Embed Size (px)
Citation preview

Comparative analysis of multi-threading on different operating systems
applied on digital image processing
Dulcinéia O. da Penha* João B. T. Corrêa Luís F. W. Góes { [email protected] } { [email protected] } { [email protected] } Luiz E. S. Ramos Christiane V. Pousa Carlos A. P. S. Martins { [email protected] } {[email protected]} { [email protected] }
Informatics Institute / Post-Graduation Program in Electrical Engineering
Computational and Digital Systems Laboratory Pontifical Catholic University of Minas Gerais
Av. Dom José Gaspar 500, 30535-610 Belo Horizonte, MG, Brazil
Telephone/Fax: 55-31-33194305
Topic area: Parallel and Distributed Systems *primary contact person

Comparative analysis of multi-threading on different operating systems
applied on digital image processing
Abstract:
This work presents a comparative analysis of parallel image convolution implementations based
on the shared-variable programming model. Those implementations use explicit compiler
directives from multi-thread support libraries. The comparison between implementations was
done in Windows and Linux operating systems. It considered both performance and
programmability. The performance was analyzed considering the execution response times of the
implementations. The convolution implementations analysis showed that the Windows sequential
implementation and the most of the tests with Linux parallel one presented better results. All
parallel implementations showed significant performance gains over sequential ones both in
Windows and Linux O.S. The programmability analysis showed that it is simpler for the
programmer to develop pthread based applications, since this library is more portable than
winthread. The first is compatible with the most of GNU gcc compilers provided with Linux,
while the latter varies from one compiler or O.S. version to another.
The objective of this work is to compare and analyze the application of a multiprocessor
programming support mechanism (shared-variable programming model) on image processing
operations, using different operating systems. The used mechanisms were multi-thread standard
support libraries: winthread and pthread, respectively for Windows and Linux operating
systems. The analysis considered: performance and programmability, response time
performance gains, programming methods, the simplicity and the transparency that those
mechanisms provide to the programmer.
Keywords:
parallel programming; shared-variable model; multi-thread; operating system; image
processing; image convolution; programmability; performance analysis

1. Introduction
Nowadays, a number of applications in many areas of knowledge (scientific, commercial,
industrial, and so on) demand very short response times. One possible solution to this problem is
the use of high performance computing [1]. Digital image processing (DIP) operations are
examples of applications that demand a considerable amount of computational resources to be
executed. The main reason for this is the fact that images are often stored in matrixes and the
computational cost to manipulate them is usually high [5]. Nevertheless, DIP operations have a
parallel nature [3], because they perform independent actions over independent data (image
pixels, which are the elements that compose the image representation matrix) [6]. Thus, in many
times the use of general-purpose parallel architectures using shared memory shows satisfactory
results in terms of performance gain [4]. DIP operations are used in many applications like
computer vision, medical and meteorological areas. Some of those are: image enhancement,
restoration, addiction, multiplication, matrix operations, filtering and so on [1].
The objective of this work is to compare and analyze the application of a multiprocessor
programming support mechanism (shared-variable programming model) on image processing
operations, using different operating systems. The used mechanisms were multi-thread standard
support libraries: winthread and pthread, respectively for Windows and Linux operating systems.
The analysis considered: performance and programmability, response time performance gains,
programming methods, the simplicity and the transparency that those mechanisms provide to the
programmer. The main goals of this work are the convolution implementations.
The DIP operation used was the image convolution. It was chosen because it is one of the
most important operations in the image processing area. It is simple and highly parallel. In that
operation, a convolution mask is applied on an input image, generating a convolved (or filtered)
output image. The masks may have different coefficients and sizes. Depending on the applied
convolution mask coefficients the convolution will result in smoothness, noise
elimination/reduction or other output image [1]. Some of the typical applications of image

