Embed Size (px)
Citation preview

1
Aplicaciones de Modelos Mixtos en Agricultura y Forestería
Dra. Mónica Balzarini (Univ. Nacional de Córdoba, Argentina) Dr. Raúl E. Macchiavelli (Universidad de Puerto Rico)
Dr. Fernando Casanoves (CATIE, Costa Rica)

2
Contenidos
Introducción. ..................................................................................................................... 3 Fundamentación ................................................................................................................................................... 3 Revisión Conceptual ........................................................................................................................................... 4 Tipos de Modelos Mixtos ................................................................................................................................. 11
Módulo 1. Ejemplos de Motivación ................................................................................. 13 1.1. Medidas Repetidas / Datos Longitudinales ......................................................................................... 13 1.2. Curvas de Crecimiento ............................................................................................................................. 21 1.3. Experimentos Multi-ambientales ............................................................................................................ 30 1.4. Correlación Espacial en Ensayos a Campo ........................................................................................ 32
Módulo 2. Introducción ................................................................................................... 37 2.1 Modelo Lineal General de Efectos Mixtos / Conceptos Generales ................................................ 37 2.2 Modelos Marginales versus Modelos Jerárquico ............................................................................... 45 2.3 Modelos para la Estructura de Covarianza Residual (modelos de patrones de covarianza) .. 45 2.4 Estimación de Covarianzas en Poblaciones Normales ..................................................................... 46 2.5. Inferencia sobre componentes de varianza. ....................................................................................... 51 2.6. Inferencia sobre Efectos Aleatorios. Mejor Predictor Lineal Insesgado (BLUP). ...................... 52 2.7 Criterios de Bondad de Ajuste ................................................................................................................. 58
Módulo 3: Modelación de Datos Normales .................................................................... 60 3.1 Modelos para Datos Longitudinales. Aplicaciones en Agricultura. ............................................... 60 3.2 Modelos Lineales para Curvas de Crecimiento. Aplicaciones en Forestería .............................. 77 3.3 Modelos para Interacción. Aplicaciones en Fitomejoramiento ..................................................... 113 3.4 Modelos de Correlación Espacial .......................................................................................................... 129
Módulo 4. Ajuste de Modelos No-Lineales con Datos Normales o No-Normales ......... 148 4.1. Modelo No Lineal de Curvas de Crecimiento con Coeficientes Aleatorios .............................. 148 4.2. Modelo Lineal Generalizado Mixto. Ingredientes claves. ............................................................... 164 4.3 Aplicaciones de Modelos Lineales Generalizados con otras distribuciones. ........................... 176
Bibliografía ................................................................................................................... 188

3
Introducción. Fundamentación
La investigación en Agricultura y Forestería comúnmente presenta situaciones en
las que es difícil utilizar los modelos lineales clásicos de análisis de varianza y regresión
porque no se cumplen los supuestos de independencia, normalidad, igualdad de
varianzas o incluso linealidad. La modelación de datos experimentales en el marco
teórico de los modelos lineales y generalizados mixtos brinda la posibilidad de analizar
datos con estructuras de dependencia, desbalances y falta de normalidad. Es así
posible relajar los supuestos tradicionales del modelo lineal general y modelar, de
manera flexible, estructuras complicadas de datos. Los modelos mixtos se adecúan
bien en situaciones son comunes en Agricultura y Forestería, como por ejemplo cuando
existe algún tipo de estructura de bloqueo de unidades experimentales que afecta las
covarianzas entre observaciones. Ilustran este tipo de situación aquellos estudios
donde el material experimental se evalúa en varios ensayos y por tanto es razonable
asumir que existen correlaciones entre observaciones del mismo ensayo. La
modelación en el marco de los modelos mixtos maneja estas correlaciones mediante la
incorporación de variables aleatorias o mediante la modelación directa de la matriz de
covarianzas residual. Diversas estrategias, bajo el mismo marco teórico permiten
modelar variabilidad sobre y más allá de la componente usual asociada a los términos
de error.
Existen muchos beneficios que pueden obtenerse con el uso de modelos mixtos.
En algunas situaciones se incrementa la precisión de las estimaciones. En otras se
contempla mejor la estructura y se amplia el espacio de inferencia, sobre todo cuando
la estructura de los datos es jerárquica. Este material de referencia se ha preparado
para ejemplificar las estrategias de ajuste mediante el análisis de casos y los recursos
computacionales que ofrece SAS versión 8 y posteriores (SAS Institute, 1998). Se
presentan contenidos preliminares sobre aspectos relacionados al modelo mixto clásico
y seguidamente ejemplos motivadores donde los modelos mixtos son particularmente
útiles, incluyendo casos de medidas repetidas / datos longitudinales, curvas de
crecimiento, experimentos multi-ambientales y de correlación espacial. Los ejemplos

4
tratados están relacionados al área de la agricultura y la forestería. En esta sección
introductoria se realiza una revisión conceptual del Modelo Lineal de Efectos Mixtos. En
el Módulo 1 se presentan los ejemplos que serán tratados posteriormente mediante
algún tipo de modelo mixto. En el Módulo 2 se introducen los conceptos teóricos más
relevantes incluyendo la idea de modelos marginales y jerárquicos y los procesos de
estimación para el caso de datos normales. El ajuste de modelos y la interpretación de
resultados para los ejemplos de casos normales se realizan en el Módulo 3, mientras
que en el Módulo 4 se hace referencia a aplicaciones para modelos no-lineales y para
datos no-normales. El material tiene la finalidad de favorecer la conceptualización de la
modelación estadística considerando las implicaciones prácticas de su uso.
Revisión Conceptual
Los modelos estadísticos mixtos permiten modelar la respuesta de un estudio
experimental u observacional como función de factores o covariables cuyos efectos
pueden considerarse tanto como constantes fijas o variables aleatorias. Cada modelo
estadístico que contiene una media general, µ, es un modelo mixto por definición, ya
que también contiene un término de error aleatorio, y por tanto contiene ambos tipos de
efectos. Sin embargo, en la práctica, el nombre modelo mixto se reserva usualmente
para cualquier modelo que contiene efectos fijos distintos a µ y efectos aleatorios
diferentes a los errores aleatorios. En casos donde existen otros efectos más allá de µ y
el término de error y todos son aleatorios, se llama al modelo como Modelo II para
diferenciarlo del Modelo I donde todos los factores tienen efectos fijos.
En general, un efecto es considerado como fijo si los niveles del factor asociado
han sido arbitrariamente determinados por el investigador mientras que se trata como
aleatorio si los niveles en el estudio pueden ser considerados como una muestra
aleatoria de una población de niveles para el factor, es decir existe una distribución de
probabilidad asociada. Para decidir cuándo un conjunto de efectos va a ser tratado
como fijo o aleatorio es importante analizar el contexto de los datos, es decir el
ambiente desde el cual ellos provienen, la manera en la cual se obtuvieron y
principalmente el espacio de inferencia. Si los niveles del factor en consideración no
pueden considerarse como una muestra aleatoria de una población de niveles para ese

5
factor, los efectos deberían considerarse fijos y la inferencia restringirse a los niveles
del factor considerados en el estudio. Por el contrario, si se desea inferir para una
población de efectos de un determinado factor, los efectos actualmente considerados
en el estudio deberían tratarse como variables aleatorias.
Situación 1: Modelos de efectos fijos.
Consideremos un pequeño experimento diseñado para comparar a tratamientos
(entiéndase existe un factor tratamiento de interés con a niveles) que incluye n
unidades experimentales o repeticiones para cada tratamiento arregladas de acuerdo a
un diseño completamente aleatorizado (cada tratamiento se asigna aleatoriamente a n
unidades experimentales). Si yij representa la respuesta observada en la unidad j del
tratamiento i, yij puede considerarse como una observación aleatoria de una población
de observaciones bajo el tratamiento i, que podemos suponer tiene una distribución
normal con media µi y varianza σ2. Luego, un posible modelo para yij podría ser:
E(yij)= µi ,
donde E(.) representa el operador esperanza µi y es la respuesta esperada para una
observación bajo el tratamiento i. En este modelo, llamado modelo de medias, cada µi
es considerada como una constante. Dichas constantes (valores fijos) representan, en
algún sentido, las magnitudes que se desean estimar y comparar. Por ejemplo, puede
ser de interés estimar µi y µj, o µi-µj. Las constantes a estimar µi´s, con i=1,…,a,
corresponden explícitamente a los a tratamientos incluidos en el experimento. Existen a
tratamientos que son de interés y que por tanto han sido arbitrariamente seleccionados
por el investigador para el experimento. El efecto del tratamiento i se define como τi=µi-
µ , donde µ es la media general de la variable respuesta, por lo que el modelo puede
ser re-escrito como:
E(yij)= µ + τi,
que se conoce como modelo de efectos fijos. Los τi representan los efectos de
tratamiento y son obviamente constantes. Si eij representa el valor de la desviación o
diferencia entre yij y su valor esperado, término llamado error en yij, es posible modelar
los datos observados como la suma de su valor esperado y un error aleatorio,

6
yij = µi + eij o equivalentemente yij = µ + τi + eij .
Conforme a las propiedades distribucionales de yij, y a la definición de eij, los términos
de error son variables aleatorias con media cero,
E(eij)=E[yij -E(yij)]=0
a los cuales usualmente se les atribuye la siguiente estructura de varianzas y
covarianzas:
1. Cada eij tiene la misma varianza, σ2.
2. Los eij son independientes e idénticamente distribuidos, con covarianza entre
cualquier par de ellos igual a cero.
Es esta distribución de probabilidades asociada con los términos de error la que
provee los medios para hacer inferencias sobre las funciones de los µi que son de
interés y, si se desea, sobre σ2. Cabe destacar entonces que la manera en que se
obtienen los datos afecta la inferencia que se puede extraer desde ellos. En este
ejemplo se ha descripto el proceso de muestreo pertinente a un modelo de efectos fijos.
Los datos se consideraron como un conjunto posible de datos para estos a
tratamientos, conjunto que podría ser obtenido si se repite el experimento. Cada
repetición del experimento proporciona un muestra diferente de n unidades
experimentales para cada una de los a tratamientos. Los errores “realizados” en el
experimento conforman una muestra aleatoria de una población de términos de error
con media cero, varianza σ2 y covarianzas cero. Los datos en este estudio proveen
estimaciones de las medias de tratamiento y de diferencias entre ellas, la distribución
de los términos de error provee las varianzas para estas estimaciones. Por ejemplo, la
media muestral de las observaciones bajo el tratamiento i, iy , es un estimador de µi,
con varianza σ2/n, y la diferencias de medias muestrales, i jy y− , un estimador de µi-µj
con varianza 2σ2/n. En realidad, σ2 es desconocida y debe ser estimada. Debido a que
los términos de error tienen todos la misma varianza, cada una de las varianzas
muestrales es un estimador de σ2 con n-1 grados de libertad, por lo que el promedio de
las varianzas muestrales es un estimador de σ2 con a(n-1) grados de libertad. Éste es el

7
estimador usualmente preferido para estimar σ2 en las fórmulas de errores estándar de
las medias de tratamiento o de sus combinaciones lineales a los fines de la inferencia,
cuando los datos son balanceados.
Para ilustrar algunos cálculos relacionados al modelo de efectos fijos, se presenta la
Tabla 1, que contiene los rendimientos de frutas de 8 árboles antes y después de
aplicar un tratamiento de herbicidas en los alrededores del árbol.
Tabla 1. Rendimiento (cantidad de frutas) de 6 árboles bajo dos tratamientos: sin
desmalezado (B) y con desmalezado (A)
UE Trat A Trat B A-B Media 1 20 12 8 16.0 2 26 24 2 25.0 3 16 17 -1 16.5 4 29 21 8 25.0 5 22 21 1 21.5 6 24 17 7 20.5
Media 22.83 18.67 4.17 20.75
Supondremos en primera instancia que se tienen datos de dos tratamientos (A=con
desmalezado y B=sin desmalezado) aplicados a 6 unidades experimentales. El modelo
de análisis (Modelo A) y los cálculos correspondientes son:
2
2
´ ´ ´ ´ ´ ´
2
~ (0, )
var( )
cov( , ) cov( , ) cov( , ) 0
22.83 20.75 2.0818.67 20.75 2.08
4.16
( ) 2 ( / 6) 2 (19.42 / 6) 2.544.16 / 2.54 1.63, 0
ij j ij
ij
ij
ij i j j ij j i j ij i j
A
B
A B
A B
y t e
e N
yy y t e t e e e
ttt t
EE t tt p valor
µ
σ
σ
µ µ
σ
= + +
=
= + + + + = =
= − == − = −− =
− = × = × =
= = − = .13

8
Se concluye por lo tanto que no hay suficiente evidencias para rechazar la
hipótesis de igualdad de medias de tratamiento.
El Modelo A no tiene en cuenta que las observaciones del tratamiento A y B se
realizaron sobre la misma unidad experimental (árbol) y por ende están correlacionadas
(datos pareados). El efecto de la unidad experimental puede ser incluido en la ecuación
del modelo. Así el modelo no solo contempla la estructura de tratamientos sino también
la de las unidades experimentales. Asumiendo el efecto de las UE como fijo, el modelo
(Modelo B) y los cálculos correspondientes son:
2
2
~ (0, )
var( ) , 7.88
4.16, ( ) 2 7.88 / 6 1.62, 0.05
ij i j ij
ij
ij
A B A B
y p t e
e N
y ahora
t t EE t t p valor
µ
σ
σ
= + + +
= →
− = − = × = − =
Las diferencias entre tratamientos resultan ahora marginalmente significativas. Una
situación análoga se produce cuando hay más de dos tratamientos y ellos se aplican a
un bloque de UE bajo un diseño en bloques completos al azar (DBCA).
Situación 2. Modelo con efectos aleatorios
Supongamos que existe un gran número de niveles para el factor tratamiento de interés
y por tanto una población de efectos. Supongamos también que a niveles se
seleccionaron aleatoriamente para ser incluidos en el experimento y que cada nivel del
factor tratamiento se asignó aleatoriamente a n unidades experimentales
(equivalentemente, que existen n observaciones aleatorias para cada uno de los a
niveles del factor de interés). La selección aleatoria de niveles de tratamiento se realiza
con el propósito de tratarlos como una representación de la población de efectos hacia
la cual se pretende inferir. Si yij representa la respuesta observada en la unidad j del
tratamiento i, un posible modelo para los datos es,
E(yij)= µ + ai,
donde µ es la media general de la variable respuesta y ai es el efecto del nivel i del
factor de interés, ai=µi-µ. A pesar de que la expresión anterior es la misma que la
correspondiente al modelo de efectos fijos, los supuestos subyacentes son diferentes

9
debido a que los niveles en estudio del factor tratamiento representan una muestra
aleatoria desde la población de niveles. La cantidad ai es la realización de una variable
aleatoria “efecto de tratamiento”. Dado que las cantidades ai son variables aleatorias es
necesario caracterizar su distribución de probabilidades. Comúnmente las cantidades ai
se consideran independiente e idénticamente distribuidas, con esperanza cero y
varianza 2aσ para todo i. No obstante, otros supuestos podrían adecuarse mejor a los
datos, por ejemplo covarianza entre pares de efectos.
Debido a que ai es una variable aleatoria, el modelo debe interpretarse como el
valor esperado de yij cuando, la variable aleatoria a, “efecto de tratamiento”, asume el
valor ai. Es decir E(yij)= µ + ai representa una esperanza condicional, la esperanza de la
respuesta dado el nivel del factor de tratamiento observado. Una notación alternativa
para el modelo de efectos aleatorios podría ser,
E(yij | a = ai) = µ + ai , o simplemente E(yij | ai) = µ + ai.
Tomando esperanza respecto a la variable ai, se tiene que E(yij ) = µ . Si definimos los
términos de error como la diferencia entre la cantidad observada y la esperada,
eij = yij - E(yij | ai) = yij - (µ + ai )
Se puede observar nuevamente que eij es una variable aleatoria. Debido a que las
observaciones para cada tratamiento han sido obtenidas de la misma manera que en la
situación 1, las propiedades distribucionales de los términos de error, eij, son similares.
Comúnmente se adiciona el supuesto de que las variables aleatorias eij y ai se
distribuyen independientemente, de manera tal que las observaciones marginalmente
se distribuyen con esperanza µ y varianza Var(yij) = 2 2aσ σ+ . Es decir que, bajo este
supuesto, la varianza de las respuestas es una suma de varianzas, una para cada
efecto aleatorio. Generalmente interesa conocer la representación de cada una de ellas
(componente de varianza) en la variabilidad total observada.
Para ilustrar cálculos relacionados a un modelo mixto, se presenta un nuevo
modelo (Modelo C) para los datos de la Tabla 1. Los efectos aleatorios en este modelo
representan efectos relacionados a la estructura de UE más que a la estructura de
tratamientos. El experimento descripto ahora tiene un diseño en bloques aleatorizado.
El factor árbol se asocia a un efecto de bloque aleatorio. Los efectos aleatorios de árbol

10
son variables aleatorias con media cero y varianza 2pσ . Las correlaciones entre
observaciones derivadas de un mismo árbol son consideradas en forma implícita,
mediante la adición de efectos aleatorios asociados a cada árbol. Los cálculos son:
2 2
2 2
2´ ´ ´ ´ ´
~ (0, ) ~ (0, )
cada efecto aleatorio componente de varianzavar( )
0 ´cov( , ) cov( , )
´
4.16, ( ) 2 7.88 / 6) 1.62,
ij i j ij
ij i p
ij p
ij i j i ij i i jp
A B A B
y p t e
e N p N
y
i iy y p e p e
i i
t t EE t t p valor
µ
σ σ
σ σ
σ
= + + +
→
= +
≠ = + + = =
− = − = × = − =2 2
0.05
2 ( 7.88) 11.54p pCMUEσ σ= − → =
Los efectos de tratamiento y los errores estándares para la diferencia entre ellos (EE)
son idénticos que en el modelo de efectos fijos (Modelo B) ya que sólo se usa
información dentro de las UE para estimar efectos de tratamientos y no hay datos
faltantes. Sin embargo, si los datos fuesen los de la Tabla 2 donde existe desbalance,
algunos valores (por ejemplo el valor 22) brindan información para estimar el nivel de la
UE pero no sobre diferencias entre tratamientos. Este hecho hace que los resultados
obtenidos bajo un modelo de efectos fijos no sean los mismos que los derivados del
modelo mixto.
Tabla 2. Rendimiento (cantidad de frutas) de 8 árboles bajo dos tratamientos (sin desmalezado (B) y con desmalezado (A)).
UE Trat A Trat B A-B Media 1 20 12 8 16.0 2 26 24 2 25.0 3 16 17 -1 16.5 4 29 21 8 25.0 5 22 - - 22 6 - 17 - 17
Media 22.83 18.67 4.17 20.75

11
En el modelo de efectos fijos, la diferencia entre medias de tratamientos se calcula
solamente con la información dentro UE, razón por la cual participan solo las UE 1 a 4.
Los cálculos correspondientes son:
4.25, ( ) 10.12var( ) 10.12(1/ 4 1/ 4) 5.06, 2.25
A B
A B
t t CMR ANAVAt t EE
− = =− = + = →
Mientras que en el modelo que incluye el efecto aleatorio, se estiman las componentes
de varianza por algún método, como por ejemplo REML, y la diferencia entre medias de
tratamientos es estimada desde el modelo en 4.32 con EE=2.01. La diferencia se
produce porque en la estimación bajo el Modelo C interviene información entre y dentro
de UE.
Tipos de Modelos Mixtos Bajo el marco general de los modelos mixtos se pueden considerar distintos tipos de
modelos. Es importante recordar que en general los modelos mixtos se presentan como
aquéllos que permiten modelar conjuntos de datos en los que las observaciones no son
independientes.
El tipo más simple de modelo mixto es el modelo de efectos aleatorios presentado en el
ejemplo anterior. En ese modelo, para algunos efectos se asume que existe una
distribución asociada que da origen a una fuente de variación distinta a la variación
residual. Tales efectos se denominan efectos aleatorios. Los modelos de efectos
aleatorios han sido ampliamente usados en agronomía, principalmente en aplicaciones
relacionadas a mejoramiento genético animal y vegetal para estimar heredabilidades y
predecir ganancia genética en programas de mejoramiento (Thompson, 1977). Se usan
también en ensayos comparativos de rendimiento para estimar componentes de
varianzas asociadas a la comparación de efectos de tratamiento conducidos a través de
varias localidades y años, asumiendo que la interacción tratamiento×ambiente es
aleatoria y que los efectos de tratamiento están contenidos dentro de la interacción
aleatoria (Casanoves, 2004). Sin embargo, en otras circunstancias, los efectos que se
permite varíen aleatoriamente están asociados a covariables en lugar de factores de

12
clasificación. Por ejemplo, en un modelo de regresión Y sobre tiempo, se podría pensar
que la pendiente de la regresión varía aleatoriamente entre los sujetos que aportan
información para el ajuste de la regresión. Si se ajusta un modelo con el efecto de
sujeto y la interacción sujeto×pendiente como aleatoria, el modelo mixto resultante se
denomina modelo de coeficientes aleatorios. Por último, en algunas circunstancias la
teoría de los modelos mixtos se usa para modelar directamente el patrón de correlación
o covarianza residual. Los modelos mixtos también pueden, en la práctica, definirse con
combinaciones de efectos aleatorios, efectos de coeficientes aleatorios y patrones de
covarianza. La selección de uno u otro tipo de modelo depende del objetivo del análisis.

13
Módulo 1. Ejemplos de Motivación En esta sección se mencionan algunos ejemplos para promover la discusión sobre el
uso de modelos mixtos. En las primeras situaciones el modelo mixto aparece como una
estrategia para contemplar las correlaciones entre observaciones provenientes de
mediciones repetidas en el tiempo, ya sea con funciones lineales o no-lineales para la
estructura de medias (medidas repetidas/datos longitudinales y curvas de crecimiento).
El caso de los experimentos multiambientales, se introduce como referencia de
situaciones donde la selección de un modelo mixto respecto a un modelo de efectos
fijos es menos obvia, ya que depende de la interpretación que se hará de los datos,
mientras que la situación referida al modelado de correlaciones espaciales en
experimentos de campo introduce la necesidad del uso de modelos de patrones de
covarianza.
1.1. Medidas Repetidas / Datos Longitudinales Las medidas repetidas se obtienen cuando una respuesta se mide repetidamente sobre
la misma unidad experimental o sujeto (árbol, parcela, familia, etc.). El término datos
longitudinales hace referencia a una clase especial de medidas repetidas, i.e. aquéllas
donde la respuesta se observa en varios momentos subsecuentes en tiempo sobre la
misma unidad experimental, i.e. interesa investigar cambios en el tiempo de
características que se miden repetidamente sobre un mismo sujeto. Para este tipo de
datos nos interesa explorar tanto la variabilidad entre sujetos como la variabilidad
correspondiente a observaciones dentro de sujetos.

14
Ejemplo 1. Datos de semillas
Estudio experimental donde se mide, durante 4 momentos, la biomasa de plántulas y el
porcentaje de germinación en 5 cajas de 50 semillas pequeñas y 5 cajas de 50 semillas
grandes de un arbusto. Es decir existe un número fijo de mediciones por sujeto (caja) y
estas mediciones se toman en momentos equiespaciados en el tiempo. Los datos se
encuentran en el archivo semillas.xls. Las Figuras 1 y 2 corresponden a los perfiles
individuales para biomasa de plántulas y porcentaje de germinación, respectivamente.
T1 T2 T3 T4Tiempo
135,10
270,43
405,77
541,10
676,43
Bio
mas
a (g
rs.)
T1 T2 T3 T4Tiempo
395,93
433,05
470,18
507,30
544,42
Bio
mas
a (g
rs.)
Figura 1. Perfiles individuales de biomasa aérea para plántulas provenientes de semillas
pequeñas (a) y de semillas grandes (b).
Es importante notar que: 1) existe una relación lineal entre biomasa y tiempo en el
periodo estudiado, 2) la variabilidad entre unidades experimentales es alta, 3) la
variabilidad dentro de unidades experimentales es relativamente menor.
Sin embargo para el porcentaje de germinación de semillas grandes se tiene que: 1)
existe una relación polinómica de orden posiblemente mayor a uno entre germinación y
tiempo en el periodo estudiado, 2) la variabilidad entre unidades es alta, 3) la
variabilidad dentro de unidades es también alta.

15
T1 T2 T3 T4Tiempo
0
25
50
75
100
Ger
min
ació
n (%
)
Figura 2. Perfiles de porcentaje de germinación de unidades de semillas grandes.
Frecuentemente, la variabilidad entre sujetos es mayor que la variabilidad dentro
sujetos, y esto se refleja en la presencia de correlaciones positivas entre las
observaciones repetidas sobre un mismo sujeto (i.e., dentro de la UE).
Ejemplo 2. Datos de Cacao
Un estudio experimental consistió en evaluar 56 híbridos de cacao. El diseño fue en
bloques completos con 4 repeticiones. Cada unidad experimental consistió de 8 árboles
hermanos. Se evaluó la producción de cacao (número total de mazorcas), obtenida a
partir del conteo del número de frutos totales, frutos sanos, frutos afectados por hongos
(TOTALES=sanos+afectados). La cosecha de mazorcas se realizó todos los meses
durante 5 años consecutivos. En primera instancia interesa encontrar los mejores
híbridos para la variable producción promedio de frutos sanos / ha. Además interesa
detectar árboles individuales (dentro de los 8 de cada unidad experimental) que sean
superiores respecto a la producción total de frutos sanos. Los datos se encuentran en el
archivo cacao.ssd. Como una primera aproximación estos datos se modelarán como
normales y se tratará de responder preguntas relacionadas a la respuesta en el tiempo,
la relación de ésta con los hibridos y a la interacción de los hibridos y el tiempo. Si bien
en el Ejemplo 1 la estructura de las UE sigue un DCA y la UE se corresponde con la

16
unidad observacional, en el Ejemplo 2 la estructura de UE corresponde a la de un
DBCA donde la UE es la parcela y el árbol constituye la unidad observacional.
Ejemplo 3. Datos longitudinales vs. transversales (cross-sectional)
Suponga que nos interesa estudiar la relación entre alguna respuesta Y y el tiempo. Un
estudio transversal produce los datos de la Figura 3, sugiriendo una relación negativa
entre Y y tiempo.
Tiempo
Res
pues
ta Y
Figura 3. Diagrama de dispersión de Y vs. tiempo.
Exactamente las mismas observaciones podrían haberse obtenido en un estudio
longitudinal, con 2 mediciones por sujeto. La Figura 4 corresponde a esta situación y si
bien sugiere una relación transversal negativa entre Y y tiempo, también evidencia una
tendencia longitudinal positiva.

17
Tiempo
Res
pues
ta Y
Figura 4. Diagrama de dispersión de Y vs. tiempo.
Los ejemplos anteriores muestran la existencia de una estructura de correlación entre
observaciones de un mismo sujeto, también conocidas como correlaciones dentro de
sujetos. Ésta no puede ignorarse en el análisis. Las aproximaciones estadísticas que
permiten tener en cuenta la correlación son varias. Para dos medidas repetidas sobre la
misma UE, el ejemplo clásico de análisis de datos correlacionados es el test t pareado.
Por ejemplo, para la situación planteada en la sección de revisión conceptual (Tabla 1),
una posibilidad podría ser analizar las diferencias entre tiempos (antes y después del
tratamiento con herbicida). Estas diferencias se obtienen por una simple transformación
lineal dentro de sujeto, i.e ∆i = YiA − YiB. La transformación reduce el número de
observaciones a una por sujeto y permite así que se puedan aplicar técnicas clásicas
de análisis como el test t, ya que los nuevos datos (los obtenidos de la transformación)
no están correlacionados. De este modo el análisis de datos longitudinales se reduce al
análisis de datos independientes.
Una técnica estadística simple, en el caso de estudios que involucran más de dos
mediciones por sujeto, es reducir el número de mediciones para el sujeto i, llevándolo
de mi a 1. Por ejemplo, calculando el área bajo la curva (AUDC) o perfil en el tiempo. El
estadístico AUDC constituye una medida de resumen para cada sujeto separadamente.

18
Otras alternativas simples son: 1) análisis bajo cada momento en el tiempo
separadamente, 2) análisis de puntos finales, 3) análisis de incrementos.
La desventaja de las aproximaciones simples mencionadas es que en todas hay
pérdida de información ya que no se analizan las tendencias de las medidas repetidas
dentro de sujeto. El análisis de medidas repetidas/datos longitudinales permite distinguir
diferencias entre sujetos de aquéllas existentes dentro de sujetos.
Las mediciones repetidas sobre la misma unidad llevan a considerar la correlación entre
observaciones. Al igual que en otros modelos ANOVA o regresión, podemos hacer esto
en forma explícita, a través de la estimación de una matriz de covarianza, o en forma
implícita, mediante la adición de efectos aleatorios en el modelo.
Por ejemplo, para un modelo de ANOVA con efectos de grupo, tiempo y tiempo×grupo,
ya sea éste bajo un DCA o un DBCA, considerar las correlaciones en forma explícita
implica modelar la matriz de correlación (Σ) entre observaciones provenientes de un
mismo sujeto. Distintos modelos de correlación pueden usarse. Por ejemplo, el modelo
de correlación constante, i.e. ´( , ) ´i j i jcorr e e j jρ= ≠ o el modelo autorregresivo
| ´ |´( , ) ´j j
ij ijcorr e e j jρ −= ≠ . El modelo menos parsimonioso es el modelo no estructurado,
que no asume ningún patrón estructural en las correlaciones y estima las correlaciones
entre todos los pares de observaciones, i.e. ´ , ´( , ) ´ij ij j jcorr e e j jρ= ≠ . Estos modelos de
correlación dan origen a distintas estructuras de matrices de varianza y covarianza. Las
estructuras más comunes en datos longitudinales igualmente espaciados son la de
Simetría Compuesta (CS), Auto-regresiva de orden 1 (AR(1)) y Toeplitz (TOEP). En la
primera se asume el modelo de correlación constante entre cualquier par de medidas
repetidas dentro de la misma unidad; los elementos de Σ tienen la forma Σjj´ = σ2ρ. En la
estructura de covarianza AR se asume un decaimiento exponencial de las
correlaciones, los elementos de Σ tienen la forma Σjj´ = σ2ρ|j−j´|. En la estructura de
covarianzas TOEP, los elementos de Σ tienen la forma Σjj´ = α|j−j´|, i.e. varianzas iguales
y covarianzas iguales entre observaciones separadas por 1, 2,… momentos de tiempo
(t). Las componentes de varianza usadas para modelar el patrón de la matriz de
covarianzas dentro de sujeto pueden ser iguales (modelo homoscedástico) o diferentes
(heteroscedástico).

