Embed Size (px)
Citation preview

BigDataAnalytics:TheApacheSparkApproach
Michael FranklinATPESC
August 2017

Nearlyeveryfieldofendeavoristransitioningfrom“datapoor”to“datarich”
Astronomy:LSST
2
Physics:LHCOceanography
Sociology:TheWeb
Biology:SequencingEconomics:mobile,
POSterminals
Neuroscience:EEG,fMRI
Data-DrivenMedicine Sports

The Fourth Paradigm of Science1. Empirical+ experimental2. Theoretical3. Computational4. Data-Intensive
3

OpenSourceEcosystem&Context
4
���
2006-2010 Autonomic Computing & Cloud
UC BERKELEY
2011-2016 Big Data Analytics
Usenix HotCloud Workshop 2010

AMPLabProjectVision“MakingSenseofDataatScale”
Algorithms
• MachineLearning,StatisticalMethods• Prediction,BusinessIntelligence
Machines
• ClustersandClouds• WarehouseScaleComputing
People
• Crowdsourcing,HumanComputation• DataScientists,Analysts
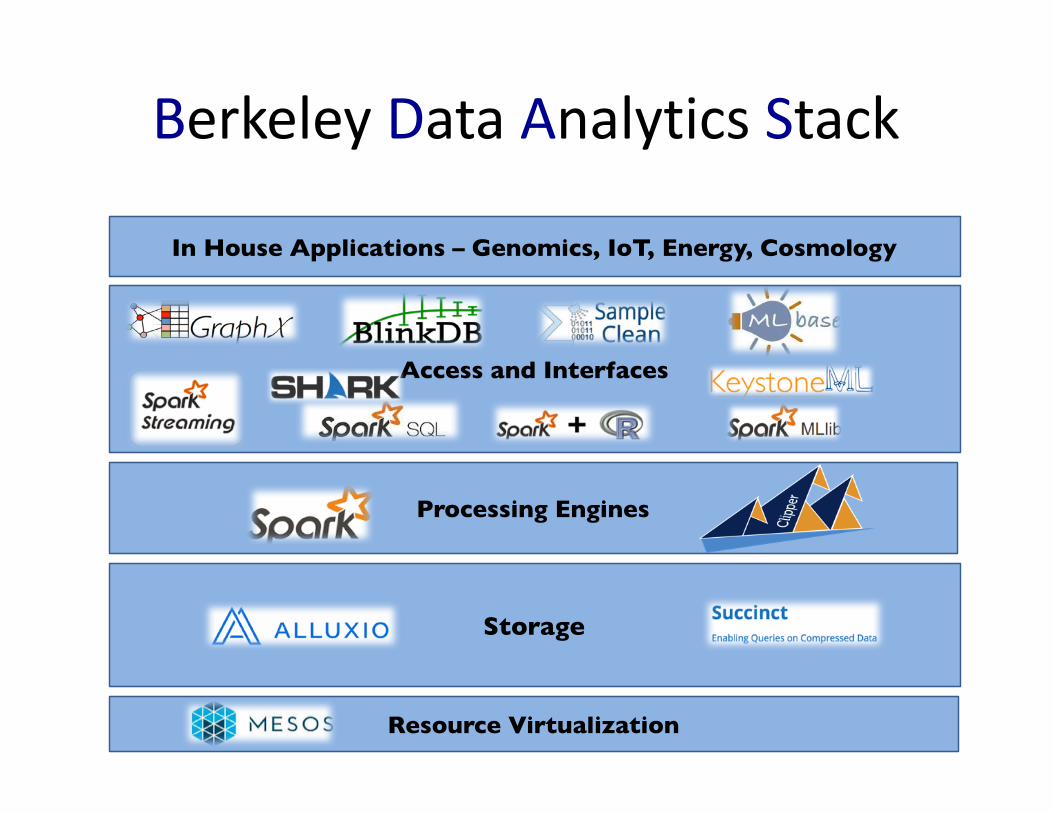
BerkeleyDataAnalyticsStack
In House Applications – Genomics, IoT, Energy, Cosmology
Access and Interfaces
Processing Engines
Resource Virtualization
Storage

