jarek” byłby dłuższy niż łańcuch ”alice”...ostream_iterator<const char*> out (cout, " ");copy(tab, tab+4, out); // jarek has a cat
struct A { void fun(int i) {cout<<"A::fun = "<< i <<endl;} };struct B { int fun2(int i) const { return 2*i; } };int x[] = {-4, -2, 0, 1, 3};// za pomocą wskaźnika, czyli mem_funvector<A*> va;va.push_back(new A);va.push_back(new A); // hej, a kto to potem usunie? ;-)for_each(va.begin(),va.end(),bind2nd(mem_fun(&A::fun), 5));// za pomocą referencji do obiektu, czyli mem_fun_refvector<B> v;v.push_back(B());v.push_back(B()); // tu posprząta się samo...transform(v.begin(), v.end(), x, ostream_iterator<int>(cout, " "), mem_fun_ref(&B::fun2) );
// -8 -4
ptr_fun, mem_fun, mem_fun_ref – przykłady (C++98)
• bind może równieżzastępować adaptory!• jeśli nie ma argumentówto mem_fn wygodniejsze

class Klasa { public:Klasa(int n) : val( n ) { }void foo() { cout << val; }void bar() const { cout << 10+val; }
private:int val;
};
template<typename T>struct pointer {
T* operator() (T& t) { return &t; }};
Klasa tab[] = {9, 1, 8, 2, 7, 3, 6, 4, 5, 0};// for_each(tab, tab+10, mem_fun_ref(&Klasa::foo)); // 9182736450for_each( tab, tab+10, bind(&Klasa::foo,_1) ); // 9182736450list<const Klasa*> lista;transform(tab, tab+10, back_inserter(lista), pointer<Klasa>());// for_each(lista.begin(), lista.end(), mem_fun(&Klasa::bar)); // 19111812171316141510for_each(lista.begin(), lista.end(), bind(&Klasa::bar,_1)); // 19111812171316141510
bind zastępuje też adaptory (C++11)

• piszemy kod, wykonujący oczekiwane zadania• kod obsługujący sytuacje niepożądane otacza kod pożądany
• większa czytelność kodu• łatwiejsza kontrola nad błędami dowolnego wywołania danej funkcji• nie można zignorować zgłoszonego wyjątku
• zgłaszany (throw) wyjątek może być dowolnego typu (wbudowanego, abstrakcyjnego), zwykle używa się specjalnie napisanych klas
class UserError {const char* const errInfo;
public:UserError(const char* const msg = 0) : errInfo(msg) {}
};void fun() {
// funkcja wyrzuci wyjątek typu UserErrorthrow UserError("jestem beznadziejną funkcją");
}int main() {
// na razie bez bloku tryfun();
}
Obsługa wyjątków [ exception handling ]

Zgłaszanie wyjątku będącego obiektem klasy - ograniczenia na rodzaj klas, których można użyć do tworzenia obiektów wyjątków
• posiada odpowiedni dostępny konstruktor do utworzenia obiektu wyjątku• posiada dostępny konstruktor kopiujący• posiada dostępny destruktor• klasa nie jest klasą abstrakcyjną
Etapy zgłoszenia wyjątku będącego obiektem klasy1. wyrażenie throw tworzy obiekt tymczasowy
- wywołanie odpowiedniego konstruktora klasy 2. utworzenie kopii obiektu tymczasowego - (wywołanie konstruktora kopiującego klasy)
utworzenie obiektu reprezentującego obiekt wyjątku w celu przekazania go do procedury obsługi
3. usunięcie obiektu tymczasowego - (wywołanie destruktora) wykonywane przed przystąpieniem do szukania procedury obsługi
• zwracany jest obiekt (wyjątek) przez wartość i następuje wyjście z danego bloku zasięgu lub z funkcji
• można definiować wyrzucenie dowolnie wielu typów obiektów• obiekty lokalne utworzone do czasu wystąpienia wyjątku są usuwane
Obsługa wyjątków [ co się dzieje - wymagania ]

• obsłużenie wyjątków wymaga wstawienia kodu rzucającego wyjątki do bloku try, zgłoszone wyjątki obsługiwane są zaraz za tym blokiem
• dla każdego typu wyjątku potrzebna procedura obsługi wyjątku
try {// tu może zostać rzucony wyjątek
} catch (typA id1) {// obsługa wyjątku typu typA
} catch (typB id2) {// obsługa wyjątku typu typB
} catch (typC) {// jak widać tutaj nie ma identyfikatora// widocznie do obsługi wyjątku typu typC// wystarczy sama informacja o złapanym typie wyjątku
}
• wejście do bloku catch oznacza obsłużenie wyjątku (co wcale nie musi oznaczać rozwiązanie problemu…)
• wykonana jest tylko jedna pasująca fraza catch• program jest kontynuowany za blokiem try• możliwe warianty: zakończenie lub kontynuacja (trzeba, po obsłużeniu wyjątku, jawnie
wywołać funkcję która wygenerowała wyjątek - czyli np. blok try z funkcją w jakiejś pętli)
Obsługa wyjątków [ przechwytywanie wyjątku ]

class A { public:A() : a_(++c) { cerr << "ctorA:" << a_ << ' '; }A(const A& aa) : a_(++c) { cerr << "cctorA:" << a_ << ' '; }~A() { cerr << "dtorA:" << a_ << ' '; }int a() const { return a_; }
protected:int a_;static int c; // licznik powstałych obiektów
};int A::c = 0;
void fun1a() { throw A(); }int main() {
// fun1a(); - ctorA:1 terminate called after throwing an instance of 'A' Abort
try { fun1a(); } // poniżej: ctorA:1 wyjatekA:1 dtorA:1catch (const A& a) { cerr << "wyjatekA:" << a.a() << ' '; }// poniżej: ctorA:1 cctorA:2 wyjatekA:2 dtorA:2 dtorA:1
// catch (const A a) { cerr << "wyjatekA:" << a.a() << ' '; }}
Obsługa wyjątków [ przykład sytuacyjny ]

