Embed Size (px)
Citation preview

A TOP DOWN APPROACH TO MULTI-NAME CREDIT
Kay Giesecke∗
Cornell University
Lisa R. Goldberg†
MSCI Barra, Inc.
February 16, 2005; this draft April 19, 2005‡.
AbstractWe examine multi-name credit models from the perspective of point processes.In this context, it is natural to pursue a top down approach: the economyas a whole is modeled first. The technique of random thinning consistentlygenerates sub-models for individual firms or portfolios.
A candidate for the top down approach is a self-exciting process, whoseintensity at any time depends on the sequence of events observed up to thattime. A self-exciting process incorporates the contagion observed in creditmarkets and avoids an ad hoc choice of copula. The familiar doubly stochas-tic process is at the opposite end of the spectrum in the sense that it isconstructed from the bottom up: individual firm intensities are estimated andthen aggregated. We rigorously analyze self-exciting and doubly stochasticprocesses with respect to their ability to capture contagion.
Model fitness can be tested using a deep result of Meyer (1971), whichshows that any point process with continuous compensator can be transformedinto a standard Poisson process by a change of time. Meyer’s result allows usto extend the scope of the tests proposed by Das, Duffie & Kapadia (2004)for a doubly stochastic model.
Key words: dependent defaults, counting process, point process, compensator,time scaling, random thinning, Poisson process, fitness test, doubly stochasticmodel, self-exciting model
∗School of Operations Research and Industrial Engineering, Cornell University, Ithaca, NY14853-3801, USA, Phone (607) 255 9140, Fax (607) 255 9129, email: [email protected],web: www.orie.cornell.edu/∼giesecke.
†MSCI Barra, Inc., 2100 Milvia Street, Berkeley, CA 94704-1113, USA, Phone (510) 649 4601,Fax (510) 848 0954, email: [email protected].
‡We thank Greg Anderson, Aaron Brown, Eymen Errais, Steve Evans, Jyh-Huei Lee andThorsten Schmidt for illuminating discussions. We are deeply grateful to Stefan Weber for hiscontributions to the development of the material in Section 2.4 and to Steven Hutt for bringingMeyer’s (1971) result to our attention.
1
1
A Top Down Approach to Multi-Name Credit
Lisa R. Goldberg
Morgan Stanley Capital International Barra
This talk is based on joint work with
Kay Giesecke
A Top Down Approach to Multi-Name Credit 2
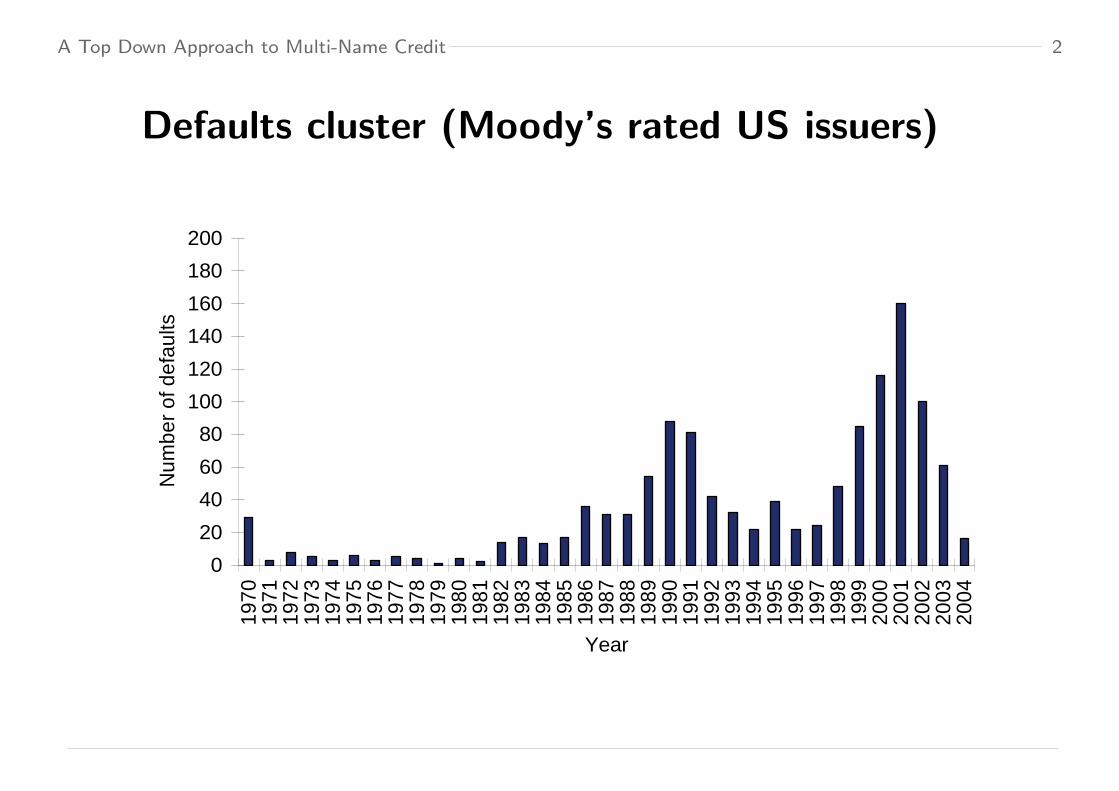
Defaults cluster (Moody’s rated US issuers)
0
20
40
60
80
100
120
140
160
180
20019
7019
7119
7219
7319
7419
7519
7619
7719
7819
7919
8019
8119
8219
8319
8419
8519
8619
8719
8819
8919
9019
9119
9219
9319
9419
9519
9619
9719
9819
9920
0020
0120
0220
0320
04
Year
Num
ber
of d
efau
lts

