Embed Size (px)
Citation preview

Computational Biology, Part 2Representing and Finding Sequence Features using
Consensus Sequences
Computational Biology, Part 2Representing and Finding Sequence Features using
Consensus SequencesRobert F. MurphyRobert F. Murphy
Copyright Copyright 1996-2001. 1996-2001.
All rights reserved.All rights reserved.

Sequence Analysis TasksSequence Analysis Tasks
Representing sequences and sequence Representing sequences and sequence features, and finding sequence features features, and finding sequence features using consensus sequences and frequency using consensus sequences and frequency matricesmatrices

Sequence featuresSequence features
A A sequencesequence is a linear set of characters is a linear set of characters (sequence elements) representing (sequence elements) representing nucleotides or amino acidsnucleotides or amino acids
A A sequence featuresequence feature is a pattern that is is a pattern that is observed to occur in more than one observed to occur in more than one sequence and (usually) to be correlated with sequence and (usually) to be correlated with some functionsome function

Sequence featuresSequence features
Features following an exact patternFeatures following an exact pattern restriction enzyme recognition sitesrestriction enzyme recognition sites
Features with approximate patternsFeatures with approximate patterns promoterspromoters transcription initiation sitestranscription initiation sites transcription termination sitestranscription termination sites polyadenylation sitespolyadenylation sites ribosome binding sitesribosome binding sites protein featuresprotein features

Consensus sequencesConsensus sequences
A A consensus sequence consensus sequence is a sequence that is a sequence that summarizes or approximates the pattern summarizes or approximates the pattern observed in a group of aligned sequences observed in a group of aligned sequences containing a sequence featurecontaining a sequence feature
Consensus sequences are Consensus sequences are regular regular expressionsexpressions

Representation of SequencesRepresentation of Sequences
characterscharacters simplestsimplest easy to read, edit, etc.easy to read, edit, etc.
bit-codingbit-coding more compact, both on disk and in memorymore compact, both on disk and in memory comparisons more efficientcomparisons more efficient more to come on this for 03-510 studentsmore to come on this for 03-510 students

Character representation of sequencesCharacter representation of sequences
DNA or RNADNA or RNA use 1-letter codes (e.g., A,C,G,T)use 1-letter codes (e.g., A,C,G,T)
proteinprotein use 1-letter codesuse 1-letter codes
can convert to/from 3-letter codescan convert to/from 3-letter codes

Representing uncertainty in nucleotide sequencesRepresenting uncertainty in nucleotide sequences It is often the case that we would like to It is often the case that we would like to
represent uncertainty in a nucleotide represent uncertainty in a nucleotide sequence, i.e., that more than one base is sequence, i.e., that more than one base is “possible” at a given position“possible” at a given position to express ambiguity during sequencingto express ambiguity during sequencing to express variation at a position in a gene to express variation at a position in a gene
during evolutionduring evolution to express ability of an enzyme to tolerate more to express ability of an enzyme to tolerate more
than one base at a given position of a than one base at a given position of a recognition siterecognition site

Representing uncertainty in nucleotide sequencesRepresenting uncertainty in nucleotide sequences To do this for nucleotides, we use a set of To do this for nucleotides, we use a set of
single character codes that represent all single character codes that represent all possible combinations of basespossible combinations of bases
This set was proposed and adopted by the This set was proposed and adopted by the International Union of Biochemistry and is International Union of Biochemistry and is referred to as the referred to as the I.U.B. codeI.U.B. code

The I.U.B. CodeThe I.U.B. Code AA, , CC, , GG, , TT, , UU RR = A, G (pu = A, G (puRRine)ine) YY = C, T (p = C, T (pYYrimidine)rimidine) SS = G, C ( = G, C (SStrong hydrogen bonds)trong hydrogen bonds) WW = A, T ( = A, T (WWeak hydrogen bonds)eak hydrogen bonds) MM = A, C (a = A, C (aMMino group)ino group) KK = G, T ( = G, T (KKeto group)eto group) BB = C, G, T (not A) = C, G, T (not A) DD = A, G, T (not C) = A, G, T (not C) HH = A, C, T (not G) = A, C, T (not G) VV = A, C, G (not T/U) = A, C, G (not T/U) NN = A, C, G, T/U (i = A, C, G, T/U (iNNdeterminate) determinate) XX or or - - are sometimes usedare sometimes used

