Embed Size (px)
Citation preview

3. Regresión con variables cualitativas
45
3
___________________
Regresión con variables cualitativas
1. Introducción
Hasta ahora hemos abordado el tema de la correlación y la regresión con variables
cuantitativas. Sin embargo, un estudio de regresión similar puede desarrollarse si
contamos con una variable -la variable X- que sea cualitativa de dos o más categorías.
En esta circunstancia se trata de conocer la regresión de X (una variable que adopta
valores cualitativamente diferentes) sobre una variable Y cuya escala de medida es al
menos de intervalo.
El análisis estadístico del contraste de medias (mediante el análisis de la varianza)
puede ser interpretado como un análisis de la regresión en el que la variable X es
cualitativa. Es más, enfocar el análisis de la varianza desde el punto de vista de la
regresión puede ser una ventaja que proporcione a dicho análisis una mayor
generalidad.
2. Regresión con una variable dicotómica.
Supongamos que deseamos conocer en qué medida se relacionan sexo y habilidad
manual para realizar una tarea. La variable sexo es una variable cualitativa de dos
categorías –dicotómica- y puede codificarse de forma arbitraria con los valores 0 y 1;
por ejemplo, 0 mujer y 1 varón. La variable habilidad se cuantifica a través de un
instrumento determinado de forma cuantitativa. Supongamos que se obtienen los
siguientes resultados teniendo una muestra total de 8 sujetos, 4 varones y 4 mujeres:
Sujetos Sexo (X) Habilidad (Y) XY 1
2
3
4
5
6
7
8
0
0
0
0
1
1
1
1
20
36
26
22
49
40
47
48
0
0
0
0
49
40
47
48
Sumas 4 288 184

3. Regresión con variables cualitativas
46
2.1. Correlación y recta de regresión.
Como en el estudio de una correlación ordinaria, calculamos los estadísticos
descriptivos que nos van a servir para este fin:
53.01
)(5.0
8
4 1 =−
−===∑
N
XXSX
N
X
96.111
)(36
8
288 1 =−
−===∑
N
YYSY
N
Y
Y con estos datos calculamos la correlación entre X e Y:
894.096.1153.0
365.07
184
1
1
=⋅
⋅−
=
−−=
∑
YX
N
XYSS
YXN
XY
r
A partir del valor de correlación calculado y bajo el supuesto que se cumplan los
supuestos requeridos, puede estimarse, bajo el mismo procedimiento que en el caso en
que ambas variables eran cuantitativas, la recta de regresión que define dicha relación:
bXaY +=ˆ
o bien:
110ˆ XBBY +=
donde
X
YXY
S
Srb
XbYa
=
−=
En nuestro caso, tendríamos:
265.02036
2053.0
96.1189.0
=⋅−=
=⋅=
a
b
de donde la ecuación de regresión es:
XY 2026ˆ +=
Nótese que dado que la variable X adopta dos posibles valores, (O para varón y 1 para
mujer), las predicciones en Y en estas circunstancias son:

3. Regresión con variables cualitativas
47
4612026ˆ
2602026ˆvar
=⋅+=
=⋅+=
mujer
ón
Y
Y
La interpretación de estas estimaciones es la siguiente: 26 es el valor esperado en Y para
un sujeto que tenga sexo varón y 46 el valor esperado para cualquiera de las mujeres.
Estos valores (26 y 46) coinciden exactamente con las medias en Y del grupo de
varones y de las mujeres, respectivamente. Recordemos los datos:
Sujetos Sexo (X) Habilidad (Y) Medias por grupo
260 =Y
1
2
3
4
5
6
7
8
0
0
0
0
1
1
1
1
20
36
26
22
49
40
47
48
461 =Y
Sumas 4 288 36=Y
Por otro lado, la diferencia entre ambas medias (46-26) coincide con el valor de b, es
decir, con el cambio esperado en Y al cambiar una unidad (de 0 a 1) el valor de X:
2001
2646=
−
−=
∆
∆=
X
Yb
Y el parámetro “a “coincide justamente con la media del grupo que se codifica como 0,
en nuestro caso, el de varones. Es decir, la ordenada en el origen de la recta de regresión
del modelo pasa por el punto 26 que es el promedio de la habilidad manual en dicho
grupo.
