Embed Size (px)
Citation preview

10/14/2005 1
Dissertation ProposalNegative selection algorithms: from the thymus to V-detector
Zhou Ji, advised by Prof. Dasgupta

2
Outline Background of the area Major contributions of current work
Description of the algorithm Demonstration of the software Experimental results
Work to do next

background 3
Background AIS (Artificial Immune Systems) – only about 10
years’ history Negative selection (development of T cells) Immune network theory (how B cells and antibodies
interact with each other) Clonal selection (how a pool of B cells, especially,
memory cells are developed) New inspirations from immunology: danger theory,
germinal center, etc. Negative selection algorithms
The earliest and most widely used AIS.

background 4
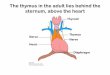
Biological metaphor of negative selection
How T cells mature in the thymus: The cell are diversified. Those that recognize self are eliminated. The rest are used to recognize nonself.

background 5
The idea of negative selection algorithms (NSA)
The problem to deal with: anomaly detection (or one-class classification)
Detector set random generation: maintain diversity censoring: eliminating those that match self samples
The concept of feature space and detectors

background 6
Outline of a typical NSA
Generation of detector setAnomaly detection:(classification of incoming data items)

background 7
Family of NSATypes of works about NSA Applications: solving real world problems by using a typical version or
adapting for specific applications Improving NSA of new detector scheme and generation method and
analyzing existing methods. Works are data representation specific, mostly binary representation.
Establishment of framework for binary representation to include various matching rules; discussion on uniqueness and usefulness of NSA; introduction of new concepts.
What defines a negative selection algorithm? Representation in negative space One-class learning Usage of detector set

background 8
Major issues in NSA Number of detectors
Affecting the efficiency of generation and detection
Detector coverage Affecting the accuracy detection
Generation mechanisms Affecting the efficiency of generation and the quality of resulted detectors
Matching rules – generalization How to interpret the training data depending on the feature space and representation scheme
Issues that are not NSA specific Difficulty of one-class classification Curse of dimensionality

contribution 9
V-detector: work done for the proposed dissertation to deal with the issues in NSA
V-detector is a new negative selection algorithm.
It embraces a series of related works to develop a more efficient and more reliable algorithm.
It has its unique process to generate detectors and determine coverage.

contribution 10
V-detector’s major features Variable-sized detectors Statistical confidence in detector coverage Boundary-aware algorithm Extensibility

contribution 11
Variable sized detectors in V-detector method are “maximized detector”
Unanswered question: what is the self space?
traditional detectors: constant size V-detector: maximized size

contribution 12
Why is the idea of “variable sized detectors” novel?
The rational of constant size: a uniform matching threshold Detectors of variable size exist in some negative selection
algorithms as a different mechanism Allowing multiple or evolving size to optimize the coverage – limited
by the concern of overlap Variable size as part of random property of detectors/candidates
V-detector uses variable sized detectors to maximize the coverage with limited number of detectors Size is decided on by the training data Large nonself region is covered easily Small detectors cover ‘holes’ Overlap is not an issue in V-detector

contribution 13
Statistical estimate of detector coverage
Exiting works: estimate necessary number of detectors – no direct relationship between the estimate and the actual detector set obtained.
Novelty of V-detector: Evaluate the coverage of the actual detector set Statistical inference is used as an integrated
components of the detector generation algorithm, not to estimate coverage of finished detector set.

contribution 14
Basic idea leading to the new estimation mechanism Random points are taken as detector
candidates. The probability that a random point falls on covered region (some exiting detectors) reflects the portion that is covered -- similar to the idea of Monte Carlo integral. Proportion of covered nonself space =
probability of a sample point to be a covered point. (the points on self region not counted)
When more nonself space has been covered, it becomes less likely that a sample point to be an uncovered one. In other words, we need try more random point to find a uncovered one - one that can be used to make a detector.

contribution 15
Statistics involved
Central limit theory: sample statistic follows normal distribution Using sample statistic to population parameter In our application, use proportion of covered random points to estimate the actual proportion of
covered area Point estimate versus confidence interval Estimate with confidence interval versus hypothesis testing
Proportion that is close to 100% will make the assumption of central limit theory invalid – not normal distribution.
Purpose of terminating the detector generation
proportion0 1

