Embed Size (px)
Citation preview

Boosting Unsupervised Language Acquisition with ADIOSEytan Ruppin
Schools of Computer Science & Medicine
Tel-Aviv University December 2006
http://www.tau.ac.il/~ruppin

Overview
• An overview of ADIOS
• The ConText algorithm
• Monty Python something completely different – Mex in the service of mankind..

Unsupervised Learning of Natural Languages - ADIOS
Zach Solan
School of Physics and Astronomy
Tel-Aviv University
http://www.tau.ac.il/~zsolan
Zach Solan, David Horn, Eytan Ruppin
Tel Aviv University
Shimon Edelman
Cornell

Previous work
• Probabilistic Context Free Grammars
• ‘Supervised’ induction methods
• Little work on raw data– Mostly work on artificial CFGs– ABL, EMILE, etc. – Unsupervised parsing -
do not examine the generative capacity of the grammar

Our goal
• Given a corpus of raw text separated into sentences, we want to derive a specification of the underlying grammar
• This means we want to be able to– Create new unseen grammatically correct
sentences (Precision)– Accept new unseen grammatically correct
sentences and reject ungrammatical ones (Recall)

A broad scope..
• Natural language sentence •A musical piece
•A biological sequence (DNA, proteins, . . .) •Successive actions of a WEB user
•Chronological series

ADIOS in outline
• Composed of three main elements– A representational data structure– A segmentation criterion (MEX)– A generalization ability
• We will consider each of these in turn
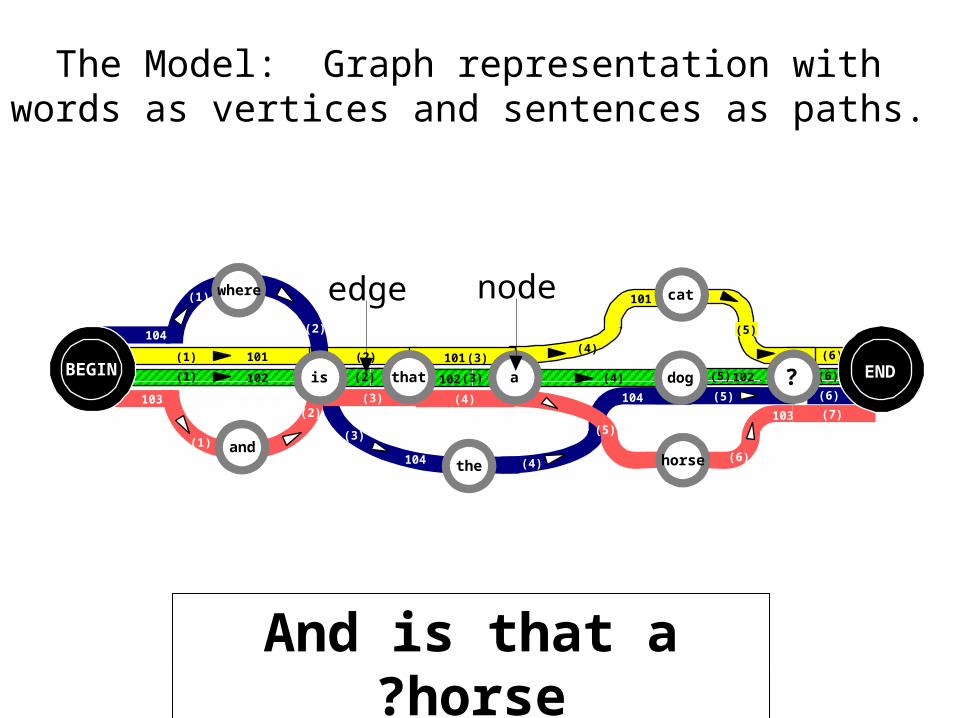
Is that a dog?
(6)102(5)(4)102 (3)
(4)
101
101)1( (2) 101 (3)
103
(1)
104
(1)
(2)
104
(3)
(2)(3)
103
(6)
(5)
(7)
(6)
)6(
(5)
where
104
(4)the
dog ? END
(4)
(5)
a
andhorse
)2( that
cat
102(1)BEGIN is
Is that a cat?Where is the dog? And is that a horse?
nodeedge
The Model: Graph representation with words as vertices and sentences as paths.