• szukanie najbliższej procedury obsługi wyjątków według kolejności bloków catch w kodzie• nie musi zajść dokładna zgodność typów• aby nie tworzyć kolejnej kopii obiektu wyjątku zamiast przechwycenia wartości lepiej
korzystać ze (stałej) referencji• podczas dopasowywania nie są przeprowadzane automatyczne konwersje typów
class A {}; class B { public: B(const A&) {} /* konstruktor konwertujący */ };void fun() { throw A(); }int main() {
try {fun();
} catch (B&) {// nie, bo nie zajdzie konwersja
} catch (A&) {// pasujący typ
}}
• obiekt lub referencja do obiektu klasy pochodnej pasują do procedury catch dotyczącej klasy bazowej (pamiętajmy o "przycinaniu" obiektu jeśli przekazywany jest przez wartość)
• kolejność bloków catch: od szczegółowego (klasa pochodna) do ogólnego (klasa bazowa)
Obsługa wyjątków [ dopasowanie wyjątków ]

• Wyjątek należący do klasy pochodnej może być obsłużony przez klauzulę catchprzeznaczoną dla wyjątków klasy podstawowej
// class A - tak jak poprzednio dwa slajdy wcześniejclass B : public A { public:
B() { cerr << "ctorB:" << a_ << ' '; }B(const B& bb) : A(bb) { cerr << "cctorB:" << a_ << ' '; }~B() { cerr << "dtorB:" << a_ << ' '; }
};void fun1b() { throw B(); }int main() {
try { fun1b(); } // kompilator ostrzeże, że pierwsza klauzula przechwyci wyjątek// przez referencję ctorA:1 ctorB:1 wyjatekA:1 dtorB:1 dtorA:1// przez wartość ctorA:1 ctorB:1 cctorA:2 wyjatekA:2 dtorA:2 dtorB:1 dtorA:1catch (const A& a) { cerr << "wyjatekA:" << a.a() << ' '; }catch (const B& b) { cerr << "wyjatekB:" << b.a() << ' '; }
}
Obsługa wyjątków [ dopasowanie wyjątków ]

• Wybór klauzuli obsługi wyjątku według zasady pierwszego dopasowania -obsługi dokona pierwsza napotkana klauzula mogąca obsłużyć wyjątek, a nie najlepiej dopasowana
int main() {try { fun1b(); } // przez referencję ctorA:1 ctorB:1 wyjatekB:1 dtorB:1 dtorA:1 // przez wartość ctorA:1 ctorB:1 cctorA:2 cctorB:2 wyjatekB:2 dtorB:2 dtorA:2// dtorB:1 dtorA:1catch (const B& b) { cerr << "wyjatekB:" << b.a() << ' '; }catch (const A& a) { cerr << "wyjatekA:" << a.a() << ' '; }
}• Podczas tworzenia obiektu wyjątku nie bada się aktualnego typu obiektuvoid fun2() { B b; A* a = &b; throw *a; }try { fun2(); }catch (const B& b) { cerr << "wyjatekB:" << b.a() << ' '; }// klauzula poniżej: ctorA:1 ctorB:1 cctorA:2 dtorB:1 dtorA:1 wyjatekA:2 dtorA:2 catch (const A& a) { cerr << "wyjatekA:" << a.a() << ' '; }
Obsługa wyjątków [ dopasowanie wyjątków ]

• procedura przechwytująca wyjątek dowolnego typucatch (…) {
// dowolny wyjątek złapany, czyli taka fraza powinna być ostatnia// nic nie wiemy o typie, można zwolnić zasoby i ponownie rzucić wyjątekthrow; // przechodzi do procedur obsługi wyjątków wyższego poziomu
}• ponowne zgłoszenie wyjątku powoduje zgłoszenie pierwotnego obiektu
reprezentującego wyjątek (czyli "rzucenie" go dalej)void fun3() {
try { fun1b(); } // przypominam: void fun1b() { throw B(); }catch (const A& a) { cerr << "wyjatekA:" << a.a() << ' '; throw; }
}try { fun3(); }// przez referencję: ctorA:1 ctorB:1 wyjatekA:1 wyjatekB:1 dtorB:1 dtorA:1// przez wartość: ctorA:1 ctorB:1 wyjatekA:1 cctorA:2 cctorB:2 wyjatekB:2// dtorB:2 dtorA:2 dtorB:1 dtorA:1catch (const B& b) { cerr << "wyjatekB:" << b.a() << ' '; }catch (const A& a) { cerr << "wyjatekA:" << a.a() << ' '; }
Obsługa wyjątków [ łap cokolwiek, ponownie rzuć ]

• wyjątek nie przechwycony na żadnym poziomie woła funkcję biblioteczną terminate() (plik nagłówkowy <exception>)
• funkcja terminate() jest wołana również gdy– destruktor obiektu lokalnego rzuci wyjątek podczas obsługi wyjątku– wyjątek zgłosi konstruktor lub destruktor obiektu statycznego lub globalnego
• domyślnie funkcja terminate() wywołuje funkcję abort() kończącą natychmiast działanie programu (core dump – można "debugować") – nie są wywołane destruktory obiektów globalnych i statycznych
• własna funkcja obsługi takiej sytuacji set_terminate() jako argument przyjmuje wskaźnik do bezargumentowej i nic nie zwracającej nowej funkcji obsługi, zwraca wskaźnik do poprzedniej funkcji obsługi (można ją odtworzyć)void newTerminate() { exit(0); /* powinna zakończyć działanie programu */ }void (*oldTerminate)() = set_terminate(newTerminate); // żeby ewentualnie odtworzyćclass A { public:
class B();void fun() { throw B(); }~A() { throw 'c'; }
};int main() {
try { A a;a.fun();
} catch (...) { /* nic */ }}
Obsługa wyjątków [ sytuacja bez wyjścia ]
wyjątek rzucony w destruktorze podczaslikwidacji obiektu przy obsłudze wyjątkupowoduje wywołanie funkcji terminate(),w tym przypadku newTermiate()

