Embed Size (px)
DESCRIPTION
Opis alata za analizu regresije u proračunskoj tablici Excel
Citation preview

351
Alat za analizu Regression (Regresija) Ovaj alat za analizu izvodi linearnu regresijsku analizu korištenjem postupka najmanjih
kvadrata da prilagodi pravac kroz skup podataka. Ovim alatom možemo analizirati kako na jednu zavisnu promjenljivu utiču vrijednosti jedne ili više nezavisnih promjenljivih. Dijaloški okvira Regression (Regresija) opisat ćemo kroz
primjer uočenih cijena i potražnje jedne robe u toku 9 godina. Pretpostavimo da su odgovarajući podaci smješteni u polje ćelija kao na slici 1.
Slika 1. Input Y Range (Upis Y opsega) Ovdje unosimo referencu za opseg zavisnih podataka. Opseg se mora sastojati od jedne kolone podataka. U našem primjeru unesena je referenca $C$1:$C$10, podaci o cijenama robe u toku devet godina. Input X Range (Upis X opsega) Ovdje unosimo referencu za opseg nezavisnih podataka. Microsoft Excel posmatra kao red nezavisne promjenljive iz ovog opsega u uzlaznom redoslijedu s lijeva na desno. Maksimalan broj nezavisnih promjenljivih (varijabli ) je 16. U našem primjeru imamo najjednostavniji slučaj sa samo jednom nezavisnom promjenljivom; odgovarajuća referenca koju unosimo za opseg nezavisnih podataka je $B$1:$B$10. Labels (Nazivi) Ovaj kvadratić potrebno je označiti ukoliko prvi red ili kolona upisanog opsega sadrži nazive. Ukoliko upisani podaci nemaju nazive onda ovaj kvadratić ne treba označavati; Microsoft Excel generiše odgovarajuće nazive nad podacima za izlaznu tablicu. U našem primjeru uključena je opcija za nazive : Potražnja xi i Cijene yi.

352
Confidence Level (Nivo pouzdanosti) Na ovom mjestu možemo uključiti dodatni nivo u zbirnoj ili sumarnoj izlaznoj tablici. U okvir treba unijeti nivo pouzdanosti koji želimo primijeniti kao dodatak zadatom 95 procentnom nivou. U našem primjeru uključen je dodatni nivo od 99 procenata. Constant is Zero (Konstanta je nula) Ovim postižemo da natjeramo regresijski pravac da prolazi kroz koordinatni početak. U našem primjeru nije uključena ova opcija zato ćemo u izlaznim rezultatima dobiti odgovarajuću vrijednost odsječka na y - osi ( intercept). Output Range (Izlazni opseg) Ovdje unosimo referencu za gornju lijevu ćeliju izlazne tablice. Potrebno je omogućiti barem sedam kolona za izlaznu sumarnu tablicu, koja uključuje tablicu analize varijance, koeficijente, standardnu grešku procjene y, r2 vrijednosti, broj parova (xi ;yi) i standardnu grešku koeficijenata. U našem primjeru, za gornju lijevu ćeliju označena je ćelija $D$1. New Worksheet Ply (Novi radni list) Ukoliko želimo da umetnemo novi radni list u tekuću radnu knjigu i postavimo rezultate počevši od ćelije A1 novog radnog lista, trebamo uključiti ovu opciju označavanjem pripadajućeg kvadratića. New Workbook (Nova radna knjiga) Ovu opciju treba uključiti ako želimo da napravimo novu radnu knjigu i postavimo rezultate na novi radni list u novoj radnoj knjizi. Residuals (Ostaci) Potrebno je ovu opciju označiti ako želimo da uključimo reziduume u izlaznu tablicu reziduuma. U ovom primjeru nije uključena ova opcija kao ni opcije koje dolaze poslije ove što se vidi iz prikazanog dijaloškog okvira Regression. Standardized Residuals (Standardizovani ostaci) Označavanjem ove opcije uključujemo standardizovane reziduume u izlaznu tablicu rezidualnih odstupanja. Residual Plots (Grafički prikazi ostataka) Ovu opciju označavamo kako bismo genesirali graf za svaku nezavisnu promjenljivu naspram rezidualnog odstupanja. Line Fit Plots (Grafički prikazi prilagođivanja pravca) Ako želimo genesirati graf za predviđene vrijednosti naspram vrijednosti opažanja potrebno je označiti pripadajući kvadratić. Normal Probability Plots (Grafički prikazi normalne vjerovatnoće) Ovim Excelu označavamo da želimo generisati graf normalne vjerovatnoće.

353
Popunom dijaloškog okvira i prtiskom na dugme OK, dobijamo izlaz kao na slici 2.
Slika 2. Takođe je kao dodatak uključen i nivo pouzdanosti 99%. Čemu odgovaraju dobijeni rezultati ? U tablici Regression Statistics: Vrijednost Multiple R odgovara apsolutnoj vrijednosti Pearsonovog koeficijenta
korelacije i može se izračunati posredstvom ugrađenih funkcija CORREL I PEARSON
Vrijednost R Square odgovara koeficijentu determinacije i može se izračunati posredstvom ugrađene ili gotove Excelove funkcije RSQ:
Adjusted R Square jednak je:

354
Vrijednost za Standard Error odgovara rezultatu ugrađene funkcije STEYX:
Vrijednost za Observations odgovara broju parova (x,y); u našem primjeru imamo 9
parova. Brojanje možemo izvršiti pomoću funkcije COUNT. U tablici ANOVA: SSTotal odgovara ukupnoj devijaciji podataka yi i odgovara rezultatu funkcije DEVSQ:
SSResidual dobijamo posredstvom sintakse:
Ova suma odgovara izrazu:
0,91135019
81005,55556
11,142791
df
MSdf
MS
1R Adjusted
Total
Total
Residual
Residual
2 =−=−=
( ) bxmy ; yySS p
9
1i
2piResidual +⋅=−=∑
=

