Embed Size (px)
Citation preview

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Grids Meet the Real World:Global Computing in High Energy
Physics
Craig E. Tull
HCG/NERSC/LBNL
2005 Science Colloquium SeriesDOE - August 23, 2005
Grids Meet the Real World:Global Computing in High Energy
Physics
Craig E. Tull
HCG/NERSC/LBNL
2005 Science Colloquium SeriesDOE - August 23, 2005

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Distributed Scientific Computing
• Supercomputing and special-purpose machines (eg LQCD) are still critical to disciplines whose codes demand tight coupling and/or large bi-section bandwidth. For them, the speed-of-light latency of distributed systems is insurmountable.
• For an increasingly large portion of the scientific community, a new reality has emerged.—Large, distributed collaborations—Commodity computing (Intel, Linux)—Polite parallelism/Partitioning of calculations—Data Intensive—The World is Networked
• Even traditionally MPP calculations are looking to more cost-effective solutions.

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Why Grid?
• Moore's Law is "falling behind"—The next generation of experimental and
observational science are generating data volumes and require compute resources which are difficult to collocate at a single facility.
• World-Wide Computing—Large-scale, international science
collaborations are the norm. Scientists at sites around the globe require equal access to data and the resources to analyze it.
• Leveraging of Regional Resources—Local universities and institutions are often
willing to match funds or provide resources.—24/7 coverage easier with sites in multiple time
zones.• Opportunistic use rather than Over-provisioning.

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
CPU, Disk and Network History(actual purchases)
1
10
100
1,000
10,000
100,000
1,000,000
10,000,000
1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005
Farm CPU box MIPS/$M
Doubling in 1.2 years
Raid Disk GB/$M
Doubling in 1.4 years
Transatlantic WAN kB/s per$M/yr
Doubling in 8.4 or 0.7 years
R.Mount

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Estimated CPU Capacity at CERN
0
500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
4,500
5,000
1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010
year
K SI95
Moore’s lawJan 2000:3.5K SI95
LHC experimentsCurrent experiments
les.
rob
ert
son
@ce
rn.c
h
< 50% of the main analysis capacity will be at CERN
• Computing requirements growing faster than Moore’s law
• CERN’s overall budget is fixed
Early predictions for LHC

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Technological Determinism
Computers
Data
Networks
We must (and can) move beyond PC science!I.Foster

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
LHC Collaborating Countries

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Why Grid?
• It is an immutable fact that Scientists and Compute resources are distributed. The Grid is one paradigm to bring them together.

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
What is Grid Computing?
• Distributed, Heterogeneous, Reliable, Dynamic• Think Electric Power Grid
—The term 'Grid' suggests a metaphor between computing goals and an electric grid that unites power producers with consumers.
— In practice, 'Grid Computing' consists of a very specific set of technologies to unite specific computing partners in a "virtual organization" paradigm.
• Grid's goal is to provide a software infrastructure to manage compute and storage resources between facilities hosted by different organizations.
• Today, Grids are almost always one-off instances and are purpose-built.
• Management of CPU, storage and, to a lesser extent, network resources are assumed of all Grids.
• Most Grids today fall far short of the initial, grand vision.

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
What should the Grid do for you?
• You submit your work, and the Grid:—Finds convenient places for it to be run—Organises efficient access to your data
• Caching, migration, replication—Deals with authentication to the different sites
that you will be using—Interfaces to local site resource allocation
mechanisms, policies—Runs your jobs—Monitors progress—Recovers from problems—Tells you when your work is complete

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Terminology
• Virtual Organization (VO):
— A community of users who share a common view of the Grid. Typically an experiment or collaboration.
• Compute Elements (CE) & Storage Elements (SE):
— CPU resources and Storage Systems with Grid Interfaces
• Grid Certificates, Certificate Authorities, Proxy Certificates
— Components of the Grid Security Infrastructure (GSI)
• Grid Information Services (GIS)
— Information provided by
• Grid Scheduler
— schedules jobs across a grid (matches CEs and SEs)
• Replica, Replica Manager, Replica Catalogue
— a copy of a file, one of which is a “master”
— manages creation of new replicas
— database of replica locations

