Embed Size (px)
Citation preview

Algoritmos para el seguimiento de los
parametros del modelo de tracto bucal
Monografıa Tratamiento Estadıstico de Senales
Pablo Arias *
1

Indice
1. Introduccion 3
2. Modelo del aparato fonador 42.1. Proceso de produccion de la voz . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2. Modelos para la senal de voz . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3. Prediccion lineal 83.1. Solucion al problema de prediccion lineal . . . . . . . . . . . . . . . . . . . . . 8
3.1.1. Enfoque estocastico . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.1.2. Caso determinıstico . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2. Estimacion de la solucion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2.1. Metodo de la autocorrelacion . . . . . . . . . . . . . . . . . . . . . . . 103.2.2. Metodo de la covarianza . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.3. Estimacion de la senal de excitacion . . . . . . . . . . . . . . . . . . . . . . . 113.4. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.4.1. Senales estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.4.2. Senales no estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4. LPC recursivo 154.1. Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.2.1. Senales estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.2.2. Senales no estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5. Kalman con suavizado 205.1. Modelo en variables de estado . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2.1. Senales estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.2.2. Senales no estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.3. Suavizado de Rauch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.3.1. Deduccion del algoritmo de suavizado . . . . . . . . . . . . . . . . . . 23
5.4. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245.4.1. Senales estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245.4.2. Senales no estacionarias . . . . . . . . . . . . . . . . . . . . . . . . . . 25
6. Comparacion y conclusiones 286.1. Rendimiento con senales sinteticas . . . . . . . . . . . . . . . . . . . . . . . . 286.2. Rendimiento con senales reales . . . . . . . . . . . . . . . . . . . . . . . . . . 28
A. Codigo 30
2

1. Introduccion
Una de las aplicaciones que propicio el estudio de las caracterıstcas de la senal de vozy de su generacion fue la codificacion para almacenamiento y transmision a tasas de bitsbajas. En este sentido, la tecnica mas usada es la codificacion por prediccion lineal, o LPC(Linear Predictive Coding) [1], [2]. Esta se basa en predecir el valor de la senal en el instanten usando usando p muestras anteriores y codificar el error en la prediccion. Para algunassenales (procesos auto-regresivos) existen codificadores para los cuales la senal de error en laprediccion tiene baja entropıa, logrando una menor tasa de bits.
El exito de la aplicacion de LPC a la codificacion de senales de voz, se debe en parte aque estas pueden modelarse como un proceso auto-regresivo [3], dado que el sistema fonadorhumano puede considerarse como un filtro lineal variante en el tiempo, del tipo todo polos.
El analisis por LPC de la senal de voz, no solo se usa para la compresion, sino que haprobado ser una de las tecnicas mas usadas para la estimacion de sus parametros basicos,como el pitch, las formantes, el espectro, etc [3]. Estos parametros condensan una gran partede la informacion disponible en la senal de voz, y son usados como insumo para aplicacionesposteriores, como ser reconocimiento de voz, reconocimiento del hablante, compresion, sınte-sis de voz artificial, sıntesis de sonidos [4].
Debido a que la senal de voz es un proceso claramente no estacionario, los coeficientes de laprediccion lineal no son constantes en el tiempo, ası como tampoco lo seran las caracterısticasde la senal de excitacion.
Existen basicamente dos formas de adaptar los coeficientes:
Los algoritmos de adaptacion por bloques trabajan en una ventana de tiempo en la queel proceso s es aproximadamente estacionario, y calculan un mismo juego de coeficientesque son validos dentro de la ventana considerada.
Los algoritmos de adaptacion por muestra actualizan los coeficientes cada instante detiempo con cada nueva muestra de senal disponible.
Los primeros tienen como principal ventaja el costo computacional. La contraparte de es-tos metodos esta en que tienen poca resolucion temporal y en que generan discontinuidadesentre juegos de coeficientes correspondientes a bloques adyacentes.
En este trabajo se presentan dos algoritmos de adaptacion por muestra para estimar losparametros del modelo de tracto bucal. El primero es simplemente el calculo de los coefi-cientes de LPC de forma recursiva para ventanas que se deslizan sobre la senal, utilizando elalgoritmo RLS de ventana deslizante [5]. El otro enfoque se basa en una variacion del filtrode Kalman [6], basado en los algoritmos propuestos por [7] y [8]. Los resultados de estosalgoritmos se comparan entre sı y con los resultados de una estrategia de LPC de adaptacionpor bloques.
El trabajo comienza con una breve resumen de la teorıa del modelado del sistema fonadorhumano en la seccion 2. En la siguiente seccion se presentan las caracterısticas generalesdel analisis de voz basado en LPC. En las secciones 4 y 5 se desarrollan los algoritmos deadaptacion por muestra considerados. Para cada uno (y tambien para LPC) se estudian losresultados con senales sinteticas. Finalmente la seccion 6 contiene una comparacion entre losalgoritmos de adaptacion por muestra y las conclusiones correspondientes.
3

2. Modelo del aparato fonador
Es necesario conocer las caracterısticas basicas de la senal de voz y del mecanismo medi-ante el cual es generada, para comprender las tecnicas usadas en su procesamiento.
Las senales de voz se producen concatenando elementos de un conjunto finito de sonidosllamados fonemas. La fonetica estudia y clasifica estos sonidos, mientras que la liguısticaestudia las reglas que especifican la forma en que se pueden concatenar los fonemas. Elconjunto de fonemas y las reglas para combinarlos es lo que se conoce como lenguaje.
En problemas de reconocimiento de voz, la linguıstica juega un papel muy importante.En problemas de mas bajo nivel, como por ejemplo el analisis de la voz, son mas importanteslas nociones de la fonetica.
2.1. Proceso de produccion de la voz
Se llama aparato fonador al sistema de organos, y musculos encargados de la produccionde la voz. Este sistema esta estrechamente ligado al sistema respiratorio, debido a que la vozes basicamente una vibracion (o variacion de la presion) en el aire que es propulsado por lospulmones.
Figura 1: Diagrama del aparato fonador.
En la figura 1 se puede ver un esquema de la estructura del aparato fonador. Los pulmonesson los que brindan la energıa, transformando energıa muscular en energıa cinetica del aire.
El aire en movimiento pasa por las cuerdas vocales, o membrana glotis, y entra en eltracto bucal. Este consiste en la faringe y la boca o cavidad oral. El velo es una membranaque puede acoplar el tracto nasal al tracto bucal, produciendose los sonidos nasales.
La glotis, junto con los pulmones, genera una senal de excitacion en la forma de un flujode aire con variaciones en la presion. Basicamente hay tres senales de excitacion distintas,que generan tres tipos de sonidos:
Sonidos sonoros. Se hace pasar aire a traves de la glotis, con las cuerdas vocales tensasde modo que vibren. Esto genera una senal de excitacion que tiene la forma de un trencuasi periodico de pulsos. Ejemplos de sonidos sonoros son las vocales.
Sonidos sordos. Se forma una constriccion en el tracto bucal. Si el aire pasa por estaconstriccion a una velocidad suficiente se torna turbulento, lo que se puede modelarcomo una excitacion ruidosa. Los fonemas asociados a algunas consonantes como la f,s, z son sonidos sordos.
4

Sonidos plosivos. Se generan cerrando completamente el pasaje de aire en algun puntodel tracto bucal, y liberando repentinamente la presion acumulada. Entran en estacategorıa los sonidos de las consonantes p, g, t.
Las de senales excitacion resuenan en el tracto bucal, que puede modelarse como un filtrolineal, variante en el tiempo. Las frecuencias de resonancia de este filtro se llaman formantesy su ubicacion en el espectro depende de la configuracion del tracto bucal, que varıa con eltiempo.
Los distintos sonidos de la voz se generan variando la senal de excitacion y la configuraciondel tracto bucal.
2.2. Modelos para la senal de voz
Tracto bucal
El tracto bucal se modela como un sistema lineal cuyos coeficientes varıan en el tiempo.La tasa de variacion de los parametros del tracto bucal es aproximadamente la misma quela frecuencia con que se cambia de fonema al hablar. Se puede asumir que cada juego deparametros se mantiene fijo por aproximadamente 10ms a 20ms.
Para modelar la funcion de transferencia en un instante de tiempo se usa un modelo todopolos de la forma
V (z) =G
1−∑Nk=1 αkz−k
donde los αk con k = 1, . . . , N son numeros reales. Los polos de V (z) corresponden a lasformantes.
Senal de excitacion
De los tres tipos de senales de excitacion que hay, el modelo mas complejo correspondea la excitacion de los sonidos sonoros. Para modelar correctamente este caso, es necesarioestudiar un poco mas en detalle el funcionamiento de la glotis.
Figura 2: Representacion esquematica del aparato fonador con la glotis abierta y cerrada(punteado).
Cuando la glotis esta abiera, esta representa un estrechamiendo del conducto por el cualcircula la voz, como se esquematiza en la figura 2. De acuerdo a la ley de Bernoulli, la presion
5

en el orificio es menor a la presion en cualquiera de los dos lados. Este decremento en lapresion causa que las cuerdas vocales, que a su vez estan sometidas a una tension, se cierren.
La glotis cerrada impide que circule el aire proveniente de los pulmones, y comienza aaumentar la presion del lado de traquea, hasta que las cuerdas vocales ceden y la glotis quedanuevamente abierta.
La repeticion de este ciclo genera una senal de excitacion casi periodica parecida a untren de pulsos. Vale cero cuando la glotis esta cerrada y tiene una forma que se asemeja aun pulso cuando la glotis al abrirse deja pasar el aire acumulado. Una senal de este tipo sepuede apreciar en la figura 3.
Figura 3: Ejemplo de senal de excitacion de un sonido sonoro.
El perıodo depende de la tension a la que se somenten las cuerdas vocales y de la presioncon la que sale en aire de los pulmones. El tono de la senal de voz producida (la frecuenciafundamental) coincide con la frecuencia del ciclo glotal1.
La senal se excitacion de sonidos sonoros se modela entonces como la convolucion de untren de impulsos con una senal parecida a los pulsos de la figura 3. Segun [9] la siguienteaproximacion puede usarse para sintetizar una senal de voz similar a las reales:
g[n] =
12 [1− cos(πn/N1)] 0 6 n 6 N1
cos(π(n−N1)/2N2) N1 6 n 6 N1 + N2
0 N1 + N2 6 n
En el caso de los sonidos sordos, la excitacion puede modelarse setisfactoriamente comola realizacion de un proceso de ruido blanco sin importar demasiado la distribucion de lasmuestras.
La excitacion de los sonidos plosivos no es tenida en cuenta en la mayorıa de los modelos,debido a que la mayor parte de los sonidos son sonoros o sordos.
Modelo completo
En la figura 4 se puede ver un diagrama de bloques del modelo completo del sistemafonador. Existen dos fuentes de senal para generar los sonidos sonoros o los sordos. Medianteestas se excita el tracto bucal, modelado como un filtro lineal variante en el tiempo, detransferencia instantanea V (z). La senal que se obtiene a la salida pL[n], es el valor de lapresion con la que sale el aire de la boca en el instante n.
1En la literatura se utiliza mas el termino pitch o altura por el cual se denomina a la frecuencia.
6