ADIOS in outline
• Composed of three main elements– A representational data structure– A segmentation criterion (MEX)– A generalization ability

Detecting significant patterns
• Identifying patterns becomes easier on a graph– Sub-paths are automatically aligned
search path
4 5
1
2
36 7
e1 end
5 4
7
1
23
vertex
path
begin
8
e4 e5 e6
86
A
e3e2
9Initialization

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p
e1 e2 e3 e4 e5
significantpattern
PR)e2|e1(=3/4
PR)e4|e1e2e3(=1
PR)e5|e1e2e3e4(=1/3
PL)e4(=6/41
PL)e3|e4(=5/6
PL)e2|e3e4(=1
PL)e1|e2e3e4(=3/5
PL
SLSR
PR
PR)e1(=4/41
PR)e3|e1e2(=1
begin end
Motif EXtraction

search path1
2
36 7
e1 end
5 4
7
1
2
3
vertex
begin
8
e4 e5 e6
54
76
5 4
6 73
e2
new vertex
86
11
e3e2
e3
9
3
9
e4
8
8
C rewiring
e2 e3 e4
P1
4 5
path9
9
Rewiring the graph
Once a pattern is identified as significant, the sub-paths it subsumes are merged into a new vertex and the graph is rewired accordingly. Repeating this process, leads to the formation of complex, hierarchically structured patterns.

ADIOS in outline
• Composed of three main elements– A representational data structure– A segmentation criterion (MEX)– A generalization ability

Generalization – defining an equivalence class
show me flights from philadelphia to san francisco on wednesdays
list all flights from boston to san francisco with the maximum number of stops
show flights from dallas to san francisco
may i see the flights from denver to san francisco please
show me flights from to san francisco on wednesdays
boston philadelphia
denverdallas
Generalized search path:

Generalization
E1
took chair
equivalent paths
bed
table
the
5
to
E1
table
bed
chair
L
took the to
identification of candidate equivalenceclasses
newequivalence class

Context-sensitive generalization
• Slide a context window of size L across current search path
• For each 1≤i≤L – look at all paths that are identical with the search
path for 1≤k≤L, except for k=i– Define an equivalence class containing the nodes
at index i for these paths– Replace i’th node with equivalence class– Find significant patterns using MEX criterion

Bootstrapping
What are the cheapest from to that stop in atlanta
boston philadelphia
denver
Generalized search path II:
denver philadelphia
dallas
flightflightsairfare
fare
_P2: the cheapest _E2 from _E3 to _E4
flightflightsairfare
fare
boston philadelphia
denver
denver philadelphia
dallas_E2 = _E3 = _E4 =

Bootstrapping
E1E2
blue
green
redthe
E1E2
green
blue table
bedbed
to
table
chair
bed
L
storedequivalence class
equivalent pathsbootstrapping
tochairtook red
newequivalence class

The ADIOS algorithm
• Initialization – load all data into a pseudograph
• Until no more patterns are found– For each path P
• Create equivalence class candidates• Detect significant patterns using MEX• If found, add best new pattern and its associated
equivalence classes and rewire the graph

The ATIS experiments
• ATIS-NL is a 13,043 sentence corpus of natural language– Transcribed phone calls to an airline reservation
service
• ADIOS was trained on 12,700 sentences of ATIS-NL– The remaining 343 sentences were used to
assess recall– Precision was determined with the help of 8
graduate students from Cornell University

The ATIS experiments
• ADIOS’ performance scores –– Single learner Recall – ~12%, approaching
40% with multiple learners (70% with semantic bootstrapping)
– Precision – 50%
• For comparison, Human-crafted ATIS-CFG reached –– Recall – 45%– Precision - <1%(!)

English as Second Language test
• A single instance of ADIOS was trained on the CHILDES corpus– 120,000 sentences of transcribed child-directed
speech
• Subjected to the Goteborg multiple choice ESL test– 100 sentences, each with open slot– Pick correct word out of three
• ADIOS got 60% of answers correctly– An average ninth-grader performance

Language dendogram
TT TE TP ET EE EP PT PE PPTT
TTT
ETT
PTE
TTE
ETE
PTP
T
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
A B
Chinese
Spanish
French
English
Swedish
Danish
C
D E

Language modeling: Perplexity
ATIS Ver Language Model Perplexity
2 ADIOS 11.5
2 Trigram Kneser-Ney Back-Off smoothing 14
2 PFA Inference (ALERGIA) + trigram 20
3 ADIOS 13.5
3 SLM-wsj + trigram 1.E+05 15.8 [10] 15.8
3 NLPwin + trigram 15.9
3 SLM-atis + trigram 15.9
The lower perplexity of ADIOS, compared with results from the standard benchmarks (McCandless & Glass 1993, Chelba 2001, and Kermorvant
2004).