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Reality Check
• Is the Grid…—…a revolutionary new computing paradyme?—…the same thing we’ve always done with a
new, fundable name?—…pure CS-fiction?
• Predictably:—All of the above.
• Trick is to identify the new, the old, and the fiction, and to understand where the Grid must be used and where it should be eschewed.
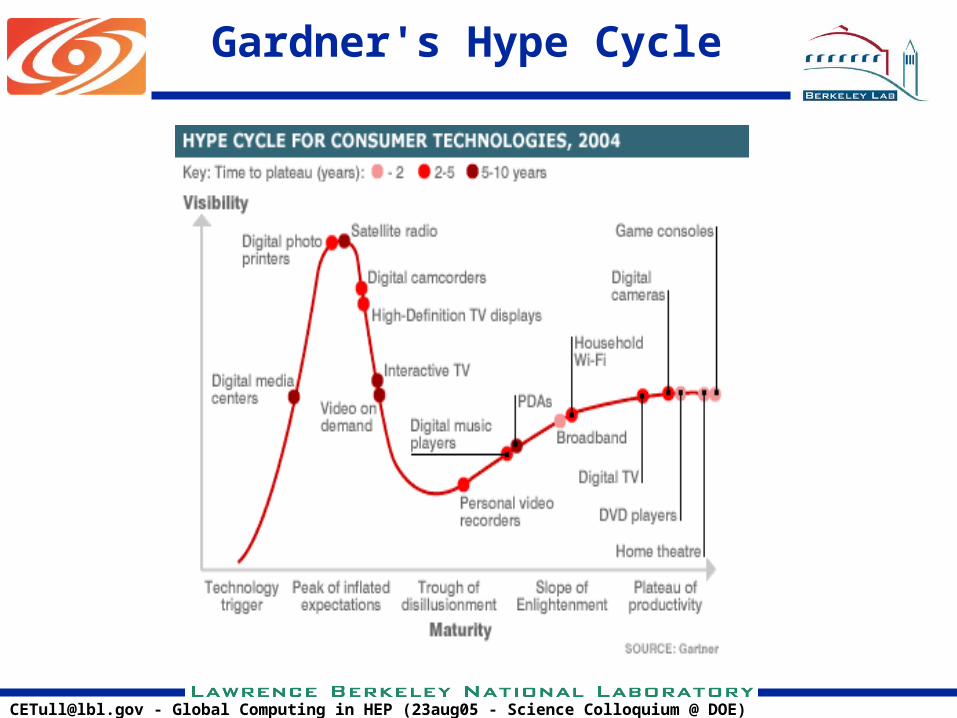
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Gardner's Hype Cycle

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Brief History of the Grid
• Distributed computing research in the 1980’s—Project Athena at MIT—Andrew at CMU—Condor project started in 1988 (Livney U.
Wisc)• Late 80’s early 90’s sees a dramatic increase in
network capacity.• I-WAY (SC 95)
—17 Sites—60+ Applications—Catalyzed the community—Start of the Globus Project
K.Jackson

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
When: The Many Origins of OSG
We will probably see the spread of 'computer utilities' which ... will service individual homes and offices across the country.
Kleinrock1969
“Worldwide distributed analysis for the next
generations of HENP experiments”
(MONARC)Newman
2000
Livny1983
The Grid: Blueprint for a New Computing Infrastructure
1998
GUSTO, 1998
“Load balancing algorithms for decentralized distributed processing systems” (PhD)
Globus international Grid testbed
I.Foster

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Primary Grid Software
• Condor (Univ. Wisconsin)—Cycle-sharing and distributed resource
management—Supports runtime I/O—Condor-G provides a powerful job
management interface for Globus based Grids—Supports DAG based workflows
• Globus Toolkit (ANL, ISI)—Open-source—Most recent release based on WS and WS-RF
protocols—Several independent implementations in
several languages, e.g., Java, C, Python, Perl, .Net

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Sampling of Grid Projects
• GEON• OSG• BIRN• CCG• NEES• TeraGrid• Earth System Grid• GriPhyN• iVDGL• GridChem
• PPDG• SEEK• SCEC• nanoHUB• World Community
Grid• PRAGMA• GGF• LCG• EGEE• NorduGrid

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
CERN site:Next to Lake Geneva
Mont Blanc, 4810 m
Downtown Geneva

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
p-p collisions at the Large Hadron Collider / CERN / Geneva (from 2007
on..
Crossing rate 40 MHzEvent Rates: ~109 Hz
Max LV1 Trigger 100 kHzEvent size ~1 MbyteReadout network 1 Terabit/sFilter Farm ~107 Si2KTrigger levels 2Online rejection 99.9997% (100 Hz from 50 MHz)System dead time ~ %Event Selection: ~1/1013
Crossing rate 40 MHzEvent Rates: ~109 Hz
Max LV1 Trigger 100 kHzEvent size ~1 MbyteReadout network 1 Terabit/sFilter Farm ~107 Si2KTrigger levels 2Online rejection 99.9997% (100 Hz from 50 MHz)System dead time ~ %Event Selection: ~1/1013
Event rate
“Discovery” rate
LuminosityLow 2x1033 cm-2 s-1
High 1034 cm-2 s-1
Level 1 Trigger
Rate to tape
D.Stickland