Figura 4: Modelo completo del sistema fonador.
7

3. Prediccion lineal
De acuerdo la figura 4, podemos expresar el valor de la senal de voz en el instante k como:
sk =p∑
j=1
ajsk−j + Guk
donde uk es la senal de excitacion que varıa entre un proceso con caracterısticas de ruidoblanco y un tren de pulsos.
Para simplificar el analisis de los sonidos sonoros, asumiremos que la senal de excitaciones un tren de impulsos. Esta asuncion equivale a considerar que la transferencia del filtroconformador G(z) es de tipo todo polos, y redefinir la transferencia del tracto bucal como elproducto de G(z)A(z).
La idea de LPC es estimar los coeficientes de un predictor lineal, que minimicen la potenciade la senal de error. En esta seccion hallaremos la solucion al problema y veremos que enalgunos casos, esta solucion coincide con los coeficientes del filtro del tracto bucal.
3.1. Solucion al problema de prediccion lineal
El problema de determinar los coeficientes de prediccion optimos puede plantearse paraprocesos estocasticos o para senales determinısticas. Ambas situaciones se presentan en elanalisis de la senal de voz: los sonidos sonoros son senales determinısticas mientras que lossordos se modelan como procesos estocasticos.
3.1.1. Enfoque estocastico
Sea sk un proceso estocastico. Se considerara que el proceso es estacionario en sentidoamplio, hipotesis que despues sera levantada.
El problema de prediccion lineal consta en hallar los coeficientes que minimicen el errorcuadratico medio en la prediccion:
w∗ = (α1, . . . , αp) | w∗ = argminE
sk −
p∑
j=1
αjsk−j
2
Derivando la expresion anterior con respecto al vector w se llega al sistema de ecuaciones:
rs(k)−p∑
j=1
αjrs(k − j) = 0 con k = 1, . . . , p (1)
donde rs(k) es la secuencia de autocorrelacion del proceso s. Expresandole matricialmente:
Rw =
rs(0) rs(−1) · · · rs(−p + 1)rs(1) rs(0) · · · rs(−p + 2)
......
. . ....
rs(p− 1) rs(p− 2) · · · rs(0)
·
α1
α2
...αp
=
rs(1)rs(2)
...rs(p)
= p
R es la matriz de autocorrelacion de s. Esta solucion no es otra que la del filtro de Wiener.Hasta el momento, no se ha hecho ninguna suposicion sobre la naturaleza del proceso sk.
Se vera a continuacion, que si sk es un proceso autorregresivo (como en el caso de los sonidossordos en la senal de voz), entonces los coeficientes hallados coinciden con los del proceso.
8

Supongase que sk es un proceso AR generado a partir de la siguiente recurrencia:
sk =p∑
j=1
ajsk−j + uk
donde uk es ruido blanco. Entonces por las ecuaciones de Yule-Walker la autocorrelaciondel proceso cumple que:
rs(k)−p∑
j=1
ajrs(k − j) = 0, con k = 1, . . . , p
Estas ecuaciones coinciden con las dadas por 1, o sea que los coeficientes del predictorlineal optimo para un proceso AR son los propios coeficientes del proceso.
3.1.2. Caso determinıstico
Considerese sk una senal determinıstica. En este caso el problema de la prediccion linealconsiste en hallar los coeficientes w = (α1, . . . , αp) que minimicen la suma de los errorescuadraticos en la prediccion:
w∗ = (α1, . . . , αp) | w∗ = argmin∑
k∈Z
sk −
p∑
j=1
αjsk−j
2
Derivando la expresion a minimizar es facil ver que cuando se alcanza el optimo, se cumpleque
∑
n∈Zsnss−k −
p∑
j=1
αj
∑
n∈Zsn−jss−k = 0 con k = 1, . . . , p (2)
Definiendo la autocorrelacion determinıstica rs(k) =∑
n∈Z snsn−k la ecuacion quedaidentica a (1). Mas adelante se vera ademas que en la practica, la estimacion de la secuenciade autocorrelacion en el caso determinıstico o en el estocastico puede hacerse, amen de unaconstante de proporcionalidad, de igual forma.
Al igual que en el caso estocastico interesa conocer en que caso los coeficientes del predictoroptimo guardan relacion con parametros de la senal. Supongase que la senal sk es la respuestaal impulso de un filtro todo polos, de la forma
sk =p∑
j=1
ajsk−j + Gδk
Calculando la autocorrelacion determinıstica de la secuencia sk se verifica que los coefi-cientes del filtro satisfacen ecuaciones iguales a 2. Por lo tanto, aplicando LPC a la respuestaal impulso de un filtro todo polos, se obtiene el vector de coeficientes del filtro. Esta es unade las razones por las que en el modelo simplificado del tracto bucal, se sustituye el tren depulsos por uno de impulsos.
3.2. Estimacion de la solucion
Los resultados de la seccion anterior establecen que los coeficientes de LPC calculadospara senales generadas por la excitacion de un filtro todo polos por ruido blanco o por un
9

impulso, coinciden con los coeficientes del filtro. De acuerdo al modelo simplificado, esto essuficiente para realizar el analisis de la senal de voz.
Cuando llega la hora de realizar implementaciones reales de LPC, tanto las series infini-tas como las esperanzas deben sustituirse por estimaciones que puedan calcularse con unnumero finito de muestras de la senal. Esto no solo se debe a que no es posible calcularnumericamente una serie infinita. Las senales de voz no son estacionarias. Los parametrosdel filtro del tracto bucal, pueden asumirse constantes a lo sumo por algunas decenas demilisegundos, propiedad que se denomina estacionariedad local. Por este motivo tampococonviene considerar intervalos muy grandes de tiempo para realizar las estimaciones, ya quede proceder ası los resultados corresponderıan a un promediado de los valores que tomaronlos coeficientes del filtro en la ventana de tiempo considerada.
Principalmente hay dos formas de calcular los estimados de LPC a partir de un numerofinito de muestras: el metodo de la covarianza y el metodo de la autocorrelacion. Ambosmetodos se aplican de igual manera para realizaciones de procesos estocasticos que parasenales deteminısticas, ya que la estimacion de la secuencia de autocorrelacion de un procesoa partir de una de sus realizaciones, difiere con el calculo de la autocorrelacion determinısticasolo en un factor de proporcionalidad.
A continuacion se desarrollaran los metodos solo para el caso estocastico.
3.2.1. Metodo de la autocorrelacion
Este metodo se basa en la estimacion de la secuencia de autocorrelacion para la senalenventanada s′k = skvk, con vk = 0 fuera del intervalo de muestras a considerar. La forma dela ventana tiene mucha influencia sobre la estimacion: conviene usar ventanas que no tengandiscontinuidades, como ser Hanning, Hamming.
Los valores de la autocorrelacion se estiman entonces (asumiendo ergodicidad) como:
rs(k) =1N
∑
j∈Zs′js
′j−k =
1N
N−1∑
j=k
s′js′j−k
donde se asumio que el soporte de la ventana es 0, 1, . . . , N − 12. Con los valores de rs(k)se arma una matriz de autocorrelacion estimada que es simetrica y toeplitz, lo que permite laresolucion del sistema en O(p2) operaciones, usando metodos como la recursion de Levinsono el algoritmo de Durbin [5].
3.2.2. Metodo de la covarianza
A diferencia del metodo de anterior, el metodo de la covarianza se basa en una modificacionen el planteo del problema. Los coeficientes buscados son los que minimizan el error cuadraticopromedio en un intervalo finito de tiempo. Como en el ejemplo anterior asumiremos que elintervalo es 0, 1, . . . , N − 13:
w∗ = (α1, . . . , αp) | w∗ = argmin1N
N−1∑
k=0
sk −
p∑
j=1
αjsk−j
2
Debido a que el operador E{·} y el 1N
∑N−1k=0 {·} tienen las mismas propiedades de lineal-
idad, se llega a que los coeficientes optimos verifican:2En el caso determinıstico la autocorrelacion se estima sin dividir entre N .3El planteo para el caso determinıstico es el mismo, sin dividir entre N
10

