Embed Size (px)
Citation preview

Building Large Corpora from the Web Using a New Efficient Tool Chain
Roland Schäfer, Felix Bildhauer
German Grammar, SFB 632/A6Freie Universität Berlin
Habelschwerdter Allee 45, 14195 [email protected], [email protected]
AbstractOver the last decade, methods of web corpus construction andthe evaluation of web corpora have been actively researched.Prominently, the WaCky initiative has provided both theoretical results and a set of web corpora for selected Europeanlanguages. We present a software toolkit for web corpus construction and a set of siginificantly larger corpora (up toover 9 billion tokens) built using this software. First, we discuss how the data should be collected to ensure that it is notbiased towards certain hosts. Then, we describe our software toolkit which performs basic cleanups as well as boilerplateremoval, simple connected text detection as well as shingling to remove duplicates from the corpora. We finally reportevaluation results of the corpora built so far, for example w. r. t. the amount of duplication contained and the text type/genredistribution. Where applicable, we compare our corpora to the WaCky corpora, since it is inappropriate, in our view, tocompare web corpora to traditional or balanced corpora. While we use some methods applied by the WaCky initiative, wecan show that we have introduced incremental improvements.
Keywords: web corpora, corpus evaluation, web crawling
Corpus N Documents N Tokens
SECOW2011 1.91 1,750ESCOW2012 1.30 1,587DECOW2012 7.63 9,108
Table 1: Document and token counts (million) for se-lected COW corpora
1. IntroductionIn this paper, we describe a new tool chain for theprocessing of web data for the purpose of web corpusconstruction. Furthermore, a growing set of very largeweb corpora, which we constructed using the afore-mentioned tools, is introduced and evaluated (Table 1lists a selection of these corpora and their respectivesizes). We proceed by discussing the methods of datacollection in 2., describing the methods implementedin the software in 3. before reporting results of theevaluation of the final corpora and the quality of thesoftware in 4.
2. Data CollectionThe purpose of the project described here is the con-struction of very huge comparable web corpora in alarge number of languages. Although we share withKilgarriff and Grefenstette (2003, p. 340) a more orless agnostic position towards the question of repre-sentativeness of web corpora, we still consider it cru-cial to define the population of which a corpus is in-
tended to be a sample. We sample from all WWWdocuments under a given national TLD, written in anofficial language of the respective country and con-taining predominantly connected text. From each doc-ument, we attempt to extract all paragraphs of con-nected text, finally making sure that the majority ofthe text within the document occurs only once in thefinal corpus (cf. 3.4.). Since the given population isunknown to a large extent, proportional sampling isout of the question, and large random samples are theonly valid option. How a random sample from the webcan be approximated is not a settled question. In webcorpus construction, it is customary to send large num-bers of requests to search engines using tuples of mid-frequency word forms as search strings (Baroni andBernardini, 2004). Either only the URLs returned arethen harvested (BootCaT method), or they are used asseed URLs for a crawler system. We apply the