LHC data (simplified)
Per experiment:
• 40 million collisions per second
• After filtering, 100 collisions of interest per second
• A Megabyte of digitised information for each collision = recording rate of 100 Megabytes/sec
• 1 billion collisions recorded = 1 Petabyte/year
CMS LHCb ATLAS ALICE
1 Megabyte (1MB)A digital photo
1 Gigabyte (1GB) = 1000MB
A DVD movie
1 Terabyte (1TB)= 1000GB
World annual book production
1 Petabyte (1PB)= 1000TB
10% of the annual production by LHC
experiments
1 Exabyte (1EB)= 1000 PB
World annual information production
With four experiments, processed data we will accumulate 15 PetaBytes of new data each year
= 1% of
D.Foster

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
level 1 - special hardware
40 MHz (40 TB/sec)level 2 - embedded processorslevel 3 - PCs
75 KHz (75 GB/sec)5 KHz (5 GB/sec)100 Hz(100 MB/sec)data recording &
offline analysis
Concorde(15 Km)
Balloon(30 Km)
CD stack with1 year LHC data!(~ 20 Km)
Mt. Blanc(4.8 Km)
~15 PetaBytes of data each year Analysis will need the computing power of ~ 100,000 of today's fastest PC processors!
D.Foster
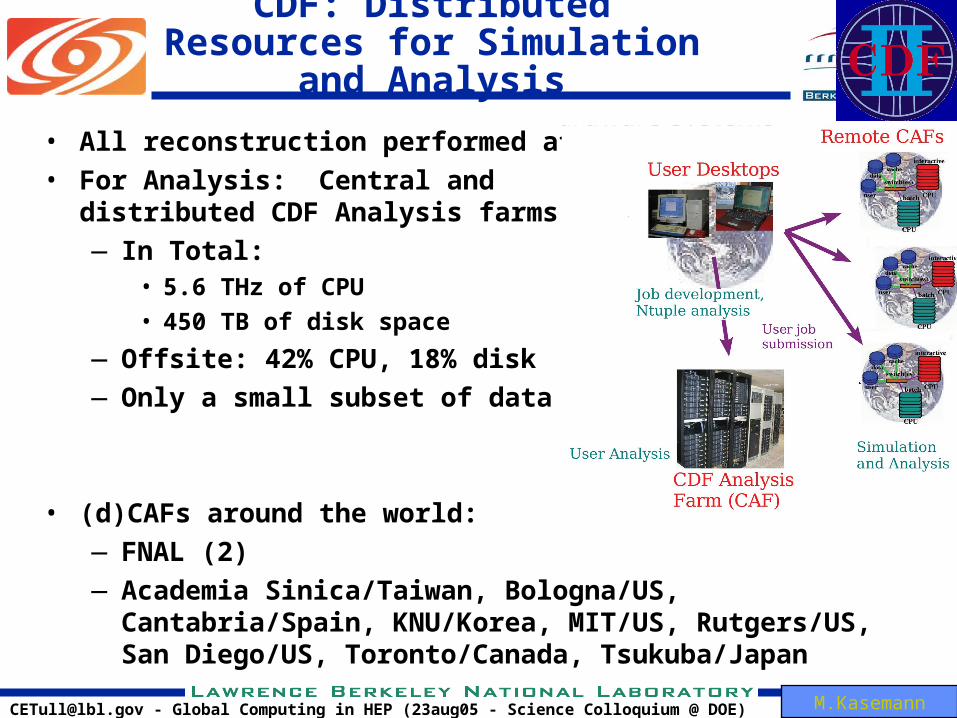
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
CDF: Distributed Resources for Simulation and Analysis
• All reconstruction performed at FNAL• For Analysis: Central and
distributed CDF Analysis farms (d)CAF— In Total:
• 5.6 THz of CPU
• 450 TB of disk space
—Offsite: 42% CPU, 18% disk—Only a small subset of data
• (d)CAFs around the world:—FNAL (2)—Academia Sinica/Taiwan, Bologna/US, Cantabria/Spain,
KNU/Korea, MIT/US, Rutgers/US, San Diego/US, Toronto/Canada, Tsukuba/Japan
M.Kasemann
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
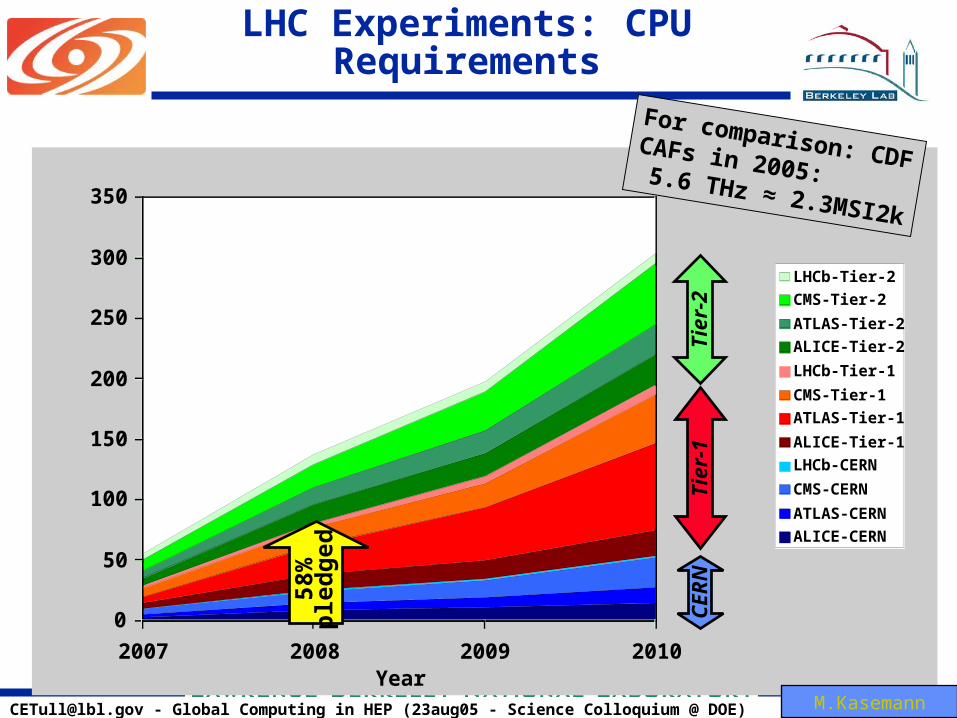
LHC Experiments: CPU Requirements
0
50
100
150
200
250
300
350
2007 2008 2009 2010Year
LHCb-Tier-2
CMS-Tier-2
ATLAS-Tier-2
ALICE-Tier-2
LHCb-Tier-1
CMS-Tier-1
ATLAS-Tier-1
ALICE-Tier-1
LHCb-CERN
CMS-CERN
ATLAS-CERN
ALICE-CERN
CE
RN
Tie
r-1
Tie
r-2
58%
pled
ged
For comparison: CDFCAFs in 2005: 5.6 THz ≈ 2.3MSI2k
M.Kasemann