Gráficamente estas ideas pueden reflejarse si se dibuja la nube de puntos (en realidad
dos series de datos alineados verticalmente –ver puntos rojos en la gráfica-) y la
correspondiente recta de regresión en un eje de coordenadas:
SEXO
2,01,00,0
HA
BIL
IDA
50
40
30
20
10
X∆
Y∆
0Y
1Y

3. Regresión con variables cualitativas
48
Obsérvese que cuando X vale 0, la recta corta el eje de la Y en el valor medio del grupo
de varones ( =0Y 26) y que el otro punto que la define es precisamente el valor medio
de Y en el grupo de mujeres ( =1Y 46 -cuando X vale 1-). Además, como hemos
indicado, la incremento en Y al cambiar el valor de X de 0 a 1 es precisamente el valor
de inclinación de la recta (b):
20)01(
)2646(=
−
−=
∆
∆=
X
Yb
o lo que es lo mismo:
20264601 =−=−= YYb
2.2. Supuestos del modelo.
Dado que trabajamos con el mismo modelo de regresión que cuando se trataba de dos
variables cuantitativas, los requisitos a los que deben adecuarse los datos para que dicho
modelo pueda se aplicado idóneamente deben ser los mismos que en aquel caso. Así
pues, debe probarse la adecuación de la nube de puntos a una recta (linealidad), la
igualdad de varianzas del error (homocedasticidad) y su normalidad, así como la
independencia entre puntuaciones (que es un requisito supuesto de antemano).
Teniendo en cuenta la representación gráfica característica cuando X adopta dos únicos
valores (dos series alineadas –verticales- de puntos que representan la variabilidad de Y
para cada uno de los valores de X), puede decirse que la recta constituye una buena
representación para unir ambas series, representando el cambio sufrido en la Y estimada
en función del cambio (de 0 a 1 – de una categoría a otra-) en X.
Por otra parte el supuesto de la homocedasticidad quedará satisfecho si la dispersión de
la serie de puntos respecto a valor predicho dentro de la condición X=0 es semejante a
dicha dispersión en la condición X=1. Para probar si se cumple o no este supuesto, tal y
como en el tema de la regresión anterior, hay que realizar un estudio de los errores.
Recuérdese que graficando cuál es la distribución de los mismos en función de los
valores de Y predichos puede obtenerse, a nivel gráfico, una primera aproximación a
dicho estudio. Formas definidas o características de esta distribución (por ejemplo, de
megáfonos o triángulos en cierto grado invertidos-) apuntan a una posible violación de
este supuesto. En último término, si deseamos probar mediante alguna prueba
estadística si los datos se ajustan o no al supuesto mencionado puede probarse la
significación de la correlación entre los errores (absolutos) y los valores de Y predichos.
La falta de significación de dicha correlación indica la satisfacción de este supuesto de
la homocedasticidad aunque como sabemos este procedimiento no detecta a veces el
incumplimiento del supuesto.
Por último, la normalidad de las puntuaciones se cumple si la distribución de puntos
alrededor de cada una de las dos medias por grupos se ajustan a una distribución tipo
campana de Gauss. Este supuesto es más difícil de corroborar cuando existen pocos
datos; de cualquier manera la prueba de análisis de la regresión es más robusta al
incumplimiento de este supuesto que a la violación de otros. La vía más cómoda y fácil

3. Regresión con variables cualitativas
49
de estudiarlo es pidiendo el gráfico de probabilidad normal en el paquete estadístico
SPSS.
2.3. Validez del modelo y bondad de ajuste.
Para probar la validez del modelo de regresión y ajuste lineal planteado, se procede de
manera similar al caso en que ambas variables eran cuantitativas. Como se sabe, puede
abordarse esta cuestión mediante tres procedimientos alternativos y coincidentes:
a) evaluando la significación de la correlación
b) evaluando la significación del coeficiente b
c) aplicando la prueba F que evalúa de manera global en qué medida la variación
de los datos de la que da cuenta el modelo de regresión sobrepasa aquella parte
de la variación de los datos de la que no es responsable dicho modelo.