19
SAS incluye un importante número de estructuras de matrices de covarianza, por
ejemplo para un vector de 3 elementos (por ejemplo 3 medidas repetidas dentro de
cada sujeto), algunas de ellas y sus nombres en SAS se presentan a continuación:

20

21
La otra alternativa (forma implícita) es usar un modelo de coeficientes aleatorios. La
idea es modelar la relación entre Y y tiempo incorporando un efecto cuantitativo de
tiempo como covariable y un efecto aleatorio de UE. Por ejemplo, para una relación
lineal en el tiempo y asumiendo distintas pendientes entre grupos, el modelo es:
. ( ) .
( ) diferencia pendiente sujeto respecto pendiente promedio= diferencia ordenada sujeto respecto media general
ij k i ij i ij i
i
i
Y t s tiempo s tiempo es i
s i
µ β β
β
= + + + + +
=
Los efectos de sujeto a nivel de ordenada y de pendiente están correlacionados dentro
de cada sujeto. Es natural modelar la distribución conjunta de los efectos aleatorios. Por
ejemplo,
2,2
,
~ ( ) i s s s
i s s s
sN
sβ
β β
σ σβ σ σ
=
0,G G
Con datos normales ambas aproximaciones (formas explicita e implícita) son
equivalentes. Sin embargo, con datos no normales o cuando el modelo es no lineal, los
parámetros bajo estas dos estrategias son intrínsecamente diferentes y se interpretan
como: 1) “parámetros promedios poblacionales” (modelos marginales), o 2) “parámetros
sujeto-específicos” (modelos con efectos aleatorios de sujeto).
1.2. Curvas de Crecimiento En la modelización de curvas de crecimiento, a diferencia de otras situaciones de
mediciones repetidas donde el objetivo es comparar tratamientos a través de su perfil
temporal, se persigue la estimación y predicción del crecimiento en función del tiempo.
Distintos tipos de ecuaciones que explican el crecimiento en función del período de
tiempo considerado son de interés. En Forestería se destacan los siguientes tipos: a)
Crecimiento anual corriente: es el incremento de un elemento dentro de un año, b)
Crecimiento periódico: es el crecimiento acumulado en un periodo de varios años, c)
Crecimiento medio anual: es el tamaño alcanzado hasta un determinado momento en el
tiempo dividido por la edad correspondiente.
Cuando el crecimiento corriente o acumulado se expresa en función de la edad, en un
dominio de tiempo suficientemente largo como para que se expresen las distintas

22
etapas del crecimiento biológico de las especies, la función resultante rara vez es lineal
en los parámetros de interés. Los incrementos acumulados como una función del
tiempo generalmente muestran una curva sigmoidea. El punto de inflexión de esta
curva de rendimiento coincide con el máximo de la curva de incremento corriente anual
(curva de crecimiento), es decir que la primera derivada de la curva de rendimiento es
la curva de incremento corriente anual. Si al crecimiento total se lo divide por la
cantidad de años considerados se obtiene el incremento medio anual. La curva de
incremento corriente y la de incremento medio se cortan en el máximo de crecimiento
medio. Este punto de corte es importante porque indica el momento en que los árboles
alcanzan la madurez biológica.
La relación funcional puede ser especificada desde un punto de vista biológico
(usualmente modelos no lineales) o empírico (en general funciones polinomiales). Los
modelos no-lineales son modelos de regresión en los cuales los parámetros aparecen
en forma no-lineal en la ecuación. Por ejemplo:
( )2
2 2 0 1 20 10 1
1 1 1, ,Y Y Yx x xxeµ µ µβ β β β ββ ββ β
= = =− + +++
( )( )( )
0 00 0 1
321 1 2
exp exp , ,1
1Y Y Yx xe xe
β βµ β β β µ µ βββ β β= − − + = =
−+ − + +
Debido a que el crecimiento está evaluado mediante mediciones obtenidas sobre un
mismo individuo es importante modelar la estructura de correlación de las
observaciones dentro de sujeto, ya sea para un modelo lineal o no-lineal. En Forestería
la información disponible para cada sujeto (árbol) puede ser una serie de ancho de
anillos de crecimiento leñoso obtenida desde una muestra dendrocronológica. En este
caso el número de mediciones en cada sujeto varía ya que depende de la edad del
árbol. Los modelos mixtos permiten contemplar dicho desbalance debido al proceso de
estimación empleado. Las series de ancho de anillos generalmente son suavizadas
para maximizar la tendencia debida al crecimiento biológico mediante la eliminación de
variaciones posiblemente debidas al clima y a disturbios producidos en el bosque. Este
tipo de filtrado de los datos previos al estudio del crecimiento biológico genera aun más

23
dependencia entre las observaciones dentro de sujeto. Adicionalmente, en situaciones
donde se modela el crecimiento de bosques, la varianza del término de error podría
estar relacionada con la variable predictora. En modelos de regresión aplicados sobre
rodales, donde el volumen del rodal es la variable dependiente y la edad se usa como
predictora, por ejemplo, se podría notar una mayor variación de los volúmenes a
edades menores que cuando el rodal está más establecido (variables respuestas no-
normales).
Las características de la información disponible para modelar crecimiento en Forestería
sugieren el uso de modelos que contemplen la alta variabilidad entre sujetos,
desbalances y que además consideren que las curvas de crecimiento involucran
variables relacionadas serialmente y generalmente no son lineales en sus parámetros.
Numerosos estudios sobre estrategias de modelación para curvas de crecimiento se
realizaron hasta el momento (Kshirsagar y Smith, 1995). El modelo lineal polinómico
(Graybill, 1996) y otros modelos biológicos no lineales (Lee, 1982) en sus parámetros
se utilizan en la modelación de curvas de crecimiento individual y poblacional. Para
modelar curvas de crecimiento teniendo en cuenta la correlación serial pueden usarse
las aproximaciones metodológicas presentadas en relación al análisis de medidas
repetidas. Lindstrom y Bates (1990), consideraron que los métodos tradicionales, i.e.
modelos fijos para el análisis de curvas de crecimiento poblacionales, donde la
estructura de dependencia de los datos se puede considerar a través del ajuste de
alguna estructura de covarianza a los términos de error, constituyen modelos
marginales cuyo objetivo es ajustar un modelo general para la estructura promedio de la
población de sujetos. Una aproximación alternativa es el uso de modelos específicos de
sujeto, que proporcionan un modelo para cada individuo, pero donde la forma general
del modelo es la misma para cada sujeto. Así, el crecimiento de cada sujeto podría ser
modelado, por ejemplo con un modelo logístico, pero los parámetros del modelo van a
variar de árbol a árbol. Estas variaciones pueden introducirse a través de la
incorporación de efectos aleatorios propios para cada individuo. Al presente, los
modelos no lineales marginales pueden ajustarse en SAS usando PROC GENMOD
sólo si son linearizables (es decir, existe una transformación de las Y que permite

24
escribir el modelo en forma lineal: ésta es la función de enlace). Los modelos no
lineales mixtos pueden ajustarse en SAS usando PROC NLMIXED.
Ejemplo 4. Datos de naranjo
Suponga que se dispone de 7 mediciones de circunferencia (en mm) de 5 árboles de
naranja. Los datos se encuentran el archivo naranjo.xls. La Figura 4 muestra los perfiles
individuales de los 5 árboles.
Figura 4. Crecimiento diametral (mm) de 5 árboles de naranjo.
Un modelo plausible es el logístico: Como los datos son longitudinales, una manera de introducir la correlación en el modelo
sería mediante efectos aleatorios. Para ello se podría asumir que la asíntota tiene un
efecto aleatorio (observar que todos parecen empezar por el mismo valor, pero cada
árbol pareciera alcanzar un tamaño diferente). La especificación del modelo sería:
Crecimiento de árboles de naranja
0
50
100
150
200
250
100 300 500 700 900 1100 1300 1500
Días
Tro
nco
(m
m)
A1
A2
A3
A4
A5
0
21
/1
βµ ββ=
−+Y xe
0
211
iij ij
ij
uY xe
β εββ
+= +
−+

25
Ejemplo 5. Datos Quebracho
La información disponible para cada sujeto (árbol) es una serie de ancho de anillos de
crecimiento leñoso obtenida desde una muestra dendrocronológica. Se trabaja con una
especie arbórea del Chaco árido argentino: quebracho blanco. Se dispone de 6 árboles.
En este caso si bien las observaciones podrían pensarse como equiespaciadas o
recolectadas en momentos fijos de tiempo (un anillo = un año de crecimiento), el
número de mediciones en cada sujeto varía ya que depende de la edad del árbol. En la
Figura 5 se presentan los incrementos radiales anuales observados y suavizados.
ESPESORES DE ANILLOS OBSERVADOS Y SUAVIZADOS EN FUNCION DE LA EDAD. A. BLANCO
ARBOL 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 10 20 30 40
EDAD (años)
ESPE
SOR
DE
AN
ILLO
S (c
m)
espesoraniespesoranisu
Fig. 1,21
ARBOL 2
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 10 20 30 40 50 60 70
EDAD (años)
ESPE
SOR
DE
AN
ILLO
S (c
m)
espesoraniespesoranisu
Fig. 1,22
ARBOL 3
0
0.1
0.2
0.3
0.4
0.5
0.6
0 20 40 60 80 100
EDAD (años)
ESPE
SOR
DE
AN
ILLO
S (c
m)
espesoraniespesoranisu
Fig. 1,23
ARBOL 4
0
0.1
0.2
0.3
0.4
0.5
0.6
0 10 20 30 40 50 60
EDAD (años)
ESPE
SOR
DE
AN
ILLO
S (c
m)
espesoraniespesoranisu
Fig. 1,24
ARBOL 5
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 10 20 30 40 50 60 70
EDAD (años)
ESPE
SOR
DE
AN
ILLO
S (c
m)
espesoraniespesoranisu
Fig. 1,25
ARBOL 6
0
0.2
0.4
0.6
0.8
1
1.2
0 20 40 60 80
EDAD (años)
ESPE
SOR
DE
AN
ILLO
S (c
m)
espesoraniespesoranisua
Fig. 1,26
Figura 5. Crecimiento del leño de Quebracho blanco en 6 árboles del Chaco Arido
Argentino.

26
Ejemplo 6. Modelos para volumen acumulado de tronco de árboles Schabenberger y Pierce (2002) presentan un conjunto de datos con el que construyen un
modelo para predecir el volumen maderable de árboles en función del diámetro del tronco.
Para ello usan árboles de álamo amarillo (“yellow poplar”, Liriodendron tulipifera L.) que se
cortaron en varias secciones y se determina el volumen total acumulado de las distintas
secciones (hasta llegar al diámetro superior que puede ser mercadeable, o hasta el extremo
del árbol si se desea el volumen total). Los datos provenientes de los mismos árboles son
dependientes (no solo por ser del mismo árbol, sino que los volúmenes se van acumulando).
Burkhart expresó el volumen Vd hasta un diámetro de tronco d como el producto del
volument total V0 y el cociente Rd entre el volumen mercadeable y el volumen total:
0d dV V R= Hasta los trabajos de Gregoire y Schabenberger (1996), estas ecuaciones se ajustaban
sin tener en cuenta la correlación entre observaciones del mismo árbol. Estos autores
usan modelos no lineales mixtos con un efecto aleatorio de árbol para inducir esta
correlación. El conjunto YellowPoplarData.xls contiene medidas de 336 árboles. En la
figura 6 se muestran los datos, y puede obervarse que los árboles varían mucho en
volumen, principalmente debido a que hay mucha variabilidad en la altura. La figura 7
muestra los mismos árboles, pero se grafican los volúmenes relativos 0.dV
V Aquí se
pueden apreciar diferencias en la forma de los perfiles de volumen.
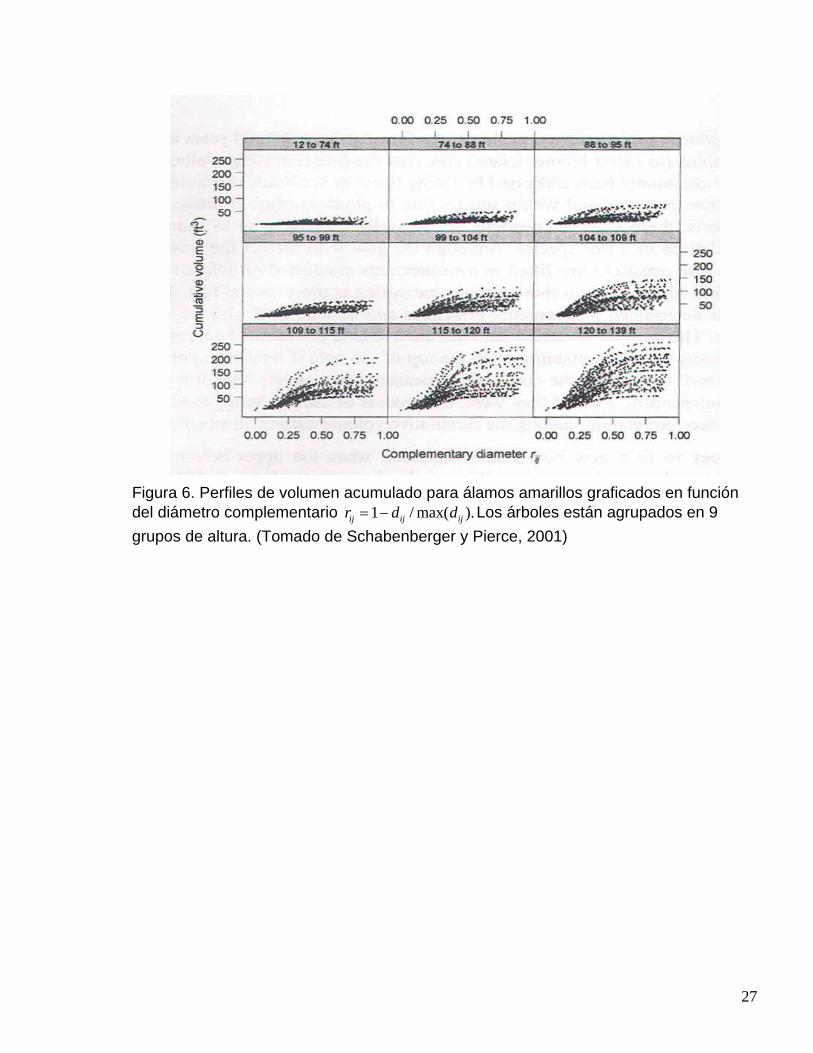
27
Figura 6. Perfiles de volumen acumulado para álamos amarillos graficados en función del diámetro complementario 1 / max( ).ij ij ijr d d= − Los árboles están agrupados en 9 grupos de altura. (Tomado de Schabenberger y Pierce, 2001)

28
Figura 7. Perfiles de volumen acumulados relativos para álamos amarillos graficados en función del diámetro complementario 1 / max( ).ij ij ijr d d= − Los árboles están agrupados en 9 grupos de altura. (Tomado de Schabenberger y Pierce, 2001)
Estos autores desarrollan modelos para V0 y Rd con el objetivo de ajustar simultáneamente
ambas cantidades y su producto teniendo en cuenta diferencias entre árboles respecto al
tamaño de los árboles y la forma de los perfiles de volumen. La relación que usan para el
volumen total es
2
0 0 1 1000i i
i iD HV eβ β= + +
en donde D es el diámetro a la altura del pecho (en pulgadas), y H es la altura del árbol (en
pies). Se divide por 1000 para que las magnitudes de los coeficientes de regresión sean
similares.

29
Para Rd se requiere una función que crezca de 0 a 1, con 0dV V≤ . La ecuación que usaron
fue
( )23exp exp
1000dtR tβ β = −
donde / .t d D=

30
1.3. Experimentos Multi-ambientales Numerosos estudios en agricultura y forestería se conducen en varios ambientes. La
característica de este tipo de experimentos es que en general, los ambientes elegidos,
intentan representar una población relativamente mayor de ambientes. Dentro de cada
ambiente se evalúan generalmente dos o más tratamientos bajo un cierto diseño
experimental con o sin repeticiones. Cuando no existen repeticiones dentro de cada
ambiente, a menudo los datos se analizan con un modelo de ANOVA para un DBCA
(si todos los tratamientos están en todos los ambientes) o como un DBI en caso
contrario donde los ambientes juegan el rol del bloque y esto se hace para contemplar
la correlación entre observaciones dentro de un mismo ambiente. Los siguientes
modelos de ANAVA representan potenciales modelos para experimentos multi-
ambientales.
(Modelo A):
(Modelo B): ; a ambiente
(Modelo C): ( )
(Modelo D): ( ) ( )
(Modelo Mixto): y ( ) aleatorios iid N(0,
ij i ij
ij i j ij
ijk i j ijk ijk
ijk i j ijk k ij ijk
j ij a
Y t eY t a eY t a ta eY t a ta b a e
a ta
µ
µ
µ
µ
σ
= + +
= + + + →
= + + + +
= + + + + +2 2) N(0, )tay σ
En el Modelo A se ignora que los datos provienen de múltiplos ambientes, en el
Modelo B se incorpora el efecto del ambiente pero se supone que éste no interactúa
con los tratamientos; este modelo podría ajustarse tanto en situaciones con
repeticiones dentro de ambiente como en casos donde existe una única observación
para cada tratamiento por ambiente. Corresponde al modelo de un diseño en bloques,
los efectos de ambiente (bloque) podrían ser considerados como fijos o aleatorios
según los supuestos que se hagan respecto a los ambientes incorporados en el
experimento. En el Modelo C se incorpora la interacción tratamiento×ambiente, se
necesitan k>1 observaciones por tratamiento dentro de cada ambiente para poder
estimar los parámetros relacionados a la interacción, este modelo seria apropiado para
situaciones donde no existe estructura de las UE dentro de ambiente. El modelo D es
parecido al Modelo C pero para situaciones donde existe un diseño en bloques dentro
de cada ambiente. Los tres últimos modelos pueden ajsutarse como modelos mixtos si
los efectos de ambiente (y/o tratamiento) se consideran como variables aleatorias; aquí

31
se ha supuesto que los efectos de ambiente y por ende los efectos de la interacción
tratamiento×ambiente son aleatorios. Este hecho convierte al modelo en un “Modelo
Jerárquico” ya que los efectos de tratamiento quedan contenidos dentro de los efectos
aleatorios de la interacción.
Los principales objetivos de los experimentos multiambientales son: (1) comparar el
desempeño de los tratamientos en base a dos tipos de inferencia: inferencia en sentido
amplio (a través de los ambientes) e inferencia específica de ambiente y (2) estimar e
interpretar los componentes de la interacción. Al ser la interacción aleatoria deben
realizarse supuestos distribucionales para los efectos de interacción, e interpretarse
que las diferencias entre tratamientos varían aleatoriamente a través de los ambientes.
La inferencia de resultados se hará con respecto a la población de ambientes. La
precisión de las estimaciones relacionadas a efectos de tratamientos será diferente en
el modelo con interacción aleatoria respecto a los otros modelos. En general los
errores estándares de las diferencias entre medias de tratamiento se incrementan en el
modelo de efectos aleatorios para considerar que el espacio de inferencia se amplía.
Es natural asumir que el conjunto de observaciones provenientes del mismo ambiente
tenderá a estar correlacionada. Variables latentes asociadas con cada ambiente
pueden causar dependencias entre las respuestas de los tratamientos o efectos de
factores de interés observados en un mismo ambiente. Más aun, el comportamiento de
los tratamientos a través de los ambientes puede generar un patrón estructurado de
dependencias entre los términos de la interacción tratamiento×ambiente. Por ello, los
modelos mixtos con efectos de interacción aleatorios han recibido particular atención,
ya que permiten modelar la matriz de covarianza de medias de tratamiento dentro de
ambiente.
Ejemplo 8. Datos Mani. Interacción Genotipo×Ambiente
La interacción Genotipo×Ambiente (G×A), i.e. la respuesta diferencial de diferentes
genotipos a través de un rango de ambientes, es una característica universal
relacionada a los seres vivos desde bacterias a plantas y humanos (Kang, 1998). El
tema es de relevancia en agricultura y forestería, ya que especialmente, los principales
caracteres de importancia agronómica-forestal y económica (como el rendimiento)

32
están altamente influenciados por el ambiente mostrando variación continua. Debido a
la omnipresencia de G×A en caracteres cuantitativos, las evaluaciones de genotipos se
llevan a cabo en experimentos multiambientales. Los datos (mani.xls) que se usarán
para la ejemplificación corresponden a peso de granos por parcela de un ensayo
comparativo de rendimiento de maní, donde intervienen 10 genotipos (seis de ciclo
largo –numerados del 1 al 6– y cuatro de ciclo corto –numerados del 7 al 11), evaluados
a través de 15 ambientes, con 4 repeticiones en bloques completos dentro de cada
ambiente. En la Tabla 4 se muestran las medias de genotipo en cada ambiente. En la
modelización los datos se asumirán normales. Se pretende analizar la interacción G×A
y predecir los efectos de interacción para inferir no sólo en sentido amplio sino también
en sentido estricto (inferencia específica de ambiente) sobre el desempeño de
genotipos.
Tabla 4. Medias de rendimiento para 10 genotipos de maní evaluados en 15 ambientes. Amb
Florman 1
Tegua 2
mf484 3
mf485 4
mf487 5
mf489 6
manf393 7
mf447 8
mf478 9
mf480 10
1 0.80 0.96 1.16 1.12 0.87 1.11 1.24 0.95 1.37 1.41 2 2.17 2.04 1.08 0.58 1.52 0.86 1.57 1.29 2.15 3.27 3 2.43 2.58 2.64 2.24 2.30 2.20 2.47 2.34 2.19 2.19 4 2.71 2.26 2.14 1.88 1.72 2.18 1.77 1.61 2.15 2.04 5 1.13 1.14 1.71 0.85 1.24 1.21 1.55 1.86 1.98 1.61 6 3.08 3.22 3.05 2.90 2.94 2.57 2.90 2.59 2.36 2.43 7 2.81 2.88 2.91 2.53 2.73 2.90 2.96 3.41 3.20 2.96 8 1.74 1.73 2.86 2.13 1.60 2.29 2.16 1.44 2.20 0.95 9 2.16 2.44 2.73 3.00 3.18 3.25 3.30 3.01 3.37 2.53 10 4.29 4.21 4.45 4.46 4.24 4.03 3.55 3.84 3.53 3.22 11 1.82 1.71 2.53 1.87 1.71 2.27 2.16 1.88 2.09 1.91 12 5.33 4.93 5.57 5.43 4.99 4.67 4.69 4.16 4.70 3.57 13 1.18 1.32 2.45 1.78 1.54 2.00 2.24 1.63 1.54 1.15 14 4.39 4.40 4.28 3.77 4.17 4.75 4.13 3.79 4.33 3.72 15 3.41 3.45 2.81 3.15 3.84 3.54 2.22 2.46 3.09 2.61
1.4. Correlación Espacial en Ensayos a Campo Las dependencias espaciales entre parcelas de ensayos de campo es un fenómeno
común en agricultura. En especial, la existencia correlación espacial positiva, i.e.

33
tendencia de observaciones que están en parcelas cercanas a ser más parecidas que
las que están más lejos.
Llamaremos matriz de correlación a ( ) { }Corr Corrij=δ , donde ( )Corr Corr ;ij i je e= es la
correlación espacial entre los errores asociados a las parcelas i y j y ijd a la distancia
entre la parcela i y la parcela j. La correlación entre los errores asociados a las parcelas i
y j será función de la distancia entre ellas y de un vector de parámetros desconocidos δ.
Asumiremos que e, el vector de errores de parcelas constituye un proceso estacionario
de segundo orden, i.e., las correlaciones entre dos parcelas dependen sólo del vector de
distancia. Luego, la función de correlación es la misma para todos los pares de parcelas
que se encuentran a igual distancia en una dirección dada. Si además se supone que la
función de correlación no depende de la dirección, el modelo de correlación espacial es
llamado isotrópico (procesos invariantes a rotaciones sobre el origen). Los modelos de
correlación espacial se llaman anisotrópicos cuando se asume que la función de
correlación no sólo depende de la magnitud de la distancia sino también de la dirección.
Por otro lado, se dice que un proceso es separable cuando se pueden tener funciones
distintas en direcciones distintas y la función de correlación resultante está dada por el
producto de la función de correlación en cada una de las dimensiones. En los casos de
arreglos rectangulares de n parcelas en F filas y C columnas (n=F×C) importan
generalmente sólo 2 direcciones (procesos bidimensionales). Smith et al. (2001) citan
que el supuesto de separabilidad es computacionalmente conveniente y razonable para
el proceso de tendencia espacial bidimensional asociado a las parcelas de los ensayos a
campo (Martin, 1990; Cullis y Gleeson, 1991). Para un proceso bidimensional separable,
la matriz de varianzas y covarianzas puede expresarse como el producto de las
correlaciones por filas y por columnas.
Zimmerman y Harville (1991) dan ejemplos usados en aplicaciones geoestadísticas que
incluyen el modelo exponencial como modelo para la función de correlación. Para una
única dimensión (modelo isotrópico) la función de correlación exponencial es exp( / )ijd δ−
o también comúnmente expresada como ( )exp pijdδ− , para algún p>0, siendo ijd la
distancia entre las parcelas i y j, y δ un parámetro desconocido. SAS llama a este

34
modelo exponencial isotrópico, si p=1 (modelo con un único parámetro) y modelo
Gaussiano si p=2 (Figura 6). El modelo con p=1 es de particular importancia para
ensayos a campo. Los modelos de varianza-covarianza asociados pueden ser
homogéneos o heterogéneos según los supuestos realizados sobre las varianzas.
Figura 6. Función de correlación exponencial (izquierda) y gaussiana (derecha)
Ejemplo 9. Datos ECR. Correlación espacial.
Con el fin de mejorar la comparación de medias de tratamiento tomando en cuenta la
correlación de parcelas dentro de ensayo tanto como la heterogeneidad de varianza
residual entre ensayos de un ECR multiambiental, se analizarán modelos mixtos
alternativos. Los datos de rendimiento (kg granos/parcela) en el archivo ecrmani.xls
corresponden a un ECR de maní, que involucra tres localidades y que dentro de cada
localidad se condujo según un DBCA con un número variable de cultivares de maní. El
objetivo del análisis será ajustar, además del DBCA, distintos modelos que incorporen
correlación espacial a nivel de los términos de error y que contemplen la posibilidad de
que las estructuras de varianza y covarianza (tanto a nivel de correlaciones como a nivel
de varianza residual) sean heterogéneas entre ambientes. La heterogeneidad de los
componentes de varianza residual en ensayos multi-ambientales es bastante frecuente
ya que los experimentos conducidos en diferentes ambientes pueden tener distinta
precisión. Por ello se deberá modelar la correlación espacial junto a la heterogeneidad
residual entre ensayos.

35
Ejemplo 10. Datos papaya. Modelación de Proporciones.
Los datos en el archivo papaya.xls provienen de un experimento realizado en la
temporada 2000-2001 en Isabela, Puerto Rico. Se usaron 5 repeticiones para cada uno
de cuatro tratamientos (suelo sin malezas, suelo con malezas, suelo cubierto con
plástico negro y suelo cubierto con plástico plateado) aplicados a plantas de papaya en
un diseño completamente aleatorizado. Cada unidad experimental (parcela) consistió
de 20 plantas de papaya, y se evaluó cada planta quincenalmente para verificar si tenía
o no síntoma de una virosis (ring spot virus) (se debe destacar que una vez que la
planta muestra síntomas, sigue mostrando síntomas hasta la cosecha final). Nos
interesa el progreso en el tiempo de la proporción de plantas afectadas (curva de
progreso de enfermedad, Campbell y Madden, 1993). En la Figura 7 se muestran las
observaciones y los ajustes a las cuatro curvas comúnmente usadas para estudiar el
progreso de una enfermedad en fitopatología. En la modelización se debería tener en
cuenta la correlación entre observaciones de una misma UE y que además de tener un
modelo no-lineal, la variable de interés es no-normal (proporción de plantas afectadas).
Figura 8. Curvas de progreso de proporción de plantas afectadas
Control
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
40 60 80 100 120 140
dds
Dis
ease
Ind
ex Y
Logistic
Gompertz
Exponential
Monomol
Weeds
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
40 60 80 100 120 140
dds
Dis
ease
ind
ex
Y
Logistic
Gompertz
Exponential
Monomol
PC
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
40 60 80 100 120 140
dds
Dis
ease
inde
x YLogisticGompertzExponentialMonomol
PP
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
40 60 80 100 120 140
dds
Dis
ease
Inde
x YLogisticGompertzExponentialMonomol

36
Ejemplo 11. Datos arce.
La poda de árboles que interfieren con líneas eléctricas en el campo y en la ciudad es
un problema que cuesta mucho dinero a las compañías de electricidad. La necesidad
de poda periódica depende del crecimiento de la especie y de la distancia mínima a la
línea eléctrica requerida. Por ejemplo, Ontario Hydro poda cerca de medio millón de
árboles al año, a un costo de $25 /árbol.
En este estudio (datos de F. Camacho, Toronto, publicados en Can. J. of Statistics,
Sep. 1995), se compararon reguladores de crecimiento para controlar el crecimiento de
los árboles de arce plateado sin que se observen síntomas de daño. Se probaron
Paclobutrazol (PP 333, (2RS, 3RS - 1 -(4-chlorophenyl) - 4,4 - dimethyl - 2 - (1,2,4-
triazol-l-yl) pentan - 3- ol) y Flurprimidol (EL-500, (alpha - (1-methylethyl) - alpha - [4-
(trifluromethoxyl) phenyl] - 5- pyrimidine - methanol). Ambos reguladores se han usado
para controlar el rebrote excesivo en varias especies cuando se aplica en aspersión
foliar, inyección en el suelo e inyección en el tronco.
El propósito de este estudio es investigar la longitud de los brotes terminales, la longitud
de los entrenudos y el número de entrenudos en árboles de arce plateado (silver maple)
luego de aplicaciones de PP333 y de EL500 por inyección al tronco. Se usaron árboles
de arce plateado de 12 años de edad con tallos múltiples que crecían en Wesleyville,
Ontario. Los árboles se inyectaron en el tronco con soluciones de metanol y EL500 o
PP333 en dos dosis diferentes (20 g/L y 4 g/L). El volumen de la solución inyectada en
cada árbol se determinó a partir del diámetro del árbol usando la fórmula vol(mL) =
(dbh)*(dbh)*.492. Se usaron dos tratamientos control: uno sin inyectar y otro inyectado
con metanol. Se usaron 10 árboles escogidos aleatoriamente para cada uno de los 6
tratamientos. Antes de la inyección, todos los árboles se podaron haciendo que su
altura se redujera aproximadamente un tercio. En enero de 1987, 20 meses después
del tratamiento, entre 6 y 8 ramas se sacaron aleatoriamente de los dos tercios
inferiores del dosel de cada árbol. Cada rama se llevó al laboratorio y se registró la
longitud de cada brote terminal, su número de entrenudos y la longitud de cada uno de
estos entrenudos. El objetivo será el análisis de solamente analizaremos la variable
número de entrenudos (archivo arce.xls).