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
LHC Experiments: Disk Requirements
0
20
40
60
80
100
120
140
160
2007 2008 2009 2010Year
PB
LHCb-Tier-2
CMS-Tier-2
ATLAS-Tier-2
ALICE-Tier-2
LHCb-Tier-1
CMS-Tier-1
ATLAS-Tier-1
ALICE-Tier-1
LHCb-CERN
CMS-CERN
ATLAS-CERN
ALICE-CERN
CE
RN
Tie
r-1
Tie
r-2
54%
pled
ged
For comparison: CDFCAFs in 2005: 450 TB
M.Kasemann

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
LHC Experiments: Tape Requirements
CE
RN
Tie
r-1
0
20
40
60
80
100
120
140
160
2007 2008 2009 2010Year
PB
LHCb-Tier-1
CMS-Tier-1
ATLAS-Tier-1
ALICE-Tier-1
LHCb-CERN
CMS-CERN
ATLAS-CERN
ALICE-CERN
75%
pled
ged
For comparison: CDFdata in 2005: 1.2 PB
M.Kasemann

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
LCG Service HierarchyTier-0 – the accelerator centre• Data acquisition & initial processing
— Close to 2GB/s during AA running• Long-term data curation• Distribution of data Tier-1 centres
— ~200MB/s per site; ~12 sites
Canada – Triumf (Vancouver)France – IN2P3 (Lyon)Germany – Forschungszentrum KarlsruheItaly – CNAF (Bologna)Netherlands – NIKHEF (Amsterdam)
Nordic countries – distributed Tier1 Spain – PIC (Barcelona)Taiwan – Academia Sinica (Taipei)UK – CLRC (Didcot)US – FermiLab (Illinois) – Brookhaven (NY)
Tier-1 – “online” to the data acquisition process high availability
• Managed Mass Storage – grid-enabled data service
• Data intensive analysis• National, regional support• 10Gbit/s dedicated links to T0• (+ significant inter-T1 traffic)
Tier-2 – ~100 centres in ~40 countries
• Simulation
• End-user analysis – batch and interactive
• 1Gbit/s networks L.Robertson

LHC Computing Hierarchy
Tier 1
Tier2 Center
Online System
CERN Center PBs of Disk;
Tape Robot
FNAL CenterIN2P3 Center INFN Center RAL Center
InstituteInstituteInstituteInstitute
Workstations
~100-1500 MBytes/sec
2.5-10 Gbps
Tens of Petabytes by 2007-8.An Exabyte ~5-7 Years later.
~PByte/sec
~2.5-10 Gbps
Tier2 CenterTier2 CenterTier2 Center
~2.5-10 Gbps
Tier 0 +1
Tier 3
Tier 4
Tier2 Center Tier 2
Experiment
CERN/Outside Resource Ratio ~1:2Tier0/( Tier1)/( Tier2) ~1:1:1
0.1 to 10 GbpsPhysics data cache
D.Foster

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE) M.Kasemann
LHC Experiments: Hierarchical Computing Model
• Tier-0 at CERN—Record RAW data (up to 1.25 GB/s ALICE)—Distribute second copy to Tier-1s—Calibrate and do first-pass reconstruction
• Tier-1 centres (11 defined + CERN)—Manage permanent storage – RAW, simulated,
processed—Capacity for reprocessing, bulk analysis
• Tier-2 centres (>~ 100 identified + CERN)—Monte Carlo event simulation—End-user analysis
• Tier-3 centres—Facilities at universities and laboratories—Access to data and processing in Tier-2s, Tier-1s

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Glossary of LHC Grids
• WLCG: All the Institutions participating in the provision of the Worldwide LHC Computing Grid with a Tier-1 and/or Tier-2 Computing Centre form the WLCG Collaboration (MoU in preparation).
• The LCG architecture will consist of an agreed set of services and applications running on the Grid infrastructures provided by the LCG partners. —These infrastructures at the present consist of those
provided by the Enabling Grids for E-sciencE (EGEE) project in Europe, the Open Science Grid (OSG) project in the U.S.A. and the Nordic Data Grid Facility in the Nordic countries.
• Grid3 was the start-up of OSG
• The LCG Project builds and maintains computing infrastructure for LHC experiments

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Relation of LCG and EGEE
• Goal Create a European-wide production quality multi-science grid infrastructure on top of national & regional grid programs• Scale 70 partners in 27 countries Initial funding (€32M) for 2 years• Activities Grid operations and support (joint LCG/EGEE operations team) Middleware re-engineering (close attention to LHC data analysis requirements) Training, support for applications groups (inc. contribution to the ARDA team) • Builds on LCG grid deployment Experience gained in HEP LHC experiments pilot applications

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
U.S. “Trillium” Grid Partnership
• Trillium = PPDG + GriPhyN + iVDGL—Particle Physics Data Grid:$15M (DOE) (1999 – 2006)—GriPhyN: $12M (NSF CISE) (2000 – 2005)— iVDGL: $14M (NSF MPS) (2001 – 2006)
• Basic composition (~150 people)—PPDG: 4 universities, 6 labs—GriPhyN: 12 universities, SDSC, 3 labs— iVDGL: 18 universities, SDSC, 4 labs, foreign partners—Expts: BaBar, D0, STAR, Jlab, CMS, ATLAS,
LIGO,SDSS/NVO• Coordinated internally to meet broad goals
—GriPhyN: CS research, Virtual Data Toolkit (VDT) development
— iVDGL: Grid laboratory deployment using VDT, applications—PPDG: “End to end” Grid services, monitoring, analysis—Common use of VDT for underlying Grid middleware— Unified entity when collaborating internationally

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
VDT Growth Over 3 Years
0
5
10
15
20
25
30
35
Jan-02Apr-02Jul-02Oct-02Jan-03Apr-03Jul-03Oct-03Jan-04Apr-04Jul-04Oct-04Jan-05Apr-05
VDT 1.1.x VDT 1.2.x VDT 1.3.x
# o
f co
mpon
en
ts
VDT 1.0Globus 2.0bCondor 6.3.1
VDT 1.1.7Switch to Globus 2.2
VDT 1.1.11Grid3
VDT 1.1.8First real use by LCG
www.griphyn.org/vdt/