Como decimos, estas tres vías o trayectorias conducen a una misma conclusión.
Probemos, por ejemplo, en primer lugar, la validación a través del índice F para los
datos anteriores. Recuérdese que:
)1/()1(
/2
2
−−−=
kNR
kRF
Entonces, para nuestros datos:
7.236/)894.01(
1/894.02
2
=−
=F
Por otra parte, la prueba de significación para la correlación:
2
1
0
2
−
−
−=
N
r
rt
XY
XY
En nuestro caso:
87.4
6
894.01
894.0
2=
−=t
Y para el coeficiente b:
∑ −
−=
N
res
XX
S
bt
1
2
2
)(
0
que sustituyendo:
87.4
2
67.33
20==t

3. Regresión con variables cualitativas
50
Compruébese la igualdad de los tres resultados teniendo en cuenta que tF =
Buscando en las tablas pertinentes el valor de p para estos estadísticos, se concluye que
la probabilidad de que la explicación de los datos a partir del modelo lineal estimado sea
irrelevante es del .003. Es decir, aceptamos el modelo de regresión estimado como una
buena aproximación de la explicación de los datos, ya que la probabilidad de que no lo
sea es muy pequeña (menor a .05). Por lo tanto, existe relación significativa entre X e Y.
A nivel teórico diremos que el sexo explica de forma relevante la diferencia existente en
la habilidad manual. El sentido de dicha relación (atendiendo a los promedios
correspondiente a cada grupo) es el de que las mujeres muestran significativamente un
nivel de habilidad manual superior al de los varones en este tipo de tarea.
Por último, resulta conveniente calcular la bondad de ajuste del modelo, esto es, la
valoración de la proporción de variación explicada por el mismo respecto a la variación
total de los datos. Como se sabe, nos estamos refiriendo a 2R que es:
22
XYrR =
Es decir:
80.0894.0 22==R
O bien.
80.01002
800
)(
)ˆ(
1
2
1
2
exp2==
−
−
==
∑
∑N
i
N
total
li
YY
YY
SC
SCR
lo que indica que el 80% de la variación manifiesta en las puntuaciones de la habilidad
manual (Y) se explica por la variable sexo (X), una porcentaje bastante alto.
2.4. Aplicación con el SPSS.
Para estimar los diferentes estadísticos y significaciones anteriormente analizados
mediante este paquete basta aplicar los mismos comandos que se utilizaban para el caso
de dos variables cuantitativas. Así, la sucesión de comandos y salidas correspondientes
se exponen a continuación.
En primer lugar, el fichero de datos será similar al cuadro que presentamos al principio
de estas páginas:

3. Regresión con variables cualitativas
51
Si pedimos Analizar/regresión/lineal donde Y funciona como variable dependiente y X
como variable independiente, obtenemos.
Resumen del modelo
Modelo R R cuadrado R cuadrado corregida
Error típ. de la estimación
1 ,894(a) ,798 ,765 5,80230
a Variables predictoras: (Constante), SEXO
ANOVA(b)
Modelo
Suma de cuadrados
gl Media
cuadrática F Sig.
Regresión 800,000 1 800,000 23,762 ,003(a)
Residual 202,000 6 33,667
1
Total 1002,000 7
a Variables predictoras: (Constante), SEXO b Variable dependiente: HABILIDA
Coeficientes(a)
Coeficientes no estandarizados Coeficientes
estandarizados
Modelo B Error típ. Beta t Sig.
(Constante) 26,000 2,901 8,962 ,000 1
SEXO 20,000 4,103 ,894 4,875 ,003
a Variable dependiente: HABILIDA
Como puede observarse, los coeficientes a y b de la última tabla coinciden plenamente
con los previamente estimados, al igual que la correlación entre X e Y (que es lo mismo
que el coeficiente Beta de la ecuación de la recta o su valor estandarizado –0..894-).
La validez del modelo se prueba reparando en el valor de p correspondiente a la F de la
tabla de ANOVA o bien por el de la t correspondiente al coeficiente b o de Beta (iguales
a .003) (véase en la segunda y tercera tablas presentadas).