convolution are edge detection, image enhacement, image blurring, morphological image
processing, feature extraction, template matching and regularization threory, and so on [6] [9].
The effective use of parallel systems is a very difficult task because it involves the project
of correct and efficient parallel aplications. In those systems, programming transparency is an
important issue for the developer of parallel applications. Some ways can be used to provide this
transparency to the programmer. Compiler directives from multi-thread support libraries are
commonly used in operating systems that provide support to multiprocessor systems.
2. The Convolution Operation
A filtering operation in space domain is called convolution. The term space domain refers
to the aggregation of pixels that compose an image. Operations in space domain are the
procedures applied directly on those pixels [6].
Equation 1 describes the convolution operation. The convolution is carried out for each
pixel (P[line][column]) of an NxN-sized image I, with a KxK-sized mask. The convolution mask
is applied on each pixel of the input image, resulting in a convolved (filtered) output image [6].
In this work, tests and comparisons were done using high-pass and low-pass spatial filters.
∑ ∑−= −=
×++=2
2
2
2
]][[]][[]][[
k
kuu
k
kvv
vuMvyuxIyxP
Equation 1. Equation of the convolution
The convolution mask that characterizes a high-pass filter is composed by positive
coefficients in its center (or next to it), and negative coefficientes in the surroundings [6]. The
high-pass filtering operating produces a highlight effect on the edges of the original image. It
happens because the appliance of a high-pass mask on a constant area (or with a small gray level

variation) makes the output a zero value or near zero [6]. This result significantly reduces the
global contrast of the image [1] [8]. Figure 1 (a) presents a 3x3 high-pass mask [1].
Figure 1 (a). 3x3 high-pass convolution mask.
Figure 1 (b). 3x3 low-pass convolution mask.
The low-pass image filtering operation produces an effect of image blurring (smoothing).
The smoothing effect is produced by attenuating the high-frequency components of the image.
High-frequency components are “filtered out” and information in the low-frequency range
“passes” without attenuation [6]. Figure 1 (b) presents the 3x3 low-pass mask [8].
Figure 2. Original image for high-pass convolution.
(a) (b)
Figure 3. Image of Figure 2 convolved with a high-pass filter (a),
and its negative image (with edge) (b).

Figure 3 presents the result of the convolution with a high-pass filter on the original
image showed in the Figure 2. The negative image is showed to validate the convolution
operation. The edge of the negative image was only introduced to show the actual image
dimensions and is not a part of the image. Figure 5 presents the result of the convolution with a
low-pass filter on the original image showed in Figure 4.
Figure 4. Original Image for low-pass convolution.
Figure 5. Image of Figure 4 convolved with a low-pass filter.
3. Parallel programming with shared-variables
Shared-memory parallel architectures can use shared-variables for communication
between the application processes. The effective use of parallel systems is a very difficult task
because it involves the project of correct and efficient parallel applications. This fact results in
several complex problems, like: process synchronization, data coherence and event ordering. In
an ideal parallel system, the user would not have to be responsible for controlling the parallel
execution of processes. There are some ways of using parallelism in order to provide some
transparency to the programmer [1]. Usually modern operating systems provide support to
multiprocessor systems, like: Unix, Linux, Windows, and so on. In those systems, the parallel
execution is activated by the creation of multiple threads that run in parallel. Usually, the number
of threads is independent from the number of physical processors available [7].

A thread (or thread of control) is a sequence of instructions being executed. Each process
has one or more threads. The threads of a process share its address space, its code, most of its
data, and most of its process descriptor information. The use of threads makes easier for the
programmer to write concurrent applications, in a transparent manner. Those applications may
run on machines with one or more processors (multiprocessors), with the advantages of using
additional processors, when they exist [1].
Creating and managing threads is much simpler than creating processes, since there is no
need to create and manipulate different address spaces. Nevertheless, multithread programming
is yet very difficult for the programmer. It happens because the programmer must explicitly
manage system features, caring about several details, like: thread creation, thread starting,
synchronization management and ordering.
There are two main multithread programming libraries, one for Unix/Linux platforms: the
pthread standard, and another for Windows platforms: winthread.
4. Implementations of the image convolution operation
In order to carry out a convolution, the pixels of a source image are changed by means of
an operation with its neighbor pixels and the coefficients in the convolution mask. All pixels
produced from that operation belong to the output image or convolved image (see Equation 1).
The edge pixels of the input image were discarded to eliminate edge effects.
The sequential algorithm that carries out the convolution operation [8] was implemented
as showed in Figure 6. It is composed of a four-loop. The sequential implementations were made
using the Borland C++ Builder 5.0 compiler, for Windows NT 4.0, and using the GNU gcc
compiler, for Mandrake 9.0 (kernel version 2.4.19-16mdksmp). The program that implements
the sequential algorithm for Windows platform was called KMT-IPS, described in [8].
In the sequential algorithm (Figure 6), the first couple of loops (outer ones) cover the
input image pixels, while the last couple of loops (inner ones) cover the convolution mask. Each