secondmethod, since corpora of roughly1010 tokens cannotpractically be constructed from search engine queriesalone. Also, the BootCaT method, as opposed to anapproach using specialized crawler software, does notallow to effectively control the politeness of the har-vesting process (Manning et al., 2009, 444ff.). As acrawler we use Heritrix 1.4 configured roughly as de-scribed by Emerson and O’Neil (2006). Seed URLswere taken from Yahoo until their discontinuation ofthe free API access, after which we switched to Mi-crosoft Bing. Besides the fact that the Yahoo API dis-continuation proves that total dependence on search
486

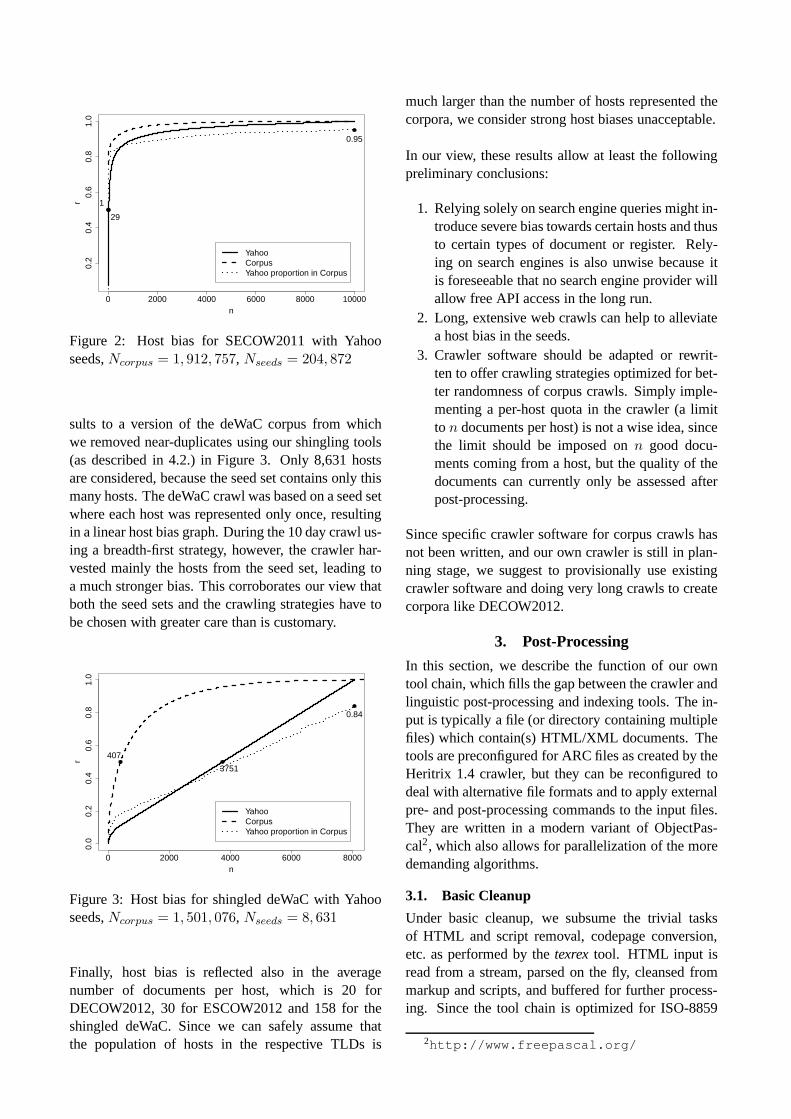
engines is generally an unsafe strategy, we would liketo point out some problems with search engine resultsand argue for much stronger reliance on very largeweb crawls for linguistic purposes.The randomness of web corpora was examined suc-cessfully in the BootCaT/WaCky community from alinguistic viewpoint. For example, Ciamarita and Ba-roni (2006) evaluate randomness of corpora based onlinguistic features. The most basic measure of ran-domness of both seed URLs retrieved from a searchengine and documents downloaded by a crawler, how-ever, is its bias towards certain hosts. Even though aweb corpus (or a set of search engine results) mightnever be called balanced, it should count as biased if itproportionally contains a huge number of documentsfrom only a few hosts. It is known from papers suchas Bar-Yossef and Gurevich (2006) that obtaining ran-dom samples from search engines is not a simple mat-ter, especially when there is only one major search en-gine left which allows free API access for large num-bers of queries. To our knowledge, nobody has everconstructed web corpora making efforts such as de-scribed by Bar-Yossef and Gurevich (2006). Since themethod described in that paper only approximates ran-dom samples from search engine indices and not fromthe web itself, even following the procedure would notensure random samples in the desired sense. The cus-tomary method, however, does not even ensure bias-free sampling from a search engine’s index.Our experiments so far have shown that a large num-ber of hosts which never occur in search engine re-sults can be discovered through long-term crawling.In Figures 1 and 2, experiments for thede andsedomain are evaluated with respect to their host bias.The graphs cumulatively plot for a random sample of10,000 URLs from either a set of unique seeds gath-ered from the search engines (Yahoo forse, Bing forde) and the document URLs of a final corpus derivedfrom these seeds (which has undergone the cleaningprocedures explained in 3.) how large a proportionr
of the total URLs comes from to then most popu-lar hosts in the whole sample. The seed URLs werequeried using 3-tuples of content word forms (nouns,verbs, adjectives, adverbs) ranked 1,001 through 6,000in frequency lists either from existing corpora or fromprevious crawl experiments. A maximum of 10 re-sults per tuple were requested from the search engine.The crawler ran for approximately seven days for these domain, and for 28 days in thede case. The to-tal sizes of the seed setsNseeds and the total numberof document URLs in the corpusNcorpus is given foreach experiment. The third curve in each graph plotsthe proportion of documents in the final corpus which
stem from the topn hosts from the seed set. It is obvi-ous that the experiments were successful to differentdegrees.