A Top Down Approach to Multi-Name Credit 3
Multi-name credit derivatives
• Trading of default dependence in a portfolio of names
– Default baskets target the number of defaults
– CDO’s and CDO tranches target the default loss
• Payoff depends on cumulative portfolio losses
– Default dependence: cyclical dependence and contagion
– Idiosyncratic factors
– Recovery uncertainty
• Complexity often requires simulation for pricing and risk
management

A Top Down Approach to Multi-Name Credit 4
Cumulative portfolio losses
• (T i) increasing sequence of default times in the portfolio with
default counting process N defined by
Nt =∑
i
1T i≤t
• (U i) sequence of default losses: U i is the loss at T i
• Cumulative portfolio losses follow the compound point process
Lt =Nt∑
i=1
U i =∑
i
U i1T i≤t
• Multi-name products are derivatives on L

A Top Down Approach to Multi-Name Credit 5
Cumulative portfolio losses and tranches
L t(ω)
KseniorU
KLsenior
5loss Z
T T T T T T1 2 3 4 5 6 T7 Tt
Equity
Mezzanine
Senior
Super Senior
K

A Top Down Approach to Multi-Name Credit 6
Cumulative tranche losses
• Losses are allocated to tranches according to a waterfall structure
– Tranche i absorbs the portfolio losses that exceed KiL up to Ki
U
– Losses on tranche are bounded by its notional KiU −Ki
L
• Cumulative losses Li on tranche i are given by the call spread
Lit = (Lt −Ki
L)+ − (Lt −KiU )+
• Tranche valuation is thus a problem of pricing options on L
– Understand the dynamics of L i.e. the default order statistics

A Top Down Approach to Multi-Name Credit 7
Bottom up versus top down
• Bottom up approach: start with single name models in the economy
wide filtration and add up to get the economy wide model
– Consistent with the single name market by construction
– Dependence structure is built into single name dynamics and
automatically ascends to the economy wide model
• Top down approach: start with the economy wide model
– Random thinning generates single name models that are
consistent with the economy wide filtration
– Consistent with the single name market by construction
– The dependence structure is built in to the economy wide model
and automatically descends to the single name dynamics