pixel at the output image is calculated by the sum of the input image pixels multiplied by the
convolution mask coefficient and divided by a division factor.
Some modifications in the obtained values are necessary when the result of the
convolution returns a value outside the limits of the grayscale representation (8 bits or values
between 0 and 255 per pixel). If the obtained value is negative the convolved pixel should have a
0 (zero) value. On the other hand, if the value exceeds 255 the pixel’s value should be 255.
This implementation is very simple. There are three matrixes: the first stores the input
image; the second stores the filter (convolution mask); and the third is a temporary matrix and
stores the output image pixels when they are convolved. When the convolution is done on all
input image pixels, the temporary matrix that stores the convoluted pixels is copied back to the
first matrix. Thus, the convoluted (output) image replaces the original (input) image.
Figure 6. Basic convolution algorithm with four loops
4.1. Parallel implementations
The image convolution operation is naturally parallel. In a convolution implementation
using shared-variables, the input image and the convolution mask can be shared between the
threads (or processes). The task of convolving an image is equally divided between all threads,
which is done when the input image lines are distributed among them. Thus, each thread is
responsible for calculating a number of output image lines, based on the source image lines that
were assigned to it.
Two parallel convolution implementations were developed, both using explicit multi-
thread programming. The first implementation is based on the winthread standard, compiled with