So far so good..

Shortcomings of ADIOS
• Problem I: Equivalence classes may be declared without sufficient evidence:– That two words are contained in an identical
5-word window is often enough for them to be declared interchangeable
• Negatively impacts the learned grammar’s precision
Brian likes to go fishingJohn and Brian like to go fishing

Shortcomings of ADIOS
• Problem II: Segmentation criterion is decoupled from search for equivalence classes, and from the potential contribution of patterns to generalization.
from baltimore
from baltimore
san francisco to
atlanta to

The ConText AlgorithmBen Sandbank
School of Computer Science
Tel-Aviv University
http://www.cs.tau.ac.il/~sandban
Eytan Ruppin
Tel Aviv University
Shimon Edelman
Cornell

The ConText Algorithm
• Main concepts– Maintain the ADIOS principle of context-
dependent generalization, but;– Utilize distributional clustering concepts to
safely detect interchangeability (Problem I)– Declare constituents only when necessary for
generalization (Problem II)

Algorithm outline• Calculate the context distribution of all word-sequences
that occur more than K times– the context of a sequence is the l-word neighborhood on both its
sides
• Cluster sequences according to distance in context-space• Find optimal alignment within each cluster
– Yielding interchangeable words and expressions (note that this process obviates ADIOS’ segmentation process)
• Merge sequences within each cluster to yield a single generalized sequence
• Load resulting equivalence classes back to the corpus in a context-sensitive way, using the remaining terminal words.
• The collection of sentences and equivalence classes hierarchy obtained forms a context-free grammar.

Clustering procedure• Each word sequence is represented as a high-dimensional
vector constructed in the following way:– For each sequence, create a context vector on its left and on its
right– The i’th entry in the left (right) context vector contains the
number of times the corresponding l-word-sequence appeared to the immediate left (right) of the represented sequence
– The two vectors are linked to form one long vector
• The distance metric used between two sequences is the angle between their corresponding vectors– No smoothing, TF/IDF or the like is performed
• A parameter determines the minimum distance between two sequences that allows for their clustering in the same cluster

Alignment procedure
• Aims at finding interchangeable words and word sequences between every pair of alignable sequnces
• A straightforward extension of dynamic programming, where in each step we look for the best alignment of the i,j+1 prefixes, given the best alignments up to the i,j prefixes (yielding an O(n^4) complexity).
• Input – clusters of word sequences• Output –
– A substitution cost matrix between subsequences• Which may each contain more than one word• Insertions and deletions currently not supported
– The optimal pairwise alignments within each cluster

Alignment procedure
• Initialize substitution cost matrix– The cost of substituting subsequence of length i
words with subsequence of length j words is min(i, j)• Unless they’re identical and the cost is zero
• Iterate until convergence in alignment– Find the optimal pairwise alignment between each
pair of sequences contained in the same cluster– For each substitution used in the optimal alignment,
multiply its cost in the substitution matrix by alpha<1• Allows ‘sharing information’ between clusters

Toy Sample - Resulting Sentence
I’d like to order a flightto order a flight
I wantneed
would like
I’d like
to a flightorderbook
I wantneed
would like
I’d like
to aorderbook
I wantneed
would like
I’d like
atlantabaltimore
washington…
flight from to
atlantabaltimore
washington…
flighttrip

Results
• Tested on ATIS-2– A natural language corpus of transcribed
spontaneous speech– Contains 11,670 sentences– 11,370 were used for training, 300 for recall testing
• Two main parameters affect quality of results – D - The minimum distance for two sequences to
become clustered– K - The minimum number of times a sequence must
appear in the corpus to be considered for clustering