• wykorzystanie metod wirtualnych obiektów reprezentujących wyjątki
class A {// ... jak poprzedniopublic:
virtual void obslugaWyj() const { cerr << "Obsluga WyjatekA:" << a_ << ' '; }};class B : public A {
// ... jak poprzedniopublic:
virtual void obslugaWyj() const { cerr << "Obsluga WyjatekB:" << a_ << ' '; }};
try { fun1b(); } // jak poprzednio, rzuca wyjątek typu Bcatch (const A& a) { a.obslugaWyj(); }
// przez referencję – polimorfizm!// ctorA:1 ctorB:1 Obsluga WyjatekB:1 dtorB:1 dtorA:1// przez wartość: // ctorA:1 ctorB:1 cctorA:2 Obsluga WyjatekA:2 dtorA:2 dtorB:1 dtorA:1// obiekt "przycięty" do klasy A, nie ma polimorfizmu
Obsługa wyjątków [ polimorficzne wołanie funkcji ]

• gwarantowane jest, że przy wychodzeniu z zasięgu, dla obiektów, których konstruktory zostały wykonane do końca, wywołane zostaną destruktoryclass C { public:
C() : c(++cs) { cerr << "ctorC:" << c << ' '; }~C() { cerr << "dtorC:" << c << ' '; }
protected:int c;static int cs;
};int C::cs = 0;void fun4sub() {
C c2;fun1a(); // rzuca wyjątek typu AC c3;
}void fun4() {
C c1;fun4sub();C c4;
}try { fun4(); }// ctorC:1 ctorC:2 ctorA:1 dtorC:2 dtorC:1 Obsluga WyjatekA:1 dtorA:1 catch (const A& a) { a.obslugaWyj(); }
Obsługa wyjątków [ sprzątanie ]
problem: • jeśli wyjątek zostanie rzucony w konstruktorze
i nie wykona się on do końca, to destruktor nie jest wołany, zasoby zaalokowane w konstruktorze na stercie, przed rzuceniem wyjątku, nie zostaną zwolnione
rozwiązania:• przechwycić wyjątek w konstruktorze i zwolnić
w nim zasoby• stosować technikę pozyskiwania zasobów
w ramach inicjalizacji (RAII – Resource AcquisitionIs Initialization), alokacja w konstruktorze, zwalnianie w destruktorze – przykład: unique_ptr,czyli zdobycie zasobu wiąże się z budową jakiegoś obiektu

Blok try funkcji służydo ochrony listy inicjowaniaskładowych w konstruktorach klas (tzw. try funkcyjny)
int fun5(int i) {if (!i) throw A();return 2*i;
}class D { public:
D(int d0) try : d(fun5(d0)) { fun1b(); }catch (const A& a){ cerr << "ctorD-"; a.obslugaWyj(); }D(int d0, int) : d(fun5(d0)){
try { fun1b(); }catch (const A& a){ cerr << "ctorD-"; a.obslugaWyj(); }
}protected:
int d;};
Obsługa wyjątków [ na poziomie funkcji ]
try { D d(1,0); }catch (const A& a) { cerr << "main()-"; a.obslugaWyj(); }// ctorA:1 ctorB:1// ctorD-WyjatekB:1 dtorB:1 dtorA:1try { D d(1); }catch (const A& a) { cerr << "main()-"; a.obslugaWyj(); }// ctorA:1 ctorB:1 // ctorD-WyjatekB:1 main()-WyjatekB:1 dtorB:1 dtorA:1try { D d(0,0); }catch (const A& a) { cerr << "main()-"; a.obslugaWyj(); }// ctorA:1 main()-WyjatekA:1 dtorA:1try { D d(0); }catch (const A& a) { cerr << "main()-"; a.obslugaWyj(); }// ctorA:1 // ctorD-WyjatekA:1 main()-WyjatekA:1 dtorA:1
int main() try { throw ”mój wyjatek main”; }catch (const char* msg) {
cout << msg << endl;return 1; // tu może zakończyć jak funkcja
}
każda funkcjamoże mieć… alelepiej wewnątrz…
patrz wyjaśnieniedalej

Obiekt – zaczyna istnieć gdy konstruktor zakończy się pomyślnie (tzn. dojdziemy do końca ciała konstruktora lub do instrukcji return; )
Obiekt – kończy istnienie gdy rozpoczyna się jego destruktor.Sposobem zgłoszenia błędu konstrukcji jest zgłoszenie wyjątku. Zgłoszenie wyjątku przez konstruktor
oznacza, że obiekt nie został skonstruowany i nie istnieje. Procedura obsługi funkcyjnego bloku try w konstruktorze lub destruktorze musi zakończyć się
zgłoszeniem wyjątku – jeśli nie zakończy się jawnym zgłoszeniem wyjątku (oryginalnego lub jakiegoś nowego) i sterowanie osiągnie koniec bloku catch konstruktora lub destruktora, to oryginalny wyjątek jest automatycznie zgłoszony ponownie, tak jakby ostatnią instrukcją procedury było throw;
Jedynym zastosowaniem funkcyjnego bloku try konstruktora jest translacja wyjątku zgłoszonego przez podobiekt bazowy lub składowy. Jednak niewielka z tego korzyść, ponieważ trzeba pamiętać, że w procedurze obsługi funkcyjnego bloku try konstruktora wszystkie zmienne lokalne ciała konstruktora są już poza zasięgiem i żaden podobiekt bazowy ani składowy już nie istnieje! (… więc nie można „zwolnić” żadnych alokowanych zasobów).
Obsługa wyjątków [ blok try – wyjątek w konstruktorze ]
Nie można sprawić, aby wyjątek zgłoszony przez konstruktory podobiektu bazowego lub składowego nie wyciekł poza zawierający je konstruktor. W języku C++ jeśli konstrukcja dowolnego podobiektu bazowego lub składowego się nie uda, to nie może się też udać konstrukcja całego obiektu.