Borland C++ Builder 5.0 (libraries) [8], for Windows platforms. The second implementation
uses the pthread standard, compiled with GNU gcc libraries for Linux platforms.
In order to implement the parallel convolution using both winthread and pthread, it was
necessary to analyze the operation and the code portions that would be implemented in parallel,
considering the shared-variables programming model. The input image matrix, the temporary
matrix and the convolution filter were shared between all threads. On its creation, each thread
receives a parameter meaning the number of line where it should start performing convolution
(initial line). With this parameter, each thread gets to know the number of the last line that it
must convolve (final line). Each thread carries out the convolution operation in the image portion
between the initial and final lines that were assigned to it.
In both implementations, some difficulties were found. One of them is the fact of that the
programmer must to know the shared-memory programming model. He must also know how to
analyze the sequential operation in order to find the parallel portions and to develop the correct
application. Moreover, the programmer must explicitly care about issues, like: variable creation
and management, thread creation, initialization and synchronization (using a thread vector),
critical section access control, and so on.
5. Tests and experimental results
The computer used to execute all tests was an Intel Dual Pentium III 933MHz with a
1024MB primary memory. In each test, the image was previously loaded and then the time was
measured for the following computations. The operating systems used to execute the tests were
Windows NT 4.0 and Linux Mandrake 9.0 (kernel version 2.4.19-16mdksmp).
The tests for the Windows environment were executed using Prober, a functional and
performance analysis tool [2]. The tests for the Linux platform were executed manually.
The pthread implementation always presented larger sequential response times (one
thread) than the ones obtained from the winthread implementation. The same fact was observed
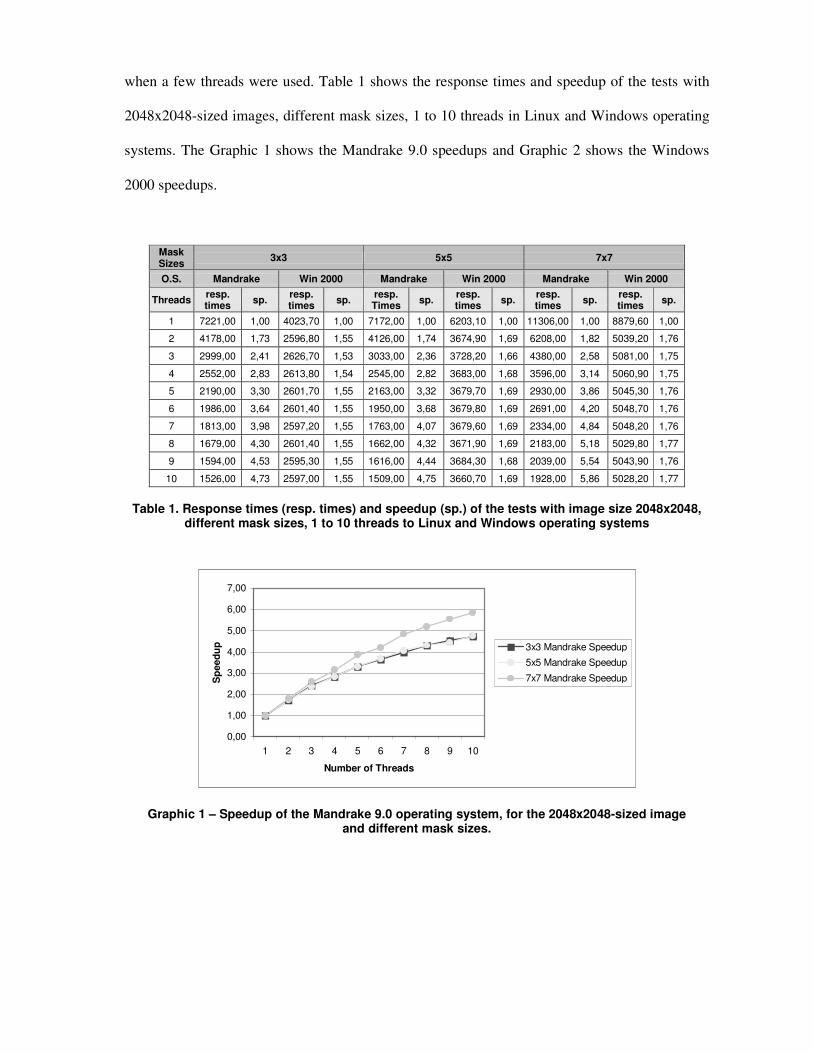
when a few threads were used. Table 1 shows the response times and speedup of the tests with
2048x2048-sized images, different mask sizes, 1 to 10 threads in Linux and Windows operating
systems. The Graphic 1 shows the Mandrake 9.0 speedups and Graphic 2 shows the Windows
2000 speedups.
Mask Sizes 3x3 5x5 7x7
O.S. Mandrake Win 2000 Mandrake Win 2000 Mandrake Win 2000
Threads resp. times sp. resp.
times sp. resp. Times sp. resp.
times sp. resp. times sp. resp.
times sp.
1 7221,00 1,00 4023,70 1,00 7172,00 1,00 6203,10 1,00 11306,00 1,00 8879,60 1,00
2 4178,00 1,73 2596,80 1,55 4126,00 1,74 3674,90 1,69 6208,00 1,82 5039,20 1,76
3 2999,00 2,41 2626,70 1,53 3033,00 2,36 3728,20 1,66 4380,00 2,58 5081,00 1,75
4 2552,00 2,83 2613,80 1,54 2545,00 2,82 3683,00 1,68 3596,00 3,14 5060,90 1,75
5 2190,00 3,30 2601,70 1,55 2163,00 3,32 3679,70 1,69 2930,00 3,86 5045,30 1,76
6 1986,00 3,64 2601,40 1,55 1950,00 3,68 3679,80 1,69 2691,00 4,20 5048,70 1,76
7 1813,00 3,98 2597,20 1,55 1763,00 4,07 3679,60 1,69 2334,00 4,84 5048,20 1,76
8 1679,00 4,30 2601,40 1,55 1662,00 4,32 3671,90 1,69 2183,00 5,18 5029,80 1,77
9 1594,00 4,53 2595,30 1,55 1616,00 4,44 3684,30 1,68 2039,00 5,54 5043,90 1,76
10 1526,00 4,73 2597,00 1,55 1509,00 4,75 3660,70 1,69 1928,00 5,86 5028,20 1,77
Table 1. Response times (resp. times) and speedup (sp.) of the tests with image size 2048x2048,
different mask sizes, 1 to 10 threads to Linux and Windows operating systems
0,00
1,00
2,00
3,00
4,00
5,00
6,00
7,00
1 2 3 4 5 6 7 8 9 10
Number of Threads
Spe
edup 3x3 Mandrake Speedup
5x5 Mandrake Speedup
7x7 Mandrake Speedup
Graphic 1 – Speedup of the Mandrake 9.0 operating system, for the 2048x2048-sized image and different mask sizes.