ϕ0k −p∑
j=1
αjϕjk = 0 con k = 1, 2, . . . , p
donde ϕij = 1N
∑N−1n=0 sn−isn−j . La matriz de este sistema, si bien es simetrica no es
toeplitz y su inversion insume un costo operacional mayor.
3.3. Estimacion de la senal de excitacion
Como un subproducto del analisis por LPC, habiendo estimado los coeficientes del filtro,puede calcularse mediante un filtrado inverso un estimativo de la senal de excitacion Guk:
Guk = sk+1 −p∑
j=1
αjsk−j
Como resulta evidente de la expresion anterior, si se considera que (α1, . . . , αp) son co-eficientes de un estimador, la senal de excitacion corresponde a la secuencia de error en laestimacion.
La estimacion de esta senal de error tiene aplicaciones en el campo del analisis de voz,pues es util por ejemplo para tener un estimado mas certero de la altura (pitch).
3.4. Resultados
En esta seccion se discuten resultados de una implementacion de LPC usando el metodode la autocorrelacion con una ventana de Hamming. Los resultados que se presentaran enesta seccion y en las siguientes, son sobre senales sintetizadas segun el modelo simplificadodel tracto bucal, a modo de poder comparar los resulados del algoritmo contra los verdaderoscoeficientes4. Los filtros de sıntesis son de orden p = 8, mismo orden que se considero en laspruebas.
El analisis LPC se hace en bloques de longitud L, que se solapan 0 6 M < L muestras.
3.4.1. Senales estacionarias
Sonidos sordos. En la figura 5 se puede ver el resultado para una senal del tipo sordosintetizada usando los coeficientes de la vocal A, para dos los ocho coeficientes usados. Eltamano de bloque corresponde a L = 2048, con un solapamiento de un 40 % del tamano dela ventana.
Se pueden apreciar las discontinuidades en los lımites de los bloques. Si se reduce eltamano de ventana los resultados empeoran sensiblemente. Como ejemplo de esto se puedever la figura 6. Esto es debido a que se estima la secuencia de autocorrelacion con una cantidadmenor de muestas.
Sonidos sonoros. Los sonidos sonoros se generan a partir de un filtro con los mismoscoeficientes que en el caso anterior, excitandolo con un tren de impulsos. En la figura 7 seobservan segmentos de senales del tipo de las generadas.
En la figura 8 se ve que los resultados para los coeficientes de la vocal A con L = 512, sonmenos ruidosos que en caso sordo. Sin embargo algunos bloques se apartan del valor real delcoeficiente. Esto se debe a estar trabajando con senales generadas con un tren de impulsos.
4Para realizar la sıntesis se utilizaron coeficientes extraıdos senales reales obtenidas grabando vocaleslargas.
11
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
LPCValor real
Figura 5: Resultados de LPC, tomando L = 2048, para sonidos sordos.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
LPCValor real
Figura 6: Resultados de LPC, tomando L = 512, para sonidos sordos.
En la seccion 3 se vio que, para la respuesta al impulso del filtro, los coeficientes LPCcoinciden con los reales. Si el tiempo entre impulsos es suficientemente largo, la senal sinteticapuede pensarse como un tren periodico de respuestas al impulso del filtro. Este es el caso dela senal generada con los coeficientes de la vocal A. La bondad de la estimacion realizada conLPC depende del segmento de la respuesta al impulso que entre en la ventana, lo que explicala variacion en la estimacion de los diferentes bloques. Para evitar este problema, existenimplementaciones de LPC que determinan el perıodo de la senal y ubican los bloques en elsegmento de senal adecuado. Estas implementaciones se llaman LPC sıncrono.
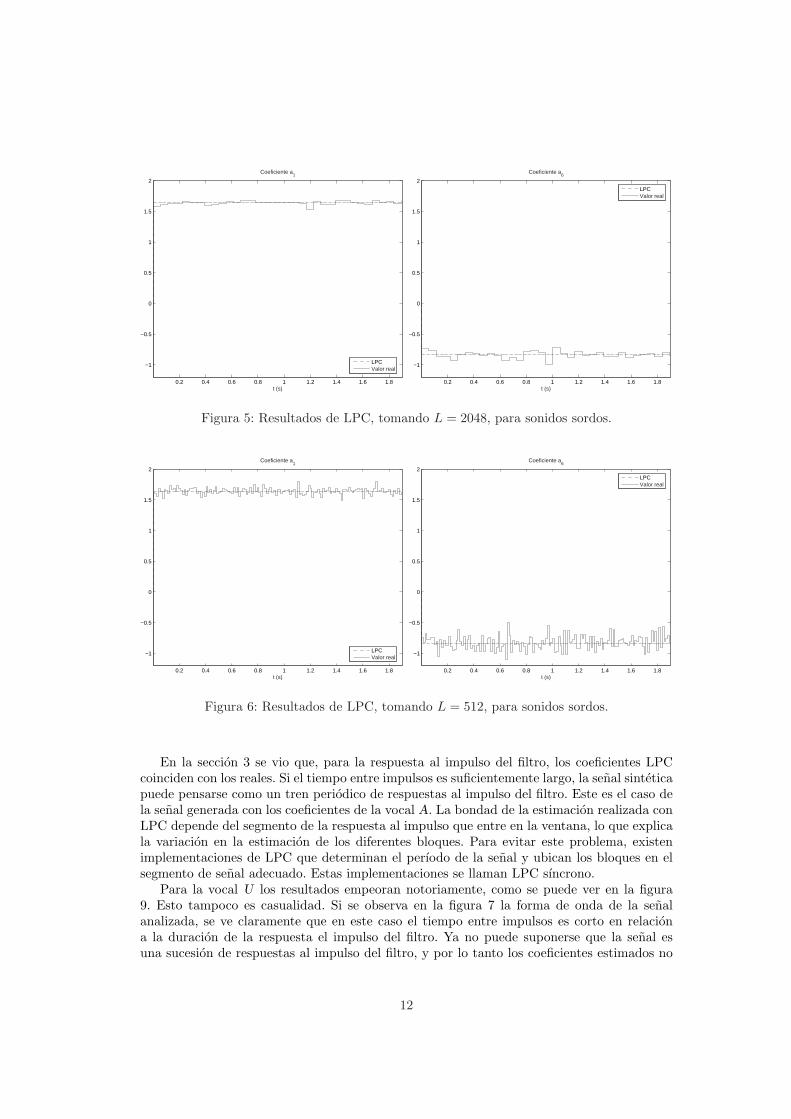
Para la vocal U los resultados empeoran notoriamente, como se puede ver en la figura9. Esto tampoco es casualidad. Si se observa en la figura 7 la forma de onda de la senalanalizada, se ve claramente que en este caso el tiempo entre impulsos es corto en relaciona la duracion de la respuesta el impulso del filtro. Ya no puede suponerse que la senal esuna sucesion de respuestas al impulso del filtro, y por lo tanto los coeficientes estimados no
12

0 50 100 150 200 250 300 350 400 450 500
−0.1
−0.05
0
0.05
0.1
0.15
0 50 100 150 200 250 300 350 400 450 500−0.25
−0.2
−0.15
−0.1
−0.05
0
0.05
0.1
0.15
0.2
0.25
Figura 7: Segmento de la senal sintetica para sonidos sonoros. A la derecha, con los coeficientesde la A y a la izquierda con los de la U.
tienen porque coincidir con los reales. De hecho la principal limitante que tiene la aplicacionde LPC al analisis de voz, es en casos de voces femeninas con pitch alto5.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
LPCValor real
Figura 8: Resultados de LPC, con L = 512, para sonidos sonoros, coeficientes de la A.
3.4.2. Senales no estacionarias
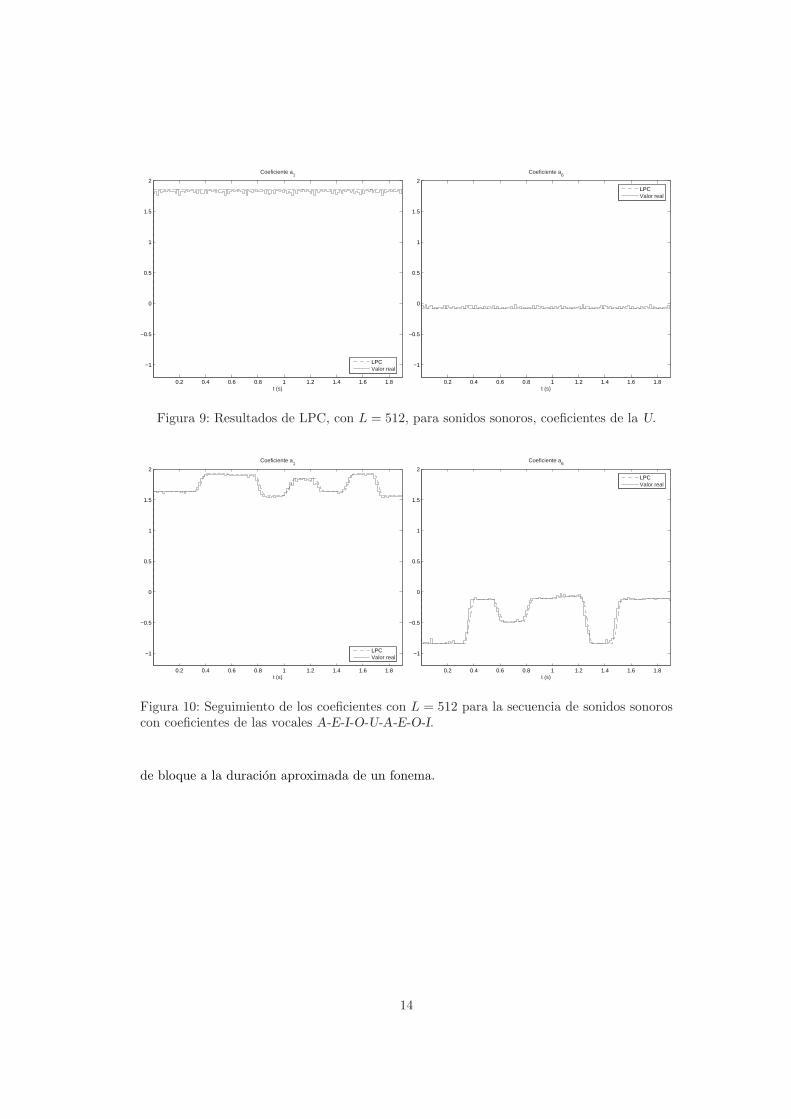
Para estudiar el desempeno del algoritmo en el analisis de senales no estacionarias, segeneraron senales sinteticas con transiciones suaves entre distintos juegos de coeficientes. Enla figura 10 se ven los resultados para sonidos sonoros con L = 512. Puede observarse quepara el caso de las vocales O y U los resultados son peores. Los resultados para senales sordascon similares.
Cabe mencionar que en aplicaciones con senales no estacionarias se pierde la propiedadde no estacionariedad con tamanos de bloque muy grandes. Esto limita el tamano maximo
5El pitch o altura es inversamente proporcional al perıodo de la senal de excitacion.
13
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
LPCValor real
Figura 9: Resultados de LPC, con L = 512, para sonidos sonoros, coeficientes de la U.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
LPCValor real
Figura 10: Seguimiento de los coeficientes con L = 512 para la secuencia de sonidos sonoroscon coeficientes de las vocales A-E-I-O-U-A-E-O-I.
de bloque a la duracion aproximada de un fonema.
14