• opcjonalnie można poinformować jakie wyjątki rzuca funkcja• specyfikacja uzupełnia deklarację funkcji i pojawia się za listą argumentów
void fun(); // ta funkcja może zgłosić dowolny wyjątekvoid fun() throw(A, B, UserErr); // tu mogą być zgłoszone wyjątki typu A, B, UserErrvoid fun() throw(); // funkcja deklaruje, że nie rzuci żadnego wyjątku C++98/03void fun() noexcept; // funkcja deklaruje, że nie rzuci żadnego wyjątku C++11/14
• rzucenie wyjątku innego niż zadeklarowany powoduje wywołanie funkcji unexpected(), która domyślnie woła funkcję terminate()
• można ustawić własną obsługę takiej sytuacji poprzez podanie funkcji set_unexpected() adresu bezparametrowej funkcji typu void, można zachować wskaźnik do poprzedniej funkcji obsługi sytuacji nieoczekiwanej
• w klasach pochodnych, redefiniując funkcje składowe, nie można dodawać do listy wyjątków żadnych nowych typów – ale można podać mniej lub żaden
• jeśli nie wiemy (nie jesteśmy pewni) jakie wyjątki mogą się pojawić, nie używajmy ich specyfikacji (vide: biblioteka standardowa C++ i szablony klas – wyjątki znane są opisane w dokumentacji, a pozostałe zależą od użytkownika)
Obsługa wyjątków [ blok try – wyjątek w konstruktorze ]

– możliwe jest ponowne rzucenie wyjątku, jeśli jest to wyjątek z zadeklarowanej listy, przeszukiwanie podejmowane jest od nowa (od wywołania funkcji z taką specyfikacją wyjątków)
– jeśli jest to znowu wyjątek nie z deklarowanej listy, wywołana jest funkcja terminate()– chyba, że na liście wyjątków jest również wyjątek std::bad_exception
void fun() throw(A, B, C, bad_exception);to wyjątek nie przewidziany do rzucenia z danej funkcji zastępowany jest obiektem bad_exception i przeszukiwanie podejmowane jest od funkcji j.w.
class A {}; class B {};void myUnexpected() { throw invalid_argument(”O jej!”); }// void myUnexpected() { throw bad_cast(); } – ponownie zgłosi wyjątek nie z listyvoid myTerminate() { cout << ”Bez wyjscia: terminate” << endl; exit(1); }
void fun1() throw ( A, invalid_argument ) { throw B(); }// void fun1() throw ( A, invalid_argument, bad_exception ) { throw B(); } – tu jest bad_exception, więc…
int main() {set_unexpected( myUnexpected );set_terminate( myTerminate );try { fun1(); }catch( const exception& e) { cout << e.what() << endl; }
}
Obsługa wyjątków [ specyfikacje wyjątków ]

Hierarchia klasy wyjątków w bibliotece standardowej C++pliki nagłówkowe <exception>, <stdexcept>• klasa bazowa exception, klasy pochodne logic_error, runtime_error,
bad_cast, bad_alloc, bad_exception, bad_typeid, ios_base::failure
• błędy logiczne: klasa bazowa logic_error, klasy pochodne invalid_argument, out_of_range, length_error, domain_error
• błędy wykonania: klasa bazowa runtime_error, klasy pochodne range_error, overflow_error, underflow_errorclass exception { public:
exception() throw() { }virtual ~exception() throw();virtual const char* what() const throw();
};class tab { public:
explicit tab(int val = 0) { for(int i = 0; i < 3; ++i) tab_[i] = val; }int& operator[] (int i) {
if (i < 0 || i > 2)throw out_of_range("zły indeks tab");return tab_[i];
}protected:
int tab_[3];};
Obsługa wyjątków [ wyjątki standardowe ]
try { tab t(3); t[1] = t[4]; }catch (const exception& e) { cerr << e.what(); }// zły indeks tab

Obsługa wyjątków [ wyjątki standardowe ]

gwarancja podstawowa – po zgłoszeniu wyjątku nie nastąpi żaden wyciek pamięci, a obiekty pozostaną w stanie niekoniecznie przewidywalnym, ale umożliwiającym zniszczenie obiektów, gwarancja ta jest odpowiednia dla kodu radzącego sobie z nieudanymi operacjami, które już zmieniły stan obiektów
gwarancja silna – po zgłoszeniu wyjątku stan obiektu pozostaje niezmieniony, oznacza to semantykę „zatwierdź lub cofnij” oraz to, że żadne referencje lub iteratory do kontenera nie zostaną unieważnione, gdy operacja się nie powiedzie
gwarancja niezgłaszania wyjątków – funkcja nie zgłosi wyjątku bez względu na okoliczności, czasem jest niemożliwa implementacja silnej lub nawet podstawowej gwarancji, jeśli nie mamy gwarancji, że pewne funkcje (np. destruktory i funkcje zwalniające pamięć) nie zgłoszą wyjątku
Kod odporny na wyjątki [ gwarancje ]

#include <iostream>#include <stdexcept>using namespace std;class Device { public:
Device(int devno) { if (devno == 2) throw runtime_error(”Problem!”); }~Device() {}
};class Broker { public:
Broker(int devno1, int devno2) : dev1_(0), dev2_(0) {try {
dev1_ = new Device(devno1);dev2_ = new Device(devno2);
} catch ( … ) {delete dev1_; // bo po dev1_ mógł się nie udać tylko dev2_throw;
}}~Broker() { delete dev1_; delete dev2_; }
private: Broker(); Device* dev1_; Device* dev2_;};int main() {
try { Broker b( 1, 2 ); }catch (exception & e) { cerr << ”Wyjatek: ” << e.what() << endl; }
}
Kod odporny na wyjątki [ c-tor z gwarancją podstawową ]