A Top Down Approach to Multi-Name Credit 8
Status quo: copula approach
• Start with marginals consistent with market and impose a copula
• Structural model for marginals: τ i ≤ T ⇔ XiT ≤ ci
– Firm value XiT has fixed distribution (Gaussian, t)
– Barrier ci is chosen to match the CDS implied T -default
probability
• Linear factor model describes the dependence among firm value
processes structure:
XiT = ai · Y +
√1− ‖ai‖2εi
– Systematic factors Y and idiosyncratic factors εi are independent
– Loadings ai are chosen to match a given asset correlation matrix
– The XiT and thus the τ i are conditionally independent given Y

A Top Down Approach to Multi-Name Credit 9
Discussion of the status quo
• This is a static bottom up approach, which starts with the marginal
distributions of the default times and a copula
– Marginals match the single name CDS market by construction
– Difficult to match multi-name market
∗ Copula is static: no dynamic stochastic effects
∗ Copula is symmetric
• Conditional independence is used to the calculate the law of Lt
– Semi-analytic methods (recursions, transforms etc)
– Simulation methods
• Default order statistics are not explicitly modeled

A Top Down Approach to Multi-Name Credit 10
Copula models do not match the skew
0
10
20
30
40
50
60
70
80
0-3% 3-7% 7-10% 10-15% 15-30%
Tranche
Bas
e C
orre
latio
n (%
)
Market Gaussian Copula T Copula (10)

A Top Down Approach to Multi-Name Credit 11
Setup and assumptions
• Uncertainty is modeled by the probability space (Ω,G,P)
• The economy wide information is modeled by the filtration G
• The default times are modeled by finite-valued stopping times (τ i)
• We focus on the associated ordered times (T i) and assume
– (T i) is strictly increasing almost surely
– T 1 > 0 almost surely
– For every positive t, P[T i > t] > 0 for all i
– limi→∞ T i = ∞ almost surely: N is non-explosive
– E[Nt] < ∞ for all t < ∞

A Top Down Approach to Multi-Name Credit 12
Ordered defaults

A Top Down Approach to Multi-Name Credit 13
Single name model
• Single name default process N it = 1τ i≤t
– Can be decomposed into the sum of a martingale M i and a
nondecreasing predictable process Ai
• Single name compensator Ai
– Describes default dynamics for firm i:
E[N it −N i
s | Gs] = E[Ait −Ai
s | Gs]
– It has an intensity hi if it can be written as Ait =
∫ t
0hi
sds
– The intensity drops to 0 at default; it can be modeled through
an extended intensity λi by setting hi = λi(1−N i−)
– If λi > 0 is a constant then τ i is exponential

A Top Down Approach to Multi-Name Credit 14
Single name model (continued)
• Start with the single name intensities hi
• Construct the economy wide model from the bottom up:
h =∑
i
hi
• The default dependence structure is not evident in this formula
– It holds for independent as well as perfectly dependent defaults
• This assumes the single name model hi is constructed with respect
to the economy wide filtration G
– Each hi incorporates the dependence among all the default times
– The single name dynamics are governed by idiosyncratic factors
and the dependence structure

A Top Down Approach to Multi-Name Credit 15
Economy wide model as a sum
• Economy wide default process Nt =∑
i 1T i≤t– Can be decomposed into the sum of a martingale M and a
nondecreasing predictable process A
N = M + A
• Economy wide compensator A
– Describes economy wide default dynamics:
E[Nt −Ns | Gs] = E[At −As | Gs]
– Has an intensity h if it can be written as At =∫ t
0hsds
– The intensity drops to 0 at Tn; it can be modeled through an
extended intensity λ by setting ht = λt1t<T n– If λ > 0 is a constant then N is a (truncated) Poisson process