4. LPC recursivo
Las implementaciones usuales de LPC, calculan los coeficientes del filtro en ventanasque cubren la senal. Estas ventanas tienen un tamano fijo L. Para minimizar la cantidadde ventanas (y por ende de opreraciones) los centros de ventanas adyacentes deben distar Lentre sı. En general, esta distancia es menor, existiendo muestras de la senal que son cubiertaspor dos ventanas. La razon de este solapamiento entre ventanas es la de darle a la secuenciade coeficientes mayor resolucion temporal.
En esta seccion se desarrolla una implementacion de LPC que actualiza los coeficientescon cada nueva muestra. Para esto se utilizan ventanas de L muestras, que se solapan enL − 1. Visto de otra forma puede pensarse como una ventana que se va deslizando sobre lasenal.
Claramente este enfoque tiene la maxima resolucion temporal alcanzable. Sin embargoes mucho mas costoso computacionalmente. Una forma de reducir su costo computacional escalcular los coeficientes del filtro de forma recursiva basandose en el algoritmo RLS [5].
4.1. Algoritmo
Consideremos una senal sk con k = 0, . . . , N . En el instante k se determinaran los coe-ficientes del predictor lineal α1(k), . . . , αp(k) que minimicen el error cuadratico medio en laventana dada por las muestras sk−L+1, . . . , sk:
ξk =1L
k∑
n=k−L+1
e2n =
1L
k∑
n=k−L+1
sn+1 −
p−1∑
j=0
αjsn−j
2
Siguiendo el metodo de la covarianza, wk = [α1(k), . . . , αp(k)]T vale
wk = Φ−1k rk (3)
donde Φk =∑k
n=k−L+1 snsTn , rk =
∑kn=k−L+1 sn+1sn, definiendo sk = (sk, . . . , sk−p+1)T.
La ecuacion 3 no es otra cosa que la solucion a un problema de mınimos cuadrados. Elalgoritmo RLS de ventana deslizante permite, si se cuenta con Φ−1
k−1 y wk−1, calcular Φ−1k
y wk de forma recursiva, evitando relizar la inversion de la matriz de correlacion. En estecaso, la senal deseada dk = sk+1. Por lo tanto, las ecuaciones que deben realizarse en cadaiteracion del algoritmo son las siguientes:
gk =Φ−1
k−1sk
1+sTk Φ−1k−1sk
gk =Φ−1
k−1sk−L
1−sTk−LΦ−1k sk−L
wk = wk−1 + gk(sk+1 −wTn−1sk) wk = wk − gk(sk+1−L − wT
n sk−L)Φ−1
k = Φ−1k−1 − gksT
k Φ−1k−1 Φ−1
k = Φ−1k + gksT
k−LΦ−1k
Las condiciones iniciales se determinan realizando el metodo de la covarianza en la primeraventana.
4.2. Resultados
Se estudiaran los resultados del algoritmo de LPC recursivo utilizando las mismas senalesque con LPC.
15

4.2.1. Senales estacionarias
Sonidos sordos En la figura 11 se pueden apreciar los resultados para sonidos sordosestacionarios utilizando una ventana deslizante de tamano L = 512 y L = 1024. Se ve quela estimacion de los estados es menos ruidosa al aumentar el tamano de la ventana. Comovimos en la seccion 3, debido a que la senal es ergodica, a medida que crece el tamano de laventana, menor es la varianza del error en la estimacion.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
LPCValor real
Figura 11: Resultados de RLPC, tomando L = 512 y L = 1024, para sonidos sordos.
L A E I O U512 0.007699 0.008282 0.009175 0.007835 0.0095431024 0.001023 0.0008276 0.001294 0.0009489 0.00093562048 0.0004364 0.0005829 0.0006134 0.0003266 0.0004293
Cuadro 1: Potencia del error en la estimacion del primer coeficiente con RLPC para sonidossordos.
En el cuadro 1 se pueden ver la potencia del error en la estimacion del primer coeficientepara el caso sordo considerando varios juegos de coeficientes y distintos tamanos de ventana.Como era de esperarse se nota una mejora al aumentar el tamano de ventana.
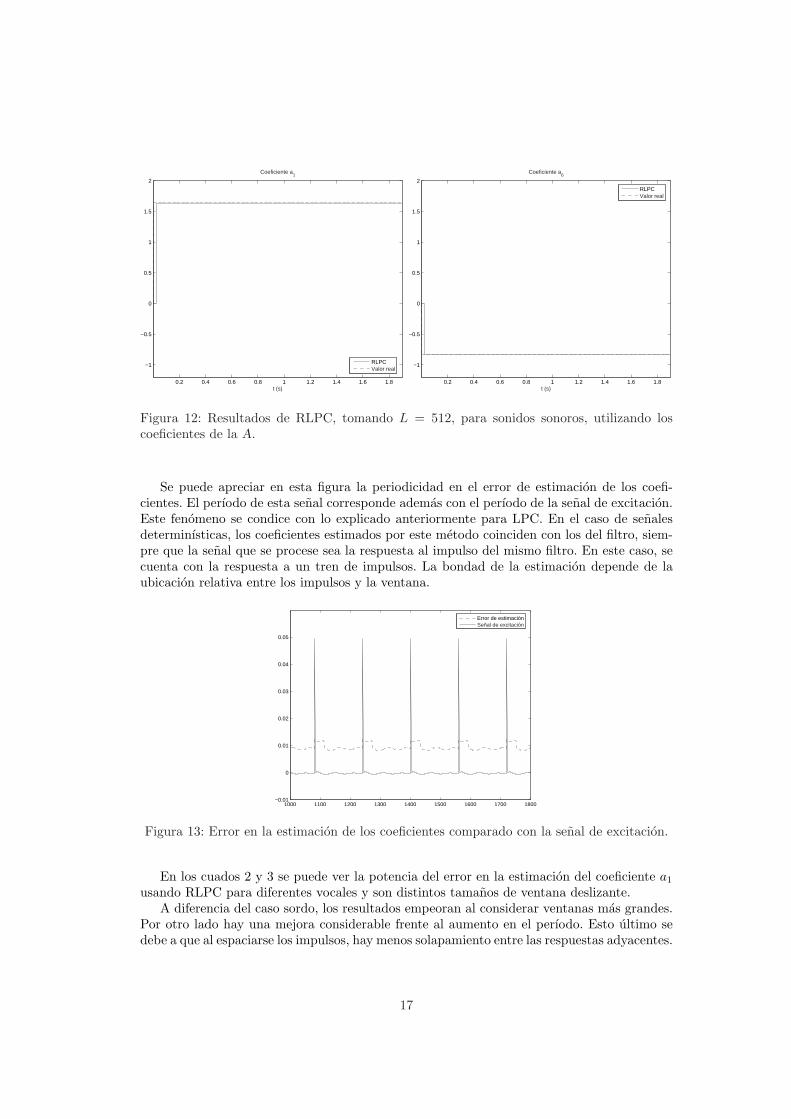
Sonidos sonoros Los resultados para sonidos sonoros se muestran en la figura 12 utilizandouna senal sintetizada a partir de los coeficientes de la vocal A. En este caso el tren de impulsostiene un periodo de T = 160 muestras. Vemos como la aproximacion en este caso es muchomejor que en el caso anterior de LPC. Si se pudiera estudiar la figura con mayor detalle, ellector verıa una componente de ruido pediodica.
Esto se condice con lo dicho en la seccion anterior: el error en la estimacion dependede la posicion de los impulsos dentro de la ventana. En la figura 13 se puede ver el erroren la estimacion de los coeficientes comparado con la senal de exitacion obtenida. Recordarque esta senal de excitacion puede calcularse como el error en la prediccion. Como era deesperarse esta senal es muy similar al tren de impulsos de entrada al filtro.
16
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
RLPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
RLPCValor real
Figura 12: Resultados de RLPC, tomando L = 512, para sonidos sonoros, utilizando loscoeficientes de la A.
Se puede apreciar en esta figura la periodicidad en el error de estimacion de los coefi-cientes. El perıodo de esta senal corresponde ademas con el perıodo de la senal de excitacion.Este fenomeno se condice con lo explicado anteriormente para LPC. En el caso de senalesdeterminısticas, los coeficientes estimados por este metodo coinciden con los del filtro, siem-pre que la senal que se procese sea la respuesta al impulso del mismo filtro. En este caso, secuenta con la respuesta a un tren de impulsos. La bondad de la estimacion depende de laubicacion relativa entre los impulsos y la ventana.
1000 1100 1200 1300 1400 1500 1600 1700 1800−0.01
0
0.01
0.02
0.03
0.04
0.05
Error de estimaciónSeñal de excitación
Figura 13: Error en la estimacion de los coeficientes comparado con la senal de excitacion.
En los cuados 2 y 3 se puede ver la potencia del error en la estimacion del coeficiente a1
usando RLPC para diferentes vocales y son distintos tamanos de ventana deslizante.A diferencia del caso sordo, los resultados empeoran al considerar ventanas mas grandes.
Por otro lado hay una mejora considerable frente al aumento en el perıodo. Esto ultimo sedebe a que al espaciarse los impulsos, hay menos solapamiento entre las respuestas adyacentes.
17