355
pri čemu m odgovara korficijentu pravca, a b odsječku regresijskog pravca na y - osi. SSRegression odgovara sumi kvadrata vertikalnih odstupanja između regresijskog pravca
od aritmetičke sredine yi podataka, odnosno:
pri čemu je aritmetička sredina ⎯y jednaka je 127,222.
MSRegression odgovara kolčniku SSRegression i broja stepena slobode dfRegression, odnosno:
MSResidual odgovara kolčniku SSResidual i broja stepena slobode dfResidual:
F veličina se dobija kao količnik
Significance F odgovara vrijednosti funkcije FDIST:
( ) yySS9
1i
2pRegression ∑
=
−=
( ) 927,556
1
yy
df
SSMS
9
1i
2p
Regression
RegressionRegression =
−
==∑=
( ) 11,1428
7
y-y
df
SSMS
9
1i
2pi
Residual
ResidualResidual ===
∑=
83,2427 11,1428927,556
MS
MSF
Residual
Regression ===

356
U narednoj tablici, izračunate vrijednosti odgovaraju:
Coefficients (Intercept) odgovara odsječku na y -osi i odgovara slobodnom članu b u ragresijskom pravcu yp=mx+b. Može se izračunati posredstvom funkcije INTERCEPT:
Coefficients (Potražnja xi ) odgovara koeficijentu pravca i odgovara članu m u
ragresijskom pravcu yp=mx+b. Može se izračunati posredstvom funkcije SLOPE:
Standard Error (Potražnja xi) odgovara standardnoj grešci koeficijenta pravca m i
izračunava se prema izrazu:
( )
( )30,21936601
B10):DEVSQ(B1B10):B1C10;:STEYX(C1
x-x
29
y-y
Error Standard 9
1i
2i
9
1i
2pi
m ==−=
∑
∑
=
=

357
Standard Error (Intercept) odgovara standardnoj grešci slobodnog člana b i izračunava se prema izrazu:
t Stat ( Intercept )jednak je količniku odsječka na y -osi (koeficijent b) i standardne greške Standard Error (Intercept): t Stat = 301,7922265/19,1659176 = 15,7463.
t Stat ( Potražnja xi )jednak je količniku koeficijenta m i standardne greške Standard Error (Potražnja xi): t Stat = -2,00143954/0,21936601 = -9,12374.
P - value (Intercept) i P- value (Potražnja xi) se dobijaju, posredstvom funkcije TDIST:
Granice intervala za slobodni član b za nivoe pouzdanosti od 95% i 99%:
Granice intervala za član m za nivoe pouzdanosti od 95% i 99%:
( )( )
( )( )
19,1659176 B10):DEVSQ(B1
2B10)):1(AVERAGE(B91
B10):B1C10;:STEYX(C1
9
1i2
x-ix
x91
29
9
1i2
py-iy n
1i2
x-ix
xn1
2n
n
1i2
py-iy
bError Standard
=+⋅=
=∑=
+⋅−
∑==
∑=
+⋅−
∑==
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛ 22

358
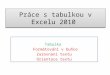
Sa uključenim izlaznim opcijama koje se odnose na reziduale (Residuals) i na grafički prikaz normalne vjerovatnoće (Normal Probability) u izlaznim podacima, pored tablica koje smo analizirali, dobijamo još dvije: RESIDUAL OUTPUT i PROBABILITY OUTPUT. Ove tablice prikazane su na slici xx. Sada ćemo, po inerciji, nastaviti sa pojašnjenjem čemu odgovaraju vrijednosti po pojedinim kolonama.
Slika xx. Vrijednosti u koloni Predicted Cijene yi odgovaraju vrijednostima regresijskog pravca yp. Možemo ih izračunati veoma jednostavno posredstvom funkcije TREND, tako što ćemo selektovati 9 praznih ćelija koje ćemo popuniti aktiviranjem formule polja istovremenim
pritiskom na kombinaciju tipki CTRL+SHIFT+ENTER. Vrijednosti u koloni Residuals dobijamo kao razliku vrijednosti opažanja yi i odgovarajućih vrijednosti na regresijskom pravcu yp=mx+b ; već smo ranije objasnili da vrijednosti m i b možemo izračunati pomoću ugrađenih funkcija SLOPE i INTERCEPT. Standardne reziduale Excel izračunava tako što

359
podijeli vrijednost reziduala sa standardnom greškom (sadržaj ćelije $E$7 u tablici
Regression Statistics) i pomnožimo sa kvadratnim korijenom količnika ukupnog broja stepeni slobode sa ovim brojem umanjenom za jedan. Grafički dio izlaza odredili smo uključenjem opcija Residual Plots, Line Fit Plots i Normal Probability Plots u izlaznim opcijama Residuals i Normal Probability.
Grafički prikazi ovih dijagrama dati su u nešto izmijenjenom obliku.
P o t ra žn ja x i R e s id u a l P lo t
-6-5-4-3-2-101
2345
75 80 85 90 95 10 0
P o t ra žn ja x i
Resid
uals
Normal Probability Plot
110116 120 124 127 130 133
140145
0
20
40
60
80
100
120
140
160
0 20 40 60 80 100
Sample Percentile
Cije
ne y
i
Potra žnja xi Line Fit Plot
y = -2,0014x + 301,79R2 = 0,9224
0
20
40
60
80
100
120
140
160
75 80 85 90 95 100
Potra žnja xi
Cije
ne y
i
Cijene yiPredicted Cijene yiLinear (Cijene yi)