37
Módulo 2. Introducción 2.1 Modelo Lineal General de Efectos Mixtos / Conceptos Generales
Comenzaremos definiendo el modelo lineal de efectos fijos para luego extender
dicha definición al caso del modelo lineal mixto. El modelo lineal es ampliamente
utilizado en la experimentación agrícola y forestal para analizar la variabilidad de
observaciones (respuestas) realizadas sobre características de importancia
agronómica, en función de una o más variables predictoras o factores. Todos los
modelos lineales de efectos fijos pueden ser especificados de la forma general:
1 1 2 2
2i
...
Var(e )= .i i i p ip iy x x x eµ β β β
σ
= + + + + +
Por ejemplo, en el Modelo B de la sección de introducción, ij i j ijy p t eµ= + + + , el
subíndice i señala que el resultado ha sido obtenido desde la i-ésima UE y el subíndice j
denota un resultado proveniente del tratamiento j. Los términos β de la forma general
corresponden a p1, p2, p3, p4, p5 y p6 y también a t1 y t2; éstos son constantes dado el
tamaño de los efectos de UE y tratamiento. Los términos x de la forma general, asumen
los valores 1 ó 0 y son usados para indicar a qué UE y a qué tratamiento corresponde la
observación yi; por ejemplo si y3 fue observada sobre la unidad 1 bajo el tratamiento B,
entonces los x correspondientes a la UE 1 y al Tratamiento B serán 1 y los restantes
cero. En notación matricial, el modelo lineal general tiene la forma:
= +y Xβ e
donde y es un vector de observaciones, X es una matriz de diseño, β es el vector de
parámetros (o efectos fijos) y e es el vector de errores, definido como
( )E= − = −e y y y Xβ . El ejemplo anterior es un caso típico del modelo de ANOVA,
donde los términos x representan a factores de clasificación (efectos categóricos) y por
tanto la matriz X será una matriz de ceros y unos. Cuando los términos x representan

38
covariables (medidas en una escala cuantitativa) en vez de que factores, se tiene el
modelo clásico de regresión lineal y en ese caso la matriz X contiene los valores de las
variables regresoras para cada observación. Para modelar efectos categóricos se
requieren varios parámetros mientras que el efecto de una covariable puede modelarse
sólo con un parámetro. Los modelos que tienen ambos factores y covariables se
denominan modelos de análisis de covarianza (ANCOVA).
Utilizando el procedimiento de mínimos cuadrados ordinarios, se puede estimar el
vector de parámetros β resolviendo las ecuaciones normales ´ ´=X Xβ X y . La solución
está dada por ˆ ( ´ ) ´−=β X X X y , donde ( ´ )−X X es una inversa generalizada de ´X X
(Searle, 1971). Para hallar una estimación del vector de parámetros, no hace falta hacer
suposiciones distribucionales sobre el vector e . Si se asumen los supuestos del modelo
de muestreo ideal, i.e. términos de error independientes y normalmente distribuidos con
media 0 y varianza 2σ , entonces, la matriz de covarianzas de β , utilizada para realizar
inferencia estadística sobre β , es 2 ( ´ )σ −X X .
Extendiendo el modelo lineal general presentado anteriormente a situaciones donde se
incorporan efectos aleatorios se tiene el modelo lineal general mixto. La ecuación
matricial para el modelo lineal mixto es:
= + +y Xβ Zu e donde y , X , β y e representan las mismas entidades del modelo de efectos fijos y los
nuevos componentes son: 1) Z que representa una segunda matriz de diseño de
dimensión nxq (matriz especificada exactamente en la misma forma que X , excepto
que no incluye una columna para el término constante) y que asocia cada observación
a los efectos aleatorios correspondientes y 2) el vector qx1 u de elementos aleatorios (
efectos o coeficientes) que usualmente se asume distribuido N ( 0 ,G ). Sobre el vector
e se supone distribución N ( 0 , R ), y este vector e es definido como:
( | ) ( )E= − = − +e y y u y Xβ Zu
Dado que la esperanza del vector aleatorio u es 0 , en el modelo lineal mixto, el valor
esperado de una observación es la esperanza incondicional de la media de y (es decir
promediada sobre todos los posibles valores de u ):

39
( ) ( )E E= + =y Xβ Zu Xβ
Es decir, los niveles observados de un efecto aleatorio son una muestra aleatoria de la
población de niveles y la esperanza incondicional es la media de y sobre toda esa
población. Por otro lado, la esperanza condicional de y dado u es:
( | )E = +y u Xβ Zu
esperanza que representa la media de y para el subconjunto específico de niveles del
efecto aleatorio observados en el experimento.
La matriz R es modelada como 2σ=R I cuando se considera que los términos de error
(generalmente asociados a la UE) son independientes y tienen la misma varianza 2σ .
Los términos aleatorios u se suponen independientes de los términos aleatorios e .
Resumiendo los supuestos usuales sobre la esperanza y la varianza de las
componentes aleatorias, se tiene que:
E =
u 0e 0
Var =
u G 0e 0 R
Cuando se asume distribución normal para el vector de observaciones, la función de
densidad (verosimilitud) queda completamente determinada por el vector de valores
esperados y la matriz de varianzas y covarianzas. La matriz de varianzas y covarianzas
de y (incondicional o promedio para la población de efectos aleatorios) está dada por:
( ) ( )( ) ´ ( )
´
V VV V
= = + += += +
y V Xβ Zu eZ u Z eZGZ R
Los supuestos clásicos de independencia y homogeneidad de varianzas para los
términos aleatorios del modelo lineal general (muestreo ideal) se flexibilizan en el marco

40
del modelo mixto general. La inclusión de efectos aleatorios produce observaciones
correlacionadas. Tanto la estructura de correlaciones como la presencia de varianzas
heterogéneas pueden ser especificadas a través de la modelación de las matrices de
covarianza G y/o R . A través de G y R es posible modelar correlaciones entre
efectos de tratamiento, entre parcelas experimentales ocasionadas por la distribución
espacial y/o temporal de las mismas en el campo y/o considerar diferentes precisiones
de ensayos cuando se combinan experimentos.
Estructura de Covarianzas: Modelo de efectos aleatorios Para un modelo con q efectos aleatorios, la matriz G de dimensión qxq es una matriz
diagonal cuando se asume que los efectos aleatorios no están correlacionados. Por
ejemplo, para un experimento multi-ambiental con 3 ambientes cuyos efectos son
tratados como aleatorios y 2aσ representa la componente de varianza asociada a la
variación entre ambientes, se tiene para G la siguiente forma:
2
2
2
0 00 00 0
a
a
a
σσ
σ
=
G
Si la interacción tratamiento×ambiente también es aleatoria y hay dos tratamientos,
entonces G tiene la siguiente forma:
2
2
2
2
2
2
2
2
2
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 0
a
a
a
ta
ta
ta
ta
ta
ta
σσ
σσ
σσ
σσ
σ
=
G

41
Dado que los errores no están correlacionados R tiene la siguiente forma:
2
2
2
2
2
2
2
2
2
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 0
σσ
σσ
σσ
σσ
σ
=
R
La matriz de varianza-covarianzas entre observaciones, dada por
( ) ´V = +y ZGZ R tiene un primer término donde se especifican las covarianzas debidas
a los efectos aleatorios. Si hay 4 observaciones en el primer ambiente (dos para un
tratamiento y dos para el otro tratamiento), dos en el segundo (uno para cada
tratamiento) y 3 en el tercero (dos para un tratamiento y una para otro), pero el modelo
sólo considera el efecto de ambiente aleatorio, se tendrá:
2 2 2 2
2 2 2 2
2 2 2 2
2 2 2 2
' 2 2
2 2
2 2 2
2 2 2
2 2 2
0 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
0 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
a a a a
a a a a
a a a a
a a a a
a a
a a
a a a
a a a
a a a
σ σ σ σσ σ σ σσ σ σ σσ σ σ σ
σ σσ σ
σ σ σσ σ σσ σ σ
=
ZGZ

42
2 2 2 2 2
2 2 2 2 2
2 2 2 2 2
2 2 2 2 2
2 2 2
2 2 2
2 2 2 2
2 2 2 2
2 2 2 2
0 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
0 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
a a a a
a a a a
a a c a
a a a a
a a
a a
a a a
a a a
a a a
σ σ σ σ σσ σ σ σ σσ σ σ σ σσ σ σ σ σ
σ σ σσ σ σ
σ σ σ σσ σ σ σσ σ σ σ
+
+ +
+ = +
+ + + +
V
resultando en una matriz diagonal en bloques con tamaños de bloques
correspondientes al número de observaciones para cada categoría del efecto aleatorio;
covarianzas entre observaciones provenientes del mismo ambiente igual a la
componente de varianza entre ambientes y varianzas (sobre la diagonal) igual a la
suma de las componentes de varianza de ambiente y residual.
Si ambos, los efectos de ambiente y de la interacción, son considerados como
aleatorios, y se mantienen los supuestos para los errores, estas matrices tienen la
siguiente forma:
2 2 2 2 2 2
2 2 2 2 2 2
2 2 2 2 2 2
2 2 2 2 2 2
2 2 2
2 2 2
2 2 2 2 2
2 2 2 2 2
0 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
0 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00
a ta a ta a a
a ta a ta a a
a a a ta a ta
a a a ta a ta
a ta a
a a ta
a ta a ta a
a ta a ta a
σ σ σ σ σ σσ σ σ σ σ σσ σ σ σ σ σσ σ σ σ σ σ
σ σ σσ σ σ
σ σ σ σ σσ σ σ σ σ
+ ++ +
+ ++ +
′ = ++
+ ++ +
ZGZ
2 2 2 20 0 0 0 0 a a a taσ σ σ σ
+

43
2 2 2 2
2 2 2 2
2 2 2 2
2 2 2 2
2
2
2 2 2
2 2 2
2 2
0 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
0 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
c ct c c
c ct c c
c c c ct
c c c ct
c
c
c ct c
c ct c
c c
θ σ σ σ σσ σ θ σ σσ σ θ σ σσ σ σ σ θ
θ σσ θ
θ σ σ σσ σ θ σσ σ θ
+
+ +
+ = + +
V
Se puede observar que V sigue siendo una matriz diagonal en bloques pero con una
estructura algo más complicada. La componente de varianza de la interacción se suma
a los términos de covarianza para observaciones obtenidas dentro de un mismo
ambiente pero que a la vez también reciben el mismo tratamiento.
Estructura de Covarianzas: Modelo de coeficientes aleatorios La estructura de covarianza en los modelos de coeficientes aleatorios es inducida por
los coeficientes aleatorios. Este concepto se ilustra con un ejemplo que involucra dos
tratamientos en un experimento con medidas repetidas donde participan 3 sujetos, el
primero observado 4 veces, el segundo 2 y el tercero 3 veces en el tiempo. Si se ajusta
un modelo con los efectos de sujeto y de la interacción sujeto×tiempo con coeficientes
aleatorios,
0 0 1 1ij ij ij ijY b t b t eβ β= + + + +
La matriz Z contiene los valores ijt que representan el tiempo j en el que el sujeto i es
observado (por ejemplo días):

44
11
12
13
14
21
22
31
32
33
1 0 0 0 01 0 0 0 01 0 0 0 01 0 0 0 00 0 1 0 00 0 1 0 00 0 0 0 10 0 0 0 10 0 0 0 1
tttt
tt
ttt
=
Z
Como en el modelo de efectos aleatorios se supone que los errores no están
correlacionados, R no cambiará respecto al ejemplo anterior. Sin embargo, en el
modelo de coeficientes aleatorios, los efectos de sujeto (interceptos) se encuentran
correlacionados con los efectos aleatorios de pendientes (es decir las pendientes
individuales varían aleatoriamente). La correlación ocurre sólo entre coeficientes del
mismo sujeto mientras que los coeficientes correspondientes a diferentes sujetos no se
encuentran correlacionados. Así la matriz G es,
2
,2
,2
,2
,2
,2
,
0 0 0 00 0 0 0
0 0 0 00 0 0 00 0 0 00 0 0 0
p p pt
p pt pt
p p pt
p pt pt
p p pt
p pt pt
σ σσ σ
σ σσ σ
σ σσ σ
=
G
donde 2pσ , 2
ptσ representan las componentes de varianza asociadas a la variación
entre sujetos o UE y entre pendientes, y ,p ptσ es la covarianza entre los coeficientes
aleatorios. La matriz 'ZGZ será también una matriz diagonal en bloques con elementos
,i jkv donde 2 2, ,( )i jk p ij jk p pt ij jk ptv t t t tσ σ σ= + + + .

45
1,11 1,12 1,13 1,14
1,12 1,22 1,23 1,24
1,13 1,23 1,33 1,34
1,14 1,24 1,34 1,44
2,11 2,12
2,12 2,22
3,11 3,12 3,13
3,12 3,22 3,23
3,13 3,23 3,
0 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
0 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
v v v vv v v vv v v vv v v v
v vv v
v v vv v vv v v
='ZGZ
33
2.2 Modelos Marginales versus Modelos Jerárquico El modelo mixto lineal general puede ser re-escrito como un modelo jerárquico (o
modelo condicional): | ~ ( , )~ ( , )
NN
+y u Xβ Zu Ru 0 G
Es decir existe un modelo para y dado u más un modelo para u . Esto sugiere que
existen supuestos específicos sobre la dependencia de la media y la estructura de
covarianza sobre las covariables en X y Z . La media marginal es Xβ y la estructura
de covarianza es V = ZGZ´ + R . Es decir que el modelo implicado para la distribución
marginal o incondicional de Y es ( )N Xβ,ZGZ + R . Esta relación entre ambos modelos
no se puede aplicar en general, y depende de propiedades de la distribución normal
multivariada y de la linealidad del modelo.
2.3 Modelos para la Estructura de Covarianza Residual (modelos de patrones de covarianza) En los modelos anteriores donde la matriz de covarianza residual R es modelada como
múltiplo de la identidad, subyace el supuesto de independencia condicional, i.e
condicionando sobre los u , los elementos en y son independientes. Sin embargo, hay
muchas situaciones en las que no hay evidencias para adicionar efectos aleatorios, las
componentes de varianza asociada a dichos efectos es pequeña o los efectos
aleatorios no son interpretables en relación al problema, el supuesto de independencia

46
condicional es poco realista. Una alternativa es modelar las correlaciones entre
observaciones directamente a través de R de manera que éstas reflejen la estructura
particular de los datos. Es decir, las correlaciones no son inducidas a partir de la
incorporación de efectos aleatorios sino que se selecciona un modelo de correlación
para R que ajuste a los datos. Los patrones en R pueden especificarse mediante el
uso de variables de bloqueo (por ejemplo sujetos) de manera tal que las observaciones
dentro de un mismo nivel de una variable de bloqueo se encuentran correlacionadas.
Por ejemplo R podría estar compuesta de submatrices iR que representan bloques de
R conteniendo covarianzas entre observaciones del sujeto i.
Es importante notar que también podría ajustarse patrones de covarianza en G , para
indicar que los efectos aleatorios se encuentran correlacionados. Por ejemplo, en un
experimento con medidas repetidas donde para cada sujeto hay t tiempos de medición
y en cada tiempo se realizan varias medidas (por ejemplo, altura, diámetro y volumen
de copa). Entonces será importante modelar no sólo las correlaciones entre tiempos
dentro de sujetos, sino también las correlaciones entre variable realizadas sobre un
sujeto en cada tiempo.
2.4 Estimación de Covarianzas en Poblaciones Normales Las estimaciones por mínimos cuadrados generalizados pueden usarse para estimar
los efectos fijos del modelo mixto. Estas estimaciones se obtienen minimizando 1−(y - Xβ)'V (y - Xβ) (Searle et al., 1992). El estimador del vector de efectos fijos β es:
1 1ˆ ( ´ ) ´− − −=β X V X X V y . Si todas las componentes de varianza en V son conocidas este
estimador es el mejor estimador lineal insesgado (BLUE) y se corresponde con el
estimador máximo verosímil. En la práctica del análisis de datos experimentales V
usualmente es desconocida y se reemplaza por su estimador ˆˆ ˆ´= +V ZGZ R . Si se
puede asumir que u y e tienen distribución normal, la mejor aproximación para la
estimación se logra con métodos basados en máxima verosimilitud. Los métodos de
estimación más usados son máxima verosimilitud (ML) y máxima verosimilitud
restringida (REML).

47
En ML el vector conteniendo todas las componentes de varianza, digamos ξ, se obtiene
a partir de la maximización de la función de verosimilitud ( , ( ))MLL L ξ β ξ=
con respecto a
ξ. La función de verosimilitud, L, mide la verosimilitud de los parámetros del modelo
dados los datos y se define usando la función de densidad de las observaciones, en
este caso la función normal. En modelos donde las observaciones se suponen
independientes (por ejemplo el modelo de efectos fijos) la función de verosimilitud es
simplemente el producto de las funciones de densidad para cada observación. En los
modelos mixtos las observaciones no se suponen independientes, por ello la función de
verosimilitud se basa en la función de densidad multivariada de las observaciones.
Como los efectos aleatorios tienen valor esperado igual a cero y por ende no afectan la
media marginal, para la estimación ML en poblaciones normales la función de
verosimilitud se basa en la distribución normal multivariada con vector de media y
matriz de covarianza V y la maximización se realiza sobre el logaritmo de dicha
función, log(L):
( ) ( )( ) ( )
1
1/ 21/ 2
1exp2
(2 ) nL
π
− ′ =
y - Xβ V y - Xβ
V
( ) ( )11log( ) log2
1 log(2 )2
L k
k n π
− ′= − +
= −
V y - Xβ V y - Xβ
La estimación β (ξ)
del vector de parámetros fijos será denotada como MLβ
. Los
vectores MLξ
y MLβ
pueden también obtenerse desde la maximización de ( )MLL L= θ con
respecto a θ , siendo θ el vector de todos los parámetros del modelo; es decir
maximizando la verosimilitud con respecto a ξ y β simultáneamente. El método clásico
se basa en el concepto de maximizar la función log(L) con respecto a los parámetros de
covarianza y tratando los efectos fijos como constantes. Una vez que se obtienen los
estimadores de los parámetros de la estructura de covarianza, se obtienen las

48
estimaciones de efectos fijos considerando los parámetros de covarianza como fijos.
Este método tiene el efecto de producir estimadores de los parámetros de la estructura
de covarianza con sesgo negativo. El sesgo es mayor cuando el número de grados de
libertad usados para estimar las componentes de varianza es menor.
Estimador REML El simple ejemplo del estimador ML de la varianza 2σ de una muestra aleatoria de
variables normales, sugiere que cuando µ no es conocida y debe estimarse, dicha
estimación introduce un sesgo en el estimador ML de la varianza. La pregunta entonces
es, ¿cómo estimar las componentes de varianza sin tener que estimar los parámetros
correspondientes a los efectos fijos? La respuesta conduce al estimador REML,
sugerido por Patterson y Thompson (1971). En esta aproximación el vector de efectos
fijos es eliminado del Log(L), es decir éste es definido solamente en términos de
parámetros de la estructura de covarianza.
Por ejemplo, para el modelo:
12.. ~ .. ,
n
yN
y
µσ
µ
=
y I
es posible transformar el vector de observaciones y tal que µ desaparezca de la
función de verosimilitud de las y transformadas:
( )1 2
2 3 2
1
~ ,...
n n
y yy y
N
y y
σ
−
− − = = −
t A´y 0 A´A
El estimador ML de σ2, basado en t es el estimador insesgado de la varianza: 2 2( ) / 1i
iS Y Y n= − −∑
Es importante notar que A define un conjunto de n−1 contrastes de error linealmente
independientes. S2 es conocido como estimador REML de σ2 y es independiente de A .

49
En general, cuando los datos son transformados ortogonalmente a X , i.e.
~ ( )Nt = A´y 0, A´V(ξ)A , el estimador ML de ξ , basado en t se llama estimador REML
( REMLξ
). La estimación resultante del vector de efectos fijos, )REMLβ(ξ
, suele denotarse
por REMLβ
. Los estimadores REMLξ
y REMLβ
pueden también obtenerse de la maximización,
con respecto a θ , de la función:
1/ 2
( )n
REML i i MLi
L L= ∑ ´X W(ξ)X θ
Esta expresión, a pesar de no ser estrictamente hablando una función de verosimilitud,
igual se denomina función de verosimilitud restringida.
La idea del estimador REML es la siguiente: Primero se obtiene la verosimilitud basada
en datos que en lugar de ser los observados son términos residuales, i.e. y - Xβ
. Estos
términos son conocidos como residuos completos ya que incluyen todas las fuentes
variación aleatoria; se demuestra que los mismos son independientes de β
(Diggle et
al., 1994). Luego la verosimilitud conjunta para los parámetros de la estructura de
media y de la estructura de covarianza, se puede expresar como el producto de las
verosimilitudes basadas en y - Xβ
y β
en:
( ) ( ) ( )L L L=ξ,β;y ξ;y - Xβ β;β,ξ
Luego la función de verosimilitud L y el log(L) que se optimiza en REML son:
( ) ( ) / ( )L L L=ξ;y - Xβ ξ,β;y β;β,ξ
( ) ( )11 11( ( )) log log2
Log L k−− − ′′= − − +
ξ;y - Xβ V X V X y - Xβ V y - Xβ

50
Propiedades del estimador de efectos fijos El estimador del vector de efectos fijos se obtiene por mínimos cuadrados
generalizados usando ξ
en lugar de ξ para construir V . Si ( )E =y Xβ , condicionando
sobre las componentes de varianza este estimador es insesgado, i.e. (E β(ξ)) = β
.
Luego, para obtener estimaciones insesgadas relacionadas a los efectos fijos es
suficiente que la media de la respuesta sea correctamente especificada.
Condicionando sobre ξ , el estimador del vector de efectos fijos tiene covarianza
independiente de la Var( y ), si se asume que la matriz Var( y ) se modela correctamente
como V = ZGZ´ + R . Por ello este estimador de covarianza suele llamarse “estimador
naif o cándido”. La variabilidad incorporada por reemplazar las componentes de
varianza por sus estimadores, no se tiene en cuenta en la construcción del estadístico
de Wald que se presenta como candidato para contrastar hipótesis del tipo 0 : 0H =Lβ ,
donde L es un arreglo de contrastes conocidos. El estadístico de Wald que se
distribuye asintótica mente como una chi-cuadrado con grados de libertad iguales al
rango de L , usa la siguiente expresión de varianza:
( ) 1var( ) −=β X´V(ξ)X
Luego, la prueba de Wald, solo proveerá de inferencia válida en caso de muestras
grandes. Una alternativa práctica es reemplazar la distribución chi-cuadrado por una
distribución F apropiada. El estadístico F para la hipótesis que contrasta efectos fijos
mediante la matriz de contrastes L , es:
( )111
( )F
rango
=
--´ -β´L´ L X V (ξ)X L´ Lβ
L
Bajo la hipótesis nula, la distribución de F se aproxima a la distribución F con grados de
libertad en el numerador igual al rango de L. Los grados de libertad del denominador se
estiman desde los datos por diversos métodos: 1) método de containment
(recomendado en modelos con efectos aleatorios y sin modelación de covarianza
residual) , 2) aproximación de Sattherthwaite (casos donde existen efectos aleatorios y
modelación de covarianza residual), 3) aproximación de Kenward-Roger (casos donde
existen efectos aleatorios y modelación de covarianza residual), 4) Between-within

51
(casos donde solo se modelación de covarianza residual; excepto que el tipo sea sin
estructura donde se usa solo Between) y 5) Residual. Cuando existen varias
observaciones por sujeto, los grados de libertad del denominador son en general
muchos por lo que los tres métodos dan valores-p muy parecidos. Cuando la hipótesis
es univariada, i.e. el rango de L es uno, la prueba F se reduce a la clásica prueba T.
Por otro lado es posible obtener el estimador robusto de Var(β
), el cual requiere que la
matriz de covarianzas de las observaciones se especifique correctamente. El estimador
robusto es obtenido mediante el reemplazo de Var( y ) por ´y - Xβ y - Xβ
. La única
condición para que ´y - Xβ y - Xβ
sea un estimador insesgado de Var( y ) es
nuevamente que la media sea correctamente especificada. El estimador robusto
también recibe el nombre de estimador “sandwich”. A partir de este estimador de
Var(β
) se pueden obtener pruebas robustas basadas en los estadísticos de Wald, T o
F.
Este resultado se presenta para señalar que, para archivos grandes de datos,
siempre que el interés esté centrado en inferir sobre la estructura de medias, el
esfuerzo de modelación de la estructura de covarianza no necesita ser grande. No
obstante, la modelación de la estructura de covarianza puede ser de interés para la
interpretación de la variación aleatoria en los datos, para ganar eficiencia y sobre todo
en presencia de observaciones faltantes ya que la inferencia robusta necesita, para ser
válida, de fuertes supuestos respecto el proceso que subyace ante la falta de datos.
2.5. Inferencia sobre componentes de varianza. Si bien la inferencia respecto a la estructura de media es generalmente aquella
donde se centra el interés, también la inferencia sobre componentes de varianza es
importante ya que: 1) permite interpretar la variación aleatoria, 2) permite identificar
estructuras de covarianza sobreparametrizadas que podrían conducir a ineficiencias en
la inferencia para la estructura de medias o bien modelos muy restrictivos que también
invalidan la inferencia sobre las medias y 3) en ocasiones, constituyen el objetivo de la
investigación por ejemplo, en estudios genéticos para estimar heredabilidad y avance
genético.

52
Asintóticamente los estimadores ML y REML tienen distribución normal con la
media correcta y matriz de covarianzas igual a la inversa de la matriz de información de
Fisher. Luego es posible obtener errores estándares aproximados y realizar la prueba
de Wald. En SAS, es posible obtener los estadísticos Z de esta prueba. En la
interpretación de modelos jerárquicos algunas componentes de varianza deberían ser
cero cuando otras de la distribución en la que se encuentran anidadas son iguales a
cero. Por esto, estas pruebas deberían ser interpretadas completamente sólo en el caso
de modelos marginales, es decir cuando no se supone una estructura de covarianza
asociada a efectos aleatorios para representar la variación entre sujetos.
2.6. Inferencia sobre Efectos Aleatorios. Mejor Predictor Lineal Insesgado (BLUP). En muchas circunstancias prácticas, los efectos (o coeficientes) de los niveles
seleccionados del factor aleatorio no son de interés particular para el experimentador
excepto por la información que ellos contienen acerca de la población de efectos. No
obstante, existen situaciones donde el interés no se centra sólo en la distribución de los
efectos aleatorios sino también en sus valores realizados, es decir en los niveles
actualmente considerados en el estudio. En tales situaciones el análisis involucra el
cálculo de predictores de esos efectos (o coeficientes) aleatorios. El mejor predictor
lineal insesgado (BLUP) de efecto aleatorios constituye el predictor natural de efectos
aleatorios en el contexto del modelo mixto lineal general, presentando propiedades
óptimas en el sentido de minimizar el error cuadrático medio de la predicción dentro del
conjunto de los predictores insesgados (Harville, 1990; Robinson, 1991).
La idea subyacente en la predicción de efectos aleatorios implica determinar, para cada
nivel del factor de efecto aleatorio, una predicción de su ubicación dentro de la
distribución normal de la que proviene. El efecto aleatorio asociado al i-ésimo sujeto
indica cómo éste se desvía del valor esperado. El BLUP produce un corrimiento de las
predicciones hacia la media general de las observaciones que depende de la relación
entre las componentes de varianza involucradas. En general, las predicciones son
menos dispersas que las estimaciones. En la Tabla 5 se comparan las estimaciones de
los efectos de bloque obtenidas bajo el modelo de efectos fijos presentado en la

53
sección de introducción (Modelo B) con las predicciones de los efectos de bloque
obtenidas bajo el Modelo C de la misma sección.
Tabla 5. Comparación de las estimaciones de efectos de bloque bajo el modelo de efectos fijos (Modelo B) con las predicciones de los efectos de bloque obtenidas bajo un modelo mixto (Modelo C)
Bloque Efecto 1 2 3 4 5 6
Fijo 16.0 25.0 16.5 25.0 21.5 20.5 Aleatorio 17.2 23.9 17.6 23.9 21.3 20.6
Mientras que la media asociada a factores de efectos fijos es un promedio realizado
sobre todos los niveles del efecto en la población, el BLUP es una regresión hacia la
media general basada en los componentes de varianza y covarianza asociados a los
efectos aleatorios del modelo (shrinkage estimation). El predictor del vector de efectos
aleatorios tiene la forma:
( )-1u = GZ'Vξ (y - Xβ)
El BLUP se distribuye normalmente con matriz de covarianza igual a:
1var( ) ( )
n
i=− ∑-1 -1 -1 -1u = GZ´ V V X( X´V X)X´V ZG
En la inferencia sobre el vector u se debe contemplar la variabilidad en u , por ello esta
generalmente se basa en la
var( ) var( )− −u u = G u
La raíz cuadrada de esta expresión es conocida como error de predicción (EP). Como
los parámetros del modelo son generalmente desconocidos y deben ser estimados, en
la práctica se calcula el estimador del BLUP(u ) o BLUP empírico como:
ˆ( )-1u = GZ'Vξ (y - Xβ)
Usando la distribución normal antes mencionada, se pueden construir intervalos de
predicción para los BLUP de efectos aleatorios, de manera análoga a la construcción de
los intervalos de confianza para las medias, i.e. BLUP ± tν, 1-α EP. También es común en

54
Agricultura, sobre todo si se desea ordenar material experimental en función de sus
BLUP, usar los BLUPt o BLUP estandarizados, obtenidos dividiendo el BLUP empírico
por su EP. Estos intervalos así como las pruebas T y F posibles son sólo aproximadas
cuando se trabaja con los BLUP empíricos.
Ejemplo 12. BLUP de mérito genético.
Como ilustración, consideremos una serie de ensayos de progenie de cruzas entre
materiales vegetales, que se realiza en varios ensayos con un DBCA en cada uno de
ellos. Supongamos que 100 cruzas se evalúan en cada ensayo, algunos padres se
encuentran representados en más de un ensayo, pero pocas cruzas se repiten entre
ensayos. Si se piensa que hay una estructura a dos vías típica, compuesta de los
efectos principales del progenitor masculino y del femenino, la tabla a dos vías para los
datos tendrá muchos datos faltantes, ya que en cada nuevo ensayo en general se
prueban nuevas cruzas. Suponga que el efecto de cruza es un factor de diseño,
mientras que el factor ensayo puede ser considerado como factor ruido o experimental.
Los factores involucrados son: ensayos, repeticiones dentro de ensayo, y cruza, el cual
depende de los efectos de ambos progenitores y de su interacción. Dado que los
padres transmiten la mitad de su contenido genético a la progenie y que además hay
recombinación, los efectos genéticos como el efecto de cruza en el modelo previo, son
modelados como variables aleatorias. Los efectos de ensayo podrían ser considerados
como fijos simplemente para descontar los niveles medios de ensayos a cada dato o
bien aleatorios para inducir correlaciones entre las observaciones provenientes de un
mismo ensayo. Aún cuando los efectos de ensayo sean aleatorios, la inferencia sobre
los mismos no es de interés, mientras que la inferencia sobre los efectos de cruza es el
motor del trabajo. Será importante realizar inferencias sobre el efecto de cada una de
estas cruzas que se están ensayando, para compararlas y para seleccionar las
mejores.
Un modelo simple para una prueba de progenie conducida según un DBCA con i=1,...,g
cruzas es:
ij i j ijy G Bµ ε= + + +

55
donde ijy es la respuesta (por ejemplo el rendimiento) del genotipo o cruza i, en el
bloque j, µ es la media general, iG es el efecto aleatorio del genotipo i, con i=1,…,g,
suponiendo que se tiene una muestra aleatoria de genotipos, jB es el efecto del bloque
j, con j=1,…,n, que puede ser fijo o aleatorio, y ijε es el término de error aleatorio. Si
los bloques son considerados como aleatorios, se supone que los efectos iG , jB y ijε
son normales, idéntica e independientemente distribuidos con media 0 y varianzas 2gσ ,
2bσ y 2σ , respectivamente. Además, todos los efectos aleatorios se asumen
independientes unos de otros.
Los objetivos clásicos para este tipo de experimentos son: 1) estimar las
componentes de varianza asociadas con los efectos de genotipo, 2) estimar si la
respuesta que se está analizando puede ser heredada, i.e. determinar la heredabilidad
del carácter, y 3) identificar los genotipos superiores con el propósito de elegir un
subconjunto del conjunto de genotipos evaluados para continuar evaluándolos a futuro.
Para realizar una estimación del mérito genético, iGµ + , debe predecirse el valor de
una combinación de efectos fijos y aleatorios del modelo. La obtención del BLUP
( iGµ + ) necesita de la estimación de las componentes de varianza genética ( 2gσ ) y
residual ( 2σ ). A partir de estas componentes de varianza también pueden calcularse
heredabilidades para las características en estudio. La heredabilidad en sentido amplio
(base individual) es: 2
22 2
g
g
Hσ
σ σ=
+ mientras que la heredabilidad en sentido amplio pero expresada en base a promedios
de parcelas es:
2
222
g
g
Hb
σσσ
=+
donde b es el número de bloques o repeticiones de cada genotipo en el ensayo.

56
Si se analizan los datos de varios experimentos donde se comparar las cruzas, un
modelo frecuentemente usado para predecir el mérito genético a partir de la
combinación de j=1,...,t ensayos conducidos cada uno según un DBCA es:
( ) ( )ijk i j k j ij ijky G E B E GEµ ε+ += + + +
donde ijky es la respuesta (rendimiento) del genotipo i, en el ensayo j; µ es la media
general; iG es el efecto aleatorio del genotipo i con i=1,...,g; jE es el efecto fijo del
ensayo j con j=1,…,t; ( )( )k jB E es el efecto de bloque k dentro del ensayo j; ijGE es el
efecto aleatorio de la interacción del genotipo i con el ensayo j; y ijkε es el término de
error aleatorio asociado a la observación ijky . El análisis no se centra en la diferencia
entre ensayos por lo que la comparación de medias del factor fijo E no es de interés.
Los efectos de ensayo sólo han sido incorporados para descontar posibles diferencias
promedios entre ensayos y para considerar que el desempeño de un genotipo podría
cambiar a través de los ensayos. El interés principal es poder evaluar el desempeño de
los genotipos experimentales sobre una base más amplia de repeticiones.
El BLUP, para la función ( )i ijG GLµ + + , usado para predecir el desempeño de un
genotipo en un determinado ensayo (inferencia ambiente-específica) puede expresarse
de acuerdo con el modelo supuesto como:
BLUP( ( )G GEi ijµ + + ) = ... .. ... ... .. . . .( ) ( )G GEi i j ijY F Y Y F Y Y Y Y+ − + − − +
donde GF y GEF son factores de corrimiento, que bajo los supuestos de este modelo
pueden expresarse como funciones de las componentes de varianzas asociadas a los
términos aleatorios del mismo: 2
2
22 2
GEG
G
eG GE
sF
ns
σσ
σσ σ
+=
+ +

57
2
22
GL GE
eGE
F
n
σσσ
=+
Cuando el interés se centra en la predicción del efecto de genotipo G i , i=1,…,g
(inferencia amplia), el objetivo es la obtención del BLUP de G y el único factor de
corrimiento involucrado (Mood, 1950) da la ecuación para este estimador del mérito
del individuo:
2
2 2
ˆ ˆˆ ˆˆ
ˆ ˆ( ) /
s ii
G
G b
µ µµ µσ
σ σ
−= +
+
donde ˆ siµ es el BLUP ( iGµ + ); µ es la media general, ˆiµ es la media del genotipo i-
ésimo, 2ˆGσ es la componente de varianza de genotipo, 2σ es la varianza residual y b es
el número de observaciones por genotipo. Otra forma de expresar el estimador es:
ˆ ˆ ˆ(1 )si i i iB Bµ µ µ= + −
donde
2
2 2
ˆˆ ˆ
ii
i G
B σσ σ
=+
y 2 2
2 ˆ ˆˆ g
i bσ σ
σ+
= .
En las expresiones anteriores puede verse que el estimador aproxima la media del
genotipo hacia la media general. El grado de corrimiento depende de la magnitud de la
varianza. Una varianza de genotipos grande produce un corrimiento pequeño mientras
que una varianza de genotipos pequeña produce un mayor acercamiento hacia la
media general. La ventaja de este estimador es que cuando las medias de genotipo
están muy por arriba o por debajo de la media general, éstas son regresadas hacia el
valor de µ teniendo en cuenta las magnitudes de 2ˆGσ relativas a 2σ . De esta forma las
medias extremas son atenuadas por el conocimiento de la variabilidad subyacente.