SomeAMPLabnumbers• Funding– roughly50/50Govt/IndustrySplit
– NSFCISEExpeditions,DARPA,DOE,DHS– Google,SAP,Amazon,IBM(FoundingSponsors)+dozensmore
• Nearly2Mvisitstoamplab.cs.berkeley.edu• 200+PapersinSys,ML,DB,…3ACMDissertationAwards
(1+2HM);NumerousBestPaperandBestDemoAwards• 40+Ph.D.s granted(sofar);AlumnionfacultyatBerkeley,
HarveyMudd,Michigan,MIT,Stanford,Texas,Wisconsin,…• 3SpinoutcompaniesdirectlyfromAMPLab:
– Databricks,Mesosphere,Alluxio– Nearly$250Mraisedtodate
• Manyindustrialproducts&servicesbasedonorusingSpark• 3Marriages(andnumerouslong-termrelationships)
7

ApacheSparkMeetups (August2017)
8
618 groups with 391,371 membersspark.meetup.com

WeHitADataManagementInflectionPoint
• Massivelyscalable processingandstorage• Pay-as-you-go processingandstorage
(a.k.a.thecloud)• Flexible schemaonreadvs.schemaonwrite• Integration ofsearch,queryandanalysis• Sophisticated machinelearning/prediction• Human-in-the-loop analytics• Opensourceecosystem drivinginnovation
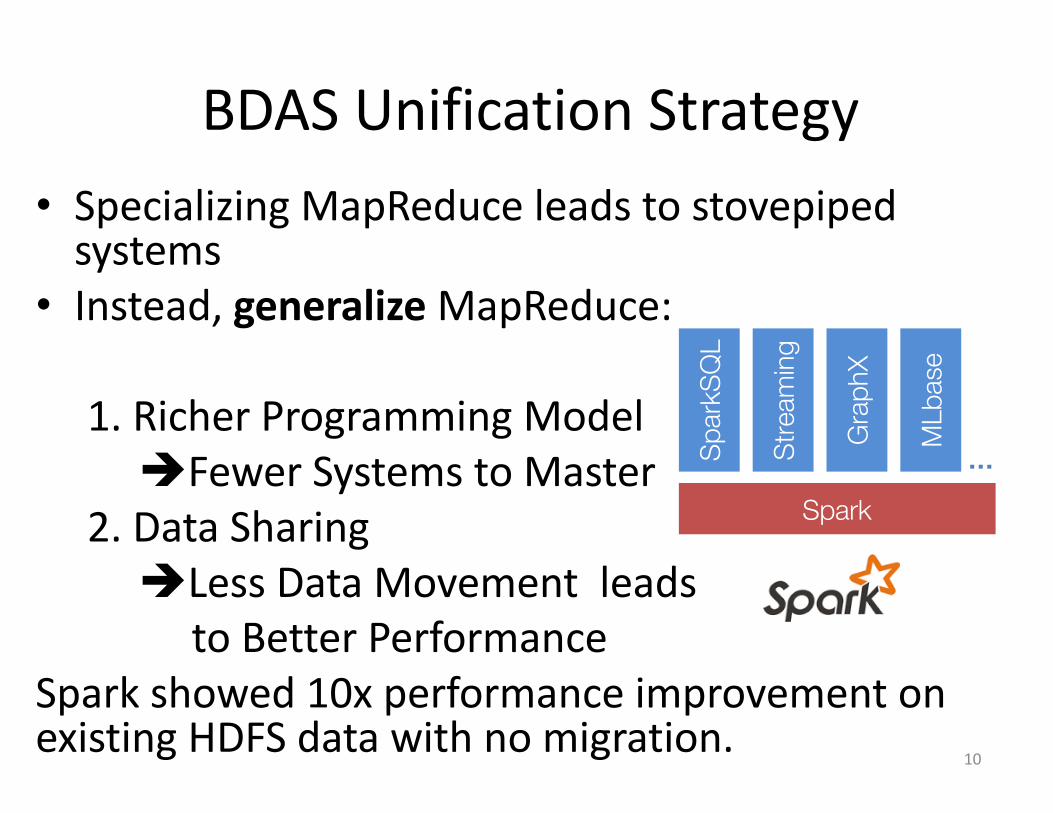
BDASUnificationStrategy• SpecializingMapReduce leadstostovepipedsystems
• Instead,generalizeMapReduce:
1.RicherProgrammingModelèFewerSystemstoMaster
2.DataSharingèLessDataMovementleads
toBetterPerformanceSparkshowed10xperformanceimprovementonexistingHDFSdatawithnomigration.
Spark
Stre
aming
Gra
phX
…Spar
kSQ
L
MLb
ase
10