0 2000 4000 6000 8000 10000
0.2
0.4
0.6
0.8
1.0
n
r
BingCorpusBing proportion in Corpus
258
12760.58
Figure 1: Host bias for DECOW2012 with Bing seeds,Ncorpus = 7, 759, 892, Nseeds = 912, 243
Using an extremely large set of unique seed URLs(over 900,000) causes the seed set to be comparativelyless biased: in the DECOW2012 seeds (Figure 1),50% of the URLs come from the 258 most popularhosts, while in the SECOW2011 (Figure 2) seed set,figures is much lower: 29 hosts contribute 50% of theseed URLs.1 A longer crawling time helped to bringdown the host bias of DECOW2012 significantly, suchthat in the final corpus, 50% of the documents in thesample come from 1,276 hosts. Also, the 10,000 mostprominent hosts in the DECOW2012 seed set con-tribute only 58% of the documents from the top 10,000hosts in the final corpus.The graph for SECOW2011 (Figure 2) in fact shows acompletely unsuccessful crawl experiment, where analready heavily biased seed set resulted in even morebiased crawl results. The seeds as returned by Yahoowere extremely biased to begin with, and the crawl,using a breadth-first strategy, got stuck trying to ex-haustively harvest the few hosts strongly representedin the seeds. This resulted in an interesting corpus, butdefinitely not in a general-purpose corpus. It contains1,443,452 documents (75.5% of the total documents)from the hostblogg.se. Since in this case, the hostis strongly tied to a certain type/genre of text and com-munication (blog posts), it is obvious that host bias canbe directly linked to linguistic biases.To illustrate further that the seed set and the crawl-ing process both play a role, we now compare the re-
1Due to the shutdown of Yahoo’s API access, it is nowimpossible to find out whether this is also due to differentbiases between Yahoo and Bing.
487
0 2000 4000 6000 8000 10000
0.2
0.4
0.6
0.8
1.0
n
r
YahooCorpusYahoo proportion in Corpus
29
1
0.95
Figure 2: Host bias for SECOW2011 with Yahooseeds,Ncorpus = 1, 912, 757, Nseeds = 204, 872
sults to a version of the deWaC corpus from whichwe removed near-duplicates using our shingling tools(as described in 4.2.) in Figure 3. Only 8,631 hostsare considered, because the seed set contains only thismany hosts. The deWaC crawl was based on a seed setwhere each host was represented only once, resultingin a linear host bias graph. During the 10 day crawl us-ing a breadth-first strategy, however, the crawler har-vested mainly the hosts from the seed set, leading toa much stronger bias. This corroborates our view thatboth the seed sets and the crawling strategies have tobe chosen with greater care than is customary.
0 2000 4000 6000 8000
0.0
0.2
0.4
0.6
0.8
1.0
n
r
YahooCorpusYahoo proportion in Corpus
3751
407
0.84
Figure 3: Host bias for shingled deWaC with Yahooseeds,Ncorpus = 1, 501, 076, Nseeds = 8, 631
Finally, host bias is reflected also in the averagenumber of documents per host, which is 20 forDECOW2012, 30 for ESCOW2012 and 158 for theshingled deWaC. Since we can safely assume thatthe population of hosts in the respective TLDs is
much larger than the number of hosts represented thecorpora, we consider strong host biases unacceptable.