A Top Down Approach to Multi-Name Credit 16
Bottom up deterministic intensity model
• Suppose the extended single name intensities λi are deterministic
– Piece-wise constant model calibrated from CDS quotes
– Implies that the default times are independent
• Adding up, the stochastic economy wide intensity is
h =∑
i
hi =∑
i
λi(1−N i−)
– At each T i, h is reduced by the intensity of the defaulter
– At Tn, h drops to 0
• Need state dependent single name intensities to model dependence

A Top Down Approach to Multi-Name Credit 17
Bottom up doubly stochastic model
• The state of the economy is described by a process X
– X generates the filtration F
• Suppose the extended single name intensities λi = f i(X)
– Affine jump diffusion models for (X, f i)
– Estimate from single name CDS quotes (MLE etc.)
• A model λi is doubly stochastic if the survival events τ i > t + u– Are conditionally independent given Gt ∨ Ft+u and
– Have probability exp(− ∫ t+u
tλi
sds)

A Top Down Approach to Multi-Name Credit 18
Discussion
• The doubly stochastic model is not consistent with contagion effects
– The default times cannot be stopping times in the doubly
stochastic filtration F
– The single name intensities are not updated at event times
• Does it reproduce the historically observed default clustering?
– Das, Duffie and Kapadia (2004) reject the hypothesis of doubly
stochastic defaults and correctly specified single name intensities
• Unclear whether the doubly stochastic model generates sufficient
default clustering under the pricing measure to match the
multi-name market

A Top Down Approach to Multi-Name Credit 19
Bottom up copula model is richer
• Suppose the marginal default probability is pi(t) = 1− e−R t0 γi(s)ds
– The deterministic functions γi are calibrated from CDS quotes
– The γi are not in general the extended single name intensities
• Suppose the default dependence structure is given by the copula C
– τ i =d inft > 0 : pi(t) ≥ U i for U i ∼ U(0, 1) with copula C
• The stochastic single name intensity is almost surely given by
hit = lim
ε↓01εP[τ i ≤ t + ε | Gt] = lim
ε↓01εP[U i ≤ pi(t + ε) | Gt]
– At each T i before τ i, hi is updated according to C
– If C is the product copula, hi = γi(1−N i−) and γi = λi is the
extended single name intensity

A Top Down Approach to Multi-Name Credit 20
Bottom up copula model: discussion
• Add up to get the stochastic economy wide intensity h =∑
i hi
– At each T i, each single name intensity hi is updated and h is
reduced by the intensity of the defaulter
– At Tn, h drops to 0
• The default dependence is governed by the updating of the hi
– Contagion
• The dynamics of L do not reproduce the multi-name market
– The unconditional default probabilities match the CDS market
– The default times have the fixed copula C, which governs the
joint evolution of the single name intensities and thus the
conditional default probabilities

A Top Down Approach to Multi-Name Credit 21
Bottom up versus top down
• Bottom up approach: start with single name models in the economy
wide filtration and add up to get the economy wide model
– Consistent with the single name market by construction
– Dependence structure is built into single name dynamics and
automatically ascends to the economy wide model
• Top down approach: start with the economy wide model
– Random thinning generates single name models that are
consistent with the economy wide filtration
– Consistent with the single name market by construction
– The dependence structure is built in to the economy wide model
and automatically descends to the single name dynamics

A Top Down Approach to Multi-Name Credit 22
A point process perspective• Top down approach: the economy wide defaults are modeled first
– Focus directly on default order statistics
– Sub-models for individual firms and portfolios of firms are
consistently generated by random thinning
• A candidate for the top down approach is a self-affecting process
– Intensity at any time depends on the sequence of events
observed up to that time
– Incorporates contagion and avoids the ad-hoc choice of copula
• Realistic models for the economy wide default process can be
generated by time-changing a standard Poisson process
• Devise efficient simulation algorithms for these models
• Goodness-of-fit tests

