Embed Size (px)
DESCRIPTION
Sistemas lineales . analisis numerico
Citation preview

Sistemas de Ecuaciones
Lineales II
• Metodos Iterativos: Matrices dispersas. Esquema general. Metodos de Jacobi y de
Gauss-Seidel.
• Metodos de descenso: Metodo del gradiente conjugado. Precondicionamiento.
Calculo Numerico IN1012C/IN1052C/MAT221N - 1 - DMFA – Universidad Catolica de la Santısima Concepcion

Matrices dispersas
• Cuando la matriz A del sistema a resolver es dispersa, pero no banda, los metodos
(directos) estudiados hasta ahora (eliminacion de Gauss o Cholesky) presentan el defecto
denominado llenado (fill-in).
• El llenado consiste en que, a medida que el proceso de eliminacion avanza, se van
creando elementos no nulos en posiciones de L y U en donde la matriz A tiene ceros.
• Como consecuencia del llenado se tiene, por una parte, el aumento del numero de flop y
con ello el aumento del error de redondeo. Por otra parte se tiene el aumento en las
necesidades de memoria para almacenar las matrices L y U , lo que puede llegar a hacer
imposible aplicar estos metodos cuando A es de gran tamano.
• Los metodos que estudieremos en seguida, llamados iterativos, evitan el llenado y sus
consecuencias, al trabajar resolviendo reiteradamente sistemas con matriz diagonal o
triangular-dispersa.
Calculo Numerico IN1012C/IN1052C/MAT221N - 2 - DMFA – Universidad Catolica de la Santısima Concepcion
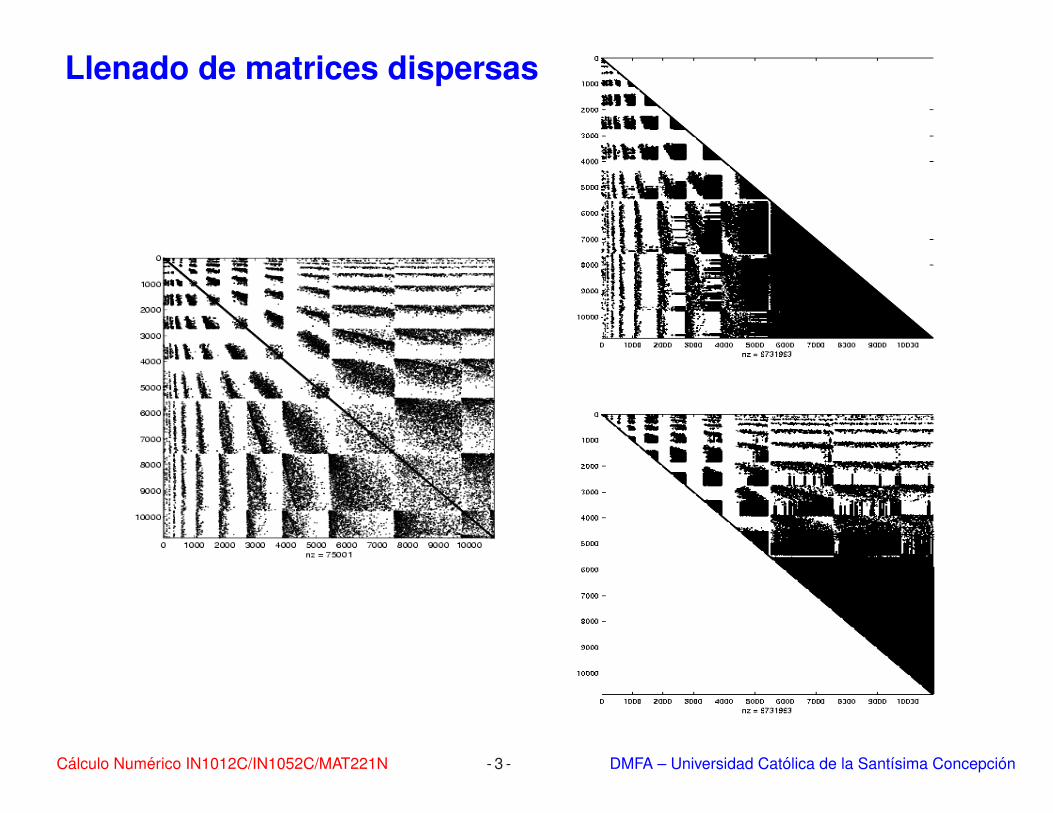
Llenado de matrices dispersas
Calculo Numerico IN1012C/IN1052C/MAT221N - 3 - DMFA – Universidad Catolica de la Santısima Concepcion