Abstraction:DataflowOperators
• map
• filter
• groupBy
• sort
• union
• join
• leftOuterJoin
• rightOuterJoin
• reduce
• count
• fold
• reduceByKey
• groupByKey
• cogroup
• cross
• zip
sample
take
first
partitionBy
mapWith
pipe
save
...
11
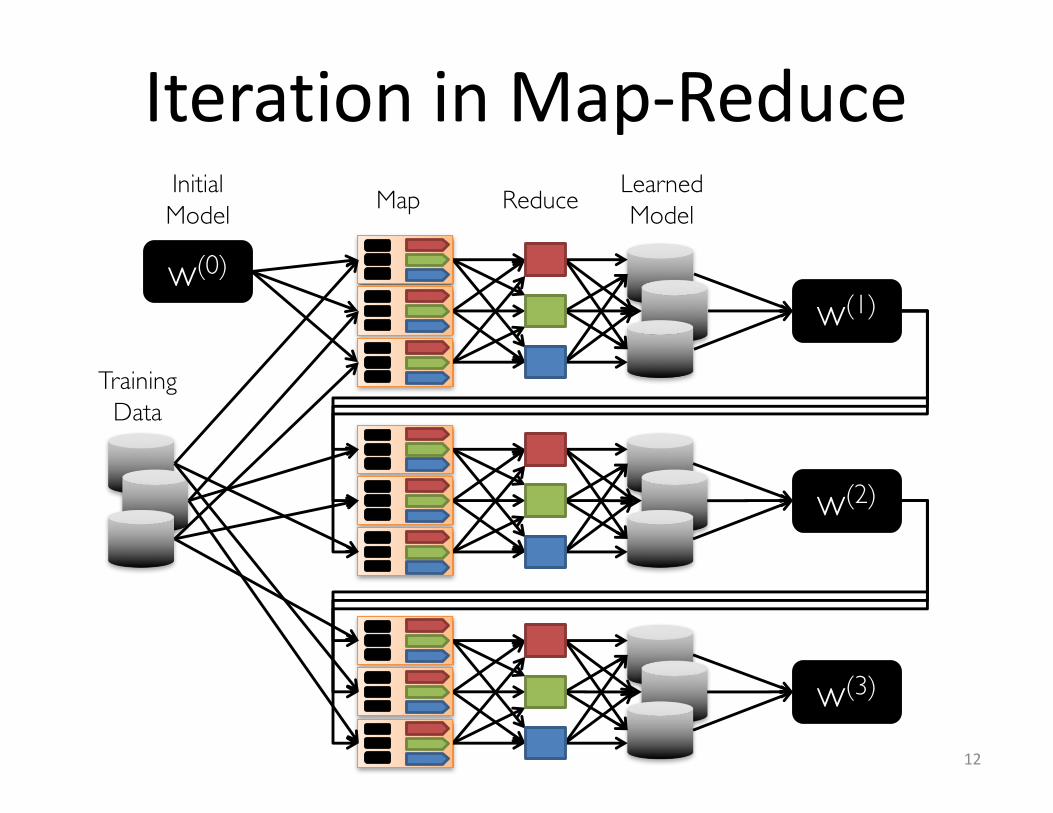
IterationinMap-Reduce
TrainingData
Map Reduce LearnedModel
w(1)
w(2)
w(3)
w(0)
InitialModel
12

CostofIterationinMap-ReduceMap Reduce Learned
Model
w(1)
w(2)
w(3)
w(0)
InitialModel
TrainingData
Read 2Repeatedlyload same data
13