16
Hypothesis testing Identifying null hypothesis/alternative hypothesis.
Type I error: falsely reject null hypothesis Type II error: falsely accept null hypothesis The null hypothesis is the statement that we’d rather take as true if there is
not strong enough evidence showing otherwise. In other words, we consider type I error more costly.
In term of coverage estimate, we consider falsely inadequate coverage is more costly. So the null hypothesis is: the current coverage is below the target coverage.
Choose significant level: maximum probability we are willing to accept in making Type I Error.
Collect sample and compute its statistic, in this case, the proportion. Calculate z score from proportion an compare with z If z is larger, we can reject null hypothesis and claim adequate coverage
with confidence

17
Boundary-aware algorithm versus point-wise interpretation A new concept in negative selection algorithm Previous works of NSA
Matching threshold is used as mechanism to control the extent of generalization
However, each self sample is used individually. The continuous area represented by a group of sample is not captured. (point-wise interpretation)
More specificityRelatively more aggressive to detect anomaly
More generalizationThe real boundary isExtended.
Desired interpretation: The area represented byThe group of points

contribution 18
Boundary–aware: using the training points as a collection
• Boundary-aware algorithmA ‘clustering’ mechanism though represented in negative space• The training data are used as a collection instead individually.• Positive selection cannot do the same thing

contribution 19
V-detector is more than a real-valued negative selection algorithm V-detector can be implemented for any data
representation and distance measure. Usually negative selection algorithms were designed with
specific data representation and distance measure. The features we just introduced are not limited by
representation scheme or generation mechanism. (as long as we have a distance measure and a threshold to decide matching)

contribution 20
V-detector algorithm withconfidence in detector coverage

contribution 21
V-detector algorithm withconfidence in detector coverage

contribution 22
V-detector algorithm withconfidence in detector coverage

contribution 23
V-detector’s contributions Efficiency:
fewer detectors fast generation
Coverage confidence Extensibility, simplicity

24
Experiments A large pool of synthetic data (2-D real space) are
experimented to understand V-detector’s behavior More detail analysis of the influence of various
parameters is planned as ‘work to do’ Real world data
Confirm it works well enough to detect real world “anomaly”
Compare with methods dealing with similar problems Demonstration
How actual training data and detector look like Basic UI and visualization of V-detector implementation

25
Parameters to evaluate its performance Detection rate False alarm rate Number of detectors

contribution 26
Control parameters and algorithm variations Self radius – key parameter Target coverage Significant level (of hypothesis testing) Boundary-aware versus point-wise Hypothesis testing versus naïve estimate Reuse random points versus minimum
detector set (to be implemented)

contribution 27
Data’s influence on performance Specific shape
Intuitively, “corners” will affect the results. Number of training points
Major influence

28
Synthetic data (‘intersection’ and pentagram): compare naïve estimate and hypothesis testing
‘intersection’ shape pentagram

29
Synthetic data : results for different shapes of self region

30
Synthetic data (ring): compare boundary-aware and point-wise
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 0.05 0.1 0.15 0.2 0.25
Self threshold
fals
e al
arm
rat
e point-wise
boundary-aware
0
0.2
0.4
0.6
0.8
1
1.2
0 0.05 0.1 0.15 0.2 0.25
Self threshold
Dete
ctio
n Ra
te
point-wiseboundary-aware
Detection rate False alarm rate

31
Synthetic data (cross-shaped self): balance of errors
0
5
10
15
20
25
30
35
40
45
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
err
or
rate
(p
erc
en
tag
e)
false negative (99% coverage) false positive (99% coverage)

contribution 32
Real world data Biomedical data Pollution data Ball bearing – preprocessed time series data Others: Iris data, gene data, India Telugu

33
Results of biomedical data
Training Data Algorithm Detection Rate False Alarm rate Number of Detectors
Mean SD Mean SD Mean SD
100% training MILA 59.07 3.85 0 0 1000* 0
NSA 69.36 2.67 0 0 1000 0
r=0.1 30.61 3.04 0 0 21.52 7.29
r=0.05 40.51 3.92 0 0 14.84 5.14
50% training MILA 61.61 3.82 2.43 0.43 1000* 0
NSA 72.29 2.63 2.94 0.21 1000 0
r = 0.1 32.92 2.35 0.61 0.31 15.51 4.85
r=0.05 42.89 3.83 1.07 0.49 12.28 4
25% training MILA 80.47 2.80 14.93 2.08 1000* 0
NSA 86.96 2.72 19.50 2.05 1000 0
r=0.1 43.68 4.25 1.24 0.5 12.24 3.97
r=0.05 57.97 5.86 2.63 0.77 8.94 2.57