A Top Down Approach to Multi-Name Credit 23
Random thinning
• We allocate the increase in the economy wide compensator A to the
single name compensators Ai via a thinning process Zi:
Ait =
∫ t
0
ZisdAs
If the economy wide model is intensity based, then
hi = Zih
• A thinning process always exists
– Zi is the Radon-Nikodym derivative of the random measure
associated to Ai with respect to the measure associated to A

A Top Down Approach to Multi-Name Credit 24
A model for the next to default
• The thinning process is a model for the next to default:
Zit =
∑
k≥1
P[τ i = T k | Gt−]1T k−1<t≤T k
• It follows that
– Zit takes values in the unit interval
– Zit drops to 0 at τ i
–∑
i Zit = 1

A Top Down Approach to Multi-Name Credit 25
Matching the single name market
• The marginal default probabilities P[τ i ≤ t] are given by
P[τ i ≤ t] = E[Ait] = E
[∫ t
0
ZisdAs
]
In the intensity based case
P[τ i ≤ t] = E[∫ t
0
hisds
]= E
[∫ t
0
Zishsds
]
• These marginals are calibrated directly from the single name market
– Replace the parametric model P[τ i ≤ t] = 1− e−R t0 γi(s)ds often
used in the copula models

A Top Down Approach to Multi-Name Credit 26
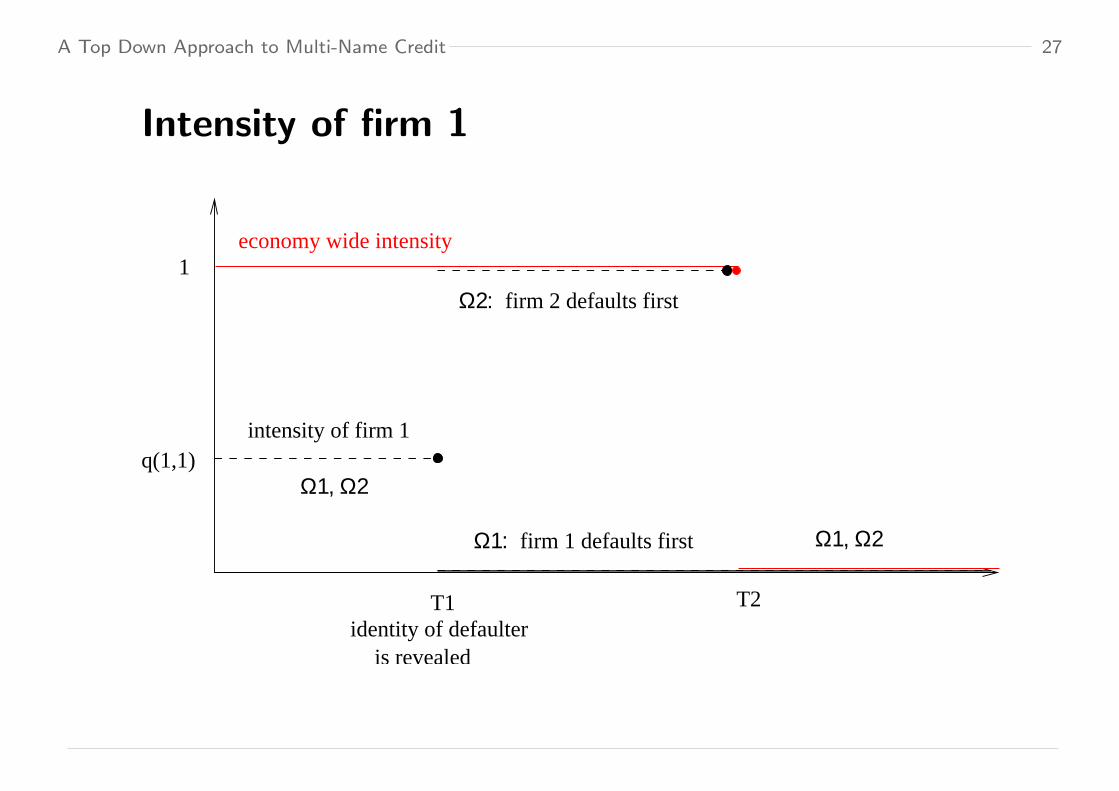
Schematic example with 2 firms
• Suppose the economy wide default counter N is a standard Poisson
process truncated at T 2 in the economy wide filtration
– The economy wide intensity is ht = 1t≤T 2– The times T 1 and T 2 − T 1 are independent and Exp(1)
• Let Ωi be the states on which firm i is the first defaulter
– At time 0 we estimate qi1 = P[Ωi] = P[T 1 = τ i]
– At time T 1 we observe the Ωi, i.e. the identity
• We have hi = Zih = Zi with
Z1t =
q11 t ≤ T 1
1Ω2 T 1 < t ≤ T 2
0 T 2 < t
and Z2t =
1− q11 t ≤ T 1
1Ω1 T 1 < t ≤ T 2
0 T 2 < t
A Top Down Approach to Multi-Name Credit 27
Intensity of firm 1
firm 1 defaults first
firm 2 defaults first
Ω1:
Ω2:
is revealedidentity of defaulter
Ω1, Ω2
Ω1, Ω2
economy wide intensity
intensity of firm 1
1
q(1,1)
T2T1