In our view, these results allow at least the followingpreliminary conclusions:
1. Relying solely on search engine queries might in-troduce severe bias towards certain hosts and thusto certain types of document or register. Rely-ing on search engines is also unwise because itis foreseeable that no search engine provider willallow free API access in the long run.
2. Long, extensive web crawls can help to alleviatea host bias in the seeds.
3. Crawler software should be adapted or rewrit-ten to offer crawling strategies optimized for bet-ter randomness of corpus crawls. Simply imple-menting a per-host quota in the crawler (a limitto n documents per host) is not a wise idea, sincethe limit should be imposed onn good docu-ments coming from a host, but the quality of thedocuments can currently only be assessed afterpost-processing.
Since specific crawler software for corpus crawls hasnot been written, and our own crawler is still in plan-ning stage, we suggest to provisionally use existingcrawler software and doing very long crawls to createcorpora like DECOW2012.
3. Post-Processing
In this section, we describe the function of our owntool chain, which fills the gap between the crawler andlinguistic post-processing and indexing tools. The in-put is typically a file (or directory containing multiplefiles) which contain(s) HTML/XML documents. Thetools are preconfigured for ARC files as created by theHeritrix 1.4 crawler, but they can be reconfigured todeal with alternative file formats and to apply externalpre- and post-processing commands to the input files.They are written in a modern variant of ObjectPas-cal2, which also allows for parallelization of the moredemanding algorithms.
3.1. Basic Cleanup
Under basic cleanup, we subsume the trivial tasksof HTML and script removal, codepage conversion,etc. as performed by thetexrex tool. HTML input isread from a stream, parsed on the fly, cleansed frommarkup and scripts, and buffered for further process-ing. Since the tool chain is optimized for ISO-8859
2http://www.freepascal.org/
488

languages, a simple conversion from UTF-8 multi-byte characters to corresponding ISO-8859 charactersas well as a complete HTML entity conversion is alsoperformed on the fly. The software deals with faultymarkup by favoring cleanliness of output over conser-vation of text and discards the whole document in caseof serious unrecoverable errors.Based on a configurable list of markup tags, a sim-ple paragraph detection is performed, inserting para-graph breaks wherever one of the configured tags oc-curs. Optionally, the results of basic cleansing arethen subjected to a second pass of markup removal,since many web pages contain literal markup piecedtogether with entities (<br> as<br> etc.).Perfectly identical subsequent lines are also removed,and excessively repeated punctuation is compressed toreasonable sequences of punctuation tokens.
3.2. Boilerplate Removal
The removal of navigational elements, date strings,copyright notices, etc. is usually referred to as boil-erplate removal. The WaCky method (Baroni et al.,2009), simply speaking, selects the window of textfrom the whole document for which the ratio of text-encoding vs. markup-encoding characters is maximal.This has the advantage of selecting a coherent block oftext from the web page, but also has the disadvantageof allowing intervening boilerplate to end up in thecorpus. Also, many web pages from blog and forumsites contain several blocks of text with interveningboilerplate, of which many can be lost if this methodis applied.Therefore, we decided to determine for each para-graph individually whether it is boilerplate or not. Thedecision is made by a multi-layer perceptron as imple-mented in the FANN library (Nissen, 2005). The in-put to the network is currently an array of nine valueswhich are calculated per paragraph:
1. the ratio of text encoding characters vs. markupencoding characters,
2. the same ratio for a window extended by oneparagraph in both directions,
3. the same ratio for a window extended by twoparagraphs in both directions,
4. the raw number of text (non-markup) characters,5. the ratio of uppercase vs. lowercase characters,6. the ratio of non-letters vs. letters in the text,7. the same ratio for a window extended by one
paragraph in both directions,8. the same ratio for a window extended by two
paragraphs in both directions,
9. the percentile of the paragraph within the textmass of the whole document.