34
Results of air pollution data
0
20
40
60
80
100
120
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
de
tec
tio
n r
ate
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
fals
e a
larm
ra
te
Detection rate (99.99% coverage) Detection rate (99% coverage)False alarm rate (99% coverage) False alarm rate (99.99% coverage)
0
200
400
600
800
1000
1200
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
nu
mb
er
of
de
tec
tors
99.99% coverage 99% coverage
Detection rate and false alarm rate Number of detectors

35
Ball bearing data
raw data: time series of acceleration measurements Preprocessing (from time domain to representation space for
detection)1. FFT (Fast Fourier Transform) with Hanning windowing: window
size 302. Statistical moments: up to 5th order
-60
-40
-20
0
20
40
60
80
1 33 65 97 129 161 193 225 257 289 321 353 385 417 449 481 513 545 577 609 641 673 705 737 769 801 833 865 897 929 961 993
Example of raw data (new bearings, first 1000 points)

contribution 36
Ball bearing experiments with two different preprocessing techniques

37
Results of Iris dataDetection rate False alarm rate
Setosa 100% MILA 95.16 0
NSA (single level) 100 0
V-detector 99.98 0
Setosa 50% MILA 94.02 8.42
NSA (single level) 100 11.18
V-detector 99.97 1.32
Versicolor 100% MILA 84.37 0
NSA (single level) 95.67 0
V-detector 85.95 0
Versicolor 50% MILA 84.46 19.6
NSA (single level) 96 22.2
V-detector 88.3 8.42
Virginica 100% MILA 75.75 0
NSA (single level) 92.51 0
V-detector 81.87 0
Virginica 50% MILA 88.96 24.98
NSA (single level) 97.18 33.26
V-detector 93.58 13.18

to do 38
Work to do next Extension to different data representation Searching for real world applications Compare with other methods, e.g. SVM Analysis on the influence of control paramete
rs and algorithm variations

39
Publications Dasgupta, Ji, Gonzalez, Artificial immune system (AIS) research in the
last five years, CEC 2003 Ji, Dasgupta, Augmented negative selection algorithm with variable-
coverage detectors, CEC 2004 Ji, Dasgupta, Real-valued negative selection algorithm with variable-sized
detectors, GECCO 2004 Ji, Dasgupta, Estimating the detector coverage in a negative selection
algorithm, GECCO 2005 Ji, A boundary-aware negative selection algorithm, ASC 2005 Ji, Dasgupta, Revisiting negative selection algorithms, submitted to the
Evolutionary Computation Journal Ji, Dasgupta, An efficient negative selection algorithm of “probably
adequate” coverage, submitted to SMC

40
Questions and comments?
Thank you!

41
What is matching rule? When a sample and a detector are considered
matching.
Matching rule plays an important role in negative selection algorithm. It largely depends on the data representation.

42
In real-valued representation, detector can be visualized as hyper-sphere.Candidate 1: thrown-away; candidate 2: made a detector.
Match or not match?

43
Experiments and Results Synthetic Data
2D. Training data are randomly chosen from the normal region. Fisher’s Iris Data
One of the three types is considered as “normal”. Biomedical Data
Abnormal data are the medical measures of disease carrier patients.
Air Pollution Data Abnormal data are made by artificially altering the normal air
measurements Ball bearings:
Measurement: time series data with preprocessing - 30D and 5D

44
Synthetic data - Cross-shaped self space Shape of self region and example detector coverage
(a) Actual self space (b) self radius = 0.05 (c) self radius = 0.1

45
Synthetic data - Cross-shaped self space Results
0
20
40
60
80
100
120
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
det
ecti
on
rat
e
0
10
20
30
40
50
60
70
80
90
fals
e a
larm
rat
e
Detection rate (99.99% coverage) Detection rate (99% coverage)False alarm rate (99% coverage) False alarm rate (99.99% coverage)
0
200
400
600
800
1000
1200
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
nu
mb
er o
f d
etec
tors
99.99% coverage 99% coverage
Detection rate and false alarm rate Number of detectors

46
Synthetic data - Ring-shaped self space Shape of self region and example detector coverage
(a) Actual self space (b) self radius = 0.05 (c) self radius = 0.1