L A E I O U512 0.0001364 2.785e-005 0.0001711 6.157e-005 8.829e-0051024 0.0001367 2.795e-005 0.0001713 6.166e-005 8.796e-0052048 0.0001368 2.802e-005 0.0001715 6.179e-005 8.796e-005
Cuadro 2: Potencia del error en la estimacion del primer coeficiente con RLPC. Caso sonorocon periodo de 160 muestras.
L A E I O U512 1.92e-005 6.044e-006 2.133e-005 1.039e-005 9.642e-0061024 1.957e-005 6.26e-006 2.162e-005 1.089e-005 1.017e-0052048 1.968e-005 6.305e-006 2.172e-005 1.097e-005 1.026e-005
Cuadro 3: Potencia del error en la estimacion del primer coeficiente con RLPC. Caso sonorocon perıodo de 320 muestras.
4.2.2. Senales no estacionarias
Nuevamente se trabajara con senales sinteticas, cuyos coeficientes alternan de forma suaveentre los coeficientes correspondientes a las vocales.
Sonidos sordos. La figura muestra los resultados en el seguimiento del primer coeficientepara la senal sintetizada utilizando ruido blanco como excitacion. Las graficas de la figuracorresponden a diferentes longitudes de ventana. A diferencia del caso estacionario, existe uncompromiso en el tamano de la ventana considerada. A ventanas mas grandes, menos ruidosasera la estimacion y menos error en las regiones constantes, pero mayor sera su inercia frentea los cambios rapidos en los coeficientes.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
RLPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
RLPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
RLPCValor real
Figura 14: Resultados de RLPC, tomando L = 512, L = 1024 y L = 2048, para sonidossordos, con coeficientes de las vocales A-E-I-O-U-A-E-O-I.
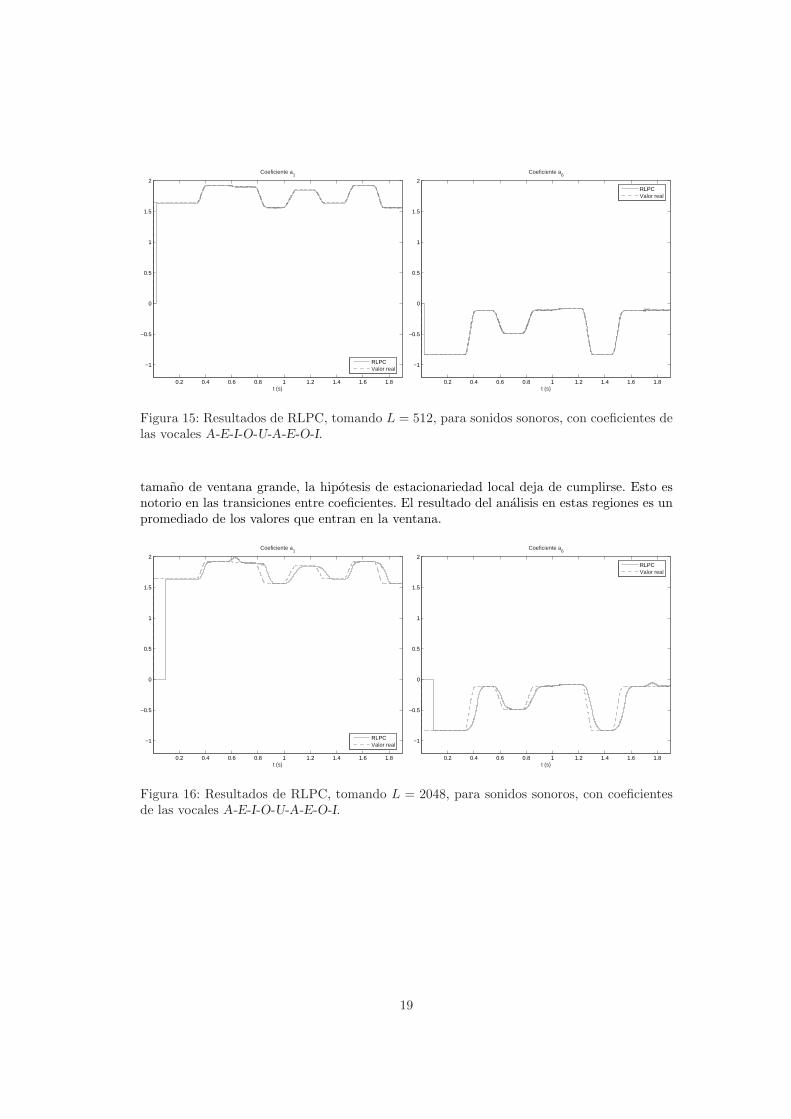
Sonidos sonoros. Los resultados obtenidos considerando L = 512 se pueden observar enla figura 15. Se puede ver que los resultados son muy buenos, considerando los obtenidosanteriormente con LPC.
En la figura 16 se muestran los resultados para la misma senal, usando esta vez unaventana de longitud L = 2048. Hay un deterioro en los resultados fruto de que frente a un
18
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
RLPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
RLPCValor real
Figura 15: Resultados de RLPC, tomando L = 512, para sonidos sonoros, con coeficientes delas vocales A-E-I-O-U-A-E-O-I.
tamano de ventana grande, la hipotesis de estacionariedad local deja de cumplirse. Esto esnotorio en las transiciones entre coeficientes. El resultado del analisis en estas regiones es unpromediado de los valores que entran en la ventana.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
RLPCValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a6
t (s)
RLPCValor real
Figura 16: Resultados de RLPC, tomando L = 2048, para sonidos sonoros, con coeficientesde las vocales A-E-I-O-U-A-E-O-I.
19

5. Kalman con suavizado
5.1. Modelo en variables de estado
En esta seccion se presenta un algoritmo de analisis de la senal de voz basado en el enfoquepropuesto en [7] y [8]. En este se modela la senal de voz sk con k = 1, . . . , N mediante unmodelo en variables de estado dado por,
wk+1 = Φwk + uk k = 1, 2, . . . , N
sk = Hkwk + vk k = 1, 2, . . . , N
donde wk = (α(k)1 , . . . , α
(k)p )T son los coeficientes del filtro, la matriz de observacion Hk =
(sk−1, . . . , sk−p) es una matriz fila con las muestras pasadas de la senal, uk y vk son procesosde ruido blanco gaussiano con matriz de autocorrelacion Q y potencia R respectivamente.La matriz de transicion de estados Φ se toma igual a la identidad. El cambio del estado entreiteraciones sucesivas queda dado por el proceso uk.
5.2. Resultados
Se muestran en esta seccion los resultados del filtro de Kalman aplicado en los casosestacionario y no estacionario, para sonidos sordos y sonoros. Se usaran senales sinteticaspara poder evaluar el desempeno.
5.2.1. Senales estacionarias
Sonidos sordos. Se puede ver en la figura 17 el resultado en la estimacion del primercoeficiente con Q = 5 · 10−5I y Q = 5 · 10−3I. Se observa que al aumentar el valor de lapotencia del proceso uk se permite una mayor variacion en el estado y por lo tanto, para elcaso estacionario, la estimacion es mas ruidosa.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
KalmanValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
−1
−0.5
0
0.5
1
1.5
2
Coeficiente a1
t (s)
KalmanValor real
Figura 17: Resultados del filtro de Kalman, tomando Q = 5 · 10−5I y Q = 5 · 10−3I, parasonidos sordos generados con los coeficientes de la vocal A.
20

Sonidos sonoros. En la figura 18 se pueden ver los resultados para senales sonoras usandoQ = 0,5I y Q = 5 · 10−3I. Como era de esperar, existe mayor variacion en el valor delcoeficiente estimado para el Q mayor. Ademas, como en el caso de LPC recursivo, se ve queel error en la estimacion es periodico.
Esto puede comprobarse en la figura 19, en la que se comparan el error en la estimaciondel coeficiente con la senal de excitacion estimada.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
Figura 18: Resultados del filtro de Kalman, tomando Q = 0,5I y Q = 5 · 10−3I, para sonidossonoros generados con los coeficientes de la vocal A.
6000 6100 6200 6300 6400 6500
0
0.01
0.02
0.03
0.04
0.05 Error en la estimaciónSeñal de excitación
9000 9200 9400 9600 9800 10000 10200 10400 10600
0
0.01
0.02
0.03
0.04
0.05Error en la estimaciónSeñal de excitación
Figura 19: Comparacion entre el error en la estimacion y la senal de excitacion, tomandoQ = 0,5I, para sonidos sonoros generados con los coeficientes de la vocal A periodo 160 y320.
Al igual que para RLPC, el valor estimado tiene variaciones bruscas que coinciden con lospicos del error en la prediccion. Esto es facil de interpretar teniendo en cuenta la dinamicadel filtro de Kalman, dado que la correccion realizada sobre el estado es proporcional al erroren la prediccion. En la misma figura puede observarse que al aumentar el perıodo del tren deimpulsos disminuye el error en exceso de la estimacion.
21