Llenado de matrices dispersas (cont.)
>> load data.0125.mat
>> [L,U]=lu(A);
>> whos
Name Size Bytes Class
A 10821x10821 951580 sparse array
L 10821x10821 151325524 sparse array
U 10821x10821 151325524 sparse array
b 10821x1 129860 sparse array
Grand total is 25300219 elements using 303732496 bytes
Calculo Numerico IN1012C/IN1052C/MAT221N - 4 - DMFA – Universidad Catolica de la Santısima Concepcion

Esquema general
• Considere el sistema de ecuaciones
Ax = b,
con A ∈ Rn×n no singular y b ∈ R
n.
Un metodo iterativo para resolver el sistema construye, a partir de un vector inicial x(0),
una sucesion de vectores x(1),x(2), . . . ,x(k), . . . la que, bajo condiciones apropiadas,
resultara convergente a x.
• Si suponemos A = N − P , donde N debe ser invertible, entonces
Ax = b ⇐⇒ Nx = Px+ b ⇐⇒ x = N−1Px+N−1b.
Calculo Numerico IN1012C/IN1052C/MAT221N - 5 - DMFA – Universidad Catolica de la Santısima Concepcion

Esquema general (cont.)
• Se usa la igualdad Nx = Px+ b para definir un esquema general para construir la
sucesion {x(k)}.
• Algoritmo del esquema general:
Dado el vector inicial x(0),
para k = 1, 2, . . . resolver:∣
∣
∣ Nx(k) = Px(k−1) + b,
hasta que se satisfaga un criterio de detencion.
• Definiendo M := N−1P (matriz de iteracion) y e(k) := x− x(k) (error de x(k)),
para cada k = 1, 2, . . . se tiene
e(k) = Mke(0), k = 1, 2, . . .
Calculo Numerico IN1012C/IN1052C/MAT221N - 6 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia de metodos iterativos.
• Teorema. (Convergencia) La sucesion{
x(k)}
converge a la solucion x de Ax = b, si y
solo si, ρ(M) < 1.
• Observacion. Si la sucesion{
x(k)}
converge, necesariamente lo hace a la solucion x
de Ax = b.
• Lema. (Cota para el radio espectral) Sea A una matriz cuadrada. Para cualquier norma
matricial se tiene que
ρ(A) ≤ ‖A‖ .
• Corolario. (Condicion suficiente de convergencia) Una condicion suficiente para que la
sucesion{
x(k)}
sea convergente a la solucion x de Ax = b es que
‖M‖ < 1,
donde M es la matriz de iteracion del metodo que genera a{
x(k)}
.
Calculo Numerico IN1012C/IN1052C/MAT221N - 7 - DMFA – Universidad Catolica de la Santısima Concepcion

Criterio de detencion
• Detencion del proceso. Cuando el proceso iterativo es convergente, este se debe
detener para un x(k+1) tal que∥
∥e(k+1)∥
∥ =∥
∥x− x(k+1)∥
∥ ≤ tol, donde tol indica
un nivel de tolerancia prefijado para el error.
• Lema. Para ‖M‖ < 1, se tiene que
∥
∥
∥x− x(k+1)
∥
∥
∥≤ ‖M‖
1− ‖M‖∥
∥
∥x(k+1) − x(k)
∥
∥
∥.
• Un criterio de detencion usual consiste en detener el proceso cuando∥
∥
∥x(k+1) − x(k)
∥
∥
∥≤ tol.
Sin embargo, este criterio resulta muchas veces inadecuado!
En efecto, si‖M‖
1− ‖M‖ ≫ 1, usualmente,
‖M‖1− ‖M‖
∥
∥
∥x(k+1) − x(k)
∥
∥
∥> tol.
Calculo Numerico IN1012C/IN1052C/MAT221N - 8 - DMFA – Universidad Catolica de la Santısima Concepcion

Criterio de detencion (cont.)
• Observacion. Al graficar
F (M) :=‖M‖
1− ‖M‖ ,
se puede ver que:
‖M‖ ≤ 1
2=⇒ F (M) ≤ 1,
‖M‖ >1
2=⇒ F (M) > 1.
Luego, si ‖M‖ > 12 , puede ser incorrecto
detener el proceso cuando solo se tiene
∥
∥
∥x(k+1) − x(k)
∥
∥
∥≤ tol.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
1
2
3
4
5
6
7
8
9
10
Calculo Numerico IN1012C/IN1052C/MAT221N - 9 - DMFA – Universidad Catolica de la Santısima Concepcion

