Embed Size (px)
Citation preview

(Artificial) Neural Networks in TensorFlow
Industrial AI Lab.

Iterations of Perceptron1. Randomly assign 𝜔
2. One iteration of the PLA (perceptron learning algorithm)
where (𝑥, 𝑦) is a misclassified training point
3. At iteration 𝑡 = 1,2,3,⋯ , pick a misclassified point from
4. And run a PLA iteration on it
5. That's it!
2

Perceptron
3

Artificial Neural Networks: Perceptron• Perceptron for ℎ 𝜃 or ℎ 𝜔– Neurons compute the weighted sum of their inputs– A neuron is activated or fired when the sum 𝑎 is positive
• A step function is not differentiable• One layer is often not enough
4
bias
weights

XOR Problem• Minsky-‐Papert Controversy on XOR– not linearly separable– Limitation of perceptron
5

Artificial Neural Networks: MLP• Multi-‐layer Perceptron (MLP) = Artificial Neural Networks (ANN)– More linear classifiers (lines)– More features
6

Artificial Neural Networks: Activation Func.• Differentiable non-‐linear activation function
7

Artificial Neural Networks• In a compact representation
8

Artificial Neural Networks• Multi-‐layer perceptron– More non-‐linearity– Features of features
9

ANN: Transformation• Affine (or linear) transformation and nonlinear activation layer
(notations are mixed: 𝑔 = 𝜎,𝜔 = 𝜃,𝜔2 = 𝑏 )
• Nonlinear activation functions 𝑔 = 𝜎
10

ANN: Multilayers• A single layer is not enough to be able to represent complex relationship between input and output ⟹ perceptron with many layers and units
11

Example: Linear Classifier• Perceptron tries to separate the two classes of data by dividing them with a line
12

Example: Neural Networks• The hidden layer learns a representation so that the data is linearly separable
13

Recall Supervised Learning Setup
14

Training Neural Networks: Optimization• Learning or estimating weights and biases of multi-‐layer perceptron from training data
• 3 key components– objective function 𝑓 5– decision variable or unknown 𝜃– constraints 𝑔 5
• In mathematical expression
15

Training Neural Networks: Loss Function• Measures error between target values and predictions
• Example– Squared loss (for regression):
– Cross entropy (for classification):
16

Training Neural Networks
17

Training Neural Networks: Gradient Descent• Negative gradients points directly downhill of the cost function• We can decrease the cost by moving in the direction of the negative gradient (𝛼 is a learning rate)
18

Training Neural Networks: Learning• Forward propagation– the initial information propagates up to the hidden units at each layer and finally produces output
• Backpropagation– allows the information from the cost to flow backwards through the network in order to compute the gradients
19

Backpropagation
20
• Chain Rule– Computing the derivative of the composition of functions• 𝑓 𝑔 𝑥 7 = 𝑓7 𝑔 𝑥 𝑔7 𝑥
• 898:= 89
8;5 8;8:
• 898<
= 898;5 8;8:
5 8:8<
• 898== 89
8;5 8;8:5 8:8<
5 8<8=
• Backpropagation– Update weights recursively
𝑧
𝑦
𝑥
𝑤
𝑢
𝑑𝑧𝑑𝑥
𝑑𝑧𝑑𝑤
𝑑𝑧𝑑𝑢
𝑑𝑧𝑑𝑦
𝑑𝑦𝑑𝑥
𝑑𝑥𝑑𝑤
𝑑𝑤𝑑𝑢
𝑓
𝑓
𝑓
𝑓𝑓′
𝑓′
𝑓′
𝑓′

Backpropagation
21
• Chain Rule– Computing the derivative of the composition of functions• 𝑓 𝑔 𝑥 7 = 𝑓7 𝑔 𝑥 𝑔7 𝑥
• 898:= 89
8;5 8;8:
• 898<
= 898;5 8;8:
5 8:8<
• 898== 89
8;5 8;8:5 8:8<
5 8<8=
• Backpropagation– Update weights recursively
𝑧
𝑦
𝑥
𝑤
𝑢
𝑑𝑧𝑑𝑥
𝑑𝑧𝑑𝑤
𝑑𝑧𝑑𝑢
𝑑𝑧𝑑𝑦
𝑑𝑦𝑑𝑥
𝑑𝑥𝑑𝑤
𝑑𝑤𝑑𝑢
𝑓
𝑓
𝑓
𝑓𝑓′
𝑓′
𝑓′
𝑓′