0,00
1,00
2,00
3,00
4,00
5,00
6,00
7,00
1 2 3 4 5 6 7 8 9 10
Number of Threads
Spe
edup 3x3 Win 2000 Speedup
5x5 Win 2000 Speedup
7x7 Win 2000 Speedup
Graphic 2 – Speedup of the Windows 2000 operating system, for the 2048x2048-sized image and different mask sizes.
A comparative analysis was made between the results obtained in this work and the
results obtained in [1]. In order to make this comparison valid, we used the same computer (Intel
Dual Pentium III 933MHz with a 1024MB primary memory) and the same sequential
implementation’s source code (KMT-IPS [8]). The only change was the operating system
version. In [1], Windows 2000 was used to perform the tests, while in this work Windows NT
4.0 was utilized. The first provided better response times than the latter. The speedup achieved
with Windows 2000 regarding NT 4.0 was 1.0803, using 2048x2048-sized images and 7x7-sized
masks on the sequential execution. Likewise, the speedup of the parallel execution (2 threads) in
Windows 2000 regarding NT 4.0 was of 1.0969 using the same image and mask sizes. Those
results can be calculated from Table 3. Windows 2000 also provided better results for the rest of
the parallel execution times, regarding NT 4.0.
The same comparison was made for the Linux platforms between the results obtained in
[1] and the ones obtained in this work. Likewise, there were maintained the computer and the
sequential implementation’s source code. However, the parallel results in [1] were obtained with
a parallel convolution implementation using the OpenMp API (Application Program Interface)
[7]. In [1], the Conectiva Linux 7.0 operating system was used, while in this work Linux
Mandrake 9.0 was utilized. The latter provided significantly better response times than the first.
The speedup of the sequential execution in Mandrake 9.0 with regard to Conectiva Linux 7.0

was of 1.6634, using 2048x2048-sized images and 7x7-sized masks. Likewise, the speedup of
the parallel execution (with 4 threads) with the Mandrake 9.0 regarding Conectiva 7.0 was of
1.4831, with the same image and mask sizes. Those results can be calculated from Table 2. The
parallel times obtained with Mandrake 9.0 for 5x5 and 7x7-sized masks were significantly better
than the ones obtained with Conectiva Linux 7.0.
Table 2 and Table 3 show the sequential and parallel response times and speedup (using 2
threads for Windows and 4 threads for Linux) in tests with the different operating systems
versions, 2048x2048-sized images and different mask sizes. In all cases the speedup obtained
with the parallel implementations regarding the sequential ones increased when the image and
mask sizes increased.
Mask Size Imagem 2048x2048
3x3 5x5 7x7
Conectiva 5113,3 10880 18840 Sequential
response time Mandrake 7221 7172 11306
Conectiva 1733,33 3286,67 5333,33 Parallel
response time Mandrake 2552 2545 3596
Conectiva 2,95 3,3103 3,5325 Speedup
Mandrake 2,8295 2,818 3,144
Table 2. Sequential and parallel (4 threads)
response time and speedup to tests to Linux O.S. to image size 2048x2048 and
different mask sizes
Mask Size Imagem 2048x2048
3x3 5x5 7x7
Win 2000 3734,33 5739,67 8219 Sequential
response time Win NT 4023,7 6203,1 8879,6
Win 2000 2427 3391 4594 Parallel
response time Win NT 2596,8 3674,9 5039,2
Win 2000 1,54 1,6926 1,79 Speedup
Win NT 1,55 1,6879 1,76
Table 3. Sequential and parallel (2 threads)
response time and speedup to tests to Windows O.S. to image size 2048x2048 and
different mask sizes
6. Conclusions
For the most of tests with different mask and image sizes, considering tests with a few
threads the response times obtained with the Windows were smaller (better) than with the Linux.
Nevertheless, with the increase of the number of threads, the response times of Linux showed a
significant reduction regarding the ones obtained with Windows. The Linux tests reached shorter
times than Windows tests to all the image and mask sizes to execution with more threads.
Considering all tests performed in this work, Linux Mandrake 9.0 showed the greatest

