Embed Size (px)
Citation preview

Algorithms (Contd.)

How do we describe algorithms?
• Pseudocode– Combines English, simple code constructs
– Works with various types of primitives• Could be + - / *
• Could be more complex operations
– Describes how data is organized
– Describes operations on the data
– Is meant to be higher level than programming

Searching with indices (pseudocode)
• Build the indices– Do this by going through the list and
determining where department names change– Store the results in an array called Indices
• Search the indices– Do a binary search on the array Indices
• Do this by comparing to the middle element– Then use binary search to compare to the upper half– Or use binary search to compare to the lower half

Building a web search engine
• Crawl/spider the web• Organize the results for fast query processing• Process queries

Crawl the web
• Every month use networking to go to as many reachable web pages as you can– 10B pages, 10 Kbytes/page, so 100 terabytes
• Can compress an average page to 3Kbytes
• Numeracy– To crawl 10B pages in 100 days:
• Crawl 100M pages per day• Crawl 4M pages per hour• Crawl 1,000 pages per second

Organize the results
• Put into alphabetical order• Build indices for faster lookup• Make multiple copies so that searching can
proceed in parallel.
• When you update, you rebuild the indices

Process search queries
• Look up indices• Look up words/phrases
– Advertiser can buy a word or phrase
• This search gives you internal addresses of web pages– Look them up to build results page
• Ranking results: content match, popularity, price paid by advertisers, …

Ranking by Popularity
• The web is a collection of links– A document’s importance is determined by
• How many pages point to it
• How important those pages are
• Used for determining– How often to crawl a page– How to order pages presented.

Content Relevance
• Simple string matching– Does the document/string contain the word
computer?
• More complex string matching– Did the word computer occur before or after the
word science? – Did it appear within 10 words of the word science?