Kontrolowanie obiektu (C++98) auto_ptr – deprecated (przestarzałe)
kontrola nad pojedyńczymi obiektami tworzonymi dynamicznie, zostaną automatycznie zniszczone gdy obiekt typu auto_ptr (stworzony na stosie) zakończy swoje życie (wyjdzie poza zasięg)
• mojObiekt dalej zachowuje się tak jak wskaźnik do typu T• auto_ptr nie można używać tego do opakowania tablic – powód to fakt, że destruktor
auto_ptr dla zawieranego wskaźnika wywołuje delete (a nie delete[])• kilka obiektów auto_ptr nie może pokazywać na ten sam fragment sterty• a co z tablicami? znacznie lepiej nadaje się do tego kontener vector !
#include <memory>auto_ptr<T> mojObiekt(new T);
auto_ptr<int> pInt1(new int(0));int* myPtr = new int(8); // inicjalizacja wartością 8auto_ptr<int> pInt2(myPtr); // teraz nie wolno usunąć myPtr ręcznieauto_ptr<int> pInt3 = pInt1; // przejęcie kontroli, pInt1 już nie ma!auto_ptr<int> pInt4; // zerowy, ale żeby to sprawdzić: pInt4.get();int a = 100; auto_ptr<int> pInt5(&a); // katastrofa, niszczenie stosuint *myPtr2 = pInt2.release(); // uwolnienie wskaźnika, obiekt pInt2 na 0pInt2.reset(); // usunięcie zawartościpInt2.reset(new int(10)); // skasowanie z ustawieniem nowej zawartości

auto_ptr kontra unique_ptr (C++11)
auto_ptr nie współpracował z kontenerami STL, właśnie ze wzgl. na filozofię „przekazywania praw własności” – kopia prowadziła do unieważnienia obiektu z prawej strony przypisania!unique_prt zastępuje auto_ptr (nagłówek memory), wspiera „semantykę przenoszenia”własności unique_ptr: • może być składowany w większości kontenerów i współdziała z algorytmami• nie można tworzyć przez kopiowanie ani przez przypisanie• można tworzyć przez kopiowanie lub przypisanie przenoszące• przykład zachowania auto_ptr i unique_ptr
• istnieje tablicowa wersja unique_ptr – jest to częściowa specjalizacja unique_ptr<T[]>
void f( unique_ptr<Foo> foo ); unique_ptr<Foo> pFoo ( new Foo() );f( move(pFoo) ); // jawne przesunięcie // za pomocą std::move() pFoo->method(); // błąd dostępu
void f( auto_ptr<Foo> foo ); // przez wartośćauto_ptr<Foo> pFoo ( new Foo() );f( pFoo ); // przekazanie przez wartość
// zeruje wewnętrzny wskaźnikpFoo->method(); // błąd dostępu
unique_ptr
auto_ptr
unique_ptr <int[]> intarr (new int[4]); // tablicowa wersja unique_ptr intarr[0]=10; intarr[1]=20; // i tak dalej// domyślny sposób usunięcia – wywołanie delete[]

unique_ptr (C++11)
unique_prt jest „referencją” do obiektu, który w sobie zawiera (przez wskaźnik), nie ma gwarancji, że jest to unikatowa referencja – unique_ptr można utworzyć z dowolnego wskaźnika
Bezpieczeństwo w sytuacjach nadzwyczajnych:
void f(unique_ptr<Foo> foo) { // na końcu zasięgu wołany destruktor obiektu foo
}Foo * foo = new Foo(); unique_ptr<Foo> upFoo(foo); f( move(upFoo) ); // jawne przesunięciefoo->method(); // niezdefiniowana sytuacja
unique_ptr<X> f() { unique_ptr<X> p(new X); // zgłoszenie wyjątkureturn p;
}
również metoda unique_ptr::get()prowadzi (przyczynia się) do potencjalnego powielania odnośników do tego samego obiektu (którego „właścicielem” jest unique_ptr)
X* f() { X* p = new X; // zgłoszenie wyjątkureturn p;
}
X* f() { unique_ptr<X> p(new X); // zgłoszenie wyjątkureturn p.release();
}
void g() { unique_ptr<X> q = f(); // konstruktor przenoszącyq->jakas_metoda(); // używamy q jak wskaźnikaX x = *q; // kopiowanie obiektu/* na koniec q i jego zawartość niszczone */ }
po zgłoszeniu wyjątku obiekt pzniszczy obiekt, którego wskaźnikprzechowuje (opakowuje)

unique_ptr (C++11) – standardowe tworzenie
• obiekt unique_prt zainicjalizowany
standardowe tworzenie obiektu, tak jak auto_ptr
• deleter – funkcja (lub obiekt funkcyjny) odpowiedzialny za poprawne usunięcie zasobu przechowywanego w unique_ptr
np. gdy trzeba usunąć 2-wym. tablicę dynamicznie zbudowaną
unique_ptr< string > a( new string(”witaj kolego”) );
struct Usuwacz {size_t rozmiar;Usuwacz( size_t roz=0 ) : rozmiar(roz) {}void operator()( string** ptr ) const {
for( size_t i=0; i < rozmiar; ++i ) delete ptr[i];delete [] ptr;
}};
unique_ptr< typ > nazwa ( new typ );
unique_ptr< typ, [ typ_deleter ] > nazwa( new typ, [ deleter ] );
// w programieunique_ptr< string*, Usuwacz >
a2( new string*[5], Usuwacz(5) );// można sprawdzić deleter:Usuwacz &ref = a2.get_deleter();

unique_ptr (C++11) – tworzenie c.d., użycie
• pusty obiekt unique_prt
– wewnętrzny wskaźnik obiektu ustawiony na 0– można obiekt unique_ptr sprawdzić „tak jak wskaźnik”
• inicjalizacja innym obiektem unique_ptr
działa wtedy konstruktor przenoszący, przejęcie zasobu– również w przypadku przenoszącego operatora przypisania
• obiekt unique_ptr zachowuje się jak wskaźni przechowywanego typu
unique_ptr< int > a;if ( !a ) cout << ” zero ”; // można to samo metodą a.get()
a1 = move( a2 ); // teraz a2 ma wskaźnik 0
unique_ptr< typ > nazwa;
unique_ptr< typ > a1( new string(”witaj kolego”) ); a1->insert( strlen(”witaj”), ” mily” ); // teraz: ”witaj mily kolego”
unique_ptr< typ > a1( new int ); // pierwszy obiekt unique_ptrunique_ptr< typ > a2( move(a1) ); // wskaźnik obiektu a1 ustawiony na 0