58
Luego, para un modelo con suposiciones simples sobre la distribución de los efectos
aleatorios, se puede interpretar al BLUP del efecto aleatorio como una regresión de las
medias de cada nivel del efecto aleatorio hacia la media general µ, con una pendiente
dada por la función GF que toma en cuenta la cantidad de información existente para
cada nivel del efecto aleatorio. Un valor grande de GF implica un corrimiento pequeño
de las medias hacia µ. En el ejemplo presentado, cuando existe una mayor credibilidad
en las medias genotípicas, los BLUP de efectos de genotipos se aproximan a las
medias de los genotipos. Un valor pequeño de GF , conduce a una regresión mayor de
la medias de genotipo hacia la media general. En este último caso, la elección de los
genotipos mediante BLUP puede resultar diferente a la que se encontraría usando las
medias de los mismos bajo un modelo de efectos fijos. Este comportamiento puede
disminuir el riesgo de determinar como diferentes a genotipos sin diferencias reales en
mérito genético. (En el ejemplo Datos Cacao se obtiene Blups de individuos en SAS.)
2.7 Criterios de Bondad de Ajuste Al ajustar distintos modelos a un mismo conjunto de datos, es necesario utilizar criterios
para la comparación de los ajustes y por tanto para la selección de un modelo. Dos
indicadores comúnmente usados son el criterio de información de Akaike (AIC) y el
criterio de Schwarz (BIC). En las versiones más modernas de SAS MIXED (SAS
Institute, 2001), los criterios AIC y BIC se definen como:
2 2AIC L d= − + 2 lnBIC L d n= − +
donde L es el máximo valor de la función de verosimilitud (restringida), d=q+p es la
dimensión del modelo, q es el número de parámetros de covarianza estimados y p es el
rango de la matriz de diseño X . Bajo estas expresiones de AIC y BIC, el mejor modelo
resulta ser aquel con menor valor para el indicador.
Otra alternativa que puede usarse para comparar dos modelos anidados, por ejemplo
con igual estructura de media pero diferente estructura de covarianza, o con diferente
estructura de medias pero igual covarianza, es la prueba del cociente de verosimilitud,
con base en la relación:

59
( , )2 ln 2ln( , )
L reducidoL completoθλθ
− = −
Para la construcción de la prueba a la cantidad –2 ln(L) del modelo con más cantidad
de parámetros (modelo completo) se le resta la cantidad –2 ln(L) del modelo reducido.
La diferencia obtenida se compara con una distribución χ2 con grados de libertad igual a
la diferencia entre el número de parámetros estimados por uno y otro modelo. Si la
prueba resulta significativa, el modelo correcto es el más completo, en caso contrario, el
modelo reducido es el adecuado. Si bien esta prueba se puede realizar tanto con lo
estimadores de máxima verosimilitud como con los estimadores de máxima
verosimilitud restringida, el uso de estimadores REML sólo es recomendable para
comparar dos modelos que difieren en estructura de covarianza pero con igual media.
Esta recomendación se basa en la naturaleza de los estimadores REML. Se discutió
que éstos se obtienen maximizando la verosimilitud de un conjunto de contrastes de
error derivados de una transformación de la variable respuesta. Si las estructuras de
medias de los dos modelos a comparar son diferentes son diferentes, los vectores de
contraste de error asociados a cada modelo también diferirán y por tanto si se aplica la
prueba del cociente de verosimilitud basada en estimadores REML se estarán
comparando verosimilitudes de variables diferentes.
Otro problema relacionado con el uso de la prueba del cociente de verosimilitud se
presenta cuando se usan para parámetros cuyo valor bajo la hipótesis nula está en la
frontera del espacio de valores (por ejemplo, cuando probamos que una componente de
varianza es cero).

60
Módulo 3: Modelación de Datos Normales 3.1 Modelos para Datos Longitudinales. Aplicaciones en Agricultura.
Ejercicio 3.1.1. Datos Semillas.
Para los datos del Ejemplo 1, en primera instancia ajustaremos un modelo no
estructurado para la media y un modelo no estructurado para la varianza. Si X es 0 para
semillas pequeñas y 1 para semillas grandes (variable grupo), una posible
parametrizacion del modelo (Modelo 1) para la caja i es la que considera un parámetro
para cada combinación tiempo×grupo. Luego, el vector de parámetros asociado a la
esperanza de la biomasa tiene 8 parámetros y el asociado a la estructura de covarianza
tiene 10.
Como en muchas circunstancias, el interés se centra en reducir el modelo para lograr
un modelo válido pero con pocos parámetros. Primero, se ajustarán modelos para la
estructura de covarianza de las observaciones repetidas dentro de sujeto (modelo
Toeplitz; modelo autorregresivo de orden 1). Si es posible reducirla se ganaría
eficiencia para inferir sobre la estructura de medias. Esta estrategia es aun más
importante cuando el número de medidas repetidas sobre un mismo sujeto es grande.
En la práctica siempre es recomendable buscar modelos más parsimoniosos. Debido a
que los gráficos exploratorios sugieren la existencia de una relación lineal, se probará si
es posible reducir el número de parámetros mediante el ajuste de esta relación, para
cada grupo, utilizando el modelo de matriz de covarianzas seleccionado previamente.
Finalmente se obtienen las estimaciones REML de todos los parametros del modelo.

61
Outline 3.1.1a. Código SAS datos semillas
ods rtf file="H:\salida_semilla.rtf"; proc import datafile=" H:\semillas.xls" out=semillas replace; run; data semillas; set semillas; tiempoclas=tiempo; Title 'Estructuras de media y covarianza no estructurada'; proc mixed data=semillas method=ML; class cajas grupo tiempo tiempoclas; model biomasa= tiempo*grupo / noint solution outpredm=pred1; repeated tiempoclas / type=UN subject=cajas(grupo) rcorr; run; Title 'Estructura de media completa, covarianza Toeplitz'; proc mixed data=semillas method=ML; class cajas grupo tiempo tiempoclas; model biomasa=tiempo*grupo / noint solution outpredm=pred2; repeated tiempoclas / type=TOEP subject=cajas(grupo) rcorr; Run; Title 'Estructura de media completa, covarianza AR(1)'; proc mixed data=semillas method=ML; class cajas grupo tiempo tiempoclas; model biomasa=tiempo*grupo / noint solution outpredm=pred2; repeated tiempoclas / type=AR(1) subject=cajas(grupo) rcorr; Run; Title 'Tendencia lineal dentro de cada grupo, covarianza no estructurada'; proc mixed data=semillas method=ML; class cajas grupo tiempoclas; model biomasa= grupo tiempo*grupo / noint solution outpredm=pred2; repeated tiempoclas / type=UN subject=cajas(grupo) rcorr; Run; Title 'Estructura de media completa, covarianza no estructurada, modelo final'; proc mixed data=semillas method=REML; class cajas grupo tiempo tiempoclas; model biomasa= tiempo*grupo / noint solution outpredm=pred2; repeated tiempoclas / type=UN subject=cajas(grupo) rcorr; Run; ods rtf close;

62
Outline 3.1.1b. Salida SAS para datos semillas
Model Information
Data Set WORK.SEMILLAS Dependent Var iable biomasa Covar iance Structure Unstructured Subject Effect cajas(Grupo) Estimation Method ML Residual Var iance Method None Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
cajas 5 1 2 3 4 5 Grupo 2 0 1 tiempo 4 8 10 12 14 tiempoclas 4 8 10 12 14
Dimensions
Covar iance Parameters 10 Columns in X 8 Columns in Z 0 Subjects 10 Max Obs Per Subject 4 Observations Used 40 Observations Not Used 0 Total Observations 40

63
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 402.19537454 1 1 313.23230203 0.00000000
Convergence criteria met.
Estimated R Correlation Matr ix for cajas(Grupo) 1 0
Row Col1 Col2 Col3 Col4
1 1.0000 0.8739 0.8005 0.8247 2 0.8739 1.0000 0.9614 0.9206 3 0.8005 0.9614 1.0000 0.9779 4 0.8247 0.9206 0.9779 1.0000
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(1,1) cajas(Grupo) 491.42 UN(2,1) cajas(Grupo) 557.19 UN(2,2) cajas(Grupo) 827.16 UN(3,1) cajas(Grupo) 777.14 UN(3,2) cajas(Grupo) 1210.89 UN(3,3) cajas(Grupo) 1917.88 UN(4,1) cajas(Grupo) 860.02 UN(4,2) cajas(Grupo) 1245.56 UN(4,3) cajas(Grupo) 2014.65 UN(4,4) cajas(Grupo) 2213.17

64
Fit Statistics
-2 Log Likelihood 313.2 AIC (smaller is better ) 349.2 AICC (smaller is better ) 381.8 BIC (smaller is better ) 354.7
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
9 88.96 <.0001
Solution for Fixed Effects
Effect Grupo tiempo Estimate Standard Error DF t Value Pr > |t|
Grupo*tiempo 0 8 208.21 9.9138 10 21.00 <.0001 Grupo*tiempo 0 10 302.22 12.8620 10 23.50 <.0001 Grupo*tiempo 0 12 420.41 19.5851 10 21.47 <.0001 Grupo*tiempo 0 14 537.65 21.0389 10 25.56 <.0001 Grupo*tiempo 1 8 413.49 9.9138 10 41.71 <.0001 Grupo*tiempo 1 10 445.71 12.8620 10 34.65 <.0001 Grupo*tiempo 1 12 494.44 19.5851 10 25.25 <.0001 Grupo*tiempo 1 14 530.08 21.0389 10 25.20 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
Grupo*tiempo 8 10 577.44 <.0001

65
Model Information
Data Set WORK.SEMILLAS Dependent Var iable biomasa Covar iance Structure Toeplitz Subject Effect cajas(Grupo) Estimation Method ML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
cajas 5 1 2 3 4 5 Grupo 2 0 1 tiempo 4 8 10 12 14 tiempoclas 4 8 10 12 14
Dimensions
Covar iance Parameters 4 Columns in X 8 Columns in Z 0 Subjects 10 Max Obs Per Subject 4 Observations Used 40 Observations Not Used 0 Total Observations 40

66
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 402.19537454 1 2 338.88269674 353646.07943 2 1 334.52306643 59821.749958 3 1 331.21471282 0.03120062 4 1 330.28973976 0.00496165 5 1 329.51184123 0.00113075 6 1 329.34365820 0.00010832 7 1 329.32885064 0.00000138 8 1 329.32867313 0.00000000
Convergence criteria met.
Estimated R Correlation Matr ix for cajas(Grupo) 1 0
Row Col1 Col2 Col3 Col4
1 1.0000 0.9158 0.7708 0.7298 2 0.9158 1.0000 0.9158 0.7708 3 0.7708 0.9158 1.0000 0.9158 4 0.7298 0.7708 0.9158 1.0000
Covar iance Parameter Estimates
Cov Parm Subject Estimate
TOEP(2) cajas(Grupo) 1192.94 TOEP(3) cajas(Grupo) 1004.09 TOEP(4) cajas(Grupo) 950.73 Residual 1302.69

67
Fit Statistics
-2 Log Likelihood 329.3 AIC (smaller is better ) 353.3 AICC (smaller is better ) 364.9 BIC (smaller is better ) 357.0
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
3 72.87 <.0001
Solution for Fixed Effects
Effect Grupo tiempo Estimate Standard Error DF t Value Pr > |t|
Grupo*tiempo 0 8 208.21 16.1412 22 12.90 <.0001 Grupo*tiempo 0 10 302.22 16.1412 22 18.72 <.0001 Grupo*tiempo 0 12 420.41 16.1412 22 26.05 <.0001 Grupo*tiempo 0 14 537.65 16.1412 22 33.31 <.0001 Grupo*tiempo 1 8 413.49 16.1412 22 25.62 <.0001 Grupo*tiempo 1 10 445.71 16.1412 22 27.61 <.0001 Grupo*tiempo 1 12 494.44 16.1412 22 30.63 <.0001 Grupo*tiempo 1 14 530.08 16.1412 22 32.84 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
Grupo*tiempo 8 22 444.03 <.0001
Model Information
Data Set WORK.SEMILLAS Dependent Var iable biomasa Covar iance Structure Autoregressive

68
Model Information
Subject Effect cajas(Grupo) Estimation Method ML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
cajas 5 1 2 3 4 5 Grupo 2 0 1 tiempo 4 8 10 12 14 tiempoclas 4 8 10 12 14
Dimensions
Covar iance Parameters 2 Columns in X 8 Columns in Z 0 Subjects 10 Max Obs Per Subject 4 Observations Used 40 Observations Not Used 0 Total Observations 40
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 402.19537454 1 2 344.81165480 0.00000007 2 1 344.81164464 0.00000000

69
Convergence criteria met.
Estimated R Correlation Matr ix for cajas(Grupo) 1 0
Row Col1 Col2 Col3 Col4
1 1.0000 0.9226 0.8512 0.7854 2 0.9226 1.0000 0.9226 0.8512 3 0.8512 0.9226 1.0000 0.9226 4 0.7854 0.8512 0.9226 1.0000
Covar iance Parameter Estimates
Cov Parm Subject Estimate
AR(1) cajas(Grupo) 0.9226 Residual 1354.91
Fit Statistics
-2 Log Likelihood 344.8 AIC (smaller is better ) 364.8 AICC (smaller is better ) 372.4 BIC (smaller is better ) 367.8
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
1 57.38 <.0001
Solution for Fixed Effects
Effect Grupo tiempo Estimate Standard Error DF t Value Pr > |t|
Grupo*tiempo 0 8 208.21 16.4616 22 12.65 <.0001 Grupo*tiempo 0 10 302.22 16.4616 22 18.36 <.0001 Grupo*tiempo 0 12 420.41 16.4616 22 25.54 <.0001 Grupo*tiempo 0 14 537.65 16.4616 22 32.66 <.0001

70
Solution for Fixed Effects
Effect Grupo tiempo Estimate Standard Error DF t Value Pr > |t|
Grupo*tiempo 1 8 413.49 16.4616 22 25.12 <.0001 Grupo*tiempo 1 10 445.71 16.4616 22 27.08 <.0001 Grupo*tiempo 1 12 494.44 16.4616 22 30.04 <.0001 Grupo*tiempo 1 14 530.08 16.4616 22 32.20 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
Grupo*tiempo 8 22 319.37 <.0001
Model Information
Data Set WORK.SEMILLAS Dependent Var iable biomasa Covar iance Structure Unstructured Subject Effect cajas(Grupo) Estimation Method ML Residual Var iance Method None Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
cajas 5 1 2 3 4 5 Grupo 2 0 1 tiempoclas 4 8 10 12 14

71
Dimensions
Covar iance Parameters 10 Columns in X 4 Columns in Z 0 Subjects 10 Max Obs Per Subject 4 Observations Used 40 Observations Not Used 0 Total Observations 40
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 402.97047111 1 3 330.43423809 0.00010002 2 2 328.98184998 0.02541007 3 2 327.82559071 0.00696570 4 1 326.72573370 0.00202832 5 1 326.41848285 0.00031963 6 1 326.37351795 0.00001271 7 1 326.37186296 0.00000003 8 1 326.37185936 0.00000000
Convergence criteria met.
Estimated R Correlation Matr ix for cajas(Grupo) 1 0
Row Col1 Col2 Col3 Col4
1 1.0000 0.8738 0.8575 0.8871 2 0.8738 1.0000 0.9569 0.9022 3 0.8575 0.9569 1.0000 0.9779 4 0.8871 0.9022 0.9779 1.0000

72
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(1,1) cajas(Grupo) 760.15 UN(2,1) cajas(Grupo) 780.51 UN(2,2) cajas(Grupo) 1049.68 UN(3,1) cajas(Grupo) 1290.49 UN(3,2) cajas(Grupo) 1692.21 UN(3,3) cajas(Grupo) 2979.57 UN(4,1) cajas(Grupo) 1551.77 UN(4,2) cajas(Grupo) 1854.60 UN(4,3) cajas(Grupo) 3386.71 UN(4,4) cajas(Grupo) 4025.43
Fit Statistics
-2 Log Likelihood 326.4 AIC (smaller is better ) 354.4 AICC (smaller is better ) 371.2 BIC (smaller is better ) 358.6
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
9 76.60 <.0001
Solution for Fixed Effects
Effect Grupo Estimate Standard Error DF t Value Pr > |t|
Grupo 0 -219.69 10.7639 8 -20.41 <.0001 Grupo 1 283.18 10.7639 8 26.31 <.0001 tiempo*Grupo 0 51.3716 1.1273 8 45.57 <.0001 tiempo*Grupo 1 14.3087 1.1273 8 12.69 <.0001

73
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
Grupo 2 8 554.35 <.0001 tiempo*Grupo 2 8 1118.91 <.0001
Model Information
Data Set WORK.SEMILLAS Dependent Var iable biomasa Covar iance Structure Unstructured Subject Effect cajas(Grupo) Estimation Method REML Residual Var iance Method None Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
cajas 5 1 2 3 4 5 Grupo 2 0 1 tiempo 4 8 10 12 14 tiempoclas 4 8 10 12 14
Dimensions
Covar iance Parameters 10 Columns in X 8 Columns in Z 0 Subjects 10 Max Obs Per Subject 4 Observations Used 40

74
Dimensions
Observations Not Used 0 Total Observations 40
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 341.77239657 1 1 270.60193856 0.00000000
Convergence criteria met.
Estimated R Correlation Matr ix for cajas(Grupo) 1 0
Row Col1 Col2 Col3 Col4
1 1.0000 0.8739 0.8005 0.8247 2 0.8739 1.0000 0.9614 0.9206 3 0.8005 0.9614 1.0000 0.9779 4 0.8247 0.9206 0.9779 1.0000
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(1,1) cajas(Grupo) 614.27 UN(2,1) cajas(Grupo) 696.49 UN(2,2) cajas(Grupo) 1033.95 UN(3,1) cajas(Grupo) 971.42 UN(3,2) cajas(Grupo) 1513.61 UN(3,3) cajas(Grupo) 2397.34 UN(4,1) cajas(Grupo) 1075.03 UN(4,2) cajas(Grupo) 1556.94 UN(4,3) cajas(Grupo) 2518.31 UN(4,4) cajas(Grupo) 2766.46

75
Fit Statistics
-2 Res Log Likelihood 270.6 AIC (smaller is better ) 290.6 AICC (smaller is better ) 301.1 BIC (smaller is better ) 293.6
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
9 71.17 <.0001
Solution for Fixed Effects
Effect Grupo tiempo Estimate Standard Error DF t Value Pr > |t|
Grupo*tiempo 0 8 208.21 11.0840 10 18.78 <.0001 Grupo*tiempo 0 10 302.22 14.3802 10 21.02 <.0001 Grupo*tiempo 0 12 420.41 21.8968 10 19.20 <.0001 Grupo*tiempo 0 14 537.65 23.5222 10 22.86 <.0001 Grupo*tiempo 1 8 413.49 11.0840 10 37.31 <.0001 Grupo*tiempo 1 10 445.71 14.3802 10 30.99 <.0001 Grupo*tiempo 1 12 494.44 21.8968 10 22.58 <.0001 Grupo*tiempo 1 14 530.08 23.5222 10 22.54 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
Grupo*tiempo 8 10 461.96 <.0001

76
Outline 3.1.1b. Comparación de modelos para la estructura de covarianzas.
Test del cociente de verosimilitud
Modelo Media Cov Par -2log(L) Referente G2 df p
1 No estr No estr 18 (8+10) 313.2
2 No estr Toeplitz 12 (8+4) 329.3 1 16.1 6 0.0133
3 No estr AR 1 10 (8+2) 344.8 1 31.6 8 0.0001
Conclusión 1: La diferencia entre la estructura de covarianza de los Modelos TOEP y
AR1 respecto al Modelo 1 es significativa, por lo que no es posible realizar la reducción.
Se rechaza la hipótesis nula (hipótesis a favor del modelo reducido). Los criterios AIC y
BIC coinciden en seleccionar la estructura UN como la más apropiada para ajustar
covarianzas en estos datos.
Outline 3.1.1c. Comparación de modelos para la estructura de media (covarianza, no
estructurado).
Test del cociente de verosimilitud Modelo 2 vs. Modelo 1
Modelo Media Cov Par -2log(L) Referente G2 df p
1 No estr No estr 18 (8+10) 313.2
2 Reg/Gr No estr 14 (4+10) 326.4 1 13.2 4 0,010
Conclusión 2: En la prueba del cociente de verosimilitud se rechaza la hipótesis nula
(que favorece al modelo reducido, en este caso el modelo reducido es el modelo de dos
rectas). Por ello se concluye que será conveniente seleccionar el modelo de 8
parámetros para la estructura de medias. Las estimaciones asociadas a cada uno de
los parámetros del modelo (parámetros de la estructura de media y de la estructura de
covarianza) se encuentran en la porcion final de la salida (estimaciones derivadas del
método REML). En la Figura 9 se presentan los valores predichos para la estructura de
medias del Modelo 1.

77
8 10 12 14tiempo
191,74
282,33
372,93
463,53
554,12
Bio
mas
a P
redi
cha
Figura 9. Modelo no estructurado para la estructura de medias. Círculo = semillas
pequeñas, cuadrado = semillas grandes.
3.2 Modelos Lineales para Curvas de Crecimiento. Aplicaciones en Forestería Ejercicio 3.2.1. Datos Quebracho
En función de los gráficos del ejemplo quebracho, parece razonable ajustar un modelo
polinómico de segundo orden a las curvas de crecimiento radial de quebrachos. El
quebracho es de crecimiento muy lento en la zona de estudio y para la edad en que se
obtuvieron las muestras dendrocronológicas parecía que no se había completado el
ciclo biológico, por lo que no hay necesidad de pensar en un modelo no-lineal. Se
ajustará este modelo para la estructura de media y se usaran modelos alternativos para
la estructura de covarianza entre las lecturas realizadas sobre un mismo árbol. La
correlación serial será contemplada mediante la matriz R (Modelos 1, 2 y 3). Debemos
observar que un modelo con covarianza no estructurada tendría demasiados
parámetros, y por lo tanto se requerirían demasiados datos para poder estimarlo
razonablemente. Para ilustrar cómo se puede inducir el modelo de Simetría Compuesta
a través de la incorporación de efectos aleatorios de árbol se ajusta el Modelo 4.
Outline 3.2.1a. Códigos SAS. Datos Quebracho.
ods rtf file="H:\salida_quebracho.rtf";

78
proc import datafile=" H:\Quebracho.xls" out=quebracho replace; run; data quebracho; set quebracho; edadclas=edad; proc mixed data=quebracho scoring=200 maxfunc=2500 maxiter=5000 method=reml; class arbol edadclas; model ir=edad edad*edad / solution; repeated edadclas / type=VC subject=arbol; proc mixed data=quebracho scoring=200 maxfunc=2500 maxiter=5000 method=reml; class arbol edadclas; model ir=edad edad*edad / solution; repeated edadclas / type=CS subject=arbol; proc mixed data=quebracho scoring=200 maxfunc=2500 maxiter=5000 method=reml; class arbol edadclas; model ir=edad edad*edad / solution; repeated edadclas / type=AR(1) subject=arbol; proc mixed data=quebracho scoring=200 maxfunc=2500 maxiter=5000 method=reml; class arbol; model ir=edad edad*edad / solution; random arbol / type=vc s; run; ods rtf close; Outline 3.2.1b. Salida SAS. Datos Quebracho.
Model Information
Data Set WORK.QUEBRACHO Dependent Var iable ir Covar iance Structure Variance Components Subject Effect arbol Estimation Method REML Residual Var iance Method Parameter Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within

79
Class Level Information
Class Levels Values
arbol 6 1 2 3 4 5 6 edadclas 76 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76
Dimensions
Covar iance Parameters 1 Columns in X 3 Columns in Z 0 Subjects 6 Max Obs Per Subject 76 Observations Used 415 Observations Not Used 0 Total Observations 415
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 -1190.31131557 1 1 -1190.31131557 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
edadclas arbol 0.002984

80
Fit Statistics
-2 Res Log Likelihood -1190.3 AIC (smaller is better ) -1188.3 AICC (smaller is better ) -1188.3 BIC (smaller is better ) -1188.5
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
0 0.00 1.0000
Solution for Fixed Effects
Effect Estimate Standard Error DF t Value Pr > |t|
Intercept 0.1427 0.008083 5 17.65 <.0001 edad 0.003496 0.000510 407 6.85 <.0001 edad*edad -0.00002 6.827E-6 407 -3.59 0.0004
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
edad 1 407 46.90 <.0001 edad*edad 1 407 12.90 0.0004
Model Information
Data Set WORK.QUEBRACHO Dependent Var iable ir Covar iance Structure Compound Symmetry Subject Effect arbol Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within

81
Class Level Information
Class Levels Values
arbol 6 1 2 3 4 5 6 edadclas 76 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76
Dimensions
Covar iance Parameters 2 Columns in X 3 Columns in Z 0 Subjects 6 Max Obs Per Subject 76 Observations Used 415 Observations Not Used 0 Total Observations 415
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 -1190.31131557 1 2 -1226.63711862 0.00000001
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
CS arbol 0.000427 Residual 0.002651

82
Fit Statistics
-2 Res Log Likelihood -1226.6 AIC (smaller is better ) -1222.6 AICC (smaller is better ) -1222.6 BIC (smaller is better ) -1223.1
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
1 36.33 <.0001
Solution for Fixed Effects
Effect Estimate Standard Error DF t Value Pr > |t|
Intercept 0.1434 0.01137 5 12.61 <.0001 edad 0.003430 0.000484 407 7.09 <.0001 edad*edad -0.00002 6.503E-6 407 -3.64 0.0003
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
edad 1 407 50.29 <.0001 edad*edad 1 407 13.24 0.0003
Model Information
Data Set WORK.QUEBRACHO Dependent Var iable ir Covar iance Structure Autoregressive Subject Effect arbol Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within

83
Class Level Information
Class Levels Values
arbol 6 1 2 3 4 5 6 edadclas 76 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76
Dimensions
Covar iance Parameters 2 Columns in X 3 Columns in Z 0 Subjects 6 Max Obs Per Subject 76 Observations Used 415 Observations Not Used 0 Total Observations 415
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 -1190.31131557 1 2 -1230.09783154 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
AR(1) arbol 0.3084 Residual 0.003005

84
Fit Statistics
-2 Res Log Likelihood -1230.1 AIC (smaller is better ) -1226.1 AICC (smaller is better ) -1226.1 BIC (smaller is better ) -1226.5
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
1 39.79 <.0001
Solution for Fixed Effects
Effect Estimate Standard Error DF t Value Pr > |t|
Intercept 0.1417 0.01083 5 13.09 <.0001 edad 0.003575 0.000684 407 5.23 <.0001 edad*edad -0.00003 9.145E-6 407 -2.82 0.0050
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
edad 1 407 27.31 <.0001 edad*edad 1 407 7.97 0.0050
Model Information
Data Set WORK.QUEBRACHO Dependent Var iable ir Covar iance Structure Variance Components Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Containment

85
Class Level Information
Class Levels Values
arbol 6 1 2 3 4 5 6
Dimensions
Covar iance Parameters 2 Columns in X 3 Columns in Z 6 Subjects 1 Max Obs Per Subject 415 Observations Used 415 Observations Not Used 0 Total Observations 415
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 -1190.31131557 1 2 -1226.63645691 0.00000061 2 1 -1226.63711668 0.00000001
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Estimate
arbol 0.000427
Residual 0.002651

86
Fit Statistics
-2 Res Log Likelihood -1226.6 AIC (smaller is better ) -1222.6 AICC (smaller is better ) -1222.6 BIC (smaller is better ) -1223.1
Solution for Fixed Effects
Effect Estimate Standard Error DF t Value Pr > |t|
Intercept 0.1434 0.01137 5 12.61 <.0001 edad 0.003430 0.000484 407 7.09 <.0001 edad*edad -0.00002 6.503E-6 407 -3.64 0.0003
Solution for Random Effects
Effect arbol Estimate Std Err Pred DF t Value Pr > |t|
arbol 1 0.02784 0.01012 407 2.75 0.0062 arbol 2 0.009171 0.01003 407 0.91 0.3608 arbol 3 -0.02720 0.01026 407 -2.65 0.0083 arbol 4 0.01148 0.009970 407 1.15 0.2503 arbol 5 -0.01099 0.009943 407 -1.11 0.2697 arbol 6 -0.01029 0.009950 407 -1.03 0.3015
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
Edad 1 407 50.29 <.0001 edad*edad 1 407 13.24 0.0003
Conclusión: Los criterios de selección de modelo sugieren que el modelo autorregresivo
de primer orden es el modelo más apropiado para estos datos. Los efectos lineales y
cuadráticos del modelo para describir el crecimiento son significativos. Es importante
notar que los criterios de bondad de ajuste, los componentes de varianza y los valores p
asociados a los parámetros de la estructura de media son idénticos para el Modelo 2 y
el Modelo 4. Estos dos enfoques son equivalentes para el caso de datos normales.

87
Ejercicio 3.2.2. Datos Cacao
Se realizaron dos análisis uno para identificar los mejores híbridos en relación a la
producción de frutos sanos en el tiempo y otro para identificar los árboles más
productivos de cada parcela mediante el uso de BLUPs.
Outline 3.2.2a. Códigos SAS. Datos Cacao. Comparación de híbridos. ods rtf file="H:\salida_cacao.rtf"; libname a "H:\"; %include "H:\pdmixed800.sas" proc sort data=a.nuevo out=cacao; by h rep_ tree; proc means data=cacao sum noprint; by a_o h rep_ tree; var s; output out=totaldearbol sum=sanos; proc means data=totaldearbol mean noprint; by a_o h rep_ ; var s; output out=mediahib mean=sanos; data a.mediahib; set mediahib; anio=a_o; rep=rep_; prod_ha=sanos*1111; drop a_o rep_ _freq_ _type_; proc mixed data=a.mediahib; class anio h rep; model prod_ha= rep anio h anio*h; repeated anio / type=un subject=rep*hib r; proc mixed data=a.mediahib; class anio h rep; model prod_ha= rep anio h anio*h; repeated anio / type=cs subject=rep*hib r; proc mixed data=a.mediahib; class anio h rep; model prod_ha= rep anio h anio*h; repeated anio / type=un subject=rep*hib r; lsmeans h anio*h / slice=anio pdiff; ods output diffs=p lsmeans=m; ods listing exclude diffs lsmeans ; ods rtf exclude diffs lsmeans ; run; %pdmix800(p,m,alpha=.05, sort=yes, slice=anio); run; ods rtf close;

88
Outline 3.2.2b. Salidas SAS. Datos Cacao. Comparación de híbridos.
Model Information
Data Set A.MEDIAHIB Dependent Var iable prod_ha Covar iance Structure Unstructured Subject Effect H*rep Estimation Method REML Residual Var iance Method None Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
anio 5 1 2 3 4 5 H 56 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56
rep 4 1 2 3 4
Dimensions
Covar iance Parameters 15 Columns in X 346 Columns in Z 0 Subjects 224 Max Obs Per Subject 5 Observations Used 1120 Observations Not Used 0 Total Observations 1120

89
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 16642.04214581 1 2 16220.31063307 0.00000071 2 1 16220.30534788 0.00000000
Convergence criteria met.
Estimated R Matr ix for H*rep 1 1
Row Col1 Col2 Col3 Col4 Col5
1 13398068 7644445 8783277 2709926 3617510 2 7644445 16624252 14702892 6592101 9131995 3 8783277 14702892 25566021 9119765 12557532 4 2709926 6592101 9119765 9327293 7392162 5 3617510 9131995 12557532 7392162 14447554
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(1,1) H*rep 13398068 UN(2,1) H*rep 7644445 UN(2,2) H*rep 16624252 UN(3,1) H*rep 8783277 UN(3,2) H*rep 14702892 UN(3,3) H*rep 25566021 UN(4,1) H*rep 2709926 UN(4,2) H*rep 6592101 UN(4,3) H*rep 9119765 UN(4,4) H*rep 9327293 UN(5,1) H*rep 3617510 UN(5,2) H*rep 9131995 UN(5,3) H*rep 12557532

90
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(5,4) H*rep 7392162 UN(5,5) H*rep 14447554
Fit Statistics
-2 Res Log Likelihood 16220.3 AIC (smaller is better ) 16250.3 AICC (smaller is better ) 16250.9 BIC (smaller is better ) 16301.5
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
14 421.74 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
rep 3 165 16.89 <.0001 anio 4 165 48.38 <.0001 H 55 165 3.61 <.0001 anio*H 220 165 1.46 0.0050
Model Information
Data Set A.MEDIAHIB Dependent Var iable prod_ha Covar iance Structure Compound Symmetry Subject Effect H*rep Estimation Method REML Residual Var iance Method Profile

91
Model Information
Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
anio 5 1 2 3 4 5 H 56 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 rep 4 1 2 3 4
Dimensions
Covar iance Parameters 2 Columns in X 346 Columns in Z 0 Subjects 224 Max Obs Per Subject 5 Observations Used 1120 Observations Not Used 0 Total Observations 1120
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 16642.04214581 1 1 16348.38631240 0.00000000
Convergence criteria met.