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Components of VDT 1.3.5
— Globus 3.2.1— Condor 6.7.6— RLS 3.0— ClassAds 0.9.7— Replica 2.2.4— DOE/EDG CA certs— ftsh 2.0.5— EDG mkgridmap— EDG CRL Update— GLUE Schema 1.0— VDS 1.3.5b— Java— Netlogger 3.2.4— Gatekeeper-Authz— MyProxy1.11— KX509
— System Profiler— GSI OpenSSH 3.4— Monalisa 1.2.32— PyGlobus 1.0.6— MySQL— UberFTP 1.11— DRM 1.2.6a— VOMS 1.4.0— VOMS Admin 0.7.5— Tomcat — PRIMA 0.2— Certificate Scripts— Apache— jClarens 0.5.3— New GridFTP Server— GUMS 1.0.1
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Grid3 in the U.S.
• We built a demonstration functioning Grid in the U.S. Strongly encouraged by NSF and supported through iVDGL, GriPhyN, PPDG (DOE) as well as US-CMS, US-ATLAS, Ligo, SDSS and University of Buffalo, LBNL, some Biology applications, and more…. Based on a simple to install VDT package—Allowing diversity at different sites
• It worked and it stays working and it is being used by ATLAS and CMS for their data challenges—http://ivdgl.org/Grid3

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Grid2003 Components• Computers & storage at 28 sites (to date)
— 2800+ CPUs• Uniform service environment at each site
— Globus Toolkit provides basic authentication, execution management, data movement
— Pacman installation system enables installation of numerous other VDT and application services
• Global & virtual organization services— Certification & registration authorities, VO membership
services, monitoring services• Client-side tools for data access & analysis
— Virtual data, execution planning, DAG management, execution management, monitoring
• IGOC: iVDGL Grid Operations Center
Courtesy of the Globus Project

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Grid 3 Shared Usage
CMS DC04
ATLASDC2
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
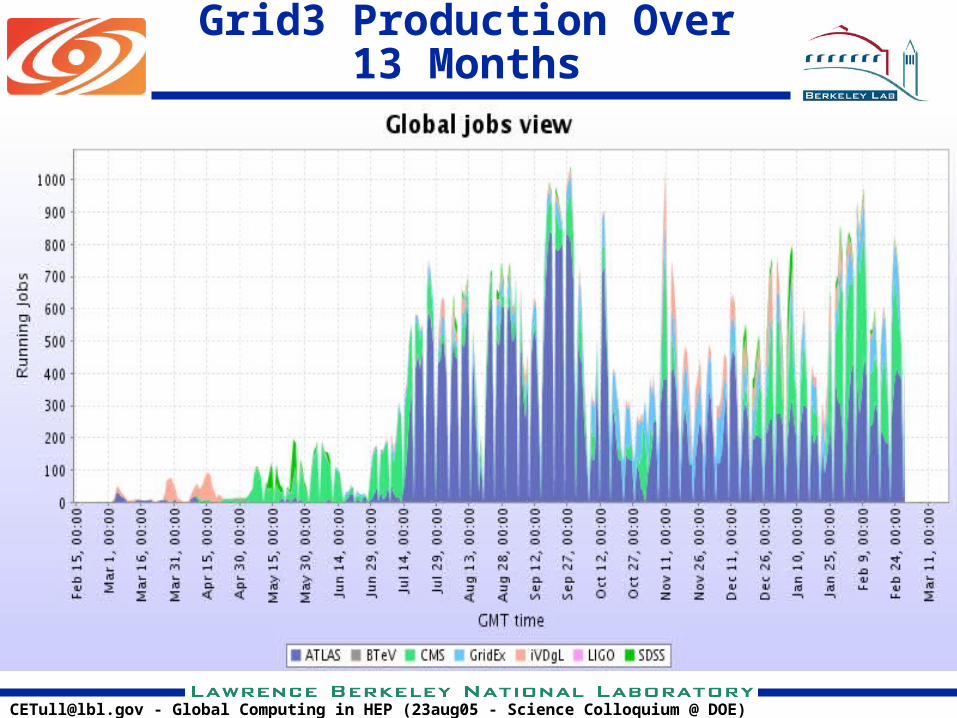
Grid3 Production Over 13 Months
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
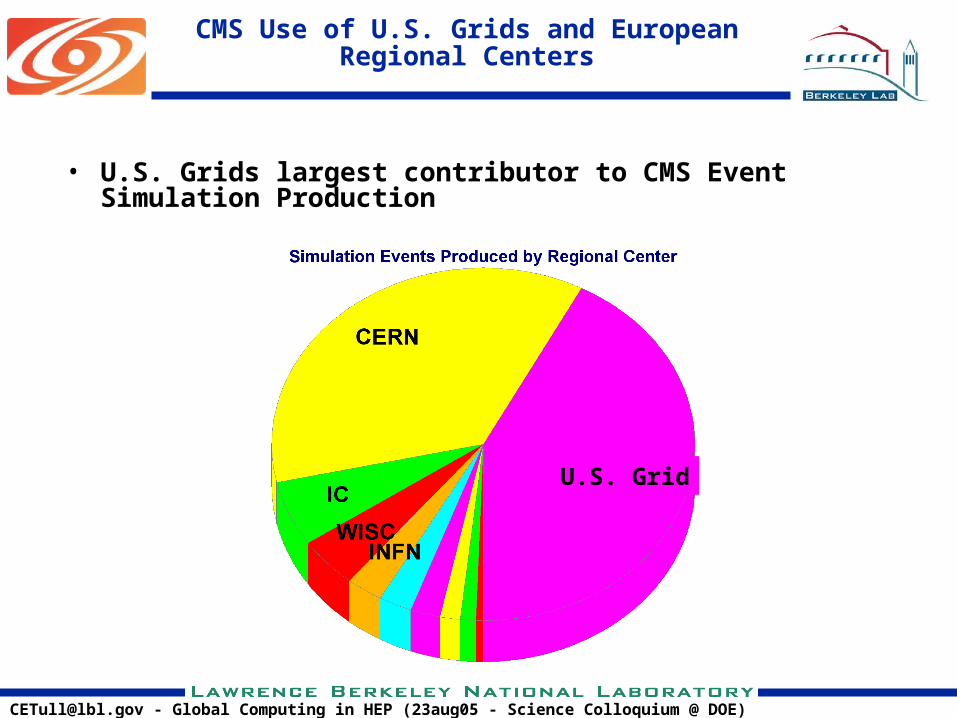
CMS Use of U.S. Grids and European Regional Centers
• U.S. Grids largest contributor to CMS Event Simulation Production
U.S. Grid