unique_ptr (C++11) – operatory i metody składowe
• operator przypisania przenoszącego =
• operatory: * i -> (wyłuskanie wskaźnika i odniesienie na składową)• metoda T* get() zwraca wskaźnik do typu T przechowywanego
przez unique_ptr, może być 0 • metoda Deleter& unique_ptr<T>::get_deleter() zwraca referencję
do obiektu „deletera” używanego przez unique_ptr• T* release() uwalania zasób przechowywany przez unique_ptr (on
sam przechodzi w stan 0), można przypisać do zwykłego wskaźnika, odpowiedzialnośc za usunięcie zasobu przekazana na zewnątrz
• void reset( T* ) podobnie jak w auto_ptr• void swap( unique_ptr<T>& ) zamiana dwóch obiektów unique_ptr
zawierających ten sam typ
unique_ptr< int > a1( new int ); unique_ptr< int > a2;a2 = std::move( a1 ); // nie można: a2 = a1; bo byłoby to przypisanie kopiujące

unique_ptr (C++11) – argument konstruktora (przykłady) (1)
• przez wartość – oznacza przekazanie zasobu („wskaźnika do…”)
– nextFoo jest „wyczyszczone”– std::move( nextFoo ) zwraca Foo&&, ponieważ argument jest przez wartość
więc tworzy obiekt tymczasowy, do którego przeniesiona jest zawartość argumentu danego konstruktorowi, a ten – przekazany (przeniesiony) do argumentu n konstruktora
Foo( std::unique_ptr<Foo> n ) : self( std::move(n) ) {}// użytkownik musi wywołać jawnie z użyciem std::moveFoo newFoo( std::move( nextFoo ) );
class Foo { public:
typedef unique_ptr<Foo> UPtrFoo;Foo( ) { } // jakie możliwości argumentów konstruktorów?virtual ~Foo() { }
protected:Foo::UPtrFoo next; // zagnieżdżone odniesienie się do Foo
};

unique_ptr (C++11) – argument konstruktora (przykłady) (2)
• przez niestałą referencję do l-wartości
– w zależności od tego co robi konstruktor, nextFoo może być wyczyszczone lub nie
• przez stałą referencję do l-wartości
– dajemy konstruktorowi dostęp do zasobu, ale tego zasobu nie można przejąć, możemy dostać się przez „wskaźnik do…” ale nie można go przejąć, bez łamania stałości (rzutowanie znoszące const)
Foo( std::unique_ptr<Foo>& n ) : self( std::move(n) ) {}// argument musi być prawdziwą, nazwaną, l-wartościąFoo newFoo( std::unique_ptr<Foo>( new Foo ) ); // błądFoo newFoo( nextFoo );
Foo( std::unique_ptr<Foo> const & n );// nie można naruszyć zawartości

unique_ptr (C++11) – argument konstruktora (przykłady) (3)
• przez referencję do p-wartości
– nie ma gwarancji, że przeniesienie zawartości ma miejsce, zależy od implementacji, sam powyższy zapis tego nie gwarantuje
• obiekt unique_ptr nie można skopiować, można tylko przesunąć– jeśli chcemy przejęcia zasobu, argument przez wartość– jeśli chcemy tylko użyć (tego co opakowuje unique_ptr) w czasie życia
(wykonania) danej metody, argument const&– jeśli metoda ma przejąć zawartość lub nie, przez && (ale jest to najmniej
czytelne bez przestudiowania co robi kod)
Foo( std::unique_ptr<Foo>&& n ) : next( std::move(n) ) { }// podobne do niestałej l-referencji, ale można wołać z tymczasowymiFoo newFoo( std::unique_ptr<Foo>( new Foo ) ); // prawidłowe// dla obiektów nietymczasowych konieczne użycie std::moveFoo newFoo( nextFoo ); // powinno być przeniesienie, ale…

shared_ptr (C++11) – inteligentny wskaźnik ze zliczaniem referencji
• zasób kontrolowany przez shared_ptr może być współdzielony, ilość udziałów jest zliczana i gdy zejdzie do 0 zasób jest usuwany
• shared_ptr obsługuje konstrutory i operatory przypisania, zarówno kopiujące jak i przenoszące
• tworzenie, składnia, metody składowe takie jak w unique_ptr• możliwe jest również kopiowanie (zwiększa się licznik referencji)
• możliwe jest też przypisanie kopiujące (lewy argument pomniejsza licznik i ew. usuwa zasób, prawy argument powiększa licznik)
• metoda stała uniqe() zwraca true, jeśli obiekt nie jest współdzielony• metoda size_t use_count() zwraca ile obiektów odnosi się do
zasobu kontrolowanego przez shared_ptr
shared_ptr< int > a1( new int(0) ); shared_ptr< int > a2( a1 );*a2 = 3; // teraz również *a1 == 3

shared_ptr (C++11) – problem z danymi cyklicznymi
• shared_ptr reprezentuje relację „posiadania”, może się zdarzyć, że obiekty zawierające shared_ptr odnoszą się wzajemnie do siebie
• gdy dwa obiekty shared_ptr odnoszą się wzajemnie do siebie, ich liczniki nigdy nie mogą zejść do 0, mimo zwolnienia zasobu!
class Rodzic;class Dziecko;class Rodzic { public: shared_ptr< Dziecko > pD; };class Dziecko { public: shared_ptr< Rodzic > pR; };int main() {
shared_ptr<Rodzic> r( new Rodzic ); // licznik 1shared_ptr<Dziecko> d( new Dziecko ); // licznik 1r->pD = d; // licznik rośnie +1d->pR = r; // licznik rośnie +1d.reset(); // zwalniam zasób, a co z licznikiem? licznik maleje -1, ale… był == 2cout << ”wsk: ” << d.get() << ” licznik: ” << d.use_count(); // wsk: 0 licznik: 1
}
gdy nie chodzi o obiekt,który jest zliczany, bo dbao „życie zasobu”, stosujemyweak_ptr (może rozwiązać problem cyklicznej relacji między obiektami)

shared_ptr (C++11) – koszty, czyli wady
• nie zamieniać swoich wskaźników bezrefleksyjnie na shared_ptr• cykliczne struktury z użyciem shared_ptr mogą prowadzić do
wycieków pamięci• obiekty shared_ptr mają tendencję do średnio dłuższego życia niż
zwykłe obiekty o ściśle określonym czasie życia (tym samym zużywają średnio więcej zasobów)
• w środowisku wielowątkowym mogą być kosztowne w obsłudze (z powodu zabezpieczenia licznika przed wyścigiem danych współużytkujących dany zasób)
• destruktor obiektu shared_ptr nie jest wywoływany w przewidywalnym czasie
• współdzielenie zasobu może powodować problemy z jego odświeżaniemBjarne Stroustrup:A shared_ptr represents shared ownership but shared ownership isn't my ideal: It is better if an object has a definite owner and a definite, predictable lifespan.