Criterio de detencion (cont.)
• El criterio de detencion implica calcular ‖M‖, lo que en general es difıcil. El siguiente
lema indica una manera de estimar ‖M‖.
• Lema. Para k = 1, 2, . . . se tiene:
mk :=
∥
∥x(k+1) − x(k)∥
∥
∥
∥x(k) − x(k−1)∥
∥
≤ ‖M‖ .
Demostracion.
mk =
∥
∥x(k+1) − x(k)∥
∥
∥
∥x(k) − x(k−1)∥
∥
=
∥
∥
[
x(k+1) − x]
−[
x(k) − x]∥
∥
∥
∥
[
x(k) − x]
−[
x(k−1) − x]∥
∥
=
∥
∥e(k+1) − e(k)∥
∥
∥
∥e(k) − e(k−1)∥
∥
=
∥
∥M[
e(k) − e(k−1)]∥
∥
∥
∥e(k) − e(k−1)∥
∥
≤ maxy∈Rn:y 6=0
‖My‖‖y‖ = ‖M‖ .
• En el criterio de detencion puede utilizarse mk como una estimacion de ‖M‖.
En tal caso, el proceso iterativo se detendra cuando:
mk
1−mk
∥
∥
∥x(k+1) − x(k)
∥
∥
∥≤ tol.
Calculo Numerico IN1012C/IN1052C/MAT221N - 10 - DMFA – Universidad Catolica de la Santısima Concepcion