A Top Down Approach to Multi-Name Credit 28
Matching the single name market
• The marginal default probabilities are given by
P[τ i ≤ t] = E[∫ t
0
hisds
]= 1− e−t − (1− qi
1)te−t
• Each τ i is a mixture of Exp(1) variables
– If qi1 = 1, then τ i = T 1 is an Exp(1) variable
– If qi1 = 0, then τ i = T 2 is the sum of two Exp(1) variables
– Shows that the times τ i are not independent
• To make the economy wide intensity model h consistent with the
single name market, we calibrate the marginals from CDS quotes

A Top Down Approach to Multi-Name Credit 29
Hawkes process
• Suppose the economy wide intensity is self-affecting:
ht = ν0(t) +∑
i:T i<t
νi(t− T i)
– The first-to-default intensity ν0(t) is a deterministic function of t
– The impact process νi(t) is a deterministic function of t, the
times T 1, . . . , T i and the marks U0, . . . , U i
• For ν0 constant and νi(t) = ν(t) a nonnegative deterministic
function of time, the counter N is the Hawkes (1971) process
• Extension to stochastic νi

A Top Down Approach to Multi-Name Credit 30
Self-affecting defaults
t
Inte
nsity
Default Times
T1 T2 T3 T4

A Top Down Approach to Multi-Name Credit 31
Hawkes process (continued)
• Flexible modeling of the default order statistics
• Dynamic specification of default dependence structure
– Can be asymmetric
– Jumps in the economy wide intensity can be random and depend
on information revealed at defaults
∗ Size of firm, loss at default or other marks
∗ Correlation estimates: asset/equity, spreads
– Compare with the copula models, where the updating is
governed by the fixed copula

A Top Down Approach to Multi-Name Credit 32
Summary
• We propose a top down approach to multi-name credit
– The economy-wide default counting process is modeled first
– Random thinning generates sub-models for individual firms
• The default counting process is represented as a time-changed
standard Poisson process
– Doubly stochastic and Hawkes processes are special cases
– Contains a wide range of other self-affecting processes
– Yields algorithms for the simulation of dependent defaults
• The compensator can be interpreted as a (stochastic) change of time
• The compensator generates rigorous fitness tests

A Top Down Approach to Multi-Name Credit 33
References
• “A Top Down Approach to Multi-Name Credit” with Kay Giesecke
• “Dependent Events and Changes of Time” Kay Giesecke Pascal
Tomecek
• “Time-changed Hawkes processes and tranche pricing” (in progress)
Eymen Errais and Kay Giesecke





