5.2.2. Senales no estacionarias
Sonidos sordos. Los resultados del seguimiento de los parametros se ven en la figura 20utilizando diferentes valores para el parametro Q. En el caso de senales no estacionarias (quees el caso de las senales reales) existe un compromiso en el ajuste del valor de Q, entre elruido en la estimacion y la capacidad de seguir varianciones en los coeficientes.
Este compromiso es similar al que hay en el caso de LPC recursivo con el tamano de laventana deslizante: cuanto mas grande la ventana, menos ruidosa la estimacion, pero peorsera la respuesta ante cambios en los coeficientes del filtro.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
Figura 20: Resultados del filtro de Kalman, tomando Q = 0,005I, Q = 0,0005I y Q = 5·10−5Ipara sonidos sordos generados con coeficientes de las vocales A-E-I-O-U-A-E-O-I.
Sonidos sonoros. Los resultados para sonidos sonoros se muestran en la figura 21. Sepuede verificar el mismo compromiso sobre el parametro Q.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
KalmanValor real
Figura 21: Resultados del filtro de Kalman, tomando Q = 0,5I, Q = 0,05I y Q = 0,005I parasonidos sonoros generados con coeficientes de las vocales A-E-I-O-U-A-E-O-I y perıodo 160.
De acuerdo a las observaciones realizadas, puede concluirse que este metodo no presentauna solucion aceptable en el caso no estacionario, que es en definitiva el que interesa. Ademas,los valores apropiados para el parametro Q difieren mucho entre sonidos sordos y sonoros.
En la lınea del enfoque propuesto por [7] y [8], en las siguientes secciones se agrega a estasolucion un suavizado, que toma en cuenta la informacion de toda la senal.
5.3. Suavizado de Rauch
Sean xk y yk procesos generados segun el siguiente modelo en variables de estado.
22

xk+1 = Φ(k + 1, k)xk + wk
yk = Mkxk + vk
(4)
Los procesos wk y vk son procesos con caracterısticas de ruido blanco gaussiano, conmatrices de autocorrelacion Qk y Rk respectivamente. Se supone que el proceso yk (observa-ciones) es conocido, y desea estimarse xk. Sea xk|N el estimado de xk dadas las observacionesyk con k = 0, . . . , N . Segun la relacion entre k y N pueden distinguirse los siguientes prob-lemas:
k = N Se conoce como problema de filtrado. Se considera que el proceso yk se filtra obteniendoseel proceso xk.
k > N Problema de prediccion. Se desea estimar un estado correspondiente a un instantefuturo, considerando a N como el instante actual.
k 6 N Problema de suavizado. Se desea estimar el valor de un estado pasado.
En [6], Kalman resuelve los problemas de filtrado y prediccion, pero no brinda una solucional problema de suavizado. En [10] y [11] Rauch propone una recursion hacia atras a partir delos estados estimados mediante el filtro de Kalman que soluciona el problema de suavizado.
5.3.1. Deduccion del algoritmo de suavizado
Antes de calcular los estimados es necesario establecer el criterio segun el cual se con-sidera buena una estimacion. Los estimados seran aquellos que maximicen la funcion deverosimilitud marginal dada por
L(xk,y0, . . . ,yN ) = log p(xk|y0, . . . ,yN )
En otras palabras, aquellos que sean mas probables dadas las observaciones disponibles.Sean xk|N y xk+1|N los estimados de los estados k y k + 1 que maximizan sus respectivas
funciones de verosimilitud marginal. Puede probarse que tambien son maximos de la funcionde verosimilitud conjunta
L(xk,xk+1,YN ) = log p(xk,xk+1|YN )
donde YN = (y0, . . . ,yN ). Por lo tanto, maximizando la funcion de verosimilitud conjuntapuede hallarse una relacion de recurrencia entre estimados sucesivos. Por la propia definicionde probabilidad condicional,
log p(xk,xk+1|YN ) = log p(xk,xk+1,YN )− log p(YN )
El ultimo termino en la relacion anterior es constante, y por lo tanto maximizar laverosimilitud conjunta equivale a maximizar p(xk,xk+1,YN ). Desarrolando un poco estetermino puede expresarse en una forma que resulte mas facil de maximizar:
p(xk,xk+1,YN ) = p(xk,xk+1,yk+1, . . . ,yN |Yk)p(Yk)= p(xk+1,yk+1, . . . ,yN |xk,Yk)p(xk|Yk)p(Yk)
23

Puede descartarse el termino p(Yk) debido a que no depende de los estimados. Ademasp(xk+1,yk+1, . . . ,yk|xk,Yk) = p(xk+1,yk+1, . . . ,yk|xk), ya que los procesos uk y vk sonindependientes para instantes de tiempo distintos. Por otro lado,
p(xk+1,yk+1, . . . ,yN |xk,Yk)p(xk|Yk) = p(yk+1, . . . ,yN |xk,xk+1)p(xk+1|xk)p(xk|Yk)= p(yk+1, . . . ,yN |xk+1)p(xk+1|xk)p(xk|Yk) (5)
El ultimo paso se debe a que dado el valor de xk+1 las observaciones siguientes sonindependientes del valor del estado en el instante k.
La expresion 5 se maximiza entonces para el mismo argumento que la funcion de verosimil-itud conjunta. Se supondra que se cuenta con la solucion al problema del filtrado xk|k y Pk|k,la matriz de covarianza del error en la estimacion. Se supondra ademas que se conoce elvalor del estimado en k + 1, xk+1|N . Entonces xk|Yk ∼ N(xk|k,Pk|k), de igual maneraxk+1|xk ∼ N(Φ(k + 1, k)xk,Qk+1), y por lo tanto pueden calcularse analıticamente los dosultimos terminos de 5, que son los unicos que dependen de xk. Maximizando 5 con respectoa xk se obtiene la siguiente relacion:
xk|N = xk|k + Ck[xk+1|N −Φ(k + 1, k)xk|k]
Ck = Pk|kΦ(k + 1,k)TP−1k+1|k
(6)
La recursion 6 permite calcular el valor de xk|N a partir del resultado del filtrado deKalman xk|k, la matriz de covarianza del error en la estimacion Pk|k, la matriz de covarian-za del error en la proyeccion del filtrado de Kalman Pk+1|k y el valor de xk+1|N . Los tresprimeros se obtienen como resultado del filtrado de Kalman.
Este metodo presenta la ventaja de utilizar toda la informacion dada por las observaciones,y por lo tanto sera menor la potencia del error en la estimacion. Sin embargo tiene comodesventajas el no ser causal y la necesidad de almacenar las matrices del error en la estimaciondel filtrado de Kalman.6
5.4. Resultados
5.4.1. Senales estacionarias
Sonidos sordos. Los resultados para sonidos sordos pueden verse en la figura 22, paradistintos valores de Q. Se nota al igual que antes un deterioro en la estimacion al crecer lapotencia del ruido en los estados.
Q Kalman Rauch5 · 10−3 0.0057 0.00435 · 10−4 0.0016 0.00115 · 10−5 3.7150e-004 5.0658e-005
Cuadro 4: Potencia del error en la estimacion del primer coeficiente con Kalman con y sinsuavizado de Rauch. Sonidos sordos con coeficientes de la vocal A.
6En el artıculo se propone una recursion hacia atras que permite calcular Pk|k a partir de Pk+1|k+1. Sinembargo, al implementar esta recursion, se observo que no es numericamente estable.
24