How does string matching work?
• State machines – Move along states as long as you keep matching– Back off when you miss a match
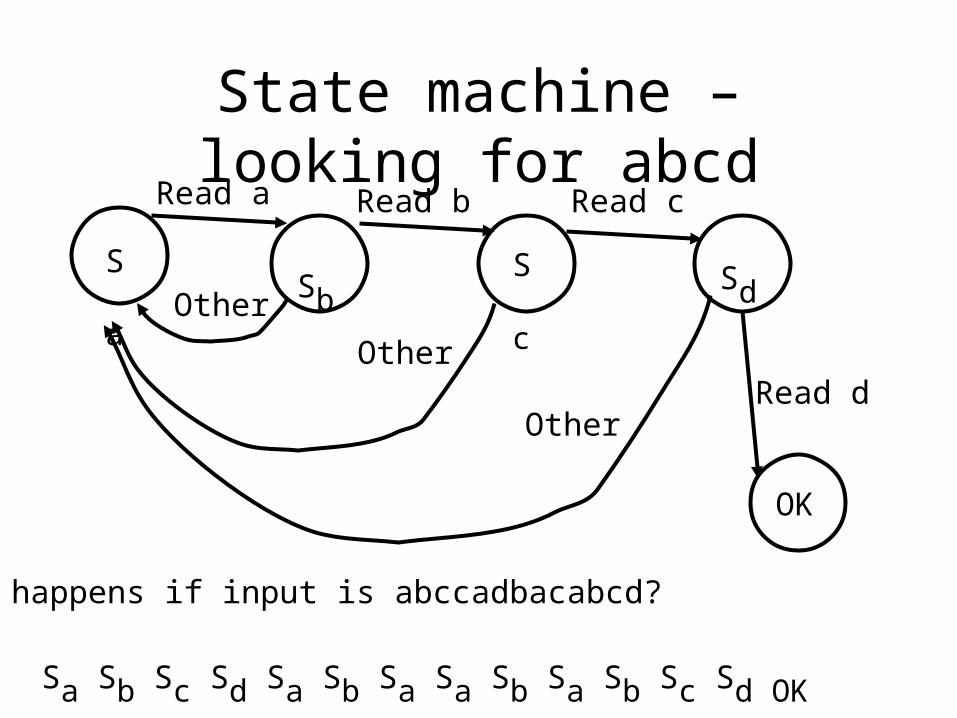
State machine – looking for abcdRead a Read b Read c
Read d
Other
Other
Other
Sa Sb ScSd
OK
What happens if input is abccadbacabcd?
Sa Sb Sc Sd Sa Sb Sa Sa Sb Sa Sb Sc Sd OK
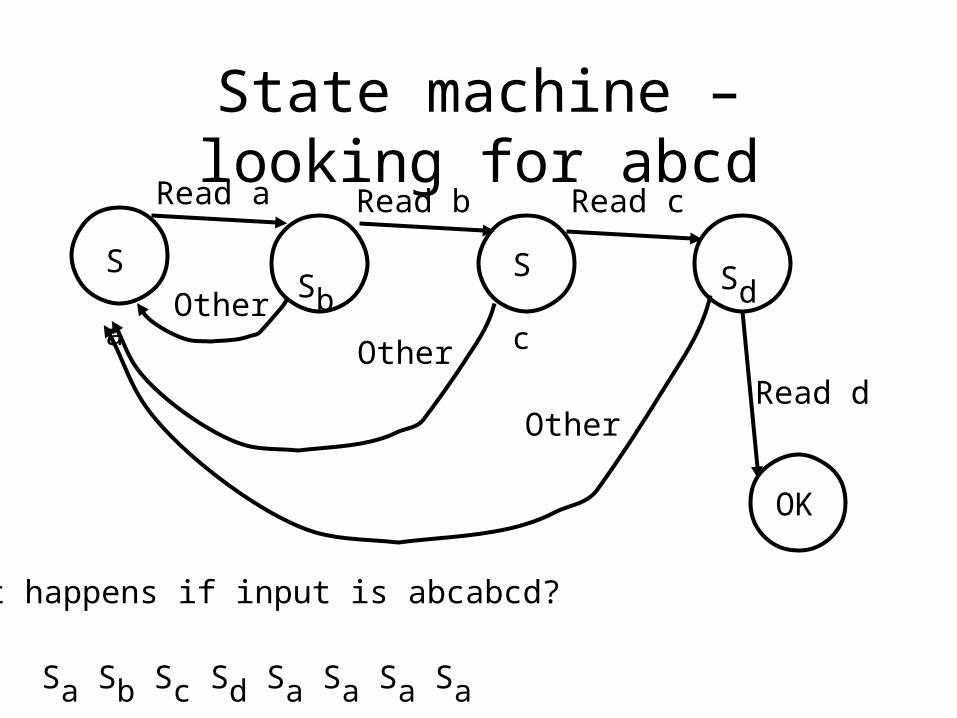
State machine – looking for abcdRead a Read b Read c
Read d
Other
Other
Other
Sa Sb ScSd
OK
What happens if input is abcabcd?
Sa Sb Sc Sd Sa Sa Sa Sa
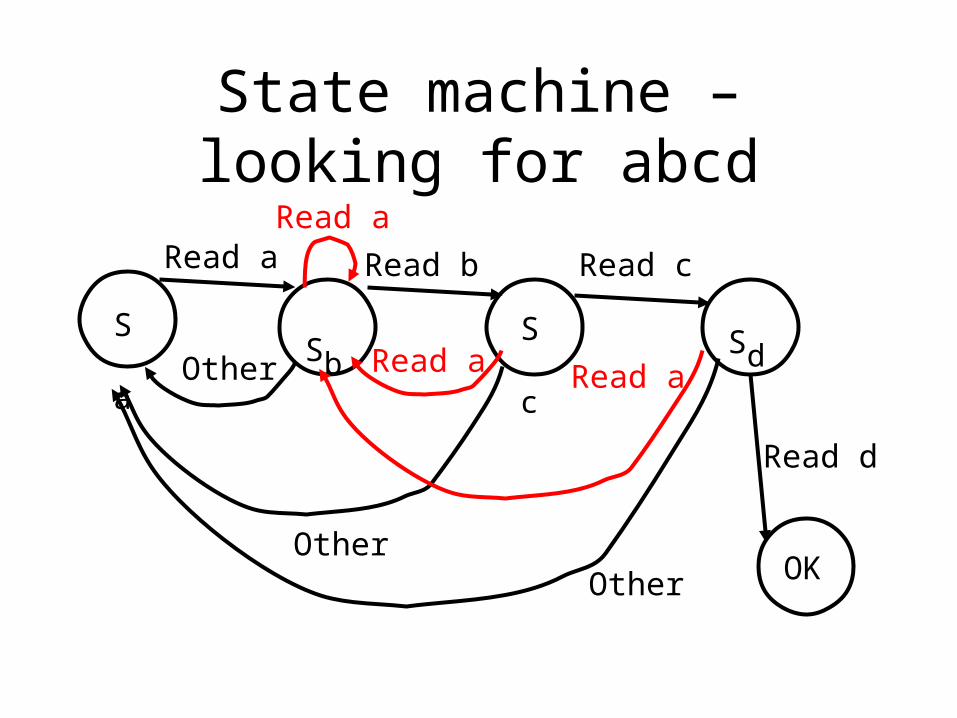
State machine – looking for abcd
Read a Read b Read c
Read d
Other
OtherOther
Sa Sb ScSd
OK
Read a Read a
Read a

Larger search challenges
• Allow strings to have don’t cares– Starts with a and ends with e– Has come number of copies of the substring ab
• Finding strings similar to but not the same as your string– For spelling corection