Representing uncertainty in protein sequencesRepresenting uncertainty in protein sequences Given the size of the amino acid “alphabet”, Given the size of the amino acid “alphabet”,
it is not practical to design a set of codes for it is not practical to design a set of codes for ambiguity in protein sequencesambiguity in protein sequences
Fortunately, ambiguity is less common in Fortunately, ambiguity is less common in protein sequences than in nucleic acid protein sequences than in nucleic acid sequencessequences
Could use bit-coding as for nucleic acids Could use bit-coding as for nucleic acids but rarely donebut rarely done

Finding occurrences of consensus sequencesFinding occurrences of consensus sequences Example: recognition site for a restriction enzymeExample: recognition site for a restriction enzyme
EcoRIEcoRI recognizes recognizes GAATTCGAATTC AccIAccI recognizes recognizes GTMKACGTMKAC
Basic AlgorithmBasic Algorithm Start with first character of sequence to be searchedStart with first character of sequence to be searched See if enzyme site matches starting at that positionSee if enzyme site matches starting at that position Advance to next character of sequence to be searchedAdvance to next character of sequence to be searched Repeat Steps 2 and 3 until all positions have been testedRepeat Steps 2 and 3 until all positions have been tested

Interactive DemonstrationInteractive Demonstration
Copies of all demo spreadsheets (Excel Copies of all demo spreadsheets (Excel files) can be found on course web page files) can be found on course web page
(A1 Pattern matching demo)(A1 Pattern matching demo)

Block Diagram for Search with a Consensus SequenceBlock Diagram for Search with a Consensus Sequence
Search Engine
Sequence to be searched
Consensus Sequence (in IUB codes)
List of positions where matches occur

Sequence Analysis TasksSequence Analysis Tasks
Calculating the probability of finding a Calculating the probability of finding a sequence patternsequence pattern

Statistics of pattern appearanceStatistics of pattern appearance Goal: Determine the significance of observing a Goal: Determine the significance of observing a
feature (pattern)feature (pattern) Method: Estimate the probability that that pattern Method: Estimate the probability that that pattern
would occur randomly in a given sequence. Three would occur randomly in a given sequence. Three different methodsdifferent methods Assume all nucleotides are equally frequentAssume all nucleotides are equally frequent Use measured frequencies of each nucleotide Use measured frequencies of each nucleotide
((mononucleotide frequenciesmononucleotide frequencies)) Use measured frequencies with which a given Use measured frequencies with which a given
nucleotide follows another (nucleotide follows another (dinucleotide frequenciesdinucleotide frequencies))

Determining mononucleotide frequenciesDetermining mononucleotide frequencies Count how many times each nucleotide appears in Count how many times each nucleotide appears in
sequencesequence Divide (normalize) by total number of nucleotidesDivide (normalize) by total number of nucleotides Result:Result: ffAA mononucleotide frequency mononucleotide frequency of A of A
(frequency that A is observed)(frequency that A is observed) Define:Define: ppAAmononucleotide probability mononucleotide probability that that
a nucleotide will be an Aa nucleotide will be an A ppAA assumed to equal f assumed to equal fAA

Determining dinucleotide frequenciesDetermining dinucleotide frequencies Make 4 x 4 matrix, one element for each Make 4 x 4 matrix, one element for each
ordered pair of nucleotidesordered pair of nucleotides Zero all elementsZero all elements Go through sequence linearly, adding one to Go through sequence linearly, adding one to
matrix entry corresponding to the pair of matrix entry corresponding to the pair of sequence elements observed at that positionsequence elements observed at that position
Divide by total number of dinucleotidesDivide by total number of dinucleotides Result: fResult: fACAC dinucleotide frequency dinucleotide frequency of AC of AC
(frequency that AC is observed out of all (frequency that AC is observed out of all dinucleotides)dinucleotides)