It is obvious that value 5 is language-dependent tosome extent. However, after training, the featureturned out to be weighted so lightly that the networkperformed equally well for English, German, French,Spanish, and Swedish and we decided to use one net-work for all languages. This pre-packaged networkwas trained on decisions for 1,000 German paragraphscoded by humans using the graphical tooltextrain in-cluded in the package. As the only coding guidelinewhich turned out to be practical, we defined:
1. Any paragraph containing coherent full sen-tences is text,
2. any heading for such text (i. e., not page headersetc.) is text,
3. everything else is boilerplate.
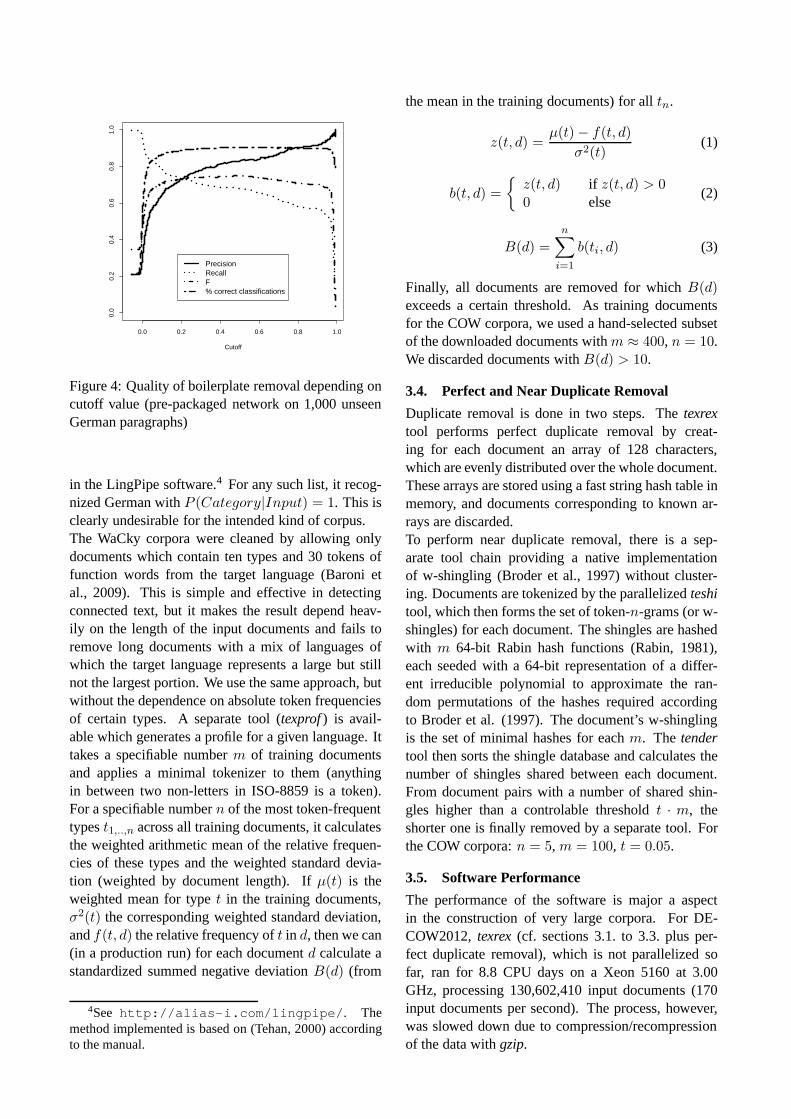
Networks can be trained with user-coded data usingthe includedtexnet tool. The network must use a sym-metric Gaussian output activation function, which pro-duces real numbers between0 and 1. The user canthen evaluate the results and determine a cutoff pointin [0..1] below which a paragraph will actually be con-sidered boilerplate in a production run.3 The mea-sures of accuracy for the pre-packaged network de-pending on the selected cutoff are shown in Figure 4,which measures the results of an application of thepre-packaged network to 1,000 unseen German para-graphs coded using identical guidelines. The over-all accuracy is quite adequate compared to the ap-proaches described in (Baroni et al., 2008). For theCOW corpora, we selected the cutoff with the high-est F-score (harmonic mean of precision and recall),which is0.48.