Descomposicion de una matriz
• Se considera resolver un sistema Ax = b con aii 6= 0, para i = 1, . . . , n.
Sea x(0) =(
x(0)1 , . . . , x
(0)n
)t
arbitrario y escribamos la matriz A en la forma
A = D −E − F ,
donde D = diag(A), −E es la matriz triangular inferior de A y −F es la matriz
triangular superior de A:
A =
. . . −F
D
−E. . .
• Notemos que tanto D como D −E son matrices inversibles, ya que aii 6= 0 para
i = 1, . . . , n.
Calculo Numerico IN1012C/IN1052C/MAT221N - 11 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodo de Jacobi
• El metodo de Jacobi corresponde al esquema iterativo general con
N := D y P := E + F .
• Algoritmo de Jacobi:
Dado el vector inicial x(0),
para k = 1, 2, . . . resolver:∣
∣
∣ Dx(k) = (E + F )x(k−1) + b,
hasta que se satisfaga un criterio de detencion.
• En la iteracion k, el vector x(k) puede obtenerse por componentes como sigue:
Para i = 1, . . . , n :∣
∣
∣
∣
∣
∣
∣
x(k)i =
1
aii
bi −
n∑
j=1
j 6=i
aijx(k−1)j
.
Calculo Numerico IN1012C/IN1052C/MAT221N - 12 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodo de Jacobi (cont.)
• La matriz de iteracion del metodo de Jacobi verifica:
M = D−1(E + F ) =
0 −a12
a11
· · · · · · −a1n
a11
−a21
a22
0. . .
.
.
.
.
.
.. . .
. . .. . .
.
.
.
.
.
.. . . 0 − an−1n
an−1n−1
− an1
ann· · · · · · −ann−1
ann0
• Para la norma infinito de M se tiene que ‖M‖∞ = max1≤i≤n
1
|aii|
n∑
j=1
j 6=i
|aij |
.
• Cuando A es de diagonal dominante estricta, es decir, cuando se tiene que
|aii| >n∑
j=1
j 6=i
|aij |, i = 1, . . . , n,
entonces ‖M‖∞ < 1 y el metodo de Jacobi resulta convergente.
Calculo Numerico IN1012C/IN1052C/MAT221N - 13 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodo de Gauss-Seidel
• El metodo de Gauss-Seidel corresponde al esquema iterativo general con
N := D −E y P := F .
La matriz de iteracion es entonces M = (D −E)−1F .
• Algoritmo de Gauss-Seidel:
Dado el vector inicial x(0),
para k = 1, 2, . . . , resolver:∣
∣
∣ (D −E)x(k) = Fx(k−1) + b,
hasta que se satisfaga un criterio de detencion.
• En la iteracion k, el vector x(k) puede obtenerse por componentes como sigue:
Para i = 1, . . . , n :∣
∣
∣
∣
∣
∣
x(k)i =
1
aii
bi −i−1∑
j=1
aijx(k)j −
n∑
j=i+1
aijx(k−1)j
.
Notemos que esto corresponde a aprovechar en el paso k, los valores x(k)j ya calculados.
Calculo Numerico IN1012C/IN1052C/MAT221N - 14 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia de los metodos de Jacobi y de Gauss-Seidel
• Teorema. Si A es de diagonal dominante estricta, entonces los metodos de Jacobi y de
Gauss-Seidel convergen.
• Observacion. Para una matriz arbitraria A, la convergencia de uno de estos metodos no
implica la convergencia del otro.
• Teorema. Si A es simetrica y definida positiva, el metodo de Gauss-Seidel es
convergente.
• Observacion. Aunque A sea simetrica y definida positiva, el metodo de Jacobi puede ser
divergente.
Calculo Numerico IN1012C/IN1052C/MAT221N - 15 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia de los metodos (cont.)
• Ejemplo. Para s ∈ R, considere la matriz simetrica
A =
1 s s
s 1 s
s s 1
,
cuyos valores propios son: 1− s (con multiplicidad 2) y 1 + 2s.
La matriz A es definida positiva cuando s ∈ (0, 1) y es de diagonal dominante estricta
para s ∈ (−0.5, 0.5).
• Se resolvio el sistema Ax = b para un par de valores de s, usando los metodos de
Jacobi y de Gauss-Seidel, con b = (1, 1, 1)t y x(0) = (0.5, 0.5, 0.5)t.
• Para s = 0.3, Jacobi itera 37 veces y Gauss-Seidel 12 veces (en ambos casos se
implemento el criterio de detencion visto en clase, con una tolerancia de 10−8).
Ambos metodos entregan como solucion x = (0.6250, 0.6250, 0.6250)t, que es la
solucion exacta.
Calculo Numerico IN1012C/IN1052C/MAT221N - 16 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia de los metodos (cont.)
• Para s = 0.8, en las mismas condiciones anteriores, Gauss-Seidel converge en la
iteracion 53 a
(0.384 615 391 735, 0.384 615 381 035, 0.384 615 381 784)t
que difiere de la solucion exacta
x = (0.384 615 384 615, 0.384 615 384 615, 0.384 615 384 615)t
en menos de tol = 10−8 en cada componente.
• En cambio, al cabo de 100 iteraciones Jacobi entrega
1019 × (−1.862 199 431 313,−1.862 199 431 313,−1.862 199 431 313)t,
vector que no tiene ninguna relacion con la solucion del sistema.
Se nota claramente que, en este caso, el metodo de Jacobi diverge.
Calculo Numerico IN1012C/IN1052C/MAT221N - 17 - DMFA – Universidad Catolica de la Santısima Concepcion

Problema de minimizacion asociado a un sistema
• Algunos de los metodos iterativos mas eficientes para resolver un sistema de ecuaciones
lineales se basan en resolver un problema de minimizacion equivalente.
• Si A ∈ Rn×n es simetrica y definida positiva, b ∈ R
n y 〈x,y〉 := xty denota el
producto escalar usual en Rn, entonces la funcion cuadratica
J : Rn −→ R
x 7−→ 12 〈Ax,x〉 − 〈b,x〉
alcanza un unico mınimo en el vector x ∈ Rn solucion del sistema Ax = b.
Calculo Numerico IN1012C/IN1052C/MAT221N - 18 - DMFA – Universidad Catolica de la Santısima Concepcion