Determining conditional dinucleotide probabilitiesDetermining conditional dinucleotide probabilities Divide each dinucleotide frequency by the Divide each dinucleotide frequency by the
mononucleotide frequency of the first mononucleotide frequency of the first nucleotidenucleotide
Result:Result: pp**ACAC conditionalconditional dinucleotide dinucleotide
probability probability of observing a C given an Aof observing a C given an A pp**
ACAC = f = fACAC/ f/ fAA

Illustration of probability calculationIllustration of probability calculation What is the probability of observing the What is the probability of observing the
sequence feature sequence feature ARTART ( (AA followed by a followed by a purine, either purine, either AA or or GG, followed by a , followed by a TT)?)?
Using equal mononucleotide frequenciesUsing equal mononucleotide frequencies ppAA = p = pCC = p = pGG = p = pTT = 1/4 = 1/4
ppARTART = 1/4 * (1/4 + 1/4) * 1/4 = 1/32 = 1/4 * (1/4 + 1/4) * 1/4 = 1/32

Illustration (continued)Illustration (continued)
Using observed mononucleotide Using observed mononucleotide frequencies:frequencies: ppARTART = p = pAA (p (pAA + p + pGG) p) pTT
Using dinucleotide frequencies:Using dinucleotide frequencies: ppARTART = p = pAA (p (p**
AAAApp**ATAT + p + p**
AGAGpp**GTGT))

Another illustrationAnother illustration
What is pWhat is pACTACT in the sequence TTTAACTGGG? in the sequence TTTAACTGGG? ffAA = 2/10, f = 2/10, fCC = 1/10 = 1/10
ppAA = 0.2 = 0.2
ffACAC = 1/10, f = 1/10, fCTCT = 1/10 = 1/10
pp**ACAC = 0.1/0.2 = 0.5, p = 0.1/0.2 = 0.5, p**
CTCT = 0.1/0.1 = 1 = 0.1/0.1 = 1
ppACTACT = p = pA A pp**AC AC pp**
CTCT = 0.2 * 0.5 * 1 = = 0.2 * 0.5 * 1 = 0.10.1
(would have been 1/5 * 1/10 * 4/10 = (would have been 1/5 * 1/10 * 4/10 = 0.0080.008 using mononucleotide frequencies)using mononucleotide frequencies)

Expected number and spacingExpected number and spacing Probabilities are Probabilities are per nucleotideper nucleotide How do we calculate How do we calculate numbernumber of expected of expected
features in a sequence of length L?features in a sequence of length L? Expected number (for large L) Expected number (for large L) Lp Lp
How do we calculate the expected How do we calculate the expected spacingspacing between features?between features? ARTART expected spacing between ART features expected spacing between ART features
= 1/p= 1/pARTART

