Embed Size (px)
Citation preview

Countermeasures to P300-based Guilty Knowledge Tests of Deception
J.Peter Rosenfeld, Matt Soskins,Joanna Blackburn, & Ann Mary RobertsonNorthwestern University.
Supported by DoDPI

Some History (earliest publications)
Rosenfeld et al., 1987,1988,1991Farwell and Donchin, 1991Allen, Iacono, & Danielson, 1992Johnson and Rosenfeld, 1992Since we were there at beginning,
why do we challenge now with countermeasures? (1) It’s about time….

2) Farwell’s web page, claiming 100% accuracy:

Stimuli:
Probes (P or R in figures): Items which subject is suspected of knowing (e.g., murder weapons). Subject denies(lies).
Targets (TR) Items: Items to which subject presses ‘YES’ . (Benchmark P300).
Irrelevants (I or W in figures): Items of which subject has no knowledge and denies, honestly, by pressing ‘NO’ .

How P300 amplitude is supposed to catch Liars:
1)P>I (‘BAD’)2)P-TR corr>P-I corr(‘BC-AD’)
1)P=I2)P-I corr>P-TR corr

Whither R-TR correlation if there are latency differences?
Probe P3 Target P3
Nothing should happen to bootstrapped amplitude difference test (BAD) but bootstrapped cross-correlation test (BC-AD) should fail.

Experiment 1, based on Farwell & Donchin (1991):
--6 Different Probes --Innocent, Guilty, and Countermeasure(CM)
Groups--Countermeasure: Associate various latent
responses to different categories (jewelry type, drawer color, operation name, etc.), all irrelevant members of the category.
--”Off the Street “ subjects (Psych 101).

General Instructions….
Mock crime scenarioPress “Yes” to Targets (on list)
Press “No” to all other stimuli (Possibly guilty probes and Irrelevants).

More simply….
Probe Target I1 I2 I3 I4 ring bracelet necklace watch broach tiara
pink brown yellow purple red bluedonkey tiger lion cow pig horse etc., etc…... (only half the matrix here.)
All these are shuffled, presented in random order, involving 4 repetitions of each item.

What are the covert countermeasures for the 6 categories of 6 probes?
1) Jewelry category……….micro right finger wiggle 2) drawer lining category…. “ left “ “ 3) owner’s name category…. “ “ toe “ 4) operation name category…” right “ “ 5) location of item category…… Imagine professor
slaps you 6) desktop category……………Do Nothing
I.e., make irrelevants into relevant targets.

Guilty group: Probe(R) > Irrelevant (W).
R > W

Guilty Group: TR vs R
Both have P300

Innocent Group: R vs W
Both lack P300

Innocent Group: TR vs R
TR towersover P (R)

CM Group : R vs W
No differenceP(R) vs I (W)

CM Group: Tr vs R
Target > Probe

Results, Exp. 1: CM works, and analysis method matters:
Diagnoses of Guilty
Guilty Group Innocent Group CM Group
9/11(82%) 1/11(9%) 2/11(18%)
Amplitude Difference (BAD) method,p=.1
Cross-Correlation(BC-AD) Method, p=.1
6/11(54%) 0/11(0%) 6/11(54%)
--with “Off the street” subjects; see next 2 slides.

Guilty Subject, probe(R) vs irrelevant(W)
R >> W: subjectclearly guilty

…but clear latency shift in TR and R P300s
..so BC-AD fails,BAD catches the S.

Do Reaction Times help?
Guilty Group CM Group
9/1090% BAD
3/10*30% BART *
These are guilty calls based on bootstrapped(Probe-Irrelevant) RTs, at p =.05
.* Bootstrapped Analysis of RT difference, R-W.

Absolute Irrel. RTs for CM and Inno. Groups overlap*.
..and 3 fastest CM-ers beat tes,3 slowest did not
*I.e., they don’t helpeither.

Experiment 2: The one probe protocol (Rosenfeld et al., 1991).
100% simpler to conceptualize:There are 6 items, repeated 30-40
times randomly, consisting of..A probe, subject maybe guilty,A target to force attention (not really
necessary but allows us to test Farwell cross-correlation method vs. ours.)
4 irrelevants.

Standard autobiographical oddball paradigm.
6 dates are presented, one is the birth date.
5 other dates with no personal significance, one is a target, four are irrelevant.
Subject is feigning head injury, the inability to recognize birth date 50% of the time, so he presses yes and no to all dates on 50-50 basis.

Design:
One group of advanced Ss run in 3 successive weeks. (Also Control group.)
Week 1: All naïve(about CM) and guilty (of having birth date and recognizing it despite overt lies.
Week 2: Use explicit countermeasure (to be explained).
Week 3: Repeat first week, stop the CM.