3. Regresión con variables cualitativas
52
Para obtener el gráfico de dispersión y recta correspondiente mediante SPSS (de forma
similar a como representamos arriba) aplicamos: Gráficos/dispersión/lineal/simple, Una
vez dibujada la nube de puntos se pulsa dos veces sobre la misma y se pide al cuadro de
diálogo que nos proporcione la recta ajustada total.
2.5. Análisis de la regresión versus contraste de medias.
Tal y como hemos indicado al principio, el análisis de la regresión para el caso en que la
variable X es de tipo cualitativo es un análisis análogo al de contraste de medias usado
tan frecuentemente en el ámbito de la experimentación. El referido contraste de medias
se desarrolla en la paquete estadístico SPSS activando el comando ANOVA. A partir de
idéntico archivo de datos como el de antes, podríamos ejecutar dicho comando para los
datos que nos ocupan aplicando las siguientes órdenes: Analizar/Comparar
medias/ANOVA de un factor (especificando cuál es la variable dependiente y cuál la
independiente). Los resultados de dicho análisis deben coincidir exactamente con
aquellos proporcionados por el análisis de la regresión desarrollado antes. Solicitando
algunos estadísticos descriptivos adicionales a dicho comando ANOVA que nos sirven
para interpretar y concluir sobre los resultados, las salidas proporcionadas son las
siguientes:
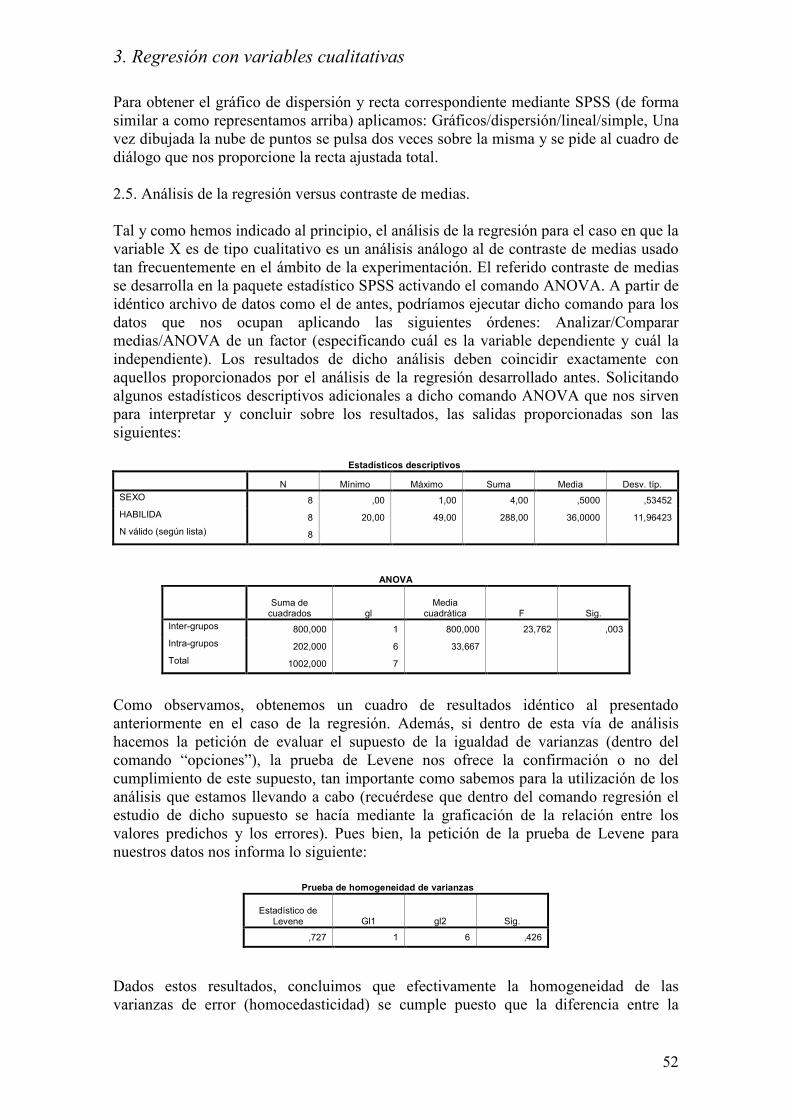
Estadísticos descriptivos
N Mínimo Máximo Suma Media Desv. típ.