92
Estimated R Matr ix for H*rep 1 1
Row Col1 Col2 Col3 Col4 Col5
1 15715869 8068284 8068284 8068284 8068284 2 8068284 15715869 8068284 8068284 8068284 3 8068284 8068284 15715869 8068284 8068284 4 8068284 8068284 8068284 15715869 8068284 5 8068284 8068284 8068284 8068284 15715869
Covar iance Parameter Estimates
Cov Parm Subject Estimate
CS H*rep 8068284 Residual 7647585
Fit Statistics
-2 Res Log Likelihood 16348.4 AIC (smaller is better ) 16352.4 AICC (smaller is better ) 16352.4 BIC (smaller is better ) 16359.2
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
1 293.66 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
rep 3 165 15.50 <.0001 anio 4 672 62.34 <.0001 H 55 165 3.67 <.0001 anio*H 220 672 1.48 <.0001

93
Model Information
Data Set A.MEDIAHIB Dependent Var iable prod_ha Covar iance Structure Unstructured Subject Effect H*rep Estimation Method REML Residual Var iance Method None Fixed Effects SE Method Model-Based Degrees of Freedom Method Between-Within
Class Level Information
Class Levels Values
anio 5 1 2 3 4 5 H 56 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 rep 4 1 2 3 4
Dimensions
Covar iance Parameters 15 Columns in X 346 Columns in Z 0 Subjects 224 Max Obs Per Subject 5 Observations Used 1120 Observations Not Used 0 Total Observations 1120

94
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 16642.04214581 1 2 16220.31063307 0.00000071 2 1 16220.30534788 0.00000000
Convergence criteria met.
Estimated R Matr ix for H*rep 1 1
Row Col1 Col2 Col3 Col4 Col5
1 13398068 7644445 8783277 2709926 3617510 2 7644445 16624252 14702892 6592101 9131995 3 8783277 14702892 25566021 9119765 12557532 4 2709926 6592101 9119765 9327293 7392162 5 3617510 9131995 12557532 7392162 14447554
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(1,1) H*rep 13398068 UN(2,1) H*rep 7644445 UN(2,2) H*rep 16624252 UN(3,1) H*rep 8783277 UN(3,2) H*rep 14702892 UN(3,3) H*rep 25566021 UN(4,1) H*rep 2709926 UN(4,2) H*rep 6592101 UN(4,3) H*rep 9119765 UN(4,4) H*rep 9327293 UN(5,1) H*rep 3617510 UN(5,2) H*rep 9131995 UN(5,3) H*rep 12557532

95
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(5,4) H*rep 7392162 UN(5,5) H*rep 14447554
Fit Statistics
-2 Res Log Likelihood 16220.3 AIC (smaller is better ) 16250.3 AICC (smaller is better ) 16250.9 BIC (smaller is better ) 16301.5
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
14 421.74 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
rep 3 165 16.89 <.0001 anio 4 165 48.38 <.0001 H 55 165 3.61 <.0001 anio*H 220 165 1.46 0.0050
Tests of Effect Slices
Effect anio Num DF Den DF F Value Pr > F
anio*H 1 55 165 3.47 <.0001 anio*H 2 55 165 4.02 <.0001 anio*H 3 55 165 2.36 <.0001 anio*H 4 55 165 2.00 0.0004 anio*H 5 55 165 2.02 0.0003

96
Effect=H Method=LSD(P<.05) Set=1
Obs anio H Estimate Standard Error Letter Group
1 _ 3 13165 1561.62 A 2 _ 14 12967 1561.62 AB 3 _ 5 10999 1561.62 ABC 4 _ 48 10250 1561.62 ABCD 5 _ 40 9631.97 1561.62 ABCDE 6 _ 6 9146.90 1561.62 ABCDEF 7 _ 41 9144.92 1561.62 ABCDEF 8 _ 47 8693.57 1561.62 BCDEFG 9 _ 15 8394.99 1561.62 CDEFGH
10 _ 21 8314.64 1561.62 CDEFGHI 11 _ 4 7971.42 1561.62 CDEFGHIJ 12 _ 7 7631.18 1561.62 CDEFGHIJK 13 _ 28 7390.46 1561.62 CDEFGHIJKL 14 _ 17 7238.36 1561.62 CDEFGHIJKLM 15 _ 29 6812.81 1561.62 CDEFGHIJKLMN 16 _ 43 6436.86 1561.62 DEFGHIJKLMN 17 _ 52 6431.90 1561.62 DEFGHIJKLMN 18 _ 20 6417.02 1561.62 DEFGHIJKLMN 19 _ 34 6237.80 1561.62 DEFGHIJKLMNO 20 _ 22 5993.45 1561.62 DEFGHIJKLMNOP 21 _ 16 5916.08 1561.62 DEFGHIJKLMNOPQ 22 _ 19 5825.81 1561.62 EFGHIJKLMNOPQ 23 _ 9 5652.21 1561.62 EFGHIJKLMNOPQR 24 _ 10 5547.06 1561.62 EFGHIJKLMNOPQRS 25 _ 33 5232.28 1561.62 FGHIJKLMNOPQRST 26 _ 50 5191.94 1561.62 FGHIJKLMNOPQRST 27 _ 45 5089.77 1561.62 FGHIJKLMNOPQRST 28 _ 23 4845.75 1561.62 FGHIJKLMNOPQRSTU 29 _ 11 4784.24 1561.62 GHIJKLMNOPQRSTU 30 _ 30 4679.10 1561.62 GHIJKLMNOPQRSTU

97
Obs anio H Estimate Standard Error Letter Group
31 _ 2 4656.61 1561.62 GHIJKLMNOPQRSTU 32 _ 12 4631.15 1561.62 GHIJKLMNOPQRSTU 33 _ 42 4575.93 1561.62 GHIJKLMNOPQRSTU 34 _ 51 4499.55 1561.62 GHIJKLMNOPQRSTU 35 _ 18 4298.18 1561.62 HIJKLMNOPQRSTU 36 _ 39 4041.26 1561.62 HIJKLMNOPQRSTU 37 _ 56 3992.66 1561.62 IJKLMNOPQRSTU 38 _ 1 3768.14 1561.62 JKLMNOPQRSTU 39 _ 55 3721.85 1561.62 JKLMNOPQRSTU 40 _ 8 3645.47 1561.62 JKLMNOPQRSTU 41 _ 25 3543.83 1561.62 KLMNOPQRSTU 42 _ 24 3427.24 1561.62 KLMNOPQRSTU 43 _ 13 3346.89 1561.62 KLMNOPQRSTU 44 _ 36 3267.53 1561.62 LMNOPQRSTU 45 _ 49 3266.34 1561.62 LMNOPQRSTU 46 _ 27 2883.97 1561.62 MNOPQRSTU 47 _ 54 2806.60 1561.62 NOPQRSTU 48 _ 46 1930.36 1561.62 OPQRSTU 49 _ 53 1775.48 1561.62 PQRSTU 50 _ 32 1562.34 1561.62 QRSTU 51 _ 35 1370.23 1561.62 RSTU 52 _ 26 1268.39 1561.62 STU 53 _ 44 990.97 1561.62 TU 54 _ 38 701.32 1561.62 U 55 _ 37 607.08 1561.62 U 56 _ 31 511.06 1561.62 U
Effect=anio*H Method=LSD(P<.05) Set=2
Obs anio H Estimate Standard Error Letter Group
57 1 14 16630 1830.17 A

98
Obs anio H Estimate Standard Error Letter Group
58 1 3 9790.69 1830.17 B 59 1 6 9423.66 1830.17 BC 60 1 5 8436.66 1830.17 BCD 61 1 15 8228.34 1830.17 BCDE 62 1 22 8000.19 1830.17 BCDEF 63 1 47 7499.25 1830.17 BCDEFG 64 1 21 7439.73 1830.17 BCDEFG 65 1 10 7117.34 1830.17 BCDEFGH 66 1 28 7006.24 1830.17 BCDEFGHI 67 1 17 6943.75 1830.17 BCDEFGHI 68 1 16 6909.03 1830.17 BCDEFGHI 69 1 40 6110.50 1830.17 BCDEFGHIJ 70 1 48 6041.06 1830.17 BCDEFGHIJ 71 1 41 5832.75 1830.17 BCDEFGHIJK 72 1 19 5416.13 1830.17 BCDEFGHIJKL 73 1 7 5173.09 1830.17 BCDEFGHIJKLM 74 1 9 5138.38 1830.17 BCDEFGHIJKLMN 75 1 30 5113.58 1830.17 BCDEFGHIJKLMN 76 1 34 4768.04 1830.17 BCDEFGHIJKLMNO 77 1 29 4503.52 1830.17 CDEFGHIJKLMNO 78 1 18 4339.84 1830.17 CDEFGHIJKLMNO 79 1 20 3794.26 1830.17 DEFGHIJKLMNO 80 1 43 3789.30 1830.17 DEFGHIJKLMNO 81 1 12 3754.58 1830.17 DEFGHIJKLMNO 82 1 23 3635.55 1830.17 DEFGHIJKLMNO 83 1 24 3496.67 1830.17 DEFGHIJKLMNO 84 1 8 3164.37 1830.17 EFGHIJKLMNO 85 1 4 3089.97 1830.17 FGHIJKLMNO 86 1 2 2493.14 1830.17 GHIJKLMNO 87 1 1 2094.70 1830.17 HIJKLMNO 88 1 33 2076.51 1830.17 HIJKLMNO

99
Obs anio H Estimate Standard Error Letter Group
89 1 42 1944.25 1830.17 IJKLMNO 90 1 11 1909.53 1830.17 IJKLMNO 91 1 45 1631.78 1830.17 JKLMNO 92 1 39 1502.83 1830.17 JKLMNO 93 1 51 1354.03 1830.17 JKLMNO 94 1 50 1254.83 1830.17 JKLMNO 95 1 25 1252.52 1830.17 JKLMNO 96 1 52 1239.96 1830.17 JKLMNO 97 1 32 833.25 1830.17 KLMNO 98 1 13 833.25 1830.17 KLMNO 99 1 36 327.35 1830.17 LMNO
100 1 35 292.63 1830.17 MNO 101 1 27 266.18 1830.17 MNO 102 1 56 208.31 1830.17 MNO 103 1 49 194.42 1830.17 MNO 104 1 26 134.91 1830.17 MNO 105 1 44 69.4375 1830.17 MNO 106 1 54 39.6786 1830.17 NO 107 1 55 34.7188 1830.17 NO 108 1 46 34.7188 1830.17 NO 109 1 37 1.48E-12 1830.17 O 110 1 53 1.48E-12 1830.17 O 111 1 31 -341E-15 1830.17 O 112 1 38 -341E-15 1830.17 O
Effect=anio*H Method=LSD(P<.05) Set=3
Obs anio H Estimate Standard Error Letter Group
113 2 3 16596 2038.64 A 114 2 48 16219 2038.64 A 115 2 14 15891 2038.64 AB

100
Obs anio H Estimate Standard Error Letter Group
116 2 4 12047 2038.64 ABC 117 2 5 11804 2038.64 ABC 118 2 40 10936 2038.64 ABCD 119 2 47 10485 2038.64 BCDE 120 2 15 10381 2038.64 BCDE 121 2 21 10257 2038.64 BCDE 122 2 41 9999.00 2038.64 CDEF 123 2 20 9661.73 2038.64 CDEFG 124 2 43 9483.18 2038.64 CDEFGH 125 2 6 8868.16 2038.64 CDEFGHI 126 2 28 8249.18 2038.64 CDEFGHIJ 127 2 16 8020.03 2038.64 CDEFGHIJ 128 2 19 7672.84 2038.64 CDEFGHIJ 129 2 29 7608.37 2038.64 CDEFGHIJ 130 2 30 7479.41 2038.64 CDEFGHIJK 131 2 7 7290.94 2038.64 CDEFGHIJKL 132 2 17 7256.22 2038.64 CDEFGHIJKL 133 2 34 7233.07 2038.64 CDEFGHIJKL 134 2 22 7176.86 2038.64 CDEFGHIJKL 135 2 45 7082.63 2038.64 CDEFGHIJKL 136 2 2 6996.65 2038.64 CDEFGHIJKL 137 2 9 6770.16 2038.64 CDEFGHIJKLM 138 2 33 6745.36 2038.64 CDEFGHIJKLMN 139 2 12 6507.29 2038.64 CDEFGHIJKLMN 140 2 10 5931.95 2038.64 DEFGHIJKLMNO 141 2 42 5798.03 2038.64 DEFGHIJKLMNO 142 2 51 5798.03 2038.64 DEFGHIJKLMNO 143 2 39 5386.37 2038.64 DEFGHIJKLMNO 144 2 52 5252.45 2038.64 DEFGHIJKLMNO 145 2 1 4883.77 2038.64 EFGHIJKLMNO 146 2 50 4830.87 2038.64 EFGHIJKLMNO

101
Obs anio H Estimate Standard Error Letter Group
147 2 18 4409.28 2038.64 FGHIJKLMNO 148 2 56 4374.56 2038.64 FGHIJKLMNO 149 2 23 4230.73 2038.64 GHIJKLMNO 150 2 8 4032.33 2038.64 GHIJKLMNO 151 2 11 3923.22 2038.64 HIJKLMNO 152 2 55 3807.49 2038.64 HIJKLMNO 153 2 36 3615.71 2038.64 IJKLMNO 154 2 25 3236.45 2038.64 IJKLMNO 155 2 24 2876.70 2038.64 JKLMNO 156 2 13 2673.34 2038.64 JKLMNO 157 2 49 1823.89 2038.64 KLMNO 158 2 54 1618.56 2038.64 LMNO 159 2 32 1249.88 2038.64 MNO 160 2 27 1238.30 2038.64 MNO 161 2 46 1145.72 2038.64 MNO 162 2 35 1061.40 2038.64 NO 163 2 26 632.87 2038.64 O 164 2 44 520.78 2038.64 O 165 2 53 458.95 2038.64 O 166 2 38 312.47 2038.64 O 167 2 31 249.98 2038.64 O 168 2 37 243.03 2038.64 O
Effect=anio*H Method=LSD(P<.05) Set=4
Obs anio H Estimate Standard Error Letter Group
169 3 3 20345 2528.14 A 170 3 40 16080 2528.14 AB 171 3 5 14755 2528.14 ABC 172 3 14 13749 2528.14 ABCD 173 3 41 12915 2528.14 BCDE

102
Obs anio H Estimate Standard Error Letter Group
174 3 48 12558 2528.14 BCDEF 175 3 6 12330 2528.14 BCDEFG 176 3 29 12142 2528.14 BCDEFG 177 3 21 11120 2528.14 BCDEFGH 178 3 7 11041 2528.14 BCDEFGH 179 3 17 10629 2528.14 BCDEFGHI 180 3 15 10103 2528.14 BCDEFGHI 181 3 47 9929.56 2528.14 BCDEFGHIJ 182 3 43 9359.18 2528.14 BCDEFGHIJK 183 3 52 8883.04 2528.14 CDEFGHIJKL 184 3 28 8668.11 2528.14 CDEFGHIJKL 185 3 4 8644.97 2528.14 CDEFGHIJKL 186 3 23 8461.46 2528.14 CDEFGHIJKL 187 3 50 8134.11 2528.14 CDEFGHIJKLM 188 3 34 7927.45 2528.14 CDEFGHIJKLMN 189 3 33 7624.90 2528.14 DEFGHIJKLMN 190 3 51 7499.25 2528.14 DEFGHIJKLMN 191 3 19 7256.22 2528.14 DEFGHIJKLMN 192 3 20 6879.27 2528.14 DEFGHIJKLMN 193 3 36 6814.79 2528.14 DEFGHIJKLMN 194 3 39 6794.96 2528.14 DEFGHIJKLMN 195 3 55 6770.16 2528.14 DEFGHIJKLMN 196 3 9 6666.00 2528.14 EFGHIJKLMN 197 3 11 6666.00 2528.14 EFGHIJKLMN 198 3 16 6422.97 2528.14 EFGHIJKLMN 199 3 30 6413.05 2528.14 EFGHIJKLMN 200 3 42 6318.81 2528.14 EFGHIJKLMN 201 3 22 6279.13 2528.14 EFGHIJKLMN 202 3 45 6145.22 2528.14 EFGHIJKLMN 203 3 1 6133.65 2528.14 EFGHIJKLMN 204 3 27 6052.64 2528.14 EFGHIJKLMN

103
Obs anio H Estimate Standard Error Letter Group
205 3 49 5980.88 2528.14 EFGHIJKLMN 206 3 18 5867.47 2528.14 EFGHIJKLMN 207 3 56 5763.31 2528.14 FGHIJKLMN 208 3 2 5763.31 2528.14 FGHIJKLMN 209 3 10 5688.92 2528.14 FGHIJKLMN 210 3 12 5389.67 2528.14 GHIJKLMN 211 3 25 4850.04 2528.14 HIJKLMN 212 3 13 4687.03 2528.14 HIJKLMN 213 3 8 4344.80 2528.14 HIJKLMN 214 3 54 4134.84 2528.14 HIJKLMN 215 3 46 4131.53 2528.14 HIJKLMN 216 3 24 3928.18 2528.14 IJKLMN 217 3 53 2990.44 2528.14 JKLMN 218 3 32 2858.51 2528.14 KLMN 219 3 26 2451.81 2528.14 KLMN 220 3 44 2299.70 2528.14 LMN 221 3 35 2023.61 2528.14 LMN 222 3 38 1145.72 2528.14 MN 223 3 37 980.39 2528.14 N 224 3 31 907.32 2528.14 N
Effect=anio*H Method=LSD(P<.05) Set=5
Obs anio H Estimate Standard Error Letter Group
225 4 5 9894.84 1527.03 A 226 4 3 8471.38 1527.03 AB 227 4 47 8297.78 1527.03 ABC 228 4 52 7896.04 1527.03 ABCD 229 4 14 7687.72 1527.03 ABCDE 230 4 4 7325.66 1527.03 ABCDEF 231 4 48 7186.78 1527.03 ABCDEFG

104
Obs anio H Estimate Standard Error Letter Group
232 4 7 7082.63 1527.03 ABCDEFGH 233 4 20 7077.67 1527.03 ABCDEFGH 234 4 6 7028.07 1527.03 ABCDEFGH 235 4 41 6874.31 1527.03 ABCDEFGHI 236 4 50 6358.49 1527.03 ABCDEFGHIJ 237 4 28 5582.77 1527.03 BCDEFGHIJK 238 4 17 5579.80 1527.03 BCDEFGHIJK 239 4 15 5207.81 1527.03 BCDEFGHIJKL 240 4 33 5111.92 1527.03 BCDEFGHIJKL 241 4 11 5034.22 1527.03 BCDEFGHIJKL 242 4 49 4953.21 1527.03 BCDEFGHIJKL 243 4 19 4860.63 1527.03 BCDEFGHIJKL 244 4 45 4756.47 1527.03 BCDEFGHIJKL 245 4 10 4726.71 1527.03 BCDEFGHIJKLM 246 4 43 4572.96 1527.03 BCDEFGHIJKLM 247 4 21 4564.69 1527.03 BCDEFGHIJKLM 248 4 40 4483.68 1527.03 BCDEFGHIJKLM 249 4 29 4429.12 1527.03 BCDEFGHIJKLM 250 4 2 4427.47 1527.03 BCDEFGHIJKLM 251 4 25 4412.26 1527.03 BCDEFGHIJKLM 252 4 42 4305.13 1527.03 BCDEFGHIJKLM 253 4 13 4235.69 1527.03 BCDEFGHIJKLM 254 4 51 4200.97 1527.03 CDEFGHIJKLM 255 4 56 4166.25 1527.03 CDEFGHIJKLM 256 4 16 3957.94 1527.03 DEFGHIJKLM 257 4 54 3762.85 1527.03 DEFGHIJKLM 258 4 9 3645.47 1527.03 DEFGHIJKLM 259 4 8 3625.63 1527.03 EFGHIJKLM 260 4 34 3610.75 1527.03 EFGHIJKLM 261 4 36 3541.31 1527.03 EFGHIJKLM 262 4 22 3536.35 1527.03 EFGHIJKLM

105
Obs anio H Estimate Standard Error Letter Group
263 4 39 3308.20 1527.03 FGHIJKLM 264 4 18 3089.97 1527.03 FGHIJKLM 265 4 55 3008.96 1527.03 GHIJKLM 266 4 27 2997.39 1527.03 GHIJKLM 267 4 12 2880.00 1527.03 HIJKLM 268 4 24 2653.50 1527.03 IJKLM 269 4 23 2479.91 1527.03 JKLM 270 4 53 2471.98 1527.03 JKLM 271 4 1 2002.11 1527.03 KLM 272 4 30 1993.85 1527.03 KLM 273 4 26 1706.84 1527.03 KLM 274 4 44 1668.15 1527.03 KLM 275 4 46 1527.63 1527.03 KLM 276 4 35 1473.07 1527.03 KLM 277 4 38 1284.59 1527.03 LM 278 4 32 948.98 1527.03 LM 279 4 37 491.02 1527.03 M 280 4 31 490.69 1527.03 M
Effect=anio*H Method=LSD(P<.05) Set=6
Obs anio H Estimate Standard Error Letter Group
281 5 14 10877 1900.50 A 282 5 3 10624 1900.50 AB 283 5 40 10550 1900.50 AB 284 5 5 10103 1900.50 ABC 285 5 41 10103 1900.50 ABC 286 5 48 9245.11 1900.50 ABCD 287 5 52 8888.00 1900.50 ABCDE 288 5 4 8749.13 1900.50 ABCDE 289 5 21 8191.97 1900.50 ABCDEF

106
Obs anio H Estimate Standard Error Letter Group
290 5 6 8084.51 1900.50 ABCDEFG 291 5 15 8054.75 1900.50 ABCDEFG 292 5 34 7649.70 1900.50 ABCDEFGH 293 5 7 7568.69 1900.50 ABCDEFGH 294 5 28 7446.01 1900.50 ABCDEFGH 295 5 47 7256.22 1900.50 ABCDEFGHI 296 5 11 6388.25 1900.50 ABCDEFGHIJ 297 5 9 6041.06 1900.50 ABCDEFGHIJK 298 5 45 5832.75 1900.50 ABCDEFGHIJK 299 5 17 5783.15 1900.50 ABCDEFGHIJK 300 5 56 5450.84 1900.50 BCDEFGHIJKL 301 5 23 5421.08 1900.50 BCDEFGHIJKL 302 5 29 5381.41 1900.50 BCDEFGHIJKL 303 5 50 5381.41 1900.50 BCDEFGHIJKL 304 5 55 4987.93 1900.50 CDEFGHIJKL 305 5 43 4979.66 1900.50 CDEFGHIJKL 306 5 22 4974.70 1900.50 CDEFGHIJKL 307 5 20 4672.15 1900.50 DEFGHIJKL 308 5 12 4624.21 1900.50 DEFGHIJKL 309 5 33 4602.71 1900.50 DEFGHIJKL 310 5 42 4513.44 1900.50 DEFGHIJKL 311 5 54 4477.07 1900.50 DEFGHIJKL 312 5 13 4305.13 1900.50 DEFGHIJKL 313 5 16 4270.41 1900.50 DEFGHIJKL 314 5 10 4270.41 1900.50 DEFGHIJKL 315 5 24 4181.13 1900.50 DEFGHIJKL 316 5 25 3967.86 1900.50 DEFGHIJKL 317 5 19 3923.22 1900.50 EFGHIJKL 318 5 27 3865.35 1900.50 EFGHIJKL 319 5 18 3784.34 1900.50 EFGHIJKL 320 5 1 3726.48 1900.50 EFGHIJKL

107
Obs anio H Estimate Standard Error Letter Group
321 5 51 3645.47 1900.50 EFGHIJKL 322 5 2 3602.48 1900.50 EFGHIJKL 323 5 49 3379.29 1900.50 FGHIJKL 324 5 39 3213.96 1900.50 FGHIJKL 325 5 8 3060.21 1900.50 FGHIJKL 326 5 53 2956.05 1900.50 FGHIJKL 327 5 46 2812.22 1900.50 GHIJKL 328 5 30 2395.59 1900.50 HIJKL 329 5 36 2038.49 1900.50 IJKL 330 5 35 2000.46 1900.50 IJKL 331 5 32 1921.10 1900.50 JKL 332 5 26 1415.53 1900.50 JKL 333 5 37 1320.97 1900.50 JKL 334 5 31 907.32 1900.50 KL 335 5 38 763.81 1900.50 KL 336 5 44 396.79 1900.50 L
Outline 3.2.2c. Códigos SAS. Datos Cacao. BLUP de árbol ods rtf file=" H:\salida_cacao2.rtf"; libname a " H:\"; proc sort data=a.nuevo out=nuevo; by h rep_ tree; proc means data=nuevo sum nmiss noprint; by h rep_ tree; var s; output out=totaldearbol sum=sanos nmiss=nmiss; data totaldearbol; set totaldearbol; if nmiss=0; rep=rep_; drop _type_ _freq_ rep_ ; run; proc mixed data=totaldearbol; class h rep tree; model sanos=rep h; random h*rep;

108
random tree / subject=h*rep solution; ods output solutionR=blup ; ods listing exclude solutionR; ods rtf exclude solutionR; data blup; set blup; if effect="TREE"; proc sort data=blup; by tvalue; proc print data=blup; var h rep tree tvalue; run; ods rtf close;
Outline 3.2.2d. Salidas SAS. Datos Cacao. BLUP de árbol
Model Information
Data Set WORK.TOTALDEARBOL Dependent Var iable sanos Covar iance Structure Variance Components Subject Effect H*rep Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Containment
Class Level Information
Class Levels Values
H 56 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56
rep 4 1 2 3 4 TREE 8 1 2 3 4 5 6 7 8

109
Dimensions
Covar iance Parameters 3 Columns in X 61 Columns in Z Per Subject 2016 Subjects 1 Max Obs Per Subject 1670 Observations Used 1670 Observations Not Used 0 Total Observations 1670
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 15231.72093223 1 2 15135.55033515 0.00000000
Convergence criteria met but final hessian is not positive definite.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
H*rep 124.36 TREE H*rep 559.90 Residual 1.0058
Fit Statistics
-2 Res Log Likelihood 15135.6 AIC (smaller is better ) 15141.6 AICC (smaller is better ) 15141.6 BIC (smaller is better ) 15151.8

110
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
rep 3 165 15.55 <.0001 H 55 165 3.55 <.0001
Obs H rep TREE tValue
1 3 3 7 -10.89 2 3 3 6 -8.96 3 14 3 2 -8.64 4 4 1 6 -7.60 5 42 1 3 -7.59 6 42 1 1 -7.45 7 5 3 7 -7.17 8 7 2 4 -6.57 9 48 3 5 -6.51
10 3 3 8 -6.33 11 6 3 8 -6.24 12 41 1 2 -6.12 13 15 1 1 -6.10 14 41 2 5 -6.09 15 15 2 1 -6.03 16 16 1 4 -5.82 17 48 2 5 -5.81 18 5 2 8 -5.78 19 42 2 8 -5.62 20 15 2 2 -5.61 … … … … …
1720 53 2 7 5.92 1721 12 2 5 5.93 1722 52 3 2 5.98 1723 34 3 6 5.99 1724 23 1 4 6.08

111
Obs H rep TREE tValue
1725 5 2 5 6.09 1726 42 3 4 6.14 1727 48 1 3 6.22 1728 13 3 4 6.22 1729 29 3 8 6.26 1730 14 3 5 6.37 1731 9 3 8 6.38 1732 51 2 3 6.39 1733 41 1 3 6.43 1734 23 1 1 6.47 1735 15 2 6 6.52 1736 52 2 1 6.55 1737 16 1 8 6.60 1738 5 3 4 6.63 1739 29 2 3 6.67 1740 52 2 8 6.69 1741 2 1 2 6.70 1742 24 1 1 6.74 1743 53 1 7 6.80 1744 30 1 5 7.14 1745 12 3 7 7.36 1746 16 3 7 7.39 1747 7 3 4 7.40 1748 11 3 8 7.43 1749 18 1 8 7.47 1750 46 2 6 7.55 1751 5 2 2 7.61 1752 44 2 6 7.62 1753 27 4 3 7.69 1754 22 3 2 7.80 1755 49 1 7 7.86

112
Obs H rep TREE tValue
1756 40 3 2 7.93 1757 6 1 1 7.97 1758 42 2 6 8.18 1759 35 2 5 8.27 1760 28 3 4 8.31 1761 11 1 6 8.52 1762 34 1 4 8.78 1763 18 1 6 8.98 1764 16 1 7 9.08 1765 41 2 1 9.22 1766 12 2 7 9.24 1767 56 2 1 9.52 1768 42 2 4 9.70 1769 48 2 8 9.79 1770 15 1 5 9.89 1771 31 2 5 9.91 1772 15 2 3 9.97 1773 45 3 8 10.71 1774 44 1 4 10.71 1775 29 2 4 11.15 1776 42 1 4 11.46 1777 3 3 5 11.60 1778 6 3 4 11.66 1779 40 2 7 11.69 1780 7 2 8 11.91 1781 11 1 3 11.97 1782 48 4 3 12.54 1783 21 3 7 13.31 1784 16 2 6 13.62 1785 30 2 3 14.20 1786 14 3 3 14.40

113
Obs H rep TREE tValue
1787 22 2 7 14.44 1788 7 4 5 15.52 1789 3 4 1 16.02 1790 48 3 6 16.38 1791 42 1 8 19.32 1792 3 3 4 36.44
3.3 Modelos para Interacción. Aplicaciones en Fitomejoramiento
El modelo mixto de interacción, para un DBCA en cada ambiente es:
( ) ( )ijk i j k j ij ijky G A B A GAµ ε+ += + + +
donde ijky es la respuesta (rendimiento) del genotipo i, en el ensayo j; µ es la media
general; iG es el efecto del genotipo i con i=1,...,g; jA es el efecto del ambiente j con
j=1,…,t; ( )( )k jB A es el efecto de bloque k dentro del ensayo j; ijGA es el efecto
aleatorio de la interacción del genotipo i con el ensayo j; y ijkε es el término de error
aleatorio asociado a la observación ijky .Los términos jA y ijGA se consideran
variables aleatorias distribuidas normalmente con media cero y varianzas constantes
denotadas por 2Aσ y 2
G Aσ × respectivamente. Las covarianzas entre los efectos
aleatorios de ambiente e interacción ijGA se considerarán nulas.
Las medias de dos genotipos en el ambiente j ijy y i jy , tienen covarianza
2ij i j ij i jCov (y ,y ) = + Cov(GA , GA ), para i i´Eσ ≠
Es posible ajustar diferentes modelos de covarianzas entre los términos aleatorios de
interacción y seleccionar el más apropiado para analizar la interacción y realizar
inferencias. La Tabla 5 muestras modelos alternativos. El modelo ANOVA mixto asume
que los términos de interacción G×A tienen la misma varianza y son independientes. En

114
el modelo Shukla mixto los términos de interacción G×A son independientes pero
heteroscedásticos, las varianzas de los términos de interacción G×A varían de genotipo
a genotipo, pero no dentro de un genotipo en particular a través de los ambientes y por
tanto el número de varianzas distintas que se pueden modelar es igual al número de
genotipos. Estas componentes de varianza, son análogas a la propuesta original de
Shukla (1972), llamada varianza de estabilidad. El modelo AMMI mixto considera los
términos multiplicativos de la interacción G×A como aleatorios. Estos se modelan con
un término (suma de términos multiplicativos) y la interacción residual. Cada término
multiplicativo puede verse como un modelo de regresión lineal de los residuos, del
modelo de efectos principales, del genotipo i sobre la variable latente no observable
relativa a los efectos de ambiente. Los componentes de la suma se denominan scores
de genotipo (efectos fijos) y de ambiente (efectos aleatorios). En cada eje de variación,
el score del genotipo i puede interpretarse como la respuesta del i-ésimo genotipo a los
cambios en la variable aleatoria latente con valor ηj en el j-ésimo ambiente (sensibilidad
del i-ésimo genotipo a una variable aleatoria ambiental no observada ηj). El modelo
denominado Eberhart y Russell mixto no contiene los efectos principales de ambiente y
sólo considera los efectos multiplicativos de la interacción G×A. Algunos parámetros de
los modelos 2, 3 y 4 constituyen medidas de estabilidad ampliamente usadas en
mejoramiento vegetal (Piepho, 1998) y por ello se identificaron en relación a su
equivalencia con tales análisis clásicos.