CostofIterationinMap-ReduceMap Reduce Learned
Model
w(1)
w(2)
w(3)
w(0)
InitialModel
TrainingDataRedundantly saveoutput between
stages
14
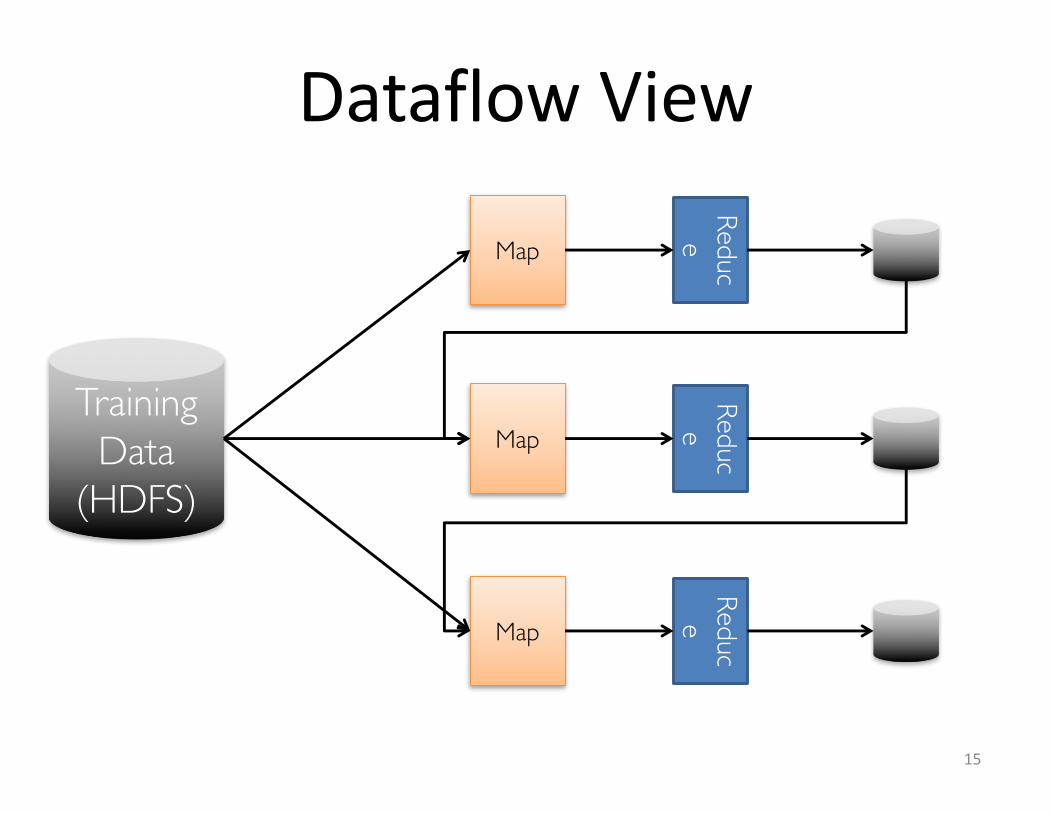
DataflowView
Training Data
(HDFS)
Map
Reduce
Map
Reduce
Map
Reduce
15

MemoryOpt.Dataflow
Training Data
(HDFS)
Map
Reduce
Map
Reduce
Map
Reduce
CachedLoad
16

MemoryOpt.DataflowView
Training Data
(HDFS)
Map
Reduce
Map
Reduce
Map
Reduce
Efficientlymove data betweenstages
Spark:10-100× faster than Hadoop MapReduce17

SparkFaultTolerance• RDDs:Immutable collectionsofobjectsthatcanbestoredinmemoryordiskacrossacluster– Builtviaparalleltransformations(map,filter,…)– Automaticallyrebuilton(partial)failure
M.Zaharia,etal,ResilientDistributedDatasets:Afault-tolerantabstractionforin-memoryclustercomputing,NSDI2012. 18
messages = textFile(...).filter(_.contains(“error”)).map(_.split(‘\t’)(2))
HadoopRDDpath=hdfs://…
FilteredRDDfunc =_.contains(...)
MappedRDDfunc =_.split(…)

DataFrames(mainabstractioninSpark2.0)
employees
.join(dept,employees("deptId")=== dept("id"))
.where(employees("gender")==="female")
.groupBy(dept("id"),dept("name"))
.agg(count("name"))
Notes:1) Some people think this is an improvement over SQL J2) Dataframes can be typed
19