Problema de minimizacion asociado a un sistema (cont.)
• En efecto,
∇J(x) =1
2
(
Ax+Atx)
− b = Ax− b, si A es simetrica.
Entonces J tiene un punto crıtico en x si y solo si
∇J(x) = 0 ⇐⇒ Ax = b.
Ademas,
HJ(x) :=
(
∂2J
∂xi∂xj
(x)
)
=(
aij
)
= A
y, por lo tanto, si A es definida positiva, el punto crıtico de J es un mınimo.
Calculo Numerico IN1012C/IN1052C/MAT221N - 19 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodos de descenso
• En los metodos de descenso se parte de un punto x(0) ∈ Rn, y, en cada paso
k = 0, 1, 2, . . . se determina un nuevo punto x(k+1) ∈ Rn tal que
J(
x(k+1))
< J(
x(k))
del siguiente modo:
1. se escoge una direccion p(k) de descenso de J ,
2. se considera la recta Lk que pasa por el punto x(k) con direccion p(k),
3. se escoge el punto x(k+1) ∈ Lk donde J alcanza su mınimo sobre Lk.
x
x
p
(k)
(k)
Lk
(k+1)xp(k+1)
x(k+2)
Lk+1
Calculo Numerico IN1012C/IN1052C/MAT221N - 20 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodos de descenso (cont.)
• Como Lk ={
x(k) + αp(k) : α ∈ R}
, entonces
J(x(k) + αp(k))
=[
12
⟨
Ax(k),x(k)⟩
−⟨
b,x(k)⟩]
+⟨
Ax(k) − b,p(k)⟩
α+ 12
⟨
Ap(k),p(k)⟩
α2
Por lo tanto,
dJ
dα
(
x(k) + αp(k))
= 0 ⇐⇒ α = αk :=
⟨
r(k),p(k)⟩
⟨
Ap(k),p(k)⟩ ,
donde r(k) = b−Ax(k) es el residuo de x(k).
Luego
x(k+1) = x(k) + αkp(k).
Calculo Numerico IN1012C/IN1052C/MAT221N - 21 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodo del maximo descenso
• Los distintos metodos de descenso se distinguen por la manera de escoger la direccion de
descenso p(k).
• La eleccion mas simple es escoger la direccion de maximo descenso de J :
p(k) = −∇J(x(k)) = b−Ax(k) = r(k).
• Esta eleccion conduce al metodo del maximo descenso o del gradiente.
• Algoritmo:
Dado el vector inicial x(0),
r(0) = b−Ax(0),
para k = 0, 1, 2, . . .∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
αk =
⟨
r(k), r(k)⟩
⟨
Ar(k), r(k)⟩ ,
x(k+1) = x(k) + αkr(k),
r(k+1) = b−Ax(k+1) = r(k) − αkAr(k),
hasta que se satisfaga un criterio de detencion.
Calculo Numerico IN1012C/IN1052C/MAT221N - 22 - DMFA – Universidad Catolica de la Santısima Concepcion

Criterio de detencion
• Un criterio usual en los metodos de descenso es detener el proceso cuando
‖r(k)‖‖b‖ ≤ tol.
• Sin embargo, eso no garantiza que el error satisfaga∥
∥e(k)∥
∥ =∥
∥x− x(k)∥
∥ ≤ tol !!
Calculo Numerico IN1012C/IN1052C/MAT221N - 23 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia del metodo del maximo descenso
• Teorema. (Convergencia) Sean A ∈ Rn×n simetrica y definida positiva y b ∈ R
n.
Para cualquier x(0) ∈ Rn, la sucesion
{
x(k)}
generada por el metodo del maximo
descenso converge a la solucion del sistema Ax = b.
Ademas, los errores e(k) = x− x(k) satisfacen
‖e(k+1)‖2 ≤ κ− 1
κ+ 1‖e(k)‖2,
donde κ = cond2(A).
• Observacion. El factor de reduccion del error en cada paso es
κ− 1
κ+ 1= 1− 2
κ+ 1< 1,
lo que asegura la convergencia.
Sin embargo, si la matriz es mal condicionada,
κ ≫ 1 =⇒ 1− 2
κ+ 1≈ 1
y el metodo converge muy lentamente.
Calculo Numerico IN1012C/IN1052C/MAT221N - 24 - DMFA – Universidad Catolica de la Santısima Concepcion