115
Tabla 5: Modelos mixtos para el análisis de ensayos-multiambientales
Modelo Ecuación del modelo(*) Supuestos sobre efectos de interacción
Estructura de covarianza para
y(j)(**) [1] ANOVA Mixto
yijk = µ + Aj + Rk(j) + Gi + GAij + εijk
GAij ~ iid N(0, 2GAσ ) Σ/amb = J 2
Aσ + I 2GAσ
[2] Shukla mixto
yijk = µ + Aj + Rk(j) + Gi + GAij + εijk
GAij ~ iid N(0, ( )
2iGAσ ) Σ/amb = J 2
Aσ + I( )
2iGAσ
[3] AMMI mixto yijk = µ + Aj + Rk(j) + Gi + GAij + εijk
GAij = mi mj ijm
dξ η +∑
GAi ~ N(0, 2 2mi d
mξ σ+∑ )
para todo j. Cov(GAij, GAi´j)=
´mi mimξ ξ∑ para i ≠i′
Σ/amb = J 2Aσ + ΛΛ′ +
I 2ρσ
[4] Eberhart y Russell mixto
yijk = µ + Aj + Rk(j) + Gi + GAij + εijk
GAij= .i j ijdξ η +
GAi ~ N(0, 2iξ +
( )
2idσ )
para todo j.
Cov(GAij, GAi´j)= ξiξi ′ para i ≠i′
Σ/amb = ΛΛ′ + diag (
( )
2iρσ )
(*) µ= media general; Aj= efecto aleatorio del ambiente j; Rk(j)= efecto aleatorio de la repetición dentro de ambiente; Gi= efecto fijo del genotipo i; GAij= efecto aleatorio de la interacción G×A; ξmi (i =1,…,g)= factor de peso del genotipo en el m-ésimo término de interacción multiplicativa; ηmj= predicho del m-ésimo store de una variable ambiental latente para el ambiente j; dji= término de interacción residual; εijk= término de error asociado con la respuesta yijk
(**) y(j)= vector de medias de genotipo en el ambiente j; Σ/amb= Matriz de varianzas y covarianzas de y(j); J= matriz con elementos 1 de orden gxg; I= matriz identidad gxg; Λ: matriz gxM de factores de peso de genotipos para cada término multiplicativo m=1,..,M. Littell et al. (1996) discuten sobre los distintos tipos de inferencia asociada a este
modelo. Si se desea estimar el desempeño promedio del i-ésimo genotipo sobre la
población de ambientes, i.e. aquellos presentes en el ensayo y aquellos que no lo
están, se deberá estimar iGµ + . De la misma forma, para estimar la diferencia media
entre los genotipos i e i´ sobre toda la población de ambientes se deberá estimar
´i iG G− . En ambos casos los términos incluyen efectos fijos y funciones estimables, las
componentes de varianza de la interacción forman parte de la varianza total con la que
se realiza la inferencia marginal, que en este contexto se denominada inferencia en
sentido amplio (Mc Lean et al., 1991).

116
Sin embargo puede ser de interés evaluar el desempeño de un genotipo para el
conjunto específico de ambientes involucrados. En este caso se usa la esperanza
condicional:
1 1 1
1 1 ge e
i j ijj i j
G A GAe e
µ= = =
+ + +∑ ∑∑
Para la diferencia promedio entre los genotipos i e i´ se usa
' '1 1
1 ( )g e
i i ij i ji j
G G GA GAe = =
− + −∑∑
Mc Lean (1991) dice que este tipo de funciones, que involucran tanto efectos fijos como
aleatorios, proveen inferencia en sentido estricto. Si el interés se centra en evaluar un
determinado ambiente o determinar qué genotipo es mejor para asignar a un ambiente
dado, no se buscan promedios sino una cantidad relativa al ambiente. Para la
evaluación de un ambiente sobre el conjunto de genotipos se pueden usar las
siguientes funciones predecibles, que proveen BLUP para espacios de inferencia
estricto y amplio respectivamente:
1 1 1
1 1g g e
i j iji i j
G A GAg g
µ= = =
+ + +∑ ∑∑
1
1 g
i ji
G Ag
µ=
+ +∑.
Para determinar la influencia de un ambiente sobre un genotipo se debe encontrar la
esperanza condicional j i ijA G GAµ + + + . Zeger et al. (1988) denominan a ese tipo de
inferencia como “específica de sujeto”.

117
Ejercicio 3.3.1. Datos maní. Análisis de interacción GxA.
Se ajustarán modelos mixtos alternativos mediante la modelación de la estructura de
varianza y covarianza de los términos de interacción dentro de ambiente. El objetivo es
encontrar el mejor modelo, para luego interpretar la información contenida en la
interacción G×A.
Outline 3.3.1a. Códigos SAS. Datos maní. Análisis de interacción GA. ods rtf file=" H:\salida_mani.rtf"; proc import datafile=" H:\mani.xls" out=mani replace; run; Proc mixed data=mani ; class amb gen rep; model y=gen; random amb rep(amb) gen*amb; run; Proc mixed data=mani; class amb gen rep; model y=gen; random int rep/subject=amb; random gen/subject=amb type=UN(1); Proc mixed data=mani ; class amb gen rep; model y=gen; random int rep/subject=amb; random gen/subject=amb type=FA0(2); Proc mixed data=mani; class amb gen rep; model y=gen; random rep/subject=amb; random gen/subject=amb type=FA1(1); run; ods rtf close;

118
Outline 3.3.1b. Salidas SAS. Datos maní. Análisis de interacción GxA.
Model Information
Data Set WORK.MANI Dependent Var iable y Covar iance Structure Variance Components Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Containment
Class Level Information
Class Levels Values
amb 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 gen 10 1 2 3 4 5 6 7 8 9 10 rep 4 1 2 3 4
Dimensions
Covar iance Parameters 4 Columns in X 11 Columns in Z 224 Subjects 1 Max Obs Per Subject 590 Observations Used 590 Observations Not Used 0 Total Observations 590

119
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 1887.55897029 1 2 957.40156889 0.00006011 2 1 957.39825425 0.00000004 3 1 957.39825232 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Estimate
amb 1.1343 rep(amb) 0.03978 amb*gen 0.1331 Residual 0.1662
Fit Statistics
-2 Res Log Likelihood 957.4 AIC (smaller is better ) 965.4 AICC (smaller is better ) 965.5 BIC (smaller is better ) 968.2
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
gen 9 126 1.46 0.1716

120
Model Information
Data Set WORK.MANI Dependent Var iable y Covar iance Structures Variance Components, Banded Subject Effects amb, amb Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Containment
Class Level Information
Class Levels Values
amb 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 gen 10 1 2 3 4 5 6 7 8 9 10 rep 4 1 2 3 4
Dimensions
Covar iance Parameters 58 Columns in X 11 Columns in Z Per Subject 15 Subjects 15 Max Obs Per Subject 40 Observations Used 590 Observations Not Used 0 Total Observations 590
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 1887.55897029 1 4 1015.79211610 9.14946442 2 3 1005.78243873 .

121
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
3 2 989.11278381 . 4 2 976.99346681 12.50057983 5 2 966.77494354 9.65965366 6 2 953.57510840 0.62607107 7 2 949.87269559 0.10836591 8 2 945.17687154 0.03462798 9 2 942.58733890 0.00907173
10 1 941.92865821 0.00107234 11 1 941.85644098 0.00002291 12 1 941.85499659 0.00000001 13 1 941.85499572 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
Intercept amb 1.1958 rep amb 0.03977 UN(1,1) amb 0.1559 UN(2,1) amb 0 UN(2,2) amb 0.06836 UN(3,1) amb 0 UN(3,2) amb 0 UN(3,3) amb 0.1302 UN(4,1) amb 0 UN(4,2) amb 0 UN(4,3) amb 0 UN(4,4) amb 0.1315 UN(5,1) amb 0

122
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(5,2) amb 0 UN(5,3) amb 0 UN(5,4) amb 0 UN(5,5) amb 0.05222 UN(6,1) amb 0 UN(6,2) amb 0 UN(6,3) amb 0 UN(6,4) amb 0 UN(6,5) amb 0 UN(6,6) amb 0.07627 UN(7,1) amb 0 UN(7,2) amb 0 UN(7,3) amb 0 UN(7,4) amb 0 UN(7,5) amb 0 UN(7,6) amb 0 UN(7,7) amb 0.08249 UN(8,1) amb 0 UN(8,2) amb 0 UN(8,3) amb 0 UN(8,4) amb 0 UN(8,5) amb 0 UN(8,6) amb 0 UN(8,7) amb 0 UN(8,8) amb 0.08575 UN(9,1) amb 0 UN(9,2) amb 0 UN(9,3) amb 0 UN(9,4) amb 0 UN(9,5) amb 0

123
Covar iance Parameter Estimates
Cov Parm Subject Estimate
UN(9,6) amb 0 UN(9,7) amb 0 UN(9,8) amb 0 UN(9,9) amb 0.07722 UN(10,1) amb 0 UN(10,2) amb 0 UN(10,3) amb 0 UN(10,4) amb 0 UN(10,5) amb 0 UN(10,6) amb 0 UN(10,7) amb 0 UN(10,8) amb 0 UN(10,9) amb 0 UN(10,10) amb 0.4487 Residual 0.1662
Fit Statistics
-2 Res Log Likelihood 941.9 AIC (smaller is better ) 967.9 AICC (smaller is better ) 968.5 BIC (smaller is better ) 977.1
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
gen 9 126 1.33 0.2260

124
Model Information
Data Set WORK.MANI Dependent Var iable y Covar iance Structures Variance Components, Factor Analytic Subject Effects amb, amb Estimation Method REML Residual Var iance Method Profile Fixed Effects SE Method Model-Based Degrees of Freedom Method Containment
Class Level Information
Class Levels Values
amb 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 gen 10 1 2 3 4 5 6 7 8 9 10 rep 4 1 2 3 4
Dimensions
Covar iance Parameters 22 Columns in X 11 Columns in Z Per Subject 15 Subjects 15 Max Obs Per Subject 40 Observations Used 590 Observations Not Used 0 Total Observations 590
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 1887.55897029 1 2 1069.57851811 1153.4587036 2 1 1067.47174184 3772.9017396

125
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
3 1 1063.84176858 4548.1033297 4 1 1056.00665595 2002.2477558 5 3 917.82096067 35.16539697 6 1 899.91863444 9.47215387 7 1 891.00916561 3.74017297 8 1 877.59311670 . 9 2 873.19650354 0.02240719
10 1 870.75137469 0.00267135 11 1 870.45471616 0.00018542 12 1 870.43555758 0.00000160 13 1 870.43539987 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
Intercept amb 0.5087 rep amb 0.03876 FA(1,1) amb 1.0598 FA(2,1) amb 0.9717 FA(2,2) amb 0.03964 FA(3,1) amb 0.8231 FA(3,2) amb 0.5337 FA(4,1) amb 0.9938 FA(4,2) amb 0.5177 FA(5,1) amb 0.9480 FA(5,2) amb 0.2123 FA(6,1) amb 0.8245 FA(6,2) amb 0.4261

126
Covar iance Parameter Estimates
Cov Parm Subject Estimate
FA(7,1) amb 0.5374 FA(7,2) amb 0.3503 FA(8,1) amb 0.5427 FA(8,2) amb 0.2440 FA(9,1) amb 0.5652 FA(9,2) amb 0.1368 FA(10,1) amb 0.4358 FA(10,2) amb -0.3259 Residual 0.1763
Fit Statistics
-2 Res Log Likelihood 870.4 AIC (smaller is better ) 914.4 AICC (smaller is better ) 916.3 BIC (smaller is better ) 930.0
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
gen 9 126 4.00 0.0002
Model Information
Data Set WORK.MANI Dependent Var iable y Covar iance Structures Variance Components, Factor Analytic Subject Effects amb, amb Estimation Method REML Residual Var iance Method Profile

127
Model Information
Fixed Effects SE Method Model-Based Degrees of Freedom Method Containment
Class Level Information
Class Levels Values
amb 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 gen 10 1 2 3 4 5 6 7 8 9 10 rep 4 1 2 3 4
Dimensions
Covar iance Parameters 13 Columns in X 11 Columns in Z Per Subject 14 Subjects 15 Max Obs Per Subject 40 Observations Used 590 Observations Not Used 0 Total Observations 590
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
0 1 1887.55897029 1 3 994.63123176 36.55121008 2 2 979.68980366 0.69290089 3 2 953.87197993 0.24610522 4 1 936.34392131 0.08089210 5 1 929.80461628 0.02255975 6 1 927.96163921 0.00356782 7 1 927.68725419 0.00014301

128
Iteration History
Iteration Evaluations -2 Res Log Like Cr iter ion
8 1 927.67708096 0.00000029 9 1 927.67706096 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
rep amb 0.04053 FA(1) amb 0.09467 FA(1,1) amb 1.2282 FA(2,1) amb 1.1763 FA(3,1) amb 1.1293 FA(4,1) amb 1.2788 FA(5,1) amb 1.2360 FA(6,1) amb 1.1534 FA(7,1) amb 0.9298 FA(8,1) amb 0.9524 FA(9,1) amb 0.9162 FA(10,1) amb 0.6545 Residual 0.1663
Fit Statistics
-2 Res Log Likelihood 927.7 AIC (smaller is better ) 953.7 AICC (smaller is better ) 954.3 BIC (smaller is better ) 962.9

129
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
gen 9 126 1.57 0.1297
3.4 Modelos de Correlación Espacial
Para la modelación de correlación espacial, los modelos mixtos más usados son
los que permiten modelar directamente la estructura de covarianza residual. Es posible
contemplar dependencia entre los errores, debidas a variabilidad espacial, a través de
la modelación de la matriz R . En ensayos multiambientales, si se denota al vector de
errores como ' ' 's 1 2e = e ,e , ...,e , donde le representa los errores asociados a las parcelas
de la localidad l y s es el número de sitios o ambientes, R tendrá la forma:
1
2
1
1
0 . . . 0 00 . . . 0 0. . . . .. . . . .. . . . .0 0 . . . 00 0 . . . 0
sl l
s
s
RR
RR
=
−
= ⊕ =
R R
Es decir, se supone que cada ensayo individual tiene su propia estructura de varianzas
y covarianzas y éstas son independientes unas de otras. Cuando se asume que el
vector de errores asociados a parcelas de una localidad refleja dependencias
espaciales, su matriz de varianzas y covarianzas se expresa como ( )2= CorrσRδ ,
donde ( )Corr δ es la matriz de correlación espacial que depende de las distancias entre
parcelas y los parámetros contenidos en δ , y σ2 es la varianza residual.

130
Ejercicio 3.4.1. Datos ECR. Correlación espacial
Para los datos provenientes de un ECR con diseño en bloque dentro de cada localidad,
primero se ajustan modelos espaciales (correlación potencia isotrópicos y
anisotrópicos) y el modelo de ANOVA para un DBCA con efectos de bloques aleatorios,
para cada localidad por separado. Luego se realiza un análisis combinando los datos de
las distintas localidades, con varianza residual homogénea y heterogénea. El modelo
para la esperanza en cada localidad es:
( ) ( )ijk i j k j ij ijky G E B E GEµ ε+ += + + +
donde ijky es la respuesta (rendimiento) del genotipo i, en el ensayo j; µ es la media
general; iG es el efecto aleatorio del genotipo i con i=1,...,g; jE es el efecto fijo del
ensayo j con j=1,…,t; ( )( )k jB E es el efecto de bloque k dentro del ensayo j; ijGE es el
efecto aleatorio de la interacción del genotipo i con el ensayo j; y ijkε es el término de
error aleatorio asociado a la observación ijky . Con la excepción de ijkε y los efectos de
bloque, todos los factores se consideran fijos. Los ijkε se asumen independientes con
varianza constante σ2 en el primer modelo, i.e. asumiendo no existe variación espacial
ni heterogeneidad de varianzas residuales entre localidades. Las varianzas de los
efectos de bloque también se asumieron homogéneas (modelo BA). El segundo
procedimiento, denotado como modelo BAH, se basa en los mismos supuestos que el
modelo BA pero permite la posibilidad de varianzas heterogéneas a través de los
ensayos (localidades). El tercer modelo consiste en ajustar un modelo de correlación
espacial isotrópico dentro de cada localidad con una función de potencia para la
correlación, incluyendo el efecto de de bloques y asumiendo correlación cero entre
parcelas provenientes de diferentes ensayos o localidades (modelo Pot). El cuarto
procedimiento fue igual al anterior pero permite la posibilidad de varianzas
heterogéneas a través de los ensayos (Modelo PotH). Los otros procedimientos se
basaron en modelos de correlación espacial anisotrópicos, con una función de potencia
dentro de localidades. Estos modelos se ajustaron asumiendo varianzas residuales

131
homogéneas a través de los ensayos (Modelo PotA) y varianzas residuales
heterogéneas a través de los ensayos (Modelo PotAH).
Outline 3.4.1a. Códigos SAS. Datos ecrmani. Sintaxis común usada en todos los modelos proc mixed scoring=200 maxfunc=2500 maxiter=5000 method=reml; Modelo Sintaxis BA class block genotype location;
model yield=genotype location genotype*location /ddfm=kenwardroger; random block(location);
BAH class block genotype location; model yield=genotype location genotype*location /ddfm=kenwardroger; random block(location); repeated/group=location;
Pot class genotype location; model yield=genotype location genotype*location /ddfm=kenwardroger; repeated/subject=location type=sp(pow) (lat long) ;
PotH class genotype location; model yield=genotype location genotype*location /ddfm=kenwardroger; repeated/subject=location type=sp(pow) (lat long) group=location ;
PotA class genotype location; model yield=genotype location genotype*location /ddfm=kenwardroger; repeated/subject=location type=sp(powa) (lat long) ;
PotAH class genotype location; model yield=genotype location genotype*location /ddfm=kenwardroger; repeated/subject=location type=sp(powa) (lat long) group=location;
Outline 3.4.1b. Resumen de Salidas SAS. Datos ecrmani Criterio de información de Akaike (AIC) para tres modelos de correlación espacial en ensayos conducidos en tres localidades para dos tipos de genotipos, genotipos de ciclo corto y genotipos de ciclo largo. Valores menores de AIC indican mejor ajuste del modelo.
Modelos Ciclo corto Ciclo largo
Localidad BA Pot PotA BA Pot PotA
General Cabrera 69.62 71.55 72.71 21.37 17.75 17.67 Manfredi 61.98 57.22 57.59 38.65 34.34 33.05 Río Tercero 62.65 56.10 55.93 60.88 60.90 62.41

132
Raíz cuadrada del promedio de las varianzas para la diferencia de medias para tres modelos de correlación espacial en ensayos conducidos en tres localidades para dos tipos de genotipos, genotipos de ciclo corto y genotipos de ciclo largo.
Modelos Ciclo corto Ciclo largo Localidad BA Pot PotA BA Pot PotA General Cabrera 0.2542 0.2686 0.2699 0.1562 0.1483 0.1437 Manfredi 0.2350 0.2220 0.2227 0.2041 0.1828 0.1804 Río Tercero 0.2439 0.2226 0.2199 0.2479 0.2581 0.2623
Criterio de información de Akaike (AIC) para seis modelos de correlación espacial en dos ensayos. Valores menores de AIC indican mejor ajuste del modelo.
Modelos Ensayo BA BAH Pot PotH PotA PotAH
1 187.41 191.12 179.30 184.87 177.07 186.24 2 126.08 121.43 117.38 113.14 115.46 113.00
Raíz cuadrada del promedio de las varianzas para seis modelos de correlación espacial en dos ensayos.
Modelos Ensayo BA BAH Pot PotH PotA PotAH
1 0.2445 0.2445 0.2518 0.2360 0.2300 0.2356
2 0.2081 0.2078 0.2110 0.2002 0.1942 0.1997 Outline 3.4.1c. Salidas SAS. Datos ECR para los modelos PotA y PotAH en ensayos de ciclo corto.Datos ECR.
Model Information
Data Set FER.DATA Dependent Var iable rendim Covar iance Structure Spatial Power Subject Effect bloque(local) Group Effect local Estimation Method ML

133
Model Information
Residual Var iance Method None Fixed Effects SE Method Prasad-Rao-Jeske-Kackar-Harville Degrees of Freedom Method Kenward-Roger
Class Level Information
Class Levels Values
bloque 4 1 2 3 4 geno 16 colirrad manf393 manf68 mf404 mf405 mf407 mf408 mf410 mf415 mf420
mf421 mf429 mf431 mf432 mf433 mf435 local 3 gralcabr manf rio3
Dimensions
Covar iance Parameters 6 Columns in X 80 Columns in Z 0 Subjects 12 Max Obs Per Subject 16 Observations Used 192 Observations Not Used 0 Total Observations 192
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 69.44390478 1 2 58.49664639 0.01726875 2 1 55.15036844 0.00237226 3 1 54.71780364 0.00023548 4 1 54.67412871 0.00001914 5 1 54.67053535 0.00000145 6 1 54.67025827 0.00000012

134
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
7 1 54.67023484 0.00000001 8 1 54.67023255 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Group Estimate
Var iance bloque(local) local gralcabr 0.09098 SP(POW) bloque(local) local gralcabr 0.1419 Var iance bloque(local) local manf 0.08079 SP(POW) bloque(local) local manf 0.5021 Var iance bloque(local) local rio3 0.09137 SP(POW) bloque(local) local rio3 0.5569
Fit Statistics
-2 Log Likelihood 54.7 AIC (smaller is better ) 180.7 AICC (smaller is better ) 243.7 BIC (smaller is better ) 211.2
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
5 14.77 0.0114

135
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
geno 15 162 10.94 <.0001 local 2 26.5 170.02 <.0001 geno*local 30 143 6.90 <.0001 bloque(local) 9 27.7 4.06 0.0021
Model Information
Data Set FER.DATA Dependent Var iable rendim Covar iance Structure Spatial Power Subject Effect bloque(local) Group Effect local Estimation Method ML Residual Var iance Method None Fixed Effects SE Method Prasad-Rao-Jeske-Kackar-Harville Degrees of Freedom Method Kenward-Roger
Class Level Information
Class Levels Values
bloque 4 1 2 3 4 geno 15 florman mf385 mf386 mf391 mf395 mf396 mf409 mf413 mf414 mf424 mv5
rc382 shulamit sunbelt sunrunne local 3 gralcabr manf rio3
Dimensions
Covar iance Parameters 6 Columns in X 76 Columns in Z 0 Subjects 12

136
Dimensions
Max Obs Per Subject 15 Observations Used 180 Observations Not Used 0 Total Observations 180
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 6.08011435 1 2 -17.05892738 0.01347105 2 1 -20.20741310 0.00212878 3 1 -20.66308675 0.00021502 4 1 -20.71038301 0.00001922 5 1 -20.71465243 0.00000153 6 1 -20.71499404 0.00000012 7 1 -20.71501999 0.00000001
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Group Estimate
Var iance bloque(local) local gralcabr 0.03486 SP(POW) bloque(local) local gralcabr 0.4386 Var iance bloque(local) local manf 0.06348 SP(POW) bloque(local) local manf 0.5478 Var iance bloque(local) local rio3 0.08614 SP(POW) bloque(local) local rio3 0.1459

137
Fit Statistics
-2 Log Likelihood -20.7 AIC (smaller is better ) 99.3 AICC (smaller is better ) 160.8 BIC (smaller is better ) 128.4
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
5 26.80 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
geno 14 133 23.77 <.0001 local 2 27.1 277.93 <.0001 geno*local 28 129 9.42 <.0001 bloque(local) 9 27.1 2.18 0.0568
Model Information
Data Set FER.DATA Dependent Var iable rendim Covar iance Structure Spatial Anisotropic Power Subject Effect local Estimation Method ML Residual Var iance Method Profile Fixed Effects SE Method Prasad-Rao-Jeske-Kackar-Harville Degrees of Freedom Method Kenward-Roger

138
Class Level Information
Class Levels Values
bloque 4 1 2 3 4 geno 16 colirrad manf393 manf68 mf404 mf405 mf407 mf408 mf410 mf415 mf420
mf421 mf429 mf431 mf432 mf433 mf435 local 3 gralcabr manf rio3
Dimensions
Covar iance Parameters 3 Columns in X 68 Columns in Z 0 Subjects 3 Max Obs Per Subject 64 Observations Used 192 Observations Not Used 0 Total Observations 192
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 122.48677842 1 4 83.84491675 0.03887408 2 1 77.03216624 0.00067471 3 1 76.91805755 0.00003591 4 1 76.91160072 0.00000390 5 1 76.91083373 0.00000073 6 1 76.91068589 0.00000016 7 1 76.91065420 0.00000003 8 1 76.91064730 0.00000001
Convergence criteria met.

139
Covar iance Parameter Estimates
Cov Parm Subject Estimate
SP(POWA) lat local 0.9101 SP(POWA) long local 0.5690 Residual 0.1161
Fit Statistics
-2 Log Likelihood 76.9 AIC (smaller is better ) 178.9 AICC (smaller is better ) 216.8 BIC (smaller is better ) 132.9
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
2 45.58 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
geno 15 144 11.40 <.0001 local 2 26.6 77.31 <.0001 geno*local 30 141 7.64 <.0001
Model Information
Data Set FER.DATA Dependent Var iable rendim Covar iance Structure Spatial Anisotropic Power Subject Effect local Estimation Method ML Residual Var iance Method Profile

140
Model Information
Fixed Effects SE Method Prasad-Rao-Jeske-Kackar-Harville Degrees of Freedom Method Kenward-Roger
Class Level Information
Class Levels Values
bloque 4 1 2 3 4 geno 15 florman mf385 mf386 mf391 mf395 mf396 mf409 mf413 mf414 mf424 mv5
rc382 shulamit sunbelt sunrunne local 3 gralcabr manf rio3
Dimensions
Covar iance Parameters 3 Columns in X 64 Columns in Z 0 Subjects 3 Max Obs Per Subject 60 Observations Used 180 Observations Not Used 0 Total Observations 180
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 32.04674937 1 2 27.64556617 0.13468110 2 1 7.81764289 0.00559205 3 1 6.27447538 0.00048271 4 1 6.15615897 0.00009448 5 1 6.13340912 0.00001968 6 1 6.12870486 0.00000418 7 1 6.12770953 0.00000089

141
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
8 1 6.12749711 0.00000019 9 1 6.12745161 0.00000004
10 1 6.12744185 0.00000001
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Estimate
SP(POWA) lat local 0.9082 SP(POWA) long local 0.4754 Residual 0.07313
Fit Statistics
-2 Log Likelihood 6.1 AIC (smaller is better ) 102.1 AICC (smaller is better ) 138.0 BIC (smaller is better ) 58.9
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
2 25.92 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
geno 14 137 28.50 <.0001 local 2 28 153.99 <.0001 geno*local 28 134 8.66 <.0001

142
Model Information
Data Set FER.DATA Dependent Var iable rendim Covar iance Structure Spatial Anisotropic Power Subject Effect local Group Effect local Estimation Method ML Residual Var iance Method None Fixed Effects SE Method Prasad-Rao-Jeske-Kackar-Harville Degrees of Freedom Method Kenward-Roger
Class Level Information
Class Levels Values
bloque 4 1 2 3 4 geno 16 colirrad manf393 manf68 mf404 mf405 mf407 mf408 mf410 mf415 mf420
mf421 mf429 mf431 mf432 mf433 mf435 local 3 gralcabr manf rio3
Dimensions
Covar iance Parameters 9 Columns in X 68 Columns in Z 0 Subjects 3 Max Obs Per Subject 64 Observations Used 192 Observations Not Used 0 Total Observations 192

143
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 122.48677842 1 3 75.09748617 0.00962647 2 1 73.34800289 0.00169934 3 1 72.92905481 0.00085731 4 1 72.71555792 0.00042927 5 1 72.61125810 0.00020022 6 1 72.56359439 0.00008846 7 1 72.54283446 0.00003768 8 1 72.53407448 0.00001567 9 1 72.53045215 0.00000642
10 1 72.52897332 0.00000261 11 1 72.52837440 0.00000105 12 1 72.52813307 0.00000042 13 1 72.52803613 0.00000017 14 1 72.52799727 0.00000007 15 1 72.52798171 0.00000003 16 1 72.52797549 0.00000001 17 1 72.52797300 0.00000000
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Group Estimate
Var iance local local gralcabr 0.1348 SP(POWA) lat local local gralcabr 0.9105 SP(POWA) long local local gralcabr 0.5110 Var iance local local manf 0.1135 SP(POWA) lat local local manf 0.8928 SP(POWA) long local local manf 0.6562

144
Covar iance Parameter Estimates
Cov Parm Subject Group Estimate
Var iance local local rio3 0.1048 SP(POWA) lat local local rio3 0.9414 SP(POWA) long local local rio3 0.5177
Fit Statistics
-2 Log Likelihood 72.5 AIC (smaller is better ) 186.5 AICC (smaller is better ) 235.9 BIC (smaller is better ) 135.1
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
8 49.96 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
geno 15 137 11.41 <.0001 local 2 16.8 67.92 <.0001 geno*local 30 121 7.82 <.0001
Model Information
Data Set FER.DATA Dependent Var iable rendim Covar iance Structure Spatial Anisotropic Power Subject Effect local Group Effect local Estimation Method ML Residual Var iance Method None

145
Model Information
Fixed Effects SE Method Prasad-Rao-Jeske-Kackar-Harville Degrees of Freedom Method Kenward-Roger
Class Level Information
Class Levels Values
bloque 4 1 2 3 4 geno 15 florman mf385 mf386 mf391 mf395 mf396 mf409 mf413 mf414 mf424 mv5
rc382 shulamit sunbelt sunrunne local 3 gralcabr manf rio3
Dimensions
Covar iance Parameters 9 Columns in X 64 Columns in Z 0 Subjects 3 Max Obs Per Subject 60 Observations Used 180 Observations Not Used 0 Total Observations 180
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
0 1 32.04674937 1 2 23.23283394 0.32578824 2 2 -12.87309327 0.00540013 3 2 -14.12573182 0.00087490 4 1 -14.33334894 0.00015946 5 1 -14.37455582 0.00004214 6 1 -14.38593049 0.00001378 7 1 -14.38972419 0.00000489

146
Iteration History
Iteration Evaluations -2 Log Like Cr iter ion
8 1 -14.39108010 0.00000179 9 1 -14.39157838 0.00000067
10 1 -14.39176413 0.00000025 11 1 -14.39183406 0.00000010 12 1 -14.39186061 0.00000004 13 1 -14.39187078 0.00000001 14 1 -14.39187472 0.00000001
Convergence criteria met.
Covar iance Parameter Estimates
Cov Parm Subject Group Estimate
Var iance local local gralcabr 0.05413 SP(POWA) lat local local gralcabr 0.9189 SP(POWA) long local local gralcabr 0.6779 Var iance local local manf 0.06016 SP(POWA) lat local local manf 0.9276 SP(POWA) long local local manf 0.4318 Var iance local local rio3 0.1052 SP(POWA) lat local local rio3 0.8960 SP(POWA) long local local rio3 0.3500
Fit Statistics
-2 Log Likelihood -14.4 AIC (smaller is better ) 93.6 AICC (smaller is better ) 141.1 BIC (smaller is better ) 44.9

147
Null Model Likelihood Ratio Test
DF Chi-Square Pr > ChiSq
8 46.44 <.0001
Type 3 Tests of Fixed Effects
Effect Num DF Den DF F Value Pr > F
geno 14 109 27.19 <.0001 local 2 16.5 147.52 <.0001 geno*local 28 110 10.27 <.0001

148
Módulo 4. Ajuste de Modelos No-Lineales con Datos Normales o No-Normales 4.1. Modelo No Lineal de Curvas de Crecimiento con Coeficientes Aleatorios En los modelos lineales los parámetros (valores poblacionales desconocidos) entran
linealmente en la ecuación. No importa que la(s) variable(s) independiente(s) estén en
la ecuación en forma no lineal: recordemos que son fijas, ya sea por el diseño o por
observación. Lo importante es que cada parámetro aparezca multiplicado por una
cantidad conocida y después sumado. Esto permite encontrar soluciones usando
métodos para resolver ecuaciones múltiples. Ejemplos clásicos de modelos lineales de
regresión son: 1) el modelo de regresión lineal simple
0 1Y xµ β β= + ,
2) el modelo de regresión múltiple
0 1 1 ...Y k kx xµ β β β= + + + y 3) el modelo de regresión polinomial
20 1 2 ... k
Y kx x xµ β β β β= + + + +
Por el contrario, los modelos no lineales son modelos de regresión en los cuales los
parámetros aparecen en forma no lineal en la ecuación. Por ejemplo,
( )2
2 2 0 1 20 10 1
1 1 1, ,Y Y Yx x xxeµ µ µβ β β β ββ ββ β
= = =− + +++
( )( )( )
0 00 0 1
321 1 2
exp exp , ,1
1
Y Y Yx xe xe
β βµ β β β µ µ βββ β β= − − + = =
−+ − + +

149
Particularmente, estas últimas tres ecuaciones son comúnmente usadas para describir
crecimiento, y se llaman, respectivamente, el modelo de Gompertz, el modelo Logístico
y el modelo de Richards.
Cuando la respuesta crece (o decrece) monotónicamente, pero la magnitud de la tasa
de crecimiento (decrecimiento) se hace cada vez más pequeña, y la variable
dependiente se aproxima a una cosntante (la “asíntota”), la siguiente función
exponencial suele usarse:
20 1Y
xe βµ β β −= +
En todos estos modelos estamos presentando la media (esperanza) de la respuesta Y
como una función no lineal de una (o más variables) independientes. Para completar la
especificación del modelo, debemos indicar además la distribución de Y y la
independencia (o dependencia) entre los valores de Y.
Al igual que lo estuvimos haciendo en modelos lineales mixtos, existen muchas
situaciones en las que el modelo para la media incluye también componentes
aleatorias. Por ejemplo, es posible que algunos de los parámetros de una curva (no
lineal) de crecimiento varíen de individuo a individuo, y podemos reflejar esta
variabilidad mediante términos aleatorios en el modelo. Lo que cambia ahora es que la
función no lineal que estamos modelando (y sobre cuyos coeficientes nos interesa
hacer inferencias) expresan la esperanza (media) condicional de la variable de
respuesta dado(s) el(los) efecto(s) aleatorio(s). Si retomamos el Ejemplo 4 del Módulo
1, donde se tienen mediciones de circunferencia (en mm) de 5 árboles de naranja,
variable medida 7 veces. Un modelo que podemos usar es el Logístico:
0
21
/1Y xe
βµ ββ=
−+
En este modelo 0β representa la asíntota, ( )11oβ
β+ representa el intercepto y 2β está
relacionado a la pendiente (velocidad con que alcanza la asíntota).