CatalystOptimizer• TypicalDBoptimizationsacrossSQLandDF– ExtensibilityviaOptimizationRuleswritteninScala– OpenSourceoptimizerevolution!
• Codegenerationforinner-loops,iteratorremoval• ExtensibleDataSources:CSV,Avro,Parquet,JDBC,…viaTableScan (allcols),PrunedScan (project),FilteredPrunedScan(pushadvisoryselectsandprojects)CatalystScan (pushadvisoryfullCatalystexpressiontrees)• Extensible(UserDefined)Types
20
M.Armbrust,etal,SparkSQL:RelationalDataProcessinginSpark,SIGMOD2015.
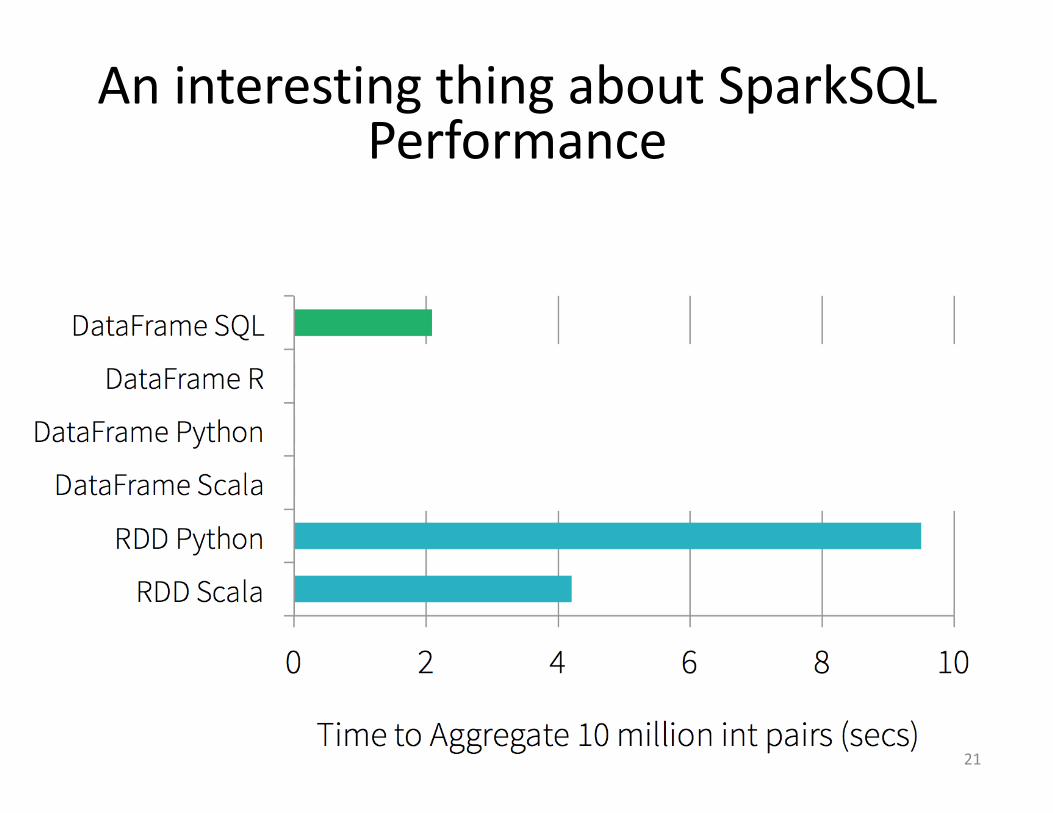
AninterestingthingaboutSparkSQLPerformance
21

LambdaArchitecture:onewaytocombineReal-Time+Batch
• lambda-architecture.net22

SparkStreaming• Microbatch approachprovideslowlatency
Additional operators provide windowed operations
M.Zaharia,etal,DiscretizedStreams:Fault-Tollerant StreamingComputationatScale,SOSP2013S.Venketaraman etal,Azkar:FastandAdaptableStreamProcessingatScale,SOSP2017 23