SEXO 8 ,00 1,00 4,00 ,5000 ,53452
HABILIDA 8 20,00 49,00 288,00 36,0000 11,96423
N válido (según lista) 8
ANOVA
Suma de
cuadrados gl Media
cuadrática F Sig.
Inter-grupos 800,000 1 800,000 23,762 ,003
Intra-grupos 202,000 6 33,667
Total 1002,000 7
Como observamos, obtenemos un cuadro de resultados idéntico al presentado
anteriormente en el caso de la regresión. Además, si dentro de esta vía de análisis
hacemos la petición de evaluar el supuesto de la igualdad de varianzas (dentro del
comando “opciones”), la prueba de Levene nos ofrece la confirmación o no del
cumplimiento de este supuesto, tan importante como sabemos para la utilización de los
análisis que estamos llevando a cabo (recuérdese que dentro del comando regresión el
estudio de dicho supuesto se hacía mediante la graficación de la relación entre los
valores predichos y los errores). Pues bien, la petición de la prueba de Levene para
nuestros datos nos informa lo siguiente: Prueba de homogeneidad de varianzas
Estadístico de Levene Gl1 gl2 Sig.
,727 1 6 ,426
Dados estos resultados, concluimos que efectivamente la homogeneidad de las
varianzas de error (homocedasticidad) se cumple puesto que la diferencia entre la
3. Regresión con variables cualitativas
53
varianza de los datos en el grupo de mujeres respecto a la de los varones puede
explicarse por azar en una proporción alta (.426).
3. Regresión con variable politómica.
Cuando la variable X en un análisis de la regresión es cualitativa de más de dos
categorías, el análisis es similar al realizado con anterioridad. Sin embargo, puede
resultar útil desarrollar a continuación un ejemplo que muestre algunas de sus
particularidades.
3.1. Codificación.
Supongamos que se desea conocer si el tipo de asistencia que reciben los niños de 2
años durante la jornada matinal incide en alguna medida en su nivel evolutivo. Se
identifican tres tipos de asistencia diferentes: En guardería (X1), en casa asistido por un
cuidador no familiar (X2) y en casa asistido por uno de sus padres (X3). Los resultados
obtenidos se ofrecen en la siguiente tabla:
Sujeto Tipo de asistencia Nivel evolutivo Medias por grupo
1 Guardería 100
2 Guardería 120
3 Guardería 140
4 Guardería 130
5 Guardería 90
116
6 C. no familiar 96
7 C. no familiar 87
8 C. no familiar 97
9 C. no familiar 100
10 C. no familiar 100
96
11 Progenitor 130
12 Progenitor 130
13 Progenitor 140
14 Progenitor 110
15 Progenitor 105
123
Las puntuaciones medias obtenidas permiten realizar una primera interpretación de los
datos a nivel descriptivo respecto al nivel evolutivo de los niños afectados por cada tipo
de cuidado. Observamos que la media del grupo de niños cuidado por el progenitor es la
más alta seguida por la del grupo de niños cuidados en guardería; por último, los niños
de nivel evolutivo inferior parecen ser aquellos cuidados por una persona ajena a la
familia. Si existen o no diferencias significativas entre dichos niveles es algo de lo que
se encargará de responder los análisis que siguen.