Backpropagation
22
• Chain Rule– Computing the derivative of the composition of functions• 𝑓 𝑔 𝑥 7 = 𝑓7 𝑔 𝑥 𝑔7 𝑥
• 898:= 89
8;5 8;8:
• 898<
= 898;5 8;8:
5 8:8<
• 898== 89
8;5 8;8:5 8:8<
5 8<8=
• Backpropagation– Update weights recursively
𝑧
𝑦
𝑥
𝑤
𝑢
𝑑𝑧𝑑𝑥
𝑑𝑧𝑑𝑤
𝑑𝑧𝑑𝑢
𝑑𝑧𝑑𝑦
𝑑𝑦𝑑𝑥
𝑑𝑥𝑑𝑤
𝑑𝑤𝑑𝑢
𝑓
𝑓
𝑓
𝑓𝑓′
𝑓′
𝑓′
𝑓′

Backpropagation
23
• Chain Rule– Computing the derivative of the composition of functions• 𝑓 𝑔 𝑥 7 = 𝑓7 𝑔 𝑥 𝑔7 𝑥
• 898:= 89
8;5 8;8:
• 898<
= 898;5 8;8:
5 8:8<
• 898== 89
8;5 8;8:5 8:8<
5 8<8=
• Backpropagation– Update weights recursively
𝑧
𝑦
𝑥
𝑤
𝑢
𝑑𝑧𝑑𝑥
𝑑𝑧𝑑𝑤
𝑑𝑧𝑑𝑢
𝑑𝑧𝑑𝑦
𝑑𝑦𝑑𝑥
𝑑𝑥𝑑𝑤
𝑑𝑤𝑑𝑢
𝑓
𝑓
𝑓
𝑓𝑓′
𝑓′
𝑓′
𝑓′

Training Neural Networks• Optimization procedure
• It is not easy to numerically compute gradients in network in general.– The good news: people have already done all the "hard work" of developing numerical solvers (or libraries)
– There are a wide range of tools: TensorFlow
24

Summary• Learning weights and biases from data using gradient descent• Learning a function approximator from data– Generic mathematical representation
25

• Complex/Nonlinear function approximator– Linearly connected networks – Simple nonlinear neurons
• Hidden layers– Autonomous feature learning
Deep Artificial Neural Networks
26
Feature learning Classification
Class 1
Class 2
nonlinearlinear
…

• Complex/Nonlinear function approximator– Linearly connected networks – Simple nonlinear neurons
• Hidden layers– Autonomous feature learning
Deep Artificial Neural Networks
27
Class 1
Class 2
…… … ………
nonlinearlinear
Feature learning Classification

• Machine learning
• Deep learning
Machine Learning vs. Deep Learning
28
Input Hand-‐engineered features Classifier output
Input Deep Learning output
end-‐to-‐end training

Training Neural Networks: Deep Learning Libraries
• Caffe– Platform: Linux, Mac OS, Windows– Written in: C++– Interface: Python, MATLAB
• Theano– Platform: Cross-‐platform– Written in: Python– Interface: Python
• TensorFlow– Platform: Linux, Mac OS, Windows– Written in: C++, Python– Interface: Python, C/C++, Java, Go, R
29

TensorFlow: Constant• TensorFlow is an open-‐source software library for deep learning– tf.constant– tf.Variable– tf.placeholder
30

TensorFlow: Session• To run any of the three defined operations, we need to create a session for that graph. The session will also allocate memory to store the current value of the variable.
31

TensorFlow
32

TensorFlow: Initialization• tf.Variable is regarded as the decision variable in optimization. • We should initialize variables to use tf.Variable.
33

TensorFlow: Placeholder• The value of tf.placeholder must be fed using the feed_dict optional argument to Session.run()
34

ANN with MNIST• MNIST database– Mixed National Institute of Standards and Technology database– Handwritten digit database– 28×28 gray scaled image– Flattened matrix into a vector of 28×28=784
35