150
Cuando observamos las curvas individuales, podemos pensar que todas las curvas
comienzan más o menos en el mismo diámetro, pero cada una alcanza un diámetro
máximo diferente. Supongamos que asumimos que la asíntota 0β tiene un efecto
aleatorio, que le llamaremos iu . La especificación del modelo condicional sería:
( ) 0
21
| (1)1
iij i
ij
uE Y u xe
ββ
β
+=
−+
Si además suponemos que cada observación, dado el efecto aleatorio del individuo, es
independiente de las otras y tiene una distribución normal con varianza constante, y si
suponemos que los iu son a su vez variables normales con cierto valor medio y cierta
varianza, tenemos completamente especificado nuestro modelo. Como hemos visto en
modelos lineales, la presencia de efectos aleatorios tiene el efecto que las
observaciones provenientes de la misma unidad están correlacionadas, ya que
comparten el mismo valor observado de iu . El problema que esta correlación no
siempre es simple de estimar, y varía dependiendo de los valores de x involucrados.
Esta formulación del modelo permite considerar varios efectos aleatorios, y no está
limitada a datos con distribución normal. La principal dificultad de realizar inferencias
con este modelo es el aspecto computacional. No existen fórmulas explícitas para el
cálculo de los estimadores máximo verosímiles, y las rutinas de optimización usadas
deben combinarse con rutinas de integración numérica, que son particularmente
difíciles de usar cuando tenemos más de 3 o 4 efectos aleatorios en un modelo. Un
modelo alternativo al presentado anteriormente podría formularse como uno que tenga
no solamente un efecto aleatorio en la asíntota sino un efecto aleatorio en 1β :
( )
[ ] [ ]
20
21
2
2
| , , (2)1
, 0,0 ,
iij i i
iji
u uvi i
uv v
uY u v N xv e
u v N
εβ σβ
β
σ σσ σ
+
− + +

151
Otra dificultad que no surge en modelos lineales con distribución normal es la
interpretación de los parámetros. Si el modelo no incluye coeficientes aleatorios el
modelo estudia la relación entre la esperanza de la respuesta y la(s) variable(s)
independiente(s). Esto significa que podemos interpretar, por ejemplo, el intercepto en
el ejemplo de crecimiento de troncos, ( )11oβ
β+ , como un intercepto promedio para la
población de árboles de la cual obtuvimos la muestra estudiada (inferencia para el
promedio poblacional). En cambio, en el modelo con coeficientes aleatorios, la relación
modelada es la de la esperanza condicional de la respuesta con la(s) variable(s)
independiente(s). Entonces ( )11oβ
β+ ahora se interpreta como el intercepto de un
árbol “típico” (típico en el sentido que el valor realizado de los efectos aleatorios es su
promedio: [0,0]). Este tipo de interpretación se denomina “inferencia específica para
sujetos”.
Es decir, que en el modelo no lineal con efectos aleatorios modelamos relaciones
condicionales (para un valor dado del efecto aleatorio), mientras que en un modelo no
lineal sin efectos aleatorios modelamos relaciones marginales. Más aún, excepto en
casos especiales, si en el modelo no lineal mixto se cumple la relación entre la Y y la x
con la función logística (como la indicada en (2)), entonces la esperanza marginal no va
a tener la misma relación. Esto se debe a que para obtener la esperanza marginal de la
Y a partir de su esperanza condicional debemos “promediar” la esperanza condicional
para cada valor posible del efecto aleatorio. En el caso de efectos aleatorios con
distribución normal como el presentado en (2), este proceso implica integrar respecto a
la distribución normal bivariada de [ ],i iu v . Este proceso no siempre mantiene la misma
relación entre la Y y la x como en el caso de los modelos lineales mixtos. Para ver un
ejemplo gráfico de este proceso, consideremos el efecto que tendría promediar
pendientes en una regresión lineal y en una regresión no lineal:

152
Figura 11. Promedio de modelos lineales.
Figura 12. Promedios de modelos no-lineales
Podemos apreciar en las Figuras 11 y 12 que cuando promediamos rectas con
pendientes iguales en una línea recta la pendiente promedio es la misma, pero cuando
promediamos curvas logísticas con pendientes iguales la pendiente promedio es menor.
¿Cuál de las dos interpretaciones (promedio poblacional o específica de sujetos) es de
mayor interés? No hay un consenso general sobre esto, y en alguna aplicaciones (por
ejemplo, curvas de crecimiento, los modelos formulados con la esperanza condicional

153
(inferencia específica para sujetos) se consideran más útiles, ya que “controlan” el
efecto del sujeto en vez de ignorarlo. Por otra parte, si lo que se desea es interpretar un
efecto para el promedio de la población (por ejemplo el efecto general de aplicar cierto
tratamiento de descontaminación a predios contaminados) la idea de usar modelos
formulados con la esperanza marginal (es decir, sin incluir efectos aleatorios) parece
preferible.
Para ajustar los modelos se usa el método de máxima verosimilitud. Recordemos que
en este caso para obtener la función de verosimilitud se debe integrar a través de la
distribución de los efectos aleatorios, por lo que los algoritmos computacionales
incluyen los aspectos de integración y maximización. Para ajustar este tipo de modelos
No-Lineales en SAS se usa Proc NLMIXED. Es necesario especificar valores iniciales
de los parámetros.
Ejercicio 4.1: Ajuste del modelo logístico (1) a los datos naranjo.
Tenemos los siguientes parámetros: 2 20 1 2, , , ,u εβ β β σ σ
Outline 4.1a: Código SAS. Datos naranjo proc import datafile="c:\naranjo.xls" out=tree replace; proc nlmixed data=tree;
parms b0=190 b1=5 b2=500 su=35 se=8;
num = b0+u;
ex = b1*exp(-day/b2);
den = 1 + ex;
model y ~ normal(num/den,se*se);
random u ~ normal(0,su*su) subject=tree;
run;
Outline 4.1b: Salida SAS . Datos naranjo
Specifications
Data Set WORK.TREE
Dependent Variable Y
Distribution for Dependent Variable Normal
Random Effects U
Distribution for Random Effects Normal

154
Specifications
Subject Variable Tree
Optimization Technique Dual Quasi-Newton
Integration Method Adaptive Gaussian Quadrature
Dimensions
Observations Used 35
Observations Not Used 0
Total Observations 35
Subjects 5
Max Obs Per Subject 7
Parameters 5
Quadrature Points 1
Parameters
b0 b1 b2 su se NegLogLike
190 5 500 35 8 148.929439
Iteration History
Iter Calls NegLogLike Diff MaxGrad Slope
1 3 143.259161 5.670278 1.646156 -57.2423
2 5 141.982244 1.276917 0.515834 -1.31485
3 7 141.869988 0.112256 0.18302 -0.08575
4 10 140.987721 0.882267 1.700026 -0.04074
… … … … … …
27 55 131.571885 9.999E-6 0.000781 -0.00002
28 57 131.571885 3.509E-7 0.000068 -5.02E-7
NOTE: GCONV convergence criterion satisfied.

155
Fit Statistics
-2 Log Likelihood 263.1
AIC (smaller is better) 273.1
AICC (smaller is better) 275.2
BIC (smaller is better) 271.2
Parameter Estimates
Parameter Estimate
Standard
Error DF t Value Pr > |t| Alpha Lower Upper Gradient
b0 192.05 15.6575 4 12.27 0.0003 0.05 148.58 235.52 -5.77E-6
b1 8.0950 0.8567 4 9.45 0.0007 0.05 5.7165 10.4736 8.521E-6
b2 348.07 27.0798 4 12.85 0.0002 0.05 272.89 423.26 -6.47E-7
su 31.6459 10.2612 4 3.08 0.0368 0.05 3.1563 60.1356 -2.85E-6
se 7.8431 1.0126 4 7.75 0.0015 0.05 5.0318 10.6544 0.000068
Se debe observar que hemos supuesto que las observaciones, dado el efecto aleatorio,
son independientes, pero que las observaciones están correlacionadas en su
distribución marginal. Es decir, observaciones que provienen del mismo árbol están
correlacionadas (por compartir el mismo valor del efecto aleatorio). La correlación entre
las observaciones del mismo árbol depende de los valores de los parámetros del
modelo y de los valores de la variable independiente (“day”):
156
Ejercicio 4.2: Modelos para volumen acumulado de tronco de árboles Como habíamos mencionado en el ejemplo 6, Schabenberger y Pierce (2002) ajustan
modelos para determinar volumen acumulado en función del diámetro. La idea es estimar
0d dV V R= , para lo cual estos autores desarrollan modelos para V0 (volumen total) y Rd
(cociente entre el volumen mercadeable hasta un diámetro d y el volumen total). La relación
que usan para el volumen total es
( )2
0 0 1 1000i i
iD HE V β β= +
en donde D es el diámetro a la altura del pecho (en pulgadas), y H es la altura del árbol (en
pies). Se divide por 1000 para que las magnitudes de los coeficientes de regresión sean
similares. Para Rd , la ecuación que usaron fue ( ) ( )23exp exp
1000dtE R tβ β = −
, donde
/ .t d D=

157
Si todos los datos fuesen independientes, el modelo que combina ambas ecuaciones,
( ) ( ) ( )2
20 0 1 3exp exp
1000 1000j j
i iid i id
D H tE V E V R tββ β β = = + −
es un modelo no lineal con efectos fijos que podría ajustarse usando, por ejemplo, PROC
NLIN en SAS.
Recordemos que las medidas tomadas en el mismo árbol están correlacionadas. Para tener
en cuenta esta correlación es posible incorporar efectos aleatorios debidos a cada árbol al
modelo: estos efectos aleatorios inducirán una correlación entre observaciones del mismo
árbol. La heterogeneidad de árbol a árbol se podía deber a variabilidad en tamaños y a
variabilidad en la forma del perfil de volúmenes (Figuras 6 y 7). La primera causa sugiere
que se incorpore un efecto aleatorio a la componente V0, mientras que la segunda causa
sugiere un efecto aleatorio en Rd. El modelo no lineal mixto que se puede ajustar es
{ } { } ( )2
2 20 0 1 1 3exp exp
1000 1000j j
ii iid i id i i
b tD HV V R b t eβ
β β β+
= = + + − +
Los errores condicionales ei se asumieron normales, homoscedásticos, independientes entre
sí e independientes de los otros dos efectos aleatorios. Los efectos aleatorios introducidos
en el modelo también se supusieron normales:
2
1 12
2 2
0 0~ ,
0 0b
Nb
σσ
Outline 4.2a: Código SAS. Datos álamos ods html body='h:\venezuela\alamo.html'; goptions device=activex; proc import datafile="h:\venezuela\YellowPoplarData.xls" out=ypoplar replace; proc nlmixed data=ypoplar; parms b0=0.25 b1=2.3 b2=2.87 b3=6.7 se=2.2 su1=0.15 su2=0.5; X = dbh*dbh*totht/1000; TotV = b0 + (b1+u1)*X; R = exp(-(b2+u2)*(t/1000)*exp(b3*t)); model cumv ~ normal(TotV*R,se*se); random u1 u2 ~ normal([0,0],[su1*su1,0,su2*su2]) subject=tn out=EBayes; predict (b0+b1*X)*exp(-b2*t/1000*exp(b3*t)) out=predtypical; predict TotV*R out=predSS; ods output ParameterEstimates=estimates; run;
158
data predictions; merge predtypical(rename=(pred=predtyp)) predSS(rename=(pred=predSS)); keep compld cumv dbh dob ht k maxd predSS predtyp tn totht; label predtyp="Prediction for a typical tree" predSS="Tree specific prediction"; run; proc gplot data=predictions; where tn in (5, 151, 279, 308); by tn notsorted; plot (cumv predtyp predSS)*compld / overlay; run; ods html close;
Outline 4.2b: Salida SAS. Datos álamos
Specifications
Data Set WORK.YPOPLAR
Dependent Variable cumv
Distribution for Dependent Variable Normal
Random Effects u1 u2
Distribution for Random Effects Normal
Subject Variable tn
Optimization Technique Dual Quasi-Newton
Integration Method Adaptive Gaussian Quad
Dimensions
Observations Used 6636
Observations Not Used 0
Total Observations 6636
Subjects 336
Max Obs Per Subject 32
Parameters 7
Quadrature Points 1

159
Parameters
b0 b1 b2 b3 se su1 su2 NegLogLike
0.25 2.3 2.87 6.7 2.2 0.15 0.5 15535.3203
Iteration History
Iter Calls NegLogLike Diff MaxGrad Slope
1 4 15534.245 1.075256 55.9918 -857.186
2 7 15533.9033 0.34174 34.4292 -275.018
3 10 15533.4538 0.449515 23.26306 -214.095
4 12 15533.2856 0.168212 56.89121 -53.5603
5 14 15532.2237 1.061837 25.1064 -117.371
6 17 15532.1528 0.070906 25.24923 -12.1798
7 18 15532.1109 0.041962 13.50692 -0.11934
8 20 15532.0946 0.016234 0.218804 -0.0327
9 23 15532.0946 3.511E-6 0.134574 -0.00002
NOTE: GCONV convergence criterion satisfied.
Fit Statistics
-2 Log Likelihood 31064
AIC (smaller is better) 31078
AICC (smaller is better) 31078
BIC (smaller is better) 31105
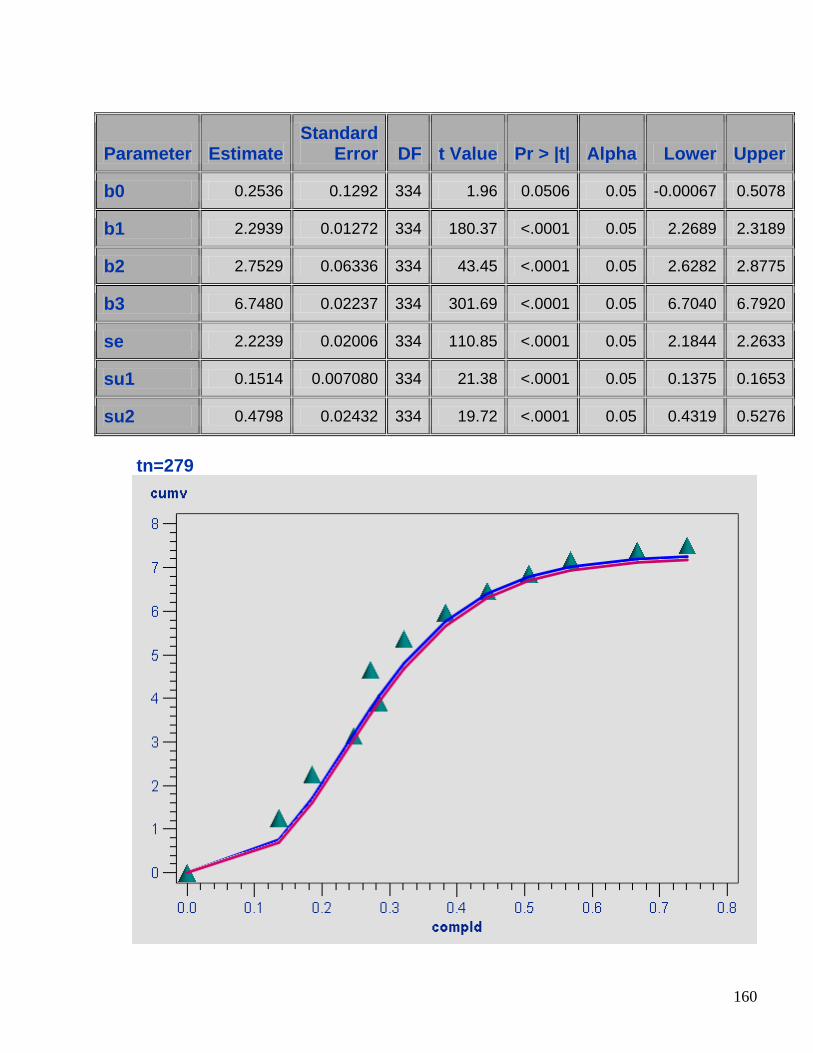
160
Parameter Estimate Standard
Error DF t Value Pr > |t| Alpha Lower Upper
b0 0.2536 0.1292 334 1.96 0.0506 0.05 -0.00067 0.5078
b1 2.2939 0.01272 334 180.37 <.0001 0.05 2.2689 2.3189
b2 2.7529 0.06336 334 43.45 <.0001 0.05 2.6282 2.8775
b3 6.7480 0.02237 334 301.69 <.0001 0.05 6.7040 6.7920
se 2.2239 0.02006 334 110.85 <.0001 0.05 2.1844 2.2633
su1 0.1514 0.007080 334 21.38 <.0001 0.05 0.1375 0.1653
su2 0.4798 0.02432 334 19.72 <.0001 0.05 0.4319 0.5276
tn=279

161

162
tn=151

163
tn=5

164
4.2. Modelo Lineal Generalizado Mixto. Ingredientes claves.
En los modelos no lineales (tanto en su formulación de esperanza marginal como en su
formulación de esperanza condicional) que hemos visto hasta ahora, existen algunos
que se denominan “linealizables”: son modelos en los que existe una función de la
esperanza que es una función lineal de los parámetros del modelo. Es decir, existe una
transformación g(.) de ( )E Y o de ( | )E Y u que hace que ( )( )g E Y sea lineal. Por
ejemplo, 20 1 2
1Y x x
µβ β β
=+ +
es linealizable porque existe una función 1( )g t t= que
hace que ( ) 20 1 2Yg x xµ β β β= + + .
Si estos modelos linealizables provienen de datos cuya distribución es una familia
exponencial (por ejemplo, distribución normal, gamma, binomial, Poisson, etc.)
entonces tenemos un modelo lineal generalizado.
Un modelo lineal generalizado es un modelo que vincula las respuestas (variables
“dependientes”) con otras variables “independientes” o “explicativas”. Tenemos que
considerar tres componentes:
1. La componente aleatoria (la distribución de las iY ). En general, se supone que
las iY son independientes, con una distribución que sea una familia exponencial
lineal (por ejemplo: normal, binomial, Poisson, gamma, etc.)
2. La componente sistemática, que indica la relación entre las variables
independientes. Éste es un modelo lineal (es decir, los parámetros entran
linealmente al modelo). Por ej., 1 1 2 2x xα β β+ + .
3. La función de enlace, que es la que vincula la media (esperanza) de la
distribución de las iY con la componente sistemática. Por ejemplo,
1 1 2 2( ) log( ) .i i i ig x xµ µ α β β= = + +

165
Algunos ejemplos de modelos lineales generalizados:
a. 21 1 2 2( , )i i iY N x xα β β σ+ +
b. Poisson( ); log( )i i i iY µ µ α τ= +
c. 0 1Bin( , ); log1
ii i i
i
Y N xππ β βπ
= + −
Si el modelo que estamos considerando está formulado en términos de su esperanza
condicional (es decir, conocemos la distribución de las observaciones dados los efectos
aleatorios y la distribución de los efectos aleatorios), y además el modelo es linealizable
(es decir, existe una función de enlace que aplicada a la media condicional está
linealmente relacionada a los parámetros) entonces tenemos un modelo lineal generalizado mixto. Para ajustar los modelos lineales generalizados mixtos en SAS también es posible usar
Proc NLMIXED, ya que constituyen un caso especial de los modelos no lineales mixtos.
En este caso tenemos que la inferencia es específica de sujetos, es decir, los
parámetros se interpretarán en términos de “controlando por el efecto aleatorio de
individuo”, “para un sujeto típico”, etc. En la versión 9 de SAS también se podrá usar
PROC GLIMMIX.
Como se indicó en el ejemplo de los árboles de naranjo, la existencia de uno o más
efectos aleatorios induce una correlación entre las observaciones que comparten el
mismo valor realizado del(los) efecto(s) aleatorio(s). Una alternativa a la modelación de
modelos lineales generalizados es la formulación marginal: es decir, el modelo se
formula directamente en términos de la esperanza marginal. En este caso se formula
otro modelo para la esperanza condicional, y se ajustan simultáneamente ambos
modelos. Esta metodología no está implementada en programas de uso común, y se
denomina “modelos marginalizados”. La otra posibilidad para formular el modelo con la
esperanza marginal es olvidarnos del efecto aleatorio, y modelar implícitamente su

166
efecto sobre la estructura de correlación que induce sobre la distribución marginal de la
respuesta. Estos modelos se denominan marginales, y permiten aprovechar las
ventajas de la formulación marginal (inferencia promedio para la población) sin
preocuparse por modelar específicamente los efectos aleatorios. Es decir, el modelo
especifica la esperanza marginal y la matriz de correlación (marginal) de las
observaciones, así como la función de enlace y la distribución marginal de las
observaciones.
Para ajustar este modelo marginal en SAS es posible usar Proc GENMOD, que tiene la
ventaja de no requerir valores iniciales para la estimación de los parámetros, además
de usar una sintaxis similar a SAS Proc GLM y Proc MIXED para especificar efectos,
interacciones, covariables, etc.
Para especificar la matriz de correlación entre observaciones del mismo sujeto, algunas
de las estructuras más usadas son análogas a las usadas en modelos lineales mixtos
(Tabla 6).
Tabla 6: Estructuras para modelar la correlación dentro de sujeto.
Estructura Elemento típico en ( )t t α×R
Fija (conocida) 0Corr( , )ij ik jkY Y r= Independiente Corr( , ) 0ij ikY Y = m-dependiente | | if | |
Corr( , )0 if | |
j kij ik
j k mY Y
j k mα − − ≤
= − ≤
Intercambiable Corr( , )ij ikY Y α= Autoregresiva deorden 1 | |Corr( , ) j k
ij ikY Y α −= Sin estructura Corr( , )ij ik jkY Y r=
El modelo no especifica la distribución conjunta de los datos, sino solamente su
esperanza y matriz de covarianza (es decir, sus dos primeros momentos), por lo que no
es posible aplicar métodos basados en la verosimilitud para la estimación y las pruebas
de hipótesis. Existe una modificación que usa una ecuación relacionada con la ecuación

167
que se maximiza en el método de máxima verosimilitud, se llama GEE (“generalized
estimating equations”). En máxima verosimilitud, igualando a cero la derivada de la
logverosimilitud se obtiene la “ecuación de estimación” que resolviéndola provee los
estimadores. En GEE ocurre lo mismo, excepto que ahora no tenemos más una
verosimilitud propiamente dicha sino un “cuasi-verosimilitud”:
( )( )'
1( ) 0.ii i i
iS −∂
= − =∂∑ μβ V Y μ ββ
Debemos observar que esta ecuación depende de α (los parámetros en la matriz de
covarianza). Como estos parámetros son desconocidos, podemos reemplazarlos por
estimadores consistentes y las propiedades de los β se mantienen.
La estimación de la matriz de covarianza de los parámetros puede basarse en el
modelo, ( )ˆmΣ β , o ser empírica, ( )ˆ
eΣ β .
( )'
1 10 0
ˆ , .i im i
i
− −∂ ∂= =
∂ ∂∑ μ μΣ β I I Vβ β
( )'
1 1 1 10 1 0 1
ˆ , Cov( ) .i ie i i i
i
− − − −∂ ∂= =
∂ ∂∑ μ μΣ β I I I I V Y Vβ β
El estimador de ( )ˆeΣ β es consistente aunque la matriz R no esté correctamente
especificada. Para esto debemos estimar la matriz central del “sandwich” en forma
empírica:
( )( ) ( )( )ˆ ˆˆCov( )i i i i i′
= − −Y Yμ β Y μ β.
Para probar hipótesis acerca de los parámetros, por ejemplo 0 : ,H =Lβ 0 se puede
realizar una prueba de score generalizado. El estadístico de esta prueba es
( )
-1ˆ ˆ ˆ( ) ' ' ' ( )m e mT S S= β Σ L LΣ L LΣ β,

168
donde β es el vector de parámetros estimados bajo 0.H Este estadístico tiene una
distribución aproximada bajo 0H de 2rχ , donde r es el rango de la matriz L .
Ejercicio 4.3. Datos Papaya.Modelo lineal generalizado mixto para proporciones.
Se consideran las curvas de progreso de enfermedad para evaluar el cambio en la
proporción de plantas de papaya infectadas con ring spot virus bajo 4 tratamientos
diferentes: suelo sin malezas, suelo con malezas, suelo cubierto con plástico negro y
suelo cubierto con plástico plateado.
Los modelos comúnmente usados en fitopatología para modelar la proporción de
individuos infectados son modelos lineales generalizados son:
Modelo Ecuación diferencial Ecuación integrada
Exponencial = e
dY r Ydt
0 exp( )= eY Y r t
Monomolecular (1 )= −mdY r Ydt
1 exp( )= − − mY B r t
Logístico (1 )= −ldY r Y Ydt
11 exp( )
=+ − + l
YB r t
Gompertz [ ]log= −gdY r Y Ydt
exp exp( ) = − − gY B r t
A partir de los gráficos presentados para este ejemplo, y también realizando pruebas de
falta de ajuste, es claro que los modelos Logístico y Gompertz ajustan razonablemente
bien estos datos. En este ejemplo indicaremos el ajuste al modelo logístico, aunque
resultados similares pueden obtenerse con el de Gompertz.
Definimos a ijkY como la cantidad de plantas enfermas en una fecha j, tratamiento i y
parcela k. Como las parcelas se observan repetidamente, podemos pensar en un efecto
aleatorio de parcela ku , con lo que el modelo no lineal mixto que podemos formular es

169
( )
( )2
| Binomial 20,
logit log dap1
Normal 0,
ijk k ijk
ijkijk i k i j
ijk
k
Y u
u r
u
π
ππ µ α
π
σ
= = + + + −
Con este modelo podemos observar que la esperanza condicional de 20ijk
ijkYp = (la
proporción de plantas con síntomas) es
( ) ( )( )
exp dap|
1 exp dapi k i j
ijk ijk ki k i j
u rE p u
u r
µ απ
µ α
+ + += =
+ + + +
Como mencionamos anteriormente, la esperanza marginal no seguirá la misma forma
funcional (es decir, no será una función logística) pero se aproximará bastante a ésta.
Si por el contrario, formulamos la esperanza marginal como una logística, debemos
imponer un modelo para la correlación entre observaciones de la misma parcela. Por
ejemplo, podemos formular una correlación de tipo autorregresivo de orden 1 para la
correlación:
( ) ( )( )
( )
* * **
* * *
| *|*
exp dap20 20
1 exp dap
Corr ,
i i
ijk
i i
jijk
j
k kijk ijk
rE Y
r
Y Y
µ απ
µ α
ρ −
+ += =
+ + +
=
Es importante notar que los parámetros de este modelo son intrínsecamente diferentes
a los del modelo mixto, por lo que hemos usado asteriscos para diferenciarlos. Los del
modelo mixto se interpretan en términos específicos para sujetos (i.e. parcelas, en este
ejemplo), mientras que los del marginal son promedios poblacionales.
Para ajustar estos modelos en SAS se puede usar Proc NLMixed (modelo no lineal
mixto) y Proc Genmod (modelo marginal). Para ajustar el modelo marginal en Proc
Genmod, no son necesarios valores iniciales de los parámetros, y se puede usar las
facilidades del comando “class”, que crea variables indicadoras (dummy variables) para

170
los tratamientos. En el caso del modelo condicional, necesitamos dar los valores
iniciales de los parámetros y crear variables indicadoras para los distintos niveles de
tratamiento. Una estrategia común es usar como valores iniciales de los parámetros en
Proc NLMixed los obtenidos del ajuste de Proc Genmod, por lo que la parametrización
debe ser la misma. Para lograr esto, se crean variables indicadoras para todos los
tratamientos excepto el último. Los siguientes programas usan esta estrategia.
Outline 4.3a. Códigos y salidas GENMOD SAS. Datos Papaya
proc genmod data=papaya;
class treat repet;
model ndiseased/trees = treat dds treat*dds /dist=bin link=logit type3;
repeated subject=repet / type=ar(1) corrw;
run;
Model Information
Data Set WORK.MEDIAS
Distribution Binomial
Link Function Logit
Response Variable (Events) ndiseased
Response Variable (Trials) trees
Observations Used 160
Number Of Events 1440
Number Of Trials 3200
Class Level Information
Class Levels Values
treat 4 M PC PP T
repet 20 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20

171
Parameter Information
Parameter Effect treat
Prm1 Intercept
Prm2 treat M
Prm3 treat PC
Prm4 treat PP
Prm5 treat T
Prm6 dds
Prm7 dds*treat M
Prm8 dds*treat PC
Prm9 dds*treat PP
Prm10 dds*treat T
Criteria For Assessing Goodness Of Fit
Criterion DF Value Value/DF
Deviance 152 280.1112 1.8428
Scaled Deviance 152 280.1112 1.8428
Pearson Chi-Square 152 289.2850 1.9032
Scaled Pearson X2 152 289.2850 1.9032
Log Likelihood -1129.2014
Algorithm converged.
GEE Model Information
Correlation Structure AR(1)
Subject Effect repet (20 levels)
Number of Clusters 20
Correlation Matrix Dimension 8
Maximum Cluster Size 8
Minimum Cluster Size 8

172
Algorithm converged.
Working Correlation Matrix
Col1 Col2 Col3 Col4 Col5 Col6 Col7 Col8
Row1 1.0000 0.6170 0.3807 0.2349 0.1449 0.0894 0.0552 0.0340
Row2 0.6170 1.0000 0.6170 0.3807 0.2349 0.1449 0.0894 0.0552
Row3 0.3807 0.6170 1.0000 0.6170 0.3807 0.2349 0.1449 0.0894
Row4 0.2349 0.3807 0.6170 1.0000 0.6170 0.3807 0.2349 0.1449
Row5 0.1449 0.2349 0.3807 0.6170 1.0000 0.6170 0.3807 0.2349
Row6 0.0894 0.1449 0.2349 0.3807 0.6170 1.0000 0.6170 0.3807
Row7 0.0552 0.0894 0.1449 0.2349 0.3807 0.6170 1.0000 0.6170
Row8 0.0340 0.0552 0.0894 0.1449 0.2349 0.3807 0.6170 1.0000
Analysis Of GEE Parameter Estimates
Empirical Standard Error Estimates
Parameter Estimate
Standard
Error
95% Confidence
Limits Z Pr > |Z|
Intercept -5.4164 0.3678 -6.1372 -4.6955 -14.73 <.0001
treat M -0.5185 0.6277 -1.7487 0.7118 -0.83 0.4088
treat PC -5.0679 1.4240 -7.8589 -2.2769 -3.56 0.0004
treat PP -6.5040 1.3186 -9.0885 -3.9196 -4.93 <.0001
treat T 0.0000 0.0000 0.0000 0.0000 . .
dds 0.0627 0.0027 0.0575 0.0679 23.64 <.0001
dds*treat M 0.0021 0.0058 -0.0093 0.0134 0.36 0.7198
dds*treat PC 0.0359 0.0130 0.0103 0.0615 2.75 0.0059
dds*treat PP 0.0457 0.0136 0.0191 0.0724 3.36 0.0008
dds*treat T 0.0000 0.0000 0.0000 0.0000 . .