What’s the CM?
When you see the first Irrelevant, do micro left finger wiggle.
When you see second Irrelevant, do micro right toe wiggle.
When you see third irrelevant, imagine me slapping your face.
When you see fourth Irrelevant, do nothing.
I.e., make irrels. into rel. targets.

Results, week 1(guilty): Probe(R) vs.Irrelevant (W)
As usual, R>>W

Week 1: Probe(R) and Target(TR):
Both have nice P3

Week 2: Explicit CM, R v W
Not so differentanymore...

Week 3: 5/12 test beaters(effortless), R v W:
Surprise! R = W

Week 3: 5/12 test beaters, R v TR--”classic defeats”:
..and TR >> Ras with innocents.

Exp. 2; quantitative.
WK BAD BC-AD
no CM 12/13(.92) 9/13(.69) CM 6/12(.50) 3/12(.25) no CM 7/12(.58) 3/12(.25)
(Control group: nothing much happened over 3 weeks of repeating week 1.)

RTs for 3 weeks; week 1= week 3, proving CM not used in week 3.
0 1 2 3 4WEEK
400
500
600
700
800
900
1000
1100
React
ion T
ime
IRRELEVTARGETPROBE

Irrelevant RTs, with and without CM. No overlap!
21
WEEKGROUP
0
500
1000
1500
2000D
WW
RT
051015Count
0 5 10 15Count
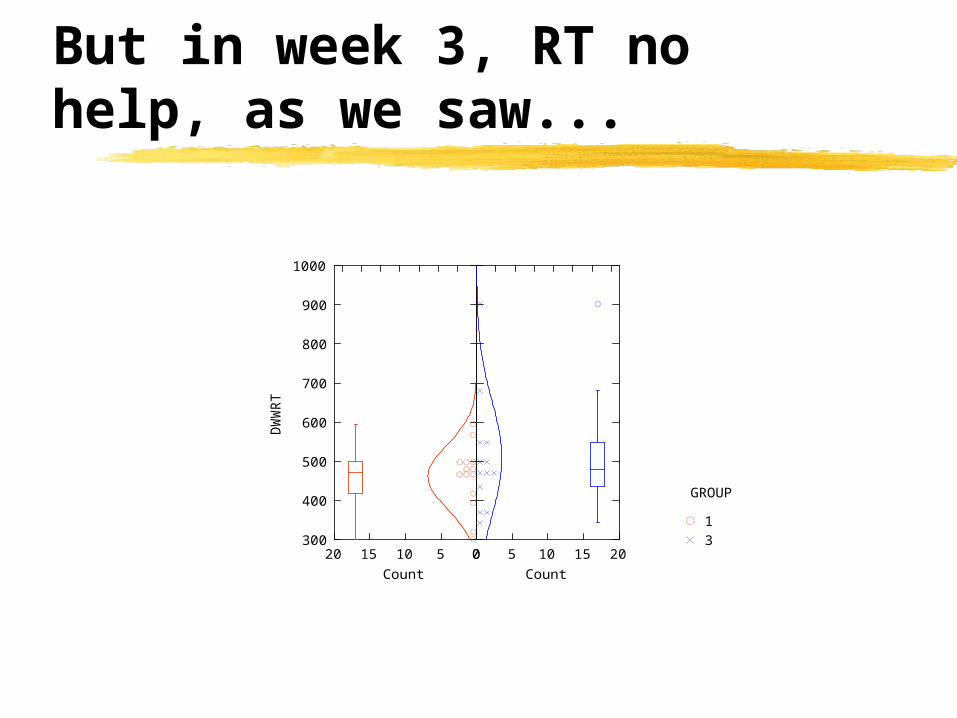
But in week 3, RT no help, as we saw...
31
GROUP
300
400
500
600
700
800
900
1000D
WW
RT
05101520Count
0 5 10 15 20Count

Overall amplitude effects...
0 1 2 3 4WEEK
200
300
400
500
600
700A
MP
LIT
UD
E,p
-p,
com
pute
r unit s
.
IRRELEVTARGETPROBE

Conclusions, bottom lines..
6-probe protocol beat-able, RT is no help, and the 6 probe combination lacks a real rationale anyway. (Lykken wouldn’t like?)
1-probe protocol may be explicitly beat-able, but the very slow Irrelevant RT distribution will raise suspicions. 1 probe per run is more Lykkenable.
BUT---1-probe paradigm after CM practice is beat-able, period.

What to do?
We have found(submitted) that within individuals, the scaled scalp distribution method detects 73% (not great) using statistical criteria yielding 0 % false positives.
This method should be worked on, because there is no obvious CM as there is with simple amplitude.





