ANN with TensorFlow• Feed a gray image to ANN
36

Our Network Model
37

Iterative Optimization
38

Mini-‐batch Gradient Descent
39

ANN with TensorFlow• Import Library
• Load MNIST Data– Download MNIST data from TensorFlow tutorial example
40

One Hot Encoding
• One hot encoding
41

Build a Model• First, the layer performs several matrix multiplication to produce a set of linear activations
42
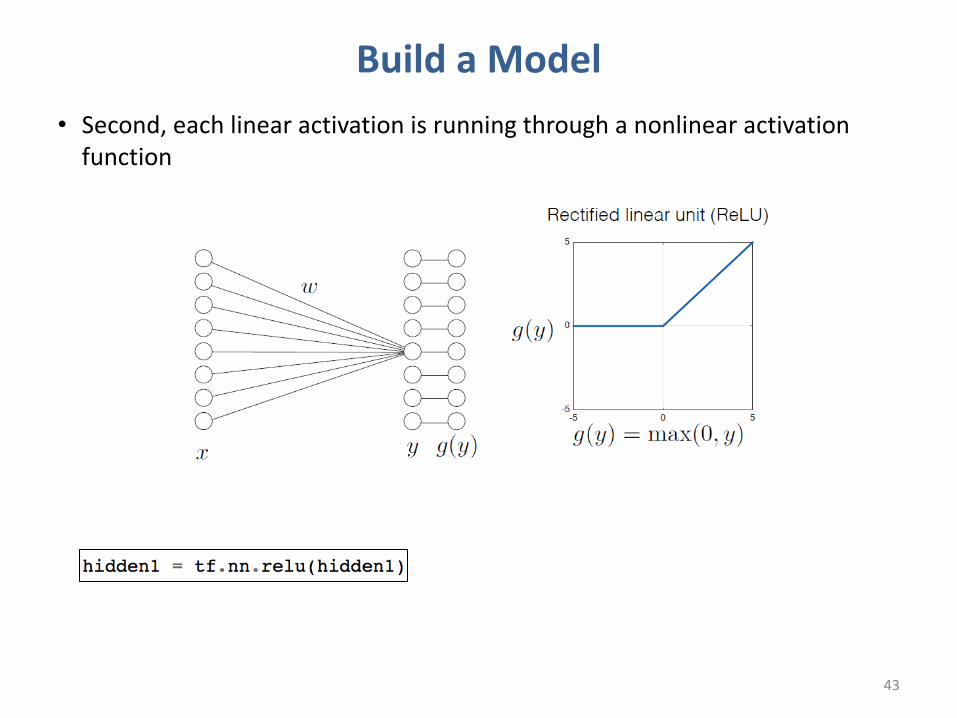
Build a Model• Second, each linear activation is running through a nonlinear activation function
43

Build a Model• Third, predict values with an affine transformation
44

ANN's Shape• Input size• Hidden layer size• The number of classes
45

Weights and Biases• Define parameters based on predefined layer size• Initialize with normal distribution with 𝜇 = 0 and 𝜎 = 0.1
46