173
Score Statistics For Type 3 GEE Analysis
Source DF Chi-Square Pr > ChiSq
treat 3 13.41 0.0038
dds 1 19.98 <.0001
dds*treat 3 12.81 0.0051
Outline 4.3b. Códigos y Salidas NLMIXED SAS. Datos Papaya
proc sort data=papaya;
by repet;
proc nlmixed data=papaya;
parms b0=-5.4 bm=-0.5 bpc=-5 bpp=-6.5
r=0.06 rm=0.002 rpc=0.036 rpp=0.046 sigma=0.3;
num=exp(b0+bm*tratm+bpc*tratpc+bpp*tratpp+u
+r*dds+rm*tratm*dds+rpc*tratpc*dds+rpp*tratpp*dds);
denom=1+num;
model ndiseased ~ binomial (20, num/denom);
random u ~normal(0,sigma*sigma) subject=repet;
run;
Specifications
Data Set WORK.MEDIAS
Dependent Variable ndiseased
Distribution for Dependent Variable Binomial
Random Effects u
Distribution for Random Effects Normal
Subject Variable repet
Optimization Technique Dual Quasi-Newton
Integration Method Adaptive Gaussian Quadrature
Dimensions
Observations Used 160
Observations Not Used 0
Total Observations 160

174
Dimensions
Subjects 20
Max Obs Per Subject 8
Parameters 9
Quadrature Points 1
Parameters
b0 bm bpc bpp r rm rpc rpp sigma NegLogLike
-5.4 -0.5 -5 -6.5 0.06 0.002 0.036 0.046 0.3 268.715105
Iteration History
Iter Calls NegLogLike Diff MaxGrad Slope
1 5 264.619766 4.095339 3387.767 -292478
2 8 264.504908 0.114858 3392.448 -278.013
3 11 264.282184 0.222724 3407.797 -388.42
4 12 253.650172 10.63201 1042.224 -209.349
… … … … … …
24 48 251.567166 2.215E-6 0.004243 -3.97E-6
25 50 251.567166 2.34E-10 0.00007 -468E-12
NOTE: GCONV convergence criterion satisfied.
Fit Statistics
-2 Log Likelihood 503.1
AIC (smaller is better) 521.1
AICC (smaller is better) 522.3
BIC (smaller is better) 530.1
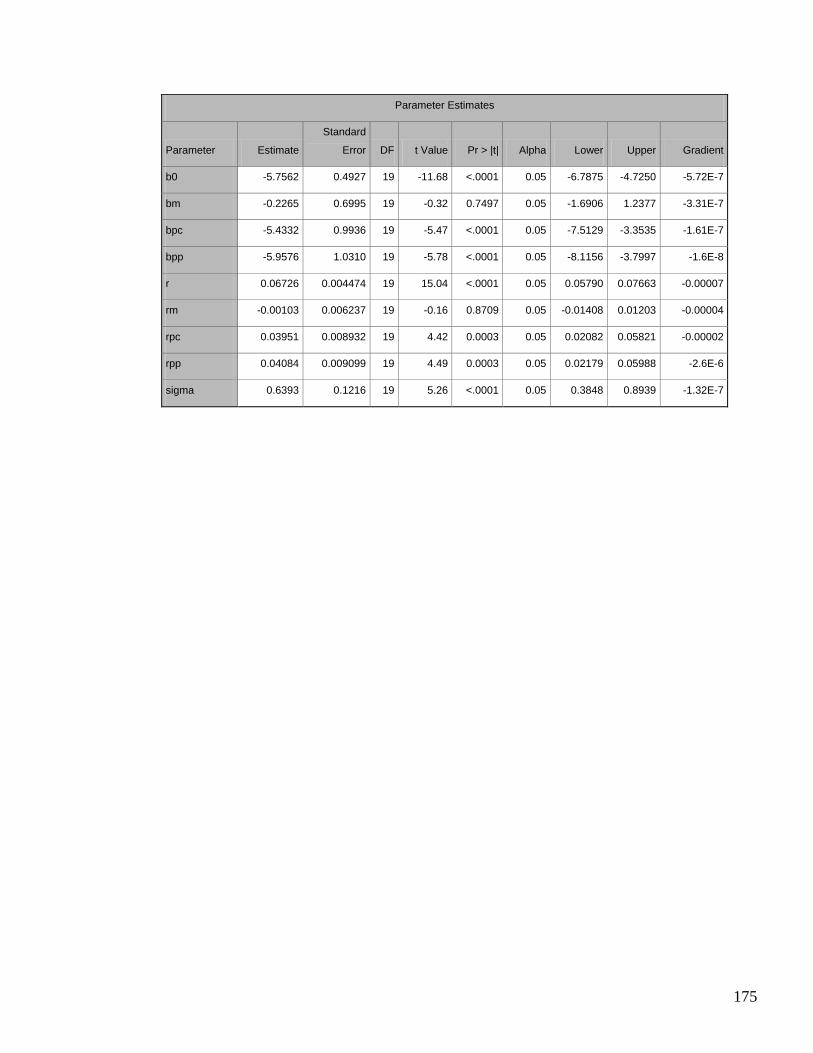
175
Parameter Estimates
Parameter Estimate
Standard
Error DF t Value Pr > |t| Alpha Lower Upper Gradient
b0 -5.7562 0.4927 19 -11.68 <.0001 0.05 -6.7875 -4.7250 -5.72E-7
bm -0.2265 0.6995 19 -0.32 0.7497 0.05 -1.6906 1.2377 -3.31E-7
bpc -5.4332 0.9936 19 -5.47 <.0001 0.05 -7.5129 -3.3535 -1.61E-7
bpp -5.9576 1.0310 19 -5.78 <.0001 0.05 -8.1156 -3.7997 -1.6E-8
r 0.06726 0.004474 19 15.04 <.0001 0.05 0.05790 0.07663 -0.00007
rm -0.00103 0.006237 19 -0.16 0.8709 0.05 -0.01408 0.01203 -0.00004
rpc 0.03951 0.008932 19 4.42 0.0003 0.05 0.02082 0.05821 -0.00002
rpp 0.04084 0.009099 19 4.49 0.0003 0.05 0.02179 0.05988 -2.6E-6
sigma 0.6393 0.1216 19 5.26 <.0001 0.05 0.3848 0.8939 -1.32E-7

176
4.3 Aplicaciones de Modelos Lineales Generalizados con otras distribuciones.
Regresión Poisson
Para modelar recuentos que poseen una distribución Poisson, es común usar un
modelo lineal generalizado con función de enlace logarítmica. Esto nos asegura que los
valores predichos van a ser positivos:
( )log ( ) ; ( ) exp( ).i i i ix x x xµ α β µ α β= + = + Podemos interpretar el efecto de la pendiente β en términos multiplicativos: si x
aumenta en 1 unidad, el promedio se multiplica por eβ :
( )( 1) .x
x e e eα β βµ + = Similarmente, para regresores cualitativos la diferencia entre los coeficientes asociados
a dos tratamientos nos indica por cuánto se multiplica la media al pasar de un
tratamiento al otro. Para el modelo ( )log ,i iµ α τ= + al pasar del tratamiento 1 al
tratamiento 3, por ejemplo, el promedio cambia: ( )3 1 3 1exp .µ µ τ τ= − Esto quiere decir
que si 3 1τ τ> , entonces el factor es mayor que 1, y por lo tanto 3 1µ µ> .
Una característica fundamental de la distribución Poisson es que la varianza es igual
que la media. Pero en modelos Poisson con efectos aleatorios esto no siempre se
cumple, ya que la variabilidad añadida por efectos aleatorios presentes da lugar al
fenómeno llamado “sobredispersión”, que debe modelarse específicamente (o tenerse
en cuenta implícitamente en una estructura de covarianza especial).
Los modelos Poisson con efectos aleatorios son modelos lineales generalizados mixtos,
por lo que todo lo discutido para estos modelos se aplica. Es decir, se pueden ajustar
modelos formulados en términos de la esperanza condicional con efectos aleatorios
explícitamente definidos, y modelos marginales con una estructura de correlación
explícitamente definida.
Existen muchas aplicaciones en las que no nos interesa modelar los recuentos
propiamente dichos sino una tasa, densidad, promedio, etc. Por ejemplo, contamos en
50 plantas tratadas y en 50 plantas control la cantidad de insectos (Y) y la cantidad de

177
hojas (h), y nos interesa modelar el promedio de insectos por hoja. Un modelo que
podemos usar es log ,o log logii i ij i
ij
hhµ α τ µ α τ= + = + + . El primer término se llama
“offset”. Las características del modelo lineal generalizado no cambian (observar que es
como agregarle una nueva variable independiente al modelo, cuyo coeficiente de
regresión es 1).
Regresión binomial negativa.
Si bien la distribución binomial negativa no es una familia exponencial para k
desconocido, la cantidad de datos biológicos que requieren de ella hace que se hayan
desarrollado métodos que permiten usar las técnicas de modelos lineales generalizados
para datos binomiales negativos. Esta distribución es:
( )( ) ( )
( )( )
1
1( ) 0,1,2,...; 0; 0.
11 1
k
y k
y kkP y y ky kk
µµ
µ +
Γ += = > >Γ + Γ +
El parámetro k se refiere comúnmente como el índice de “agregación”. La función de
varianza es 2
Var( )Ykµµ= + , con lo que vemos que ésta es una distribución alternativa
para modelar sobredispersión en recuentos Poisson. Si k es conocido, se puede
modelar directamente ya que es una familia exponencial. Si k es desconocido, la
estrategia es estimarlo conjuntamente con los parámetros del modelo mediante máxima
verosimilitud (análogo a estimar 2σ junto con los otros parámetros en regresión normal).
Por la misma razón que usamos modelos logarítmico-lineales en regresión Poisson,
también en la regresión binomial negativa usamos modelos con enlace logarítmico. La
interpretación de los parámetros es siempre en términos multiplicativos. Los modelos
marginales pueden ajustarse usando Proc Genmod. Si tenemos efectos aleatorios
presentes podemos plantear un modelo condicional con distribución binomial negativa,
y éste podría ajustarse en SAS usando Proc NLMixed, aunque la parametrización que
usa no es la presentada aquí. Una alternativa es escribir la verosimilitud
específicamente en el programa.

178
Ejercicio 4.4. Modelo lineal generalizado para recuentos. Datos Arce.
Para el análisis consideraremos que la variable de interés es un recuento, y que por lo
tanto sería razonable usar un modelo relacionado con la distribución Poisson o binomial
negativa. Una característica fundamental de estos datos es que, si bien hay más de
2700 recuentos, hay solamente 60 árboles. Es decir, observaciones obtenidas del
mismo árbol pueden estar correlacionadas. Por lo tanto, debemos considerar esta
correlación, ya sea modelarla directamente en una formulación marginal del modelo, o
inducirla a través de un modelo condicional (jerárquico) que incluya uno o más efectos
aleatorios de árbol.
Outline 4.4a. Códigos y Salidas NLMIXED SAS. Datos Arce. proc genmod data=trees; class tratam tree; model num_int=tratam /dist=POI link=LOG type3 ; repeated subject=tree /type=EXCH ; lsmeans tratam / pdiff; proc genmod data=arce; class tratam tree; model num_int=tratam /dist=negbin link=LOG type3 ; repeated subject=tree /type=EXCH ; lsmeans tratam / pdiff; run; proc sort; by tree; proc nlmixed data=trees qpoints=100; parms b0=1.7 bc=0 bcm=0.25 bp2=-0.17 be2=-0.36 be4=-0.3 logsu=2; media=exp(b0+u+bc*treatc+bcm*treatcm+bp2*treatp2+be2*treate2+be4*treate4); model num_int ~ Poisson(media); random u ~ N(0,exp(2*logsu)) subject=tree; contrast 'bc vs. bcm' bc-bcm; contrast 'bc vs. p 20' bc-bp2; contrast 'bc vs. p4' bc; contrast 'bc vs. e2' bc-be2; contrast 'bc vs. e4' bc-be4; contrast 'bcm vs. p 20' bcm-bp2; contrast 'bcm vs. p4' bcm; contrast 'bcm vs. e2' bcm-be2; contrast 'bcm vs. e4' bcm-be4; contrast 'p20 vs. p4' bp2; contrast 'p20 vs. e2' bp2-be2; contrast 'p20 vs. e4' bp2-be4; contrast 'p4 vs. e2' be2; contrast 'p4 vs. e4' be4; contrast 'e2 vs. e4' be2-be4; run;

179
Model Information
Data Set WORK.TREES
Distr ibution Poisson
Link Function Log
Dependent Var iable num_int
Observations Used 2796
Class Level Information
Class Levels Values
tratam 6 control control methanol el500 20g/l el500 4g/l p333 20g/l p333 4g/l
TREE 57 D10 D13 D14 D16 D18 D19 D20 D21 D22 G10 G2 G20 G21 G24 G27 G28 G29 G4 G5 G6 G7 G8 G9 J1 J10 J12 J13 J15 J17 J19 J20 J25 J27 J29 J31 J6 J8 M10 M17 M20 M25 M33 M6 O20 O27 O28 O33 O3O Q12 Q17 Q19 Q23 Q25 Q3 Q34 Q4 Q5
Parameter Information
Parameter Effect tratam
Prm1 Intercept
Prm2 tratam control
Prm3 tratam control methanol
Prm4 tratam el500 20g/l
Prm5 tratam el500 4g/l
Prm6 tratam p333 20g/l
Prm7 tratam p333 4g/l
Cr iter ia For Assessing Goodness Of Fit
Cr iter ion DF Value Value/DF
Deviance 2790 6071.3544 2.1761
Scaled Deviance 2790 6071.3544 2.1761
Pearson Chi-Square 2790 8351.9722 2.9935
Scaled Pearson X2 2790 8351.9722 2.9935
Log Likelihood 7205.0671

180
Algorithm converged.
Analysis Of Initial Parameter Estimates
Parameter DF Estimate Standard
Error
Wald 95% Confidence
Limits Chi-Square Pr > ChiSq
Intercept 1 1.6110 0.0198 1.5723 1.6497 6641.45 <.0001
tratam control 1 0.0697 0.0290 0.0129 0.1266 5.79 0.0161
tratam control methanol 1 0.2858 0.0306 0.2257 0.3458 87.01 <.0001
tratam el500 20g/l 1 -0.2247 0.0287 -0.2810 -0.1684 61.22 <.0001
tratam el500 4g/l 1 -0.0796 0.0320 -0.1424 -0.0169 6.18 0.0129
tratam p333 20g/l 1 -0.3067 0.0281 -0.3617 -0.2516 119.06 <.0001
tratam p333 4g/l 0 0.0000 0.0000 0.0000 0.0000 . .
Scale 0 1.0000 0.0000 1.0000 1.0000
NOTE: The scale parameter was held fixed.
GEE Model Information
Correlation Structure Exchangeable
Subject Effect TREE (57 levels)
Number of Cluster s 57
Correlation Matr ix Dimension 139
Maximum Cluster Size 139
Minimum Cluster Size 4
Algorithm converged.
Analysis Of GEE Parameter Estimates
Empir ical Standard Error Estimates
Parameter Estimate Standard
Error
95% Confidence
Limits Z Pr > |Z|
Intercept 1.7430 0.1082 1.5309 1.9550 16.11 <.0001
tratam control 0.0196 0.1460 -0.2666 0.3058 0.13 0.8934
tratam control methanol 0.2309 0.1350 -0.0338 0.4955 1.71 0.0873

181
Analysis Of GEE Parameter Estimates
Empir ical Standard Error Estimates
Parameter Estimate Standard
Error
95% Confidence
Limits Z Pr > |Z|
tratam el500 20g/l -0.2877 0.1439 -0.5696 -0.0057 -2.00 0.0455
tratam el500 4g/l -0.1683 0.1463 -0.4550 0.1184 -1.15 0.2499
tratam p333 20g/l -0.3555 0.1332 -0.6165 -0.0945 -2.67 0.0076
tratam p333 4g/l 0.0000 0.0000 0.0000 0.0000 . .
Score Statistics For Type 3 GEE Analysis
Source DF Chi-Square Pr > ChiSq
tratam 5 15.50 0.0084
Least Squares Means
Effect tratam Estimate Standard
Error DF Chi-Square Pr > ChiSq
tratam control 1.7625 0.0981 1 322.92 <.0001
tratam control methanol 1.9738 0.0808 1 596.50 <.0001
tratam el500 20g/l 1.4553 0.0948 1 235.44 <.0001
tratam el500 4g/l 1.5746 0.0985 1 255.62 <.0001
tratam p333 20g/l 1.3875 0.0777 1 319.04 <.0001
tratam p333 4g/l 1.7430 0.1082 1 259.63 <.0001
Differences of Least Squares Means
Effect tratam _tratam Estimate Standard
Error DF Chi-Square Pr > ChiSq
tratam control control methanol -0.2113 0.1271 1 2.76 0.0964
tratam control el500 20g/l 0.3073 0.1364 1 5.07 0.0243
tratam control el500 4g/l 0.1879 0.1390 1 1.83 0.1764
tratam control p333 20g/l 0.3751 0.1251 1 8.99 0.0027
tratam control p333 4g/l 0.0196 0.1460 1 0.02 0.8934
tratam control methanol el500 20g/l 0.5185 0.1246 1 17.32 <.0001
tratam control methanol el500 4g/l 0.3992 0.1274 1 9.82 0.0017

182
Differences of Least Squares Means
Effect tratam _tratam Estimate Standard
Error DF Chi-Square Pr > ChiSq
tratam control methanol p333 20g/l 0.5864 0.1121 1 27.36 <.0001
tratam control methanol p333 4g/l 0.2309 0.1350 1 2.92 0.0873
tratam el500 20g/l el500 4g/l -0.1193 0.1367 1 0.76 0.3827
tratam el500 20g/l p333 20g/l 0.0678 0.1226 1 0.31 0.5801
tratam el500 20g/l p333 4g/l -0.2877 0.1439 1 4.00 0.0455
tratam el500 4g/l p333 20g/l 0.1872 0.1254 1 2.23 0.1356
tratam el500 4g/l p333 4g/l -0.1683 0.1463 1 1.32 0.2499
tratam p333 20g/l p333 4g/l -0.3555 0.1332 1 7.13 0.0076
Model Information
Data Set WORK.TREES
Distr ibution Negative Binomial
Link Function Log
Dependent Var iable num_int
Observations Used 2796
Class Level Information
Class Levels Values
tratam 6 control control methanol el500 20g/l el500 4g/l p333 20g/l p333 4g/l
TREE 57 D10 D13 D14 D16 D18 D19 D20 D21 D22 G10 G2 G20 G21 G24 G27 G28 G29 G4 G5 G6 G7 G8 G9 J1 J10 J12 J13 J15 J17 J19 J20 J25 J27 J29 J31 J6 J8 M10 M17 M20 M25 M33 M6 O20 O27 O28 O33 O3O Q12 Q17 Q19 Q23 Q25 Q3 Q34 Q4 Q5
Parameter Information
Parameter Effect tratam
Prm1 Intercept
Prm2 tratam control
Prm3 tratam control methanol
Prm4 tratam el500 20g/l
Prm5 tratam el500 4g/l
Prm6 tratam p333 20g/l
Prm7 tratam p333 4g/l

183
Cr iter ia For Assessing Goodness Of Fit
Cr iter ion DF Value Value/DF
Deviance 2790 2511.4867 0.9002
Scaled Deviance 2790 2511.4867 0.9002
Pearson Chi-Square 2790 3894.5530 1.3959
Scaled Pearson X2 2790 3894.5530 1.3959
Log Likelihood 7992.9813
Algorithm converged.
Analysis Of Initial Parameter Estimates
Parameter DF Estimate Standard
Error
Wald 95% Confidence
Limits Chi-Square Pr > ChiSq
Intercept 1 1.6110 0.0294 1.5533 1.6687 2993.22 <.0001
tratam control 1 0.0697 0.0436 -0.0158 0.1553 2.55 0.1100
tratam control methanol 1 0.2858 0.0480 0.1917 0.3798 35.46 <.0001
tratam el500 20g/l 1 -0.2247 0.0415 -0.3061 -0.1433 29.29 <.0001
tratam el500 4g/l 1 -0.0796 0.0471 -0.1718 0.0126 2.86 0.0907
tratam p333 20g/l 1 -0.3067 0.0403 -0.3856 -0.2277 57.90 <.0001
tratam p333 4g/l 0 0.0000 0.0000 0.0000 0.0000 . .
Dispersion 1 0.2434 0.0111 0.2227 0.2660
NOTE: The negative binomial dispersion parameter was estimated by maximum likelihood.
GEE Model Information
Correlation Structure Exchangeable
Subject Effect TREE (57 levels)
Number of Cluster s 57
Correlation Matr ix Dimension 139
Maximum Cluster Size 139
Minimum Cluster Size 4

184
Algorithm converged.
Analysis Of GEE Parameter Estimates
Empir ical Standard Error Estimates
Parameter Estimate Standard
Error
95% Confidence
Limits Z Pr > |Z|
Intercept 1.7430 0.1082 1.5309 1.9550 16.11 <.0001
tratam control 0.0196 0.1460 -0.2666 0.3058 0.13 0.8934
tratam control methanol 0.2309 0.1350 -0.0338 0.4955 1.71 0.0873
tratam el500 20g/l -0.2877 0.1439 -0.5696 -0.0057 -2.00 0.0455
tratam el500 4g/l -0.1683 0.1463 -0.4550 0.1184 -1.15 0.2499
tratam p333 20g/l -0.3555 0.1332 -0.6165 -0.0945 -2.67 0.0076
tratam p333 4g/l 0.0000 0.0000 0.0000 0.0000 . .
Score Statistics For Type 3 GEE Analysis
Source DF Chi-Square Pr > ChiSq
tratam 5 15.50 0.0084
Least Squares Means
Effect tratam Estimate Standard
Error DF Chi-Square Pr > ChiSq
tratam control 1.7625 0.0981 1 322.92 <.0001
tratam control methanol 1.9738 0.0808 1 596.50 <.0001
tratam el500 20g/l 1.4553 0.0948 1 235.44 <.0001
tratam el500 4g/l 1.5746 0.0985 1 255.62 <.0001
tratam p333 20g/l 1.3875 0.0777 1 319.04 <.0001
tratam p333 4g/l 1.7430 0.1082 1 259.63 <.0001

185
Differences of Least Squares Means
Effect tratam _tratam Estimate Standard
Error DF Chi-Square Pr > ChiSq
tratam control control methanol -0.2113 0.1271 1 2.76 0.0964
tratam control el500 20g/l 0.3073 0.1364 1 5.07 0.0243
tratam control el500 4g/l 0.1879 0.1390 1 1.83 0.1764
tratam control p333 20g/l 0.3751 0.1251 1 8.99 0.0027
tratam control p333 4g/l 0.0196 0.1460 1 0.02 0.8934
tratam control methanol el500 20g/l 0.5185 0.1246 1 17.32 <.0001
tratam control methanol el500 4g/l 0.3992 0.1274 1 9.82 0.0017
tratam control methanol p333 20g/l 0.5864 0.1121 1 27.36 <.0001
tratam control methanol p333 4g/l 0.2309 0.1350 1 2.92 0.0873
tratam el500 20g/l el500 4g/l -0.1193 0.1367 1 0.76 0.3827
tratam el500 20g/l p333 20g/l 0.0678 0.1226 1 0.31 0.5801
tratam el500 20g/l p333 4g/l -0.2877 0.1439 1 4.00 0.0455
tratam el500 4g/l p333 20g/l 0.1872 0.1254 1 2.23 0.1356
tratam el500 4g/l p333 4g/l -0.1683 0.1463 1 1.32 0.2499
tratam p333 20g/l p333 4g/l -0.3555 0.1332 1 7.13 0.0076
Specifications Data Set WORK.TREES
Dependent Variable num_int
Distribution for Dependent Variable Poisson
Random Effects u
Distribution for Random Effects Normal
Subject Variable TREE
Optimization Technique Dual Quasi-Newton
Integration Method Adaptive Gaussian Quadrature
Dimensions Observations Used 2796
Observations Not Used 0
Total Observations 2796
Subjects 57
Max Obs Per Subject 139

186
Dimensions Parameters 7
Quadrature Points 100
Parameters
b0 bc bcm bp2 be2 be4 logsu NegLogLike 1.7 0 0.25 -0.17 -0.36 -0.3 2 7266.64189
Iteration History
Iter Calls NegLogLike Diff MaxGrad Slope
1 6 7116.23204 150.4099 12.00679 -284.44
2 8 7114.31587 1.916169 39.06443 -52.6045
3 10 7113.3631 0.952767 21.5109 -69.5419
4 11 7113.17529 0.187806 7.964028 -1.18203
5 13 7113.05596 0.11933 9.610313 -1.26885
6 15 7112.9938 0.062161 4.613924 -0.36337
7 16 7112.97038 0.023424 3.188386 -0.24882
8 18 7112.96049 0.009891 2.882186 -0.09018
9 19 7112.94549 0.014999 0.645599 -0.06309
10 22 7112.94511 0.000375 0.374203 -0.00186
11 23 7112.94471 0.000405 0.051505 -0.0029
12 25 7112.9447 7.409E-6 0.000564 -0.00001
NOTE: GCONV convergence criterion satisfied.
Fit Statistics -2 Log Likelihood 14226
AIC (smaller is better) 14240
AICC (smaller is better) 14240
BIC (smaller is better) 14254

187
Parameter Estimates
Parameter Estimate Standard
Error DF t Value Pr > |t| Alpha Lower Upper Gradient
b0 1.7020 0.09403 56 18.10 <.0001 0.05 1.5137 1.8904 0.000189
bc 0.03234 0.1366 56 0.24 0.8137 0.05 -0.2413 0.3060 0.0004
bcm 0.2495 0.1336 56 1.87 0.0671 0.05 -0.01818 0.5171 0.000413
bp2 -0.3280 0.1337 56 -2.45 0.0173 0.05 -0.5959 -0.06003 0.000279
be2 -0.2828 0.1370 56 -2.06 0.0436 0.05 -0.5572 -0.00836 0.000544
be4 -0.1558 0.1377 56 -1.13 0.2627 0.05 -0.4316 0.1200 0.000564
logsu -1.2390 0.1017 56 -12.18 <.0001 0.05 -1.4428 -1.0352 -0.00004
Contrasts
Label Num
DF Den DF F Value Pr > F
bc vs. bcm 1 56 2.50 0.1192
bc vs. p 20 1 56 6.88 0.0112
bc vs. p4 1 56 0.06 0.8137
bc vs. e2 1 56 5.03 0.0289
bc vs. e4 1 56 1.78 0.1881
bcm vs. p 20 1 56 18.47 <.0001
bcm vs. p4 1 56 3.49 0.0671
bcm vs. e2 1 56 14.96 0.0003
bcm vs. e4 1 56 8.59 0.0049
p20 vs. p4 1 56 6.01 0.0173
p20 vs. e2 1 56 0.11 0.7443
p20 vs. e4 1 56 1.55 0.2188
p4 vs. e2 1 56 4.26 0.0436
p4 vs. e4 1 56 1.28 0.2627
e2 vs. e4 1 56 0.81 0.3734

188
Bibliografía Casanoves, F. (2004). Análisis de ensayos comparativos de rendimiento en mejoramiento
vegetal en el marco de los modelos lineales mixtos. Tesis Doctoral. Escuela para
Graduados, Facultad de Ciencias Agropecuarias, Univ. Nacional de Córdoba.
Cullis B.R. y Gleeson A.C. 1991. Spatial analysis of field experiments-an extension to two
dimensions. Biometrics 47: 1449-1460.
Diggle, P., P. Heagerty, K. Liang y S. Zeger (2002). Analysis of Longitudinal Data. 2nd edition.
London: Oxford University Press.
Everitt, B. S. (1995). The analysis of repeated measures: a practical review with examples. The
Statistician 44: 113-135.
Finney, D.J. (1990). Repeated measurements: What is measured and what is repeated?
Statistics in Medicine 9: 639-644.
Graybill, F.A. (1976). Theory and Application of the Linear Model. Wadsworth Publishing
Company: Pacific Grove (CA).
Gregoire, T. y O. Schabenberger (1996). Nonlinear mixed-effects modeling of
cumulative bole volume with spatially correlated within-tree data. J. of Agric.,
Biological and environmental Statistics 1: 107-119.
Kang M.S. 1998. Using genotype-by-environment interaction for crop cultivar development. Adv.
Agron. 62: 199-252.
Lee, Y. y J. A. Nelder (1996). Hierarchical Generalized Linear Models. J. R. Statist Soc. B. 58(3):
Lindsey, J.K. (2001). Models for repeated measurements. 2da. Ed. Oxford Univ. Press: NY
Lindstrom, M. J. y D. M. Bates (1990). Nonlinear mixed effects model for repeated measures
data. Biometrics 46,673-687.
Littell, R., G. Milliken, W. Stroup y R. Wolfinger (1996). SAS System for Mixed Models. SAS
Institute Inc.: Cary, NC
Little, R., P. Henry y C. Ammerman (1998). Statistical analysis of repeated measures data using
SAS Procedures. Journal of Animal Science 76: 1216-1231.

189
Macchiavelli, R. y Moser, E. (1997). Analysis of repeated measurements with ante-dependence
covariance models. Biometrical Journal 39: 339-350.
Martin, R.J. 1990. The use of time-series models and method in the analysis of agricultural field
trials. Comm. Stat. A 19: 55-81.
McLean R.A., Sanders W.L. y Stroup W.W. 1991. A unified approach to mixed linear models.
American Statistician 45: 54-64.
Patterson, H.D. y Thompsom, R. 1971. Recovery of interblock information when block sizes are
unequal. Biometrika 58, 545-554.
Piepho H.P. 1998. Empirical best linear unbiased prediction in cultivar trials using factor-analytic
variance-covariance structures. Theor. Appl. Genet. 97: 195-201.
SAS Institute. 1997. SAS/STAT software: changes and enhancements through release 6.12.
SAS Inst., Cary, NC.
SAS Institute. 2001. SAS/STAT release 8.2. SAS Inst., Cary, NC.
Schabenberger, O. y F. Pierce 2002. Contemporary Statistical Models for the Plant and Soil
Sciences. CRC Press, Boca Raton, FL.
Searle S.R., Casella G. y McCulloch C.E. 1992. Variance Components. John Wiley & Sons, NY
Searle S.R. 1971. Linear Models. John Wiley & Sons, New York.
Stokes, M., C. Davis y G. Koch (2000). Categorical Data Analysis using SAS. 2nd edition. Cary,
NC: SAS Institute, Inc.
Verbeke, G. y G. Molenberghs (2000). Linear Mixed Models for Longitudinal Data. New York:
Springer.
Zeger S.L., Liang K.Y. y Albert P.S. 1988. Model for longitudinal data: a generalized estimating
equation approach. Biometrics 44: 1049-1060.
Zimmerman, D.L. y Harville, D.A. 1991. A random field approach to the analysis of field plot
experiments and other spatial experiments. Biometrics 47: 223-239.





