Recuérdese que en el caso de una X de tipo dicotómico el archivo de datos contenía una
sola columna para dicha X mediante la cual se conocía, utilizando los códigos 1 y 0, la
categoría a la que pertenecía cada uno de los sujetos (la condición de X por la que
estaba afectado). Ahora con tres valores de X no es posible agotar todas las
posibilidades de asociación sujetos-valores mediante este sistema pues tenemos tres
alternativas de pertenencia. Sin embargo, utilizando dos columnas para representar dos
de las tres categorías de que consta la variable X es suficiente para conocer toda esta
3. Regresión con variables cualitativas
54
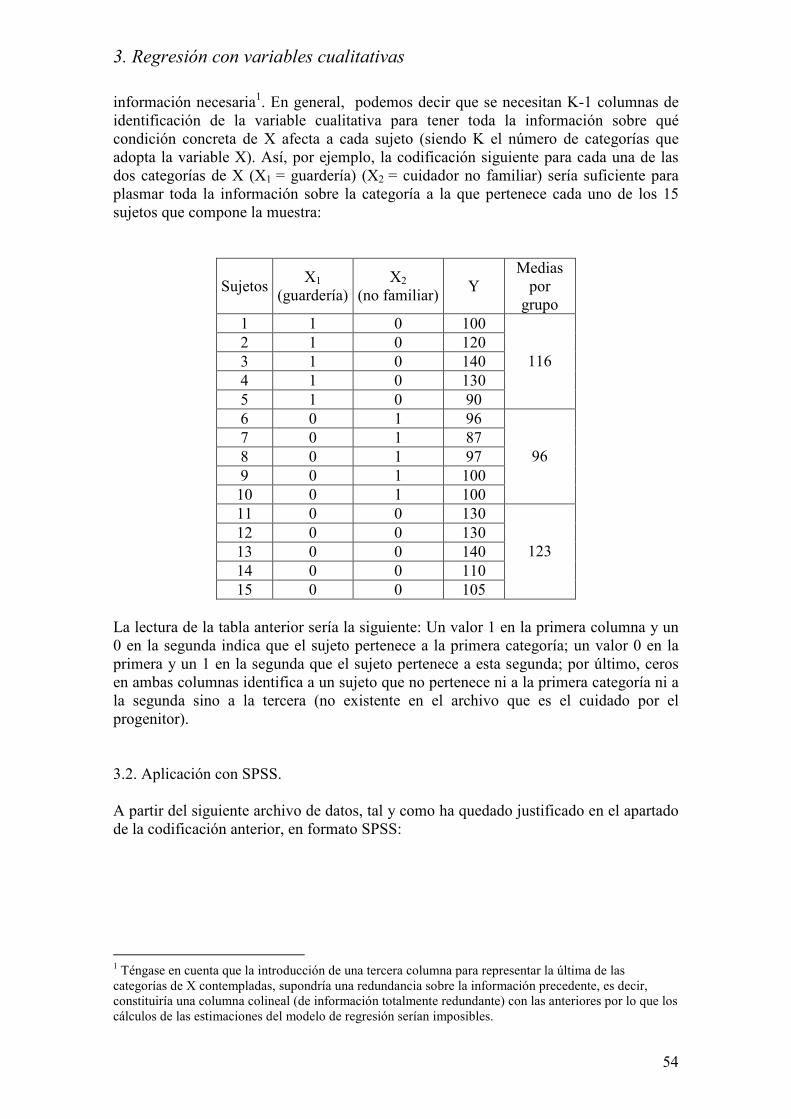
información necesaria1. En general, podemos decir que se necesitan K-1 columnas de
identificación de la variable cualitativa para tener toda la información sobre qué
condición concreta de X afecta a cada sujeto (siendo K el número de categorías que
adopta la variable X). Así, por ejemplo, la codificación siguiente para cada una de las
dos categorías de X (X1 = guardería) (X2 = cuidador no familiar) sería suficiente para
plasmar toda la información sobre la categoría a la que pertenece cada uno de los 15
sujetos que compone la muestra:
Sujetos X1
(guardería)
X2
(no familiar) Y
Medias
por
grupo
1 1 0 100
2 1 0 120
3 1 0 140
4 1 0 130
5 1 0 90
116
6 0 1 96
7 0 1 87
8 0 1 97
9 0 1 100
10 0 1 100
96
11 0 0 130
12 0 0 130
13 0 0 140
14 0 0 110
15 0 0 105
123
La lectura de la tabla anterior sería la siguiente: Un valor 1 en la primera columna y un
0 en la segunda indica que el sujeto pertenece a la primera categoría; un valor 0 en la
primera y un 1 en la segunda que el sujeto pertenece a esta segunda; por último, ceros
en ambas columnas identifica a un sujeto que no pertenece ni a la primera categoría ni a
la segunda sino a la tercera (no existente en el archivo que es el cuidado por el
progenitor).