Interesa contrastar estos resultados con la salida del filtro de Kalman sin suavizado. Enel cuadro 4 se da una comparacion cuantitativa. Se comprueba que en este caso existe unamejorıa gracias al suavizado de Rauch, para los tres casos considerados.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor real
Figura 22: Resultados del suavizado de Rauch, tomando Q = 5 · 10−3I, Q = 5 · 10−4I yQ = 5 · 10−5I, para sonidos sordos generados con los coeficientes de la vocal A.
Sonidos sonoros. En la figura 23 se comparan los resultados del filtro de Kalman cony sin suavizado para sonidos sonoros. Es notorio el efecto del suavizado sobre todo en losresultados correspondientes a Q = 0,5I.
0.32 0.325 0.33 0.335 0.34 0.345 0.35 0.355 0.361.5
1.52
1.54
1.56
1.58
1.6
1.62
1.64
1.66
1.68
1.7
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
0.32 0.325 0.33 0.335 0.34 0.345 0.35 0.355 0.361.5
1.52
1.54
1.56
1.58
1.6
1.62
1.64
1.66
1.68
1.7
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
Figura 23: Resultados del filtro de Kalman con y sin suavizado, tomando Q = 0,5I y Q =5 · 10−3I, para sonidos sonoros generados con los coeficientes de la vocal A.
5.4.2. Senales no estacionarias
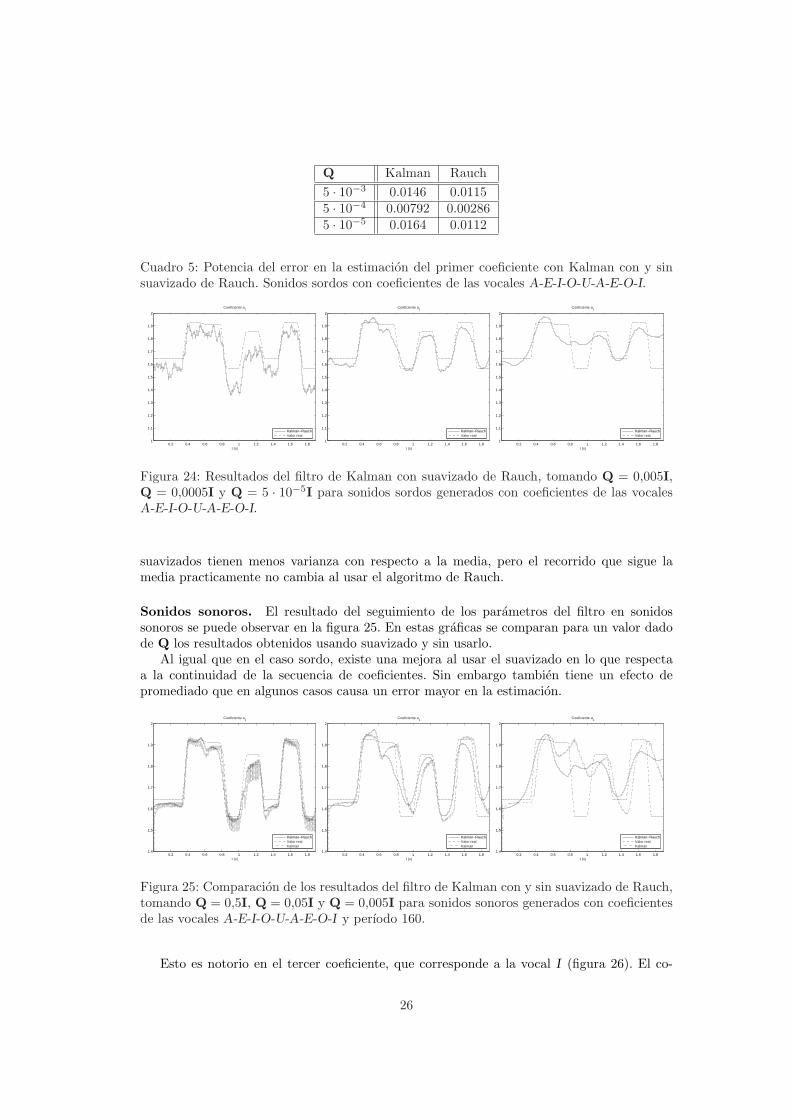
Sonidos sordos. Los resultados del suavizado de Rauch en el caso no estacionario sepueden ver en la figura 24 para sonidos sordos. En el cuadro 5 se comparan estos resultadoscon el filtro de Kalman sin suavizado.
Del analisis de estos resultados se puede concluir que si bien existe una mejorıa dada porel suavizado de Rauch, al menos en el caso sordo, la mejora no es sustancial. Los coeficientes
25
Q Kalman Rauch5 · 10−3 0.0146 0.01155 · 10−4 0.00792 0.002865 · 10−5 0.0164 0.0112
Cuadro 5: Potencia del error en la estimacion del primer coeficiente con Kalman con y sinsuavizado de Rauch. Sonidos sordos con coeficientes de las vocales A-E-I-O-U-A-E-O-I.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor real
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor real
Figura 24: Resultados del filtro de Kalman con suavizado de Rauch, tomando Q = 0,005I,Q = 0,0005I y Q = 5 · 10−5I para sonidos sordos generados con coeficientes de las vocalesA-E-I-O-U-A-E-O-I.
suavizados tienen menos varianza con respecto a la media, pero el recorrido que sigue lamedia practicamente no cambia al usar el algoritmo de Rauch.
Sonidos sonoros. El resultado del seguimiento de los parametros del filtro en sonidossonoros se puede observar en la figura 25. En estas graficas se comparan para un valor dadode Q los resultados obtenidos usando suavizado y sin usarlo.
Al igual que en el caso sordo, existe una mejora al usar el suavizado en lo que respectaa la continuidad de la secuencia de coeficientes. Sin embargo tambien tiene un efecto depromediado que en algunos casos causa un error mayor en la estimacion.
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.81.4
1.5
1.6
1.7
1.8
1.9
2
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
Figura 25: Comparacion de los resultados del filtro de Kalman con y sin suavizado de Rauch,tomando Q = 0,5I, Q = 0,05I y Q = 0,005I para sonidos sonoros generados con coeficientesde las vocales A-E-I-O-U-A-E-O-I y perıodo 160.
Esto es notorio en el tercer coeficiente, que corresponde a la vocal I (figura 26). El co-
26
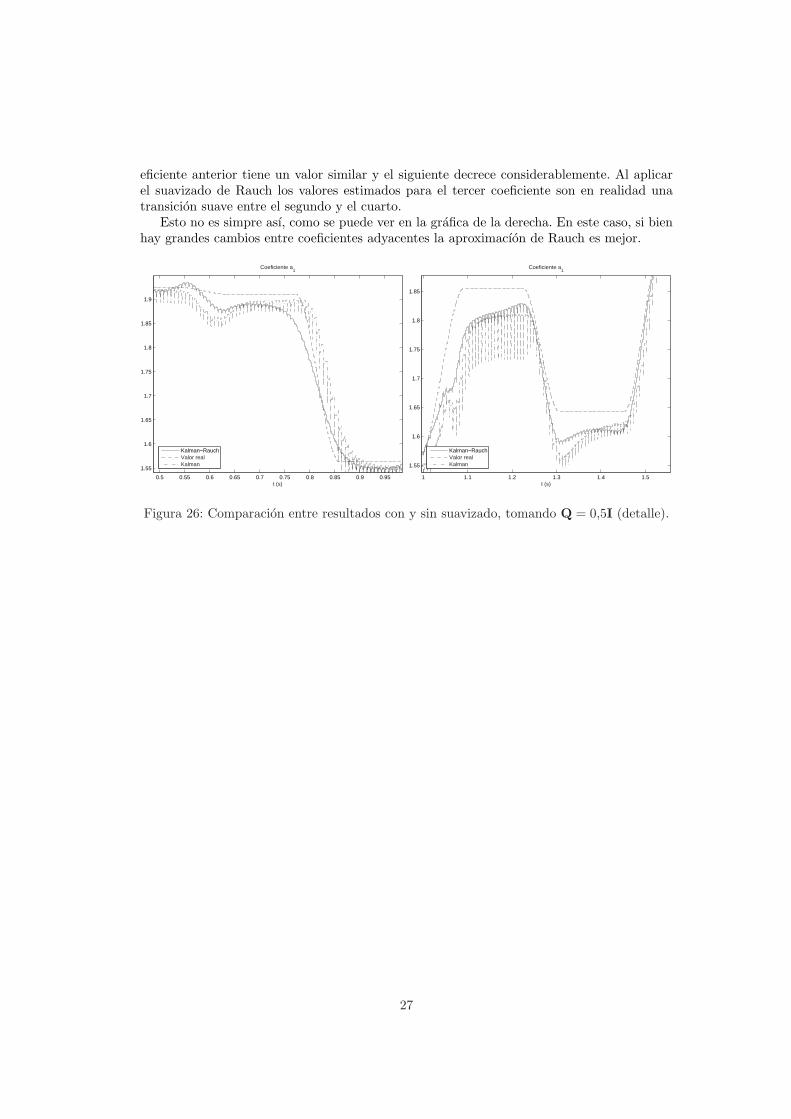
eficiente anterior tiene un valor similar y el siguiente decrece considerablemente. Al aplicarel suavizado de Rauch los valores estimados para el tercer coeficiente son en realidad unatransicion suave entre el segundo y el cuarto.
Esto no es simpre ası, como se puede ver en la grafica de la derecha. En este caso, si bienhay grandes cambios entre coeficientes adyacentes la aproximacıon de Rauch es mejor.
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95
1.55
1.6
1.65
1.7
1.75
1.8
1.85
1.9
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
1 1.1 1.2 1.3 1.4 1.5
1.55
1.6
1.65
1.7
1.75
1.8
1.85
Coeficiente a1
t (s)
Kalman−RauchValor realKalman
Figura 26: Comparacion entre resultados con y sin suavizado, tomando Q = 0,5I (detalle).
27

6. Comparacion y conclusiones
En esta seccion se compararan los mejores rendimientos obtenidos con cada uno de losfiltros en los cuatro casos considerados a lo largo del trabajo: estacionario sordo y sonoro, y noestacionario sordo y sonoro. Se trabajara con senales sinteticas para evaluar el rendimiento.
Finalmente se estudiara el funcionamiento del algoritmo con algunas secuencias reales.Para evaluar el desempeno en este caso se comparara la respuesta en frecuencia del filtroestimado con el resultado de analisis espectrales de la senal de voz.
6.1. Rendimiento con senales sinteticas
La tabla 6 resume los resultados obtenidos. En cada caso se consideraron los parametrosque dan un mejor desempeno de acuerdo a la discucion anterior. Para aplicaciones de estosfiltros a senales de voz reales, el desempeno en el caso estacionario no es de interes. Sinembargo se incluye en la tabla porque da luz sobre la naturaleza de los filtros utilizados.
Puede observarse que el filtro de Kalman, en sus dos variantes, da muy buenos resultadosen el caso estacionario. Sin embargo su desempeno decrece mucho al considerar procesos vari-antes en el tiempo. Este comportamiento no debe sorprender, dado que este filtro esta basadoen un modelo en variables de estado invariante en el tiempo. La matriz de transicion de es-tados es la identidad, asumiendo que el estado permanece constante.
El suavizado de Rauch es un proceso no causal, que utiliza informacion del total de lasenal. En este sentido, al considerar muestras futuras, puede ayudar a un mejor seguimientode las transiciones. Tambien fue visto en la seccion 5 que en algunas ocasiones esta propiedadjuega en contra.
E-Sordo E-Sonoro NE-Sordo NE-SonoroLPC 9.898e-3 9.288e-3 0.01638 0.01333RLPC 5.325e-4 1.368e-4 0.001866 1.208e-4Kalman 3.715e-4 0.001471 0.00792 0.003801Kalman-R 5.066e-5 1.441e-4 0.00286 0.001022
Cuadro 6: Potencia del error en la estimacion del primer coeficiente. Comparacion de losmejores rendimientos obtenidos con cada algoritmo.
De los algoritmos considerados, LPC recursivo da los mejores resultados, no solo porlos valores del error cuadratico medio en la estimacion, sino porque es mucho mas establecon respecto a la eleccion del parametro. El parametro ademas tiene una interpretacionmas intuitiva que permite, conociendo algunas caracterısticas de la senal, elejir un valor delparametro que sea razonable.
6.2. Rendimiento con senales reales
Habiendo estimado los coeficientes del filtro del tracto bucal H(z), pueden estimarse laforma del espectro de la senal de voz para ambos casos: sonidos sordos y sonoros.
Sonidos sordos. Al excitar al filtro con ruido blanco, se obtiene un proceso cuyo expectroes un multiplo de |H(jω)|2.
Sonidos sonoros. La senal de excitacion en este caso puede asumirse como un tren deimpulsos. El espectro de la senal generada corresponde a la multiplicacion de |H(jω)|por un tren de impulsos en frecuencias multiplos del pitch.
28