3.3. Detecting Connected Text
Language identification on the document level hasbeen around since the 1960s, and detecting a knownlanguage is a simple text-book matter. Since our cor-pora are designed mainly for research in theoreticallinguistics, we were not satisfied with simple languagedetection, for example based on character n-grams.Many documents on the web contain some text in aspecific language, but it is often not connected text buttables, tag clouds, or any other non-sentence material.For example, we ran lists of German content wordswithout function words (artificial tag clouds) throughstandard language identifiers such as the one included
3The texrex tool provides functions to create evaluationoutput where decisions are logged but not executed.
489
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Cutoff
PrecisionRecallF% correct classifications
Figure 4: Quality of boilerplate removal depending oncutoff value (pre-packaged network on 1,000 unseenGerman paragraphs)
in the LingPipe software.4 For any such list, it recog-nized German withP (Category|Input) = 1. This isclearly undesirable for the intended kind of corpus.The WaCky corpora were cleaned by allowing onlydocuments which contain ten types and 30 tokens offunction words from the target language (Baroni etal., 2009). This is simple and effective in detectingconnected text, but it makes the result depend heav-ily on the length of the input documents and fails toremove long documents with a mix of languages ofwhich the target language represents a large but stillnot the largest portion. We use the same approach, butwithout the dependence on absolute token frequenciesof certain types. A separate tool (texprof ) is avail-able which generates a profile for a given language. Ittakes a specifiable numberm of training documentsand applies a minimal tokenizer to them (anythingin between two non-letters in ISO-8859 is a token).For a specifiable numbern of the most token-frequenttypest1,..,n across all training documents, it calculatesthe weighted arithmetic mean of the relative frequen-cies of these types and the weighted standard devia-tion (weighted by document length). Ifµ(t) is theweighted mean for typet in the training documents,σ2(t) the corresponding weighted standard deviation,andf(t, d) the relative frequency oft in d, then we can(in a production run) for each documentd calculate astandardized summed negative deviationB(d) (from
4See http://alias-i.com/lingpipe/. Themethod implemented is based on (Tehan, 2000) accordingto the manual.
the mean in the training documents) for alltn.
z(t, d) =µ(t)− f(t, d)
σ2(t)(1)
b(t, d) =
{
z(t, d) if z(t, d) > 00 else
(2)
B(d) =
n∑
i=1
b(ti, d) (3)
Finally, all documents are removed for whichB(d)exceeds a certain threshold. As training documentsfor the COW corpora, we used a hand-selected subsetof the downloaded documents withm ≈ 400, n = 10.We discarded documents withB(d) > 10.
3.4. Perfect and Near Duplicate Removal
Duplicate removal is done in two steps. Thetexrextool performs perfect duplicate removal by creat-ing for each document an array of 128 characters,which are evenly distributed over the whole document.These arrays are stored using a fast string hash table inmemory, and documents corresponding to known ar-rays are discarded.To perform near duplicate removal, there is a sep-arate tool chain providing a native implementationof w-shingling (Broder et al., 1997) without cluster-ing. Documents are tokenized by the parallelizedteshitool, which then forms the set of token-n-grams (or w-shingles) for each document. The shingles are hashedwith m 64-bit Rabin hash functions (Rabin, 1981),each seeded with a 64-bit representation of a differ-ent irreducible polynomial to approximate the ran-dom permutations of the hashes required accordingto Broder et al. (1997). The document’s w-shinglingis the set of minimal hashes for eachm. The tendertool then sorts the shingle database and calculates thenumber of shingles shared between each document.From document pairs with a number of shared shin-gles higher than a controlable thresholdt · m, theshorter one is finally removed by a separate tool. Forthe COW corpora:n = 5, m = 100, t = 0.05.
3.5. Software Performance
The performance of the software is major a aspectin the construction of very large corpora. For DE-COW2012,texrex (cf. sections 3.1. to 3.3. plus per-fect duplicate removal), which is not parallelized sofar, ran for 8.8 CPU days on a Xeon 5160 at 3.00GHz, processing 130,602,410 input documents (170input documents per second). The process, however,was slowed down due to compression/recompressionof the data withgzip.