advantages regarding concurrency, while Windows NT 4.0 showed the worse concurrency
results. The reasons for those results are not discussed here. Usually, these reasons are related
with process and memory management.
For all parallel implementations, both with pthread and winthread, the combination of
parallelism and concurrency showed satisfactory results. Unexpectedly, in all cases the response
time decreased significantly with the increase of the number of threads, in spite of the
consequent concurrency increase between the threads. To explain this behavior, further analysis
must be done. One probable cause for that is the existence of operating system processes running
concurrently with user processes and thus, consuming processing time. Considering that the
processor schedules threads instead of processes, the larger the number of application’s threads,
more processing time is occupied. In this case, the time wasted in context switching (between the
threads) can be insignificant.
The decrease of response times caused by the increase of concurrency was greater in Linux than
in Windows. The use of concurrency provided even better speedup regarding the sequential and
purely parallel implementations (one thread per processor). Considering all analysis and
comparisons realized in this work, it was concluded that the use of parallelism and concurrency
is better than the use of pure parallelism (in the case of these tests).
7. Future Works
As future works we intend to investigate the performance improvements due to the use of
many threads; to compare and analyze the results obtained in this work (implementations with
shared-variable model, using multi-thread libraries) with message-passing based
implementations; and to analyze the cooperative use of multi-threading and message-passing in
the same implementation.

8. Acknowledgment
We would like to acknowledge: ProPPG (Pró-reitoria de Pesquisa e de Pós-Graduação
da PUC-Minas), PPGEE (Programa de Pós-Graduação em Engenharia Elétrica), LSDC
(Laboratório de Sistemas Digitais e Computacionais), CAPES (Coordenação de
Aperfeiçoamento de Pessoal de Nível Superior) and PUC-Minas for supporting our research and
for providing us the infra-structure for the experiments.
9. References
[1] D.O. Penha, J.B.T. Corrêa, C.A.P.S. Martins, “ Análise Comparativa do Uso de Multi-Thread
e OpenMp Aplicados a Operações de Convolução de Imagem”, III Workshop de Sistemas
Computacionais de Alto Desempenho (WSCAD), 2002.
[2] L.F.W. Góes, L.E.S. Ramos, C.A.P.S. Martins, “Performance Analysis of Parallel Programs
using Prober as a Single Aid Tool”. 14th Symposium on Computer Architecture and High
Performance Computing (SBAC-PAD), 2002.
[3] G.S. Almasi and A. Gottlieb, “Highly Parallel Computing” 2.ed, Benjamin/Cummings, 1994.
[4] K. Hwang and Z. Xu, “Scalable Parallel Computing: Technology, Architecture,
Programming”, McGraw-Hill, 1998.
[5] C. A. P. S. Martins, "Subsistema de exibição de imagens digitais com desacoplamento de
resolução - SEID-DR", in Doctor’s thesis, Universidade de São Paulo, SP, 1998. (in portuguese)
[6] R.C. Gonzalez and R.E. Woods, "Processamento de Imagens Digitais" 3.ed, Nova Iorque,
Ed. Edgard Blucher, 2000.
[7] “Introduction to OpenMP”, Advanced Computational Research Laboratory, Faculty of
Computer Science, UNB Fredericton, New Brunswick.
[8] J. B. T. Corrêa, C. A. P. S. Martins, “Performance Optimization on Digital Image Filtering”,
International Conference on Computer Science, Software Engineering, Information Technology,
e-Business, and Applications (CSITeA), 2002.

[9] N.K. Ratha, A.K. Janin, and D.T. Rover, "Convolution on Splash 2 ", Michigan State
University, IEEE, 1995.


![Threading - [“Advanced Computer Programming in Python”] · Threading 7.1 Threading Threads are the smallest program units that an operating system can execute. Programming with](https://img.dokumen.tips/doc/110x75/5e30ce3dc69a2869e234e2d8/threading-aoeadvanced-computer-programming-in-pythona-threading-71-threading.jpg)


