3.2. Aplicación con SPSS.
A partir del siguiente archivo de datos, tal y como ha quedado justificado en el apartado
de la codificación anterior, en formato SPSS:
1 Téngase en cuenta que la introducción de una tercera columna para representar la última de las
categorías de X contempladas, supondría una redundancia sobre la información precedente, es decir,
constituiría una columna colineal (de información totalmente redundante) con las anteriores por lo que los
cálculos de las estimaciones del modelo de regresión serían imposibles.

3. Regresión con variables cualitativas
55
se activa el comando regresión/lineal de dicho paquete para estimar la ecuación de
regresión del modelo así como su significación estadística. En dicho comando se
especifica que la variable dependiente es el nivel evolutivo y las independientes las dos
X representadas en las columnas del archivo de datos (guardería y cuidado no familiar),
obteniendo los siguientes resultados:
Resumen del modelo
,648a ,420 ,323 15,03884
Modelo
1
R R cuadradoR cuadradocorregida
Error típ. de laestimación
Variables predictoras: (Constante), casanfamiliar, guarderíaa.
Como ya sabemos, este cuadro (resumen del modelo) informa que la proporción de
variación del nivel evolutivo de los niños por cuenta del tipo de cuidado que reciben en
periodo laboral es del .420. Además, la relación analizada es significativa (α=.05),
puesto que la tabla de ANOVA siguiente proporciona un valor de F = 4.34, con una p =
.038<.05; es decir, el tipo de cuidado en periodo laboral incide significativamente sobre
el nivel evolutivo del niño.
ANOVAb
1963,333 2 981,667 4,340 ,038a
2714,000 12 226,167
4677,333 14
Regresión
Residual
Total
Modelo
1
Suma decuadrados gl
Mediacuadrática F Sig.
Variables predictoras: (Constante), casanfamiliar, guarderíaa.
Variable dependiente: nivelb.
Hasta ahora –a través de la información expuesta- no puede conocerse si existen
diferencias estadísticamente significativas entre unos tipos de condiciones de cuidados
respecto a otros, esto es, sólo podemos concluir globalmente que el tipo de cuidado
incide en el nivel evolutivo. Para discriminar entre condiciones específicas del nivel
evolutivo, estudiamos la tabla de coeficientes de la ecuación de regresión estimada:
3. Regresión con variables cualitativas
56