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
ATLAS DC2 Jobs Per Grid
[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
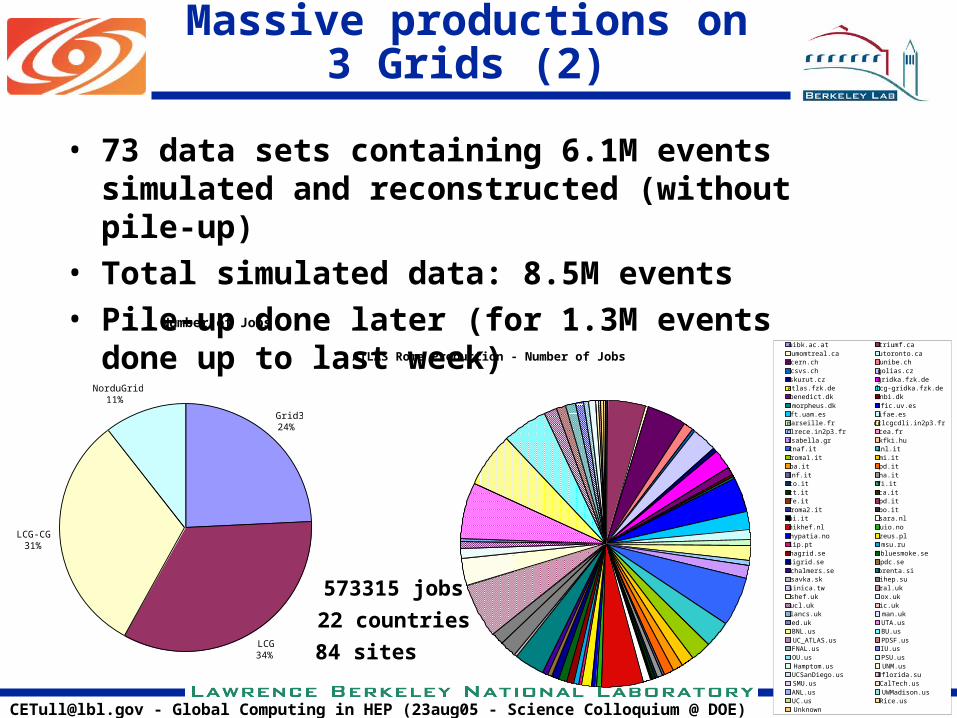
Massive productions on 3 Grids (2)
• 73 data sets containing 6.1M events simulated and reconstructed (without pile-up)
• Total simulated data: 8.5M events• Pile-up done later (for 1.3M events done up to last
week)Number of Jobs
Grid324%
LCG34%
LCG-CG31%
NorduGrid11%
Grid3
LCG
LCG-CG
NorduGrid
ATLAS Rome Production - Number of Jobsuibk.ac.at triumf.caumomtreal.ca utoronto.cacern.ch unibe.chcsvs.ch golias.czskurut.cz gridka.fzk.deatlas.fzk.de lcg-gridka.fzk.debenedict.dk nbi.dkmorpheus.dk ific.uv.esft.uam.es ifae.esmarseille.fr cclcgcdli.in2p3.frclrece.in2p3.fr cea.frisabella.gr kfki.hucnaf.it lnl.itroma1.it mi.itba.it pd.itlnf.it na.itto.it fi.itct.it ca.itfe.it pd.itroma2.it bo.itpi.it sara.nlnikhef.nl uio.nohypatia.no zeus.pllip.pt msu.ruhagrid.se bluesmoke.sesigrid.se pdc.sechalmers.se brenta.sisavka.sk ihep.susinica.tw ral.ukshef.uk ox.ukucl.uk ic.uklancs.uk man.uked.uk UTA.usBNL.us BU.usUC_ATLAS.us PDSF.usFNAL.us IU.usOU.us PSU.usHamptom.us UNM.usUCSanDiego.us Uflorida.suSMU.us CalTech.usANL.us UWMadison.usUC.us Rice.usUnknown
573315 jobs
22 countries
84 sites