Algorithms -- summary
• Methods for solving problems
• Understand at a high level
• Make sure your reasoning is correct
• Worry about efficiency in situations where that matters
• Write as pseudocode

Distributed Algorithms

Distributed computing
• Key idea– Buying 1000 machines of speed x is significantly cheaper
than buying one machine of speed 1000x– No one person has to buy all 1000 machines: A lot of
computational, communication and storage resources already in place and can be harvested for bigger things
• Key challenge– Making the machines work together for effective speedup.
Communication between machines is a key challenge.
• Approaches– Find problems that can be distributed easily

Distributed problems• Problems that can use decentralized computing
– Weather prediction• Weather in a location is most affected by weather nearby
– Movie generation• Individual frames can be generated separately
– Google search engine• 10,000s PC’s. all of them cheap, many of them identical• Can answer over 100,000,000 queries per day in ½ sec or less each
– Looking for the origin of the universe• Can be localized like weather prediction
– File swapping and access (distributed storage)– Looking for extra terrestrial intelligence– Content caching and distribution

Distributed computers
• Scales of distributed computing– Cluster-in-a-room hundreds of machines
• All dedicated to the task
– PCs on a campus thousands of machines• Using spare cycles
– SETI cluster millions of machines• Screen saver situation

Cluster in a Room
• Machines are dedicated to the network
• All machines run similar software
• Problem is divided into pieces– Each piece is assigned to a machine in the cluster
• Problem pieces should be loosely linked– Computation is faster than communication

PCs on a Campus
• Loosely coupled on a local-area-network
• PCs do other things some of the time
• When free cycles are available, they’re used
• Many more machines, but less of each machine available
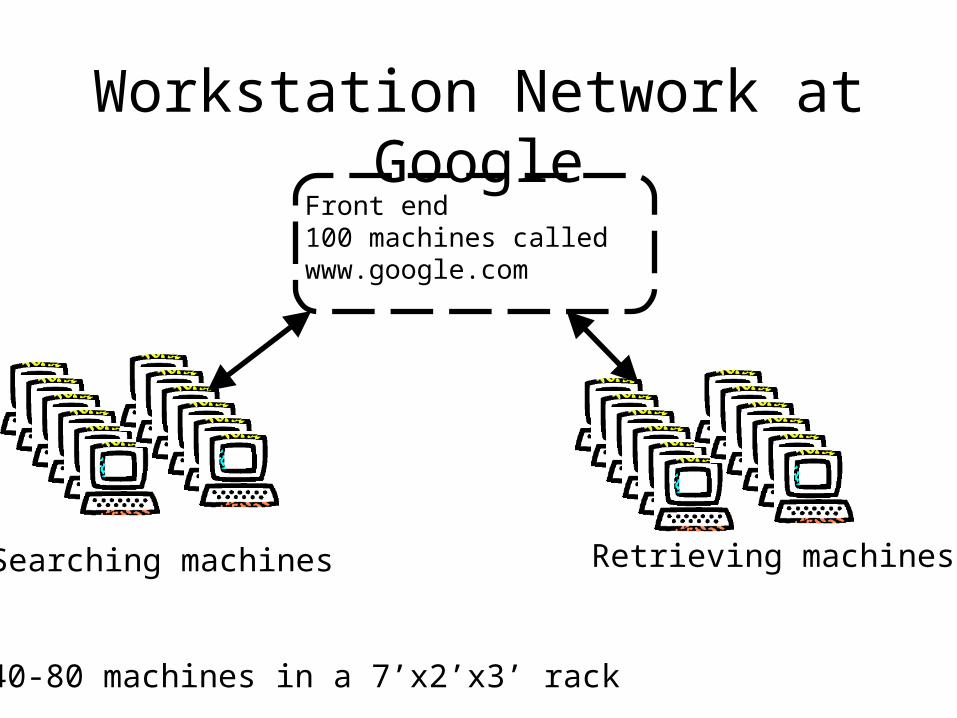
Workstation Network at GoogleFront end100 machines called www.google.com
Searching machines Retrieving machines
Fit 40-80 machines in a 7’x2’x3’ rack

SETI
• Telescope at Arecibo, PR collects data
• Data is processed in real time by fast machines
• But, no one looks for weak signals– Too costly
• SETI@Home project built to do this

SETI@Home
• Receive data from Arecibo– 35 Gbytes per day by snail mail
• Break into Work Units– .25 Mbyte each, so 140,000 WU’s per day
• WU takes 20 hours to process
• Need about 117,000 dedicated machines to process one day

SETI@Home
• Get individual users to download software• Machine idle and screen saver runs software
– Download WU– Compute– When finished send back result
• Database at Berkeley reassembles results• Progress to date -- Seti@HomeStats

Medical/Biological Applications
• Peer-to-Peer Medicine• Cancer Research• …





