47
0
20
40
60
80
100
120
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
det
ecti
on
rat
e
0
10
20
30
40
50
60
70
fals
e a
larm
rat
e
Detection rate (99.99% coverage) Detection rate (99% coverage)False alarm rate (99% coverage) False alarm rate (99.99% coverage)
0
200
400
600
800
1000
1200
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
nu
mb
er o
f d
etec
tors
99.99% coverage 99% coverage
Synthetic data - Ring-shaped self space Results
Detection rate and false alarm rate Number of detectors

48
Iris dataComparison with other methods: number of detectors
mean max Min SD
Setosa 100% 20 42 5 7.87
Setosa 50% 16.44 33 5 5.63
Veriscolor 100% 153.24 255 72 38.8
Versicolor 50% 110.08 184 60 22.61
Virginica 100% 218.36 443 78 66.11
Virginica 50% 108.12 203 46 30.74

49
Iris dataVirginica as normal, 50% points used to train
0
20
40
60
80
100
120
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
de
tec
tio
n r
ate
0
10
20
30
40
50
60
fals
e a
larm
ra
te
Detection rate (99.99% coverage) Detection rate (99% coverage)False alarm rate (99% coverage) False alarm rate (99.99% coverage)
0
200
400
600
800
1000
1200
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
nu
mb
er
of
de
tec
tors
99.99% coverage 99% coverage
Detection rate and false alarm rate Number of detectors

50
Biomedical data Blood measure for a group of 209 patients Each patient has four different types of
measurement 75 patients are carriers of a rare genetic
disorder. Others are normal.

51
Biomedical data
0
10
20
30
40
50
60
70
80
90
100
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radius
de
tec
tio
n r
ate
0
10
20
30
40
50
60
fals
e a
larm
ra
te
Detection rate (99.99% coverage) Detection rate (99% coverage)False alarm rate (99% coverage) False alarm rate (99.99% coverage)
0
200
400
600
800
1000
1200
0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 0.17 0.19
self radiusn
um
be
r o
f d
ete
cto
rs
99.99% coverage 99% coverage
Detection rate and false alarm rate Number of detectors

52
Air pollution data Totally 60 original records. Each is 16 different measurements concerning air pollution. All the real data are considered as normal. More data are made artificially:
1. Decide the normal range of each of 16 measurements2. Randomly choose a real record3. Change three randomly chosen measurements within a larger
than normal range4. If some the changed measurements are out of range, the record
is considered abnormal; otherwise they are considered normal Totally 1000 records including the original 60 are used as
test data. The original 60 are used as training data.

53
Example of data (FFT of new bearings) --- first 3 coefficients of the first 100 points
0
100
200
300
400
500
600
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 100
coefficient 1 coefficient 2 coeffcient 3

54
Example of data (statistical moments of new bearings) --- moments up to 3rd order of the first 100 points
-2000
-1000
0
1000
2000
3000
4000
5000
6000
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 100
1st order 2nd order 3rd order

55
Ball bearing’s structure and damage
Damaged cage

56
Ball bearing data: resultsBall bearing conditions Total number of data points Number of detected
anomaliesPercentage detected
New bearing (normal) 2739 0 0%
Outer race completely broken 2241 2182 97.37%
Broken cage with one loose element 2988 577 19.31%
Damage cage, four loose elements 2988 337 11.28%
No evident damage; badly worn 2988 209 6.99%
Ball bearing conditions Total number of data points Number of detectedanomalies
Percentage detected
New bearing (normal) 2651 0 0%
Outer race completely broken 2169 1674 77.18%
Broken cage with one loose element 2892 14 0.48%
Damage cage, four loose elements 2892 0 0%
No evident damage; badly worn 2892 0 0%
Preprocessed with FFT
Preprocessed with statistical moments

57
Ball bearing data: performance summary
Statistical Moments
77.18
Statistical Moments
21.22
FourierTransform97.37
FourierTransform37.68
FourierTransform3.65
Statistical Moments
00
20
40
60
80
100
120
Detection Rate for the WorstDamage
Detection Rate for AllDamages
False Alarm Rate

58
How much one sample tells

59
Samples may be on boundary

60
In term of detectors

61
Comparing three methods
Constant-sized detectors V-detector New algorithm
Self radius = 0.05

62
Comparing three methods
Constant-sized detectors V-detectors New algorithm
Self radius = 0.1

contribution 63
Experiments on 2-D synthetic data
Training points (1000) Test data (1000 points) and the ‘real shape’ we try to learn

contribution 64
Detector sets generated
Trained with 1000 points Trained with 100 points

65Back to the presentation