490
The partly parallelized shingling tools ran for a totalof 2.3 CPU days (using eight shingling threads) onthe same machine as above, processing the 16,935,227documents left over by the previous tools (85 inputdocuments per second).
4. Corpus Evaluation
4.1. Effect of the Different Algorithms
First, we report the amount of data filtered (as thenumber of documents discarded) by the different al-gorithms described in 3. The figures are for DE-COW2012, for which a total of 130,602,410 docu-ments was crawled. To keep the processing demandsof the more costly algorithms like duplicate detec-tion and boilerplate removal down, we added a sim-ple threshold filter after the basic cleanup (cf. 3.1.),which in the case of the COW2012 corpora causeddocuments with less than 2,000 characters to be dis-carded right away.
Algorithm Documents Percentage
Threshold 93,604,922 71.67%Language 16,882,377 12.93%Perfect dup. 3,179,884 2.43%Near dup. 9,175,335 7.03%
Total 122,842,518 94.06%
Table 2: Number of documents discarded by the con-secutive post-processing algorithms and percentagediscarded from the total number of crawled documents(DECOW2012)
4.2. Duplication
Although w-shingling removes more than half of thedocuments left over from previous post-processingsteps (see Table 4), we still have some amount ofduplication in our corpora. In order to roughly esti-mate the magnitude of the remaining duplication, weare considering keywords in context (KWIC), usingthe following procedure: (1) Choose a frequent wordform. (2) Extract all its occurrences from the corpus,plus a context ofn characters to its left and right. (3)Count the repetitions. The results reported below wereobtained withn = 60, corresponding to approx. 7 – 9words on either side of the keyword. Thus, the stretchof text is, in almost all cases, larger than the 5-shinglesused in duplicate detection. This approach is not di-rectly indicative of the number duplicated documents,both because it is likely to yield more than one rep-etition in the case where two documents are actually
DECOW2012 DEWAC9.1 G tokens 1.6 G tokens
keyword % keyword %und 9.25 der 11.40die 5.70 die 11.19der 6.11 und 11.09
ESCOW2012 FRWAC1,6 G tokens 1.6 G tokens
keyword % keyword %de 7.15 de 17.38la 5.99 la 17.33que 7.28 et 17.80
Table 3: Duplicated strings: keyword plus 60 charac-ters to left and right
Corpus Before After % Reduction
DECOW2012 16.94 7.63 54.9ESCOW2012 3.50 1.30 63.0
DEWAC 1.75 1.50 14.3
FRWAC 2.27 1.47 35.0
Table 4: Reduction in millions of documents by w-shingling (5% or higher w-shingling overlap; samecriteria applied to the WaCky corpora).
duplicated, and because it will not only count dupli-cated documents, but also all sorts of quotations oc-curring in documents, which represent an unavoidablekind of duplication. In short, the method is likely tooverestimate the actual amount of duplication ratherthan to underestimate it. Table 3 shows the amountof duplication that remains in the published versionsof both the COW and the WaCky corpora detected bythe KWIC method. For each corpus, the three mostfrequent types were chosen as keywords.Finally, Table 4 shows the number of documents be-fore and after w-shingling, both for our German (DE-COW2012) and Spanish (ESCOW2012) corpora, andfor the German and French WaCky corpora. Notethat the WaCky corpora had already passed througha weaker process of duplicate detection (Baroni et al.,2009), and the counts shown illustrate the remainingamount of duplication which our tools (cf. 3.4.) re-moved.