Results – K=25
ADIOS results:
Recall 0.12
Precision 0.5

Results – D=0.7K Recall Precision
10 0.13 0.76
20 0.14 0.64
30 0.12 0.8
40 0.13 0.85
•Surprisingly – no clear connection
between K and recall/precision rates
–Although a general precision trend is
discernable

Conclusions
• On ATIS-2, ConText is superior in performance to ADIOS
• Use of distributional clustering method provides significantly higher precision
• Recall is marginally improved, – Additional iterations (after rewiring) are expected to improve
recall further, but when naively implemented hamper precision– Introducing asynchronous dynamics in the alignment procedure
may enable higher recall through multiple learners.
• Quality of results seems to depend more on D than on K

Functional representation of enzymes by specific peptides
David HornTel Aviv University
http://horn.tau.ac.il
in collaboration with
Vered Kunik, Yasmine Meroz, Zach Solan, Ben Sandbank, Eytan Ruppin

Application to Biology
Vertices of the graph: 4 or 20 lettersPaths: gene-sequences, protein-
sequences.
Transition probabilities on the graph are proportional to the number of
pathsTrial-path: testing transition
probabilities to extract motifs

The functionality of an enzyme is determined
according to its EC number
Classification Hierarchy [ Webb, 1992 ]
n1.n2: sub-class / 2nd level
n1: class
n1.n2.n3: sub-subclass / 3rd level
n1.n2.n3.n4: precise enzymatic activity
Enzyme Function
EC number: n1.n2.n3.n4 (a unique identifier)

Mex motifs are extracted from the enzymes dataA linear SVM is applied to evaluate the predictive
power of MEX motifs Enzyme sequences are randomly partitioned
into a training-set and a test-set (75%-25%) 16 2nd level classification tasks 32 3rd level classification tasks Performance measurement: Jaccard Score The train-test procedure was repeated 40 times
to gather sufficient statistics
Methods

Assessing Classification Results
Classifications performance are compared to those of two other methods:
Smith-Waterman algorithm [ Identification of Common Molecular Subsequences. JMB, 1981 ]
p-value of pairwise similarity score SVMProt [ Cai et al. Nucleic Acids Research, 2003 ]
physicochemical properties of AA
Both methods require additional information
apart from the raw sequential data

0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
11
.1
1.1
4
1.6
1.9
1.2
1.1
1
1.3
1.8
1.1
5
1.4
1.1
8
1.7
1.1
7
1.1
3
1.1
0
1.5
MEXSmith-Waterman SVMProt
* * **
* ***
*
*
Jaccard
Score
EC Subclassα < 0.01
2nd Level Classification

0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
1.05
1.1
1.1.1
1.9.3
1.2.1
1.6.5
1.11.1
1.14.1
41.1
5.1 1.3.3
1.8.4
1.18.6
1.14.1
3 1.8.1
1.17.4 1.4
.11.6
.991.1
3.11 1.7
.11.4
.31.1
4.99 1.3
.11.2
.41.1
4.15
1.3.99
1.10.3
1.14.1
9 1.5.1
1.14.1
11.1
4.16 1.6
.21.1
8.11.4
.991.1
.99
MEXSmith-Waterman
**
* * *
*
* *
*
*
*
*
*
* * **
* *
*
* *
3rd Level Classification
α < 0.01
Jaccard
Score
EC Sub-subclass

EC hierarchy and specific peptides

questions
• Do SPs have biological relevance?
• Are they accounted for in the literature?
• Generalization of the classification
• The question of bias
• Remote homology

Examples of two level 4 classes
5.1.3.20 protobacteria 5.1.3.2 bacteria and eukaryotes

P67910
1,2,3
are active sites
S,Y,K
4 :RYFNV



Generalization: double annotation
Doubly annotated enzymes were not included in the training set (the data)
260 such enzymes exist.
SPs have 421 hits on 69 of them. Most agree with annotations. 30 disagree, leading to new predictions.

Remote homology
Examples taken from Rost 2002, pointing out disparity between identity and function. Here function verified by SPs.

Summary
• Specific peptides (average length 8.4), extracted by MEX, are useful for functional representation of most enzymes (average length 380).
• SPs are deterministic motifs conserved by evolution, hence expected to have biological significance.
• SP4s are observed to cover active and binding sites.
• Some other SPs seem to be important, judging by their spatial locations.
• SPs are important for remote homologies





