weak_ptr (C++11) – obserwator zasobów shared_ptr
• weak_ptr reprezentuje relację „obserwatora”, który patrzy na zasób, ale zasób może być usunięty mimo obiektu weak_ptr
• weak_ptr może pokazywać na shared_ptr, ale nie powiększa to licznika referencji do zasobu
• weak_ptr nie zachowuje się jak wskaźnik (nie można np. go wyłuskać operatorem *), żeby użyć go jako wskaźnika, trzeba:– utworzyć obiekt shared_ptr zbudowany z obiektu weak_ptr
(shared_ptr ma stosowny konstruktor) lub:– użyć metody składowej lock(), która zwraca shared_ptr<T>
• metoda expired() bada, czy obserwowany zasób (obiekt shared_ptr) jeszcze istnieje – odpowiada to warunkowi use_count() == 0
• weak_ptr zwykle użyte w kontekście rozwiązania problemówcyklicznej zależności (weak_ptr nie ma – i nie kontroluje zasobu)
// rozwiązanie problemu cyklicznej zależności obiektów shared_ptrclass Dziecko { public: weak_ptr< Rodzic > pR; };

Szablony funkcji [ function templates ]
• Rodzina funkcji z niektórymi elementami sparametryzowanymi
template < typename T >inline T const& max ( T const& a, T const& b ){
return a < b ? b : a;}
• typ nie jest jawnie określony, występuje jako parametr szablonu T ("T" jest zwyczajowe, zamiast "T" może być dowolny identyfikator…)
• parametry szablonu (składnia)
template < lista-parametrów-oddzielona-przecinkami >
• T reprezentuje typ umowny precyzowany dopiero w miejscu wywołania funkcji
• typ T może być dowolny o ile wszystkie operacje wykorzystane w szablonie są dla niego zdefiniowane (inaczej błąd kompilacji)
dawniej: classnadal można używać,ale nie należy mieszaćw jednym class i typename

Szablony funkcji [ wywołania ]
double x = 3.4;// konieczny operator zakresu :: bo inaczej wywołane zostanie std::maxcout << ::max( 3.2, x ) << endl; // 3.4 string s1 = "alfa";string s2 = "beta";cout << ::max( s1, s2 ) << endl; // "alfa"
• zwykle dla każdego nowego typu wywołania szablonu generowana jest osobna jednostka programowa• konkretyzacja (instantiation) szablonu - utworzenie egzemplarza
(instance) szablonu… w przykładach powyżej:const double& max( double const&, double const& );const std::string& max( std::string const&, std::string const& );
• dwukrotna kompilacja:• sam szablon, bez konkretyzacji - poprawność składniowa• konkretyzacja - pod kątem poprawności wywołań (kompilator musi się
odwołać do definicji szablonu - co narusza regułę, że do kompilacji powinna wystarczyć tylko deklaracja funkcji)

Szablony funkcji [ parametry i dedukcja typów ]
• typ T musi być określony jawnie (nie zachodzi automatyczna konwersja)max( 2, 3.4 ); // błąd, pierwszy jest int, a drugi double
• sposoby wołania z różnymi typami• jawne rzutowanie
max( static_cast<double>(2), 3.4 );• jawne określenie typu T
max<double>(2, 3.4 );• zdefiniowanie szablonu o dwóch różnych parametrach
• nie ma ograniczeń co do liczby parametrów (od C++11 mogą być domyślne): template < typename T1, typename T2 >
inline T1 max ( T1 const& a, T2 const& b ) {return a < b ? b : a;
}• zwracany typ determinowany przez jeden z parametrów, więc musi zajść
niejawna konwersja drugiego z parametrów na typ zwracany!• podczas konwersji tworzony obiekt tymczasowy - nie można zwracać
referencji do obiektu tymczasowego (stąd w przykładzie funkcja zwraca wartość - jeśli b > a, to zwracane b typu T2 konwertowane na typ T1)

Szablony funkcji [ dedukcja typów ]
• dedukcja argumentów szablonu funkcji - powiązanie parametrów szablonu z parametrami wywołania funkcji
• jawna konkretyzacja typu (czasem konieczna)
template < typename T1, typename T2, typename RT >inline RT max ( T1 const& a, T2 const& b );// powyżej nie można wydedukować typu wartości zwracanej,// typ ten nie figuruje jako jeden z parametrów wywołania funkcji// konkretyzacja:max< int, double, char > ( 3, 3.4 );
// chyba że: auto max ( T1 const& a, T2 const& b ) -> decltype( „jakaś operacja” )• częściowa dedukcja - jawnie podaje się aż do tego parametru,
który nie może być wydedukowany
// powyższy przykład po drobnej modyfikacji kolejności parametrówtemplate < typename RT, typename T1, typename T2 >inline RT max ( T1 const& a, T2 const& b );// konkretyzacja:max< char > (3, 3.4 );// parametry T1 i T2 wydedukowane na podstawie argumentów wywołania