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
SC2 met its throughput targets
• >600MB/s daily average for 10 days was achieved - Midday 23rd March to Midday 2nd April—Not without outages, but system showed it
could recover rate again from outages—Load reasonable evenly divided over sites
(give network bandwidth constraints of Tier-1 sites)

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
What we haven't covered
• A lot• Networking & Facilities• Technical Grid details and challenges:
—Architecture, protocols, security, ...• Specific Grid Tools:
—SRM, GridFTP, VOMS, MonaLisa, ...• Comparison of LCG, OSG, NorduGrid• Other Grids: TeraGrid, Earth Science, Chem, ...• Commercial Grids: IBM, HP, …• The role of Global Grid Forum• Other distributed approaches: P2P, BOINC, …• Web Services (OGSA)
—The future of Grid technology? Not clear.• New Concepts (eg. Edge Services)

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Where do we go from here?
• There are many areas where work is needed: • Security, Accounting, Monitoring, ...• Interoperability, Federation, and Standardization• Ease of Use and the Startup Threshold • Monitoring and Error Recovery
—Manpower scalability
• HEP is faced with hard deadlines and requirements at LHC.—Compromises will necessarily be made.
• eg. Eschew Web Services
—Partnership with other domains and CS.

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Summary and Conclusions
• Computing Resources are distributed. Scientists are distributed.
• Grid Computing is the predominant technology used in science to bring these two together.—Many attractive technical advantages: Security,
Information Services, ...—Computer Scientists have been highly engaged
from the beginning.• Grid computing is today providing access to most
of the CPU and Storage resources in LHC experiments.
• LCG, Grid3 and OSG are proving the opportunistic model viable and important.
• Deploying production Grids is still too hard.• Users still need to be too expert in Grid.• Where to learn more…

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Grid Project References
• Open Science Grid—www.opensciencegrid.
org• Grid3
—www.ivdgl.org/grid3• Virtual Data Toolkit
—www.griphyn.org/vdt• GriPhyN
—www.griphyn.org• iVDGL
—www.ivdgl.org• PPDG
—www.ppdg.net• CHEPREO
—www.chepreo.org
• UltraLight—ultralight.cacr.caltech.e
du• Globus
—www.globus.org• Condor
—www.cs.wisc.edu/condor
• LCG—www.cern.ch/lcg
• EGEE—www.eu-egee.org
• Global Grid Forum—www.gridforum.org

[email protected] - Global Computing in HEP (23aug05 - Science Colloquium @ DOE)
Science Grid Communications
Broad set of activitiesNews releases, PR, etc.Science Grid This WeekKatie Yurkewicz