Interactive DemonstrationInteractive Demonstration
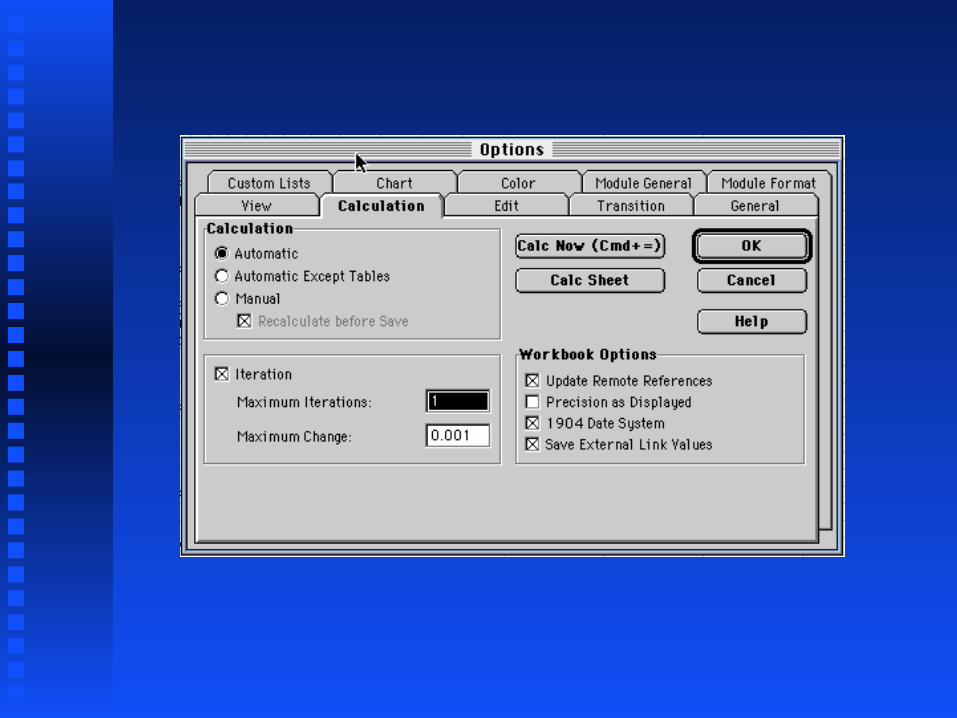
For this demo, need to set maximum iterations For this demo, need to set maximum iterations during calculations to 1. For Excel, select during calculations to 1. For Excel, select Options... Options... from from ToolsTools, select the , select the CalculationCalculation tab, check the tab, check the IterationIteration box and enter 1 for box and enter 1 for Maximum IterationsMaximum Iterations (see following slide for (see following slide for illustration). These options are loaded along illustration). These options are loaded along with the spreadsheet with the spreadsheet IF IT IS THE FIRST IF IT IS THE FIRST ONE LOADEDONE LOADED..

Interactive DemonstrationInteractive Demonstration
(A3 Mono- and Dinucleotide Frequencies)(A3 Mono- and Dinucleotide Frequencies)

RenewalsRenewals
For greatest accuracy in calculating spacing For greatest accuracy in calculating spacing of features, need to consider of features, need to consider renewalsrenewals of a of a feature (taking into account whether a feature feature (taking into account whether a feature can overlap with a neighboring copy of that can overlap with a neighboring copy of that feature)feature)
See Eric S. Lander (1989) in See Eric S. Lander (1989) in Mathematical Mathematical Methods for DNA SequencesMethods for DNA Sequences, M.S. Waterman , M.S. Waterman (ed.), CRC Press, Inc. Boca Raton, FL(ed.), CRC Press, Inc. Boca Raton, FL

CommentsComments Note that we are calculating probabilities Note that we are calculating probabilities
given a consensus sequence and therefore given a consensus sequence and therefore how how wellwell such sites might match typical such sites might match typical sites is not known. The probability analysis sites is not known. The probability analysis applies well to restriction enzymes but applies well to restriction enzymes but poorly to promoters. poorly to promoters.
Be careful to distinguish Be careful to distinguish dinucleotide dinucleotide frequenciesfrequencies, , conditional dinucleotide conditional dinucleotide probabilitiesprobabilities, and , and expected number of expected number of occurencesoccurences..

Summary, Part 2Summary, Part 2
Sequences can be represented with Sequences can be represented with characters or binary (bit-coded) valuescharacters or binary (bit-coded) values
Ambiguity in a nucleic acid sequence can Ambiguity in a nucleic acid sequence can be represented using I.U.B. codesbe represented using I.U.B. codes
Features of more than one sequence element Features of more than one sequence element can be represented by a string of characters can be represented by a string of characters (including ambiguity) - e.g., restriction (including ambiguity) - e.g., restriction enzyme sitesenzyme sites

Summary, Part 2Summary, Part 2
Mononucleotide and dinucleotide Mononucleotide and dinucleotide frequencies can be used to estimate the frequencies can be used to estimate the probability of observing a featureprobability of observing a feature














![SCIENCE CHINA Life Sciences - Springer · 2017-08-23 · X-ray crystallography [12]. Later, the cryo-electron mi- ... East Asia, North America, or South America. The consensus sequences](https://img.dokumen.tips/doc/110x75/5f216c9227b44741bc3fd5ad/science-china-life-sciences-springer-2017-08-23-x-ray-crystallography-12.jpg)