Szablony funkcji [ przeciążanie ]Zwykłe funkcje mogą współistnieć z szablonami funkcji o tych samych nazwach, nawet konkretyzowanych dla tych samych typów co w funkcjach zwykłych
inline int const& max (int const& a, int const& b) {return a < b ? b : a;
}template <typename T>inline T const& max (T const& a, T const& b) {return a < b ? b : a;
}template <typename T>inline T const&
max (T const& a, T const& b, T const& c) {return max(max(a, b), c);
}
jeżeli do wyboru jest albo funkcja zwykła, albo konkretyzacja szablonu, proces rozstrzygający przeciążenie preferuje funkcję zwykłą
max (1, 24); // funkcja zwykła
jeżeli na podstawie szablonu można wygenerować lepsze dopasowanie, to wybierany jest szablon
max (3.0, 3.1); // max<double>max ('a', 'b'); // max<char>
można zażądać wykorzystania szablonu (wraz z dedukcją typu argumentów) wywołując z pustą listą argumentów szablonu
max<> (1, 24); // max<int>
w przypadku szablonów nie jest wykonywana automatyczna konwersja, która może zajść dla zwykłych funkcji, wtedy wołana jest funkcja zwykła// oba parametry zostaną// niejawnie zmienione na intmax (1.5, 'a'); // funkcja zwykła
trzeba pamiętać o widoczności wszystkich wersji przeciążonych w miejscu wywołania funkcji, np. przeniesienie definicji zwykłej funkcji max poza definicje szablonowe spowodowałoby wywołanie wewnątrz drugiego szablonu wersji szablonowej (wersja zwykła w tym miejscu wtedy jeszcze nie znana)

Szablony klas [ class templates ]
template < typename T >class A {
std::vector< T > tablica;public:
// konstruktor kopiującyA ( A< T > const& m); // operator przypisaniaA< T >& operator=( A< T > const& ); void put( T const& );T get() const;
};
// zewnętrzna implementacja
template < typename T >void A< T >::put( T const& m) {
tablica.push_back( m );}
nazwa klasy jest A tam gdzie stosuje się typ, to jest to: A< T > gdzie T jest parametrem szablonu
korzystanie z obiektu szablonuklasy oznacza konieczność jawnego określenia argumentu:A< float* > ptrFloatA;A< std::string > stringA;A< A< int > > intAA;
kod jest konkretyzowany tylkodla tych metod klasy, które zostanąwywołane w programie
można więc konkretyzować również dla typów, w których nie wszystkie operacje w metodach klasy da się wykonać - byle by ich nie wywoływać
metody statyczne konkretyzowaneraz dla każdego typu

Szablony klas [ specjalizacje ]
Dla pewnych typów konieczne może okazać się napisanie specjalnej wersji klasy… wszędzie wtedy typ T zastępujemy naszym typem specjalizowanym
template <>class A< std::string > {
std::deque< std::string > tablica; public:
// konstruktor kopiującyA ( A< std::string > const& m); // operator przypisaniaA< std::string >& operator=( A< std::string > const& ); void put( std::string const& );std::string get() const;
};
Specjalizacje częściowetemplate < typename T1, typename T2 >class A {
// …};
• oba parametry - ten sam typtemplate< typename T >class A< T, T > {
// …};
• jeden z parametrów określonytemplate< typename T >class A< int, T > {
// …};
• oba parametry wskaźnikamitemplate< typename T1, typename T2 >class A< T1*, T2* > {
// …};

Szablony klas [ domyślne argumenty, pozatypowe argumenty ]
Można określić wartości domyślne dla parametrów szablonów, mogą być oneokreślone przez odwołania do poprzednich parametrów szablonutemplate < typename T1, typename T2 = std::vector< T > >class A {
T2 tablica; public:
// konstruktor kopiującyA ( A< T1, T2 > const& m); // operator przypisaniaA< T1, T2 >&
operator=( A< T1, T2 > const& ); };
Pozatypowe parametry szablonów• klas:
template< typename T, int MAX >class A { };
• funkcji:template< typename T, int VAL >
Można teraz zmienić np. typ używanego kontenera:
A< int, std::deque< double > > nowyDA;A< double, std::list< double > > nowyLA;
Mogą być wartości domyślnetemplate< typename T, int MAX = 10 >class A { };Uwaga: A< int, 10 > i np. A< int, 20 > to dwa różne typy!
Pozatypowe parametry szablonówmuszą być stałymi wartościami całkowitymi lub wskaźnikami doobiektów łączonych zewnętrznie(zmiennoprzecinkowe i obiekty klas - nie)

Szablony klas [ użycie typename i this-> ]
typename trzeba stosować tam, gdzie nazwa uzależniona od parametru szablonu ma być interpretowana jako typ
template < typename T >class A {
typename T::SubType *ptr;};
typename służy tu do oznaczenia typu definiowanego wewnątrz klasy A, jeśli by opuścić typename, zostałoby to zrozumiane jako iloczyn składowej statycznej SubType klasy T oraz zmiennej ptr
przykład z iteratoremtemplate < typename T >void printContainer( T const& a ) // a jest kontenerem{
typename T::iterator pos; // iterator do odczytu byłby: T::const_iteratortypename T::iterator end( a.end() ); // koniec kontenera
for ( pos = a.begin(); pos != end; ++pos ) {std::cout << *pos << ' ';
}std::cout << std::endl;
}

Szablony klas [ szablony zagnieżdżone ]
Składowe klasy też mogą być szablonami - przydaje się to np. do napisania operatora przypisania jednego typu do drugiego:template < typename T >class A {
std::deque< T > tablica;public:
// tylko to co istotne dla przykładutemplate< typename T2 >A< T >& operator=( A< T2 > const& );
};
zewnętrzna definicjatemplate < typename T >template < typename T2 >A< T >& A< T >::operator=( A< T2 > const& op ) {
A< T2 > tmp( op ); // lokalna kopia do operacji na tym kontenerzetablica.clear();while ( !tmp.empty() ) { // tu napisać parę linii kopiowania…}return *this;
}
Inicjalizacja zerowatypy podstawowe nie zainicjalizowanemają wartość nieokreśloną, ale np. dla typu int wywołanie konstruktoradomyślnego int() da nam wartość zerotemplate < typename T >void foo() {
T zmienna = T(); // inicjalizacja}




![Podstawy programowania w Scratch. - e-kompetencje.wmzdz.ple-kompetencje.wmzdz.pl/.../11/Podstawy-programowania-w-Scratch.pdf · [1/23] Podstawy programowania w Scratch. Programowanie](https://img.dokumen.tips/doc/110x75/5c768cff09d3f2b0618bd0d7/podstawy-programowania-w-scratch-e-123-podstawy-programowania-w-scratch.jpg)