Build a Model
47

Cost, Initializer and Optimizer• Loss: cross entropy
• Initializer– Initialize all the empty variables
• Optimizer– AdamOptimizer: the most popular optimizer
48
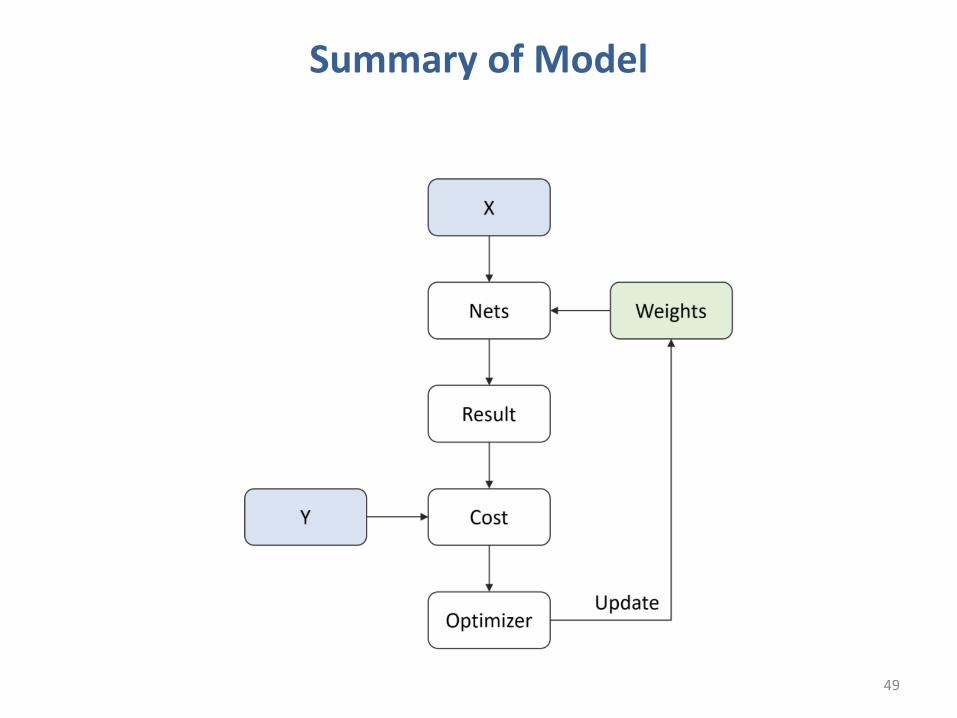
Summary of Model
49

Iteration Configuration• Define parameters for training ANN– n_batch: batch size for stochastic gradient descent– n_iter: the number of learning steps– n_prt: check loss for every n_prt iteration
50
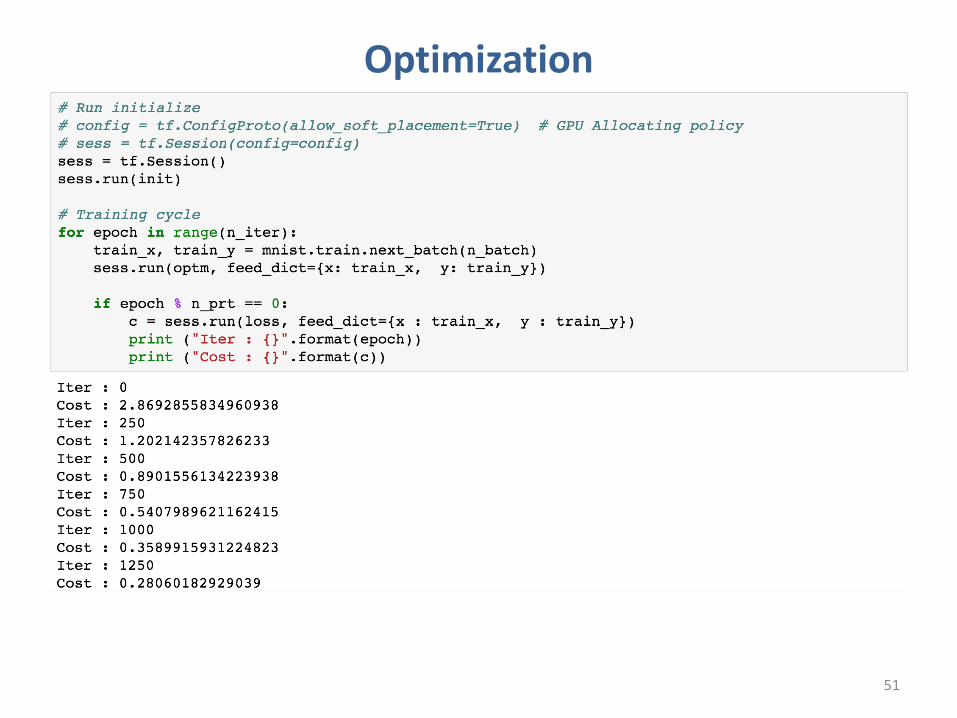
Optimization
51

Test or Evaluation
52

Test or Evaluation
53












![Chapter 2 Introduction to Neural networktomczak/PDF/[Grbic]Neural...Chapter 2 Introduction to Neural network 2.1 Introduction to Artiflcial Neural Net-work Artiflcial Neural Networks](https://img.dokumen.tips/doc/110x75/5f22a87bbf292e3b5d18b33c/chapter-2-introduction-to-neural-network-tomczakpdfgrbicneural-chapter-2.jpg)
