En ambos casos, podemos estimar la respuesta en frecuencia del filtro en un determinadoinstante de tiempo a partir de la senal, calculando la transformada discreta de Fourier de losdatos en un entorno local.
En la figura 27 se pueden ver la respuesta en frecuencia |H(jw)| estimada con los filtrosRLPC, Kalman y Kalman-Rauch, comparada con la transformada discreta de un intervalode 1024 datos centrado en la muestra a considerar.
0 2000 4000 6000 8000 10000−50
−40
−30
−20
−10
0
10
20
30
40
50
f(Hz)
dB
Comparación en t = 0.99773
fftkalman rkalmanrlpc
0 2000 4000 6000 8000 10000−50
−40
−30
−20
−10
0
10
20
30
40
50
f(Hz)
dB
Comparación en t = 1.2245
fftkalman rkalmanrlpc
0 2000 4000 6000 8000 10000−50
−40
−30
−20
−10
0
10
20
30
40
50
f(Hz)
dB
Comparación en t = 1.678
fftkalman rkalmanrlpc
0 2000 4000 6000 8000 10000−50
−40
−30
−20
−10
0
10
20
30
40
50
f(Hz)
dB
Comparación en t = 1.9048
fftkalman rkalmanrlpc
Figura 27: Resultados para senales reales.
Al trabajar con senales reales es mas difıcil comparar en desempeno de los tres filtros.Probablemente los criterios pasen mas por el tipo de aplicacion a desarrollarse. Muchas aplica-ciones de reconocimiento de voz trabajan estimando los maximos de la respuesta en frecuenciade tracto bucal (frecuencias de resonancia). Estas frecuencias son llamadas formantes.
En el caso de que esta fuera la aplicacion, los mejores resultados parecen obtenerse conalguno de los filtros de Kalman, tanto por la ubicacion de las formantes, como por sus anchosde banda7.
Por otro lado, como vimos en las secciones anteriores, el filtro de Kalman posee unamayor inercia frente a las transiciones en la senal que el de LPC recursivo, ademas de sermas constoso computacionalmente. La gran desventaja del suavizado de Rauch es que parapoder usarse tiene que conocerse la totalidad de la senal.
7Concepto analogo al factor de calidad de un resonador.
29

A. Codigo
Algoritmo LPC
% [X,exc] = lpcFixedFrame(s,p,nwindow,folapp)%% LPC de ventana fija con solapamiento.%% -> s :: se\~{n}al% -> p :: orden del filtro% -> nwindow :: tama\~{n}o de ventana% -> folapp :: porcentaje de solapamiento% <- X :: coeficientes del filtro% <- exc :: residuofunction [X,exc] = lpcFixedFrame(s,p,nwindow,folapp)
N = length(s); nsamplesOlapp = ceil(folapp*nwindow);
% cantidad de ventanas necesariasm = ceil((N - nwindow)/(nwindow - nsamplesOlapp));
lefti = 1; righti = nwindow; X = zeros(p,N); exc = zeros(N,1); for k= 1:m,
% enventano segmento de se\~{n}alsw = s(lefti:righti).*hamming(righti - lefti + 1);
% lpc[temp1,perr] = lpc(sw,p);temp2 = repmat(- temp1(2:end)’,1,righti - lefti + 1);
X(:,lefti:righti) = temp2;
% calculo del residuoexc(lefti:righti) = filter(temp1,1,sw);
% actualizo l\’{\i}mites de la ventanarighti = min(righti + nwindow - nsamplesOlapp , N);lefti = lefti + nwindow - nsamplesOlapp;
end
Algoritmo LPC recursivo
% [X,exc] = rlpc(s,n,L,P,w)%% LPC de ventana fija recursivo usando sliding window.%% -> s :: se\~{n}al% -> n :: orden del filtro% -> L :: tama\~{n}o de ventana% -> P :: matriz de error inicial% -> w :: coeficientes iniciales
30

% <- X :: coeficientes del filtro% <- exc :: residuofunction [W,exc] = rlpc(s,p,L,P,w)
s = s(:); N = length(s);
% matriz con los vectores XX = convmtx(s(1:N-1)’,p); X = X(:,1:N-1);
% se\~{n}al deseadad = s(2:N);
% coeficientesW = zeros(p,N-1); W(:,L + p -1) = w;
% errorexc = zeros(N-1,1);
for k = L + p:N-1,
% vector con las muestrasx = X(:,k);w = W(:,k - 1);
% RLS growing windowg = P*x/(1 + x’*P*x);wq = w + g*(d(k) - w’*x);Pq = P - g*x’*P;
% vector con la muestra k - lxv = X(:,k - L);
% elimino la muestra k - Lgq = Pq*xv/(1 - xv’*Pq*xv);w = wq - gq*(d(k - L) - wq’*xv);P = Pq + gq*xv’*Pq;
W(:,k) = w;exc(k) = d(k) - w’*x;
end
Algoritmo de Kalman
% [X, exc, logDP, PN] = KalmanSpeech1(s,p,Q,R,phi,xm,Pm)%% Filtro de Kalman para el an\’{a}lisis de la voz.%% -> s :: Se\~{n}al de voz% -> p :: orden del modelo
31

% -> Q :: covarianza del ruido de evoluci\’{o}n de estados% -> R :: desviaci\’{o}n est\’{a}ndar del ruido de observaci\’{o}n% -> phi :: matriz de transici\’{o}n de estados% -> xm :: proyecci\’{o}n del primer estado% -> Pm :: proyecci\’{o}n de la primer covarianza del error% -> fg :: matriz de datos faltantes% <- X :: evoluci\’{o}n de los par\’{a}metros del modelo% <- exc :: se\~{n}al de excitaci\’{o}n% <- lDP :: vector con los logaritmos de los determinantes de% las matrices de la covarianza del errorfunction [X, exc, logDP] = KalmanSpeech1(s,p,Q,R,phi,xm,Pm,fg)
N = length(s) - 1;
if nargin == 7, fg = ones(N,1); end
X = zeros(p,N); logDP = zeros(N,1); exc = zeros(N,1);
% datos faltantesd = s(2:end).*fg;
% matriz de observaci\’{o}nM = convmtx(s,p); M = M(1:N,:);
nmat = 1000; Ps = zeros(p,p,nmat); Pms = zeros(p,p,nmat);
for k = p:N,
m = M(k,:)*fg(k);
% ganancian de KalmanK = Pm*m’*(m*Pm*m’ + R)^(-1);
% correcci\’{o}nX(:,k) = xm + K*(d(k) - m*xm);
% errorexc(k) = d(k) - m*X(:,k);
% covarianza del errorP = (eye(p) - K*m)*Pm;
logDP(k) = log(det(P));
% proyeccionesxm = phi*X(:,k);Pm = phi*P*phi’ + Q;
if mod(k,nmat) ~= 0Ps(:,:,mod(k,nmat)) = P;
32

Pms(:,:,mod(k,nmat)) = Pm;else
Ps(:,:,nmat) = P;Pms(:,:,nmat) = Pm;
end
% las matrices de error se guardan para el suvizado de rauchif (mod(k,nmat) == 0)|(k == N),
narchivo = [’matrices\PPm’ num2str(ceil(k/nmat)) ’.mat’];save(narchivo,’Ps’,’Pms’);Ps = zeros(p,p,nmat);Pms = zeros(p,p,nmat);
end
end
Algoritmo de suavizado de Rauch
% [Xs, exc, logDP] = smoothSpeech(X)%% Filtro de suavizado recursivo hacia atr\’{a}s, que usa el% resultado del filtro de Kalman para el an\’{a}lisis de la voz.% Propuesto por Rauch, Tung Y Streibel.%% -> X :: resultado del filtro de Kalman% <- Xs :: evoluci\’{o}n suavizada de los par\’{a}metros del modelo% <- lDP :: vector con los logaritmos de los determinantes de las% matrices de la covarianza del errorfunction [Xs, lDP] = smoothSpeech(X)
[p,N] = size(X); Xs = zeros(p,N); Xs(:,N) = X(:,N);
load(’matrices\PPm1.mat’); nmat = size(Ps,3);
narchivo = [’matrices\PPm’ num2str(ceil(N/nmat)) ’.mat’];load(narchivo);
phi = eye(p); if mod(N,nmat) ~= 0,Psu = Ps(:,:,mod(N,nmat));
elsePsu = Ps(:,:,nmat);
end
lDP = zeros(N,1); lDP(N) = log(det(Psu));
for k = N - 1:-1:p,
if mod(k,nmat) == 0,
33

narchivo = [’matrices\PPm’ num2str(k/nmat) ’.mat’];load(narchivo);
P = Ps(:,:,nmat);Pm = Pms(:,:,nmat);
elseP = Ps(:,:,mod(k,nmat));Pm = Pms(:,:,mod(k,nmat));
end
C = P*inv(phi)*inv(Pm);
Xs(:,k) = X(:,k) + C*(Xs(:,k + 1) - phi*X(:,k));
Psu = P + C*(Psu - Pm)*C’;
lDP(k) = log(det(Psu));
end
Referencias
[1] John Makhoul. Linear prediction: A tutorial review. In Proceedings of the IEEE, vol-ume 63, pages 561–580. IEEE, April 1975.
[2] Peter Kabal. Adaptive linear prediction in speech coding. In Preprints IFAC/IFORSSymp. Identification, System Parameter Estimation, pages 203–207, 1991.
[3] L.R. Rabiner, R.W. Schafer. Digital Processing of Speech Signals. Prentice Hall, 1978.
[4] Florian Keiler, Daniel Arfib, Udo Zoelzer. Efficient linear prediction for digital audioeffects. In Proceedings of the COST G-6 Conference on Digital Audio Effects (DAFX-00), December 2000.
[5] Monson H. Hayes. Statistical Digital Signal Processing and Modelling. John Wiley &Sons, INC., 1966.
[6] Kalman, R.E. A new approach to linear filtering and prediction problems. Transactionsof the ASME Journal of Basic Engineering, 82:35–45, 1960.
[7] John G. McKenna, Stephen Isard. Tailoring kalman filtering towards speaker character-isation. September 1999.
[8] John G. McKenna. Automatic glottal closed-phase location and analysis by kalmanfiltering. August 2001.
[9] A. E. Rosenberg. Effect of glottal pulse shape on the quality of natural vowels. Journalof Acoustic Society of America, 43(4):583–590, 1971.
[10] H. E. Rauch, F. Tung, C. T. Streibel. Maximum likelihood estimates of linear dynamicsystems. AIAA Journal, 3:1445–1450, August 1965.
[11] H. E. Rauch. Solutions to the linear smoothing problem. IEEE Transactions on Auto-matic Control, pages 371–372, 1963.
34





