SparkStructuredStreams(unified)
24
Batch Analytics
Streaming Analytics

25
SQL
MachineLearning
Streaming
PuttingitallTogether:Multi-modalAnalytics


27
From:SparkUserSurvey2016,1615respondentsfrom900organizationshttp://go.databricks.com/2016-spark-survey

28
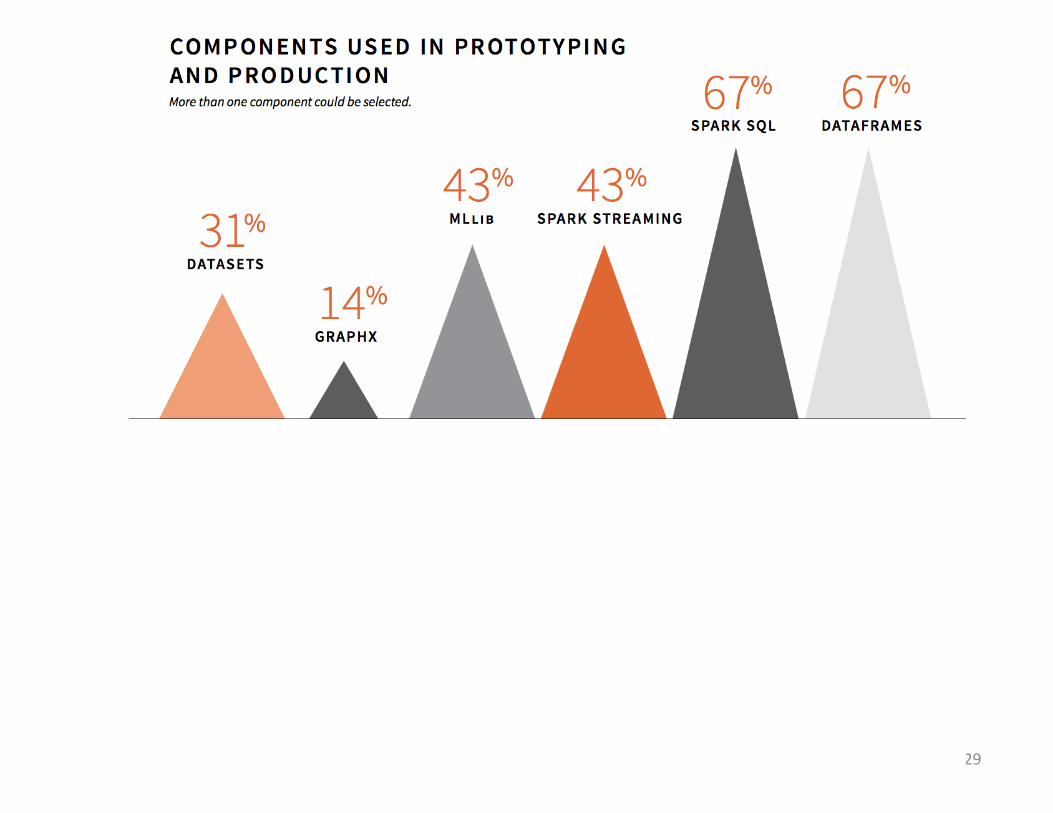
29

30

SparkEcosystemAttributes
• Sparkfocuswasinitiallyon– Performance +Scalability withFaultTolerance
• Eventually,easeofdevelopment wasakeyfeature– especiallyacrossmultiplemodalities:DB,Graph,Stream,etc.
• ThiswastrueofmostBigDatasoftwareofthatgeneration
• LowLatency(streaming)andDeepLearning arealsogarneringsignificantattentionlately

What’sNext?Innovationin(opensource)BigDataSoftwarecontinues.Performance,Scalability,andFaultToleranceremainimportant,butwefacenewchallenges,including:DataScienceLifecycle
• DataAcquisition,Integration,Cleaning(i.e.,wrangling)• DataIntegrationremainsa“wickedproblem”• ModelBuilding• Communicatingresults,Curation,“TranslationalDataScience”
EaseofDevelopmentandDeployment• Canleveragedatabaseideas(e.g.,declarativequeryoptimization)• Newcomponentsfor“modelserving”and“modelmanagement”
“Safe”DataScience• end-to-endBiasMitigation• Security,EthicsandDataPrivacy• Explainingandinfluencingdecisions• Human-in-the-loop






