4.3. Quality of Connected Text Detection
The quality of the connected text filter described in3.3. is difficult to assess. At this point, we can saythat as a language identifier, the algorithm can be con-figured to achievePrecision = 1, Recall = 0.97,
491

preliminarily evaluated on 120 randomly selected Ger-man Wikipedia documents, 100 German literary textsfrom the twentieth century, 5 German blog posts, and15 Wikipedia documents in Dutch, English, and 5 dif-ferent German dialects. The minimal loss in recallcomes from the negative classification of a few of theliterary documents which, admittedly, could be con-sidered stylistically marked.To make the algorithm work as a connected textdetector, the threshold has to be lowered consider-ably, and it then achieves (e. g., for DECOW2012):Precision > 0.95, Recall < 0.8. These last val-ues were obtained in an evaluation with 1,100 artificialdocuments consisting of a mix of sentences from con-nected German text and non-connected content wordsin varying proportions. These figures, however, arerough estimates, mainly because we lacked a satisfy-ing answer to the question of what defines a “doc-ument containing a significant amount of connectedtext in languageL”, which is why we chose to useartificial documents. Only with a proper operational-ization of this notion would a report of the precisionand recall of the connected text filter make true sense.Future work will therefore involve the definition of agold standard set of training and evaluation documentsfor each language.
4.4. Text Types and Genres
It is not our goal to build corpora which parallel anyexisting balanced corpora. Given this goal, providinginformation on the text type composition of our cor-pora is rather a matter of characterization than one ofevaluation. Although Sharoff (2006) is slightly differ-ent in his goals, we build on the taxonomy suggestedthere, which is itself derived from an EAGLES speci-fication. He examines a set of experimental web cor-pora and established general-purpose corpora with re-gard toauthorship, mode, audience, aim, domain. Werefer the reader to the paper (Sharoff, 2006, 77ff.) forthe details. In a test coding of two random samplesof 200 documents from the DECOW2011 test corpus,two coders were satisfied with the available categoriesfor authorship (with some necessary clarifications),mode, audience, andaim, but amendments were feltto be necessary fordomain. We therefore introducedone new value formode and completely re-groupeddomain. The modequasi-spontaneous is a relabel-ing of Sharoff’selectronic. The full revised codingguidelines are omitted here for space reasons, but canbe downloaded from the project web page.5 We areaware that there is an active research community onweb genres including interest in automatic detection
5http://hpsg.fu-berlin.de/cow/
Variable % Agreement Cohen’sκAuthorship 89.0 .85Mode 98.0 .94Audience 88.0 .64Aim 73.0 .61Domain 86.0 .82
Table 5: Inter-rater agreement for document classifi-cation categories (DECOW2012,n = 200)
and involving special fields such as sentiment analy-sis. However, at this point we are only interested in apreliminary overview of the balance of the major gen-res in our corpora.A major problem was how to deal with possible mul-tiple categorizations. For example, a blog post canbe aim: information, but the comments can turn thewhole web page into predominantlyaim: discussion.The problem manifests itself even more strongly inthe coding decisions fordomain. Since such conflictswere unresolvable in the given time frame and for thegiven purpose, we interpreted the lists of possible val-ues for most categories as hierarchical in the sensethat, in case of doubt, the topmost value should be se-lected. For the very frequent mix of blog posts (mode:written) and comments (mode: quasi-spontaneous)we introduced the new valuemode: blogmix. In Ta-ble 5, the inter-rater agreement (raw agreement andCohen’sκ) per category for two independent coders ofa DECOW2012 sample is shown. Table 6 provides thecategorization results for DECOW2012 (percentagesare consistently those of one of the coders, namely thefirst author of this paper) and ESCOW2012 (secondauthor). The sample size wasn = 200 as suggested bySharoff (2006), and we explicitly give the confidenceintervals at a90% confidence level. While the inter-rater reliability is very good, the confidence intervalsshow that taking a larger sample would be preferable.
5. Outlook
Future versions of the software are planned to include,among other things, (i) parallelization oftexrex, (ii)a minimal crawler system to allow corpus construc-tion without the need for search engines and complexcrawler systems like Heritrix, (iii) full Unicode sup-port and codepage conversion (based on the ICU li-brary). We are also planning to report on the qualityof existing models of POS taggers and other tools forlinguistic post-processing when applied to web cor-pus data, possibly training new models that are bet-ter suited to the kind of data. Finally, better auto-matic recognition of document structure and richer
492






