Direcciones conjugadas
• Una eleccion de la direccion de descenso p(k) que genera un metodo mas eficiente se
basa en ortogonalizar el residuo r(k) respecto a todas las direcciones de descenso
anteriores p(j), j = 1, . . . , k − 1, en el producto interior
〈x,y〉A := 〈Ax,y〉 , x,y ∈ Rn.
• Las direcciones obtenidas de esta manera satisfacen
⟨
Ap(k),p(j)⟩
= 0 ∀j 6= k
y por ello se dice que son direcciones conjugadas o A-ortogonales.
• Este procedimiento conduce a otro metodo que se denomina el metodo del gradiente
conjugado.
Calculo Numerico IN1012C/IN1052C/MAT221N - 25 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodo del gradiente conjugado
• Algoritmo:
Dado el vector inicial x(0),
r(0) = b−Ax(0),
p(0) = r(0),
para k = 0, 1, 2, . . .∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
αk =
⟨
r(k),p(k)⟩
⟨
Ap(k),p(k)⟩ ,
x(k+1) = x(k) + αkp(k),
r(k+1) = r(k) − αkAp(k),
βk+1 =
⟨
r(k+1), r(k+1)⟩
⟨
r(k), r(k)⟩ ,
p(k+1) = r(k+1) + βk+1p(k),
hasta que se satisfaga un criterio de detencion.
Calculo Numerico IN1012C/IN1052C/MAT221N - 26 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia del metodo del gradiente conjugado
• Teorema. (Convergencia) Sean A ∈ Rn×n simetrica y definida positiva y b ∈ R
n.
Para cualquier x(0) ∈ Rn, la sucesion
{
x(k)}
generada por el metodo del gradiente
conjugado converge a la solucion del sistema Ax = b en a lo mas n pasos.
Ademas, los errores e(k) = x− x(k) satisfacen
‖e(k+1)‖2 ≤√κ− 1√κ+ 1
‖e(k)‖2, donde κ = cond2(A).
• Observacion. Debido a los errores de redondeo, en las condiciones del teorema anterior,
igual pueden ser necesarios mas de n pasos del metodo.
Calculo Numerico IN1012C/IN1052C/MAT221N - 27 - DMFA – Universidad Catolica de la Santısima Concepcion

Convergencia del metodo del gradiente conjugado (cont.)
• El factor de reduccion del error en cada paso es
√κ− 1√κ+ 1
= 1− 2√κ+ 1
< 1.
• Si κ > 1, este metodo converge mas velozmente que el del maximo descenso, pues
2√κ+ 1
<2
κ+ 1.
Por ejemplo, si κ = 100, entonces
– Maximo descenso:κ− 1
κ+ 1≈ 0.98 (2% de reduccion del error por paso)
– Gradiente conjugado:
√κ− 1√κ+ 1
≈ 0.82 (18% de reduccion del error por paso).
Sin embargo, si la matriz es muy mal condicionada, el metodo aun converge lentamente.
Calculo Numerico IN1012C/IN1052C/MAT221N - 28 - DMFA – Universidad Catolica de la Santısima Concepcion

Precondicionamiento
• Si la matriz es mal condicionada, una estrategia usual para resolver un sistema Ax = b,
se basa en encontrar una matriz P tal que P−1A sea bien condicionada, para luego
resolver el sistema equivalente(
P−1A)
x = P−1b.
• Sin embargo, si se quiere utilizar un metodo como el del gradiente conjugado, debe
notarse que aunque A sea simetrica y definida positiva, en general P−1A no lo es!
• En el caso en que P es simetrica y definida positiva, P = HHt, con H invertible
(Cholesky). En tal caso, P−1 = H−tH−1y
Ax = b ⇐⇒ Ax = b,
con A = H−1AH−t, x = Htx y b = H−1b.
• Si A es simetrica y definida positiva, la matriz A = H−1AH−ttambien lo es, por
lo que pueden aplicarse metodos como el del gradiente conjugado a Ax = b. Ademas,
σ(
P−1A)
= σ(A) =⇒ cond2(A) =max
{
σ(
P−1A)}
min{
σ(
P−1A)} =
λmax
(
P−1A)
λmin
(
P−1A) .
Calculo Numerico IN1012C/IN1052C/MAT221N - 29 - DMFA – Universidad Catolica de la Santısima Concepcion

Metodo del gradiente conjugado precondicionado
• Algoritmo:
Dado el vector inicial x(0),
r(0) = b−Ax(0),
resolver Pz(0) = r(0),
p(0) = z(0),
para k = 0, 1, 2, . . .∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
αk =
⟨
z(k),p(k)⟩
⟨
Ap(k),p(k)⟩ ,
x(k+1) = x(k) + αkp(k),
r(k+1) = r(k) − αkAp(k),
resolver Pz(k+1) = r(k+1),
βk+1 =
⟨
z(k+1), r(k+1)⟩
⟨
z(k), r(k)⟩ ,
p(k+1) = z(k+1) + βk+1p(k),
hasta que se satisfaga un criterio de detencion.
Calculo Numerico IN1012C/IN1052C/MAT221N - 30 - DMFA – Universidad Catolica de la Santısima Concepcion