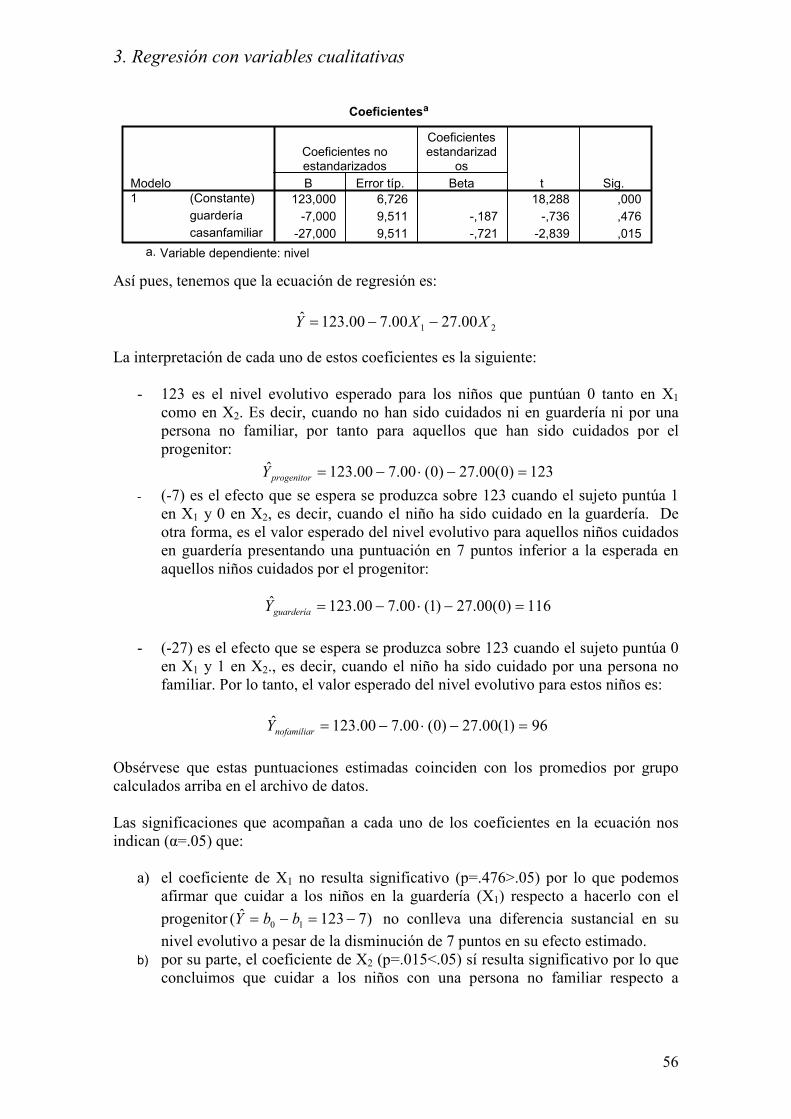
Coeficientesa
123,000 6,726 18,288 ,000
-7,000 9,511 -,187 -,736 ,476
-27,000 9,511 -,721 -2,839 ,015
(Constante)
guardería
casanfamiliar
Modelo
1
B Error típ.
Coeficientes noestandarizados
Beta
Coeficientesestandarizad
os
t Sig.
Variable dependiente: nivela.
Así pues, tenemos que la ecuación de regresión es:
21 00.2700.700.123ˆ XXY −−=
La interpretación de cada uno de estos coeficientes es la siguiente:
- 123 es el nivel evolutivo esperado para los niños que puntúan 0 tanto en X1
como en X2. Es decir, cuando no han sido cuidados ni en guardería ni por una
persona no familiar, por tanto para aquellos que han sido cuidados por el
progenitor:
123)0(00.27)0(00.700.123ˆ =−⋅−=progenitorY
- (-7) es el efecto que se espera se produzca sobre 123 cuando el sujeto puntúa 1
en X1 y 0 en X2, es decir, cuando el niño ha sido cuidado en la guardería. De
otra forma, es el valor esperado del nivel evolutivo para aquellos niños cuidados
en guardería presentando una puntuación en 7 puntos inferior a la esperada en
aquellos niños cuidados por el progenitor:
116)0(00.27)1(00.700.123ˆ =−⋅−=guarderíaY
- (-27) es el efecto que se espera se produzca sobre 123 cuando el sujeto puntúa 0
en X1 y 1 en X2., es decir, cuando el niño ha sido cuidado por una persona no
familiar. Por lo tanto, el valor esperado del nivel evolutivo para estos niños es:
96)1(00.27)0(00.700.123ˆ =−⋅−=nofamiliarY
Obsérvese que estas puntuaciones estimadas coinciden con los promedios por grupo
calculados arriba en el archivo de datos.
Las significaciones que acompañan a cada uno de los coeficientes en la ecuación nos
indican (α=.05) que:
a) el coeficiente de X1 no resulta significativo (p=.476>.05) por lo que podemos
afirmar que cuidar a los niños en la guardería (X1) respecto a hacerlo con el
progenitor )7123ˆ( 10 −=−= bbY no conlleva una diferencia sustancial en su
nivel evolutivo a pesar de la disminución de 7 puntos en su efecto estimado.
b) por su parte, el coeficiente de X2 (p=.015<.05) sí resulta significativo por lo que
concluimos que cuidar a los niños con una persona no familiar respecto a

3. Regresión con variables cualitativas
57
hacerlo con el progenitor hace disminuir significativamente su nivel evolutivo
esperado en una cantidad de 27 puntos )27123ˆ( 20 −=−= bbY .





