Precondicionadores
• Para que el metodo del gradiente conjugado precondicionado sea eficiente, debe
escogerse un precondicionador P tal que
1. P simetrica y definida positiva, de manera que P = HHt(Cholesky);
2. P ≈ A, de manera que P−1A ≈ I , y ası
cond2(A) =λmax
(
P−1A)
λmin
(
P−1A) ≈ 1 ≪ cond2 (A) ;
3. resolver los sistemas Pz = r sea poco costoso.
• Ejemplo. Precondicionador de Jacobi. Consiste en tomar como P , la diagonal de A:
P = diag (A) = diag (a11, . . . , ann) .
Este precondicionador es efectivo cuando A es simetrica y definida positiva y con
elementos diagonales muy distintos.
Ademas resolver sistemas Pz = r con P diagonal es muy poco costoso.
Calculo Numerico IN1012C/IN1052C/MAT221N - 31 - DMFA – Universidad Catolica de la Santısima Concepcion

Descomposicion incompleta de Cholesky
• Ejemplo. Precondicionador de Cholesky incompleto. Consiste en utilizar P = HHt,
donde H = (hij) se obtiene aplicando a A el algoritmo del metodo de Cholesky, pero
solo para las entradas hij tales que aij 6= 0. Para las restantes se toma hij = 0.
• Algoritmo de la descomposicion incompleta de Cholesky.
Para j = 1, . . . , n∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
∣
hjj =
√
√
√
√ajj −j−1∑
k=1
h2jk
para i = j + 1, . . . , n∣
∣
∣
∣
∣
∣
∣
∣
si aij = 0, entonces hij = 0,
si no, hij =1
hjj
(
aij −j−1∑
k=1
hikhjk
)
Calculo Numerico IN1012C/IN1052C/MAT221N - 32 - DMFA – Universidad Catolica de la Santısima Concepcion

Descomposicion incompleta de Cholesky (cont.)
• Si hjj 6= 0, j = 1, . . . , n, entonces H resulta no singular y P = HHtpuede usarse
como precondicionante.
• Si A no tuviera entradas nulas, la descomposicion de Cholesky serıa completa y, en tal
caso, P = HHt = A.
Para matrices dispersas, esto no es cierto, pero usualmente P ≈ A.
• Resolver los sistemas Pz = r es poco costoso pues ya se dispone de la factorizacion de
Cholesky P = HHty basta resolver dos sistemas triangulares.
Ademas H es igualmente dispersa que A.
Calculo Numerico IN1012C/IN1052C/MAT221N - 33 - DMFA – Universidad Catolica de la Santısima Concepcion

Comparacion de costos computacionales
• Se considera como ejemplo un sistema con A ∈ Rn×n y b ∈ R
n provenientes de un
programa MATLAB para la resolucion de un problema de EDPs que modela la deformacion
de una membrana bajo la accion de una fuerza (como se vera en el laboratorio
correspondiente).
• Se utiliza una tolerancia tol = 10−6.
• Se resuelve el sistema Ax = b mediante el comando MATLAB pcg (metodo del
gradiente conjugado precondicionado):
1. sin precondicionador,
2. con precondicionador P obtenido mediante el comando MATLAB cholinc (Cholesky
incompleto con llenado parcial), con el parametro droptol = 10−2.
Tabla I: Numero de iteraciones para cada metodo
n 145 632 2629 10821 44071
MGC 32 66 125 261 500
MGCP 5 10 16 35 65
Calculo Numerico IN1012C/IN1052C/MAT221N - 34 - DMFA – Universidad Catolica de la Santısima Concepcion

Comparacion de costos operacionales
102
103
104
105
10-2
10-1
100
101
102
103
Tiempo de CÆlculo vs. Tamaæo del Sistema
Tie
mpo
de
CP
U (
s)
Nœmero de incógnitas
A\bCG PCG
Calculo Numerico IN1012C/IN1052C/MAT221N - 35 - DMFA – Universidad Catolica de la Santısima Concepcion

Comparacion de costos de almacenamiento
102
103
104
105
104
105
106
107
108
109
Costo de Almacenamiento vs. Tamaæo del Sistema
Mem
oria
util
izad
a (
byte
s)
Nœmero de incógnitas
A\bCG PCG
Calculo Numerico IN1012C/IN1052C/MAT221N - 36 - DMFA – Universidad Catolica de la Santısima Concepcion





























